The Conversion Process
This document describes the Oracle Enterprise Taxation Management conversion process.
Contents
Appendix A - Entity Relationship Diagramming Standards
Appendix B - Multiple Owners In A Single Database
When you’re ready to convert data from your legacy system into Oracle Enterprise Taxation Management, you will have analyzed your requirements according to your business and organizational needs and set up the control tables accordingly.
Refer to the Administration Guide for a complete discussion of the various control tables and the order in which they must be set up.
After the control tables are set up, you are ready to load data into the system from your legacy system. This conversion effort involves several steps as illustrated in the following diagram:
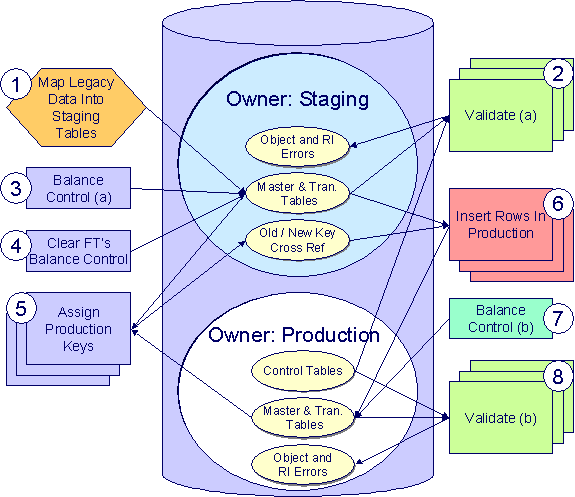
The following points briefly outline each of the above tasks:
· Map Legacy Data Into Staging. During this step, your legacy master data (e.g., account, person, location) and transaction data (e.g., bills, payments) is migrated into the system. Notice that you are not migrating this data directly into production. Rather, your rows are loaded into tables that are identical to the production tables; they just have a different owner. Refer to Appendix B – Multiple Owners In A Single Database for information about table ownership.
Different Databases For Staging and Production. The above diagram illustrates how the system is configured to support the conversion effort in the standard installation, i.e., the staging tables are in the same database as the production tables (each with a different owner). However, it is possible for the staging tables to be in a separate database. This option requires additional effort on your part (because you would have to copy the control tables from production into your staging database). Please refer to Appendix B – Multiple Owners In A Single Database for information about this alternative.
Mapping legacy data into the system is probably the most challenging part of the conversion process because the system is a normalized database (and most legacy applications are not).
· Validate (a). During the validation (a) step, the system validates the data you loaded into the staging tables. Two types of validation programs exist:
· Object Validation Programs. Each of the system’s master data objects (e.g., person, account, location, etc.) is validated using the same logic that is used to validate data added by users in your production system.
· Referential Integrity Validation Programs. After you have successfully validated the master data objects, the referential integrity validation programs are executed to validate transaction data and to highlight “orphaned” rows. These programs check the validity of the foreign keys on all rows on all tables.
Control tables from production. It’s important to notice that the validation programs validate your staging data using the control tables that have been set up in production. Refer to Appendix B – Multiple Owners In A Single Database for a description of how this works.
· Balance Control (a). During this step, you run the balance control program and then verify that the balances that it generates are consistent with the balances in your legacy system.
· Clear FT’s Balance Control. In the previous step, the system creates a balance control and links it to the FT’s. If the balance control’s balances are consistent with the amount of receivables being transferred into the system, you should run the Clear FT’s Balance Control program. This program simply resets the Balance Control column on the FT so that the FT’s can be included in a balance control (see the last step below) after they have been transferred to production.
· Assign Production Keys. During this step, the system allocates random, clustered keys to the rows in the staging database.
· Insert Rows Into Production. During this step, the system populates your production tables with rows from the staging. When the rows are inserted, their prime keys are reassigned using the data populated in the previous step.
· Balance Control (b). During this step, you run the balance control program against production. You do this to verify the balances in production are consistent with the values of receivables converted from your legacy application.
· Validate (b). During this step, you rerun the object validation programs, but this time against production. We recommend rerunning these programs to confirm that the insertion programs have executed successfully. We recommend running these programs in random sample mode (e.g., validate every 1000th object) rather than conducting a full validation in order to save time. However, if you have time, you should run these programs in full validation mode (to validate every object).
The following sections provide more details about the steps in the conversion process.
Contents
Map Legacy Data Into Staging Tables
Validate Information In The Staging Tables
Run Balance Control Against Production
Map Legacy Data Into Staging Tables
This section provides some high level discussion about mapping legacy data to the system's staging tables. Refer to The Staging Tables for details about the staging tables in the system.
Recommendation. You can use any method you prefer to load Oracle Enterprise Taxation Management data from your legacy application. However, we recommend that you investigate your database’s mass load utility (as opposed to using insert statements) as the mechanism to load the staging tables. In addition, we strongly recommend that you disable the indexes on these tables before populating these tables and then enable the indexes after populating these tables.
A Note About Keys
The prime keys of the tables in the staging database are either system-assigned random numbers or they aren't. Those tables that don't have system-assigned random numbers have keys that are a concatenation of the parent's prime-key plus one or more additional fields.
Every table whose prime key is a system-assigned random number has a related table that manages its keys; we refer to these secondary tables as "key tables". The following points provide more information about the key tables:
· Key tables are used by programs that allocate new keys. For example, before a new account ID is allocated, the key assignment program checks the account key table to see if it exists.
· Key tables exist to support archiving and ConfigLab requirements.
· When an object is archived, its row is removed from the primary table, but its key remains on the key table. This is done so that they key isn't reused in production, as we want to be able to reinstate an archived object.
· From a ConfigLab perspective, these key tables are used to prevent a key from being reused in production for an object added in a ConfigLab. For example, a user might add an account in a ConfigLab environment and we don't want its key to be allocated to an account added in production.
· Key tables only have two columns:
· The key of the object.
· An environment ID. The environment ID identifies the database in which the object resides.
· Key tables are named the same as their primary table with a suffix of "_K". For example:
· The key table for CI_ACCT is CI_ACCT_K
· The key table for CI_PREM is CI_PREM_K
The name of every table's key table is defined under the Generated Keys column in the Table Names sections in The Staging Tables.
· When you populate rows in tables with system-assigned keys, you must also populate a row in the related key table. For example, if you insert a row into CI_ACCT, you must also insert a row into CI_ACCT_K. The environment ID of these rows must be the same as the environment ID on this database's installation record.
· When you populate rows in tables that reference this record as a foreign key, you must use the appropriate key to ensure the proper data relationships. For example, if you insert a row in CI_SA for the above account, the ACCT_ID column must contain the temporary account key.
· When you insert rows into your staging database, the keys do not have to be random, system-assigned numbers. They just have to be unique. A later process, Allocate Production Keys, will allocate random, system-assigned keys prior to production being populated.
Validate Information In The Staging Tables
During the first validation step, the system validates the data you loaded into the staging tables. Two types of validation programs exist:
· Object Validation Programs. The object validation programs validate each of the system’s master data objects (e.g., person, account, location, etc.) and a limited number of transaction data objects (e.g., billable charge). Please note that these programs call the same programs that are used to validate data added by users in your production system.
· Referential Integrity Validation Programs. After the master data objects have been validated, the referential integrity validation programs are executed to validate transaction data and to highlight “orphaned” rows. These programs simply check the validity of the foreign keys on all rows on all tables.
The contents of this section describe how to execute the validation programs.
Contents
Submitting Object Validation Programs
Referential Integrity Validation Programs
Submitting Referential Integrity Validation Programs
Recommendations To Speed Up Validation Programs
Object Validation Programs
Each of the objects described under Master Data must be validated using the respective object validation program indicated in its Table Names section.
In a limited number of cases object validation is available for Transaction Data objects, where customers may convert transaction data that is still pending. For the same objects you may also be converting historic records. You may not want to perform validation on completed records. As a result the background processes provided for transaction data allow you to limit the validation to records in a given status.
We strongly recommend validating each object in the following steps:
· Execute each object’s validation program in random-sample mode to highlight pervasive errors. When you execute a validation in random-sample mode, you are actually telling it to validate every X records (where X is a parameter that you supply to the job). Refer to Submitting Object Validation Programs for more information about the parameters supplied to these background processes.
· You can view errors highlighted by validation programs using the Validation Error Summary transaction.
· Correct the errors using SQL. Note, you can use the base package’s transactions to correct an error if the error isn’t so egregious that it prevents the object from being displayed on the browser.
· After all pervasive errors have been corrected; re-execute each object’s validation program in all-instances mode to highlight elusive, one-off errors. Refer to Submitting Object Validation Programs for more information about the parameters supplied to these background processes.
Take note! Whenever an object validation program is run, it is necessary to delete all previously recorded errors associated with its tables from the validation error table before it inserts new errors.
After the various object validation programs run cleanly, run the referential integrity validation programs as described in the next section.
Submitting Object Validation Programs
The object validation programs that are described in the staging tables table names matrices are classic background processes as they can also be run against production data. You submit these processes in the same way you submit any background process in production. Refer to Object Validation Processes for information about these processes and their parameters.
Referential Integrity Validation Programs
It’s important to understand that only master data objects (e.g., persons, accounts, assets, locations, etc.) are validated by the object validation programs discussed above. This means that only master data objects will have their foreign keys checked for validity by the object validation programs. You must run the referential integrity programs to validate all other data.
The referential integrity validation programs highlight:
· Orphaned rows because orphan rows, by definition, don’t reference an object.
· Invalid foreign keys on transaction data.
Validating Transaction Data. You may wonder why transaction data is not subject to the object validation routines. This is because: a) the production system only needs validation logic for master data because transaction data is not entered by users, and b) most conversions necessitate loading skeletal transaction data because the legacy system typically doesn’t contain enough information to create accurate transactions in the system.
Each of the tables described under Transaction Data must be validated using the respective referential integrity validation program indicated in its Table Names section. We strongly recommend validating each table in the following steps:
· Execute each table’s referential integrity validation program. Refer to Submitting Referential Integrity Validation Programs for more information about the parameters supplied to these background processes.
· You can view errors highlighted by this process using the FK Validation Summary transaction.
· Correct the errors using SQL (you cannot use the application to correct these types of errors).
· Rerun the referential integrity programs until no errors are produced.
Take note! Whenever you run a referential integrity validation program, it deletes all errors associated with its table from the referential integrity error table.
In order to highlight orphaned rows in the master data, run the referential integrity validation programs against all tables described under Master Data using the procedure described above.
Submitting Referential Integrity Validation Programs
The referential integrity validation programs described under Master Data and Transaction Data (in the Table Names matrices) are submitted using a batch driver program, CIPVRNVB, and this program is executed in the staging database. Please note that the referential integrity validation programs may also be run in the production environment on occasion, to determine the integrity of data in the production database.
Refer to Referential Integrity Validation Processes for information about these processes and their parameters.
You should supply the following parameters to this program:
· Batch code. The batch code associated with the appropriate table's referential integrity validation program. Refer to each table listed under Master Data and Transaction Data (in the Table Names matrices) for each referential integrity batch code / program.
· Batch thread number. Thread number is not used and should be left blank.
· Batch thread count. Thread count is not used and should be left blank.
· Batch rerun number. Rerun number is not used and should be left blank.
· Batch business date. Business date is the date supplied to the referential integrity validation programs and the date under which statistics will be logged.
· Total number of commits. Total number of commits is not used and should be left blank.
· Maximum minutes between cursor re-initiation. Maximum minutes between cursor re-initiation is not used and should be left blank.
· User ID. User ID is only used to log statistics for the execution of the batch job.
· Password. Password is not used.
· Language Code. Language code is used to access language-specific control table values. For example, error messages are presented in this language code.
· Trace program at start (Y/N), trace program exit (Y/N), trace SQL (Y/N) and output trace (Y/N). These switches are only used during QA and benchmarking. If trace program start is set to Y, a message is displayed whenever a program is started. If trace program at exist is set to Y, a message is displayed whenever a program is exited. If trace SQL is set to Y, a message is displayed whenever an SQL statement is executed.
Recommendations To Speed Up Validation Programs
The following points describe ways to accelerate the execution of the validation programs:
· Ensure that statistics are recalculated after data has been inserted into the staging tables. For Oracle users, we strongly recommend using the Oracle-provided PL/SQL package to generate statistics rather than the analyze command.
· Object validation programs should be run multi threaded.
· Execute shorter running validation processes (e.g., less records) first so that the error data can be analyzed while other processes are busy running.
· Referential integrity validation programs run fairly quickly without much tuning. However, additional benefits are gained by running several programs at the same time.
· Remember that the object validation programs can be run in “validate every nth row”. We recommend running these programs using a largish value for this parameter until the pervasive problems have been rectified.
Balance Control (a)
During this step, you run the balance control programs and then verify that the balances that it generates are consistent with the balances in your legacy system.
Submitting this process. You submit this process in the staging database. Refer to The Big Picture of Balance Control for more information about the balance control processes. Refer to Balance Control for information about the page used to view the balances generated by this process.
Clear FT Balance Control
In the previous step, the system created a balance control and links it to the FT’s. If the balance control’s balances are consistent with the amount of receivables being transferred into the system, you should run the Clear FT’s Balance Control program. This program simply resets the Balance Control column on the FT so that the FT’s can be included in a balance control (see the last step below) after they have been transferred to production. Note: the batch control ID of CNV-BCG is used to request this process.
Submitting this process. You submit this process in the staging database. Refer to Reset Balances for a description of this process and its parameters.
Allocate Production Keys
The topics in this section describe the background processes used to assign production keys to the staging data.
Contents
The Big Picture of Key Assignment
Submitting Key Assignment Programs
Recommendations To Speed Up Key Generation Programs
The Big Picture of Key Assignment
It’s important to understand that the system does not overwrite the prime-keys or foreign keys on the rows in the staging database, as this is a very expensive IO transaction. Rather, a series of tables exist that hold each row's old key and the new key that will be assigned to it when the row is transferred into the production database. We refer to these tables as the "old key / new key" tables. The old key / new key tables are named the same as their primary table, but rather than being prefixed by "CI", they are prefixed by "CK". For example, the old key / new key table for CI_ACCT is called CK_ACCT.
The insertion programs that transfer the rows into the production database use the new key for the main record of the key along with any other record where this key is a foreign key. Note that the capability of assigning the new key to a foreign key applies to
· "True" foreign keys, i.e. where the key is a column in another table. For example, CI_SA has a column for ACCT_ID.
· FK reference characteristics. These are characteristics that define, through an FK reference, the table and the key that this characteristic represents.
The insertion programs are not able to assign "new keys" to foreign keys defined in an XML structure field (CLOB).
The key assignment programs listed under Master Data and Transaction Data (in the table names sections) are responsible for populating the old key / new key tables (i.e., you don't have to populate these tables). Because the population of the rows in these tables is IO intensive, we have supplied detailed instructions that will accelerate the execution time of these programs.
Why are keys reassigned? The conversion process allocates new prime keys to take advantage of the system’s parallel processing and data-clustering techniques in the production system (these techniques are dependent on randomly assigned, clustered keys).
Iterative conversions. Rather than perform a “big bang” conversion (one where all customers are populated at once), some implementations have the opportunity to go live on subsets of their customer base. If this describes your implementation, please be aware that the system takes into account the existing prime keys in the production database before it allocates a new key value. This means when you convert the next subset of customers, you can be assured of getting clean keys.
Program Dependencies. The programs used to assign production keys are listed in the Table Names matrices. Most of these programs have no dependencies (i.e., they can be executed in any order you please). The exceptions to this statement are noted in Program Dependencies.
Submitting Key Assignment Programs
The key assignment programs described under Master Data and Transaction Data (in the Table Names matrices) are submitted using a batch driver program, CIPVRNKB, and this program is executed in the staging database. You should supply the following parameters to this program:
· Batch code. The batch code associated with the appropriate table's key assignment program. Refer to each table listed under Master Data and Transaction Data (in the Table Names matrices) for each key assignment batch code / program.
· Batch thread number. Thread number is not used and should be left blank.
· Batch thread count. Thread count is not used and should be left blank.
· Batch rerun number. Rerun number is not used and should be left blank.
· Batch business date. Business date is the date supplied to the key assignment programs and the date under which statistics will be logged.
· Total number of commits. Total number of commits is not used and should be left blank.
· Maximum minutes between cursor re-initiation. Maximum minutes between cursor re-initiation is not used and should be left blank.
· User ID. User ID is only used to log statistics for the execution of the batch job.
· Password. Password is not used.
· Language Code. Language code is used to access language-specific control table values. For example, error messages are presented in this language code.
· Trace program at start (Y/N), trace program exit (Y/N), trace SQL (Y/N) and output trace (Y/N). These switches are only used during QA and benchmarking. If trace program start is set to Y, a message is displayed whenever a program is started. If trace program at exist is set to Y, a message is displayed whenever a program is exited. If trace SQL is set to Y, a message is displayed whenever an SQL statement is executed.
· Mode. The proper use of this parameter will greatly speed up the key assignment step as described under Recommendations To Speed Up Key Generation. This parameter has three values:
· If you supply a mode with a value of I (initial key generation), the system allocates new keys to the rows in the staging tables (i.e., it populate the respective old key / new key table).
· If you supply a mode with a value of D (resolve duplicate keys), the system reassigns keys that are duplicates.
· If you supply a mode with a value of B (both generate keys and resolve duplicates), the system performs both of the above steps. This is the default value if this parameter is not supplied.
· Please see Recommendations To Speed Up Key Generation for how to use this parameter to speed up the execution of these processes.
Parallel Key Generation. Note well, no key generation program should be run (either in mode I or B) while another program is being run unless that program is in the same tier (see Program Dependencies for a description of the tiers).
· Start Row Number. This parameter is only used if you are performing conversions where data already exists in the tables in the production database (subsequent conversions). In an Oracle database the key assignment routines create the initial values of keys by manipulation of the Oracle row number, starting from 1. After any conversion run, a subsequent conversion run will start with that row number again at 1, and the possibility of duplicate keys being assigned will be higher. The purpose of this parameter is to increase the value of row number by the given value, and minimize the chance of duplicate key assignment.
Recommendations To Speed Up Key Generation Programs
The following points describe ways to accelerate the execution of the key generation programs.
Naming convention. The convention “CK_<table_name>” is used to denote the old key / new key tables described under The Big Picture of Key Assignment.
· Make the size of your rollback segments large. The exact size is dependent on the number of rows involved in your conversion. Our research has shown that processing 7 million rows generates roughly 3GB of rollback information.
· Setup the rollback segment(s) to about 10GB with auto extend to a maximum size of 20GB to determine the high water mark
· A next extent value on the order of 100M should be used.
· Make sure to turn off all small rollback segments (otherwise Oracle will use them rather than the large rollback segments described above).
· After the key assignment programs execute, you can reclaim the space by:
· Keep a low value for the “minimum extent” parameter for the rollback.
· Shrink the rollback segments and the underlying data files at the end of the large batch jobs.
·
Compute statistics on the CK_<table_name> tables
after every 50% increase in table size.
Key generation is performed in tiers or steps because of the inheritance
dependency between some tables and their keys. Although key generation for the
tier currently being processed is performed by means of set-based SQL,
computation of statistics between tiers will allow the database to compute the
optimum access path to the keys being inherited from the previous tier’s
generation run.
For Oracle users, we strongly recommend using the Oracle-provided PL/SQL
package to generate statistics rather than the analyze command.
· Optimal use of the Mode parameter under Submitting Key Assignment Programs.
· Before any key assignments, alter both the “old key” CX_ID index and the “new key” CI_ID index on the CK_<table_name> tables to be unusable.
· Run all key assignment tiers, submitting each job with MODE = “I”.
· Rebuild the CX_ID and CI_ID indexes on the CK_<table_name>. Rebuilding the indexes using both the PARALLEL and NOLOGGING parameters will speed the index creation process in an Oracle DB. Statistics should be computed for these indexes.
· Run all key assignment tiers that were previously run in MODE = ‘I’, submitting each job with MODE = “D”. This will reassign all duplicate keys.
Insert Production Data
The topics in this section describe the background processes used to populate the production database with the information in the staging database.
Contents
The Big Picture Of Insertion Programs
Recommendations To Speed Up Insertion Programs
The Big Picture Of Insertion Programs
All insertion programs are independent and may run concurrently. Also note, all insertion programs can be run in many parallel threads as described in the next section (in order to speed execution).
Submitting Insertion Programs
The insertion programs described under Master Data and Transaction Data (in the Table Names matrices) are submitted using a batch driver program, CIPVRNIB, and this program is executed in the staging database. You should supply the following parameters to this program:
· Batch code. The batch code associated with the appropriate table's insertion program. Refer to each table listed under Master Data and Transaction Data (in the Table Names matrices) for each insertion batch code / program.
· Batch thread number. Thread number contains the relative thread number of the process. For example, if you want to insert accounts into production in 20 parallel threads, each of the 20 execution instances receives its relative thread number (1 through 20). Refer to Parallel Background Processes for more information.
· Batch thread count. Thread count contains the total number of parallel threads that have been scheduled. For example, if the account insertion process has been set up to run in 20 parallel threads, each of the 20 execution instances receives a thread count of 20. Refer to Parallel Background Processes for more information.
· Batch rerun number. Rerun number is not used and should be left blank.
· Batch business date. Business date is the date supplied to the insertion programs and the date under which statistics will be logged.
· Total number of commits. This is the number of commits IN TOTAL that you want to perform. For example, if you have 1,000,000 accounts and you supply a value of 100; then a commit will be executed for approximately every 10,000 accounts.
· Maximum minutes between cursor re-initiation. This should only be populated if you want to override the default value of 15.
· User ID. User ID is only used to log statistics for the execution of the batch job.
· Password. Password is not used.
· Language Code. Language code is used to access language-specific control table values. For example, error messages are presented in this language code.
· Trace program at start (Y/N), trace program exit (Y/N), trace SQL (Y/N) and output trace (Y/N). These switches are only used during QA and benchmarking. If trace program start is set to Y, a message is displayed whenever a program is started. If trace program at exist is set to Y, a message is displayed whenever a program is exited. If trace SQL is set to Y, a message is displayed whenever an SQL statement is executed.
Recommendations To Speed Up Insertion Programs
The following points describe ways to accelerate the execution of the insertion programs:
· Before running the first insertion program:
· Rebuild the index on the prime key on the old key / new key table (i.e., those tables prefixed with "CK").
· Re-analyze the statistics on the old key / new key table (i.e., those tables prefixed with "CK"). For Oracle users, we strongly recommend using the Oracle-provided PL/SQL package to generate statistics rather than the analyze command.
· Alter all indexes on the production tables being inserted into to be unusable.
· After the insertion programs have populated production data, rebuild the indexes and compute statistics for these tables. For Oracle users, we strongly recommend using the Oracle-provided PL/SQL package to generate statistics rather than the analyze command.
Run Balance Control Against Production
During this step, you rerun the balance control program, but this time against production. You do this to verify the balances in production are consistent with the values of receivables converted from your legacy application.
Submitting this process. You submit this process in the production database. Refer to The Big Picture of Balance Control for more information about the balance control processes. Refer to Balance Control for information about the page used to view the balances generated by this process.
Validate Production
During this step, you rerun the object validation programs, but this time in production. We recommend rerunning these programs to confirm that the insertion programs have executed successfully. We recommend running these programs in random sample mode (e.g., validate every 1000th object) rather than conducting a full validation in order to save time. However, if you have time, you should run these programs in full validation mode (to validate every object). Please refer to the various “Table Names” sections above for the respective names of the programs to run.
The topics in this section describe the various pages that assist in the conversion effort.
Contents
Validation Error Summary
Navigate to the Admin menu and open Validation Error Summary to view validation errors associated with the objects defined in Master Data.
Description of Page
You can use Table Name to restrict errors to a specific object. If this field is left blank, all errors on all objects will be displayed.
The grid contains a separate row for each type of error. The following information is displayed:
· Table Name is the name of the main table associated with the object.
· Message Category and Message Number define the type of error. These fields are the unique identifier of the message that describes the error (the verbiage of this message is displayed in the Message Text column).
· Count contains the number of records with this error. Press the Go To button to see the individual records with the error.
Validation Error Detail
This page is used to view validation errors of a given type associated with one of the objects defined in Master Data. This transaction is not intended to be invoked from the Admin menu. Rather, drill into the validation details from Validation Error Summary.
Description of Page
Use Table Name, Message Category, and Message Number to define the object and the type of error you wish to display. The grid contains a separate row for each object with the given type of error. The following information is displayed:
· Table Name is the name of the main table associated with the object.
· Record Identifier is the unique identifier of the object with the error (e.g., the person ID, the account ID, the location ID, etc.). Press the Go To button to transfer to the maintenance page associated with the object.
· Message Category and Message Number define the type of error. These fields are the unique identifier of the message that describes the error (the verbiage of this message is displayed in the Message Text column).
FK Validation Summary
Navigate to the Admin menu and open FK Validation Summary to view foreign key validation errors associated with the objects defined in Master Data.
Description of Page
You can use Table Name to restrict errors to a specific object. If this field is left blank, all errors on all objects will be displayed.
The grid contains a separate row for each type of error. The following information is displayed:
· Table Name is the name of the main table associated with the object.
· Count contains the number of records on this table that have this error.
· Foreign Key Field Names 1 to 6 contain the names of the foreign keys contained on this table that have been found to be in error.
· Foreign Key Values 1 to 6 contain the values within the foreign key fields that are found to be in error.
FK Validation Detail
This page is used to view foreign key validation errors of a given type associated with one of the objects defined in Master Data. This transaction is not intended to be invoked from the Admin menu. Rather, drill into the validation details from FK Validation Summary.
Description of Page
Use Table Name to specify the table you wish to view. The names and values of the foreign key fields on the table are displayed. The grid that follows contains the primary key values of this table’s records that are in error. The following information is displayed:
· Table Name is the name of the main table.
· FK Fields 1 to 6 are the names of the foreign keys contained in this table. Displayed alongside the key names are the values within these fields. These identify records on other tables to which this tables record is related. For example, the CI_PREM_GEO record identified by its displayed primary keys should be related to a Location record with the Location ID shown – it appears in this list only if there is something amiss with this relationship.
This section describes the objects into which your legacy data is mapped. For each object, we provide the following:
· A data model.
· An indication of which tables have system-assigned keys.
· The physical table names.
· The name of the batch control to submit to validate the object.
· The name of the program (and related batch control) that validates each table for referential integrity.
· The name of the program (and related batch control) that performs key assignment for each table.
· The name of the program (and related batch control) that inserts the table’s rows into production from staging.
· Suggestions to assist in the conversion process.
Recommendation. We recommend you read this document on a browser (or using Word under windows) so you can take advantage of the Color Coding.
Column details do not appear in this document. When you’re ready to examine an object’s tables, use the hyperlinks in the respective Table Names section to transfer to the data dictionary. The data dictionary will show you the required columns, the foreign keys (and their related tables), the source code of the program that validates the contents of the table, and a host of other information that will assist the conversion process.
Look Up and Control Tables. In the data models that appear below, you will find a variety of entities that are classified as either a control table or a lookup table. Please refer to Color Coding for more information about how to recognize such an entity.
Contents
A Note About Programs in the Table Names Matrices
A Note About Programs in the Table Names Matrices
For each object described in the master data and transaction data sections, there is a "table names" section that includes a matrix listing the name of each table that is part of the maintenance object. Included in the matrix is information about the programs provided to perform object validation, referential integrity validation, key assignment and insertion. The following are some points about these programs:
· One object validation program exists for the entire set of tables for the maintenance object. The Object Validation Batch Control column indicates the batch control used to submit the object validation. Refer to Submitting Object Validation Programs for more information. Drilling down on the hypertext allows you to see more information about the batch control, including the program associated with it.
· A referential integrity validation program exists for every table whose key includes a parent key of another object. As described in Submitting Referential Integrity Validation Programs, these programs are submitted using a driver supplied by the system where the batch code for the appropriate table is provided. (The driver then executes the program whose name matches the batch code). The Referential Integrity Validation Batch Control column indicates the table's batch control / program name.
· One key assignment program exists for the parent table for the maintenance object. As described in Submitting Key Assignment Programs, these programs are submitted using a driver supplied by the system where the batch code for the appropriate table is provided. (The driver then executes the program whose name matches the batch code). The Key Assignment Batch Control column indicates the table's batch control / program name.
· An insertion program exists for every table for the maintenance object. As described in Submitting Insertion Programs, these programs are submitted using a driver supplied by the system where the batch code for the appropriate table is provided. (The driver then executes the program whose name matches the batch code). The Insertion Batch Control column indicates the table's batch control / program name.
Master Data
This section describes the various “master data” objects (e.g., person, account etc.) that must be created before you can convert transaction data.
Key Assignment Dictates The Order Of Conversion. The following contents are listed in the order in which the objects should be converted in order to maintain referential integrity.
Contents
Person
This section describes the person object. Refer to Account for details about the account object.
Contents
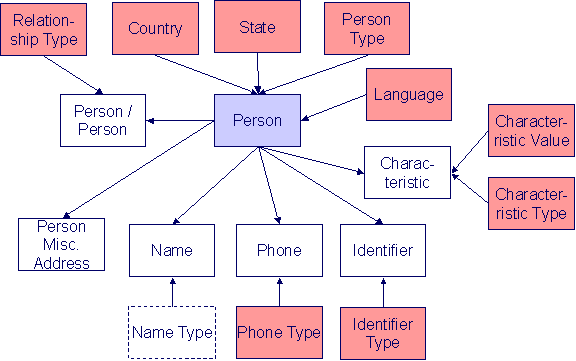
Person Data Model
The following data model illustrates the person object.
Person Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Object Validation Batch Control |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Person |
Yes CI_PER_K |
|
CIPVPERK |
CIPVPERI |
||
|
Name |
No. The key is PER_ID plus a sequence number. |
|
CIPVPNMV |
|
CIPVPNMI |
|
|
Person / Person |
No. The key is PER_ID1, PER_ID2, relationship type and start date. |
|
CIPVPPEV |
|
CIPVPPEI |
|
|
Phone |
No. The key is PER_ID plus phone type. |
|
CIPVPPHV |
|
CIPVPPHI |
|
|
Identifier |
No. The key is PER_ID plus identifier type. |
|
CIPVPIDV |
|
CIPVPIDI |
|
|
Characteristic |
No. The key is PER_ID plus an edate and a char type. |
|
CIPVPRCV |
|
CIPVPRCI |
|
|
Miscellaneous Address |
No. The key is PER_ID plus a sequence number. |
|
CIPVPSAV |
|
CIPVPSAI |
Person Suggestions
A person must have at least one row on the name table and at least one of the names must be marked as being the primary name.
A person must have at least one row on the identity table and at least one of the identities must be marked as being the primary ID.
The country and state are only necessary if the person has an override mailing address.
This maintenance object includes a character large object field that your organization may be using to capture implementation specific data as defined by your business objects. For records of this type, the process to insert the records to the staging table is responsible for populating the data in this CLOB as per the record's business object schema.
Account
Each customer must have a person and an account object. This section describes the account object, refer to Person for details about the person object.
Contents
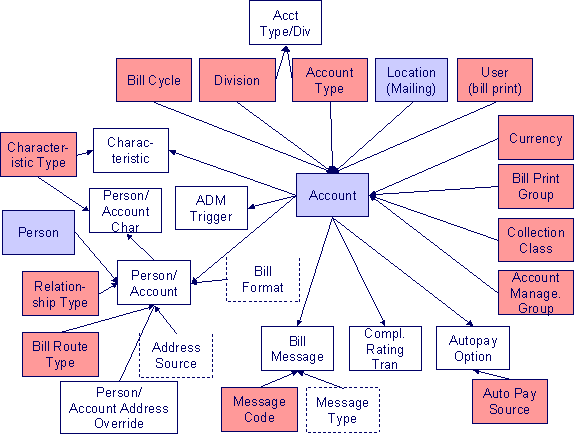
Account Data Model
The following data model illustrates the account object.
Account Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Object Validation Batch Control |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Account |
Yes CI_ACCT_K |
|
CIPVACCK |
CIPVACCI |
||
|
Bill Message |
No. The key is account ID plus bill message code. |
|
CIPVMSGV |
|
CIPVMSGI |
|
|
Autopay Option |
Yes CI_ACCT_APAY_K |
|
CIPVAAPV |
CIPVAAPK |
CIPVAAPI |
|
|
Characteristic |
No. The key is ACCT_ID plus an edate and a char type. |
|
CIPVACHV |
|
CIPVACHI |
|
|
Person/Account |
No. The key is account ID plus person ID. |
|
CIPVACPV |
|
CIPVACPI |
|
|
Person / Account Char |
No. The key is account ID plus person ID plus an edate and a char type. |
|
CIPVAPCV |
|
CIPVAPCI |
|
|
Person/Account Address Override |
No. The key is Account ID plus Person ID |
|
CIPVPAOV |
|
CIPVPAOI |
|
|
Compliance Rating Transaction |
Yes CI_CR_RAT_HIST_K |
|
CIPVCRTV |
CIPVCRRK |
CIPVCRTI |
|
|
ADM Trigger |
No. The key is account ID plus date |
|
CIPVARSV |
|
CIPVARSI |
Account Suggestions
An account must have at least one row on the account / person table and at least one account / person must be marked as being the main customer. Please see column notes for the account / person table for inter-field validation in respect of the various switches (e.g., if main customer switch is on, then the person must also be financially responsible).
We recommend storing an ADM trigger (CI_ADM_RVW_SCH) for every account where the trigger date is the conversion date. This will cause the account to be reviewed by the overdue monitor when it next runs. We have supplied a dedicated batch process for this purpose that simply inserts a row in this table with the review date set equal to the current date. This will ensure that all converted accounts are reviewed after they are inserted into production. This program is named CIPVADMB and goes by the batch control ID of CNV-ADM.
If your legacy system has the equivalent of a compliance rating, you should create compliance rating transactions. The values you create need to be consistent with the base and threshold compliance rating on the installation record. Refer to the account user documentation for more information.
This maintenance object includes a character large object field that your organization may be using to capture implementation specific data as defined by your business objects. For records of this type, the process to insert the records to the staging table is responsible for populating the data in this CLOB as per the record's business object schema.
Location
Contents
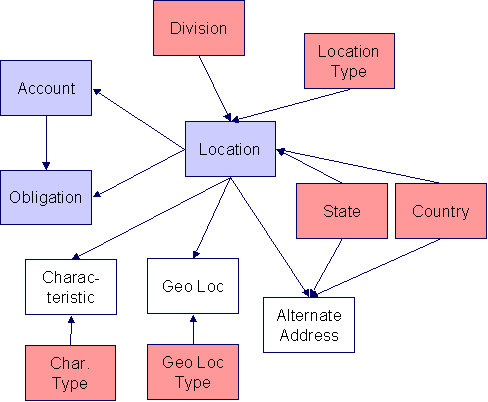
Location Data Model
The following data model illustrates the location object.
Location Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Object Validation Batch Control |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Location |
Yes CI_PREM_K |
|
CIPVPRMK |
CIPVPRMI |
||
|
Characteristic |
No. The key is PREM_ID plus an edate and a char type. |
|
CIPVPCHV |
|
CIPVPCHI |
|
|
Geo Loc |
No. The key is PREM_ID plus geo loc type. |
|
CIPVPGOV |
|
CIPVPGOI |
|
|
Alternate Address |
|
CIPVAPAV |
CIPVAPAK |
CIPVAPAI |
Location Suggestions
This maintenance object includes a character large object field that your organization may be using to capture implementation specific data as defined by your business objects. For records of this type, the process to insert the records to the staging table is responsible for populating the data in this CLOB as per the record's business object schema.
Obligation
Contents
Obligation Data Model
The following data model illustrates the obligation object.
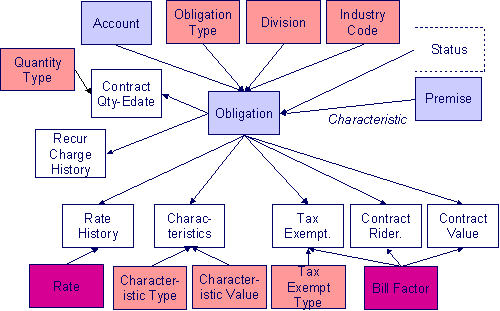
Obligation Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Object Validation Batch Control |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Obligation |
Yes CI_SA_K |
VAL-SA |
|
CIPVSVAK |
CIPVSVAI |
|
|
Characteristic |
No. The key is obligation_ID plus an edate and a char type. |
|
CIPVSACV |
|
CIPVSACI |
|
|
Contract Quantity Edate |
No. The key is obligation ID plus quantity type plus edate. |
|
CIPVSAQV |
|
CIPVSAQI |
|
|
Message |
No. The key is obligation ID plus Bill message code. |
|
CIPVSMGV |
|
CIPVSMGI |
|
|
Recurring Charge |
No. The key is obligation ID plus edate. |
|
CIPVSARV |
|
CIPVSARI |
|
|
Rate History |
No. The key is obligation ID plus edate. |
|
CIPVSAHV |
|
CIPVSAHI |
|
|
Tax Exempt |
CI_SA_CONTERM – this table is also used for the next 2 entities, the key contains CONTERM_TYPE_FLG that controls the entity |
No. This key is obligation ID plus CONTERM_TYPE_FLG plus BF_CD plus START_DT |
|
CIPVSAOV |
|
CIPVSAOI |
|
Contract Rider |
CI_SA_CONTERM – this table is also used for the previous and next entities, the key contains CONTERM_TYPE_FLG that controls the entity |
No. This key is obligation ID plus CONTERM_TYPE_FLG plus BF_CD plus START_DT |
|
CIPVSAOV |
|
CIPVSAOI |
|
Contract Value |
CI_SA_CONTERM – this table is also used for the previous 2 entities, the key contains CONTERM_TYPE_FLG that controls the entity |
No. This key is obligation ID plus CONTERM_TYPE_FLG plus BF_CD plus START_DT |
|
CIPVSAOV |
|
CIPVSAOI |
Obligation Suggestions
This maintenance object includes a character large object field that your organization may be using to capture implementation specific data as defined by your business objects. For records of this type, the process to insert the records to the staging table is responsible for populating the data in this CLOB as per the record's business object schema.
Tax Role
Contents
Tax Role Data Model
The following data model illustrates the tax role object.
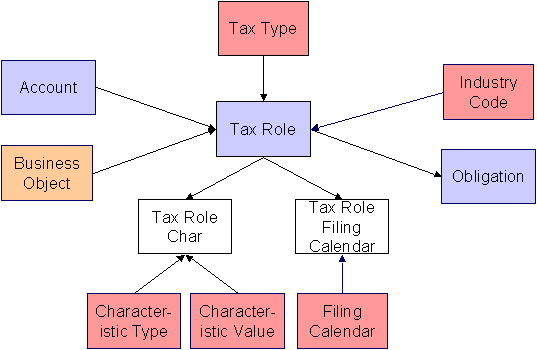
Tax Role Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Object Validation Batch Control |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Tax Role |
Yes. CI_TAX_ROLE_K |
CIPVTXRV |
CIPVTXRK |
CIPVTXRI |
||
|
Tax Role Filing Calendar |
No. The key is Tax Role ID and Effective Date. |
|
|
|
|
|
|
Tax Role Characteristic |
No. The key is Tax Role ID, Characteristic Type, and Effective Date. |
|
CIPVTXCV |
|
CIPVTXCI |
Tax Role Suggestions
This maintenance object includes a character large object field that your organization may be using to capture implementation specific data as defined by your business objects. For records of this type, the process to insert the records to the staging table is responsible for populating the data in this CLOB as per the record's business object schema.
Transaction Data
This section describes the tables in which your transaction data (e.g., bills, payments, customer contacts, etc.) resides.
Bill
Contents
Bill Data Model
Contents
The following data model illustrates the bill object.
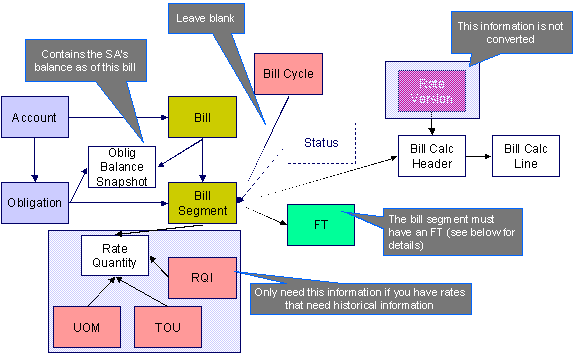
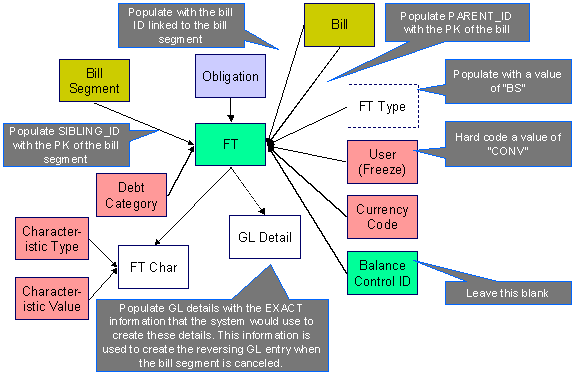
The following data model illustrates the FT that must be associated with a bill segment.
The following data model illustrates Bill Characteristics.
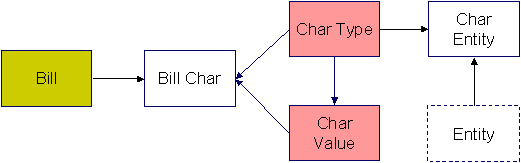
The following data model illustrates Bill Messages and Bill Routing.
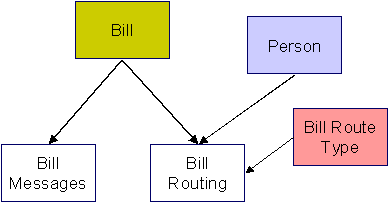
Bill Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Bill |
Yes CI_BILL_K |
CIPVBLLV |
CIPVBILK |
CIPVBLLI |
|
|
Obligation Balance Snapshot |
No. The key is bill ID plus obligation ID. |
CIPVBSAV |
|
CIPVBSAI |
|
|
Bill Segment |
Yes CI_BSEG_K |
CIPVSEGV |
CIPVBSGK |
CIPVSEGI |
|
|
Calc Header |
No. The key is bill segment id and a sequence number |
CIPVBSCV |
|
CIPVBSCI |
|
|
Calc Lines |
No. The key is bill segment id, the header sequence number, and a sequence number |
CIPVBSLV |
|
CIPVBSLI |
|
|
Read Detail |
No. The key is bill segment id and a sequence number. |
CIPVSRRV |
|
CIPVSRRI |
|
|
Asset Detail |
No. The key is bill segment id and a sequence number |
CIPVBSIV |
|
CIPVBSII |
|
|
Rate Quantity |
No. The key is bill segment id, uom code, tou code and RQI code |
CIPVSQTV |
|
CIPVSQTI |
|
|
FT (financial transaction) |
Yes CI_FT_K |
CIPVFTFV |
CIPVFTXK |
CIPVFTFI |
|
|
FT Characteristic |
No. The key is FT id, char type code and a sequence number |
CIPVFTCV |
|
CIPVFTCI |
|
|
FT GL (FT general ledger) |
No. The key is FT id and a GL sequence number |
CIPVFTGV |
|
CIPVFTGI |
|
|
Characteristics |
No. The key is bill id, char type code and a sequence number |
CIPVBCHV |
|
CIPVBCHI |
|
|
Bill Messages |
No. The key is bill id and bill message code. |
CIPVBLMV |
|
CIPVBLMI |
|
|
Bill Routing |
No. The key is bill id and a sequence number |
CIPVBLRV |
|
CIPVBLRI |
Bill Suggestions
Most companies have found it impossible to load bill segment item, bill calc header and lines with sufficient information and therefore these tables are not populated. See the comments in the above ERD’s for more information.
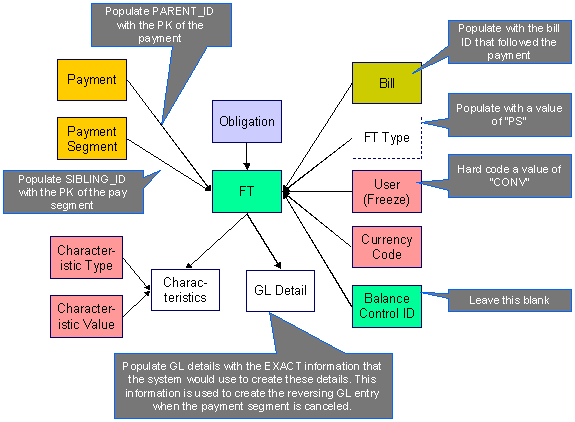
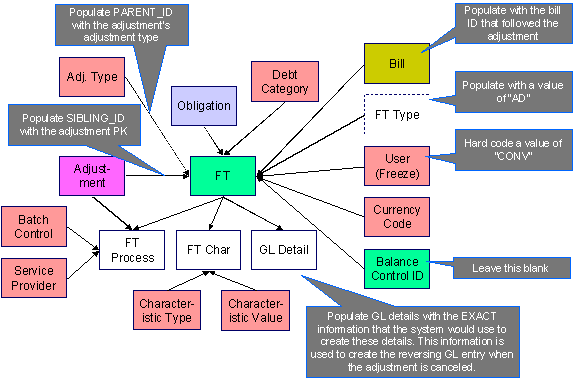
Please populate the columns on the FT that’s associated with the bill segment as follows:
· CUR_AMT should be set equal to the bill segment amount
· PAY_AMT should be set equal to the bill segment amount
· CRE_DTTM should be set equal to the bill segment end date / time
· FREEZE_SW should be “Y”
· FREEZE_DTTM should be set equal to the bill segment end date / time
· ARS_DT should be set equal to the bill segment end date
· CORRECTION_SW should be “N”
· REDUNDANT_SW should be “N”
· NEW_DEBIT_SW should be “N”
· NOT_IN_ARS_SW should be set to “N”
· SHOW_ON_BILL_SW should be set to “N”
· ACCOUNTING_DT should be set to the current date
· SCHED_DISTRIB_DT should be left blank
· CURRENCY_CD should be the currency on the installation record
· BAL_CTL_GRP_ID should be left blank
· XFERRED_OUT_SW should be set to “Y”
· PARENT_ID should be set to the bill ID
· SIBLING_ID should be set to the bill segment ID
· Do NOT create any GL details for the FT. If GL details are converted, ensure they are populated with the EXACT information the system would use to create them. This information is used to create the reversing GL entry when the bill segment is canceled.
Payment
Contents
Payment Data Model
Contents
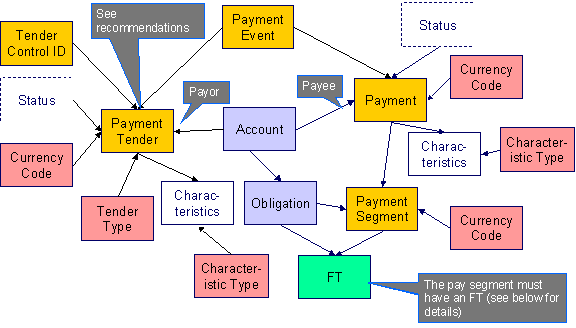
The following data model illustrates the payment object.
The following data model illustrates the FT that must be associated with a payment segment.
Payment Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Payment |
Yes CI_PAY_K |
CIPVPAYV |
CIPVPAYK |
CIPVPAYI |
|
|
Payment Characteristic |
No. The key is PAY_ID, plus a sequence number and a char type |
CIPVPYCV |
|
CIPVPYCI |
|
|
Payment Event |
Yes CI_PAY_EVENT_K |
|
CIPVPYEK |
CIPVPYEI |
|
|
Payment Tender |
Yes CI_PAY_TNDR_K |
CIPVTNDV |
CIPVTNDK |
CIPVTNDI |
|
|
Payment Tender Characteristic |
No. The key is PAY_TENDER_ID, plus a sequence number and a char type |
CIPVTNCV |
|
CIPVTNCI |
|
|
Payment Segment |
Yes CI_PAY_SEG_K |
CIPVPSGV |
CIPVPSGK |
CIPVPSGI |
|
|
FT (financial transaction) |
Yes CI_FT_K |
CIPVFTFV |
CIPVFTXK |
CIPVFTFI |
|
|
FT Characteristic |
No. The key is FT id, char type code and a sequence number |
CIPVFTCV |
|
CIPVFTCI |
|
|
FT GL (FT general ledger) |
No. The key is FT id and a GL sequence number |
CIPVFTGV |
|
CIPVFTGI |
Payment Suggestions
We recommend that you use the system to create a single deposit control and link to it a single tender control using the PRODUCTION tables. The tender control should reference a tender source of “conversion”. Use the prime key of the tender control as the foreign key on the tenders that you insert into the STAGING tables. This means you will have an invalid foreign key relationship on CI_PAY_TNDR (it will reference a tender control that doesn’t exist).
After converting the payments:
· Re-access the tender control in production and enter the appropriate amounts (per tender type) to balance the tender control.
· Re-access the deposit control in production and enter the appropriate amounts to balance the deposit control.
Please populate the columns on the FT that’s associated with the payment segment as follows:
· CUR_AMT should be set equal to the payment segment amount
· PAY_AMT should be set equal to the payment segment amount
· CRE_DTTM should be set equal to the payment segment date / time
· FREEZE_SW should be “Y”
· FREEZE_DTTM should be set equal to the payment segment date / time
· ARS_DT should be set equal to the payment segment date
· CORRECTION_SW should be “N”
· REDUNDANT_SW should be “N”
· NEW_DEBIT_SW should be “N”
· NOT_IN_ARS_SW should be set to “N”
· SHOW_ON_BILL_SW should be set to “N” on all payments other than payments that have been received since the last bill. For recent payments that you want to show on the next bill, this switch must be “Y”
· ACCOUNTING_DT should be set to the current date
· SCHED_DISTRIB_DT should be left blank
· CURRENCY_CD should be the currency on the installation record
· BAL_CTL_GRP_ID should be left blank
· XFERRED_OUT_SW should be set to “Y”
· PARENT_ID should be set to the payment ID
· SIBLING_ID should be set to the payment segment ID
· Do NOT create any GL details for the FT. If GL details are converted, ensure they are populated with the EXACT information the system would use to create them. This information is used to create the reversing GL entry when the payment segment is canceled.
Adjustment
Contents
Adjustment Data Model
Contents
The following data model illustrates the adjustment object.
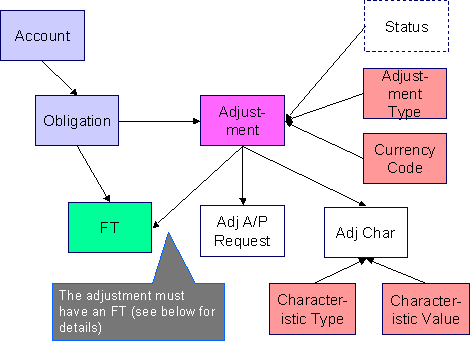
The following data model illustrates the FT that must be associated with an adjustment segment.
Adjustment Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Adjustment |
Yes CI_ADJ_K |
CIPVADJV |
CIPVADJK |
CIPVADJI |
|
|
Adjustment A/P Request |
Yes CI_ADJ_APREQ_K |
CIPVAPRV |
CIPVAPRK |
CIPVAPRI |
|
|
FT (financial transaction) |
Yes CI_FT_K |
CIPVFTFV |
CIPVFTXK |
CIPVFTFI |
|
|
FT Characteristic |
No. The key is FT id, char type code and a sequence number |
CIPVFTCV |
|
CIPVFTCI |
|
|
FT GL (FT general ledger) |
No. The key is FT id and a GL sequence number |
CIPVFTGV |
|
CIPVFTGI |
|
|
FT Process |
No. The key is FT id and a sequence number |
CIPVFTPV |
|
CIPVFTPI |
|
|
Adjustment Characteristic |
No. The key is adjustment id, char type code and a sequence number |
CIPVADCV |
|
CIPVADCI |
Adjustment Suggestions
Please populate the columns on the FT that’s associated with the adjustment as follows:
· CUR_AMT should be set equal to the adjustment amount
· PAY_AMT should be set equal to the adjustment amount
· CRE_DTTM should be set equal to the adjustment date / time
· FREEZE_SW should be “Y”
· FREEZE_DTTM should be set equal to the adjustment date / time
· ARS_DT should be set equal to the adjustment date
· CORRECTION_SW should be “N”
· REDUNDANT_SW should be “N”
· NEW_DEBIT_SW should be “N”
· NOT_IN_ARS_SW should be set to “N”
· SHOW_ON_BILL_SW should be set to “N” on all adjustments other than adjustments that have been generated since the last bill. For recent adjustments that you want to show on the next bill, this switch must be “Y”
· ACCOUNTING_DT should be set to the current date
· SCHED_DISTRIB_DT should be left blank
· CURRENCY_CD should be the currency on the installation record
· BAL_CTL_GRP_ID should be left blank
· XFERRED_OUT_SW should be set to “Y”
· PARENT_ID should be set to the adjustment’s adjustment type
· SIBLING_ID should be set to the adjustment ID
· Do NOT create any GL details for the FT. If GL details are converted, ensure they are populated with the EXACT information the system would use to create them. This information is used to create the reversing GL entry when the adjustment is canceled.
Customer Contact
Contents
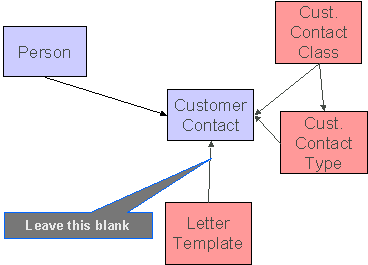
Customer Contact Data Model
The following data model illustrates the Customer Contact object.
Customer Contact Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Customer Contact |
Yes CI_CC_K |
CIPVCSCV |
CIPVCCTK |
CIPVCSCI |
Customer Contact Suggestions
This maintenance object includes a character large object field that your organization may be using to capture implementation specific data as defined by your business objects. For records of this type, the process to insert the records to the staging table is responsible for populating the data in this CLOB as per the record's business object schema.
Rate Factor Value
Contents
Rate Factor Value Data Model
The following data model illustrates the rate factor objects.
Rate Factor Value Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Rate Factor Value |
No. The key is BF_CD plus CHAR_TYPE_CD plus CHAR_VAL plus EFFDT |
CIPVBFVV |
|
CIPVBFVI (Not threadable) |
Rate Factor Value Suggestions
N/A
Payment Plans
Contents
Payment Plan Data Model
The following data model illustrates the Payment Plan objects.
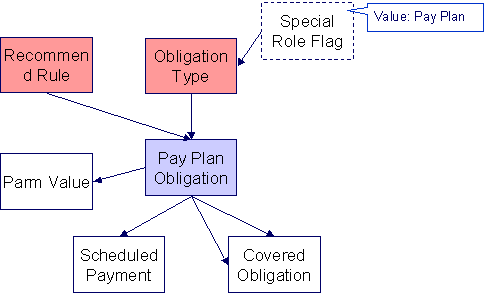
Payment Plan Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Covered Obligation |
No. The key is SA_ID plus CVRD_SA_ID |
CIPVNBSV |
|
CIPVNBSI |
|
|
Scheduled Payments |
CIPVNSPV |
CIPVNSPK |
CIPVNSPI |
||
|
Pay Plan Parameters |
No. The key is SA_ID plus Sequence Number. |
CIPVNPMV |
|
CIPVNPMI |
Payment Plan Suggestions
This maintenance object includes a character large object field that your organization may be using to capture implementation specific data as defined by your business objects. For records of this type, the process to insert the records to the staging table is responsible for populating the data in this CLOB as per the record's business object schema.
Billable Charge
Contents
Billable Charge Data Model
The following data model illustrates the Billable Charge objects.
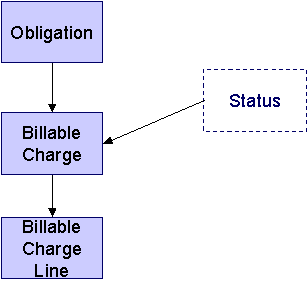
Billable Charge Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Object Validation Batch Control |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Billable Charge |
Yes. CI_BILL_CHG_K |
CIPVBCGV |
CIPVBCGK |
CIPVBCGI |
||
|
Billable Charge Line |
No. The key is billable charge id and a sequence number |
|
CIPVBCLV |
|
CIPVBCLI |
Billable Charge Suggestions
N/A
Collection Agency Referral
Contents
Collection Agency Referral Data Model
Collection Agency Referral Table Names
Collection Agency Referral Suggestions
Collection Agency Referral Data Model
The following data model illustrates the Collection Agency Referral object.
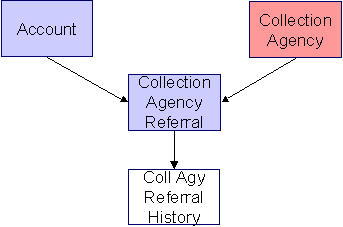
Collection Agency Referral Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Collection Agency Referral |
Yes. CI_COLL_AGY_REF_K |
CIPVCARV |
CIPVCARK |
CIPVCARI |
|
|
Collection Agency Referral History |
No. The key is collection agency referral id and characteristic type code |
CIPVARHV |
|
CIPVARHI |
Collection Agency Referral Suggestions
N/A
Case
Contents
Case Data Model
The following data model illustrates the Case object.
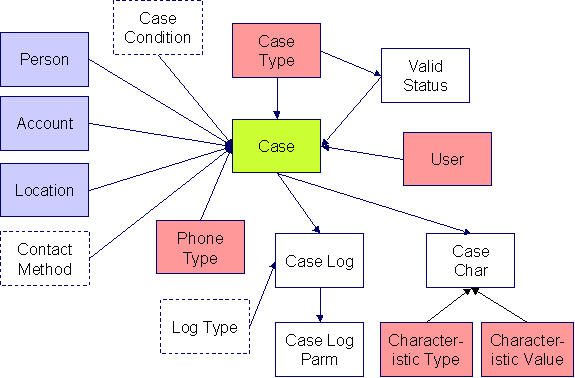
Case Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Object Validation Batch Control |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Case |
Yes. CI_CASE_K |
|
CIPVCSEK |
CIPVCSEI |
||
|
Case Characteristic |
No. The key is case id, char type code and a sequence number |
|
CIPVCCHV |
|
CIPVCCHI |
|
|
Case Log |
No. The key is case id and a log sequence number |
|
CIPVCLGV |
|
CIPVCLGI |
|
|
Case Log Parameter |
No. The key is case id, log sequence number and a parameter sequence number |
|
CIPVCPAV |
|
CIPVCPAI |
Case Suggestions
This maintenance object includes a character large object field that your organization may be using to capture implementation specific data as defined by your business objects. For records of this type, the process to insert the records to the staging table is responsible for populating the data in this CLOB as per the record's business object schema.
Tax Form
Contents
Tax Form Data Model
The following data model illustrates the Tax Form object.
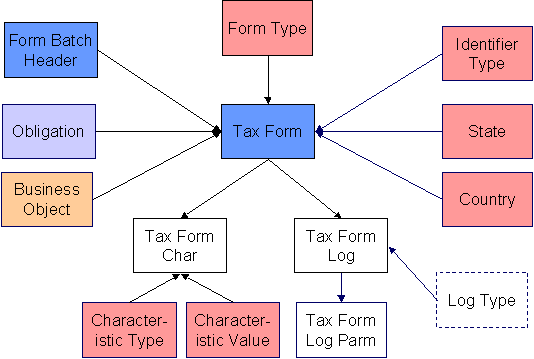
Tax Form Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Object Validation Batch Control |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Tax Form |
Yes. CI_TAX_FORM_K |
CIPVTXFV |
CIPVTXFK |
CIPVTXFI |
||
|
Tax Form Characteristic |
No. The key is Tax Form ID, Characteristic Type, and Sequence. |
|
CIPVTFCV |
|
CIPVTFCI |
|
|
Tax Form Log |
No. The key is Tax Form ID and Sequence. |
|
CIPVTFLV |
|
CIPVTFLI |
|
|
Tax Form Log Parameter |
No. The key is Tax Form ID, Sequence, and Message Parameter Sequence. |
|
CIPVTLPV |
|
CIPVTLPI |
Tax Form Suggestions
This maintenance object includes a character large object field that your organization may be using to capture implementation specific data as defined by your business objects. For records of this type, the process to insert the records to the staging table is responsible for populating the data in this CLOB as per the record's business object schema.
Collection Case
Contents
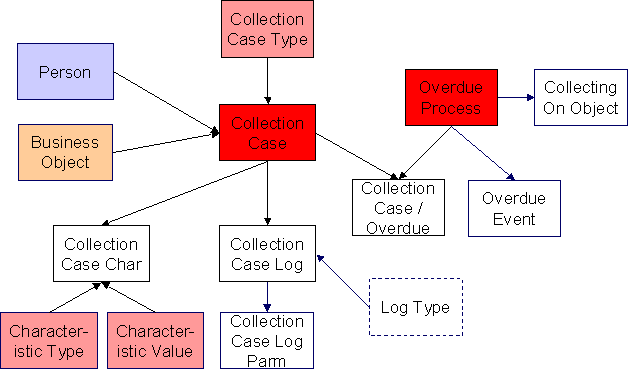
Collection Case Data Model
The following data model illustrates the Collection Case object.
Collection Case Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Object Validation Batch Control |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Collection Case |
Yes. CI_COLL_CASE_K |
CIPVCCSV |
CIPVCCSK |
CIPVCCSI |
||
|
Collection Case Characteristic |
No. The key is Collection Case ID. Characteristic Type, and Sequence. |
|
CIPVCCCV |
|
CIPVCCCI |
|
|
Collection Case Log |
No. The key is Collection Case ID and Sequence. |
|
CIPVCCLV |
|
CIPVCCLI |
|
|
Collection Case Log Parameter |
No. The key is Collection Case ID, Sequence, and Message Parameter Sequence. |
|
CIPVCCPV |
|
CIPVCCPI |
|
|
Collection Case Overdue Process |
No. The key is Collection Case ID and Overdue Process ID. |
|
CCIPVCCOV |
|
CCIPVCCOI |
Collection Case Suggestions
This maintenance object includes a character large object field that your organization may be using to capture implementation specific data as defined by your business objects. For records of this type, the process to insert the records to the staging table is responsible for populating the data in this CLOB as per the record's business object schema.
Overpayment Process
Contents
Overpayment Process Data Model
Overpayment Process Table Names
Overpayment Process Suggestions
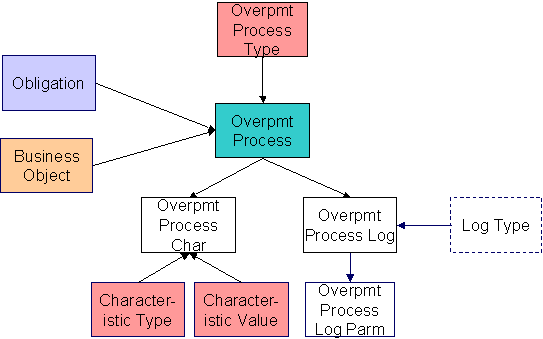
Overpayment Process Data Model
The following data model illustrates the Overpayment Process object.
Overpayment Process Table Names
|
Data Model Name |
Table Name |
Generated Keys |
Object Validation Batch Control |
Referential Integrity Validation Batch Control |
Key Assignment Batch Control |
Insertion Batch Control |
|
Overpayment Process |
Yes. CI_OP_PROC_K |
CIPVOPPV |
CIPVOPPK |
CIPVOPPI |
||
|
Overpayment Process Character |
No. The key is Overpayment Process ID, Characteristic Type, and Sequence. |
|
CIPVOPCV |
|
CIPVOPCI |
|
|
Overpayment Process Log |
No. The key is Overpayment Process ID and Sequence. |
|
CIPVOPLV |
|
CIPVOPLI |
|
|
Overpayment Process Log Parameter |
No. The key is Overpayment Process ID, Sequence, and Message Parameter Sequence. |
|
CIPVOPMI |
|
CIPVOPMI |
Overpayment Process Suggestions
This maintenance object includes a character large object field that your organization may be using to capture implementation specific data as defined by your business objects. For records of this type, the process to insert the records to the staging table is responsible for populating the data in this CLOB as per the record's business object schema.
Program Dependencies
The programs used to assign production keys are listed under Master Data and Transaction Data (in the Table Names matrices). Most of these programs have no dependencies (i.e., they can be executed in any order you please). The only exceptions to this statement are illustrated in the following diagram.
The tiers in this diagram contain a box for each table whose key assignment program is dependent on the successful execution of other key assignment programs. The numbers that appear in the boxes describe the order in which these programs must be executed.
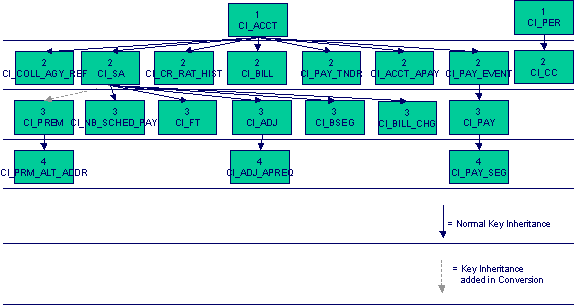
Please refer to the various “Table Names” sections above for the respective names of the programs to allocate each table’s keys.
Take note! Prior to running the key generation program for a particular object, it is required that any previously generated keys be cleared from the key allocation tables and the key allocation temporary storage table. It is recommended that the key allocation tables be analyzed between runs to maximize performance.
Appendix A - Entity Relationship Diagramming Standards
Because all data is stored in relational table, you need to be able to read diagrams that illustrate relationships between the various tables. The following entity diagram uses every diagramming notation used in this course:
Contents
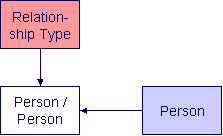
Entity
Every box on the above diagram represents an entity (i.e., a table). An entity may be a physical entity, such as a Person, or a logical construct, such as an Account.
Color Coding
If you can view this document in color, you will notice that each entity is colored. The color indicates the “subsystem” which governs the entity. Know the governing subsystem is important because:
· The system’s menu structure is subsystem-oriented (i.e., if you know the subsystem, you will know how to use the menus to navigate to the page used to view and update the entity).
· The system’s documentation is subsystem-oriented (i.e., if you know the subsystem, you will know which chapter contains information about the entity).
Some entities are not color-coded (i.e., they are white). These entities do not have a dedicated page, as they are part of a parent entity. For example, the Person / Person entity above is related to the Person object and does not have its own page. You must display the parent entity in order to view such an entity. For example, if you want to look at Person / Person information, you must go to the Person page.
The following table describes the colors utilized in the documentation:
|
Color |
Subsystem |
|
|
Taxpayer Information |
|
|
Admin (Control) Table. These tables are referenced as foreign keys on master and transaction tables. We do not document the names of these tables in this document as the table names are easily accessible using the Table transaction. |
|
|
N/A – the entity is maintained in respect of a higher level entity. |
|
|
N/A – the values in these types of entities are defined in a special table referred to as the lookup table. In order to determine the valid values for a column that references a lookup table, use the name of the column as the search value on the Look Up user interface. |
|
|
Rates |
|
|
Billing |
|
|
Financial Transaction |
|
|
Payment |
|
|
Adjustment |
|
|
Case |
Relationships
The solid line connecting the two entities that is terminated by an arrow represents a relationship between two entities. You read the relationship from the entity without the arrow to the entity with the arrow. For example, the line between account type and Account illustrates that an account type may have many Accounts, but an Account may be part of a single account type.
Appendix B - Multiple Owners In A Single Database
In the schematic referenced in the Introduction, you’ll notice that there are two table owners in the system database. We refer to the first owner as “staging” and the second owner as “production”.
The staging owner is linked to the tables into which you insert your pre-validated data. These tables have an owner ID of CISSTG.
Multiple staging databases. It is possible to have multiple staging databases. In this situation, each one would have a unique owner ID, e.g., CISSTG1, CISSTG2, etc.
The production owner is linked to the tables used by your production system. These tables have an owner ID of CISADM.
When the validation programs run against your staging data, they validate the staging data against the production control tables (and insert errors into the staging error table). This means that the SQL statements that access / update master and transaction data need to use the staging owner (CISSTG). Whereas the SQL statements that access control tables need to use the production owner (CISADM).
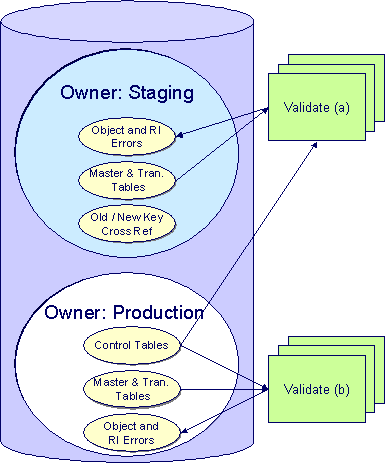
But notice that when these same programs run against production (Validate (b)), the SQL statements will never access the staging owner. Rather, they all point at the production owner.
This is accomplished as follows:
· A separate application server must exist for each owner. Each application server points at a specific Tuxedo server. The Tuxedo server references a specific database user ID.
· The database user ID associated with the staging database uses CISSTG as the owner for the master and transaction tables, but it uses CISADM as the owner of the production control tables.
· The database user ID associated with the production database uses CISADM as the owner for the master, transaction, and control tables.
You may wonder why we went to this trouble. There are several reasons:
· We wanted to re-use the validation logic that exists in the programs that validate your production data. In order to achieve this, these programs must sometimes point at the staging owner, and other times they must point at the production owner (and this must be transparent to the programs otherwise two sets of SQL would be necessary).
· We wanted to let you use the application to look at and correct staging data. This can be accomplished by creating an application server that points at your staging database with the ownership characteristics described above.
· We wanted the validation programs to be able to validate your production data (in addition to your staging data). Why would you want to validate production data if only clean data can be added to production? Consider the following scenarios:
· After an upgrade, you might want to validate your production data to ensure your pre-existing user-exit logic still works.
· You may want to conduct an experiment of the ramifications of changing your validation logic. To do this, you could make a temporary change to user exit logic (in production) and then run the validation jobs on a random sample basis.
· You forget to run a validation program before populating production and you want to see the damage. If you follow the instructions in this document, this should never happen. However, accidents happen. And if they do, at least there’s a way to determine the ramifications.
While the redirection of owner ID’s is a useful technique for the validation programs, it cannot be used by the key assignment and production insert programs? Why, because these programs have to access the same tables but with different owners. For example, the program that inserts rows into the person table must select rows from staging.Person and insert them into production.Person.
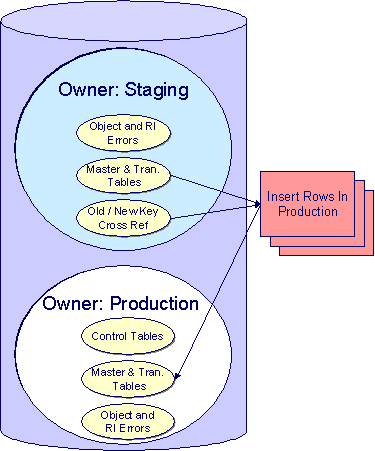
This is accomplished as follows:
· Views exist for each table that exists in both databases. These views have hard-coded the database owner CISADM (production). For example, there is a view called CX_PER that points at person table in production.
· The key assignment and insertion programs use these views whenever then need to access production data.
Be aware that the following tables reference master data (e.g., persons, accounts). This means that if you look at them using a user ID that defaults ownership to the staging level, you will not be able to see the related master data (because the person / account doesn’t exist in the staging owner’s tables).
· Collection Agency. References a person.
· Tender Source. References a suspense account.