| Oracle® Databaseグローバリゼーション・サポート・ガイド 11gリリース2 (11.2) B56307-04 |
|


 前 |
 次 |
この章では、Oracleデータベース環境でのUnicodeの使用方法について説明します。この章の内容は、次のとおりです。
Unicodeは、世界中で話されているほとんどの言語のあらゆる文字を定義する文字コード・システムです。
既存の文字エンコーディングの制約を克服するために、1980年代の後半、複数の組織がグローバル・キャラクタ・セットの作成に着手しました。グローバル・キャラクタ・セットの必要性は、1990年代中頃に入り、World Wide Webの発展とともにますます大きくなりました。インターネットの普及によってビジネスの形態が変化し、グローバル・マーケットに重点が置かれるようになったため、ユニバーサル・キャラクタ・セットが重要な必要条件になってきました。
このグローバル・キャラクタ・セットは、次の条件を満たす必要があります。
現在使用されているすべての主要文字を網羅していること。
レガシー・データや実装をサポートしていること。
1つのアプリケーションの1つの実装で、世界中で使用できるような単純なキャラクタ・セットであること。
また、グローバル・キャラクタ・セットには次の機能も必要です。
多言語ユーザーや組織のサポート
国際規格への準拠
世界規模でのデータ交換
現在、Unicodeは広く使用され、グローバル・キャラクタ・セットに対するあらゆる要求と機能に満たします。
Unicodeは、任意の言語の情報を単一のキャラクタ・セットを使用して格納できる全世界共通のエンコード・キャラクタ・セットです。Unicodeでは、プラットフォーム、プログラムまたは言語に関係なく、すべての文字に一意のコード値が指定されます。
多くのソフトウェアおよびハードウェア・ベンダーがUnicode規格を採用しており、多くのオペレーティング・システムやブラウザがUnicodeをサポートしています。Unicodeは、XML、Java、JavaScript、LDAPおよびWMLなどの規格には必須です。ISO/IEC 10646規格とも同期化されています。
Oracle Database 7で、データベース・キャラクタ・セットとしてUnicodeが導入されました。Oracle Database 11gではUnicodeのサポートが拡張され、Unicode 5.0がサポートされています。
この項の内容は、次のとおりです。
Unicodeの最初のバージョンは16ビットの固定幅エンコーディングで、各文字のエンコーディングに2バイトを使用していました。このため、65,536文字を表現できました。しかし、サポートを必要とする文字数が増え、特に中国語、日本語および韓国語市場では、追加のCJK表意文字のサポートが必要となりました。
Unicodeでは、このニーズを満たすために補助文字が定義されています。2つの16ビット・コード・ポイント(補助文字とも呼ばれる)を使用して、1つの文字が表現されます。補助文字を実装すると、さらに100万以上の文字を定義できます。
補助文字の追加によってUnicodeは複雑度を増しましたが、同じ構成で複数の異なるエンコーディングを管理するよりは単純です。
Unicode規格では、文字はUTF-8、UCS-2およびUTF-16という方法でエンコードされます。Unicodeエンコーディング間の変換は、Unicode規格に定義されている単純なビット単位操作です。
この項の内容は、次のとおりです。
UTF-8とは、Unicodeの8ビット・エンコーディングのことです。これは可変幅エンコーディングであり、ASCIIの完全なスーパーセットです。これは、ASCIIキャラクタ・セットの各文字を、UTF-8で同じコード・ポイント値とともに使用できることを意味します。UTF-8エンコーディングでは、1つのUnicode文字を、1バイト、2バイト、3バイトまたは4バイトで表すことができます。ヨーロッパ言語の文字は、1バイトまたは2バイトで表します。ほとんどのアジア言語の文字は、3バイトで表します。補助文字は、4バイトで表します。
UTF-8は、HTMLやほとんどのインターネット・ブラウザで使用されるUnicodeエンコーディングです。
UTF-8の利点は、次のとおりです。
ASCIIの完全なスーパーセットであるため、ヨーロッパ言語の記憶要件が小規模です。
ASCIIベースのキャラクタ・セットとUTF-8の間の移行が容易です。
UCS-2は固定幅の16ビット・エンコーディングで、各文字は2バイトです。UCS-2は、バージョンJ2SE 5.0より前のJavaおよびMicrosoft Windows NTで内部処理に使用されているUnicodeエンコーディングです。UCS-2ではUnicode 3.0に定義されている文字がサポートされるため、補助文字のサポート機能はありません。
UTF-8と比較したUCS-2の利点は、次のとおりです。
すべての文字が2バイトであるため、アジア言語の場合は記憶要件がさらに小規模です。
文字が固定幅であるため、文字列の処理が高速です。
JavaおよびMicrosoftクライアントとの優れた互換性があります。
UTF-16エンコーディングとは、Unicodeの16ビット・エンコーディングのことです。UTF-16は、UCS-2の拡張です。これは、各補助文字に2つのUCS-2コード・ポイントを使用することで補助文字をサポートするためです。UTF-16は、UCS-2の完全なスーパーセットです。
UTF-16では、1文字を2バイトか4バイトで表すことができます。ヨーロッパ言語とほとんどのアジア言語の文字は、ともに2バイトで表します。補助文字は、4バイトで表します。UTF-16は、バージョンJ2SE 5.0以降のJavaおよびバージョン2000以降のMicrosoft Windowsで内部処理に使用されているメインのUnicodeエンコーディングです。
UTF-8と比較したUTF-16の利点は、次のとおりです。
一般に使用されるアジア言語の文字のほとんどは2バイトで表されるため、アジア言語の場合は記憶要件がさらに小規模です。
JavaおよびMicrosoftクライアントとの優れた互換性があります。
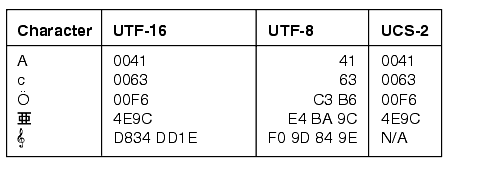
図6-1に、UTF-16、UTF-8およびUCS-2の各エンコーディングの文字とその文字コードを示します。最後の文字はト音記号(音楽記号)で、補助文字です。
Oracleデータベースのキャラクタ・セットとして、リリース7のときにUnicodeのサポートを開始しました。表6-1に、OracleデータベースでサポートされているUnicodeキャラクタ・セットを示します。
表6-1 Oracle DatabaseでサポートされているUnicodeキャラクタ・セット
次の2つの方法でUnicode文字をOracle Databaseに格納できます。
Unicodeデータベースを作成すると、UTF-8エンコードされた文字をSQL CHARデータ型(CHAR、VARCHAR2、CLOBおよびLONG)として格納できます。
Unicodeサポートを段階的に実装する場合、または特定の列の多言語データのみをサポートする必要がある場合、UnicodeデータはSQL NCHARデータ型(NCHAR、NVARCHAR2およびNCLOB)のUTF-16またはUTF-8エンコーディング方式のいずれかで格納できます。SQL NCHARデータ型は、Unicodeデータの格納専用に使用されるため、Unicodeデータ型と呼ばれます。
|
注意: Unicodeデータベース・ソリューションは、Unicodeデータ型ソリューションと組み合せることができます。 |
次の項で、2つのUnicodeソリューションの使用方法とその選択方法を説明します。
データベース・キャラクタ・セットでは、SQL CHARデータ型の他に、表名、列名およびSQL文などのメタデータに使用するエンコーディングが指定されます。Unicodeデータベースとは、UTF-8をデータベース・キャラクタ・セットとして持つデータベースのことです。UTF-8エンコーディングを実装しているOracleキャラクタ・セットは3つあります。最初の2つは、ASCIIベースのプラットフォーム用に設計されており、3つ目は、EBCDICプラットフォーム上で使用する必要があります。
AL32UTF8
AL32UTF8 キャラクタ・セットは、最新バージョンのUnicode規格をサポートしています。このキャラクタ・セットは、各文字を1バイト、2バイトまたは3バイトでエンコードします。このキャラクタ・セットでは、各文字は1バイト、2バイトまたは3バイトでエンコードされ、 補助文字には4バイトが必要です。ASCIIベースのプラットフォーム用です。
UTF8
UTF8キャラクタ・セットは、各文字を1バイト、2バイトまたは3バイトでエンコードします。ASCIIベースのプラットフォーム用です。
UTF8データベースに補助文字が挿入されても、データベース内のデータは破損しません。補助文字は、6バイトを占める2つの別個のユーザー定義文字として処理されます。データベース・キャラクタ・セット内の補助文字を全面的にサポートするために、AL32UTF8に切り替えることをお薦めします。
UTFE
UTFEキャラクタ・セットはEBCDICプラットフォーム用です。このキャラクタ・セットはASCIIプラットフォーム上でのUTF8に似ていますが、各文字を1バイト、2バイト、3バイトおよび4バイトでエンコードします。補助文字は2つの4バイト文字として変換されます。
例6-1 Unicodeキャラクタ・セットを使用したデータベースの作成
AL32UTF8キャラクタ・セットを使用してデータベースを作成するには、CREATE DATABASE文にCHARACTER SET AL32UTF8句を使用します。次に例を示します。
CREATE DATABASE sample
CONTROLFILE REUSE LOGFILE
GROUP 1 ('diskx:log1.log', 'disky:log1.log') SIZE 50K,
GROUP 2 ('diskx:log2.log', 'disky:log2.log') SIZE 50K
MAXLOGFILES 5 MAXLOGHISTORY 100 MAXDATAFILES 10 MAXINSTANCES 2 ARCHIVELOG CHARACTER SET AL32UTF8 NATIONAL CHARACTER SET AL16UTF16 DATAFILE
'disk1:df1.dbf' AUTOEXTEND ON, 'disk2:df2.dbf' AUTOEXTEND ON NEXT 10M MAXSIZE UNLIMITED
DEFAULT TEMPORARY TABLESPACE temp_ts UNDO TABLESPACE undo_ts SET TIME_ZONE = '+02:00';
|
注意: データベース・キャラクタ・セットは、データベースの作成時に指定します。 |
データベースにUnicodeデータを格納する代替方法は、SQL NCHARデータ型(NCHAR、NVARCHAR、NCLOB)を使用することです。データベース・キャラクタ・セットの定義方法に関係なく、これらのデータ型の列にUnicode文字を格納できます。NCHARデータ型はUnicodeデータ型専用です。つまり、このデータ型は、Unicodeとしてエンコードされたデータを格納します。
NVARCHAR2とNCHARのデータ型を使用すると、表を作成できます。NCHAR列とNVARCHAR2列に指定する列の長さは、次のように常にバイト数ではなく文字数です。
CREATE TABLE product_information
( product_id NUMBER(6)
, product_name NVARCHAR2(100)
, product_description VARCHAR2(1000));
SQL NCHARデータ型で使用するエンコーディングは、データベース用に指定される各国語キャラクタ・セットです。次のOracleキャラクタ・セットのいずれかを、各国語キャラクタ・セットとして指定できます。
AL16UTF16
これは、SQL NCHARデータ型のデフォルトのキャラクタ・セットです。このキャラクタ・セットは、UnicodeデータをUTF-16エンコーディングでエンコードします。また、4バイトとして格納される補助文字をサポートします。
UTF8
SQL NCHARデータ型にUTF8を指定すると、SQLデータ型で格納されているデータは、UTF-8エンコーディングになります。
NATIONAL CHARACTER SET句を指定したCREATE DATABASE文を使用してデータベースを作成する場合は、SQL NCHARデータ型に各国語キャラクタ・セットを指定できます。次の文では、データベース・キャラクタ・セットとしてWE8ISO8859P1を持ち、各国語キャラクタ・セットとしてAL16UTF16を持つデータベースを作成します。
例6-2 各国語キャラクタ・セットを使用したデータベースの作成
CREATE DATABASE sample
CONTROLFILE REUSE LOGFILE
GROUP 1 ('diskx:log1.log', 'disky:log1.log') SIZE 50K,
GROUP 2 ('diskx:log2.log', 'disky:log2.log') SIZE 50K
MAXLOGFILES 5 MAXLOGHISTORY 100 MAXDATAFILES 10 MAXINSTANCES 2 ARCHIVELOG CHARACTER SET WE8ISO8859P1 NATIONAL CHARACTER SET AL16UTF16 DATAFILE
'disk1:df1.dbf' AUTOEXTEND ON, 'disk2:df2.dbf' AUTOEXTEND ON NEXT 10M MAXSIZE UNLIMITED
DEFAULT TEMPORARY TABLESPACE temp_ts UNDO TABLESPACE undo_ts SET TIME_ZONE = '+02:00';
データベースに対する適切なUnicodeソリューションを選択するには、次の問題を考慮してください。
プログラミング環境: アプリケーションで使用されている主要なプログラミング言語は何か。これらのプログラミング言語は、どのようにUnicodeをサポートしているか。
移行の容易さ: Unicodeソリューションを利用するために、データとアプリケーションを移行することに問題はないか。
データの種類: データの大部分は、アジア言語、あるいはヨーロッパ言語か。多言語ドキュメントをLOB列に格納する必要があるか。
アプリケーションの種類: 実装しているアプリケーションの種類は何か。パッケージ・アプリケーションか、あるいはカスタマイズしたエンド・ユーザー・アプリケーションか。
この項では、Unicodeデータベース・ソリューションまたはUnicodeデータ型ソリューションを選択する場合の一般的なガイドラインを説明します。最終的な決定は、主として各自の正確な環境と要件に基づいて行います。この項の内容は、次のとおりです。
表6-2に、Unicodeデータベースを使用する状況を示します。
表6-2 Unicodeデータベースの使用
| 状況 | 説明 |
|---|---|
|
JavaまたはPL/SQLに対する簡単なコード移行が必要な場合 |
既存のアプリケーションが主としてJavaとPL/SQLで作成されており、複数言語のサポートに必要なコード変更を最小限にすることが最優先の課題である場合は、Unicodeデータベース・ソリューションを使用できます。データの格納に使用するデータ型がSQL |
|
多言語データを均等に分散した場合 |
多言語データが既存のスキーマ表に均等に分散されていて、多言語データが格納されている表が確認できない場合には、Unicodeデータベースを使用する必要があります。これは、このUnicodeデータベースでは、各列に格納されているデータの種類を識別する必要がないためです。 |
|
SQL文とPL/SQLコードにUnicodeデータが含まれている場合 |
Unicodeデータベースを使用する必要があります。SQL文とPL/SQLコードは、処理前にデータベース・キャラクタ・セットに変換されます。SQL文とPL/SQLコードにデータベース・キャラクタ・セットに変換できない文字が含まれている場合、その文字は失われます。SQL文でUnicodeデータを使用する一般的な場所は、文字列リテラルにあります。 |
|
多言語ドキュメントを |
Unicodeデータベースを使用する必要があります。 |
表6-3に、Unicodeデータ型を使用する状況を示します。
表6-3 Unicodeデータ型の使用
| 状況 | 説明 |
|---|---|
|
多言語サポートを段階的に追加する場合 |
キャラクタ・セットを移行せずに、Unicodeサポートを既存のデータベースに追加する場合は、Unicodeデータの格納にUnicodeデータ型を使用することを考慮してください。SQL |
|
パッケージ・アプリケーションを作成する場合 |
顧客に販売するパッケージ・アプリケーションを作成している場合は、SQL |
|
シングルバイトのデータベース・キャラクタ・セットを使用してパフォーマンスを改善する場合 |
パフォーマンスの向上が主な優先事項である場合は、シングルバイトのデータベース・キャラクタ・セットを使用して、UnicodeデータをSQL |
|
WindowsクライアントでUTF-16のサポートが必要な場合 |
アプリケーションが、Windows上で稼働するVisual C/C++やVisual Basicで作成されている場合は、SQL |
|
注意: UnicodeデータベースとUnicodeデータ型は併用できます。 |
Oracleには、データベースにUnicode文字を格納するためのソリューションが2つ用意されています。Unicodeデータベース・ソリューションとUnicodeデータ型ソリューションです。Unicodeデータベース・ソリューション、Unicodeデータ型ソリューションまたはその組合せを選択した後は、UnicodeデータベースまたはUnicodeデータ型で使用するキャラクタ・セットを決定します。
表6-4に、Unicodeデータベース・ソリューションの様々なキャラクタ・セットのメリットとデメリットを示します。Unicodeデータベース・キャラクタ・セットを使用できるOracleキャラクタ・セットは、AL32UTF8、UTF8およびUTFEです。
表6-4 Unicodeデータベース・ソリューション用キャラクタ・セットのメリットとデメリット
| データベース・キャラクタ・セット | メリット | デメリット |
|---|---|---|
|
AL32UTF8 |
|
|
|
UTF8 |
|
|
|
UTFE |
|
|
表6-5に、Unicodeデータ型ソリューションの様々なキャラクタ・セットのメリットとデメリットを示します。各国語キャラクタ・セットに使用できるOracleキャラクタ・セットは、AL16UTF16およびUTF8です。デフォルトはAL16UTF16です。
表6-5 Unicodeデータ型ソリューション用キャラクタ・セットのメリットとデメリット
| 各国語キャラクタ・セット | メリット | デメリット |
|---|---|---|
|
AL16UTF16 |
|
|
|
UTF8 |
|
|
この項では、Unicode文字をOracle Databaseに格納する場合の代表的な使用例を説明します。
例6-3 Unicodeデータベースを使用したUnicodeソリューション
Javaアプリケーションを実行しているある米国の企業では、アプリケーションの次のリリースでドイツ語とフランス語のサポートを追加しようとしています。その後、日本語のサポートを追加する予定です。この会社には、現在次のようなシステム構成があります。
既存のデータベースは、US7ASCIIのデータベース・キャラクタ・セットです。
既存のデータベースの全文字データは、ASCII文字で構成されています。
データベースでは、PL/SQLストアド・プロシージャが使用されています。
データベースは、およそ300 GBです。
夜間の停止時間は4時間です。
この場合、代表的なソリューションは、データベース・キャラクタ・セットにUTF8を選択します。その理由は、次のとおりです。
データベースが非常に大規模で、予定されている停止時間が短いこと。Unicodeへのデータベースの移行の高速化が不可欠です。データベースがUS7ASCIIであるため、データベースのUnicodeサポートを有効化する最も簡単で迅速な方法は、CSALTER文を実行して、データベース・キャラクタ・セットをUTF8に切り替えることです。US7ASCIIは、UTF-8のサブセットであるため、データ変換は不要です。
コードの大部分がJavaとPL/SQLで記述されているため、データベース・キャラクタ・セットのUTF8への変更によって、既存のコードが無駄になることはないこと。Unicodeサポートはアプリケーションで自動的に有効化されます。
アプリケーションがフランス語、ドイツ語および日本語をサポートするため、補助文字はほとんどないこと。AL32UTF8とUTF8の両方が適しています。
例6-4 Unicodeデータ型を使用したUnicodeソリューション
主としてWindowsプラットフォームでアプリケーションを実行しているあるヨーロッパの企業では、Visual C/C++で作成された新しいWindowsアプリケーションを追加する必要があります。このアプリケーションでは、日本語と中国語の顧客名をサポートするために、既存のデータベースが使用されます。この会社には、現在次のようなシステム構成があります。
既存のデータベースには、WE8ISO8859P1のデータベース・キャラクタ・セットがあります。
既存のデータベースの全文字データは、西ヨーロッパの文字で構成されています。
データベースは、およそ50 GBです。
代表的なソリューションでは、次のアクションが実行されます。
NCHARおよびNVARCHAR2データ型を使用してUnicode文字が格納されます。
WE8ISO8859P1がデータベース・キャラクタ・セットとして維持されます。
AL16UTF16が各国語キャラクタ・セットとして使用されます。
このソリューションを選択する理由は、次のとおりです。
データベース・キャラクタ・セットのWE8ISO8859P1(Latin-1キャラクタ・セット)はUTF8のサブセットでないため、既存のデータベースをUnicodeデータベースに移行するには、データ変換が必要になること。その結果、データをUTF8に変換するときにオーバーヘッドが発生します。
追加した言語は、新しいアプリケーションでのみサポートされること。既存のアプリケーションまたはスキーマに依存しません。Unicodeデータ型は新しいスキーマで使用し、既存のスキーマは変更しないままのほうが簡単です。
Unicodeのサポートが必要なのは、顧客名の列のみであること。1つのNCHAR列のみを使用することで、データベース全体を移行せずに顧客の要件を満たすことができます。
サポート対象言語がほとんどアジア言語であるため、AL16UTF16を各国語キャラクタ・セットとして使用する必要があり、結果として、ディスク領域をより効率的に使用できること。
SQL NCHARデータ型の長さは文字数として定義されること。この処理方法は、Windows C/C++プログラムでwchar_t文字列を使用する場合と同じです。この方法は、プログラミングの複雑さを軽減します。
既存のスキーマを使用している既存のアプリケーションに対する影響はないこと。
例6-5 UnicodeデータベースとUnicodeデータ型を使用したUnicodeソリューション
ある日本の企業では、新しいJavaアプリケーションを開発する必要があります。会社では、このアプリケーションによって、できるだけ多数の言語を長期にわたってサポートする予定です。
そこで、ドキュメントを現状のまま格納するために、BLOBデータ型を使用して複数言語のドキュメントを格納することに決定しました。
また、B2Bでのデータ交換のためにリレーショナル・データからUTF-8 XMLドキュメントを生成する必要もあります。
バックエンドには、C/C++で作成したWindowsアプリケーションがあり、OracleデータベースにアクセスするためにODBCを使用しています。
この場合、代表的なソリューションは、データベース・キャラクタ・セットにAL32UTF8を使用してUnicodeデータベースを作成し、SQL NCHARデータ型を使用して多言語データを格納します。各国語キャラクタ・セットは、AL16UTF16に設定する必要があります。このソリューションを選択する理由は、次のとおりです。
異なる言語のドキュメントがBLOB形式で格納されている場合、Oracle Textでは、データベース・キャラクタ・セットがUTF-8キャラクタ・セットの1つである必要があること。アプリケーションでは、リレーショナル・データをUTF-8 XMLフォーマットとして取得する可能性があるため(補助文字が4バイトで格納されている場合)、AL32UTF8をデータベース・キャラクタ・セットとして使用し、UTF-8データの取得時または挿入時のデータ変換を回避する必要があります。
アプリケーションが新規で、JavaとWindows C/C++の両方で作成されているため、この会社ではリレーショナル・データに対してSQL NCHARデータ型を使用する必要があること。JavaとWindowsの両方がUTF-16文字のデータ型をサポートしていて、文字列の長さは常に文字数で測定されます。
データの大部分がアジア言語の場合は、AL16UTF16をSQL NCHARデータ型と併用する必要があること。これは、AL16UTF16によって、格納の効率が向上するためです。
複数言語をサポートするようにデータベース・スキーマを設計する場合は、Unicodeソリューションの選択に加えて、次の問題も考慮する必要があります。
多言語データの格納にNCHARおよびNVARCHAR2データ型を使用する場合、列に指定するサイズは文字数で定義します。(文字数はUnicodeのコード数を意味します。)表6-6に、AL16UTF16およびUTF8の各国語キャラクタ・セットに対するNCHARおよびNVARCHAR2データ型の最大サイズを示します。
表6-6 データ型の最大サイズ
| 各国語キャラクタ・セット | NCHARデータ型の最大列サイズ | NVARCHAR2データ型の最大列サイズ |
|---|---|---|
|
AL16UTF16 |
1000文字 |
2000文字 |
|
UTF8 |
2000バイト |
4000バイト |
多言語データの格納にCHARおよびVARCHAR2のデータ型を使用する場合、各列に指定する最大長は、デフォルトではバイト数で指定します。データベースで、タイ語、アラビア語、あるいは中国語や日本語などのマルチバイトの言語をサポートする必要がある場合は、CHAR、VARCHARおよびVARCHAR2の各列の最大サイズを拡張する必要があります。これは、これらの言語をUTF8またはAL32UTF8でエンコードするためのバイト数が、英語や西ヨーロッパの言語に比較してかなり多いためです。たとえば、タイ語キャラクタ・セットの1つのタイ文字は、UTF8またはAL32UTF8で3バイト必要です。さらに、CHAR、VARCHARおよびVARCHAR2の各データ型の最大列長は、それぞれ2000バイト、4000バイトおよび4000バイトとなります。アプリケーションで4000バイトを超えるバイト数を格納する必要がある場合は、そのデータに対してCLOBデータ型を使用する必要があります。
Unicodeキャラクタ・セットには、世界中で使用されているほとんどの記述言語の文字が含まれます。ただし、特定の文字が所属している言語に関する情報は含まれません。たとえば、äという文字には、それがフランス語の文字なのかドイツ語の文字なのかに関する情報は含まれません。情報をユーザーが望む言語で表示するには、Unicodeデータベースに格納されているデータに、そのデータが所属している言語の情報を含める必要があります。
データベース・スキーマがデータを言語に関連付ける方法は多数あります。次の各項では、様々なアプローチについて説明します。
製品説明や製品名などのデータの場合は、CHARまたはVARCHAR2のデータ型の言語列(language_id)を製品表に追加して、対応する製品情報の言語を識別できます。これによって、アプリケーションは、必要な言語による情報を取り出すことができます。この言語列に可能な値は、データベースの有効なNLS_LANGUAGE値の3文字の略称です。
ビューを作成して、現在の言語のデータを選択することもできます。次に例を示します。
ALTER TABLE scott.product_information ADD (language_id VARCHAR2(50)):
CREATE OR REPLACE VIEW product AS
SELECT product_id, product_name
FROM product_information
WHERE language_id = SYS_CONTEXT('USERENV','LANG');
ファイングレイン・アクセス・コントロールを使用すると、表またはビューでユーザーが参照できる情報の程度を制限できます。これは一般に、WHERE句を追加して行います。WHERE句をファイングレイン・アクセス・ポリシーとして表またはビューに追加すると、表にあるすべてのSQL文にそのWHERE句が実行時に自動的に追加されます。その結果、WHERE句を満たす行のみがアクセス可能になります。
この機能を使用すると、アプリケーションのSELECT文ごとに、ユーザーの必要な言語をWHERE句で指定しなくてすみます。次のWHERE句は、表のビューをユーザーが必要な言語に対応している行に制限しています。
WHERE language_id = SYS_CONTEXT('userenv', 'LANG')
このWHERE句をファイングレイン・アクセス・ポリシーとしてproduct_informationに対して次のように指定します。
CREATE FUNCTION func1 (sch VARCHAR2 , obj VARCHAR2 )
RETURN VARCHAR2(100);
BEGIN
RETURN 'language_id = SYS_CONTEXT(''userenv'', ''LANG'')';
END
/
DBMS_RLS.ADD_POLICY ('scott', 'product_information', 'lang_policy', 'scott', 'func1', 'select');
その結果、product_information表にあるすべてのSELECT文は自動的にWHERE句を追加します。
|
関連項目: ファイングレイン・アクセス・コントロールの詳細は、『Oracle Databaseアドバンスト・アプリケーション開発者ガイド』を参照してください。 |
複数言語によるドキュメントをCLOB、NCLOBまたはBLOBデータ型に格納してOracle Textを設定すると、そのドキュメントの内容検索を使用できます。
データベース・キャラクタ・セットがUTF8やAL32UTF8などのマルチバイトである場合、CLOB列のデータはUCS-2互換形式で格納されます。つまり、データの変換時には、英語のドキュメントに必要な記憶領域は2倍になります。アジア言語のドキュメントをCLOB列に格納する場合は、同じドキュメントをUTF8を使用してLONG列に格納する場合に比較して、必要な記憶領域が少なくなります。ドキュメントの内容にもよりますが、通常およそ30%少なくなります。
NCLOB形式のドキュメントも、データベース・キャラクタ・セットや各国語キャラクタ・セットに関係なく、UCS-2互換の独自形式で格納されます。記憶領域の必要量は、CLOBデータの場合と同じです。ドキュメントの内容は、NCLOB列への挿入時に、UTF-16に変換されます。非Unicodeデータベースに多言語ドキュメントを格納する場合は、NCLOBを選択してください。ただし、NCLOB上での内容検索は、現段階ではサポートされていません。
BLOB書式のドキュメントは、そのまま格納されます。挿入時および取得時にデータ変換は発生しません。ただし、SQL文字列操作関数(LENGTHやSUBSTRなど)と照合関数(NLS_SORTやORDER BYなど)は、BLOBデータ型に適用できません。
表6-7に、ドキュメント格納時のCLOB、NCLOBおよびBLOBデータ型のメリットとデメリットを示します。
表6-7 ドキュメント格納に関するLOBデータ型の比較
| データ型 | メリット | デメリット |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Oracle Textでは、索引を作成して、CLOB形式およびBLOB形式で格納されている多言語ドキュメントの内容を検索できます。言語固有のレクサーを使用して、CLOBやBLOBのデータを解析し、検索可能なキーワードのリストを生成します。
多言語ドキュメントを検索するには、マルチレクサーを作成します。マルチレクサーは、言語列に基づいて、行ごとに言語固有のレクサーを選択します。この項では、複数言語のドキュメントに対して索引を作成するための高度な手順を説明します。内容は次のとおりです。
|
関連項目: 『Oracle Textリファレンス』 |
マルチレクサーを作成する最初の手順は、サポート対象言語ごとに言語固有のレクサー・プリファレンスを作成することです。次の例では、英語、ドイツ語および日本語のレクサーをPL/SQLプロシージャで作成しています。
ctx_ddl.create_preference('english_lexer', 'basic_lexer');
ctx_ddl.set_attribute('english_lexer','index_themes','yes');
ctx_ddl.create_preference('german_lexer', 'basic_lexer');
ctx_ddl.set_attribute('german_lexer','composite','german');
ctx_ddl.set_attribute('german_lexer','alternate_spelling','german');
ctx_ddl.set_attribute('german_lexer','mixed_case','yes');
ctx_ddl.create_preference('japanese_lexer', 'JAPANESE_VGRAM_LEXER');
作成された言語固有のレクサー・プリファレンスは、単一のマルチレクサー・プリファレンスの下に集める必要があります。最初に、MULTI_LEXERオブジェクトを使用して、次のようにマルチレクサー・プリファレンスを作成します。
ctx_ddl.create_preference('global_lexer','multi_lexer');
ここで、add_sub_lexerコールを使用して、言語固有のレクサーをマルチレクサー・プリファレンスに追加します。
ctx_ddl.add_sub_lexer('global_lexer', 'german', 'german_lexer');
ctx_ddl.add_sub_lexer('global_lexer', 'japanese', 'japanese_lexer');
ctx_ddl.add_sub_lexer('global_lexer', 'default','english_lexer');
これによって、german_lexerプリファレンスはドイツ語ドキュメントを処理し、japanese_lexerプリファレンスは日本語ドキュメントを処理し、english_lexerプリファレンスは、言語にDEFAULTを使用して、それ以外のすべてのドキュメントを処理するように指名されます。
マルチレクサーによって、表の言語列に基づいて、行ごとに使用するレクサーが決定されます。これは、テキスト列内のドキュメントの言語が格納されているキャラクタ列です。Oracleの言語名を使用して、この列にあるドキュメントの言語を識別します。たとえば、CLOBデータ型を使用してドキュメントを格納する場合は、言語列をそのドキュメントが格納されている表に追加します。
CREATE TABLE globaldoc (doc_id NUMBER PRIMARY KEY, language VARCHAR2(30), text CLOB);
この表に索引を作成するには、次のようにマルチレクサー・プリファレンスを使用して言語列名を指定します。
CREATE INDEX globalx ON globaldoc(text)
indextype IS ctxsys.context
parameters ('lexer
global_lexer
language
column
language');
言語列の他に、キャラクタ・セットと書式列を、ドキュメントが格納されている表に追加する必要があります。キャラクタ・セット列には、Oracleキャラクタ・セット名を使用してドキュメントのキャラクタ・セットを格納します。書式列には、ドキュメントがテキスト・ドキュメントであるかバイナリ・ドキュメントであるかを指定します。たとえば、CREATE TABLE文では、次のように列charactersetおよびformatを指定できます。
CREATE TABLE globaldoc ( doc_id NUMBER PRIMARY KEY, language VARCHAR2(30), characterset VARCHAR2(30), format VARCHAR2(10), text BLOB );
ワードプロセッシングまたはスプレッドシートのドキュメントを表に入力し、format列にbinaryを指定できます。HTML、XMLおよびテキスト・フォーマットのドキュメントの場合は、表にドキュメントを入力して、format列にtextを指定します。
キャラクタ・セットを指定する列があるため、様々なキャラクタ・セットによるテキスト・ドキュメントを格納できます。
索引の作成時に、書式列とキャラクタ・セット列の名前を指定します。
CREATE INDEX globalx ON globaldoc(text)
indextype is ctxsys.context
parameters ('filter inso_filter
lexer global_lexer
language column language
format column format
charset column characterset');
全ドキュメントがテキスト・フォーマットの場合は、charset_filterを使用できます。このcharset_filterによって、データはcharset列で指定されたキャラクタ・セットからデータベース・キャラクタ・セットに変換されます。