| Oracle® Databaseアドバンスト・レプリケーション・マネージメントAPIリファレンス 11g リリース2 (11.2) B72090-02 |
|


 前 |
 次 |
この章では、レプリケーション環境に競合解消メソッドを定義する方法を説明します。
この章には、次の項が含まれます。
レプリケーション環境において複数のサイト間での競合を防ぐようにデータベースおよびフロントエンド・アプリケーションを設計していても、競合の可能性をなくすことはできないでしょう。レプリケーションの最も重要な側面の1つは、レプリケーション環境に参加しているすべてのサイトでデータ収束を確保することです。
データの競合が発生した場合、競合がビジネス・ルールに従って解消され、すべてのサイトでデータを正常に収束させるためのメカニズムが必要です。
Advanced Replicationでは、ビジネス・ルールに従って競合を解消する、データベース用の競合解消システムを定義できます。Oracleの組込みの競合解消メソッドで競合を解消できない場合は、独自の競合解消メソッドを作成し、それを使用して競合を解消できます。
レプリケート表に競合解消メソッドを実装する前に、システム内のデータを分析し、競合の起こりやすい領域を確認します。たとえば、従業員番号などの静的データは、頻繁には変更されないため、競合はあまり起こりません。これに対して、従業員の担当顧客は頻繁に変わるので、データの競合が起こりやすくなります。
競合の起こりやすい領域を特定した後、その解消方法を決定する必要があります。たとえば、最新の変更を優先させたり、特定のサイトを優先させたりします。
様々な競合解消メソッドを説明したそれぞれの項を読むと、それぞれのメソッドが何に最も適しているかを理解できます。そのため、それぞれの項を読み、自分のビジネスで競合の可能性をどのように解消するのがよいかを検討してください。
問題の起こりうる領域を特定し、その問題を解決するビジネス・ルールを決定した後、Oracleの競合解消メソッド(またはユーザー独自のメソッドのいずれか)を使用して競合解消システムを実装します。
|
関連項目: 競合解消メソッドの概念および各メソッドに対するデータ収束の詳細は、『Oracle Databaseアドバンスト・レプリケーション』を参照してください。 |
データの競合は、複数のサイトでほぼ同時に同じ行が更新された場合、またはあるサイトの遅延トランザクションが他のサイトに正しく伝播される前に最も発生します。
更新の競合を回避する方法の1つは、同期レプリケーション環境を実装することです。ただし、この方法は、大量のネットワーク・リソースを必要とします。
もう1つの方法は、Oracle競合解消メソッドを使用することです。これらの方法を使用すると、同じ行が複数の更新を受信した場合に起こる更新の競合に対処できます。
上書きによるメソッドと廃棄によるメソッドは、レプリケーション元またはレプリケーション先のサイトからの値を無視するため、複数のマスター・サイトでの確実なデータ収束は保証されません。これらのメソッドは、単一のマスター・サイトと複数のマテリアライズド・ビュー・サイトで使用するか、あるいは、なんらかのユーザー定義の通知機能と使用することを前提としています。
上書きによるメソッドは、レプリケーション元の新しい値で、レプリケーション先のカレント値を置き換えます。これに対して、廃棄によるメソッドは、レプリケーション元からの新しい値を無視します。
次の手順に従って、上書きまたは廃棄の競合解消メソッドを作成します。次の例は、マスター・サイトでの廃棄による競合解消メソッドの使用を示しています。したがって、競合が発生すると、マテリアライズド・ビュー・サイトからのデータは廃棄され、マスター・サイトのデータは保持されます。
|
注意: このドキュメントをオンラインで参照している場合は、次の「BEGINNING OF SCRIPT」の行から「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーして編集し、使用している環境に適したスクリプトを作成します。 |
/************************* BEGINNING OF SCRIPT ******************************
次の手順のプロシージャは、レプリケーション管理者が実行します。
*/ SET ECHO ON SPOOL discard_conflictres.out CONNECT repadmin@orc1.example.com /*
上書きまたは廃棄による競合解消メソッドを定義する前に、競合解消メソッドを適用する表を含むマスター・グループを静止します。単一のマスター・レプリケーション環境においては、マスター・グループの静止は必要ありません。
*/ BEGIN DBMS_REPCAT.SUSPEND_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / /*
Oracleの競合解消メソッドはすべて、列グループと呼ばれる論理列グループ化に基づいています。
*/ BEGIN DBMS_REPCAT.MAKE_COLUMN_GROUP ( sname => 'hr', oname => 'departments', column_group => 'dep_cg', list_of_column_names => 'manager_id,location_id'); END; / /*
この例では、OVERWRITE競合解消メソッドを作成します。
*/ BEGIN DBMS_REPCAT.ADD_UPDATE_RESOLUTION ( sname => 'hr', oname => 'departments', column_group => 'dep_cg', sequence_no => 1, method => 'DISCARD', parameter_column_name => 'manager_id,location_id'); END; / /*
*/
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'hr',
oname => 'departments',
type => 'TABLE',
min_communication => TRUE);
END;
/
/*
*/
BEGIN DBMS_REPCAT.RESUME_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / SET ECHO OFF SPOOL OFF /************************* END OF SCRIPT **********************************/
Advanced Replicationによって列グループの競合が検出され、最小のメソッドまたは最大のメソッドがコールされると、列グループ内の該当する列で、レプリケーション元の新しい値とレプリケーション先のカレント値が比較されます。競合解消メソッドを定義する場合は、この列を指定します。
指定した列の新規値が現行値より小さい場合または大きい場合(使用するメソッドによる)、その行の他のすべてのエラーが解消された場合、接続元サイトの列グループ値が接続先サイトに適用されます。そうでない場合は、行が変更されずにそのまま保持されます。
次の手順に従って、最小または最大の競合解消メソッドを作成します。
|
注意: このドキュメントをオンラインで参照している場合は、次の「BEGINNING OF SCRIPT」の行から「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーして編集し、使用している環境に適したスクリプトを作成します。 |
/************************* BEGINNING OF SCRIPT ******************************
次の手順のプロシージャは、レプリケーション管理者が実行します。
*/ SET ECHO ON SPOOL min_conflictres.out CONNECT repadmin@orc1.example.com /*
最小または最大の競合解消メソッドを定義する前に、競合解消メソッドを適用する表を含むマスター・グループを静止します。単一のマスター・レプリケーション環境においては、マスター・グループの静止は必要ありません。
*/ BEGIN DBMS_REPCAT.SUSPEND_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / /*
Oracleの競合解消メソッドはすべて、列グループと呼ばれる論理列グループ化に基づいています。
*/ BEGIN DBMS_REPCAT.MAKE_COLUMN_GROUP ( sname => 'hr', oname => 'jobs', column_group => 'job_minsal_cg', list_of_column_names => 'min_salary'); END; / /*
この例では、MINIMUM競合解消メソッドを作成します。
*/ BEGIN DBMS_REPCAT.ADD_UPDATE_RESOLUTION ( sname => 'hr', oname => 'jobs', column_group => 'job_minsal_cg', sequence_no => 1, method => 'MINIMUM', parameter_column_name => 'min_salary'); END; / /*
*/
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'hr',
oname => 'jobs',
type => 'TABLE',
min_communication => TRUE);
END;
/
/*
*/
BEGIN DBMS_REPCAT.RESUME_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / SET ECHO OFF SPOOL OFF /************************* END OF SCRIPT **********************************/
最古のタイムスタンプによるメソッドと最新のタイムスタンプによるメソッドは、最小のメソッドと最大のメソッドに類似しています。タイムスタンプによるメソッドを使用するには、DATE型のレプリケート表にある列を指定する必要があります。アプリケーションで列グループのいずれかの列を更新する場合は、レプリケーション先のtimestamp列の値をローカルのSYSDATE値で更新する必要があります。他のサイトから適用された変更に対しては、タイムスタンプ値をレプリケート元のタイムスタンプ値に設定します。
タイムスタンプによる競合解消が正しく機能するための2つの要素は次のとおりです。
コンピュータ間で同期化された時刻の設定
タイムスタンプを自動的に記録するためのタイムスタンプ・フィールドとトリガー
次の手順に従って、タイムスタンプによる競合解消メソッドを作成します。
|
注意: このドキュメントをオンラインで参照している場合は、次の「BEGINNING OF SCRIPT」の行から「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーして編集し、使用している環境に適したスクリプトを作成します。 |
/************************* BEGINNING OF SCRIPT ******************************
次の手順のプロシージャは、レプリケーション管理者が実行します。
*/ SET ECHO ON SPOOL timestamp_conflictres.out CONNECT repadmin@orc1.example.com /*
タイムスタンプによる競合解消メソッドを定義する前に、競合解消メソッドを適用する表を含むマスター・グループを静止します。単一のマスター・レプリケーション環境においては、マスター・グループの静止は必要ありません。
*/ BEGIN DBMS_REPCAT.SUSPEND_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / /*
ターゲット表にタイムスタンプ・フィールドが存在しない場合は、行が挿入または更新されたときにタイムスタンプ値を記録する表に、列を追加します。DDLをターゲット表に適用するには、ALTER_MASTER_REPOBJECTプロシージャを使用します。DDLを発行するのみでレプリケート・オブジェクトが無効になります。
*/ BEGIN DBMS_REPCAT.ALTER_MASTER_REPOBJECT ( sname => 'hr', oname => 'countries', type => 'TABLE', ddl_text => 'ALTER TABLE hr.countries ADD (timestamp DATE)'); END; / /*
*/
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'hr',
oname => 'countries',
type => 'TABLE',
min_communication => TRUE);
END;
/
/*
記録された値は、タイムスタンプによるメソッドに基づいた競合の解消で使用されます。トリガーを作成して、マスター・グループに追加するには、DDLを直接実行するのではなく、DBMS_REPCAT.CREATE_MASTER_REPOBJECTプロシージャを使用します。
|
注意: 優先グループによる競合解消には、datetimeおよびintervalデータ型の列は使用できません。 |
*/ BEGIN DBMS_REPCAT.CREATE_MASTER_REPOBJECT ( gname => 'hr_repg', type => 'TRIGGER', oname => 'insert_time', sname => 'hr', ddl_text => 'CREATE TRIGGER hr.insert_time BEFORE INSERT OR UPDATE ON hr.countries FOR EACH ROW BEGIN IF DBMS_REPUTIL.FROM_REMOTE = FALSE THEN :NEW.TIMESTAMP := SYSDATE; END IF; END;'); END; / /*
Oracleの競合解消メソッドはすべて、列グループと呼ばれる論理列グループ化に基づいています。
*/ BEGIN DBMS_REPCAT.MAKE_COLUMN_GROUP ( sname => 'hr', oname => 'countries', column_group => 'countries_timestamp_cg', list_of_column_names => 'country_name,region_id,timestamp'); END; / /*
この例では、以前作成したtimestamp列を使用して、LATEST TIMESTAMP競合解消メソッドを指定します。
*/ BEGIN DBMS_REPCAT.ADD_UPDATE_RESOLUTION ( sname => 'hr', oname => 'countries', column_group => 'countries_timestamp_cg', sequence_no => 1, method => 'LATEST TIMESTAMP', parameter_column_name => 'timestamp'); END; / /*
*/
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'hr',
oname => 'countries',
type => 'TABLE',
min_communication => TRUE);
END;
/
/*
*/
BEGIN DBMS_REPCAT.RESUME_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / SET ECHO OFF SPOOL OFF /************************* END OF SCRIPT **********************************/
加算によるメソッドと平均によるメソッドは、1つの数値列のみから構成される列グループに使用します。この競合解消メソッドは、一方の値のみを受け付けるのではなく、比較対象の2つの値を加算するか、またはその2つの平均を取ります。
次の手順に従って、加算競合解消メソッドまたは平均競合解消メソッドを作成します。この例では、競合が発生した場合に、従業員のコミッション率の平均を取ります。
|
注意: このドキュメントをオンラインで参照している場合は、次の「BEGINNING OF SCRIPT」の行から「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーして編集し、使用している環境に適したスクリプトを作成します。 |
/************************* BEGINNING OF SCRIPT ******************************
次の手順のプロシージャは、レプリケーション管理者が実行します。
*/ SET ECHO ON SPOOL average_conflictres.out CONNECT repadmin@orc1.example.com /*
加算競合解消メソッドおよび平均競合解消メソッドを定義する前に、競合解消メソッドを適用する表を含むマスター・グループを静止します。単一のマスター・レプリケーション環境においては、マスター・グループの静止は必要ありません。
*/ BEGIN DBMS_REPCAT.SUSPEND_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / /*
Oracleの競合解消メソッドはすべて、列グループと呼ばれる論理列グループ化に基づいています。
*/ BEGIN DBMS_REPCAT.MAKE_COLUMN_GROUP ( sname => 'hr', oname => 'employees', column_group => 'commission_average_cg', list_of_column_names => 'commission_pct'); END; / /*
この例では、sal列を使用して、AVERAGE競合解消メソッドを指定します。
*/ BEGIN DBMS_REPCAT.ADD_UPDATE_RESOLUTION ( sname => 'hr', oname => 'employees', column_group => 'commission_average_cg', sequence_no => 1, method => 'AVERAGE', parameter_column_name => 'commission_pct'); END; / /*
*/
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'hr',
oname => 'employees',
type => 'TABLE',
min_communication => TRUE);
END;
/
/*
*/
BEGIN DBMS_REPCAT.RESUME_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / SET ECHO OFF SPOOL OFF /************************* END OF SCRIPT **********************************/
優先グループでは、特定の列にある値ごとに優先レベルを指定できます。Oracleによって競合が検出されると、優先列で優先順位の低い値を持つ表が、優先順位の高い値を持つ表のデータで更新されます。
次の手順に従って、優先グループによる競合解消メソッドを作成します。
|
注意: このドキュメントをオンラインで参照している場合は、次の「BEGINNING OF SCRIPT」の行から「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーして編集し、使用している環境に適したスクリプトを作成します。 |
/************************* BEGINNING OF SCRIPT ******************************
次の手順のプロシージャは、レプリケーション管理者が実行します。
*/ SET ECHO ON SPOOL priority_groups_conflictres.out CONNECT repadmin@orc1.example.com /*
優先グループによる競合解消メソッドを定義する前に、競合解消メソッドを適用する表を含むマスター・グループを静止します。単一のマスター・レプリケーション環境においては、マスター・グループの静止は必要ありません。
*/ BEGIN DBMS_REPCAT.SUSPEND_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / /*
この列を既存の列グループに追加するには、ADD_GROUPED_COLUMNプロシージャを使用します。列グループを作成していない場合は、DBMS_REPCAT.MAKE_COLUMN_GROUPプロシージャを使用して、新しい列グループを作成できます。
*/ BEGIN DBMS_REPCAT.MAKE_COLUMN_GROUP ( sname => 'hr', oname => 'employees', column_group => 'employees_priority_cg', list_of_column_names => 'manager_id,hire_date,salary,job_id'); END; / /*
*/
BEGIN DBMS_REPCAT.DEFINE_PRIORITY_GROUP ( gname => 'hr_repg', pgroup => 'job_pg', datatype => 'VARCHAR2'); END; / /*
DBMS_REPCAT.ADD_PRIORITY_datatypeプロシージャは、複数のバージョンが利用できます。利用可能な各データ型にはバージョンがあります(NUMBER、VARCHAR2など)。利用するすべての表に対して優先順位の値を定義し終えるまで、必要に応じてこのプロシージャを実行します。
*/
BEGIN
DBMS_REPCAT.ADD_PRIORITY_VARCHAR2(
gname => 'hr_repg',
pgroup => 'job_pg',
value => 'ad_pres',
priority => 100);
END;
/
BEGIN
DBMS_REPCAT.ADD_PRIORITY_VARCHAR2(
gname => 'hr_repg',
pgroup => 'job_pg',
value => 'sa_man',
priority => 80);
END;
/
BEGIN
DBMS_REPCAT.ADD_PRIORITY_VARCHAR2(
gname => 'hr_repg',
pgroup => 'job_pg',
value => 'sa_rep',
priority => 60);
END;
/
BEGIN
DBMS_REPCAT.ADD_PRIORITY_VARCHAR2(
gname => 'hr_repg',
pgroup => 'job_pg',
value => 'pu_clerk',
priority => 40);
END;
/
BEGIN
DBMS_REPCAT.ADD_PRIORITY_VARCHAR2(
gname => 'hr_repg',
pgroup => 'job_pg',
value => 'st_clerk',
priority => 20);
END;
/
/*
次の例では、このメソッドは指定した列グループの第2の競合解消メソッドです(sequence_noパラメータ)。
*/ BEGIN DBMS_REPCAT.ADD_UPDATE_RESOLUTION ( sname => 'hr', oname => 'employees', column_group => 'employees_priority_cg', sequence_no => 2, method => 'PRIORITY GROUP', parameter_column_name => 'job_id', priority_group => 'job_pg'); END; / /*
*/
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'hr',
oname => 'employees',
type => 'TABLE',
min_communication => TRUE);
END;
/
/*
*/
BEGIN DBMS_REPCAT.RESUME_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / SET ECHO OFF SPOOL OFF /************************* END OF SCRIPT **********************************/
サイトの優先順位は、優先グループを特殊化したものです。このため、サイトの優先順位に対応付けられたプロシージャは、優先グループに対応付けられたプロシージャと同じように機能します。競合は、フィールドの値の優先順位ではなく、関係するサイトの優先順位に基づいて解消されます。
たとえば、orc2.example.comの優先順位がorc1.example.comよりも高い場合に、この2つのサイトで競合が起こると、orc2.example.comの値が使用されます。
次の手順に従って、サイトの優先順位による競合解消メソッドを作成します。
|
注意: このドキュメントをオンラインで参照している場合は、次の「BEGINNING OF SCRIPT」の行から「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーして編集し、使用している環境に適したスクリプトを作成します。 |
/************************* BEGINNING OF SCRIPT ******************************
次の手順のプロシージャは、レプリケーション管理者が実行します。
*/ SET ECHO ON SPOOL site_priority_conflictres.out CONNECT repadmin@orc1.example.com /*
サイトの優先順位による競合解消メソッドを定義する前に、競合解消メソッドを適用する表を含むマスター・グループを静止します。単一のマスター・レプリケーション環境においては、マスター・グループの静止は必要ありません。
*/ BEGIN DBMS_REPCAT.SUSPEND_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / /*
DDLをターゲット表に適用するには、DBMS_REPCAT.ALTER_MASTER_REPOBJECTプロシージャを使用します。DDLを発行するのみでレプリケート・オブジェクトが無効になります。
*/ BEGIN DBMS_REPCAT.ALTER_MASTER_REPOBJECT ( sname => 'hr', oname => 'regions', type => 'TABLE', ddl_text => 'ALTER TABLE hr.regions ADD (site VARCHAR2(20))'); END; / /*
*/
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'hr',
oname => 'regions',
type => 'TABLE',
min_communication => TRUE);
END;
/
/*
記録された値は、サイトの優先順位によるメソッドに基づいた競合の解消で使用されます。トリガーを作成して、マスター・グループに追加するには、DDLを直接実行するのではなく、DBMS_REPCAT.CREATE_MASTER_REPOBJECTプロシージャを使用します。
*/ BEGIN DBMS_REPCAT.CREATE_MASTER_REPOBJECT ( gname => 'hr_repg', type => 'TRIGGER', oname => 'insert_site', sname => 'hr', ddl_text => 'CREATE TRIGGER hr.insert_site BEFORE INSERT OR UPDATE ON hr.regions FOR EACH ROW BEGIN IF DBMS_REPUTIL.FROM_REMOTE = FALSE THEN SELECT global_name INTO :NEW.SITE FROM GLOBAL_NAME; END IF; END;'); END; / /*
この列を既存の列グループに追加するには、ADD_GROUPED_COLUMNプロシージャを使用します。列グループを作成していない場合は、DBMS_REPCAT.MAKE_COLUMN_GROUPプロシージャを使用して、新しい列グループを作成できます。
*/ BEGIN DBMS_REPCAT.MAKE_COLUMN_GROUP ( sname => 'hr', oname => 'regions', column_group => 'regions_sitepriority_cg', list_of_column_names => 'region_id,region_name,site'); END; / /*
*/
BEGIN DBMS_REPCAT.DEFINE_SITE_PRIORITY ( gname => 'hr_repg', name => 'regions_sitepriority_pg'); END; / /*
レプリケーション環境の各サイトに対し、サイトの優先順位の値を定義し終えるまで、必要に応じてこのプロシージャを実行します。
*/ BEGIN DBMS_REPCAT.ADD_SITE_PRIORITY_SITE ( gname => 'hr_repg', name => 'regions_sitepriority_pg', site => 'orc1.example.com', priority => 100); END; / BEGIN DBMS_REPCAT.ADD_SITE_PRIORITY_SITE ( gname => 'hr_repg', name => 'regions_sitepriority_pg', site => 'orc2.example.com', priority => 50); END; / BEGIN DBMS_REPCAT.ADD_SITE_PRIORITY_SITE ( gname => 'hr_repg', name => 'regions_sitepriority_pg', site => 'orc3.example.com', priority => 25); END; / /*
次の例では、このメソッドは指定した列グループの第3の競合解消メソッドです(sequence_noパラメータ)。
*/ BEGIN DBMS_REPCAT.ADD_UPDATE_RESOLUTION ( sname => 'hr', oname => 'regions', column_group => 'regions_sitepriority_cg', sequence_no => 1, method => 'SITE PRIORITY', parameter_column_name => 'site', priority_group => 'regions_sitepriority_pg'); END; / /*
*/
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'hr',
oname => 'regions',
type => 'TABLE',
min_communication => TRUE);
END;
/
/*
*/
BEGIN DBMS_REPCAT.RESUME_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / SET ECHO OFF SPOOL OFF /************************* END OF SCRIPT **********************************/
レプリケーション環境では、一意制約に関してデータの挿入を主な原因とする競合が発生する場合があります。ビジネス・ルールで重複行の削除が可能な場合、Oracleの組込み競合解消メソッドを使用して解消メソッドを定義できます。
ただし、競合する値を変更して、一意制約に違反しないようにする方が一般的です。競合する値を変更すれば、重要なデータが失われることはありません。Oracleの組込みの一意性競合解消メソッドを使用すると、値にサイト名や順序番号を付けることで、競合する値を一意にできます。
この他に、一意性競合解消メソッドの追加コンポーネントとして、通知機能があります。競合する情報はOracleによって変更されるので、その情報を表に挿入できますが、その場合、競合を通知して、その通知に基づいて競合を分析し、レコードを削除するのか、データを他のレコードにマージするのか、または競合するデータにまったく新しい値を定義するのかを決定することが必要です。
一意性競合解消メソッドでは列内の競合は一意制約により検出され、解消されます。この項の例では、email列に一意制約emp_email_ukが設定されているhrサンプル・スキーマのemployees表を使用します。
|
注意: 列に一意性競合解消メソッドを追加するには、列の一意索引名が一意制約名または主キー制約名と一致する必要があります。 |
次の手順に従って、一意性競合解消メソッドを作成します。
|
注意: このドキュメントをオンラインで参照している場合は、次の「BEGINNING OF SCRIPT」の行から「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーして編集し、使用している環境に適したスクリプトを作成します。 |
/************************* BEGINNING OF SCRIPT ******************************
*/
SET ECHO ON SPOOL unique_conflictres.out CONNECT repadmin@orc1.example.com /*
一意性競合解消メソッドを定義する前に、競合解消メソッドを適用する表を含むマスター・グループが静止していることを確認します。
*/ BEGIN DBMS_REPCAT.SUSPEND_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / /*
この例で使用する表の名前は、conf_reportです。
*/ BEGIN DBMS_REPCAT.EXECUTE_DDL ( gname => 'hr_repg', ddl_text => 'CREATE TABLE hr.conf_report ( line NUMBER(2), txt VARCHAR2(80), timestamp DATE, table_name VARCHAR2(30), table_owner VARCHAR2(30), conflict_type VARCHAR2(7))'); END; / /*
*/
CONNECT hr@orc1.example.com /*
この例で使用するパッケージの名前は、notifyです。
*/
CREATE OR REPLACE PACKAGE notify AS
FUNCTION emp_unique_violation (email IN OUT VARCHAR2,
discard_new_values IN OUT BOOLEAN)
RETURN BOOLEAN;
END notify;
/
CREATE OR REPLACE PACKAGE BODY notify AS
TYPE message_table IS TABLE OF VARCHAR2(80) INDEX BY BINARY_INTEGER;
PROCEDURE report_conflict(conflict_report IN MESSAGE_TABLE,
report_length IN NUMBER,
conflict_time IN DATE,
conflict_table IN VARCHAR2,
table_owner IN VARCHAR2,
conflict_type IN VARCHAR2) IS
BEGIN
FOR idx IN 1..report_length LOOP
BEGIN
INSERT INTO hr.conf_report
(line, txt, timestamp, table_name, table_owner, conflict_type)
VALUES (idx, SUBSTR(conflict_report(idx),1,80), conflict_time,
conflict_table, table_owner, conflict_type);
EXCEPTION WHEN others THEN NULL;
END;
END LOOP;
END report_conflict;
FUNCTION emp_unique_violation(email IN OUT VARCHAR2,
discard_new_values IN OUT BOOLEAN)
RETURN BOOLEAN IS
local_node VARCHAR2(128);
conf_report MESSAGE_TABLE;
conf_time DATE := SYSDATE;
BEGIN
BEGIN
SELECT global_name INTO local_node FROM global_name;
EXCEPTION WHEN others THEN local_node := '?';
END;
conf_report(1) := 'UNIQUENESS CONFLICT DETECTED IN EMPLOYEES ON ' ||
TO_CHAR(conf_time, 'MM-DD-YYYY HH24:MI:SS');
conf_report(2) := ' AT NODE ' || local_node;
conf_report(3) := 'ATTEMPTING TO RESOLVE CONFLICT USING' ||
' APPEND SITE NAME METHOD';
conf_report(4) := 'EMAIL: ' || email;
conf_report(5) := NULL;
report_conflict(conf_report,5,conf_time,'employees','hr','UNIQUE');
discard_new_values := FALSE;
RETURN FALSE;
END emp_unique_violation;
END notify;
/
/*
*/
CONNECT repadmin@orc1.example.com /*
この手順によって、すべてのマスター・サイトで通知機能を利用できるようになります。
*/ BEGIN DBMS_REPCAT.CREATE_MASTER_REPOBJECT ( gname => 'hr_repg', type => 'PACKAGE', oname => 'notify', sname => 'hr'); END; / BEGIN DBMS_REPCAT.CREATE_MASTER_REPOBJECT ( gname => 'hr_repg', type => 'PACKAGE BODY', oname => 'notify', sname => 'hr'); END; / /*
競合の発生を通知する機能のみの場合でも追加します。次の例では、USER FUNCTIONとして通知機能を追加しています。
*/ BEGIN DBMS_REPCAT.ADD_UPDATE_RESOLUTION ( sname => 'hr', oname => 'employees', constraint_name => 'emp_email_uk', sequence_no => 1, method => 'USER FUNCTION', comment => 'Notify DBA', parameter_column_name => 'email', function_name => 'hr.notify.emp_unique_violation'); END; / /*
次の例では、APPEND SITE NAME一意性競合解消メソッドをレプリケート表へ追加しています。
*/ BEGIN DBMS_REPCAT.ADD_UPDATE_RESOLUTION ( sname => 'hr', oname => 'employees', constraint_name => 'emp_email_uk', sequence_no => 2, method => 'APPEND SITE NAME', parameter_column_name => 'email'); END; / /*
*/
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'hr',
oname => 'employees',
type => 'TABLE',
min_communication => TRUE);
END;
/
/*
*/
BEGIN DBMS_REPCAT.RESUME_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / SET ECHO OFF SPOOL OFF /************************* END OF SCRIPT **********************************/
行の削除を行う場合は、比較する2つの値がある更新の競合とは違って、1つの値しか存在しないので、前述の更新の競合解消メソッドを適用できません。
レプリケーション環境で行を削除する最善の方法は、削除対象の行をマークし、マークされたすべてのレコードを表から定期的にパージして競合を回避することです。物理的に行が削除されるのではなく、比較される2つの値が存在するので、競合が発生しても、すべてのマスター・サイトでデータを収束させることができます(ただし、他のエラーが発生していないことを前提とします)。データが収束したことを確認した後、レプリケート・パージ・プロシージャを使用して、マークされた行をパージします。
データベース用のフロントエンド・アプリケーションを開発しているときに、削除用にマークされた行を除外したい場合があります。これは、こうすることでその行が物理的に削除されたようにユーザーに見えるためです。その場合単純に、データ・セットのSELECT文で削除用にマークされた行を除外します。
たとえば、次のようにSELECT文を指定して、現在の従業員をリストします。
SELECT * FROM hr.locations WHERE remove_date IS NULL;
次に、削除の競合を回避するレプリケート表を作成するメソッドを示します。また、削除対象としてマークされたレコードをパージするために、プロシージャ・レプリケーションを使用する方法も学びます。
次の手順に従って、削除の競合の競合防止メソッドを作成します。
|
注意: このドキュメントをオンラインで参照している場合は、次の「BEGINNING OF SCRIPT」の行から「END OF SCRIPT」の行までのテキストをテキスト・エディタにコピーして編集し、使用している環境に適したスクリプトを作成します。 |
/************************* BEGINNING OF SCRIPT ******************************
*/
SET ECHO ON SPOOL delete_conflictres.out CONNECT repadmin@orc1.example.com /*
*/
BEGIN DBMS_REPCAT.SUSPEND_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / /*
タイムスタンプを使用して削除の記録をマークすることをお薦めします(タイムスタンプでは、削除の記録がマークされた日時が示されます)。タイムスタンプを使用するということで、新しい列のデータ型はDATEとなります。remove_date列を既存のレプリケート表に追加するには、DBMS_REPCAT.ALTER_MASTER_REPOBJECTプロシージャを使用します。
*/ BEGIN DBMS_REPCAT.ALTER_MASTER_REPOBJECT ( sname => 'hr', oname => 'locations', type => 'TABLE', ddl_text => 'ALTER TABLE hr.locations ADD (remove_date DATE)'); END; / /*
*/
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'hr',
oname => 'locations',
type => 'TABLE',
min_communication => TRUE);
END;
/
/*
このパッケージは、指定した表からマーク済の記録をすべてパージします。
*/ BEGIN DBMS_REPCAT.CREATE_MASTER_REPOBJECT ( gname => 'hr_repg', type => 'PACKAGE', oname => 'purge', sname => 'hr', ddl_text => 'CREATE OR REPLACE PACKAGE hr.purge AS PROCEDURE remove_locations(purge_date DATE); END;'); END; / BEGIN DBMS_REPCAT.CREATE_MASTER_REPOBJECT ( gname => 'hr_repg', type => 'PACKAGE BODY', oname => 'purge', sname => 'hr', ddl_text => 'CREATE OR REPLACE PACKAGE BODY hr.purge AS PROCEDURE remove_locations(purge_date IN DATE) IS BEGIN DBMS_REPUTIL.REPLICATION_OFF; LOCK TABLE hr.locations IN EXCLUSIVE MODE; DELETE hr.locations WHERE remove_date IS NOT NULL AND remove_date < purge_date; DBMS_REPUTIL.REPLICATION_ON; EXCEPTION WHEN others THEN DBMS_REPUTIL.REPLICATION_ON; END; END;'); END; / /*
レプリケーション・サポートの生成後、使用者用のシノニムが作成されて、レプリケート・オブジェクトとしてマスター・グループに追加されます。このシノニムには、defer_purge.remove_locationsというラベルが付けられます。
*/
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'hr',
oname => 'purge',
type => 'PACKAGE',
min_communication => TRUE);
END;
/
BEGIN
DBMS_REPCAT.GENERATE_REPLICATION_SUPPORT (
sname => 'hr',
oname => 'purge',
type => 'PACKAGE BODY',
min_communication => TRUE);
END;
/
/*
複数の手順を含む管理操作も存在するため、DBMS_REPCATパッケージのDO_DEFERRED_REPCAT_ADMINプロシージャを数回実行します。次に例を示します。
*/ BEGIN DBMS_REPCAT.DO_DEFERRED_REPCAT_ADMIN ( gname => 'hr_repg', all_sites => FALSE); END; / */ PAUSE Press <RETURN> to continue when you have verified that there are no pending administrative requests in the DBA_REPCATLOG data dictionary view. /*
*/
BEGIN DBMS_REPCAT.RESUME_MASTER_ACTIVITY ( gname => 'hr_repg'); END; / SET ECHO OFF SPOOL OFF /************************* END OF SCRIPT **********************************/
この項では、アプリケーションの競合を回避するための先進の設計方法について説明しています。トークン渡しとして知られているこの方法は、次の項で説明するワークフロー・メソッドに似ています。この項では、このメソッドを使用してすべての行の所有権を管理する方法を説明していますが、このメソッドを変更して行内の個々の列グループの所有権を管理することもできます。
ワークフローおよびトークン渡しの両方とも、データの動的所有権に対応しています。動的所有権の行の更新は一度に1サイトのみ可能ですが、サイト間での行の所有権の受渡しは可能です。ワークフローおよびトークン渡しの両方とも、1つ以上の識別子列の値を使用して、現在、行の更新が許可されている者を特定します。
ワークフロー・パーティション分割では、サイト間で受け渡されるデータの所有権を考慮します。行の現在の所有者のみが、識別子列の値を変更することで行の所有権を他のサイトに渡せます。
受注、出荷および請求サイト別に簡単な例を紹介します。ここでは、受注のステータスを表示するのに識別子列を使用します。行の更新を許可されたサイトはステータスで特定します。受注サイトのユーザーは受注の入力後、この行のステータスをshipへと更新します。所有権が出荷サイトに渡されるため、受注サイトのユーザーはこの行を修正できません。
受注の出荷後、出荷サイトのユーザーは行のステータスをbillへと更新するため、所有権は請求サイトその他へ渡されます。
競合を回避するために、動的データ所有権を実装するアプリケーションが、次の条件を満たすことを確認します。
行の所有者のみが行を更新可能。
ある行を2つ以上のサイトで共有することは不可。
すべてのサイトにおける受注の競合が解消可能。
ワークフロー・パーティション分割では、行のカレント所有者のみが識別子列を更新することで、行の所有権を次のサイトに渡すことができます。他のサイトが所有権を放棄しないかぎり別のサイトに所有権が渡されることはないため、所有者が2人以上となることはありません。
ワークフローが順序付けされているため、ワークフローで最近発生したサイトからの変更を適用することによって、受注の競合を解決できます。受注の競合は、優先値がワークフロー・プロセスの各ステップで増える、優先順位による競合解消メソッドの形式を使用して解決できます。優先順位による競合解消メソッドは、優先値が常に増加しているかぎり、1つ以上のマスター・サイトに対して正常に収束します。
トークン渡しでは、より一般化されたアプローチを使用してこれらの基準を満たします。トークン渡しを実装する場合は、識別子列ではなくレプリケート表が所有者およびエポック列を保有します。所有者列には、現在、行を所有サイトのグローバル・データベース名を格納します。
トークン渡しメカニズムの設計を終了すると、これを使用してワークフローなど各種データ所有権の動的パーティション化を実装できます。
トークン渡しを自動的に実装するようにアプリケーションを設計します。このアプリケーション以外から所有者またはエポック列を更新しないでください。
行の更新では、アプリケーションは次の条件に従います。
行のカレント所有者の位置を特定します。
行の所有権を設定します。
行をロックして、所有権変更時の更新を防止します。
更新を実行します。
Oracleは、トランザクションのコミット時にロックを解放します。
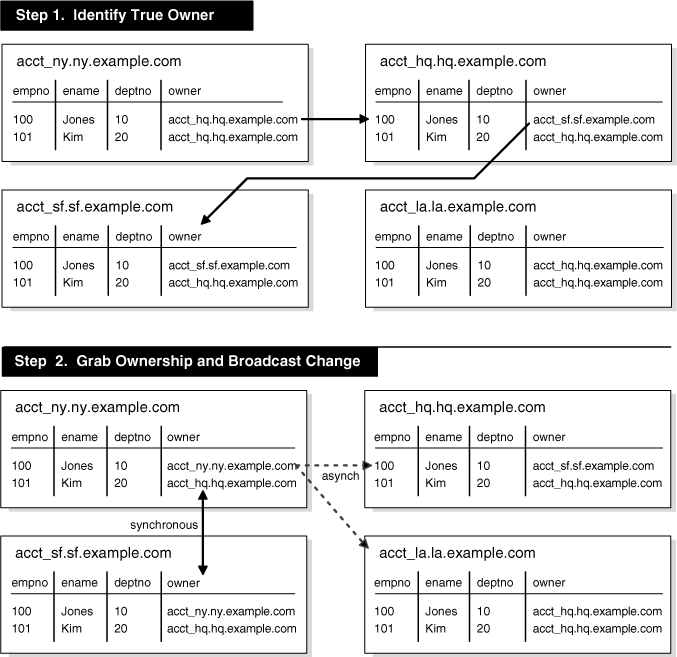
たとえば、図6-1では、従業員100の所有権をacct_sfデータベースからacct_nyデータベースへ渡す方法を説明しています。
所有権を取得する場合、acct_nyデータベースは単純な再帰的アルゴリズムを使用して、行の所有者を検索します。このアルゴリズムのサンプル・コードを次に示します。
-- Sample code for locating the token owner.
-- This is for a table TABLE_NAME with primary key PK.
-- Initial call should initialize loc_epoch to 0 and loc_owner
-- to the local global name.
get_owner(PK IN primary_key_type, loc_epoch IN OUT NUMBER,
loc_owner IN OUT VARCHAR2)
{
-- use dynamic SQL (dbms_sql) to perform a select similar to
-- the following:
SELECT owner, epoch into rmt_owner, rmt_epoch
FROM TABLE_NAME@loc_owner
WHERE primary_key = PK FOR UPDATE;
IF rmt_owner = loc_owner AND rmt_epoch >= loc_epoch THEN
loc_owner := rmt_owner;
loc_epoch := rmt_epoch;
RETURN;
ELSIF rmt_epoch >= loc_epoch THEN
get_owner(PK, rmt_epoch, rmt_owner);
loc_owner := rmt_owner;
loc_epoch := rmt_epoch;
RETURN;
ELSE
raise_application_error(-20000, 'No owner for row');
END IF;}
行の所有権を検索した後、acct_nyサイトは次の手順に従ってacct_sfサイトから所有権を取得します。
sfサイトの行をロックして、所有権交換で生じる変更を防止します。
この操作により常に1つのサイトのみが所有者となれます。sfサイトでの更新はDBMS_REPUTIL.REPLICATION_OFFを使用してレプリケートしないでください。手順4のnyサイトでレプリケートされた所有権の変更は、影響を一切受けないsfサイトなど、レプリケーション環境の他のすべてのサイトに伝播されます。
sfサイトおよびnyサイトの所有者情報を同期式で更新します。
新しい所有者サイトnyの行情報を、カレント所有者サイトsfの情報で更新します。
最新のデータであることが保証されます。今回は、nyサイトでの変更をレプリケートしないでください。sfサイトでこのデータに対して行うキューの変更は、通常の方法で他のすべてのサイトに伝播されます。sfの変更がnyに伝播されても、次の項目で説明するエポック番号の値を理由として無視されます。
新しい所有者サイトのエポック番号を以前のサイトの値に1を加えた値で更新します。
この更新は新しい所有者でのみ行い、この更新を他のマスター・サイトに非同期式に伝播します。新しい所有者サイトでエポック番号を増やすと、受注の競合を防ぎます。
sfの変更(前述の手順2で示した遅延キューに対する変更)がnyサイトに伝播されたとき、nyサイトはこれを無視します。これは、同一のデータに対するエポック番号が、nyサイトのエポック番号より小さいためです。
その他、hqサイトがnyの変更を受信した後にsfの変更を受信したものの、nyサイトからの変更のエポック番号が大きいためhqサイトがsfの変更を無視するような例も考えられます。
Oracleによって更新、削除または一意性競合が検出され、正常に解消された場合は、ALL_REPRESOLUTION_STATISTICSデータ・ディクショナリ・ビューを問い合せることによって、競合解消に使用された方法の情報を表示できます。このビューは、競合に関連する表に対して競合解消統計収集を有効化した場合にのみ更新されます。
DBMS_REPCATパッケージのREGISTER_STATISTICSプロシージャを使用して、正常に実行された表の更新、削除および一意性の競合解消の情報を収集します。次の例では、hrスキーマ内の従業員表の統計が収集されます。
BEGIN
DBMS_REPCAT.REGISTER_STATISTICS (
sname => 'hr',
oname => 'employees');
END;
/
ある表に対してREGISTER_STATISTICSをコールすると、その表で正常に解消された各競合はALL_REPRESOLUTION_STATISTICSデータ・ディクショナリ・ビューに記録されます。解消不可能な競合の情報は、オブジェクトが登録されているかどうかに関係なく、通常、DEFERRORビューに記録されます。
正常に実行された表の更新、削除および一意性の競合解消の情報収集が不要になった場合は、DBMS_REPCATパッケージのCANCEL_STATISTICSプロシージャを使用します。次の例では、hrスキーマ内のemployees表に収集された統計を取り消します。
BEGIN
DBMS_REPCAT.CANCEL_STATISTICS (
sname => 'hr',
oname => 'employees');
END;
/
正常に実行された更新、削除、および一意性の競合解消の情報を記録するように表を登録している場合は、DBMS_REPCATパッケージのPURGE_STATISTICSプロシージャをコールすることによって、DBA_REPRESOLUTION_STATISTICSデータ・ディクショナリ・ビューからこの情報を削除できます。
次の例では、1月1日から3月31日の、employees表に対する挿入、更新および削除により解消した競合についての統計がパージされます。
BEGIN
DBMS_REPCAT.PURGE_STATISTICS (
sname => 'hr',
oname => 'employees',
start_date => '01-JAN-2001',
end_date => '31-MAR-2001');
END;
/