| Oracle® Databaseグローバリゼーション・サポート・ガイド 11gリリース2 (11.2) B56307-04 |
|


 前 |
 次 |
この章では、キャラクタ・セット変換とキャラクタ・セットの移行について説明します。この章の内容は、次のとおりです。
使用しているデータベースに適切なキャラクタ・セットを選択することは、重要な決定事項です。データベース・キャラクタ・セットの選択時には、次の要因を考慮する必要があります。
格納する必要があるデータの型
データベースで現在および将来対応する必要のある言語
各キャラクタ・セットの異なるサイズ要件とその要件がパフォーマンスに与える影響
関連するトピックとして、既存のデータベース用の新規キャラクタ・セットの選択があります。既存のデータベース用のデータベース・キャラクタ・セットを変更することを、キャラクタ・セットの移行と呼びます。データベース・キャラクタ・セットを移行する場合、適切なキャラクタ・セットを選択する必要があります。また、次の原因によるデータの消失を最小限に抑える必要があります。
データベースがバイト・セマンティクスを使用して作成されている場合、CHARおよびVARCHAR2データ型のサイズは、文字単位ではなくバイト単位で指定されます。たとえば、表定義でCHAR(20)と指定すると、文字データを格納するために20バイトが割り当てられます。データベース・キャラクタ・セットでシングルバイト文字コード体系が使用されている場合は、文字数がバイト数と同じであるため、文字の格納時にデータ消失は発生しません。データベース・キャラクタ・セットでマルチバイト・キャラクタ・セットが使用されている場合は、1文字が1バイト以上で構成される場合があるため、バイト数は文字数とは異なります。
新規キャラクタ・セットへの移行時には、既存のCHARおよびVARCHAR2列の列幅を検証することが重要です。これは、マルチバイトを格納する必要があるエンコーディングをサポートするために、列幅の拡張が必要となる場合があるためです。変換によってデータが拡張されると、データが切り捨てられる可能性があります。
表11-1に、変換を通じてシングルバイト文字がマルチバイト文字になる場合のデータ拡張例を示します。
表11-1 シングルバイトとマルチバイトのエンコーディング
| 文字 | WE8MSWIN 1252エンコーディング | AL32UTF8エンコーディング |
|---|---|---|
|
ä |
E4 |
C3 A4 |
|
ö |
F6 |
C3 B6 |
|
© |
A9 |
C2 A9 |
|
€ |
80 |
E2 82 AC |
表11-1の1列目は選択した文字、2列目はWE8MSWIN1252キャラクタ・セットでの文字の16進表現、3列目はAL32UTF8キャラクタ・セットでの各文字の16進表現を示します。文字と数字のペアは、それぞれ1バイトを表します。たとえば、ä(ウムラウト付きのa)は、WE8MSWIN1252のシングルバイト文字(E4)ですが、AL32UTF8では、2バイト文字(C3 A4)になります。また、ユーロ記号のエンコーディングは1バイト(80)から3バイト(E2 82 AC)に拡張されます。
新しいキャラクタ・セットのデータにデータ型でサポートされるバイト・サイズより大きい記憶域が必要な場合は、スキーマを変更する必要があります。CLOB列の使用が必要になる場合があります。
データベース・データ・ディクショナリ内でのスキーマ・オブジェクト名は、30バイトを超えることはできません。スキーマ・オブジェクト名が新規データベース・キャラクタ・セットで30バイトを超える場合は、そのオブジェクト名を変更する必要があります。たとえば、タイ語の各国語キャラクタ・セットではタイ語1文字に1バイト必要です。一方、AL32UTF8では3バイト必要です。タイ語11文字の名前を持つ表を定義している場合、データベース・キャラクタ・セットをAL32UTF8に変更するときは、この表名を10文字以下に短縮する必要があります。
既存のOracleユーザー名またはパスワードが文字ベースで作成されており、その内容が変換先のキャラクタ・セットでサイズ変更された場合、新規キャラクタ・セットへの移行後は認証がエラーとなるため、ユーザーのログイン時に問題が発生します。この問題が発生するのは、データ・ディクショナリに格納されている暗号化されたユーザー名とパスワードを、新規キャラクタ・セットへの移行時に更新できないためです。たとえば、現行のデータベース・キャラクタ・セットがWE8MSWIN1252で、変換先のデータベース・キャラクタ・セットがAL32UTF8の場合、ユーザー名scött(ウムラウト付きのo)の長さは5バイトから6バイトに変更されます。AL32UTF8では、ユーザー名が異なるため、scöttはログインできなくなります。ユーザー名とパスワードにはASCII文字を使用することをお薦めします。ASCII文字以外の場合は、新規キャラクタ・セットへの移行後に、影響のあるユーザー名とパスワードを再設定する必要があります。
|
注意: データ・ディクショナリに暗号化された状態で格納されているユーザー名およびパスワードは、CSALTERスクリプトを使用して移行すると更新されませんが、インポート・ユーティリティおよびエクスポート・ユーティリティを使用して移行すると更新されます。 |
CHARデータに、新規キャラクタ・セットへの移行後に拡張される文字が含まれている場合、デフォルトでは、データベースのエクスポート時に空白埋込みは削除されません。つまり、これらの行は、新規キャラクタ・セットでデータベースにインポートされるときに拒否されます。これを回避するには、CHARデータをインポートする前にBLANK_TRIMMING初期化パラメータをTRUEに設定します。
|
関連項目: BLANK_TRIMMING初期化パラメータの詳細は、『Oracle Databaseリファレンス』を参照してください。 |
この項の内容は、次のとおりです。
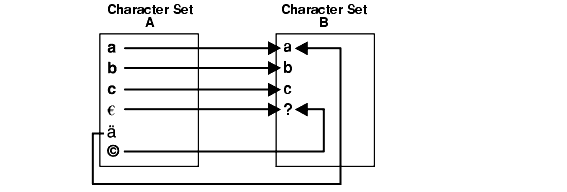
エクスポート・ユーティリティとインポート・ユーティリティでは、オリジナルのデータベース・キャラクタ・セットから新規のデータベース・キャラクタ・セットにキャラクタ・セットを変換できます。ただし、キャラクタ・セット変換によって、データが消失したり、破損する可能性があります。たとえば、キャラクタ・セットAからキャラクタ・セットBに移行する場合に、変換先キャラクタ・セットBはキャラクタ・セットAのスーパーセットであることが必要です。変換先キャラクタ・セットBがスーパーセットであるのは、キャラクタ・セットAで定義されているすべての文字が含まれる場合です。キャラクタ・セットBで使用できない文字は、置換文字に変換されます。この置換文字は、通常、?または¿として指定されるか、使用不可能な文字に関連する1文字として指定されます。たとえば、ä(ウムラウト付きのa)はaで変換できます。置換文字は、変換先キャラクタ・セットで定義されます。
|
注意: 変換先キャラクタ・セットBは、キャラクタ・セットAのスーパーセットであることが必要という必要条件に対して例外があります。キャラクタ・セットAに含まれるが、キャラクタ・セットBに含まれない文字がデータの中に入っていなければ、データ消失またはデータ破損を防ぐために、変換先キャラクタ・セットがキャラクタ・セットAのスーパーセットである必要はありません。 |
図11-1に、著作権記号とユーロ記号が?に変換され、äがaに変換されるキャラクタ・セット変換の例を示します。
データ消失のリスクを削減するには、類似する文字レパートリを持つキャラクタ・セットを変換先に選択してください。AL32UTF8には既存のキャラクタ・セットのほとんどの文字が含まれているため、Unicodeへの移行は最もよい選択肢である可能性があります。
データ消失の可能性があるキャラクタ・セット移行の使用例として、無効なデータを含むデータベースの移行が考えられます。NLS_LANGパラメータがクライアント上で適切に設定されていないため、通常は、データベースに無効なデータが含まれます。NLS_LANG値には、クライアント・オペレーティング・システム・コード・ページを反映する必要があります。たとえば、英語版Windows環境では、コード・ページはWE8MSWIN1252です。NLS_LANGパラメータを適切に設定すると、データベースはクライアント・オペレーティング・システムからのデータを自動的に変換できます。NLS_LANGパラメータが適切に設定されていないと、データベースに入ってくるデータは適切に変換されません。たとえば、データベース・キャラクタ・セットがAL32UTF8で、クライアントが英語版Windowsオペレーティング・システムで、クライアント上でのNLS_LANG設定がAL32UTF8であるとします。データベースに入ってくるデータはWE8MSWIN1252でエンコードされており、クライアント上のNLS_LANG設定がデータベース・キャラクタ・セットと一致するため、AL32UTF8データには変換されません。そのため、Oracleでは変換は不要であるとみなされ、データベースに無効なデータが入力されます。
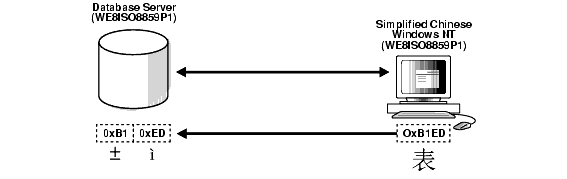
この結果、データの非一貫性の問題が2つ発生する可能性があります。一方の問題が発生するのは、データベースに含まれているデータのキャラクタ・セットがデータベース・キャラクタ・セットとは異なっているが、両方のキャラクタ・セットに同じコード・ポイントが存在する場合です。たとえば、データベース・キャラクタ・セットがWE8ISO8859P1で、中国語版Windows NTクライアントのNLS_LANG設定がSIMPLIFIED CHINESE_CHINA.WE8ISO8859P1の場合、(ZHS16GBKキャラクタ・セットの)すべてのマルチバイトの中国語データは、シングルバイトWE8ISO8859P1データの倍数として格納されます。これは、Oracleではこれらの文字がシングルバイトWE8ISO8859P1文字として処理されることを意味します。そのため、SUBSTRやLENGTHなどのSQL文字列操作関数はすべて、文字ではなくバイトを基準にして処理されます。ZHS16GBKデータを構成するすべてのバイトは、有効なWE8ISO8859P1コードです。このようなデータベースをAL32UTF8などの別のキャラクタ・セットに移行する場合、文字コードは、WE8ISO8859P1内の文字コードと同様に変換されます。このように、ZHS16GBK文字の2バイトはそれぞれ個別に変換され、AL32UTF8では意味のない値になります。図11-2に、この不適切なキャラクタ・セット置換の例を示します。
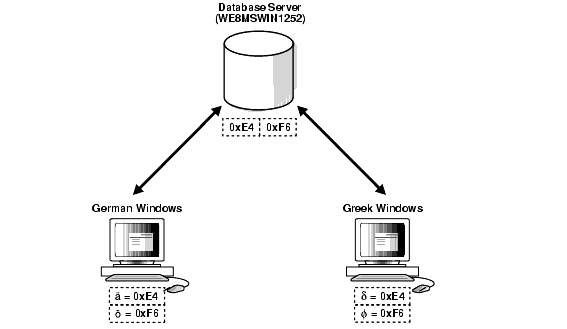
2つ目の問題は、混在するキャラクタ・セットのデータがデータベースにある場合です。たとえば、データ・キャラクタ・セットがWE8MSWIN1252で、ドイツ語とギリシャ語を使用している2つの別々のWindowsクライアントがともに、NLS_LANGキャラクタ・セットとしてWE8MSWIN1252を使用している場合、データベースにはドイツ語とギリシャ語の文字が混在することになります。図11-3に、異なるクライアントが、同一データベースの異なるキャラクタ・セットを使用する方法を示します。
データベース・キャラクタ・セットの移行を適切に行うには、この2つの状況の場合、手作業による調整が必要です。これは、Oracle Databaseでは格納されているデータのキャラクタ・セットを判断できないためです。不適切なデータ変換はデータを破損する恐れがあるため、新規キャラクタ・セットにデータを移行する前に、データベース全体のバックアップを作成します。
データベース・キャラクタ・セットの移行には、データ・スキャニングとデータ変換という2つの段階があります。データベース・キャラクタ・セットを変更する前に、考えられるデータベース・キャラクタ・セット変換の問題とデータの切捨てを識別する必要があります。このステップはデータ・スキャニングと呼ばれます。
データ・スキャニングによって、データベース・キャラクタ・セットの変更前に、データを新しい文字コード体系に移行するために必要な作業量が識別されます。データ・スキャニング時に検出される例には、列幅の拡張が必要なスキーマ・オブジェクトの数や、変換先の文字レパートリに存在しないデータの分布などがあります。この情報は、データベース・キャラクタ・セットの最適な変換方法の決定に役立ちます。
不適切なデータ変換はデータを破損する恐れがあるため、新規キャラクタ・セットにデータを移行する前に、データベース全体のバックアップを作成します。
データベースに「キャラクタ・セット変換の問題」で説明した非一貫性がない場合、あるデータベース・キャラクタ・セットから別のデータベース・キャラクタ・セットにデータを変換するには、3つの方法があります。このような非一貫性があるデータベースを移行する方法は、ここでは説明しません。詳細は、Oracleコンサルティング・サービスにお問い合せください。
この項の内容は、次のとおりです。
多くの場合、すべてのデータを新規キャラクタ・セットに正しく変換するには、全体エクスポートおよび全体インポートをお薦めします。文字データ型の列は、サイズ増加を処理するためにインポート前に拡張が必要となる場合があるため、データ切捨ての問題に注意することが重要です。既存のPL/SQLコードをレビューして、LENGTHB、SUBSTRBおよびINSTRBなどのバイトベースのすべてのSQL関数、PL/SQL CHARおよびVARCHAR2の宣言が有効であることを確認する必要があります。
|
関連項目: エクスポート・ユーティリティとインポート・ユーティリティの詳細は、『Oracle Databaseユーティリティ』を参照してください。 |
CSALTERスクリプトは、Database Character Set Scannerユーティリティに付属しています。CSALTERスクリプトはキャラクタ・セットの移行方法としては最も簡単ですが、使用できるのは、すべてのスキーマ・データが、新しいキャラクタ・セットの完全なサブセットである場合のみです。新規キャラクタ・セットが現行のキャラクタ・セットの完全なスーパーセットであるのは、次の場合です。
現行のキャラクタ・セット内のすべての文字が、新規キャラクタ・セットで使用可能な場合。
現行のキャラクタ・セット内のすべての文字が、新規キャラクタ・セット内で同じコード・ポイント値を持つ場合。たとえば、多くのキャラクタ・セットはUS7ASCIIの完全なスーパーセットです。
完全なスーパーセットという基準からみると、CSALTERスクリプトにより新しいキャラクタ・セットに変換されるのはメタデータのみとなります。ただし、CSALTERスクリプトでは、Oracleにより作成されたデータ・ディクショナリとサンプル・スキーマのCLOB列に対してのみデータ変換が実行されます。ユーザーが作成したCLOB列には、別個の処理が必要になる場合があります。Oracle9iからは、データ・ディクショナリおよびサンプル・スキーマの一部の内部フィールドはCLOB列に格納されます。ユーザーもCLOBフィールドにデータを格納できます。データベース・キャラクタ・セットがマルチバイトの場合、CLOBデータはUCS-2データとの互換形式で格納されます。データベース・キャラクタ・セットがシングルバイトの場合、CLOBデータはデータベース・キャラクタ・セットを使用して格納されます。CSALTERスクリプトで変換されるのは、Oracleにより作成されたデータ・ディクショナリおよびサンプル・スキーマのCLOB列にあるデータのみであるため、CSALTERスクリプトを実行する前に、他に作成されたCLOB列をエクスポートしてスキーマから削除する必要があります。
データベース・キャラクタ・セットを変更する手順は、次のとおりです。
SHUTDOWN IMMEDIATE文またはSHUTDOWN NORMAL文のいずれかを使用して、データベースをシャットダウンします。
CSALTERスクリプトはロールバックできないため、データベースの全体バックアップを実行します。
データベースを起動します。
Database Character Set Scannerユーティリティを実行します。
CSSCAN /AS SYSDBA FULL=Y...
CSALTERスクリプトを実行します。
@@CSALTER.PLB SHUTDOWN IMMEDIATE; -- or SHUTDOWN NORMAL; STARTUP;
CSALTERスクリプトは、ユーザーのデータ変換は実行しないことに注意してください。このスクリプトで変更されるのは、データ・ディクショナリ内のキャラクタ・セット・メタデータのみです。したがって、CSALTER操作の後、Oracleは、新規のキャラクタ・セットを使用してデータベースが作成されたかのように動作します。
Oracle Real Application Clusters環境では、CSALTERスクリプトを発行する前に、ユーザーが接続に使用しているインスタンスに関連付けられたバックグラウンド・プロセス以外に、Oracleバックグラウンド・プロセスが実行されていないことを確認してください。これを確認するには、DBA権限を使用して次のSQL文を発行します。
SELECT SID, SERIAL#, PROGRAM FROM V$SESSION;
キャラクタ・セットの変更を完了できるように、CLUSTER_DATABASE初期化パラメータをFALSEに設定します。キャラクタ・セットの変更後に、TRUEにリセットしてください。
もう1つの文字データ移行方法は、選択式のエクスポートを指定した後に再スキャンしてCSALTERスクリプトを実行することです。この方法は、シングルバイトのサブセット・キャラクタ・セットからマルチバイト・キャラクタ・セットに移行する場合に最も一般的です。この使用例では、エンコーディングがシングルバイトのキャラクタ・セットからUCS-2互換形式に変化するため、ユーザー作成のCLOBを変換する必要があります。UCS-2は、マルチバイトのエンコーディングに関係なくOracleでCLOBの格納に使用されます。Database Character Set Scannerでは、これらの列が変換可能として識別されます。ユーザーは、これらの列をエクスポートし、スキーマから削除した後で再スキャンし、残りのデータに問題がなければCSALTERスクリプトを実行する必要があります。これらの手順が完了した後、CLOB列をデータベースにインポートして移行を完了します。
Oracleデータベースでは、NCHARデータ型の列に格納されるデータには、データベース・キャラクタ・セットに関係なくUnicodeエンコーディングのみが使用されます。このため、データベース・キャラクタ・セットとしてUnicodeを使用しないデータベースに、Unicodeを格納できます。
この項の内容は、次のとおりです。
バージョン8のOracleデータベースでは、各国語文字データ型(NCHAR)を導入しました。このデータ型によって、データベース・キャラクタ・セットに加えて、2つ目の代替キャラクタ・セットが使用できるようになりました。NCHARデータ型は、複数の固定幅のアジア言語のキャラクタ・セットをサポートしています。これらのキャラクタ・セットは、アジア言語の文字データの処理パフォーマンスを向上させるために導入されたものです。
Oracle9iからは、SQL NCHARデータ型の使用は、Unicodeキャラクタ・セット・エンコーディング(UTF8とAL16UTF16)に制限されています。JA16SJISFIXEDなどのアジア言語のキャラクタ・セットも含めて、NCHARデータ型で使用可能であったバージョン8の他のキャラクタ・セットは、現在ではサポートされていません。
既存のNCHAR、NVARCHAR2およびNCLOBの各列をOracle9i以上のNCHARデータ型に移行する手順は、次のとおりです。
すべてのNCHAR列をバージョン8またはOracle8i のデータベースからエクスポートします。
NCHAR列を削除します。
データベースを新しいリリースにアップグレードします。
NCHAR列をアップグレード後のデータベースにインポートします。
移行ユーティリティでは、バージョン8およびOracle8iのNCHAR列を新しいリリースのNCHAR列に変換することもできます。移行ユーティリティでは、utlnchar.sqlというSQL NCHARのアップグレード・スクリプトが提供されています。このスクリプトをデータベース移行操作の最後に実行して、バージョン8とOracle8iのNCHAR列を新しいリリースのNCHAR列に変換します。スクリプトの実行後は、データをダウングレードできません。バージョン8またはOracle8iに移動して戻る唯一の方法は、すべてのNCHAR列を削除してデータベースをダウングレードし、古いNCHARデータを前のバージョン8またはOracle8i のエクスポート・ファイルからインポートすることです。データベースを将来ダウングレードする必要がある場合は、バージョン8またはOracle8iのNCHARデータのバックアップ(エクスポート・ファイル)があることを確認してください。
|
関連項目:
|
各国語キャラクタ・セットを変更するには、CSALTERスクリプトを使用します。
次の方法で列のデータ型定義を変更できます。
ALTER TABLE MODIFY文には、表のオンライン再定義に比べて次の利点があります。
使用方法が簡単
制限が少ない
表のオンライン再定義には、ALTER TABLE MODIFY文に比べて次の利点があります。
列に大量のデータが含まれている場合に高速である
一度に複数の列を移行可能
ほとんどの移行プロセス中に表をDMLに使用可能
表の断片化が回避されるため、領域が節約され、データへの高速アクセスが可能
CLOBデータ型からNCLOBデータ型への移行に使用可能
この項の内容は、次のとおりです。
ALTER TABLE MODIFY文を使用すると、表の列定義をCHARデータ型からNCHARデータ型に変更できます。また、列のすべてのデータをデータベース・キャラクタ・セットからNCHARキャラクタ・セットに変換できます。ALTER TABLE MODIFY文の構文は、次のとおりです。
ALTER TABLEtable_nameMODIFY(column_name datatype);
移行する列に索引が作成されている場合、索引は各行とともに更新されるため、索引を削除するとALTER TABLE MODIFY文のパフォーマンスを改善できます。
NCHAR列とNVARCHAR2列の最大列長は、2000バイトと4000バイトです。NCHARのキャラクタ・セットがAL16UTF16の場合、NCHAR列とNVARCHAR2列の最大長は1000文字と2000文字、つまり2000バイトと4000バイトです。移行中にこのサイズ制限に対する違反となる場合は、かわりに列をNCLOBデータ型に変更することを考慮してください。
|
注意: ALTER TABLE MODIFY文を使用してCLOB列をNCLOB列に移行することはできません。列をCLOBデータ型からNCLOBデータ型に変更するには、表のオンライン再定義を使用します。 |
多数の行を含む大きい表をUnicodeデータ型に移行するには、長時間かかります。この移行中は、列データを読込みや更新に使用できません。表のオンライン再定義を使用すると、移行時間を大幅に短縮できます。また、この場合、移行時間中の大部分は、表にDMLでアクセスできます。
次のタスクを実行し、表のオンライン再定義を使用して、表をUnicodeデータ型に移行します。
DBMS_REDEFINITION.CAN_REDEF_TABLE PL/SQLプロシージャを使用して、表をオンラインで再定義できることを確認します。たとえば、scott.emp表を移行するには、次のコマンドを入力します。
DBMS_REDEFINITION.CAN_REDEF_TABLE('scott','emp');
再定義する表と同じスキーマに空の仮表を作成します。作成時には、属性にNCHARデータ型を指定します。たとえば、次のように文を入力します。
CREATE TABLE int_emp( empno NUMBER(4), ename NVARCHAR2(10), job NVARCHAR2(9), mgr NUMBER(4), hiredate DATE, sal NUMBER(7,2), deptno NUMBER(2), org NVARCHAR2(10));
表のオンライン再定義を開始します。次のようにコマンドを入力します。
DBMS_REDEFINITION.START_REDEF_TABLE('scott',
'emp',
'int_emp',
'empno empno,
to_nchar(ename) ename,
to_nchar(job) job,
mgr mgr,
hiredate hiredate,
sal sal,
deptno deptno,
to_nchar(org) org');
CLOB列をNCLOB列に移行する場合は、TO_NCLOB SQL関数のかわりにTO_NCHAR SQL変換関数を使用します。
仮表のトリガー、索引、権限付与および制約を作成します。仮表に適用される参照制約は、DISABLEDモードで作成する必要があります(仮表は、参照制約の親表または子表です)。仮表に定義するトリガーは、表のオンライン再定義プロセスが完了するまで実行されません。
仮表を元の表と同期化できます。オンライン再定義の開始後に元の表に多数のDML操作が適用されている場合は、DBMS_REDEFINITION.SYNC_INTERIM_TABLEプロシージャを実行します。これにより、DBMS_REDEFINITION.FINISH_REDEF_TABLEプロシージャの所要時間が短縮されます。次のようにコマンドを入力します。
DBMS_REDEFINITION.SYNC_INTERIM_TABLE('scott', 'emp', 'int_emp');
DBMS_REDEFINITION.FINISH_REDEF_TABLEプロシージャを実行します。次のようにコマンドを入力します。
DBMS_REDEFINITION.FINISH_REDEF_TABLE('scott', 'emp', 'int_emp');
このプロセスが完了すると、次の条件が満たされます。
元の表は、仮表のすべての属性、索引、制約、権限付与およびトリガーを持つように再定義されます。
仮表に適用される参照制約が、再定義後の元の表に適用されます。
仮表を削除します。次のような文を入力します。
DROP TABLE int_emp;
表のオンライン再定義タスクの結果は、次のようになります。
元の表がUnicode列に移行されます。
START_REDEF_TABLEサブプログラムからFINISH_REDEF_TABLEサブプログラムまでに、仮表に対して定義されたトリガー、権限付与、索引および制約が、再定義後の元の表に定義されます。仮表に適用される参照制約が、再定義後の元の表に適用され、使用可能になります。
再定義前に元の表に定義されていたトリガー、権限付与、索引および制約が仮表に転送され、仮表を削除すると一緒に削除されます。仮表に再定義を適用する前に元の表に適用されていた参照制約が、使用禁止になります。
再定義前に元の表に定義されていたPL/SQLプロシージャとカーソルが無効になります。これらは、次回に使用されるときに自動的に再検証されます。表の定義が変更されているため、再検証は失敗することがあります。
|
関連項目: 表のオンライン再定義の詳細は、『Oracle Database管理者ガイド』を参照してください。 |
移行後のデータベース・スキーマを元の状態にリカバリするために、追加のタスクが必要になる場合があります。表11-2に、考慮が必要な問題を示します。
表11-2 移行したデータベース・スキーマのリカバリ中の問題
| 問題 | 説明 |
|---|---|
|
索引 |
|
|
制約 |
移行前に制約を使用禁止にした場合は、移行後に再び使用可能にします。 |
|
トリガー |
移行前にトリガーを使用禁止にした場合は、移行後に再び使用可能にします。 |
|
レプリケーション |
Unicodeデータ型に移行する列が複数のサイト間でレプリケートされる場合は、マスター定義サイトで変更を実行する必要があります。これにより、変更が他のサイトに伝播します。 |
|
バイナリ順序 |
データベースと |
|
アプリケーション |
アプリケーションのAPIコールを変更して、入力変数および出力変数のキャラクタ・セット・フォームを |