| Oracle® Databaseデータ・ウェアハウス・ガイド 11gリリース2 (11.2) B56309-04 |
|


 前 |
 次 |
この章では、データ・ウェアハウス環境の論理設計の作成方法について説明します。内容は次のとおりです。
組織でのデータ・ウェアハウス構築がすでに決定されているとします。そして、ビジネス要件の定義、アプリケーションの適用範囲の打合せ、および概念的な設計も完了しているとします。そこで、その要件をシステムに移行できるように変換する必要があります。そのためには、データ・ウェアハウスの論理設計と物理設計を行います。定義する内容は、次のとおりです。
具体的なデータ内容
データ・グループ内およびデータ・グループ間の関係
データ・ウェアハウスをサポートするシステム環境
必要なデータ変換
データのリフレッシュ頻度
論理設計は、物理設計に比べて概念的で抽象的です。論理設計では、オブジェクト間の論理的な関係を検討します。物理設計では、オブジェクトの格納と取出しの他、転送処理およびバックアップ/リカバリの観点から、最も効果的な方法を検討します。
設計では、エンド・ユーザーのニーズを優先させる必要があります。エンド・ユーザーは、通常、個々のトランザクションではなく、分析を行って集計されたデータを見ます。ただし、実際にデータを見るまで、何が必要であるかがエンド・ユーザーにはわからない場合があります。適切に計画された設計であれば、ユーザーのニーズの変化や発展に応じて、拡張および変更を行うことができます。
まず、論理設計から始めると、情報についての要件に集中でき、実装の詳細は後で検討できます。
論理設計とは、概念的で抽象的な設計です。ここでは、物理的な実装の詳細は説明しません。必要な情報の種類の定義方法のみを扱います。
組織の論理的な情報要件のモデリングに使用できるテクニックの1つが、E-Rモデリングです。E-Rモデリングでは、重要事項(エンティティ)、重要事項のプロパティ(属性)および相互の関連(リレーションシップ)を特定します。
物理設計プロセスでは、データを、エンティティおよび属性と呼ばれる、一連の論理的な関係に配置します。エンティティは、情報の大きいまとまりを表します。エンティティは、リレーショナル・データベースの表にマップされます。属性はエンティティのコンポーネントで、エンティティの一意性を定義します。属性は、リレーショナル・データベースの列にマップされます。
データの一貫性を確実にするには、一意識別子を使用する必要があります。一意識別子は、同じ項目が異なる場所に表示される場合に、両者を区別できるように表に追加する識別子です。これは通常、物理設計における主キーです。
従来、E-RダイアグラムはOLTPアプリケーションなど高度に正規化されたモデルに関連付けられてきましたが、そのテクニックは、ディメンショナル・モデリングにも役立ちます。ディメンショナル・モデリングでは、情報の基本単位(エンティティや属性など)およびそれらのすべてのリレーションシップを明確にするのではなく、情報を、中心となるファクト表の情報と、関係するディメンション表の情報とに識別します。ビジネス・サブジェクトかデータ・フィールドかの識別、ビジネス・サブジェクト間のリレーションシップの定義、および各サブジェクトに対する属性のネーミングを行います。
論理設計で作成する必要があるのは、(1)ファクト表とディメンション表に対応するエンティティと属性のセット、および(2)ソースの業務系データを、ターゲットとなるデータ・ウェアハウス・スキーマ内の、サブジェクト指向情報に入れるまでのモデルです。
論理設計は、ペンと紙を使用するか、またはOracle Warehouse Builder(ETLプロセスのモデリング・サポート用に特別に設計されたツール)などの設計ツールを使用して作成できます。
|
関連項目: Oracle Warehouse Builderのドキュメント・セット |
スキーマとは、表、ビュー、索引およびシノニムを含むデータベース・オブジェクトのコレクションです。データ・ウェアハウス用に設計されたスキーマ・モデルには、様々な方法でスキーマ・オブジェクトを配置できます。ほとんどのデータ・ウェアハウスでは、ディメンショナル・モデルが使用されます。
データ・ウェアハウス・スキーマの設計には、ソース・データのモデルとユーザー要件を使用できます。会社のエンタープライズ・データ・モデルからソース・データを取得し、これを基にデータ・ウェアハウス用の論理データ・モデルをリバース・エンジニアすることが可能な場合があります。論理データ・ウェアハウス・モデルの物理的な実装には、コンピュータのサイズ、ユーザー数、記憶域の容量、ネットワークの種類、ソフトウェアなどのシステム・パラメータに応じて、多少の変更が必要な場合があります。
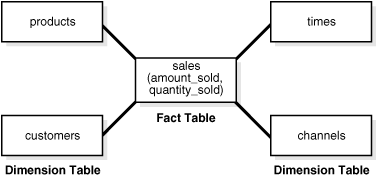
スター・スキーマは、最も単純なデータ・ウェアハウス・スキーマです。スター・スキーマを図で表すと、星(スター)のように中央から放射状に広がっているため、スター・スキーマと呼ばれます。図2-1に示すように、スターの中心には1つ以上のファクト表があり、スターの先端にはディメンション表があります。
データ・ウェアハウス・モデルを作成する最も自然な方法はスター・スキーマです。スター・スキーマでは、ファクト表と1つのディメンション表とのリレーションシップを確立するために必要な結合は1つのみです。
スター・スキーマでは、問合せを単純化し、応答時間を短縮することでパフォーマンスが最適化されます。各レベルに関するすべての情報は、1つの行に格納されます。
データ・ウェアハウス環境の一部のスキーマでは、スター・スキーマではなく第3正規形が使用されます。また、スノーフレーク・スキーマが有効なスキーマもあります。スノーフレーク・スキーマは、ディメンションがツリー構造で正規化されているスター・スキーマです。さらに、OLAPのスキーマも使用できます。OLAPスキーマは、Oracle Database内のキューブやディメンションなどの次元データ型をサポートします。
|
関連項目: データ・ウェアハウスでのスター・スキーマとスノーフレーク・スキーマの詳細は、第20章「スキーマのモデリング化技法」、概念情報の詳細は、『Oracle Database概要』、OLAPスキーマの詳細は『Oracle OLAPユーザーズ・ガイド』を参照してください。 |
ファクト表とディメンション表は、データ・ウェアハウスのディメンション・スキーマで一般的に使用される2種類のオブジェクトです。
ファクト表は、ビジネス関連の測定データが格納されるデータ・ウェアハウス・スキーマ内の大規模な表です。通常、ファクト表には、ディメンション表への外部キーおよびファクトが含まれます。また、ファクト表は、分析および調査のできる数値データおよび加算データを表します。たとえば、売上、コスト、利益などです。
ディメンション表(参照表とも呼ぶ)には、データ・ウェアハウスの比較的静的なデータが含まれます。たとえば、問合せを含めるために通常使用する情報が格納されます。通常、ディメンション表は説明的なテキストであり、結果セットの行ヘッダーとして使用できます。たとえば、顧客、製品などです。
ファクト表には、通常、数値ファクト(メジャーとも呼ぶ)を含む列と、ディメンション表への外部キーとなる列の2種類の列があります。ファクト表には、ディテール・レベルのファクトまたは集計ファクトのいずれかが含まれます。集計ファクトを含むファクト表は、一般にサマリー表と呼ばれます。通常、ファクト表には同じ集計レベルのファクトが含まれています。ほとんどのファクトは加算的ですが、準加算的なものや非加算的なものもあります。加算ファクトは、単純な加算で集計できます。その最も一般的な例が売上です。非加算ファクトは加算できません。その一例が平均です。準加算ファクトは、ディメンションの一部については集計できますが、他の部分については集計できません。その一例が在庫レベルで、レベルが何を意味するかは単に見ただけではわかりません。
ディメンションは、データを分類する1つの構造であり、1つ以上の階層から構成されています。ディメンション属性を使用して、ディメンション値を記述できます。通常、ディメンションは説明的なテキスト値です。ファクトと結合した複数の独立したディメンションにより、ビジネス上の問題に対応できます。最も一般的なディメンションは、顧客(customers)、製品(products)および時間(times)です。
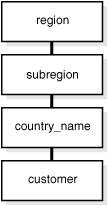
ディメンション・データは、通常、詳細な最下位レベルで収集されてから、分析に有効な上位レベルの合計に集計されます。このようなディメンション表内でのロールアップまたは集計を階層と呼びます。
階層は、データを構成する順序付けられたレベルを使用する論理構造です。階層は、データ集計の定義に使用できます。たとえば、時間ディメンションであれば、月レベルから四半期レベル、さらに年レベルへとデータを集計する階層を定義できます。階層は、ナビゲーショナル・ドリル・パスの定義およびファミリ構造の作成にも使用できます。
階層内では、各レベルがその上下のレベルと論理的に接続されます。下位レベルのデータ値は、上位レベルのデータ値に集計されます。ディメンションは複数の階層で構成できます。たとえば、製品ディメンションには、2つの階層(製品カテゴリおよび製品仕入先)がある場合があります。
また、ディメンション階層は、要約レベルから詳細レベルまでカテゴリ化されます。階層は、問合せツールによって使用されます。これにより、データをドリルダウンし、詳細度の異なるレベルを参照できるようになります。これは、データ・ウェアハウスの主なメリットの1つです。
階層を設計する場合は、ビジネス構造におけるリレーションシップを考慮する必要があります。たとえば、部門別の複数レベルの営業組織などが考えられます。
階層では、ディメンション値はファミリ構造で表現されます。あるレベルの値に対して、1つ上のレベルの値はその親になり、1つ下のレベルの値はその子になります。これらのファミリ関係によって、アナリストはデータに迅速にアクセスできます。
レベルは、階層における1つの位置を表します。たとえば、時間ディメンションには、月、四半期および年レベルのデータを表す階層があります。レベルには、要約レベルから詳細レベルまであり、ルート・レベルは最上位レベルで、最も要約の進んだレベルです。ディメンション内のレベルは、1つ以上の階層に編成されます。
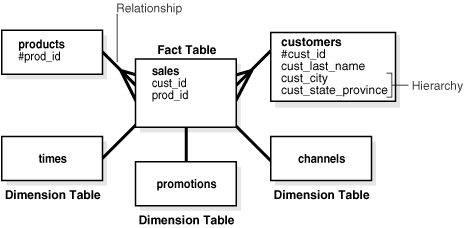
一意識別子は、ディメンション表の値が一意なレコードに対して指定されます。一意識別子が指定されたデータの変更による問題を回避するために、通常は人為的に作成された一意識別子が使用されます。一意識別子は、#文字で表されます。たとえば、#customer_idとなります。
リレーションシップにより、ビジネスの整合性が保証されます。たとえば、販売会社は必ず顧客と製品を持っています。ファクト表とディメンション表の製品および顧客について売上情報のリレーションシップを設計することで、データベース内でビジネス・ルールが規定されます。
図2-3に、salesファクト表とディメンション表customers、products、promotions、timesおよびchannelsの一般的な例を示します。