| Oracle® Clusterware管理およびデプロイメント・ガイド 11gリリース2 (11.2) B56289-08 |
|


 前 |
 次 |
この章では、Oracle Grid Infrastructureホームをクローニングする方法およびクローニングされたホームを使用してクラスタを作成する方法について説明します。この章のクローニング手順を実行するには、サイレント・モードでスクリプトを使用します。クローニング手順は、LinuxおよびUNIXシステムに適用できます。この章の例ではLinuxおよびUNIXのコマンドを使用しますが、通常、クローニングの概念および手順はすべてのプラットフォームに適用されます。
|
注意: この章は、次のように構成されたOracle Clusterware 11gリリース2(11.2)インストールをクローニングすることを前提としています。
|
内容は次のとおりです。
クローニングとは、既存のOracle Clusterwareインストールを別の場所にコピーし、その後、コピーしたインストールを新しい環境で動作するよう更新するプロセスです。クローニング元のOracle Grid Infrastructureホームに適用済の個別パッチによる変更は、クローニング後も継承されます。クローニング中には、Oracle Grid Infrastructureホームのインストールで実行された操作を再実行するスクリプトを実行します。
クローニングには、正常にインストールされたOracle Grid Infrastructureホームを使用することが必要です。このホームを、Oracle Grid Infrastructureホームを拡張するスクリプト実装のベースにして、元のGridホームに基づくクラスタを作成します。
手動でのクローニング・スクリプトの作成では、入力を検証する対話形式のチェックを使用せずにスクリプトを準備するため、エラーが発生しやすくなる場合があります。ただし、数十または数百のクラスタに対して単一スクリプトを実行するような場合には、この最初の作業は意味があります。インストールするクラスタが1つのみの場合は、Oracle Universal Installer(OUI)またはOracle Enterprise ManagerのProvisioning Pack機能など、従来の自動化された対話形式のインストール方法を使用してください。
|
注意: クローニングは、Provisioning Packの一部であるOracle Enterprise Managerクローニングの代替機能ではありません。Oracle Enterprise Managerによるクローニングでは、プロビジョニング・プロセスによってOracleホームの詳細が対話形式で確認されることで、クローニングが単純化されています。対話時の質問では、クローニングされた環境のデプロイ先、Oracle Databaseホームの名前、クラスタ内のノードのリストなどが確認されます。 |
Oracle Enterprise Manager Grid ControlのProvisioning Pack機能では、ノードおよびクラスタのプロビジョニングを自動化するフレームワークが提供されています。多数のクラスタを持つデータ・センターの場合、既存のクラスタに新規クラスタおよび新規ノードをプロビジョニングするためのクローニング手順を作成する作業は、その労力に見合った価値があります。
次のリストに、クローニングが有効ないくつかの状況を示します。
クローニングにより、Oracle Grid Infrastructureホームを1回準備するだけで、多数のホストに同時にデプロイされます。非対話形式のプロセスとして、サイレント・モードでインストールを完了できます。グラフィカル・ユーザー・インタフェース(GUI)のコンソールを使用する必要がなく、必要に応じて、セキュア・シェル(SSH)・ターミナル・セッションからクローニングを実行できます。
クローニングにより、すべてのパッチが適用されたインストール(本番、テスト、または開発用インストールのコピー)を1回の手順で作成できます。ベース・インストールを実行してソース・システムにすべてのパッチ・セットとパッチを適用した後は、クローニングにより、それらの個別の手順はすべて単一の手順で実行されます。これにより、クラスタの各ノードですべてのインストール・プロセスを通して行い、インストール、構成およびパッチ適用を個別の手順で実行するのとは、対照的な効果が得られます。
クローニングによるOracle Clusterwareのインストールでは、非常に短時間で処理を完了できます。たとえば、3つ以上のノードを持つクラスタにOracle Grid Infrastructureホームをクローニングする場合、必要な時間は、Oracleソフトウェアのインストールにかかる数分間と各ノードにかかる数分間を合わせた時間(合計時間はroot.shスクリプトの実行にかかる時間とほぼ等しい)となります。
クローニングでは、複数のクラスタで同一のOracle Clusterwareインストールを正確に繰り返すための確実な方法が提供されます。
クローニングされたインストールは、クローニング元のインストールと同じ動作をします。たとえば、クローニングされたOracle Grid Infrastructureホームは、OUIを使用して削除したり、OPatchを使用してパッチを適用することができます。また、クローニングされたOracle Grid Infrastructureホームを、別のクローニング操作のソースとして使用できます。コマンドラインのクローニング・スクリプトを使用して、テスト用、開発用または本番用のインストールをクローニングしたコピーを作成できます。
多くの場合、デフォルトのクローニング手順で十分です。さらに、カスタム・ポート割当ての指定や、カスタム設定の保存など、クローニングの様々な側面をカスタマイズすることもできます。
クローニング・プロセスでは、クローニング元のOracle Grid Infrastructureホームからクローニング先のOracle Grid Infrastructureホームにすべてのファイルをコピーします。Oracle Grid Infrastructureホームは、ローカル(非共有)ホームまたは共有ホームのどちらの場合でもクローニングできます。したがって、ソース・インスタンスで使用されているファイルの中で、クローニング元のOracle Grid Infrastructureホームのディレクトリ構造の外部に置かれているものがある場合、それはクローニング先にコピーされません。
ソースおよび宛先のバイナリ・ファイルのサイズは異なる場合がありますが、これはクローニング操作の一部としてこれらのファイルが再リンクされており、これら2つの位置のオペレーティング・システムのパッチ・レベルが異なっていることがあるためです。また、ソースからコピーされるいくつかのファイル、特にインスタンス化されているファイルは、クローニング操作の一部としてバックアップされるため、クローン・ホームのファイルの数は増加します。
クローニング元のOracle Grid Infrastructureホームでクローニングを準備するには、インストール済のOracle Grid Infrastructureホームのコピーを作成し、別のノードでクローニング手順を実行する際に使用します。次の段階ごとの手順に従って、Oracle Grid Infrastructureホームのコピーを準備します。
『Oracle Grid Infrastructureインストレーション・ガイド』の詳細指示に従って、ソース・ノードで、次の手順を実行します。
Oracle Clusterware 11gリリース2(11.2)をインストールします。このインストールによって、Oracle Cluster Registry(OCR)および投票ディスクがOracle Automatic Storage Management (Oracle ASM)に配置されます。
|
注意: クラスタ用のグリッド・インフラストラクチャをインストールして構成するか、Oracle Clusterwareソフトウェアのみをインストールしてください(ご使用のプラットフォーム固有の『Oracle Grid Infrastructureインストレーション・ガイド』を参照)。 |
クラスタ用のグリッド・インフラストラクチャをインストールして構成した場合は、クローニング手順を実行する前にOracle Clusterwareを停止する必要があります。ソフトウェアのみのインストールを実行する場合は、Oracle Clusterwareを停止する必要はありません。
必要に応じて、適切なパッチ(グリッド・インフラストラクチャ・バンドル・パッチなど)をインストールします。
必要に応じて、個別パッチを適用します。
|
関連項目: Oracle Clusterwareのインストール手順については、『Oracle Grid Infrastructureインストレーション・ガイド』を参照してください。 |
クローニング元のOracle Grid Infrastructureホームをコピーする前に、ノードで実行されているサービス、データベース、リスナー、アプリケーション、Oracle ClusterwareおよびOracle ASMインスタンスをすべて停止します。サーバー制御(SRVCTL)ユーティリティを使用してデータベースを停止してから、Oracle Clusterware制御(CRSCTL)ユーティリティを使用して残りのコンポーネントを停止することをお薦めします。
|
関連項目:
|
インストールしたOracle Grid Infrastructureホームを作業ホームとして保持するために、クローニング元のOracle Grid Infrastructureホームの全体コピーを作成します。
|
ヒント: コピーの作成時には、ファイル名にリリース番号を含めることをお薦めします。 |
次のいずれかの方法を使用して、Oracle Grid Infrastructureホームの圧縮コピーを作成します。
方法1: Oracle Grid Infrastructureホームのコピーを作成し、そのコピーから不要なファイルを削除する
ソース・ノードで、Oracle Grid Infrastructureホームのコピーを作成します。インストールしたOracle Grid Infrastructureホームを作業ホームとして保持するために、クローニング元のOracle Grid Infrastructureホームの全体コピーを作成し、そのコピーから不要なファイルを削除します。たとえば、Linuxシステムでは、rootユーザーとしてcpコマンドを実行します。
# cp -prf Grid_home copy_path
前述のコマンドは、Grid_homeのすべての内容(たとえば、/u01/app/grid/11.2.0)を新しい場所(たとえば、/home/grid/gridcopy)にコピーします。
コピーから不要なファイルを削除します。
Oracle Grid Infrastructureホームには、ソース・ノードにのみ関連するファイルが含まれているため、log、crs/init、crfおよびcdataディレクトリのグリッド・インフラストラクチャ・ホームのコピーから不要なファイルを削除できます。次に、LinuxおよびUNIXシステムでOracle Grid Infrastructureホームのコピーから不要なファイルを削除する場合に実行するコマンドの例を示します。
[root@node1 root]# cd copy_path [root@node1 grid]# rm -rf crs/install/crsconfig_addparams [root@node1 grid]# rm -rf host_name [root@node1 grid]# rm -rf log/host_name [root@node1 grid]# rm -rf gpnp/host_name [root@node1 grid]# find gpnp -type f -exec rm -f {} \; [root@node1 grid]# find cfgtoollogs -type f -exec rm -f {} \; [root@node1 grid]# rm -rf crs/init/* [root@node1 grid]# rm -rf cdata/* [root@node1 grid]# rm -rf crf/* [root@node1 grid]# rm -rf network/admin/*.ora [root@node1 grid]# find . -name '*.ouibak' -exec rm {} \; [root@node1 grid]# find . -name '*.ouibak.1' -exec rm {} \; [root@node1 grid]# rm -rf root.sh*
LinuxおよびUNIXシステムではtarまたはgzipを使用して、前述のコピー済Oracle Grid Infrastructureホームの圧縮コピーを作成します。使用するツールによって、権限およびファイル・タイムスタンプが保持されることを確認してください。次に例を示します。
LinuxおよびUNIXシステムの場合:
[root@node1 root]# cd copy_path [root@node1 grid]# tar -zcvpf /copy_path/gridHome.tgz .
前述の例で、cdコマンドは、この手順の最初の2つの手順で作成したOracle Grid Infrastructureのホームのコピー(不要なファイルは削除済み)に場所を変更し、tarコマンドはgridHome.tgzという名前のファイルを作成します。tarコマンドで、copy_pathは、Oracle Grid Infrastructureホームのコピーの場所を表します。
AIXまたはHPUXシステムの場合は、次のコマンドを発行します。
tar cpf - . | compress -fv > temp_dir/gridHome.tar.Z
Windowsシステムで、WinZipを使用してzipファイルを作成します。
方法2: -Xオプションを使用してOracle Grid Infrastructureホームの圧縮コピーを作成する
Oracle Grid Infrastructureホーム内の不要なファイルを示すファイルを作成します。たとえば、excludeFileListというファイルに、アスタリスク(*)のワイルドカードを使用して次のファイル名を示します。
Grid_home/host_name Grid_home/log/host_name Grid_home/gpnp/host_name Grid_home/crs/init/* Grid_home/cdata/* Grid_home/crf/* Grid_home/network/admin/*.ora Grid_home/root.sh* *.ouibak *.ouibak1
tarコマンドまたはWinzipを使用して、Oracle Grid Infrastructureホームの圧縮コピーを作成します。たとえば、LinuxおよびUNIXシステムでは、次のコマンドを実行して、クローニング元のOracle Grid Infrastructureホームをアーカイブおよび圧縮します。
tar cpfX - excludeFileList Grid_home | compress -fv > temp_dir/gridHome.tar.Z
|
注意: Oracle Grid Infrastructureホームをコピーおよび圧縮するために、jarユーティリティは使用しないでください。 |
この項では、正常にインストールされたOracle Clusterware環境をクローニングし、それをクローニング先のクラスタ上のノードにコピーすることにより、クラスタを作成する方法を説明します。この項の手順では、Linux、UNIXおよびWindowsシステムでクローニングを使用する方法について説明します。クローニングでクラスタを正常に作成した後、OCRおよび投票ディスクは2つのクラスタ間で共有されません。
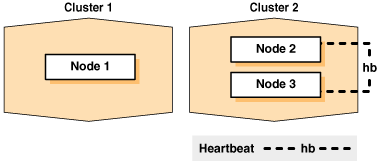
たとえば、クローニングを使用して、正常にインストールされたOracle Clusterware環境を複製し、クラスタを作成することができます。図5-1では、クローニング手順の最終結果を示しており、ここでは、ノード1上のOracle Grid Infrastructureホームがクラスタ2上のノード2およびノード3にクローニングされ、クラスタ2が新規の2ノード・クラスタとして作成されています。
クローニングでクラスタを作成する手順は次のとおりです。
各宛先ノードで、次のインストール前の手順を実行します。
カーネル・パラメータの指定
Oracle Clusterwareデバイス用のブロック・デバイスの構成
ブロック・デバイスの権限が正しく設定されていることの確認
/etc/hostsファイル内のすべての名前に対する短い非ドメイン修飾の名前の使用
pingコマンドによる、インターコネクト・インタフェースが到達可能かどうかのテスト
pingコマンドによる、クローニング・プロセスの開始時にVIPアドレスがアクティブでないことの検証(VIPアドレスのpingコマンドは失敗する必要があります)
次のOracle Automatic Storage Management Cluster File Systemチューニング可能ファイルをソース・ノードから各宛先ノードにコピーします。
LinuxおよびUNIXの場合: /etc/sysconfig/advmtunablesおよび/etc/sysconfig/acfstunables
AIXの場合: /etc/advmtunablesおよび/etc/acfstunables
Solarisの場合: /etc/advmtunablesおよび/etc/acfstunables
Windowsの場合: C:\windows\system32\drivers\advm\tunablesおよびC:\windows\system32\drivers\acfs\tunables
ベンダーのクラスタウェアを実行しているAIXシステムおよびSolaris x86-64-bitシステムでクラスタにノードを追加する場合は、クラスタにノードを追加する前に、ノードでrootpre.shスクリプト(DVDからOracle Clusterwareをインストールした場合はマウント・ポイント、ソフトウェアをダウンロードした場合はtarファイルを解凍したディレクトリにあります)を実行する必要があります。
CVUの実行によるハードウェアおよびオペレーティング・システム環境の検証
インストール前の全チェックリストは、ご使用のプラットフォーム固有のOracle Clusterwareインストレーション・ガイドを参照してください。
|
注意: 従来のインストール方法とは異なり、クローニング・プロセスでは、準備フェーズ中に入力が検証されません。(これと比較して、OUIを使用した従来のインストール方法では、インタビュー・フェーズ中に様々なチェックが実行されます。)したがって、ハードウェア設定または準備フェーズ中にミスをすると、クローニング・インストールは失敗します。 |
この項で説明しているクローニング手順を開始する前に、Oracle Grid Infrastructureホームのコピーを作成するための必須タスクを完了していることを確認してください(「Oracle Grid Infrastructureホームをクローニングするための準備」を参照)。
各宛先ノードに、「手順3: Oracle Grid Infrastructureホームのコピーの作成」で作成したOracle Grid Infrastructureホームのコピーを次のようにデプロイします。
Oracle Grid Infrastructureホームが共有ホームでない場合は、Oracle Grid Infrastructureホームのコピーを宛先クラスタの各ノードにリストアします。ソース・ノードのOracle Grid Infrastructureホームで使用されているディレクトリ構造と同じディレクトリ構造を使用します。Oracle Grid Infrastructureホームが共有ホームの場合、この手順はスキップします。
たとえば、LinuxまたはUNIXシステムで、次のようなコマンドを実行します。
[root@node1 root]# mkdir -p location_of_the_copy_of_the_Grid_home [root@node1 root]# cd location_of_the_copy_of_the_Grid_home [root@node1 crs]# tar -zxvf /path_name/gridHome.tgz
この例で、path_nameはOracle Grid Infrastructureホームのインストール先のディレクトリ構造を表します。クローニング・プロセスでは、Gridホームの場所を変更できます。
Windowsシステムの宛先ノードで、Oracle Grid Infrastructureホームを解凍します。ディレクトリ構造は、Oracle Grid Infrastructureホームが存在するソース・ノードのディレクトリ構造と同じにします。
Oracle Grid Infrastructureホームから不要なファイルを削除していない場合は、「方法1: Oracle Grid Infrastructureホームのコピーを作成し、そのコピーから不要なファイルを削除する」の手順2を繰り返します。
宛先ノードでOracle Inventory用のディレクトリを作成し、必要に応じてOracle Grid Infrastructureホームのすべてのファイルの所有権をOracle Grid Infrastructureインストール所有者およびOracle Inventory(oinstall権限)グループによって所有されるように変更します。次の例では、Oracle Grid Infrastructureインストール所有者がoracleで、Oracle Inventoryグループがoinstallの場合にLinuxシステムでこれを行うコマンドを示します。
[root@node1 crs]# mkdir /u01 [root@node1 crs]# chown oracle:oinstall /u01 [root@node1 crs]# mkdir -p /u01/app/oraInventory [root@node1 crs]# mkdir -p /u01/app/11.2.0/grid
Gridホームで前述の最後のコマンドを実行すると、Oracleバイナリからsetuidおよびsetgidの情報が消去されます。また、次のバイナリからsetuidも消去されます。
Grid_home/bin/extjob Grid_home/bin/jssu Grid_home/bin/oradism
消去された情報をリストアするには、次のコマンドを実行します。
chmod u+s Grid_home/bin/oracle chmod g+s Grid_home/bin/oracle chmod u+s Grid_home/bin/extjob chmod u+s Grid_home/bin/jssu chmod u+s Grid_home/bin/oradism
処理を続行する前に、ソースおよび宛先の両方のノードのGrid_homeディレクトリからすべてのOracleネットワーク・ファイルを削除することも重要です。たとえば、tnsnames.ora、listener.oraまたはsqlnet.oraファイルをすべて削除します。
新しいOracle Clusterware環境を設定する場合、clone.plスクリプトではいくつかの設定値の指定が必要となります。変数の値を指定するには、clone.plスクリプトの実行時にコマンドライン上で入力値を指定するか、またはファイルを作成してそこでクローン変数に値を割り当てるかのいずれかの方法があります。次の説明では、これらの方法を示します。
|
注意: clone.plを実行した後、スクリプトによりorainstRoot.shおよびroot.shを実行するプロンプトが表示されます。orainstRoot.shのみを実行し、「手順4: 構成ウィザードの起動」に進んでください。この構成ウィザードにより、root.shを実行するプロンプトが表示されます。 |
Oracle Grid Infrastructureホームが共有ホームでない場合は、各宛先ノードのGrid_home/clone/binディレクトリに移動して、clone.plスクリプトを実行します(これによって、Oracle Clusterwareの主要なクローニング・タスクが実行されます)。スクリプトを実行するには、複数のパラメータへの入力が必要です。表5-1で、clone.plスクリプトのパラメータについて説明します。
表5-1 clone.plスクリプトのパラメータ
| パラメータ | 説明 |
|---|---|
|
|
クローニング元のOracleベースの完全パス。無効なパスを指定すると、スクリプトは終了します。このパラメータは必須です。 |
|
|
クローニング元のグリッド・インフラストラクチャ・ホームの完全パス。無効なパスを指定すると、スクリプトは終了します。このパラメータは必須です。 |
|
|
クローニング元のホームのOracleホーム名。必要に応じて、 |
|
|
Oracleインベントリの場所。 |
-O'"CLUSTER_
NODES={node_
name,node_
name,...}"'
|
この新しいクラスタに含まれるノードの短縮名のカンマ区切りリスト。 |
-O'"LOCAL_NODE=node_name"'
|
|
CRS=TRUE |
このパラメータは、Oracle Universal Installerインベントリでこのプロパティを設定するために必要です。 |
|
|
OSDBA権限グループとして使用するオペレーティング・システム・グループを指定します。デフォルト値を必要としない場合、このパラメータはオプションです。 |
|
|
OSASM権限グループとして使用するオペレーティング・システム・グループを指定します。デフォルト値を必要としない場合、このパラメータはオプションです。 |
|
|
OSOPER権限グループとして使用するオペレーティング・システム・グループを指定します。デフォルト値を必要としない場合、このパラメータはオプションです。 |
|
|
デバッグ・モードで |
|
|
|
たとえば、LinuxおよびUNIXシステムで次のように指定します。
$ perl clone.pl -silent ORACLE_BASE=/u01/app/oracle ORACLE_HOME=
/u01/app/11.2.0/grid ORACLE_HOME_NAME=OraHome1Grid
INVENTORY_LOCATION=/u01/app/oraInventory -O'"CLUSTER_NODES={node1, node2}"'
-O'"LOCAL_NODE=node1"' CRS=TRUE
Windowsシステムの場合:
|
注意: Windowsでこのコマンドを実行する場合は、-Oオプションを使用しないでください。 |
C:\>perl clone.pl ORACLE_BASE=D:\u01\app\grid ORACLE_HOME=D:\u01\app\grid\11.2.0
ORACLE_HOME_NAME=OraHome1Grid "CLUSTER_NODES={node1, node2}"
"LOCAL_NODE=node1" CRS=TRUE
前述の例に示す様々なパラメータの詳細は、表5-1を参照してください。
Oracle Grid Infrastructureホームが共有ホームの場合は、この手順のコマンド例に-cfsオプションを追加し、クラスタ・ファイル・システムの完全なパス位置を指定します。
clone.plスクリプトは取得したパラメータの値に依存するため、括弧、一重引用符および二重引用符は正確に使用する必要があります。エラーの発生を回避するために、例5-1に示すstart.shスクリプトに類似したファイルを作成して、そこでclone.plスクリプトに対する環境変数およびクローニング・パラメータを指定できます。
例5-1は、clone.plスクリプトをコールするstart.shというサンプル・スクリプトからの抜粋を示しており、例はcrsclusterというクラスタ用に構成されています。Oracle Clusterwareをインストールしたオペレーティング・システム・ユーザーとしてスクリプトを実行します。
例5-1 Oracle Clusterwareをクローニングするstart.shスクリプトの抜粋
#!/bin/sh ORACLE_BASE=/u01/app/oracle GRID_HOME=/u01/app/11.2.0/grid THIS_NODE=’hostname -s’ E01=ORACLE_BASE=${ORACLE_BASE} E02=ORACLE_HOME=${GRID_HOME} E03=ORACLE_HOME_NAME=OraGridHome1 E04=INVENTORY_LOCATION=${ORACLE_BASE}/oraInventory #C00="-O'-debug'" C01="-O'\"CLUSTER_NODES={node1,node2}\"'" C02="-O'\"LOCAL_NODE=${THIS_NODE}\"'" perl ${GRID_HOME}/clone/bin/clone.pl -silent $E01 $E02 $E03 $E04 $C01 $C02
start.shスクリプトでは、表5-2に示すように、いくつかの環境変数およびクローニング・パラメータが設定されます。表5-2に、環境変数E01、E02、E03、E04(例5-1では太字でしめされている)、およびC01およびC02を示します。
表5-2 clone.plスクリプトに渡される環境変数
| 記号 | 変数 | 説明 |
|---|---|---|
|
|
|
Oracleベース・ディレクトリの場所。 |
|
|
|
Oracle Grid Infrastructureホームの場所。このディレクトリの場所は存在している必要があり、Oracleオペレーティング・システム・グループのoinstallによって所有されている必要があります。 |
|
|
|
Oracle Grid Infrastructureホームの名前。これは、Oracleインベントリに格納されます。 |
|
|
|
Oracleインベントリの場所。このディレクトリの場所は存在している必要があり、最初にOracleオペレーティング・システム・グループのoinstallによって所有されている必要があります。 |
|
|
|
クラスタ内のノードの短縮名のリスト。 |
|
|
|
ローカル・ノードの短縮名。 |
構成ウィザードでは、crsconfig_paramsファイルを簡単に準備することができます。また、(rootcrs.plスクリプトをコールする)root.shスクリプトを実行するように求められ、Oracleバイナリの再リンクとクラスタ検証が実行されます。
次のように、構成ウィザードを起動します。
$ Oracle_home/crs/config/config.sh
オプションで、次のようにレスポンス・ファイルを指定して、構成ウィザードを暗黙的に実行できます。
$ Oracle_home/crs/config/config.sh -silent -responseFile file_name
|
関連項目: レスポンス・ファイルの準備の詳細は、『Oracle Grid Infrastructureインストレーション・ガイドfor Linux』を参照してください。 |
GNSを使用する場合は、クローニングされたクラスタの実行後に、GNSをクラスタに追加することをお薦めします。srvctl add gnsコマンドを使用してGNSを追加します。
|
関連項目: srvctl add gnsコマンドの詳細は、『Oracle Real Application Clusters管理およびデプロイメント・ガイド』 |
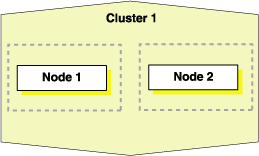
また、クローニングを使用してクラスタにノードを追加することもできます。図5-2では、クローニング手順の最終結果を示しており、ここでは、ノード1上のOracle Grid Infrastructureホームが同じクラスタ上のノード2にクローニングされ、クラスタ2が2ノード・クラスタとして作成されています。クラスタへ新しく追加されたノードは、同じOCRおよび投票ディスクを共有します。
図5-2を例とし、次の手順では、クローニングを使用してクラスタへノードを追加する方法を説明します。この手順では、ノード1はクローニングしたコピーを取得するソース・ノードで、ノード2はノード1のクローンをコピーする宛先ノードです。
「手順1: 新規クラスタ・ノードの準備」で説明されているように、ノード2を準備します。
「手順2: 宛先ノードでのOracle Grid Infrastructureホームのデプロイ」で説明されているように、ノード2でOracle Grid Infrastructureホームをデプロイします。
ノード2のGrid_home/clone/binディレクトリに格納されているclone.plスクリプトを実行します。
次の例は、LinuxまたはUNIXシステムの場合です。
$ perl clone.pl ORACLE_HOME=/u01/app/11.2.0/grid ORACLE_HOME_NAME=OraHome1Grid
ORACLE_BASE=/u01/app/oracle -O'"CLUSTER_NODES={node1, node2}"'
-O'"LOCAL_NODE=node2"' CRS=TRUE
SHOW_ROOTSH_CONFIRMATION=false INVENTORY_LOCATION=/u01/app/oraInventory
前述のコマンドのnode_listは、クラスタ内のすべてのノードのカンマ区切りリストです。
次の例は、Windowsシステムの場合です。
|
注意: Windowsでこのコマンドを実行する場合は、-Oオプションを使用しないでください。 |
C:\>perl clone.pl ORACLE_BASE=D:\u01\app\grid ORACLE_HOME=D:\u01\app\grid\11.2.0
ORACLE_HOME_NAME=OraHome1Grid '"CLUSTER_NODES={node1, node2}"'
'"LOCAL_NODE=node1"' CRS=TRUE
root.shの実行を求めるプロンプトが表示されたら、そのプロンプトを無視して、次の手順に進みます。
この手順はWindowsには適用されません。
ノード2の中央インベントリ・ディレクトリで、rootとしてorainstRoot.shスクリプトを実行します。このスクリプトは、/etc/oraInst.locディレクトリに中央インベントリの場所を移入します。次に例を示します。
[root@node2 root]# /opt/oracle/oraInventory/orainstRoot.sh
複数の宛先ノードで同時にスクリプトを実行することができます。
次のように、ノード1のGrid_home/oui/binディレクトリに格納されているaddNode.sh(WindowsではaddNode.bat)スクリプトを実行します。
$ addNode.sh -silent -noCopy ORACLE_HOME=Grid_home "CLUSTER_NEW_NODES={node2}"
"CLUSTER_NEW_VIRTUAL_HOSTNAMES={node2-vip}" "CLUSTER_NEW_VIPS={node2-vip}"
CRS_ADDNODE=true CRS_DHCP_ENABLED=false
|
注意:
|
次の2つのファイルとgpnpディレクトリを、addnode.shを実行可能なノード1からノード2にコピーします。
Grid_home/crs/install/crsconfig_addparams Grid_home/crs/install/crsconfig_params Grid_home/gpnp
ノード2で、Grid_home/root.shスクリプトを実行します。
|
注意: この例のクラスタのノードは2つのみです。クラスタに複数のノードを追加する場合、すべてのノードでroot.shを同時に実行することができます。 |
次の例はLinuxまたはUNIXシステム用の例です。ノード2で、次のコマンドを実行します。
[root@node2 root]# Grid_home/root.sh
root.shスクリプトにより、次のノード・アプリケーションが自動的に構成されます。
グローバル・サービス・デーモン(GSD)
Oracle Notification Service(ONS)
Oracle Cluster Registry(OCR)の仮想IP(VIP)リソース
単一クライアント・アクセス名(SCAN)VIPおよびSCANリスナー
Oracle ASM
Windowsでは、ノード2で次のコマンドを実行します。
C:\>Grid_home\crs\config\gridconfig.bat
ノード1のOracle_home/oui/binディレクトリに移動し、次の構文を使用してaddNode.shスクリプトを実行します。
$ ./addNode.sh -silent -noCopy "CLUSTER_NEW_NODES={node2}"
|
注意: 宛先ノードのOracleホームが完全にソフトウェアに移入されている場合のみ、-noCopyオプションを使用します。それ以外の場合は、addnode.shスクリプトの実行時に-noCopyオプションを省略し、宛先ノードにソフトウェアをコピーします。 |
rootとしてノード2でOracle_home/root.shスクリプトを実行します(この場合のOracle_homeはOracle RACホームです)。
rootとしてノード2でGrid_home/crs/install/rootcrs.plスクリプトを実行し、前の手順でroot.shを実行したときに生成された説明に従います。
ノード1で次のクラスタ検証ユーティリティ(CVU)・コマンドを実行します。
$ cluvfy stage -post nodeadd -n destination_node_name [-verbose]
クローニング・スクリプトは、それぞれがログ・ファイルを生成できる複数のツールを実行します。clone.plスクリプトの実行が終了した後、これらのログ・ファイルを参照して、クローニング手順のステータスに関する詳細情報を入手することができます。表5-3では、クローニング時に生成される、診断に重要なログ・ファイルを示します。
表5-3 クローニングのログ・ファイルおよび説明
| ログ・ファイルの名前および場所 | 説明 |
|---|---|
Central_inventory/logs/cloneActions/timestamp.log |
クローニングのOUI部分で行われたアクションの詳細ログが含まれます。 |
Central_inventory/logs/oraInstall/timestamp.err |
OUIの実行中に発生したエラーに関する情報が含まれます。 |
Central_inventory/logs/oraInstall/timestamp.out |
その他の情報が含まれます。 |
表5-4は、様々なプラットフォーム用のOracle Inventoryディレクトリの場所を示しています。