| Oracle® Database概要 11gリリース2 (11.2) B56306-06 |
|


 前 |
 次 |
この章では、Oracle Databaseインスタンスのメモリー・アーキテクチャについて説明します。
この章の内容は、次のとおりです。
|
関連項目: メモリーの構成方法および管理方法は、『Oracle Database管理者ガイド』を参照してください。 |
インスタンスが開始されると、Oracle Databaseによってメモリー領域が割り当てられ、バックグラウンド・プロセスが起動されます。メモリー領域には、次のような情報が格納されています。
プログラム・コード
接続されているセッションについての情報(現在はアクティブかどうかは不問)
プログラムの実行時に必要な情報(行をフェッチしている問合せの現在の状態など)
プロセス間で共有および通信されるロック・データなどの情報
データ・ブロックやREDOレコードなどの、ディスク上にも存在するキャッシュ・データ
Oracle Databaseに関連する基本的なメモリー構造は、次のような領域で構成されています。
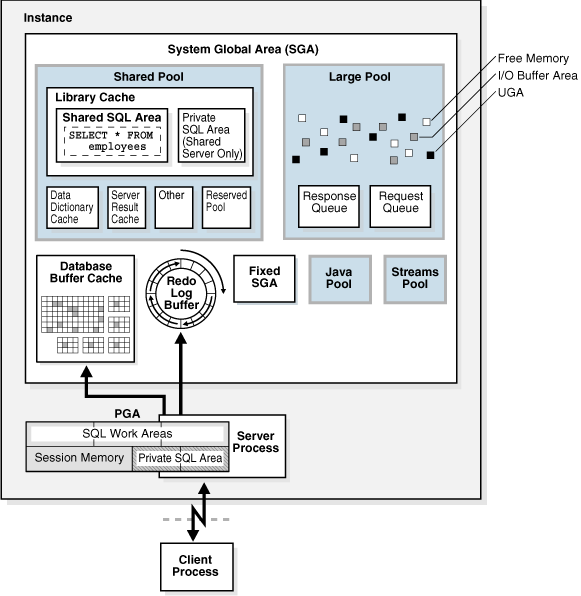
システム・グローバル領域(SGA)
SGAは、SGAコンポーネントと呼ばれる共有メモリー構造のグループで、1つのOracle Databaseインスタンスに関するデータと制御情報が保存されています。SGAは、すべてのサーバーおよびバックグラウンド・プロセスで共有されます。SGAに保存されるデータの例としては、キャッシュ・データ・ブロックや共有SQL領域があります。
プログラム・グローバル領域(PGA)
PGAは、Oracleプロセス専用のデータや制御情報を含む、非共有メモリー領域です。PGAは、Oracleプロセスの起動時に、Oracle Databaseによって作成されます。
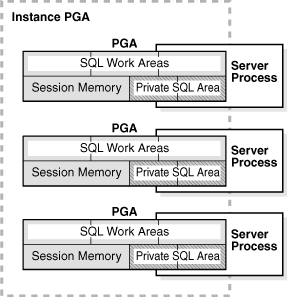
PGAは、サーバー・プロセスごと、およびバックグラウンド・プロセスごとに存在します。個々のPGAの集合は、合計インスタンスPGAまたはインスタンスPGAと呼ばれています。個々のPGAではなく、データベース初期化パラメータを使用してインスタンスPGAのサイズを設定します。
ユーザー・グローバル領域(UGA)
UGAは、ユーザー・セッションに関連付けられたメモリーです。
ソフトウェア・コード領域
ソフトウェア・コード領域とは、実行中または実行される可能性のあるコードを格納するためのメモリー部分です。Oracle Databaseのコードはソフトウェア領域に格納され、通常、この場所はユーザー・プログラムの格納場所とは異なり、より排他的で保護されています。
図14-1に、これらのメモリー構造の関係を示します。
メモリー管理では、データベースの変化に応じて、Oracleインスタンスのメモリー構造を最適なサイズに維持します。Oracle Databaseでは、メモリー関連の初期化パラメータの設定に基づいてメモリーが管理されます。メモリー管理の基本的なオプションは、次のとおりです。
自動メモリー管理
インスタンス・メモリーのターゲット・サイズを指定します。データベース・インスタンスは自動的にターゲット・メモリー・サイズにチューニングされ、必要に応じて、SGAとインスタンスPGAとの間でメモリーの再配分が行われます。
自動共有メモリー管理
この管理モードでは、一部の処理が自動化されます。SGAは、ターゲット・サイズを設定し、PGAは、ターゲット・サイズの合計を設定するか、作業領域を個別に管理できます。
手動メモリー管理
合計メモリー・サイズを設定するかわりに、SGAのコンポーネントおよびインスタンスPGAを個別に管理するための数多くの初期化パラメータを設定します。
Database Configuration Assistant(DBCA)を使用してデータベースを作成し、基本インストール・オプションを選択した場合のデフォルトは、自動メモリー管理です。
|
関連項目:
|
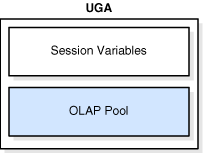
UGAはセッション・メモリーで、ログオン情報やデータベース・セッションに必要なその他の情報などのセッション変数に割り当てられるメモリーです。基本的に、UGAにはセッション状態が格納されています。図14-2に、UGAを示します。
セッションによってPL/SQLパッケージがメモリーにロードされると、特定の時点においてすべてのパッケージ変数に格納されている値のセットであるパッケージ状態がUGAに格納されます(「PL/SQLパッケージ」を参照)。パッケージのサブプログラムによって変数が変更されると、パッケージ状態も変更されます。デフォルトで、パッケージ変数はセッションの存続期間に対して固有の変数であり、セッションの存続期間中保持されます。
UGAには、OLAPページ・プールも格納されています。このプールでは、OLAPデータ・ページが管理され、データ・ページはデータ・ブロックと同じものです。ページ・プールは、OLAPセッションの開始時に割り当てられて、セッションの終了時に解放されます。OLAPセッションは、ユーザーがキューブなどのディメンション・オブジェクトを問い合せると、常に自動的に開かれます。
データベース・セッションの存続期間中は、セッションでUGAが使用可能である必要があります。このことは、PGAは単一のプロセス固有の領域であるため、共有サーバー接続を使用する場合にはUGAをPGAに格納できないことを意味しています。したがって、共有サーバー接続を使用する場合は、すべての共有サーバー・プロセスからUGAにアクセスできるよう、UGAはSGAに格納されます。専用サーバー接続を使用する場合は、UGAはPGAに格納されます。
|
関連項目:
|
PGAは、システムの他のプロセスやスレッドによって共有されていない、動作中のプロセスやスレッドに固有のメモリーです。PGAはプロセス固有であるため、SGA内で割り当てられることはありません。
PGAは、専用サーバー・プロセスまたは共有サーバー・プロセスが必要とするセッション依存の変数を含むメモリー・ヒープです。サーバー・プロセスでは、必要なメモリー構造がPGA内に割り当てられます。
PGAは、文書係が使用するカウンタ上の一時的な作業領域に似ています。このたとえの場合、文書係はサーバー・プロセスを表しており、顧客(クライアント・プロセス)のために作業を行います。文書係は、作業のための場所をカウンタ上に準備し、その場所に顧客のリクエストの詳細をまとめ、顧客が要求するフォルダをソートし、作業が終わるとその場所を解放します。
図14-3に、共有サーバー用に構成されていないインスタンスのインスタンスPGA(すべてのPGAの集合)を示します。初期化パラメータを使用して、インスタンスPGAの最大ターゲット・サイズを設定できます(「メモリー管理方法の概要」を参照)。個々のPGAでは、必要に応じて最大このターゲット・サイズまでサイズを増加できます。
|
注意: バックグラウンド・プロセスにも独自のPGAが割り当てられます。ここでは、サーバー・プロセスPGAのみを説明します。 |
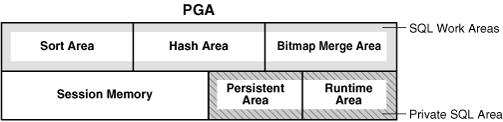
PGAは、それぞれ異なる目的を持つ複数の領域によって構成されています。図14-4に、専用サーバー・セッションのPGAの内容を示します。どの場合にもすべてのPGA領域が揃っているとはかぎりません。
プライベートSQL領域には、解析済のSQL文に関する情報と、処理に使用するその他のセッション固有の情報が保持されます。サーバー・プロセスでSQLまたはPL/SQLのコードが実行される場合、プロセスではプライベートSQL領域を使用してバインド変数値、問合せ実行状態情報、問合せ実行作業領域が格納されます。
UGA内のプライベートSQL領域は、SGAにおいて実行計画が格納される共有SQL領域とは異なります。同じセッション内または異なるセッション内の複数のプライベートSQL領域から、SGA内の単一の実行計画を指すことができます。たとえば、あるセッションにおけるSELECT * FROM employeesの20回の実行および別のセッションにおける同じ問合せの10回の実行において、同じ計画を共有できます。各実行におけるプライベートSQL領域は共有されず、異なる値やデータが含まれている可能性があります。
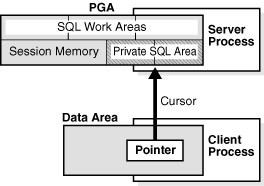
カーソルは、特定のプライベートSQL領域の名前またはハンドルです。図14-5に示すように、カーソルはクライアントから見るとポインタ、サーバーから見ると状態のようなものです。カーソルはプライベートSQL領域と密接に関連しているため、これらの用語は同じ意味で使用されることがあります。
プライベートSQL領域は、次の領域によって構成されています。
ランタイム領域
この領域には、問合せ実行状態情報が含まれています。たとえば、ランタイム領域では、全表スキャンで現在までに取得された行数が追跡されます。
Oracle Databaseでは、ランタイム領域は実行要求の最初の処理で作成されます。DML文では、SQL文が終了するとランタイム領域が解放されます。
持続領域
この領域には、バインド変数値が含まれています。バインド変数値は、SQL文が実行される実行時にSQL文に指定されます。持続領域は、カーソルのクローズ時にのみ解放されます。
クライアント・プロセスは、プライベートSQL領域の管理を担当します。クライアント・プロセスが割り当てることのできるプライベートSQL領域の数は、初期化パラメータOPEN_CURSORSによって制限されますが、プライベートSQL領域の割当ておよび割当て解除は、アプリケーションに大きく依存します。
ほとんどのユーザーはデータベース・ユーティリティの自動カーソル処理を使用しますが、Oracle Databaseのプログラム・インタフェースを利用すると、開発者はカーソルをより制御できるようになります。一般的に、持続領域を解放し、アプリケーション・ユーザーが必要とするメモリーを最小限に抑えるには、オープンされているカーソルのうち再利用しないすべてのカーソルをアプリケーション側でクローズする必要があります。
|
関連項目:
|
作業領域は、メモリー集中型の操作に使用されるPGAメモリーを個別に割り当てるための領域です。たとえば、ソート演算子では、ソート領域を使用して行のセットがソートされます。同様に、ハッシュ結合演算子ではハッシュ領域を使用して左側の入力からハッシュ表が構築され、ビットマップ・マージ演算子ではビットマップ・マージ領域を使用して複数のビットマップ索引のスキャンにより取得されたデータがマージされます。
例14-1に、employeesとdepartmentsとの結合およびその問合せ計画を示します。
例14-1 表結合の問合せ計画
SQL> SELECT * 2 FROM employees e JOIN departments d 3 ON e.department_id=d.department_id 4 ORDER BY last_name; . . . ---------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ---------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 106 | 9328 | 7 (29)| 00:00:01 | | 1 | SORT ORDER BY | | 106 | 9328 | 7 (29)| 00:00:01 | |* 2 | HASH JOIN | | 106 | 9328 | 6 (17)| 00:00:01 | | 3 | TABLE ACCESS FULL| DEPARTMENTS | 27 | 540 | 2 (0)| 00:00:01 | | 4 | TABLE ACCESS FULL| EMPLOYEES | 107 | 7276 | 3 (0)| 00:00:01 | ----------------------------------------------------------------------------------
例14-1では、ランタイム領域で全表スキャンの進行状況が追跡されます。セッションでは、ハッシュ領域を使用してハッシュ結合が実行されて、2つの表の行が照合されます。ORDER BYによるソートは、ソート領域で行われます。
演算子で処理するデータが作業領域に収まらない場合は、Oracle Databaseによって入力データがより小さく分割されます。データベースでは、このようにして一部のデータがメモリー内で処理され、残りのデータは後で処理するために一時ディスク記憶域に格納されます。
自動PGAメモリー管理が有効になっている場合、作業領域サイズはデータベースにより自動的にチューニングされます。作業領域のサイズを手動で制御してチューニングすることもできます。詳細は、「メモリーの管理」を参照してください。
通常、作業領域を増やすとメモリー使用率は増えますが、演算子のパフォーマンスが大幅に改善されます。作業領域は、入力データや関連するSQL演算子によって割り当てられる補助メモリー構造を格納するために十分なサイズにすることをお薦めします。十分なサイズが確保されていない場合は、一部の入力データがディスクにキャッシュされるため、レスポンス時間が長くなります。作業領域のサイズが入力データ・サイズに比べて非常に小さい場合は、データを分割して何度も渡すことが必要となるため、レスポンス時間が大幅に長くなります。
|
関連項目:
|
PGAにメモリーが割り当てられるかどうかは、データベースで専用サーバー接続が使用されるか、共有サーバー接続が使用されるかに応じて異なります。表14-1に相違点を示します。
表14-1 専用サーバーと共有サーバーのメモリー割当て方法の相違点
| メモリー領域 | 専用サーバー | 共有サーバー |
|---|---|---|
|
セッション・メモリーの性質 |
プライベート |
共有 |
|
持続領域の位置 |
PGA |
SGA |
|
DML/DDL文のランタイム領域の位置 |
PGA |
PGA |
|
関連項目: 共有サーバーを使用するためのデータベースの構成方法の詳細は、『Oracle Database Net Services管理者ガイド』を参照してください。 |
SGAは、Oracleバックグラウンド・プロセスとともにデータベース・インスタンスを構成する、読取り/書込み可能なメモリー領域です。ユーザー用に実行されるすべてのサーバー・プロセスで、インスタンスSGA内の情報の読取りが可能です。データベース操作中にSGAに書き込むプロセスもあります。
|
注意: サーバー・プロセスおよびバックグラウンド・プロセスは、SGA内ではなく、別のメモリー領域内に存在しています。 |
各データベース・インスタンスには、独自のSGAがあります。Oracle Databaseでは、インスタンスの開始時にSGAのメモリーが自動的に割り当てられて、インスタンスが停止するとメモリーが再利用されます。SQL*PlusまたはOracle Enterprise Managerを使用してインスタンスを開始した場合、SGAは次の例に示すサイズになります。
SQL> STARTUP ORACLE instance started. Total System Global Area 368283648 bytes Fixed Size 1300440 bytes Variable Size 343935016 bytes Database Buffers 16777216 bytes Redo Buffers 6270976 bytes Database mounted. Database opened.
図14-1に示すように、SGAはいくつかのメモリー・コンポーネントによって構成され、これらのコンポーネントは、特定の種類のメモリー割当て要求を満たすために使用されるメモリーのプールです。REDOログ・バッファを除くすべてのSGAコンポーネントは、グラニュルと呼ばれる連続したメモリーの単位で割当ておよび割当て解除されます。グラニュルのサイズはプラットフォーム固有であり、SGAサイズの合計から決定されます。
SGAコンポーネントの情報は、V$SGASTATビューに問い合せることができます。
バッファ・キャッシュとも呼ばれるデータベース・バッファ・キャッシュとは、データファイルから読み取られたデータ・ブロックのコピーを格納するメモリー領域のことです。バッファとは、現在使用されているデータ・ブロックまたは最近使用されたデータ・ブロックがバッファ・マネージャによって一時的にキャッシュされるメイン・メモリーのアドレスのことです。データベース・インスタンスに同時接続されたユーザーはすべて、バッファ・キャッシュへのアクセスを共有します。
Oracle Databaseでは、次の目的でバッファ・キャッシュが使用されます。
物理I/Oを最適化します。
データベースでは、キャッシュ内のデータ・ブロックが更新されて、REDOログ・バッファに変更についてのメタデータが格納されます。COMMITの後、データベースによってREDOバッファがディスクに書き込まれますが、データ・ブロックが即座にディスクに書き込まれるわけではありません。かわりに、データベース・ライター(DBW)によって、バックグラウンドで遅延書込みが実行されます。
頻繁にアクセスされるブロックをバッファ・キャッシュに保持して、頻繁にアクセスされないブロックはディスクに書き込みます。
データベース・スマート・フラッシュ・キャッシュ(フラッシュ・キャッシュ)を有効にすると、バッファ・キャッシュの一部をフラッシュ・キャッシュ内に保持できます。このバッファ・キャッシュの拡張部分は、フラッシュ・ディスク・キャッシュという、フラッシュ・メモリーを搭載した半導体ストレージ・デバイスに保存されます。フラッシュ・メモリー内にバッファがキャッシュされ、磁気ディスクからの読取りが必要なくなるため、データベースのパフォーマンスが向上します。
|
注意: データベース・スマート・フラッシュ・キャッシュは、SolarisおよびOracle Enterprise Linux環境でのみ使用できます。 |
データベースでは、内部アルゴリズムを使用してキャッシュ内のバッファが管理されます。バッファには、次のような相互に排他的な状態があります。
未使用
このバッファはまだ使用されていないか、現在使用されていないため、使用可能です。このタイプのバッファは、最も使用しやすいバッファです。
クリーン
このバッファは過去に使用され、現在はある時点において読取り一貫性があるバージョンのブロックが含まれています。このブロックにはデータが含まれていますが、クリーンであるため、チェックポイントを作成する必要はありません。データベースでは、このブロックを確保して再利用できます。
使用済
このバッファには、まだディスクに書き込まれていない変更されたデータが含まれています。データベースでこのバッファを再利用する前に、このブロックのチェックポイントを作成する必要があります。
すべてのバッファには、使用中または使用可能(確保解除)というアクセス・モードがあります。バッファは、ユーザー・セッションによってアクセスされている間にメモリーからエージ・アウトされないように、キャッシュ内で確保されます。確保されたバッファを複数のセッションから同時に変更することはできません。
Oracle Databaseでは、高度なアルゴリズムを使用して効率的にバッファにアクセスできるようにしています。使用済のバッファと未使用のバッファへのポインタは、同じ最低使用頻度(LRU)リスト上に存在し、このリストの両端はそれぞれホットとコールドと呼ばれます。コールド・バッファは、最近使用されていないバッファです。ホット・バッファは、頻繁にアクセスされ、最近使用されたバッファです。
クライアントがデータを要求すると、Oracle Databaseでは、次のいずれかのモードでデータベース・バッファ・キャッシュからバッファが取得されます。
現在のモード
現在のモード取得は、DBブロック取得とも呼ばれ、バッファ・キャッシュ内の現行のブロックをそのまま取得します。たとえば、コミットされていないトランザクションによってブロック内の2つの行が更新された場合、現行モード取得により、これらのコミットされていない行を含むブロックが取得されます。Oracle Databaseでは、ブロックの現行バージョンのみを更新する必要がある変更文を実行する際に、最も頻繁にDBブロック取得が使用されます。
一貫したモード
読取り一貫性取得は、ブロックの読取り一貫性バージョンを取得します。この取得では、UNDOデータが使用される場合があります。たとえば、トランザクションによってブロック内の2つの行が更新されたがまだコミットされていない場合に、別のセッションの問合せがそのブロックを要求すると、Oracle DatabaseではUNDOデータを使用して、コミットされていない更新を含まない、このブロックの読取り一貫性バージョン(読取り一貫性クローンと呼ばれます)が作成されます。一般に、問合せは一貫性モードでブロックを取得します。
論理I/Oは、バッファI/Oとも呼ばれ、バッファ・キャッシュ内でのバッファの読取りおよび書込みを表しています。要求されたバッファがメモリーにない場合、Oracle Databaseでは物理I/Oを実行してフラッシュ・キャッシュまたはディスクからメモリーにバッファをコピーし、次に論理I/Oを実行して、キャッシュされたバッファを読み取ります。
データベース・ライター(DBW)プロセスでは、コールドかつ使用済のバッファが定期的にディスクに書き込まれます。DBWnでは、次の状況でバッファが書き込まれます。
サーバー・プロセスで、新しいブロックをデータベース・バッファ・キャッシュに読み取るときにクリーンなバッファが見つからなかった場合。
バッファが使用されるにつれて、使用可能バッファの数が減少します。使用可能バッファの数が内部のしきい値未満になり、クリーンなバッファが必要な場合には、サーバー・プロセスからDBWnに対して、書込みを行うように通知されます。
Oracle Databaseでは、LRUを使用して、どの使用済バッファに書き込むかが決定されます。使用済バッファがLRUのコールド・エンドに達すると、そのバッファはLRUから書込みキューに移動されます。DBWnによって、可能な場合にはマルチブロック書込みを使用して、キュー内のバッファがディスクに書き込まれます。このメカニズムによって、LRUの終端に使用済バッファが滞留しなくなり、クリーンなバッファを検出して再利用できるようになります。
データベースで、REDOスレッド内のインスタンス・リカバリを開始する位置であるチェックポイントを進める必要がある場合。
表領域が読取り専用ステータスに変更されたか、オフラインにされた場合。
|
関連項目:
|
クリーン・バッファまたは未使用バッファの数が減少したら、データベースにより、バッファ・キャッシュからバッファが削除されます。アルゴリズムはフラッシュ・キャッシュが有効かどうかに応じて変わります。
フラッシュ・キャッシュが無効な場合
各クリーン・バッファは、必要に応じて上書きされ、再使用されます。上書きされたバッファが後から必要になった場合は、そのバッファが磁気ディスクから読み取られます。
フラッシュ・キャッシュが有効な場合
DBWnがフラッシュ・キャッシュにクリーン・バッファ本体を書き込めるため、メモリー内のバッファの再利用が可能になります。データベースは、フラッシュ・キャッシュ内のバッファ本体の状態と場所を追跡できるように、メイン・メモリー内のLRUリストにバッファのヘッダーを保持します。バッファが後で必要になったときに、データベースは磁気ディスクからではなく、フラッシュ・キャッシュからバッファを読み取ります。
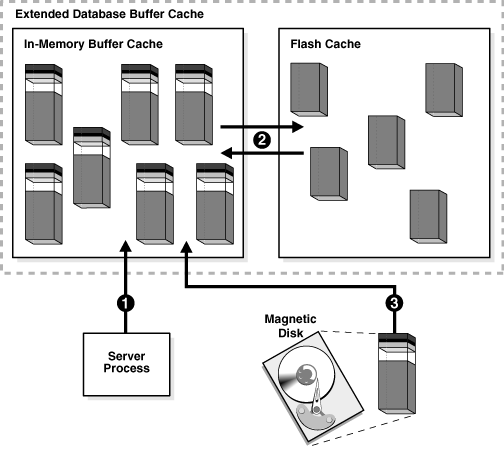
クライアント・プロセスからバッファが要求されると、サーバー・プロセスは最初にバッファ・キャッシュ内でそのバッファを検索します。データベースによるメモリー内のバッファの検索時には、キャッシュ・ヒットの処理が実行されます。検索順序は、次のとおりです。
サーバー・プロセスによってバッファ・キャッシュ内にバッファ全体があるかどうかが検索されます。
バッファ全体が見つかった場合は、データベースによってそのバッファの論理読取りが実行されます。
サーバー・プロセスによってフラッシュ・キャッシュのLRUリスト内にバッファのヘッダーがあるかどうかが検索されます。
バッファのヘッダーが見つかった場合、データベースによってフラッシュ・キャッシュからメモリー内のキャッシュにバッファ本体の最適化物理読取りが実行されます。
キャッシュ・メモリー内にバッファが見つからない場合は(キャッシュ・ミス)、サーバー・プロセスによって次のステップが実行されます。
データファイルからメモリーへのブロックのコピー(物理読取り)
メモリーに読み取られたバッファの論理読取りの実行
図14-6に、バッファの検索順序を示します。拡張バッファ・キャッシュは、バッファ全体を格納するインメモリーのバッファ・キャッシュと、バッファ本体を格納するフラッシュ・キャッシュから構成されます。図では、データベースによってバッファ・キャッシュ内にバッファがあるかどうか検索され、バッファが見つからなければ、磁気ディスクからメモリーにバッファが読み込まれます。
通常、キャッシュにヒットした場合のデータへのアクセスは、キャッシュ・ミスの場合よりも高速です。バッファ・キャッシュ・ヒット率は、要求されたブロックがバッファ・キャッシュ内に見つかり、ディスクからの読取りが不要である確率を示しています。
データファイルまたは一時ファイルから物理読取りが実行されます。データファイルからの読取りの後には、論理I/Oが実行されます。一時ファイルからの読取りは、メモリー不足によってデータベースがデータを一時表に書き込み、後からそのデータを読み取る必要がある場合に行われます。このような物理読取りでは、バッファ・キャッシュにはアクセスされないため、論理I/Oは発生しません。
|
関連項目: バッファ・キャッシュ・ヒット率の計算方法の詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
データベースでは、タッチ・カウントを使用して、LRUリスト上のバッファへのアクセス頻度が測定されます。このメカニズムによって、バッファが確保されたときに常にLRUリスト上でバッファをシャッフルするかわりに、カウンタを増加できます。
|
注意: メモリー内のブロックは、物理的には移動されません。移動は、リスト上のポインタの位置を変更することによって行われます。 |
バッファが確保されると、最後にタッチ・カウントが増加された時間が特定されます。カウントが3秒前より以前に増加されている場合は、カウントが増加され、そうでない場合は、カウントはそのままです。この3秒ルールによって、バッファが非常に多くの回数確保されたときに、同じ数だけタッチ・カウントが増加されることを防止できます。たとえば、セッションでデータ・ブロックに複数の行を挿入する場合に、データベースではこれらの挿入が1回のタッチであるとみなされます。
バッファがLRUのコールド・エンドにあり、タッチ・カウントが大きい場合、バッファはホット・エンドに移動されます。タッチ・カウントが小さい場合、バッファはキャッシュからエージ・アウトされます。
バッファをディスクから読み取る必要がある場合、そのバッファはLRUリストの中央に挿入されます。これにより、ホット・ブロックがキャッシュ内に維持されて、再度ディスクから読み取る必要がなくなります。
表の最高水位標より下のすべての行を順次読み取る全表スキャンでは、問題が発生します(「セグメント領域と最高水位標」を参照)。表セグメント内のブロックの合計サイズが、バッファ・キャッシュのサイズよりも大きいとします。この表を全体スキャンすると、バッファ・キャッシュが一掃されて、頻繁にアクセスされるブロックのキャッシュが維持されなくなる可能性があります。
そのため、大規模な表を全体スキャンした結果データベース・キャッシュに読み取られたブロックは、他のタイプの読取りとは異なる方法で処理されます。スキャンによって実質的にバッファ・キャッシュが一掃されることを防止するために、これらのブロックは即座に再利用可能となります。
まれに、デフォルトの動作が望ましくないことがありますが、その場合は、表のCACHE属性を変更できます。この場合、データベースでは、バッファ・キャッシュ内のブロックは強制的に確保されず、他のブロックの場合と同じようにキャッシュからエージ・アウトされます。このオプションを使用すると、大規模な表の全体スキャンを行ったときに、キャッシュ内の他のほとんどのブロックが一掃される可能性があるため、注意が必要です。
|
関連項目:
|
バッファ・プールとは、バッファの集合のことです。データベース・バッファ・キャッシュは、1つ以上のバッファ・プールによって構成されています。
バッファ・キャッシュ内のデータを保持するバッファ・プール、または新しいデータがデータ・ブロックを使用した直後に使用可能なバッファを提供するバッファ・プールを手動で個別に構成できます。その後、適切なバッファ・プールに特定のスキーマ・オブジェクトを割り当て、ブロックがキャッシュからエージ・アウトされる方法を制御できます。
次のバッファ・プールがあります。
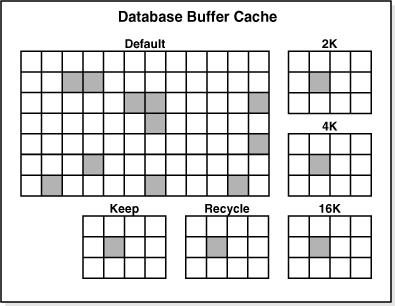
DEFAULTプール
このプールは、ブロックが通常キャッシュされる場所です。手動で個別にプールを構成しない場合は、DEFAULTプールが唯一のバッファ・プールとなります。
KEEPプール
このプールは、頻繁にアクセスされたが、領域が不足したためにDEFAULTプールからエージ・アウトされたブロック用のプールです。KEEPバッファ・プールの目的は、メモリー内にオブジェクトを保持して、I/O操作を回避することです。
RECYCLEプール
このプールは、頻繁に使用されないブロック用のプールです。RECYCLEプールによって、キャッシュ内の領域が不要なオブジェクトによって消費されることを防止できます。
データベースには、標準ブロック・サイズがあります(「データベース・ブロック・サイズ」を参照)。標準のサイズとは異なるブロック・サイズを持つ表領域を作成できます。非デフォルトのブロック・サイズには、それぞれ独自のプールがあります。Oracle Databaseでは、これらのプールのブロックもDEFAULTプールと同様に管理されます。
図14-7に、複数のプールが使用された場合のバッファ・キャッシュの構造を示します。このキャッシュには、DEFAULTプール、KEEPプールおよびRECYCLEプールが含まれています。デフォルトのブロック・サイズは8KBです。このキャッシュには、2KB、4KBおよび16KBという非標準のブロック・サイズを使用する表領域用の個別のプールが含まれています。
|
関連項目:
|
REDOログ・バッファとは、SGA内の循環バッファであり、データベースに加えられた変更についてのREDOエントリが格納されます。REDOエントリには、DML操作やDDL操作によって行われた変更を再構築または再実行するために必要な情報が含まれています。データベースのリカバリでは、データファイルにREDOエントリを適用して、失われた変更が再構築されます。
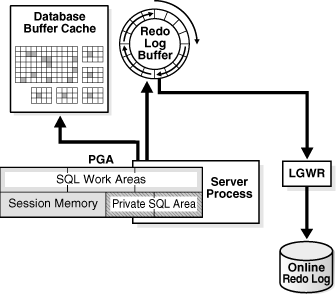
REDOエントリは、Oracle Databaseプロセスによってユーザーのメモリー領域からSGA内のREDOログ・バッファにコピーされます。REDOエントリは、バッファ内で連続した領域を占めます。REDOログ・バッファは、バックグラウンド・プロセスのログ・ライター(LGWR)によって、ディスク上のアクティブなオンラインREDOログ・グループに書き込まれます。図14-8に、このREDOバッファのアクティビティを示します。
DBWnではデータ・ブロックは分散してディスクに書き込まれますが、LGWRではREDOログ・バッファはディスクに対して順次書き込まれます。通常、分散書込みの速度は順次書込みよりも大幅に遅くなります。LGWRでは、ユーザーはDBWnによる遅い書込みが完了するまで待機する必要がないため、パフォーマンスが向上します。
LOG_BUFFER初期化パラメータでは、Oracle DatabaseでREDOエントリをバッファリングする場合に使用するメモリー量を指定します。他のSGAコンポーネントとは異なり、REDOログ・バッファおよび固定SGAバッファのメモリーは、グラニュルに分割されません。
|
関連項目:
|
共有プールには、様々なタイプのプログラム・データがキャッシュされます。たとえば、共有プールには、解析済のSQLやPL/SQLのコード、システム・パラメータ、データ・ディクショナリ情報などが格納されます。共有プールは、データベースで行われるほぼすべての操作に関連します。たとえば、ユーザーがSQL文を実行する場合にも、Oracle Databaseは共有プールにアクセスします。
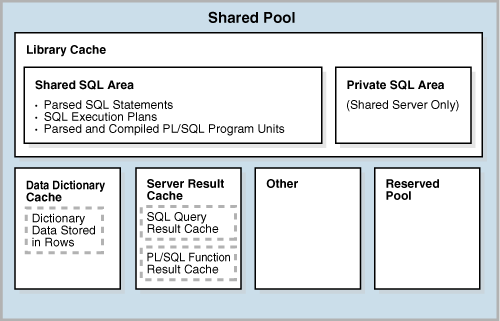
共有プールは、複数のサブコンポーネントから構成されています。図14-9に、最も重要なサブコンポーネントを示します。
この項の内容は、次のとおりです。
ライブラリ・キャッシュとは、実行可能なSQLコードやPL/SQLコードが格納されている共有プール・メモリー構造です。このキャッシュには、SQLとPL/SQLの共有領域や、ロックやライブラリ・キャッシュ・ハンドルなどの制御構造が含まれています。共有サーバー・アーキテクチャでは、ライブラリ・キャッシュにはプライベートSQL領域も含まれています。
SQL文が実行されると、データベースでは、以前に実行されたコードの再利用が試みられます。ライブラリ・キャッシュ内にSQL文の解析済表現が存在し、共有可能である場合には、そのコードが再利用され、これはソフト解析またはライブラリ・キャッシュ・ヒットと呼ばれます。それ以外の場合には、データベースでアプリケーション・コードの実行可能バージョンを新たに構築する必要があり、これは ハード解析またはライブラリ・キャッシュ・ミスと呼ばれます。
データベースでは、実行される各SQL文の表現が次のSQL領域内に保持されます。
共有SQL領域
SQL文が最初に実行されたときは、共有SQL領域を使用してSQL文が処理されます。この領域にはすべてのユーザーがアクセス可能であり、文の解析ツリーと実行計画が含まれています。一意の文に対して、共有SQL領域は1つのみ存在します。
プライベートSQL領域
SQL文を発行するそれぞれのセッションには、PGA内にプライベートSQL領域があります(「プライベートSQL領域」を参照)。同じ文を発行する各ユーザーのプライベートSQL領域は、同じ共有SQL領域を指しています。これにより、異なるPGA内の数多くのプライベートSQL領域を同一の共有SQL領域に関連付けることができます。
データベースでは、アプリケーションによって同じSQL文が発行されたことが自動的に判断されます。ユーザーやアプリケーションが直接発行したSQL文も、他の文によって内部的に発行された再帰的SQL文も対象となります。
データベースでは、次のステップが実行されます。
構文およびセマンティクスが同一の文について共有SQL領域が存在しているかどうかを確認するため、共有プールがチェックされます。
同一の文が存在する場合、これ以降この文の新たなインスタンスが実行されるときには共有SQL領域が使用されるため、メモリー消費が削減されます。
同一の文が存在しない場合は、共有プールに新しい共有SQL領域が割り当てられます。構文が同じであるもののセマンティクスが異なる文の場合は、子カーソルが使用されます。
どちらの場合も、ユーザーのプライベートSQL領域が、その文と実行計画を含む共有SQL領域に対応付けられます。
セッションのためにプライベートSQL領域が割り当てられます。
プライベートSQL領域の位置は、セッションのために確立される接続に応じて異なります。セッションが共有サーバーを介して接続されている場合、プライベートSQL領域の一部はSGA内に保持されます。
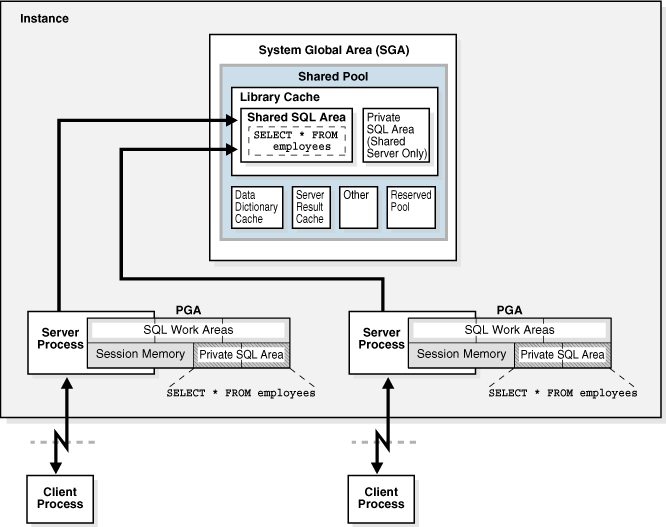
図14-10に、専用サーバー・アーキテクチャにおいて、2つのセッションが同じSQL文のコピーをそれぞれのPGA内に保持する様子を示します。共有サーバーでは、このコピーはラージ・プール内のUGAにあり、ラージ・プールが存在しない場合は、共有プール内のUGAにあります。
|
関連項目:
|
ライブラリ・キャッシュには、PL/SQLプログラムおよびJavaクラスの実行可能形式が保持されます。これらは、プログラム・ユニットと総称されます。
データベースでは、プログラム・ユニットはSQL文と同様に処理されます。たとえば、データベースでは、割り当てられた共有領域にPL/SQLプログラムの解析済かつコンパイル済の形式が保持されます。データベースでは、ローカル変数、グローバル変数、パッケージ変数、SQL実行用バッファなど、プログラムを実行するセッションに固有の値を保持するためのプライベート領域が割り当てられます。複数のユーザーが同じプログラムを実行する場合は、各ユーザーが独自のプライベートSQL領域を持ち、セッション固有の値はそこに保持され、単一の共有SQL領域にアクセスします。
データベースでは、PL/SQLプログラム・ユニット内の個別のSQL文はすでに説明したように処理されます。PL/SQLプログラム・ユニット内の起点には関係なく、これらのSQL文は解析された表現を保持するために共有領域を使用し、その文を実行するセッションごとにプライベートSQL領域を使用します。
データベースでは、新しいSQL文が解析されたときに共有プール・メモリーが割り当てられます。このメモリーのサイズは、文の複雑度に応じて決められます。
通常、共有プール内の項目は、LRUアルゴリズムによって削除されるまで保持されます。多数のセッションが使用している共有プール項目は、その項目を作成したプロセスが終了しても、その項目が使用されているかぎりメモリーに残ります。このメカニズムによって、SQL文のオーバーヘッドと処理を最小限に抑えることができます。
新しい項目の領域が必要になった場合は、頻繁に使用されていない項目のメモリーが解放されます。共有SQL領域がオープンしているカーソルに対応していても、しばらく使用されていないカーソルであれば、その共有SQL領域を共有プールから削除できます。オープンしているカーソルが、その後その文を実行するために使用される場合、その文はOracle Databaseにより再解析されて新しい共有SQL領域が割り当てられます。
データベースでは、次のような場合にも共有プールから共有SQL領域が削除されます。
表、表クラスタまたは索引に対して統計が収集されている場合は、デフォルトで、特定の時間が経過した後、その分析対象オブジェクトを参照する文を含むすべての共有SQL領域が徐々に削除されます。削除された文を次に実行するときには、その文はスキーマ・オブジェクトの新しい統計を反映するように新しい共有SQL領域で解析されます。
スキーマ・オブジェクトがSQL文内で参照されており、このオブジェクトが後でDDL文によって変更された場合、共有SQL領域は無効化されます。オプティマイザでは、次回この文を実行するときに文を再解析する必要があります。
ALTER SYSTEM FLUSH SHARED_POOL文を使用して共有プール内のすべての情報を手動で削除すると、インスタンスを再起動した後のパフォーマンスを評価できます。
|
関連項目:
|
データ・ディクショナリとは、データベース、データベースの構造およびそのユーザーについての参照情報を含むデータベース表およびビューの集合です。Oracle Databaseは、SQL文の解析時にデータ・ディクショナリに頻繁にアクセスします。
データ・ディクショナリはOracle Databaseによって頻繁にアクセスされるので、ディクショナリ・データを保持するために、次のような特別な場所がメモリー内に指定されています。
データ・ディクショナリ・キャッシュ
このキャッシュには、データベース・オブジェクトについての情報が保持されています。データがバッファではなく行として保持されるため、このキャッシュは行キャッシュとも呼ばれます。
ライブラリ・キャッシュ
これらのキャッシュは、データ・ディクショナリ情報にアクセスするすべてのサーバー・プロセスによって共有されます。
|
関連項目:
|
バッファ・プールとは異なり、サーバー結果キャッシュにはデータ・ブロックではなく結果セットが保持されています。サーバー結果キャッシュには、同一のインフラストラクチャを共有するSQL問合せ結果キャッシュとPL/SQLファンクション結果キャッシュが含まれています。
クライアント結果キャッシュは、サーバー結果キャッシュとは異なります。クライアント・キャッシュはアプリケーション・レベルで構成されており、データベース・メモリーではなくクライアント・メモリー内に配置されます。
|
関連項目:
|
データベースでは、将来の問合せおよび問合せ断片用にキャッシュされた結果を使用して、SQL問合せ結果キャッシュに問合せおよび問合せの断片の結果を格納できます。ほとんどのアプリケーションにとって、このキャッシュによるパフォーマンス向上は有益です。
たとえば、アプリケーションで繰り返し同じSELECT文が実行されるとします。結果がキャッシュされている場合には、データベースから即座に結果が戻されます。これにより、データベースでは、ブロックの再読取りおよび結果の再計算という多くのリソースを消費する操作を行う必要がなくなります。データまたはキャッシュされた結果の構成に使用されているデータベース・オブジェクトのメタデータがトランザクションで変更されると、キャッシュされた結果はデータベースにより自動的に無効化されます。
ユーザーは、RESULT_CACHEヒントを使用して問合せまたは問合せ断片に注釈を付け、結果をSQL問合せ結果キャッシュに保存することを指定できます。RESULT_CACHE_MODE初期化パラメータによって、SQL問合せ結果キャッシュが可能なかぎりすべての問合せで使用されるか、注釈が付けられた問合せにのみ使用されるかが決定されます。
|
関連項目:
|
PL/SQLファンクション結果キャッシュには、ファンクションの結果セットが格納されています。キャッシュがない場合には、1コール当たり1秒かかるファンクションを1000回コールすると、1000秒かかります。キャッシュがある場合は、このファンクションを同じ入力を使用して1000回コールしても全体で1秒しかかかりません。結果キャッシュは、比較的静的なデータに依存し、頻繁に起動されるファンクションに適しています。
PL/SQLファンクション・コードには、その結果をキャッシュするように要求するコードを含めることができます。このようなファンクションが起動されると、システムによってキャッシュがチェックされます。同じパラメータ値が指定された以前のファンクション・コールの結果がキャッシュに含まれている場合は、実行者にはキャッシュされた結果が戻され、ファンクション本体は再実行されません。キャッシュに結果が含まれていない場合は、ファンクション本体が実行され、実行元に制御が戻される前に、指定されたパラメータ値での結果がキャッシュに追加されます。
|
注意: キャッシュされた結果を計算するために使用されるデータベース・オブジェクトを指定して、これらのオブジェクトのいずれかが更新された場合にキャッシュされた結果が無効になり、再計算されるように設定できます。 |
キャッシュには数多くの結果を含むことができ、ファンクションの起動に使用されたパラメータの一意の組合せごとに1つの結果がキャッシュされます。データベースでさらにメモリーが必要になった場合は、1つ以上のキャッシュ済の結果がエージ・アウトされます。
|
関連項目:
|
予約プールは共有プール内のメモリー領域であり、Oracle Databaseで大量の連続したメモリーのチャンクを割り当てる場合に使用できます。
共有プールからのメモリーの割当ては、チャンク単位で実行されます。チャンクを使用することによって、単一の連続した領域がない場合でもキャッシュに大きなオブジェクト(5KBよりも大きいオブジェクト)をロードできます。これにより、データベースでは、断片化によって連続したメモリーが使用できなくなる可能性が低減されます。
まれに、Java、PL/SQLまたはSQLカーソルによって、5KBを超える領域が共有プールから割り当てられることがあります。このような割当てが最も効率的に行われるように、データベースでは共有プールの一部分が予約プールとして分離されています。
|
関連項目: 予約プールの構成方法の詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
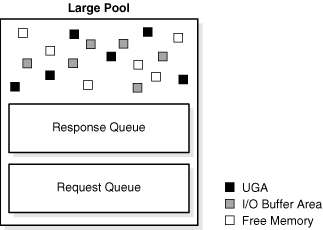
ラージ・プールは、共有プールでの割当てには適さない大量のメモリー割当て用のオプションのメモリー領域です。ラージ・プールでは、次のような領域に対して大量のメモリー割当てを行うことができます。
共有サーバーおよびOracle XAインタフェース用のUGA(トランザクションが複数のデータベースと対話する環境で使用)
文のパラレル実行で使用されるメッセージ・バッファ
Recovery Manager(RMAN)I/Oスレーブ用のバッファ
共有SQLのセッション・メモリーをラージ・プールから割り当てることによって、共有SQLキャッシュが小さくなることによるパフォーマンス上のオーバーヘッドを回避できます。ラージ・プールでは、RMAN操作、I/Oサーバー・プロセスおよびパラレル・バッファ用のメモリーを大きなバッファに割り当てることによって、大量のメモリーのリクエストを共有プールよりも効率的に処理できます。
図14-11に、ラージ・プールを視覚的に示します。
ラージ・プールは、同じ共有プールから割り当てられる他のメモリーと同じLRUリストが使用される、共有プール内の確保されている領域とは異なります。ラージ・プールには、LRUリストはありません。割り当てられた各メモリーは、そのメモリーの使用が終了するまでは解放できません。メモリーのチャンクが解放されると、その領域は他のプロセスがすぐに使用できます。
|
関連項目:
|
Javaプールは、Java仮想マシン(JVM)内のセッション固有のすべてのJavaコードとデータが格納されるメモリー領域です。このメモリーには、コール終了時にJavaセッション領域に移行されるJavaオブジェクトが含まれています。
専用サーバー接続では、Javaプールには各Javaクラスの共有部分(メソッドおよびコード配列などの読取り専用メモリー)が含まれていますが、各セッションのセッションごとのJava状態は含まれていません。共有サーバーでは、Javaプールには、各クラスの共有部分および各セッションの状態に使用される一部のUGAが含まれています。各UGAは必要に応じて拡大および縮小されますが、UGAの合計サイズはJavaプール領域に収まる必要があります。
Java Pool Advisor統計は、Javaに使用されるライブラリ・キャッシュ・メモリーに関する情報を提供し、Javaプールのサイズの変化が解析率に及ぼす影響を予測します。Java Pool Advisorは、statistics_levelをTYPICAL以上に設定すると内部的にオンに設定されます。これらの統計は、アドバイザをオフにするとリセットされます。
|
関連項目:
|
ストリーム・プールには、バッファ・キュー・メッセージが保存され、Oracle Streamsの取得プロセスおよび適用プロセス用のメモリーが用意されています。ストリーム・プールは、Oracle Streamsによって排他的に使用されます。
明示的に構成しないかぎり、ストリーム・プールのサイズはゼロから開始されます。プール・サイズは、Oracle Streamsの必要に応じて動的に増加します。
|
関連項目: 『Oracle Database 2日でデータ・レプリケーションおよび統合ガイド』および『Oracle Streamsレプリケーション管理者ガイド』 |
固定SGAは、内部のハウスキーピング用領域です。固定SGAには、たとえば次のような情報が含まれています。
バックグラウンド・プロセスがアクセスする必要のある、データベースとインスタンスの状態に関する一般的な情報
ロックに関する情報などの、プロセス間で通信される情報(「自動ロックの概要」を参照)
固定SGAのサイズはOracle Databaseによって設定され、手動では変更できません。固定SGAのサイズは、リリースによって異なります。
ソフトウェア・コード領域とは、実行中または実行される可能性のあるコードを格納するメモリー部分です。Oracle Databaseのコードはソフトウェア領域に格納され、通常、この場所はユーザー・プログラムの格納場所よりも排他的であり、保護されています。
ソフトウェア領域のサイズは通常固定されており、ソフトウェアの更新時か再インストール時にかぎり変化します。これらの領域に必要なサイズは、オペレーティング・システムによって異なります。
ソフトウェア領域は読取り専用で、共有または非共有でインストールされます。Oracle FormsやSQL*Plusなど一部のデータベース・ツールおよびユーティリティは共有でインストールできますが、共有でインストールできないものもあります。データベースのコードは、メモリー内に複数のコピーを格納することなくすべてのユーザーがアクセスできるよう、可能なかぎり共有され、これにより、メイン・メモリーの使用量が削減されて、全体的にパフォーマンスが向上します。データベースの複数のインスタンスが同じコンピュータ上で実行されている場合、それらのインスタンスは異なるデータベースにおいても同じデータベース・コード領域を使用できます。
|
注意: ソフトウェアを共有でインストールするオプションは、すべてのオペレーティング・システムで使用できるわけではありません(たとえば、Windowsが稼働しているPCでは使用できません)。詳細は、オペレーティング・システム別のドキュメントを参照してください。 |