15 Optimizing Pipeline Manager Performance
This chapter describes tools and techniques you can use to optimize Oracle Communications Billing and Revenue Management (BRM) Pipeline Manager performance.
Before reading this chapter, you should be familiar with the following topics:
-
"About Pipeline Rating" in BRM Configuring Pipeline Rating and Discounting
Pipeline Manager Optimization Overview
When you optimize Pipeline Manager performance, your objective is to increase the percentage of CPU time spent on user processes and to decrease the percentage of time spent idle or on system processes.
Complete performance tuning requires much testing. Due to the complexity of most Pipeline Manager configurations, optimization is a highly iterative process. You cannot configure options formulaically, but you must test many configurations and then implement the optimal configuration. This chapter describes optimization methods to guide your testing for a given set of hardware resources.
Software optimization techniques can include modifying the following:
-
The number and type of function modules.
-
The design of custom iScripts and iRules.
-
The number of system threads used by a pipeline.
-
The number of call data record (CDR) files configured for a transaction.
-
The number of pipelines configured for the system.
Note:
Available hardware resources can constrain the usefulness of some optimization techniques. For example, if your system has only a few CPUs, you probably will not see performance gains by using multithreaded mode.
Key Metrics for Measuring Performance
When evaluating performance improvement, the primary metrics to monitor are:
-
The ratio of CPU time spent on system processes to CPU time spent on user processes. This ratio should be about 1 to 2 or lower.
-
The percentage of idle CPU time. This percentage should be 20 percent or less.
-
The results of performance tests using sample CDR files.
About Measuring Pipeline Manager Performance
You use the Pipeline Manager instrumentation feature as the primary tool for measuring Pipeline Manager performance. See "Measuring System Latencies with Instrumentation" for more information. When instrumentation is enabled, information about how much time in microseconds each function module uses to process a certain number of files is written to the pipeline log file (pipeline.log). You then use this information when you apply some optimization techniques.
Note:
For more information on the pipeline log, see "LOG" in BRM Configuring Pipeline Rating and Discounting.Other Pipeline Manager performance monitoring tools are:
-
Monitor event data record (EDR) throughput. See "Monitoring Pipeline Manager EDR Throughput".
-
Monitor recent log files. See "Getting Recent Pipeline Log File Entries".
-
Monitor memory usage. See "Memory Monitor" in BRM Configuring Pipeline Rating and Discounting.
Information Requirements
Before you optimize Pipeline Manager, be familiar with your existing system configuration, such as:
-
Total system memory.
-
Other (nonpipeline) processes running on the Pipeline Manager system that will share system resources.
-
The number and types of pipelines required for your business logic or planned load balancing.
-
The expected load for each pipeline.
-
Whether your business logic is more CPU intensive or I/O intensive. (For example, if you use the FCT_Discount module, your business logic is likely to be more CPU intensive.)
Testing Requirements
Before you optimize Pipeline Manager, you should have a set of error-free sample CDRs that resemble those used in your production system.
Optimizing Pipeline Manager
To optimize Pipeline Manager, consider the following actions:
-
(Oracle Solaris, Linux, HP-UX IA64, and AIX) Be sure that OS-specific system configurations were put in place during installation. See the following topics in BRM Installation Guide:
-
(Solaris) Configuring Memory Allocation and Block Transfer Mode on Solaris Systems
-
(HP-UX IA64) Setting Maximum Open Files on HP-UX IA64
Important:
For HP-UX IA64, you must set the _M_ARENA_OPTS and _M_CACHE_OPTS environment variables to achieve acceptable system performance. -
(AIX) Setting Maximum Open Files on AIX
-
Configure pipelines to run in either single-threaded or multithreaded mode. See "Configuring Single-Threaded or Multithreaded Operation" for more information.
It is especially important to maximize the performance of the DAT_AccountBatch and DAT_BalanceBatch modules. See:
-
Configure function pools within pipelines. See "Optimizing a Pipeline by Using Function Pools" for more information.
-
If you have CDR files smaller than a few thousand records, consider grouping multiple CDR files into one transaction. See "Combining Multiple CDR Files into One Transaction" for more information.
-
Configure multithreading in the Output Controller. See "Increasing Pipeline Manager Throughput When an EDR Is Associated with Multiple Output Streams" for more information.
-
Add additional pipelines. See "Configuring Multiple Pipelines" for more information.
-
Verify that any custom iScripts and iRules are efficiently designed. See "Optimizing Function Modules" for more information.
-
Configure event and service mapping to only supply the Pipeline Rating Engine with the services being rated. See "Mapping Events and Services" in BRM Setting Up Pricing and Rating.
-
Configure the DAT_USC_Map module to improve startup performance. See "Configuring the DAT_USC_Map Module for Startup Performance" and "DAT_USC_Map" in BRM Configuring Pipeline Rating and Discounting.
Troubleshooting Pipeline Performance
Use the following checklist to troubleshoot drops in performance.
-
If you installed a patch, find out if the patch changed operating system functions, such as threading or memory management, or made any changes to Pipeline Manager framework modules.
-
Check recent customizations, such as iScripts. Look for customizations that might impact database access or hash usage.
-
Use database monitoring tools to monitor the Pipeline Manager database to see if there is a lot of activity. If so, check which queries are used and which indexes are used. This might point to the data involved, which might point to the module processing that data.
-
Use a monitoring command such as iostat to check I/O activity.
-
Use a memory monitoring command such as prstat, vmstat, or sar to check if the Pipeline Manager memory usage has changed. If Pipeline Manager uses an unexpected amount of memory, check for duplicate keys related to buffers and call assembly.
-
Check for large numbers of files in the following directories:
-
in
-
err
-
done
-
dupl
-
assembl
-
rej
Delete old files that are no longer needed.
-
-
Look for bottlenecks in the pipeline by using the prstat command and the thread ID in the process.log file to identify slow threads. Check for:
-
icx (involuntary context switch)
-
vcx (voluntary context switch)
-
scl (system call)
-
slp (sleep)
-
-
Check the pipeline.log file for records of a large amount of rollbacks.
Optimizing Function Modules
Slow function modules can be very detrimental to overall Pipeline Manager performance. To optimize individual function modules:
-
Identify the high latency modules by using instrumentation. See "Measuring System Latencies with Instrumentation" for more information.
-
Check if the high latency modules can be optimized. For example, you might discover that the business logic used in high latency iScripts or iRules can be redesigned to improve performance.
Configuring Single-Threaded or Multithreaded Operation
You configure pipelines to run in single-threaded or multithreaded mode by using the MultiThreaded registry entry in the registry file.
-
Single-threaded mode: Use this mode if you are using a system with just a few CPUs and limited RAM.
In a single-threaded environment, pipelines use a single thread to run all modules and only one CPU is used for each pipeline.
If the MultiThreaded registry entry is not included in the registry file, pipelines will by default run in multithreaded mode.
Note:
Business logic can prevent the setup of multiple pipelines. -
Multithreaded mode: Use this mode if your system has many CPUs.
In a multithreaded environment, pipelines use three or more threads to process each transaction. By default, one thread is used for the input module and one for the output module. An additional thread is used for each function pool that you configure to process function modules.
For information on optimizing pipelines when using multithreaded mode, see:
For information about the MultiThreaded registry entry, see "Pipeline Controller" in BRM Configuring Pipeline Rating and Discounting.
To configure single-threaded or multithreaded operation:
-
Open the registry file in a text editor.
-
Set the input controller MultiThreaded registry entry to the appropriate value:
-
True to configure the pipeline for multithreaded processing.
-
False to configure the pipeline for single-threaded processing.
Pipelines { PipelineName { MultiThreaded = value ... } } -
-
Restart the pipeline. See "Starting and Stopping Individual Pipelines" for more information.
Note:
For more information on all registry entries pertaining to individual pipelines, see "Pipeline Controller" in BRM Configuring Pipeline Rating and Discounting.
Reducing Startup Times with Parallel Loading
You can reduce your startup times by configuring Pipeline Manager to:
-
Load all pipelines in parallel.
-
Load data modules in parallel.
-
Load function modules in parallel.
By default, Pipeline Manager loads pipelines, data modules, and function modules sequentially.
To enable parallel loading, use the Parallel Load Manager module:
-
Open the registry file in a text editor.
-
Configure the ifw.ParallelLoadManager section of the registry file:
-
Set the Active registry entry to True.
-
Set the NumberOfThreads registry entry to the number of threads you want Pipeline Manager to use for loading your pipelines, data modules, and function modules.
For example:
ifw { ... ParallelLoadManager { Active = True NumberOfThreads = 4 } … } -
-
Restart the pipeline. See "Starting and Stopping Individual Pipelines" for more information.
Assigning Multiple Threads to Process Function Modules
If a pipeline is configured for multithreaded processing and you have idle CPU resources, you might be able to increase performance by grouping function modules into two or more function pools. The pipeline runs each function pool in a separate thread.
Important:
Adding too many function pools to a pipeline can decrease performance because the buffers between the threads consume system CPU overhead and RAM. (Typically, two to six function pools is optimal.)Tip:
If you are using a high-latency module such as FCT_AccountBatch or FCT_Discount and have sufficient hardware resources, assign the module to its own function pool and test for performance improvement.To create a separate thread for an individual function module or a group of function modules, you use the FunctionPool registry entry.
Important:
Before you perform this procedure, read "Optimizing a Pipeline by Using Function Pools" for more information.-
Submit some sample CDRs to the pipeline with instrumentation enabled. See "Measuring System Latencies with Instrumentation" for more information.
-
Locate the instrumentation results in the pipeline.log file.
-
Open the registry file in a text editor.
-
Using the instrumentation data, reduce the processing time required by the slowest function pool by:
-
(Optional) Adding an additional function pool to the Functions section of the registry file.
-
Shifting one or more modules from a function pool to an adjacent function pool.
The objective is to make the processing times of all function pools as similar as possible.
-
-
Save the registry file.
-
Restart the pipeline. See "Starting and Stopping Individual Pipelines" for more information.
-
Measure pipeline performance with the sample CDRs by measuring transaction start times and end times in the pipeline.log file.
-
Go to Step 3 and repeat testing until optimal results are achieved.
Configuring the DAT_AccountBatch Module Database Connections and Threads
To improve performance, you can configure multiple DAT_AccountBatch connections to the BRM database. See "DAT_AccountBatch" in BRM Configuring Pipeline Rating and Discounting. Configure the following registry entries:
-
Use the Threads registry entry to specify the number of threads. Set this value to at least the number of CPUs in the system. Increasing the number of threads increases performance, up to a point. Specifying too many threads decreases performance.
The default is 4.
-
Use the Connections registry entry to specify the number of connections to the database. This value must be at least one more than the number of threads.
The default is 5.
-
Use the LoadPercentage registry entry to specify the percentage of account POIDs to store locally when determining the account blocks for which each thread is responsible.
Values must be greater than 0.000000 and less than or equal to 100.0.
The default is 10.
Setting the Hash Map Size for Threads
You can use the following DAT_AccountBatch registry entries to set the temporary hash map size built for each thread. Each entry controls the hash map size for a different type of data; for example, accounts, logins, and services.
In general, larger maps perform better but consume more memory. Smaller maps save memory but can slow down Pipeline Manager startup. Very low numbers can dramatically slow down Pipeline Manager startup.
The default system-calculated value uses the following formula:
((number of accounts/number of threads) * 2).
The registry entries are:
-
ThreadAccountHashMapSize: Used for account data.
Important:
Changing the default system-calculated values for this entry is not recommended. Replacing this entry with one larger than the default wastes memory. Replacing this entry with one smaller than the default slows Pipeline Manager startup. -
ThreadGroupSharingChargesHashMapSize: Used for charge sharing group data. The system-calculated default value might not be appropriate.
If your accounts average fewer than two or more than four GroupSharingCharges per account, use the following formula as a guideline to calculate an entry:
(((number of accounts * average number of GroupSharingCharges per account) / number of threads) * 75%).
-
ThreadGroupSharingDiscountsHashMapSize: Used for discount sharing group data. The system-calculated default value might not be appropriate.
If your accounts average fewer than two or more than four GroupSharingDiscounts per account, use the following formula as a guideline to calculate an entry:
(((number of accounts * average number of GroupSharingDiscounts per account) / number of threads) * 75%).
-
ThreadGroupSharingProfilesHashMapSizes: Used for profile sharing group data. The system-calculated default value might not be appropriate.
If your accounts average fewer than two or more than four profile sharing groups per account, use the following formula as a guideline to calculate an entry:
(((number of accounts * average number of GroupSharingProfiles per account) / number of threads) * 75%).
-
ThreadLoginHashMapSize: Used for login data. The system-calculated default value is appropriate for most implementations.
If your accounts average more than four logins per account, use the following formula as a guideline to calculate an entry:
(((number of accounts * average number of logins per account) / number of threads) * 75%).
-
ThreadServiceHashMapSize: Used for service data. The system-calculated default value is appropriate for most implementations.
If your accounts average more than four services per account, use the following formula as a guideline to calculate an entry:
(((number of accounts * average number of services per account) / number of threads) * 75%).
Locking Objects during DAT_AccountBatch Processing
You can set the number of pre-allocated mutex objects that are used to lock individual objects during processing to prevent multiple threads from contending for access to the same object. You can use different settings for account, login, and service objects by setting the following DAT_AccountBatch registry entries:
-
AccountLocks
-
LoginLocks
-
ServiceLocks
Usually, the default value for these entries should be appropriate. If you use a larger value, less allocation is needed for additional mutex objects during processing, but more memory is used.
The default for all entries is 10.
Configuring Threads for DAT_BalanceBatch Connections
Use the following DAT_BalanceBatch registry entry to configure connections to the BRM database:
-
Threads: Specifies the number of threads for loading the balance data from the BRM database. The number of threads must be smaller than or equal to the number of connections.
The default is 4.
-
ThreadHashMapSize: Specifies the size of the hash map in each thread used for loading balance data from the BRM database.
The default is 1024.
Improving Pipeline Manager Startup Performance
For information about improving Pipeline Manager startup performance, see:
Improving DAT_BalanceBatch Loading Performance
The DAT_BalanceBatch module uses the noncurrency resource validity to select the noncurrency subbalances to load from the BRM database into pipeline memory. If the noncurrency resource validity is not configured, at Pipeline Manager startup, DAT_BalanceBatch selects the subbalances that were valid for 366 days by default. When the BRM database contains a large number of noncurrency subbalances, loading them leads to increased Pipeline Manager startup times.
To improve Pipeline Manager startup performance, you can set the noncurrency resource validity to specify the subbalances to load. See "Specifying Which Non-Currency Subbalances to Load on Startup" in BRM Setting Up Pricing and Rating for more information.
Improving DAT_AccountBatch and DAT_BalanceBatch Load Balancing
The DAT_AccountBatch and DAT_BalanceBatch modules use multithreaded framework to load account and balance data from the BRM database into Pipeline Manager memory. The modules group the accounts and balances into batches or jobs. Multiple worker threads run in parallel to process the jobs. When a thread completes processing, it is assigned another job from the jobs pool, which improves load balancing between the threads and increases Pipeline Manager startup performance.
By default, the number of jobs per thread is 3, which is appropriate in most installations to achieve load balancing. However, if thread loading times vary greatly, you can use the PerThreadJobsCount entry in the DAT_AccountBatch registry and the BalancesPerThreadJobsCount entry in the DAT_BalanceBatch registry to adjust the number of jobs per thread.
Important:
Setting the number of jobs per thread to a large number can outweigh the performance gain because of the system overhead associated with creating too many jobs. (Typically, three to eight jobs per thread is optimal). To adjust the number of accounts or balances per job, you can do this by increasing or decreasing the number of threads. However, when the number of accounts or balances is too small, the data modules use one thread to optimize performance.Breaking Up Large Nested Subsections in Registry Files
Pipeline Manager can encounter parser stack overflow errors when a pipeline registry section contains a large number of nested subsections.
You can break up large nested subsections and prevent parser stack overflow errors by using anonymous blocks in your registry file. An anonymous block consists of a nested subsection with braces { } and no subsection name, as shown below:
#------------------------------------------------------------------------
# Input section
#------------------------------------------------------------------------
Input
{
UnitsPerTransaction = 1
InputModule
{
{ # <-- Beginning of Anonymous Block
ModuleName = INP_GenericStream
Module
{
Grammar = ./formatDesc/Formats/Solution42/SOL42_V670_REL_InGrammar.dsc
DefaultOutput = TELOutput
InputStream
{
ModuleName = EXT_InFileManager
Module
{
InputPath = ./data/incollect/reprice/in
InputPrefix = test_
InputSuffix = .edr
...
}
} # end of InputStream
} # end of InputModule
} # --> End of Anonymous Block
} # end of InputDataPool
}
You can place anonymous blocks in any location and at any hierarchy level of the registry file. For the best effect, divide large sections by placing an anonymous block around a group of smaller subsections. This breaks up the section without affecting the hierarchy of the subsections enclosed within the anonymous block.
Optimizing a Pipeline by Using Function Pools
In general, the performance of a multithreaded pipeline varies directly with its slowest thread. The objective of optimizing a multithreaded pipeline is to group the function modules into function pools so that the slowest function pool is as fast as possible. In this environment, faster threads wait a minimum amount of time for data to be delivered or processed by slower threads.
Important:
Adding too many function pools to a pipeline can decrease performance because the buffers between the threads consume system CPU overhead and RAM. (Typically, two to six function pools is optimal.)You use instrumentation results to guide function pool configuration. Instrumentation results indicate how many microseconds are required by each module to process a given number of requests. You use this information to add function pools or regroup the modules in existing function pools.
Tip:
You cannot improve performance by adding function pools or shifting function modules to adjacent function pools if your slowest function pool:-
Has one function module in it. (or)
-
Is faster than the input or output module.
You might be able to improve performance by reducing the number of function pools as long as the slowest function pool is faster than the output module. (Any performance gain comes from the reduced number of buffers. Fewer buffers require less system process overhead.)
Adding Function Pools
You might improve system performance by adding one or more function pools.
The following example shows a high-level schema of a portion of a registry file for a pipeline called ALL_RATE:
Note:
For information on the buffers between the function pools, see "Configuring Buffers" for more information.
input {...}
Functions
{
PreProcessing
{
FunctionPool
{
module_1 {}
module_2 {}
module_3 {}
}
}
Buffer1 {...}
Rating
{
FunctionPool
{
module_4 {}
module_5 {}
module_6 {}
}
}
Buffer2 {...}
PostRating
{
FunctionPool
{
module_7 {}
module_8 {}
}
}
output {...}
The instrumentation output in the pipeline.log file reveals the following latencies for each module for processing a fixed set of test transactions:
Note:
For simplicity, the sample latencies have been rounded to the nearest 5,000,000 microseconds.15.03.2004 13:25:07 testserver ifw IFW NORMAL 00516 - (ifw.Pipelines.ALL_RATE.Functions.PreProcessing) Plugin processing time statistics: ' ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.module_1.Module, 40000000 ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.module_2.Module, 15000000 ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.module_3.Module, 45000000 15.03.2004 13:25:07 testserver ifw IFW NORMAL 00516 - (ifw.Pipelines.ALL_RATE.Functions.Rating) Plugin processing time statistics: ' ifw.Pipelines.ALL_RATE.Functions.Rating.FunctionPool.module_4.Module, 65000000 ifw.Pipelines.ALL_RATE.Functions.Rating.FunctionPool.module_5.Module, 30000000 ifw.Pipelines.ALL_RATE.Functions.Rating.FunctionPool.module_6.Module, 90000000 15.03.2004 13:25:07 testserver ifw IFW NORMAL 00516 - (ifw.Pipelines.ALL_RATE.Functions.PostRating) Plugin processing time statistics: ' ifw.Pipelines.ALL_RATE.Functions.Postrating.FunctionPool.module_7.Module, 35000000 ifw.Pipelines.ALL_RATE.Functions.Postrating.FunctionPool.module_8.Module, 50000000
This output is summarized in Table 15-1:
Table 15-1 Example 1 Module Latencies Summary
| Module | Module Latency (Microseconds) | Function Pool | Function Pool Latency (Microseconds) |
|---|---|---|---|
|
module_1 |
40,000,000 |
PreProcessing |
100,000,000 |
|
module_2 |
15,000,000 |
PreProcessing |
100,000,000 |
|
module_3 |
45,000,000 |
PreProcessing |
100,000,000 |
|
module_4 |
65,000,000 |
Rating |
185,000,000 |
|
module_5 |
30,000,000 |
Rating |
185,000,000 |
|
module_6 |
90,000,000 |
Rating |
185,000,000 |
|
module_7 |
35,000,000 |
PostRating |
85,000,000 |
|
module_8 |
50,000,000 |
PostRating |
85,000,000 |
The total latency in this configuration is 185,000,000; this represents the microseconds used by the slowest function pool.
Figure 15-1 shows that about a third of the CPU cycles used by the function pool threads are idle:

In this example, the pipeline can be optimized if module_6 is assigned to its own function pool, as in this revised sample:
input {...}
Functions
{
PreProcessing
{
FunctionPool
{
module_1 {}
module_2 {}
module_3 {}
}
}
Buffer1 {...}
Rating
{
FunctionPool
{
module_4 {}
module_5 {}
}
Buffer2 {...}
Discounting
{
functionpool
{
module_6 {}
}
}
Buffer3 {...}
PostRating
{
FunctionPool
{
module_7 {}
module_8 {}
}
}
output {...}
The latency table now appears as shown in Table 15-2:
Table 15-2 Example 2 Modules Latencies Summary
| Module | Module Latency (Microseconds) | Function Pool | Function Pool Latency (Microseconds) |
|---|---|---|---|
|
module_1 |
40,000,000 |
PreProcessing |
100,000,000 |
|
module_2 |
15,000,000 |
PreProcessing |
100,000,000 |
|
module_3 |
45,000,000 |
PreProcessing |
100,000,000 |
|
module_4 |
65,000,000 |
Rating |
95,000,000 |
|
module_5 |
30,000,000 |
Rating |
95,000,000 |
|
module_6 |
90,000,000 |
Discounting |
90,000,000 |
|
module_7 |
35,000,000 |
PostRating |
85,000,000 |
|
module_8 |
50,000,000 |
PostRating |
85,000,000 |
Total function module latency in the new configuration is 100,000,000 microseconds, equivalent to the latency of the PreProcessing function pool. Less than eight percent of function pool CPU cycles are now idle as shown by the gray cycles in Figure 15-2:
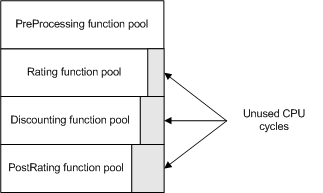
Shifting Modules between Function Pools
Adding an additional function pool can decrease performance in some situations (see "Adding Function Pools" for more information). This can occur if the system overhead for the additional buffer more than offsets the performance gains from a faster highest-latency function pool. When this occurs, you might be able to improve performance by keeping the number of function pools constant and shifting modules to adjoining function pools.
In the sample above, if adding an additional function pool decreased performance, you could return to using three function pools and then move module 4 to the end of the PreProcessing function pool as shown in Table 15-3:
Table 15-3 Example 3 Modules Latencies Summary
| Module | Module Latency (Microseconds) | Function Pool | Function Pool Latency (Microseconds) |
|---|---|---|---|
|
module_1 |
40,000,000 |
PreProcessing |
165,000,000 |
|
module_2 |
15,000,000 |
PreProcessing |
165,000,000 |
|
module_3 |
45,000,000 |
PreProcessing |
165,000,000 |
|
module_4 |
65,000,000 |
PreProcessing |
165,000,000 |
|
module_5 |
30,000,000 |
Rating |
120,000,000 |
|
module_6 |
90,000,000 |
Rating |
120,000,000 |
|
module_7 |
35,000,000 |
PostRating |
85,000,000 |
|
module_8 |
50,000,000 |
PostRating |
85,000,000 |
Total function module latency in the new configuration is 165,000,000 microseconds. This is equivalent to the latency of the PreProcessing function pool. Though performance gains might be more modest than in the first scenario (where a new function pool was added), the performance gain is more certain because no additional buffer overhead was added.
Configuring Buffers
In a multithreaded pipeline, each pair of consecutive threads communicates through a buffer. Because each function pool is assigned a thread, you must configure a buffer between consecutive function pools.
You configure the buffers between function pool sections in the pipeline registry file. Normally, each buffer can be configured as follows:
Buffer1
{
Size = 100
}
Important:
On Solaris systems, you should configure block transfer mode. See "Block Transfer Mode" in BRM Installation Guide.Combining Multiple CDR Files into One Transaction
Pipeline Manager is generally more efficient when it processes large CDR files. If a pipeline receives and processes small CDR files, you can improve processing performance by combining multiple CDR input files into one pipeline transaction. You use the UnitsPerTransaction registry entry in the input controller to implement this functionality. See "Input Controller" in BRM Configuring Pipeline Rating and Discounting.
The UnitsPerTransaction entry specifies the number of CDR input files that make up a transaction. By default, each CDR file forms its own transaction.
Note:
The optimal transaction size depends on your system configuration and pricing model. In general, most system configurations perform best when the total number of CDRs, which is the average number of CDRs per input file multiplied by the number of input files in the transaction, is greater than 10,000.If the UnitsPerTransaction value is greater than 1, you can use the SequenceGeneration registry entry in the output controller to specify whether the pipeline generates one output file per CDR input file or one output file for the entire transaction (see "Output Controller" in BRM Configuring Pipeline Rating and Discounting). Pipeline Manager performance is generally faster when one output file is generated for the entire (multi-CDR) transaction.
To combine multiple CDR files into one transaction:
-
In the Input section of the registry file, set the UnitsPerTransaction entry to the number of CDR input files that make up one transaction. For example, set UnitsPerTransaction to 100 to combine 100 CDR input files into one transaction.
Note:
The default UnitsPerTransaction value is 1.Input { ... UnitsPerTransaction = 100 ... } -
(Optional) In the Output section of the registry file, set the SequenceGeneration entry to Transaction. This configures the pipeline to generate one output file for the entire transaction.
Note:
The default SequenceGeneration value is Units, which configures the pipeline to generate one output file per CDR input file.Output { ... SequenceGeneration = Transaction ... } -
Stop and restart the pipeline. See "Starting and Stopping Individual Pipelines".
Increasing Pipeline Manager Throughput When an EDR Is Associated with Multiple Output Streams
You can enhance Pipeline Manager throughput by configuring multithreading in the Output Controller. This enables Pipeline Manager to write multiple EDRs in parallel when the EDRs are associated with multiple output streams.
Important:
Enable multithreading in the Output Controller only if the EDRs are associated with multiple output streams.Enabling multithreading may cause an increase in the overall memory usage of the Output Controller. However, the memory usage becomes constant after processing EDRs for some time.
To configure multithreading in the Output Controller:
-
Open the registry file (for example, Pipeline_home/conf/wireless.reg) in a text editor.
-
In the MultiThreading section, do the following:
-
Set the Active registry entry to True.
-
Set the NumberOfThreads registry entry to the number of threads you want the Output Controller to create for Pipeline Manager to write multiple EDRs in parallel.
-
Set the BatchSize registry entry to the appropriate value:
-
0 indicates that the Output Controller does not run in batch mode.
-
A value greater than 0 indicates that the Output Controller operates in batch mode with the batch size equal to the specified value.
-
For example:
Output { ... ... MultiThreading { Active = True NumberOfThreads = 5 BatchSize = 500 } } -
-
Save and close the file.
-
Restart the pipeline. See "Starting and Stopping Individual Pipelines".
For information about the MultiThreading registry entry, see "Output Controller" in BRM Configuring Pipeline Rating and Discounting.
Configuring Multiple Pipelines
If you have high transaction throughput requirements and additional system resources, you might improve system performance by running multiple pipelines that perform the same function.
In general, consider running multiple pipelines if:
-
Your system has a relatively large number of CPUs.
-
The order of the input streams is not important.
Note:
When you use the FCT_CallAssembling or the FCT_DuplicateCheck module, you must process the EDRs for the same account in the same pipeline. See "Using Duplicate Check with Multiple Pipelines" and "Assembling Calls with Multiple Pipelines" in BRM Configuring Pipeline Rating and Discounting.Tip:
If you configure multiple pipelines and your system is running at near full capacity on a limited number of CPUs, test running the pipelines in single-threaded mode. This configuration reduces the buffer memory allocation requirement and thread-handling overhead. To enable single-threaded operation, set the MultiThreaded entry to False. See "Assigning Multiple Threads to Process Function Modules" for more information.
Customizing Flists Sent to a Real-Time Pipeline
You can configure the fields included in flists sent to a real-time pipeline by using the load_pin_rtp_trim_flist utility. See "load_pin_rtp_trim_flist" in BRM Developer's Guide. This utility is useful for:
-
Improving system efficiency by removing (trimming) fields that the pipeline does not use.
-
Supporting custom iScripts and iRules in the pipeline by adding fields to default flists that are not included in the flists by default.
To optimize the set of fields sent to a real-time pipeline:
-
Determine which fields are required by the real-time pipeline.
-
Create an XML file that describes the fields to be sent to the real-time pipeline based on one or more event types.
-
Load the XML file using the load_pin_rtp_trim_flist utility.
Configuration Object Dot Notation
The load_pin_rtp_trim_flist utility creates a configuration object (/config/rtp/trim_flist). This object is used to create the trimmed flists.
The configuration object uses dot notation. For example, the PIN_FLD_STATUS_FLAGS field at the end of this portion of a sample flist:
0 PIN_FLD_INHERITED_INFO SUBSTRUCT [0] allocated 32, used 32 1 PIN_FLD_POID POID [0] 0.0.0.1 /account 10243 13 1 PIN_FLD_MOD_T TSTAMP [0] (1063218065) Wed Sep 10 11:21:05 2003 1 PIN_FLD_ACCOUNT_NO STR [0] "0.0.0.1-10243" 1 PIN_FLD_CURRENCY INT [0] 840 1 PIN_FLD_BILL_WHEN INT [0] 1 1 PIN_FLD_LAST_BILL_T TSTAMP [0] (1063217469) Wed Sep 10 11:11:09 2003 1 PIN_FLD_BAL_GRP_OBJ POID [0] 0.0.0.1 /balance_group 8323 4 1 PIN_FLD_SERVICE_INFO SUBSTRUCT [0] allocated 32, used 32 2 PIN_FLD_STATUS ENUM [0] 10100 2 PIN_FLD_STATUS_FLAGS INT [0] 0
is represented as:
PIN_FLD_INHERITED_INFO.PIN_FLD_SERVICE_INFO.PIN_FLD_STATUS_FLAGS
in the configuration object.
About the field_list.xml File
The field_list.xml file specifies the fields from the /account and /service objects that are included in the flist that is sent to Pipeline Manager. You can define conditions in <EventMap> sections in the XML file that indicate which fields should be included in the flist depending on the event type.
The following example shows the XML file structure with session and provisioning event filters:
<EventMapList>
<!--* The following event map specifies fields sent
* when the event type is exactly /event/session -->
<EventMap>
<Event>
<Type>/event/session</Type>
<Flags>0</Flags>
</Event>
<RequiredField>
<!-- List of fields sent put here. -->
</RequiredField>
</EventMap>
<!--* The following event map specifies fields sent
* when the event type starts with /event/session/ -->
<EventMap>
<Event>
<Type>/event/session/</Type>
<Flags>1</Flags>
</Event>
<RequiredField>
<!-- List of fields sent put here. -->
</RequiredField>
</EventMap>
<!--* The following event map specifies fields sent
* when when a provisioning event matches any of three conditions. -->
<EventMap>
<Event>
<Type>/event/provisioning</Type>
<Flags>0</Flags>
</Event>
<Event>
<Type>/event/provisioning/session</Type>
<Flags>0</Flags>
</Event>
<Event>
<Type>/event/provisioning/</Type>
<Flags>1</Flags>
</Event>
<RequiredField>
<!-- List of fields sent put here. -->
</RequiredField>
</EventMap>
<!--* The following event map specifies fields sent when none of the
* above conditions are true. -->
<EventMap>
<Event>
<Type>*</Type>
<Flags>1</Flags>
</Event>
<RequiredField>
<!-- List of fields sent put here. -->
</RequiredField>
</EventMap>
</EventMapList>
The Flags tag in the XML file specifies event matching criteria.
-
A Flags value of 0 specifies that an exact match is required.
-
A Flags value of 1 specifies that the event type must start with the string specified in the Type tag. The value 1 is also used when indicating Type value asterisk (*). This value matches all event types.
Important:
Search order is important. The fields included with the flist are the fields specified in the first event map section of the XML file where the event type matches the string in the Type field.
You can use the sample XML fields list (BRM_home/sys/data/config/pin_config_rtp_trim_flist.xml) as a base for your custom XML file.
For a detailed example using session event filters, see "Usage Example".
Mapping Events to Flists
Because one flist can be used by more than one event, you can specify the relationship between an event and the flist.
For example, the following section is of an event map XML file:
<EventMap>
<Event>
<Type>/event/session</Type>
<Flags>0</Flags>
</Event>
<Event>
<Type>/event/session/</Type>
<Flags>1</Flags>
</Event>
is mapped to an flist as follows:
0 PIN_FLD_EVENT_MAP ARRAY [0] allocated 20, used 8 1 PIN_FLD_EVENTS ARRAY [0] allocated 20, used 8 2 PIN_FLD_EVENT_TYPE STR [0] "/event/session" 2 PIN_FLD_FLAGS INT [0] 0 1 PIN_FLD_EVENTS ARRAY [1] allocated 20, used 8 2 PIN_FLD_EVENT_TYPE STR [0] "/event/session/" 2 PIN_FLD_FLAGS INT [0] 1
Usage Example
An unmodified flist might look like the sample shown in "Sample Unmodified Flist". However, in this example, Pipeline Manager only requires subsets of fields listed in "Sample Fields Required by Pipeline Manager" depending on the event type.
In this example, to implement the trimmed flist:
-
Create the XML file shown in "sample.xml File" to modify the default list of fields ("Sample Unmodified Flist") included in the flist.
-
Load the XML file using the utility:
load_pin_rtp_trim_flist -f sample.xml [-v] [-d]
Sample Unmodified Flist
The following is the default (untrimmed) list of fields sent to Pipeline Manager.
0 PIN_FLD_POID POID [0] 0.0.0.1 /event/session -1 0 0 PIN_FLD_EVENT SUBSTRUCT [0] allocated 25, used 25 1 PIN_FLD_POID POID [0] 0.0.0.1 /event/session -1 0 1 PIN_FLD_NAME STR [0] "Activity Session Log" 1 PIN_FLD_USERID POID [0] 0.0.0.1 /service/pcm_client 1 0 1 PIN_FLD_ACCOUNT_OBJ POID [0] 0.0.0.1 /account 10243 0 1 PIN_FLD_PROGRAM_NAME STR [0] "testnap" 1 PIN_FLD_START_T TSTAMP [0] (1065785673) Fri Oct 10 04:34:33 2003 1 PIN_FLD_END_T TSTAMP [0] (1065785683) Fri Oct 10 04:34:43 2003 1 PIN_FLD_SERVICE_OBJ POID [0] 0.0.0.1 /service/ip 11907 1 1 PIN_FLD_SYS_DESCR STR [0] "Session: generic" 1 PIN_FLD_RUM_NAME STR [0] "Duration" 1 PIN_FLD_UNIT ENUM [0] 1 1 PIN_FLD_TOD_MODE ENUM [0] 2 1 PIN_FLD_NET_QUANTITY DECIMAL [0] 60.000000000000000 1 PIN_FLD_MIN_QUANTITY DECIMAL [0] 60.000000000000000 1 PIN_FLD_INCR_QUANTITY DECIMAL [0] 60.000000000000000 1 PIN_FLD_MIN_UNIT ENUM [0] 2 1 PIN_FLD_INCR_UNIT ENUM [0] 2 1 PIN_FLD_ROUNDING_MODE ENUM [0] 1 1 PIN_FLD_TIMEZONE_MODE ENUM [0] 1 1 PIN_FLD_RATED_TIMEZONE_ID STR [0] "GMT-08:00" 1 PIN_FLD_TIMEZONE_ADJ_START_T TSTAMP [0] (1065760473) Thu Oct 09 21:34:33 2003 1 PIN_FLD_TIMEZONE_ADJ_END_T TSTAMP [0] (1065760483) Thu Oct 09 21:34:43 2003 1 PIN_FLD_TOTAL ARRAY [840] allocated 20, used 1 2 PIN_FLD_AMOUNT DECIMAL [0] 0.0166667 1 PIN_FLD_BAL_IMPACTS ARRAY [0] allocated 20, used 17 2 PIN_FLD_ACCOUNT_OBJ POID [0] 0.0.0.1 /account 10243 13 2 PIN_FLD_AMOUNT DECIMAL [0] 0.0166667 2 PIN_FLD_RESOURCE_ID INT [0] 840 2 PIN_FLD_PRODUCT_OBJ POID [0] 0.0.0.1 /product 10030 0 2 PIN_FLD_RATE_OBJ POID [0] 0.0.0.1 /rate 9390 1 2 PIN_FLD_DISCOUNT DECIMAL [0] 0 2 PIN_FLD_AMOUNT_DEFERRED DECIMAL [0] 0 2 PIN_FLD_GL_ID INT [0] 104 2 PIN_FLD_IMPACT_TYPE ENUM [0] 1 2 PIN_FLD_QUANTITY DECIMAL [0] 60.00000000 2 PIN_FLD_RATE_TAG STR [0] "$1 per hour" 2 PIN_FLD_TAX_CODE STR [0] "" 2 PIN_FLD_IMPACT_CATEGORY STR [0] "default" 2 PIN_FLD_PACKAGE_ID INT [0] 20030910 2 PIN_FLD_LINEAGE STR [0] "" 2 PIN_FLD_PERCENT DECIMAL [0] 1 2 PIN_FLD_BAL_GRP_OBJ POID [0] 0.0.0.1 /balance_group 8323 4 1 PIN_FLD_UNRATED_QUANTITY DECIMAL [0] 0 0 PIN_FLD_DISCOUNTS ARRAY [0] allocated 20, used 8 1 PIN_FLD_ACCOUNT_OBJ POID [0] 0.0.0.1 /account 10243 0 1 PIN_FLD_OWNER_OBJ POID [0] 0.0.0.1 /service/ip 11907 1 1 PIN_FLD_BAL_GRP_OBJ POID [0] 0.0.0.1 /balance_group 8323 4 1 PIN_FLD_DISCOUNT_LIST ARRAY [0] allocated 20, used 19 2 PIN_FLD_CREATED_T TSTAMP [0] (1063218065) Wed Sep 10 11:21:05 2003 2 PIN_FLD_CYCLE_END_T TSTAMP [0] (0) <null> 2 PIN_FLD_CYCLE_START_T TSTAMP [0] (1052871608) Tue May 13 17:20:08 2003 2 PIN_FLD_DEAL_OBJ POID [0] 0.0.0.0 0 0 2 PIN_FLD_DESCR STR [0] "" 2 PIN_FLD_DISCOUNT_OBJ POID [0] 0.0.0.1 /discount 8273 0 2 PIN_FLD_LAST_MODIFIED_T TSTAMP [0] (1063218065) Wed Sep 10 11:21:05 2003 2 PIN_FLD_PACKAGE_ID INT [0] 12222 2 PIN_FLD_PLAN_OBJ POID [0] 0.0.0.0 0 0 2 PIN_FLD_PURCHASE_END_T TSTAMP [0] (0) <null> 2 PIN_FLD_PURCHASE_START_T TSTAMP [0] (1052871608) Tue May 13 17:20:08 2003 2 PIN_FLD_QUANTITY DECIMAL [0] 1 2 PIN_FLD_SERVICE_OBJ POID [0] 0.0.0.0 0 0 2 PIN_FLD_STATUS ENUM [0] 1 2 PIN_FLD_STATUS_FLAGS INT [0] 1 2 PIN_FLD_USAGE_END_T TSTAMP [0] (0) <null> 2 PIN_FLD_USAGE_START_T TSTAMP [0] (1052871608) Tue May 13 17:20:08 2003 2 PIN_FLD_FLAGS INT [0] 1 2 PIN_FLD_TYPE ENUM [0] 602 1 PIN_FLD_DISCOUNT_LIST ARRAY [1] allocated 20, used 19 2 PIN_FLD_CREATED_T TSTAMP [0] (1063218065) Wed Sep 10 11:21:05 2003 2 PIN_FLD_CYCLE_END_T TSTAMP [0] (1071385462) Sat Dec 13 23:04:22 2003 2 PIN_FLD_CYCLE_START_T TSTAMP [0] (1052895862) Wed May 14 00:04:22 2003 2 PIN_FLD_DEAL_OBJ POID [0] 0.0.0.0 0 0 2 PIN_FLD_DESCR STR [0] "" 2 PIN_FLD_DISCOUNT_OBJ POID [0] 0.0.0.1 /discount 11345 0 2 PIN_FLD_LAST_MODIFIED_T TSTAMP [0] (1063218065) Wed Sep 10 11:21:05 2003 2 PIN_FLD_PACKAGE_ID INT [0] 22222 2 PIN_FLD_PLAN_OBJ POID [0] 0.0.0.0 0 0 2 PIN_FLD_PURCHASE_END_T TSTAMP [0] (1068793462) Thu Nov 13 23:04:22 2003 2 PIN_FLD_PURCHASE_START_T TSTAMP [0] (1052871608) Tue May 13 17:20:08 2003 2 PIN_FLD_QUANTITY DECIMAL [0] 1 2 PIN_FLD_SERVICE_OBJ POID [0] 0.0.0.1 /service/ip 11907 1 2 PIN_FLD_STATUS ENUM [0] 1 2 PIN_FLD_STATUS_FLAGS INT [0] 1 2 PIN_FLD_USAGE_END_T TSTAMP [0] (1068793462) Thu Nov 13 23:04:22 2003 2 PIN_FLD_USAGE_START_T TSTAMP [0] (1052871608) Tue May 13 17:20:08 2003 2 PIN_FLD_FLAGS INT [0] 1 2 PIN_FLD_TYPE ENUM [0] 602 1 PIN_FLD_DISCOUNT_LIST ARRAY [2] allocated 28, used 28 2 PIN_FLD_POID POID [0] 0.0.0.1 /discount 8219 1 2 PIN_FLD_CREATED_T TSTAMP [0] (1064333980) Tue Sep 23 09:19:40 2003 2 PIN_FLD_MOD_T TSTAMP [0] (1061399955) Wed Aug 20 10:19:15 2003 2 PIN_FLD_READ_ACCESS STR [0] "B" 2 PIN_FLD_WRITE_ACCESS STR [0] "S" 2 PIN_FLD_ACCOUNT_OBJ POID [0] 0.0.0.1 /account 1 1 2 PIN_FLD_DESCR STR [0] "" 2 PIN_FLD_END_T TSTAMP [0] (1069333980) Thu Nov 20 05:13:00 2003 2 PIN_FLD_MODE ENUM [0] 801 2 PIN_FLD_NAME STR [0] "System discount 1" 2 PIN_FLD_OWN_MAX DECIMAL [0] 0 2 PIN_FLD_OWN_MIN DECIMAL [0] 0 2 PIN_FLD_PERMITTED STR [0] "" 2 PIN_FLD_PRIORITY DECIMAL [0] 1 2 PIN_FLD_PURCHASE_MAX DECIMAL [0] 0 2 PIN_FLD_PURCHASE_MIN DECIMAL [0] 0 2 PIN_FLD_START_T TSTAMP [0] (1061399955) Wed Aug 20 10:19:15 2003 2 PIN_FLD_TYPE ENUM [0] 603 2 PIN_FLD_USAGE_MAP ARRAY [0] allocated 20, used 4 3 PIN_FLD_DISCOUNT_MODEL STR [0] "DMStandard" 3 PIN_FLD_EVENT_TYPE STR [0] "/event" 3 PIN_FLD_FLAGS INT [0] 0 3 PIN_FLD_SNOWBALL_FLAG INT [0] 0 2 PIN_FLD_DISCOUNT_OBJ POID [0] 0.0.0.1 /discount 8219 1 2 PIN_FLD_SERVICE_OBJ POID [0] NULL poid pointer 2 PIN_FLD_PACKAGE_ID INT [0] 2 PIN_FLD_PURCHASE_START_T TSTAMP [0] (1061399955) Wed Aug 20 10:19:15 2003 2 PIN_FLD_USAGE_START_T TSTAMP [0] (1061399955) Wed Aug 20 10:19:15 2003 2 PIN_FLD_PURCHASE_END_T TSTAMP [0] (1069333980) Thu Nov 20 05:13:00 2003 2 PIN_FLD_USAGE_END_T TSTAMP [0] (1069333980) Thu Nov 20 05:13:00 2003 2 PIN_FLD_STATUS ENUM [0] 1 2 PIN_FLD_FLAGS INT [0] 1 1 PIN_FLD_DISCOUNT_LIST ARRAY [3] allocated 28, used 28 2 PIN_FLD_POID POID [0] 0.0.0.1 /discount 9755 1 2 PIN_FLD_CREATED_T TSTAMP [0] (1064334036) Tue Sep 23 09:20:36 2003 2 PIN_FLD_MOD_T TSTAMP [0] (1061399955) Wed Aug 20 10:19:15 2003 2 PIN_FLD_READ_ACCESS STR [0] "B" 2 PIN_FLD_WRITE_ACCESS STR [0] "S" 2 PIN_FLD_ACCOUNT_OBJ POID [0] 0.0.0.1 /account 1 1 2 PIN_FLD_DESCR STR [0] "" 2 PIN_FLD_END_T TSTAMP [0] (1069334036) Thu Nov 20 05:13:56 2003 2 PIN_FLD_MODE ENUM [0] 801 2 PIN_FLD_NAME STR [0] "Sys discount 3" 2 PIN_FLD_OWN_MAX DECIMAL [0] 0 2 PIN_FLD_OWN_MIN DECIMAL [0] 0 2 PIN_FLD_PERMITTED STR [0] "" 2 PIN_FLD_PRIORITY DECIMAL [0] 14 2 PIN_FLD_PURCHASE_MAX DECIMAL [0] 0 2 PIN_FLD_PURCHASE_MIN DECIMAL [0] 0 2 PIN_FLD_START_T TSTAMP [0] (1061399955) Wed Aug 20 10:19:15 2003 2 PIN_FLD_TYPE ENUM [0] 603 2 PIN_FLD_USAGE_MAP ARRAY [0] allocated 20, used 4 3 PIN_FLD_DISCOUNT_MODEL STR [0] "DMStandard" 3 PIN_FLD_EVENT_TYPE STR [0] "/event/session" 3 PIN_FLD_FLAGS INT [0] 1 3 PIN_FLD_SNOWBALL_FLAG INT [0] 0 2 PIN_FLD_DISCOUNT_OBJ POID [0] 0.0.0.1 /discount 9755 1 2 PIN_FLD_SERVICE_OBJ POID [0] NULL poid pointer 2 PIN_FLD_PACKAGE_ID INT [0] 2 PIN_FLD_PURCHASE_START_T TSTAMP [0] (1061399955) Wed Aug 20 10:19:15 2003 2 PIN_FLD_USAGE_START_T TSTAMP [0] (1061399955) Wed Aug 20 10:19:15 2003 2 PIN_FLD_PURCHASE_END_T TSTAMP [0] (1069334036) Thu Nov 20 05:13:56 2003 2 PIN_FLD_USAGE_END_T TSTAMP [0] (1069334036) Thu Nov 20 05:13:56 2003 2 PIN_FLD_STATUS ENUM [0] 1 2 PIN_FLD_FLAGS INT [0] 1 1 PIN_FLD_DISCOUNT_LIST ARRAY [4] allocated 28, used 28 2 PIN_FLD_POID POID [0] 0.0.0.1 /discount 11291 1 2 PIN_FLD_CREATED_T TSTAMP [0] (1064334029) Tue Sep 23 09:20:29 2003 2 PIN_FLD_MOD_T TSTAMP [0] (1061399955) Wed Aug 20 10:19:15 2003 2 PIN_FLD_READ_ACCESS STR [0] "B" 2 PIN_FLD_WRITE_ACCESS STR [0] "S" 2 PIN_FLD_ACCOUNT_OBJ POID [0] 0.0.0.1 /account 1 1 2 PIN_FLD_DESCR STR [0] "" 2 PIN_FLD_END_T TSTAMP [0] (1069334029) Thu Nov 20 05:13:49 2003 2 PIN_FLD_MODE ENUM [0] 801 2 PIN_FLD_NAME STR [0] "Sys discount 2" 2 PIN_FLD_OWN_MAX DECIMAL [0] 0 2 PIN_FLD_OWN_MIN DECIMAL [0] 0 2 PIN_FLD_PERMITTED STR [0] "" 2 PIN_FLD_PRIORITY DECIMAL [0] 200 2 PIN_FLD_PURCHASE_MAX DECIMAL [0] 0 2 PIN_FLD_PURCHASE_MIN DECIMAL [0] 0 2 PIN_FLD_START_T TSTAMP [0] (1061399955) Wed Aug 20 10:19:15 2003 2 PIN_FLD_TYPE ENUM [0] 603 2 PIN_FLD_USAGE_MAP ARRAY [0] allocated 20, used 4 3 PIN_FLD_DISCOUNT_MODEL STR [0] "DMStandard" 3 PIN_FLD_EVENT_TYPE STR [0] "/event/session" 3 PIN_FLD_FLAGS INT [0] 1 3 PIN_FLD_SNOWBALL_FLAG INT [0] 0 2 PIN_FLD_DISCOUNT_OBJ POID [0] 0.0.0.1 /discount 11291 1 2 PIN_FLD_SERVICE_OBJ POID [0] NULL poid pointer 2 PIN_FLD_PACKAGE_ID STR [0] 2 PIN_FLD_PURCHASE_START_T TSTAMP [0] (1061399955) Wed Aug 20 10:19:15 2003 2 PIN_FLD_USAGE_START_T TSTAMP [0] (1061399955) Wed Aug 20 10:19:15 2003 2 PIN_FLD_PURCHASE_END_T TSTAMP [0] (1069334029) Thu Nov 20 05:13:49 2003 2 PIN_FLD_USAGE_END_T TSTAMP [0] (1069334029) Thu Nov 20 05:13:49 2003 2 PIN_FLD_STATUS ENUM [0] 1 2 PIN_FLD_FLAGS INT [0] 1 0 PIN_FLD_BAL_INFO ARRAY [0] allocated 20, used 3 1 PIN_FLD_BAL_GRP_OBJ POID [0] 0.0.0.1 /balance_group 8323 4 1 PIN_FLD_BALANCES ARRAY [840] allocated 11, used 6 2 PIN_FLD_NEXT_BAL DECIMAL [0] 0 2 PIN_FLD_RESERVED_AMOUNT DECIMAL [0] 0 2 PIN_FLD_CURRENT_BAL DECIMAL [0] 19.590836 2 PIN_FLD_CREDIT_LIMIT DECIMAL [0] 100 2 PIN_FLD_CREDIT_FLOOR DECIMAL [0] 0 2 PIN_FLD_CREDIT_THRESHOLDS INT [0] 0 1 PIN_FLD_BALANCES ARRAY [1000001] allocated 7, used 6 2 PIN_FLD_NEXT_BAL DECIMAL [0] 0 2 PIN_FLD_RESERVED_AMOUNT DECIMAL [0] 0 2 PIN_FLD_CURRENT_BAL DECIMAL [0] 0 2 PIN_FLD_CREDIT_LIMIT DECIMAL [0] 100 2 PIN_FLD_CREDIT_FLOOR DECIMAL [0] 0 2 PIN_FLD_CREDIT_THRESHOLDS INT [0] 0 0 PIN_FLD_INHERITED_INFO SUBSTRUCT [0] allocated 32, used 32 1 PIN_FLD_POID POID [0] 0.0.0.1 /account 10243 13 1 PIN_FLD_MOD_T TSTAMP [0] (1063218065) Wed Sep 10 11:21:05 2003 1 PIN_FLD_ACCOUNT_NO STR [0] "0.0.0.1-10243" 1 PIN_FLD_BRAND_OBJ POID [0] 0.0.0.1 /account 1 0 1 PIN_FLD_TIMEZONE_ID STR [0] "" 1 PIN_FLD_STATUS ENUM [0] 10100 1 PIN_FLD_STATUS_FLAGS INT [0] 0 1 PIN_FLD_CURRENCY INT [0] 840 1 PIN_FLD_CURRENCY_SECONDARY INT [0] 0 1 PIN_FLD_GROUP_OBJ POID [0] 0.0.0.0 0 0 1 PIN_FLD_CLOSE_WHEN_T TSTAMP [0] (0) <null> 1 PIN_FLD_ITEM_POID_LIST STR [0] "0.0.0.1|/item/misc 8835 0" 1 PIN_FLD_NEXT_ITEM_POID_LIST STR [0] "" 1 PIN_FLD_ACTG_TYPE ENUM [0] 2 1 PIN_FLD_LAST_STATUS_T TSTAMP [0] (1063217469) Wed Sep 10 11:11:09 2003 1 PIN_FLD_GL_SEGMENT STR [0] "." 1 PIN_FLD_BILL_WHEN INT [0] 1 1 PIN_FLD_PAY_TYPE ENUM [0] 10001 1 PIN_FLD_AR_BILLINFO_OBJ POID [0] 0.0.0.1 /billinfo 8451 0 1 PIN_FLD_NEXT_BILL_OBJ POID [0] 0.0.0.0 0 0 1 PIN_FLD_NEXT_BILL_T TSTAMP [0] (1065769200) Fri Oct 10 00:00:00 2003 1 PIN_FLD_LAST_BILL_T TSTAMP [0] (1063217469) Wed Sep 10 11:11:09 2003 1 PIN_FLD_ACTG_LAST_T TSTAMP [0] (1063217469) Wed Sep 10 11:11:09 2003 1 PIN_FLD_ACTG_FUTURE_T TSTAMP [0] (1068451200) Mon Nov 10 00:00:00 2003 1 PIN_FLD_BILL_ACTGCYCLES_LEFT INT [0] 1 1 PIN_FLD_PAYINFO_OBJ POID [0] 0.0.0.1 /payinfo/invoice 11267 0 1 PIN_FLD_ACTG_NEXT_T TSTAMP [0] (1065769200) Fri Oct 10 00:00:00 2003 1 PIN_FLD_LAST_BILL_OBJ POID [0] 0.0.0.0 0 0 1 PIN_FLD_BILL_OBJ POID [0] 0.0.0.1 /bill 10499 0 1 PIN_FLD_PENDING_RECV DECIMAL [0] 0 1 PIN_FLD_BAL_GRP_OBJ POID [0] 0.0.0.1 /balance_group 8323 4 1 PIN_FLD_SERVICE_INFO SUBSTRUCT [0] allocated 51, used 26 2 PIN_FLD_POID POID [0] 0.0.0.1 /service/ip 11907 5 2 PIN_FLD_CREATED_T TSTAMP [0] (1063217471) Wed Sep 10 11:11:11 2003 2 PIN_FLD_MOD_T TSTAMP [0] (1063217473) Wed Sep 10 11:11:13 2003 2 PIN_FLD_READ_ACCESS STR [0] "L" 2 PIN_FLD_WRITE_ACCESS STR [0] "L" 2 PIN_FLD_AAC_ACCESS STR [0] "" 2 PIN_FLD_AAC_PACKAGE STR [0] "" 2 PIN_FLD_AAC_PROMO_CODE STR [0] "" 2 PIN_FLD_AAC_SERIAL_NUM STR [0] "" 2 PIN_FLD_AAC_SOURCE STR [0] "" 2 PIN_FLD_AAC_VENDOR STR [0] "" 2 PIN_FLD_ACCOUNT_OBJ POID [0] 0.0.0.1 /account 10243 0 2 PIN_FLD_CLOSE_WHEN_T TSTAMP [0] (0) <null> 2 PIN_FLD_EFFECTIVE_T TSTAMP [0] (1063217469) Wed Sep 10 11:11:09 2003 2 PIN_FLD_ITEM_POID_LIST STR [0] "0.0.0.1|/item/cycle_forward 11651 0" 2 PIN_FLD_LASTSTAT_CMNT STR [0] "" 2 PIN_FLD_LAST_STATUS_T TSTAMP [0] (1063217469) Wed Sep 10 11:11:09 2003 2 PIN_FLD_LOGIN STR [0] "00491732411" 2 PIN_FLD_NAME STR [0] "PIN Service Object" 2 PIN_FLD_NEXT_ITEM_POID_LIST STR [0] "" 2 PIN_FLD_PASSWD STR [0] "clear|00491732411" 2 PIN_FLD_PROFILE_OBJ POID [0] 0.0.0.0 0 0 2 PIN_FLD_STATUS ENUM [0] 10100 2 PIN_FLD_STATUS_FLAGS INT [0] 0 2 PIN_FLD_SERVICE_IP SUBSTRUCT [0] allocated 20, used 3 3 PIN_FLD_COMPRESSION ENUM [0] 0 3 PIN_FLD_IPADDR BINSTR [0] 1 00 3 PIN_FLD_PROTOCOL ENUM [0] 0 2 PIN_FLD_BAL_GRP_OBJ POID [0] 0.0.0.1 /balance_group 8323 4
Sample Fields Required by Pipeline Manager
The following are sample fields, in flist format, required by Pipeline Manager when the event type is /event/session:
Important:
You cannot trim the default fields for the PIN_FLD_INHERITED_INFO substruct listed in "Sample Unmodified Flist". However, you can specify additional /account and /service fields. In the text below, the /account field PIN_FLD_RESIDENCE_FLAG is specified at the end of the list. It is added to the default PIN_FLD_INHERITED_INFO fields sent to Pipeline Manager.0 PIN_FLD_POID POID [0] 0.0.0.1 /event/session -1 0 0 PIN_FLD_EVENT SUBSTRUCT [0] allocated 25, used 25 1 PIN_FLD_POID POID [0] 0.0.0.1 /event/session -1 0 1 PIN_FLD_START_T TSTAMP [0] (1065785673) Fri Oct 10 04:34:33 2003 1 PIN_FLD_END_T TSTAMP [0] (1065785683) Fri Oct 10 04:34:43 2003 1 PIN_FLD_BAL_IMPACTS ARRAY [0] allocated 20, used 17 and other array elements 2 PIN_FLD_AMOUNT DECIMAL [0] 0.0166667 2 PIN_FLD_AMOUNT_DEFERRED DECIMAL [0] 0 2 PIN_FLD_RESOURCE_ID INT [0] 840 2 PIN_FLD_GL_ID INT [0] 104 2 PIN_FLD_IMPACT_TYPE ENUM [0] 1 2 PIN_FLD_QUANTITY DECIMAL [0] 60.00000000 2 PIN_FLD_RATE_TAG STR [0] "$1 per hour" 2 PIN_FLD_TAX_CODE STR [0] "" 0 PIN_FLD_DISCOUNTS ARRAY [0] allocated 20, used 8 and other array elements 1 PIN_FLD_ACCOUNT_OBJ POID [0] 0.0.0.1 /account 10243 0 1 PIN_FLD_OWNER_OBJ POID [0] 0.0.0.1 /service/ip 11907 1 1 PIN_FLD_BAL_GRP_OBJ POID [0] 0.0.0.1 /balance_group 8323 4 1 PIN_FLD_DISCOUNT_LIST ARRAY [0] allocated 20, used 19 and other array elements 2 PIN_FLD_DISCOUNT_OBJ POID [0] 0.0.0.1 /discount 8273 0 2 PIN_FLD_PACKAGE_ID INT [0] 12222 2 PIN_FLD_PURCHASE_END_T TSTAMP [0] (0) <null> 2 PIN_FLD_PURCHASE_START_T TSTAMP [0] (1052871608) Tue May 13 17:20:08 2003 2 PIN_FLD_QUANTITY DECIMAL [0] 1 2 PIN_FLD_STATUS ENUM [0] 1 2 PIN_FLD_USAGE_END_T TSTAMP [0] (0) <null> 2 PIN_FLD_USAGE_START_T TSTAMP [0] (1052871608) Tue May 13 17:20:08 2003 2 PIN_FLD_FLAGS INT [0] 1 2 PIN_FLD_TYPE ENUM [0] 602 0 PIN_FLD_BAL_INFO ARRAY [0] allocated 20, used 3 and other array elements 1 PIN_FLD_BAL_GRP_OBJ POID [0] 0.0.0.1 /balance_group 8323 4 1 PIN_FLD_BALANCES ARRAY [840] allocated 11, used 6 and other array elements 2 PIN_FLD_CURRENT_BAL DECIMAL [0] 19.590836 1 PIN_FLD_BALANCES ARRAY [1000001] allocated 7, used 6 and other array elements 2 PIN_FLD_CURRENT_BAL DECIMAL [0] 0 0 PIN_FLD_INHERITED_INFO SUBSTRUCT [0] allocated 32, used 32 1 PIN_FLD_RESIDENCE_FLAG ENUM [0] 1
A different set of fields is required when the event type is /event/session/ (including the final forward slash), and another set of fields is sent for any other type of event.
To implement the trimmed flist in the example, create the following XML file (sample.xml). When this XML file is loaded with load_pin_rtp_trim_flist, the flist sent to Pipeline Manager is constructed as follows:
-
If the event type is exactly /event/session, the PIN_FLD_RESIDENCE_FLAG field is included with the trimmed flist as shown in the flist sample above.
-
If the event type starts with /event/session/ (including the last forward slash), the PIN_FLD_RESIDENCE_FLAG field is not included with the trimmed flist.
-
If the event type is any other value (which matches the section specified by Type value * with Flags value 1), then neither the PIN_FLD_RESIDENCE_FLAG field nor the PIN_FLD_BAL_IMPACTS array is included with the trimmed flist.
Important:
You cannot trim the default fields for the PIN_FLD_INHERITED_INFO substruct listed in "Sample Unmodified Flist". However, you can specify additional /account and /service fields. In the text below, the /account field PIN_FLD_RESIDENCE_FLAG is specified at the end of the list. It is added to the default PIN_FLD_INHERITED_INFO fields sent to Pipeline Manager.
sample.xml File
<?xml version="1.0" encoding="UTF-8" ?>
<!--
================================================================
Copyright (c) 2004 Portal Software, Inc. All rights reserved.
This material is the confidential property of Portal Software, Inc.
or its Subsidiaries or licensors and may be used, reproduced, stored
or transmitted only in accordance with a valid Portal license or
sublicense agreement.
================================================================
-->
<RTPTrimFlistConfiguration xmlns="http://www.portal.com/InfranetXMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.portal.com/InfranetXMLSchema pin_config_rtp_trim_flist.xsd">
<EventMapList>
<EventMap>
<!-- Section which specifies fields sent when the event type is exactly /event/session -->
<Event>
<Type>/event/session</Type>
<Flags>0</Flags>
</Event>
<RequiredField>
<Name>PIN_FLD_POID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_EVENT</Name>
<RequiredField>
<Name>PIN_FLD_POID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_START_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_END_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_BAL_IMPACTS</Name>
<RequiredField>
<Name>PIN_FLD_AMOUNT</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_AMOUNT_DEFERRED</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_RESOURCE_ID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_GL_ID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_IMPACT_TYPE</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_QUANTITY</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_RATE_TAG</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_TAX_CODE</Name>
</RequiredField>
</RequiredField>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_DISCOUNTS</Name>
<RequiredField>
<Name>PIN_FLD_ACCOUNT_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_OWNER_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_BAL_GRP_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_DISCOUNT_LIST</Name>
<RequiredField>
<Name>PIN_FLD_DISCOUNT_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_PACKAGE_ID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_PURCHASE_END_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_PURCHASE_START_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_QUANTITY</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_STATUS</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_USAGE_END_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_USAGE_START_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_FLAGS</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_TYPE</Name>
</RequiredField>
</RequiredField>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_BAL_INFO</Name>
<RequiredField>
<Name>PIN_FLD_BAL_GRP_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_BALANCES</Name>
<RequiredField>
<Name>PIN_FLD_CURRENT_BAL</Name>
</RequiredField>
</RequiredField>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_INHERITED_INFO</Name>
<RequiredField>
<Name>PIN_FLD_RESIDENCE_FLAG</Name>
</RequiredField>
</RequiredField>
</EventMap>
<!-- Section which specifies fields sent when the event type starts with /event/session/ -->
</EventMap>
<Event>
<Type>/event/session/</Type>
<Flags>1</Flags>
</Event>
<RequiredField>
<Name>PIN_FLD_POID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_EVENT</Name>
<RequiredField>
<Name>PIN_FLD_POID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_START_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_END_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_BAL_IMPACTS</Name>
<RequiredField>
<Name>PIN_FLD_AMOUNT</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_RESOURCE_ID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_GL_ID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_IMPACT_TYPE</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_QUANTITY</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_RATE_TAG</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_TAX_CODE</Name>
</RequiredField>
</RequiredField>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_DISCOUNTS</Name>
<RequiredField>
<Name>PIN_FLD_ACCOUNT_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_OWNER_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_BAL_GRP_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_DISCOUNT_LIST</Name>
<RequiredField>
<Name>PIN_FLD_DISCOUNT_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_PACKAGE_ID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_PURCHASE_END_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_PURCHASE_START_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_QUANTITY</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_STATUS</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_USAGE_END_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_USAGE_START_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_FLAGS</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_TYPE</Name>
</RequiredField>
</RequiredField>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_BAL_INFO</Name>
<RequiredField>
<Name>PIN_FLD_BAL_GRP_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_BALANCES</Name>
<RequiredField>
<Name>PIN_FLD_CURRENT_BAL</Name>
</RequiredField>
</RequiredField>
</RequiredField>
</EventMap>
<!--* Section which specifies fields sent when the event type is
* any other value.-->
<EventMap>
<Event>
<Type>*</Type>
<Flags>1</Flags>
</Event>
<RequiredField>
<Name>PIN_FLD_POID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_EVENT</Name>
<RequiredField>
<Name>PIN_FLD_POID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_START_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_END_T</Name>
</RequiredField>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_DISCOUNTS</Name>
<RequiredField>
<Name>PIN_FLD_ACCOUNT_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_OWNER_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_BAL_GRP_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_DISCOUNT_LIST</Name>
<RequiredField>
<Name>PIN_FLD_DISCOUNT_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_PACKAGE_ID</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_PURCHASE_END_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_PURCHASE_START_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_QUANTITY</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_STATUS</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_USAGE_END_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_USAGE_START_T</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_FLAGS</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_TYPE</Name>
</RequiredField>
</RequiredField>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_BAL_INFO</Name>
<RequiredField>
<Name>PIN_FLD_BAL_GRP_OBJ</Name>
</RequiredField>
<RequiredField>
<Name>PIN_FLD_BALANCES</Name>
<RequiredField>
<Name>PIN_FLD_CURRENT_BAL</Name>
</RequiredField>
</RequiredField>
</RequiredField>
</EventMap>
</EventMapList>
</RTPTrimFlistConfiguration>
Measuring System Latencies with Instrumentation
You use the Pipeline Manager instrumentation feature to determine how much processing time each Pipeline Manager component (function modules, iScripts, and iRules) is consuming in microseconds. This information enables you to:
-
Determine system benchmarks.
-
Identify performance bottlenecks at the function module level.
-
Add or reconfigure function pools to optimize CPU utilization.
Instrumentation collects statistics for the following components:
-
The input module.
-
Each function module.
-
The output module.
After each transaction, the statistics for each pipeline tested are written to the pipeline.log file.
Using Instrumentation to Collect Module Performance Statistics
To enable instrumentation:
-
Start the pipeline.
-
Send a signal to the pipeline to toggle instrumentation on and off. Use the following commands to toggle the instrumentation state:
Solaris, Linux, and AIX:
kill -s USR1 ifw_process_pid
HP-UX IA64:
kill -USR1 ifw_process_pid
AIX:
kill -s USR1 ifw_process_pid
At the end of each transaction, the statistics are logged to the pipeline.log file and the statistics counters are reset.
Note:
By default, Pipeline Manager instrumentation is disabled on startup. When Pipeline Manager is running, you can toggle between the disabled and enabled modes.Important:
Pipeline Manager begins gathering statistics immediately after receiving the signal. To assure accurate measurements, be sure that Pipeline Manager is not processing transactions when the signal is sent. -
Process a sample CDR file.
-
Check the pipeline log files for processing time statistics. See "Viewing Instrumentation Testing Results" for more information.
-
When testing is complete, stop the instrumentation process by sending another signal. See step 2.
Viewing Instrumentation Testing Results
Each log file record consists of the fully qualified module name and the accumulated processing time spent in the module.
Note:
Pipeline processing time statistics are not cumulative. The output module writes data to a file whereas a function module processes EDRs in a different thread.Sample Log File
The following sample log file shows instrumentation data:
15.03.2004 13:25:07 test ifw IFW NORMAL 00516 - (ifw.Pipelines.ALL_RATE.Functions.PreProcessing) Plugin processing time statistics: 'ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.APNMap .Module, 7676390 ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.CustomerRating.Module, 22629863 ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.CustomerSearch.Module, 239523272 ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.EventDiscarding.Module, 19874050 ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.PreRatingZone.Module, 18751824 ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.PreRecycle.Module, 1916139 ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.PrefixDesc.Module, 8001348 ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.ServiceCodeMap.Module, 4543899 ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.UsageClassMap.Module, 6083775 ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.UsageScenarioMap.Module, 9786078 ifw.Pipelines.ALL_RATE.Functions.PreProcessing.FunctionPool.UsageType.Module, 57114053 ' 15.03.2004 13:25:07 test ifw IFW NORMAL 00516 - (ifw.Pipelines.ALL_RATE.Functions.Rating) Plugin processing time statistics: 'ifw.Pipelines.ALL_RATE.Functions.Rating.FunctionPool.AddInfranetBillingRe cord.Module, 44927730 ifw.Pipelines.ALL_RATE.Functions.Rating.FunctionPool.MainRating.Module, 78250224 ifw.Pipelines.ALL_RATE.Functions.Rating.FunctionPool.RateAdjustment.Module, 2358093 ifw.Pipelines.ALL_RATE.Functions.Rating.FunctionPool.Recycle.Module, 1225628 ifw.Pipelines.ALL_RATE.Functions.Rating.FunctionPool.Rejection.Module, 1785748 ifw.Pipelines.ALL_RATE.Functions.Rating.FunctionPool.ServiceOutputSplit.Module, 6480466 ifw.Pipelines.ALL_RATE.Functions.Rating.FunctionPool.SpecialDayRate.Module, 8109825 ' 15.03.2004 13:25:07 test ifw IFW NORMAL 00516 - (ifw.Pipelines.ALL_RATE.Output.OutputCollection) Plugin processing time statistics: 'ifw.Pipelines.ALL_RATE.Output.OutputCollection.DevNull.Module, 67 ifw.Pipelines.ALL_RATE.Output.OutputCollection.DuplicateOutput.Module, 23 ifw.Pipelines.ALL_RATE.Output.OutputCollection.FAXOutput.Module, 561 ifw.Pipelines.ALL_RATE.Output.OutputCollection.GPRSOutput.Module, 728 ifw.Pipelines.ALL_RATE.Output.OutputCollection.RejectOutput.Module, 30 ifw.Pipelines.ALL_RATE.Output.OutputCollection.SMSOutput.Module, 552 ifw.Pipelines.ALL_RATE.Output.OutputCollection.TELOutput.Module, 178434585 ifw.Pipelines.ALL_RATE.Output.OutputCollection.WAPOutput.Module, 550 Note: To aggregate the counters into a nice report, please take a look at TracePerformanceReporting
Optimizing the DAT_USC_Map Module
The DAT_USC_Map module uses the Pipeline Manager framework component (FSM) to compile data mapping rules, which are stored in the database as regular expressions. The FSM compiles the data mapping structures only during Pipeline Manager startup because the rules can contain many comparisons of mapping patterns; this impacts startup performance. You can optimize the DAT_USC_Map module to enable Pipeline Manager to serialize the data structures and restore them from the serialized format.
About Precompiling USC Mapping Rules
Not all USC mapping data is stored in a compiled format: for example, rules used to define zone models. When the DAT_USC_Map module loads event data, it reorganizes it according to zone models to enable faster searching of the data structures during run time. This increases load time and memory requirements. To reduce the impact, you can configure Pipeline Manager to serialize the data structures the first time they are loaded and then reuse the serialized version during subsequent startup operations.
When Pipeline Manager begins processing data for a given zone model, it checks to see if a precompiled data file exists for that zone model. If so, it prepares the complex data structure by using the serialized format rather than by recompiling the structure from the USC map data.
If you enable the precompiling functionality, the following data is serialized:
-
USC group
-
Usage class and usage type
-
Service code and service class
-
Wholesale zone and retail zone
Note:
Data that is not in the precompiled format is read from the database or file system, depending on your DAT_USC_Map module configuration. See "DAT_USC_Map" in BRM Configuring Pipeline Rating and Discounting.
For more information, see "Precompiling Usage Scenario Mapping Data".
About Filtering Mapping Rules
You use USC groups to assemble the rules that define which services and service configurations are available to the pipeline; they contain the rules for mapping the service EDR attributes to each usage class.
You can configure your system to filter mapping rules based on USC groups so only the rules in the USC groups you specify are compiled and loaded into the DAT_USC_Map module. All other rules are ignored. This is more efficient than having one zone model that uses a large number of rules.
Note:
This is necessary only when your USC mapping rules are stored in the database; if they are read from a file, the data is already organized according to USC groups.Generally you define USC Groups to contain the mapping rules for a specific type of EDR processing. For example, say you rate telephony services and process EDRs by using three USC groups (GSM, SMS, and GPRS), each of which contains mapping rules to determine domestic standard charges, domestic roaming charges, and international charges.
To increase performance, you can define the mapping rules for each set of charges in a separate zone model. Then, when an EDR is processed, based on the USC group specified, only the rules used in those zone models are compiled and loaded. This increases startup performance.
For more information, see "Filtering the Mapping Data to Compile and Load".
For information on USC groups, see "About Usage Scenario Mapping" in BRM Setting Up Pricing and Rating.
Configuring the DAT_USC_Map Module for Startup Performance
You improve startup performance of the DAT_USC_Map module by:
-
Increasing the number of threads used to load mapping data.
-
Precompiling usage scenario mapping data.
-
Filtering the mapping data to compile and load.
You define these configurations in the Pipeline Manager registry file. For more information, see "About Configuring Pipeline Manager".
Increasing the Number of Threads Used to Load Mapping Data
The DAT_USC_Map module loads mapping rules for each zone model in a USC group by using a separate thread; therefore, it is only necessary to increase the number of threads when your USC groups contain multiple zone models.
To use multiple threads, set the NumberOfThreads registry entry to the desired number of threads. This enables Pipeline Manager to compile data in parallel and to restore it from the precompiled data files.
For example:
NumberOfThreads = 4
The default is 1.
Note:
You can use this entry as a semaphore.Precompiling Usage Scenario Mapping Data
To enable precompiling of USC mapping data, set the PreCompiledDataDir registry entry. This entry both enables the precompile functionality and defines the location of the compiled data files. By default, compiled data files are saved in the ./compiled_usc_data directory.
Pipeline Manager saves them with the following naming convention:
USCzoneModelID.pc
For example, GSM.pc, GSM_DOMESTIC.pc, and GSM_ROAMING.pc.
If this entry is set, compiled files are created the next time the pipeline starts. For each subsequent run, the data files are validated against the data structures in the database and, if necessary, recompiled and resaved to the file system.
Note:
You can use this entry as a semaphore.Filtering the Mapping Data to Compile and Load
If the source for your USC mapping rules is the database rather than a file, you can filter which rules are compiled and loaded into the DAT_USC_Map module when a pipeline starts by setting the UscGroupsregistry entry to one or more USC groups. For example:
UscGroups {GSM GSM_ROAMING}
Important:
You can specify only one USC group per each pipeline running in your system. If you use multiple USC groups, you must configure Pipeline Manager to run multiple pipeline instances. To do this, configure the Pipeline Manager registry file so the FCT_USC_Map in each pipeline instance refers to the appropriate DAT_USC_Map module reference and UscGroups entry. For more information, see "About Configuring Pipeline Manager".By default, all mapping rules are loaded into the pipeline. see "About Filtering Mapping Rules" for more information.
Note:
You can use this entry as a semaphore.Using Semaphores
You can use the new NumberOfThreads, PreCompiledDataDir, and UscGroups registry entries as semaphores to configure and control Pipeline Manager during pipeline startup. These semaphores perform the same tasks that the Reload semaphore performs, as specified in the startup registry or last-processed semaphore:
-
Load mapping data from the source (Database or File).
-
Create the USC zone model (from data in PreCompiledDataDir or USCMapFile).
-
Compile or precompile each USC zone model.
When you change the values of these semaphores after startup, they are not updated automatically in your system; you must use the Reload semaphore to update them during run time.
For example:
-
To use multiple threads to load data, edit the NumberOfThreads semaphore and then call the Reload semaphore. Each thread processes a different zone model when loading the USC data.
-
To reload USC data using a different set of files in the PreCompiledDataDir directory, edit the PreCompiledDataDir semaphore and then call the Reload semaphore.
-
To filter a different set of mapping rules, edit the UscGroups semaphore and then call the Reload semaphore.
For more information on the DAT_USC_Map semaphore entries, see "Semaphore File Entries" in BRM Configuring Pipeline Rating and Discounting.
Other Pipeline Manager Monitoring Tools
This section describes additional Pipeline Manager performance-monitoring tools.
Viewing the Pipeline Log
You can see the results of tests for each pipeline in that pipeline's pipeline.log file.
Tip:
Open each log file in a terminal windows and run tail -f on the logs.After each batch stream is processed, the pipeline writes the following information to the pipeline.log files:
-
The number of processed EDRs.
-
The number of errors that occurred during EDR processing.
-
The number of EDRs processed per second for a stream.
-
If instrumentation is on, the instrumentation results. See "Viewing Instrumentation Testing Results" for more information.
-
Let the system process a few files before you measure performance. This assures that any additional memory needed (for example, for the buffers) has been allocated.
-
Use the system monitor tool to monitor system utilization.
Configuring Buffer Size Polling
Use the QueueRequestTimeout Controller entry in the registry to specify the interval in seconds that each queue's fill status is written to the log. For example:
ifw
{
Active = TRUE
ProcessLoopTimeout = 10
QueueRequestTimeout = 10 # Optional, 0 disables
...
The default is 0 (no polling).
Buffer fill status information can indicate which function pool is the slowest. Over time, buffers in front of the slowest function pool fill up, and those that occur later in the stream are empty.
Note:
Instrumentation is the recommended tool for identifying the slowest function pool. See "Measuring System Latencies with Instrumentation".OS-Specific Pipeline Manager Monitoring Tools
This section describes OS-specific tools that you can use to monitor and maintain your Pipeline Manager system.
Solaris Monitoring Tools
This section describes Solaris monitoring tools.
Displaying Thread Details
To display details of the threads within a process, use the prstat command:
prstat -Lmv -p
Example output:
prstat -Lmv -p 22376 PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID 22376 integ 86 13 0.0 0.0 0.0 0.0 0.0 0.9 12 3K .1M 0 ifw/4 22376 integ 61 34 0.0 0.0 0.0 0.5 2.8 2.0 298 1K 64K 0 ifw/16 22376 integ 52 0.8 0.0 0.0 0.0 42 0.0 4.9 56 11K 11K 0 ifw/117 22376 integ 43 3.6 0.0 0.0 0.0 52 0.0 1.8 158 1K 7K 0 ifw/5 22376 integ 22 0.1 0.0 0.0 0.0 75 0.0 2.6 393 125 463 0 ifw/116 22376 integ 21 0.1 0.0 0.0 0.0 77 0.0 2.6 89 357 412 0 ifw/115 ... Total: 1 processes, 48 lwps, load averages: 4.18, 1.94, 2.38
In the pipeline process.log file, you can see when a thread is created, its name, and corresponding OS number:
09.12.2003 19:54:38 igscoll1 ifw IFW NORMAL 00000 - (ifw.ProcessLog.Module) Thread instance ID '2'; and Name 'ifw.ProcessLog.Module'. ... 09.12.2003 20:01:31 igscoll1 ifw IFW NORMAL 00000 - (ifw.Pipelines.GSM.Input) Thread instance ID '16'; and Name 'ifw.Pipelines.GSM.Input'. ... 09.12.2003 21:38:40 igscoll1 ifw IFW NORMAL 00000 - (ifw.Pipelines.GSM.Functions.PreProcessing2) Thread instance ID '135'; and Name 'ifw.Pipelines.GSM.Functions.PreProcessing2'. ...
HP-UX IA64 Monitoring Tools
Tools useful for monitoring Pipeline Manager on HP-UX IA64 systems include:
-
glance
-
sar -AM
-
top
-
vmstat
-
iostat
For more information on these and other tools, see the HP documentation.