| Oracle® Databaseグローバリゼーション・サポート・ガイド 11gリリース2 (11.2) B56307-04 |
|


 前 |
 次 |
この章では、Oracleのデータベースのプログラミングおよびアクセス製品とUnicodeを併用する方法について説明します。この章の内容は、次のとおりです。
Oracleには、Unicodeデータの挿入と取出しを行うためのデータベース・アクセス製品がいくつか用意されています。Oracleでは、JavaやC/C++などの一般的に使用されているプログラミング環境に対応したデータベース・アクセス製品を提供しています。データはデータベースとクライアント・プログラム間で透過的に変換されるため、クライアント・プログラムがデータベース・キャラクタ・セットと各国語キャラクタ・セットの影響を受けないことが保証されます。さらに、クライアント・プログラムは、データベースで使用されるNCHARやCHARなどの文字データ型の影響も受けない場合があります。
データ変換操作によってデータベース・サーバーに負荷をかけないように、Oracleは常に、これらの操作をクライアント側のデータベース・アクセス製品に移動しようとします。データベースでデータ変換が必要な場合があり、この操作はパフォーマンスに影響します。この章では、データ変換の流れの詳細を説明します。
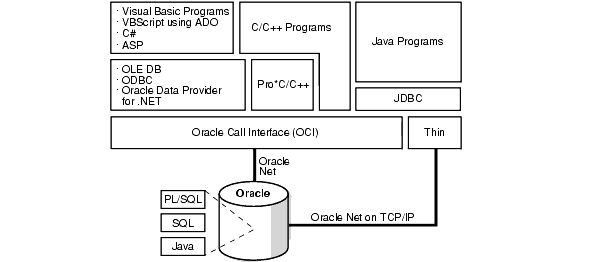
Oracleは総合的なデータベース・アクセス製品を提供しています。これらの製品によって、データベースに格納されているUnicodeデータに異なる開発環境のプログラムでアクセスできます。表7-1に、これらの製品を示します。
表7-1 Oracleのデータベース・アクセス製品
| プログラミング環境 | Oracleのデータベース・アクセス製品 |
|---|---|
|
C/C++ |
Oracle Call Interface (OCI)、Oracle Pro*C/C++、Oracle ODBCドライバ、Oracle Provider for OLE DB、Oracle Data Provider for .NET |
|
Java |
Oracle JDBC OCIまたはThinドライバ、Oracleサーバー側Thinドライバ、Oracleサーバー側内部ドライバ |
|
PL/SQL |
Oracle PL/SQLおよびSQL |
|
Visual Basic/C# |
Oracle ODBCドライバ、Oracle Provider for OLE DB |
図7-1は、データベース・アクセス製品によるデータベースへのアクセス方法を示しています。
Oracle Call Interface(OCI)は、残りのクライアント側データベース・アクセス製品で使用される最下位レベルのAPIです。SQL CHARデータ型およびNCHARデータ型で格納されているUnicodeデータにC/C++プログラムでアクセスするための、柔軟な方法を提供します。OCIを使用して、データの挿入または取出しに使用するキャラクタ・セット(UTF-8やUTF-16など)をプログラムで指定できます。データベースには、Oracle Netを介してアクセスします。
Oracle Pro*C/C++を使用すると、プログラム内にSQLおよびPL/SQLを埋め込むことができます。OCIのUnicode機能を使用して、SQL CHARデータ型およびNCHARデータ型のUTF-16およびUTF-8データへのアクセスを提供します。
Oracle ODBCドライバを使用すると、Windowsプラットフォームで実行されているC/C++、Visual BasicおよびVBScriptプログラムで、データベースにSQL CHARデータ型およびNCHARデータ型で格納されているUnicodeデータにアクセスできます。ODBC標準仕様で指定されているSQLWCHARインタフェースを実装することで、UTF-16データへのアクセスを提供します。
Oracle Provider for OLE DBを使用すると、Windowsプラットフォームで実行されているC/C++、Visual BasicおよびVBScriptプログラムで、SQL CHARデータ型およびNCHARデータ型で格納されているUnicodeデータにアクセスできます。ワイド文字列のOLE DBデータ型を介してUTF-16データへのアクセスを提供します。
Oracle Data Provider for .NETを使用すると、Windowsプラットフォーム上の任意の.NETプログラミング環境で実行されているプログラムで、SQL CHARデータ型およびNCHARデータ型で格納されているUnicodeデータにアクセスできます。Unicodeのデータ型を介してUTF-16データへのアクセスを提供します。
Oracle JDBCドライバは、Oracle Databaseにアクセスするための主要なJavaプログラム・インタフェースです。Oracleには次のJDBCドライバが用意されています。
純粋なJavaドライバで、Javaアプレットで主に使用され、TCP/IPを介したOracle NetプロトコルをサポートするJDBC Thinドライバ
純粋なJavaドライバで、Javaストアド・プロシージャ内で他のOracleサーバーへの接続に使用されるサーバー側JDBC Thinドライバ
ドライバはすべて、データベースに格納されているSQL CHARデータ型およびNCHARデータ型へのUnicodeデータ・アクセスをサポートします。
PL/SQLとSQLのエンジンは、OCIなどのクライアント側プログラムやサーバー側のPL/SQLストアド・プロシージャのかわりに、PL/SQLプログラムとSQL文を処理します。これらのエンジンを使用すると、PL/SQLプログラムでCHAR、VARCHAR2、NCHARおよびNVARCHAR2の各変数を宣言し、データベースのSQL CHARおよびNCHARデータ型にアクセスできます。
次の項では、各データベース・アクセス製品が、Oracle DatabaseへのUnicodeデータ・アクセスをどのようにサポートしているかを説明し、これらの製品の使用例を示します。
SQLは、すべてのプログラムとユーザーが、Oracle Databaseのデータに直接的または間接的にアクセスするときに使用する基本言語です。PL/SQLは、SQLのデータ操作能力と手続き型言語のデータ処理能力を結合した手続き型言語です。SQLとPL/SQLは両方とも、他のプログラム言語に埋め込むことができます。この項では、多言語アプリケーションにデプロイ可能なSQLとPL/SQLのUnicode関連機能について説明します。
この項の内容は、次のとおりです。
|
関連項目:
|
SQL NCHARデータ型は次の3つです。
表の列またはPL/SQL変数をNCHARデータ型として定義する場合、長さは常に文字数として指定します。たとえば次の文では、最大文字長が30の列が1つ作成されます。
CREATE TABLE table1 (column1 NCHAR(30));
この列の最大バイト数は、次のように決定されます。
maximum number of bytes = (maximum number of characters) x (maximum number of bytes for each character)
たとえば、各国語キャラクタ・セットがUTF8の場合、最大バイト長は30文字に1文字当たり3バイトを乗算した値、つまり90バイトとなります。
すべてのNCHARデータ型に使用する各国語キャラクタ・セットは、データベースの作成時に定義します。各国語キャラクタ・セットはUTF8またはAL16UTF16のいずれかです。デフォルトはAL16UTF16です。
使用可能な最大列サイズは、各国語キャラクタ・セットがUTF8の場合は2000文字、AL16UTF16の場合は1000文字です。実際のデータが最大バイト制限の2000の対象となります。2つのサイズ制限は同時に満たす必要があります。PL/SQLでは、NCHARデータの最大長は32767バイトです。NCHAR変数は32767文字まで定義できますが、実際のデータは32767バイトを超えることはできません。列の長さより短い値を挿入すると、最大文字長と最大バイト長のいずれか小さいほうの値まで空白で埋められます。
|
注意: UTF8は可変幅キャラクタ・セットであるため、パフォーマンスに影響する場合があります。NCHARフィールドの空白埋めが過剰に行われると、パフォーマンスが低下します。NVARCHARデータ型を使用するか、NCHARデータ型のキャラクタ・セットをAL16UTF16に変更することを考慮してください。 |
NVARCHAR2データ型は、各国語キャラクタ・セットを使用する可変長文字列を指定します。NVARCHAR2列を使用して表を作成するときは、列の最大文字数を指定します。NVARCHAR2の長さは、NCHARの場合と同様に常に文字単位です。続いて、値が列の最大長を超えないかぎり、ユーザーが指定したとおりに各値が列内に格納されます。文字列の値が最大長まで埋め込まれることはありません。
使用可能な最大列サイズは、各国語キャラクタ・セットがUTF8の場合は4000文字、AL16UTF16の場合は2000文字です。バイト単位では、NVARCHAR2列の最大長は4000バイトです。バイト数の上限と文字数の上限の両方を満たす必要があるため、実際にNVARCHAR2列に使用できる最大文字数は、4000バイトに書込み可能な文字数となります。
PL/SQLでは、NVARCHAR2変数の最大長は32767バイトです。NVARCHAR2変数は32767文字まで定義できますが、実際のデータは32767バイトを超えることはできません。
次の文では、最大文字長が2000で最大バイト長が4000のNVARCHAR2列を1つ含む表が作成されます。
CREATE TABLE table2 (column2 NVARCHAR2(2000));
NCLOBは、最大4GBのUnicode文字を格納する、キャラクタ・ラージ・オブジェクトです。BLOBデータ型とは異なり、NCLOBデータ型では完全なトランザクション・サポートがあるため、SQL、DBMS_LOBパッケージまたはOCIを使用して行われた変更は、完全にトランザクションに組み込まれます。NCLOB値の操作は、コミットおよびロールバックできます。ただし、あるトランザクションでPL/SQLまたはOCI変数に保存したNCLOBロケータを別のトランザクションまたはセッションで使用することはできません。
NCLOB値は、各国語キャラクタ・セットに関係なく、UCS-2互換形式でデータベースに格納されます。格納されたUnicode値は、クライアントまたはサーバーで要求された固定幅または可変幅のキャラクタ・セットに変換されます。可変幅のキャラクタ・セットを使用してNCLOB列に挿入したデータは、データベースに格納される前にUCS-2互換形式に変換されます。
|
関連項目: NCLOBデータ型の詳細は、『Oracle Database SecureFilesおよびラージ・オブジェクト開発者ガイド』を参照してください。 |
Oracleでは、SQL NCHARデータ型と、他のOracleデータ型(CHAR、VARCHAR2、NUMBER、DATE、ROWIDおよびCLOBなど)の間の暗黙的な変換がサポートされています。SQL NCHARデータ型については、CHARおよびVARCHAR2データ型に関する暗黙的な変換もサポートされています。SQL NCHARデータ型は、SQL CHARデータ型と同様に使用できます。
SQL CHARデータ型とSQL NCHARデータ型の間の型変換では、データベース・キャラクタ・セットと各国語キャラクタ・セットが異なるときに、キャラクタ・セットの変換が行われる場合があります。ターゲット・データがCHARまたはNCHARの場合は、空白埋めが発生することがあります。
|
関連項目: 『Oracle Database SQL言語リファレンス』 |
キャラクタ・セット変換が必要なときは、データ型変換時にデータを消失する可能性があります。ソース・キャラクタ・セット内の文字がターゲットのキャラクタ・セット内で定義されていない場合、その場所には置換文字が使用されます。たとえば、NCHARデータを通常のCHAR列に挿入しようとしたときに、NCHAR(Unicode)フォーム内の文字データがデータベース・キャラクタ・セットに変換できない場合、その文字はデータベース・キャラクタ・セットで定義されている置換文字に置き換えられます。文字列型変換時のデータ消失に関する対処方法は、NLS_NCHAR_CONV_EXCP初期化パラメータによって制御されます。このパラメータがTRUEに設定されているときは、データ消失が発生するSQL文はORA-12713エラーを戻し、対応する操作は停止します。このパラメータがFALSEに設定されているときは、データ消失はレポートされず、変換不可能な文字は置換文字で置き換えられます。デフォルト値はFALSEです。このパラメータは、暗黙的な変換と明示的な変換の両方に対して機能します。
PL/SQLの場合は、SQL CHARデータ型とNCHARデータ型の変換時にデータ消失が発生すると、暗黙的な変換の場合も明示的な変換の場合もLOSSY_CHARSET_CONVERSION例外が発生します。
状況によって、一方向のデータ型変換のみが可能な場合と、両方向のデータ型変換が可能な場合があります。Oracleでは、データ型間の変換に関して一連の規則が定義されています。表7-2に、データ型間の変換に関する規則を示します。
表7-2 データ型間の変換に関する規則
| 文 | 規則 |
|---|---|
|
|
値は、ターゲット・データベース列のデータ型に変換されます。 |
|
|
データベースのデータは、ターゲット変数のデータ型に変換されます。 |
|
変数の代入 |
等号の右辺の値は、等号の左辺のターゲット変数のデータ型に変換されます。 |
|
SQL関数とPL/SQL関数のパラメータ |
|
|
連結(||)操作または |
あるオペランドがSQL |
|
SQL |
文字の値は |
|
SQL |
文字の値は |
|
SQL |
文字の値は |
|
SQL |
SQL
SQL |
SQL NCHARデータ型は、明示的な変換関数を使用して、SQL CHARデータ型や他のデータ型と相互に変換できます。この項の例では、次の文で作成された表を使用します。
CREATE TABLE customers (id NUMBER, name NVARCHAR2(50), address NVARCHAR2(200), birthdate DATE);
例7-1 TO_NCHAR関数を使用したcustomers表の移入
TO_NCHAR関数は実行時にデータを変換しますが、N関数はコンパイル時にデータを変換します。
INSERT INTO customers VALUES (1000,
TO_NCHAR('John Smith'),N'500 Oracle Parkway',sysdate);
例7-2 TO_CHAR関数を使用したcustomers表からの選択
次の文では、nameの値が各国語キャラクタ・セットの文字からデータベース・キャラクタ・セットの文字に変換され、その後でLIKE句に従って選択されます。
SELECT name FROM customers WHERE TO_CHAR(name) LIKE '%Sm%';
次の出力が表示されます。
NAME -------------------------------------- John Smith
例7-3 TO_DATE関数を使用したcustomers表からの選択
N関数を使用すると、NCHARまたはCHARデータ型のデータをTO_DATE関数のパラメータとして渡すことができます。データ型変換は実行時に行われるため、データ型を混在させることができます。
DECLARE ndatestring NVARCHAR2(20) := N'12-SEP-1975'; ndstr NVARCHAR2(50); BEGIN SELECT name INTO ndstr FROM customers WHERE (birthdate)> TO_DATE(ndatestring, 'DD-MON-YYYY', N'NLS_DATE_LANGUAGE = AMERICAN'); END;
例7-3に示したように、SQL NCHARデータ型のデータを明示的な変換関数に渡すことができます。複数の文字列パラメータを使用すると、SQL CHARおよびNCHARデータ型のデータを混在させることができます。
|
関連項目: SQLNCHARデータ型の明示的な変換関数の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
大部分のSQL関数は、SQL NCHARデータ型および混合した文字データ型の引数を取ることができます。戻されるデータ型は、最初の引数の型に基づきます。これらの関数に渡されたNUMBERやDATEなどの非文字列データ型は、VARCHAR2に変換されます。次の例では、「Unicodeデータ型のSQL関数」で作成したcustomers表を使用します。
例7-4 INSTR関数
この例では、文字列リテラル'Sm'がNVARCHAR2に変換されてから、INSTRによってスキャンされ、nameで最初に出現するこの文字列の位置が検出されます。
SELECT INSTR(name, N'Sm', 1, 1) FROM customers;
例7-6 RPAD関数
SELECT RPAD(name,100,' ') FROM customers;
出力は次のようになります。
RPAD(NAME,100,'') ------------------------------------------ John Smith
スペース文字' 'がNCHARキャラクタ・セットの対応する文字に変換された後、表示の全長が100になるようにnameの右側に埋め込まれます。
|
関連項目: 『Oracle Database SQL言語リファレンス』 |
Unicode文字列リテラルは、次の方法でSQLおよびPL/SQLに入力できます。
引用符で囲まれた文字列リテラルの前に接頭辞Nを付加します。この接頭辞によって、その後に続く文字列リテラルがNCHAR文字列リテラルであることが明示的に示されます。たとえば、N'résumé'はNCHAR文字列リテラルです。このメソッドの制限事項の詳細は、「NCHAR文字列リテラルの置換」を参照してください。
NCHR(n)SQL関数を使用します。この関数は、各国語キャラクタ・セット(AL16UTF16またはUTF8)内の文字コードの数を戻します。複数のNCHR(n)ファンクションを連結した結果は、NVARCHAR2データになります。このように、クライアントとサーバーのキャラクタ・セット変換を行わずに、NVARCHAR2文字列を直接作成できます。たとえば、NCHR(32)は空白文字を表します。
NCHR(n)は同じ各国語キャラクタ・セットに関連付けられているため、結果値の移植性はその各国語キャラクタ・セットで実行されるアプリケーションに限定されます。この移植性が重要な場合は、UNISTR関数を使用して移植性の制限を解除します。
UNISTR('string')SQL関数を使用します。UNISTR('string')は、文字列を各国語キャラクタ・セットに変換します。移植性を確保してデータを保持するには、ASCII文字と\xxxx形式のUnicodeエンコーディングのみを含めます。xxxxは、UTF-16エンコーディング形式で文字コード値を表す16進値です。たとえば、UNISTR('G\0061ry')は'Gary'を表します。ASCII文字は、データベース・キャラクタ・セットに変換されてから、各国語キャラクタ・セットに変換されます。Unicodeエンコーディングは、各国語キャラクタ・セットに直接変換されます。
最後の2つの方法を使用すると、すべてのUnicode文字列リテラルをエンコードできます。
この項では、NCHAR文字列リテラル置換の実行時にデータの損失を防ぐ方法を説明します。
リテラルのテキストがSQLまたはPL/SQL文の一部になると、接頭辞Nの有無にかかわらず、残りの文と同じキャラクタ・セットでエンコードされます。クライアント側では、文にクライアント・キャラクタ・セットが使用されます。これは、NLS_LANGで定義されているクライアント・キャラクタ・セットにより決定されるか、OCIEnvNlsCreate()コールで指定されるか、またはJDBCでUTF-16として事前定義されます。サーバー側では、文はデータベース・キャラクタ・セットです。
SQLまたはPL/SQL文がクライアントからデータベース・サーバーに送信されると、それに応じてキャラクタ・セットが変換されます。データベース・キャラクタ・セットに、テキスト・リテラルで使用されるキャラクタの一部が含まれない場合、変換時にデータが失われるので、注意が必要です。この問題は、CHARテキスト・リテラルよりもNCHAR文字列リテラルにより大きな影響を及ぼします。これは、N'リテラルがデータベース・キャラクタ・セットに依存しないよう設計されており、クライアント・キャラクタ・セットがサポートするデータを提供できる必要があるためです。
互換性のないデータベース・キャラクタ・セットへの変換時にデータの損失を防ぐため、NCHARリテラル置換機能をアクティブにできます。この機能では、クライアント側でN'リテラルが内部書式により透過的に置換されます。データベース・サーバーは、文の実行時にこのリテラルをUnicodeにデコードします。
「OCIでのSQL NCHAR文字列リテラルの処理」および「JDBCでのSQL NCHAR文字列リテラルの使用」の項では、OCIおよびJDBCのそれぞれで置換機能を有効にする方法を示しています。SQL*Plusなどの多くのアプリケーションでは、データベースへの接続にOCIを使用し、NCHARリテラル置換を明示的に制御しないため、クライアント環境変数ORA_NCHAR_LITERAL_REPLACEをTRUEに設定してこの機能を制御できます。デフォルトでは、この機能は、下位互換性を維持するために無効になっています。
UTL_FILEパッケージは、NVARCHAR2データ型のUnicode各国語キャラクタ・セットのデータを処理します。NCHARおよびNCLOBは、暗黙的な変換でサポートされています。次の関数とプロシージャがあります。
FOPEN_NCHAR
この関数は、最大行サイズを指定して、入力用または出力用のファイルを各国語キャラクタ・セット・モードでオープンします。NVARCHAR2バッファのコンテンツが(データベースの各国語キャラクタ・セットに応じて)AL16UTF16またはUTF8の場合でも、ファイルのコンテンツは、常に、UTF8で読取りおよび書込みされます。詳細は、「OracleデータベースによるUnicodeのサポート」を参照してください。必要に応じて、UTL_FILEはUTF8とAL16UTF16間の変換を行います。
GET_LINE_NCHAR
このプロシージャは、ファイル・ハンドルで識別されたオープン・ファイルからテキストを読み込み、そのテキストを出力バッファ・パラメータに入れます。ファイルは、各国語キャラクタ・セット・モードでオープンし、UTF8キャラクタ・セットでエンコードする必要があります。必要なバッファ・データ型は、NVARCHAR2です。NCHAR、NCLOBまたはVARCHAR2など、その他のデータ型の変数が指定された場合、テキストの読取りの後で、PL/SQLでNVARCHAR2からの標準の暗黙的な変換が実行されます。
PUT_NCHAR
このプロシージャは、バッファ・パラメータに格納されているテキスト文字列を、ファイル・ハンドルで識別されたオープン・ファイルに書き込みます。このファイルは、各国語キャラクタ・セットでオープンする必要があります。テキスト文字列は、UTF8キャラクタ・セットで書き込まれます。必要なバッファ・データ型は、NVARCHAR2です。その他のデータ型の変数が指定された場合、テキストの書込みの前に、PL/SQLでNVARCHAR2への暗黙的な変換が実行されます。
PUT_LINE_NCHAR
このプロシージャは、行セパレータが書き込まれたテキストに追加される以外は、PUT_NCHARと同じです。
PUTF_NCHAR
このプロシージャは、PUT_NCHARプロシージャの書式設定されたバージョンです。このプロシージャは、書式要素\nおよび%sを含む書式文字列を受け入れ、書式文字列内の%sの連続インスタンスを最大で5つの引数に置き換えることができます。書式文字列および引数に想定されるデータ・タイプは、NVARCHAR2です。別のデータ型の変数が指定されていると、テキストの書式設定前に、PL/SQLでNVARCHAR2への暗黙的な変換が実行されます。書式化されたテキストは、ファイル・ハンドルが示すファイルにUTF8キャラクタ・セットで書き込まれます。このファイルは、各国語キャラクタ・セットでオープンする必要があります。
前述の関数およびプロシージャでは、UTF8キャラクタ・セット、つまりUnicode CESU-8エンコーディングでエンコードされたテキスト・ファイルを処理します。CESU-8の詳細は、「ユニバーサル・キャラクタ・セット」を参照してください。関数およびプロシージャは、必要に応じてUTF8とデータベースの各国語キャラクタ・セット(UTF8またはAL16UTF16)間の変換を行います。
|
関連項目: UTL_FILEパッケージの詳細は、『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』を参照してください。 |
OCIはデータベースにアクセスするための最下位レベルのAPIであるため、可能な最大のパフォーマンスを提供します。OCIでUnicodeを使用するときは、次の内容を考慮してください。
OCIEnvNlsCreate()関数を使用して、OCI環境の作成時にSQL CHARのキャラクタ・セットとSQL NCHARのキャラクタ・セットを指定します。これはOCIEnvCreate()関数の拡張バージョンであり、2つのキャラクタ・セットIDを指定できるように拡張された引数を取ります。OCI_UTF16ID UTF-16キャラクタ・セットIDによって、Oracle9iリリース1(9.0.1)で導入されたUnicodeモードが置き換えられています。次に例を示します。
OCIEnv *envhp; status = OCIEnvNlsCreate((OCIEnv **)&envhp, (ub4)0, (void *)0, (void *(*) ()) 0, (void *(*) ()) 0, (void(*) ()) 0, (size_t) 0, (void **)0, (ub2)OCI_UTF16ID, /* Metadata and SQL CHAR character set */ (ub2)OCI_UTF16ID /* SQL NCHAR character set */);
Unicodeモードでは、OCIEnvCreate()関数とともにOCI_UTF16フラグが使用されますが、このモードは非推奨です。
SQL CHARのキャラクタ・セットとSQL NCHARのキャラクタ・セットの両方にOCI_UTF16IDを指定すると、すべてのメタデータのバインドされた定義済データは、UTF-16でエンコードされます。メタデータには、SQL文、ユーザー名、エラー・メッセージおよび列名が含まれます。そのため、継承される操作はいずれもNLS_LANGの設定に依存せず、すべてのメタテキスト・データ・パラメータ(text*)は、UTF-16エンコーディングではUnicodeテキスト・データ型(utext*)とみなされます。
OCI_UTF16IDキャラクタ・セットIDを使用してOCIEnv()関数を初期化するときにSQL文を準備するには、(utext*)文字列を指定してOCIStmtPrepare()関数をコールします。次の例は、Windowsプラットフォームでのみ動作します。他のプラットフォームの場合は、wchar_tデータ型を変更する必要があります。
const wchar_t sqlstr[] = L"SELECT * FROM ENAME=:ename"; ... OCIStmt* stmthp; sts = OCIHandleAlloc(envh, (void **)&stmthp, OCI_HTYPE_STMT, 0, NULL); status = OCIStmtPrepare(stmthp, errhp,(const text*)sqlstr, wcslen(sqlstr), OCI_NTV_SYNTAX, OCI_DEFAULT);
OCIEnv()関数はすでにUTF-16のキャラクタ・セットIDを使用して初期化されているため、データをバインドして定義するためにOCI_ATTR_CHARSET_ID属性を設定する必要はありません。バインド変数名もUTF-16文字列であることが必要です。
/* Inserting Unicode data */
OCIBindByName(stmthp1, &bnd1p, errhp, (const text*)L":ename",
(sb4)wcslen(L":ename"),
(void *) ename, sizeof(ename), SQLT_STR, (void
*)&insname_ind,
(ub2 *) 0, (ub2 *) 0, (ub4) 0, (ub4 *)0,
OCI_DEFAULT);
OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *)
&ename_col_len,
(ub4) 0, (ub4)OCI_ATTR_MAXDATA_SIZE, errhp);
...
/* Retrieving Unicode data */
OCIDefineByPos (stmthp2, &dfn1p, errhp, (ub4)1, (void *)ename,
(sb4)sizeof(ename), SQLT_STR, (void *)0, (ub2 *)0,
(ub2*)0, (ub4)OCI_DEFAULT);
この操作はOCIExecute()関数で実行されます。
クライアントとサーバーのキャラクタ・セットが異なる場合は、OCIクライアントとデータベース・サーバーの間でUnicodeキャラクタ・セット変換が行われます。この変換は、環境によってクライアントまたはサーバーのいずれの側でも行われますが、通常はクライアント側で行われます。
OCI APIを適切にコールしないと、変換時にデータが消失する可能性があります。サーバーとクライアントのキャラクタ・セットが異なる場合は、変換先キャラクタ・セットが変換元キャラクタ・セットより小さいセットであると、データが消失する可能性があります。両方のキャラクタ・セットがUnicodeキャラクタ・セット(UTF8やAL16UTF16など)の場合、この潜在的な問題は回避できます。
SQL NCHARデータ型をバインドまたは定義するときは、OCI_ATTR_CHARSET_FORM属性をSQLCS_NCHARに設定する必要があります。この設定を行わないと、データはデータベース・キャラクタ・セットに変換されてから、各国語キャラクタ・セットとの間で変換されるため、データが消失する可能性があります。データが消失するのは、データベース・キャラクタ・セットがUnicodeでない場合のみです。
冗長なデータ変換は、OCIアプリケーションのパフォーマンス低下の原因となる場合があります。このような冗長な変換は、次の2つの場合に発生します。
SQL CHARデータ型をバインドまたは定義して、OCI_ATTR_CHARSET_FORM属性をSQLCS_NCHARに設定すると、クライアントのキャラクタ・セットから各国語キャラクタ・セットへのデータ変換と、各国語キャラクタ・セットからデータベース・キャラクタ・セットへのデータ変換が行われます。データ消失はないと思われますが、必要な変換が1回の場合でも変換が2回行われます。
SQL NCHARデータ型をバインドまたは定義して、OCI_ATTR_CHARSET_FORMを設定しないと、クライアントのキャラクタ・セットからデータベース・キャラクタ・セットへの変換と、データベース・キャラクタ・セットから各国語データベース・キャラクタ・セットへのデータ変換が行われます。最悪の場合、データベース・キャラクタ・セットがクライアントのキャラクタ・セットより小さいと、データが消失する可能性があります。
パフォーマンス上の問題を回避するために、ターゲット列のデータ型に基づいてOCI_ATTR_CHARSET_FORMを常に適切に設定する必要があります。ターゲットのデータ型が不明の場合に、バインドおよび定義を行うときは、OCI_ATTR_CHARSET_FORM属性をSQLCS_NCHARに設定してください。
表7-3に、OCIのキャラクタ・セット変換を示します。
表7-3 OCIのキャラクタ・セットの変換
| OCIクライアント・バッファのデータ型 | OCI_ATTR_CHARSET_FORM | データベース内のターゲット列のデータ型 | 変換元と変換先 | コメント |
|---|---|---|---|---|
|
|
|
|
OCIでの、UTF-16とデータベース・キャラクタ・セット |
予期しないデータ消失はありません。 |
|
|
|
|
OCIでの、UTF-16と各国語キャラクタ・セット |
予期しないデータ消失はありません。 |
|
|
|
|
OCIでの、UTF-16と各国語キャラクタ・セット データベース・サーバーでの、各国語キャラクタ・セットとデータベース・キャラクタ・セット |
予期しないデータ消失はありませんが、各国語キャラクタ・セットを経由して変換が行われるため、パフォーマンスが低下する可能性があります。 |
|
|
|
|
OCIでの、UTF-16とデータベース・キャラクタ・セット データベース・サーバーでの、データベース・キャラクタ・セットと各国語キャラクタ・セット |
データベース・キャラクタ・セットがUnicodeでない場合は、データが消失する可能性があります。 |
|
|
|
|
OCIでの、 |
予期しないデータ消失はありません。 |
|
|
|
|
OCIでの、 |
予期しないデータ消失はありません。 |
|
|
|
|
OCIでの、 データベース・サーバーでの、各国語キャラクタ・セットとデータベース・キャラクタ・セット |
予期しないデータ消失はありませんが、各国語キャラクタ・セットを経由して変換が行われるため、パフォーマンスが低下する可能性があります。 |
|
|
|
|
OCIでの、 データベース・サーバーでの、データベース・キャラクタ・セットと各国語キャラクタ・セット |
データベース・キャラクタ・セットを経由して変換が行われるため、データが消失する可能性があります。 |
データ変換によってデータが拡張し、バッファがオーバーフローする原因となる場合があります。バインド操作では、OCI_ATTR_MAXDATA_SIZE属性をサーバー上に拡張後のデータを格納するのに十分なサイズに設定する必要があります。この設定が困難な場合は、表スキーマの変更を考慮する必要があります。定義操作では、拡張後のデータに対して十分なバッファ領域をクライアント・アプリケーションで割り当てる必要があります。バッファのサイズは、拡張後のデータの最大長に設定してください。次の計算で最大バッファ長を見積もることができます。
列データのバイト・サイズを取得します。
取得したサイズに、クライアント・キャラクタ・セットの1文字当たりの最大バイト数を乗算します。
この方法は最も簡単で速い方法ですが、正確ではないためメモリーを浪費する可能性があります。この方法は、キャラクタ・セットのすべての組合せに適用できます。たとえば、UTF-16データのバインドと定義の場合は、次の例でクライアント・バッファを計算します。
ub2 csid = OCI_UTF16ID;
oratext *selstmt = "SELECT ename FROM emp";
counter = 1;
...
OCIStmtPrepare(stmthp, errhp, selstmt, (ub4)strlen((char*)selstmt),
OCI_NTV_SYNTAX, OCI_DEFAULT);
OCIStmtExecute ( svchp, stmthp, errhp, (ub4)0, (ub4)0,
(CONST OCISnapshot*)0, (OCISnapshot*)0,
OCI_DESCRIBE_ONLY);
OCIParamGet(stmthp, OCI_HTYPE_STMT, errhp, &myparam, (ub4)counter);
OCIAttrGet((void*)myparam, (ub4)OCI_DTYPE_PARAM, (void*)&col_width,
(ub4*)0, (ub4)OCI_ATTR_DATA_SIZE, errhp);
...
maxenamelen = (col_width + 1) * sizeof(utext);
cbuf = (utext*)malloc(maxenamelen);
...
OCIDefineByPos(stmthp, &dfnp, errhp, (ub4)1, (void *)cbuf,
(sb4)maxenamelen, SQLT_STR, (void *)0, (ub2 *)0,
(ub2*)0, (ub4)OCI_DEFAULT);
OCIAttrSet((void *) dfnp, (ub4) OCI_HTYPE_DEFINE, (void *) &csid,
(ub4) 0, (ub4)OCI_ATTR_CHARSET_ID, errhp);
OCIStmtFetch(stmthp, errhp, 1, OCI_FETCH_NEXT, OCI_DEFAULT);
...
Unicode UTF-8エンコーディングをサポートするOCIクライアント・アプリケーションの場合、データベース・キャラクタ・セットがUTF8でないかぎり、AL32UTF8を使用してNLS_LANGキャラクタ・セットを指定します。データベース・キャラクタ・セットがUTF8である場合は、UTF8を使用します。
AL16UTF16はサーバー用の各国語キャラクタ・セットであるため、NLS_LANGをAL16UTF16に設定しないでください。UTF-16を使用する必要がある場合は、データをバインドまたは定義するときに、OCIAttrSet()関数を使用してクライアント・キャラクタ・セットをOCI_UTF16IDに指定してください。
SQL CHARデータ型を使用してデータをバインドおよび定義するためのUnicodeキャラクタ・セットを指定するには、OCIBind()またはOCIDefine() API後に、OCIAttrSet()関数をコールして、適切なキャラクタ・セットIDを設定する必要があります。次に一般的な2つの例を示します。
OCIBind()またはOCIDefine()の後にOCIAttrSet()をコールして、UTF-16 Unicodeキャラクタ・セット・エンコーディングを指定します。次に例を示します。
...
ub2 csid = OCI_UTF16ID;
utext ename[100]; /* enough buffer for ENAME */
...
/* Inserting Unicode data */
OCIBindByName(stmthp1, &bnd1p, errhp, (oratext*)":ENAME",
(sb4)strlen((char *)":ENAME"), (void *) ename, sizeof(ename),
SQLT_STR, (void *)&insname_ind, (ub2 *) 0, (ub2 *) 0, (ub4) 0,
(ub4 *)0, OCI_DEFAULT);
OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &csid,
(ub4) 0, (ub4)OCI_ATTR_CHARSET_ID, errhp);
OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &ename_col_len,
(ub4) 0, (ub4)OCI_ATTR_MAXDATA_SIZE, errhp);
...
/* Retrieving Unicode data */
OCIDefineByPos (stmthp2, &dfn1p, errhp, (ub4)1, (void *)ename,
(sb4)sizeof(ename), SQLT_STR, (void *)0, (ub2 *)0,
(ub2*)0, (ub4)OCI_DEFAULT);
OCIAttrSet((void *) dfn1p, (ub4) OCI_HTYPE_DEFINE, (void *) &csid,
(ub4) 0, (ub4)OCI_ATTR_CHARSET_ID, errhp);
...
バインドされたバッファがutextデータ型の場合は、OCIBind()またはOCIDefine()のコール時にキャスト(text*)を追加する必要があります。OCI_ATTR_MAXDATA_SIZE属性の値は通常、サーバーのキャラクタ・セットの列サイズによって決まります。これは、このサイズが、バインド操作の際に変換用の一時的なバッファ領域をサーバーに割り当てるためにのみ使用されているためです。
NLS_LANGキャラクタ・セットをUTF8またはAL32UTF8として指定して、OCIBind()またはOCIDefine()をコールします。
環境変数NLS_LANGにUTF8またはAL32UTF8を設定できます。Unicodeを使用していない場合と同様に、OCIBind()およびOCIDefine()をコールします。環境変数NLS_LANGをUTF8またはAL32UTF8に設定し、次のOCIプログラムを実行します。
...
oratext ename[100]; /* enough buffer size for ENAME */
...
/* Inserting Unicode data */
OCIBindByName(stmthp1, &bnd1p, errhp, (oratext*)":ENAME",
(sb4)strlen((char *)":ENAME"), (void *) ename, sizeof(ename),
SQLT_STR, (void *)&insname_ind, (ub2 *) 0, (ub2 *) 0,
(ub4) 0, (ub4 *)0, OCI_DEFAULT);
OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &ename_col_len,
(ub4) 0, (ub4)OCI_ATTR_MAXDATA_SIZE, errhp);
...
/* Retrieving Unicode data */
OCIDefineByPos (stmthp2, &dfn1p, errhp, (ub4)1, (void *)ename,
(sb4)sizeof(ename), SQLT_STR, (void *)0, (ub2 *)0, (ub2*)0,
(ub4)OCI_DEFAULT);
...
OCI使用時は、UTF-16のバインドまたは定義を使用してSQL NCHARデータ型にアクセスすることをお薦めします。Oracle9i から、SQL NCHARデータ型は、UTF8またはAL16UTF16のいずれかのエンコーディングを使用したUnicodeデータ型になっています。SQL NCHARデータ型のデータにアクセスするには、データ消失が発生しない適切なデータ変換が実行されるように、バインドまたは定義してから実行するまでにOCI_ATTR_CHARSET_FORM属性をSQLCS_NCHARに設定します。SQL NCHARデータ型のデータ長は常に、Unicodeコード単位の数で表されます。
次のプログラムは、NCHARデータ列に対するデータの挿入とフェッチの一般的な例です。
...
ub2 csid = OCI_UTF16ID;
ub1 cform = SQLCS_NCHAR;
utext ename[100]; /* enough buffer for ENAME */
...
/* Inserting Unicode data */
OCIBindByName(stmthp1, &bnd1p, errhp, (oratext*)":ENAME",
(sb4)strlen((char *)":ENAME"), (void *) ename,
sizeof(ename), SQLT_STR, (void *)&insname_ind, (ub2 *) 0,
(ub2 *) 0, (ub4) 0, (ub4 *)0, OCI_DEFAULT);
OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &cform, (ub4) 0,
(ub4)OCI_ATTR_CHARSET_FORM, errhp);
OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &csid, (ub4) 0,
(ub4)OCI_ATTR_CHARSET_ID, errhp);
OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &ename_col_len,
(ub4) 0, (ub4)OCI_ATTR_MAXDATA_SIZE, errhp);
...
/* Retrieving Unicode data */
OCIDefineByPos (stmthp2, &dfn1p, errhp, (ub4)1, (void *)ename,
(sb4)sizeof(ename), SQLT_STR, (void *)0, (ub2 *)0, (ub2*)0,
(ub4)OCI_DEFAULT);
OCIAttrSet((void *) dfn1p, (ub4) OCI_HTYPE_DEFINE, (void *) &csid, (ub4) 0,
(ub4)OCI_ATTR_CHARSET_ID, errhp);
OCIAttrSet((void *) dfn1p, (ub4) OCI_HTYPE_DEFINE, (void *) &cform, (ub4) 0,
(ub4)OCI_ATTR_CHARSET_FORM, errhp);
...
デフォルトでは、NCHARのリテラル置換はOCIでは実行されません。(「NCHAR文字列リテラルの置換」を参照してください。)
リテラル置換を有効にするには、環境変数ORA_NCHAR_LITERAL_REPLACEをTRUEに設定します。また、OCIEnvCreate()およびOCIEnvNlsCreate()でOCI_NCHAR_LITERAL_REPLACE_ONモードとOCI_NCHAR_LITERAL_REPLACE_OFFモードを使用すると、この動作をプログラムで制御できます。たとえば、OCIEnvCreate(OCI_NCHAR_LITERAL_REPLACE_ON)と記述するとNCHARのリテラル置換がオンになり、OCIEnvCreate(OCI_NCHAR_LITERAL_REPLACE_OFF)と記述すると置換はオフになります。
例として、次の文を考えてみます。
int main(argc, argv)
{
OCIEnv *envhp;
if (OCIEnvCreate((OCIEnv **) &envhp,
(ub4)OCI_THREADED|OCI_NCHAR_LITERAL_REPLACE_ON,
(dvoid *)0, (dvoid * (*)(dvoid *, size_t)) 0,
(dvoid * (*)(dvoid *, dvoid *, size_t))0,
(void (*)(dvoid *, dvoid *)) 0,
(size_t) 0, (dvoid **) 0))
{
printf("FAILED: OCIEnvCreate()\n";
return 1;
}
...
}
NCHARのリテラル置換がオンの場合、OCIStmtPrepareおよびOCIStmtPrepare2は、SQLテキスト内のN'リテラルをU'リテラルに変換し、結果のSQLテキストを文ハンドルに格納します。この結果、アプリケーションがOCI_ATTR_STATEMENTを使用してOCI文ハンドルからSQLテキストを取り出す場合、SQLテキストは元のテキストで指定されたN'ではなくU'を戻します。
|
関連項目: 環境変数の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
CLOBまたはNCLOBの列に対してUTF-16データの書込み(バインド)および読込み(定義)を行うには、UTF-16キャラクタ・セットIDをOCILobWrite()およびOCILobRead()として指定する必要があります。UTF-16データをCLOB列に書き込むときは、OCILobWrite()を次のようにコールしてください。
...
ub2 csid = OCI_UTF16ID;
err = OCILobWrite (ctx->svchp, ctx->errhp, lobp, &amtp, offset, (void *) buf,
(ub4) BUFSIZE, OCI_ONE_PIECE, (void *)0,
(sb4 (*)()) 0, (ub2) csid, (ub1) SQLCS_IMPLICIT);
amtpパラメータは、Unicodeコード単位でのデータ長です。offsetパラメータは、データ列の開始からのデータのオフセットを示しています。csidパラメータは、UTF-16データ用に設定する必要があります。
CLOB列からUTF-16データを読み込むには、OCILobRead()を次のようにコールします。
...
ub2 csid = OCI_UTF16ID;
err = OCILobRead(ctx->svchp, ctx->errhp, lobp, &amtp, offset, (void *) buf,
(ub4)BUFSIZE , (void *) 0, (sb4 (*)()) 0, (ub2)csid,
(ub1) SQLCS_IMPLICIT);
データ長は常に、Unicodeコード単位の数で表されます。エンコーディングがUTF-16であるため、1つのUnicode補助文字は2コード単位としてカウントされます。LOB列のバインドまたは定義後、OCILobGetLength()を使用してLOB列に格納されているデータ長を測定できます。UTF-16としてデータをバインドまたは定義している場合、戻り値はコード単位によるデータ長です。
err = OCILobGetLength(ctx->svchp, ctx->errhp, lobp, &lenp);
NCLOBを使用している場合は、OCI_ATTR_CHARSET_FORMをSQLCS_NCHARに設定する必要があります。
Pro*C/C++には、データベースとの間でUnicodeデータの挿入や取出しを行う方法が3通り用意されています。
Pro*C/C++のVARCHARデータ型またはネイティブなC/C++のtextデータ型を使用すると、UTF8またはAL32UTF8データベースのSQL CHARデータ型で格納されているUnicodeデータにプログラムでアクセスできます。C/C++ のネイティブなtext型をプログラムで使用することもできます。
Pro*C/C++のUVARCHARデータ型またはネイティブなC/C++のutextデータ型を使用すると、データベースのNCHARデータ型で格納されているUnicodeデータにプログラムでアクセスできます。
Pro*C/C++ のNVARCHARデータ型を使用すると、NCHARデータ型で格納されているUnicodeデータにプログラムでアクセスできます。Pro*C/C++プログラムでのUVARCHARとNVARCHARの相違は、UVARCHARデータ型のデータはutextバッファに格納されているのに対して、NVARCHARデータ型のデータはtextデータ型で格納されている点です。
Pro*C/C++では、SQLテキストに対してUnicode OCI APIを使用しません。そのため、埋込みSQLテキストは、環境変数NLS_LANGに指定されているキャラクタ・セットでエンコードする必要があります。
この項の内容は、次のとおりです。
データ変換はOCIレイヤーで行われますが、Pro*C/C++プログラムで使用されているデータ型に基づいて、どの変換手順を使用するかをOCIに対して指示するのは、Pro*C/C++プリプロセッサです。表7-4に、変換手順を示します。
表7-4 Pro*C/C++のバインドと定義でのデータ変換
| Pro*C/C++データ型 | SQLデータ型 | 変換手順 |
|---|---|---|
|
|
|
OCIで発生する、 |
|
|
|
OCIで発生する、 データベース・サーバーで発生する、データベース・キャラクタ・セットと各国語キャラクタ・セットの間の変換 |
|
|
|
OCIで発生する、 |
|
|
|
OCIで発生する、 データベース・サーバーでの、各国語キャラクタ・セットとデータベース・キャラクタ・セットの間の変換 |
|
|
|
OCIで発生する、UTF-16と各国語キャラクタ・セットの間の変換 |
|
|
|
OCIで発生する、UTF-16と各国語キャラクタ・セットの間の変換 データベース・サーバーで発生する、各国語キャラクタ・セットからデータベース・キャラクタ・セットへの変換 |
Pro*C/C++のVARCHARデータ型は、lengthフィールドとtextバッファ・フィールド付きの構造体に事前処理されます。次の例では、C/C++のシステム固有のデータ型textとPro*C/C++のVARCHARデータ型を使用して、表の列をバインドおよび定義します。
#include <sqlca.h>
main()
{
...
/* Change to STRING datatype: */
EXEC ORACLE OPTION (CHAR_MAP=STRING) ;
text ename[20] ; /* unsigned short type */
varchar address[50] ; /* Pro*C/C++ varchar type */
EXEC SQL SELECT ename, address INTO :ename, :address FROM emp;
/* ename is NULL-terminated */
printf(L"ENAME = %s, ADDRESS = %.*s\n", ename, address.len, address.arr);
...
}
Pro*C/C++プログラムでVARCHARデータ型またはシステム固有のtextデータ型を使用すると、プリプロセッサでは、そのプログラムがデータベースのSQL NCHARデータ型ではなく、SQL CHARデータ型の列にアクセスしているとみなします。次に、プリプロセッサは、OCI_ATTR_CHARSET_FORM属性に対するSQLCS_IMPLICIT値を使用してバインドまたは定義することで、この動きを反映するためのC/C++コードを生成します。その結果、バインド変数または定義変数がデータベースのSQL NCHARデータ型の列にバインドされると、データベース・サーバーでの暗黙的な変換によって、データベース・キャラクタ・セットと各国語データベース・キャラクタ・セットの間でデータの変換が行われます。データベース・キャラクタ・セットが各国語キャラクタ・セットより小さい場合は、変換時にデータが消失します。
Pro*C/C++のNVARCHARデータ型は、Pro*C/C++のVARCHARデータ型と類似しています。データベースのSQL NCHARデータ型にアクセスするために使用する必要があります。このデータ型は、SQL NCHARデータ型の列にテキスト・バッファをバインドまたは定義するようにPro*C/C++プリプロセッサに通知します。プリプロセッサは、バインド変数または定義変数のOCI_ATTR_CHARSET_FORM属性にSQLCS_NCHAR値を指定します。この結果、データベースで暗黙的な変換は行われません。
SQL CHARデータ型の列に対してNVARCHARバッファがバインドされると、(NLS_LANGキャラクタ・セットでエンコードされている)NVARCHARバッファのデータは、OCIで各国語キャラクタ・セットとの変換が行われ、次に、データベース・サーバーでデータベース・キャラクタ・セットに変換されます。NLS_LANGキャラクタ・セットがデータベース・キャラクタ・セットより大きい場合は、データが消失する可能性があります。
UVARCHARデータ型は、lengthフィールドとutextバッファ・フィールド付きの構造体に事前処理されます。次のコード例には、2つのホスト変数enameとaddressが含まれています。enameホスト変数は、Unicode文字を20文字格納するutextバッファとして宣言されています。addressホスト変数は、Unicode文字を50文字格納するuvarcharバッファとして宣言されています。lenフィールドとarrフィールドは、構造体のフィールドとしてアクセス可能です。
#include <sqlca.h>
#include <sqlucs2.h>
main()
{
...
/* Change to STRING datatype: */
EXEC ORACLE OPTION (CHAR_MAP=STRING) ;
utext ename[20] ; /* unsigned short type */
uvarchar address[50] ; /* Pro*C/C++ uvarchar type */
EXEC SQL SELECT ename, address INTO :ename, :address FROM emp;
/* ename is NULL-terminated */
wprintf(L"ENAME = %s, ADDRESS = %.*s\n", ename, address.len,
address.arr);
...
}
Pro*C/C++プログラムでUVARCHARデータ型またはシステム固有のutextデータ型を使用すると、プリプロセッサでは、プログラムがSQL NCHARデータ型にアクセスしているとみなします。次に、プリプロセッサは、OCI_ATTR_CHARSET_FORM属性に対するSQLCS_NCHAR値を使用してバインドまたは定義することで、C/C++コードを生成します。この結果、バインド変数または定義変数がSQL NCHARデータ型の列にバインドされると、データベース・サーバーでは各国語キャラクタ・セットからのデータの暗黙的な変換が行われます。ただし、各国語キャラクタ・セットは常にデータベース・キャラクタ・セットより大きいため、この状況でデータが消失することはありません。
Oracleには、Oracleデータベースの文字データにJavaプログラムでアクセスするために次のJDBCドライバが用意されています。
JDBC OCIドライバ
JDBC Thinドライバ
サーバー側JDBC内部ドライバ
サーバー側JDBC Thinドライバ
Javaプログラムでは、SQL CHARデータ型およびNCHARデータ型の列との間で文字データの挿入や取出しを行うことができます。特に、JDBCを使用すると、JavaプログラムでJava文字列をSQL CHARデータ型およびNCHARデータ型にバインドしたり定義できます。Javaのstringデータ型はUTF-16でエンコードされているため、データベースとの間で取り出したり挿入するデータは、UTF-16とデータベース・キャラクタ・セットまたは各国語キャラクタ・セット間で変換する必要があります。また、JDBCを使用すると、PL/SQL文とSQL文をJava文字列に指定できるため、非ASCIIスキーマ・オブジェクト名と文字列リテラルを参照できます。
データベースの接続時、JDBCは、サーバーのNLS_LANGUAGEおよびNLS_TERRITORYパラメータを、JDBCドライバを実行するJava VMのロケールに対応する値に設定します。この操作により、サーバーとJavaクライアントが確実に同じ言語で通信できるようになります。その結果、サーバーから戻されるOracleエラー・メッセージは、クライアントのロケールと同じ言語になります。
この項の内容は、次のとおりです。
Oracle JDBCドライバを使用すると、Java文字列のバインド変数または定義変数を使用して、データベースのSQL CHARデータ型にアクセスできます。次のコードは、Java文字列をCHAR列にバインドする方法を示しています。
int employee_id = 12345;
String last_name = "Joe";
PreparedStatement pstmt = conn.prepareStatement("INSERT INTO" +
"employees (last_name, employee_id) VALUES (?, ?)");
pstmt.setString(1, last_name);
pstmt.setInt(2, employee_id);
pstmt.execute(); /* execute to insert into first row */
employee_id += 1; /* next employee number */
last_name = "\uFF2A\uFF4F\uFF45"; /* Unicode characters in name */
pstmt.setString(1, last_name);
pstmt.setInt(2, employee_id);
pstmt.execute(); /* execute to insert into second row */
ターゲットSQL列は、そのデータ型と長さを指定することで定義できます。データ型と長さを指定してSQL CHAR列を定義すると、JDBCではこの情報を使用してSQL CHAR列からデータをフェッチする操作のパフォーマンスが最適化されます。次に、SQL CHAR列の定義例を示します。
OraclePreparedStatement pstmt = (OraclePreparedStatement)
conn.prepareStatement("SELECT ename, empno from emp");
pstmt.defineColumnType(1,Types.VARCHAR, 3);
pstmt.defineColumnType(2,Types.INTEGER);
ResultSet rest = pstmt.executeQuery();
String name = rset.getString(1);
int id = reset.getInt(2);
PreparedStatementをOraclePreparedStatementにキャストして、defineColumnType()をコールする必要があります。defineColumnType()の2番目のパラメータは、ターゲットSQL列のデータ型です。3番目のパラメータは、文字数による長さです。
Java文字列の変数をSQL NCHARデータ型にバインドまたは定義するために、OracleにはsetFormOfUse()メソッドを含む拡張PreparedStatementが用意されています。このメソッドを使用して、バインド変数のターゲット列がSQL NCHARデータ型であることを明示的に指定できます。次のコードは、Java文字列をNCHAR列にバインドする方法を示しています。
int employee_id = 12345;
String last_name = "Joe"
oracle.jdbc.OraclePreparedStatement pstmt =
(oracle.jdbc.OraclePreparedStatement)
conn.prepareStatement("INSERT INTO employees (last_name, employee_id)
VALUES (?, ?)");
pstmt.setFormOfUse(1, oracle.jdbc.OraclePreparedStatement.FORM_NCHAR);
pstmt.setString(1, last_name);
pstmt.setInt(2, employee_id);
pstmt.execute(); /* execute to insert into first row */
employee_id += 1; /* next employee number */
last_name = "\uFF2A\uFF4F\uFF45"; /* Unicode characters in name */
pstmt.setString(1, last_name);
pstmt.setInt(2, employee_id);
pstmt.execute(); /* execute to insert into second row */
ターゲットのSQL NCHAR列は、そのデータ型、使用フォームおよび長さを指定することで定義できます。JDBCでは、この情報を使用して、これらの列からSQL NCHARデータをフェッチする操作のパフォーマンスが最適化されます。次に、SQL NCHAR列の定義例を示します。
OraclePreparedStatement pstmt = (OraclePreparedStatement)
conn.prepareStatement("SELECT ename, empno from emp");
pstmt.defineColumnType(1,Types.VARCHAR, 3,
OraclePreparedStatement.FORM_NCHAR);
pstmt.defineColumnType(2,Types.INTEGER);
ResultSet rest = pstmt.executeQuery();
String name = rset.getString(1);
int id = reset.getInt(2);
SQL NCHAR列を定義するには、defineColumnType()の最初の引数にSQL CHAR列と等価のデータ型を指定し、第2の引数に文字数による長さを指定し、第4の引数に使用フォームを指定する必要があります。
使用フォームの引数を明示的に指定しなくても、NCHAR列にJava文字列をバインドまたは定義できます。その場合は、次のことに注意してください。
setString()メソッドに引数を指定しないと、JDBCはバインド変数または定義変数がSQL CHAR列用であるとみなします。その結果、JDBCはこれらの変数をデータベース・キャラクタ・セットに変換しようとします。データがデータベースに到着すると、そのデータベースはデータベース・キャラクタ・セットのデータを各国語キャラクタ・セットに暗黙的に変換します。データベース・キャラクタ・セットが各国語キャラクタ・セットのサブセットの場合は、この変換時にデータが消失する可能性があります。各国語キャラクタ・セットはUTF8またはAL16UTF16であるため、データベース・キャラクタ・セットがUTF8またはAL32UTF8以外の場合、データは消失します。
SQL CHARデータ型からSQL NCHARデータ型への暗黙的な変換はデータベースで行われるため、データベースのパフォーマンスが低下します。
また、SQL CHARデータ型の列にJava文字列をバインドまたは定義しても、使用フォームの引数を指定すると、データベースのパフォーマンスが低下します。ただし、各国語キャラクタ・セットは常にデータベース・キャラクタ・セットより大きいため、データが消失することはありません。
JDBC 11.1では、新しいJDBC 4.0 (JDK6) SQLデータ型NCHAR、NVARCHAR、LONGNVARCHARおよびNCLOBに対するサポートが追加されています。各国語の文字値を取得するために、アプリケーションから次のいずれかのメソッドをコールできます。
getNString
getNClob
getNCharacterStream
getNClobメソッドは、取り出した値が確かにNCLOBかどうかを検証します。他の点では、これらのメソッドは文字Nのない対応するメソッドと同等です。
各国語キャラクタ・タイプのパラメータ・マーカーの値を指定するために、アプリケーションから次のいずれかのメソッドをコールできます。
setNString
setNCharacterStream
setNClob
これらのメソッドは、setFormOfUse(..., OraclePreparedStatement.FORM_NCHAR)のコールが先行する文字Nのない対応するメソッドと同等です。
|
関連項目: 『Oracle Database JDBC開発者ガイドおよびリファレンス』のJDK 1.6での各国語キャラクタ・セット用の新しいメソッドに関する項 |
Javaアプリケーションで使用フォームの引数をデフォルトで指定するかどうかを指示できるように、Oracle JDBCドライバにはJavaシステム・プロパティが導入されています。このプロパティの用途は次のとおりです。
SQL CHARデータ型にアクセスする既存のアプリケーションは、SQL NCHARデータ型をサポートするように移行できます。これにより、コード行を変更せずに世界中にデプロイできるようになります。
アプリケーションでは、SQL NCHAR列をバインドおよび定義するときに、setFormOfUse()メソッドをコールする必要はありません。アプリケーション・コードは、バックエンド・データベースで使用中のデータ型に依存せずにそのまま使用できます。このプロパティ・セットを使用すると、アプリケーションをSQL CHARまたはSQL NCHARの使用から簡単に移行できます。
Javaシステム・プロパティは、Javaアプリケーションを起動するコマンドラインで指定します。このフラグを指定する構文は、次のとおりです。
java -Doracle.jdbc.defaultNChar=true <application class>
このプロパティを指定すると、Oracle JDBCドライバでは、アプリケーションのすべてのバインドおよび定義操作に使用フォームの引数が存在するものとみなされます。
データベース・スキーマがSQL CHAR列とSQL NCHAR列の両方で構成されている場合は、このフラグを使用すると、データベース・サーバーで暗黙的な変換が実行されるため、SQL CHAR列へのアクセス時にパフォーマンスが低下することがあります。
JDBCでNCHAR文字列リテラルを使用する場合は、処理前に文字がデータベース・キャラクタ・セットに変換されるため、データ消失の可能性があります。詳細は、「NCHAR文字列リテラルの置換」を参照してください。
NCHAR文字列リテラルを保持する処理を適切に実行するには、プロパティ・セットoracle.jdbc.convertNcharLiteralsを有効にします。値がtrueの場合、このオプションは有効化され、それ以外の場合は無効化されます。デフォルトでは「False」に設定されています。オプションを有効化する方法は2通りあり、a)Javaシステム・プロパティとしてまたはb)接続プロパティとして設定できます。有効化すると、VM(システム・プロパティ)または接続(接続プロパティ)のすべてのSQLで変換が実行されます。たとえば、次のように、Javaシステム・プロパティとしてプロパティを設定できます。
java -Doracle.jdbc.convertNcharLiterals="true" ...
または、次のように接続プロパティとして設定できます。
Properties props = new Properties();
...
props.setProperty("oracle.jdbc.convertNcharLiterals", "true");
Connection conn = DriverManager.getConnection(url, props);
接続プロパティとして設定した場合は、システム・プロパティの設定が上書きされます。
Java文字列は常にUTF-16でエンコードされているため、JDBCドライバは、データベース・キャラクタ・セットからUTF-16または各国語キャラクタ・セットにデータを透過的に変換します。変換手順は、JDBCドライバごとにそれぞれ異なります。
OCIドライバの場合、SQL文はデータベースに送信され処理される前に、ドライバによって常にデータベース・キャラクタ・セットに変換されます。データベース・キャラクタ・セットがUS7ASCIIでもWE8ISO8859P1でもない場合、ドライバはまずSQL文をJavaでUTF-8に変換し、その後Cでデータベース・キャラクタ・セットに変換します。それ以外の場合は、SQL文をデータベース・キャラクタ・セットに直接変換します。Java文字列のバインド変数については、表7-5に様々な状況に対応する変換手順が要約されています。Java文字列の定義変数については、同じ変換手順が逆方向に行われます。
表7-5 OCIドライバの変換手順
| 使用フォーム | SQLデータ型 | 変換手順 |
|---|---|---|
|
|
|
JDBCドライバで行われる、UTF-16エンコーディングのJava文字列とデータベース・キャラクタ・セットの間の変換。 |
|
|
|
JDBCドライバで行われる、UTF-16エンコーディングのJava文字列とデータベース・キャラクタ・セットの間の変換。さらに、データベース・サーバーで行われる、データベース・キャラクタ・セットと各国語キャラクタ・セットの間の変換。 |
|
|
|
JDBCドライバで行われる、UTF-16エンコーディングのJava文字列と各国語キャラクタ・セットの間の変換。 |
|
|
|
JDBCドライバで行われる、UTF-16エンコーディングのJava文字列と各国語キャラクタ・セットの間の変換。さらに、データベース・サーバーで行われる、各国語キャラクタ・セットとデータベース・キャラクタ・セットの間の変換。 |
SQL文は、データベースに送信され処理される前に、ドライバによって常にデータベース・キャラクタ・セットまたはUTF-8のいずれかに変換されます。データベース・キャラクタ・セットが次のいずれかのキャラクタ・セットの場合、ドライバはSQL文をデータベース・キャラクタ・セットに変換します。
US7ASCII
WE8ISO8859P1
WE8DEC
WE8MSWIN1252
それ以外の場合、ドライバはSQL文をUTF-8に変換し、データベースに対してSQL文を処理するにはさらに変換が必要であることを通知します。その場合、データベースはSQL文をデータベース・キャラクタ・セットに変換します。Java文字列のバインド変数の場合、Thinドライバに対しては、表7-6に示されている変換手順が使用されます。Java文字列の定義変数については、同じ変換手順が逆方向に行われます。前述の4つのキャラクタ・セットは、表では選択されたキャラクタ・セットと表示されています。
表7-6 Thinドライバの変換手順
| 使用フォーム | SQLデータ型 | データベース・キャラクタ・セット | 変換手順 |
|---|---|---|---|
|
|
|
選択されたキャラクタ・セットの1つ |
thinドライバで行われる、UTF-16エンコーディングのJava文字列とデータベース・キャラクタ・セットの間の変換。 |
|
|
|
選択されたキャラクタ・セットの1つ |
thinドライバで行われる、UTF-16エンコーディングのJava文字列とデータベース・キャラクタ・セットの間の変換。さらに、データベース・サーバーで行われる、データベース・キャラクタ・セットと各国語キャラクタ・セットの間の変換。 |
|
|
|
選択されたキャラクタ・セット以外 |
thinドライバで行われる、UTF-16エンコーディングのJava文字列とUTF-8の間の変換。さらに、データベース・サーバーで行われる、UTF-8とデータベース・キャラクタ・セットの間の変換。 |
|
|
|
選択されたキャラクタ・セット以外 |
thinドライバで行われる、UTF-16エンコーディングのJava文字列とUTF-8の間の変換。さらに、データベース・サーバーで行われる、UTF-8からデータベース・キャラクタ・セット、さらに各国語キャラクタ・セットへの変換。 |
|
|
|
任意 |
thinドライバで行われる、UTF-16エンコーディングのJava文字列と各国語キャラクタ・セットの間の変換。さらに、データベース・サーバーで行われる、各国語キャラクタ・セットとデータベース・キャラクタ・セットの間の変換。 |
|
|
|
任意 |
thinドライバで行われる、UTF-16エンコーディングのJava文字列と各国語キャラクタ・セットの間の変換。 |
サーバー側内部ドライバはデータベース内部で動作するため、すべてのデータ変換はデータベース・サーバーで行われます。
JDBCドライバはOracleオブジェクト型をサポートしています。Oracleオブジェクトは、データベース・キャラクタ・セットまたは各国語キャラクタ・セットで表現したオブジェクトとして、常にデータベースからクライアントに送信されます。つまり、「JDBCドライバのデータ変換」に示したデータ変換の流れは、Oracleオブジェクトのアクセスには適用されないことを意味します。かわりに、データベースからクライアントにオブジェクト型のSQL CHARおよびSQL NCHARデータを送信するために、oracle.sql.CHARクラスが使用されます。
この項の内容は、次のとおりです。
oracle.sql.CHARクラスには、文字データを変換するための特別な機能があります。Oracleキャラクタ・セットは、oracle.sql.CHARクラスの主な属性です。oracle.sql.CHARオブジェクトの構成時には、常にOracleキャラクタ・セットが渡されます。既知のキャラクタ・セットがない場合、oracle.sql.CHARオブジェクトのデータのバイトには意味がありません。
oracle.sql.CHARクラスは、文字データを文字列に変換するために、次のメソッドを提供します。
oracle.sql.CHARオブジェクトが表現する一連の文字を文字列に変換し、Java文字列オブジェクトを戻します。キャラクタ・セットが認識されない場合、getString()はSQLExceptionを戻します。
getString()に類似していますが、キャラクタ・セットが認識されない場合、toString()はoracle.sql.CHARデータを16進表現で戻し、SQLExceptionは戻しません。
getString()に類似していますが、このoracle.sql.CHARオブジェクトのキャラクタ・セットにUnicode表現のない文字は、デフォルトの置換文字で置き換えられます。デフォルトの置換文字は、キャラクタ・セットによって異なりますが、通常は疑問符(?)です。
oracle.sql.CHARオブジェクトを(プリコンパイルされたSQL文に渡すなどの目的で)手動で構成できます。oracle.sql.CHARオブジェクトを構成する場合は、oracle.sql.CharacterSetクラスのインスタンスを使用して、oracle.sql.CHARオブジェクトにキャラクタ・セット情報を提供する必要があります。oracle.sql.CharacterSetクラスの各インスタンスは、Oracleでサポートしているキャラクタ・セットの1つを表します。
次のタスクを実行してoracle.sql.CHARオブジェクトを構成します。
静的CharacterSet.makeメソッドをコールして、CharacterSetインスタンスを作成します。これは、キャラクタ・セットのクラスを作成するメソッドです。入力として有効なOracleキャラクタ・セット(OracleId)が必要です。次に例を示します。
int OracleId = CharacterSet.JA16SJIS_CHARSET; // this is character set 832 ... CharacterSet mycharset = CharacterSet.make(OracleId);
Oracleでサポートされている各キャラクタ・セットには、一意の事前定義済OracleIdがあります。OracleIdは、Oracle_character_set_name_CHARSETとして指定したキャラクタ・セットとしていつでも参照できます。Oracle_character_set_nameは、Oracleキャラクタ・セットです。
oracle.sql.CHARオブジェクトを構成します。コンストラクタに、文字列(または文字列を表現するバイト)と、キャラクタ・セットに基づくバイトの解析方法を示すCharacterSetオブジェクトを渡します。次に例を示します。
String mystring = "teststring"; ... oracle.sql.CHAR mychar = new oracle.sql.CHAR(teststring, mycharset);
oracle.sql.CHARクラスには複数のコンストラクタがあり、CharacterSetオブジェクトとともに文字列、バイト配列またはオブジェクトを入力としてとることができます。文字列の場合は、oracle.sql.CHARオブジェクトに置かれる前に、CharacterSetオブジェクトが示すキャラクタ・セットに変換されます。
サーバー(データベース)とクライアント(またはクライアントで実行中のアプリケーション)は、異なるキャラクタ・セットを使用できます。このクラスのメソッドを使用してサーバーとクライアントの間でデータを転送する場合、JDBCドライバはサーバー・キャラクタ・セットとクライアント・キャラクタ・セットの間でデータを変換する必要があります。
次に、SQLでオブジェクト型を作成する例を示します。
CREATE TYPE person_type AS OBJECT ( name VARCHAR2(30), address NVARCHAR2(256), age NUMBER); CREATE TABLE employees (id NUMBER, person PERSON_TYPE);
このオブジェクト型に対応するJavaクラスは、次のように構成できます。
public class person implement SqlData
{
oracle.sql.CHAR name;
oracle.sql.CHAR address;
oracle.sql.NUMBER age;
// SqlData interfaces
getSqlType() {...}
writeSql(SqlOutput stream) {...}
readSql(SqlInput stream, String sqltype) {...}
}
ここでは、oracle.sql.CHARクラスは、Oracleオブジェクト型のNAME属性(VARCHAR2データ型)にマップするために使用されています。JDBCは、このクラスに、データベースのVARCHAR2データのバイト表現およびデータベース・キャラクタ・セットに対応するCharacterSetオブジェクトを導入します。次のコードでは、employees表からpersonオブジェクトを取り出しています。
TypeMap map = ((OracleConnection)conn).getTypeMap();
map.put("PERSON_TYPE", Class.forName("person"));
conn.setTypeMap(map);
. . .
. . .
ResultSet rs = stmt.executeQuery("SELECT PERSON FROM EMPLOYEES");
rs.next();
person p = (person) rs.getObject(1);
oracle.sql.CHAR sql_name = p.name;
oracle.sql.CHAR sql_address=p.address;
String java_name = sql_name.getString();
String java_address = sql_address.getString();
oracle.sql.CHARクラスのgetString()メソッドは、OracleのJavaデータ変換クラスをコールしてJava文字列を戻すことで、データベース・キャラクタ・セットまたは各国語キャラクタ・セットのバイト配列をUTF-16に変換します。rs.getObject(1)コールが動作するように、SqlDataインタフェースをクラスpersonに実装し、オブジェクト型PERSON_TYPEのJavaクラスへのマッピングを示すようにTypemap mapを設定する必要があります。
この項の内容は、次のとおりです。
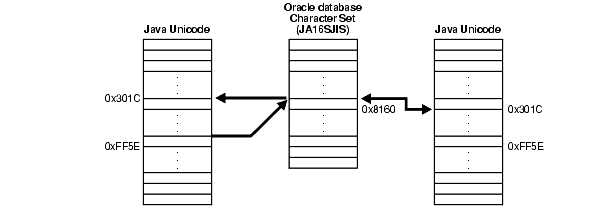
Oracle JDBCドライバは、文字データがデータベースに挿入されるときまたはデータベースから取り出されるときに、適切にキャラクタ・セット変換を実行します。このドライバは、Javaクライアントが使用するUnicode文字とOracleデータベース・キャラクタ・セットの間の変換を行います。Java Unicodeキャラクタ・セットとデータベース・キャラクタ・セットの間のラウンドトリップ変換で、Javaに戻された文字データは、情報の一部が消失している場合があります。これは、複数のUnicode文字が、データベース・キャラクタ・セットの1つの文字にマップされた場合に発生します。たとえば、Unicodeの全角のチルド付き文字(0xFF5E)が、OracleのJA16SJISキャラクタ・セットにマップされている場合があります。Unicode文字のラウンドトリップ変換で、このUnicode文字は0x301Cとなります。これは波形のダッシュ(日本語で、一般的に範囲を示す場合に使用されます)で、チルドではありません。
図7-2に、チルド文字のラウンドトリップ変換を示します。
この問題は、OracleのJDBCの不具合ではありません。異なるオペレーティング・システムでの文字マッピング仕様が不確定であるために発生する問題です。この問題は、一部のOracleキャラクタ・セット(JA16SJIS、JA16EUC、ZHT16BIG5およびKO16KS5601)の、わずかな文字についてのみ発生します。問題を回避するために、これらの文字に対する完全なラウンドトリップ変換は避けてください。
Windowsプラットフォームを使用している場合は、OracleサーバーへのアクセスにOracle ODBCドライバまたはOracle Provider for OLE DBを使用する必要があります。この項では、これらのドライバによるUnicodeのサポート方法を説明します。内容は次のとおりです。
OracleのODBCドライバとOracle Provider for OLE DBは、データを消失することなく、Unicodeデータを正しく処理できます。たとえば、日本語フォントと日本語文字を入力するためのIMEをインストールしている場合は日本語データが含まれたUnicode ODBCアプリケーションを英語版Windowsで実行できます。
Oracleが提供しているODBCおよびOLE DB製品は、Windowsプラットフォーム専用です。UNIXプラットフォームについては、ベンダーにお問い合せください。
Unicodeデータを処理するために、ODBCドライバとOLE DBドライバは、OCI Unicodeのバインド機能と定義機能を使用します。OCI Unicodeデータのバインド機能と定義機能はNLS_LANGの影響を受けません。つまり、プラットフォームのNLS_LANG設定に関係なく、Unicodeデータは正しく処理されます。
通常は、サーバーと異なるデータ型をクライアントのデータ型に指定しないかぎり、冗長なデータ変換は発生しません。たとえば、UnicodeバッファSQL_C_WCHARをNCHARなどのUnicodeデータ列にバインドすると、ODBCドライバとOLE DBドライバは、アプリケーションとOCIレイヤー間の変換を行いません。
フェッチする前にデータ型を指定せずに、クライアントのデータ型でSQLGetDataをコールすると、表7-7の変換が行われます。
表7-7 ODBCの暗黙的なバインド・コード変換
| ODBCクライアント・バッファのデータ型 | データベース内のターゲット列のデータ型 | フェッチ時の変換 | コメント |
|---|---|---|---|
|
|
|
データベース・キャラクタ・セットが
|
予期しないデータ消失はありません。 データベース・キャラクタ・セットが |
|
|
|
データベース・キャラクタ・セットが OCIでの、データベース・キャラクタ・セットから データベース・キャラクタ・セットが OCIとODBCでの、データベース・キャラクタ・セット、UTF-16から |
予期しないデータ消失はありません。 データベース・キャラクタ・セットが |
挿入操作と更新操作のためには、データ型を指定する必要があります。
ODBCクライアント・バッファのデータ型は、SQLGetDataのコール時に提供されますが、即時ではありません。このため、SQLFetchには情報はありません。
ODBCドライバではデータ整合性が保証されるため、暗黙的なバインドを実行すると、冗長な変換が行われ、パフォーマンスが低下する場合があります。明示的なバインドでパフォーマンスを優先するか、暗黙的なバインドで利便性を優先するかのいずれかを選択します。
ODBCとは異なり、OLE DBでは、データの挿入、更新およびフェッチに対する暗黙的なバインドのみ実行できます。中間のキャラクタ・セットを決定するための変換アルゴリズムは、ODBCの暗黙的なバインドの場合と同じです。
表7-8 OLE DBの暗黙的なバインド
| OLE_DBクライアント・バッファのデータ型 | データベース内のターゲット列のデータ型 | インバインドとアウトバインドの変換 | コメント |
|---|---|---|---|
|
|
|
データベース・キャラクタ・セットが OCIでの、データベース・キャラクタ・セットと データベース・キャラクタ・セットが OCIでの、データベース・キャラクタ・セットとUTF-16の間の変換 |
予期しないデータ消失はありません。 データベース・キャラクタ・セットが |
|
|
|
データベース・キャラクタ・セットが OCIでの、データベース・キャラクタ・セットから データベース・キャラクタ・セットが OCIでの、データベース・キャラクタ・セットとUTF-16の間の変換。OLE DBでの、UTF-16から |
予期しないデータ消失はありません。 データベース・キャラクタ・セットが |
ODBCのUnicodeアプリケーションでは、SQLWCHARを使用してUnicodeデータを格納します。SQLWCHARのデータ操作には、すべての標準的なWindows Unicode関数を使用できます。たとえば、wcslenはSQLWCHARデータの文字数をカウントします。
SQLWCHAR sqlStmt[] = L"select ename from emp"; len = wcslen(sqlStmt);
Microsoft社のODBC 3.5仕様には、クライアントのSQL_C_WCHAR、SQL_C_WVARCHARおよびSQL_WLONGVARCHARに対して3つのUnicodeデータ型識別子が定義され、サーバーのSQL_WCHAR、SQL_WVARCHARおよびSQL_WLONGVARCHARに対して3つのUnicodeデータ型識別子が定義されています。
バインド操作の場合は、SQLBindParameterを使用して、クライアントとサーバーの両方にデータ型を指定します。次に、Unicodeバインドの例を示します。クライアント・バッファNameは、Unicodeデータ(SQL_C_WCHAR)がUnicode列(SQL_WCHAR)に関連付けられている最初のバインド変数にバインドされていることを示しています。
SQLBindParameter(StatementHandle, 1, SQL_PARAM_INPUT, SQL_C_WCHAR, SQL_WCHAR, NameLen, 0, (SQLPOINTER)Name, 0, &Name);
表7-9に、SQL NCHARデータ型に対するサーバーのODBC Unicodeデータ型のデータ型マッピングを示します。
表7-9 サーバーのODBC Unicodeデータ型マッピング
| ODBCデータ型 | Oracleデータ型 |
|---|---|
|
|
|
|
|
|
|
|
|
SQL_WCHAR、SQL_WVARCHARおよびSQL_WLONGVARCHARは、ODBC仕様に従ってUnicodeデータとして処理されます。したがって、これらのデータ型はバイト数ではなく文字数で測定されます。
OLE DBでは、UnicodeのCクライアントに対してwchar_t、BSTRおよびOLESTRデータ型が用意されています。実際には、wchar_tが最も一般的なデータ型で、他のデータ型は特定の目的に使用されます。次の例では、静的なSQL文が割り当てられます。
wchar_t *sqlStmt = OLESTR("SELECT ename FROM emp");
OLESTRマクロは、"L"修飾子と同様に機能してUnicode文字列を示します。OLESTRを使用してUnicodeデータ・バッファを動的に割り当てる必要がある場合は、IMallocアロケート関数(例: CoTaskMemAlloc)を使用します。ただし、OLESTRの使用は、可変長データに対する通常の方法ではありません。一般的な文字列型には、かわりにwchar_t*を使用してください。BSTRも機能は同様です。BSTRは、文字列の前のメモリー位置に長さの接頭辞が付いている文字列です。一部の関数とメソッドでは、BSTR Unicodeデータ型のみが受け入れられます。したがって、割当てを行うSysAllocStringやメモリーを解放するSysFreeStringなどの特別な関数では、BSTR Unicode文字列を操作する必要があります。
ODBCとは異なり、OLE DBではサーバーのデータ型を明示的に指定することはできません。クライアントのデータ型を設定すると、OLE DBドライバは、必要に応じて自動的にデータ変換を実行します。
表7-10に、OLE DBのデータ型マッピングを示します。
DBTYPE_BSTRが指定されていると、DBTYPE_WCHARであるとみなされます。これは、両方ともUnicode文字列であるためです。
ADOは、OLE DBドライバとODBCドライバを使用してデータベースにアクセスするための高水準APIです。ほとんどのデータベース・アプリケーション開発者が、Windows上でADOインタフェースを使用しています。これは、このインタフェースが、Internet Information Server(IIS)用のActive Server Pages(ASP)に対する主要なスクリプト言語であるVisual Basicから簡単にアクセスできるためです。OLE DBおよびODBCドライバに対しては、ADOは単なるOLE DBコンシューマまたはODBCアプリケーションです。ADOは、OLE DBおよびODBCドライバがUnicode認識コンポーネントであることを前提としているため、常にUnicodeデータを操作しようとします。
グローバル市場向けのソフトウェア開発では、テキスト情報をあらゆる言語でやり取りできるように、UnicodeのXMLサポートが不可欠です。Unicodeでは、ほぼすべての文字と言語が一様にサポートされているため、XMLによる複数言語のサポートがはるかに容易になります。Oracle Database内のXMLでUnicodeを使用可能にするには、データベースのキャラクタ・セットがUTF-8である必要があります。アプリケーションでUnicodeテキスト処理を使用可能にすることが、あらゆる言語をサポートするための基礎となります。各XML文書は、Unicode文字の既知のサブセットのみの使用が保証されないかぎり、Unicodeテキストであり、多言語が使用されている場合もあります。そのため、XMLにUnicodeを使用可能にすることをお薦めします。Unicodeサポートは、Javaおよび他の多数の最新プログラミング環境に用意されています。
この項の内容は、次のとおりです。
XMLファイルを読み書きする際の一般的な誤りは、文字の入出力にReaderおよびWriterクラスを使用することです。XMLファイルにReaderおよびWriterを使用すると、ランタイム環境のデフォルトの文字コード体系に基づくキャラクタ・セット変換が必要になるため、この方法は使用しないでください。
たとえば、FileWriterクラスを使用すると、文書がデフォルトの文字コード体系に変換されるため、問題が生じることがあります。文書にデフォルトの文字コード体系で使用できない文字が含まれていると、出力ファイルの解析エラーやデータ消失が発生する可能性があります。
XML文書にはUTF-8が一般的ですが、通常、UTF-8はJavaのデフォルトのファイル・エンコーディングではありません。そのため、デフォルトのファイル・エンコーディングを想定するJavaクラスを使用すると、問題が発生する可能性があります。
次の例に、これらの問題を回避する方法を示します。
import java.io.*;
import oracle.xml.parser.v2.*;
public class I18nSafeXMLFileWritingSample
{
public static void main(String[] args) throws Exception
{
// create a test document
XMLDocument doc = new XMLDocument();
doc.setVersion( "1.0" );
doc.appendChild(doc.createComment( "This is a test empty document." ));
doc.appendChild(doc.createElement( "root" ));
// create a file
File file = new File( "myfile.xml" );
// create a binary output stream to write to the file just created
FileOutputStream fos = new FileOutputStream( file );
// create a Writer that converts Java character stream to UTF-8 stream
OutputStreamWriter osw = new OutputStreamWriter( fos, "UTF8" );
// buffering for efficiency
Writer w = new BufferedWriter( osw );
// create a PrintWriter to adapt to the printing method
PrintWriter out = new PrintWriter( w );
// print the document to the file through the connected objects
doc.print( out );
}
}
XMLファイルをテキスト入力として読み取らないでください。ファイル・システムに格納されているXML文書の読取り時には、Parserを使用して文書の文字コード体系を自動的に検出します。Readerクラスの使用や、入力ストリームでの文字コード体系の指定は避けてください。外部エンコーディング情報のないバイナリ入力ストリームの場合、ParserはXML文書のバイト順マークとエンコーディング宣言に基づいて文字コード体系を自動的に検出します。サポート対象のエンコーディングによる整形式の文書は、次のサンプル・コードを使用して正常に解析できます。
import java.io.*;
import oracle.xml.parser.v2.*;
public class I18nSafeXMLFileReadingSample
{
public static void main(String[] args) throws Exception
{
// create an instance of the xml file
File file = new File( "myfile.xml" );
// create a binary input stream
FileInputStream fis = new FileInputStream( file );
// buffering for efficiency
BufferedInputStream in = new BufferedInputStream( fis );
// get an instance of the parser
DOMParser parser = new DOMParser();
// parse the xml file
parser.parse( in );
}
}
XML文書のソースがファイル・システム以外の場合、通常、エンコーディング情報は文書の読取り前に使用可能です。たとえば、入力文書がJava文字ストリームまたはReaderの形式で提供される場合、そのエンコーディングは明らかであり、検出する必要はありません。Parserは、文字コード体系に関係なくUnicodeでReaderの解析を開始できます。
次に、外部エンコーディング情報を使用した文書の解析例を示します。
import java.io.*;
import java.net.*;
import org.xml.sax.*;
import oracle.xml.parser.v2.*;
public class I18nSafeXMLStreamReadingSample
{
public static void main(String[] args) throws Exception
{
// create an instance of the xml file
URL url = new URL( "http://myhost/mydocument.xml" );
// create a connection to the xml document
URLConnection conn = url.openConnection();
// get an input stream
InputStream is = conn.getInputStream();
// buffering for efficiency
BufferedInputStream bis = new BufferedInputStream( is );
/* figure out the character encoding here */
/* a typical source of encoding information is the content-type header */
/* we assume it is found to be utf-8 in this example */
String charset = "utf-8";
// create an InputSource for UTF-8 stream
InputSource in = new InputSource( bis );
in.setEncoding( charset );
// get an instance of the parser
DOMParser parser = new DOMParser();
// parse the xml stream
parser.parse( in );
}
}