| Oracle® Databaseグローバリゼーション・サポート・ガイド 11gリリース2 (11.2) B56307-04 |
|


 前 |
 次 |
この章では、キャラクタ・セットの選択方法について説明します。この章の内容は、次のとおりです。
文字を処理する場合、コンピュータ・システムは文字をグラフィカルな表現としてではなく数値コードとして処理します。たとえば、データベースに文字Aを格納すると、実際はコンピュータ・システムによって解析される数値コードが格納されます。特に、異なるキャラクタ・セット間のデータ変換を必要とする可能性があるグローバル環境では、この数値コードが重要になります。
この項の内容は、次のとおりです。
データベースの作成時に、エンコードされたキャラクタ・セットを指定します。キャラクタ・セットの選択によって、データベース内で表現できる言語が決定します。また、キャラクタ・セットの選択は次の方法にも影響します。
データベース・スキーマの作成方法
文字データを処理するアプリケーションの開発方法
オペレーティング・システムでのデータベースの動作
データベースのパフォーマンス
キャラクタ・データの格納に必要な記憶域
特定の文字グループ(アルファベット文字、表意文字、記号、句読点、制御文字など)をキャラクタ・セットとしてエンコードできます。エンコードされたキャラクタ・セットは、キャラクタ・セット内のそれぞれの文字を表す一意の数値コードに対応しています。数値コードはコード・ポイントまたはエンコーディング値と呼ばれます。表2-1に、ASCIIキャラクタ・セットの16進コード値が割り当てられている文字の例を示します。
表2-1 ASCIIキャラクタ・セットでエンコードされた文字
| 文字 | 説明 | 16進コード値 |
|---|---|---|
|
! |
感嘆符 |
21 |
|
# |
数値記号 |
23 |
|
$ |
ドル記号 |
24 |
|
1 |
数字の1 |
31 |
|
2 |
数字の2 |
32 |
|
3 |
数字の3 |
33 |
|
A |
大文字のA |
41 |
|
B |
大文字のB |
42 |
|
C |
大文字のC |
43 |
|
a |
小文字のa |
61 |
|
b |
小文字のb |
62 |
|
c |
小文字のc |
63 |
コンピュータ業界では、様々にエンコードされたキャラクタ・セットが使用されています。各キャラクタ・セットは、次の点で異なります。
Oracle Databaseでは、各国の規格、国際規格およびベンダー固有のエンコードされたキャラクタ・セット規格のほとんどすべてがサポートされています。
キャラクタ・セットでエンコードされる文字は、表現する記述法によって異なります。記述法は、1つの言語または1つの言語グループを表現するために使用できます。記述法は次の2つに分類できます。
この項の内容は、次のとおりです。
表音的記述法は、1つの言語に対応付けられた様々な音声を表現する、複数の記号で構成されています。たとえば、ギリシア語、ラテン語、キリル文字およびデーバナーガリ語はすべて、アルファベットに基づいた表音的記述法です。アルファベットは、複数の言語を表現できます。たとえば、ラテン・アルファベットでは、多くの西ヨーロッパ諸国の言語(フランス語、ドイツ語、英語など)を表現できます。
表音的記述法に対応付けられた文字は、文字レパートリが通常256文字より少ないため、一般的には1バイトでエンコードできます。
表意的記述法は、言語の音声ではなく、単語の意味を表す表意文字または象形文字で構成されています。中国語と日本語は、何万という表意文字に基づいた表意的記述法の例です。表意的記述法を使用する言語では、表音文字セットを使用する場合もあります。表音文字セットでは、追加の表音的情報を伝達する方法が提供されます。たとえば、日本語には2つの表音文字セットがあり、通常、文法的な要素にはひらがなが、外来語や擬音語にはカタカナが使用されます。
表意的記述法に対応付けられた文字は、文字のレパートリが何万とあるため、一般的には複数バイトでエンコードします。
言語スクリプトのエンコーディングに加えて、次のように他の特殊文字もエンコードする必要があります。
カンマ、ピリオドおよびアポストロフィなどの句読点
数字
通貨記号や数学演算子などの特殊な記号
キャリッジ・リターンやタブなどの制御文字
ほとんどの欧米言語は、ページの上から下へ向かって左から右へ記述されます。東アジアの言語は、通常、ページの右から左に向かって上から下へ記述されますが、欧米言語から翻訳された技術文書ではしばしば例外が見られます。アラビア語とヘブライ語は、上から下へ向かって右から左へ記述されます。
アラビア語とヘブライ語では、数字の記述方向が逆になります。テキストが右から左に書かれている場合でも、文中の数字は左から右に向かって書かれます。たとえば、「I wrote 32 books」は「skoob 32 etorw I」と書かれます。書込み方向に関係なく、データは論理順序で格納されます。論理順序は、入力している言語の画面上での表示方法ではなく、その言語の入力で使用されている順序を意味します。
記述方向は、文字のエンコーディングには影響しません。
様々なキャラクタ・セットによって、様々な文字レパートリがサポートされています。一般的に、キャラクタ・セットは特定の書込みスクリプトに基づいているため、複数の言語をサポートできます。キャラクタ・セットが最初に開発されたとき、文字レパートリには制限がありました。今でも、特定の文字を複数のプラットフォームで使用すると、問題が発生する場合があります。次のCHAR文字およびVARCHAR文字は、すべてのOracleデータベース・キャラクタ・セットで表示可能で、どのプラットフォームにもトランスポートできます。
大文字と小文字の英文字: AからZおよびaからz
アラビア数字: 0から9
句読点記号: % ' ' ( ) * + - , . / \ : ; < > = ! _ & ~ { } | ^ ? $ # @ " [ ]
制御文字: スペース、水平タブ、垂直タブ、改ページ
これ以外の文字を使用する場合は、選択したデータベース・キャラクタ・セットでデータがサポートされているかどうか注意する必要があります。
適切なデータ変換を行うには、NLS_LANGパラメータを適切に設定する必要があります。NLS_LANGパラメータでは、クライアント・オペレーティング・システムの設定を反映するキャラクタ・セットを指定してください。NLS_LANGを適切に設定すると、クライアント・オペレーティング・システムの文字コード体系からデータベース・キャラクタ・セットへと適切に変換できます。これらの設定が同じときは、Oracle Databaseによって、送受信されるデータはデータベース・キャラクタ・セットと同一のキャラクタ・セットでエンコードされているとみなされるため、キャラクタ・セットの妥当性チェックや変換が行われない場合があります。このため、変換が必要な場合は、データが破損する可能性があります。
キャラクタ・セット間での変換中に、Oracleはクライアント側のデータがNLS_LANGパラメータで指定されたキャラクタ・セットでエンコードされるものと想定します。文字列に(たとえば、CHRまたはCONVERT SQL関数を使用して)他の値を入力すると、その値は、データベースに送信されたときに、適切に変換されないため損われる可能性があります。環境を適切に構成しており、データベース・キャラクタ・セットでデータベースに入力される可能性のある文字データのレパートリ全体がサポートされていれば、現行のデータベース・キャラクタ・セットを変更する必要はありません。ただし、企業がよりグローバルになり、追加の文字や新規の言語のサポートが必要になった場合は、より大きな文字レパートリを持つキャラクタ・セットの選択が必要になる可能性があります。このような場合は、Unicodeデータベースとデータ型の使用をお薦めします。
|
関連項目:
|
表2-2に、ASCIIキャラクタ・セットがどのようにエンコードされているかを示します。行および列のヘッダーは、16進数字を示しています。文字のコード値を調べるには、列の数字の次に行の数字を読みます。たとえば、文字Aのコード値は0x41です。
表2-2 7ビットASCIIキャラクタ・セット
| - | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
|
0 |
NUL |
DLE |
SP |
0 |
@ |
P |
' |
p |
|
1 |
SOH |
DC1 |
! |
1 |
A |
Q |
a |
q |
|
2 |
STX |
DC2 |
" |
2 |
B |
R |
b |
r |
|
3 |
ETX |
DC3 |
# |
3 |
C |
S |
c |
s |
|
4 |
EOT |
DC4 |
$ |
4 |
D |
T |
d |
t |
|
5 |
ENQ |
NAK |
% |
5 |
E |
U |
e |
u |
|
6 |
ACK |
SYN |
& |
6 |
F |
V |
f |
v |
|
7 |
BEL |
ETB |
' |
7 |
G |
W |
g |
w |
|
8 |
BS |
CAN |
( |
8 |
H |
X |
h |
x |
|
9 |
TAB |
EM |
) |
9 |
I |
Y |
i |
y |
|
A |
LF |
SUB |
* |
: |
J |
Z |
j |
z |
|
B |
VT |
ESC |
+ |
; |
K |
[ |
k |
{ |
|
C |
FF |
FS |
, |
< |
L |
\ |
l |
| |
|
D |
CR |
GS |
- |
= |
M |
] |
m |
} |
|
E |
SO |
RS |
. |
> |
N |
^ |
n |
~ |
|
F |
SI |
米国 |
/ |
? |
O |
_ |
o |
DEL |
世界中のユーザーの要求を満たすために言語は拡張されて、新規キャラクタ・セットが作成されました。一般的に、この新規キャラクタ・セットでは、同じスクリプトに基づいた関連のある言語グループがサポートされています。たとえば、ISO 8859キャラクタ・セット・シリーズは、多様なヨーロッパ諸国の言語をサポートするために作成されました。表2-3に、ISO 8859キャラクタ・セットでサポートされている言語を示します。
表2-3 lSO 8859キャラクタ・セット
| 規格 | サポートしている言語 |
|---|---|
|
ISO 8859-1 |
西ヨーロッパ諸国の言語(アルバニア語、バスク語、ブルトン語、カタロニア語、デンマーク語、オランダ語、英語、フェロー語、フィンランド語、フランス語、ドイツ語、グリーンランド語、アイスランド語、アイルランドのゲール語、イタリア語、ラテン語、ルクセンブルク語、ノルウェー語、ポルトガル語、レートロマンス語、スコットランドのゲール語、スペイン語、スウェーデン語) |
|
ISO 8859-2 |
東ヨーロッパ諸国の言語(アルバニア語、クロアチア語、チェコ語、英語、ドイツ語、ハンガリー語、ラテン語、ポーランド語、ルーマニア語、スロバキア語、スロベニア語、セルビア語) |
|
ISO 8859-3 |
南東ヨーロッパ諸国の言語(アフリカーンス語、カタロニア語、オランダ語、英語、エスペラント語、ドイツ語、イタリア語、マルタ語、スペイン語、トルコ語) |
|
ISO 8859-4 |
北ヨーロッパ諸国の言語(デンマーク語、英語、エストニア語、フィンランド語、ドイツ語、グリーンランド語、ラテン語、ラトビア語、リトアニア語、ノルウェー語、サーミ語、スロベニア語、スウェーデン語) |
|
ISO 8859-5 |
東ヨーロッパ諸国の言語(キリル文字ベース: ブルガリア語、ベラルーシ語、マケドニア語、ロシア語、セルビア語、ウクライナ語) |
|
ISO 8859-6 |
アラビア語 |
|
ISO 8859-7 |
ギリシア語 |
|
ISO 8859-8 |
ヘブライ語 |
|
ISO 8859-9 |
西ヨーロッパ諸国の言語(アルバニア語、バスク語、ブルトン語、カタロニア語、コーンウォール語、デンマーク語、オランダ語、英語、フィンランド語、フランス語、フリースランド語、ガリシア語、ドイツ語、グリーンランド語、アイルランドのゲール語、イタリア語、ラテン語、ルクセンブルク語、ノルウェー語、ポルトガル語、レートロマンス語、スコットランドのゲール語、スペイン語、スウェーデン語、トルコ語) |
|
ISO 8859-10 |
北ヨーロッパ諸国の言語(デンマーク語、英語、エストニア語、フェロー語、フィンランド語、ドイツ語、グリーンランド語、アイスランド語、アイルランドのゲール語、ラテン語、リトアニア語、ノルウェー語、サーミ語、スロベニア語、スウェーデン語) |
|
ISO 8859-13 |
バルト海沿岸諸国の言語(英語、エストニア語、フィンランド語、ラテン語、ラトビア語、ノルウェー語) |
|
ISO 8859-14 |
ケルト系言語(アルバニア語、バスク語、ブルトン語、カタロニア語、コーンウォール語、デンマーク語、英語、ガリシア語、ドイツ語、グリーンランド語、アイルランドのゲール語、イタリア語、ラテン語、ルクセンブルク語、マン島のゲール語、ノルウェー語、ポルトガル語、レートロマンス語、スコットランドのゲール語、スペイン語、スウェーデン語、ウェールズ語) |
|
ISO 8859-15 |
西ヨーロッパ諸国の言語(アルバニア語、バスク語、ブルトン語、カタロニア語、デンマーク語、オランダ語、英語、エストニア語、フェロー語、フィンランド語、フランス語、フリースランド語、ガルシア語、ドイツ語、グリーンランド語、アイスランド語、アイルランドのゲール語、イタリア語、ラテン語、ルクセンブルク語、ノルウェー語、ポルトガル語、レートロマンス語、スコットランドのゲール語、スペイン語、スウェーデン語) |
これまで、キャラクタ・セットは、多言語を制限付きでサポートしてきました。この制限とは、類似するスクリプトに基づく言語グループにかぎりサポートしてきたという意味です。最近では、ユニバーサル・キャラクタ・セットが、多言語サポートのための有効なソリューションになってきました。Unicodeは、このようなユニバーサル・キャラクタ・セットの1つで、現代の主要なスクリプトのほとんどを包含しています。バージョン5.0の時点で、Unicodeは99,000文字以上をサポートしています。
コンピュータ業界では、様々なタイプのコード体系が作成されてきました。選択するキャラクタ・セットによって、使用するコード体系の種類が異なります。コード体系には様々なパフォーマンス特性があります。これらの特性は、データベース・スキーマやアプリケーションの開発に影響を及ぼす場合があります。選択したキャラクタ・セットは、次のコード体系のいずれかを使用します。
シングルバイト・コード体系は効率的です。シングルバイトの1文字は1バイトで表現されるため、文字を表現するのに必要な領域量が最も小さく、処理およびプログラミングでの使用が容易です。シングルバイト・コード体系は、次のいずれかのタイプとして分類されます。
シングルバイト7ビット・コード体系は、128文字までの文字を定義でき、通常、1つの言語のみをサポートします。最も一般的なシングルバイト・キャラクタ・セットは、ASCII(American Standard Code for Information Interchange)で、コンピュータ処理の初期から使用されています。
シングルバイト8ビット・コード体系は、256文字までの文字を定義でき、通常、1つの関連言語グループをサポートします。たとえば、ISO 8859-1は、西ヨーロッパ諸国の多数の言語をサポートしています。図2-1に、ISO 8859-1の8ビット・コード体系を示します。
マルチバイト・コード体系は、中国語や日本語のようなアジア言語の表意文字をサポートするために必要です。これは、中国語や日本語では何千という文字が使用されるためです。このコード体系では、各文字を表現するために固定または可変のバイト数を使用します。
固定幅マルチバイト・コード体系では、各文字が固定のバイト数で表現されます。マルチバイト・コード体系では、バイト数は2以上です。
可変幅コード体系は、1バイト以上を使用して1つの文字を表現します。一部のマルチバイト・コード体系は、特定のビットを使用して、1文字を表現するためのバイト数を示します。たとえば、1文字の表現に使用する最大のバイト数が2バイトの場合は、最上位ビットを使用して、そのバイトがシングルバイト文字であるか、ダブルバイト文字の1番目のバイトであるかを示します。
一部の可変幅コード体系では、制御コードを使用して、同じコード値を持つシングルバイト文字とマルチバイト文字が区別されます。シフトアウト・コードは後続の文字がマルチバイトであることを示します。シフトイン・コードは後続の文字がシングルバイトであることを示します。シフト・センシティブ・コード体系は、主にIBMプラットフォームで使用されます。ISO-2022キャラクタ・セットは、データベース・キャラクタ・セットとしては使用できませんが、メール・サーバーなどのアプリケーションには使用できることに注意してください。
Oracleデータベースのキャラクタ・セット名には、次のネーミング規則が使用されます。
<region><number of bits used to represent a character><standard character set name>[S|C]
名前のうち山カッコで囲まれた各部は連結されます。オプションのSまたはCを使用して、サーバー(S)またはクライアント(C)でのみ使用できるキャラクタ・セットを区別します。
|
注意: 次の点に注意してください。
|
表2-4に、Oracle Databaseのキャラクタ・セット名の例を示します。
シングルバイト・キャラクタ・セットの場合、文字列のバイト数と文字数は同じです。マルチバイト・キャラクタ・セットの場合は、1文字または1つのコード・ポイントが1つ以上のバイトで構成されています。可変幅キャラクタ・セットの場合は、バイト長に基づく文字数の計算が困難な場合があります。列の長さをバイト数単位で計算することをバイト・セマンティクス、文字数単位で計算することをキャラクタ・セマンティクスと呼びます。
キャラクタ・セマンティクスは、可変幅のマルチバイト文字列の記憶要件を定義する場合に役立ちます。たとえば、Unicodeデータベース(AL32UTF8)で、VARCHAR2列を英語の5文字とともに最大5文字の中国語文字を格納できるように定義する必要があるとします。バイト・セマンティクスを使用すると、この列には、長さ3バイトである中国語文字用に15バイトと、長さ1バイトである英語文字用に5バイト、合計20バイトが必要です。キャラクタ・セマンティクスを使用すると、この列に必要な文字数は10となります。
次の式では、バイト・セマンティクスが使用されています。
VARCHAR2(20 BYTE)
SUBSTRB(string, 1, 20)
VARCHAR2式のBYTE修飾子とSQL関数名のB接尾辞に注意してください。
次の式では、キャラクタ・セマンティクスが使用されています。
VARCHAR2(10 CHAR)
SUBSTR(string, 1, 10)
VARCHAR2式のCHAR修飾子に注意してください。
文字データ型の列、ユーザー定義タイプ属性、PL/SQL変数の長さセマンティックスは、それぞれの定義でBYTEまたはCHAR修飾子を使用して明示的に指定できます。DDL文の作成で必要なセマンティックスが正しく記述され、DDL文が実行環境に非依存になるため、この方法で長さセマンティックスを指定することをお薦めします。
列、ユーザー定義タイプ属性またはPL/SQL変数の定義にBYTE修飾子もCHAR修飾子も含まれない場合、列、属性または変数に関連する長さセマンティックスは、セッション・パラメータNLS_LENGTH_SEMANTICSの値によって決定されます。レガシー・スクリプトを使用してデータベース・オブジェクトを作成する際、そのスクリプトが非常に大きく複雑で明示的にBYTEまたはCHAR修飾子を含めて更新できない場合、必要なセマンティックスでオブジェクトが作成されるように、各スクリプトを実行する前に明示的にALTER SESSION SET NLS_LENGTH_SEMANTICS文を実行します。
NLS_LENGTH_SEMANTICS初期化パラメータは、新しいセッションのNLS_LENGTH_SEMANTICSセッション・パラメータのデフォルト値を決定します。デフォルト値はBYTEです。Oracle SQLにキャラクタ長さセマンティックスが導入される前に記述された可能性のある既存のアプリケーション・インストール手順と互換性を保つために、この初期化パラメータを未定義のままにするか、BYTEに設定することをお薦めします。そうでない場合、作成された列が予想よりも大きいために、アプリケーション障害が発生したり、場合によってはバッファ・オーバーフローが発生する可能性があります。
バイト・セマンティクスは、データベース・キャラクタ・セットのデフォルトです。文字長セマンティクスはNCHARデータ型のデフォルトであり、このデータ型に使用できる唯一の長さセマンティクスです。NCHARの定義には、CHARまたはBYTE修飾子を指定できません。
次の例を考えてみます。
CREATE TABLE employees
( employee_id NUMBER(4) , last_name NVARCHAR2(10) , job_id NVARCHAR2(9) , manager_id NUMBER(4) , hire_date DATE , salary NUMBER(7,2) , department_id NUMBER(2) ) ;
NCHARのキャラクタ・セットがAL16UTF16の場合、last_nameに保持できるのは最大10個のUnicodeコード・ポイントです。NCHARのキャラクタ・セットがAL16UTF16の場合、last_nameに保持できるのは最大20バイトです。
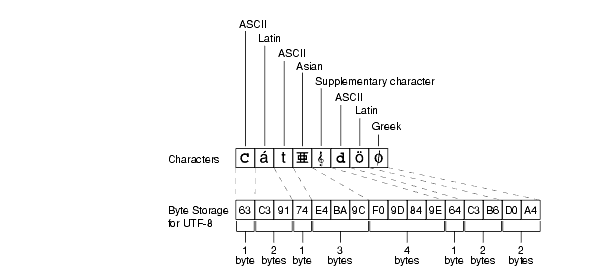
図2-2に、UTF-8キャラクタ・セットで各種文字を格納するために必要なバイト数を示します。ASCII文字には1バイト、ラテン語文字とギリシャ語文字には2バイト、アジア言語の文字には3バイト、補助文字には4バイトの記憶域が必要です。
|
関連項目:
|
Oracleデータベースでは、次の項目でデータベース・キャラクタ・セットを使用します。
データベースで使用される文字コード体系は、CREATE DATABASE文の一部として定義されます。データ・ディクショナリ内の列を含めて、すべてのSQL CHARデータ型列(CHAR、CLOB、VARCHAR2およびLONG)のデータは、データベース・キャラクタ・セットに格納されます。さらに、選択するデータベース・キャラクタ・セットによって、データベース内のオブジェクトに名前を指定できる文字が決定されます。SQL NCHARデータ型列(NCHAR、NCLOBおよびNVARCHAR2)では、各国語キャラクタ・セットが使用されます。
データベースの作成後は、一部の例外を除いて、データベースを再作成せずにキャラクタ・セットを変更することはできません。
データベース用のOracle Databaseキャラクタ・セットを選択する場合は、次の項目について考慮する必要があります。
データベースでサポートする必要がある言語
データベースで将来サポートが必要になる言語
キャラクタ・セットがオペレーティング・システムで使用可能かどうか
クライアントで使用するキャラクタ・セット
そのキャラクタ・セットがアプリケーションで適切に処理されるかどうか
キャラクタ・セットがパフォーマンスに与える影響
キャラクタ・セットに関連付けられている制限
Oracle Databaseキャラクタ・セットのリストは、「キャラクタ・セット」を参照してください。Oracleキャラクタ・セット名は、言語とそれが使用される地域に基づいています。地域名が付いている一部のキャラクタ・セットは、リストに言語でも明示的に示されています。
あるキャラクタ・セットに含まれている文字を確認するには、次の方法があります。
各国製品、国際的製品またはベンダー製品のドキュメントあるいは規格ドキュメントをチェックします。
Oracle Locale Builderを使用します。
この項の内容は、次のとおりです。
複数のキャラクタ・セットを使用して現在の言語要件を満たすことができる可能性があります。データベース・キャラクタ・セットの選択時には、将来の言語要件を考慮してください。将来、追加の言語サポートが必要になると思われる場合は、後で異なるキャラクタ・セットへの移行が必要にならないように、その言語をサポートしているキャラクタ・セットを選択します。
Oracleデータベースには独自のグローバリゼーション・アーキテクチャがあるため、データベース・キャラクタ・セットはオペレーティング・システムに依存しません。たとえば、英語版Windowsオペレーティング・システムで、日本語キャラクタ・セットを使用してデータベースを作成し、稼働させることができます。ただし、クライアントのオペレーティング・システム上のアプリケーションがそのデータベースにアクセスするには、適切なフォントと入力メソッドでデータベース・キャラクタ・セットをサポートできる必要があります。たとえば、英語版Windowsオペレーティング・システムでは、先に日本語フォントと入力メソッドをインストールしなければ、日本語データの挿入や取出しができません。日本語のデータを挿入および取得するもう1つの方法として、リモートで日本語オペレーティング・システムを使用してデータベース・サーバーにアクセスする方法もあります。
クライアントのオペレーティング・システム上のキャラクタ・セットと異なるデータベース・キャラクタ・セットを選択した場合、Oracleデータベースでは、オペレーティング・システムのキャラクタ・セットをデータベース・キャラクタ・セットに変換できます。キャラクタ・セット変換には、次のデメリットがあります。
データ消失の可能性
オーバーヘッドの増加
キャラクタ・セット変換がデータ消失の原因になる場合があります。たとえば、キャラクタ・セットAをキャラクタ・セットBに変換する場合、変換先のキャラクタ・セットBには、Aと同じキャラクタ・セット・レパートリが含まれている必要があります。キャラクタ・セットBで使用できない文字は、置換文字に変換されます。この置換文字は、多くの場合、疑問符や言語的に関連する文字で指定されます。たとえば、ä(ウムラウト付きのa)は、aに変換できます。分散環境の場合には、類似した文字レパートリを持つキャラクタ・セットを使用してデータ消失を回避してください。
キャラクタ・セット変換では、データがクライアントに到達するまでに文字列が何度もバッファ間でコピーされる場合があります。データベース・キャラクタ・セットは、常に、クライアントのオペレーティング・システム固有のキャラクタ・セットと同等か、そのスーパーセットである必要があります。通常は、データベースにアクセスするクライアント・アプリケーションのキャラクタ・セットによって、最適なスーパーセットが決定します。
すべてのクライアント・アプリケーションが同じキャラクタ・セットを使用している場合は、そのキャラクタ・セットが、通常、データベース・キャラクタ・セットとして最善の選択肢です。複数のクライアント・アプリケーションが異なるキャラクタ・セットを使用している場合、データベース・キャラクタ・セットは、クライアントのすべてのキャラクタ・セットのスーパーセットである必要があります。これによって、クライアント・キャラクタ・セットからデータベース・キャラクタ・セットへの変換時に、すべての文字が確実に受け渡されます。
最適なパフォーマンスのためには、変換が不要なキャラクタ・セットを選択し、使用言語にとって最も効率的なエンコーディングを使用してください。シングルバイト・キャラクタ・セットは、パフォーマンスの点で、マルチバイト・キャラクタ・セットよりも優れており、領域要件に関しても、シングルバイト・キャラクタ・セットが最も効率的です。ただし、シングルバイト・キャラクタ・セットには、サポートできる言語の種類に制限があります。
ASCIIベースのキャラクタ・セットがサポートされているのは、ASCIIベースのプラットフォーム上のみです。同様に、EBCDICベースのキャラクタ・セットが使用できるのは、EBCDICベースのプラットフォーム上のみです。
データベース・キャラクタ・セットは、SQLとPL/SQLソース・コードの識別に使用します。このためには、データベース・キャラクタ・セットに、プラットフォーム固有のEBCDICまたは7ビットASCIIのいずれかがサブセットとして含まれている必要があります。したがって、固定幅のマルチバイト・キャラクタ・セットをデータベース・キャラクタ・セットとして使用することはできません。現在、データベース・キャラクタ・セットとして使用できないのはAL16UTF16キャラクタ・セットのみです。
表2-5に、名前を表すために使用できるキャラクタ・セットに関する制限事項を示します。
表2-5 名前を表すために使用するキャラクタ・セットに関する制限事項
| 名前 | シングルバイト | 可変幅 | コメント |
|---|---|---|---|
|
列名 |
可能 |
可能 |
- |
|
スキーマ・オブジェクト |
可能 |
可能 |
- |
|
コメント |
可能 |
可能 |
- |
|
データベース・リンク名 |
可能 |
不可 |
- |
|
データベース名 |
可能 |
不可 |
- |
|
ファイル名(データファイル、ログ・ファイル、制御ファイル、初期化パラメータ・ファイル) |
可能 |
不可 |
- |
|
インスタンス名 |
可能 |
不可 |
- |
|
ディレクトリ名 |
可能 |
不可 |
- |
|
キーワード |
可能 |
不可 |
英語ASCIIまたはEBCDIC文字でのみ表現可能です。 |
|
Recovery Managerファイル名 |
可能 |
不可 |
- |
|
ロールバック・セグメント名 |
可能 |
不可 |
|
|
ストアド・スクリプト名 |
可能 |
可能 |
- |
|
表領域名 |
可能 |
不可 |
- |
LOBデータ(LOB、BLOB、CLOBおよびNCLOB)などのサポート対象の文字列形式とキャラクタ・セットについては、表2-7を参照してください。
データベース・キャラクタ・セットとして使用するためにオラクル社が強く推奨するキャラクタ・セットのリストがコンパイルされました(表A-4「推奨するASCIIデータベース・キャラクタ・セット」および表A-5「推奨するEBCDICデータベース・キャラクタ・セット」)。このリストにない、Oracleでサポートされるその他のキャラクタ・セットは、引き続きOracle Database 11gリリース2で使用できますが、将来のリリースでサポートされなくなる可能性があります。Oracle Database 11gリリース1以降、Oracle Universal InstallerおよびOracle Database Configuration Assistantの共通インストール・パスでのデータベース・キャラクタ・セットの選択肢は、この推奨キャラクタ・セットのリストに制限されます。ただし、キャラクタ・セットが推奨リストに含まれていない場合でも、従来どおりカスタム・インストールのパスを使用して新規データベースを作成し、既存のデータベースを移行できます。ただし、できるだけ早く推奨キャラクタ・セットに移行することをお薦めします。すべての新規システム・デプロイメントについて推奨するキャラクタ・セット・リストの最上部には、Unicodeキャラクタ・セットAL32UTF8があります。
すべての新規システム・デプロイメントにUnicodeを使用することをお薦めします。レガシー・システムもUnicodeに移行することをお薦めします。現在システムをUnicodeでデプロイすると、利便性、互換性および拡張性の面で多くの利点があります。Oracleデータベースによって、Unicodeの利点を活かしながら高パフォーマンス・システムを高速かつ容易にデプロイできます。現時点で多言語データをサポートする必要がない場合、またはUnicodeが必要ない場合でも、長期的には新規システムに最適な選択となる可能性が高く、結局は時間を短縮してコストを節減し、競争上の優位性を得ることになります。Unicodeの詳細は、第6章「Unicodeを使用した多言語データベースのサポート」を参照してください。
各国語キャラクタ・セットとは、Unicodeデータベース・キャラクタ・セットがないデータベースにUnicodeの文字データを格納するための代替キャラクタ・セットです。その他、各国語キャラクタ・セットを選択するには次の理由があります。
大量の文字処理操作には、別の文字コード体系のプロパティのほうが適している場合
各国語キャラクタ・セットでのプログラミングのほうが容易な場合
SQL NCHAR、NVARCHAR2およびNCLOBデータ型は、Unicodeデータのみをサポートします。UTF8またはAL16UTF16キャラクタ・セットを使用できます。デフォルトはAL16UTF16です。
表2-6に、様々なコード体系についてサポート対象のデータ型を示します。
表2-6 コード体系のサポート対象のSQLデータ型
| データ型 | シングルバイト | マルチバイトのUnicode以外 | マルチバイトのUnicode |
|---|---|---|---|
|
|
可能 |
可能 |
可能 |
|
|
可能 |
可能 |
可能 |
|
|
不可 |
不可 |
可能 |
|
|
不可 |
不可 |
可能 |
|
|
可能 |
可能 |
可能 |
|
|
可能 |
可能 |
可能 |
|
|
可能 |
可能 |
可能 |
|
|
不可 |
不可 |
可能 |
|
注意: BLOBでは、文字は一連のバイト順序として処理されます。データは、NLSに関連した操作の対象にはなりません。 |
表2-7に、抽象データ型についてサポート対象のSQLデータ型を示します。
表2-7 SQLデータ型のサポート対象の抽象データ型
| 抽象データ型 | CHAR | NCHAR | BLOB | CLOB | NCLOB |
|---|---|---|---|---|---|
|
オブジェクト |
可能 |
可能 |
可能 |
可能 |
可能 |
|
コレクション |
可能 |
可能 |
可能 |
可能 |
可能 |
次のように、NCHAR属性を使用して抽象データ型を作成できます。
SQL> CREATE TYPE tp1 AS OBJECT (a NCHAR(10)); Type created. SQL> CREATE TABLE t1 (a tp1); Table created.
|
関連項目: オブジェクトとコレクションの詳細は、『Oracle Databaseオブジェクト・リレーショナル開発者ガイド』を参照してください。 |
データベースの作成後に、データベース・キャラクタ・セットの変更が必要になる場合があります。たとえば、使用しているデータベースでサポートする必要がある言語数が増加する場合があります。ほとんどの場合は、全体エクスポートまたは全体インポートを行い、すべてのデータを新しいキャラクタ・セットに正しく変換する必要があります。ただし、新しいキャラクタ・セットがすべてのスキーマ・データの完全なスーパーセットである場合にかぎり、CSALTERスクリプトを使用して、データベース・キャラクタ・セット内の変更を効率よく処理できます。
|
関連項目:
|
最も単純なデータベース構成の例は、クライアントとサーバーが同じ言語環境で稼働し、同じキャラクタ・セットを使用している場合です。この単一言語の使用例には、レスポンスが高速であるという利点があります。これは、キャラクタ・セット変換に関連するオーバーヘッドが回避されるためです。図2-3に、同じキャラクタ・セットを使用するデータベース・サーバーとクライアントを示します。日本語クライアントとサーバーの両方が、JA16EUCキャラクタ・セットを使用しています。
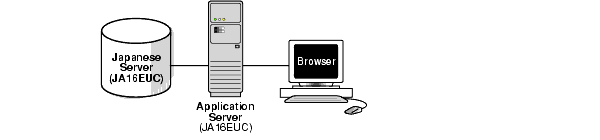
また、複数層アーキテクチャも使用できます。図2-4に、データベース・サーバーとクライアントの間にあるアプリケーション・サーバーを示します。アプリケーション・サーバーとデータベース・サーバーは、単一言語の使用例と同じキャラクタ・セットを使用しています。サーバー、アプリケーション・サーバーおよびクライアントは、JA16EUCキャラクタ・セットを使用しています。
クライアント/サーバー環境では、クライアント・アプリケーションがサーバーと異なるプラットフォームにある場合や、プラットフォームで同じ文字コード体系が使用されていない場合に、キャラクタ・セット変換が必要になります。クライアントとサーバーの間で受け渡される文字データは、2つのコード体系間で変換される必要があります。文字の変換は、Oracle Netを介して、ユーザーが意識することなく自動的に実行されます。
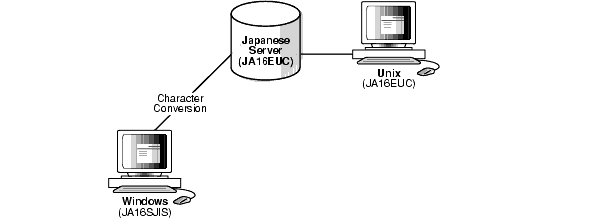
任意の2つのキャラクタ・セット間で変換を行うことができます。図2-5に、サーバーと日本語JA16EUCキャラクタ・セットを使用している1つのクライアントを示します。他方のクライアントは、日本語JA16SJISキャラクタ・セットを使用しています。
ターゲットのキャラクタ・セットにソース・データにあるすべての文字がない場合は、置換文字が使用されます。たとえば、サーバーではUS7ASCIIを、ドイツ語クライアントではWE8ISO8859P1を使用している場合、ドイツ語の文字ßは?に置換され、äはaに置換されます。
置換文字は、キャラクタ・セットの定義の一部として、特定の文字に対して定義できます。特定の置換文字を定義しないと、デフォルトの置換文字が使用されます。クライアント・キャラクタ・セットからデータベース・キャラクタ・セットへの変換時に置換文字を使用しないようにするには、サーバーのキャラクタ・セットが、クライアントのすべてのキャラクタ・セットのスーパーセットである必要があります。
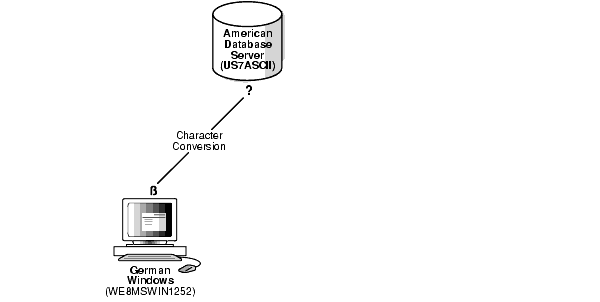
図2-6に、データベース・キャラクタ・セットにクライアント・キャラクタ・セットのすべての文字が含まれていない場合に発生するデータ消失を示します。データベース・キャラクタ・セットはUS7ASCIIです。クライアントのキャラクタ・セットはWE8MSWIN1252で、クライアントの使用言語はドイツ語です。クライアントがßを含む文字列を挿入すると、データベースではßが?に置換され、データが消失します。
ドイツ語データがサーバーに格納されると想定される場合は、データ消失と変換オーバーヘッドを回避するために、サーバーとクライアントの両方で、ドイツ語文字をサポートするデータベース・キャラクタ・セットを使用する必要があります。
キャラクタ・セットの一方が可変幅マルチバイト・キャラクタ・セットの場合は、変換によって著しいオーバーヘッドが生じる可能性があります。状況を慎重に評価した上でキャラクタ・セットを選択し、変換をできるかぎり回避する必要があります。
多言語サポートには、制限付きと無制限があります。この項の内容は、次のとおりです。
一部のキャラクタ・セットでは、関連する記述法やスクリプトがあるため、多言語がサポートされます。たとえば、Oracleデータベースのキャラクタ・セットWE8ISO8859P1は、次の西ヨーロッパ諸国の言語をサポートしています。
これらの言語は、いずれもラテン語ベースの記述文字を使用します。
言語グループをサポートするキャラクタ・セットを使用する場合、データベースは制限付き多言語サポート機能を持つことになります。
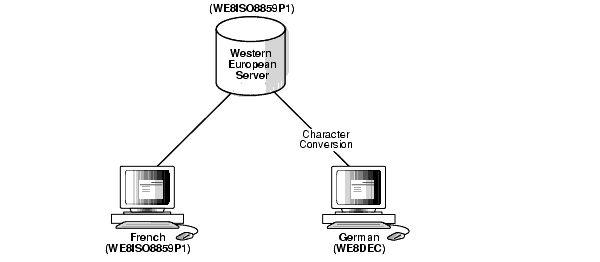
図2-7に、Oracleデータベース・キャラクタ・セットWE8ISO8850P1を使用する西ヨーロッパ言語のサーバー、サーバーと同じキャラクタ・セットを使用するフランス語クライアントおよびWE8DECキャラクタ・セットを使用するドイツ語クライアントします。ドイツ語クライアントは、サーバーと異なるキャラクタ・セットを使用しているため、文字変換が必要です。
無制限多言語サポートが必要な場合は、サーバーのデータベース・キャラクタ・セットにUnicodeなどのユニバーサル・キャラクタ・セットを使用します。Unicodeには、主に次の2つのコード体系があります。
UTF-16: 各文字は長さ2バイトまたは4バイトです。
UTF-8: 各文字の格納には1から4バイト必要です。
Oracle Databaseでは、データベース・キャラクタ・セットとしてUTF-8が、各国語キャラクタ・セットとしてUTF-8とUTF-16の両方がサポートされています。
UTF-8のデータベースとシングルバイト・キャラクタ・セットとの間でのキャラクタ・セット変換では、ごくわずかなオーバーヘッドが生じます。
UTF-8とマルチバイト・キャラクタ・セットとの間での変換では、多少のオーバーヘッドが生じます。変換によるデータ消失はありませんが、これには次の例外があります。
一部のマルチバイト・キャラクタ・セットは、UTF-8との間のキャラクタ・セット変換で、ユーザー定義文字をサポートしていません。
一部のUnicode文字は、他のキャラクタ・セットで複数文字にマップされます。たとえば、1つのUnicode文字はJA16SJISキャラクタ・セットの3文字にマップされます。これは、ラウンドトリップ変換でオリジナルのJA16SJIS文字に変換されない場合があることを意味します。
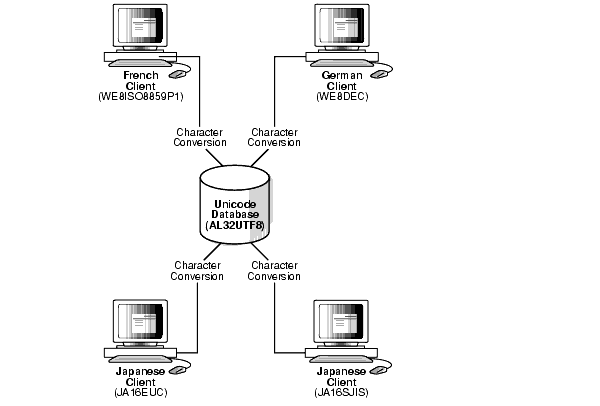
図2-8に、Unicode UTF-8キャラクタ・セットに基づくOracleデータベース・キャラクタ・セットAL32UTF8を使用するサーバーを示します。
次の4つのクライアントがあるとします。
Oracle Databaseのキャラクタ・セットWE8ISO8859P1を使用するフランス語クライアント
WE8DECキャラクタ・セットを使用するドイツ語クライアント
JA16EUCキャラクタ・セットを使用する日本語クライアント
JA16SJISキャラクタ・セットを使用する日本語クライアント
各クライアントとサーバーの間で文字変換が発生しますが、AL32UTF8がユニバーサル・キャラクタ・セットであるためデータ消失は生じません。ドイツ語クライアントが日本語クライアントの1つからデータを取り出そうとすると、キャラクタ・セット変換中にデータに含まれる日本語文字がすべて消失します。
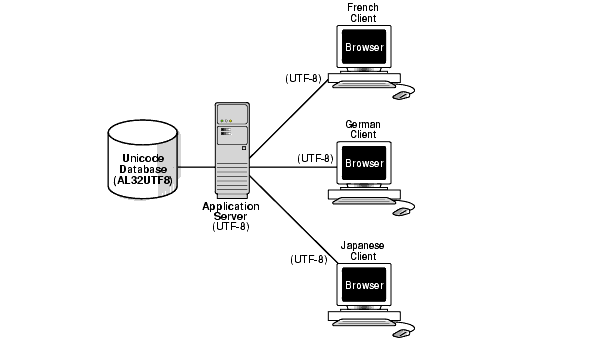
図2-9に、複数層構成でのUnicodeソリューションを示します。
データベース、アプリケーション・サーバーおよび各クライアントは、AL32UTF8キャラクタ・セットを使用しています。このため、クライアントがフランス語、ドイツ語および日本語であっても、文字変換を行う必要はありません。