| Oracle® Database概要 11gリリース2 (11.2) B56306-06 |
|


 前 |
 次 |
最も重要かつ一般的に使用されるスキーマ・オブジェクトは表と索引ですが、データベースでは他のタイプの多数のスキーマ・オブジェクトもサポートされています。この章では、最も一般的なスキーマ・オブジェクトについて説明します。
この章の内容は、次のとおりです。
パーティション化により、大規模な表や索引をパーティションという、より小さく管理しやすい部分に分割できます。各パーティションは独自の名前を持つ独立したオブジェクトであり、独自の記憶特性を持つ場合があります。
パーティション化の例として、ある人事管理マネージャが複数の従業員フォルダを含む1つの大きな箱を管理しているとします。各フォルダは従業員の雇用日を示しています。特定の月に雇用された従業員に対する問合せが頻繁に行われます。このような要求を満たす1つのアプローチとして、箱の中に分散しているフォルダの位置を特定する索引を、従業員の雇用日に対して作成する方法があります。一方、パーティション化計画ではより小さな箱を多数使用して、指定した月に雇用された従業員のフォルダをそれぞれの箱に格納します。
より小さな箱の使用には、いくつかの利点があります。6月に雇用された従業員のフォルダを取り出すよう依頼された場合、人事管理マネージャは6月の箱を取り出します。さらに、いずれかの小さな箱が破損したとしても、他の小さな箱は引き続き使用できます。また、マネージャは1つの重い箱を移動するのではなく、複数の小さな箱を移動すればよいため、オフィスの移転も容易になります。
アプリケーションから見ると、スキーマ・オブジェクトは1つのみ存在します。パーティション表にアクセスするためにDML文を修正する必要はありません。パーティション化は様々なタイプのデータベース・アプリケーションで有効ですが、特に大量のデータを管理するアプリケーションで便利です。次のような利点があります。
可用性の向上
いずれかのパーティションが使用できない場合も、オブジェクトの使用には関係ありません。問合せオプティマイザは参照されないパーティションを問合せ計画から自動的に削除するため、パーティションが使用できない場合にも、問合せは影響を受けません。
スキーマ・オブジェクトの管理の簡素化
パーティション・オブジェクトには、集中管理および個別管理のいずれも可能な要素があります。DDL文では、表全体または索引ではなくパーティションを操作できます。このため、索引または表の再作成など、リソース集中型のタスクを細分化できます。たとえば、一度に1つずつ表のパーティションを移動できます。問題が発生した場合は、表の移動ではなく、パーティションの移動のみを再実行します。また、パーティションを削除すると、DELETE文を多数実行する必要がなくなります。
OLTPシステムの共有リソースの競合の軽減
一部のOLTPシステムでは、パーティションによって共有リソースの競合を軽減できます。たとえば、DMLを1つのセグメントではなく、多数のセグメントに分散します。
データ・ウェアハウスでの問合せパフォーマンスの向上
データ・ウェアハウスでは、パーティションによって非定型問合せの処理を高速化できます。たとえば、100万行ある売上表を四半期ごとにパーティション化できます。
|
関連項目: パーティション化の概要は、『Oracle Database VLDBおよびパーティショニング・ガイド』を参照してください。 |
表や索引の各パーティションは、列名、データ型、制約などの論理属性が同じである必要があります。たとえば、表内のすべてのパーティションが同じ列と制約の定義を共有し、索引内のすべてのパーティションが索引付けされた同じ列を共有します。ただし、パーティションが属する表スペースなど、各パーティションの物理属性は異なる場合があります。
パーティション・キーは、パーティション表の各行が属するパーティションを決定する1つ以上の列のセットです。各行は、単一パーティションに明示的に割り当てられます。
たとえば、sales表で、レンジ・パーティションのキーとしてtime_id列を指定できます。Oracle Databaseにより、この列の日付が指定された範囲内にあるかどうかに基づいてパーティションに行が割り当てられます。Oracle Databaseでは、パーティション・キーを使用して適切なパーティションに対して挿入、更新および削除操作が自動的に行われます。
Oracle Partitioningは、データベースによる個々のパーティションへのデータの配置方法を制御する、複数のパーティション化計画を提供します。基本的な計画は、レンジ・パーティション化、リスト・パーティション化およびハッシュ・パーティション化です。
単一レベル・パーティション化計画では、リスト・パーティションのみまたはレンジ・パーティションのみなど、データ配分方法を1つのみ使用します。コンポジット・パーティション化では、1つのデータ配分方法で表をパーティション化し、別のデータ配分方法を使用して、各パーティションをさらに小さなサブパーティションに分割します。たとえば、channel_idにリスト・パーティションを使用し、time_idにレンジ・サブパーティションを使用できます。
レンジ・パーティション化では、Oracle Databaseはパーティション化キーの値の範囲に基づいて、行をパーティションにマップします。レンジ・パーティション化は、最も一般的なタイプのパーティション化であり、通常は日付とともに使用されます。
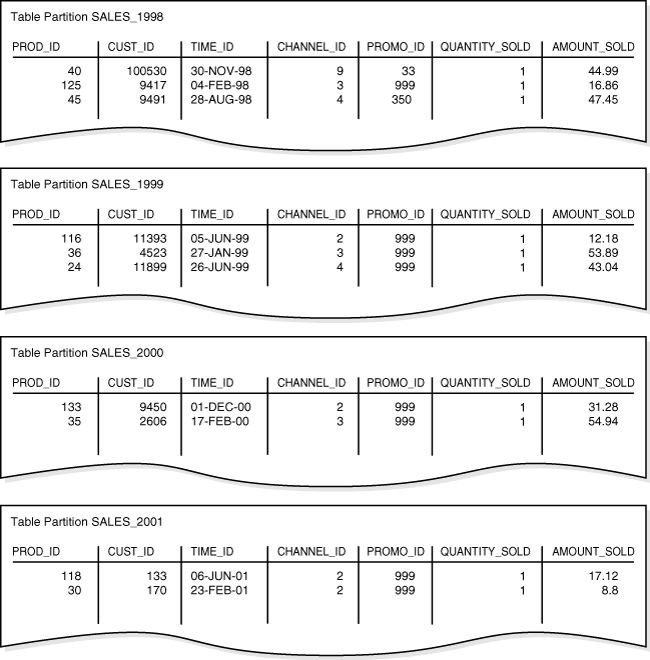
例4-1に示されているsales行をパーティション表に移入するとします。
例4-1 パーティション表のサンプル行セット
PROD_ID CUST_ID TIME_ID CHANNEL_ID PROMO_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- --------- ---------- ---------- ------------- -----------
116 11393 05-JUN-99 2 999 1 12.18
40 100530 30-NOV-98 9 33 1 44.99
118 133 06-JUN-01 2 999 1 17.12
133 9450 01-DEC-00 2 999 1 31.28
36 4523 27-JAN-99 3 999 1 53.89
125 9417 04-FEB-98 3 999 1 16.86
30 170 23-FEB-01 2 999 1 8.8
24 11899 26-JUN-99 4 999 1 43.04
35 2606 17-FEB-00 3 999 1 54.94
45 9491 28-AUG-98 4 350 1 47.45
例4-2に示されている文を使用して、パーティション表としてtime_range_salesを作成します。time_id列がパーティション・キーです。
例4-2 レンジ・パーティション化された表
CREATE TABLE time_range_sales ( prod_id NUMBER(6) , cust_id NUMBER , time_id DATE , channel_id CHAR(1) , promo_id NUMBER(6) , quantity_sold NUMBER(3) , amount_sold NUMBER(10,2) ) PARTITION BY RANGE (time_id) (PARTITION SALES_1998 VALUES LESS THAN (TO_DATE('01-JAN-1999','DD-MON-YYYY')), PARTITION SALES_1999 VALUES LESS THAN (TO_DATE('01-JAN-2000','DD-MON-YYYY')), PARTITION SALES_2000 VALUES LESS THAN (TO_DATE('01-JAN-2001','DD-MON-YYYY')), PARTITION SALES_2001 VALUES LESS THAN (MAXVALUE) );
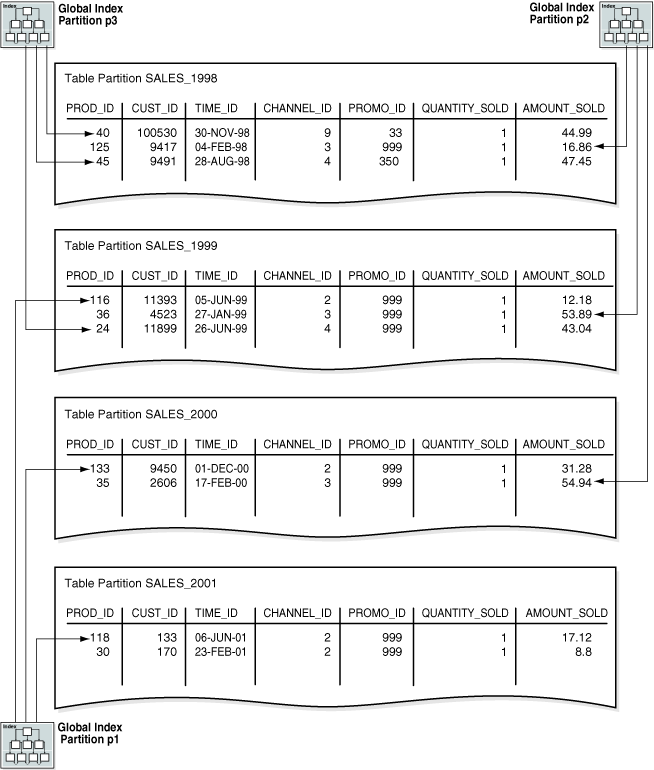
その後、例4-1の行をtime_range_salesにロードします。図4-1に、4つのパーティションへの行の配分を示します。Oracle Databaseでは、PARTITION BY RANGE句に指定されたルールに従って、time_id値に基づいて各行のパーティションが選択されます。
レンジ・パーティション・キーの値は、遷移ポイントと呼ばれるレンジ・パーティションの値の上限を決定します。図4-1では、SALES_1998パーティションに、パーティション化キーtime_idの値が遷移ポイント01-JAN-1999より小さい行が含まれています。
データベースでは遷移ポイントを超えるデータに対して、時間隔パーティションを作成します。時間隔パーティション化は、表に挿入されたデータがすべてのレンジ・パーティションを超える場合に、指定された範囲または間隔のパーティションを自動的に作成するようデータベースに指示するレンジ・パーティション化の拡張機能です。図4-1では、SALES_2001パーティションに、パーティション化キーtime_idの値が遷移ポイント01-JAN-2001と等しいか、それより大きい行が含まれています。
リスト・パーティション化の場合、Oracle Databaseでは、各パーティションのパーティション・キーとして離散値のリストが使用されます。リスト・パーティション化を使用して、特定のパーティションに対する個々の行のマップ方法を制御できます。リストを使用すると、データの識別に使用されるキーの並び順が目的にそぐわない場合に、関連するデータのセットをグループ化して整理できます。
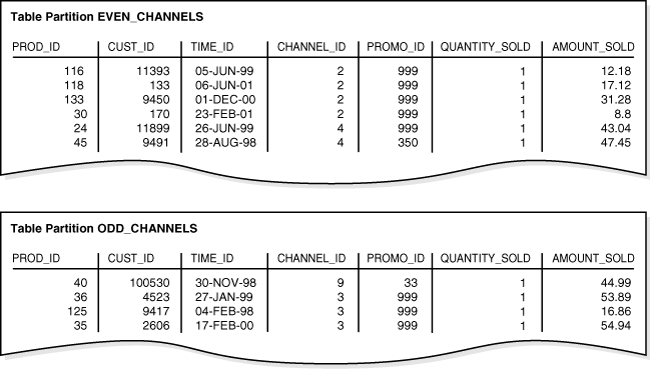
例4-3に示されている文を使用して、リスト・パーティション表としてlist_salesを作成するとします。channel_id列がパーティション・キーです。
例4-3 リスト・パーティション化された表
CREATE TABLE list_sales ( prod_id NUMBER(6) , cust_id NUMBER , time_id DATE , channel_id CHAR(1) , promo_id NUMBER(6) , quantity_sold NUMBER(3) , amount_sold NUMBER(10,2) ) PARTITION BY LIST (channel_id) (PARTITION even_channels VALUES (2,4), PARTITION odd_channels VALUES (3,9) );
その後、例4-1の行を表にロードします。図4-2に、2つのパーティションへの行の配分を示します。データベースでは、PARTITION BY LIST句に指定されたルールに従って、channel_id値に基づいて各行のパーティションが選択されます。channel_idの値が2または4である行はEVEN_CHANNELSパーティションに格納され、channel_idの値が3または9である行はODD_CHANNELSパーティションに格納されます。
ハッシュ・パーティション化では、データベースがユーザー指定のパーティション・キーに適用するハッシング・アルゴリズムに基づいて、行をパーティションにマップします。行のマップ先は、データベースが行に適用する内部ハッシュ関数によって決定されます。ハッシュ・アルゴリズムは、各パーティションにほぼ同じ行数が含まれるように、行を複数のデバイスに均等に分散させるように設計されています。
ハッシュ・パーティション化は、大きな表を分割して管理しやすくする場合に役立ちます。1つの大きな表ではなく、複数のより小さい単位を管理します。1つのハッシュ・パーティションが失われても、残りのパーティションに影響はなく、個別にリカバリできます。また、ハッシュ・パーティション化は、更新時に競合が発生しやすいOLTPシステムにも役立ちます。たとえば、競合が発生しやすい1つのセグメントを複数の単位に分割し、各単位が個別に更新されるようにできます。
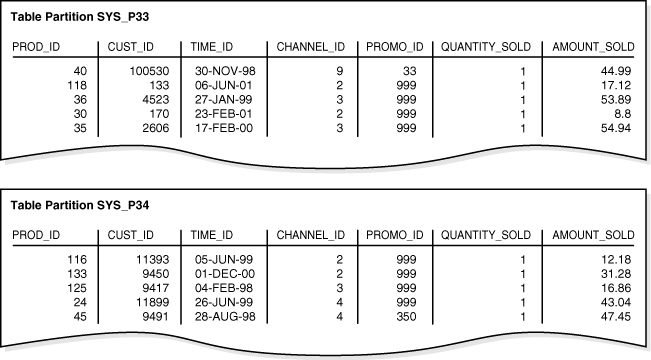
例4-4に示されている文を使用して、パーティション化されたhash_sales表を作成するとします。prod_id列がパーティション・キーです。
例4-4 ハッシュ・パーティション化された表
CREATE TABLE hash_sales ( prod_id NUMBER(6) , cust_id NUMBER , time_id DATE , channel_id CHAR(1) , promo_id NUMBER(6) , quantity_sold NUMBER(3) , amount_sold NUMBER(10,2) ) PARTITION BY HASH (prod_id) PARTITIONS 2;
その後、例4-1の行を表にロードします。図4-3に、2つのパーティションへの行の配分の例を示します。これらのパーティションの名前は、システムによって生成されます。
ユーザーが行を挿入すると、データベースではすべてのパーティションへのランダムかつ均等な行の配分が試行されます。行をどのパーティションに配置するかは指定できません。データベースはハッシュ関数を適用し、関数の出力結果に基づいて、どのパーティションに行を格納するかを決定します。パーティションの数を変更すると、データベースでは再度すべてのパーティションにデータが配分されます。
|
関連項目:
|
パーティション表は1つ以上のパーティションで構成されており、パーティションは個別に管理され、他のパーティションから独立して機能できます。表はパーティション化または非パーティション化のいずれかの状態です。パーティション表が1つのパーティションのみで構成されている場合も、この表は、パーティションを追加できない非パーティション表とは異なります。「パーティションの特性」に、パーティション表の例を示してあります。
パーティション表は、1つ以上の表パーティション・セグメントで構成されています。hash_productsという名前のパーティション表を作成した場合、この表に表セグメントは割り当てられません。かわりに、データベースでは独自のパーティション・セグメントに各表パーティションのデータを格納します。各表パーティション・セグメントには表データの断片が含まれます。
ヒープ構成表の一部またはすべてのパーティションは圧縮形式で格納できます。圧縮すると領域を節約でき、問合せの実行を高速化できます。このため、圧縮は挿入および更新操作の量が少ないデータ・ウェアハウスなどの環境およびOLTP環境で役立つ場合があります。
表圧縮の属性は、表領域、表または表パーティションについて宣言できます。表領域レベルで宣言した場合、その表領域に作成される表はデフォルトで圧縮されます。表の圧縮属性を変更すると、変更はその表に格納される新規データにのみ適用されます。このため、1つの表またはパーティションには圧縮ブロックと非圧縮ブロックの両方を含むことができ、これにより、圧縮によってデータ・サイズが大きくならないことが保証されます。圧縮によってブロック・サイズが大きくなる場合、そのブロックに圧縮は適用されません。
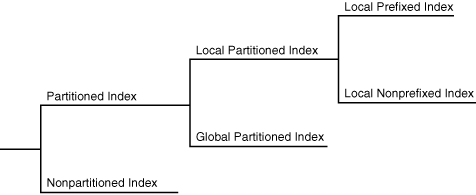
パーティション索引とは、パーティション表のように、より小さく管理しやすい単位に分割された索引です。グローバル索引は索引の作成対象の表から独立してパーティション化されますが、ローカル索引 は表のパーティション化方法に自動的にリンクされます。パーティション表と同様、パーティション索引も管理性、可用性、パフォーマンスおよびスケーラビリティを改善します。
次の図に、索引パーティション化のオプションを示します。
|
関連項目:
|
ローカル・パーティション索引では、その表と同じパーティション数および同じパーティション・バウンドで、同じ列に対して索引がパーティション化されます。索引パーティションにあるすべてのキーが単一の表パーティションに格納された行のみを参照するように、各索引パーティションは、基礎となる表のパーティションと1対1で関連付けられます。この方法で、データベースは索引パーティションと関連する表パーティションを自動的に同期化し、表と索引の各ペアを独立させます。
ローカル・パーティション索引はデータ・ウェアハウス環境で共通のものです。ローカル索引には、次の利点があります。
パーティションのデータを無効または使用不可能にするアクションは、該当のパーティションにのみ反映されるため、可用性が向上します。
パーティションのメンテナンスが簡単になります。表パーティションを移動した場合、またはデータがパーティションをエージ・アウトした場合、再作成またはメンテナンスが必要となるのは、関連するローカル索引パーティションのみです。グローバル索引では、すべての索引パーティションを再作成またはメンテナンスする必要があります。
パーティションのポイント・イン・タイム・リカバリが発生した場合は、索引をリカバリ時間までリカバリできます(「データファイル・リカバリ」を参照)。索引全体を再作成する必要はありません。
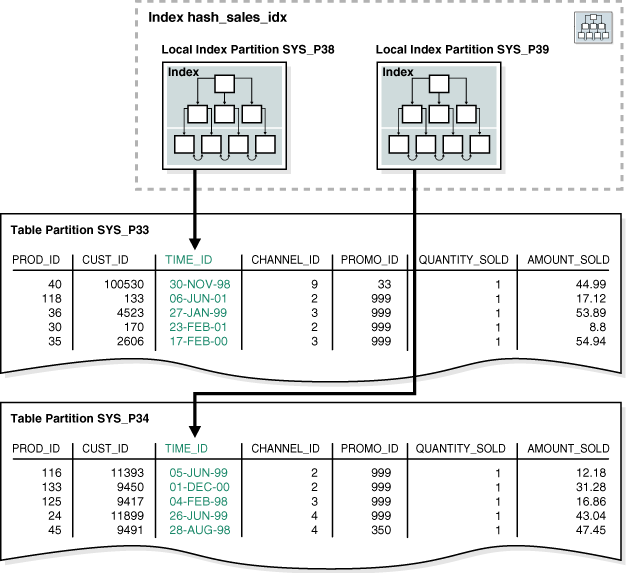
例4-4は、prod_id列をパーティション・キーとして使用して、パーティション化されたhash_sales表を作成する文を示しています。例4-5では、hash_sales表のtime_id列にローカル・パーティション索引を作成します。
図4-4では、hash_products表に2つのパーティションがあり、そのため、hash_sales_idxにも2つのパーティションがあります。各索引パーティションは異なる表パーティションに関連付けられています。索引パーティションSYS_P38は表パーティションSYS_P33の行を索引付けするのに対し、索引パーティションSYS_P39は表パーティションSYS_P34の行を索引付けします。
パーティションは、明示的にローカル索引に追加することはできません。基礎となる表にパーティションを追加した場合のみ、新しいパーティションがローカル索引に追加されます。同様に、パーティションを明示的にローカル索引から削除することもできません。基礎となる表からパーティションを削除した場合のみ、ローカル索引のパーティションが削除されます。
他の索引の場合と同じように、ビットマップ索引もパーティション表に対して作成できます。ただし、ただ1つの制限として、ビットマップ索引はパーティション表に対してローカルであることが必要で、グローバル索引にはできません。グローバル・ビットマップ索引は、非パーティション表でのみサポートされます。
ローカル・パーティション索引は次のサブカテゴリに分類されます。
この索引の場合、パーティション・キーは索引定義の最初に配置されます。例4-2では、表がtime_idの範囲によってパーティション化されています。この表のローカル同一キー索引では、time_idがリストの最初の列になります。
ローカル非同一キー索引
この索引の場合、パーティション・キーは索引付けされた列のリストの最初にはなく、またリスト内に存在する必要もありません。例4-5では、パーティション・キーproduct_idが最初に置かれていないため、索引はローカル非同一です。
これらの両方のタイプの索引で、パーティション絞込み(パーティション・プルーニングとも呼ばれる)を活用でき、この機能は、オプティマイザがパーティションを対象外とすることによって、データ・アクセスを高速化する場合に使用されます。問合せでパーティションを除外できるかどうかは、問合せの述語によって決まります。ローカル同一キー索引を使用する問合せでは、常に索引のパーティション絞込みが可能ですが、ローカル非同一キー索引を使用している問合せでは、絞込みはできない場合があります。
|
関連項目: 同一キー索引および非同一キー索引の使用方法の詳細は、『Oracle Database VLDBおよびパーティショニング・ガイド』を参照してください。 |
グローバル・パーティション索引は、この索引の作成対象である基礎となる表とは別にパーティション化されたBツリー索引です。単一の索引パーティションは、任意またはすべての表パーティションを指す場合があり、その一方で、ローカル・パーティション索引では、索引パーティションと表パーティションの間に1対1のパリティが存在します。
一般的に、グローバル索引は高速アクセス、データ整合性および可用性が重要となるOLTPアプリケーションに役立ちます。OLTPシステムでは、employees.department_id列など1つのキーによって表がパーティション化される場合がありますが、アプリケーションではemployee_idまたはjob_idなどの多数の異なるキーによるデータへのアクセスが必要になる可能性があります。このような使用例では、グローバル索引が便利な場合があります。
グローバル索引は、レンジ・パーティション化またはハッシュ・パーティション化できます。レンジ・パーティション化の場合、データベースでは、列リストで指定した表の列の値範囲を基にグローバル索引をパーティション化します。ハッシュ・パーティション化の場合、データベースでは、パーティション・キー列の値を基にハッシュ関数を使用して行をパーティションに割り当てます。
たとえば、例4-2のtime_range_sales表にグローバル・パーティション索引を作成するとします。この表では、1998年の売上を含む行が1つのパーティションに格納され、1999年の売上を含む行は別のパーティションに格納されるというように、行が格納されます。例4-6では、channel_id列の範囲別にパーティション化されたグローバル索引を作成します。
例4-6 グローバル・パーティション索引
CREATE INDEX time_channel_sales_idx ON time_range_sales (channel_id) GLOBAL PARTITION BY RANGE (channel_id) (PARTITION p1 VALUES LESS THAN (3), PARTITION p2 VALUES LESS THAN (4), PARTITION p3 VALUES LESS THAN (MAXVALUE));
図4-5に示すように、グローバル索引パーティションには、複数の表パーティションをそれぞれ指すエントリを含めることができます。索引パーティションp1はchannel_idが2の行を指し、索引パーティションp2はchannel_idが3の行を指し、索引パーティションp3はchannel_idが4または9の行を指しています。
|
関連項目:
|
索引構成表(IOT)に対してレンジ・パーティション化、リスト・パーティション化またはハッシュ・パーティション化を実行できます。パーティション化はIOTの管理性、可用性およびパフォーマンスの改善に役立ちます。さらに、IOTを使用するデータ・カートリッジも、格納したデータをパーティション化する機能を活用できます。
パーティション化したIOTには、次の特性がある点に注意してください。
パーティション列は、主キー列のサブセットであることが必要です。
2次索引はローカルにもグローバルにもパーティション化できます。
OVERFLOWデータ・セグメントは、常に表パーティションと同一レベルでパーティション化されます。
Oracle Databaseでは、パーティション化または非パーティション化された索引構成表のビットマップ索引がサポートされています。索引構成表のビットマップ索引の作成には、マッピング表が必要です。
ビューは、1つまたは複数の表の論理表現です。本質的には、ビューはストアド・クエリーです。ビューは、実表と呼ばれる基礎となる表からデータを導出します。実表には、表または他のビューを指定できます。ビュー上で実行されるすべての操作は、実際にその実表に影響します。多くの場合、ビューは表と同じように使用できます。
ビューを使用すると、様々なタイプのユーザーに合せてデータの表現形式を変化させることができます。通常、ビューは次の目的で使用されます。
事前に定義された行や列の集合のみにアクセスを限定して、表のセキュリティ・レベルを強化します。
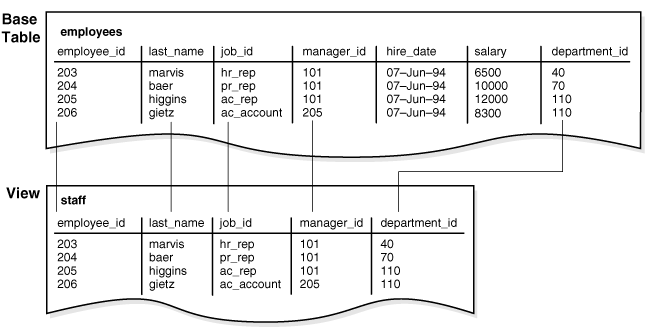
たとえば、図4-6は、staffビューに実表employeesの列salaryまたはcommission_pctが含まれない仕組みを示しています。
たとえば、複数の表の関連した列または行を1つにまとめる結合によって、単一のビューを定義できます。ただし、ビューからは、この情報が複数の表から抽出されたものであるということはわかりません。1つの問合せで、表情報に対して複雑な計算を実行する場合もあります。これにより、ユーザーはビューに対して問い合せることができ、結合または計算の実行方法を知る必要がなくなります。
実表とは異なる視点からデータを提示します。
たとえば、ビューが基礎にしている表に影響を与えずに、ビューの列名を変更できます。
実表の定義の変更からアプリケーションを分離します。
たとえば、ビューを定義している問合せが表の4つの列の中の3つの列を参照している場合、たとえ5番目の列が追加されてもビューの定義は影響を受けないため、ビューを使用しているすべてのアプリケーションも影響を受けません。
ビューの使用例として、複数の列と膨大な行を持つhr.employees表について検討します。ユーザーがそのうちの5つの列または特定の行しか参照できないようにする場合は、次のようにビューを作成します。
CREATE VIEW staff AS SELECT employee_id, last_name, job_id, manager_id, department_id FROM employees;
すべての副問合せと同様に、ビューを定義する問合せにFOR UPDATE句を含めることはできません。図4-6に、staffという名前のビューを示します。ビューが、実表の5つの列のみを表示していることに注目してください。
|
関連項目:
|
表とは異なり、ビューには記憶域は割り当てられず、データが格納されることもありません。ビューは、参照する実表からデータを抽出または導出する問合せによって定義されます。ビューは他のオブジェクトを基盤としているため、データ・ディクショナリ.内でビューを定義する問合せ用の記憶域以外には記憶域が必要ありません。
ビューは、データベースによって自動的に操作される参照先のオブジェクトに依存します。たとえば、ビューの実表を削除してから再作成した場合、データベースは新しい実表がビュー定義と一致するかどうかを確認します。
ビューは表から導出されるため、ビューと表には多数の類似点があります。たとえば、ビューには表と同じように最大1000個の列を含めることができます。ユーザーはビューを問い合せることができ、いくつかの制限付きでビューに対してDMLを実行できます。ビューに対して実行される操作は、そのビューの実表のデータに影響し、実表の整合性制約とトリガーの対象になります。
次の例では、hr.employees表のビューを作成します。
CREATE VIEW staff_dept_10 AS
SELECT employee_id, last_name, job_id,
manager_id, department_id
FROM employees
WHERE department_id = 10
WITH CHECK OPTION CONSTRAINT staff_dept_10_cnst;
定義された問合せでは部門10の行のみを参照します。CHECK OPTIONは、ビューに対して発行されたINSERTおよびUPDATE文の結果が必ずビューで選択できる行になるよう、制約を持つビューを作成します。これにより、部門10の従業員の行は挿入できますが、部門30の行は挿入できません。
|
関連項目: CREATE VIEW文の副問合せ制限の詳細は、『Oracle Database SQL言語リファレンス』 |
Oracle Databaseでは、ビューの定義は、ビューを定義する問合せテキストとしてデータ・ディクショナリに保存されます。SQL文でビューを参照すると、Oracle Databaseでは次のタスクが実行されます。
可能な場合は常に、ビューに対する問合せとそのビューおよび基礎となるビューを定義する問合せをマージします。
Oracle Databaseにより、マージされた問合せは、ビューを参照せずに問合せを発行したものとして最適化されます。そのため、Oracle Databaseでは、列がビュー定義で参照されても、またはビューに対するユーザーの問合せで参照されても、参照される実表の列に対する索引を使用できます。
Oracle Databaseでは、ユーザーの問合せとビュー定義をマージできないこともあります。その場合、Oracle Databaseは参照された列の索引すべてを使用できるとはかぎりません。
共有SQL領域内のマージ済の文を解析します。
Oracle Databaseでは、新しい共有SQL領域内のビューを参照する文は、既存の共有SQL領域に同様の文が含まれていない場合にのみ解析されます。したがって、ビューを使用すると、共有SQLに関連付けられているメモリーの使用量を減らせるという利点があります。
SQL文を実行します。
次の例に、ビューが問合せを受ける際のデータ・アクセスを示します。employeesおよびdepartments表を基にemployees_viewを作成するとします。
CREATE VIEW employees_view AS SELECT employee_id, last_name, salary, location_id FROM employees JOIN departments USING (department_id) WHERE department_id = 10;
ユーザーはemployees_viewの次の問合せを実行します。
SELECT last_name FROM employees_view WHERE employee_id = 200;
Oracle Databaseはビューとユーザーの問合せをマージして、データ取得のために実行する次の問合せを構成します。
SELECT last_name FROM employees, departments WHERE employees.department_id = departments.department_id AND departments.department_id = 10 AND employees.employee_id = 200;
結合ビューは、FROM句に複数の表またはビューのある1つのビューとして定義されます。例4-7では、staff_dept_10_30ビューがemployees表とdepartments表を結合し、部門10または30の従業員のみを含めるように指定しています。
例4-7 結合ビュー
CREATE VIEW staff_dept_10_30 AS SELECT employee_id, last_name, job_id, e.department_id FROM employees e, departments d WHERE e.department_id IN (10, 30) AND e.department_id = d.department_id;
更新可能な結合ビューは変更可能な結合ビューとも呼ばれ、2つ以上の実表またはビューを含み、DMLの各操作が可能です。更新可能なビューはSELECT文のトップレベルのFROM句に複数の表を含み、WITH READ ONLY句で制限されません。
本質的に更新可能であるためには、ビューは複数の条件を満たす必要があります。たとえば、結合ビューに対するINSERT、UPDATEまたはDELETE操作では、1回に変更可能な実表は1つのみであることが一般的なルールです。次のUSER_UPDATABLE_COLUMNSデータ・ディクショナリ・ビューの問合せは、例4-7で作成されたビューが更新可能であることを示しています。
SQL> SELECT TABLE_NAME, COLUMN_NAME, UPDATABLE 2 FROM USER_UPDATABLE_COLUMNS 3 WHERE TABLE_NAME = 'STAFF_DEPT_10_30'; TABLE_NAME COLUMN_NAME UPD ------------------------------ ------------------------------ --- STAFF_DEPT_10_30 EMPLOYEE_ID YES STAFF_DEPT_10_30 LAST_NAME YES STAFF_DEPT_10_30 JOB_ID YES STAFF_DEPT_10_30 DEPARTMENT_ID YES
結合ビューの更新可能なすべての列が、キー保存表の列にマップされる必要があります。結合の問合せにおけるキー保存表とは、その問合せの出力で、基礎となる表の各行が最大1回のみ表示される表のことです。例4-7では、department_idがdepartments表の主キーであるため、employees表をキー保存表にして、employees表からの各行が結果セットに最高で1回のみ表示されます。departments表は、表内の各行が結果セットに複数回表示される可能性があるため、キー保存表ではありません。
|
関連項目: 結合ビューの更新方法の詳細は、『Oracle Database管理者ガイド』を参照してください。 |
ビューが仮想表であるのと同様に、オブジェクト・ビューは仮想オブジェクト表です。ビュー内の各行はオブジェクトであり、オブジェクト・タイプのインスタンスです。オブジェクト型はユーザー定義データ型です。
リレーショナル・データは、オブジェクト型として格納されているかのように検索、更新、挿入および削除できます。また、オブジェクト、REFおよびコレクション(ネストした表とVARRAY)などのオブジェクト・データ型である列を持つビューを定義できます。
リレーショナル・ビューと同様、オブジェクト・ビューにはユーザーに表示されるデータのみを表示できます。たとえば、オブジェクト・ビューにITプログラマについてのデータは表示し、給与に関する機密データは除外することが可能です。次の例では、employee_typeオブジェクトを作成してから、このオブジェクトを基にしたビューit_prog_viewを作成しています。
CREATE TYPE employee_type AS OBJECT ( employee_id NUMBER (6), last_name VARCHAR2 (25), job_id VARCHAR2 (10) ); / CREATE VIEW it_prog_view OF employee_type WITH OBJECT IDENTIFIER (employee_id) AS SELECT e.employee_id, e.last_name, e.job_id FROM employees e WHERE job_id = 'IT_PROG';
オブジェクト・ビューは、ビュー内のデータをリレーショナル表から取得し、この表がオブジェクト表として定義されているものとしてデータにアクセスできるため、プロトタイプ化、およびオブジェクト指向アプリケーションへの移行に便利です。オブジェクト指向アプリケーションは、既存の表を別の物理構造に変換せずに実行できます。
|
関連項目:
|
マテリアライズド・ビューは、スキーマ・オブジェクトとして事前に格納またはマテリアライズされた問合せ結果です。問合せのFROM句では表、ビューおよびマテリアライズド・ビューの名前を指定できます。これらのオブジェクトは、総称として マスター表(レプリケーション用語)またはディテール表(データ・ウェアハウス用語)と呼ばれます。
マテリアライズド・ビューは、データの集計、計算、レプリケートおよび分配に使用されます。これらは、次のような様々なコンピューティング環境に適しています。
データ・ウェアハウスでは、マテリアライズド・ビューを使用して、合計値や平均値など、集計関数から生成されたデータを計算し、格納できます。
サマリーは集計ビューで、結合および集計操作を事前に計算して結果を表に格納することで、問合せ時間が短縮されます。マテリアライズド・ビューは、サマリーと同じものです(「データ・ウェアハウスのアーキテクチャ(基本)」を参照)。また、マテリアライズド・ビューを使用して、集計操作の有無に関係なく、結合を計算できます。互換性がOracle9i以上に設定されていると、フィルタ選択を含む問合せにマテリアライズド・ビューを使用できます。
マテリアライズド・ビューの レプリケーションでは、ある時点からの表の全体または一部のコピーがビューに含まれます。マテリアライズド・ビューは分散サイトにデータをレプリケートし、複数のサイトで実行される更新を同期化します。このレプリケーション形式は、データベースが常時ネットワークに接続されていない場合のフィールド・セールスなどの環境に適しています。
モバイル・コンピューティング環境では、マテリアライズド・ビューを使用して、中央のサーバーからモバイル・クライアントにデータのサブセットをダウンロードし、中央のサーバーから定期的にリフレッシュし、クライアントで実行された更新を中央のサーバーに伝播できます。
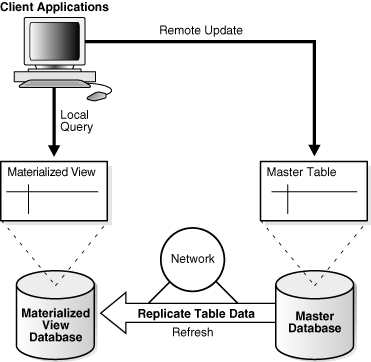
レプリケーション環境では、マテリアライズド・ビューはマスター・データベースと呼ばれる別のデータベース内の表とデータを共有します。マテリアライズド・ビューに関連付けられたマスター・サイトの表がマスター表です。図4-7に、別のデータベース内のマスター表に基づく、1つのデータベース内のマテリアライズド・ビューを示します。マスター表を更新すると、マテリアライズド・ビューのデータベースにレプリケートされます。
|
関連項目:
|
マテリアライズド・ビューには、非マテリアライズド・ビューおよび索引と同じ特性がいくつかあります。マテリアライズド・ビューは、次の点が索引に類似しています。
実際のデータを含み、記憶域を使用します。
マスター表のデータに変更があった場合は、リフレッシュできます。
クエリー・リライト操作に使用すると、SQLの実行効率が改善されます。
その存在は、SQLアプリケーションとユーザーに対して透過的です。
マテリアライズド・ビューは他の表およびビューのデータを表す点において、非マテリアライズド・ビューに類似しています。索引とは異なり、ユーザーはSELECT文を使用してマテリアライズド・ビューを直接問合せできます。必要なリフレッシュのタイプによっては、DML文を使用してビューを更新することも可能です。
次の例では、shサンプル・スキーマの3つのマスター表に基づくマテリアライズド集計ビューを作成して、データを投入しています。
CREATE MATERIALIZED VIEW sales_mv AS SELECT t.calendar_year, p.prod_id, SUM(s.amount_sold) AS sum_sales FROM times t, products p, sales s WHERE t.time_id = s.time_id AND p.prod_id = s.prod_id GROUP BY t.calendar_year, p.prod_id;
次の例では、sales_mvのマスター表であるsales表を削除してから、sales_mvを問い合せます。行はマスター表のデータとは別に格納(マテリアライズ)されているため、問合せによってデータが選択されます。
SQL> DROP TABLE sales;
Table dropped.
SQL> SELECT * FROM sales_mv WHERE ROWNUM < 4;
CALENDAR_YEAR PROD_ID SUM_SALES
------------- ---------- ----------
1998 13 936197.53
1998 26 567533.83
1998 27 107968.24
マテリアライズド・ビューはパーティション化できます。マテリアライズド・ビューは、そのパーティション表および1つ以上の索引上で定義できます。
|
関連項目: データ・ウェアハウスでマテリアライズド・ビューを使用する方法の詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。 |
データベースでは、マスター表の変更後にマテリアライズド・ビューをリフレッシュして、マテリアライズド・ビューのデータを管理します。リフレッシュ方法には、増分リフレッシュとしての高速リフレッシュまたは完全リフレッシュがあります。
マテリアライズド・ビューが事前作成表を参照しないかぎり、完全リフレッシュは、マテリアライズド・ビューが最初にBUILD IMMEDIATEとして定義されたときに行われます。リフレッシュを実行すると、マテリアライズド・ビューを定義する問合せも実行されます。この処理は、特にデータベースが大量のデータを読み取って処理する必要がある場合に遅くなることがあります。
高速リフレッシュにより、マテリアライズ・ビューを最初から再作成する必要がなくなります。このように変更内容のみを処理すると、リフレッシュ時間が非常に速くなります。マテリアライズド・ビューは、必要時に、または定期的にリフレッシュできます。また、マスター表と同じデータベース内のマテリアライズド・ビューは、トランザクションによってマスター表の変更がコミットされるたびにリフレッシュできます。
高速リフレッシュ方法を使用する場合、マスター表に対する変更はマテリアライズド・ビュー・ログまたはダイレクト・ローダー・ログに記録されます。マテリアライズド・ビュー・ログとは、マスター表に定義されているマテリアライズド・ビューの増分リフレッシュを実行できるように、マスター表の変更を記録するスキーマ・オブジェクトです。マテリアライズド・ビュー・ログは、それぞれ1つのマスター表に対応付けられています。マテリアライズド・ビュー・ログは、マスター表と同じデータベースおよびスキーマに格納されます。
|
関連項目:
|
クエリー・リライトは、マスター表に関して記述されたユーザーのリクエストを、マテリアライズド・ビューを含み、同等の意味を持つリクエストに変換する最適化技術です。実表に大量のデータが含まれている場合には、集計および結合の計算は負荷が大きく、時間がかかります。マテリアライズド・ビューには事前に計算された集計と結合が含まれているため、クエリー・リライトはマテリアライズド・ビューを使用してすぐに問合せに応答できます。
オプティマイザ問合せトランスフォーマは、マテリアライズド・ビューを使用するために透過的にリクエストをリライトし、ユーザー操作およびSQL文によるマテリアライズド・ビューへの参照は必要ありません。クエリー・リライトは透過的であるため、アプリケーション・コードのSQLを無効にしなくても、マテリアライズド・ビューを追加または削除できます。
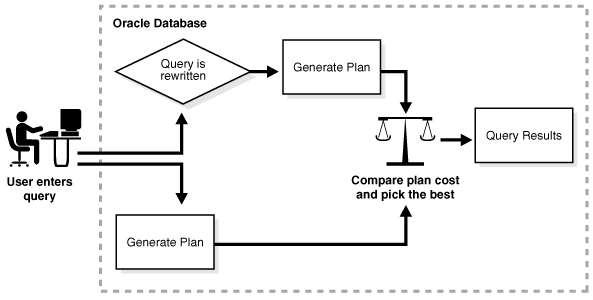
一般的に、ディテール表ではなくマテリアライズド・ビューを使用するクエリー・リライトでは、レスポンス時間が短縮されます。図4-8は、オリジナルまたはリライトされた問合せに対してデータベースが実行計画を生成し、最もコストの低い計画を選択する仕組みを示しています。
順序とは、複数のユーザーが一意の整数を生成できるスキーマ・オブジェクトです。順序ジェネレータは、数値データ型に対してサロゲート・キーを生成するスケーラブルかつパフォーマンスの高い方法を提供します。
順序の定義には、次のように一般的な情報を指定します。
順序の名前
昇順または降順
数値の増分値
データベースが、メモリー内に生成された一連の順序番号をキャッシュするかどうか
制限に到達したときに、順序を循環させるかどうか
次の例では、サンプル・スキーマoeに順序customers_seqを作成します。customers表に行が追加されると、アプリケーションはこの順序を使用して、顧客ID番号を付与します。
CREATE SEQUENCE customers_seq START WITH 1000 INCREMENT BY 1 NOCACHE NOCYCLE;
最初のcustomers_seq.nextvalの参照では、1000が戻されます。2回目には1001が戻されます。以降の各参照では、前回の参照よりも1大きい値が戻されます。
|
関連項目:
|
同じ順序ジェネレータから、複数の表に対して数値を生成できます。この方法により、データベースは自動的に主キーを生成して、複数の行または表にまたがるキーを統合できます。たとえば、順序はorders表およびcustomers表の主キーを生成できます。
順序ジェネレータは、ディスクI/Oのオーバーヘッドまたはトランザクション・ロックを発生させずに、一意の番号を生成するため、マルチ・ユーザー環境で便利です。たとえば、2人のユーザーがorders表に新しい行を同時に挿入するとします。順序を使用してorder_id列に一意の番号を生成すると、一方のユーザーは、他方のユーザーが注文番号を入力するのを待機する必要はありません。どちらのユーザーにも、順序により、正しい値が自動的に生成されるためです。
順序を参照する各ユーザーは、セッションで生成された最後の順序である現行の順序番号にアクセスできます。ユーザーは、文を発行して新しい順序番号を生成することも、セッションで最後に生成された現行の番号を使用することもできます。セッション内の文が順序番号を生成すると、その番号はこのセッションでのみ使用可能となります。最終的にロールバックされたトランザクションで生成されて使用された個々の順序番号はスキップされます。
|
注意: アプリケーションが連続する番号を使用する場合、Oracleの順序は使用できません。独自に開発したコードを使用して、データベースのアクティビティをシリアライズする必要があります。 |
データ・ウェアハウスには通常、ディメンションとファクトという2つの重要な要素があります。ディメンションは、時刻、地理、製品、部門および販売チャネルなどのビジネス上の質問を指定する場合に使用される任意のカテゴリです。ファクトは、売上単位または利益などの特定のディメンション値のセットに関連付けられたイベントまたはエンティティです。
多次元要求の例には、次の処理が含まれます。
2010年と2011年について、州、国、地域というように地理ディメンションの集計レベルの昇順で全製品の総売上を表示します。
2010年と2011年における南アメリカの地域別経費を示す事業のクロス集計分析を作成します。可能な小計をすべて組み込みます。
自動車製品に関する2011年の販売収入に従って、アジアでの販売代理店の上位10社をリストし、そのコミッションのランキングを作成します。
多次元による多くの質問では、通常は時間、地理または予算にまたがって集計されたデータと、データ・セットの比較が必要になります。
ディメンションを作成すると、より広範囲でのクエリー・リライト機能の使用が許可されます。データベースでは、マテリアライズド・ビューを使用した透過的なクエリー・リライトによって、問合せのパフォーマンスを改善できます。
ディメンション表は列または列セットのペア間の階層関係を定義する論理構造です。ディメンションには、この論理構造に割り当てるデータ記憶域がありません。ディメンション情報がディメンション表に格納されるのに対して、ファクト情報は ファクト表に格納されます。
顧客ディメンション内では、顧客は都市、州、国、準地域、地域までロールアップできます。通常、データ分析はディメンション階層の高いレベルから開始され、必要に応じて徐々に階層がドリルダウンされます。
子レベルの値は、それぞれが親レベルの1つの値にのみ対応付けられます。階層関係は、ある階層レベルから次のレベルへの機能上の依存関係です。
|
関連項目:
|
ディメンションはSQL文を使用して作成されます。CREATE DIMENSION文では、次の事項を指定します。
次の文は、サンプル・スキーマshにcustomers_dimディメンションを作成するために使用されました。
CREATE DIMENSION customers_dim
LEVEL customer IS (customers.cust_id)
LEVEL city IS (customers.cust_city)
LEVEL state IS (customers.cust_state_province)
LEVEL country IS (countries.country_id)
LEVEL subregion IS (countries.country_subregion)
LEVEL region IS (countries.country_region)
HIERARCHY geog_rollup (
customer CHILD OF
city CHILD OF
state CHILD OF
country CHILD OF
subregion CHILD OF
region
JOIN KEY (customers.country_id) REFERENCES country )
ATTRIBUTE customer DETERMINES
(cust_first_name, cust_last_name, cust_gender,
cust_marital_status, cust_year_of_birth,
cust_income_level, cust_credit_limit)
ATTRIBUTE country DETERMINES (countries.country_name);
ディメンション内の列は、同じ表のもの(非正規化)でも複数の表のもの(完全正規化または一部正規化)でもかまいません。たとえば、正規化されているtimeディメンションには、date表、month表およびyear表と、各date行をmonth行に、各month行をyear行に接続する結合条件を含めることができます。完全な非正規化のtimeディメンションでは、date、monthおよびyear列は同じ表に格納されます。正規化されているかどうかに関係なく、列相互の階層関係をCREATE DIMENSION文で指定する必要があります。
|
関連項目:
|
シノニムとは、スキーマ・オブジェクトの別名です。たとえば、表またはビュー、順序、PL/SQLプログラム単位、ユーザー定義オブジェクト型または別のシノニムなどに対してシノニムを作成できます。シノニムは単なる別名であるため、データ・ディクショナリ内の定義以外に記憶域は必要ありません。
シノニムを使用すると、データベース・ユーザー側のSQL文を単純化できます。また、シノニムは、基礎となるスキーマ・オブジェクトのIDおよび場所を非表示にする場合にも便利です。基礎となるオブジェクトを改名または移動する必要がある場合、シノニムのみを再定義すればよいことになります。シノニムに基づくアプリケーションは、今後も変更なしに機能し続けることができます。
プライベート・シノニムとパブリック・シノニムの両方を作成できます。プライベート・シノニムは、特定のユーザーのスキーマに含まれており、そのユーザーが他のユーザーに対するシノニムの使用許可を制御します。パブリック・シノニムはPUBLICという名前の特別なユーザー・グループが所有しており、すべてのデータベース・ユーザーがアクセスできます。
例4-9では、データベース管理者がhr.employees表のpeopleという名前のパブリック・シノニムを作成しています。その後、ユーザーがoeスキーマに接続して、シノニムが参照する表内の行数をカウントしています。
例4-8 パブリック・シノニム
SQL> CREATE PUBLIC SYNONYM people FOR hr.employees;
Synonym created.
SQL> CONNECT oe
Enter password: password
Connected.
SQL> SELECT COUNT(*) FROM people;
COUNT(*)
----------
107
パブリック・シノニムではデータベースの統合が困難になるため、パブリック・シノニムは慎重に使用してください。例4-9に示すように、データベース内に存在するパブリック・シノニムpeopleは1つのみであるため、別の管理者がパブリック・シノニムpeopleの作成を試行すると失敗します。パブリック・シノニムを多用すると、アプリケーション間でネームスペースに競合が発生します。
例4-9 パブリック・シノニム
SQL> CREATE PUBLIC SYNONYM people FOR oe.customers;
CREATE PUBLIC SYNONYM people FOR oe.customers
*
ERROR at line 1:
ORA-00955: name is already used by an existing object
SQL> SELECT OWNER, SYNONYM_NAME, TABLE_OWNER, TABLE_NAME
2 FROM DBA_SYNONYMS
3 WHERE SYNONYM_NAME = 'PEOPLE';
OWNER SYNONYM_NAME TABLE_OWNER TABLE_NAME
---------- ------------ ----------- ----------
PUBLIC PEOPLE HR EMPLOYEES
シノニム自体は安全ではありません。シノニムに対してオブジェクト権限を付与すると、実際には基礎となるオブジェクトに権限を付与することになります。シノニムは、GRANT文のオブジェクトの別名としてのみ機能しています。
|
関連項目:
|