| Oracle® Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド 11gリリース2 (11.2) B61350-02 |
|



 前 |
 次 |
Oracle Warehouse Builderでは、ディメンション・オブジェクトを使用してETLを実行するマッピングを設計できます。この章では、ディメンション・オブジェクトからのデータ抽出やデータ削除、およびディメンション・オブジェクトへのデータ・ロードについて説明します。
この章の内容は次のとおりです。
ディメンション演算子では、ディメンション、緩やかに変化するディメンション(SCD)および時間ディメンション上のETLを実行できます。ディメンション演算子を使用して、ディメンションからのデータ抽出、ディメンションへのデータ・ロード、またはディメンションからのデータ削除が可能です。ディメンションでは、リレーショナル形式でOracle Databaseまたはアナリティック・ワークスペースに配布される場合があります。
マッピングでディメンション演算子をターゲットとして使用し、ディメンションおよびSCDにデータをロードします。演算子からディメンションまたはSCDへのデータ・フローを定義します。
Oracle Warehouse Builderは、ディメンションの最上位から順にデータをロードします。
|
注意: レベルのサロゲート識別子または親サロゲート識別子参照にはデータ・フローをマップできません。 |
ディメンションにデータをロードする際、Oracle Warehouse Builderは、ソース・レコードのビジネス識別子を既存のディメンション・レコードのビジネス識別子と比較することで、類似のレコードがディメンション内に存在するかどうかをチェックします。
ディメンションにデータをロードする手順は次のとおりです。
「マッピングの定義」の説明に従って、マッピングを定義します。
ディメンション演算子をマッピングに追加します。この演算子が、データをロードするディメンションにバインドされていることを確認します。
マッピングへの演算子の追加は、「マッピングへの演算子の追加」を参照してください。
ソース・オブジェクトに対応する演算子、およびディメンションにソース・データがロードされる前に実行する必要のあるあらゆる変換に対応する演算子を追加します。
属性を、ソース演算子から中間変換演算子(ソース・データをディメンションにロードする前に変換する場合)、ターゲット・ディメンションの順にマップします。必要に応じてすべての属性のマッピングを完了します。
ロードされた識別子と同じビジネス識別子を持つレコードがディメンションに存在する場合、レコードはソースからの属性値によって更新されます。それ以外の場合、ソース・レコードはディメンションにロードされます。
ディメンション演算子の「ロード・タイプ」プロパティを「ロード」に設定します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「検証」をクリックし、マッピングを検証します。
必要に応じて検証プロセスからのエラーを解決します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「生成」をクリックし、マッピングを検証します。
生成結果は、「ログ」ウィンドウの新規「結果」タブに表示されます。必要に応じて生成エラーを解決します。
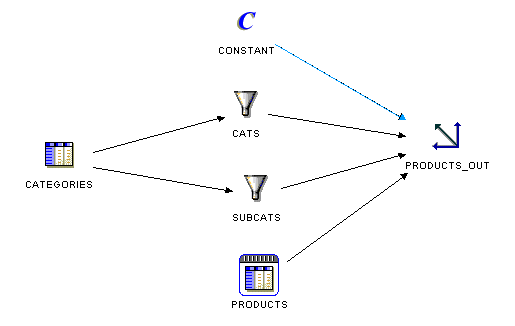
図6-1 PRODUCTSディメンションにデータをロードするマッピングを演算子PRODUCTS_OUTで表しています。ソース・データはCATEGORIESおよびPRODUCTSという2つの表に格納されています。CATEGORIES表には、カテゴリおよびサブカテゴリ情報の両方が格納されています。そのため、この表のデータは2つのフィルタ演算子CATSおよびSUBCATSを使用してフィルタされます。フィルタされたデータはこの後CATEGORIESレベルおよびSUBCATEGORIESディメンション・レベルにマップされます。ディメンションのTOTALレベルは定数演算子を使用してロードされます。PRODUCTS表のデータはディメンション内のPRODUCTSレベルに直接マップされます。
ディメンションをロードするためのデータ・フローを定義する場合、データを実際にディメンションにロードするインライン・プラッガブル・マッピングが作成されます。このプラッガブル・マッピングを表示するには、マッピング・エディタのキャンバスでディメンション演算子を選択し、グラフィカル・ツールバーの「子グラフの表示」をクリックします。
タイプ2のSCDは、過去レコードと現行レコードの両方を保存します。タイプ2のSCD内のトリガー属性の値が変更されると、現行のレコードはクローズ済としてマーク付けされて、変更された値を含む新規レコードが作成されます。「デフォルトのオープン・レコード終了時間」プロパティで有効期限属性に指定した値を設定すると、レコードはクローズ済としてマークされます。マッピングで定義された接続の入力に関係なく、過去レコードの有効期限は、「デフォルトのオープン・レコード終了時間」プロパティを使用して設定されます。
|
注意: タイプ2のSCDをロードする際、ターゲットがOracle9iデータベースの場合は、行ベース・モードしかサポートされません。問題を回避するには、親サロゲート識別子の参照属性をすべてのレベルに対するトリガーとして設定して、階層バージョニングをオンにします。 |
タイプ2のSCDにレコードをロードする前に、同じビジネス識別子を持つレコードがタイプ2のSCDに存在するかどうかがチェックされます。レコードが存在しない場合、タイプ2のSCDにそのレコードが追加されます。レコードが存在する場合、次の手順が実行されます。
プロパティ「デフォルトのオープン・レコード終了時間」で指定した値を設定し、既存のレコードをクローズ済としてマークします。
変更された属性値を使用して新規レコードを作成します。
そのレベルの有効日入力がマップされていない場合、演算子の「デフォルトのオープン・レコード有効時間」および「デフォルトのオープン・レコード終了時間」プロパティを使用して、有効時間および終了時間が設定されます。
そのレベルの有効日入力がマップされている場合は、新規レコードの有効時間が、有効日入力データ・フローから取得された値に設定されます。有効日入力(接続されている場合)は、各新規レコードの実際の有効日を表します。
タイプ2のSCDにデータをロードする手順
「マッピングの定義」の説明に従って、マッピングを定義します。
ディメンション演算子をマッピングに追加します。この演算子が、データをロードするタイプ2のSCDにバインドされていることを確認します。
マッピングへの演算子の追加は、「マッピングへの演算子の追加」を参照してください。
(オプション)演算子名をクリックして、キャンバス上のディメンション演算子を選択し、プロパティ・インスペクを使用して次のプロパティを設定します。
これらのプロパティの値を明示的に設定しない場合、デフォルト値が使用されます。
ディメンション演算子の「ロード・タイプ」プロパティを「ロード」に設定します。
ソース・オブジェクトに対応する演算子、およびディメンションにソース・データがロードされる前に実行する必要のあるあらゆる変換に対応する演算子を追加します。
属性を、ソース演算子から中間変換演算子(ソース・データをディメンションにロードする前に変換する場合)、ターゲット・ディメンション演算子の順にマップします。必要に応じてすべての属性のマッピングを完了します。
|
注意: タイプ2のSCDの有効期限日属性に、属性をマップできません。 |
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「検証」をクリックし、マッピングを検証します。
必要に応じて検証プロセスからのエラーを解決します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「生成」をクリックし、マッピングを検証します。
生成結果は、「ログ」ウィンドウの新規「結果」タブに表示されます。必要に応じて生成エラーを解決します。
タイプ2のSCDをロードするマッピングでソース演算子の属性をレベルの有効日属性にマップする場合、次の処理が実行されます。
初期レコードのロード中、ソース属性の値が、(タイプ2のSCDにバインドされている)ディメンション演算子の「デフォルトの初期レコード有効時間」プロパティで指定されている値よりも前である場合は、ソースの値がレコードの有効日として使用されます。前ではない場合は、「デフォルトの初期レコード有効時間」プロパティに指定されている値がレコードの有効日として使用されます。
後続レコードのロード中、レコードがバージョン管理されている場合、新しいレコードの有効時間はソースから取得されます。有効時間に値が指定されていない場合、SYSDATEが使用されます。クローズ済レコードの終了時間は、新しいレコードの有効時間からギャップを引いた値に設定されます。
ソースの属性をレベルの有効日属性にマップしない場合、次の処理が実行されます。
初期レコードのロード中、「デフォルトの初期レコード有効時間」プロパティに指定されている値がレコードの有効日として使用されます。
後続レコードのロード中、新しいバージョンが作成されている場合、新しいレコードの有効時間はソースから取得されます。有効時間に値が指定されていない場合、SYSDATEが使用されます。前のバージョンの終了時間は、新しいバージョンの有効時間からギャップを引いた値に設定されます。
ギャップの詳細は、「Type2 Gap」および「Type2 Gap Units」を参照してください。
|
注意: レベルの有効期限属性へのマッピングは使用できません。レコードのロード中、「デフォルトのオープン・レコード終了時間」プロパティが有効期限として使用されます。このプロパティのデフォルト値はNULLです。 |
例: タイプ2のSCDバージョニング対象レコードに割り当てられた値
タイプ2のSCDであるProductsをロードするマッピングを作成します。このタイプ2のSCDのリーフ・レベルProductは、ソース表からロードされます。Productレベルの有効日属性はソース属性EFF_DATEからマップされます。
ディメンション演算子には、次のプロパティがあります。
デフォルトの初期レコード有効時間: 01-jan-2000
デフォルトのオープン・レコード有効時間: SYSDATE
デフォルトのオープン・レコード終了時間: 01-jan-2099
Type2 Gap: 1
ソースのProductレベルのレコードのEFF_DATEの値が21-mar-2007 10.25.05.000000 PMであるとします。Productレベルの初期レコードがロードされるときに、このレコードに割り当てられる値は次のとおりです。
有効日: 01-jan-2000
有効期限: 01-jan-2099
Productレベルのレコードが21-mar-2007の後続ロード中にバージョン管理されると、次のようになります。
ソース属性の値で「デフォルトのオープン・レコード有効時間」プロパティが上書きされます。新しいProductレベルのレコードに格納される有効日は21-mar-2007になり、有効期限は01-jan-2099に設定されます。
Productレベルの初期レコードはクローズされ、有効期限の値は21-mar-200710.25.04.000000 PMに設定されます。
タイプ3のSCDにデータをロードするには、次の手順を使用します。
「マッピングの定義」の説明に従って、マッピングを定義します。
ディメンション演算子をマッピングに追加します。この演算子が、データをロードするタイプ3のSCDにバインドされていることを確認します。
マッピングへの演算子の追加は、「マッピングへの演算子の追加」を参照してください。
ディメンション演算子の「ロード・タイプ」プロパティを「ロード」に設定します。
ソース・オブジェクトに対応する演算子、およびタイプ3のSCDにソース・データがロードされる前に実行する必要のあるあらゆる変換に対応する演算子を追加します。
属性を、ソース演算子から中間変換演算子(ソース・データをディメンションにロードする前に変換する場合)、ターゲット・ディメンション演算子の順にマップします。必要に応じてすべての属性のマッピングを完了します。
データのロード中、Oracle Warehouse Builderは、同じビジネス識別子を持つレコードがタイプ3のSCDに存在するかどうかをチェックします。レコードが存在しない場合は、追加されます。レコードが存在する場合、次の手順が実行されます。
バージョン属性の値は、バージョン属性の以前の値を格納する属性に移動されます。
レコードはソース・レコードの値で更新されます。
ディメンション演算子の「ロード・タイプ」プロパティを「ロード」に設定します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「検証」をクリックし、マッピングを検証します。
必要に応じて検証プロセスからのエラーを解決します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「生成」をクリックし、マッピングを検証します。
生成結果は、「ログ」ウィンドウの新規「結果」タブに表示されます。必要に応じて生成エラーを解決します。
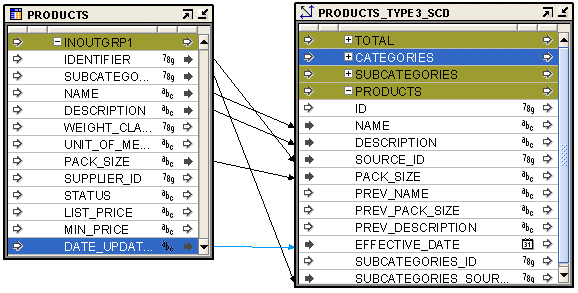
図6-2 に、タイプ3 SCDのPRODUCTSレベルにデータをロードするマッピングを示します。このマッピングでは、レコードの有効時間がソースからロードされます。デフォルトの現行レコード有効時間プロパティを使用して、レベル・レコードの有効時間のデフォルト値を設定することもできます。
バージョン属性の以前の値を表す属性にはデータ・フローをマップできません。
たとえば、図6-2に示すマッピングでは、PRODUCTSレベルのPREV_PACK_SIZEおよびPREV_DESCRIPTION属性に属性をマップできません。
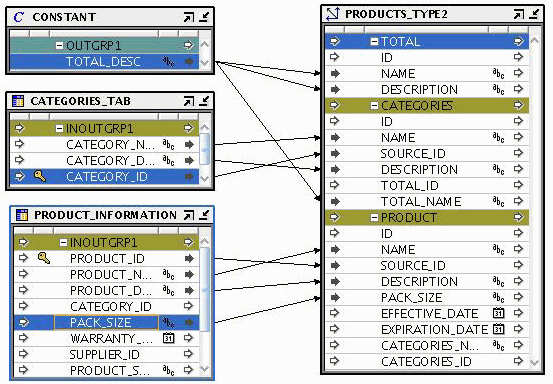
タイプ2 SCD PRODUCTS_TYPE2には、Total、Categories、およびProductのレベルが含まれます。Productはリーフ・レベルで、その属性のPack_sizeはバージョニング対象属性です。Effective_date属性およびexpiration_date属性は、製品レコードについてそれぞれ有効日と有効期限を格納します。
このディメンションにロードされるソース・データは、Categories_tabおよびProduct_informationという2つの表に格納されます。タイプ2 SCDの最上位の名前と説明は、定数演算子のTotal_desc属性を使用してロードされます。
PRODUCTS_TYPE2 Type 2 SCDにデータをロードするには、次の手順を使用します。
「マッピングの定義」の説明に従って、マッピングを定義します。
プロジェクト・ナビゲータから「PRODUCTS_TYPE2 Type 2 SCD」、「Categories_tab」表、および「Product_information」表をマッピング・キャンバスにドラッグ・アンド・ドロップします。
ディメンション演算子の「ロード・タイプ」プロパティを「ロード」に設定します。
キャンバスでディメンション演算子を選択します。プロパティ・インスペクタに、ディメンションのプロパティが表示されます。「ディメンション・プロパティ」ノードに「ロード・タイプ」がリストされます。
マッピング・キャンバスに「TOTAL」レベルをロードするために使用する定数演算子をドラッグ・アンド・ドロップします。
また、Total_descという出力属性をこの演算子に追加します。Total_desc演算子の「式」プロパティを、total_nameおよびtotal_desc属性に割り当てる値に設定します。
ソース演算子からタイプ2 SCDへ属性をマップします。
図6-3 に、ターゲットにマップされるソース演算子を含むマッピングを示しています。タイプ2 SCD。
この例では、レコードの有効時間がソースからロードされます。デフォルトの現行レコード有効時間プロパティを使用して、SYSDATEなどのデフォルト値に設定することも選択できます。
値が履歴のロギング・プロパティに明示的に割り当てられていないため、デフォルト値が使用されます。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「検証」をクリックし、マッピングを検証します。
必要に応じて検証プロセスからのエラーを解決します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「生成」をクリックし、マッピングを検証します。
生成結果は、「ログ」ウィンドウの新規「結果」タブに表示されます。必要に応じて生成エラーを解決します。
タイプ2 SCDにデータをロードするマッピングが設計されました。実際にソース表からタイプ2のSCDにデータを移動するには、このマッピングを配布して実行する必要があります。マッピングの配布と実行については、「ETLジョブの開始」を参照してください。
マッピングのソースとしてのディメンション演算子を使用すると、ワークスペース・ディメンション、緩やかに変化するディメンション(SCD)および時間ディメンションに格納されているデータを抽出できます。
|
注意: MOLAP実装を使用するディメンションからデータを抽出することはできません。 |
次の手順に従い、ディメンションに格納されているデータを抽出するマッピングを定義します。
「マッピングの定義」の説明に従って、マッピングを定義します。
ディメンション演算子をマッピングに追加します。この演算子が、データ抽出元のディメンションにバインドされていることを確認します。
マッピングへの演算子の追加は、「マッピングへの演算子の追加」を参照してください。
ターゲット・オブジェクトに対応する演算子、およびターゲットにディメンション・データがロードされる前に実行する必要のあるあらゆる変換に対応する演算子を追加します。
属性を、ディメンション・レベルからターゲット演算子またはソース・データを変換する中間演算子にマップします。必要に応じてすべての属性のマッピングを完了します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「検証」をクリックし、マッピングを検証します。
必要に応じて検証プロセスからのエラーを解決します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「生成」をクリックし、マッピングを検証します。
生成結果は、「ログ」ウィンドウの新規「結果」タブに表示されます。必要に応じて生成エラーを解決します。
ディメンション演算子を含むマッピングを使用して、タイプ2 SCDに格納されているデータを抽出します。ディメンション演算子は、ソース・データを含むタイプ2 SCDにバインドされている必要があります。
タイプ2 SCDは、単一レコードの複数のバージョンを保存するため、抽出するレコードのバージョンを指定する必要があります。現行バージョンのレコードを抽出するには、ディメンション演算子の「タイプ2 現行のみ抽出/削除」プロパティを「はい」に設定します。履歴レコードも含め、すべてのレコードを抽出するには、「タイプ2 現行のみ抽出/削除」プロパティを「いいえ」に設定します。
さらに、ディメンション演算子のプロパティである「デフォルトの初期レコード有効時間」、「デフォルトのオープン・レコード有効時間」、「デフォルトのオープン・レコード終了時間」、「Type2 Gap」および「Type2 Gap Units」を設定できます。これらのプロパティで、タイプ2 SCD内のバージョニング対象属性に値を割り当てることができます。これらすべてのプロパティは、ディメンション演算子のプロパティ・インスペクタに表示されているようにデフォルト値が用意されています。これらのプロパティに明示的に値を割り当てない場合は、デフォルト値が使用されます。
タイプ2 SCDからデータを抽出するマッピングの定義手順は、次のとおりです。
「マッピングの定義」の説明に従って、マッピングを定義します。
ディメンション演算子をマッピングに追加します。この演算子が、データの抽出元であるタイプ2のSCDにバインドされていることを確認します。
マッピングへの演算子の追加は、「マッピングへの演算子の追加」を参照してください。
ターゲット・オブジェクトに対応する演算子、およびターゲットにタイプ2 SCDデータがロードされる前に実行する必要のあるあらゆる変換に対応する演算子を追加します。
属性を、ソース・タイプ2 SCDからターゲット演算子またはソース・データを変換する中間演算子にマップします。必要に応じてすべての属性のマッピングを完了します。
抽出するタイプ2 SCDからソース・レコードのバージョンを指定します。
現行レコードを抽出するには、「タイプ2 現行のみ抽出/削除」プロパティを「はい」に設定します。
履歴レコードを抽出するには、「タイプ2 現行のみ抽出/削除」プロパティを「いいえ」に設定します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「検証」をクリックし、マッピングを検証します。
必要に応じて検証プロセスからのエラーを解決します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「生成」をクリックし、マッピングを検証します。
生成結果は、「ログ」ウィンドウの新規「結果」タブに表示されます。必要に応じて生成エラーを解決します。
ディメンション演算子を含むマッピングを使用して、タイプ3 SCDからデータを抽出します。演算子は、ソース・データを含むタイプ3 SCDにバインドされている必要があります。
タイプ3 SCDは、個別の属性を使用して、バージョニング対象属性の履歴値を格納します。現行レコードまたは過去値を抽出するかどうかによって、タイプ3 SCD内の属性をターゲット演算子にマップします。
タイプ3 SCDからデータを抽出するマッピングの定義手順は、次のとおりです。
「マッピングの定義」の説明に従って、マッピングを定義します。
ディメンション演算子をマッピングに追加します。この演算子が、データの抽出元であるタイプ3のSCDにバインドされていることを確認します。
マッピングへの演算子の追加は、「マッピングへの演算子の追加」を参照してください。
ターゲット・オブジェクトの演算子、およびターゲットにディメンション・データがロードされる前に必要となるあらゆる変換に対応する演算子を追加します。
属性を、ソース・タイプ3 SCDからターゲット演算子またはソース・データを変換する演算子にマップします。
履歴データを抽出するには、以前のバージョン属性の値を表す属性をターゲットまたは中間演算子にマップします。
現行レコードを抽出するには、レベル属性を格納する属性をターゲットまたは中間演算子にマップします。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「検証」をクリックし、マッピングを検証します。
必要に応じて検証プロセスからのエラーを解決します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「生成」をクリックし、マッピングを検証します。
生成結果は、「ログ」ウィンドウの新規「結果」タブに表示されます。必要に応じて生成エラーを解決します。
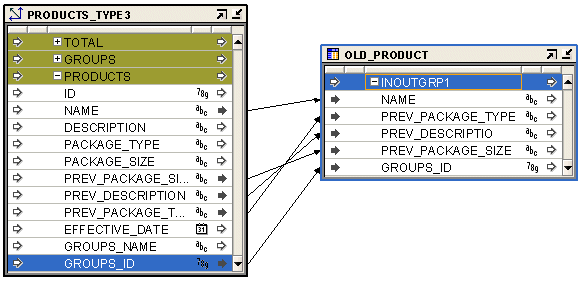
図6-4 に、タイプ3のディメンションPRODUCTSから履歴データ・レコードをソーシングするマッピングを示します。この例では、履歴データをソーシングするために、PREV_DESCRIPTION、PREV_PACKAGE_TYPE、またはPREV_PACKAGE_SIZE属性を使用しています。現在のデータをソーシングするには、DESCRIPTION、PACKAGE_TYPE、またはPACKAGE_SIZEを使用します。
ディメンションおよびSCDからデータを移動するには、ディメンション演算子を使用します。ディメンション演算子、ディメンションから削除する必要のあるデータを含むソース・オブジェクト、およびあらゆる必要な変換演算子を持つマッピングを作成します。ソースまたは変換演算子からの属性をディメンション演算子にマップします。マップが実行されると、ソース・レコードのビジネス識別子がディメンションのビジネス識別子と比較されます。ビジネス識別子が一致すると、ディメンション内の対応するレコードが削除されます。
ディメンションまたはSCDからデータを削除するには、ディメンション演算子の「ロード・タイプ」プロパティを「削除」に設定します。
ディメンション・データ削除でのサロゲート・キーの影響
サロゲート・キーを使用して作成されたディメンションからデータを削除すると、既存の子レコードの親レコードは削除されますが、子レコードは存在しない親を参照したままで残ります。
サロゲート・キーを指定せずに作成したディメンションからデータを削除すると、既存の子レコードの親レコードと、その子レコードが削除されます。これは、カスケード操作に影響します。
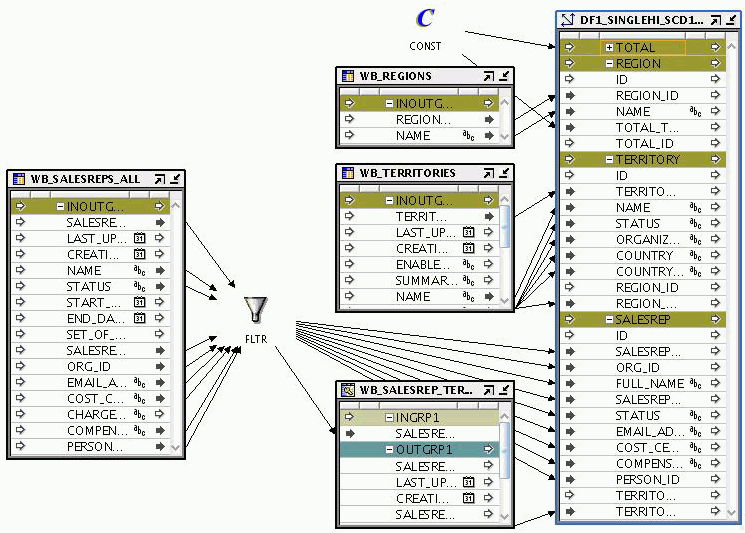
DF1_SINGLEH1_SCD1は、Total、Region、TerritoryおよびSalesrepのレベルを含むディメンションです。このディメンションは、別のマッピングを使用してこれよりも前にロードされた既存のデータを含みます。表WBSALESREP_ALL、WB_REGIONS、WB_TERRITORIESおよびWBSALESREPTERRITORIESは、ディメンションの様々なレベルから削除される必要のあるデータを含みます。
DF1_SINGLEH1_SCD1ディメンションからデータを削除する手順は、次のとおりです。
「マッピングの定義」の説明に従って、マッピングを定義します。
DF1_SINGLEH1_SCD1ディメンションを、プロジェクト・ナビゲータからマッピング・キャンバスにドラッグ・アンド・ドロップします。
ディメンション演算子の「ロード・タイプ」プロパティを「削除」に設定します。
プロジェクト・ナビゲータから、WBSALESREP_ALL、WB_REGIONS、WB_TERRITORIESおよびWBSALESREPTERRITORIESの表をマッピング・キャンバスにドラッグ・アンド・ドロップします。
定数演算子をマッピングに追加します。2つの出力属性のIDおよび名前を作成します。両方の属性の「式」プロパティに、Totalレベルから削除する値を割り当てます。
たとえば、IDの式属性を100に、NameをAsiaに設定する場合、Totalレベルのすべてのレベルのレコードにおいて、IDとNameが設定した値と一致するものが削除されます。また、定数演算子のID属性がRegion属性にマップされているため、削除されるTotalレベル・レコードのすべての子レコードも同様に削除されます。
ソース演算子からの属性をディメンション演算子にマップします。
図6-5 に、ディメンション演算子に接続される属性を含むマッピングを示しています。
ソース・レコードのビジネス識別子は、マップされるディメンション・レベル・レコードのビジネス識別子と比較されます。ビジネス識別子が一致すると、ディメンションから対応するレコードが削除されます。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「検証」をクリックし、マッピングを検証します。
必要に応じて検証プロセスからのエラーを解決します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「生成」をクリックし、マッピングを検証します。
生成結果は、「ログ」ウィンドウの新規「結果」タブに表示されます。必要に応じて生成エラーを解決します。
ディメンションからデータを削除するマッピングが設計されました。指定したデータをディメンションから実際に削除するには、このマッピングを配布して実行する必要があります。マッピングの配布と実行については、「ETLジョブの開始」を参照してください。
キューブ演算子によって、データをキューブから抽出、キューブにロード、およびキューブから削除することができます。キューブからデータを抽出するには、マッピングのソースとしてのキューブ演算子を使用します。
|
注意: MOLAP実装を使用するキューブからデータを抽出することはできません。 |
データをキューブにロードするのか、キューブから削除するのかを指定するには、キューブ演算子の「ロード・タイプ」プロパティを使用します。キューブについては、ロード・タイプのプロパティに、「LOAD」、「INSERT_LOAD」、「REMOVE」の3つがあります。
キューブ演算子にはACTIVE_DATEと呼ばれる属性が含まれています。この属性は、タイプ2のSCD内のどのレコードがアクティブ・レコードであるかを決定するために使用される時点を示します。このプロパティは、ロード中のキューブにタイプ2のSCDが1つ以上存在する場合にのみ適用可能です。
ソースの属性をACTIVE_DATEにマップしない場合、デフォルトとしてSYSDATEが使用されます。
ソースの属性をACTIVE_DATEにマップした場合、ソースの属性の値を使用して、キューブ・レコードで参照されるタイプ2のSCDレコードのバージョンが決定されます。レベルがタイプ2のSCDであるディメンションを参照するキューブの場合、ディメンション・メンバーを決定するために生成されるWHERE句は次のとおりです。
...
WHERE
(...
(<dim_name>.DIMKEY = <lookup_for_dimension_dimkey> AND
(<level>_EFFECTIVE_DATE <= ACTIVE_DATE AND
<level>_EXPIRATION_DATE >= ACTIVE_DATE) OR
(<level>_EFFECTIVE_DATE <= ACTIVE_DATE AND
<level>_EXPIRATION_DATE IS NULL))
...)
キューブをロードするマッピングで、「デフォルトのオープン・レコード終了時間」がNULL以外の値に設定されているタイプ2のSCDを1つ以上参照する場合、キューブ演算子のACTIVE_DATE属性は、ディメンション・レコードの範囲を定義する日付値が含まれているソースからマップされる必要があります。
ACTIVE_DATE属性がソースからマップされていない場合は、SYSDATE値によってディメンション・レコードの日付範囲が定義されます。
ACTIVE_DATE属性がソースからマップされた場合、ソースの属性値を使用して範囲の比較が実行され、ロードする必要があるディメンション・レコードが決定されます。
前述のWHERE句を使用して、ディメンション・メンバーの参照を実行する際に使用するロジックを記述します。
キューブをロードする場合、ソースのデータ・フローを、参照レベルのビジネス識別子を表す属性にマップします。Oracle Warehouse Builderによりディメンションの参照が実行され、該当するサロゲート識別子がキューブ表に格納されます。たとえば、属性をディメンション演算子からキューブ演算子にマップする場合は、ディメンションのサロゲート識別子の検索に必要であれば、キー参照演算子が作成されます。
参照条件で複数の行が戻される可能性がある場合は、戻された行から1行のみ選択するようにしてください。これは、デュプリケータ解除演算子またはフィルタ演算子を使用して実行できます。
キューブにデータをロードするには、次の手順を使用します。
「マッピングの定義」の説明に従って、マッピングを定義します。
キューブ演算子をマッピングに追加します。この演算子が、データをロードするキューブにバインドされていることを確認します。
マッピングへの演算子の追加は、「マッピングへの演算子の追加」を参照してください。
ソース・オブジェクトに対応する演算子、およびディメンションにソース・データがロードされる前に実行する必要のあるあらゆる変換に対応する演算子を追加します。すべてのソース・データ・オブジェクトがリポジト・リオブジェクトにバインドされていることを確認します。
属性を、ソース演算子から中間変換演算子(ソース・データをディメンションにロードする前に変換する場合)、ターゲット・キューブの順にマップします。必要に応じてすべての属性のマッピングを完了します。
キューブ演算子の「ロード・タイプ」プロパティを「ロード」に設定します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「検証」をクリックし、マッピングを検証します。
必要に応じて検証プロセスからのエラーを解決します。
プロジェクト・ナビゲータ内のマッピングを選択して、ツールバーにある「生成」をクリックし、マッピングを検証します。
生成結果は、「ログ」ウィンドウの新規「結果」タブに表示されます。必要に応じて生成エラーを解決します。
|
注意: キューブのソース・データがディメンション参照に無効な値またはNULL値を含む場合、孤立管理またはDMLエラー・ロギングを使用して後続キューブのロード中の潜在的な問題を回避することをお薦めします。 |
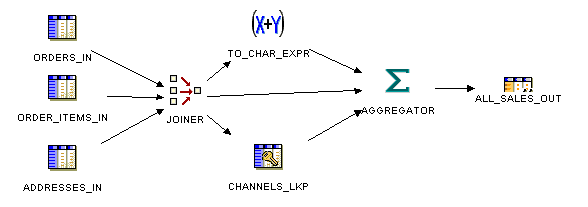
図6-6 では、キューブ演算子をターゲットとして使用するマッピングを示します。3つのソース表からのデータは、ジョイナ演算子を使用して結合されます。結合データと他のソース表からのデータの集計には、アグリゲータ演算子が使用されます。アグリゲータ演算子の出力は、キューブ演算子にマップされます。