| Oracle® Database概要 11gリリース2 (11.2) B56306-06 |
|


 前 |
 次 |
これまでに、Oracle Databaseの基本的なアーキテクチャについて説明しました。この章では、データベース管理者と開発者にとって重要で一般的なデータベース・トピックを要約し、ここで網羅的にデータベースの機能を説明するかわりに、参照可能な他のマニュアルを紹介します。
この章の内容は、次のとおりです。
通常、データベース・セキュリティには、ユーザー認証、暗号化、アクセス制御および監視が含まれます。
各Oracleデータベースには、有効なデータベース・ユーザーのリストがあります。データベースには、デフォルトの管理アカウントSYSTEM(「SYSスキーマとSYSTEMスキーマ」を参照)を含む、複数のデフォルトのアカウントが含まれます。ユーザー・アカウントは必要に応じて作成できます。
データベースにアクセスするには、有効なユーザー名と認証用の資格証明を提供する必要があります。資格証明には、パスワード、Kerberosチケットまたは公開鍵インフラストラクチャ(PKI)の証明書などがあります。データベース・セキュリティでは、ログオン試行の失敗に基づいてアカウントをロックするよう構成できます。
通常、データベース・アクセス制御には、データ・アクセスおよびデータベース・アクティビティの制限が含まれます。たとえば、指定された表への問合せや指定されたデータベース・コマンドの実行を制限できます。
ユーザー権限とは、特定のSQL文を実行できる権利のことです。権限は、次のカテゴリに分類できます。
システム権限
これは、データベース内で特定のアクションを実行する権限、または特定のタイプのオブジェクトに対してアクションを実行する権限のことです。システム権限の例として、CREATE USER、CREATE SESSIONがあります。
オブジェクト権限
これは、employees表への問合せなど、指定されたアクションをオブジェクトに対して実行できる権限のことです。権限のタイプは、データベースによって定義されます。
権限は、他のユーザーの裁量で任意に付与されます。管理者は、ユーザーが業務に必要な作業を実行できるよう、必要な権限をユーザーに付与する必要があります。セキュリティの観点から、権限は必要な作業を行うためにその権限を必要とするユーザーにのみ付与することをお薦めします。
ロールは、関連する権限のグループに名前を付けたもので、ユーザーまたは他のロールに付与します。ロールを使用すると、データベース・アプリケーションまたはユーザー・グループの権限の管理が容易になります。
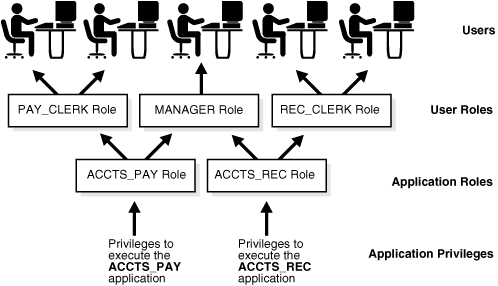
図17-1は、ロールの一般的な使用方法を示しています。PAY_CLERK、MANAGER、およびREC_CLERKの各ロールが、異なるユーザーに割り当てられます。ACCTS_PAYアプリケーションを実行する権限を含むACCTS_PAYアプリケーション・ロールが、PAY_CLERKおよびMANAGERロールを持つユーザーに割り当てられます。ACCTS_RECアプリケーションを実行する権限を含むACCTS_RECアプリケーション・ロールが、REC_CLERKおよびMANAGERロールを持つユーザーに割り当てられます。
|
関連項目:
|
システム・リソースのコンテキストにおけるユーザー・プロファイルとは、リソース制限とパスワード・パラメータをセットにして名前を付けたもので、ユーザーに対してデータベースの使用およびインスタンス・リソースを制限します。プロファイルでは、ユーザーが同時に確立できるセッションの数、各セッションに使用可能なCPU処理時間、および使用可能な論理I/O量を制限できます(「バッファI/O」を参照)。たとえば、clerkプロファイルでは、ユーザーのシステム・リソースが事務作業に必要な程度に制限されます。
|
注意: リソースの制限にはデータベース・リソース・マネージャを使用し、パスワードの管理にはプロファイルを使用することをお薦めします。 |
プロファイルを使用すると、一連の属性を共有する複数のユーザーに対して1つの参照先を指定できます。一連のユーザーにプロファイルを割り当て、それ以外のすべてのユーザーにデフォルト・プロファイルを割り当てることができます。各ユーザーには、任意の時点で最大1つのプロファイルを割り当てることができます。
|
関連項目:
|
Oracle Databaseでは、データベース認証は、ユーザーがデータベースに資格証明を提示し、この資格証明をデータベースが検証してデータベースへのアクセスを許可するプロセスです。アイデンティティを検証することで、その後の対話に関する信頼関係が確立されます。また、認証により、アクセスとアクションを特定のアイデンティティにリンクでき、アカウンタビリティが有効化されます。
Oracle Databaseでは、次のものを含む様々な認証方式が提供されています。
データベースによる認証
Oracleデータベースは、パスワード、KerberosチケットまたはPKIの証明書を使用してユーザーを認証できます。Oracleでは、生体認証を含む、他の認証方式用のRADIUS準拠のデバイスもサポートしています。認証のタイプは、Oracleデータベースでユーザーを作成する際に指定する必要があります。
オペレーティング・システムによる認証
一部のオペレーティング・システムでは、オペレーティング・システムがユーザー認証のために管理している情報を、Oracle Databaseで使用できます。オペレーティング・システムから認証を受けたユーザーは、ユーザー名やパスワードを指定することなくデータベースに接続できます。
データベースの起動や停止などのデータベース操作は、データベース管理者以外のデータベース・ユーザーが実行しないようにする必要があります。これらの操作には、SYSDBAまたはSYSOPER権限が必要です(「管理者権限での接続」を参照)。
|
関連項目:
|
通常、暗号化は、秘密鍵と暗号化アルゴリズムを使用して、データを読取り不可能な形式に変換するプロセスです。多くの場合、暗号化は、Payment Card Industry Data Security Standard(PCI-DSS)や侵害通知法に関連する要件などの法令遵守要件を満たすために使用されます。たとえば、クレジット・カード番号、社会保障番号、患者の病状に関わる情報などを暗号化する必要があります。
クライアントとサーバー間のネットワーク上を移動するデータを暗号化することを、ネットワーク暗号化といいます。侵入者は、ネットワーク・パケット・スニファを使用することにより、ネットワーク上を移動する情報を取得してファイルにスプールし、悪用できます。このような行為は、ネットワーク上のデータを暗号化することによって防ぐことができます。
Oracle Advanced Securityの透過的データ暗号化を使用すると、表の個々の列または表領域を暗号化できます。ユーザーが暗号化された列にデータを挿入すると、データベースによって自動的にデータが暗号化されます。ユーザーが列を選択すると、データは復号化されます。このような形式の暗号化は透過的であり、パフォーマンスが高く、実装が容易です。
透過的データ暗号化には、Advanced Encryption Standard(AES)や組込み鍵管理などの複数の業界標準の暗号化アルゴリズムが含まれます。
|
関連項目: 『Oracle Database 2日でセキュリティ・ガイド』および『Oracle Database Advanced Security管理者ガイド』 |
Oracle Database 11gリリース2 (11.2.0.4)以降では、Oracle Data Redactionを使用して、権限の少ないユーザーまたはアプリケーションによって問い合されるデータを隠す(リダクションする)ことができます。このリダクションは、ユーザーがデータを問い合せるときに、リアルタイムで発生します。Oracle Data Redactionは、Oracle Advanced Securityの一部です。
データ・リダクションでは次のリダクション機能タイプがサポートされています。
完全データ・リダクション
この場合、表またはビューの指定した列の内容全体がリダクションされます。たとえば、姓のVARCHAR2列には、1つの空白が表示されます。
部分データ・リダクション
この場合、表示された出力の一部がリダクションされます。たとえば、アプリケーションでは、1234で終わるクレジット・カード番号をxxxx-xxxx-xxxx-1234と表示できます。完全と部分のどちらのリダクションにも、正規表現を使用できます。正規表現は、検索パターンに基づいて、データをリダクションできます。たとえば、正規表現を使用して、特定の電話番号または電子メール・アドレスをリダクションできます。
ランダム・データ・リダクション
この場合、列のデータ型に応じて、データがランダムに生成された値として表示されます。たとえば、数値1234567は、83933895として表示される可能性があります。
データ・リダクションは、包括的なセキュリティの解決策ではありません。たとえば、直接接続し権限を付与されたユーザーが、リダクションされたデータに対して推論攻撃を実行することを阻止できません。このような攻撃では、リダクションされた列を識別し、削除の処理で、格納された値を推測するSQL問合せを繰り返すことにより、実際のデータに戻そうとします。権限を持つユーザーから発生する推論およびその他の攻撃を検出し、阻止するには、Oracle Data Redactionと関連のデータベース・セキュリティ製品(Oracle Audit Vault and Database Firewall、Oracle Database Vaultなど)と組み合せることをお薦めします。
データ・リダクションは、次のように機能します。
ポリシーで、事前定義のリダクション機能を指定します。
データベースで表示される列の値が実際の値かそれともリダクションされた値かは、ポリシーによって決まります。データがリダクションされると、そのリダクションがただちに最上位の選択リストに反映されから、ユーザーに表示されます。
次の例では、hr.employees表のemployee_id列をリダクションする完全データ・リダクション・ポリシーが追加されています。
BEGIN DBMS_REDACT.ADD_POLICY( object_schema => 'hr' , object_name => 'employees' , column_name => 'employee_id' , policy_name => 'mask_emp_ids' , function_type => DBMS_REDACT.FULL , expression => '1=1' ); END; /
この例では、表現の設定(trueと評価)により、EXEMPT REDACTION POLICY権限を付与されていないユーザーに対して、リダクションが適用されます。
|
関連項目:
|
Oracle Databaseでは、データへのアクセスを制御するための技術が数多く提供されています。この項では、これらの技術の概要を示します。
Oracle Database Vaultは、権限を持つユーザーによるアクセスをアプリケーション・データに制限するセキュリティ・オプションです。Oracle Database Vaultを使用すると、データベース、データおよびアプリケーションに対するアクセスのタイミング、場所および方法を制御できます。このため、法令遵守および責務の分離を実現しながら、関係者による脅威からの保護など、一般的なセキュリティ上の問題にも対応できます。
|
関連項目: 『Oracle Database 2日でセキュリティ・ガイド』および『Oracle Database Vault管理者ガイド』 |
Oracle Virtual Private Database (VPD)を使用すると、行および列レベルでセキュリティを確保できます。セキュリティ・ポリシーによって、予期しないまたは悪意のあるデータの破壊やデータベース・インフラストラクチャの破損からデータベースを保護する方法が確立されます。
VPDでは、権限やロールなどのセキュリティ保護では設定できない詳細な設定が可能です。たとえば、すべてのユーザーに対してemployees表へのアクセスを許可する場合は、セキュリティ・ポリシーを作成して、ユーザーが同じ部門の従業員にアクセスすることを禁止できます。
基本的にデータベースは、Oracle VPDセキュリティ・ポリシーが適用された表、ビューまたはシノニムに対して発行されるSQL文に、動的なWHERE句を追加します。このWHERE句によって、保護データへのアクセスが、セキュリティ・ポリシーに準拠する資格証明を持つユーザーにのみ許可されます。
|
関連項目: 『Oracle Database 2日でセキュリティ・ガイド』および『Oracle Databaseセキュリティ・ガイド』 |
Oracle Label Security(OLS)は、セキュリティ・ラベルを使用してデータ分類の割当てとアクセスの制御を行うことができるセキュリティ・オプションです。ラベルはデータとユーザーの両方に割り当てることができます。
データに割り当てる場合、ラベルを非表示の列として既存の表に添付できるため、既存のSQLが透過的になります。たとえば、機密性が非常に高いデータを含む行にはHIGHLY SENSITIVEというラベルを、またそれほど機密性が高くない行にはSENSITIVEというラベルを添付できます。ユーザーがデータにアクセスしようとすると、OLSにより、ユーザー・ラベルとデータ・ラベルが比較され、アクセスを付与するかどうかが決定されます。VPDとは異なり、OLSには、ラベルの定義および格納について独創的なセキュリティ・ポリシーとメタデータ・リポジトリが採用されています。
|
関連項目: 『Oracle Database 2日でセキュリティ・ガイド』および『Oracle Label Security管理者ガイド』 |
Oracle Databaseには、ユーザー・アクティビティを監視するために複数のツールおよび技術が採用されています。
データベース監査とは、選択したユーザー・データベース・アクションを監視して記録する処理のことです。標準監査では、SQL文、権限、スキーマ、オブジェクト、ネットワーク・アクティビティおよび複数層アクティビティを監査できます。また、ファイングレイン監査では、データベース表に対する操作などの特定のデータベース・アクティビティと、そのアクティビティが発生した時間を監視できます。たとえば、9:00 p.m.以降にアクセスされた表を監査できます。
監査は、次のような理由で使用します。
現在のアクションのアカウンタビリティの有効化
アカウンタビリティに基づいた、ユーザー(または侵入者などの非ユーザー)の不適切なアクションの阻止
不審なアクティビティの調査、監視および記録
監査要件の準拠に対応するため
|
関連項目:
|
Oracle Audit Vault and Database Firewall (Oracle AVDF)は、データベースの最初の防衛線を提供し、データベース、オペレーティング・システムおよびディレクトリからの監査データを統合します。SQL文法に基づくエンジンは、認可されていなSQLトラフィックがデータベースに到達する前に監視およびブロックします。コンプライアンス・レポートとアラートのために、Oracle AVDFはネットワークからのデータベース・アクティビティ・データを詳細な監査データと統合します。監査および監視制御を調整してエンタープライズ・セキュリティ要件を満たすことができます。
|
関連項目: 『Oracle Audit Vault and Database Firewall管理者ガイド』 |
Oracle Enterprise Manager (Enterprise Manager)を使用すると、監査関連の初期化パラメータを表示および構成できます。また、文およびスキーマ・オブジェクトの監査時にオブジェクトを管理することもできます。たとえば、Enterprise Managerを使用して、現行の監査対象の文、権限およびオブジェクトのプロパティを表示および検索できます。監査は必要に応じて有効/無効を切り替えることができます。
可用性とは、アプリケーション、サービスおよび機能が必要なときにどの程度使用可能であるかということです。たとえば、オンライン書店で使用されるOLTPデータベースには、本を購入する顧客がアクセスできる程度の可用性があります。高可用性の主な特徴として、信頼性、リカバリ可能性、タイミングのよいエラー検出、継続的稼働などをあげることができます。
データベース環境において高可用性が重要である理由は、停止時間のコストに関連するためです(停止時間とは、リソースを使用できない時間のことです)。停止時間は、計画停止時間と計画外停止時間のいずれかに分類されます。高可用性環境を設計する場合の主要な課題は、可能性のある停止時間の原因をすべて調査し、対策を講じることです。
|
関連項目: 高可用性の概要は、『Oracle Database高可用性概要』を参照してください。 |
Oracle Databaseでは、あらゆるタイプの予期しない障害により発生する停止時間を防止、許容および短縮する高可用性ソリューションが提供されています。計画外停止時間は、その原因によって次のように分類されます。
|
関連項目: 計画外停止時間からの保護方法の詳細は、『Oracle Database高可用性概要』を参照してください。 |
サイト障害は、なんらかの原因でアプリケーションのすべてまたは大部分の処理が停止したか、サービスが利用できないほど速度が低下した場合に発生します。サイト障害は、データ・センターのすべての処理、またはデータ・センターによってサポートされているアプリケーション・サブセットに影響を及ぼす場合があります。サイト障害の例には、サイト全体にわたる広範囲な停電またはネットワーク障害、データ・センターが運用できなくなるほどの自然災害、運営あるいはサイト自体に対する悪意のある攻撃などがあります。
サイト障害に対する最も簡単な保護方法は、RMANを使用してデータベース・バックアップを作成し、オフサイトに保存することです。データベースを別のホストにリストアできます。ただし、この方法は時間がかかる場合があり、バックアップが最新でない可能性もあります。1つ以上のスタンバイ・データベースを持つData Guard環境では、本番サイトに障害が発生した場合でもデータベース・サービスの継続性を維持できます。
|
関連項目:
|
コンピュータ障害による停止は、データベースを実行しているシステムが停止またはアクセス不能になることによって、システムが使用不可能になった場合に発生します。コンピュータ障害の例には、ハードウェア障害やオペレーティング・システム障害などがあります。
コンピュータ障害を防止、またはコンピュータ障害への対応をサポートするOracle機能は、次のとおりです。
エンタープライズ・グリッド
Oracle Real Applications Cluster(Oracle RAC)環境では、Oracle Databaseは単一の共有データベースに同時にアクセスしながら、クラスタ内の2つ以上のシステム上で稼働します。複数のハードウェア・システムにまたがる単一のデータベース・システムが、アプリケーションでは単一のデータベースとして認識されます。「グリッド・コンピューティングの概要」を参照してください。
Oracle Data Guard
Data Guardを使用すると、スタンバイ・データベースと呼ばれる本番データベースのコピーを保持でき、スタンバイ・データベースは、地理的に離れた場所に設置することも、同じデータベース・センターに設置することも可能です。停止によりプライマリ・データベースが使用できなくなった場合、Data Guardにより任意のスタンバイ・データベースがプライマリ用に切り替えられるため、停止時間が最小限に抑えられます。『Oracle Data Guard概要および管理』を参照してください。
Oracle Restart
データベース・インスタンス、リスナー、Oracle ASMインスタンスなどのOracle Databaseソフトウェア・スタックのコンポーネントは、コンポーネントに障害が発生するか、データベース・ホスト・コンピュータが再起動されると、自動的に再起動されます。Oracle Restartは、Oracleコンポーネントをコンポーネントの依存性に従って適切な順番で起動します。Oracle Restartの構成方法の詳細は、『Oracle Database管理者ガイド』を参照してください。
ファスト・スタート・リカバリ
計画外停止時間の一般的な原因は、システム障害またはクラッシュです。Oracle Databaseのファスト・スタート・リカバリ・テクノロジは、データベース・インスタンス・リカバリ時間を自動的にバインドします。ファスト・スタート・リカバリの詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。
|
関連項目: 単一インスタンス・データベースで実行されるプロセスおよびアプリケーションに対する高可用性の使用方法の詳細は、『Oracle Database高可用性ベスト・プラクティス』を参照してください。 |
ストレージ障害による停止は、一部またはすべてのデータベース・コンテンツを保持しているストレージが停止またはアクセス不能になり、使用できなくなった場合に発生します。ストレージ障害の例には、ディスク・ドライブ障害やストレージ・アレイ障害などがあります。
ストレージ障害に対して、Oracle Data Guard以外に次のソリューションが提供されています。
Oracle Automatic Storage Management (Oracle ASM)
Oracle ASMは、ファイルシステムとボリューム・マネージャをデータベース・カーネル内で垂直に統合します(「Oracle Automatic Storage Management(Oracle ASM)」を参照)。Oracle ASMにより、データおよびディスクの管理に伴う複雑な仕組みが排除され、ミラー化やディスクの追加および削除プロセスが簡略化されます。
バックアップおよびリカバリ
Recovery Manager(RMAN)ユーティリティでは、データのバックアップ、以前のバックアップからのリストア、障害発生時までのデータ変更のリカバリなどを実行できます(「バックアップおよびリカバリ」を参照)。
|
関連項目:
|
データ破損は、ハードウェア、ソフトウェアまたはネットワーク・コンポーネントによって、破損したデータが読み取られた場合、または書き込まれた場合に発生します。たとえば、ボリューム・マネージャのエラーにより、不正なディスク読取りまたは書込みが実行されます。データ破損はほとんどありませんが、発生した場合にはデータベース、つまりビジネスに壊滅的な影響があります。
データ破損については、Data GuardおよびRecovery Manager以外にも、次の保護方法がOracle Databaseでサポートされています。
書込み欠落の保護
データ・ブロックの書込み欠落は、実際には行われていないブロック書込みの完了がI/Oサブシステムにより認識された場合に発生します。バッファ・キャッシュ・ブロックの読取りをREDOログに記録するように、データベースを構成できます。書込み欠落の検出は、Data Guardとともに使用することによって、最大の効果を発揮します。
データ・ブロック破損の検出
ブロック破損とは、認識されているOracle形式ではないデータ・ブロック、または内容の一貫性が内部で保たれていないデータ・ブロックです。RMANなどのいくつかのデータベース・コンポーネントおよびユーティリティでは、破損ブロックを検出し、V$DATABASE_BLOCK_CORRUPTIONに記録できます。リアルタイムのスタンバイ・データベースが使用されている環境では、RMANにより自動的に破損ブロックを修復できます。
データ・リカバリ・アドバイザ
データ・リカバリ・アドバイザは、データ障害を自動的に診断し、適当な修復オプションを提示し、ユーザーのリクエストに基づいて修復を実行するOracleツールです。
|
関連項目:
|
人為的エラーによる停止は、過失または悪意による操作によって、データベース内のデータが論理的に破損するか、使用不可能になった場合に発生します。人為的エラーによる停止のサービス・レベルへの影響は、影響を受けたデータの量および重要度によって大きく異なる場合があります。
多くの研究で、停止時間の最大の原因は人為的エラーだと指摘されています。Oracle Databaseでは、人為的なエラーを迅速に診断してリカバリするために役立つ、管理者用の強力なツールが提供されています。また、エンド・ユーザーが、管理者の介入なしで問題からのリカバリを実行できる機能も備えられています。
Oracle Databaseを使用する場合、次の方法により人為的エラーから保護することをお薦めします。
ユーザー・アクセスの制限
エラーを回避する最善の方法は、データおよびサービスへのユーザー・アクセスを制限することです。Oracle Databaseでは、ユーザー認証によりアプリケーション・データへのアクセスを制御する様々なセキュリティ・ツールが提供されており、管理者は、各ユーザーに対し、それぞれの職務の実行に必要な権限のみを付与できます(「データベース・セキュリティの概要」を参照)。
Oracle Flashback Technology
Oracle Flashbackテクノロジは、人為的エラーを修復する一連のOracle Database機能です。Oracle Flashbackでは、人為的エラーを迅速に分析して修復するSQLインタフェースを提供しています。たとえば、次の操作を実行できます。
部分的な損害を対象としたファイングレイン分析と修復
広範囲の損害の迅速な修正
行、トランザクション、表、表領域、およびデータベース・レベルでのリカバリ
Oracle LogMiner
Oracle LogMinerは、SQLを使用したオンライン・ファイルの読取り、分析および解析が可能な完全なリレーショナル・ツールです(「Oracle LogMiner」を参照)。
|
関連項目:
|
特に複数のタイムゾーンのユーザーをサポートしているグローバル・エンタープライズでは、計画停止時間は運用に大きな損害を与える可能性があります。このような場合、ルーチン操作、定期的なメンテナンスおよび新規デプロイメントなどの計画的な中断を最小化するようシステムを設計することが重要です。
計画停止時間は、その原因によって次のように分類されます。
|
関連項目: 計画停止時間の機能およびソリューションの詳細は、『Oracle Database高可用性概要』を参照してください。 |
計画的なシステム変更は、日常的および定期的なメンテナンス操作や新規デプロイメントを実行する場合に発生し、データベースの組織データ構造の外部で行われる運用環境の計画的変更もその1つです。その例としては、CPUやクラスタ・ノード(ノードは、データベース・インスタンスのあるコンピュータ)の追加または削除、システム・ハードウェアまたはソフトウェアのアップグレード、およびシステム・プラットフォームの移行などがあります。
Oracle Databaseでは、計画的なシステムおよびデータベース変更に対するソリューションとして、リソースの動的プロビジョニングを提供しています。
データベースの動的再構成
Oracle Databaseでは、ハードウェアおよびデータベース構成の動的な変更がサポートされており、SMPサーバーのプロセッサの追加および削除、Oracle ASMを使用したストレージ・アレイの追加および削除などを動的に実行できます。たとえば、Oracle Databaseはオペレーティング・システムを監視して、CPU数の変更を検出します。CPU_COUNT初期化パラメータがデフォルトに設定されている場合、データベースのワークロードは、新規に追加されたプロセッサでも負担されます。
自動調整によるメモリー管理
Oracle Databaseでは、非一元化ポリシーを使用して、SGAおよびPGAの各サブコンポーネントのメモリーを解放および取得します。Oracle Databaseは、オペレーティング・システムにプロンプトを発行し、メモリーを必要とするコンポーネントにメモリーのグラニュルを転送することによってメモリーを自動調整します。「メモリーの管理」を参照してください。
データファイル、制御ファイル、およびオンラインREDOログ・ファイルの自動配布
Oracle ASMでは、すべての使用可能なディスクにデータファイル、制御ファイル、およびログ・ファイルが自動配布されるため、それらのファイルのレイアウトが自動化され、簡素化されます。Oracle ASMの詳細は、『Oracle Automatic Storage Management管理者ガイド』を参照してください。
計画的なデータ変更は、Oracle Databaseオブジェクトの論理構造または物理的な編成が変更された場合に発生します。これらの変更は、主にパフォーマンスまたは管理性を向上させる目的で行われます。例として、表の再定義、表パーティションの追加、および索引の作成または再作成などがあります。
Oracle Databaseでは、オンラインで再編成および再定義することによって、データ変更に伴う停止時間を最小化します。このアーキテクチャを使用すると、データベースのオープン中に、次のタスクを実行できます。
表の可用性に大きな影響を与えることなく表構造を変更できる、オンライン表再定義
索引の作成、分析および再編成(第3章「索引と索引構成表」を参照)
表パーティションの移動(「パーティションの概要」を参照)
|
関連項目: オンラインでデータ構造を変更する方法の詳細は、『Oracle Database管理者ガイド』を参照してください。 |
計画的なアプリケーション変更には、データ、スキーマおよびプログラムの変更が含まれる場合があります。これらの変更は、主にパフォーマンス、管理性、および機能性を向上させる目的で行われます。例として、アプリケーションのアップグレードがあります。
Oracle Databaseでは、アプリケーション・データベース・オブジェクトの変更に必要なアプリケーションの停止時間を最小限に抑えるために、次のソリューションがサポートされています。
ローリング・パッチ更新
Oracle Databaseは、ローリング方式によるOracle RACシステムのノードへのパッチの適用をサポートします。『Oracle Database高可用性ベスト・プラクティス』を参照してください。
ローリング・リリース・アップグレード
Oracle Databaseでは、ローリング方式によるデータベース・ソフトウェア・アップグレードのインストールおよびパッチセットの適用がサポートされており、この方式では、Data Guard SQL Applyおよびロジカル・スタンバイ・データベースが使用され、データベースの停止時間はほとんどありません。『Oracle Databaseアップグレード・ガイド』を参照してください。
エディションベースの再定義
エディションベースの再定義を使用すると、アプリケーションの使用中にアプリケーションのデータベース・オブジェクトをアップグレードできるため、停止時間を最小限に抑えることや解消することが可能です。Oracle Databaseでは、エディションと呼ばれるプライベート環境でデータベース・オブジェクトを変更(再定義)することにより、このタスクを実行します。『Oracle Databaseアドバンスト・アプリケーション開発者ガイド』を参照してください。
デフォルトがWAITオプションのDDL
DDLコマンドには、内部構造の排他ロックが必要です(「DDLロック」を参照)。以前のリリースでは、ロックを取得できない場合、DDLコマンドが失敗しました。この問題は、DDLにWAITオプションを指定することで解決できます。『Oracle Database高可用性概要』を参照してください。
無効な状態のトリガーの作成
無効な状態のトリガーを作成でき、コードが正常にコンパイルされることを確認してから、トリガーを有効にできます。『Oracle Database PL/SQL言語リファレンス』を参照してください。
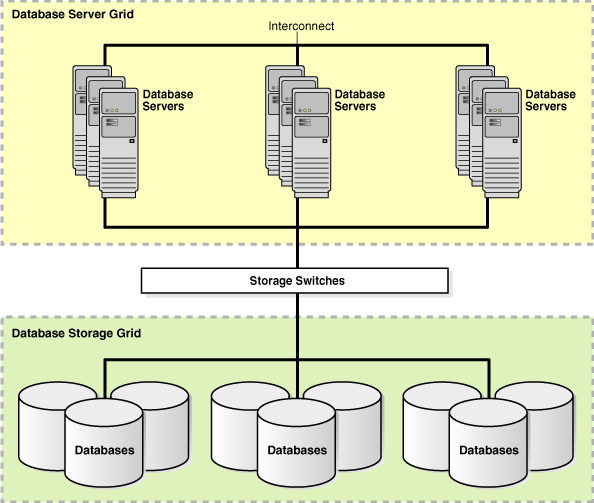
グリッド・コンピューティングは、すべての企業のコンピューティング・ニーズに応じて、柔軟なオンデマンド・リソースに多くのサーバーおよび記憶域を効果的にプールするコンピューティング・アーキテクチャです。データベース・サーバー・グリッドは、互いに接続されたコモディティ・サーバーのコレクションで、1つ以上のデータベースを実行します。データベース記憶域グリッドは、低コストのモジュール・ストレージ・アレイのコレクションで、互いに結合されており、データベース・サーバー・グリッド内のコンピュータによってアクセスされます。
データベース・サーバー・グリッドとデータベース記憶域グリッドにより、システム・リソースのプールを構築できます。これらのシステム・リソースは、業務の優先順位に従って動的に割当ておよび割当解除できます。
図17-2に、エンタープライズ・グリッド・コンピューティング環境でのデータベース・サーバー・グリッドおよびデータベース記憶域グリッドを示します。
|
関連項目:
|
Oracle Real Application Clusters(Oracle RAC)では、相互接続された複数のインスタンス間で、Oracle Databaseへのアクセスを共有できます。Oracle RAC環境では、Oracle Databaseは単一の共有データベースに同時にアクセスしながら、クラスタ内の2つ以上のシステム上で稼働します。Oracle RACでは、複数の低コストのサーバーにまたがる単一のデータベース(アプリケーションでは単一の統合されたデータベース・システムとして認識される)を提供することによって、データベース・サーバー・グリッドを有効にします。
Oracle Clusterwareは、複数のサーバーを1つのサーバーのように操作できるソフトウェアです。各サーバーは、普通のスタンドアロン・サーバーのように見えます。ただし、各サーバーには相互に通信を行うための追加的なプロセスが組み込まれているため、別々のサーバーが1つのサーバーであるかのように連携して動作します。Oracle Clusterwareには、ノード・メンバーシップおよびメッセージ・サービスなど、クラスタの実行に必要なすべての機能が用意されています。
|
関連項目:
|
データベース・サーバー・グリッドでOracle RACを使用すると、容量を増加するためにクラスタにノードを追加できます。Oracle RACに実装されているキャッシュ・フュージョン・テクノロジにより、アプリケーションを変更しなくても容量を拡張できます。これにより、システムを段階的に拡張してコストを節約でき、小規模な単一ノード・システムを大規模なシステムに置き換える必要がなくなります。
既存のシステムを大規模なノードに置き換えるかわりに、ノードを段階的にクラスタに追加できます。グリッド・プラグ・アンド・プレイを使用すると、クラスタのノードの追加と削除が簡素化されるため、動的にプロビジョニングされた環境でクラスタをデプロイしやすくなります。また、グリッド・プラグ・アンド・プレイでは、データベースとサービスを位置に依存しない方法で管理することもできます。SCANを使用すると、クライアントはグリッド内の位置とは関係なくデータベース・サービスに接続できるようになります。
|
関連項目:
|
フォルト・トレランスは、高可用性アーキテクチャによって提供される、アーキテクチャ内のコンポーネント障害に対する保護機能です。Oracle RACアーキテクチャの主な利点は、複数のノードによって実現される本質的なフォルト・トレランスです。物理ノードは独立して動作しているため、1つ以上のノードに障害が発生してもクラスタ内の他のノードには影響しません。
フェイルオーバーはグリッド上の任意のノードで発生します。極端な場合、1つのノードを除くすべてのノードが停止しても、Oracle RACシステムはデータベース・サービスを提供し続けます。このアーキテクチャでは、メンテナンスのためにノードのグループを透過的にオンラインまたはオフラインにすると同時に、クラスタの残りの部分によってデータベース・サービスを提供し続けることができます。
Oracle RACには、Oracleクライアントおよび接続プールとの統合が組み込まれています。この機能により、接続を終了する障害がプールを介してアプリケーションに即座に通知されます。アプリケーションは、TCPタイムアウトを待機することなく、適切なリカバリ・アクションを即座に実行できます。Oracle RACでは、リスナーとOracleクライアントおよび接続プールを統合することによって、最適なアプリケーション・スループットを実現します。Oracle RACは、トランザクション時の負荷に基づいて、クラスタ・ワークロードのバランスを調整します。
|
関連項目:
|
Oracle RACはサービスをサポートしており、これによりデータベースのワークロードをグループ化し、サービスを提供するために割り当てられている最適なインスタンスに処理をルーティングできます。サービスとは、共通の属性、パフォーマンスしきい値、および優先順位を持つアプリケーションのワークロードです。
ビジネス・ポリシーを定義してこれらのサービスに適用し、ピーク処理時用のノードの割当てや、サービス障害の自動処理などのタスクを実行します。サービスを使用してシステム・リソースを必要な場所と時間に応じて適用することにより、ビジネス上の目標を達成します。
サービスは、データベース・リソース・マネージャに統合されており、データベース・リソース・マネージャでは、インスタンス内のサービスが使用するリソースを制限できます。また、特定のインスタンスを使用するかわりに、サービスを使用してOracle Schedulerジョブを実行することもできます。
|
関連項目:
|
DBAまたはストレージ管理者は、Oracle ASMインタフェースを使用してデータベース記憶域グリッド内のディスクを指定でき、指定されたディスクは、すべてのサーバーおよび記憶域プラットフォームでASMにより管理されます。ASMは、ディスク領域をパーティションに区切り、データをASMに提供されたディスク全体に均等に配分します。また、ASMは、データベース記憶域グリッドのストレージ・アレイのディスクが追加または削除されると、データを自動的に再配分します。
|
関連項目:
|
データ・ウェアハウスは、トランザクション処理ではなく問合せおよび分析用に設計されたリレーショナル・データベースです。たとえば、データ・ウェアハウスでは、株価の履歴や所得税の記録を追跡できます。通常、ウェアハウスには履歴トランザクション・データから導出されたデータが格納されますが、他のソースからのデータも格納できます。
データ・ウェアハウス環境には、リレーショナル・データベースの他に、様々なツールがあります。典型的な環境には、ETLソリューション、OLAPエンジン、Oracle Warehouse Builder、クライアント分析ツール、データを収集してユーザーに配信するその他のアプリケーションがあります。
一般的なデータ・ウェアハウスの紹介として、William Inmonが規定したデータ・ウェアハウスの特性について説明します。脚注1
サブジェクト指向
データ・ウェアハウスでは、売上などの主題別にデータベースを定義できます。
統合
データ・ウェアハウスには、様々なソースからのデータを一貫性のある形式で格納する必要があります。また、名前の競合や単位間の不一致などの問題を解決する必要があります。この目標が達成されて初めて、データ・ウェアハウスは統合されたことになります。
恒常的
ウェアハウスの目的は、発生した事柄を分析できるようにすることです。このため、ウェアハウスに格納されたデータは変更されません。
時系列
データ・ウェアハウスは時間経過による変化に焦点を当てています。
データ・ウェアハウスとOLTPデータベースでは、要件が異なります。たとえば、データ・ウェアハウスでは、ビジネスの傾向を把握するために、大量のデータを保持する必要があります。それとは対照的に、OLTPシステムでは、パフォーマンスを維持するために、履歴データを定期的にアーカイブに移動する必要があります。表17-1にデータ・ウェアハウスとOLTPの相違点を示します。
表17-1 データ・ウェアハウスとOLTPシステム
| 特徴 | データ・ウェアハウス | OLTP |
|---|---|---|
|
ワークロード |
非定型問合せに適応するように設計されています。データ・ウェアハウスのワークロードは事前にはわからない場合があり、データ・ウェアハウスは様々な問合せを適切に実行できるように最適化する必要があります。 |
事前定義済の操作のみをサポートします。これらの操作のみをサポートするように、アプリケーションの特別なチューニングや設計が必要になる場合があります。 |
|
データ修正 |
バルク・データ修正テクニックを使用してETLプロセスにより定期的に更新されます。データ・ウェアハウスのエンド・ユーザーがデータベースを直接更新することはありません。 |
エンド・ユーザーにより定期的に発行される個々のDML文によって行われます。OLTPデータベースは常に最新であり、各ビジネス・トランザクションの現在の状態が反映されます。 |
|
スキーマ設計 |
全体または一部が非正規化されたスキーマ(スター・スキーマなど)を使用して、問合せパフォーマンスが最適化されます。 |
完全に正規化されたスキーマを使用して、DMLパフォーマンスが最適化され、データの整合性が保証されます。 |
|
典型的な操作 |
典型的な問合せでは、数千または数百万の行がスキャンされます。たとえば、すべての顧客についての先月の総売上を要求できます。 |
典型的な操作は、少数のレコードにのみアクセスします。たとえば、1人の顧客の現行の注文を取得できます。 |
|
履歴データ |
履歴分析をサポートするために、数か月または数年分のデータが格納されます。 |
数週間または数か月分のデータしか格納されません。現行のトランザクションの要件を適切に満たすために必要な履歴データが保持されます。 |
|
関連項目:
|
データ・ウェアハウスとそのアーキテクチャは、ビジネス要件によって異なります。この項では、一般的なデータ・ウェアハウス・アーキテクチャについて説明します。
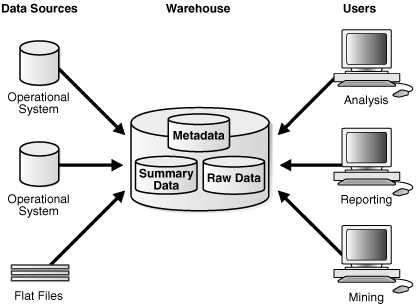
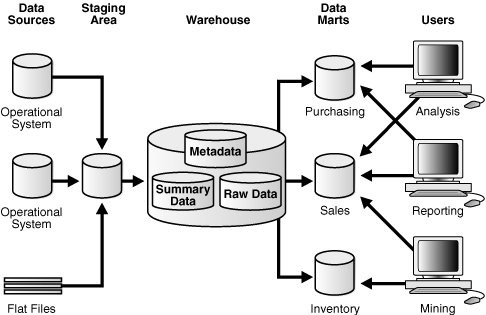
図17-3に、データ・ウェアハウスの単純なアーキテクチャを示します。エンド・ユーザーは、複数のソース・システムからデータ・ウェアハウスに転送されたデータに直接アクセスします。
図17-3には、従来型OLTPシステムのメタデータと生データの他に、サマリー・データが示されています。サマリーは集計ビューで、高コストの結合および集計操作を事前に計算して結果を表に格納することで、問合せのパフォーマンスが向上します。たとえば、サマリー表に地域別、製品別の売上合計を含めることができます。サマリーは、マテリアライズド・ビューとも呼ばれます。
|
関連項目: 基本マテリアライズド・ビューの詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。 |
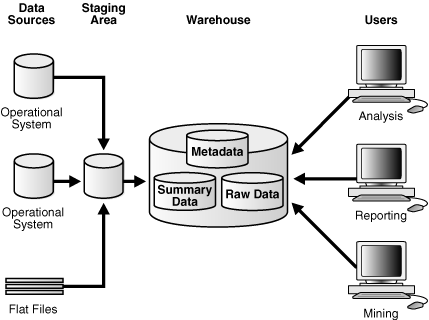
図17-3のアーキテクチャでは、業務系データをウェアハウスに入れる前に、クリーン・アップおよび処理する必要があります。図17-4では、ウェアハウスに入れる前にデータを事前に処理する場所であるステージング領域が含まれるデータ・ウェアハウスを示しています。ステージング領域により、サマリーの作成とウェアハウス管理のタスクが簡素化されます。
|
関連項目: 異なる転送メカニズムの詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。 |
ウェアハウス・アーキテクチャを組織内の様々なグループ向けにカスタマイズできます。そのためには、ウェアハウス内のデータを、特定の業務またはプロジェクト用に設計された独立したデータベースであるデータ・マートに転送します。通常、データ・マートには多くのサマリー表が含まれています。
図17-5では、購買、売上および在庫情報が別々のデータ・マートに分離されています。財務アナリストはデータ・マートに対して購買と売上の履歴情報を問い合せることができます。
|
関連項目: 変換メカニズムの詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。 |
ソース・システムからデータを抽出してウェアハウスに取り込む処理は、一般にETLと呼ばれ、抽出、変換、ロードを表します。ETLは、詳細に定義された3つのステップではなく、広範囲なプロセスを指します。
典型的なシナリオでは、1つ以上の業務系システムからデータを抽出し、処理用にターゲット・システムまたは中間システムに物理的に転送します。転送方法によっては、このプロセスでなんらかの変換処理が行われる場合もあります。たとえば、ゲートウェイを介してリモート・ターゲットに直接アクセスするSQL文では、SELECT文の一部として2つの列を連結できます。
Oracle Database自体は、ETLツールではありません。ただし、Oracle Databaseには、Oracle Warehouse BuilderやカスタマイズされたETLソリューションなど、ETLツールに使用される多くの機能が提供されています。Oracle Databaseが提供するETL機能は、次のとおりです。
トランスポータブル表領域
異なるコンピュータ・アーキテクチャやオペレーティング・システム間で表領域を転送することもできます。トランスポータブル表領域は、2つのOracleデータベース間で大量のデータを移動する場合に最も高速な方法です。トランスポータブル表領域の詳細は、『Oracle Database管理者ガイド』を参照してください。
テーブル・ファンクション
テーブル・ファンクションは、出力として行セットを生成でき、行セットを入力として受け入れることができます。テーブル・ファンクションでは、PL/SQL、CまたはJavaで実装されている変換のパイプライン実行とパラレル実行がサポートされており、中間のステージング表を使用する必要はありません。テーブル・ファンクションの詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。
外部表
外部表により、最初に外部データをデータベースにロードしなくても、パラレルで直接結合できます(「外部表」を参照)。このため、外部表を使用すると、ロード・フェーズと変換フェーズをパイプライン処理できます。
表の圧縮
ディスク使用量とメモリー使用量を減少させるために、表とパーティション表を圧縮形式で格納できます(「表の圧縮」を参照)。通常は、表の圧縮を使用すると、読取り専用操作のパフォーマンスが向上し、問合せ実行も速くなります。
チェンジ・データ・キャプチャ
この機能により、リレーショナル表に対して追加、更新または削除されたデータが効率的に識別および取得され、この変更データのアプリケーションまたはユーザーでの使用が可能になります。
|
関連項目:
|
ビジネス・インテリジェンスは、ビジネスにおける意志決定を支援するために組織内の情報を分析することです。ビジネス・インテリジェンスおよび分析アプリケーションでのアクションのほとんどは、階層のドリルアップやドリルダウン、および集計値の比較によって占められています。Oracle Databaseでは、ビジネス・インテリジェンスをサポートするテクノロジを提供しています。
Oracle Databaseには、分析操作を実行するための多数のSQL操作が導入されています。たとえば、ランキング、移動平均、累計、対比レポート、期間対比などです。Oracle Databaseでは、次の形式による分析SQLがサポートされています。
集計用SQL
COUNTなどの集計関数は、個々の行ではなく、行グループに1つの結果行を戻します。集計は、データ・ウェアハウスの基盤です。ウェアハウスでの集計効率を改善するために、データベースには問合せとレポートを容易かつ高速にするGROUP BY句の拡張機能が用意されています。集計の詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。
分析用SQL
分析関数では、行グループに基づいて集計値を計算します。集計関数との違いは、グループごとに複数の行を戻す点です。Oracleは、分析SQL関数ファミリを使用した拡張SQL分析処理機能を備えています。たとえば、これらの分析関数を使用すると、ランキングやパーセンタイル、変動ウィンドウを計算できます。分析用およびレポート用SQLの詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。
モデル化用SQL
MODEL句を使用すると、問合せ結果から多次元配列を作成し、この配列にルールを適用して新規の値を計算できます。たとえば、売上ビューのデータを国別にパーティション化し、複数のルールによって定義されたモデル計算を国別に実行できます。ある製品の2009年と2010年の売上の合計として2011年の売上を計算するルールを定義できます。SQLのモデル化の詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。
|
関連項目: SQL関数の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
Oracleオンライン分析処理(OLAP)では、複数のディメンション間でのデータ分析において、システム固有の多次元記憶域を提供し、レスポンス時間の短縮を実現します。OLAPを使用すると、アナリストは複雑な反復問合せの結果を対話形式のセッションで迅速に取得できます。
Oracle OLAPには、主に次の特性があります。
Oracle OLAPはデータベースに統合されているため、標準的なSQLの管理、問合せおよびレポート・ツールを使用できます。
OLAPエンジンは、Oracle Databaseのカーネル内で動作します。
ディメンション・オブジェクトは、システム固有の多次元形式でOracle Databaseに格納されます。
キューブおよび他のディメンション・オブジェクトは、Oracleデータ・ディクショナリ内に存在する最上位のデータ・オブジェクトです。
データ・セキュリティは、Oracle Databaseユーザーおよびロールの権限の付与と取消しにより、標準的な方法で管理されます。
Oracle OLAPの特長はシンプルさで、1つのデータベース、標準的な管理とセキュリティ、および標準的なインタフェースと開発ツールで構成されています。
データ・マイニングでは、単なる分析の域を超えたパターンや傾向を大量の保存データの中から自動的に検索します。データ・マイニングでは、高度な数学的アルゴリズムを使用してデータをセグメント化し、イベントが将来発生する確率を計算します。通常、データ・マイニングは、コール・センター、ATM、E-Businessリレーショナル管理(ERM)およびビジネス・プランニングなどで使用されます。
Oracle Data Miningでは、データ、データ準備、モデル構築およびモデルのスコアリングの結果は、すべてデータベースに残ります。Oracle Data Miningでは、PL/SQL API、Java API、モデルのスコアリングを行うSQL関数、およびOracle Data Minerと呼ばれるGUIをサポートします。これにより、Oracle Databaseはアプリケーション開発者に、データ・マイニングをデータベース・アプリケーションとシームレスに統合するためのインフラストラクチャを提供します。
|
関連項目: 『Oracle Data Mining概要』 |
組織が成長するにつれて、複数のデータベースおよびアプリケーション間で情報を共有できることに対する重要性が高まってきます。情報を共有するには、次の基本的な方法があります。
連結
情報を1つのデータベースに連結でき、これによって、それ以上の統合は必要なくなります。Oracle RAC、グリッド・コンピューティング、およびOracle VPDを使用して、情報を1つのデータベースに連結できます。
統合
情報は分散した状態にしておき、この情報を統合するツールを提供できます。これによって、情報が1つの仮想データベース内にあるかのように見せることができます。
共有
情報を共有することで、複数のデータ・ストアおよびアプリケーションで情報を保持できます。
この項では、主に情報を統合および共有するためのOracleソリューションについて説明します。
|
関連項目: データ・レプリケーションおよび統合の概要は、『Oracle Database 2日でデータ・レプリケーションおよび統合ガイド』を参照してください。 |
統合されたアクセスの基本となるのは分散環境で、これは、相互にシームレスに通信する様々なシステムで構成されるネットワークです。分散環境では、各システムをノードと呼びます。ユーザーが直接接続するシステムをローカル・システムと呼びます。このユーザーがアクセスする他のシステムをリモート・システムと呼びます。
分散環境では、アプリケーションからローカル・システムやリモート・システムのデータにアクセスして相互に交換できます。すべてのデータに同時にアクセスして変更できます。
分散SQLを使用すると、複数のデータベース間に分散されたデータに同時にアクセスして更新できます。Oracle分散データベース・システムはユーザーに対して透過的であるため、単一のOracle Databaseであるかのように見せることができます。
分散SQLには、分散問合せおよび分散トランザクションが含まれます。Oracleの分散データベース・アーキテクチャによって、問合せおよびトランザクションが透過的になります。たとえば、標準DML文の動作は、非分散データベース環境の場合と同じです。また、アプリケーションでは標準SQL文COMMIT、SAVEPOINTおよびROLLBACKを使用してトランザクションを制御します。
|
関連項目:
|
データベース・リンクは、2つの物理データベースを結ぶ接続で、これにより、クライアントは1つの論理データベースとして物理データベースにアクセスできます。Oracle Databaseは、データベース・リンクを使用して、あるデータベース上のユーザーがリモート・データベース内のオブジェクトにアクセスできるようにします。ローカル・ユーザーは、リモート・データベースのユーザーでなくても、リモート・データベースへのリンクにアクセスできます。
図17-6の例では、ユーザーhrが、hq.example.comというグローバル名を持つリモート・データベース上にあるemployees表にアクセスしています。employeesシノニムにより、リモート・スキーマ・オブジェクトのアイデンティティおよび位置は意識されなくなります。
|
関連項目: データベース・リンクの詳細は、『Oracle Database管理者ガイド』を参照してください。 |
どのような統合であっても、その中心は社内のアプリケーション間でデータを共有することです。Oracle Streamsは、Oracle Databaseにおける非同期の情報共有インフラストラクチャです。このインフラストラクチャを使用すると、データベース内またはデータベース間で、データ・ストリーム内のデータ、トランザクションおよびイベントを伝播させ、管理できます。
Oracle Streamsには、レプリケーションおよびメッセージ機能が含まれています。レプリケーションとは、データベース・オブジェクトおよびデータを複数のデータベースで共有するプロセスのことです。メッセージとは、アプリケーションとユーザー間で情報を共有することです。
|
関連項目:
|
Oracle Streamsレプリケーションでは、あるデータベースのデータベース・オブジェクトに対する変更をレプリケーション環境内の他のデータベースと共有できます。たとえば、Oracle Streamsを使用すると、employees表に対する更新を別のデータベースにある同一のemployees表に伝播できます。このように、レプリケーション環境のすべてのデータベースで、データベース・オブジェクトおよびデータの同期が維持されます。
Oracle Streamsレプリケーションの典型的な使用目的は、次のとおりです。
プライマリOLTPサイトから処理をオフロードするためのレポート・サイトの作成。
コール・センターまたは同様の業務におけるロード・バランシングの実装、スケーラビリティおよび可用性の向上。
一般的なビジネス要件を満たすためのサイト間の自律性の実現。
複数の場所からのデータの転送および連結。
異なるプラットフォームおよびOracle Databaseリリース間、およびWide Area Network(WAN)全体でのデータのレプリケート。
Oracle Streamsのアーキテクチャはきわめて柔軟です。図17-7に、レプリケーション環境での基本的な情報フローを示します。
図17-7に示すように、Oracle Streamsには次の基本要素があります。
取得
Oracle Streamsは、暗黙的にDMLおよびDDLの変更を取得します。ルールによって、取得する変更が決定されます。変更は、データベースの変更を記述する固有の形式を備えたメッセージである、論理変更レコード(LCR)形式にフォーマットされます。
ステージング
LCRは、取得したメッセージを格納して管理するキューであるステージング領域に置かれます。メッセージのステージングにより、メッセージ・データの監査と追跡のみでなく保持のための、セキュリティ機能を備えた領域が提供されます。伝播によってメッセージを1つのキューから別のキューに送信できます。キューは、同じまたは異なるデータベースに格納できます。
使用
LCRは、サブスクライバにより暗黙的または明示的に使用されるまでステージング領域に保持されます。適用プロセスは、LCRにカプセル化されている変更を暗黙的に適用します。
|
注意: Oracle Streamsは、マテリアライズド・ビューと完全に相互運用可能です。マテリアライズド・ビューを使用して、更新可能または読取り専用のデータのコピーを維持できます(「マテリアライズド・ビューの概要」を参照)。 |
|
関連項目: Oracle Streamsを使用したデータのレプリケート方法の詳細は、『Oracle Database 2日でデータ・レプリケーションおよび統合ガイド』を参照してください。 |
Oracle Streamsでは、様々なタイプのカスタム・レプリケーション環境を構成できます。ただし、次のタイプのレプリケーション環境が最も一般的です。
2データベース
レプリケートしたデータベース・オブジェクトは、2つのデータベース間でのみ共有されます。一方のデータベースでレプリケートしたデータベース・オブジェクトに対して行われた変更は、取得されて、もう一方のデータベースに直接送信され、変更が適用されます。
一方向レプリケーション環境では、レプリケートしたデータベース・オブジェクトを一方のデータベースでのみ変更でき、もう一方のデータベースは、これらのオブジェクトの読取り専用レプリカを格納します。双方向レプリケーション環境では、レプリケートしたオブジェクトを両方のデータベースで変更できます。この場合、データベースは両方とも、これらのデータベース・オブジェクトに対する変更を取得し、もう一方のデータベースに送信して適用します。
ハブ・アンド・スポーク
中央データベース(ハブ)と2次データベース(スポーク)との間で通信が行われます。各スポークが相互に直接通信することはありません。ハブ・アンド・スポーク・レプリケーション環境では、レプリケートしたデータベース・オブジェクトに変更が可能かどうかはスポークによって異なります。
N方向
各データベースは、環境内のその他のデータベースと直接通信します。一方のデータベースでレプリケートしたデータベース・オブジェクトに対して行われた変更は、取得されて環境内のその他のデータベースにそれぞれ直接送信され、変更が適用されます。
|
関連項目: 一般的なレプリケーション環境の詳細は、『Oracle Database 2日でデータ・レプリケーションおよび統合ガイド』を参照してください。 |
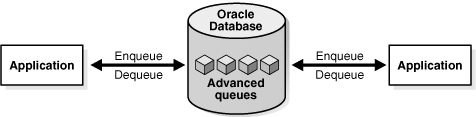
Oracle Streams Advanced Queuing(AQ)は、堅牢で豊富な機能を持つメッセージ・キューイング・システムであり、Oracle Databaseに統合されています。組織内の異なるシステム間で通信を行う必要がある場合は、メッセージング環境によって、これらのシステム間で重要な情報を転送する、標準的で信頼性の高い方法が提供されます。
ユースケースの例として、本社のOracleデータベースに注文を入力するとします。注文が入力されると、AQにより、注文IDと注文日がウェアハウスのデータベースに送信されます。これらのメッセージにより、ウェアハウスの従業員は注文があったことを知り、商品を梱包および出荷できます。
アドバンスト・キューイングでは、ユーザー・メッセージがキューと呼ばれる抽象的な記憶単位に保存されます。エンキューは、プロデューサがメッセージをキューに入れるプロセスです。デキューは、コンシューマがキューからメッセージを取得するプロセスです。
明示的デキューがサポートされるため、開発者はOracle Streamsを使用してメッセージを確実に交換できます。また、Oracle Streamsの変更取得および伝播機能を活用することで、変更をアプリケーションに通知できます。
図17-8では、サンプル・アプリケーションがアドバンスト・キューイングを介して、明示的にメッセージをエンキューおよびデキューしており、これにより、異なるメッセージ・システムを使用しているパートナとも情報を共有できます。エンキューした後、パートナのアプリケーションにデキューされる前に、メッセージを変換および伝播することもできます。
Oracle Streams Advanced Queuingでは、メッセージ・キューイング・システムの標準的な機能がすべてサポートされています。これらの機能は、次のとおりです。
非同期によるアプリケーションの統合
Oracle Streams Advanced Queuingでは、複数の方法でメッセージをエンキューできます。メッセージは、取得プロセスまたは同期取得が暗黙的に取得するか、アプリケーションやユーザーが明示的に取得できます。
拡張可能な統合アーキテクチャ
多くのアプリケーションは、Oracle Databaseをハブとする分散ハブ・アンド・スポーク・モデルを使用して統合されます。Oracleデータベース上の分散アプリケーションは、同じハブのキューと通信します。複数のアプリケーションが同じキューを共有できるので、サポートするアプリケーション数を増やすためにキューを追加する必要がありません。
異機種間アプリケーションの統合
アドバンスト・キューイングは、アプリケーションにOracleタイプ・システムの全機能を提供します。これには、スカラー・データ型、継承を伴うOracle Databaseオブジェクト型、XMLデータ用の追加演算子を持つXMLType、およびANYDATAのサポートが含まれます。
従来型アプリケーションの統合
Oracle Messaging Gatewayは、Oracle DatabaseアプリケーションをWebSphere MQやTibcoなどの他のメッセージ・キューイング・システムと統合します。
Oracle Streams Advanced Queuingは、業界標準のAPIであるSQL、JMSおよびSOAPをサポートしています。SQLを使用して行われた変更は、メッセージとして自動的に取得されます。
|
関連項目:
|
ユースケースの例として、会社がOracle Streamsを使用して自社のWebサイトのコピーを複数管理するとします。この場合のビジネス要件は、次のとおりです。
ニューヨークのオフィスのアナリストが非定型問合せを実行できるように、最新のデータがレポート用データベースに格納されている必要があります。
現場の営業担当が、更新可能なマテリアライズド・ビューによってサポートされる必要があります。
Sybaseデータベースで管理されているアプリケーションでデータが共有される必要があります。
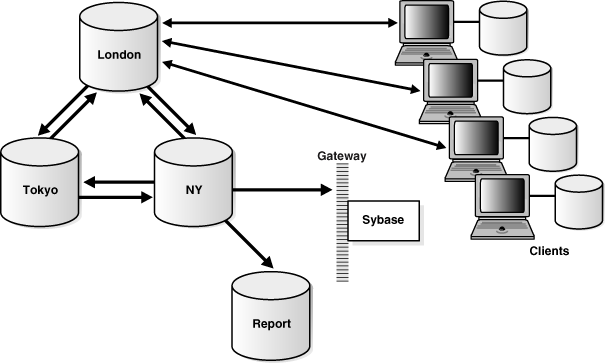
図17-9に、Oracle Streamsの構成を示します。
Oracle Streamsは、ニューヨーク、ロンドンおよび東京にあるサイトで構成されるN方向の構成でデータをレプリケートするために使用されます。各サイトでは、Oracle Streamsの暗黙的な取得機能により、各地のサブスクライブ表に発生する変更が収集され、ローカルでキューにステージングされます。各地で取得された変更は、その他の地域のそれぞれのデータベースに転送されます。各データベースで行われた変更はその他すべてのデータベースに反映でき、これにより、サブスクライブされた世界中のオブジェクトの完全なデータが提供されます。
各地のデータベースでは、Oracle Streamsの適用プロセスにより自動的に変更が行われます。変更が適用されると、Oracle Streamsは競合の有無をチェックし、競合を解消します。また、Oracle Streamsを使用してOracle以外のデータベースとの間で特定の表データを交換することもできます。Oracle Database Gateway for Sybaseを利用すると、Oracle Streamsの適用プロセスはOracle Databaseの場合と同じメカニズムを使用して変更をSybaseデータベースに適用します。
レポート用データベースは、ニューヨークにホスティングされます。このデータベースは、該当するアプリケーション表の読取り専用コピーが格納されている、全機能を備えたOracle Databaseです。レポート・サイトは、これらのアプリケーション表に対する変更を取得するように構成されていません。このレポート用データベースの構成と使用には制限が課されません。
ロンドンのサイトは、複数の更新可能マテリアライズド・ビュー・サイトのマスター・サイトとしても機能します。各営業担当は、データのうち必要な部分の更新可能なコピーを受け取ります。通常、これらのサイトは、前回のリフレッシュ以降に発生した注文をアップロードして変更をダウンロードするために、1日に1度のみ接続します。
|
関連項目: Oracle Streamsの構成の例は、『Oracle Database 2日でデータ・レプリケーションおよび統合ガイド』を参照してください。 |
脚注の凡例
脚注1: 『Building the Data Warehouse』(1996年John Wiley and Sons社)