Table of Contents
This chapter discusses using MySQL Cluster with MySQL Cluster Connector for Java, which includes ClusterJ and ClusterJPA, a plugin for use with OpenJPA, both of which became available in MySQL Cluster NDB 7.1.
ClusterJ is a high level database API that is similar in style and concept to object-relational mapping persistence frameworks such as Hibernate and JPA. Because ClusterJ does not use the MySQL Server to access data in MySQL Cluster, it can perform some operations much more quickly than can be done using JDBC. ClusterJ supports primary key and unique key operations and single-table queries; it does not support multi-table operations, including joins.
ClusterJPA is an OpenJPA implementation for MySQL Cluster that attempts to offer the best possible performance by leveraging the strengths of both ClusterJ and JDBC. ID lookups and other such operations are performed using ClusterJ, while more complex queries that can benefit from the MySQL query optimizer are sent through the MySQL Server, using JDBC.
MySQL Cluster Connector for Java is currently considered beta quality software, indicating that it is appropriate for use with new development, and that its features and compatibility should remain consistent. However, as with all beta releases, MySQL Cluster Connector for Java may contain numerous and major unaddressed bugs. Although MySQL Cluster Connector for Java is feature-complete, some implementation details may change prior to a final release; thus, this documentation is currently also subject to change without notice.
This section provides a conceptual and architectural overview of the APIs available using the MySQL Cluster Connector for Java.
MySQL Cluster Connector for Java is a collection of Java APIs for writing applications against MySQL Cluster, including JDBC, JPA, and ClusterJ. These provide a number of different access paths and styles of access to MySQL Cluster data. Section 4.1, “MySQL Cluster Connector for Java: Overview”, describes each of these APIs in more detail.
MySQL Cluster Connector for Java is included with MySQL Cluster source and binary releases beginning with MySQL Cluster NDB 7.1.1. Building MySQL Cluster Connector for Java from source can be done as part of building MySQL Cluster; however, it can also be built with Maven.
A MySQL Cluster is
defined as one or more MySQL Servers providing access to an
NDBCLUSTER storage engine—that
is, to a set of MySQL Cluster data nodes (ndbd
processes). There are four main access paths from Java to
NDBCLUSTER, listed here:
JDBC and mysqld. JDBC works by sending SQL statements to the MySQL Server and returning result sets. When using JDBC, you must write the SQL, manage the connection, and copy any data from the result set that you want to use in your program as objects. The JDBC implementation most often used with the MySQL Server is MySQL Connector/J.
Java Persistence API (JPA) and JDBC. JPA uses JDBC to connect to the MySQL Server. Unlike JDBC, JPA provides an object view of the data in the database.
ClusterJ. ClusterJ uses a JNI bridge to the NDB API for direct access to
NDBCLUSTER. It employs a style of data access that is based on a domain object model, similar in many ways to that employed by JPA. ClusterJ does not depend on the MySQL Server for data access.ClusterJPA. ClusterJPA is an adapter for the OpenJPA implementation. It can use either of two different access paths—JDBC or ClusterJ—to MySQL Cluster data, depending on the type of operation to be performed. This can significantly improve performance for some uses, bypassing SQL, JDBC, and the MySQL Server entirely when it is more efficient to do so.
These paths are shown in the following API stack diagram:
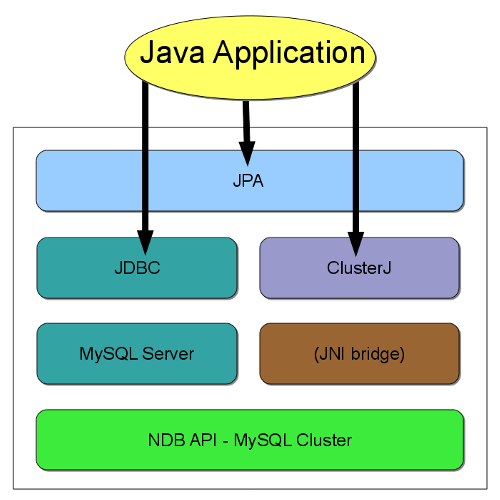
JDBC and mysqld. Connector/J provides standard access through the MySQL JDBC driver. Using Connector/J, JDBC applications can be written to work with a MySQL server acting as a MySQL Cluster SQL node in much the same way that other Connector/J applications work with any other MySQL Server instance.
For more information, see Section 4.2.4, “Using Connector/J with MySQL Cluster”.
ClusterJ.
ClusterJ is a native Java Connector for
NDBCLUSTER (or
NDB), the storage engine for MySQL
Cluster, in the style of
Hibernate,
JPA,
and JDO. Like
other persistence frameworks, ClusterJ uses the
Data
Mapper pattern, in which data is represented as domain
objects, separate from business logic, mapping Java classes to
database tables stored in the
NDBCLUSTER storage engine.
The NDBCLUSTER storage engine is
often referred to (in MySQL documentation and elsewhere) simply
as NDB. The terms
NDB and
NDBCLUSTER are synonymous, and you
can use either ENGINE=NDB or
ENGINE=NDBCLUSTER in a
CREATE TABLE statement to create
a clustered table.
ClusterJ does not need to connect to a mysqld
process, having direct access to
NDBCLUSTER using a JNI bridge that is
included in the dynamic library libnbdclient.
However, unlike JDBC, ClusterJ does not support table creation and
other data definition operations; these must be performed by some
other means, such as JDBC or the mysql client.
OpenJPA (ClusterJPA). ClusterJPA is an adapter for OpenJPA that can also bypass JDBC and MySQL Server, using ClusterJ for fast-track access to the cluster. However, for complex queries (not primary key lookups) ClusterJPA uses JDBC.
OpenJPA is an implementation of the JPA (Java Persistence API) specification, which provides an object-relational persistence framework with relationships, inheritance, and persistent classes. See openjpa.apache.org, for more information about OpenJPA.
ClusterJ is independent of ClusterJPA as well as JDBC. However, ClusterJ can be used together with these APIs. Because ClusterJ is limited to queries on single tables, and does not support relations or inheritance, you should use JPA if you need support for these features in your applications.
For more information, see Section 4.2.3, “Using JPA with MySQL Cluster”.
Differences Between ClusterJPA and ClusterJ. While ClusterJPA and ClusterJ are similar in many ways, there are importance differences between the two, highlighted in the following list.
ClusterJPA supports persistent classes, whereas ClusterJ only supports persistent interfaces.
ClusterJPA supports relationships between persistent classes (typically modeled as logical foreign keys), whereas ClusterJ only supports single-valued fields directly mapped to database columns.
ClusterJPA makes it possible for you to formulate queries that contain joins based on relationships in the domain object model, while ClusterJ does not support either relationships or joins.
However, once you retrieve instances using a JPA query, you can update or delete these using the fast path of ClusterJ.
ClusterJPA makes it possible to use the JPA API to declare some fields as lazily loaded, meaning that the data is only brought into memory when your program actually references it. ClusterJ, however, reads all mapped columns from the table whenever you access a row.
This section discusses the ClusterJ API and the object model used to represent the data handled by the application.
Application Programming Interface.
The ClusterJ API depends on 4 main interfaces:
Session, SessionFactory,
Transaction, and
QueryBuilder.
Session interface.
All access to MySQL Cluster data is done in the context of a
session. The
Session
interface represents a user's or application's
individual connection to a MySQL Cluster. It contains methods
for the following operations:
Finding persistent instances by primary key
Creating, updating, and deleting persistent instances
Getting a query builder (see com.mysql.clusterj.query.QueryBuilder)
Getting the current transaction (see com.mysql.clusterj.Transaction).
SessionFactory interface.
Sessions are obtained from a
SessionFactory,
of which there is typically a single instance for each MySQL
Cluster that you want to access from the Java VM.
SessionFactory stores configuration
information about the cluster, such as the hostname and port
number of the MySQL Cluster management server. It also stores
parameters regarding how to connect to the cluster, including
connection delays and timeouts. For more information about
SessionFactory and its use in a ClusterJ application, see
Getting the SessionFactory and getting a
Session.
Transaction interface.
Transactions are not managed by the Session
interface; like other modern application frameworks, ClusterJ
separates transaction management from other persistence methods.
Transaction demarcation might be done automatically by a
container or in a web server servlet filter. Removing
transaction completion methods from Session
facilitates this separation of concerns.
The
Transaction
interface supports the standard begin, commit, and rollback
behaviors required by a transactional database. In addition, it
enables the user to mark a transaction as being rollback-only,
which makes it possible for a component that is not responsible
for completing a transaction to indicate that—due to an
application or database error—the transaction must not be
permitted to complete normally.
QueryBuilder interface.
The
QueryBuilder
interface makes it possible to construct criteria queries
dynamically, using domain object model properties as query
modeling elements. Comparisons between parameters and database
column values can be specified, including equal, greater and
less than, between, and in operations. These comparisons can be
combined using methods corresponding to the Boolean operators
AND, OR, and NOT. Comparison of values to
NULL is also supported.
Data model. ClusterJ provides access to data in MySQL Cluster using domain objects, similar in many ways to the way that JPA models data.
In ClusterJ, the domain object mapping has the following characteristics:
All tables map to persistent interfaces. For every
NDBtable in the cluster, ClusterJ uses one or more interfaces. In many cases, a single interface is used; but for cases where different columns are needed by different parts of the application, multiple interfaces can be mapped to the same table.However, the classes themselves are not persistent.
Users map a subset of columns to persistent properties in interfaces. Thus, all properties map to columns; however, not all columns necessarily map to properties.
All ClusterJ property names default to column names. The interface provides getter and setter methods for each property, with predictable corresponding method names.
Annotations on interfaces define mappings.
The user view of the application environment and domain objects is illustrated in the following diagram, which shows the logical relationships among the modeling elements of the ClusterJ interfaces:
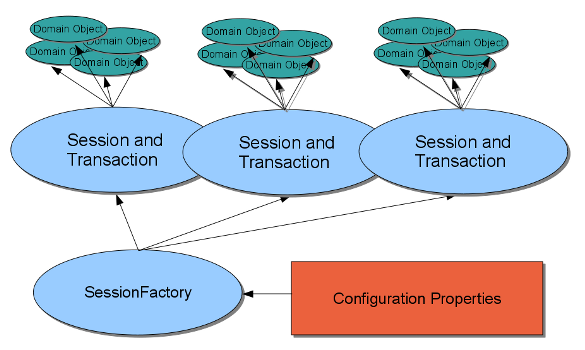
The SessionFactory is configured by a
properties object that might have been loaded from a file or
constructed dynamically by the application using some other means
(see Section 4.2.2.1, “Executing ClusterJ Applications and Sessions”).
The application obtains Session instances from
the SessionFactory, with at most one thread
working with a Session at a time. A thread can
manage multiple Session instances if there is
some application requirement for multiple connections to the
database.
Each session has its own collection of domain objects, each of which represents the data from one row in the database. The domain objects can represent data in any of the following states:
New; not yet stored in the database
Retrieved from the database; available to the application
Updated; to be stored back in the database
To be deleted from the database
This section provides basic information about building and running Java applications using MySQL Cluster Connector for Java.
This section discusses how to obtain MySQL Cluster Connector for Java sources, binaries, compiling, installing, getting started.
Obtaining MySQL Cluster Connector for Java. You can obtain the most recent MySQL Cluster NDB 7.1 or later source or binary release incorporating MySQL Cluster Connector for Java from downloads.mysql.com.
Building and installing MySQL Cluster Connector for Java from source.
You can build and install ClusterJ, ClusterJPA, or both as part
of building and installing MySQL Cluster, which always requires
you to configure the build using a
--with-plugins option that causes
NDB support to be included, such as
--with-plugins=ndbcluster or
--with-plugins=max. Other relevant plugin names
that can be used with this option include the following:
clusterj: Required for building MySQL Cluster with ClusterJ support.openjpa: Required for building MySQL Cluster with ClusterJPA support.
In addition, you should use the following two configure options when configuring a build to include ClusterJ, ClusterJPA, or both:
--with-classpath=: Required for building MySQL Cluster with ClusterJPA support.pathpathmust include the path or paths to the OpenJPA libraries and OpenJPA dependencies on your system.--with-extra-charsets: ClusterJ uses theucs2character set for internal storage, and ClusterJ cannot be built without it. The simplest way to ensure that this character set is available is to configure using--with-extra-charsets=all. This is what we recommend that you use, unless you have some reason for not wanting to include all character sets, in which case you should make sure thatucs2is specified in the character set list passed to this option.
A typical configuration step in building MySQL Cluster with support for both ClusterJ and ClusterJPA might look like this:
shell> ./configure --with-plugins=ndbcluster,clusterj,openjpa \
--with-extra-charsets=all \
--with-classpath=path/to/openjpa/libs \
--prefix=path/to/install/directory
path/to/openjpa/libs must include the
following:
openjpa-1.2.0.jardriver-5.1.10.jar(This is the MySQL JDBC driver)geronimo-jta_1.1_spec-1.1.jargeronimo-jpa_3.0_spec-1.0.jarserp-1.13.1.jarcommons-lang-2.1.jarcommons-collections-3.2.jar
Not all available options for configuring a MySQL Cluster build are shown in this section. For information about other options that can be used, see Installing from the Development Source Tree, or consult the output of configure --help.
After configuring the build, run make and
make install as you normally would to compile
and install the MySQL Cluster software. Following installation,
the MySQL Cluster Connector for Java jar files can be found in
share/mysql/java under the MySQL installation
directory (by default, this is
/usr/local/mysql/share/mysql/java).
You can also use the included file
storage/ndb/clusterj/pom.xml for building
ClusterJ with Maven.
MySQL Cluster Connector for Java jar files.
After building and installing MySQL Cluster with MySQL Cluster Connector for Java, you
should find the following JAR files that are needed for using
ClusterJ and ClusterJPA in
share/mysql/java/ under the MySQL Cluster
installation directory:
clusterj-api.jar: This is the compile-time jar file, required for compiling ClusterJ application code.clusterj.jar: This is the runtime library required for executing ClusterJ applications.clusterjpa.jar: This is the runtime library required for executing ClusterJPA applications. This jar file must be in your classpath when running OpenJPA with ClusterJPA.
This section provides basic information for writing, compiling, and executing applications that use ClusterJ.
Requirements. ClusterJ requires Java 1.5 or 1.6, and ClusterJ applications should run with MySQL Cluster NDB 7.0 and later. MySQL Cluster must be compiled with ClusterJ support; MySQL Cluster binaries supplied by Sun Microsystems include ClusterJ support beginning with MySQL Cluster NDB 7.0.12 and MySQL Cluster NDB 7.1.1. If you are building MySQL Cluster from source, see Building and installing MySQL Cluster Connector for Java from source, for information on configuring the build to enable ClusterJ support.
Beginning with MySQL Cluster NDB 7.1.2, to compile applications
that use ClusterJ, you need the clusterj-api
jar file in your classpath. To run applications that use ClusterJ,
you need the clusterj runtime jar file; in
addition, libndbclient must be in the directory
specified by java.library.path.
Section 4.2.2.1, “Executing ClusterJ Applications and Sessions”, provides more
information about these requirements.
The requirements for running ClusterJ applications were somewhat different in MySQL Cluster NDB 7.1.1; see Building and executing ClusterJ applications in MySQL Cluster NDB 7.1.1, if you are using this release.
In this section, we discuss how to start ClusterJ applications and the ClusterJ application environment as of MySQL Cluster NDB 7.1.2.
These requirements were somewhat different for MySQL Cluster NDB 7.1.1, as the implementation had not yet completely stabilized in that version. See Building and executing ClusterJ applications in MySQL Cluster NDB 7.1.1, at the end of this section, for more information.
Executing a ClusterJ application.
All of the ClusterJ jar files are normally found in
share/mysql/java/ in the MySQL
installation directory. When executing a ClusterJ application,
you must set the classpath to point to these files. In
addition, you must set java.library.path
variable to point to the directory containing the Cluster
ndbclient library, normally found in
lib/mysql (also in the MySQL installation
directory). Thus you might execute a ClusterJ program
MyClusterJApp in a manner similar to what
is shown here:
shell> java -classpath /usr/local/mysql/share/mysql/java/clusterj.jar -Djava.library.path=/usr/local/mysql/lib MyClusterJApp
The precise locations of the ClusterJ jar files and of
libndbclient depend on how the MySQL
Cluster software was installed. See
Installation Layouts, for more information.
ClusterJ encourages you to use different jar files at compile
time and run time. This is to remove the ability of applications
to access implementation artifacts accidentally. ClusterJ is
intended to be independent of the MySQL Cluster software
version, whereas the ndbclient layer is
version-specific. This makes it possible to maintain a stable
API, so that applications written against it using a given MySQL
Cluster version continue to run following an upgrade of the
cluster to a new version.
Building and executing ClusterJ applications in MySQL Cluster NDB 7.1.1.
As in later versions, only
clusterj-api.jar is required in your
classpath to compile a ClusterJ application. However, in order
to run ClusterJ applications in MySQL Cluster NDB 7.1.1,
several jar files are needed:
clusterj-core.jar,
clusterj-tie.jar,
jtie.jar, and
ndbjtie.jar; in addition,
libndbjtie must be in your
java.library.path.
Beginning with MySQL Cluster NDB 7.1.2, the runtime jar files
just named have been combined as
clusterj.jar, and
libndbjtie has been made part of
libndbclient.
Getting the SessionFactory and getting a
Session.
SessionFactory
is the source of all ClusterJ sessions that use a given MySQL
Cluster. Usually, there is only a single
SessionFactory per MySQL Cluster, per Java
Virtual Machine.
SessionFactory can be configured by setting
one or more properties. The preferred way to do this is by
putting these in a properties file, like this:
com.mysql.clusterj.connectstring=localhost:1186 com.mysql.clusterj.database=mydb
The name of the properties file is arbitrary; howver, by
convention, such files are named with a
.properties extension. For ClusterJ
applications, it is customary to name the file
clusterj.properties.
After editing and saving the file, you can load the its contents
into an instance of
Properties,
as shown here:
File propsFile = new File("clusterj.properties");
InputStream inStream = new FileInputStream(propsFile);
Properties props = new Properties();
props.load(inStream);
It is also possible to set these properties directly, without the use of a properties file:
Properties props = new Properties();
props.put("com.mysql.clusterj.connectstring", "localhost:1186");
props.put("com.mysql.clusterj.database", "mydb");
Once the properties have been set and loaded (using either of
the techniques just shown), you can obtain a
SessionFactory, and then from that a
Session
instance. For this, you use the
SessionFactory's
getSession()
method, as shown here:
SessionFactory factory = ClusterJHelper.getSessionFactory(props); Session session = factory.getSession();
It is usually sufficient to set and load the
com.mysql.clusterj.connectstring
and
com.mysql.clusterj.database
properties (and these properties, along with
com.mysql.clusterj.max.transactions,
cannot be changed after starting the
SessionFactory). For a complete list of
available SessionFactory properties and usual
values, see com.mysql.clusterj.Constants.
Session instances must not be shared among
threads. Each thread in your application should use its own
instance of Session.
For
com.mysql.clusterj.connectstring,
we use the default MySQL Cluster connectstring
localhost:1186 (see
The MySQL Cluster Connectstring, for more
information). For the value of
com.mysql.clusterj.database,
we use mydb in this example, but this value
can be the name of any database containing
NDB tables. For a listing of all
SessionFactory properties that can be set in
this manner, see com.mysql.clusterj.Constants.
ClusterJ's main purpose is to read, write, and update row
data in an existing database, rather than to perform DDL. You
can create the employee table that matches
this interface, using the following CREATE
TABLE statement, in a MySQL client application such as
mysql.
CREATE TABLE employee (
id INT NOT NULL PRIMARY KEY,
first VARCHAR(64) DEFAULT NULL,
last VARCHAR(64) DEFAULT NULL,
municipality VARCHAR(64) DEFAULT NULL,
started DATE DEFAULT NULL,
ended DATE DEFAULT NULL,
department INT NOT NULL DEFAULT 1,
UNIQUE KEY idx_u_hash (lname,fname) USING HASH,
KEY idx_municipality (municipality)
) ENGINE=NDBCLUSTER;
Now that the table has been created in MySQL Cluster, you can map a ClusterJ interface to it using annotations. We show you how to do this in the next section.
In ClusterJ (as in JPA), annotations are used to describe how the interface is mapped to tables in a database. An annotated interface looks like this:
@PersistenceCapable(table="employee")
@Index(name="idx_uhash")
public interface Employee {
@PrimaryKey
int getId();
void setId(int id);
String getFirst();
void setFirst(String first);
String getLast();
void setLast(String last);
@Column(name="municipality")
@Index(name="idx_municipality")
String getCity();
void setCity(String city);
Date getStarted();
void setStarted(Date date);
Date getEnded();
void setEnded(Date date);
Integer getDepartment();
void setDepartment(Integer department);
}
This interface maps seven columns: id,
first, last,
municipality started,
ended, and department. The
annotation
@PersistenceCapable(table="employee") is used
to let ClusterJ know which database table to map the
Employee to (in this case, the
employee table). The
@Column annotation is used because the
city property name implied by the
getCity() and setCity()
methods is different from the mapped column name
municipality. The annotations
@PrimaryKey and @Index
inform ClusterJ about indexes in the database table.
The implementation of this interface is created dynamically by
ClusterJ at runtime. When the
newInstance()
method is called, ClusterJ creates an implementation class for
the Employee interface; this class stores the
values in an internal object array.
ClusterJ does not require an annotation for every attribute. ClusterJ automatically detects the primary keys of tables; while there is an annotation in ClusterJ to permit the user to describe the primary keys of a table (see previous example), when specified, it is currently ignored. (The intended use of this annotation is for the generation of schemas from the domain object model interfaces, but this is not yet supported.)
The annotations themselves must be imported from the ClusterJ
API. They can be found in package
com.mysql.clusterj.annotation,
and can be imported like this:
import com.mysql.clusterj.annotation.Column; import com.mysql.clusterj.annotation.Index; import com.mysql.clusterj.annotation.PersistenceCapable; import com.mysql.clusterj.annotation.PrimaryKey;
In this section, we describe how to perform operations basic to ClusterJ applications, including the following:
Creating new instances, setting their properties, and saving them to the database
Performing primary key lookups (reads)
Updating existing rows and saving the changes to the database
Deleting rows from the database
Constructing and executing queries to fetch a set of rows meeting certain criteria from the database
Creating new rows.
To insert a new row into the table, first create a new
instance of Employee. This can be
accomplished by calling the Session method
newInstance(),
as shown here:
Employee newEmployee = session.newInstance(Employee.class);
Set the Employee instance properties
corresponding with the desired employee table
columns. For example, the following sets the
id, firstName,
lastName, and started
properties.
emp.setId(988);
newEmployee.setFirstName("John");
newEmployee.setLastName("Jones");
newEmployee.setStarted(new Date());
Once you are satisfied with the changes, you can persist the
Employee instance, causing a new row
containing the desired values to be inserted into the
employee table, like this:
session.persist(newEmployee);
If the row with the same id as this
Employee instance already exists in the
database, the persist() method fails. If you
want to save the data even if the row already exists, use the
savePersistent() method instead of the
persist() method. The
savePersistent() method updates an existing
instance or creates a new instance without throwing an
exception.
Values that you have not specified are stored with their Java
default values (0 for integral types,
0.0 for numeric types, and
null for reference types).
Primary key lookups.
You can find an existing row in an
NDB table using the
Session's
find()
method, like this:
Employee theEmployee = session.find(Employee.class, 988);
This is equivalent to the primary key lookup query
SELECT * FROM employee WHERE id = 988.
ClusterJ also supports compound primary keys. The
find()
method can take an object array as a key, where the components
of the object array are used to represent the primary key
columns in the order they were declared. In addition, queries
are optimized to detect whether columns of the primary key are
specified as part of the query criteria, and if so, a primary
key lookup or scan is executed as a strategy to implement the
query.
ClusterJ also supports multiple column ordered btree and unique hash indexes. As with primary keys, if a query specifies values for ordered or unique index fields, ClusterJ optimizes the query to use the index for scanning the table.
MySQL Cluster automatically spreads table data across multiple data nodes. For some operations—find, insert, delete, and update—it is more efficient to tell the cluster on which data node the data is physically located, and to have the transaction execute on that data node. ClusterJ automatically detects the partition key; if the operation can be optimized for a specific data node, ClusterJ automatically starts the transaction on that node.
Update and save a row.
To update the value of a given column in the row that we just
obtained as theEmployee, use the
set*() method whose name corresponds to the
name of that column. For example, to update the
started date for this
Employee, use the
Employee's
setStarted() method, as shown here:
theEmployee.setStarted(new Date(getMillisFor(2010, 01, 04)));
For convenience, we use in this example a method
getMillisFor(), which is defined as shown
here, in the file
AbstractClusterJModelTest.java (found in
the
storage/ndb/clusterj/clusterj-test/src/main/java/testsuite/clusterj
directory of the MySQL Cluster source tree):
/** Convert year, month, day into milliseconds after the Epoch, UTC.
* Set hours, minutes, seconds, and milliseconds to zero.
* @param year the year
* @param month the month (0 for January)
* @param day the day of the month
* @return
*/
protected static long getMillisFor(int year, int month, int day) {
Calendar calendar = Calendar.getInstance();
calendar.clear();
calendar.set(Calendar.YEAR, year);
calendar.set(Calendar.MONTH, month);
calendar.set(Calendar.DATE, day);
calendar.set(Calendar.HOUR, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
long result = calendar.getTimeInMillis();
return result;
}
See the indicated file for further information.
You can update additional columns by invoking other
Employee setter methods, like this:
theEmployee.setDepartment(3);
To save the changed row back to the MySQL Cluster database, use
the Session's
updatePersistent()
method, like this:
session.updatePersistent(theEmployee);
Deleting rows.
You can delete a single row easily using the
deletePersistent()
method of Session. In this example, we find
the employee whose ID is 13, then delete this row from the
employee table:
Employee exEmployee = session.find(Employee.class, 13);
session.deletePersistent(exEmployee);'
System.out.println("Deleted employee named " + exEmployee.getFirst()
+ " " + exEmployee.getLast() + ".");
There also exists a method for deleting multiple rows, which provides two options:
Delete all rows from a table.
Delete an arbitrary collection of rows.
Both kinds of multi-row delete can be performed using the
deletePersistentAll() method. The
first
variant of this method acts on a
Class. For example, the following statement
deletes all rows from the employee table and
returns the number of rows deleted, as shown here:
int numberDeleted = session.deletePersistentAll(Employee);
System.out.println("There used to be " + numberDeleted + " employees, but now there are none.");
The call to deletePersistentAll() just shown
is equivalent to issuing the SQL statement
DELETE FROM
employee in the mysql client.
deletePersistentAll()
can also be used to delete a collection of rows, as shown in
this example:
// Assemble the collection of rows to be deleted...
List<Employee> redundancies = new ArrayList<Employee>();
for (int i = 1000; i < 2000; i += 100) {
Employee redundant = session.newInstance(Employee.class);
redundant.setId(i);
redundancies.add(redundant);
}
numberDeleted = session.deletePersistentAll(redundancies);
System.out.println("Deleted " + numberDeleted + " rows.");
It is not necessary to find the instances in the database before deleting them.
Writing queries.
The ClusterJ
QueryBuilder
interface is used to instantiate queries. The process begins
with obtaining an instance of
QueryBuilder,
which is supplied by the current
Session;
we can then obtain a
QueryDefinition,
as shown here:
QueryBuilder builder = session.getQueryBuilder(); QueryDomainType<Employee> domain = builder.createQueryDefinition(Employee.class);
This is then used to set a column for comparison by the query.
Here, we show how to prepare a query that compares the value of
the employee table's
department column with the constant value
8.
domain.where( domain.get("department").equal(domain.param("department") );
Query<Employee> query = session.createQuery(domain);
query.setParameter("department", 8);
To obtain the results from the query, invoke the
Query's
getResultList()
method, as shown here;
List<Employee> results = query.getResultList();
The return value is a
List
that you can iterate over to retrieve and process the rows in
the usual manner.
Transactions.
The
Transaction
interface can optionally be used to bound transactions, via
the following methods:
begin(): Begin a transaction.commit(): Commit a transaction.rollback(): Roll back a transaction.
It is also possible using
Transaction
to check whether the transaction is active (via the
isActive()
method, and to get and set a rollback-only flag (using
getRollbackOnly()
and
setRollbackOnly(),
respectively).
If you do not use the Transaction interface,
methods in Session that affect the
database—such as persist(),
deletePersistent(),
updatePersistent(), and so on—are
automatically enclosed in a database transaction.
ClusterJ provides mappings for all of the common MySQL database types to Java types. Java object wrappers of primitive types should be mapped to nullable database columns.
Since Java does not have native unsigned data types,
UNSIGNED columns should be avoided in table
schemas if possible.
Compatibility with JDBC mappings. ClusterJ is implemented so as to be bug-compatible with the JDBC driver in terms of mapping from Java types to the database. That is, if you use ClusterJ to store or retrieve data, you obtain the same value as if you used the JDBC driver directly or through JPA.
The following tables show the mappings used by ClusterJ between common Java data types and MySQL column types. Separate tables are provided for numeric, floating-point, and variable-width types.
Numeric types. This table shows the ClusterJ mappings between Java numeric data types and MySQL column types:
| Java Data Type | MySQL Column Type |
|---|---|
boolean,
Boolean | BIT(1) |
byte,
Byte | BIT(1) to
BIT(8),
TINYINT |
short,
Short | BIT(1) to
BIT(16),
SMALLINT,
YEAR |
int,
Integer | BIT(1) to
BIT(32),
INT |
long,
Long | BIT(1) to
BIT(64),
BIGINT,
BIGINT
UNSIGNED |
float,
Float | FLOAT |
double,
Double | DOUBLE |
java.math.BigDecimal | NUMERIC,
DECIMAL |
java.math.BigInteger | NUMERIC (precision = 0),
DECIMAL (precision = 0) |
Date and time types. The following table shows the ClusterJ mappings between Java date and time data types and MySQL column types:
| Java Data Type | MySQL Column Type |
|---|---|
Java.util.Date | DATETIME,
TIMESTAMP,
TIME,
DATE |
Java.sql.Date | DATE |
Java.sql.Time | TIME |
Java.sql.Timestamp | DATETIME,
TIMESTAMP |
ClusterJ maps the MySQL YEAR
type to a Java short (or
java.lang.Short), as shown in the first
table in this section.
java.util.Date
represents date and time similar to the way in which Unix does
so, but with more precision and a larger range. Where Unix
represents a point in time as a 32-bit signed number of
seconds since the Unix Epoch (01 January 1970), Java uses a
64-bit signed number of milliseconds since the Epoch.
Variable-width types. The following table shows the ClusterJ mappings between Java data types and MySQL variable-width column types:
| Java Data Type | MySQL Column Type |
|---|---|
String | CHAR,
VARCHAR,
TEXT |
byte[] | BINARY,
VARBINARY,
BLOB |
No translation binary data is performed when mapping from
MySQL BINARY,
VARBINARY, or
BLOB column values to Java byte
arrays. Data is presented to the application exactly as it is
stored.
ClusterJPA is implemented as a plugin for OpenJPA. The best way to use ClusterJPA is to start with the standard configuration of OpenJPA with JDBC and MySQL Server. Once you know that this configuration works for your application, you can switch to the ClusterJ code path.
In MySQL Cluster NDB 7.1.2 and later, compiling applications for ClusterJPA is the same as compiling them for OpenJPA. To do this, you must have the following jar files in your classpath:
openjpa-1.2.0.jardriver-5.1.10.jar(This is the MySQL JDBC driver)geronimo-jta_1.1_spec-1.1.jargeronimo-jpa_3.0_spec-1.0.jarserp-1.13.1.jarcommons-lang-2.1.jarcommons-collections-3.2.jar
You must also have the OpenJPA jar files to run OpenJPA
applications. To run them using ClusterJPA, you also need the
clusterj.jar jar file in your classpath, as
well as the MySQL Server JDBC connector jar file
mysql-connector-j.jar (see
Connector/J Installation), and your
java.library.path must include the directory
where libndbclient can be found.
The requirements for compiling and running OpenJPA applications
were slightly different in MySQL Cluster NDB 7.1.1. In that
version of MySQL Cluster, in addition to the OpenJPA jar files,
clusterj-openjpa.jar was also required for
compilation and execution, and the jar files
clusterj-core.jar,
clusterj-tie.jar,
jtie.jar, and
ndbjtie.jar were required to run the
application; in addition, you needed
libndbjtie to be found in your
java.library.path.
In MySQL Cluster NDB 7.1.2 and later, these multiple ClusterJPA
jar files have been merged into
clusterj.jar, and
libndbjtie has become part of
libndbclient.
You must also update the persistence.xml
file, which selects the JPA implementation to be used by the
application. The contents of a sample
persistence.xml file are shown here (with the
relevant portions shown in emphasized text):
<persistence-unit name="personnel" transaction-type="RESOURCE_LOCAL">
<provider>
org.apache.openjpa.persistence.PersistenceProviderImpl
</provider>
<class>com.mysql.clusterj.jpatest.model.Employee</class>
<properties>
<property name="openjpa.BrokerFactory" value="ndb"/>
<property name="openjpa.ndb.connectString" value="localhost:1186"/>
<property name="openjpa.ConnectionURL" value="jdbc:mysql://localhost:3306/test"/>
<property name="openjpa.ConnectionDriverName" value="com.mysql.jdbc.Driver"/>
<property name="openjpa.ConnectionRetainMode" value="transaction"/>
</properties>
</persistence-unit>
To activate ClusterJPA, the property named
openjpa.BrokerFactory must have the value
ndb.
The name of the persistence unit is arbitrary; for this example,
we have chosen personnel.
JDBC clients of a MySQL Cluster data source, and using Connector/J
5.0.6 (or later), accept
jdbc:mysql:loadbalance:// URLs (see
Driver/Datasource Class Names, URL Syntax and Configuration Properties for Connector/J),
with which you can take advantage of the ability to connect with
multiple MySQL servers to achieve load balancing and failover.
However, while Connector/J does not depend on the MySQL client libraries, it does require a connection to a MySQL Server, which ClusterJ does not. JDBC also does not provide any object mappings for database objects, properties, or operations, or any way to persist objects.
See MySQL Connector/J, for general information about using Connector/J.
- 4.3.1.1. Major Interfaces
- 4.3.1.2. Exception ClusterJDatastoreException
- 4.3.1.3. Exception ClusterJException
- 4.3.1.4. Exception ClusterJFatalException
- 4.3.1.5. Exception ClusterJFatalInternalException
- 4.3.1.6. Exception ClusterJFatalUserException
- 4.3.1.7. Class ClusterJHelper
- 4.3.1.8. Exception ClusterJUserException
- 4.3.1.9. Interface Constants
- 4.3.1.10. Class LockMode
- 4.3.1.11. Interface Query
- 4.3.1.12. Interface Results
- 4.3.1.13. Interface Session
- 4.3.1.14. Interface SessionFactory
- 4.3.1.15. Interface SessionFactoryService
- 4.3.1.16. Interface Transaction
Provides classes and interfaces for using MySQL Cluster directly from Java.
This package contains three main groups of classes and interfaces:
A class for bootstrapping
Interfaces for use in application programs
Classes to define exceptions
ClusterJ provides these major interfaces for use by application
programs:
com.mysql.clusterj.SessionFactory,
com.mysql.clusterj.Session,
com.mysql.clusterj.Transaction,
com.mysql.clusterj.query.QueryBuilder,
and
com.mysql.clusterj.Query.
The helper class
com.mysql.clusterj.ClusterJHelper
contains methods for creating the
com.mysql.clusterj.SessionFactory.
Bootstrapping is the process of
identifying a MySQL Cluster and obtaining the SessionFactory
for use with the cluster. There is one SessionFactory per
cluster per Java VM.
The
com.mysql.clusterj.SessionFactory
is configured via properties, which identify the MySQL
Cluster that the application connects to:
com.mysql.clusterj.connectstring identifies the ndb_mgmd host name and port
com.mysql.clusterj.connect.retries is the number of retries when connecting
com.mysql.clusterj.connect.delay is the delay in seconds between connection retries
com.mysql.clusterj.connect.verbose tells whether to display a message to System.out while connecting
com.mysql.clusterj.connect.timeout.before is the number of seconds to wait until the first node responds to a connect request
com.mysql.clusterj.connect.timeout.after is the number of seconds to wait until the last node responds to a connect request
com.mysql.clusterj.connect.database is the name of the database to use
File propsFile = new File("clusterj.properties");
InputStream inStream = new FileInputStream(propsFile);
Properties props = new Properties();
props.load(inStream);
SessionFactory sessionFactory = ClusterJHelper.getSessionFactory(props);
The
com.mysql.clusterj.Session
represents the user's individual connection to the
cluster. It contains methods for:
finding persistent instances by primary key
persistent instance factory (newInstance)
persistent instance life cycle management (persist, remove)
getting the QueryBuilder
getting the Transaction (currentTransaction)
Session session = sessionFactory.getSession();
Employee existing = session.find(Employee.class, 1);
if (existing != null) {
session.remove(existing);
}
Employee newemp = session.newInstance(Employee.class);
newemp.initialize(2, "Craig", 15, 146000.00);
session.persist(newemp);
Transaction
The
com.mysql.clusterj.Transaction
allows users to combine multiple operations into a single
database transaction. It contains methods to:
begin a unit of work
commit changes from a unit of work
roll back all changes made since the unit of work was begun
mark a unit of work for rollback only
get the rollback status of the current unit of work
Transaction tx = session.currentTransaction();
tx.begin();
Employee existing = session.find(Employee.class, 1);
Employee newemp = session.newInstance(Employee.class);
newemp.initialize(2, "Craig", 146000.00);
session.persist(newemp);
tx.commit();
QueryBuilder
The
com.mysql.clusterj.query.QueryBuilder
allows users to build queries. It contains methods to:
define the Domain Object Model to query
compare properties with parameters using:
equal
lessThan
greaterThan
lessEqual
greaterEqual
between
in
combine comparisons using "and", "or", and "not" operators
QueryBuilder builder = session.getQueryBuilder();
QueryDomainType<Employee> qemp = builder.createQueryDefinition(Employee.class);
Predicate service = qemp.get("yearsOfService").greaterThan(qemp.param("service"));
Predicate salary = qemp.get("salary").lessEqual(qemp.param("salaryCap"));
qemp.where(service.and(salary));
Query<Employee> query = session.createQuery(qemp);
query.setParameter("service", 10);
query.setParameter("salaryCap", 180000.00);
List<Employee> results = query.getResultList();
ClusterJUserException represents a database error. The underlying cause of the exception is contained in the "cause".
public class com.mysql.clusterj.ClusterJDatastoreException extends com.mysql.clusterj.ClusterJException {
// Public Constructorspublic ClusterJDatastoreException(java.lang.String message);public ClusterJDatastoreException(java.lang.String msg,
int code,
int mysqlCode,
int status,
int classification);public ClusterJDatastoreException(java.lang.String message,
java.lang.Throwable t);public ClusterJDatastoreException(java.lang.Throwable t);
// Public Methodspublic int getClassification();public int getStatus();
}
Methods inherited from
com.mysql.clusterj.ClusterJException:
printStackTrace
Methods inherited from
java.lang.Throwable:
fillInStackTrace
, getCause
, getLocalizedMessage
, getMessage
, getStackTrace
, initCause
, setStackTrace
, toString
Methods inherited from
java.lang.Object:
equals
, getClass
, hashCode
, notify
, notifyAll
, wait
ClusterJException is the base for all ClusterJ exceptions. Applications can catch ClusterJException to be notified of all ClusterJ reported issues.
Exceptions are in three general categories: User exceptions, Datastore exceptions, and Internal exceptions.
User exceptions are caused by user error, for example providing a connect string that refers to an unavailable host or port.
If a user exception is detected during bootstrapping (acquiring a SessionFactory), it is thrown as a fatal exception.
com.mysql.clusterj.ClusterJFatalUserExceptionIf an exception is detected during initialization of a persistent interface, for example annotating a column that doesn't exist in the mapped table, it is reported as a user exception.
com.mysql.clusterj.ClusterJUserException
Datastore exceptions report conditions that result from datastore operations after bootstrapping. For example, duplicate keys on insert, or record does not exist on delete.
com.mysql.clusterj.ClusterJDatastoreExceptionInternal exceptions report conditions that are caused by errors in implementation. These exceptions should be reported as bugs.
com.mysql.clusterj.ClusterJFatalInternalException
public class com.mysql.clusterj.ClusterJException extends java.lang.RuntimeException {
// Public Constructorspublic ClusterJException(java.lang.String message);public ClusterJException(java.lang.String message,
java.lang.Throwable t);public ClusterJException(java.lang.Throwable t);
// Public Methodspublic synchronized void printStackTrace(java.io.PrintStream s);
}
Direct known subclasses:
com.mysql.clusterj.ClusterJDatastoreException
, com.mysql.clusterj.ClusterJFatalException
, com.mysql.clusterj.ClusterJUserException
Methods inherited from
java.lang.Throwable:
fillInStackTrace
, getCause
, getLocalizedMessage
, getMessage
, getStackTrace
, initCause
, printStackTrace
, setStackTrace
, toString
Methods inherited from
java.lang.Object:
equals
, getClass
, hashCode
, notify
, notifyAll
, wait

ClusterJFatalException represents an exception that is not recoverable.
public class com.mysql.clusterj.ClusterJFatalException extends com.mysql.clusterj.ClusterJException {
// Public Constructorspublic ClusterJFatalException(java.lang.String string);public ClusterJFatalException(java.lang.String string,
java.lang.Throwable t);public ClusterJFatalException(java.lang.Throwable t);
}
Direct known subclasses:
com.mysql.clusterj.ClusterJFatalInternalException
, com.mysql.clusterj.ClusterJFatalUserException
Methods inherited from
com.mysql.clusterj.ClusterJException:
printStackTrace
Methods inherited from
java.lang.Throwable:
fillInStackTrace
, getCause
, getLocalizedMessage
, getMessage
, getStackTrace
, initCause
, setStackTrace
, toString
Methods inherited from
java.lang.Object:
equals
, getClass
, hashCode
, notify
, notifyAll
, wait
ClusterJFatalInternalException represents an implementation error that the user cannot recover from.
public class com.mysql.clusterj.ClusterJFatalInternalException extends com.mysql.clusterj.ClusterJFatalException {
// Public Constructorspublic ClusterJFatalInternalException(java.lang.String string);public ClusterJFatalInternalException(java.lang.String string,
java.lang.Throwable t);public ClusterJFatalInternalException(java.lang.Throwable t);
}
Methods inherited from
com.mysql.clusterj.ClusterJException:
printStackTrace
Methods inherited from
java.lang.Throwable:
fillInStackTrace
, getCause
, getLocalizedMessage
, getMessage
, getStackTrace
, initCause
, setStackTrace
, toString
Methods inherited from
java.lang.Object:
equals
, getClass
, hashCode
, notify
, notifyAll
, wait
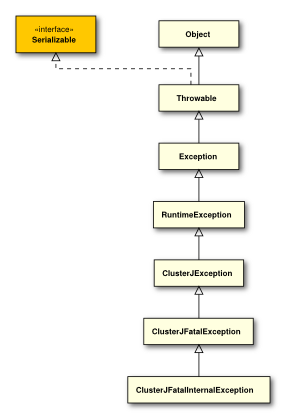
ClusterJFatalUserException represents a user error that is unrecoverable, such as programming errors in persistent classes or missing resources in the execution environment.
public class com.mysql.clusterj.ClusterJFatalUserException extends com.mysql.clusterj.ClusterJFatalException {
// Public Constructorspublic ClusterJFatalUserException(java.lang.String string);public ClusterJFatalUserException(java.lang.String string,
java.lang.Throwable t);public ClusterJFatalUserException(java.lang.Throwable t);
}
Methods inherited from
com.mysql.clusterj.ClusterJException:
printStackTrace
Methods inherited from
java.lang.Throwable:
fillInStackTrace
, getCause
, getLocalizedMessage
, getMessage
, getStackTrace
, initCause
, setStackTrace
, toString
Methods inherited from
java.lang.Object:
equals
, getClass
, hashCode
, notify
, notifyAll
, wait

- 4.3.1.7.1. Synopsis
- 4.3.1.7.2. getServiceInstance(Class<T>)
- 4.3.1.7.3. getServiceInstance(Class<T>, ClassLoader)
- 4.3.1.7.4. getServiceInstance(Class<T>, String)
- 4.3.1.7.5. getServiceInstances(Class<T>, ClassLoader, StringBuffer)
- 4.3.1.7.6. getSessionFactory(Map)
- 4.3.1.7.7. getSessionFactory(Map, ClassLoader)
ClusterJHelper provides helper methods to bridge between the API and the implementation.
public class com.mysql.clusterj.ClusterJHelper {
// Public Constructorspublic ClusterJHelper();
// Public Static Methodspublic static T getServiceInstance(java.lang.Class<T> cls);public static T getServiceInstance(java.lang.Class<T> cls,
java.lang.ClassLoader loader);public static T getServiceInstance(java.lang.Class<T> cls,
java.lang.String implementationClassName);public static java.util.List<T> getServiceInstances(java.lang.Class<T> cls,
java.lang.ClassLoader loader,
java.lang.StringBuffer errorMessages);public static com.mysql.clusterj.SessionFactory getSessionFactory(java.util.Map props);public static com.mysql.clusterj.SessionFactory getSessionFactory(java.util.Map props,
java.lang.ClassLoader loader);
}
Methods inherited from
java.lang.Object:
equals
, getClass
, hashCode
, notify
, notifyAll
, toString
, wait

public static T getServiceInstance(java.lang.Class<T> cls);Locate a service implementation by services lookup of the context class loader.
Parameters | |
cls | the class of the factory |
return | the service instance |
public static T getServiceInstance(java.lang.Class<T> cls,
java.lang.ClassLoader loader);Locate a service implementation for a service by services lookup of a specific class loader. The first service instance found is returned.
Parameters | |
cls | the class of the factory |
loader | the class loader for the factory implementation |
return | the service instance |
public static T getServiceInstance(java.lang.Class<T> cls,
java.lang.String implementationClassName);Locate a service implementation for a service. If the implementation name is not null, use it instead of looking up. If the implementation class is not loadable or does not implement the interface, throw an exception.
Parameters | |
cls | |
implementationClassName | |
return | the implementation instance for a service |
public static java.util.List<T> getServiceInstances(java.lang.Class<T> cls,
java.lang.ClassLoader loader,
java.lang.StringBuffer errorMessages);Locate all service implementations by services lookup of a specific class loader. Implementations in the services file are instantiated and returned. Failed instantiations are remembered in the errorMessages buffer.
Parameters | |
cls | the class of the factory |
loader | the class loader for the factory implementation |
errorMessages | a buffer used to hold the error messages |
return | the service instance |
public static com.mysql.clusterj.SessionFactory getSessionFactory(java.util.Map props);Locate a SessionFactory implementation by services lookup. The class loader used is the thread's context class loader.
Parameters | |
props | properties of the session factory |
return | the session factory |
Exceptions
-
ClusterFatalUserException if the connection to the cluster cannot be made
public static com.mysql.clusterj.SessionFactory getSessionFactory(java.util.Map props,
java.lang.ClassLoader loader);Locate a SessionFactory implementation by services lookup of a specific class loader. The properties are a Map that might contain implementation-specific properties plus standard properties.
Parameters | |
props | the properties for the factory |
loader | the class loader for the factory implementation |
return | the session factory |
Exceptions
-
ClusterFatalUserException if the connection to the cluster cannot be made
ClusterJUserException represents a user programming error.
public class com.mysql.clusterj.ClusterJUserException extends com.mysql.clusterj.ClusterJException {
// Public Constructorspublic ClusterJUserException(java.lang.String message);public ClusterJUserException(java.lang.String message,
java.lang.Throwable t);public ClusterJUserException(java.lang.Throwable t);
}
Methods inherited from
com.mysql.clusterj.ClusterJException:
printStackTrace
Methods inherited from
java.lang.Throwable:
fillInStackTrace
, getCause
, getLocalizedMessage
, getMessage
, getStackTrace
, initCause
, setStackTrace
, toString
Methods inherited from
java.lang.Object:
equals
, getClass
, hashCode
, notify
, notifyAll
, wait

- 4.3.1.9.1. Synopsis
- 4.3.1.9.2. DEFAULT_PROPERTY_CLUSTER_CONNECT_DELAY
- 4.3.1.9.3. DEFAULT_PROPERTY_CLUSTER_CONNECT_RETRIES
- 4.3.1.9.4. DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER
- 4.3.1.9.5. DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE
- 4.3.1.9.6. DEFAULT_PROPERTY_CLUSTER_CONNECT_VERBOSE
- 4.3.1.9.7. DEFAULT_PROPERTY_CLUSTER_DATABASE
- 4.3.1.9.8. DEFAULT_PROPERTY_CLUSTER_MAX_TRANSACTIONS
- 4.3.1.9.9. PROPERTY_CLUSTER_CONNECT_DELAY
- 4.3.1.9.10. PROPERTY_CLUSTER_CONNECT_RETRIES
- 4.3.1.9.11. PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER
- 4.3.1.9.12. PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE
- 4.3.1.9.13. PROPERTY_CLUSTER_CONNECT_VERBOSE
- 4.3.1.9.14. PROPERTY_CLUSTER_CONNECTION_SERVICE
- 4.3.1.9.15. PROPERTY_CLUSTER_CONNECTSTRING
- 4.3.1.9.16. PROPERTY_CLUSTER_DATABASE
- 4.3.1.9.17. PROPERTY_CLUSTER_MAX_TRANSACTIONS
- 4.3.1.9.18. PROPERTY_DEFER_CHANGES
- 4.3.1.9.19. PROPERTY_JDBC_DRIVER_NAME
- 4.3.1.9.20. PROPERTY_JDBC_PASSWORD
- 4.3.1.9.21. PROPERTY_JDBC_URL
- 4.3.1.9.22. PROPERTY_JDBC_USERNAME
- 4.3.1.9.23. SESSION_FACTORY_SERVICE_CLASS_NAME
- 4.3.1.9.24. SESSION_FACTORY_SERVICE_FILE_NAME
Constants used in the ClusterJ project.
public interface com.mysql.clusterj.Constants {
// Public Static Fieldspublic static final int DEFAULT_PROPERTY_CLUSTER_CONNECT_DELAY = 5;public static final int DEFAULT_PROPERTY_CLUSTER_CONNECT_RETRIES = 4;public static final int DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER = 20;public static final int DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE = 30;public static final int DEFAULT_PROPERTY_CLUSTER_CONNECT_VERBOSE = 0;public static final java.lang.String DEFAULT_PROPERTY_CLUSTER_DATABASE = "test";public static final int DEFAULT_PROPERTY_CLUSTER_MAX_TRANSACTIONS = 4;public static final java.lang.String PROPERTY_CLUSTER_CONNECTION_SERVICE = "com.mysql.clusterj.connection.service";public static final java.lang.String PROPERTY_CLUSTER_CONNECTSTRING = "com.mysql.clusterj.connectstring";public static final java.lang.String PROPERTY_CLUSTER_CONNECT_DELAY = "com.mysql.clusterj.connect.delay";public static final java.lang.String PROPERTY_CLUSTER_CONNECT_RETRIES = "com.mysql.clusterj.connect.retries";public static final java.lang.String PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER = "com.mysql.clusterj.connect.timeout.after";public static final java.lang.String PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE = "com.mysql.clusterj.connect.timeout.before";public static final java.lang.String PROPERTY_CLUSTER_CONNECT_VERBOSE = "com.mysql.clusterj.connect.verbose";public static final java.lang.String PROPERTY_CLUSTER_DATABASE = "com.mysql.clusterj.database";public static final java.lang.String PROPERTY_CLUSTER_MAX_TRANSACTIONS = "com.mysql.clusterj.max.transactions";public static final java.lang.String PROPERTY_DEFER_CHANGES = "com.mysql.clusterj.defer.changes";public static final java.lang.String PROPERTY_JDBC_DRIVER_NAME = "com.mysql.clusterj.jdbc.driver";public static final java.lang.String PROPERTY_JDBC_PASSWORD = "com.mysql.clusterj.jdbc.password";public static final java.lang.String PROPERTY_JDBC_URL = "com.mysql.clusterj.jdbc.url";public static final java.lang.String PROPERTY_JDBC_USERNAME = "com.mysql.clusterj.jdbc.username";public static final java.lang.String SESSION_FACTORY_SERVICE_CLASS_NAME = "com.mysql.clusterj.SessionFactoryService";public static final java.lang.String SESSION_FACTORY_SERVICE_FILE_NAME = "META-INF/services/com.mysql.clusterj.SessionFactoryService";
}

public static final int DEFAULT_PROPERTY_CLUSTER_CONNECT_DELAY = 5;The default value of the connection delay property
public static final int DEFAULT_PROPERTY_CLUSTER_CONNECT_RETRIES = 4;The default value of the connection retries property
public static final int DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER = 20;The default value of the connection timeout after property
public static final int DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE = 30;The default value of the connection timeout before property
public static final int DEFAULT_PROPERTY_CLUSTER_CONNECT_VERBOSE = 0;The default value of the connection verbose property
public static final java.lang.String DEFAULT_PROPERTY_CLUSTER_DATABASE = "test";The default value of the database property
public static final int DEFAULT_PROPERTY_CLUSTER_MAX_TRANSACTIONS = 4;The default value of the maximum number of transactions property
public static final java.lang.String PROPERTY_CLUSTER_CONNECT_DELAY = "com.mysql.clusterj.connect.delay";The name of the connection delay property. For details, see Ndb_cluster_connection::connect()
public static final java.lang.String PROPERTY_CLUSTER_CONNECT_RETRIES = "com.mysql.clusterj.connect.retries";The name of the connection retries property. For details, see Ndb_cluster_connection::connect()
public static final java.lang.String PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER = "com.mysql.clusterj.connect.timeout.after";The name of the connection timeout after property. For details, see Ndb_cluster_connection::wait_until_ready()
public static final java.lang.String PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE = "com.mysql.clusterj.connect.timeout.before";The name of the connection timeout before property. For details, see Ndb_cluster_connection::wait_until_ready()
public static final java.lang.String PROPERTY_CLUSTER_CONNECT_VERBOSE = "com.mysql.clusterj.connect.verbose";The name of the connection verbose property. For details, see Ndb_cluster_connection::connect()
public static final java.lang.String PROPERTY_CLUSTER_CONNECTION_SERVICE = "com.mysql.clusterj.connection.service";The name of the connection service property
public static final java.lang.String PROPERTY_CLUSTER_CONNECTSTRING = "com.mysql.clusterj.connectstring";The name of the connection string property. For details, see Ndb_cluster_connection constructor
public static final java.lang.String PROPERTY_CLUSTER_DATABASE = "com.mysql.clusterj.database";The name of the database property. For details, see the catalogName parameter in the Ndb constructor. Ndb constructor
public static final java.lang.String PROPERTY_CLUSTER_MAX_TRANSACTIONS = "com.mysql.clusterj.max.transactions";The name of the maximum number of transactions property. For details, see Ndb::init()
public static final java.lang.String PROPERTY_DEFER_CHANGES = "com.mysql.clusterj.defer.changes";The flag for deferred inserts, deletes, and updates
public static final java.lang.String PROPERTY_JDBC_DRIVER_NAME = "com.mysql.clusterj.jdbc.driver";The name of the jdbc driver
public static final java.lang.String PROPERTY_JDBC_PASSWORD = "com.mysql.clusterj.jdbc.password";The jdbc password
public static final java.lang.String PROPERTY_JDBC_URL = "com.mysql.clusterj.jdbc.url";The jdbc url
public static final java.lang.String PROPERTY_JDBC_USERNAME = "com.mysql.clusterj.jdbc.username";The jdbc username
Lock modes for read operations.
SHARED: Set a shared lock on rows
EXCLUSIVE: Set an exclusive lock on rows
READ_COMMITTED: Set no locks but read the most recent committed values
public final class com.mysql.clusterj.LockMode extends java.lang.Enum<com.mysql.clusterj.LockMode> {
// Public Static Fieldspublic static final com.mysql.clusterj.LockMode EXCLUSIVE ;public static final com.mysql.clusterj.LockMode READ_COMMITTED ;public static final com.mysql.clusterj.LockMode SHARED ;
// Public Static Methodspublic static com.mysql.clusterj.LockMode valueOf(java.lang.String name);public static com.mysql.clusterj.LockMode[] values();
}
Methods inherited from
java.lang.Enum:
compareTo
, equals
, getDeclaringClass
, hashCode
, name
, ordinal
, toString
, valueOf
Methods inherited from
java.lang.Object:
getClass
, notify
, notifyAll
, wait

- 4.3.1.11.1. Synopsis
- 4.3.1.11.2. INDEX_USED
- 4.3.1.11.3. SCAN_TYPE
- 4.3.1.11.4. SCAN_TYPE_INDEX_SCAN
- 4.3.1.11.5. SCAN_TYPE_PRIMARY_KEY
- 4.3.1.11.6. SCAN_TYPE_TABLE_SCAN
- 4.3.1.11.7. SCAN_TYPE_UNIQUE_KEY
- 4.3.1.11.8. execute(Map<String, ?>)
- 4.3.1.11.9. execute(Object...)
- 4.3.1.11.10. execute(Object)
- 4.3.1.11.11. explain()
- 4.3.1.11.12. getResultList()
- 4.3.1.11.13. setParameter(String, Object)
A Query instance represents a specific query with bound
parameters. The instance is created by the method
com.mysql.clusterj.Session.createQuery.
public interface com.mysql.clusterj.Query<E> {
// Public Static Fieldspublic static final java.lang.String INDEX_USED = "IndexUsed";public static final java.lang.String SCAN_TYPE = "ScanType";public static final java.lang.String SCAN_TYPE_INDEX_SCAN = "INDEX_SCAN";public static final java.lang.String SCAN_TYPE_PRIMARY_KEY = "PRIMARY_KEY";public static final java.lang.String SCAN_TYPE_TABLE_SCAN = "TABLE_SCAN";public static final java.lang.String SCAN_TYPE_UNIQUE_KEY = "UNIQUE_KEY";
// Public Methodspublic com.mysql.clusterj.Results<E> execute(java.lang.Object parameter);public com.mysql.clusterj.Results<E> execute(java.lang.Object[] parameters);public com.mysql.clusterj.Results<E> execute(java.util.Map<java.lang.String, ?> parameters);public java.util.Map<java.lang.String, java.lang.Object> explain();public java.util.List<E> getResultList();public void setParameter(java.lang.String parameterName,
java.lang.Object value);
}

public static final java.lang.String SCAN_TYPE_INDEX_SCAN = "INDEX_SCAN";The query explain scan type value for index scan
public static final java.lang.String SCAN_TYPE_PRIMARY_KEY = "PRIMARY_KEY";The query explain scan type value for primary key
public static final java.lang.String SCAN_TYPE_TABLE_SCAN = "TABLE_SCAN";The query explain scan type value for table scan
public static final java.lang.String SCAN_TYPE_UNIQUE_KEY = "UNIQUE_KEY";The query explain scan type value for unique key
public com.mysql.clusterj.Results<E> execute(java.util.Map<java.lang.String, ?> parameters);Execute the query with one or more named parameters. Parameters are resolved by name.
Parameters | |
parameters | the parameters |
return | the result |
public com.mysql.clusterj.Results<E> execute(java.lang.Object[] parameters);Execute the query with one or more parameters. Parameters are resolved in the order they were declared in the query.
Parameters | |
parameters | the parameters |
return | the result |
public com.mysql.clusterj.Results<E> execute(java.lang.Object parameter);Execute the query with exactly one parameter.
Parameters | |
parameter | the parameter |
return | the result |
public java.util.Map<java.lang.String, java.lang.Object> explain();Explain how this query will be or was executed. If called before binding all parameters, throws ClusterJUserException. Return a map of key:value pairs that explain how the query will be or was executed. Details can be obtained by calling toString on the value. The following keys are returned:
ScanType: the type of scan, with values:
PRIMARY_KEY: the query used key lookup with the primary key
UNIQUE_KEY: the query used key lookup with a unique key
INDEX_SCAN: the query used a range scan with a non-unique key
TABLE_SCAN: the query used a table scan
IndexUsed: the name of the index used, if any
Parameters | |
return | the data about the execution of this query |
Exceptions
-
ClusterJUserException if not all parameters are bound
public java.util.List<E> getResultList();Get the results as a list.
Parameters | |
return | the result |
Exceptions
-
ClusterJUserException if not all parameters are bound
-
ClusterJDatastoreException if an exception is reported by the datastore
public void setParameter(java.lang.String parameterName,
java.lang.Object value);Set the value of a parameter. If called multiple times for the same parameter, silently replace the value.
Parameters | |
parameterName | the name of the parameter |
value | the value for the parameter |
Results of a query.
public interface com.mysql.clusterj.Results<E> extends java.lang.Iterable<E> {
// Public Methodspublic java.util.Iterator<E> iterator();
}

- 4.3.1.13.1. Synopsis
- 4.3.1.13.2. close()
- 4.3.1.13.3. createQuery(QueryDefinition<T>)
- 4.3.1.13.4. currentTransaction()
- 4.3.1.13.5. deletePersistent(Class<T>, Object)
- 4.3.1.13.6. deletePersistent(Object)
- 4.3.1.13.7. deletePersistentAll(Class<T>)
- 4.3.1.13.8. deletePersistentAll(Iterable<?>)
- 4.3.1.13.9. find(Class<T>, Object)
- 4.3.1.13.10. flush()
- 4.3.1.13.11. getQueryBuilder()
- 4.3.1.13.12. isClosed()
- 4.3.1.13.13. makePersistent(T)
- 4.3.1.13.14. makePersistentAll(Iterable<?>)
- 4.3.1.13.15. markModified(Object, String)
- 4.3.1.13.16. newInstance(Class<T>)
- 4.3.1.13.17. newInstance(Class<T>, Object)
- 4.3.1.13.18. persist(Object)
- 4.3.1.13.19. remove(Object)
- 4.3.1.13.20. savePersistent(T)
- 4.3.1.13.21. savePersistentAll(Iterable<?>)
- 4.3.1.13.22. setLockMode(LockMode)
- 4.3.1.13.23. setPartitionKey(Class<?>, Object)
- 4.3.1.13.24. updatePersistent(Object)
- 4.3.1.13.25. updatePersistentAll(Iterable<?>)
Session is the primary user interface to the cluster.
public interface com.mysql.clusterj.Session {
// Public Methodspublic void close();public com.mysql.clusterj.Query<T> createQuery(com.mysql.clusterj.query.QueryDefinition<T> qd);public com.mysql.clusterj.Transaction currentTransaction();public void deletePersistent(java.lang.Class<T> cls,
java.lang.Object key);public void deletePersistent(java.lang.Object instance);public int deletePersistentAll(java.lang.Class<T> cls);public void deletePersistentAll(java.lang.Iterable<?> instances);public T find(java.lang.Class<T> cls,
java.lang.Object key);public void flush();public com.mysql.clusterj.query.QueryBuilder getQueryBuilder();public boolean isClosed();public T makePersistent(T instance);public java.lang.Iterable<?> makePersistentAll(java.lang.Iterable<?> instances);public void markModified(java.lang.Object instance,
java.lang.String fieldName);public T newInstance(java.lang.Class<T> cls);public T newInstance(java.lang.Class<T> cls,
java.lang.Object key);public void persist(java.lang.Object instance);public void remove(java.lang.Object instance);public T savePersistent(T instance);public java.lang.Iterable<?> savePersistentAll(java.lang.Iterable<?> instances);public void setLockMode(com.mysql.clusterj.LockMode lockmode);public void setPartitionKey(java.lang.Class<?> cls,
java.lang.Object key);public void updatePersistent(java.lang.Object instance);public void updatePersistentAll(java.lang.Iterable<?> instances);
}

public com.mysql.clusterj.Query<T> createQuery(com.mysql.clusterj.query.QueryDefinition<T> qd);Create a Query from a QueryDefinition.
Parameters | |
qd | the query definition |
return | the query instance |
public com.mysql.clusterj.Transaction currentTransaction();
Get the current
com.mysql.clusterj.Transaction.
Parameters | |
return | the transaction |
public void deletePersistent(java.lang.Class<T> cls,
java.lang.Object key);Delete an instance of a class from the database given its primary key. For single-column keys, the key parameter is a wrapper (e.g. Integer). For multi-column keys, the key parameter is an Object[] in which elements correspond to the primary keys in order as defined in the schema.
Parameters | |
cls | the class |
key | the primary key |
public void deletePersistent(java.lang.Object instance);Delete the instance from the database. Only the id field is used to determine which instance is to be deleted. If the instance does not exist in the database, an exception is thrown.
Parameters | |
instance | the instance to delete |
public int deletePersistentAll(java.lang.Class<T> cls);Delete all instances of this class from the database. No exception is thrown even if there are no instances in the database.
Parameters | |
cls | the class |
return | the number of instances deleted |
public void deletePersistentAll(java.lang.Iterable<?> instances);Delete all parameter instances from the database.
Parameters | |
instances | the instances to delete |
public T find(java.lang.Class<T> cls,
java.lang.Object key);Find a specific instance by its primary key. The key must be of the same type as the primary key defined by the table corresponding to the cls parameter. The key parameter is the wrapped version of the primitive type of the key, e.g. Integer for INT key types, Long for BIGINT key types, or String for char and varchar types. For multi-column primary keys, the key parameter is an Object[], each element of which is a component of the primary key. The elements must be in the order of declaration of the columns (not necessarily the order defined in the CONSTRAINT ... PRIMARY KEY clause) of the CREATE TABLE statement.
Parameters | |
cls | the class to find an instance of |
key | the key of the instance to find |
return | the instance of the class with the specified key |
public void flush();Flush deferred changes to the back end. Inserts, deletes, and updates made when the deferred update flag is true are sent to the back end.
public com.mysql.clusterj.query.QueryBuilder getQueryBuilder();Get a QueryBuilder.
Parameters | |
return | the query builder |
public boolean isClosed();Is this session closed?
Parameters | |
return | true if the session is closed |
public T makePersistent(T instance);Insert the instance into the database. If the instance already exists in the database, an exception is thrown.
Parameters | |
instance | the instance to insert |
return | the instance |
- See Also
- savePersistent(T)
public java.lang.Iterable<?> makePersistentAll(java.lang.Iterable<?> instances);Insert the instances into the database.
Parameters | |
instances | the instances to insert. |
return | the instances |
public void markModified(java.lang.Object instance,
java.lang.String fieldName);Mark the field in the object as modified so it is flushed.
Parameters | |
instance | the persistent instance |
fieldName | the field to mark as modified |
public T newInstance(java.lang.Class<T> cls);Create an instance of an interface that maps to a table.
Parameters | |
cls | the interface for which to create an instance |
return | an instance that implements the interface |
public T newInstance(java.lang.Class<T> cls,
java.lang.Object key);Create an instance of an interface that maps to a table and set the primary key of the new instance. The new instance can be used to create, delete, or update a record in the database.
Parameters | |
cls | the interface for which to create an instance |
return | an instance that implements the interface |
public void persist(java.lang.Object instance);Insert the instance into the database. This method has identical semantics to makePersistent.
Parameters | |
instance | the instance to insert |
public void remove(java.lang.Object instance);Delete the instance from the database. This method has identical semantics to deletePersistent.
Parameters | |
instance | the instance to delete |
public T savePersistent(T instance);Save the instance in the database without checking for existence. The id field is used to determine which instance is to be saved. If the instance exists in the database it will be updated. If the instance does not exist, it will be created.
Parameters | |
instance | the instance to update |
public java.lang.Iterable<?> savePersistentAll(java.lang.Iterable<?> instances);Update all parameter instances in the database.
Parameters | |
instances | the instances to update |
public void setLockMode(com.mysql.clusterj.LockMode lockmode);Set the lock mode for read operations. This will take effect immediately and will remain in effect until this session is closed or this method is called again.
Parameters | |
lockmode | the LockMode |
public void setPartitionKey(java.lang.Class<?> cls,
java.lang.Object key);Set the partition key for the next transaction. The key must be of the same type as the primary key defined by the table corresponding to the cls parameter. The key parameter is the wrapped version of the primitive type of the key, e.g. Integer for INT key types, Long for BIGINT key types, or String for char and varchar types. For multi-column primary keys, the key parameter is an Object[], each element of which is a component of the primary key. The elements must be in the order of declaration of the columns (not necessarily the order defined in the CONSTRAINT ... PRIMARY KEY clause) of the CREATE TABLE statement.
Parameters | |
key | the primary key of the mapped table |
Exceptions
-
ClusterJUserException if a transaction is enlisted
-
ClusterJUserException if a partition key is null
-
ClusterJUserException if called twice in the same transaction
-
ClusterJUserException if a partition key is the wrong type
public void updatePersistent(java.lang.Object instance);Update the instance in the database without necessarily retrieving it. The id field is used to determine which instance is to be updated. If the instance does not exist in the database, an exception is thrown.
Parameters | |
instance | the instance to update |
SessionFactory represents a cluster.
public interface com.mysql.clusterj.SessionFactory {
// Public Methodspublic void close();public com.mysql.clusterj.Session getSession();public com.mysql.clusterj.Session getSession(java.util.Map properties);
}

public com.mysql.clusterj.Session getSession();Create a Session to use with the cluster, using all the properties of the SessionFactory.
Parameters | |
return | the session |
public com.mysql.clusterj.Session getSession(java.util.Map properties);Create a session to use with the cluster, overriding some properties. Properties PROPERTY_CLUSTER_CONNECTSTRING, PROPERTY_CLUSTER_DATABASE, and PROPERTY_CLUSTER_MAX_TRANSACTIONS may not be overridden.
Parameters | |
properties | overriding some properties for this session |
return | the session |
This interface defines the service to create a SessionFactory from a Map<String, String> of properties.
public interface com.mysql.clusterj.SessionFactoryService {
// Public Methodspublic com.mysql.clusterj.SessionFactory getSessionFactory(java.util.Map<java.lang.String, java.lang.String> props);
}

public com.mysql.clusterj.SessionFactory getSessionFactory(java.util.Map<java.lang.String, java.lang.String> props);Create or get a session factory. If a session factory with the same value for PROPERTY_CLUSTER_CONNECTSTRING has already been created in the VM, the existing factory is returned, regardless of whether other properties of the factory are the same as specified in the Map.
Parameters | |
props | the properties for the session factory, in which the keys are defined in Constants and the values describe the environment |
return | the session factory |
- See Also
- com.mysql.clusterj.Constants
Transaction represents a user transaction active in the cluster.
public interface com.mysql.clusterj.Transaction {
// Public Methodspublic void begin();public void commit();public boolean getRollbackOnly();public boolean isActive();public void rollback();public void setRollbackOnly();
}
public boolean getRollbackOnly();Has this transaction been marked for rollback only?
Parameters | |
return | true if the transaction has been marked for rollback only |
public boolean isActive();Is there a transaction currently active?
Parameters | |
return | true if a transaction is active |
- 4.3.2.1. Annotation Type Column
- 4.3.2.2. Annotation Type Columns
- 4.3.2.3. Annotation Type Extension
- 4.3.2.4. Annotation Type Extensions
- 4.3.2.5. Annotation Type Index
- 4.3.2.6. Annotation Type Indices
- 4.3.2.7. Annotation Type Lob
- 4.3.2.8. Annotation Type NotPersistent
- 4.3.2.9. Class NullValue
- 4.3.2.10. Annotation Type PartitionKey
- 4.3.2.11. Annotation Type PersistenceCapable
- 4.3.2.12. Class PersistenceModifier
- 4.3.2.13. Annotation Type Persistent
- 4.3.2.14. Annotation Type PrimaryKey
This package provides annotations for domain object model interfaces mapped to database tables.
Annotation for a column in the database.
@Target(value={java.lang.annotation.ElementType.FIELD, java.lang.annotation.ElementType.METHOD}) @Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME) public @interface com.mysql.clusterj.annotation.Column {public java.lang.String name ;public java.lang.String allowsNull ;public java.lang.String defaultValue ;
}

Whether the column allows null values to be inserted. This overrides the database definition and requires that the application provide non-null values for the database column.
Parameters | |
return | whether the column allows null values to be inserted |
Default value for this column.
Parameters | |
return | the default value for this column |
Annotation for a group of columns. This annotation is used for multi-column structures such as indexes and keys.
@Target(value={java.lang.annotation.ElementType.FIELD, java.lang.annotation.ElementType.METHOD, java.lang.annotation.ElementType.TYPE}) @Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME) public @interface com.mysql.clusterj.annotation.Columns {public com.mysql.clusterj.annotation.Column[] value ;
}

Annotation for a non-standard extension.
@Target(value={java.lang.annotation.ElementType.TYPE, java.lang.annotation.ElementType.FIELD, java.lang.annotation.ElementType.METHOD}) @Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME) public @interface com.mysql.clusterj.annotation.Extension {public java.lang.String vendorName ;public java.lang.String key ;public java.lang.String value ;
}
Annotation for a group of extensions.
@Target(value={java.lang.annotation.ElementType.TYPE, java.lang.annotation.ElementType.FIELD, java.lang.annotation.ElementType.METHOD}) @Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME) public @interface com.mysql.clusterj.annotation.Extensions {public com.mysql.clusterj.annotation.Extension[] value ;
}

Annotation for a database index.
@Target(value={java.lang.annotation.ElementType.TYPE, java.lang.annotation.ElementType.FIELD, java.lang.annotation.ElementType.METHOD}) @Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME) public @interface com.mysql.clusterj.annotation.Index {public java.lang.String name ;public java.lang.String unique ;public com.mysql.clusterj.annotation.Column[] columns ;
}
Columns that compose this index.
Parameters | |
return | columns that compose this index |
Annotation for a group of indices. This is used on a class where there are multiple indices defined.
@Target(value=java.lang.annotation.ElementType.TYPE) @Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME) public @interface com.mysql.clusterj.annotation.Indices {public com.mysql.clusterj.annotation.Index[] value ;
}
Annotation for a Large Object (lob). This annotation can be used with byte[] and InputStream types for binary columns; and with String and InputStream types for character columns.

Annotation to specify that the member is not persistent. If used, this is the only annotation allowed on a member.
Enumeration of the "null-value" behavior values. This behavior is specified in the @Persistent annotation.
public final class com.mysql.clusterj.annotation.NullValue extends java.lang.Enum<com.mysql.clusterj.annotation.NullValue> {
// Public Static Fieldspublic static final com.mysql.clusterj.annotation.NullValue DEFAULT ;public static final com.mysql.clusterj.annotation.NullValue EXCEPTION ;public static final com.mysql.clusterj.annotation.NullValue NONE ;
// Public Static Methodspublic static com.mysql.clusterj.annotation.NullValue valueOf(java.lang.String name);public static com.mysql.clusterj.annotation.NullValue[] values();
}
Methods inherited from
java.lang.Enum:
compareTo
, equals
, getDeclaringClass
, hashCode
, name
, ordinal
, toString
, valueOf
Methods inherited from
java.lang.Object:
getClass
, notify
, notifyAll
, wait
Annotation on a class or member to define the partition key. If annotating a class or interface, either a single column or multiple columns can be specified. If annotating a member, neither column nor columns should be specified.
@Target(value={java.lang.annotation.ElementType.TYPE, java.lang.annotation.ElementType.FIELD, java.lang.annotation.ElementType.METHOD}) @Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME) public @interface com.mysql.clusterj.annotation.PartitionKey {public java.lang.String column ;public com.mysql.clusterj.annotation.Column[] columns ;
}

Name of the column to use for the partition key
Parameters | |
return | the name of the column to use for the partition key |
Annotation for whether the class or interface is persistence-capable.
@Target(value=java.lang.annotation.ElementType.TYPE) @Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME) public @interface com.mysql.clusterj.annotation.PersistenceCapable {public java.lang.String table ;public java.lang.String database ;public java.lang.String schema ;
}
Enumeration of the persistence-modifier values for a member.
public final class com.mysql.clusterj.annotation.PersistenceModifier extends java.lang.Enum<com.mysql.clusterj.annotation.PersistenceModifier> {
// Public Static Fieldspublic static final com.mysql.clusterj.annotation.PersistenceModifier NONE ;public static final com.mysql.clusterj.annotation.PersistenceModifier PERSISTENT ;public static final com.mysql.clusterj.annotation.PersistenceModifier UNSPECIFIED ;
// Public Static Methodspublic static com.mysql.clusterj.annotation.PersistenceModifier valueOf(java.lang.String name);public static com.mysql.clusterj.annotation.PersistenceModifier[] values();
}
Methods inherited from
java.lang.Enum:
compareTo
, equals
, getDeclaringClass
, hashCode
, name
, ordinal
, toString
, valueOf
Methods inherited from
java.lang.Object:
getClass
, notify
, notifyAll
, wait

Annotation for defining the persistence of a member.
@Target(value={java.lang.annotation.ElementType.FIELD, java.lang.annotation.ElementType.METHOD}) @Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME) public @interface com.mysql.clusterj.annotation.Persistent {public com.mysql.clusterj.annotation.NullValue nullValue ;public java.lang.String primaryKey ;public java.lang.String column ;public com.mysql.clusterj.annotation.Extension[] extensions ;
}

Column name where the values are stored for this member.
Parameters | |
return | the name of the column |
Non-standard extensions for this member.
Parameters | |
return | the non-standard extensions |
Behavior when this member contains a null value.
Parameters | |
return | the behavior when this member contains a null value |
Annotation on a member to define it as a primary key member of a class or persistent interface.
@Target(value={java.lang.annotation.ElementType.TYPE, java.lang.annotation.ElementType.FIELD, java.lang.annotation.ElementType.METHOD}) @Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME) public @interface com.mysql.clusterj.annotation.PrimaryKey {public java.lang.String name ;public java.lang.String column ;public com.mysql.clusterj.annotation.Column[] columns ;
}

Name of the column to use for the primary key
Parameters | |
return | the name of the column to use for the primary key |
The column(s) for the primary key
Parameters | |
return | the column(s) for the primary key |
Provides interfaces for building queries for ClusterJ.
Used to combine multiple predicates with boolean operations.
public interface com.mysql.clusterj.query.Predicate {
// Public Methodspublic com.mysql.clusterj.query.Predicate and(com.mysql.clusterj.query.Predicate predicate);public com.mysql.clusterj.query.Predicate not();public com.mysql.clusterj.query.Predicate or(com.mysql.clusterj.query.Predicate predicate);
}

public com.mysql.clusterj.query.Predicate and(com.mysql.clusterj.query.Predicate predicate);Combine this Predicate with another, using the "and" semantic.
Parameters | |
predicate | the other predicate |
return | a new Predicate combining both Predicates |
public com.mysql.clusterj.query.Predicate not();Negate this Predicate.
Parameters | |
return | this predicate |
- 4.3.3.2.1. Synopsis
- 4.3.3.2.2. between(PredicateOperand, PredicateOperand)
- 4.3.3.2.3. equal(PredicateOperand)
- 4.3.3.2.4. greaterEqual(PredicateOperand)
- 4.3.3.2.5. greaterThan(PredicateOperand)
- 4.3.3.2.6. in(PredicateOperand)
- 4.3.3.2.7. lessEqual(PredicateOperand)
- 4.3.3.2.8. lessThan(PredicateOperand)
PredicateOperand represents a column or parameter that can be compared to another
public interface com.mysql.clusterj.query.PredicateOperand {
// Public Methodspublic com.mysql.clusterj.query.Predicate between(com.mysql.clusterj.query.PredicateOperand lower,
com.mysql.clusterj.query.PredicateOperand upper);public com.mysql.clusterj.query.Predicate equal(com.mysql.clusterj.query.PredicateOperand other);public com.mysql.clusterj.query.Predicate greaterEqual(com.mysql.clusterj.query.PredicateOperand other);public com.mysql.clusterj.query.Predicate greaterThan(com.mysql.clusterj.query.PredicateOperand other);public com.mysql.clusterj.query.Predicate in(com.mysql.clusterj.query.PredicateOperand other);public com.mysql.clusterj.query.Predicate lessEqual(com.mysql.clusterj.query.PredicateOperand other);public com.mysql.clusterj.query.Predicate lessThan(com.mysql.clusterj.query.PredicateOperand other);
}

public com.mysql.clusterj.query.Predicate between(com.mysql.clusterj.query.PredicateOperand lower,
com.mysql.clusterj.query.PredicateOperand upper);Return a Predicate representing comparing this to another using "between" semantics.
Parameters | |
lower | another PredicateOperand |
upper | another PredicateOperand |
return | a new Predicate |
public com.mysql.clusterj.query.Predicate equal(com.mysql.clusterj.query.PredicateOperand other);Return a Predicate representing comparing this to another using "equal to" semantics.
Parameters | |
other | the other PredicateOperand |
return | a new Predicate |
public com.mysql.clusterj.query.Predicate greaterEqual(com.mysql.clusterj.query.PredicateOperand other);Return a Predicate representing comparing this to another using "greater than or equal to" semantics.
Parameters | |
other | the other PredicateOperand |
return | a new Predicate |
public com.mysql.clusterj.query.Predicate greaterThan(com.mysql.clusterj.query.PredicateOperand other);Return a Predicate representing comparing this to another using "greater than" semantics.
Parameters | |
other | the other PredicateOperand |
return | a new Predicate |
public com.mysql.clusterj.query.Predicate in(com.mysql.clusterj.query.PredicateOperand other);Return a Predicate representing comparing this to a collection of values using "in" semantics.
Parameters | |
other | another PredicateOperand |
return | a new Predicate |
public com.mysql.clusterj.query.Predicate lessEqual(com.mysql.clusterj.query.PredicateOperand other);Return a Predicate representing comparing this to another using "less than or equal to" semantics.
Parameters | |
other | the other PredicateOperand |
return | a new Predicate |
QueryBuilder represents a factory for queries.
public interface com.mysql.clusterj.query.QueryBuilder {
// Public Methodspublic com.mysql.clusterj.query.QueryDomainType<T> createQueryDefinition(java.lang.Class<T> cls);
}
- See Also
- getQueryBuilder()

QueryDefinition allows users to define queries.
public interface com.mysql.clusterj.query.QueryDefinition<E> {
// Public Methodspublic com.mysql.clusterj.query.Predicate not(com.mysql.clusterj.query.Predicate predicate);public com.mysql.clusterj.query.PredicateOperand param(java.lang.String parameterName);public com.mysql.clusterj.query.QueryDefinition<E> where(com.mysql.clusterj.query.Predicate predicate);
}

public com.mysql.clusterj.query.Predicate not(com.mysql.clusterj.query.Predicate predicate);Convenience method to negate a predicate.
Parameters | |
predicate | the predicate to negate |
return | the inverted predicate |
public com.mysql.clusterj.query.PredicateOperand param(java.lang.String parameterName);Specify a parameter for the query.
Parameters | |
parameterName | the name of the parameter |
return | the PredicateOperand representing the parameter |
QueryDomainType represents the domain type of a query. The domain type validates property names that are used to filter results.
public interface com.mysql.clusterj.query.QueryDomainType<E> extends com.mysql.clusterj.query.QueryDefinition<E> {
// Public Methodspublic com.mysql.clusterj.query.PredicateOperand get(java.lang.String propertyName);public java.lang.Class<E> getType();
}
public com.mysql.clusterj.query.PredicateOperand get(java.lang.String propertyName);Get a PredicateOperand representing a property of the domain type.
Parameters | |
propertyName | the name of the property |
return | a representation the value of the property |
In this section, we discuss limitations and known issues in the MySQL Cluster Connector for Java APIs.
Joins. With ClusterJ, queries are limited to single tables. This is not a problem with JPA or JDBC, both of which support joins.
Database views.
Because MySQL database views do not use the
NDB storage engine, ClusterJ
applications cannot “see” views, and thus cannot
access them. To work with views using Java, you should use JPA
or JDBC.
Relations and inheritance.
ClusterJ does not support relations or inheritance. This means
that ClusterJ does not handle foreign keys. While
NDB tables do not support foreign
keys, it is possible using JPA to enforce them programmatically.
Known issues in MySQL Cluster. For information about limitations and other known issues with MySQL Cluster, see Known Limitations of MySQL Cluster.
Known issues in JPA. For information about limitations and known issues with OpenJPA, see the OpenJPA documentation.
Known issues in JDBC and Connector/J. For information about limitations and known issues with JDBC and Connector/J, see JDBC API Implementation Notes, and Connector/J: Common Problems and Solutions.