The memcached client interface supports a number of different distribution algorithms that are used in multi-server configurations to determine which host should be used when setting or getting data from a given memcached instance. When you get or set a value, a hash is constructed from the supplied key and then used to select a host from the list of configured servers. Because the hashing mechanism uses the supplied key as the basis for the hash, the same server is selected during both set and get operations.
You can think of this process as follows. Given an array of servers (a, b, and c), the client uses a hashing algorithm that returns an integer based on the key being stored or retrieved. The resulting value is then used to select a server from the list of servers configured in the client. Most standard client hashing within memcache clients uses a simple modulus calculation on the value against the number of configured memcached servers. You can summarize the process in pseudocode as:
@memcservers = ['a.memc','b.memc','c.memc']; $value = hash($key); $chosen = $value % length(@memcservers);
Replacing the above with values:
@memcservers = ['a.memc','b.memc','c.memc'];
$value = hash('myid');
$chosen = 7009 % 3;
In the above example, the client hashing algorithm chooses the
server at index 1 (7009 % 3 = 1), and stores
or retrieves the key and value with that server.
This selection and hashing process is handled automatically by the memcached client you are using; you need only provide the list of memcached servers to use.
You can see a graphical representation of this below in Figure 16.3, “memcached Hash Selection”.
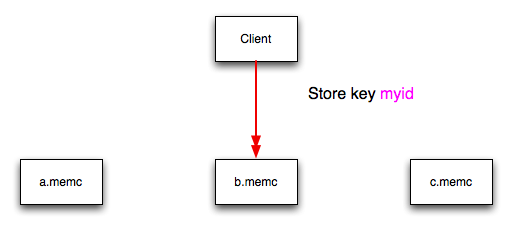
The same hashing and selection process takes place during any operation on the specified key within the memcached client.
Using this method provides a number of advantages:
The hashing and selection of the server to contact is handled entirely within the client. This eliminates the need to perform network communication to determine the right machine to contact.
Because the determination of the memcached server occurs entirely within the client, the server can be selected automatically regardless of the operation being executed (set, get, increment, etc.).
Because the determination is handled within the client, the hashing algorithm returns the same value for a given key; values are not affected or reset by differences in the server environment.
Selection is very fast. The hashing algorithm on the key value is quick and the resulting selection of the server is from a simple array of available machines.
Using client-side hashing simplifies the distribution of data over each memcached server. Natural distribution of the values returned by the hashing algorithm means that keys are automatically spread over the available servers.
Providing that the list of servers configured within the client remains the same, the same stored key returns the same value, and therefore selects the same server.
However, if you do not use the same hashing mechanism then the same data may be recorded on different servers by different interfaces, both wasting space on your memcached and leading to potential differences in the information.
One way to use a multi-interface compatible hashing mechanism
is to use the libmemcached library and the
associated interfaces. Because the interfaces for the
different languages (including C, Ruby, Perl and Python) use
the same client library interface, they always generate the
same hash code from the ID.
The problem with client-side selection of the server is that the list of the servers (including their sequential order) must remain consistent on each client using the memcached servers, and the servers must be available. If you try to perform an operation on a key when:
A new memcached instance has been added to the list of available instances
A memcached instance has been removed from the list of available instances
The order of the memcached instances has changed
When the hashing algorithm is used on the given key, but with a different list of servers, the hash calculation may choose a different server from the list.
If a new memcached instance is added into the
list of servers, as new.memc is in the
example below, then a GET operation using the same key,
myid, can result in a cache-miss. This is
because the same value is computed from the key, which selects
the same index from the array of servers, but index 2 now points
to the new server, not the server c.memc
where the data was originally stored. This would result in a
cache miss, even though the key exists within the cache on
another memcached instance.
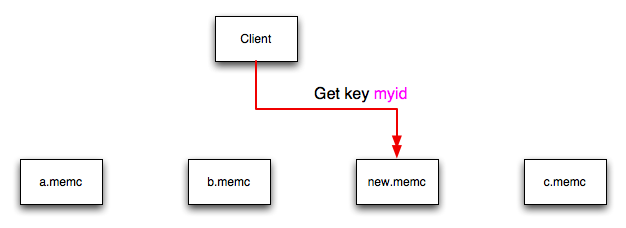
This means that servers c.memc and
new.memc both contain the information for
key myid, but the information stored against
the key in each server may be different in each instance. A more
significant problem is a much higher number of cache-misses when
retrieving data, as the addition of a new server changes the
distribution of keys, and this in turn requires rebuilding the
cached data on the memcached instances,
causing an increase in database reads.
The same effect can occur if you actively manage the list of servers configured in your clients, adding and removing the configured memcached instances as each instance is identified as being available. For example, removing a memcached instance when the client notices that the instance can no longer be contacted can cause the server selection to fail as described here.
To prevent this causing significant problems and invalidating your cache, you can select the hashing algorithm used to select the server. There are two common types of hashing algorithm, consistent and modula.
With consistent hashing algorithms, the
same key when applied to a list of servers always uses the same
server to store or retrieve the keys, even if the list of
configured servers changes. This means that you can add and
remove servers from the configure list and always use the same
server for a given key. There are two types of consistent
hashing algorithms available, Ketama and Wheel. Both types are
supported by libmemcached, and
implementations are available for PHP and Java.
Any consistent hashing algorithm has some limitations. When you add servers to an existing list of configured servers, keys are distributed to the new servers as part of the normal distribution. When you remove servers from the list, the keys are re-allocated to another server within the list, meaning that the cache needs to be re-populated with the information. Also, a consistent hashing algorithm does not resolve the issue where you want consistent selection of a server across multiple clients, but where each client contains a different list of servers. The consistency is enforced only within a single client.
With a modula hashing algorithm, the client selects a server by first computing the hash and then choosing a server from the list of configured servers. As the list of servers changes, so the server selected when using a modula hashing algorithm also changes. The result is the behavior described above; changes to the list of servers mean that different servers are selected when retrieving data, leading to cache misses and increase in database load as the cache is re-seeded with information.
If you use only a single memcached instance for each client, or your list of memcached servers configured for a client never changes, then the selection of a hashing algorithm is irrelevant, as it has no noticeable effect.
If you change your servers regularly, or you use a common set of servers that are shared among a large number of clients, then using a consistent hashing algorithm should help to ensure that your cache data is not duplicated and the data is evenly distributed.