| Oracle® Database概要 11gリリース2 (11.2) B56306-06 |
|


 前 |
 次 |
この章では、Oracle Databaseのプロセスについて説明します。
この章の内容は、次のとおりです。
プロセスは一連の処理を実行できるオペレーティング・システムのメカニズムです。このメカニズムはオペレーティング・システムによって異なります。たとえば、Linuxでは、Oracleバックグラウンド・プロセスはLinuxプロセスです。Windowsでは、Oracleバックグラウンド・プロセスはプロセス内の実行スレッドです。
コード・モジュールは、プロセスによって実行されます。Oracle Databaseに接続されたすべてのユーザーは、データベース・インスタンスにアクセスするために、次のモジュールを実行する必要があります。
アプリケーションまたはOracle Databaseユーティリティ
データベース・ユーザーは、プリコンパイラ・プログラムなどのデータベース・アプリケーションや、データベースに対してSQL文を発行するSQL*Plusなどのデータベース・ツールを実行します。
Oracleデータベース・コード
各ユーザーには、各ユーザーのために実行されるOracleデータベース・コードがあり、これによってアプリケーションのSQL文を解釈および処理します。
プロセスは通常、そのプロセスのプライベート・メモリー領域で実行されます。ほとんどのプロセスは、関連付けられたトレース・ファイルに定期的に書き込むことができます(「トレース・ファイル」を参照)。
マルチ・プロセスOracle(マルチユーザーOracleとも呼ばれる)は、Oracle Databaseコードの各部分の実行およびユーザー用に複数のプロセスを使用します(ユーザー用のプロセスは、接続するユーザーごとに個別のプロセスの場合や、複数のユーザーが共有する1つ以上のプロセスの場合があります)。データベースの主な利点が、複数のユーザーが同時に必要とするデータを管理できることにあるため、多くのデータベースはマルチユーザー対応です。
データベース・インスタンスの各プロセスは、特定のジョブを実行します。データベースとアプリケーションの処理を複数のプロセスに分割することにより、複数のユーザーおよびアプリケーションが1つのインスタンスに同時に接続でき、優れたパフォーマンスを確保できます。
次のタイプのプロセスは、データベース・インスタンスに含まれているか、データベース・インスタンスと対話します。
クライアント・プロセスは、アプリケーションまたはOracleツールのコードを実行します。
Oracleプロセスは、Oracleデータベース・コードを実行します。Oracleプロセスには、次のサブタイプがあります。
バックグラウンド・プロセスは、データベース・インスタンスとともに起動し、インスタンス・リカバリの実行、プロセスのクリーン・アップ、ディスクへのREDOバッファの書込みなどのメンテナンス・タスクを実行します。
サーバー・プロセスは、クライアントの要求に基づいて処理を実行します。
たとえば、これらのプロセスではSQL問合せを解析して共有プールに入れ、問合せごとに問合せ計画を作成して実行し、データベース・バッファ・キャッシュまたはディスクからバッファを読み取ります。
|
注意: サーバー・プロセスおよびサーバー・プロセス内で割り当てられたプロセス・メモリーは、インスタンス内で実行されます。サーバー・プロセスが終了しても、インスタンスは機能し続けます。 |
スレーブ・プロセスは、バックグラウンドまたはサーバー・プロセスに対して追加タスクを実行します。
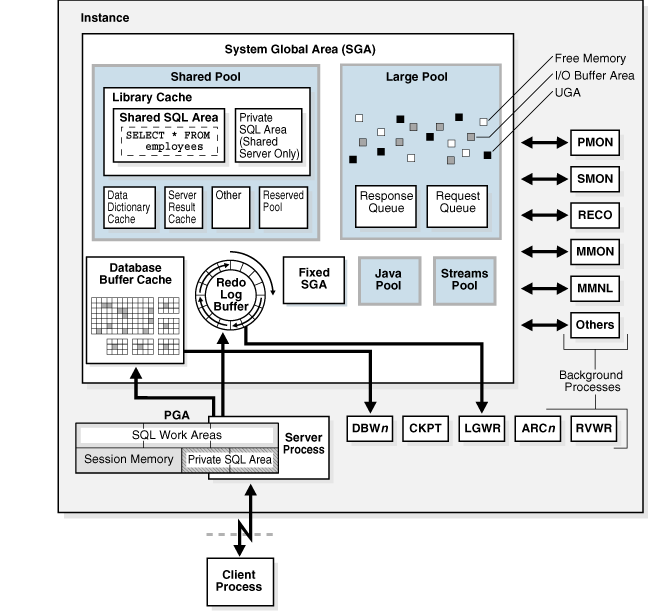
プロセスの構造は、オペレーティング・システムおよびOracle Databaseオプションの選択に応じて異なります。たとえば、接続されたユーザーのコードは、専用サーバーまたは共有サーバー接続に対して構成できます。共有サーバー・アーキテクチャでは、データベース・コードを実行する各サーバー・プロセスが複数のクライアント・プロセスに対応できます。
図15-1に、専用のサーバー接続を使用する、システム・グローバル領域(SGA)およびバックグラウンド・プロセスを示します。それぞれのユーザー接続で、データベース・コードを実行するためのサーバー・プロセスとは別のクライアント・プロセスでアプリケーションが実行されます。各クライアント・プロセスは、それ自体のサーバー・プロセスに関連付けられ、そのサーバー・プロセスには、それ自体のプログラム・グローバル領域(PGA)があります。
|
関連項目:
|
ユーザーがPro*CプログラムやSQL*Plusなどのアプリケーションを実行する場合、オペレーティング・システムでは、そのユーザー・アプリケーションを実行するために、クライアント・プロセス(ユーザー・プロセスとも呼ばれる)を作成します。クライアント・アプリケーションにはOracle Databaseライブラリがリンクされており、このライブラリによってデータベースとの通信に必要なAPIが提供されます。
クライアント・プロセスは、インスタンスと直接対話するOracleプロセスとは大きく異なります。クライアント・プロセスにサービスを提供するOracleプロセスでは、SGAからの読取りおよびSGAへの書込みが可能ですが、クライアント・プロセスではできません。クライアント・プロセスは、データベース・ホストとは別のホストで実行できますが、Oracleプロセスは実行できません。
たとえば、クライアント・ホストのユーザーがSQL*Plusを起動し、ネットワークを介して別のホストのデータベース、sampleに接続するとします(データベース・インスタンスは開始されません)。
SQL> CONNECT SYS@inst1 AS SYSDBA Enter password: ********* Connected to an idle instance.
クライアント・ホスト上でsqlplusまたはsampleのプロセスを検索すると、sqlplusクライアント・プロセスのみが表示されます。
% ps -ef | grep -e sample -e sqlplus | grep -v grep clientuser 29437 29436 0 15:40 pts/1 00:00:00 sqlplus as sysdba
データベース・ホスト上でsqlplusまたはsampleのプロセスを検索すると、ローカル以外の接続を伴うサーバー・プロセスが表示されますが、クライアント・プロセスは表示されません。
% ps -ef | grep -e sample -e sqlplus | grep -v grep serveruser 29441 1 0 15:40 ? 00:00:00 oraclesample (LOCAL=NO)
接続とは、クライアント・プロセスとデータベース・インスタンスとの間の物理的な通信経路のことです。通信経路は、使用可能なプロセス間通信メカニズムまたはネットワーク・ソフトウェアを使用して確立されます。一般的に、接続はクライアント・プロセスとサーバー・プロセスまたはディスパッチャとの間で確立されますが、クライアント・プロセスとOracle Connection Manager(CMAN)との間でも確立されます。
セッションは、データベースに対する現在のユーザー・ログインの状況を示す、データベース・インスタンス・メモリー内の論理エンティティです。たとえば、ユーザーがパスワードによってデータベースから認証されると、このユーザーに対してセッションが確立されます。セッションは、ユーザーがデータベースから認証された時点から、ユーザーが接続を切断するか、データベース・アプリケーションを終了する時点まで続きます。
1つの接続では、セッションが確立されないか、1つ以上のセッションが確立されます。セッションはそれぞれ独立していて、あるセッションでのコミットは、他のセッションのトランザクションには影響しません。
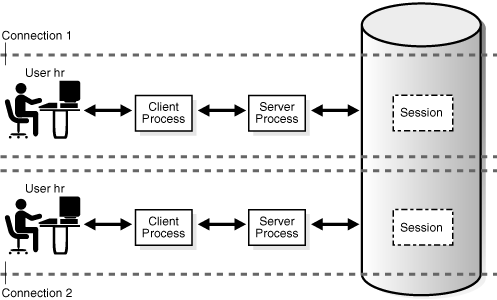
単独のデータベース・ユーザーに対して、複数のセッションが同時に存在できます。図15-2に示すように、ユーザーhrが1つのデータベースに複数の接続を確立できます。専用サーバー接続の場合、それぞれの接続のかわりに1つのサーバー・プロセスがデータベースによって作成されます。これは、専用サーバーを作成するクライアント・プロセスのみが使用します。共有サーバー接続では、多数のクライアント・プロセスが1つの共有サーバー・プロセスにアクセスします。
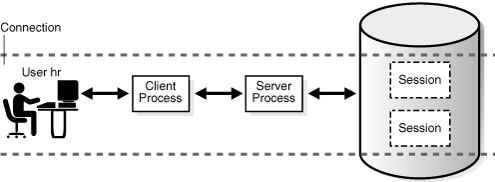
図15-3は、ユーザーhrが1つのデータベースに1つの接続を確立していることを示していますが、この接続には2つのセッションがあります。
SQL文実行統計の自動トレース・レポートを作成すると、図15-3のシナリオが再作成されます。例15-2では、ユーザーSYSTEMとしてデータベースにSQL*Plusを接続してトレースを実行可能にし、新規セッションを作成しています(サンプル出力を含みます)。
例15-1 1接続に2セッション
SQL> SELECT SID, SERIAL#, PADDR FROM V$SESSION WHERE USERNAME = USER;
SID SERIAL# PADDR
--- ------- --------
90 91 3BE2E41C
SQL> SET AUTOTRACE ON STATISTICS;
SQL> SELECT SID, SERIAL#, PADDR FROM V$SESSION WHERE USERNAME = USER;
SID SERIAL# PADDR
--- ------- --------
88 93 3BE2E41C
90 91 3BE2E41C
...
SQL> DISCONNECT
例15-1のDISCONNECTコマンドは、実際には、接続ではなくセッションを終了しています。新規端末を開いて別のユーザーとしてインスタンスに接続し、例15-2の問合せを実行すると、例15-1からの接続がアクティブなままであることが示されます。
例15-2 セッションなしの接続
SQL> CONNECT dba1@inst1
Password: ********
Connected.
SQL> SELECT PROGRAM FROM V$PROCESS WHERE ADDR = HEXTORAW('3BE2E41C');
PROGRAM
------------------------------------------------
oracle@stbcs09-1 (TNS V1-V3)
Oracle Databaseでは、インスタンスに接続されたクライアント・プロセスの要求を処理するために、サーバー・プロセスが作成されます。クライアント・プロセスは常に別のサーバー・プロセスを介してデータベースと通信します。
データベース・アプリケーション用に作成されるサーバー・プロセスは、次のタスクを1つ以上実行できます。
アプリケーションを介して発行されたSQL文を解析し、実行します。これには問合せ計画の作成および実行も含まれます(「SQL処理の段階」を参照)。
PL/SQLコードを実行します。
データファイルからデータベース・バッファ・キャッシュにデータ・ブロックを読み取ります(DBWnバックグラウンド・プロセスには、修正されたブロックをディスクに戻して書き込むというタスクがあります)。
アプリケーションが情報を処理できるような方法で結果を戻します。
専用サーバー接続の場合、クライアント接続は、1つのサーバー・プロセスにのみ関連付けられています(「専用サーバー・アーキテクチャ」を参照)。Linuxでは、1つのデータベース・インスタンスに接続された20のクライアント・プロセスに、20のサーバー・プロセスが対応します。
各クライアント・プロセスは、そのサーバー・プロセスと直接通信します。セッションの継続中、このサーバー・プロセスはそのクライアント・プロセス専用になります。サーバー・プロセスでは、PGAにプロセス固有の情報およびUGAを格納します(「専用サーバー・モードおよび共有サーバー・モードにおけるPGAの使用」を参照)。
共有サーバー接続の場合、クライアント・アプリケーションはネットワーク上でサーバー・プロセスではなく、ディスパッチャ・プロセスに接続します(「共有サーバー・アーキテクチャ」を参照)。たとえば、20のクライアント・プロセスが1つのディスパッチャ・プロセスに接続できます。
ディスパッチャ・プロセスでは、接続されたクライアントからのリクエストを受け取り、ラージ・プールのリクエスト・キューに入れます(「ラージ・プール」を参照)。最初に使用可能な共有サーバー・プロセスが、キューからリクエストを受け取って処理します。その後、共有サーバーは、その結果をディスパッチャ・レスポンス・キューに入れます。ディスパッチャ・プロセスはこのキューを監視し、結果をクライアントに送信します。
専用サーバー・プロセスと同様、共用サーバー・プロセスにはそれ自体のPGAがあります。ただし、共有サーバーがセッション・データにアクセスできるように、セッションのUGAはSGAにあります。
マルチ・プロセスOracle Databaseでは、バックグラウンド・プロセスと呼ばれる、いくつかの追加プロセスを使用します。バックグラウンド・プロセスでは、データベースの操作、および複数ユーザーのパフォーマンスの最大化に必要なメンテナンス・タスクを実行します。
各バックグラウンド・プロセスには個別のタスクがありますが、他のプロセスと連携して動作します。たとえば、LGWRプロセスでは、REDOログ・バッファのデータをオンラインREDOログに書き込みます。ログ・ファイルがいっぱいになり、アーカイブできるようになると、LGWRは別のプロセスに対してそのファイルをアーカイブするよう信号を送ります。
Oracle Databaseは、データベース・インスタンスが起動すると、自動的にバックグラウンド・プロセスを作成します。インスタンスは多数のバックグラウンド・プロセスを持つことができますが、そのすべてが常にそれぞれのデータベース構成に存在するとはかぎりません。次の問合せを実行すると、データベースで実行中のバックグラウンド・プロセスが表示されます。
SELECT PNAME FROM V$PROCESS WHERE PNAME IS NOT NULL ORDER BY PNAME;
この項の内容は、次のとおりです。
|
関連項目: すべてのバックグラウンド・プロセスの詳細は、『Oracle Databaseリファレンス』を参照してください。 |
必須のバックグラウンド・プロセスは、すべての一般的なデータベース構成に存在します。これらのプロセスは、デフォルトでは、最小限に構成された初期化パラメータ・ファイルを使用して起動されるデータベース・インスタンス内で実行されます(例13-1を参照)。
この項では、次の必須のバックグラウンド・プロセスについて説明します。
|
関連項目:
|
プロセス・モニター(PMON)では、他のバックグラウンド・プロセスを監視し、サーバーまたはディスパッチャ・プロセスが異常終了した場合には、プロセス・リカバリを実行します。PMONは、データベース・バッファ・キャッシュをクリーン・アップしたり、クライアント・プロセスが使用していたリソースを解放します。たとえば、PMONでアクティブ・トランザクション表の状態をリセットして、不要になったロックを解除し、アクティブ・プロセスのリストからプロセスIDを削除します。
また、PMONは、インスタンスおよびディスパッチャ・プロセスに関する情報をOracle Net Listenerに登録します(「Oracle Net Listener」を参照)。インスタンスの起動時に、PMONはリスナーに対してポーリングを実行し、リスナーが実行されているかどうかを確認します。リスナーが実行されている場合、PMONはリスナーに該当パラメータを渡します。実行されていない場合には、PMONは定期的にリスナーとの接続を試行します。
システム・モニター・プロセス(SMON)は、システム・レベルで様々なクリーン・アップ作業を実行します。SMONには次のような役割があります。
必要に応じて、インスタンスの起動時に、インスタンス・リカバリを実行します。Oracle RACデータベースでは、障害の発生したインスタンスのインスタンス・リカバリを、データベース・インスタンスのSMONプロセスが実行できます。
ファイル読取りまたは表領域オフライン・エラーが原因で、インスタンス・リカバリ時にスキップされた終了済トランザクションがリカバリされます。表領域またはファイルがオンラインに戻ると、SMONによってトランザクションがリカバリされます。
未使用の一時セグメントをクリーン・アップします。たとえば、Oracle Databaseでは、索引を作成するときにエクステントを割り当てます。この操作が失敗すると、SMONによって一時領域がクリーン・アップされます。
ディクショナリ管理表領域内の、連続した空きエクステントを結合します。
SMONは、処理が必要かどうかを定期的にチェックします。他のプロセスは、必要性が検出された場合にSMONをコールできます。
データベース・ライター・プロセス(DBWn)は、データベース・バッファの内容をデータファイルに書き込みます。DBWnプロセスは、データベース・バッファ・キャッシュ内の変更されたバッファをディスクに書き込みます(「データベース・バッファ・キャッシュ」を参照)。
ほとんどのシステムでは1つのデータベース・ライター・プロセス(DBW0)があれば十分ですが、追加プロセス(DBW1からDBW9およびDBWaからDBWj)を構成して、システムでデータを頻繁に変更する場合の書込みのパフォーマンスを改善できます。これらの追加DBWnプロセスは、ユニプロセッサ・システムでは効果がありません。
DBWnプロセスは、次のような場合に使用済バッファをディスクに書き込みます。
サーバー・プロセスがしきい値の数までバッファをスキャンしても、クリーンな再利用可能バッファが見つからない場合は、DBWnに書込み信号が送られます。DBWnは、可能であれば、他の処理中に使用済バッファをディスクに非同期に書き込みます。
DBWnは、定期的にバッファを書き込んで、REDOスレッド内のインスタンス・リカバリを開始する位置(チェックポイント)を進めます(「チェックポイントの概要」を参照)。チェックポイントのログ位置は、バッファ・キャッシュ内の最も古い使用済バッファ・キャッシュによって決まります。
多くの場合、DBWnによって書き込まれるブロックは、ディスク内に分散されます。このため、この書込みは、LGWRが実行する順次書込みよりも遅くなる傾向があります。効率を向上させるために、可能であればDBWnは、マルチブロック書込みを実行します。マルチブロック書込みで書き込まれるブロックの数は、オペレーティング・システムによって異なります。
|
関連項目: DBWnの構成、監視およびチューニングの詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
ログ・ライター・プロセス(LGWR)では、REDOログ・バッファを管理します。LGWRは、バッファの連続した一部分をオンラインREDOログに書き込みます。データベース・バッファを変更するタスクを切り離すことによって、分散した使用済バッファのディスクへの書込み、およびREDOのディスクへの高速順次書込みの処理で、データベースのパフォーマンスが向上します。
次の状況では、LGWRは、最後の書込み以降にバッファにコピーされたREDOエントリすべてを、REDOログ・ファイルに書き込みます。
ユーザーがトランザクションをコミットしたとき(「トランザクションのコミット」を参照)
オンラインREDOログ・スイッチが発生したとき
LGWRによる最後の書込みから3秒経過したとき
REDOログ・バッファが3分の1になったとき、またはバッファ・データが1MBになったとき
DBWnが修正済のバッファをディスクに書き込む必要があるとき
DBWnが使用済バッファを書き込むには、バッファの変更に関連するすべてのREDOレコードがディスクに書き込まれている必要があります(事前書込みプロトコル)。DBWnは、書き込まれていないREDOレコードがあることを検出すると、そのレコードをディスクに書き込むようにLGWRに信号を送り、LGWRの処理が完了するまで待機して、データ・バッファをディスクに書き込みます。
Oracle Databaseは、コミットされたトランザクションのパフォーマンスを向上させるために、高速コミット・メカニズムを使用します。ユーザーがCOMMIT文を発行すると、トランザクションにシステム変更番号(SCN)が割り当てられます。LGWRはREDOログ・バッファ内にコミット・レコードを入れ、コミットSCNおよびトランザクションのREDOエントリとともにそれを即時にディスクに書き込みます。
REDOログ・バッファは循環バッファです。LGWRがREDOログ・バッファからオンラインREDOログ・ファイルにREDOエントリを書き込んだ後、サーバー・プロセスはディスクに書き込まれたREDOログ・バッファのエントリ上に新しいエントリをコピーできます。オンラインREDOログへのアクセスが頻繁なときにも、新しいエントリを書き込めるよう常にバッファ内の領域を空けておくため、LGWRが行う書込みは通常は非常に高速になります。
トランザクションのコミット・レコードを含むREDOエントリのアトミックな書込みは、トランザクションがコミットされたかどうかを判別する1つのイベントです。Oracle Databaseでは、データ・バッファがまだディスクに書き込まれていない場合でも、コミットしたトランザクションに対する成功コードが戻されます。対応するデータ・ブロックの変更は、DBWnがそれらの変更を効率的にデータファイルに書き込めるようになるまで延期されます。
|
注意: LGWRでは、トランザクションがコミットする前に、REDOログ・エントリをディスクに書き込むことができます。後でトランザクションがコミットされた場合にのみ、REDOエントリにより保護された変更が確定します。 |
アクティビティが高いとき、LGWRはグループ・コミットを使用できます。たとえば、ユーザーがコミットし、これによって、LGWRがトランザクションのREDOエントリをディスクに書き込むとします。この書込み中、他のユーザーがコミットします。LGWRでは、前の書込みが完了するまで、これらのトランザクションをディスクに書き込んでコミットすることはできません。完了すると、LGWRは、(まだコミットされていない)待機しているトランザクションに関するREDOエントリのリストを1回の操作で書き込むことができます。これにより、データベースでは、ディスクI/Oが最小化され、パフォーマンスが最大化されます。コミットの要求が高い頻度で続くと、LGWRによる毎回の書込みに複数のコミット・レコードが含まれることがあります。
LGWRは、ミラー化されたアクティブなオンラインREDOログ・ファイルのグループにも同時に書き込みます。ログ・ファイルにアクセスできない場合、LGWRはグループ内の他のファイルに書込みを続け、LGWRトレース・ファイルおよびアラート・ログにエラーを書き込みます。グループ内のすべてのファイルが破損している場合や、アーカイブされていないためにグループ全体が使用できない場合、LGWRは機能を続行できません。
|
関連項目:
|
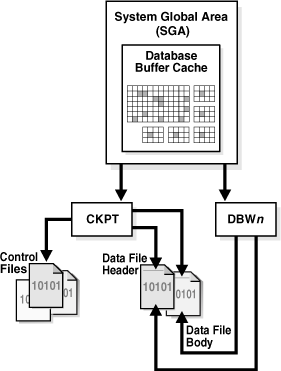
チェックポイント・プロセス(CKPT)は、チェックポイント情報により制御ファイルおよびデータファイル・ヘッダーを更新し、DBWnに対してブロックをディスクに書き込むように信号を送ります。チェックポイント情報には、チェックポイント位置、SCN、オンラインREDOログの中でリカバリを開始する位置などが含まれます。図15-4に示すように、CKPTではデータファイルへのデータ・ブロックの書込み、およびオンラインREDOログ・ファイルへのREDOブロックの書込みは行いません。
管理性モニター・プロセス(MMON)は、自動ワークロード・リポジトリ(AWR)に関連する多数のタスクを実行します。たとえば、MMONはスナップショットを取得し、前回変更されたSQLオブジェクトの統計値を取得して、メトリックがそのしきい値を超えたときに書込みを行います。
管理性モニター・ライト・プロセス(MMNL)は、SGAのアクティブ・セッション履歴(ASH)バッファ内の統計をディスクに書き込みます。MMNLは、ASHバッファがいっぱいになるとディスクに書き込みます。
分散データベースでは、リカバラ・プロセス(RECO)によって、分散トランザクションに関連する障害が自動的に解決されます。ノードのRECOプロセスは、インダウト分散トランザクションにかかわる他のデータベースに自動的に接続されます。RECOでは、データベース間の接続を再確立するとき、すべてのインダウト・トランザクションを自動的に解決し、解決されるトランザクションに対応する行を各データベースの保留中のトランザクション表からすべて削除します。
|
関連項目: 分散トランザクション・リカバリの詳細は、『Oracle Database管理者ガイド』を参照してください。 |
オプションのバックグラウンド・プロセスは、必須として定義されていないバックグラウンド・プロセスです。ほとんどのオプションのバックグラウンド・プロセスは、タスクまたは機能に固有です。たとえば、Oracle Streams Advanced Queuing(AQ)またはOracle Automatic Storage Management(Oracle ASM)をサポートするバックグラウンド・プロセスは、これらの機能が使用可能である場合にのみ使用できます。
この項では、いくつかの一般的なオプションのプロセスについて説明します。
|
関連項目:
|
アーカイバ・プロセス(ARCn)は、REDOログ・スイッチが行われると、オンラインREDOログ・ファイルをオフライン・ストレージにコピーします。また、トランザクションのREDOデータを収集し、そのデータをスタンバイ・データベースの宛先に転送できます。ARCnプロセスは、データベースがARCHIVELOGモードに設定され、自動アーカイブが使用可能になっている場合にのみ存在します。
|
関連項目:
|
Oracle Databaseでは、ジョブ・キュー・プロセスを使用して、多くの場合、バッチ・モードでユーザー・ジョブを実行します。ジョブは、1回以上実行することがスケジュールされている、ユーザー定義タスクです。たとえば、ジョブ・キューを使用して、バックグラウンドで長時間実行される更新をスケジュールできます。開始日と時間間隔を指定すると、ジョブ・キュー・プロセスは、指定された間隔でジョブの実行を試行します。
Oracle Databaseではジョブ・キュー・プロセスが動的に管理されるため、ジョブ・キュー・クライアントは、必要に応じてより多くのジョブ・キュー・プロセスを使用できます。新規プロセスが使用するリソースは、そのプロセスがアイドル状態になると解放されます。
動的ジョブ・キュー・プロセスは、指定された間隔で多数のジョブを同時に実行できます。イベントの順序は、次のようになります。
ジョブ・コーディネータ・プロセス(CJQ0)は、Oracle Schedulerの必要に応じて、自動的に起動し、停止します(「Oracle Scheduler」を参照)。コーディネータ・プロセスは、システムのJOB$表から、実行する必要があるジョブを定期的に選択します。選択された新規ジョブは、時間順に並べ替えられます。
コーディネータ・プロセスは、ジョブを実行するためにジョブ・キュー・スレーブ・プロセス(Jnnn)を動的に生成します。
ジョブ・キュー・プロセスは、実行のためにCJQ0プロセスによって選択されたジョブの1つを実行します。ジョブ・キュー・プロセスは、一度に1つずつジョブを実行して完了します。
ジョブ・キュー・プロセスは、1つのジョブの実行が終了すると、次のジョブの問合せを行います。実行予定のジョブが存在しない場合、ジョブ・キュー・プロセスはスリープ状態に入り、定期的な周期で起動すると次のジョブの問合せを行います。新しいジョブがない場合、事前に設定した周期が経過した後に終了します。
初期化パラメータJOB_QUEUE_PROCESSESは、1つのインスタンスで同時に実行できるジョブ・キュー・プロセスの最大数を示します。ただし、クライアントは、すべてのジョブ・キュー・プロセスがジョブの実行に使用可能であると想定することはできません。
|
注意: 初期化パラメータJOB_QUEUE_PROCESSESが0(ゼロ)に設定されている場合、コーディネータ・プロセスは起動しません。 |
|
関連項目:
|
フラッシュバック・データ・アーカイバ・プロセス(FBDA)は、フラッシュバック・データ・アーカイブに追跡した表の履歴行をアーカイブします。追跡した表に対するDMLを含むトランザクションがコミットされると、このプロセスは、行の事前イメージをフラッシュバック・データ・アーカイブに保存します。また、現在の行にメタデータを保存します。
FBDAは、フラッシュバック・データ・アーカイブの領域、編成および保存に関する管理を自動的に行います。また、追跡対象トランザクションのアーカイブがどの程度発生するかを追跡します。
SMCOプロセスは、予防的な領域の割当ておよび領域の再生など、様々な領域管理関連タスクの実行を調整します。SMCOにより、自動的にスレーブ・プロセス(Wnnn)が起動され、タスクが実行されます。
|
関連項目: フラッシュバック・データ・アーカイブの詳細は、『Oracle Databaseアドバンスト・アプリケーション開発者ガイド』を参照してください。 |
スレーブ・プロセスは、他のプロセスにかわって作業を実行するバックグラウンド・プロセスです。この項では、Oracle Databaseが使用するスレーブ・プロセスの一部について説明します。
|
関連項目: Oracle Databaseのスレーブ・プロセスの詳細は、『Oracle Databaseリファレンス』を参照してください。 |
I/Oスレーブ・プロセス(Innn)は、非同期I/Oがサポートされていないシステムおよびデバイスにかわって、非同期I/Oをシミュレートします。非同期I/Oの場合、伝送のためのタイミング要件がないため、伝送が終了する前に他のプロセスを起動できます。
たとえば、非同期I/Oがサポートされていないオペレーティング・システムのディスクに、アプリケーションが1000ブロックを書き込むとします。それぞれの書込みは順次実行され、書込みの完了確認まで待機します。非同期ディスクの場合、アプリケーションは一括でブロックを書き込み、すべてのブロックが書き込まれたというオペレーティング・システムからのレスポンスを待機している間、他の作業を実行できます。
非同期I/Oをシミュレートするには、1プロセスがいくつかのスレーブ・プロセスを監視します。実行者プロセスでは、それぞれの書込みの完了報告を待機し、完了時にそれを実行者に転送する各スレーブ・プロセスに作業を割り当てます。真の非同期I/Oでは、オペレーティング・システムがI/Oの完了と、その報告のプロセスへの転送を待機しますが、シミュレートされた非同期I/Oの場合、スレーブが完了報告を待機し、実行者へそれを転送します。
Oracle Databaseでは、次のような様々なタイプのI/Oスレーブがサポートされています。
Recovery Manager(RMAN)のI/Oスレーブ
データのバックアップまたはリストアにRMANを使用するとき、ディスクおよびテープ・デバイスにI/Oスレーブを使用できます。
データベース・ライター・スレーブ
複数のデータベース・ライター・プロセスを使用することが現実的でない場合、たとえば、コンピュータのCPUが1つのみである場合、Oracle Databaseは、複数のスレーブ・プロセスにI/Oを分散できます。DBWRは、ディスクへのブロックの書込みを可能にするため、バッファ・キャッシュLRUリストをスキャンする唯一のプロセスです。ただし、I/Oスレーブは、これらのブロックに対するI/Oを実行します。
|
関連項目:
|
パラレル実行またはパラレル処理では、同時に多数のプロセスが連携して1つのSQL文を実行します。複数プロセス内で作業を分割すると、Oracle Databaseでは、より迅速にSQL文を実行できます。たとえば、1つのプロセスで4つの四半期分をすべて処理するのではなく、4つのプロセスが1年のそれぞれの四半期を分担して処理するなどがこの例です。
パラレル実行では、データ・ウェアハウスなどの大規模データベースでの、データ処理集中型の操作におけるレスポンス時間が短縮されます。対称型マルチプロセッサ(SMP)およびクラスタ化されたシステムでは、文の処理を多数のCPUに分割できるため、パラレル実行によりパフォーマンスが大幅に改善されます。パラレル実行は、特定のタイプのOLTPおよびハイブリッド・システムにとっても利点があります。
Oracle RACシステムでは、特定のサービスに対するサービスの配置によって、パラレル実行が制御されています。つまり、パラレル・プロセスはサービスを構成したノードで実行されます。デフォルトで、Oracle Databaseはデータベースに接続するときに使用されるサービスを提供するインスタンスでのみ、パラレル処理を実行します。これは、パラレル・リカバリやGV$問合せの処理などの他のパラレル操作には影響しません。
|
関連項目:
|
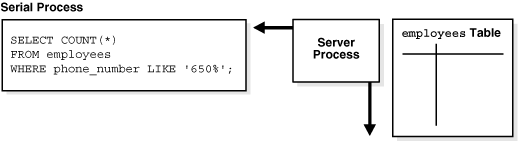
シリアル実行の場合、SQL文の順次実行に必要な処理のすべてを1つのサーバー・プロセスが実行します。たとえば、SELECT * FROM employeesなどの全表スキャンを実行するには、図15-5に示すように、1つのサーバー・プロセスですべての処理が実行されます。
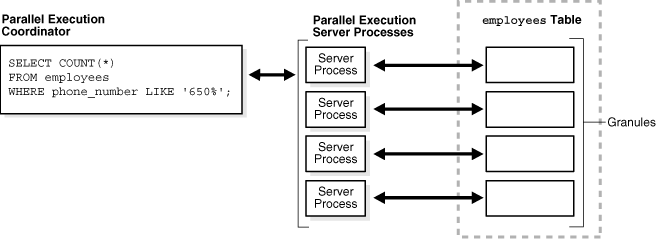
パラレル実行の場合、サーバー・プロセスは、問合せの解析、スレーブ・プロセスの割当てと制御、およびユーザーへの出力送信を行うパラレル実行コーディネータの役割を果します。SQL問合せの問合せ計画では、まずコーディネータがSQL問合せ内の各演算子をパラレル・ピースに分割し、それらを問合せで指定した順序に従って実行し、その後、演算子を実行するスレーブ・プロセスによって作成された部分的な実行結果を統合します。
図15-6に、employees表のパラレル・スキャンを示します。この表は、グラニュルと呼ばれるロード単位に動的に分割されます(動的パーティション化)。各グラニュルは、パラレル実行サーバーと呼ばれる、単一のスレーブ・プロセスによって読み取られる表のデータ・ブロックの範囲で、その名前の形式はPnnnです。
データベースでは、実行時にグラニュルを実行サーバーにマップします。実行サーバーがグラニュルに対応する行の読取りを終了したとき、グラニュルがまだ残っている場合、コーディネータから他のグラニュルを取得します。この操作は、表全体が読み取られるまで続行されます。実行サーバーは結果をコーディネータに送り返し、それぞれの結果が組み立てられて、最終的な全表スキャンになります。
1つの操作に割り当てられたパラレル実行サーバーの数が、その操作の並列度となります。同じSQL文中の複数の操作の並列度は、すべて同じです。
|
関連項目:
|