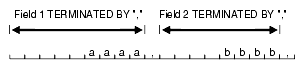| Oracle® Databaseユーティリティ 11gリリース2 (11.2) B56303-08 |
|


 前 |
 次 |
この章では、SQL*Loader制御ファイルのフィールド・リストについて説明します。この章の内容は、次のとおりです。
SQL*Loader制御ファイルのフィールド・リストには、位置、データ型、条件、デリミタなど、ロードするフィールドの情報が提供されます。
例10-1に、「第9章」で説明したサンプル制御ファイルのフィールド・リスト・セクションを示します。
例10-1 サンプル制御ファイルのフィールド・リスト・セクション
. . . 1 (hiredate SYSDATE, 2 deptno POSITION(1:2) INTEGER EXTERNAL(2) NULLIF deptno=BLANKS, 3 job POSITION(7:14) CHAR TERMINATED BY WHITESPACE NULLIF job=BLANKS "UPPER(:job)", mgr POSITION(28:31) INTEGER EXTERNAL TERMINATED BY WHITESPACE, NULLIF mgr=BLANKS, ename POSITION(34:41) CHAR TERMINATED BY WHITESPACE "UPPER(:ename)", empno POSITION(45) INTEGER EXTERNAL TERMINATED BY WHITESPACE, sal POSITION(51) CHAR TERMINATED BY WHITESPACE "TO_NUMBER(:sal,'$99,999.99')", 4 comm INTEGER EXTERNAL ENCLOSED BY '(' AND '%' ":comm * 100" )
このサンプル制御ファイルの左側の数字は、実際の制御ファイルでは表示されません。これらの数字は、次の説明の番号に対応しています。
SYSDATEに、列を現在のシステム日付に設定します。詳細は、「列への現在の日付の設定」を参照してください。
POSITIONに、データ・フィールドの位置を指定します。詳細は、「データ・フィールドの位置指定」を参照してください。
INTEGER EXTERNALは、フィールド用のデータ型です。詳細は、「データ・フィールドのデータ型の指定」および「数値型EXTERNAL」を参照してください。
NULLIF句は、フィールド条件の指定に使用する句の1つです。詳細は、「WHEN、NULLIFおよびDEFAULTIF句の使用」を参照してください。
このサンプルでは、BLANKSパラメータを使用して、フィールドを空白と比較しています。詳細は、「フィールドとBLANKSの比較」を参照してください。
TERMINATED BY WHITESPACE句は、フィールドを指定できるデリミタの1つです。詳細は、「デリミタの指定」を参照してください。
ENCLOSED BY句は、もう1つの使用可能なフィールド・デリミタです。詳細は、「デリミタの指定」を参照してください。
データ・ファイルからデータをロードする場合は、フィールドの位置と長さをSQL*Loaderに対して明示する必要があります。論理レコード中のフィールド位置は、列指定の中でPOSITION句を使用して指定します。このときフィールド位置は、明示的に指定することも、前のフィールドからの相対位置で指定することもできます。POSITIONに対する引数は、カッコで囲む必要があります。文字長セマンティクスをデータ・ファイルに使用しても、start、endおよびintegerは、常にバイト単位です。
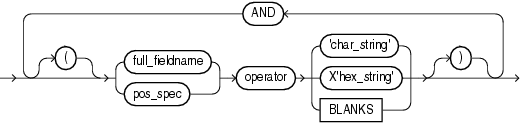
位置指定(pos_spec)句の構文は次のとおりです。

表10-1では、位置指定句のパラメータについて説明します。
表10-1 位置指定句のパラメータ
| パラメータ | 説明 |
|---|---|
|
|
論理レコード中のデータ・フィールドの開始位置です。論理レコードの先頭バイト位置は1となります。 |
|
|
論理レコード中のデータ・フィールドの終了位置です。 |
|
|
対象となるデータ・フィールドが前のフィールドの直後にあることを示します。制御ファイル中の最初のデータ・フィールドに対して |
|
+i |
+ |
POSITIONを完全に省略することも可能です。省略した場合のデータ・フィールドの位置指定は、POSITION(*)と指定した場合と同じです。
フィールド位置の指定で、データ・ファイル中にタブが含まれている場合は注意が必要です。SQL*Loaderの拡張SQL文字列機能を使用して、書式化されたレポートのデータをロードするとします。最初に、レポートの印刷出力を見て、すべての文字位置を正確に調べ、制御ファイルを作成します。このような状況でデータをロードしようとすると、無効な数字および欠落フィールドによる多数のエラーが発生し、ロードが失敗する場合があります。
これらの種類のエラーはデータにタブが含まれる場合に発生します。用紙上では、各タブは複数の列に分かれて印刷されます。一方、データ・ファイル内では各タブは単なる1文字です。この結果、データ・ファイルがSQL*Loaderによって読み取られるとき、POSITION指定が正しくなくなります。
この問題を解決するには、データ・ファイル中のタブを探して該当箇所のPOSITION指定を調整するか、フィールドをデリミタで区切ります。
複数表のロードでは、複数のINTO TABLE句を指定します。このとき最初の表の最初の列に対してPOSITION(*)を使用すると、論理レコードの先頭から相対的に位置が計算されます。2番目以降の表の最初の列に対してPOSITION(*)が使用された場合は、その時点で最後にロードされた表の最終列から相対的に位置が計算されます。
したがって、2番目以降のINTO TABLE句の処理開始時に、位置が論理レコードの先頭に自動的に設定されるわけではありません。このため、複数のINTO TABLE句を指定して、同一物理レコード中の異なる箇所を処理できます。例については、「複数の論理レコードの抽出」を参照してください。
論理レコード中のデータには、2つの表の両方ではなく、片方の表のみにロードするデータもあります。その場合は、POSITIONを設定しなおす必要があります。このとき、位置指定を省略するか、またはINTO TABLE句で先頭フィールドに対するPOSITION(*+n)を指定するかわりに、POSITION(1)またはPOSITION(n)を指定します。
siteid POSITION (*) SMALLINT siteloc POSITION (*) INTEGER
これらが最初の2つの列を指している場合、siteidは1列目から始まり、sitelocがその次の列から始まります。
ename POSITION (1:20) CHAR empno POSITION (22-26) INTEGER EXTERNAL allow POSITION (*+2) INTEGER EXTERNAL TERMINATED BY "/"
列enameは、位置1から20までを占める文字データで、その次の列empnoは、位置22から26までを占める数値型データです。列allowは、empnoの終了直後の位置(27)から+2の位置、つまり列29から、スラッシュが検出されるまでのデータとなります。
表の列はいくつでもロードできます。データベース中に定義されていて制御ファイル中で指定されていない列には、NULL値が割り当てられます。
列指定には、列名とその列に入る値の指定を記述します。これらの列指定はカンマで区切って、全体を小カッコで囲みます。
(columnspec,columnspec, ...)
(FILLERのマークが付けられていない)それぞれの列名は、INTO TABLE句で指定した表中の列名に対応させてください。列名にSQLやSQL*Loaderの予約語または特殊文字が含まれているか、大/小文字の区別がある場合は、列名を引用符で囲みます。
列の値をSQL*Loaderで生成する場合は、列指定の中でRECNUMパラメータ、SEQUENCEパラメータまたはCONSTANTパラメータを指定します。詳細は、「SQL*Loaderを使用した入力データの生成」を参照してください。
データ・ファイルから列の値を読み込む場合は、列の値に対応するデータ・フィールドを指定します。このとき、列指定には、データベース表中の列を示す列名(column name)およびデータ・レコード中のフィールドを示すフィールド指定(field specification)を指定します。フィールド指定には、フィールドの位置、データ型、NULL値の制限およびデフォルト値を指定します。
列オブジェクトのロード時に、必ずしもすべての属性を指定する必要はありません。指定しなかった属性には、NULLが設定されます。
BOUNDFILLERまたはFILLERで指定されたFILLERフィールドは、データ・ファイルをマップしたフィールドで、データベースの列とは対応しません。FILLERフィールドは、データ・ファイルがマップされているデータ・フィールドから割り当てられた値です。
FILLERフィールドに関しては次のことに注意してください。
FILLERフィールドの構文は、フィールド名の後にFILLERを付けること以外は、列ベースのフィールドと同じです。
FILLERフィールドには名前がありますが、表にはロードされません。
FILLERフィールドは、引数としてinit_specs(たとえば、NULLIFおよびDEFAULTIF)に使用できます。
FILLERフィールドは、引数として指示句(たとえば、SID、OID、REFおよびBFILE)に使用できます。
FillerフィールドがBFILEなどの指示句で参照され、列オブジェクト内の制御ファイルで宣言されている場合にあいまいな指定を行わないようにするために、フィールド名にオブジェクトの名前を修飾する必要があります。次に、例を示します。
LOAD DATA INFILE * INTO TABLE BFILE1O_TBL REPLACE FIELDS TERMINATED BY ',' ( emp_number char, emp_info_b column object ( bfile_name FILLER char(12), emp_b BFILE(constant "SQLOP_DIR", emp_info_b.bfile_name) NULLIF emp_info_b.bfile_name = 'NULL' ) ) BEGINDATA 00001,bfile1.dat, 00002,bfile2.dat, 00003,bfile3.dat,
FILLERフィールドは、NULLIF句、DEFAULTIF句およびWHEN句のフィールド条件指定で使用できます。ただし、SQL文字列では使用できません。
FILLERフィールドの指定に、NULLIF句またはDEFAULTIF句を含めることはできません。
FILLERフィールドは、TRAILING NULLCOLSが指定されて適用可能な場合、NULLで初期化されます。他のフィールドが、無効なFILLERフィールドを参照している場合は、エラーになります。
FILLERフィールドは、オブジェクトのフィールド・リスト内部またはVARRAYの定義の内部を含む、データ・ファイルのどこにでも指定できます。
バイナリ配列のFILLERには領域が割り当てられていないため、SQL文字列をFILLERフィールドの一部としては指定できません。
FILLERフィールド指定の例を次に示します。
field_1_count FILLER char,
field_1 varray count(field_1_count)
(
filler_field1 char(2),
field_1 column object
(
attr1 char(2),
filler_field2 char(2),
attr2 char(2),
)
filler_field3 char(3),
)
filler_field4 char(6)
フィールドのデータ型を指定することによって、SQL*Loaderでフィールドのデータが処理される方法が決まります。たとえば、INTEGERデータ型を指定するとバイナリ・データとして処理され、INTEGER EXTERNALを指定すると数字を表す文字データとして処理されます。CHARを指定したフィールドには、すべての文字データを含むことができます。
各フィールドに対して指定できるデータ型は1つのみです。データ型を指定しない場合は、CHARが想定されます。
SQL*Loaderデータ型からOracleデータ型への変換処理およびSQL*Loaderの各データ型の詳細は、「SQL*Loaderのデータ型」を参照してください。
データ型を指定する前に、フィールドの位置を指定する必要があります。
SQL*Loaderデータ型は、移植可能なデータ型と移植不能なデータ型に分類されます。さらに、これら2つのグループは、VALUE データ型およびLENGTH-VALUE データ型に分類されます。
移植可能なデータ型および移植不能なデータ型は、データ型のプラットフォーム依存性によって分類されます。プラットフォーム依存性は、異なるプラットフォームのバイト順序スキーム(ビッグ・エンディアンとリトル・エンディアン)の違い、プラットフォームのビット数(16ビット、32ビット、64ビット)の違い、符号付き数表現のスキーマの違い(2の補数と1の補数)などの様々な理由から存在します。バイト順序スキーム、プラットフォームのワード長などの場合は、SQL*Loaderで、プラットフォーム依存性を解決するメカニズムが提供されます。これらのメカニズムの詳細は、該当するデータ型の説明を参照してください。
移植可能なデータ型および移植不能なデータ型の両方ともVALUEまたはLENGTH-VALUEをとることができます。VALUEデータ型のデータ・フィールド部分は単一であるとします。LENGTH-VALUEデータ型では、データ・フィールドが2つのサブフィールド(lengthサブフィールドがvalueサブフィールドの長さを指定)で構成される必要があります。
|
参照: 列オブジェクト、オブジェクト表、REF列およびLOB(BLOB、CLOB、NCLOBおよびBFILE)などの様々なデータ型のロードの詳細は、第10章「SQL*Loaderフィールド・リスト・リファレンス」を参照してください。 |
移植不能なデータ型は、VALUEデータ型およびLENGTH-VALUEデータ型に分類されます。移植不能なVALUEデータ型は次のとおりです。
INTEGER(n)
SMALLINT
FLOAT
DOUBLE
BYTEINT
ZONED
(パック) DECIMAL
移植不能なLENGTH-VALUEデータ型は次のとおりです。
VARGRAPHIC
VARCHAR
VARRAW
LONG VARRAW
移植不能なデータ型の構文の詳細は、「datatype_spec」の構文図を参照してください。
データは、フルワード2進整数(nは、1、2、4または8から選択して指定した長さ)です。長さが指定されていない場合、その長さはバイト単位で、ご使用のプラットフォームのCプログラミング言語におけるLONG INTのサイズに基づいて決まります。
INTEGERは、バイト・サイズ、バイト順序および符号付きの値の表現がシステム間で異なるため、移植不能です。ただし、符号付きの値の表現がシステム間で同じ場合は、SQL*Loaderを使用して、正しい結果でINTEGERデータにアクセスできます。長さ指定(n)でINTEGERを指定し、必要に応じて適切な方法でデータのバイト順序を指定すると、SQL*Loaderを使用してシステム間で正しい結果でデータにアクセスできます。長さ指定なしにINTEGERを指定すると、C言語のLONG INTの長さが両方のシステムで同じバイト数である場合のみ、SQL*Loaderを使用して正しい結果でデータにアクセスできます。その場合も、必要に応じて、適切な方法でデータのバイト順序を指定する必要があります。
2進整数の長さを明示的に指定すると、ワード長がSQL*Loaderで使用されているものとは異なるプラットフォーム上で入力データを作成する場合に有効です。たとえば、2進整数を含む入力データは、64ビットのプラットフォームで作成され、32ビットのプラットフォーム上のSQL*Loaderを使用しているデータベースにロードされます。この場合、INTEGER(8)を指定して、SQL*Loaderによってその整数を4バイトの量ではなく、8バイトの量として処理します。
デフォルトでは、INTEGERはSIGNED量として処理されます。SQL*Loaderで、符号なしの量として処理する場合は、UNSIGNEDを指定します。デフォルトの動作に戻すには、SIGNEDを指定します。
データはハーフワードの2進整数で表現されます。このフィールド長には、使用しているシステムのハーフワード整数の長さが取られます。デフォルトでは、SIGNED量として処理されます。SQL*Loaderで、符号なしの量として処理する場合は、UNSIGNEDを指定します。デフォルトの動作に戻すには、SIGNEDを指定します。
SMALLINTは、SHORT INTの長さが同じバイト数のシステム間のみで、正しい結果でロードできます。バイト順序がシステム間で異なる場合は、適切な方法でデータのバイト順序を指定します。詳細は、「バイト順序」を参照してください。
|
注意: このデータ型のフィールド長は、C言語のSHORT INTデータ型と同じです。フィールド長を決定する1つの方法は、データを入れずに小さい制御ファイルを作成し、その結果のログ・ファイルを調べることです。このデータ型のサイズは、制御ファイルを使用しては変更できません。 |
データは単精度浮動小数点2進数で表現されます。POSITION句でendを指定するとendは無視されます。このフィールド長には、システムの単精度浮動小数点2進数の長さが取られます。(C言語のデータ型はFLOATに相当する長さです。)このデータ型のサイズは、制御ファイルを使用しては変更できません。
FLOATは、FLOATの表現に互換性があり、長さが同じのシステム間のみで、正しい結果でロードできます。バイト順序が2つのシステム間で異なる場合は、適切な方法でデータのバイト順序を指定します。詳細は、「バイト順序」を参照してください。
データは倍精度浮動小数点2進数で表現されます。POSITION句でendを指定するとendは無視されます。このフィールド長には、システムの倍精度浮動小数点2進数の長さが取られます。(C言語のデータ型DOUBLEまたはLONG FLOATに相当する長さです。)このデータ型のサイズは、制御ファイルを使用しては変更できません。
DOUBLEは、DOUBLEの表現に互換性があり、長さが同じのシステム間のみで、正しい結果でロードできます。バイト順序が2つのシステム間で異なる場合は、適切な方法でデータのバイト順序を指定します。詳細は、「バイト順序」を参照してください。
2進数で表されている1バイト分のデータを10進数に直した値がロードされます。たとえば、入力文字x"1C"は28としてロードされます。BYTEINTフィールドの長さは、常に1バイトになります。POSITION(start:end)を指定すると、endは無視されます。(C言語のデータ型UNSIGNED CHARに相当する長さです。)
このデータ型の構文の例は次のとおりです。
(column1 position(1) BYTEINT, column2 BYTEINT, ... )
ZONED型のデータは、ZONED型の10進数形式で表現されます。つまり、10進数の各1桁が1バイトで表され、最終バイトに符号が入ります。(COBOLのSIGN TRAILINGフィールドに相当)このフィールド長には、精度(桁数)として指定された長さが取られます。
ZONEDデータ型の構文は次のとおりです。

ここでのprecisionは数字の桁数です。scale(指定されている場合)は(暗黙の)小数点の右側の桁数です。次の例では、位置32から始まる8桁の整数を表します。
sal POSITION(32) ZONED(8),
Oracle Databaseでは、ZONED型のデータがASCIIベースのプラットフォームで生成される場合、VAX/VMS ZONED型10進数形式を使用します。EBCDICベースのプラットフォームで生成されるZONED型10進データのロードも可能です。この場合、Oracleでは、ESA/390 Principles of Operationsバージョン8.1マニュアルで指定されているIBM形式を使用します。使用される形式は、入力データ・ファイルのキャラクタ・セット・エンコーディングによって異なります。詳細は、「CHARACTERSETパラメータ」を参照してください。
DECIMAL型のデータは、PACKED型の10進数形式で記述されます。つまり、10進数の各2桁が1バイトで表され、最終バイトに1桁と符号が入ります。DECIMALフィールドでは暗黙の小数点位置を指定できるため、分数の値を表すこともできます。
DECIMALデータ型の構文は次のとおりです。

precisionパラメータは、数値の桁数です。フィールドのバイト長は、桁数から計算します。(N+1)/2を求め、その小数点以下を切り上げた値がバイト長となります。
scaleパラメータは、小数点の右側にくる桁数のことで、スケール変更係数と呼びます。デフォルト値は0(ゼロ)です(整数となります)。全体の桁数より大きい数は指定できますが、負数は指定できません。
次に例を示します。
sal DECIMAL (7,2)
この例では、+12345.67の形式の数値がロードされます。このフィールドは、データ・レコード中で4バイトを占有します。(DECIMALフィールドのバイト長は、(N+1)/2の小数点以下を切り上げた値になります。ここで、Nは数値の桁数です。また、1は符号用として追加されています。)
このデータは、可変長のダブルバイト・キャラクタ・セット(DBCS)です。lengthサブフィールドおよびダブルバイト文字の文字列で構成されます。ダブルバイト・キャラクタ・セットは、Oracle Databaseではサポートされていないため、SQL*Loaderを使用してシングルバイトとして読み込み、RAWデータとしてロードします。RAWデータ型と同様、VARGRAPHICフィールドは変更されずに指定の列に格納されます。
|
注意: lengthサブフィールドのサイズには、システム上のSQL*LoaderのSMALLINTデータ型の長さ(C言語のSHORT INT型に相当する長さ)が取られます。詳細は、「SMALLINT」を参照してください。 |
VARGRAPHICデータは、SHORT INTの長さが同じバイト数のシステム間でのみ、正しい結果でロードできます。バイト順序がシステム間で異なる場合は、適切な方法でlengthサブフィールドのバイト順序を指定します。詳細は、「バイト順序」を参照してください。
VARGRAPHICデータ型の構文は次のとおりです。
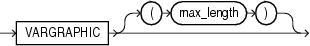
現行のフィールドの長さは、先頭の2バイトで示されます。VARGRAPHICデータ型に指定する最大長には、lengthサブフィールドの長さは含まれません。この最大長には、グラフィック(ダブルバイト)文字の文字数を指定します。フィールドのバイト単位の最大長を決定するには、このmaximum_lengthの値を2倍します。
フィールド最大長のデフォルトは、グラフィック文字で2KB、つまり4KB (2×2KB)です。
必要なメモリーを最小限にするには、このような可変フィールドに対して、できるだけ最大長を指定します。
VARGRAPHIC文の前に(pos_specを使用して)位置指定が指定されている場合、グラフィック文字の1文字目ではなく、lengthサブフィールドの位置がわかります。pos_spec(start:end)を指定すると、endの位置によってそのフィールドの最大長が決まります。ここでのstartやendは、そのファイルにおける1バイト単位の文字位置を示します。したがって、(end+1)からstartの値を引くと、フィールドの実際のバイト長が求められます。最大長を指定した場合は、その最大長の方が、位置指定から計算された最大長より優先されます。
VARGRAPHICフィールドのフィールド長全体が、読み込まれる前に論理レコードの終わりで切り捨てられた場合、警告が出力されます。VARGRAPHIC型のフィールド長は、そのフィールドの各入力データ中に埋め込まれているため、そのフィールド長の方が正確であるとみなされます。
VARGRAPHICデータに対してはデリミタを使用できません。
VARCHARフィールドは、LENGTH-VALUEデータ型です。バイナリのlengthサブフィールドおよびその長さを持つ文字列で構成されます。データ・ファイルに文字長セマンティクスが使用されないかぎり、長さはバイト単位です。文字長セマンティクスが使用される場合は、文字単位になります。詳細は、「文字長セマンティクス」を参照してください。
VARCHARフィールドは、SHORTデータ・フィールドINTの長さが同じバイト数のシステム間のみで、正しい結果でロードできます。バイト順序がシステム間で異なる場合、またはVARCHARフィールドにUTF16キャラクタ・セットのデータが含まれている場合は、適切な方法でlengthサブフィールドおよびデータのバイト順序を指定します。データのバイト順序は、UTF16キャラクタ・セットに対してのみ問題となります。詳細は、「バイト順序」を参照してください。
|
注意: lengthサブフィールドのサイズには、システム上のSQL*LoaderのSMALLINTデータ型の長さ(C言語のSHORT INT型に相当する長さ)が取られます。詳細は、「SMALLINT」を参照してください。 |
VARCHARデータ型の構文は次のとおりです。
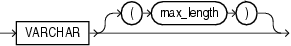
制御ファイルに指定する最大長には、lengthサブフィールドのサイズは含まれません。VARCHARデータ型にオプションで最大長を指定すると、そのサイズ分のバッファがこのフィールドに対してバイト単位で割り当てられます。ただし、文字長セマンティクスがデータ・ファイルに使用される場合、バイト単位のバッファ・サイズは、キャラクタ・セット内の最大限の文字のバイト単位のサイズのmax_length倍となります。詳細は、「文字長セマンティクス」を参照してください。
デフォルトの最大サイズは4KBです。データのロードに必要な最小限の値を最大値として指定することによって、SQL*Loaderで使用されるメモリーを最小限に抑えることができます。特に、VARCHARフィールドを多数使用する場合有効です。
POSITION句を使用する場合、指定する位置は、テキスト文字の先頭ではなく、lengthサブフィールドのバイト単位の位置になります。POSITION(start:end)と指定すると、endの位置によってそのフィールドの最大長が決まります。したがって、(end+1)からstartの値を引くと、フィールドの実際のバイト長が求められます。最大長を指定した場合は、その最大長の方がPOSITION句から計算された長さよりも優先されます。
VARCHARフィールドのフィールド長全体が、読み込まれる前に論理レコードの終わりで切り捨てられた場合、警告が出力されます。VARCHAR型のフィールド長は、そのフィールドの各入力データ中に埋め込まれているため、そのフィールド長の方が正確であるとみなされます。
VARCHARデータに対してはデリミタを使用できません。
VARRAWは、2バイトのバイナリのlengthサブフィールドおよびその後に続くRAW文字列のVALUEサブフィールドで構成されています。
デフォルトでは、VARRAWは、lengthサブフィールドが2バイトで、最大サイズが4KBのVARRAWになります。VARRAW(65000)は、lengthサブフィールドが2バイトで、最大サイズが65000バイトのVARRAWになります。
VARRAWフィールドは、適切な方法でlengthサブフィールドのバイト順序を指定すると、異なるバイト順序のシステム間でロードできます。詳細は、「バイト順序」を参照してください。
LONG VARRAWは、2バイトのlengthサブフィールドではなく、4バイトのlengthサブフィールドを持つVARRAWです。
デフォルトでは、LONG VARRAWは、lengthサブフィールドが4バイトで、最大サイズが4KBのVARRAWになります。LONG VARRAW(300000)は、lengthサブフィールドが4バイトで、最大サイズが300000バイトのVARRAWになります。
LONG VARRAWフィールドは、適切な方法でlengthサブフィールドのバイト順序を指定すると、異なるバイト順序のシステム間でロードできます。詳細は、「バイト順序」を参照してください。
移植可能なデータ型は、VALUEデータ型およびLENGTH-VALUEデータ型に分類されます。移植可能なVALUEデータ型は次のとおりです。
CHAR
日時データ型および期間データ型
GRAPHIC
GRAPHIC EXTERNAL
数値型EXTERNAL(INTEGER、FLOAT、DECIMALおよびZONED)
RAW
移植可能なLENGTH-VALUEデータ型は次のとおりです。
VARCHARC
VARRAWC
これらのデータ型の構文の詳細は、「datatype_spec」の構文図を参照してください。
文字データ型には、CHAR型、DATE型および数値型EXTERNALデータ型があります。これらのフィールドにはデリミタを使用できます。また、制御ファイルにフィールド長(または最大長)を指定することができます。
このデータ・フィールドには、文字データが入ります。データ長には最大長を指定します(オプション)。長さに関して、次のことに注意してください。
データ長が指定されていない場合、データ長はPOSITION句の指定から導出されます。
データ長が指定されている場合は、POSITION句で指定したデータ長より優先されます。
データ長もPOSITION句による位置も指定されていない場合、フィールドが区切られていないかぎり、CHARのデータ長は1文字とみなされます。
デリミタ付きCHARフィールドでは、長さが指定されている場合、その長さが最大長として使用されます。
長さが指定されていないデリミタ付きCHARフィールドでは、デフォルトの255バイトが使用されます。
デリミタ付きで255バイトを超えるCHARフィールドには、最大長を指定する必要があります。指定しない場合は、データ・ファイルのフィールドが最大長を超えているというエラーを受信します。
CHARデータ型の構文は次のとおりです。
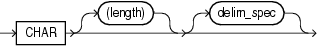
日時および期間の両方ともフィールドで構成されています。これらのフィールドの値によってデータ型の値が決定されます。
日時データ型には次のものがあります。
DATE
TIME
TIME WITH TIME ZONE
TIMESTAMP
TIMESTAMP WITH TIME ZONE
TIMESTAMP WITH LOCAL TIME ZONE
日時データ型の値は、Datetimesと呼ばれる場合があります。次に説明する日時データ型(DATEを除く)では、オプションでfractional_second_precisionの値を指定できます。fractional_second_precisionには、SECOND日時フィールドの小数部分に格納する桁数を指定します。このデータ型の列を作成する場合は、値を0から9に指定できます。デフォルトは6です。
期間データ型には次のものがあります。
INTERVAL YEAR TO MONTH
INTERVAL DAY TO SECOND
期間データ型の値は、Intervalsと呼ばれる場合があります。INTERVAL YEAR TO MONTHデータ型では、オプションでyear_precisionの値を指定できます。year_precisionには、YEAR日時フィールドの桁数を指定します。デフォルトは2です。
INTERVAL DAY TO SECONDデータ型では、オプションでday_precisionおよびfractional_second_precisionの値を指定できます。day_precisionには、DAY日時フィールドの桁数を指定します。0から9の値を指定できます。デフォルトは2です。fractional_second_precisionには、SECOND日時フィールドの小数部分に格納する桁数を指定します。このデータ型の列を作成する場合は、値を0から9に指定できます。デフォルトは6です。
|
参照: fractional_second_precision、year_precisionおよびday_precisionを使用する、日時データ型と期間データ型の指定の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
DATEフィールドには文字データが入り、その文字データは、指定された日付マスクを使用してOracleの日付に変換されます。DATEフィールドの構文は次のとおりです。
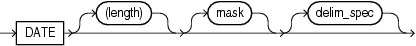
次に例を示します。
LOAD DATA INTO TABLE dates (col_a POSITION (1:15) DATE "DD-Mon-YYYY") BEGINDATA 1-Jan-2008 1-Apr-2008 28-Feb-2008
デリミタがない場合、空白は無視され、日付は左から右に構文解析されます(DATEフィールドのデータがすべて空白の場合、NULLフィールドとしてロードされます)。
可変長の日付マスクを指定していない場合、データ長の指定はオプションになります。データ・ファイルに文字長セマンティクスが使用されないかぎり、長さはバイト単位です。文字長セマンティクスが使用される場合は、文字単位になります。詳細は、「文字長セマンティクス」を参照してください。
前述の例では、日付マスク"DD-Mon-YYYY"は、バイト長セマンティクスで11バイトあります。そのため、SQL*Loaderによってこのフィールドの最大文字数が11文字とみなされ、前述の指定は正しく処理されます。ただし、次のように指定される場合は注意が必要です。
DATE "Month dd, YYYY"
この場合、日付マスクは14バイトです。"September 30, 2008"などのように14バイトを超える長さの値が指定されている場合は、長さを指定する必要があります。
同様に、ユリウス日(日付マスク「J」)の場合も長さを指定する必要があります。日付文字列の長さがマスクの長さ(マスク内のバイト数)を超える可能性がある場合は、必ずフィールド長を指定してください。
長さを明示的に指定していない場合は、POSITION句から長さが求められます。マスクを使用するときは、データ長がマスクの長さ以下であることが確実でないかぎり、常に長さを指定してください。
長さを明示的に指定した場合、この長さは、POSITION句で指定された長さよりも優先されます。これらはいずれも、マスクから求められる長さより優先されます。マスクについては、Oracle日付マスクとして有効なものを指定します。マスクの指定を省略すると、デフォルトのOracle日付マスク「dd-mon-yy」が使用されます。
データ長は小カッコで囲み、マスクは引用符で囲む必要があります。
DATE型のフィールドでは、デリミタも使用できます。詳細は、「デリミタの指定」を参照してください。
TIME WITH TIME ZONEデータ型は、タイムゾーンの置換えを含むTIMEデータ型の変形です。タイムゾーンの置換えは、ローカル時刻とUTCの差(時および分)です。次のように指定します。
TIME [(fractional_second_precision)] WITH [LOCAL] TIME ZONE
LOCALオプションが指定されている場合、データベースに格納されているデータはデータベース・タイムゾーンに指定されます。データが取得されると、ユーザーのローカル・セッション・タイムゾーンに返されます。
TIMESTAMPデータ型は、DATEデータ型の拡張です。DATEデータ型の年、月、日に加えて、TIMEデータ型の時、分、秒の値を格納します。次のように指定します。
TIMESTAMP [(fractional_second_precision)]
日付値を指定する場合、時間構成要素を指定しないと、デフォルト時間の12:00:00 AM(真夜中)が採用されます。
TIMESTAMP WITH TIME ZONEデータ型は、タイムゾーンの置換えを含むTIMESTAMPデータ型の変形です。タイムゾーンの置換えは、ローカル時刻とUTCの差(時および分)です。次のように指定します。
TIMESTAMP [(fractional_second_precision)] WITH TIME ZONE
TIMESTAMP WITH LOCAL TIME ZONEデータ型は、タイムゾーンの置換えを含むTIMESTAMPデータ型の変形です。データベースに格納されているデータは、データベース・タイムゾーンに指定されます。データが取得されると、ユーザーのローカル・セッション・タイムゾーンに返されます。次のように指定します。
TIMESTAMP [(fractional_second_precision)] WITH LOCAL TIME ZONE
このデータは、ダブルバイト・キャラクタ・セット(DBCS)形式の文字列データです。ダブルバイト・キャラクタ・セットはOracle Databaseではサポートされていないため、SQL*Loaderを使用してシングルバイトとして読み込みます。RAWデータ型と同様、GRAPHICフィールドは変更されずに指定の列に格納されます。
GRAPHICデータ型の構文は次のとおりです。
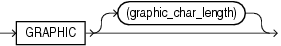
GRAPHIC型およびGRAPHIC EXTERNAL型では、POSITION(start:end)を指定すると、論理レコードにおけるフィールドの正確な位置が決まります。
ただし、GRAPHIC (EXTERNAL)データ型にデータ長を指定する場合は、ダブルバイト・グラフィック文字の文字数を指定します。この値を2倍してフィールドのバイト長が求められます。グラフィック文字の長さを指定した場合は、POSITION句から求められたデータ長は無視されます。GRAPHICデータ型の指定では、データ・フィールドの区切りの指定はできません。
DBCSフィールドがシフトイン/シフトアウト文字で囲まれている場合は、GRAPHIC EXTERNAL型を使用します。このデータ型は、データの先頭と最後の文字(シフトイン/シフトアウト文字)がロードされないことを除き、GRAPHIC型とほぼ同じです。
GRAPHIC EXTERNALデータ型の構文は次のとおりです。

GRAPHICは、ダブルバイト文字のデータであることを示します。EXTERNALは、先頭と最後の文字が無視されることを示します。graphic_char_lengthの値は、DBCSのデータ長を指定します(「GRAPHIC」を参照)。
たとえば、[ ]をシフトイン/シフトアウト文字とし、#を任意のダブルバイト文字とします。
[####]を表現する場合は、POSITION(1:4) GRAPHICまたはPOSITION(1) GRAPHIC(2)と指定します。
[####]を表現する場合は、POSITION(1:6) GRAPHIC EXTERNALまたはPOSITION(1) GRAPHIC EXTERNAL(2)と指定します。
数値型EXTERNALデータ型は、数値データ型(INTEGER、FLOAT、DECIMALおよびZONED)にEXTERNALを、オプションのデータ長およびデリミタ指定を指定したものです。データ・ファイルに文字長セマンティクスが使用されないかぎり、長さはバイト単位です。文字長セマンティクスが使用される場合は、文字単位になります。詳細は、「文字長セマンティクス」を参照してください。
このデータ型は、判読可能な文字形式の数値データです。長さ、位置およびデリミタについては、CHARデータと同じ規則が数値型EXTERNALにも適用されます。これらの規則の詳細は、「CHAR」を参照してください。
数値型EXTERNALデータ型の構文は、「datatype_spec」を参照してください。
|
注意: このデータは、バイナリ表現ではなく、文字形式の数字になります。したがって、これらのデータ型の処理方法は、DEFAULTIFを使用する場合を除き、CHARと同じです。デフォルトをNULLにする場合はCHARを使用します。デフォルトを0(ゼロ)にする場合はEXTERNALを使用します。詳細は、「WHEN、NULLIFおよびDEFAULTIF句の使用」を参照してください。 |
FLOAT EXTERNALデータは科学表記法または通常表記法のどちらででも指定できます。「5.33」と「533E-2」は両方とも同じ値の正しい表現です。
RAW型のバイナリ・データが無条件でRAW型のデータベース列にロードされた場合、Oracle Databaseによるデータ変換は行われません。CHAR列にロードした場合は、Oracle Databaseによって、16進数にデータ変換されます。DATE型や数値型の列にはロードできません。
RAWデータ型の構文は次のとおりです。
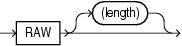
このフィールドのlengthは、制御ファイルに指定されたバイト数です。この長さは、データベース中のターゲット列の長さとメモリー・リソースによってのみ制限されます。データ・ファイルに文字長セマンティクスが使用される場合でも、長さは常にバイト単位です。RAWデータ・フィールドに対してはデリミタは使用できません。
VARCHARCデータ型は、文字のlengthサブフィールドおよびその後に続く文字列VALUEサブフィールドで構成されます。
VARCHARCに対する宣言には、lengthサブフィールドの長さが含まれます。また、オプションで文字列の最大サイズがその後に続く場合もあります。データ・ファイルにバイト長セマンティクスが使用される場合、長さおよび最大サイズはともにバイト単位です。データ・ファイルに文字長セマンティクスが使用される場合、長さおよび最大サイズはともに文字単位です。最大サイズが指定されていない場合、バイト長セマンティクスまたは文字長セマンティクスのいずれが使用されていても、デフォルトは4KBです。
次に例を示します。
少なくとも長さサブフィールドに値を指定する必要があるため、VARCHARCはエラーになります。
データ・ファイルにバイト長セマンティクスが使用されている場合、VARCHARC(7)は、lengthサブフィールドが7バイトで、最大サイズが4KB(デフォルト)のVARCHARCになります。文字長セマンティクスが使用されている場合は、lengthサブフィールドが7文字で、最大サイズが4KB(デフォルト)のVARCHARCになります。最大サイズが指定されていない場合、バイト長セマンティクスまたは文字長セマンティクスのいずれが使用されていても、常にデフォルトの4KBが使用されることに注意してください。
データ・ファイルにバイト長セマンティクスが使用されている場合、VARCHARC(3,500)は、lengthサブフィールドが3バイトで、最大サイズが500バイトのVARCHARCになります。文字長セマンティクスが使用されている場合は、lengthサブフィールドが3文字で、最大サイズが500文字のVARCHARCになります。
詳細は、「文字長セマンティクス」を参照してください。
VARRAWCデータ型は、RAW文字列のVALUEサブフィールドで構成されています。
次に例を示します。
VARRAWCはエラーになります。
VARRAWC(7)は、lengthサブフィールドが7バイトで、最大サイズが4KB(デフォルト)のVARRAWCになります。
VARRAWC(3,500)は、lengthサブフィールドが3バイトで、最大サイズが500バイトのVARRAWCになります。
フィールド長を指定する方法は数通りあります。それぞれの指定方法で異なる値を指定して、値が競合する場合は、そのうちの1つの値が優先されます。競合が発生した時点で警告が出されます。どのフィールド長を採用するかは、次の規則に基づいて決定されます。
POSITION句で指定されたバイト数に関係なく、SMALLINT、FLOATおよびDOUBLEのデータ・サイズは固定長です。
DECIMAL、INTEGER、ZONED、GRAPHIC、GRAPHIC EXTERNALまたはRAWで指定されたフィールド長(または精度)が、POSITION(start:end)から計算されたサイズと異なる場合は、指定されたフィールド長(または精度)を採用します。
文字フィールドまたはVARGRAPHICフィールドにおいて指定された最大長が、POSITION(start:end)から計算されたフィールド長と異なる場合は、指定された最大長を採用します。
たとえば、システム固有のデータ型INTEGERが4バイトであるときに、次のようなフィールドが指定されたとします。
column1 POSITION(1:6) INTEGER
この場合、警告が出力され、正しいフィールド長である4バイトが採用されます。実際に使用されたフィールド長は、ログ・ファイル内の列表の「Len」という見出しの箇所に記録されます。
Column Name Position Len Term Encl Datatype ----------------------- --------- ----- ---- ---- --------- COLUMN1 1:6 4 INTEGER
制御ファイルに指定したデータ型で、データ・ファイル中のデータをどのように解釈するかを、SQL*Loaderに対して指定します。一方、サーバーでは、これとは別にデータベース中の列に対してデータ型を定義します。これらの2つのデータ型を対応付ける手がかりとなるのが、制御ファイル中に指定している列名です。
SQL*Loaderでは、入力ファイル中のフィールドからデータが抽出されます。抽出処理は、制御ファイルに指定したデータ型に基づいて行われます。次にSQL*Loaderでは、そのフィールドがサーバーに送信されます。送信されたフィールドは、該当する列に(行挿入配列の一部として)格納されます。
SQL*Loaderまたはサーバーでは、変換の必要なデータに対してデータ変換が行われ、適切な内部形式でデータが格納されます。これには、データ・ファイルのキャラクタ・セットとデータベースのキャラクタ・セットが異なる場合に、データ・ファイルのデータをデータベース用に変換する機能も含まれます。
|
注意: SQL*Loaderの従来型パスを使用して、データ・ファイルの文字データをLONG RAW列にロードする場合、その文字データはHEX文字列として解釈されます。SQLは、HEX文字列をバイナリ表現に変換します。ここで、4000バイトより長い文字列は、SQL HEXTORAW変換演算子のバイト制限を超えていることに注意してください。エラーが返されます。SQL*Loaderはその行を拒否してロードを続行します。 |
入力ファイル中のデータ型は、Oracle表における列のデータ型に一致している必要はありません。データ型が一致していない場合、Oracle Databaseサーバーで自動的に変換が行われます。ただし、変換が正常に実行されたか、エラーは発生していないかについては実行後に確認する必要があります。たとえば、CHARデータ型のデータ・ファイル・フィールドをNUMBER型のデータベース列にロードしたとします。この場合、その文字フィールドの値が有効な数値となっているかどうかを必ず確認してください。
表10-2に、Oracle Databaseデータ型とSQL*Loader制御ファイルの日時データ型および期間データ型の間でサポートされている変換およびサポートされていない変換を示します。
この表で使用されているOracle Databaseデータ型の略称は次のとおりです。
N = NUMBER
C: CHARまたはVARCHAR2
D = DATE
T: TIMEおよびTIME WITH TIME ZONE
TS = TIMESTAMPおよびTIMESTAMP WITH TIME ZONE
YM: INTERVAL YEAR TO MONTH
DS: INTERVAL DAY TO SECOND
SQL*Loaderデータ型でも、D、T、TS、YMおよびDSに関しては、表の略称の定義は同じです。ただし、前述のとおり、SQL*Loaderには、NUMBER、CHAR、VARCHAR2などのOracle内部データ型に関するデータ型指定は定義されていません。ただし、Oracle Databaseで変換可能なデータは、これらのデータ型やその他のデータ型のデータベース列にロードできます。
この表の読み方の例を、SQL*Loaderデータ型DATE(略称D)の行で示します。行全体を見ると、Oracle Databaseデータ型のCHAR、VARCHAR2、DATE、TIMESTAMPおよびTIMESTAMP WITH TIME ZONEデータ型に対してデータ型変換がサポートされていることを確認できます。ただし、Oracle Databaseデータ型のNUMBER、TIME、TIME WITH TIME ZONE、INTERVAL YEAR TO MONTHまたはINTERVAL DAY TO SECONDデータ型に対しては変換がサポートされていません。
表10-2 日時データ型および期間データ型のデータ型変換
| SQL*Loaderのデータ型 | Oracle Databaseデータ型(変換のサポート) |
|---|---|
|
N |
N(可)、C(可)、D(不可)、T(不可)、TS(不可)、YM(不可)、DS(不可) |
|
C |
N(可)、C(可)、D(可)、T(可)、TS(可)、YM(可)、DS(可) |
|
D |
N(不可)、C(可)、D(可)、T(不可)、TS(可)、YM(不可)、DS(不可) |
|
T |
N(不可)、C(可)、D(不可)、T(可)、TS(可)、YM(不可)、DS(不可) |
|
TS |
N(不可)、C(可)、D(可)、T(可)、TS(可)、YM(不可)、DS(不可) |
|
YM |
N(不可)、C(可)、D(不可)、T(不可)、TS(不可)、YM(可)、DS(不可) |
|
DS |
N(不可)、C(可)、D(不可)、T(不可)、TS(不可)、YM(不可)、DS(可) |
CHAR、日時、期間または数値型EXTERNAL型のフィールドの境界は、デリミタ文字を使用して、入力データ・レコード中に指定することもできます。デリミタ文字は、TERMINATED BY、ENCLOSED BYおよびOPTIONALLY ENCLOSED BY句を様々に組み合せて指定できます(ただし、TERMINATED BY句を使用する場合は、最初に指定する必要があります)。デリミタは、データ型の指定の後で指定します。
デリミタ句を様々に組み合せて使用した場合にデータがどのように処理されるかについては、「デリミタ付きデータの処理方法」を参照してください。
|
注意: RAWデータ型でもデリミタを使用できます。ただし、RAWデータ型が入力LOBFILEにある場合、およびデリミタがTERMINATED BY EOF(ファイルの終わり)の場合のみです。 |
次の図に、termination_specおよびenclosure_specの構文を示します。
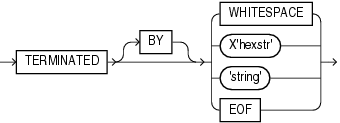

表10-3では、デリミタの指定に使用する、終了および囲みの指定に関する構文について説明します。
表10-3 デリミタの指定に使用するパラメータ
| パラメータ | 説明 |
|---|---|
|
|
データは、最初にデリミタが現れるまで読み込まれます。 |
|
|
可読性を向上させるために使用されるオプションのワードです。 |
|
|
デリミタには、スペース、タブ、空白、LF、改ページ、改行などの任意の空白文字を使用できます。( |
|
|
指定する文字でデータを囲むこともできます。SQL*Loaderでは、この指定文字が最初に現れたところから、次に同じ文字が現れたところまでのデータ値が読み込まれます。データが囲まれていない場合は、終了デリミタ付きのフィールドとして読み込まれます。オプションで囲みデリミタを指定する場合は、必ず |
|
|
データは2つのデリミタで囲まれます。 |
|
|
デリミタは文字列です。 |
|
|
デリミタは、文字コード体系における |
|
|
後続の囲みデリミタを指定する場合に使用します。後続の囲みデリミタには、先頭の囲みデリミタとは異なる文字を指定できます。 |
|
|
ファイル全体がLOBにロードされたことを示します。これは、LOBファイルからデータがロードされる場合のみ有効です。 |
各指定方法によるデリミタの指定例およびそれぞれの場合の実際のデータの例を示します。
TERMINATED BY ',' a data string,
ENCLOSED BY '"' "a data string"
TERMINATED BY ',' ENCLOSED BY '"' "a data string",
ENCLOSED BY '(' AND ')' (a data string)
デリミタとして定義した句読点を、データの中でも使用する必要があります。このような場合、デリミタ文字を2つ続けて記述すると、この文字は1文字のみ指定されたものと解釈され、データの一部として組み込まれます。たとえば、データベースに次の文字列を格納するとします。
(The delimiters are left parentheses, (, and right parentheses, )).)
フィールド指定は次のようにします。
ENCLOSED BY "(" AND ")"
この場合、データベースには次の文字列が格納されます。
The delimiters are left parentheses, (, and right parentheses, ).
このため、隣接するフィールドが同じデリミタを使用すると、問題が発生します。たとえば、次のように指定されている場合、
field1 TERMINATED BY "/" field2 ENCLOSED by "/"
次のデータは正しく解釈されます。
This is the first string/ /This is the second string/
ただし、field1およびfield2が次のように隣接している場合、誤った処理が行われます。
This is the first string//This is the second string/
この場合、このデータ全体が、中央に1つの「/」のみを持つ単一の文字列とみなされ、field1に属するものと解釈されてしまいます。
デリミタ付きデータの最大長のデフォルトは、255バイトです。したがって、デリミタ付きフィールドでは、バインド配列に対して記憶域が大量に使用される場合があります。フィールドが255バイトより短い場合、最大長にはできるだけ小さい値を指定してください。フィールドが255バイトより長い場合は、フィールド長指定子またはPOSITION句を使用して、フィールドに最大長を指定する必要があります。
たとえば、文字列リテラルが255バイトより長い場合は、SUBSTR()およびCHAR()を使用して、フィールドのすべてのレコードの中で最も長い文字列を指定します。たとえば、field1のすべてのレコードの中で最も長い文字列が600バイトの場合は、次のようになります。
field1 CHAR(600) SUBSTR(:field, 1, 240)
後続の空白は、PRESERVE BLANKSを指定しないかぎり、デリミタなしのデータ型ではロードされません。たとえば、データ・フィールド長が9文字で、DANIELbbbという値のデータがあるとします。ここでのbbbは3つの空白を示します。このとき、CHAR(9)と宣言されていると、Oracle Databaseには「DANIEL」がロードされます。
この例で後続の空白も必要な場合は、CHAR(9) TERMINATED BY ':'と宣言し、さらにデータ・ファイルにコロンを追加してフィールドをDANIELbbb:とします。このフィールドは、後続の空白とともに、「DANIEL」としてロードされます。TERMINATED BY句を使用しないでPRESERVE BLANKSを指定し、同じ結果を得ることもできます。
デリミタは、TERMINATED BY、ENCLOSED BYおよび OPTIONALLY ENCLOSED BY句の様々な組合せをフィールド定義で使用して定義できます。次の項では、それぞれの場合に行われる処理について説明します。
これらの使用例を、それぞれ次の項で説明します。
フィールドに対してTERMINATED BYが指定され、ENCLOSED BYは指定されていない場合、フィールドの開始位置から最初のTERMINATED BYデリミタまでがフィールドのデータとして読み込まれます(デリミタ自体は読み込まれません)。終了デリミタがフィールドの最初の列位置にある場合、そのフィールドはNULLとなります。TERMINATED BYデリミタが検出される前にレコードの終わりが検出された場合は、レコードの末尾までのすべてのデータがフィールドの要素とみなされます。
TERMINATED BY WHITESPACEを指定すると、最初に空白文字(スペース、タブ、空白、LF、改ページまたは改行)が現れるまでデータが読み込まれます。空白文字が現れると、隣接する空白文字が検出されなくなるまで現在の位置が進められます。したがって、フィールド値の間に入る空白は、いくつあってもかまいません。ただし、空白の終端文字がフィールドの最初の列位置にある場合は、空白以外の終端文字のときとは異なり、フィールドがNULLとして扱われないため、レコードが拒否されたり、フィールドが誤った列にロードされる可能性があります。
TERMINATED BY句を使用せずにENCLOSED BY句を使用するフィールドの場合は、次の処理が行われます。
フィールドの先頭に空白がある場合は、その空白がすべてスキップされます。
最初に検出される空白以外の文字は、最初のENCLOSED BYデリミタに一致する文字列の先頭である必要があります。そうでない場合、行は拒否されます。
最初のENCLOSED BYデリミタが検出された場合は、2番目のENCLOSED BYデリミタの検索が開始されます。
2番目のENCLOSED BYデリミタが最初のデリミタと隣合せで検出された場合は、1つのデリミタが記述されていると解釈した上で、フィールドのデータ要素に含まれます。引き続き、2番目のENCLOSED BYデリミタが検索されます。
2番目のENCLOSED BYデリミタが検出される前にレコードの終わりが検出された場合、その行は拒否されます。
ENCLOSED BY句を使用し、TERMINATED BY句も使用するフィールドの場合は、次の処理が行われます。
フィールドの先頭に空白がある場合は、その空白がすべてスキップされます。
最初に検出される空白以外の文字は、最初のENCLOSED BYデリミタに一致する文字列の先頭である必要があります。そうでない場合、行は拒否されます。
最初のENCLOSED BYデリミタが検出された場合は、2番目のENCLOSED BYデリミタの検索が開始されます。
2番目のENCLOSED BYデリミタが最初のデリミタと隣合せで検出された場合は、1つのデリミタが記述されていると解釈した上で、フィールドのデータ要素に含まれます。引き続き、次にある2番目のENCLOSED BYデリミタが検索されます。
2番目のENCLOSED BYデリミタが検出される前にレコードの終わりが検出された場合、その行は拒否されます。
2番目のENCLOSED BYデリミタが検出された場合は、パーサーによりTERMINATED BYデリミタが検索されます。TERMINATED BYデリミタがWHITESPACE以外の場合、2番目のENCLOSED BYデリミタの最後とTERMINATED BYデリミタの間にある空白はスキップされます。
|
注意: 2番目のENCLOSED BYデリミタとTERMINATED BYデリミタの間に使用できるのは、WHITESPACEのみです。それ以外の文字があると、エラーが発生します。 |
TERMINATED BYデリミタが検出される前にレコードの終わりが検出された場合でも、行は拒否されません。
OPTIONALLY ENCLOSED BY句およびTERMINATED BY句を使用するフィールドの場合は、次の処理が行われます。
フィールドの先頭に空白がある場合は、その空白がすべてスキップされます。
最初に検出された空白以外の文字が、最初のOPTIONALLY ENCLOSED BYデリミタに一致する文字列の先頭であるかどうかがパーサーによって確認されます。そうでない場合に、OPTIONALLY ENCLOSED BYデリミタがデータ内に存在しないと、フィールドの現在の位置から最初のTERMINATED BYデリミタまでがフィールドのデータとして読み込まれます(デリミタ自体は読み込まれません)。TERMINATED BYデリミタが最初の列位置にある場合、そのフィールドはNULLとなります。TERMINATED BYデリミタが検出される前にレコードの終わりが検出された場合は、レコードの末尾までのすべてのデータがフィールドの要素とみなされます。
最初のOPTIONALLY ENCLOSED BYデリミタが検出された場合は、2番目のOPTIONALLY ENCLOSED BYデリミタの検索が開始されます。
2番目のOPTIONALLY ENCLOSED BYデリミタが2つ隣合せで検出された場合は、1つのデリミタが記述されていると解釈した上で、フィールドのデータ要素に含まれます。引き続き、2番目のOPTIONALLY ENCLOSED BYデリミタが検索されます。
2番目のOPTIONALLY ENCLOSED BYデリミタが検出される前にレコードの終わりが検出された場合、その行は拒否されます。
OPTIONALLY ENCLOSED BYデリミタがデータ内に存在する場合は、パーサーによりTERMINATED BYデリミタが検索されます。TERMINATED BYデリミタがWHITESPACE以外の場合、2番目のOPTIONALLY ENCLOSED BYデリミタの最後とTERMINATED BYデリミタの間にある空白はスキップされます。
TERMINATED BYデリミタが検出される前にレコードの終わりが検出された場合でも、行は拒否されません。
|
注意: 空白文字をTERMINATED BYデリミタとして指定し、OPTIONALLY ENCLOSED BYも使用する場合は注意が必要です。SQL*Loaderでは、OPTIONALLY ENCLOSED BYデリミタを検索するときに、先頭の空白が取り除かれます。2つのTERMINATED BYデリミタがレコードの途中に隣り合って含まれている場合(通常は、レコードのフィールドをNULLに設定する目的でこのように記述します)、最初のTERMINATED BYデリミタの空白を使用してフィールドが終了されますが、残りの空白は、次のフィールドの先頭の空白とみなされ、次のフィールドのTERMINATED BYデリミタとはみなされません。NULL値をロードする場合は、データ内にENCLOSED BYデリミタを含める必要があります。 |
CHAR型、DATE型および数値型EXTERNAL型の文字データ・フィールドの場合は、そのフィールド長を制御ファイルに複数指定できます。複数指定したときの長さが異なり、値が競合する場合は、そのうちの1つが優先されます。競合が発生すると、警告が出力されます。 この項では、指定された長さのうちのどれが優先されるかについて説明します。
前述のデータ型のフィールドに対して開始位置と終了位置を指定すると、そのフィールド長は指定された開始/終了位置から求められます。データ型指定の中で長さを指定し、終了位置は指定しない場合、データ型指定の中で指定された長さがそのフィールド長になります。開始位置、終了位置および長さがすべて指定されていて、その長さが異なる場合は、次のように、データ型指定の中で指定されている長さがフィールド長として使用されます。
POSITION(1:10) CHAR(15)
この場合、このフィールド長は15になります。
デリミタ付きフィールドに長さを指定した場合、または開始位置と終了位置から長さを計算できる場合は、その長さがフィールドの最大長となります。指定される最大長は、フィールドにバイト長セマンティクスが使用される場合はバイト単位で、文字長セマンティクスが使用される場合は文字単位です。長さが指定されていない場合、または開始位置と終了位置から長さが計算できない場合は、最大長のデフォルトは255バイトです。実際の長さはデリミタの位置によって変わりますが、長さの上限はこの最大長の値となります。
フィールドにデリミタのみでなく、開始位置および終了位置が指定されている場合は、位置指定のみが影響します。囲みデリミタまたは終了デリミタは無視されます。
デリミタが見つからない場合は、レコードの終わりがフィールドの終端となります。TRAILING NULLCOLSが指定されている場合は、残りのフィールドにはNULL値が設定されます。デリミタまたはレコードの終端で区切った結果、フィールド長が最大長よりも大きくなる場合は、SQL*Loaderによってレコードが拒否され、エラーが返されます。
マスクを指定した場合、日付フィールド長は、使用するマスクによって異なります。指定されたマスクによって形式が決定され、SQL*Loaderではその形式に基づいてレコード中のデータが解釈されます。たとえば、次のようなマスクを指定したとします。
"Month dd, yyyy"
この場合、「May 3, 2008」はレコード(バイト長セマンティクスを含む)中で11バイトを占有し、「January 31, 2009」は16バイトを占有することになります。
ただし、開始位置および終了位置を指定すると、この位置指定から計算されるフィールド長は、マスクから求められるフィールド長よりも優先されます。DATE(12)のようにフィールド長が指定された場合は、このフィールド長が最優先となります。日付フィールドが、終了デリミタまたは囲みデリミタでも区切られている場合は、制御ファイル中で指定された長さがそのフィールドの最大長と解釈されます。
フィールド条件とは、論理レコード中のフィールドに関して、それが真か偽かを評価する条件を記述したものです。フィールド条件は、WHEN句、NULLIF句およびDEFAULTIF句で使用します。
フィールド条件は、CONTINUEIF句の中で指定する条件と同様ですが、次の2つの点で異なります。第1に、フィールド条件で指定する位置は、物理レコードではなく論理レコードの位置を示します。第2に、論理レコード内の位置またはデータ・ファイル内のフィールド名(FILLERフィールドを含む)のいずれかを指定できます。
|
注意: フィールド条件は、セカンダリ・データ・ファイル(SDF)のフィールドに基づくことができません。 |
field_condition句の構文は次のとおりです。
pos_spec句の構文は次のとおりです。
表10-4では、フィールド条件句のパラメータについて説明します。位置指定パラメータの詳細は、表10-1を参照してください。
表10-4 フィールド条件句のパラメータ
| パラメータ | 説明 |
|---|---|
|
|
論理レコード中の比較対象フィールドの開始および終了位置です。それらの位置は小カッコで囲んでください。 開始位置の指定は、列番号、 終了位置を省略した場合、フィールド長は、比較文字列の長さから判断されます。対象フィールドと比較文字列の長さが異なるときは、短い方を埋めるために文字列が追加されます。文字列の場合は空白が追加され、16進数のバイト列の場合は0(ゼロ)が追加されます。 |
|
|
論理レコード中の比較対象フィールドの開始位置です。 |
|
|
論理レコード中の比較対象フィールドの終了位置です。 |
|
|
|
|
|
比較演算子として、等価または不等価を示す記号を指定します。 |
|
|
比較フィールドとの比較に使用する文字列で、一重引用符または二重引用符で囲んで指定します。比較の結果が真の場合は、現在のレコードが表に挿入されます。 |
|
|
16進数の文字列で、16進数2桁がフィールドの1バイトに相当します。一重引用符または二重引用符で囲まれます。比較の結果が真の場合は、現在のレコードが表に挿入されます。 |
|
|
フィールドが完全に空白かどうかをテストできます。 |
BLANKSパラメータを使用すると、長さが不明なフィールドのデータが空白かどうかを知ることができます。
次の指定を実行すると、空白のフィールドにNULL値を設定できます。
full_fieldname ... NULLIF column_name=BLANKS
BLANKSパラメータが認識できるのは空白のみです。タブは認識できません。これは、どのようなフィールド比較の場合でも、比較文字列のかわりに指定できます。列の値がすべて空白のときにのみ条件が真となります。
BLANKSは、固定長フィールドに対しても指定できます。その場合は、対象フィールドに合った長さの空白文字列を指定したのと同じことになります。たとえば、次の指定はどちらも同じことを意味します。
fixed_field CHAR(2) NULLIF fixed_field=BLANKS
fixed_field CHAR(2) NULLIF fixed_field=" "
マルチバイト・キャラクタ・セットには複数の空白が存在することもあります。このようなキャラクタ・セットには、空白文字列を指定するかわりにBLANKSを使用します。
文字列は特定の空白文字の組合せのみに一致しますが、BLANKSパラメータは様々な空白文字の組合せに一致します。マルチバイト・キャラクタ・セットの詳細は、「マルチバイト(アジア系言語)・キャラクタ・セット」を参照してください。
次の説明は、スカラー・フィールドに適用されます。非スカラー・フィールド(列オブジェクト、LOBおよびコレクション)はより複雑なため、WHEN、NULLIFおよびDEFAULTIF句は異なる方法で処理されます。
WHEN、NULLIFまたはDEFAULTIF句は、フィールド名を指定するか、フィールド位置を指定するかによって、結果が異なります。
WHEN、NULLIFまたはDEFAULTIF句でフィールド名を指定すると、これらの句は、SQL*Loaderによってフィールドの評価値と比較されます。評価値には、切り捨てられた空白文字が考慮されます。空白およびタブの切捨ての詳細は、「空白の切捨て」を参照してください。
WHEN、NULLIFまたはDEFAULTIF句で位置を指定すると、これらの句は、SQL*Loaderによってデータ・ファイル内の元の論理レコードと比較されます。この場合、論理レコードでは空白の切捨ては行われません。
フィールドに切り捨てられた空白がある場合、あるいはWHEN、NULLIFまたはDEFAULTIF句に空白およびタブが含まれているか、BLANKSパラメータが使用されている場合は、異なる結果が得られます。名前で指定されているフィールドおよび位置で指定されているフィールドに対して同じ結果が必要な場合は、PRESERVE BLANKSオプションを使用します。PRESERVE BLANKSオプションによって、フィールド値の評価時にSQL*Loaderによって空白文字が切り捨てられないようにします。
WHEN、NULLIFまたはDEFAULTIF句は、SQL*Loaderの処理手順によっても結果に影響します。SQL*Loaderは次の手順を順番に実行します。ただし、すべての手順を実行するわけではありません。フィールドが設定されると、設定作業の残りの手順は無視されます。たとえば、手順5でフィールドが設定された場合、SQL*Loaderは手順6には進みません。
SQL*Loaderで、入力レコードの各フィールドの値が評価され、空白およびタブの切り捨てに関する既存のガイドラインに従って、切り捨てる必要のある空白が切り捨てられます。
各レコードに対して、SQL*Loaderで表のWHEN句が評価されます。
レコードが表のWHEN句を満たす場合、またはWHENが指定されていない場合は、SQL*Loaderで、NULLIF句の各フィールドが確認されます。
NULLIF句が存在する場合は、SQL*Loaderで評価されます。
NULLIF句が満たされている場合は、SQL*LoaderではフィールドがNULLに設定されます。
NULLIF句が満たされていない場合、またはNULLIF句がない場合は、SQL*Loaderのフィールド評価によってフィールド長が確認されます。フィールドがフィールド評価の結果、0の長さを持っている場合(たとえば、NULLフィールドまたは結果としてNULLフィールドとなる空白の切捨て)は、SQL*LoaderでフィールドがNULLに設定されます。この場合、フィールドに指定されたDEFAULTIF句は評価されません。
指定されたNULLIF句が偽の場合、またはNULLIF句がない場合、およびフィールドがフィールド評価の結果、0の長さを持たない場合は、SQL*Loaderで、DEFAULTIF句に対するフィールドが確認されます。
DEFAULTIF句が存在する場合は、SQL*Loaderで評価されます。
DEFAULTIF句が満たされていて、データ・ファイルのフィールドが数値フィールドの場合、フィールドは0に設定されます。フィールドが数値フィールドではない場合、NULLに設定されます。次のフィールドは数値フィールドで、DEFAULTIF句を満たす場合は、0に設定されます。
BYTEINT
SMALLINT
INTEGER
FLOAT
DOUBLE
ZONED
(パック) DECIMAL
数値型 EXTERNAL(INTEGER、FLOAT、DECIMALおよびZONED)
DEFAULTIF句が満たされていない場合、またはDEFAULTIF句がない場合は、SQL*Loaderによって、手順1の評価値でフィールドが設定されます。
SQL*Loaderの操作順序が原因で、予期しない結果となる場合があります。たとえば、DEFAULTIF句は、数値フィールドを0ではなくNULLに設定しているように見える場合があります。
|
注意: これらの手順に示したとおり、NULLIFおよびDEFAULTIF句を使用した場合は、SQL*Loaderによる処理が増えます。そのためパフォーマンスに影響する可能性があります。手順1では、0と評価されたフィールドは、SQL*LoaderによってNULL値に設定されます。パフォーマンスを向上させるには、この機能を利用するためにデータを変更できるかどうかを検討してください。手順1でのNULL値の検出は、NULLIF句またはDEFAULTIF句の処理よりはるかに迅速に行われます。
たとえば、 また、文字フィールドの場合は、通常、 |
例10-2から例10-5に、異なる条件でWHEN句、NULLIF句およびDEFAULTIF句を使用した場合の結果を示します。これらの例では、空白またはスペースはピリオド(.)で示されています。col1およびcol2は、データベースのVARCHAR2(5)列です。
例10-2 DEFAULTIF句の無評価
制御ファイルが次のように指定されています。
(col1 POSITION (1:5), col2 POSITION (6:8) CHAR INTEGER EXTERNAL DEFAULTIF col1 = 'aname')
データ・ファイルには次の情報が格納されています。
aname...
例10-2では、行のcol1がanameと評価され、col2が長さが0(「...」ですが、後続の空白は位置フィールドでは切り捨てられます)であるNULLと評価されます。
SQL*Loaderでcol2にロードされた最終値が確認される場合、WHEN句およびNULLIF句は評価されません。フィールド長(フィールド評価の結果、0と評価された長さ)が確認されます。したがって、SQL*Loaderでは、col2の最終値にNULLが設定されます。DEFAULTIF句は評価されず、行はcol1の場合はaname、col2の場合はNULLとしてロードされます。
例10-3 DEFAULTIF句の評価
制御ファイルが次のように指定されています。
. . . PRESERVE BLANKS . . . (col1 POSITION (1:5), col2 POSITION (6:8) INTEGER EXTERNAL DEFAULTIF col1 = 'aname'
データ・ファイルには次の情報が格納されています。
aname...
例10-3では、行のcol1が再度anameと評価されます。col2は、PRESERVE BLANKSが指定された場合、後続の空白が切り捨てられないため、「...」と評価されます。
SQL*Loaderでcol2にロードされた最終値が確認される場合、WHEN句およびNULLIF句は評価されません。0でなく3と評価されたフィールド評価からフィールド長が確認されます。
次に、SQL*LoaderではDEFAULTIF句が評価されます。col1がanameでanameと同じであるため、真と評価されます。
col2は数値フィールドであるため、SQL*Loaderではcol2の最終値に0が設定されます。行は、col1の場合は「aname」、col2の場合は0としてロードされます。
例10-4 DEFAULTIF句を使用した位置の指定
制御ファイルが次のように指定されています。
(col1 POSITION (1:5), col2 POSITION (6:8) INTEGER EXTERNAL DEFAULTIF (1:5) = BLANKS)
データ・ファイルには次の情報が格納されています。
.....123
例10-4では、行のcol1が長さが0 (...ですが、後続の空白は切り捨てられます)であるNULLと評価されます。col2は、123と評価されます。
SQL*Loaderでcol2にロードされる最終値が設定される場合、WHEN句およびNULLIF句は評価されません。0でなく3と評価されたフィールド評価からフィールド長が確認されます。
次に、SQL*LoaderではDEFAULTIF句が評価されます。.....である(1:5)を、真と評価されているBLANKSと比較されます。したがって、col2が数値フィールド(integer EXTERNALは数値)のため、SQL*Loaderではcol2の最終値に「0」が設定されます。行は、col1の場合はNULL、col2の場合は0としてロードされます。
例10-5 DEFAULTIF句を使用したフィールド名の指定
制御ファイルが次のように指定されています。
(col1 POSITION (1:5), col2 POSITION(6:8) INTEGER EXTERNAL DEFAULTIF col1 = BLANKS)
データ・ファイルには次の情報が格納されています。
.....123
例10-5では、行のcol1が長さが0(...ですが、後続の空白は切り捨てられます)であるNULLと評価されます。col2は、123と評価されます。
SQL*Loaderでcol2の最終値が確認される場合、WHEN句およびNULLIF句は評価されません。0でなく3と評価されたフィールド評価からフィールド長が確認されます。
次に、SQL*LoaderではDEFAULTIF句が評価されます。評価の一部として、col1のフィールド評価がNULLであることが確認されます。NULLのため、DEFAULTIF句は偽と評価されます。したがって、SQL*Loaderではcol2の最終値に、フィールド評価の元の値である123が設定されます。行は、col1の場合はNULL、col2の場合は123としてロードされます。
データ・ファイルを作成するプラットフォームと、そのデータ・ファイルのロード先となるプラットフォームが異なる場合は、ターゲット・システムが読取り可能な形式でデータを作成する必要があります。たとえば、ソース・システムではシステム固有の浮動小数点の内部表現に16バイトを使用し、ターゲット・システムでは浮動小数点を12バイトで表現しているとします。この場合、ソース・システムで生成されたデータを、ターゲット・システムに直接読み込ませることはできません。
この問題を解決する方法として、Oracle Netデータベース・リンクを使用してデータをロードし、データ型の自動変換機能を利用する方法があります。前述のような問題が発生した場合は、できるだけこの方法を使用してください。この場合、SQL*Loaderはソース・システムで実行する必要があります。
プラットフォーム間のロードに関する問題は、通常、システム固有のデータ型に関連して発生します。フィールドに0(ゼロ)を追加してフィールド長を長くするか、またはフィールドの一部分のみを読み込んでフィールド長を短くする(4バイト整数を使用しているシステム上に8バイト整数を読み込む場合、またはその逆のパターンがこれに相当)ことによって、問題を回避できる場合もあります。ただし、データ型の実装に互換性がない場合は、この方法で問題の解決はできません。
Oracle Netデータベース・リンクが使用できず、ターゲット・システム上で実行しているSQL*Loaderを使用してデータ・ファイルにアクセスする必要がある場合は、移植可能なSQL*Loaderデータ型(たとえば、CHAR、DATE、VARCHARC、数値型EXTERNAL)のみを使用してください。このようにして作成したデータ・ファイルは、システム固有のデータ型を使用して作成したデータ・ファイルよりサイズが大きくなる場合があります。そのため、ロードに時間がかかりますが、異なるプラットフォームに直接転送することができます。
バイト順序スキームまたはシステム固有の整数の長さが、入力データが作成されるプラットフォームとSQL*Loaderを実行するプラットフォームの間で異なることが事前にわかっている場合は、適切な方法で、データのバイト順序またはシステム固有の整数の長さを指定します。バイト順序を指定する方法には、BYTEORDERパラメータを使用する方法、またはファイルにバイト順序マーク(BOM)を設定する方法があります。この2つの方法の詳細は、「バイト順序」を参照してください。これらの方法を実行すると、非互換性を排除し、プラットフォーム間での正常なデータ・ロードを実現できます。バイト順序がSQL*Loaderのデフォルトと異なる場合は、バイト順序を指定する必要があります。
|
注意: この項の説明は、SQL*Loaderを実行するシステムとは異なるバイト順序スキームを持つシステム上で入力データを作成する場合のみに適用されます。それ以外の場合は、次の項に進んでください。 |
SQL*Loaderを使用して、SQL*Loaderが実行されているシステムとはバイト順序が異なるシステム上で作成されたデータ・ファイルから、(データ・ファイルに移植不能な特定のデータ型が含まれている場合であっても)データをロードできます。
デフォルトでは、すべてのデータ・ファイルに対するバイト順序として実行されているシステムのバイト順序が、SQL*Loaderで使用されます。たとえば、Sun Solarisシステム上では、SQL*Loaderでビッグ・エンディアン・バイト順序が使用されます。IntelまたはIntelと互換性のあるPC上では、SQL*Loaderでリトル・エンディアン・バイト順序が使用されます。
バイト順序は、データが一度に偶数バイト(通常、2バイト、4バイトまたは8バイト)書き込まれる場合、および読み込まれる場合の結果に影響します。次に例をいくつか示します。
2バイト整数値の1は、ビッグ・エンディアン・システムでは0x0001、リトル・エンディアン・システムでは0x0100として書き込まれます。
4バイト整数の66051は、ビッグ・エンディアン・システムでは0x00010203、リトル・エンディアン・システムでは0x03020100として書き込まれます。
バイト順序は、UTF16キャラクタ・セットの文字データが2バイトのエントリとして書き込まれる場合、および読み込まれる場合の結果にも影響します。たとえば、文字「a」(ASCIIでは0x61)は、ビッグ・エンディアン・システムでは0x0061、リトル・エンディアン・システムでは0x6100として書き込まれます。
Oracleでサポートされるすべてのキャラクタ・セットでは、UTF16を除いて、一度に1バイト書き込まれます。そのため、UTF8などのマルチバイト・キャラクタ・セットの場合も、文字の書込み、読取りには、システムのバイト順序に関係なく、すべてのシステムで同じ方法が使用されます。したがって、UTF16キャラクタ・セットのデータは、バイト順序依存のため移植不能です。Oracleでサポートされる他のすべてのキャラクタ・セットのデータは移植可能です。
データ・ファイルのバイト順序が問題となるのは、バイト順序依存データを含むデータ・ファイルが、SQL*Loaderが実行されているシステムとは異なるバイト順序のシステムで作成される場合のみです。SQL*Loaderでデータのバイト順序を認識できる場合、必要に応じてバイトを入れ替えて、データが正常にターゲット・データベースにロードされることを確認します。バイト・スワップとは、ビッグ・エンディアン形式のデータをリトル・エンディアン形式に変換すること、またはその逆の変換を意味します。
SQL*Loaderにデータのバイト順序を指定するには、BYTEORDERパラメータを使用するか、またはそのファイルにバイト順序マーク(BOM)を設定します。この2つの方法のいずれも使用しない場合、SQL*Loaderではデータを正常にデータ・ファイルにロードできません。
|
参照: SQL*Loaderでのバイト・スワップの処理例については、「事例11: Unicodeキャラクタ・セットのデータのロード」を参照してください。(事例の使用方法については、「SQL*Loaderの事例」を参照してください。) |
入力データ・ファイルのデータのバイト順序を指定するには、SQL*Loader制御ファイルの次の構文を使用します。

BYTEORDERは、SQL*Loader制御ファイルのLENGTHパラメータの後に置かれます。
異なるデータ・ファイルに異なるバイト順序を指定できます。ただし、INFILEパラメータの前のBYTEORDER指定が、プライマリ・データ・ファイルのすべてのリストに適用されます。
プライマリ・データ・ファイルに対するBYTEORDER指定は、LOBFILEおよびSDFに対するデフォルトとしても使用されます。このデフォルトを上書きするには、LOBFILEまたはSDF指定を使用してBYTEORDERを指定します。
BYTEORDERパラメータは、制御ファイル内のデータには適用されません。
BYTEORDERパラメータは次のものに適用されます。
2進INTEGERデータおよびSMALLINTデータ
可変長フィールドのバイナリ長(VARCHAR、VARGRAPHIC、VARRAWおよびLONG VARRAWデータ型用)
UTF16キャラクタ・セットのデータ・ファイルの文字データ
FLOATおよびDOUBLEデータ型(データが書き込まれたシステムに、SQL*Loaderが実行されているシステム上のデータと互換性のある浮動小数点の表現がある場合)
BYTEORDERパラメータは、次のものには適用されません。
RAWデータ型(RAW、VARRAWまたはVARRAWC)
図形データ型(GRAPHIC、VARGRAPHICまたはGRAPHIC EXTERNAL)
UTF16以外のキャラクタ・セットのデータ・ファイルの文字データ
ZONEDデータ型または(PACKED)DECIMALデータ型
Unicodeエンコーディング(UTF-16またはUTF-8)が使用されているデータ・ファイルには、ファイルの最初の数バイトにバイト順序マーク(BOM)が含まれている場合があります。キャラクタ・セットUTF-16が使用されているデータ・ファイルでは、ファイルの最初の2バイトの値{0xFE,0xFF}は、ファイルがビッグ・エンディアンのデータを含んでいることを示すBOMです。{0xFF,0xFE}という値は、ファイルにリトル・エンディアンのデータが含まれていることを示すBOMです。
第1プライマリ・データ・ファイルでUTF16キャラクタ・セットが使用され、BOMで開始されている場合は、そのマークを読み込んで解釈し、すべてのプライマリ・データ・ファイルのバイト順序を決定します。SQL*Loaderで、BOMを読み込んで解釈し、スキップして、BOMの直後のバイトからデータを処理し始めます。BOM設定は、第1プライマリ・データ・ファイルに対するBYTEORDER指定より優先されます。第1プライマリ・データ・ファイル以外のデータ・ファイルのBOMは、バイト順序競合の確認のみに使用されます。データ・ファイルの処理中にSQL*Loaderで使用されるバイト順序の設定は変更されません。
つまり、第1プライマリ・データ・ファイルに対するバイト順序インジケータの優先順位は次のようになります。
第1プライマリ・データ・ファイルのBOM(データ・ファイルでバイト順序に依存したUnicodeキャラクタ・セット(UTF16)を使用し、BOMが存在する場合)
BYTEORDERパラメータの値(INFILEパラメータの前に指定された場合)
SQL*Loaderが実行されているシステムのバイト順序
UTF8キャラクタ・セットが使用されているデータ・ファイルでは、最初の3バイトの{0xEF,0xBB,0xBF}というBOMによって、ファイルにUTF8データが含まれていることが示されます。UTF8のデータはバイト順序依存ではないため、データのバイト順序を指定しません。UTF8のBOMが検出された場合は、SQL*LoaderでBOMをスキップしますが、データ・ファイルの処理のためのバイト順序の設定変更は実行しません。
SQL*Loaderによって、まず、定義済の優先順位を使用して第1プライマリ・データ・ファイルのバイト順序設定を確立します。このバイト順位設定は、すべてのプライマリ・データ・ファイルに使用されます。別のプライマリ・データ・ファイルでキャラクタ・セットUTF16が使用され、BOMも含まれている場合、そのBOMの値は、第1プライマリ・データ・ファイルで確立されたバイト順序設定と比較されます。BOMの値が第1プライマリ・データ・ファイルのバイト順序設定と一致する場合は、SQL*LoaderでそのBOMをスキップし、そのバイト順序設定を使用して、BOMの直後のバイトからデータを処理し始めます。BOMの値が、第1プライマリ・データ・ファイルで確立されたバイト順序設定と一致しない場合は、SQL*Loaderでエラー・メッセージを発行し、処理を停止します。
LOBFILEまたはセカンダリ・データ・ファイル(SDF)が制御ファイルで指定される場合、ファイルを処理する準備が整うと、SQL*Loaderで各LOBFILEおよびSDFのバイト順序設定を確立します。LOBFILEおよびSDFのデフォルトのバイト順序設定は、第1プライマリ・データ・ファイルで確立されたバイト順序設定です。これは、BYTEORDERパラメータがLOBFILEまたはSDFで指定される場合は、上書きされます。いずれの場合も、LOBFILEまたはSDFでUTF16キャラクタ・セットが使用され、BOMが含まれている場合、BOMの値はファイルのバイト順序と比較されます。BOMの値がファイルのバイト順序設定と一致する場合は、SQL*LoaderでそのBOMをスキップし、そのバイト順序設定を使用して、BOMの直後のバイトからデータを処理し始めます。BOMの値が一致しない場合、SQL*Loaderからエラーが発行され、処理が停止します。
つまり、LOBFILEおよびSDFに対するバイト順序インジケータの優先順位は次のようになります。
LOBFILEまたはSDFで指定されたBYTEORDERパラメータ値
第1プライマリ・データ・ファイルで確立されたバイト順序設定
|
注意: データ・ファイルのキャラクタ・セットがUnicodeキャラクタ・セットで、ファイルの最初の数バイトにバイト順序マークが設定されている場合、SKIPパラメータは使用しないでください。使用した場合、バイト順序マークは読み込まれず、バイト順序マークとして解釈されません。 |
Unicodeキャラクタ・セットのデータ・ファイルには、ファイルの最初のバイトにBOMと一致するバイナリ・データが含まれています。たとえば、integer(2)型の値0xFEFF = 65279小数点は、UTF16のビッグ・エンディアンBOMと一致します。この場合、SQL*Loaderを使用してデータ・ファイルの最初のバイトをデータとして読み込むことができます。また、値NOCHECKでBYTEORDERMARKパラメータを指定して、SQL*LoaderによってBOMを確認しないようにできます。BYTEORDERMARKパラメータの構文は次のとおりです。
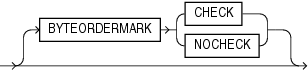
BYTEORDERMARK NOCHECKを指定すると、SQL*LoaderではBOMが確認されず、データ・ファイルのすべてのデータがデータとして読み込まれます。
BYTEORDERMARK CHECKを指定すると、BOMを確認するようSQL*Loaderに指示します。これはUnicodeキャラクタ・セットのデータ・ファイルについてのデフォルト動作です。ただし、この指定は明確化の目的で制御ファイル内で使用されることがあります。Unicode以外のキャラクタ・セットを使用するデータ・ファイルについてBYTEORDERMARK CHECKを指定すると、エラーとなります。
BYTEORDERMARKパラメータには、次の特長があります。
SQL*Loader制御ファイル内のオプションのBYTEORDERパラメータの後に置かれます。
プライマリ・データ・ファイルの構文指定に適用される以外に、LOBFILEとセカンダリ・データ・ファイル(SDF)にも適用されます。
異なるデータ・ファイルに異なるBYTEORDERMARK値を指定できます。ただし、INFILEパラメータの前のBYTEORDERMARK指定が、プライマリ・データ・ファイルのリスト全体に適用されます。
プライマリ・データ・ファイルに対するBYTEORDERMARK指定は、LOBFILEおよびSDFに対するデフォルトとしても使用されます。ただし、LOBFILEまたはSDFでUnicode以外のキャラクタ・セットが使用されている場合は、値CHECKは無視されます。LOBFILEおよびセカンダリ・データ・ファイルに対するこのデフォルト設定は、LOBFILEまたはSDF指定にBYTEORDERMARKを指定することによって上書きできます。
フィールドが完全に空白のレコードは拒否されます。これらのフィールドのいずれかをNULLとしてロードするには、BLANKSパラメータを持つNULLIF句を使用します。
空白のフィールドがCHAR型で、囲みデリミタによって囲まれている場合は、囲みデリミタで囲まれている空白部分がロードされます。囲みデリミタで囲まれていない場合は、そのフィールドはNULLとしてロードされます。
DATEフィールドまたは数値フィールドのデータがすべて空白の場合は、NULLフィールドとしてロードされます。
|
参照:
|
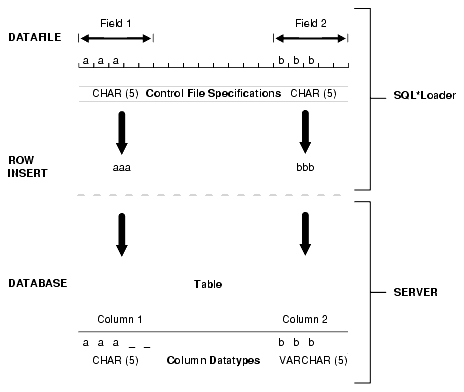
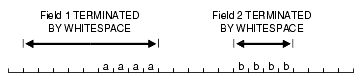
空白、タブおよびその他の印字されない文字(改行、LFなど)が空白を構成します。先頭の空白は、フィールドの開始位置にあります。後続の空白は、フィールドの終了位置にあります。フィールドの指定方法にもよりますが、空白は、フィールドのデータベースへの挿入時に、データの一部として含めることも切り捨てることもできます。これについて、図10-1に示します。この図では、2つのCHARフィールドがデータ・レコードに定義されています。
フィールド指定は制御ファイルに含まれています。制御ファイルのCHAR指定は、データベースのCHAR指定と同じではありません。制御ファイル内でCHARとして定義されたデータ・フィールドは、SQL*Loaderに行挿入の作成方法を指定するのみです。Oracle Databaseで必要な変換が行われ、データベースのCHAR、VARCHAR2、NCHAR、NVARCHAR2、NUMBERまたはDATE列にデータを挿入できるようになります。
デフォルトでは、SQL*Loaderを使用してCHARデータから後続の空白を削除した後、このデータをデータベースに渡します。その後、図10-1に示すとおり、フィールド1とフィールド2は3バイトのフィールドとしてデータベースに渡されます。ただし、データを表に挿入する場合は処理が異なります。
列1は、データベース内で長さ5の固定長CHAR列として定義されます。そのため、データ(aaa)は5バイトの幅を保持したまま、その列で左揃えにされます。余った右側の部分は空白で埋められます。一方、列2は、最大長5バイトの可変長フィールドとして定義されています。その列(bbb)のデータも左揃えにされますが、長さは3バイトのままです。
表10-5に、PRESERVE BLANKSが指定されていない場合に空白が入力データ・フィールドから切り捨てられるケースおよびその処理方法を示します。空白の切捨てを回避する方法については、「空白の切捨てに対するPRESERVE BLANKSオプションの影響」を参照してください。
表10-5 空白の切捨てに関する動作のサマリー
| 指定 | データ | 結果 | 先頭の空白脚注 1 | 後続の空白脚注参照 1 |
|---|---|---|---|---|
|
サイズ指定あり |
__aa__ |
__aa |
あり |
なし |
|
終了デリミタ |
__aa__, |
__aa__ |
あり |
あり脚注 2 |
|
囲みデリミタ |
"__aa__" |
__aa__ |
あり |
あり |
|
終了と囲み |
"__aa__", |
__aa__ |
あり |
あり |
|
オプションの囲み(あり) |
"__aa__", |
__aa__ |
あり |
あり |
|
オプションの囲み(なし) |
__aa__, |
aa__ |
なし |
あり |
|
前のフィールドが空白で区切られている場合 |
__aa__ |
aa脚注 3 |
なし |
|
脚注 1 空白のみのフィールドが切り捨てられた場合、その値はNULLになります。
脚注 2 空白で終了するフィールドを除きます。
脚注 3 後続の空白があるかどうかは、表中の他の項目に示すとおり、現行のフィールドの指定によって異なります。
この項の残りの部分では、空白の切捨てに関する次の項目について説明します。
次の説明は、データ型が文字データ型であるフィールドにのみ適用できます。
CHARデータ型
日時データ型および期間データ型
数値型EXTERNALデータ型:
INTEGER EXTERNAL
FLOAT EXTERNAL
(パック) DECIMAL EXTERNAL
ZONED (10進) EXTERNAL
|
注意: VARCHAR型およびVARCHARC型フィールドも文字データを含みますが、フィールド中の空白は切り捨てられません。これらのフィールドは、データ・ファイルのフィールド中の空白文字をすべて含みます。 |
フィールド長の指定には2通りの方法があります。制御ファイルで位置指定またはデータ型および長さについてフィールド長の定数を定義した場合、そのフィールドは、事前にサイズが決まっていることになります。一方、フィールド長を事前に指定しないでレコード中のインジケータでフィールド長を決める場合は、そのフィールドを囲みデリミタまたは終了デリミタのいずれかを使用して区切ります。
開始値および終了値での位置指定は、囲みデリミタまたは終了デリミタが定義されるフィールドに対して定義されます。囲みデリミタまたは終了デリミタは無視されます。
フィールドのサイズを事前に決定するには、フィールドの開始位置と終了位置を指定するか、フィールド長を指定します。それぞれの指定例を示します。
loc POSITION(19:31) loc CHAR(14)
2番目の例では、フィールド位置は指定されていませんが、フィールド長は事前に指定されています。
この項では、次の条件でSQL*Loaderを使用してフィールドの開始位置を決定する方法について説明します。
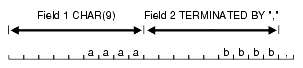
フィールドの開始位置が指定されていない場合は、前のフィールドの終了位置の直後の位置が、そのフィールドの開始位置となります。図10-2に、前のフィールド(フィールド1)のサイズが事前に決定されている場合の例を示します。
前のフィールド(フィールド1)の終端がデリミタで指定されている場合、次のフィールドはそのデリミタの直後から開始します。この例を図10-3に示します。
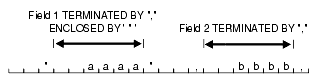
フィールドが囲みデリミタと終了デリミタの両方で指定された場合、その次のフィールドは終了デリミタの直後の位置から開始します。この例を図10-4に示します。囲みデリミタから終了デリミタまでの間に空白以外の文字がある場合は、エラーが出力されます。
図10-4の例では、2つのフィールドはともに先頭の空白が付いた状態で格納されます。ただし、次のような場合、先頭の空白はフィールドのデータに含まれません。
前のフィールドが空白で区切られて(終了して)いて、現行のフィールドの開始位置が指定されていない場合。
フィールドに対してオプションの囲みデリミタが指定されているにもかかわらず、その囲みデリミタが使用されていない場合。
これらの事例については、次の項で例示します。
前のフィールドがTERMINATED BY WHITESPACEで区切られていると、そのフィールドの後に続く空白はすべてデリミタとみなされます。この場合、次のフィールドは、次に空白以外の文字が現れた位置から開始します。この例を図10-5に示します。
このようなケースは、前述の例のとおり前のフィールドがTERMINATED BY WHITESPACE句で明示的に指定された場合に発生します。グローバルにFIELDS TERMINATED BY WHITESPACE句が指定された場合も、このケースに相当します。
オプションの囲みデリミタが指定されているにもかかわらず、それが使用されていない場合も、先頭の空白は切り捨てられます。
オプションの囲みデリミタが指定されると、SQL*Loaderによって前方スキャンが実行され、最初の囲みデリミタが検索されます。囲みデリミタがない場合は、空白がスキップされ、フィールドから削除されます。最初に見つかった空白以外の文字がフィールドの開始と判断されます。この例を図10-6のフィールド2に示します。(フィールド1では、SQL*Loaderによってフィールドの囲みデリミタが検出されたため空白が含まれます)。
前のフィールドがTERMINATED BY WHITESPACEで区切られた場合と異なり、前述のように指定された場合は、現行のフィールドの開始位置が指定されていても先頭の空白は切り捨てられます。
|
注意: 囲みデリミタが存在する場合は、最初の囲みデリミタの後の先頭の空白はそのままデータとして保持されますが、この囲みデリミタの前にある空白は切り捨てられます。図10-6のフィールド1の最初の引用符がこのケースに相当します。 |
フィールドが囲みデリミタで囲まれている場合、または、図10-6の最初のフィールドのように終了デリミタと囲みデリミタの両方で区切られている場合、囲みデリミタの外側にある空白は、フィールドの一部とはみなされません。囲みデリミタの内側に空白があれば、それが先頭の空白または後続の空白のいずれであっても、フィールドの一部とみなされます。
すべてのCHARフィールド、DATEフィールド、および数値型EXTERNALフィールドで空白が切り捨てられないようにするには、制御ファイル内のLOAD文でPRESERVE BLANKSを指定します。ただし、すべてのCHAR、DATEまたは数値型EXTERNALフィールドに空白を残す必要がない場合があります。その場合は、SQL*Loaderを使用して、PRESERVE BLANKSを、LOAD文でグローバルに指定するのではなく、個々のフィールドのデータ型指定で指定することもできます。
次の例では、PRESERVE BLANKSがLOAD文で指定されていない場合に、空白を含むc1フィールドをデフォルトでゼロにします。これは、個々のフィールドに対してPRESERVE BLANKSを指定することで実現できます。指定したフィールドのみで空白が切り捨てられ、その他のフィールドでは空白はそのまま残されます。
c1 INTEGER EXTERNAL(10) PRESERVE BLANKS DEFAULTIF c1=BLANKS
この例では、PRESERVE BLANKSがフィールドに対して指定されていない場合、そのフィールドがNULL(0ではなく)として誤ってロードされます。
LOAD文に対するオプションとしてPRESERVE BLANKSを指定して、ほとんどのCHAR、DATEおよび数値型EXTERNALフィールドに適用する必要がある場合があります。このオプションの指定は、個々のフィールドのデータ型指定でNO PRESERVE BLANKSを指定して上書きできます。次に例を示します。
c1 INTEGER EXTERNAL(10) NO PRESERVE BLANKS
デリミタ句が指定されていると、PRESERVE BLANKSオプションに次のような影響があります。
オプションの囲みデリミタがない場合、先頭の空白はそのまま残ります。
事前にフィールド・サイズが指定された場合にも、後続の空白を残します。
たとえば、次のフィールドについて考えてみます。ここでは、アンダースコアは空白を表します。
__aa__,
このフィールドが次のデリミタ句でロードされるとします。
TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
この場合、PRESERVE BLANKSを指定すると、先頭の空白および後続の空白がともに保存されます。PRESERVE BLANKSを指定しない場合は、先行する空白は切り捨てられます。
次に、このフィールドが次の句でロードされるとします。
TERMINATED BY WHITESPACE
この場合、PRESERVE BLANKSを指定すると、次のフィールドの先頭の空白は、このフィールドが空白を含むPOSITION句で指定されていないかぎり保存されません。そうしない場合は、SQL*Loaderによって前のフィールドの終わりにあるすべての空白を読み込まずにスキャンが実行され、次に空白以外の文字またはタブ以外の文字が現れた位置が次のフィールドの開始位置と認識されます。
SQL文字列を使用することによって、様々なSQL演算子をフィールド・データに適用できます。SQL文字列には、任意に組み合せたSQL式を組み込むことができます。ただし、このSQL式は、Oracle DatabaseによってINSERT文中のVALUES句に対して有効であると認識されたものにかぎります。通常、ターゲット列のデータ型と互換性のある単一の値を返すSQL関数を使用できます。SQL文字列は、列オブジェクトおよびコレクションなどのユーザー定義の複合型に加えて、単純なスカラー列型にも適用できます。式の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。
列名とSQL文字列のバインド変数における列名は、SQL識別子のルールによる解釈の結果、同じ列に対応している必要があります。ただし、次の制御ファイルの指定例に示すとおり、2つの名前を完全に同じ記述にする必要はありません。
LOAD DATA INFILE * APPEND INTO TABLE XXX ( "Last" position(1:7) char "UPPER(:\"Last\")" first position(8:15) char "UPPER(:first || :FIRST || :\"FIRST\")" ) BEGINDATA Phil Grant Jason Taylor
前述の例では、次のことに注意してください。
表の作成時、(前述の"Last"という列のように)列識別子に小文字または特殊文字(あるいはその両方)が含まれているために二重引用符を使用して宣言されている場合、バインド変数の列名は、CREATE TABLE文で使用される列名と完全に一致する必要があります。
表の作成時、(前述のfirstという列のように)列識別子が二重引用符を使用しないで宣言されている場合は、first、FIRSTおよび"FIRST"のすべてが同じ列を指すため、SQL文字列のバインド変数では、これらのいずれの書式も使用できます。
次の要件および制限はSQL文字列を使用している場合に適用されます。
関連付けられたSQL文字列を含む文字入力が制御ファイルによって指定されている場合、SQL*Loaderによるデータ変更は試行されません。これは、SQL*Loaderでは、SQL演算子を使用して変更した文字入力データは、データベースの挿入に対し正しい結果を生成すると仮定されているためです。
SQL文字列を指定する位置は、その列に関するその他の指定がすべて記述された後になります。
SQL文字列は、二重引用符で囲んで記述します。
SQL文字列内の列名を引用符で囲むには、エスケープ文字を使用する必要があります。
前述の例では、Lastを二重引用符で囲んで大文字および小文字の組合せを保持しています。また、二重引用符を使用すると、バックスラッシュ(エスケープ)文字も使用する必要があります。
SQL文字列に列オブジェクト属性を参照する列名が含まれている場合は、バインド変数にオブジェクト属性をフルネームで指定する必要があります。フルネームの各属性名は、個々の識別子です。各識別子は、SQL識別子の引用符ルールに従い、フルネームの他の識別子からは独立しています。たとえば、"HEIGHT_%TILE"という名前の属性を持つCHILDという列オブジェクトがあるとします。(その属性名は、二重引用符で囲まれています。)バインド変数にオブジェクト属性をフルネームで指定するには、次のいずれかの書式を使用します。
:CHILD.\"HEIGHT_%TILE\"
:child.\"HEIGHT_%TILE\"
フルネームを引用符で囲む(:\"CHILD.HEIGHT_%TILE\")と、バインド変数で使用されるオブジェクト属性名の引用符ルールは変更されたという警告メッセージが生成されます。この警告は、バインド変数を正確に指定するように求めるためのものであり、ロードが異常終了することはありません。名前を引用符で囲むと、SQLでは、名前が複数の識別子で構成される列オブジェクト属性フルネームとしてではなく、1つの識別子として解釈されるため、引用符ルールは変更されました。
SQL文字列の評価は、NULLIF句またはDEFAULTIF句の後、日時マスクよりも前に行われます。
Oracle Databaseで文字列を認識できない場合は、エラーが発生してロードは終了します。文字列が認識されても、データベース・エラーが発生すると、エラーの発生した行は拒否されます。
フィールド指定でEXPRESSIONパラメータを使用する場合は、SQL文字列が必要です。
SQL文字列では、OID、SID、REFまたはBFILEを使用してロードしたフィールドは参照できません。また、FILLERフィールドも参照できません。
ダイレクト・パス・モードでは、SQL文字列でのVARRAY、ネストした表またはLOB列の参照はできません。これには、列オブジェクトの属性であるVARRAY、ネストした表またはLOB列も含まれます。
SQL文字列は、RECNUM、SEQUENCE、CONSTANTまたはSYSDATEフィールドでは使用できません。
SQL文字列は、LOB、BFILE、XML列またはコレクションの要素であるファイルでは使用できません。
ダイレクト・パス・モードでは、SQL文字列の式の評価後に返される最後の結果はスカラー・データ型である必要があります。つまり、ダイレクト・パス・ロードの実行時、式によってはオブジェクトまたはコレクション・データを返さない場合があります。
レコード中のフィールドを参照する場合は、フィールド名の前にコロン(:)を付けます。このように指定すると、現在のレコードのフィールド値が代入されます。SQL文字列で、前にコロン(:)が付いたフィールド名もバインド変数として参照されます。一重引用符で囲まれたバインド変数は、バインド変数としてではなくテキスト・リテラルとして扱われることに注意してください。
次の例では、制御ファイルの現行のフィールドおよび他のフィールドの参照方法を示します。また、バインド変数を一重引用符で囲むことにより、テキスト・リテラルとして扱われることを示しています。示されている概念を十分に理解するために、次の例の説明も参照してください。
LOAD DATA
INFILE *
APPEND INTO TABLE YYY
(
field1 POSITION(1:6) CHAR "LOWER(:field1)"
field2 CHAR TERMINATED BY ','
NULLIF ((1) = 'a') DEFAULTIF ((1)= 'b')
"RTRIM(:field2)"
field3 CHAR(7) "TRANSLATE(:field3, ':field1', ':1')",
field4 COLUMN OBJECT
(
attr1 CHAR(3) "UPPER(:field4.attr3)",
attr2 CHAR(2),
attr3 CHAR(3) ":field4.attr1 + 1"
),
field5 EXPRESSION "MYFUNC(:FIELD4, SYSDATE)"
)
BEGINDATA
ABCDEF1234511 ,:field1500YYabc
abcDEF67890 ,:field2600ZZghl
この例に関する注意事項:
次の行では、:field1は一重引用符で囲まれていないため、バインド変数として解釈されます。
field1 POSITION(1:6) CHAR "LOWER(:field1)"
次の行では、':field1'と':1'は一重引用符で囲まれているため、テキスト・リテラルとして解釈され、変更されずにTRANSLATE関数に渡されます。
field3 CHAR(7) "TRANSLATE(:field3, ':field1', ':1')"
引用符で囲まれた文字列中で引用符を使用する方法の詳細は、「ファイル名およびオブジェクト名の指定」を参照してください。
各入力データ読取りでは、バインド変数で参照されたフィールドの値はバインド変数に置き換えられます。たとえば、最初のレコードの値ABCDEFは、最初のフィールド:field1にマップされます。この値は、引数としてLOWER関数に渡されます。
SQL文字列のバインド変数によって現行のフィールドを参照する必要はありません。前述の例では、フィールドFIELD4.ATTR1に対するSQL文字列のバインド変数によって、フィールドFIELD4.ATTR3を参照しています。フィールドFIELD4.ATTR1は、入力レコードの値500および600にマップされます。ただし、対応する列に格納された最終値はABCおよびGHLです。
field5は、入力レコードのどのフィールドにもマップされません。ターゲット列に格納されている値は、2つの引数をとるPL/SQL関数MYFUNCの実行結果です。EXPRESSIONパラメータの使用には、入力データがフィールドにマップされないため、SQL文字列を使用して列の最終値を計算する必要があります。
次のタスクでは、共通してSQL演算子が使用されています。
暗黙の小数点が付いているEXTERNALデータをロードするには、次のように指定します。
field1 POSITION(1:9) DECIMAL EXTERNAL(8) ":field1/1000"
また、長すぎるフィールドを切り捨てるには、次のように指定します。
field1 CHAR TERMINATED BY "," "SUBSTR(:field1, 1, 10)"
複数の演算子を次の例のように組み合せることができます。
field1 POSITION(*+3) INTEGER EXTERNAL
"TRUNC(RPAD(:field1,6,'0'), -2)"
field1 POSITION(1:8) INTEGER EXTERNAL
"TRANSLATE(RTRIM(:field1),'N/A', '0')"
field1 CHAR(10)
"NVL( LTRIM(RTRIM(:field1)), 'unknown' )"
日付マスクと併用する場合、日付マスクはSQL文字列の後で評価されます。次のように指定されるフィールドがあるとします。
field1 DATE "dd-mon-yy" "RTRIM(:field1)"
SQL*Loaderの内部で次の文が生成され、挿入されます。
TO_DATE(RTRIM(<field1_value>), 'dd-mon-yyyy')
DATEフィールド・データ型を使用する場合、日付マスクなしのSQL文字列は使用できないことに注意してください。これは、SQL*Loaderで、DATEパラメータの後の最初の引用符付き文字列が日付マスクであるとみなされるためです。たとえば、次のフィールド指定では、エラー(ORA-01821: 日付書式コードが無効です)が発生します。
field1 DATE "RTRIM(TO_DATE(:field1, 'dd-mon-yyyy'))"
この場合、単純な解決策としては、CHARデータ型を使用します。
TO_CHAR演算子を使用して、書式化された日付および数値を格納できます。次に例を示します。
field1 ... "TO_CHAR(:field1, '$09999.99')"
この例では、数値型の入力データを、書式化された形式で格納することができます。この場合、field1はデータベース中ではキャラクタ列です。この指定にある書式化文字(ドル記号やピリオドなど)は、データとともにそのままフィールドに格納されます。
ただし、このような値を数量や日付として格納すると、より柔軟な処理を行うことができます。この場合、データベース内の値に算術関数を指定しても、書式化された値を選択してレポートを作成することができます。
SQL文字列を使用して、書式化されたレポートからデータをロードする例は、「事例7: 書式化されたレポートからのデータの抽出」にあります。(事例の使用方法については、「SQL*Loaderの事例」を参照してください。)
ANYDATAデータベース型には、異なる型のデータを格納できます。SQL*loaderを使用してANYDATA型をロードするには、ファンクション・コールによって明示的に構築する必要があります。ファンクションは、この項で説明したとおり、SQL文字列のサポートを使用して起動します。
たとえば、ANYDATA型のmiscellaneousという名前の列を含む表があるとします。この列は、次のようにしてロードできます。この場合、番号を含むANYDATA型が作成されます。
LOAD DATA INFILE * APPEND INTO TABLE ORDERS ( miscellaneous CHAR "SYS.ANYDATA.CONVERTNUMBER(:miscellaneous)" ) BEGINDATA 4
レコード内の値によっては、さらに複雑な条件で、異なる型を含むANYDATA型を作成する場合もあります。そのためには、レコード内の値に基づいて、ANYDATA型にする型を決定する独自のPL/SQLファンクションを記述し、適切なANYDATA.Convert*()ファンクションをコールしてその型を作成する必要があります。
|
参照:
|
この項では、データ・ファイルからデータを読み込むのではなく、SQL*Loaderでデータを生成してデータベース・レコードに格納するパラメータについて説明します。ここで説明するパラメータは次のとおりです。
フィールドの指定として順序、レコード番号、システム日付、定数およびSQL文字列式のみを指定してSQL*Loaderでデータを生成できます。
SQL*Loaderを使用して、LOAD文で指定された数のレコードを挿入します。この場合、SKIPパラメータは指定できません。
SQL*Loaderは、このような場合用に最適化されています。生成された指定のみが使用されていることを検出すると、SQL*Loaderでは、常に、指定されたすべてのデータ・ファイルが無視されます。I/Oの読取りは実行されません。
バインド配列用のメモリーも不要です。制御ファイル中にWHEN句が指定されている場合は、SQL*Loaderでデータの評価が必要であると判断され、入力レコードが読み込まれます。
これは、生成するデータとしては最も単純な形式です。ロード中であっても、何回ロードしても、このデータは変わりません。
列に定数値を設定するには、CONSTANTを指定して、その後に値を指定します。
CONSTANT value
CONSTANTデータは、SQL*Loaderでは、文字入力として認識されます。このデータは、必要に応じてデータベース列のデータ型に変換されます。
値を引用符で囲むこともできます。特に、指定する値に空白や予約語が含まれている場合は、必ず引用符で囲んでください。また、ターゲット列に対して必ず有効な値を指定してください。指定した値が無効な場合は、すべてのレコードが拒否されてしまいます。
2の32乗-1(4,294,967,295)より大きい数値は引用符で囲んでください。
列名の後にEXPRESSIONパラメータを使用して、SQL演算子または特別に書き込まれたPL/SQL関数によって返された値に、その列を設定します。EXPRESSIONパラメータの後に続くSQL文字列に、演算子または関数が指定されます。演算子または関数に必要なパラメータが適切に指定され、その演算子または関数によって返された結果が、ロード中の列のデータ型と互換性がある場合、任意の式を使用できます。
RECNUMパラメータを列名の後に指定すると、レコードのロード元である論理レコードの番号が、その列に設定されます。レコードの番号は、最初のデータ・ファイルの先頭をレコード1として、順番にカウントされます。RECNUMは、各論理レコードが構成されるたびに増えていきます。廃棄、スキップ、拒否またはロードされたレコードもカウントされます。SKIP=10と指定した場合、最初にロードされるレコードのRECNUMの値は11になります。
列名およびRECNUMの組合せを指定すると、列指定は完結します。
column_name RECNUM
SYSDATEを使用して列を指定すると、SQL言語のSYSDATEパラメータで定義されているとおりに現在のシステム日付が取得されます。『Oracle Database SQL言語リファレンス』のDATEデータ型に関する項を参照してください。
列名とSYSDATEパラメータの組合せを指定すると、列指定は完結します。
column_name SYSDATE
データベースの列のデータ型は、CHARまたはDATE型にしてください。列がCHAR型の場合、日付は'dd-mon-yy'の書式でロードされます。ロード後は、この書式でのみ日付のロードができます。システム日付をDATE列にロードすると、そのシステム日付は、時間と日付を含む様々な書式でロードできます。
新しいシステム日付/時間は、従来型パス・ロードで挿入されたレコードの各配列や、ダイレクト・パス・ロード中にロードされた各レコード・ブロックで使用されます。
SEQUENCEパラメータは、特定の列に対して一意の値を設定します。SEQUENCEの値は、ロードされたレコードまたは拒否されたレコードが発生するたびに増加します。廃棄またはスキップされたレコードに対しては、値は増加しません。
列名とSEQUENCEパラメータの組合せを指定すると、列指定は完結します。

表10-6では、列指定に使用されるパラメータについて説明します。
表10-6 列指定に使用されるパラメータ
| パラメータ | 説明 |
|---|---|
|
|
データベース内の、順序を割り当てる列の名前。 |
|
|
列の値を指定するには、この |
|
|
順序番号は表中にすでにあるレコード数で始まり、以降は増分値を加えた値が設定されます。 |
|
|
順序番号は列の現在の最大値で始まり、以降は増分値を加えた値が設定されます。 |
|
|
先頭となる特定の順序番号を指定します。 |
|
|
レコードがロードまたは拒否された後の順序番号の増分値。これはオプションです。デフォルトは1です。 |
レコードが拒否された場合(書式エラーがあるか、またはOracleエラーが発生した場合)でも、その欠落を埋めるために生成された順序番号が変更されることはありません。たとえば、ある列に関して、4つの行に順序番号10、12、14および16が割り当てられ、番号12の行が拒否されたとします。この場合、挿入された3つの行の番号は10、14および16であって、10、12および14ではありません。このような処理が行われることによって、データ・エラーが発生しても、挿入時の順番を保持できます。拒否されたデータを修正して再度挿入する場合は、列の順序番号に一致するようにデータを手動で設定できます。
「事例3: 自由区分形式ファイルのロード」に、SEQUENCEパラメータの使用例があります。(事例の使用方法については、「SQL*Loaderの事例」を参照してください。)
一意の順序番号は、各表への挿入時に生成されるのではなく、各論理入力レコードに対して生成されます。したがって、データを複数の表に挿入する場合、同じ順序番号を使用することができます。この仕様は、多くの場合に有効です。
ただし、INTO TABLE句ごとに別の順序番号を生成する場合もあります。たとえば、各入力レコード中に3つの論理レコードが定義された形式のデータについて考えます。この場合、INTO TABLE句を3つ使用して、レコードの3つの異なる部分を同じ表に挿入するように指定できます。SEQUENCE(MAX)を使用すると、各表の最大値が採用されるため、順序番号に一貫性がなくなります。
このレコードの順序番号を生成する場合は、挿入する3つの論理レコードそれぞれに対して、重複しない番号を生成する必要があります。1レコード当たりの表挿入の回数を順序番号の増分値として使用し、各挿入の順序番号をその続き番号で始めるようにします。
次に示す部門名をdept表にロードするとします。各入力レコードには部門名が3つ入っています。この部門番号を自動生成する方法について考えます。
Accounting Personnel Manufacturing Shipping Purchasing Maintenance ...
部門番号を重複しないように生成するには、次のような制御ファイル・エントリを作成します。
INTO TABLE dept (deptno SEQUENCE(1, 3), dname POSITION(1:14) CHAR) INTO TABLE dept (deptno SEQUENCE(2, 3), dname POSITION(16:29) CHAR) INTO TABLE dept (deptno SEQUENCE(3, 3), dname POSITION(31:44) CHAR)
最初のINTO TABLE句で生成される部門番号は1で、2番目では2が、3番目では3が生成されます。これらすべてで増分値として3が使用されます(増分値は各レコードに含まれる部門名の数と一致します)。この制御ファイルでロードを実行すると、Accounting部門は部門番号1、Personnel部門は部門番号2、Manufacturing部門は部門番号3でロードされます。
また、次のレコードになると、順序番号は増分値分のみ増加するので、Shipping部門は部門番号4、Purchasing部門は部門番号5でロードされ、以降も同様にロードされます。