| Oracle® Database概要 11gリリース2 (11.2) B56306-06 |
|


 前 |
 次 |
この章では、Structured Query Language(SQL)の概要およびOracle DatabaseによるSQL文の処理方法について説明します。
この章の内容は、次のとおりです。
SQL(「シーキューエル」と読みます)は、すべてのプログラムおよびユーザーがOracleデータベースのデータへアクセスする際に使用する、セットベースの高度な宣言型コンピュータ言語です。 いくつかのOracleツールおよびアプリケーションでは、SQLの使用はマスクされていますが、すべてのデータベース操作はSQLを使用して実行されます。その他のデータ・アクセス方法を使用すると、Oracle Databaseに組み込まれているセキュリティが活用されず、データのセキュリティと整合性が損われる可能性があります。
SQLはOracle Databaseなどのリレーショナル・データベースに対するインタフェースを提供します。SQLでは、次のようなタスクを1つの一貫した言語に統合します。
SQLは対話的に使用できます(つまり、文を手動でプログラムに入力できます)。SQL文はCまたはJavaなどの異なる言語で記述されたプログラム内に埋め込むこともできます。
コンピュータ言語には大きく分けて2つの種類があり、1つは実行目的を表す非手続き型の宣言型言語、もう1つは処理の実行経緯を表すC++およびJavaなどの手続き型言語です。SQLは、ユーザーが結果の導出方法ではなく目的とする結果を指定するという意味において、宣言型です。SQL言語コンパイラが手続きを生成する作業を実行し、データベースに指示して目的のタスクを実行します。
SQLを使用すると、論理レベルでデータを操作できます。実装の詳細は、データを操作する場合にのみ、考慮する必要があります。たとえば、次の文を使用すると、姓がKで始まる従業員のレコードを問い合せることができます。
SELECT last_name, first_name FROM hr.employees WHERE last_name LIKE 'K%' ORDER BY last_name, first_name;
データベースはWHERE条件(述語とも呼ばれる)を満たすすべての行を1つの手順で取得します。これらの行は1つの単位としてユーザー、別のSQL文またはアプリケーションに渡すことができます。行を1つずつ処理する必要はなく、また、行の物理的な格納方法または取得方法を認識する必要もありません。
すべてのSQL文でオプティマイザ(指定されたデータへの最も効率的なアクセス手段を決定するOracle Databaseの機能)が使用されます。Oracle Databaseでは、オプティマイザにジョブを適切に実行させるための技術もサポートされています。
オラクル社は業界で承認されている標準への準拠に努め、SQLの規格協会に積極的に参加しています。業界が認可している協会として、米国規格協会(ANSI)および国際標準化機構(ISO)があります。ANSIおよびISO/IECはいずれも、リレーショナル・データベースの標準言語としてSQLを認可しています。
最新のSQL規格は2003年7月に採用され、一般的にSQL:2003と呼ばれています。SQL規格の一部であるPart 14: SQL/XML(ISO/IEC 9075-14)は2006年に改訂されており、一般的にはSQL/XML:2006と呼ばれています。
Oracle SQLには、ANSI/ISO標準SQL言語に対応する多くの拡張機能が組み込まれており、Oracle Databaseのツール製品とアプリケーションを使用することで、文を追加できます。SQL*Plus、SQL DeveloperおよびOracle Enterprise Managerなどのツールを使用すると、Oracle Databaseに対してANSI/ISO標準のSQL文を実行でき、さらにこれらのツール製品で使用可能な追加の文や機能を実行できます。
|
関連項目:
|
Oracle Database内の情報に対するすべての操作は、SQL文を使用して実行します。SQL文は識別子、パラメータ、変数、名前、データ型およびSQL予約語で構成されるコンピュータ・プログラムまたは命令です。
|
注意: SQL予約語は、SQLで特別な意味を持ち、他の目的には使用できません。たとえば、SELECTとUPDATEは予約語のため、表名には使用できません。 |
SQL文は、完全なSQL文と等価であることが必要です。次に例を示します。
SELECT last_name, department_id FROM employees
Oracle Databaseでは、完全なSQL文のみが実行されます。次のような不完全文を実行しようとすると、テキストの不足を示すエラーが発生します。
SELECT last_name;
データ定義言語(DDL)文は、スキーマ・オブジェクトに対し、定義、構造の変更および削除を実行します。たとえば、DDL文で次の操作を実行できます。
スキーマ・オブジェクトと他のデータベース構造(データベースとデータベース・ユーザーを含む)を作成、変更および削除します。ほとんどのDDL文はCREATE、ALTERまたはDROPのキーワードで始まります。
スキーマ・オブジェクトの構造を削除することなく、それらのオブジェクトの中のすべてのデータを削除します(TRUNCATE)。
データ・ディクショナリにコメントを追加します(COMMENT)。
DDLを使用すると、オブジェクトにアクセスするアプリケーションを変更することなく、オブジェクトの属性を変更できます。たとえば、アプリケーションをリライトせずに、人事管理アプリケーションからアクセスする表に列を追加できます。また、DDLを使用して、データベース・ユーザーがデータベース内で作業を実行している間に、オブジェクトの構造を変更することもできます。
例7-1では、DDL文を使用してplants表を作成した後、DMLを使用して表に2つの行を挿入します。次に、DDLを使用して表構造を変更し、この表に対するユーザーの権限を付与および取り消してから、表を削除します。
例7-1 DDL文
CREATE TABLE plants
( plant_id NUMBER PRIMARY KEY,
common_name VARCHAR2(15) );
INSERT INTO plants VALUES (1, 'African Violet'); # DML statement
INSERT INTO plants VALUES (2, 'Amaryllis'); # DML statement
ALTER TABLE plants ADD
( latin_name VARCHAR2(40) );
GRANT SELECT ON plants TO scott;
REVOKE SELECT ON plants FROM scott;
DROP TABLE plants;
データベースがDDL文を実行する直前に暗黙的なCOMMITが行われ、直後にCOMMITまたはROLLBACKが行われます。例7-1では、2つのINSERT文の後にALTER TABLE文が続くため、データベースによって2つのINSERT文がコミットされます。ALTER TABLE文が成功した場合は、この文はデータベースによってコミットされ、失敗した場合は、この文はデータベースによってロールバックされます。いずれの場合も、2つのINSERT文はすでにコミットされています。
|
関連項目:
|
データ操作言語(DML)文は、既存のスキーマ・オブジェクト内のデータの問合せや操作を実行します。DDL文ではデータベースの構造を変更できるのに対して、DML文では内容の問合せまたは変更が可能です。たとえば、ALTER TABLEは表の構造を変更するのに対して、INSERTは1つ以上の行を表に追加します。
DML文は、最も頻繁に使用するSQL文であり、次の操作を実行できます。
列値のリストを指定するか、既存のデータを選択および操作する副問合せを使用して、表またはビューに新しいデータ行を追加します(INSERT)。
行の更新または、条件付きで表またはビューに行の挿入を行います(MERGE)。
SQL文の実行計画を表示します(EXPLAIN PLAN)。「Oracle DatabaseによるDML処理方法」を参照してください。
次の例では、DMLを使用してemployees表に問い合せます。例では、DMLを使用してemployeesに行を挿入し、この行を更新した後、行を削除します。
SELECT * FROM employees; INSERT INTO employees (employee_id, last_name, email, job_id, hire_date, salary) VALUES (1234, 'Mascis', 'JMASCIS', 'IT_PROG', '14-FEB-2011', 9000); UPDATE employees SET salary=9100 WHERE employee_id=1234; DELETE FROM employees WHERE employee_id=1234;
論理作業単位を形成するDML文のコレクションは、トランザクションと呼ばれます。たとえば、預金を振り替えるトランザクションは、普通預金口座の残高の減額、当座預金口座の残高の増額および預金口座履歴表への振替えの記録という3つの別々の操作を伴います。DDL文とは異なり、DML文は現行のトランザクションを暗黙的にコミットしません。
|
関連項目:
|
問合せは、表またはビューからデータを取得する操作です。SELECTはデータの問合せに使用できる唯一のSQL文です。SELECT文の実行から取得した一連のデータは結果セットと呼ばれます。
表7-1に、SELECT文で一般的に使用される2つの必須キーワードおよび2つのキーワードを示します。また、表では、キーワードとSELECT文の機能を関連付けています。
表7-1 SQL文のキーワード
| キーワード | 必須 | 説明 | 機能 |
|---|---|---|---|
|
|
はい |
結果に表示される列を指定します。投影により、表内の列のサブセットが作成されます。 式は1つ以上の値、演算子、および値を評価するSQL機能の組合せです。 |
投影 |
|
|
はい |
データの取得元の表またはビューを指定します。 |
結合 |
|
|
いいえ |
条件を指定して行をフィルタ処理し、表内の行のサブセットを作成します。条件は、1つ以上の式および論理(ブール)演算子の組合せを指定し、 |
選択 |
|
|
いいえ |
行の表示順序を指定します。 |
|
関連項目: SELECTの構文およびセマンティクスについては、『Oracle Database SQL言語リファレンス』 |
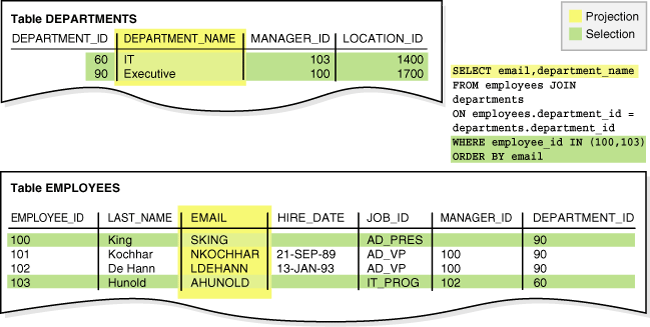
結合は2つ以上の表、ビューまたはマテリアライズド・ビューからの行を組み合せる問合せです。例7-2は、employees表およびdepartments表を結合して(FROM句)、指定した条件に一致する行のみを選択し(WHERE句)、投影を使用して2つの列からデータを取得します(SELECT)。SQL文の後にサンプルの出力を示しています。
例7-2 結合のサンプル
SELECT email, department_name FROM employees JOIN departments ON employees.department_id = departments.department_id WHERE employee_id IN (100,103) ORDER BY email; EMAIL DEPARTMENT_NAME ------------------------- ------------------------------ AHUNOLD IT SKING Executive
図7-1に、例7-2の結合で示した投影および選択の操作を視覚的に表します。
ほとんどの結合には、FROM句またはWHERE句のいずれかに1つ以上の結合条件があり、それぞれ異なる表の2つの列をこの条件によって比較します。データベースでは1対の行を組み合せ、それぞれの対には、結合条件がTRUEになる各表の行を1行ずつ含みます。オプティマイザは結合条件、索引、および表に使用できる任意の統計に基づいて、データベースが表を結合する順序を決定します。
結合タイプは次のとおりです。
内部結合は、結合条件を満たす行のみを戻す2つ以上の表の結合です。たとえば、結合条件がemployees.department_id=departments.department_idの場合、この条件を満たさない行は戻されません。
外部結合
外部結合は結合条件を満たすすべての行を戻すとともに、一方の表からは、他方の表の条件を満たさない行に対応する行も戻します。たとえば、employeesおよびdepartmentsの左側外部結合では、departmentsに一致する行がない場合でも、employees表のすべての行を取得します。右側外部結合では、employeesに一致する行がない場合でも、departmentsのすべての行を取得します。
デカルト積
結合問合せ内の2つの表に結合条件がない場合、データベースはデカルト積を戻します。一方の表の各行を他方の表の各行と組み合せます。たとえば、employeesに107行ありdepartmentsには27行ある場合、デカルト積には107*27行が含まれます。デカルト積が便利な場合はほとんどありません。
|
関連項目: 結合の詳細および例は、『Oracle Database SQL言語リファレンス』を参照してください。 |
副問合せは別のSQL文内にネストされたSELECT文です。副問合せは、1つの問題を解決するために複数の問合せを実行する必要がある場合に便利です。
各文の問合せ部分は問合せブロックと呼ばれます。例7-3では、カッコ内の副問合せが内部問合せブロックです。内部SELECT文により、場所IDが1800の部門のIDが取得されます。これらの部門IDは、副問合せによってIDが戻された部門の従業員名を取得する外部問合せブロックに必要です。
例7-3 副問合せ
SELECT first_name, last_name FROM employees WHERE department_id IN (SELECT department_id FROM departments WHERE location_id = 1800);
このSQL文の構造では、内部問合せを最初に実行することをOracle Databaseに強制しているわけではありません。たとえば、Oracle Databaseにより問合せ全体がemployeesとdepartmentsの結合としてリライトされることもあり、その場合は副問合せ自体が実行されません。また、別の例として、Virtual Private Database(VPD)機能では、WHERE句を使用して従業員の問合せが絞り込まれることがあり、この場合は、Oracle Databaseでは、最初に従業員を問い合せてから部門IDが取得されます。オプティマイザにより、要求された行を取得するための手順の最適な順序が決定されます。
暗黙的問合せは、副問合せを使用せずにデータを取得するDML文のコンポーネントです。SELECT文を明示的に含まないUPDATE、DELETEまたはMERGE文では、暗黙的問合せを使用して変更対象の行を取得します。たとえば、次の文にはBaerレコードの暗黙的問合せが含まれます。
UPDATE employees SET salary = salary*1.1 WHERE last_name = 'Baer';
問合せコンポーネントを必ずしも含まなくてよいDML文は、VALUES句を伴うINSERT文のみです。たとえば、INSERT INTO TABLE mytable VALUES (1)文では、行を挿入する前に行が取得されることはありません。
トランザクション制御文は、DML文による変更の内容を管理し、一連のDML文をトランザクションとしてグループ化します。これらの文によって、次のことを実行できます。
トランザクションの開始以降(ROLLBACK)またはセーブポイント以降(ROLLBACK TO SAVEPOINT)に実行されたトランザクション内での変更を取り消します。セーブポイントは、トランザクションのコンテキスト内のユーザー宣言による中間マーカーです。
|
注意: ROLLBACKコマンドはトランザクションを終了しますが、ROLLBACK TO SAVEPOINTは終了しません。 |
後に続く各DML文の遅延可能整合性制約をチェックするかどうか、またはトランザクションをコミットするタイミングを指定します(SET CONSTRAINT)。
次の例はUpdate salariesという名前のトランザクションを開始します。例ではセーブポイントを作成し、従業員の給与を更新した後、セーブポイントまでトランザクションをロールバックします。さらに、給与を別の値に更新してコミットします。
SET TRANSACTION NAME 'Update salaries'; SAVEPOINT before_salary_update; UPDATE employees SET salary=9100 WHERE employee_id=1234 # DML ROLLBACK TO SAVEPOINT before_salary_update; UPDATE employees SET salary=9200 WHERE employee_id=1234 # DML COMMIT COMMENT 'Updated salaries';
セッション制御文は、ユーザー・セッションのプロパティを動的に管理します。「接続とセッション」で説明しているように、セッションは、データベースに対する現在のユーザー・ログインの状態を示す、データベース・インスタンス・メモリー内の論理エンティティです。セッションは、ユーザーがデータベースに認証された時点から、ユーザーが接続を切断するか、データベース・アプリケーションを終了する時点まで続きます。
セッション制御文によって、次のことを実行できます。
次の例では、セッションのSQLトレースをオンにして、dw_manager以外の現行のセッションで付与されているすべてのロールを有効にします。
ALTER SESSION SET SQL_TRACE = TRUE; SET ROLE ALL EXCEPT dw_manager;
セッション制御文は現行のトランザクションを暗黙的にコミットしません。
|
関連項目: ALTER SESSIONの構文およびセマンティクスについては、『Oracle Database SQL言語リファレンス』 |
システム制御文は、データベース・インスタンスのプロパティを変更します。システム制御文は、ALTER SYSTEMのみです。この文は、設定値(共有サーバーの最小数など)の変更、セッションの終了およびその他のシステム・レベルでのタスクの実行に使用します。
システム制御文の例を次に示します。
ALTER SYSTEM SWITCH LOGFILE; ALTER SYSTEM KILL SESSION '39, 23';
ALTER SYSTEM文は現行のトランザクションを暗黙的にコミットしません。
|
関連項目: ALTER SYSTEMの構文およびセマンティクスについては、『Oracle Database SQL言語リファレンス』 |
埋込みSQL文は、手続き型言語プログラム内にDDL、DMLおよびトランザクション制御文を取り込みます。これらの文は、Oracleプリコンパイラで使用されます。埋込みSQLは、手続き型言語アプリケーションにSQLを取り込むための1つの方法です。他に、Open Database Connectivity(ODBC)またはJava Database Connectivity(JDBC)などの手続き型APIを使用する方法もあります。
埋込みSQL文によって、次のことを実行できます。
カーソルの定義、割当ておよび解放を行います(DECLARE CURSOR、OPEN、CLOSE)。
記述子を初期化します(DESCRIBE)。
エラー条件と警告の処理方法を指定します(WHENEVER)。
Oracle DatabaseがSQL文を処理する仕組みを理解するには、データベースのオプティマイザと呼ばれる部分(問合せオプティマイザまたはコストベース・オプティマイザとも呼ばれる)を理解する必要があります。すべてのSQL文でオプティマイザを使用して、指定されたデータへの最も効率的なアクセス手段を決定します。
DML文を実行するために、Oracle Databaseで多くの処理を必要とする場合があります。各処理では、データベースからデータ行を物理的に検索するか、文を発行したユーザーのためにデータ行を準備します。
多くの場合、DML文の処理には多くの様々な方法を使用できます。たとえば、表または索引のアクセス順序を変更できます。データベースが文を実行するときに使用する手順は、文の実行速度に大きく影響します。オプティマイザは、使用可能な実行方法を表す実行計画を生成します。
オプティマイザは、問合せ条件、使用可能なアクセス・パス、収集された対象システムの統計およびヒントなどの複数の情報ソースを考慮して、最も効率的な実行計画を決定します。Oracleによって処理されるSQL文に対して、オプティマイザは次の操作を実行します。
オプティマイザは、問合せの処理に使用できる方法の大部分を生成し、生成した実行計画の各手順にコストを割り当てます。コストが最も低い計画が、実行する問合せ計画として選択されます。
|
注意: SQL文の実行計画は、その計画を実行しなくても取得できます。データベースが問合せの実行に実際に使用する実行計画は、適切に規定された問合せ計画のみです。 |
オプティマイザが選択する内容は、オプティマイザの目的を設定して、オプティマイザ用の代表的な統計を収集することにより決まります。たとえば、オプティマイザの目的を次のいずれかに設定できます。
合計スループット
結果の最後の行を可能なかぎり迅速にクライアント・アプリケーションに取得するよう、ALL_ROWSヒントがオプティマイザに指示します。
初期レスポンス時間
最初の行を可能なかぎり迅速にクライアントに取得するよう、FIRST_ROWSヒントがオプティマイザに指示します。
典型的なエンド・ユーザーの対話型アプリケーションの場合、初期レスポンス時間による最適化が有用であるのに対して、バッチモードの非対話型アプリケーションの場合、合計スループットによる最適化が有用です。
|
関連項目:
|
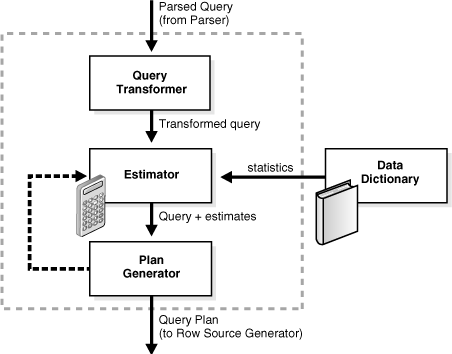
オプティマイザには、図7-2に示す主要な3つのコンポーネントが含まれます。
オプティマイザには、解析済の問合せが入力されます(「SQLの解析」を参照)。オプティマイザは、次の操作を実行します。
オプティマイザは解析済の問合せを受け取り、使用可能なアクセス・パスおよびヒントに基づいてSQL文に対する一連の計画候補を生成します。
オプティマイザはデータ・ディクショナリの統計に基づいて各計画のコストを見積ります。コストとは、特定の計画を使用して文を実行するために必要な、予想されるリソース使用に比例した見積り値です。
オプティマイザは各計画のコストを比較し、コストが最も低い計画(問合せ計画と呼ばれる)を選択して、行ソース・ジェネレータに渡します(「SQLの行ソース生成」を参照)。
問合せトランスフォーマは、オプティマイザがより優れた実行計画を生成できるように、問合せの形式を変更することが有用かどうかを判断します。問合せトランスフォーマには、一連の問合せブロックによって表現された解析済の問合せが入力されます。
エスティメータは指定された実行計画の全体コストを判断します。この目的を達成するために、エスティメータは3つの異なる計測タイプを生成します。
選択性
この計測タイプは、行セット内の行の一部分を表します。選択性は、問合せの述語(last_name='Smith'など)や述語の組合せに関連します。
カーディナリティ
コスト
この計測タイプは、使用される作業またはリソースの単位を表します。問合せオプティマイザでは、作業単位としてディスクI/O、CPU使用率およびメモリー使用量を使用します。
統計が使用できる場合、エスティメータは統計を使用して計測値を計算します。統計によって、計測値の精度が向上します。
プラン・ジェネレータは、発行済の問合せに対して複数の異なる計画を試行し、最もコストが低い計画を選択します。オプティマイザは、ネストされた副問合せおよびマージ解除したビューそれぞれ(個別の問合せブロックで表現されている)に対して、サブプランを生成します。プラン・ジェネレータは、異なるアクセス・パス、結合方法および結合順序を試行して、問合せブロックに対する様々な計画を検索します。
オプティマイザは自動的に計画を管理し、検証された計画のみが使用されることを保証します。SQL計画の管理(SPM)では、現在の計画よりも新しい計画の方がより適切に実行されることが検証された場合にかぎり、その新しい計画を使用することによって、計画の更新を制御できます。
EXPLAIN PLAN文などの診断ツールを使用すると、オプティマイザが選択した実行計画を表示できます。EXPLAIN PLANは、指定したSQLの問合せが現行のセッション内で実行された場合の、その問合せに対する問合せ計画を示します。他の診断ツールとして、Oracle Enterprise ManagerおよびSQL*Plus AUTOTRACEコマンドがあります。例7-6に、AUTOTRACEが有効な場合の問合せの実行計画を示します。
|
関連項目:
|
アクセス・パスは、データベースからデータを取得するための方法です。たとえば、索引を使用する問合せは、索引を使用しない問合せとは異なるアクセス・パスになります。通常、表内の行の小規模なサブセットを取得する文には、索引アクセス・パスが最適です。表内の大きな一部分にアクセスするには、全体スキャンがより効率的です。
データベースは、表からデータを取得するために、複数の異なるアクセス・パスを使用できます。代表的なものは次のとおりです。
このタイプのスキャンは、表からすべての行を読み取り、選択基準に合致しない行をフィルタ処理して除外します。データベースは、使用済領域と未使用領域を分離する最高水位標より下のものも含め、セグメント内のすべてのデータ・ブロックを順次スキャンします(「セグメント領域と最高水位標」を参照)。
ROWIDスキャン
行のROWIDは、そのブロック内の行および行の位置を含むデータファイルおよびデータ・ブロックを指定します。データベースは、最初に文中のWHERE句または索引スキャンのいずれかから選択した行のROWIDを取得し、次にそのROWIDに基づいて選択した各行の位置を特定します。
索引スキャン
このスキャンは、SQL文によってアクセスする索引付けされた列値に対応した索引を検索します(「索引スキャン」を参照)。文によって索引の列のみにアクセスする場合、Oracle Databaseは索引付けされた列値を索引から直接読み取ります。
クラスタ・スキャン
クラスタ・スキャンは、索引付きの表クラスタに格納された表からデータを取得するために使用され、表クラスタでは、同じクラスタ・キー値を持つすべての行が同じデータ・ブロックに格納されています(「索引付きクラスタの概要」を参照)。データベースは最初にクラスタ索引をスキャンして、選択した1つの行のROWIDを取得します。Oracle DatabaseはこのROWIDに基づいて行の位置を特定します。
ハッシュ・スキャン
ハッシュ・スキャンは、ハッシュ・クラスタ内の行の位置を特定するために使用され、ハッシュ・クラスタ内では、同じハッシュ値を持つすべての行が同じデータ・ブロックに格納されています(「ハッシュ・クラスタの概要」を参照)。データベースは最初に、文によって指定されたクラスタ・キー値にハッシュ関数を適用することにより、ハッシュ値を取得します。次に、Oracle Databaseはこのハッシュ値の行を含むデータ・ブロックをスキャンします。
オプティマイザは、文に対して使用可能なアクセス・パスと、各アクセス・パスまたはパスの組合せの使用時の見積りコストに基づいて、1つのアクセス・パスを選択します。
|
関連項目: アクセス・パスの詳細は、『Oracle Database 2日でパフォーマンス・チューニング・ガイド』および『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
オプティマイザ統計は、データベースの詳細を記述したデータとデータベース内のオブジェクトのコレクションです。統計は、アクセス・パスを評価する場合にオプティマイザが使用できるデータ記憶域とデータ配分に関する、統計的に正しいピクチャを提示します。
オプティマイザ統計のタイプは次のとおりです。
表統計
行数、ブロック数および行の平均長が含まれます。
列統計
列内の個々の値とNULLの数およびデータ配分が含まれます。
索引統計
リーフ・ブロックおよび索引レベルの数が含まれます。
システム統計
CPUとI/Oのパフォーマンスおよび使用率が含まれます。
Oracle Databaseは、すべてのデータベース・オブジェクトのオプティマイザ統計を自動的に収集し、これらの統計を自動メンテナンス・タスクとして保持します。また、DBMS_STATSパッケージを使用して、手動で統計を収集することもできます。このPL/SQLパッケージでは、統計を変更、表示、エクスポート、インポートおよび削除できます。
オプティマイザ統計は問合せの最適化を目的として作成され、データ・ディクショナリに格納されます。これらの統計と動的パフォーマンス・ビューを介して表示できるパフォーマンス統計を混同しないでください。
|
関連項目:
|
ヒントは、オプティマイザへの指示として機能するSQL文内のコメントです。特定のアプリケーションのデータについて、オプティマイザよりもさらに詳細な知識を持つアプリケーション設計者の方が、SQL文をより効率的に実行する方法を選択できることもあります。アプリケーション設計者は、SQL文内にヒントを使用して文の実行方法を指定できます。
たとえば、対話型アプリケーションによって、50行を戻す問合せが実行されるとします。このアプリケーションでは、問合せによって戻される最初の25行のみを初めにフェッチしてエンド・ユーザーに表示します。オプティマイザを使用して、最初の25レコードを可能なかぎり迅速に取得する計画を生成し、ユーザーが待たずに済むようにします。この指示をオプティマイザに渡すには、例7-4のSELECT文およびAUTOTRACE出力に示すように、ヒントを使用します。
例7-4 FIRST_ROWSヒントを指定したSELECTの実行計画
SELECT /*+ FIRST_ROWS(25) */ employee_id, department_id FROM hr.employees WHERE department_id > 50; ------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes ------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 26 | 182 | 1 | TABLE ACCESS BY INDEX ROWID | EMPLOYEES | 26 | 182 |* 2 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | | ------------------------------------------------------------------------
例7-4の実行計画では、オプティマイザがemployees.department_id列の索引を選択して部門IDが50を超えるemployeesの最初の25行を検索しています。オプティマイザは索引から取得したROWIDを使用してemployees表からレコードを取得し、クライアントに戻します。通常、最初のレコードの取得はほとんど即時です。
例7-5に、オプティマイザ・ヒントを指定しない同じ文を示します。
例7-5 ヒントを指定しないSELECTの実行計画
SELECT employee_id, department_id FROM hr.employees WHERE department_id > 50; ------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cos ------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 50 | 350 | |* 1 | VIEW | index$_join$_001 | 50 | 350 | |* 2 | HASH JOIN | | | | |* 3 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 50 | 350 | | 4 | INDEX FAST FULL SCAN| EMP_EMP_ID_PK | 50 | 350 |
例7-5の実行計画では2つの索引を結合し、可能なかぎり迅速に要求されたレコードを戻します。オプティマイザは、例7-4のように索引から表へと繰り返し移動するのではなく、EMP_DEPARTMENT_IXのレンジ・スキャンを選択して、部門IDが50を超えるすべての行を検索し、ハッシュ表にこれらの行を配置します。オプティマイザは次に、EMP_EMP_ID_PK索引を読み取ることを選択します。この索引の各行について、ハッシュ表を調査して部門IDを検索します。
この場合、EMP_DEPARTMENT_IXの索引レンジ・スキャンが完了するまで、データベースはクライアントに最初の行を戻すことができません。このため、生成されたこの計画では最初のレコードを戻すために、より長い時間がかかります。索引のROWIDによって表にアクセスする例7-4の計画とは異なり、例7-5の計画はマルチブロックI/Oを使用し、読取りの範囲が大きくなります。読取りによって、全結果セットの最後の行をより迅速に戻すことができます。
|
関連項目: オプティマイザ・ヒントの使用方法の詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
この項では、Oracle DatabaseによるSQL文の処理の仕組みについて説明します。特に、データベースがDDL文を処理してオブジェクトを作成する仕組み、DMLを使用してデータを変更する仕組み、問合せを使用してデータを取得する仕組みについて説明します。
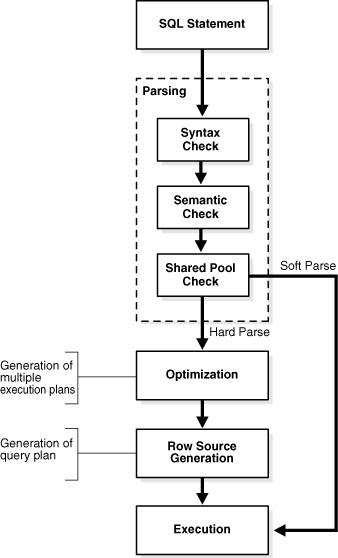
図7-3は、解析、最適化、行ソース生成および実行というSQL処理の一般的な段階を示しています。文によっては、データベースがこれらの手順の一部を省略する場合があります。
図7-3に示すように、SQL処理の最初の段階は解析です。この段階では、SQL文の各部分を他のルーチンで処理できるデータ構造に分解する処理が行われます。Oracle Databaseは、アプリケーションから指示されたときに文を解析するため、解析回数を削減できるのはアプリケーションのみです(Oracle Database自体ではありません)。
アプリケーションがSQL文を発行すると、アプリケーションはOracle Databaseに解析コールを出して、文の実行を準備します。解析コールによって、解析済のSQL文と処理に使用するその他の情報が保持されるセッション固有のプライベートSQL領域のハンドルであるカーソルがオープンまたは作成されます。カーソルおよびプライベートSQL領域はPGA内にあります。
解析コール時には、データベースでは次のチェックを実行します。
これらのチェックによって、文の実行前に検出できるエラーを特定します。解析では捕捉できないエラーもあります。たとえば、データベースでは文の実行時にしかデッドロックまたはデータ変換エラーが発生しません(「ロックとデッドロック」を参照)。
Oracle Databaseは各SQL文の構文上の妥当性を必ずチェックします。SQL構文の形式が整っていても、規則に違反している文はチェックが失敗します。たとえば、次の文ではキーワードFROMがFORMという誤ったスペルになっているため、失敗します。
SQL> SELECT * FORM employees;
SELECT * FORM employees
*
ERROR at line 1:
ORA-00923: FROM keyword not found where expected
文のセマンティクスとは、文の意味のことです。このため、セマンティクス・チェックでは、文内のオブジェクトおよび列が存在するかどうかなど、文の意味が有効かどうかを判断します。次に示す存在しない表の問合せの例のように、構文的に正しい文でも、セマンティクス・チェックに失敗します。
SQL> SELECT * FROM nonexistent_table;
SELECT * FROM nonexistent_table
*
ERROR at line 1:
ORA-00942: table or view does not exist
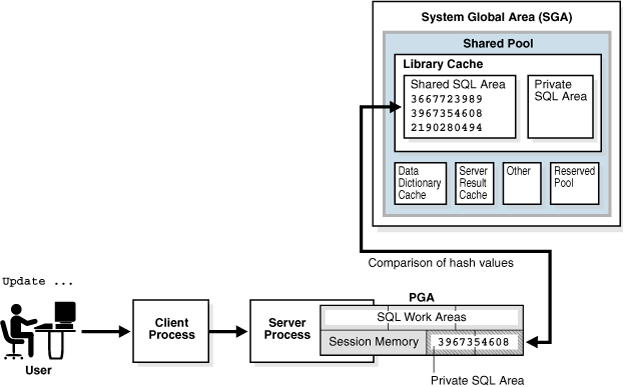
解析中、データベースは共有プール・チェックを実行して、文の処理のうちリソース集中型の手順を省略できるかどうかを判断します。これを行うために、データベースはハッシング・アルゴリズムを使用してSQL文ごとにハッシュ値を生成します。文のハッシュ値は、V$SQL.SQL_IDに示されるSQL IDです。
ユーザーがSQL文を発行すると、データベースは共有SQL領域を検索して、既存の解析済の文に同じハッシュ値があるかどうかを確認します。SQL文のハッシュ値は、次の値とは異なります。
文のメモリー・アドレス
Oracle Databaseでは、SQL IDをキーとして使用して検索対象の表を読み取ります。これにより、Oracle Databaseは文のメモリー・アドレスを取得します。
文の実行計画のハッシュ値
1つのSQL文で、複数の計画を共有プールに設定できます。各計画には、異なるハッシュ値を設定します。同じSQL IDに複数の計画ハッシュ値が設定されていると、Oracle Databaseでは、そのSQL IDに対して複数の計画が存在することが認識されます。
発行される文のタイプとハッシュ・チェックの結果に応じて、解析操作は次のカテゴリに分類されます。
Oracle Databaseは、既存のコードを再利用できない場合、新しく実行可能なバージョンのアプリケーション・コードを作成する必要があります。この操作はハード解析またはライブラリ・キャッシュ・ミスと呼ばれます。データベースは常にDDLのハード解析を実行します。
ハード解析時には、データベースはライブラリ・キャッシュおよびデータ・ディクショナリ・キャッシュに何度もアクセスして、データ・ディクショナリをチェックします。データベースはこれらの領域にアクセスするとき、定義が変更されないように、必要なオブジェクト上にラッチと呼ばれるシリアライズ・デバイスを使用します(「ラッチ」を参照)。ラッチの競合が発生すると、文の実行時間が長くなり、同時実行性が低下します。
ソフト解析は、ハード解析以外のすべての解析です。発行される文が共有プール内の再利用可能なSQL文と同じ場合、Oracle Databaseは既存のコードを再利用します。コードの再利用は、ライブラリ・キャッシュ・ヒットとも呼ばれます。
ソフト解析によって実行される作業の量は、解析ごとに異なる場合があります。たとえば、セッションの共有SQL領域の構成によって、ソフト解析はラッチ量が減少し、よりソフト解析らしくなる場合があります。
データベースが最適化および行ソース生成の手順を省略してそのまま実行に進むため、通常ソフト解析はハード解析よりも優れています。
図7-4に、専用サーバー・アーキテクチャのUPDATE文の共有プール・チェックを簡単に示します。
チェックにより、共有プール内の文に同じハッシュ値があると判断された場合、データベースはセマンティクス・チェックおよび環境チェックを実行して、文の意味が同一かどうかを判断します。構文が同一であるだけでは不十分です。たとえば、データベースに異なる2人のユーザーがログインし、次のSQL文を発行したと想定します。
CREATE TABLE my_table ( some_col INTEGER ); SELECT * FROM my_table;
2人のユーザーのSELECT文は構文上同一ですが、2つの別々のスキーマ・オブジェクトがmy_tableという名前になっています。この意味の相違によって、2番目の文では最初の文のコードを再利用できません。
2つの文が意味的に同一であったとしても、環境の違いによりハード解析が強制的に行われることがあります。この場合の環境とは、作業領域サイズまたはオプティマイザの設定など、実行計画の生成に影響する可能性があるすべてのセッション設定です。単一のユーザーによって実行される次の一連のSQL文を考えてみます。
ALTER SYSTEM FLUSH SHARED_POOL; SELECT * FROM my_table; ALTER SESSION SET OPTIMIZER_MODE=FIRST_ROWS; SELECT * FROM my_table; ALTER SESSION SET SQL_TRACE=TRUE; SELECT * FROM my_table;
この例では、同じSELECT文が3つの異なるオプティマイザ環境で実行されます。結果として、データベースはこれらの文に対して3つの個別の共有SQL領域を作成し、各文にハード解析を強制的に実行します。
「オプティマイザの概要」で説明しているように、問合せの最適化は、SQL文の実行の最も効率的な手段を選択するための処理です。データベースは、アクセスする実際のデータに関して収集した統計に基づいて、問合せを最適化します。オプティマイザは行数、データ・セットのサイズおよびその他の要因を使用して、使用可能な実行計画を生成し、各計画に数値コストを割り当てます。データベースは最もコストが低い計画を使用します。
データベースは一意のDML文ごとに必ず1回以上のハード解析を実行して、この解析中に最適化を実行します。最適化を要求する副問合せなどのDMLコンポーネントを含まないかぎり、DDLは最適化されません。
|
関連項目: 問合せオプティマイザの詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
行ソース・ジェネレータは、オプティマイザから最適な実行計画を受け取り、データベースのその他の部分で使用可能な問合せ計画と呼ばれる反復計画を作成するソフトウェアです。反復計画は、SQL仮想マシンで実行される場合に、結果セットを作成するバイナリ・プログラムです。
問合せ計画では、手順の組合せ形式を使用します。各手順では行セットが戻されます。このセット内の行は次の手順または最後の手順のいずれかで使用され、SQL文を発行するアプリケーションに戻されます。
行ソースは、行を反復的に処理できる制御構造に沿って、実行計画の手順から戻された行セットです。表、ビュー、または結合処理あるいはグループ化処理の結果が行ソースになる可能性があります。
行ソース・ジェネレータは、行ソースのコレクションである行ソース・ツリーを作成します。行ソース・ツリーには次の情報が表示されます。
文が参照する表の順序
文内に記述された各表へのアクセス方法
文の結合操作によって影響を受ける表の結合方法
フィルタ、ソートまたは集計などのデータ操作
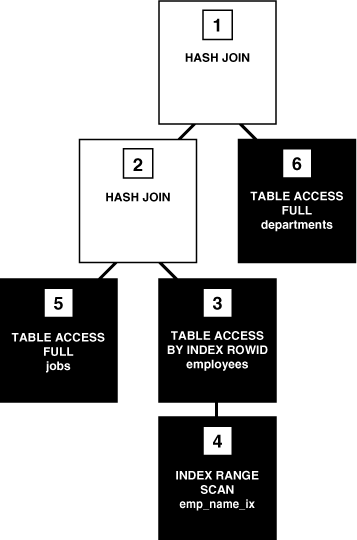
例7-6に、AUTOTRACEが有効な場合のSELECT文の実行計画を示します。この文では、姓が文字Aで始まるすべての従業員の姓、職種、部門名を選択します。この文の実行計画は行ソース・ジェネレータから出力されます。
例7-6 実行計画
SELECT e.last_name, j.job_title, d.department_name
FROM hr.employees e, hr.departments d, hr.jobs j
WHERE e.department_id = d.department_id
AND e.job_id = j.job_id
AND e.last_name LIKE 'A%' ;
Execution Plan
----------------------------------------------------------
Plan hash value: 975837011
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 189 | 7 (15)| 00:00:01 |
|* 1 | HASH JOIN | | 3 | 189 | 7 (15)| 00:00:01 |
|* 2 | HASH JOIN | | 3 | 141 | 5 (20)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 3 | 60 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | EMP_NAME_IX | 3 | | 1 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | JOBS | 19 | 513 | 2 (0)| 00:00:01 |
| 6 | TABLE ACCESS FULL | DEPARTMENTS | 27 | 432 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
2 - access("E"."JOB_ID"="J"."JOB_ID")
4 - access("E"."LAST_NAME" LIKE 'A%')
filter("E"."LAST_NAME" LIKE 'A%')
実行時には、SQLエンジンが行ソース・ジェネレータによって作成されたツリー内の各行ソースを実行します。この手順のみがDML処理の必須手順です。
図7-5は、各手順間の行ソースのフローを示す実行ツリー(解析ツリーとも呼ばれる)です。通常、実行時の手順の順序は計画時の順序とは逆になるため、計画の場合は下から上へと読み取ります。Operation列の最初のスペースは階層の関係を示します。たとえば、操作の名前の前に2つのスペースがある場合、この処理は1つのスペースの後続となる子処理です。前に1つのスペースがある操作は、SELECT文自体の子です。
図7-5では、ツリーの各ノードが行ソースとして機能しており、実行計画の各手順がデータベースから行を取得するか、1つ以上の行ソースから入力として行を受け取ります。SQLエンジンは各行のソースを次のように実行します。
黒のボックスで示された手順は、データベース内のオブジェクトから物理的にデータを取り出します。これらの手順はアクセス・パス、つまりデータベースからデータを取得する技法です。
手順6は全表スキャンを使用してdepartments表のすべての行を取得します。
手順5は全表スキャンを使用してjobs表のすべての行を取得します。
手順4はemp_name_ix索引を順番にスキャンして、文字Aで始まる各キーを検索し、該当のROWIDを取得します(「索引レンジ・スキャン」を参照)。たとえば、Atkinsonに対応するROWIDはAAAPzRAAFAAAABSAAeです。
手順3はemployees表から手順4でROWIDが戻された行を取得します。たとえば、データベースはROWID AAAPzRAAFAAAABSAAeを使用して、Atkinsonの行を取得します。
透明のボックスで示された手順は行ソースを操作します。
一部の実行計画では、手順が他の順序で反復されます。例7-6に示した計画は、SQLエンジンが索引から表、さらにクライアントへと移動して手順を繰り返すため反復されます。
実行中、データがメモリー内にない場合は、データベースがディスクからメモリーへとデータを読み取ります。また、データベースはデータ整合性を保証するために必要なすべてのロックおよびラッチを取り除き、SQL実行時に行われたすべての変更を記録します。SQL文の処理の最後の段階は、カーソルのクローズです。
|
関連項目: 実行計画およびEXPLAIN PLAN文の詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』 |
ほとんどのDML文には問合せコンポーネントがあります。問合せでは、カーソルを実行すると、問合せの結果が結果セットと呼ばれる行の集合に配置されます。
結果セットの行は、1行ごとにまたはグループ単位でフェッチできます。フェッチ段階では、データベースで行が選択され、問合せで要求された場合には行が順序付けされます。最後の行がフェッチされるまで、毎回のフェッチで結果の行が連続して取得されます。
通常、データベースは、最後の行がフェッチされるまで問合せによって取得する確実な行数を判定できません。Oracle Databaseはフェッチ・コールに応じてデータを取得するため、データベースが読み取る行が多いほど、データベースが実行する作業が増加します。一部の問合せではデータベースが最初の行を可能なかぎり迅速に戻すのに対して、別の問合せでは最初の行を戻す前にデータベースは全結果セットを作成します。
通常、問合せはOracle Databaseの読取り一貫性メカニズムを使用してデータを取得します。UNDOデータを使用して過去のバージョンのデータを表示するこのメカニズムでは、問合せによって読み取られるすべてのデータ・ブロックがある時点のものと一貫していることを保証します。
読取り一貫性の例として、1つの問合せで全表スキャンにより100個のデータ・ブロックを読み取る必要があるとします。問合せが最初の10個のブロックを処理している間に、別のセッションのDMLがブロック75を変更します。最初のセッションがブロック75に到達したとき、問合せは変更を認識し、変更前の古いバージョンのデータを取り出すためにUNDOデータを使用し、メモリー内に現時点のバージョンではないブロック75を構成します。
Oracle DatabaseはDMLとは異なる方法でDDLを処理します。たとえば、表を作成するとき、データベースはCREATE TABLE文を最適化しません。かわりに、Oracle DatabaseはDDL文を解析してコマンドを実行します。
DDLはデータ・ディクショナリ内のオブジェクトを定義する手段であるため、データベースはDDLを異なる方法で処理します。通常、DDLコマンドを実行するために、Oracle Databaseは多くの 再帰的SQL文を解析して実行する必要があります。次のような表を作成するとします。
CREATE TABLE mytable (mycolumn INTEGER);
通常、この文を実行するために、データベースは多数の再帰的な文を実行します。再帰的SQLでは、次のようなアクションが実行されます。
CREATE TABLE文を実行する前にCOMMITを発行します。
ユーザー権限が表の作成に十分であることを検証します。
表が属する表領域を決定します。
表領域の割当てが超過していないことを確認します。
スキーマ内に同じ名前のオブジェクトがないことを確認します。
データ・ディクショナリに表を定義する行を挿入します。
DDL文が成功した場合はCOMMITを発行し、失敗した場合はROLLBACKを発行します。
|
関連項目: アプリケーション開発者のためのSQL処理の詳細は、『Oracle Databaseアドバンスト・アプリケーション開発者ガイド』を参照してください。 |