| Oracle® Databaseグローバリゼーション・サポート・ガイド 11gリリース2 (11.2) B56307-04 |
|


 前 |
 次 |
この章では、ロケール・データのカスタマイズ方法について説明します。この章の内容は、次のとおりです。
Oracle Locale Builderは、ロケール・データをカスタマイズするための簡単で効率的な方法を提供します。ロケール固有のデータを簡単に表示、変更および定義できるGUIも提供します。Oracle Locale Builderではテキストおよびバイナリ定義ファイルからデータを抽出して、読取り可能な形式で表示するため、ユーザーはこれらのファイルで使用されている形式を気にせずに情報を処理できます。
Oracle Locale Builderでは、言語、地域、キャラクタ・セットおよび言語ソートの4種類のロケール定義を管理します。ユーザー定義文字やカスタマイズされた言語規則もサポートします。既存のテキスト定義ファイルやバイナリ定義ファイルの定義を表示して、変更を加えたり、独自の定義を作成できます。
この項の内容は、次のとおりです。
Oracle Locale Builderでは、多くの機能でUnicode文字が使用されます。たとえば、Unicodeコード・ポイントへのローカル文字コード・ポイントのマッピングが表示されます。Oracle Locale Builderは、文字が表現されるオペレーティング・システム上で使用可能なローカル・フォントに依存します。したがって、Oracle Locale Builderを完全にサポートするUnicodeフォントの使用をお薦めします。ローカル・フォントで文字を表現できない場合、その文字は空の四角として表示される可能性があります。
Windowsには、Unicodeをサポートする多数のTrueTypeフォントおよびOpenTypeフォントがあります。MicrosoftのArial Unicode MSフォントを使用することをお薦めします。このフォントには、50,000を超える絵文字が含まれ、Unicode 5.0のほとんどの文字をサポートしているためです。
インストールしたUnicodeフォントは、Oracle Locale Builderで使用できるように、Java Runtimeのfont.propertiesファイルに追加します。このfont.propertiesファイルは、$JAVAHOME/jre/libディレクトリにあります。たとえば、Arial Unicode MSフォントの場合は、font.propertiesファイルに次のエントリを追加します。
dialog.n=Arial Unicode MS, DEFAULT_CHARSET dialoginput.n=Arial Unicode MS, DEFAULT_CHARSET serif.n=Arial Unicode MS, DEFAULT_CHARSET sansserif.n=Arial Unicode MS, DEFAULT_CHARSET
n は、フォント・リスト内でArial Unicode MSフォントに割り当てるための次の順序番号です。Java Runtimeは、各仮想フォントについてフォント・マッピング・リストを検索し、システムで使用可能な最初のフォントを使用します。
font.propertiesファイルの編集後に、Oracle Locale Builderを再起動してください。
|
関連項目: font.propertiesファイルの詳細は、Sun社の国際化Webサイトを参照してください。 |
Windows以外のプラットフォーム用Unicodeフォントは、Windowsプラットフォームよりも選択肢が限られています。文字を十分にカバーするUnicodeフォントが見つからない場合は、異なる言語に複数のフォントを使用します。前述のWindowsプラットフォームの場合の手順に従って、各フォントをインストールし、そのフォントのエントリをfont.propertiesファイルに追加してください。
たとえば、フォントricoh-hg minchoを使用してSun社のSolarisで日本語の文字を表示するには、エントリを$JAVAHOME/libにある既存のfont.propertiesファイルのdialog、dialoginput、serifおよびsansserifセクションに追加します。次に例を示します。
serif.plain.3=-ricoh-hg mincho l-medium-r-normal--*-%d-*-*-m-*-jisx0201.1976-0
|
注意: オペレーティング・システムのロケールによっては、ロケール固有のfont.propertiesファイルを使用できます。たとえば、Sun社のSolarisで現行のオペレーティング・システムのロケールがja_JP.eucJPの場合は、font.properties.jaを使用できます。 |
|
関連項目: 使用可能なフォントの詳細は、ご使用のオペレーティング・システムのマニュアルを参照してください。 |
Oracle Locale Builderを起動する前に、ORACLE_HOMEパラメータが設定されていることを確認してください。
UNIXオペレーティング・システム上でOracle Locale Builderを起動するには、$ORACLE_HOME/nls/lbuilderディレクトリに変更して次のコマンドを発行します。
% ./lbuilder
Windowsオペレーティング・システム上では、「スタート」メニューからOracle Locale Builderを起動します。「スタート」→「プログラム」→Oracle-OraHome10→「コンフィグレーションおよび移行ツール」→「Locale Builder」を選択します。DOSプロンプトから%ORACLE_HOME%\nls\lbuilderディレクトリに移動してlbuilder.batコマンドを実行する方法もあります。
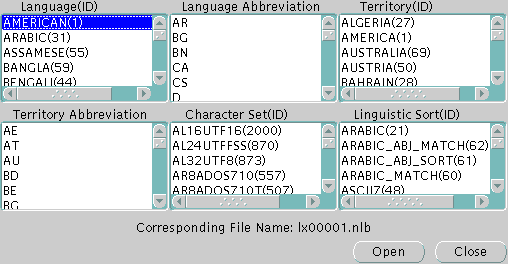
Oracle Locale Builderを起動すると、図13-1の画面が表示されます。
Oracle Locale Builderでの特定のタスクを使用する前に、次のようなタブ・ページとダイアログ・ボックスについて理解しておく必要があります。
|
注意: Oracle Locale Builderには、オンライン・ヘルプが付属しています。 |
「新規言語」、「新規地域」、「新規キャラクタ・セット」または「新規言語ソート」を選択すると、最初に「一般」タブ・ページが表示されます。「既存の定義の表示」をクリックすると、「既存の定義」ダイアログ・ボックスが表示されます。
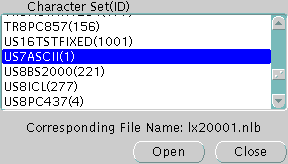
「既存の定義」ダイアログ・ボックスでは、ロケール・オブジェクトを名前でオープンできます。起動する特定の言語、地域、言語ソート(照合)またはキャラクタ・セットがわかっている場合は、表示されている名前をクリックします。たとえば、図13-2では、AMERICAN言語定義ファイルをオープンできます。
「AMERICAN」を選択すると、lx00001.nlbファイルがオープンします。NLBファイルは、特定の言語、地域、キャラクタ・セットまたは言語ソートの設定を含むバイナリ・ファイルです。
言語と地域の略称は参照用のため、オープンできません。
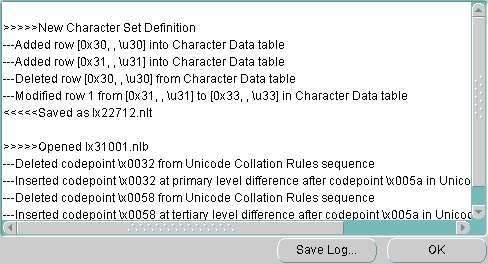
「ツール」→「ログの表示」を選択すると、「セッション・ログ」ダイアログ・ボックスが表示されます。「セッション・ログ」ダイアログ・ボックスには、現行のセッションで行われた処理が表示されます。「ログの保存」をクリックすると、すべての変更のレコードが保存されます。図13-3に、セッション・ログの例を示します。
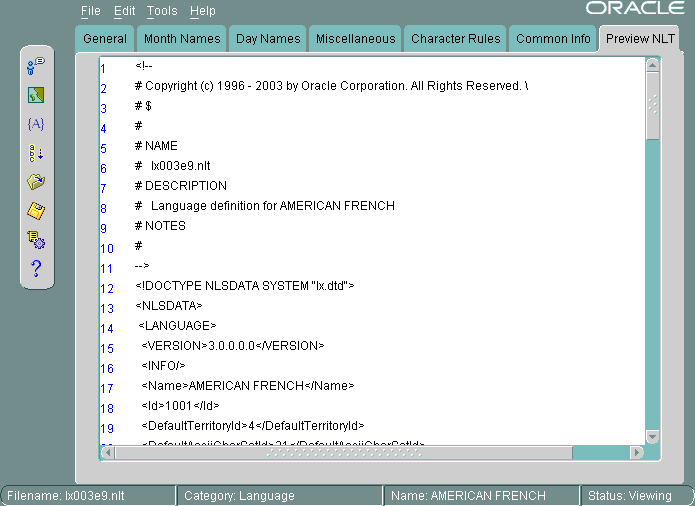
NLT(National Languare Text)ファイルは、ファイル拡張子が.nltのXMLファイルで、特定の言語、地域、キャラクタ・セットまたは言語ソートの設定を格納します。「NLTのプレビュー」タブ・ページには、ファイルが読取り可能な書式で表示されるため、変更内容が適切かどうかを確認できます。「NLTのプレビュー」タブ・ページからはNLTファイルを変更できません。NLTファイルを変更するには、Oracle Locale Builderで提供される特定のツールとプロシージャを使用する必要があります。
図13-4に、ユーザー定義言語AMERICAN FRENCHの「NLTのプレビュー」タブ・ページの例を示します。
「ファイル」→「開く」→ファイル名で指定を選択すると、「ファイルを開く」ダイアログ・ボックスを表示できます。次に、変更あるいはテンプレートとして使用するNLB(National Language Binary)ファイルを選択します。NLBファイルは、ファイル拡張子が.nlbのバイナリ・ファイルで、そのNLTファイル内の情報に相当するバイナリが含まれています。図13-5に、lx00001.nlbファイルが選択されているファイルを開くダイアログ・ボックスを示します。「プレビュー」ペインは、このNLBファイルがAMERICAN言語用であることを示しています。
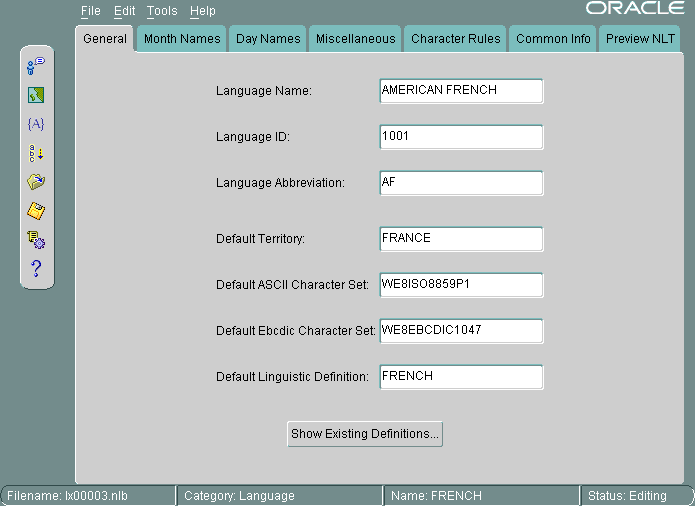
この項では、フランス語に基づいて新規言語を作成する方法について説明します。この新しい言語は、AMERICAN FRENCHと呼ぶことにします。最初に、「既存の定義」ダイアログ・ボックスからFRENCHをオープンします。次に、「一般」タブ・ページで言語名をAMERICAN FRENCHに変更し、「言語の略称」を「AF」に変更します。他の設定はデフォルト値のままにします。図13-6に、設定後の「一般」タブ・ページを示します。
言語などのロケール・オブジェクトの名前を選択するときには、次の制限事項が適用されます。
名前にはASCII文字のみを使用する必要があります。
名前は文字で開始する必要があります。
言語、地域およびキャラクタ・セット名にはアンダースコアを使用できません。
ユーザー定義言語の場合、「言語ID」フィールドの有効範囲は1,000から10,000です。Oracle Locale Builderで提供される値を受け入れるか、この範囲内の値を指定できます。
|
注意: 特定のID範囲は、ユーザー定義のLANGUAGE、TERRITORY、CHARACTER SET、MONOLINGUAL COLLATIONおよびMULTILINGUAL COLLATIONの定義に対してのみ有効です。この章の各項では、各タイプのユーザー定義ロケール・オブジェクトに関係する範囲が指定されています。 |
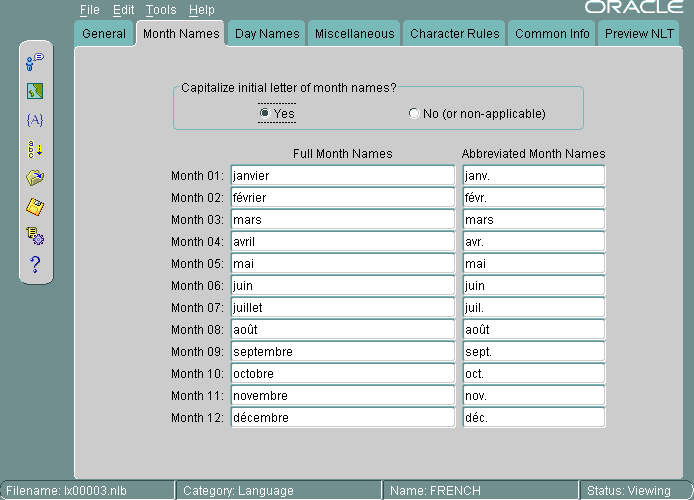
図13-7に、「月名」タブ・ページを使用して月の名前を設定する方法を示します。
すべての名前は、NLTファイルに表示されているとおりに示されます。先頭の文字を大文字にするかどうかに対して「はい」を選択すると、アプリケーションでは月の名前の先頭に大文字が使用されますが、「月名」タブ・ページでは大文字で表示されません。
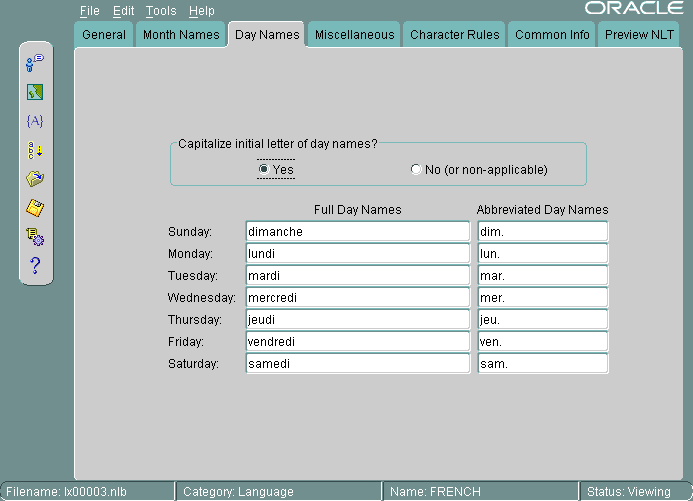
図13-8に、「曜日」タブ・ページを示します。
ユーザー定義言語に曜日名を選択できます。すべての名前は、NLTファイルに表示されているとおりに示されます。先頭の文字を大文字にするかどうかに対して「はい」を選択すると、アプリケーションでは曜日名の先頭に大文字が使用されますが、曜日タブ・ページでは大文字で表示されません。
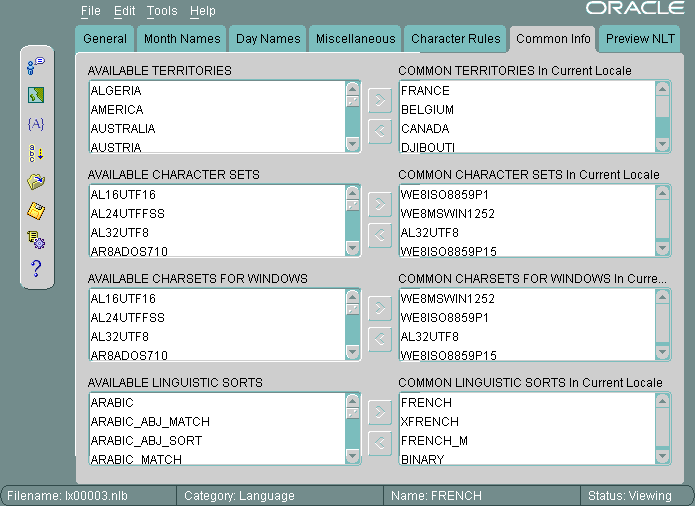
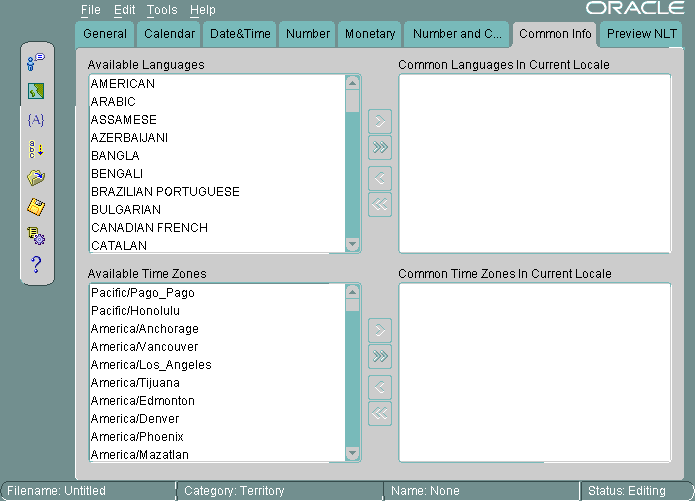
図13-9に、「共通情報」タブ・ページを示します。
現在の言語に関連付けられている地域、キャラクタ・セット、Windows用キャラクタ・セットおよび言語ソートを表示できます。通常、最も適切な項目または最も一般的に使用されている項目が、最初に表示されます。たとえば、FRENCH言語では、共通地域はFRANCE、BELGIUM、CANADAおよびDJIBOUTIで、サポートされているキャラクタ・セットは、WE8ISO8859P1、WE8MSWIN1252、AL32UTF8およびWE8ISO8859P15です。Windows環境では、WE8ISO8859P1よりもWE8MSWIN1252が一般的であるため、最初に表示されます。
この項では、新規の地域REDWOOD SHORESを作成し、地域の略称としてRSを使用する方法について説明します。新規の地域は、既存の地域定義に基づいていません。
基本タスクは次のとおりです。
地域名の割当て
カレンダ、数値、日付、時刻および通貨の各書式の選択
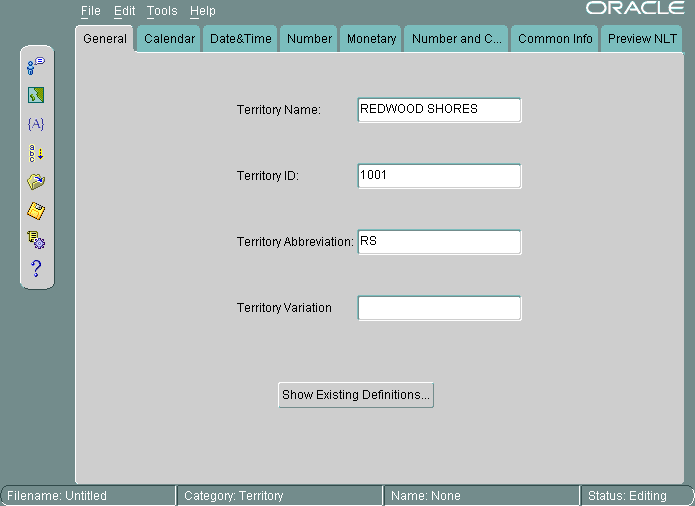
図13-10に、「地域名」としてREDWOOD SHORES、「地域ID」として1001、「地域の略称」としてRSが設定されている「一般」タブ・ページを示します。
ユーザー定義地域に対する「地域ID」フィールドの有効範囲は、1000から10000です。
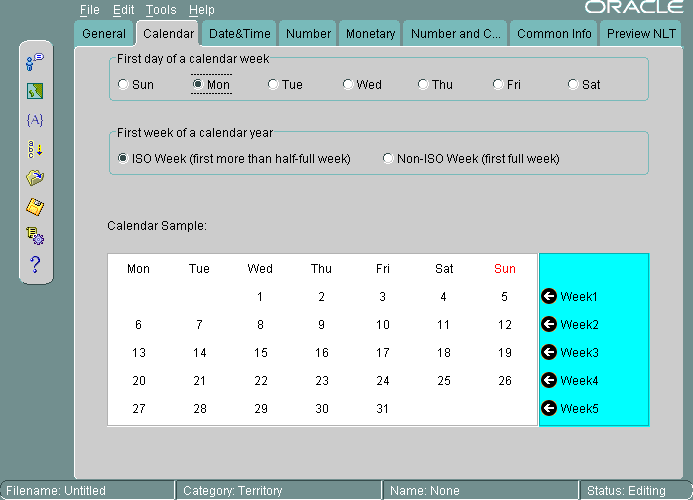
図13-11に、「暦」タブ・ページのカレンダ書式の設定を示します。
月曜日が週の開始日として設定され、暦年の第1週がISO週として設定されています。図13-11には、サンプル・カレンダを示しています。
|
関連項目:
|
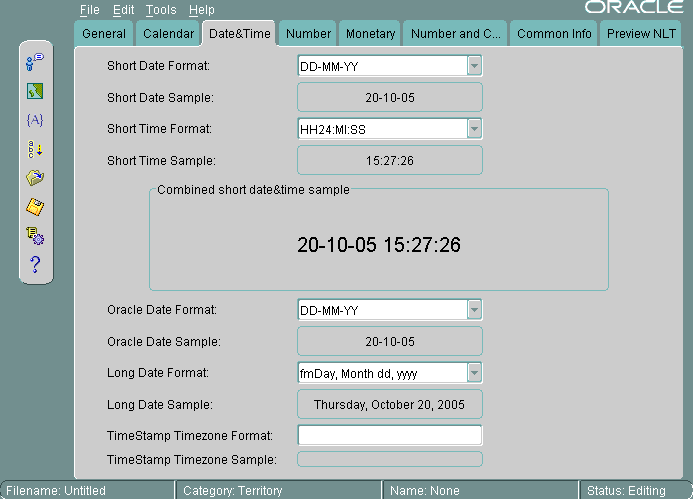
図13-12に、「日付と時間」タブ・ページを示します。
リストから書式を選択すると、書式の例が表示されます。このケースでは、短い日付書式がDD-MM-YY、短い時間書式がHH24:MI:SS、Oracle日付書式がDD-MM-YY、長い日付書式がfmDay, Month dd, yyyyに設定されています。タイムスタンプ・タイムゾーン書式は設定されていません。
ドロップダウン・メニューから選択せずに、独自のフォーマットを入力することもできます。
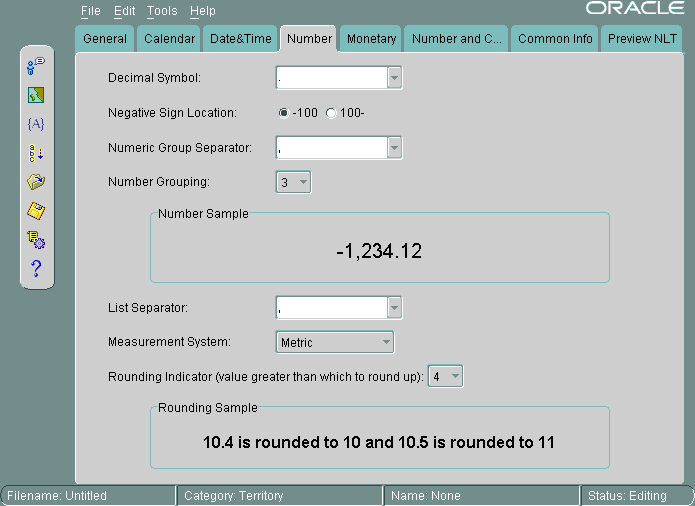
図13-13に、「数値」タブ・ページを示します。
「小数点記号」にはピリオドが選択されています。負の記号の位置は数値の左に設定されています。数値グループ・セパレータはカンマです。数値グループ化は3桁、リスト・セパレータはカンマ、測定法はメトリック、丸め指定は4に指定されています。
リストの値を使用せずに、独自の値を入力することもできます。
リストから書式を選択すると、書式の例が表示されます。
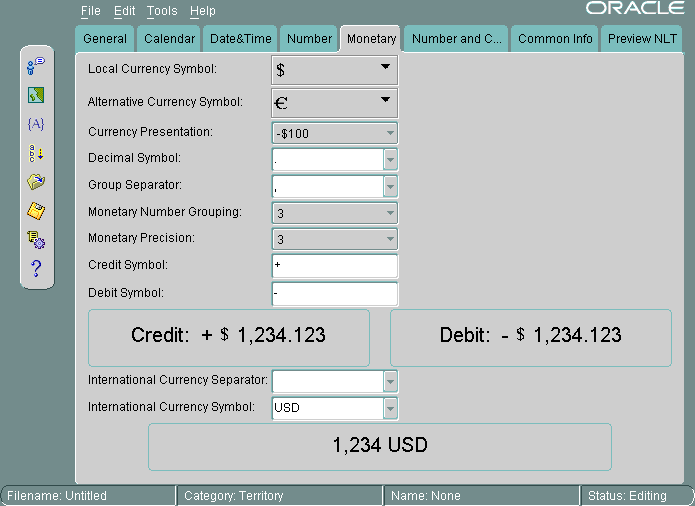
図13-14に、「通貨」タブ・ページの通貨書式の設定を示します。
各国通貨記号には$が設定されています。代替通貨記号はユーロ記号です。通貨表記には、各国通貨記号、借方記号および数値が順に並びます。「小数点記号」はピリオド、「グループ・セパレータ」はカンマ、通貨数値のグループ化は3です。通貨の精度、つまり小数点以下の桁数は3です。貸方記号は+、借方記号は-です。国際通貨セパレータは空白であるため、フィールドには表示されていません。国際通貨記号(ISO通貨記号)はUSDです。Oracle Locale Builderには、ユーザーが選択した通貨書式の例が表示されます。
リストを使用せずに、独自の値を入力することもできます。
図13-15に、「共通情報」タブ・ページを示します。
現在の地域の共通言語と共通タイム・ゾーンを表示できます。たとえば、地域がCANADAの場合、共通言語はENGLISH、CANADIAN FRENCHおよびFRENCHです。共通タイム・ゾーンは、America/Montreal、America/St_Johns、America/Halifax、America/Winnipeg、America/Regina、America/EdmontonおよびAmerica/Vancouverです。
これ以降の内容は、次のとおりです。
タイム・ゾーン・ファイルには、有効なタイム・ゾーン名が含まれています。各タイム・ゾーンには、次の情報が含まれています。
協定世界時(UTC)からのオフセット。
夏時間への移行時間。
標準時間と夏時間の略称。略称は、タイム・ゾーン名とともに使用されます。
タイム・ゾーン・ファイルはOracleデータベースのホーム・ディレクトリにあります。デフォルト・ファイルはoracore/zoneinfo/timezlrg_14.datです。一般に使用される、より小さいタイム・ゾーンは、oracore/zoneinfo/timezone_14.datに含まれています。
Oracleデータベースは、複数のカレンダをサポートしています。これらのカレンダはすべてOracleデータベースのグローバリゼーション・サポートから導出されるデータで定義されていますが、一部は、将来、元号やうるう年の追加が必要になる場合があります。Oracleデータベースの新リリースまで待たずにこの情報を追加するには、カレンダ機能の実行時に自動的にロードされる外部ファイルを使用できます。
カレンダのデータは、最初にテキスト・ファイルに定義します。このテキスト定義ファイルは、バイナリ形式に変換する必要があります。NLSカレンダ・ユーティリティ(lxegen)を使用すると、テキスト定義ファイルをバイナリ形式に変換できます。
テキスト定義ファイルの名前とlxegenユーティリティに対する位置は、プラットフォーム依存の値でハードコード化されています。UNIXプラットフォームの場合、ファイル名はlxecal.nltで、$ORACLE_HOME/nlsディレクトリにあります。テキスト定義ファイルのサンプルは、$ORACLE_HOME/nls/demoディレクトリに含まれています。デモ・ファイルのインストール方法の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。
lxegenユーティリティでは、テキスト定義ファイルからバイナリ・ファイルが生成されます。バイナリ・ファイル名もプラットフォーム依存の値でハードコード化されています。UNIXプラットフォームの場合、バイナリ・ファイル名はlxecal.nlbです。このバイナリ・ファイルは、テキスト・ファイルと同じディレクトリに生成され、既存のバイナリ・ファイルが上書きされます。
バイナリ・ファイルが生成されると、そのファイルはシステムの初期化時に自動的にロードされます。このファイルを移動したり名前を変更しないでください。
カレンダ・ユーティリティを起動するには、コマンドラインから次のように入力します。
% lxegen
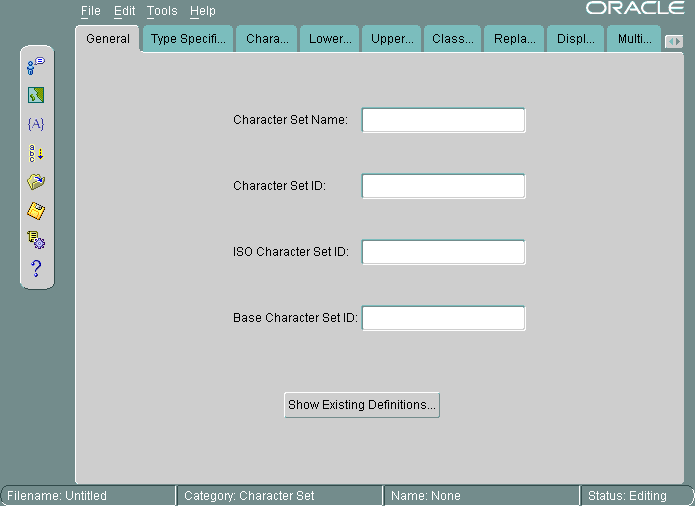
Oracle Locale Builderでは、キャラクタ・セットのコード・チャートを表示して印刷できます。Oracle Locale Builderの初期画面から「ファイル」→「新規」→「キャラクタ・セット」を選択します。図13-16に、表示される画面を示します。
「既存の定義の表示」をクリックします。表示するキャラクタ・セットを選択します。図13-17に、US7ASCIIが選択されている「既存の定義」ダイアログ・ボックスを示します。
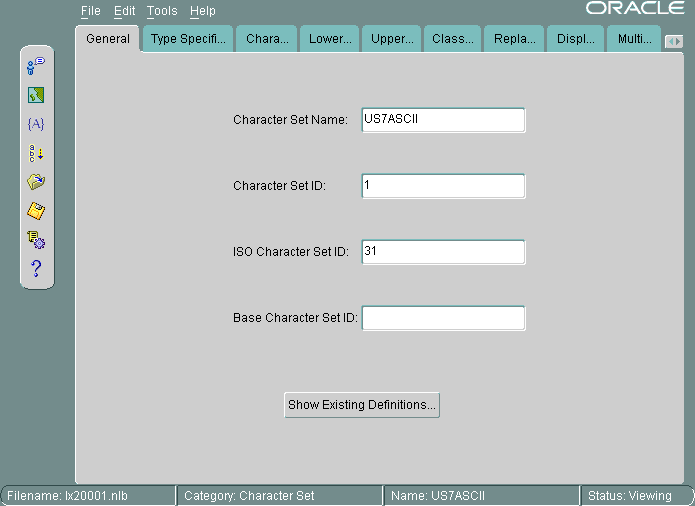
「開く」をクリックしてキャラクタ・セットを選択します。図13-18に、US7ASCIIが選択されている「一般」タブ・ページを示します。
「文字データのマッピング」タブをクリックします。図13-19に、US7ASCIIの「文字データのマッピング」タブ・ページを示します。
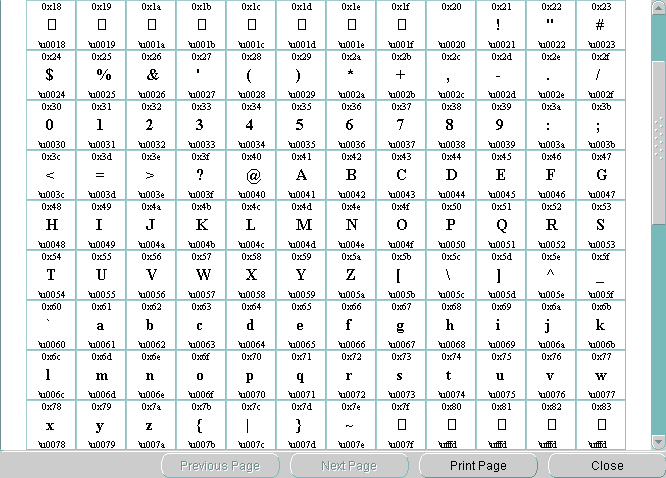
「コード・チャートの表示」をクリックします。図13-20に、US7ASCIIのコード・チャートを示します。
このコード・チャートは、ローカル・キャラクタ・セットでの各文字のエンコーディング値、各文字に関連付けられた絵文字、およびUnicode値を示しています。
コード・チャートを印刷する場合は、「ページの印刷」をクリックします。
特定のユーザーのニーズにあわせてキャラクタ・セットをカスタマイズできます。エンコードされた既存のキャラクタ・セット定義を拡張できます。ユーザー定義文字は、多くの場合、次のような文字要素を表現する特殊文字をエンコードするために使用されます。
固有名
既存のキャラクタ・セット規格で定義されていない旧漢字
ベンダー固有の文字
ユーザーが新たに定義した記号または文字
この項では、Oracle Databaseでユーザー定義文字がどのようにサポートされているかを説明します。内容は次のとおりです。
一般的に、ユーザー定義文字は東アジア諸国のキャラクタ・セットでサポートされています。東アジア諸国のキャラクタ・セットには、ユーザー定義文字を使用するために、コード・ポイントの予約域が少なくとも1つ用意されています。たとえば、日本語シフトJISでは、1880のコード・ポイントがユーザー定義文字用に確保されています。表13-1を参照してください。
表13-1 シフトJISのユーザー定義文字の範囲
| 日本語シフトJISのユーザー定義文字の範囲 | コード・ポイント数 |
|---|---|
|
F040-F07E、F080-F0FC |
188 |
|
F140-F17E、F180-F1FC |
188 |
|
F240-F27E、F280-F2FC |
188 |
|
F340-F37E、F380-F3FC |
188 |
|
F440-F47E、F480-F4FC |
188 |
|
F540-F57E、F580-F5FC |
188 |
|
F640-F67E、F680-F6FC |
188 |
|
F740-F77E、F780-F7FC |
188 |
|
F840-F87E、F880-F8FC |
188 |
|
F940-F97E、F980-F9FC |
188 |
表13-2に示すOracleキャラクタ・セットには、ユーザー定義文字をサポートする事前定義済の範囲が含まれています。
特定の文字を表すコード・ポイントの値は、キャラクタ・セットによって異なります。図13-21に、日本語の漢字を示します。
次の表に、この文字が様々なキャラクタ・セットでどのようにエンコードされるかを示します。
| Unicodeエンコーディング | JA16SJISエンコーディング | JA16EUCエンコーディング | JA16DBCSエンコーディング |
|---|---|---|---|
| 4E9C | 889F | B0A1 | 4867 |
Oracleデータベースでは、すべてのキャラクタ・セットをUnicode 5.0のコード・ポイントの見地から定義しています。つまり、それぞれの文字はUnicode 5.0のコード値として定義されています。中間フォームとしてUnicodeを使用することによって、ユーザーが意識することなく文字変換が行われます。たとえば、JA16SJISのクライアントがJA16EUCのデータベースに接続する場合、JA16SJISのクライアントから入力した図13-21の文字のコード・ポイント値は889Fとなります。この文字は内部的にUnicode(コード・ポイント値は4E9C)に変換された後、JA16EUC(コード・ポイント値はB0A1)に変換されます。
Unicode 5.0では、Private Use Area(PUA)用にE000からF8FFの範囲が予約されています。PUAは、エンド・ユーザーまたはベンダーがプライベートで使用する文字を定義するためのものです。
ユーザー定義文字は、標準文字と同様に中間フォームとしてUnicode 5.0のPUAを使用して、2つのOracleデータベース・キャラクタ・セット間で変換されます。
ユーザー定義文字を複数のオペレーティング・システムにまたがって登録する場合は、異なるキャラクタ・セット間のクロス・リファレンスが必要になります。クロス・リファレンスにより、キャラクタ・セットがUnicode PUAの値にマッピングされ、ユーザー定義文字を異なるキャラクタ・セット間で確実に正しく変換できます。
たとえば、ユーザー定義文字を日本語シフトJISのオペレーティング・システムと日本語IBMホスト・オペレーティング・システムの両方に登録する場合、この文字に対して、シフトJISのオペレーティング・システムではF040コード・ポイント、IBMホスト・オペレーティング・システムでは6941コード・ポイントの割当てができます。これによって、キャラクタ・セットJA16SJISとJA16DBCSの間で、この文字が正しくマップされます。
Oracle Locale Builderを使用してキャラクタ・セット定義を表示すると、ユーザー定義文字のクロス・リファレンス情報を検索できます。たとえば、シフトJISのUDC値F040とIBMホストのUDC値6941が、同じUnicode PUA値E000にマップされていることがわかります。
デフォルトの場合、Oracle Locale Builderは次に使用可能なキャラクタ・セットIDを生成します。独自のキャラクタ・セットIDを選択することもできます。キャラクタ・セット定義用NLTファイルのネーミングには、次の書式を使用します。
lx2dddd.nlt
ddddは、16進数で4桁のキャラクタ・セットIDです。
キャラクタ・セットを変更する場合は、次のガイドラインに従ってください。
既存の文字を再マップしないでください。
すべての文字のマッピングは一意であることが必要です。
新規文字は、Unicodeのプライベート使用範囲(e000からf4ff)にマップする必要があります。(実際のUnicode 5.0のプライベート使用範囲はe000からf8ffです。ただし、f500からf8ffはOracleデータベース固有のプライベート使用のために予約されています。)
キャラクタ・セット定義ファイルでは、1行の最大文字数は80文字です。
|
注意: 既存のキャラクタ・セットから新規のマルチバイト・キャラクタ・セットを作成する場合は、元のキャラクタ・セットとして8ビットまたはマルチバイト・キャラクタ・セットを使用してください。 |
新規キャラクタ・セットを既存のOracle Databaseキャラクタ・セットから導出する場合は、次のキャラクタ・セットのネーミング規則を使用することをお薦めします。
<Oracle_character_set_name><organization_name>EXT<version>
たとえば、Sun社などの会社がJA16EUCキャラクタ・セットにユーザー定義文字を追加する場合、適切なキャラクタ・セット名は次のようになります。
JA16EUCSUNWEXT1
このキャラクタ・セット名は、次の各部分で構成されています。
JA16EUCは、Oracle Databaseが定義したキャラクタ・セット名です。
SUNWは、会社名(Sun社の株式取引上の略称)を表します。
EXTは、JA16EUCキャラクタ・セットに対する拡張要素であることを示します。
1はバージョンを示します。
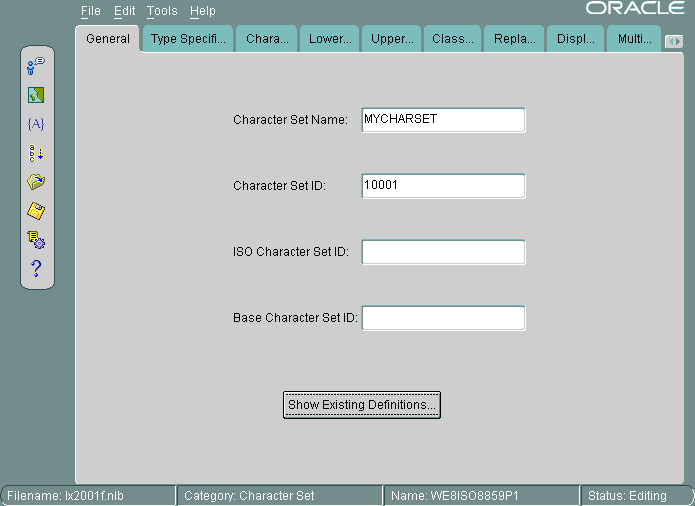
この項では、キャラクタ・セットIDに10001を指定して、新規のキャラクタ・セットMYCHARSETを作成する方法について説明します。この例では、WE8ISO8859P1キャラクタ・セットを使用して中国語の10文字を追加します。
図13-22に、MYCHARSETの「一般」タブ・ページを示します。
「既存の定義の表示」をクリックし、「既存の定義」ダイアログ・ボックスからWE8ISO8859P1キャラクタ・セットを選択します。
「ISOキャラクタ・セットID」フィールドと「基本キャラクタ・セットID」フィールドはオプションです。「基本キャラクタ・セットID」は値の継承に使用され、基本キャラクタ・セットのプロパティがテンプレートとして使用されます。「キャラクタ・セットID」は自動的に生成されますが、オーバーライドして変更することもできます。ユーザー定義キャラクタ・セットIDの有効範囲は、8000から8999または10000から20000です。
|
注意: Pro*COBOLを使用している場合は、8000から8999のキャラクタ・セットIDを選択してください。 |
ユーザー定義キャラクタ・セットの場合、「ISOキャラクタ・セットID」フィールドは空白のままです。
この例では、「基本キャラクタ・セットID」フィールドは空白のままです。ただし、テンプレートとして使用するキャラクタ・セットを指定できます。「型指定」タブ・ページの設定は、「基本キャラクタ・セットID」フィールドに入力した基本キャラクタ・セットの型設定と一致する必要があります。型設定が一致しない場合、カスタム・キャラクタ・セットの生成時にエラーが表示されます。
図13-23に、「型指定」タブ・ページを示します。
キャラクタ・セット・カテゴリはASCII_BASEDで、「BYTE_UNIQUE」ボタンが選択されています。
既存のキャラクタ・セットを選択した場合、「型指定」タブ・ページのフィールドはすでに適切な値に設定されています。変更する特別な理由がないかぎり、これらの値を保持してください。設定の変更が必要な場合は、次のガイドラインを使用します。
「FIXED_WIDTH」は、同じ長さの文字のキャラクタ・セットを示すために使用します。
「BYTE_UNIQUE」は、コード・ポイントのシングルバイト範囲がマルチバイト範囲と区別されていることを示します。先頭バイトのコードは、その文字がシングルバイトかマルチバイトかを示します。例: JA16EUC。
「DISPLAY」は、格納用ではなくクライアントでの表示用にのみ使用されるキャラクタ・セットを示します。一部のアラビア語、デーバナーガリ語およびヘブライ語のキャラクタ・セットは、表示用キャラクタ・セットです。
「SHIFT」は、シングルバイト文字とマルチバイト文字とを区別するために、追加のシフト文字が必要なキャラクタ・セットに対して使用します。
図13-24に、ユーザー定義文字の追加方法を示します。
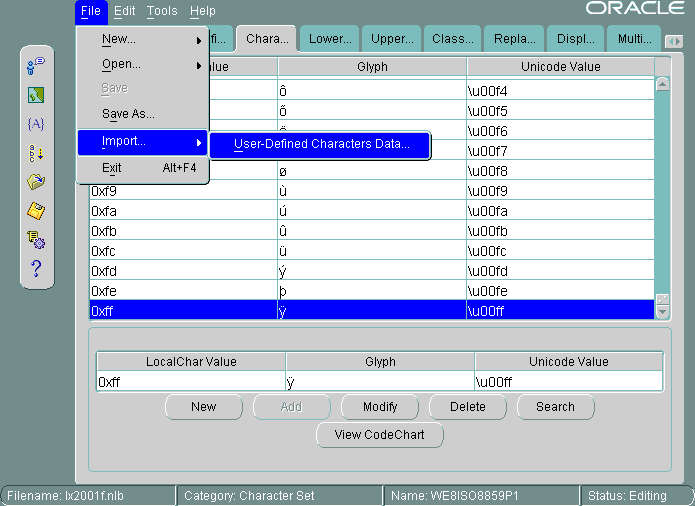
「文字データのマッピング」タブ・ページをオープンします。キャラクタ・セット内で追加する文字の前になる文字を選択します。この例では、0xffローカル文字の値が選択されています。
1回に1文字を追加することも、テキスト・ファイルを使用して大量の文字をインポートすることも可能です。この例では、テキスト・ファイルをインポートしています。最初の列は、ローカル文字の値です。2列目はUnicode値です。このファイルには、次の文字の値が含まれています。
88a2 963f 88a3 54c0 88a4 611b 88a5 6328 88a6 59f6 88a7 9022 88a8 8475 88a9 831c 88aa 7a50 88ab 60aa
「ファイル」→「インポート」→「ユーザー定義文字データ」を選択します。
図13-25に、インポートした文字をキャラクタ・セットの0xffの後に追加した状態を示します。
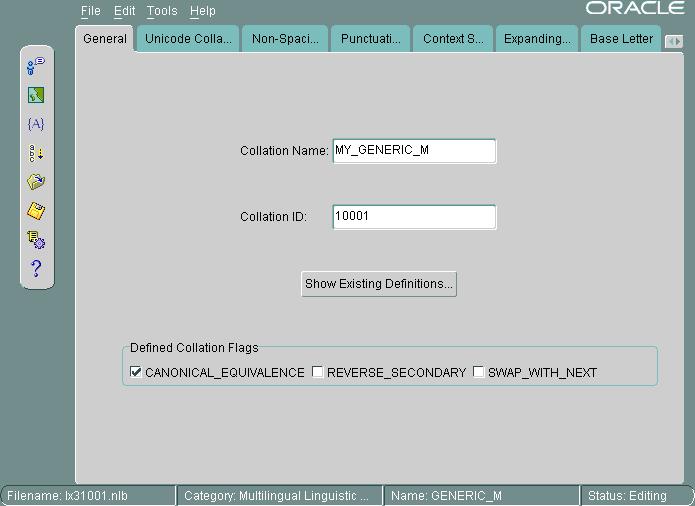
この項では、「照合ID」を10001に設定してMY_GENERIC_Mと呼ばれる新規の多言語ソートを作成する方法を示します。新規言語ソートの基礎としてGENERIC_M言語ソートを使用しています。図13-26に、この操作の開始方法を示します。
フラグの設定は、自動的に導出されます。「SWAP_WITH_NEXT」は、タイ語とラオ語のソートに関係します。「REVERSE_SECONDARY」は、フランス語のソート用です。「CANONICAL_EQUIVALENCE」は、標準的な規則を使用するかどうかを決定します。この例では、「CANONICAL_EQUIVALENCE」がオンになっています。
ユーザー定義ソートのための「照合ID」(ソートID)の有効範囲は、単一言語照合の場合は1000から2000、多言語照合の場合は10000から11000です。
図13-27に、「Unicode照合順序」タブ・ページを示します。
この例では、文字の後にソートされるように数字を移動して、言語ソートをカスタマイズします。手順は次のとおりです。
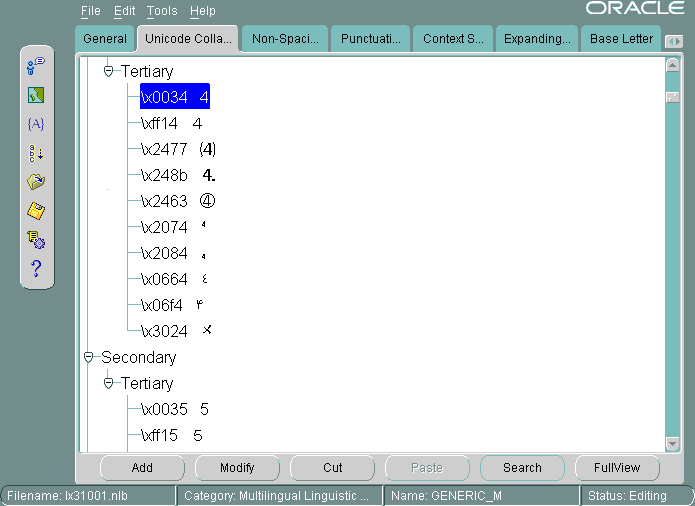
移動するUnicode値を選択します。図13-27では、\x0034 Unicode値が選択されています。「Unicode照合順序」タブ・ページでの値の位置は、ノードと呼ばれます。
「切取り」をクリックします。ノードを移動する位置を選択します。
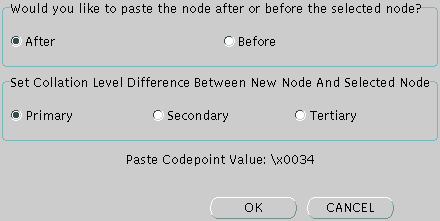
「貼付け」をクリックします。「貼付け」をクリックすると、図13-28に示す「ノードの貼付け」ダイアログ・ボックスがオープンします。
「ノードの貼付け」ダイアログ・ボックスでは、選択した位置の後にノードを貼り付けるか前に貼り付けるかを選択できます。隣に貼り付けるノードに対するノードのレベル(1次、2次または3次)を選択することもできます。
ノードを貼り付ける位置とレベルを選択します。
図13-28では、「後」ボタンと「1次」ボタンが選択されています。
「OK」をクリックしてノードを貼り付けます。
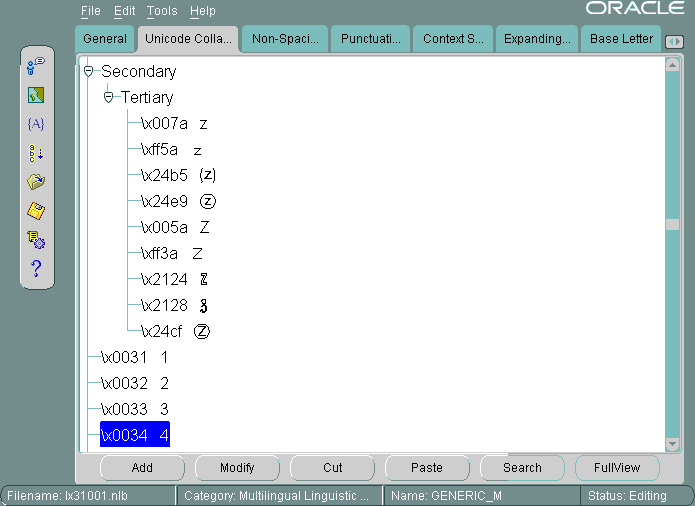
同様の手順に従って、他の数字を文字aからzの後の位置に移動します。
図13-29に、数字0から4を文字aからzの後の位置に移動した後の「Unicode照合順序」タブ・ページを示します。
これ以降の内容は、次のとおりです。
次の例に、発音区別記号付きの文字のソート順序を変更する方法を示します。そのためには、特定の発音区別記号を含むすべての文字のソート順序を変更する方法と、一度に1文字ずつ変更する方法があります。この例では、曲折アクセント記号付きの各文字(ûなど)のソート順序を、チルドが付いた同じ文字の後になるように変更します。
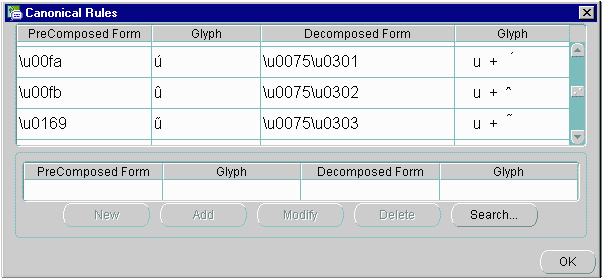
「ツール」→「標準規則」を選択して、現在のソート順序を確認します。図13-30の「標準規則」ダイアログ・ボックスが開きます。
図13-30に、アクセント記号付き文字が、対応する標準的な文字に分解される方法と現在のソート順序を示します。たとえば、ûはuと^の組合せとして表されます。
Oracle Locale Builderの照合の「一般」タブ・ページ(図13-26)で、「空白以外の文字」タブをクリックします。「空白以外の文字」タブ・ページを使用すると、発音区別記号に対する変更がすべての文字に適用されます。図13-31に、「空白以外の文字」タブ・ページを示します。
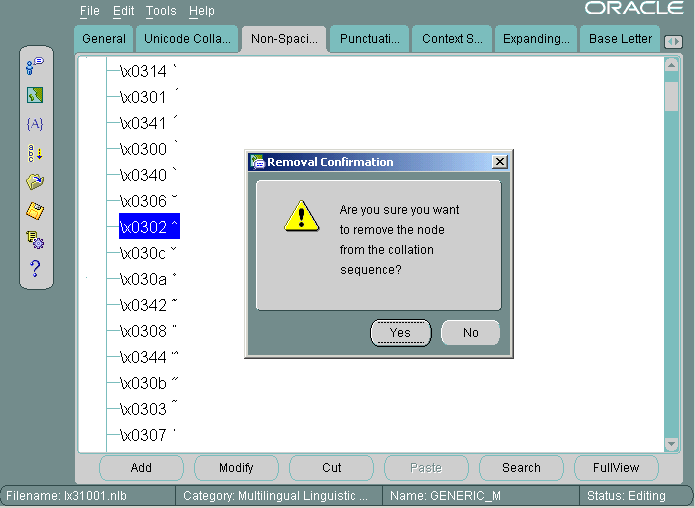
曲折アクセント記号を選択して「切取り」をクリックします。「削除の確認」ダイアログ・ボックスで「はい」をクリックします。チルドを選択して「貼付け」をクリックします。「ノードの貼付け」ダイアログ・ボックスで「後」と「2次」を選択して「OK」をクリックします。
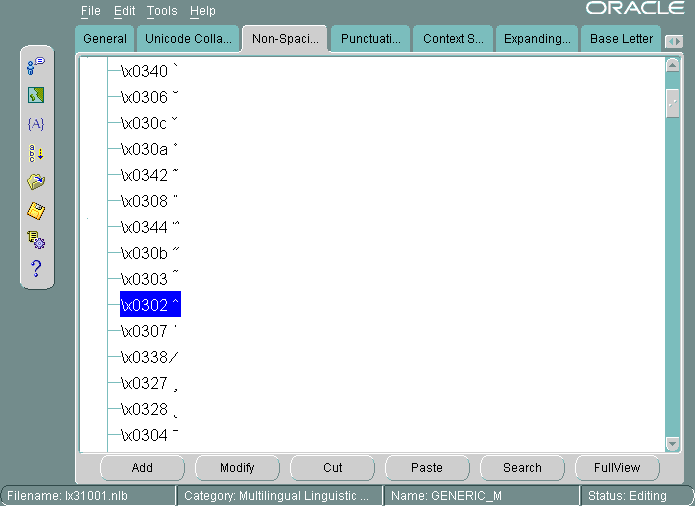
図13-32に、新しいソート順序を示します。
発音区別記号を持つ特定の文字の順序を変更するには、その文字を適切な位置に直接挿入します。発音区別記号付きの文字は「Unicode照合順序」タブ・ページに表示されないため、新しい位置へのカット・アンド・ペーストはできません。
この例では、äのソート順序をZの後にソートされるように変更します。
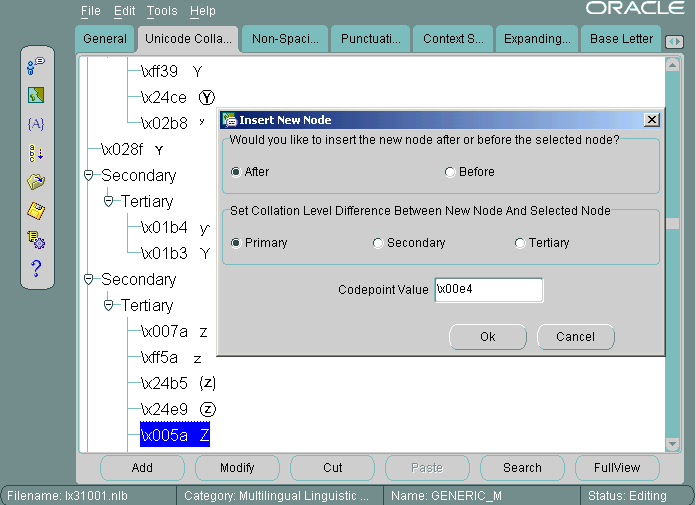
「Unicode照合」タブをクリックします。äの隣に配置する文字Zを選択します。「追加」をクリックします。図13-33の「新規ノードの挿入」ダイアログ・ボックスが表示されます。
「新規ノードの挿入」ダイアログ・ボックスで「後」と「1次」を選択します。äのUnicodeコード・ポイント値を入力します。このコード・ポイント値は、\x00e4です。「OK」をクリックします。
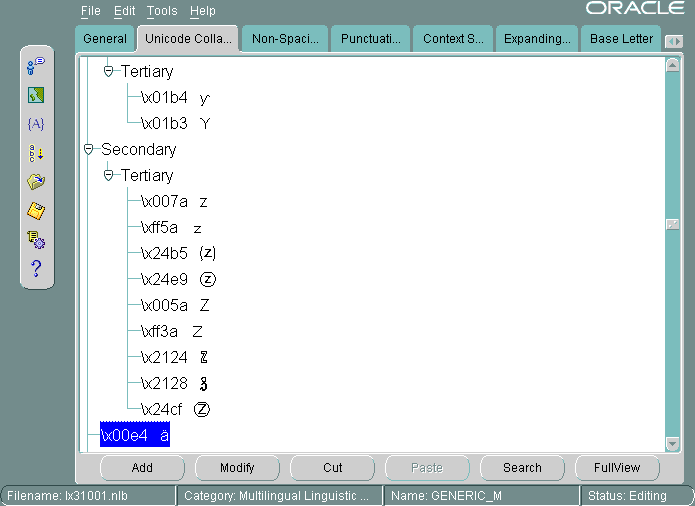
図13-34に、変更後のソート順序を示します。
新規言語、地域、キャラクタ・セットまたは言語ソートを定義した後は、NLTファイルから新規のNLBファイルを次のように生成します。
ファイルの所有者(通常はユーザーoracle)として、ORA_NLS10ディレクトリ内で、NLSインストール・ブート・ファイル(lx0boot.nlb)とNLSシステム・ブート・ファイル(lx1boot.nlb)のバックアップを作成します。UNIXプラットフォームの場合は、次のようなコマンドを入力します。
% setenv ORA_NLS10 $ORACLE_HOME/nls/data % cd $ORA_NLS10 % cp -p lx0boot.nlb lx0boot.nlb.orig % cp -p lx1boot.nlb lx1boot.nlb.orig
-pオプションを指定すると、元のファイルのタイムスタンプが保たれることに注意してください。
Oracle Locale Builderで、「ツール」→「NLBの生成」を選択するか、左側のバーで「NLBの生成」アイコンをクリックします。
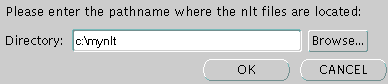
「参照」をクリックして、NLTファイルが格納されているディレクトリを検索します。位置を指定するダイアログ・ボックスは、図13-35のとおりです。
NLTファイルは指定しないでください。Oracle Locale Builderは、各NLTファイルに対してNLBファイルを生成します。
「OK」をクリックしてNLBファイルを生成します。
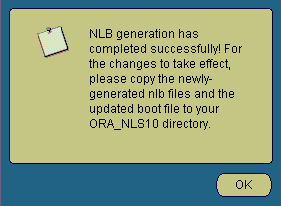
図13-36は、ディレクトリ内の全NLTファイルに対してNLBファイルが正常に生成されたことを示す最終的な通知を示しています。
lx1boot.nlbファイルをORA_NLS10環境変数で指定したパスにコピーします。たとえば、UNIXプラットフォームの場合は、次のようなコマンドを入力します。
% cp /directory_name/lx1boot.nlb $ORA_NLS10/lx1boot.nlb
新規のNLBファイルをORA_NLS10ディレクトリにコピーします。たとえば、UNIXプラットフォームの場合は、次のようなコマンドを入力します。
% cp /directory_name/lx22710.nlb $ORA_NLS10 % cp /directory_name/lx52710.nlb $ORA_NLS10
|
注意: Oracle Locale Builderでは、NLTファイルと同じディレクトリにNLBファイルが生成され、一般的には../nlsrtl3/admin/dataです。 |
新規に作成したロケール・データを使用できるように、データベースを再起動します。
新規のロケール・データをクライアント側で使用するには、NLBファイルをインストールしてからクライアントを終了し、再起動します。
ロケール・カスタマイズ・ファイルを、同じOracleデータベースのリリースで動作し、かつ同じオペレーティング・システム・プラットフォームを使用する他のOracleデータベースのインストールにデプロイする場合、すべてのカスタムNLBファイルとlx1boot.nlbファイルをターゲット・マシンにコピーする必要があります。カスタムNLBファイルを別のプラットフォームにデプロイするには、カスタム.NLTファイルを新規プラットフォームにコピーしてから、「NLBファイルの生成とインストール」の項で説明しているNLBの生成とインストールの手順を繰り返す必要があります。
ロケール定義ファイルは、データベースのリリースに依存しています。たとえば、Oracle Database 9iおよびOracle Database 10gのNLBファイルは、Oracle Database 11gリリース1などで直接サポートされていません。ロケール・カスタマイズ・ファイルを旧リリースのデータベースから現行のリリースに移行するには、最初にこのファイルを最新のNLT形式に変換する必要があります。そのためには、ロケール・カスタマイズ・ファイル(NLBまたはNLT)をロードし、現行バージョンのOracle Locale Builderを使用してこれらのファイルを個別にNLTファイルに保存します。次に、「NLBファイルの生成とインストール」の項で説明しているNLBの生成とインストールの手順を繰り返す必要があります。
Oracle Locale Builderは、旧バージョンのNLTファイルおよびNLBファイルの読込みと処理、さらに別のプラットフォームからのこれらのファイルの読込みと処理が可能である点に注意してください。ただし、Oracle Locale Builderでは、インストールされているOracle Databaseのリリースの最新の書式でNLTファイルが保存および生成されます。
あるプラットフォーム上で生成されるNLBデータを、FTPまたはその他のコピー・ユーティリティを使用して別のプラットフォームに転送できます。転送されたNLBファイルは、元のプラットフォームで生成されたNLBファイルと同じ方法で使用できます。たとえば、Solarisプラットフォーム上で生成されたNLBファイルをFTPでWindowsプラットフォームにコピーし、そこで同じ機能を提供できます。これにより、あるプラットフォームでロケール・データを変更して他のプラットフォームにコピーできるため便利です。プラットフォーム間では、変更があったファイルのみでなく、すべてのNLBファイルをコピーする必要があることに注意してください。また、「NLBファイルの生成とインストール」の操作の実行方法は、以前のリリースと同じであることにも注意してください。
NLBのロード中には、様々なバイナリ形式(32ビット、64ビット、ビッグ・エンディアン、リトル・エンディアン、ASCIIおよびEBCDICなど)が、透過的に処理されます。
ginstallユーティリティは、使用するアプリケーションのJavaコンポーネントにカスタム・キャラクタ・セット、言語、地域、および言語ソートを追加します。Locale Builderを使用して、カスタム・キャラクタ・セット、言語、地域、および言語ソートを定義します。カスタム定義を含むNLTファイルがLocale Builderによって生成されます。カスタム定義をJavaコンポーネントを追加するには、ginstallを実行してgdk_custom.jarを生成します。Oracle Databaseリリース10.2および10.1でも、リリース11.1および11.2と同様の手順を使用できます。
キャラクタ・セット、言語、地域、および言語ソートにカスタム定義を追加する手順は、次のとおりです。
Oracle Locale Builderを使用して、NLTファイルを生成します。
カスタムのNLBファイルを旧リリースからアップグレードする場合、「旧リリースOracle DatabaseからのカスタムNLBファイルのアップグレード」で説明する手順に従ってください。
ginstallを-addまたは-aオプションを指定して実行し、gdk_custom.jarを生成します。
ginstall –[add | a] lx2dddd.nlt
NLTファイルを生成する手順は、次のとおりです。
ginstall -[add | a] lx2ddd.nlt lx2dddd.nlt lx2dddd.nlt
gdk_custom.jarを、orai18n.jarまたはorai18n-mapping.jarと同じディレクトリにコピーします。
カスタム定義を削除する手順は、次のとおりです。
次のようにして、ginstallを実行します。
ginstall –[remove | r] <path to gdk_custom.jar> <name of NLT file>
カスタム定義を更新する手順は、次のとおりです。
次のようにして、ginstallを実行します。
ginstall –[update | u] <path to gdk_custom.jar> <name of NLT file>