Table of Contents
- 2.1. Getting Started with the NDB API
- 2.2. The NDB API Class Hierarachy
- 2.3. NDB API Classes, Interfaces, and Structures
- 2.3.1. The
ColumnClass - 2.3.2. The
DatafileClass - 2.3.3. The
DictionaryClass - 2.3.4. The
EventClass - 2.3.5. The
IndexClass - 2.3.6. The
LogfileGroupClass - 2.3.7. The
ListClass - 2.3.8. The
NdbClass - 2.3.9. The
NdbBlobClass - 2.3.10. The
NdbDictionaryClass - 2.3.11. The
NdbEventOperationClass - 2.3.12. The
NdbIndexOperationClass - 2.3.13. The
NdbIndexScanOperationClass - 2.3.14. The
NdbInterpretedCodeClass - 2.3.15. The
NdbOperationClass - 2.3.16. The
NdbRecAttrClass - 2.3.17. The
NdbScanFilterClass - 2.3.18. The
NdbScanOperationClass - 2.3.19. The
NdbTransactionClass - 2.3.20. The
ObjectClass - 2.3.21. The
TableClass - 2.3.22. The
TablespaceClass - 2.3.23. The
UndofileClass - 2.3.24. The
Ndb_cluster_connectionClass - 2.3.25. The
NdbRecordInterface - 2.3.26. The
AutoGrowSpecificationStructure - 2.3.27. The
ElementStructure - 2.3.28. The
GetValueSpecStructure - 2.3.29. The
IndexBoundStructure - 2.3.30. The
Key_part_ptrStructure - 2.3.31. The
NdbErrorStructure - 2.3.32. The
OperationOptionsStructure - 2.3.33. The
PartitionSpecStructure - 2.3.34. The
RecordSpecificationStructure - 2.3.35. The
ScanOptionsStructure - 2.3.36. The
SetValueSpecStructure
- 2.3.1. The
- 2.4. NDB API Examples
- 2.4.1. Using Synchronous Transactions
- 2.4.2. Using Synchronous Transactions and Multiple Clusters
- 2.4.3. Handling Errors and Retrying Transactions
- 2.4.4. Basic Scanning Example
- 2.4.5. Using Secondary Indexes in Scans
- 2.4.6. Using
NdbRecordwith Hash Indexes - 2.4.7. Comparing
RecAttrandNdbRecord - 2.4.8. NDB API Event Handling Example
- 2.4.9. Basic
BLOBHandling Example - 2.4.10. Handling
BLOBs UsingNdbRecord
Abstract
This chapter contains information about the NDB API, which is
used to write applications that access data in the
NDBCLUSTER storage engine.
This section discusses preparations necessary for writing and compiling an NDB API application.
Abstract
This section provides information on compiling and linking NDB API applications, including requirements and compiler and linker options.
To use the NDB API with MySQL, you must have the
NDB client library and its header files
installed alongside the regular MySQL client libraries and
headers. These are automatically installed when you build MySQL
using the --with-ndbcluster
configure option or when using a MySQL binary
package that supports the NDBCLUSTER storage
engine.
MySQL 4.1 does not install the required
NDB-specific header files. You should use
MySQL 5.0 or later when writing NDB API applications, and this
Guide is targeted for use with MySQL Cluster in MySQL 5.1,
MySQL Cluster NDB 6.X, MySQL Cluster NDB 7.X, and later.
The library and header files were not included in MySQL 5.1
binary distributions prior to MySQL 5.1.12; beginning with
5.1.12, you can find them in
/usr/include/storage/ndb. This issue did
not occur when compiling MySQL 5.1 from source.
Header Files.
In order to compile source files that use the NDB API, you
must ensure that the necessary header files can be found.
Header files specific to the NDB API are installed in the
following subdirectories of the MySQL
include directory:
include/mysql/storage/ndb/ndbapiinclude/mysql/storage/ndb/mgmapi
Compiler Flags. The MySQL-specific compiler flags needed can be determined using the mysql_config utility that is part of the MySQL installation:
$ mysql_config --cflags -I/usr/local/mysql/include/mysql -Wreturn-type -Wtrigraphs -W -Wformat -Wsign-compare -Wunused -mcpu=pentium4 -march=pentium4
This sets the include path for the MySQL header files but not
for those specific to the NDB API. The
--include option to
mysql_config returns the generic include path
switch:
shell> mysql_config --include -I/usr/local/mysql/include/mysql
It is necessary to add the subdirectory paths explicitly, so
that adding all the needed compile flags to the
CXXFLAGS shell variable should look something
like this:
CFLAGS="$CFLAGS "`mysql_config --cflags` CFLAGS="$CFLAGS "`mysql_config --include`/storage/ndb CFLAGS="$CFLAGS "`mysql_config --include`/storage/ndb/ndbapi CFLAGS="$CFLAGS "`mysql_config --include`/storage/ndb/mgmapi
If you do not intend to use the Cluster management functions,
the last line in the previous example can be omitted. However,
if you are interested in the management functions only, and do
not want or need to access Cluster data except from MySQL,
then you can omit the line referencing the
ndbapi directory.
NDB API applications must be linked against both the MySQL and
NDB client libraries. The
NDB client library also requires some
functions from the mystrings library, so this
must be linked in as well.
The necessary linker flags for the MySQL client library are
returned by mysql_config
--libs. For multithreaded
applications you should use the --libs_r
instead:
$ mysql_config --libs_r -L/usr/local/mysql-5.1/lib/mysql -lmysqlclient_r -lz -lpthread -lcrypt -lnsl -lm -lpthread -L/usr/lib -lssl -lcrypto
Formerly, to link an NDB API application, it was necessary to
add -lndbclient, -lmysys, and
-lmystrings to these options, in the order
shown, and adding all the required linker flags to the
LDFLAGS variable looked something like this:
LDFLAGS="$LDFLAGS "`mysql_config --libs_r` LDFLAGS="$LDFLAGS -lndbclient -lmysys -lmystrings"
Beginning with MySQL 5.1.24-ndb-6.2.16 and MySQL
5.1.24-ndb-6.3.14, it is necessary only to add
-lndbclient to LD_FLAGS, as
shown here:
LDFLAGS="$LDFLAGS "`mysql_config --libs_r` LDFLAGS="$LDFLAGS -lndbclient"
(For more information about this change, see Bug#29791.)
It is often faster and simpler to use GNU autotools than to
write your own makefiles. In this section, we provide an
autoconf macro WITH_MYSQL that can be used to
add a --with-mysql option to a configure file,
and that automatically sets the correct compiler and linker
flags for given MySQL installation.
All of the examples in this chapter include a common
mysql.m4 file defining
WITH_MYSQL. A typical complete example
consists of the actual source file and the following helper
files:
acincludeconfigure.inMakefile.m4
automake also requires that you provide
README, NEWS,
AUTHORS, and ChangeLog
files; however, these can be left empty.
To create all necessary build files, run the following:
aclocal
autoconf
automake -a -c
configure --with-mysql=/mysql/prefix/path
Normally, this needs to be done only once, after which make will accommodate any file changes.
Example 1-1: acinclude.m4.
m4_include([../mysql.m4])
Example 1-2: configure.in.
AC_INIT(example, 1.0) AM_INIT_AUTOMAKE(example, 1.0) WITH_MYSQL() AC_OUTPUT(Makefile)
Example 1-3: Makefile.am.
bin_PROGRAMS = example example_SOURCES = example.cc
Example 1-4: WITH_MYSQL source for inclusion in
acinclude.m4.
dnl
dnl configure.in helper macros
dnl
AC_DEFUN([WITH_MYSQL], [
AC_MSG_CHECKING(for mysql_config executable)
AC_ARG_WITH(mysql, [ --with-mysql=PATH path to mysql_config binary or mysql prefix dir], [
if test -x $withval -a -f $withval
then
MYSQL_CONFIG=$withval
elif test -x $withval/bin/mysql_config -a -f $withval/bin/mysql_config
then
MYSQL_CONFIG=$withval/bin/mysql_config
fi
], [
if test -x /usr/local/mysql/bin/mysql_config -a -f /usr/local/mysql/bin/mysql_config
then
MYSQL_CONFIG=/usr/local/mysql/bin/mysql_config
elif test -x /usr/bin/mysql_config -a -f /usr/bin/mysql_config
then
MYSQL_CONFIG=/usr/bin/mysql_config
fi
])
if test "x$MYSQL_CONFIG" = "x"
then
AC_MSG_RESULT(not found)
exit 3
else
AC_PROG_CC
AC_PROG_CXX
# add regular MySQL C flags
ADDFLAGS=`$MYSQL_CONFIG --cflags`
# add NDB API specific C flags
IBASE=`$MYSQL_CONFIG --include`
ADDFLAGS="$ADDFLAGS $IBASE/storage/ndb"
ADDFLAGS="$ADDFLAGS $IBASE/storage/ndb/ndbapi"
ADDFLAGS="$ADDFLAGS $IBASE/storage/ndb/mgmapi"
CFLAGS="$CFLAGS $ADDFLAGS"
CXXFLAGS="$CXXFLAGS $ADDFLAGS"
LDFLAGS="$LDFLAGS "`$MYSQL_CONFIG --libs_r`" -lndbclient -lmystrings -lmysys"
LDFLAGS="$LDFLAGS "`$MYSQL_CONFIG --libs_r`" -lndbclient -lmystrings"
AC_MSG_RESULT($MYSQL_CONFIG)
fi
])
Abstract
This section covers connecting an NDB API application to a MySQL cluster.
NDB API applications require one or more of the following include files:
Applications accessing Cluster data using the NDB API must include the file
NdbApi.hpp.Applications making use of both the
NDBAPI and the regular MySQL client API also need to includemysql.h.Applications that use cluster management functions need the include file
mgmapi.h.
Before using the NDB API, it must first be initialised by
calling the ndb_init() function. Once an NDB
API application is complete, call ndb_end(0)
to perform a cleanup.
To establish a connection to the server, it is necessary to
create an instance of Ndb_cluster_connection,
whose constructor takes as its argument a cluster connectstring;
if no connectstring is given, localhost is
assumed.
The cluster connection is not actually initiated until the
Ndb_cluster_connection::connect() method is
called. When invoked without any arguments, the connection
attempt is retried each 1 second indefinitely until successful,
and no reporting is done. See
Section 2.3.24, “The Ndb_cluster_connection Class”, for details.
By default an API node connects to the “nearest”
data node—usually a data node running on the same machine,
due to the fact that shared memory transport can be used instead
of the slower TCP/IP. This may lead to poor load distribution in
some cases, so it is possible to enforce a round-robin node
connection scheme by calling the
set_optimized_node_selection() method with
0 as its argument prior to calling
connect(). (See
Section 2.3.24.1.6, “Ndb_cluster_connection::set_optimized_node_selection()”.)
The connect() method initiates a connection
to a cluster management node only—it does not wait for any
connections to data nodes to be made. This can be accomplished
by using wait_until_ready() after calling
connect(). The
wait_until_ready() method waits up to a given
number of seconds for a connection to a data node to be
established.
In the following example, initialisation and connection are
handled in the two functions example_init()
and example_end(), which will be included in
subsequent examples using the file
example_connection.h.
Example 2-1: Connection example.
#include <stdio.h>
#include <stdlib.h>
#include <NdbApi.hpp>
#include <mysql.h>
#include <mgmapi.h>
Ndb_cluster_connection* connect_to_cluster();
void disconnect_from_cluster(Ndb_cluster_connection *c);
Ndb_cluster_connection* connect_to_cluster()
{
Ndb_cluster_connection* c;
if(ndb_init())
exit(EXIT_FAILURE);
c= new Ndb_cluster_connection();
if(c->connect(4, 5, 1))
{
fprintf(stderr, "Unable to connect to cluster within 30 seconds.\n\n");
exit(EXIT_FAILURE);
}
if(c->wait_until_ready(30, 0) < 0)
{
fprintf(stderr, "Cluster was not ready within 30 seconds.\n\n");
exit(EXIT_FAILURE);
}
}
void disconnect_from_cluster(Ndb_cluster_connection *c)
{
delete c;
ndb_end(2);
}
int main(int argc, char* argv[])
{
Ndb_cluster_connection *ndb_connection= connect_to_cluster();
printf("Connection Established.\n\n");
disconnect_from_cluster(ndb_connection);
return EXIT_SUCCESS;
}
Abstract
This section discusses NDB naming and other conventions with regard to database objects.
Databases and Schemas.
Databases and schemas are not represented by objects as such in
the NDB API. Instead, they are modelled as attributes of
Table and Index objects.
The value of the database attribute of one of
these objects is always the same as the name of the MySQL
database to which the table or index belongs. The value of the
schema attribute of a
Table or Index object is
always 'def' (for “default”).
Tables.
MySQL table names are directly mapped to NDB
table names without modification. Table names starting with
'NDB$' are reserved for internal use>, as
is the SYSTAB_0 table in the
sys database.
Indexes. There are two different type of NDB indexes:
Hash indexes are unique, but not ordered.
B-tree indexes are ordered, but permit duplicate values.
Names of unique indexes and primary keys are handled as follows:
For a MySQL
UNIQUEindex, both a B-tree and a hash index are created. The B-tree index uses the MySQL name for the index; the name for the hash index is generated by appending '$unique' to the index name.For a MySQL primary key only a B-tree index is created. This index is given the name
PRIMARY. There is no extra hash; however, the uniqueness of the primary key is guaranteed by making the MySQL key the internal primary key of theNDBtable.
Column Names and Values.
NDB column names are the same as their MySQL
names.
Data Types.
MySQL data types are stored in NDB columns as
follows:
The MySQL
TINYINT,SMALLINT,INT, andBIGINTdata types map toNDBtypes having the same names and storage requirements as their MySQL counterparts.The MySQL
FLOATandDOUBLEdata types are mapped toNDBtypes having the same names and storage requirements.The storage space required for a MySQL
CHARcolumn is determined by the maximum number of characters and the column's character set. For most (but not all) character sets, each character takes one byte of storage. When using UTF-8, each character requires three bytes. You can find the number of bytes needed per character in a given character set by checking theMaxlencolumn in the output ofSHOW CHARACTER SET.In MySQL 5.1 and later, the storage requirements for a
VARCHARorVARBINARYcolumn depend on whether the column is stored in memory or on disk:For in-memory columns, the
NDBCLUSTERstorage engine supports variable-width columns with 4-byte alignment. This means that (for example) a the string'abcde'stored in aVARCHAR(50)column using thelatin1character set requires 12 bytes—in this case, 2 bytes times 5 characters is 10, rounded up to the next even multiple of 4 yields 12. (This represents a change in behavior from Cluster in MySQL 5.0 and 4.1, where a column having the same definition required 52 bytes storage per row regardless of the length of the string being stored in the row.)In Disk Data columns,
VARCHARandVARBINARYare stored as fixed-width columns. This means that each of these types requires the same amount of storage as aCHARof the same size.
Each row in a Cluster
BLOBorTEXTcolumn is made up of two separate parts. One of these is of fixed size (256 bytes), and is actually stored in the original table. The other consists of any data in excess of 256 bytes, which stored in a hidden table. The rows in this second table are always 2000 bytes long. This means that record ofsizebytes in aTEXTorBLOBcolumn requires256 bytes, if
size<= 256256 + 2000 * ((bytes otherwisesize– 256) \ 2000) + 1)
This section provides a hierarchical listing of all classes, interfaces, and structures exposed by the NDB API.
- 2.3.1. The
ColumnClass - 2.3.2. The
DatafileClass - 2.3.3. The
DictionaryClass - 2.3.4. The
EventClass - 2.3.5. The
IndexClass - 2.3.6. The
LogfileGroupClass - 2.3.7. The
ListClass - 2.3.8. The
NdbClass - 2.3.9. The
NdbBlobClass - 2.3.10. The
NdbDictionaryClass - 2.3.11. The
NdbEventOperationClass - 2.3.12. The
NdbIndexOperationClass - 2.3.13. The
NdbIndexScanOperationClass - 2.3.14. The
NdbInterpretedCodeClass - 2.3.15. The
NdbOperationClass - 2.3.16. The
NdbRecAttrClass - 2.3.17. The
NdbScanFilterClass - 2.3.18. The
NdbScanOperationClass - 2.3.19. The
NdbTransactionClass - 2.3.20. The
ObjectClass - 2.3.21. The
TableClass - 2.3.22. The
TablespaceClass - 2.3.23. The
UndofileClass - 2.3.24. The
Ndb_cluster_connectionClass - 2.3.25. The
NdbRecordInterface - 2.3.26. The
AutoGrowSpecificationStructure - 2.3.27. The
ElementStructure - 2.3.28. The
GetValueSpecStructure - 2.3.29. The
IndexBoundStructure - 2.3.30. The
Key_part_ptrStructure - 2.3.31. The
NdbErrorStructure - 2.3.32. The
OperationOptionsStructure - 2.3.33. The
PartitionSpecStructure - 2.3.34. The
RecordSpecificationStructure - 2.3.35. The
ScanOptionsStructure - 2.3.36. The
SetValueSpecStructure
This section provides a detailed listing of all classes, interfaces,
and stuctures defined in the NDB API.
Each listing includes the following information:
Description and purpose of the class, interface, or structure.
Pointers, where applicable, to parent and child classes.
A diagram of the class and its members.
NoteThe sections covering the
NdbDictionaryandNdbOperationclasses also include entity-relationship diagrams showing the hierarchy of inner classes, subclasses, and public type descending from them.Detailed listings of all public members, including descriptions of all method parameters and type values.
Class, interface, and structure descriptions are provided in alphabetic order. For a hierarchical listing, see Section 2.2, “The NDB API Class Hierarachy”.
Abstract
This class represents a column in an NDB Cluster table.
Parent class. NdbDictionary
Child classes. None
Description.
Each instance of the Column is characterised by
its type, which is determined by a number of type specifiers:
Built-in type
Array length or maximum length
Precision and scale (currently not in use)
Character set (applicable only to columns using string data types)
Inline and part sizes (applicable only to
BLOBcolumns)
These types in general correspond to MySQL data types and their
variants. The data formats are same as in MySQL. The NDB API
provides no support for constructing such formats; however, they are
checked by the NDB kernel.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
getName() | Gets the name of the column |
getNullable() | Checks whether the column can be set to NULL |
getPrimaryKey() | Check whether the column is part of the table's primary key |
getColumnNo() | Gets the column number |
equal() | Compares Column objects |
getType() | Gets the column's type (Type value) |
getLength() | Gets the column's length |
getCharset() | Get the character set used by a string (text) column (not applicable to columns not storing character data) |
getInlineSize() | Gets the inline size of a BLOB column (not applicable
to other column types) |
getPartSize() | Gets the part size of a BLOB column (not applicable
to other column types) |
getStripeSize() | Gets a BLOB column's stripe size (not applicable to other column types) |
getSize() | Gets the size of an element |
getPartitionKey() | Checks whether the column is part of the table's partitioning key |
getArrayType() | Gets the column's array type |
getStorageType() | Gets the storage type used by this column |
getPrecision() | Gets the column's precision (used for decimal types only) |
getScale() | Gets the column's scale (used for decimal types only) |
Column() | Class constructor; there is also a copy constructor |
~Column() | Class destructor |
setName() | Sets the column's name |
setNullable() | Toggles the column's nullability |
setPrimaryKey() | Determines whether the column is part of the primary key |
setType() | Sets the column's Type |
setLength() | Sets the column's length |
setCharset() | Sets the character set used by a column containing character data (not applicable to nontextual columns) |
setInlineSize() | Sets the inline size for a BLOB column (not
applicable to non-BLOB columns) |
setPartSize() | Sets the part size for a BLOB column (not applicable
to non-BLOB columns) |
setStripeSize() | Sets the stripe size for a BLOB column (not
applicable to non-BLOB columns) |
setPartitionKey() | Determines whether the column is part of the table's partitioning key |
setArrayType() | Sets the column's ArrayType |
setStorageType() | Sets the storage type to be used by this column |
setPrecision() | Sets the column's precision (used for decimal types only) |
setScale() | Sets the column's scale (used for decimal types only) |
setDefaultValue() | Sets the column's default value |
getDefaultValue() | Returns the column's default value |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.1.2, “Column Methods”.
In the NDB API, column names are handled in case-sensitive fashion. (This differs from the MySQL C API.) To reduce the possibility for error, it is recommended that you name all columns consistently using uppercase or lowercase.
Types.
These are the public types of the Column class:
| Type | Purpose / Use |
|---|---|
ArrayType | Specifies the column's internal storage format |
StorageType | Determines whether the column is stored in memory or on disk |
Type | The column's data type. NDB columns have the data
types as found in MySQL |
For a discussion of each of these types, along with its possible
values, see Section 2.3.1.1, “Column Types”.
Class diagram.
This diagram shows all the available methods and enumerated types
of the Column class:

Abstract
This section details the public types belonging to the
Column class.
Abstract
This type describes the Column's internal
attribute format.
Description. The attribute storage format can be either fixed or variable.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
ArrayTypeFixed | stored as a fixed number of bytes |
ArrayTypeShortVar | stored as a variable number of bytes; uses 1 byte overhead |
ArrayTypeMediumVar | stored as a variable number of bytes; uses 2 bytes overhead |
The fixed storage format is faster but also generally requires
more space than the variable format. The default is
ArrayTypeShortVar for Var*
types and ArrayTypeFixed for others. The
default is usually sufficient.
Abstract
This type describes the storage type used by a
Column object.
Description.
The storage type used for a given column can be either in
memory or on disk. Columns stored on disk mean that less RAM
is required overall but such columns cannot be indexed, and
are potentially much slower to access. The default is
StorageTypeMemory.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
StorageTypeMemory | Store the column in memory |
StorageTypeDisk | Store the column on disk |
Abstract
Type is used to describe the
Column object's data type.
Description.
Data types for Column objects are analogous
to the data types used by MySQL. The types
Tinyint,
Tinyintunsigned,
Smallint, Smallunsigned,
Mediumint,
Mediumunsigned, Int,
Unsigned, Bigint,
Bigunsigned, Float, and
Double (that is, types
Tinyint through Double
in the order listed in the Enumeration Values table) can be
used in arrays.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
Undefined | Undefined |
Tinyint | 1-byte signed integer |
Tinyunsigned | 1-byte unsigned integer |
Smallint | 2-byte signed integer |
Smallunsigned | 2-byte unsigned integer |
Mediumint | 3-byte signed integer |
Mediumunsigned | 3-byte unsigned integer |
Int | 4-byte signed integer |
Unsigned | 4-byte unsigned integer |
Bigint | 8-byte signed integer |
Bigunsigned | 8-byte signed integer |
Float | 4-byte float |
Double | 8-byte float |
Olddecimal | Signed decimal as used prior to MySQL 5.0 |
Olddecimalunsigned | Unsigned decimal as used prior to MySQL 5.0 |
Decimal | Signed decimal as used by MySQL 5.0 and later |
Decimalunsigned | Unsigned decimal as used by MySQL 5.0 and later |
Char | A fixed-length array of 1-byte characters; maximum length is 255 characters |
Varchar | A variable-length array of 1-byte characters; maximum length is 255 characters |
Binary | A fixed-length array of 1-byte binary characters; maximum length is 255 characters |
Varbinary | A variable-length array of 1-byte binary characters; maximum length is 255 characters |
Datetime | An 8-byte date and time value, with a precision of 1 second |
Date | A 4-byte date value, with a precision of 1 day |
Blob | A binary large object; see Section 2.3.9, “The NdbBlob Class” |
Text | A text blob |
Bit | A bit value; the length specifies the number of bits |
Longvarchar | A 2-byte Varchar |
Longvarbinary | A 2-byte Varbinary |
Time | Time without date |
Year | 1-byte year value in the range 1901-2155 (same as MySQL) |
Timestamp | Unix time |
Do not confuse Column::Type with
Object::Type or
Table::Type.
- 2.3.1.2.1.
ColumnConstructor - 2.3.1.2.2.
Column::getName() - 2.3.1.2.3.
Column::getNullable() - 2.3.1.2.4.
Column::getPrimaryKey() - 2.3.1.2.5.
Column::getColumnNo() - 2.3.1.2.6.
Column::equal() - 2.3.1.2.7.
Column::getType() - 2.3.1.2.8.
Column::getPrecision() - 2.3.1.2.9.
Column::getScale() - 2.3.1.2.10.
Column::getLength() - 2.3.1.2.11.
Column::getCharset() - 2.3.1.2.12.
Column::getInlineSize() - 2.3.1.2.13.
Column::getPartSize() - 2.3.1.2.14.
Column::getStripeSize() - 2.3.1.2.15.
Column::getSize() - 2.3.1.2.16.
Column::getPartitionKey() - 2.3.1.2.17.
Column::getArrayType() - 2.3.1.2.18.
Column::getStorageType() - 2.3.1.2.19.
Column::setName() - 2.3.1.2.20.
Column::setNullable() - 2.3.1.2.21.
Column::setPrimaryKey() - 2.3.1.2.22.
Column::setType() - 2.3.1.2.23.
Column::setPrecision() - 2.3.1.2.24.
Column::setScale() - 2.3.1.2.25.
Column::setLength() - 2.3.1.2.26.
Column::setCharset() - 2.3.1.2.27.
Column::setInlineSize - 2.3.1.2.28.
Column::setPartSize() - 2.3.1.2.29.
Column::setStripeSize() - 2.3.1.2.30.
Column::setPartitionKey() - 2.3.1.2.31.
Column::setArrayType() - 2.3.1.2.32.
Column::setStorageType() - 2.3.1.2.33.
Column::setDefaultValue() - 2.3.1.2.34.
Column::getDefaultValue()
Abstract
This section documents the public methods of the
Column class.
The assignment (=) operator is overloaded for
this class, so that it always performs a deep copy.
As with other database objects, Column object
creation and attribute changes to existing columns done using
the NDB API are not visible from MySQL. For example, if you
change a column's data type using
Column::setType(), MySQL will regard the type
of column as being unchanged. The only exception to this rule
with regard to columns is that you can change the name of an
existing column using Column::setName().
Also remember that the NDB API handles column names in case-sensitive fashion.
Description.
You can create a new Column or copy an
existing one using the class constructor.
A Column created using the NDB API will
not be visible to a MySQL server.
The NDB API handles column names in case-sensitive fashion. For example, if you create a column named “myColumn”, you will not be able to access it later using “Mycolumn” for the name. You can reduce the possibility for error, by naming all columns consistently using only uppercase or only lowercase.
Signature.
You can create either a new instance of the
Column class, or by copying an existing
Column object. Both of these are shown
here:
Constructor for a new
Column:Column ( const char*name= "" )Copy constructor:
Column ( const Column&column)
Parameters.
When creating a new instance of Column, the
constructor takes a single argument, which is the name of the
new column to be created. The copy constructor also takes one
parameter—in this case, a reference to the
Column instance to be copied.
Return value.
A Column object.
Destructor.
The Column class destructor takes no
arguments and None.
Description. This method returns the name of the column for which it is called.
The NDB API handles column names in case-sensitive fashion. For example, if you retrieve the name “myColumn” for a given column, attempting to access this column using “Mycolumn” for the name fails with an error such as Column is NULL or Table definition has undefined column. You can reduce the possibility for error, by naming all columns consistently using only uppercase or only lowercase.
Signature.
const char* getName
(
void
) const
Parameters. None.
Return value. The name of the column.
Description.
This method is used to determine whether the column can be set
to NULL.
Signature.
bool getNullable
(
void
) const
Parameters. None.
Return value.
A Boolean value: true if the column can be
set to NULL, otherwise
false.
Description. This method is used to determine whether the column is part of the table's primary key.
The NDB API handles column names in case-sensitive fashion; “myColumn” and “Mycolumn” are not considered to refer to the same column. It is recommended that you minimize the possibility of errors from using the wrong lettercase for column names by naming all columns consistently using only uppercase or only lowercase.
Signature.
bool getPrimaryKey
(
void
) const
Parameters. None.
Return value.
A Boolean value: true if the column is part
of the primary key of the table to which this column belongs,
otherwise false.
Description. This method gets the number of a column—that is, its horizontal position within the table.
The NDB API handles column names in case-sensitive fashion, “myColumn” and “Mycolumn” are not considered to be the same column. It is recommended that you minimize the possibility of errors from using the wrong lettercase by naming all columns consistently using only uppercase or only lowercase.
Signature.
int getColumnNo
(
void
) const
Parameters. None.
Return value. The column number as an integer.
Description.
This method is used to compare one Column
with another to determine whether the two
Column objects are the same.
Signature.
bool equal
(
const Column& column
) const
Parameters.
equal() takes a single parameter, a
reference to an instance of Column.
Return value.
true if the columns being compared are
equal, otherwise false.
Description. This method gets the column's data type.
The NDB API handles column names in case-sensitive fashion, “myColumn” and “Mycolumn” are not considered to be the same column. It is recommended that you minimize the possibility of errors from using the wrong lettercase by naming all columns consistently using only uppercase or only lowercase.
Signature.
Type getType
(
void
) const
Parameters. None.
Return value.
The Type (data type) of the column. For a
list of possible values, see
Section 2.3.1.1.3, “Column::Type”.
Description. This method gets the precision of a column.
This method is applicable to decimal columns only.
Signature.
int getPrecision
(
void
) const
Parameters. None.
Return value.
The column's precision, as an integer. The precision is
defined as the number of significant digits; for more
information, see the discussion of the
DECIMAL data type in
Numeric Types, in the MySQL Manual.
Description. This method gets the scale used for a decimal column value.
This method is applicable to decimal columns only.
Signature.
int getScale
(
void
) const
Parameters. None.
Return value.
The decimal column's scale, as an integer. The scale of a
decimal column represents the number of digits that can be
stored following the decimal point. It is possible for this
value to be 0. For more information, see
the discussion of the DECIMAL data type in
Numeric Types, in the MySQL Manual.
Description. This method gets the length of a column. This is either the array length for the column or—for a variable length array—the maximum length.
The NDB API handles column names in case-sensitive fashion; “myColumn” and “Mycolumn” are not considered to refer to the same column. It is recommended that you minimize the possibility of errors from using the wrong lettercase for column names by naming all columns consistently using only uppercase or only lowercase.
Signature.
int getLength
(
void
) const
Parameters. None.
Return value. The (maximum) array length of the column, as an integer.
Description. This gets the character set used by a text column.
This method is applicable only to columns whose
Type value is Char,
Varchar, or Text.
The NDB API handles column names in case-sensitive fashion; “myColumn” and “Mycolumn” are not considered to refer to the same column. It is recommended that you minimize the possibility of errors from using the wrong lettercase for column names by naming all columns consistently using only uppercase or only lowercase.
Signature.
CHARSET_INFO* getCharset
(
void
) const
Parameters. None.
Return value.
A pointer to a CHARSET_INFO structure
specifying both character set and collation. This is the same
as a MySQL MY_CHARSET_INFO data structure;
for more information, see
mysql_get_character_set_info(),in the MySQL
Manual.
Description.
This method retrieves the inline size of a
BLOB column—that is, the number of
initial bytes to store in the table's blob attribute. This
part is normally in main memory and can be indexed.
This method is applicable only to BLOB
columns.
Signature.
int getInlineSize
(
void
) const
Parameters. None.
Return value.
The BLOB column's inline size, as an
integer.
Description.
This method is used to get the part size of a
BLOB column—that is, the number of
bytes that are stored in each tuple of the blob table.
This method is applicable to BLOB columns
only.
Signature.
int getPartSize
(
void
) const
Parameters. None.
Return value.
The column's part size, as an integer. In the case of a
Tinyblob column, this value is
0 (that is, only inline bytes are stored).
Description.
This method gets the stripe size of a BLOB
column—that is, the number of consecutive parts to store
in each node group.
Signature.
int getStripeSize
(
void
) const
Parameters. None.
Return value. The column's stripe size, as an integer.
Description. This function is used to obtain the size of a column.
The NDB API handles column names in case-sensitive fashion; “myColumn” and “Mycolumn” are not considered to refer to the same column. It is recommended that you minimize the possibility of errors from using the wrong lettercase for column names by naming all columns consistently using only uppercase or only lowercase.
Signature.
int getSize
(
void
) const
Parameters. None.
Return value. The column's size in bytes (an integer value).
Description. This method is used to check whether the column is part of the table's partitioning key.
A partitioning key is a set of
attributes used to distribute the tuples onto the
NDB nodes. This key a hashing function
specific to the NDBCLUSTER storage engine.
An example where this would be useful is an inventory tracking application involving multiple warehouses and regions, where it might be good to use the warehouse ID and district id as the partition key. This would place all data for a specific district and warehouse in the same database node. Locally to each fragment the full primary key will still be used with the hashing algorithm in such a case.
For more information about partitioning, partitioning schemes, and partitioning keys in MySQL 5.1, see Partitioning, in the MySQL Manual.
The only type of user-defined partitioning that is supported
for use with the NDBCLUSTER storage engine
in MySQL 5.1 is key partitioning.
Signature.
bool getPartitionKey
(
void
) const
Parameters. None.
Return value.
true if the column is part of the
partitioning key for the table, otherwise
false.
Description. This method gets the column's array type.
Signature.
ArrayType getArrayType
(
void
) const
Parameters. None.
Return value.
An ArrayType; see
Section 2.3.1.1.1, “The Column::ArrayType Type” for possible values.
Description. This method obtains a column's storage type.
Signature.
StorageType getStorageType
(
void
) const
Parameters. None.
Return value.
A StorageType value; for more information
about this type, see Section 2.3.1.1.2, “The Column::StorageType Type”.
Description. This method is used to set the name of a column.
setName() is the only
Column method whose result is visible from
a MySQL Server. MySQL cannot see any other changes made to
existing columns using the NDB API.
Signature.
void setName
(
const char* name
)
Parameters. This method takes a single argument—the new name for the column.
Return value. This method None.
Description. This method toggles the nullability of a column.
Changes made to columns using this method are not visible to MySQL.
Signature.
void setNullable
(
bool nullable
)
Parameters.
A Boolean value. Using true makes it
possible to insert NULLs into the column;
if nullable is
false, then this method performs the
equivalent of changing the column to NOT
NULL in MySQL.
Return value. None.
Description. This method is used to make a column part of the table's primary key, or to remove it from the primary key.
Changes made to columns using this method are not visible to MySQL.
The NDB API handles column names in case-sensitive fashion; “myColumn” and “Mycolumn” are not considered to refer to the same column. It is recommended that you minimize the possibility of errors from using the wrong lettercase for column names by naming all columns consistently using only uppercase or only lowercase.
Signature.
void setPrimaryKey
(
bool primary
)
Parameters.
This method takes a single Boolean value. If it is
true, then the column becomes part of the
table's primary key; if false, then the
column is removed from the primary key.
Return value. None.
Description.
This method sets the Type (data type) of a
column.
setType() resets all
column attributes to their (type dependent) default values; it
should be the first method that you call when changing the
attributes of a given column.
Changes made to columns using this method are not visible to MySQL.
The NDB API handles column names in case-sensitive fashion; “myColumn” and “Mycolumn” are not considered to refer to the same column. It is recommended that you minimize the possibility of errors from using the wrong lettercase for column names by naming all columns consistently using only uppercase or only lowercase.
Signature.
void setType
(
Type type
)
Parameters.
This method takes a single parameter—the new
Column::Type for the column. The default is
Unsigned. For a listing of all permitted
values, see Section 2.3.1.1.3, “Column::Type”.
Return value. None.
Description. This method can be used to set the precision of a decimal column.
This method is applicable to decimal columns only.
Changes made to columns using this method are not visible to MySQL.
Signature.
void setPrecision
(
int precision
)
Parameters.
This method takes a single parameter—precision is an
integer, the value of the column's new precision. For
additional information about decimal precision and scale, see
Section 2.3.1.2.8, “Column::getPrecision()”, and
Section 2.3.1.2.9, “Column::getScale()”.
Return value. None.
Description. This method can be used to set the scale of a decimal column.
This method is applicable to decimal columns only.
Changes made to columns using this method are not visible to MySQL.
Signature.
void setScale
(
int scale
)
Parameters.
This method takes a single parameter—the integer
scale is the new scale for the
decimal column. For additional information about decimal
precision and scale, see
Section 2.3.1.2.8, “Column::getPrecision()”, and
Section 2.3.1.2.9, “Column::getScale()”.
Return value. None.
Description. This method sets the length of a column. For a variable-length array, this is the maximum length; otherwise it is the array length.
Changes made to columns using this method are not visible to MySQL.
The NDB API handles column names in case-sensitive fashion; “myColumn” and “Mycolumn” are not considered to refer to the same column. It is recommended that you minimize the possibility of errors from using the wrong lettercase by naming all columns consistently using only uppercase or only lowercase.
Signature.
void setLength
(
int length
)
Parameters.
This method takes a single argument—the integer value
length is the new length for the
column.
Return value. None.
Description.
This method can be used to set the character set and collation
of a Char, Varchar, or
Text column.
This method is applicable to Char,
Varchar, and Text
columns only.
Changes made to columns using this method are not visible to MySQL.
Signature.
void setCharset
(
CHARSET_INFO* cs
)
Parameters.
This method takes one parameter. cs
is a pointer to a CHARSET_INFO structure.
For additional information, see
Section 2.3.1.2.11, “Column::getCharset()”.
Return value. None.
Description.
This method gets the inline size of a BLOB
column—that is, the number of initial bytes to store in
the table's blob attribute. This part is normally kept in main
memory, and can be indexed and interpreted.
This method is applicable to BLOB columns
only.
Changes made to columns using this method are not visible to MySQL.
Signature.
void setInlineSize
(
int size
)
Parameters.
The integer size is the new inline
size for the BLOB column.
Return value. None.
Description.
This method sets the part size of a BLOB
column—that is, the number of bytes to store in each
tuple of the BLOB table.
This method is applicable to BLOB columns
only.
Changes made to columns using this method are not visible to MySQL.
Signature.
void setPartSize
(
int size
)
Parameters.
The integer size is the number of
bytes to store in the BLOB table. Using
zero for this value means only inline bytes can be stored, in
effect making the column's type TINYBLOB.
Return value. None.
Description.
This method sets the stripe size of a BLOB
column—that is, the number of consecutive parts to store
in each node group.
This method is applicable to BLOB columns
only.
Changes made to columns using this method are not visible to MySQL.
Signature.
void setStripeSize
(
int size
)
Parameters.
This method takes a single argument. The integer
size is the new stripe size for the
column.
Return value. None.
Description. This method makes it possible to add a column to the partitioning key of the table to which it belongs, or to remove the column from the table's partitioning key.
Changes made to columns using this method are not visible to MySQL.
For additional information, see
Section 2.3.1.2.16, “Column::getPartitionKey()”.
Signature.
void setPartitionKey
(
bool enable
)
Parameters.
The single parameter enable is a
Boolean value. Passing true to this method
makes the column part of the table's partitioning key; if
enable is false,
then the column is removed from the partitioning key.
Return value. None.
Description. Sets the array type for the column.
Signature.
void setArrayType
(
ArrayType type
)
Parameters.
A Column::ArrayType value. See
Section 2.3.1.1.1, “The Column::ArrayType Type”, for more information.
Return value. None.
Description. Sets the storage type for the column.
Signature.
void setStorageType
(
StorageType type
)
Parameters.
A Column::StorageType value. See
Section 2.3.1.1.2, “The Column::StorageType Type”, for more
information.
Return value. None.
Description.
This method sets a column value to its default, if it has one;
otherwise it sets the column to NULL.
This method was added in MySQL Cluster NDB 7.0.15 and MySQL Cluster NDB 7.1.4.
To determine whether a table has any columns with default
values, use
Table::hasDefaultValues().
Signature.
int setDefaultValue
(
const void* buf,
unsigned int len
)
Parameters.
This method takes 2 arguments: a value pointer
buf; and the length
len of the data, as the number of
significant bytes. For fixed size types, this is the type
size. For variable length types, the leading 1 or 2 bytes
pointed to by buffer also contain
size information as normal for the type.
Return value. 0 on success, 1 on failure..
Description. Gets a column's default value data.
This method was added in MySQL Cluster NDB 7.0.15 and MySQL Cluster NDB 7.1.4.
To determine whether a table has any columns with default
values, use
Table::hasDefaultValues().
Signature.
const void* getDefaultValue
(
unsigned int* len = 0
) const
Parameters.
len holds either the length of the
default value data, or 0 in the event that the column is
nullable or has no default value.
Return value. The default value data.
Abstract
This section covers the Datafile class.
Parent class. Object
Child classes. None
Description.
The Datafile class models a Cluster Disk Data
datafile, which is used to store Disk Data table data.
In MySQL 5.1, only unindexed column data can be stored on disk. Indexes and indexes columns continue to be stored in memory as with previous versions of MySQL Cluster.
Versions of MySQL prior to 5.1 do not support Disk Data storage
and so do not support datafiles; thus the
Datafile class is unavailable for NDB API
applications written against these MySQL versions.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
Datafile() | Class constructor |
~Datafile() | Destructor |
getPath() | Gets the file system path to the datafile |
getSize() | Gets the size of the datafile |
getFree() | Gets the amount of free space in the datafile |
getNode() | Gets the ID of the node where the datafile is located |
getTablespace() | Gets the name of the tablespace to which the datafile belongs |
getTablespaceId() | Gets the ID of the tablespace to which the datafile belongs |
getFileNo() | Gets the number of the datafile in the tablespace |
getObjectStatus() | Gets the datafile's object status |
getObjectVersion() | Gets the datafile's object version |
getObjectId() | Gets the datafile's object ID |
setPath() | Sets the name and location of the datafile on the file system |
setSize() | Sets the datafile's size |
setTablespace() | Sets the tablespace to which the datafile belongs |
setNode() | Sets the Cluster node where the datafile is to be located |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.2.1, “Datafile Methods”.
Types.
The Datafile class defines no public types.
Class diagram.
This diagram shows all the available methods of the
Datafile class:
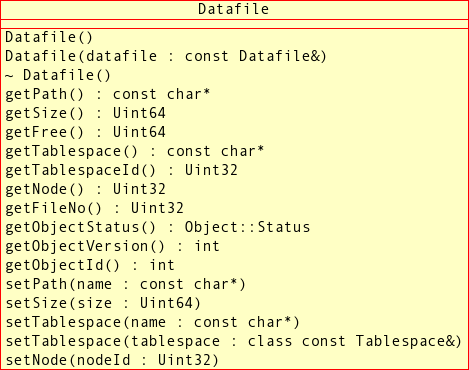
- 2.3.2.1.1.
DatafileClass Constructor - 2.3.2.1.2.
Datafile::getPath() - 2.3.2.1.3.
Datafile::getSize() - 2.3.2.1.4.
Datafile::getFree() - 2.3.2.1.5.
Datafile::getTablespace() - 2.3.2.1.6.
Datafile::getTablespaceId() - 2.3.2.1.7.
Datafile::getNode() - 2.3.2.1.8.
Datafile::getFileNo() - 2.3.2.1.9.
Datafile::getObjectStatus() - 2.3.2.1.10.
Datafile::getObjectVersion() - 2.3.2.1.11.
Datafile::getObjectId() - 2.3.2.1.12.
Datafile::setPath() - 2.3.2.1.13.
Datafile::setSize() - 2.3.2.1.14.
Datafile::setTablespace() - 2.3.2.1.15.
Datafile::setNode()
Abstract
This section provides descriptions of the public methods of the
Datafile class.
Description.
This method creates a new instance of
Datafile, or a copy of an existing one.
Signature. To create a new instance:
Datafile
(
void
)
To create a copy of an existing Datafile
instance:
Datafile
(
const Datafile& datafile
)
Parameters.
New instance: None. Copy constructor: a
reference to the Datafile instance to be
copied.
Return value.
A Datafile object.
Description. This method returns the file system path to the datafile.
Signature.
const char* getPath
(
void
) const
Parameters. None.
Return value. The path to the datafile on the data node's file system, a string (character pointer).
Description. This method gets the size of the datafile in bytes.
Signature.
Uint64 getSize
(
void
) const
Parameters. None.
Return value. The size of the data file, in bytes, as an unsigned 64-bit integer.
Description. This method gets the free space available in the datafile.
Signature.
Uint64 getFree
(
void
) const
Parameters. None.
Return value. The number of bytes free in the datafile, as an unsigned 64-bit integer.
Description. This method can be used to obtain the name of the tablespace to which the datafile belongs.
You can also access the associated tablespace's ID directly.
See Section 2.3.2.1.6, “Datafile::getTablespaceId()”.
Signature.
const char* getTablespace
(
void
) const
Parameters. None.
Return value. The name of the associated tablespace (as a character pointer).
Description. This method gets the ID of the tablespace to which the datafile belongs.
You can also access the name of the associated tablespace
directly. See Section 2.3.2.1.5, “Datafile::getTablespace()”.
Signature.
Uint32 getTablespaceId
(
void
) const
Parameters. None.
Return value. This method returns the tablespace ID as an unsigned 32-bit integer.
Description. This method retrieves the ID of the data node on which the datafile resides.
Signature.
Uint32 getNode
(
void
) const
Parameters. None.
Return value. The node ID as an unsigned 32-bit integer.
Description. This method gets the number of the file within the associated tablespace.
Signature.
Uint32 getFileNo
(
void
) const
Parameters. None.
Return value. The file number, as an unsigned 32-bit integer.
Description. This method is used to obtain the datafile's object status.
Signature.
virtual Object::Status getObjectStatus
(
void
) const
Parameters. None.
Return value.
The datafile's Status. See
Section 2.3.20.1.3, “The Object::Status Type”.
Description. This method retrieves the datafile's object version.
Signature.
virtual int getObjectVersion
(
void
) const
Parameters. None.
Return value. The datafile's object version, as an integer.
Description. This method is used to obtain the object ID of the datafile.
Signature.
virtual int getObjectId
(
void
) const
Parameters. None.
Return value. The datafile's object ID, as an integer.
Description. This method sets the path to the datafile on the data node's file system.
Signature.
const char* setPath
(
void
) const
Parameters. The path to the file, a string (as a character pointer).
Return value. None.
Description. This method sets the size of the datafile.
Signature.
void setSize
(
Uint64 size
)
Parameters.
This method takes a single parameter—the desired
size in bytes for the datafile, as
an unsigned 64-bit integer.
Return value. None.
Description. This method is used to associate the datafile with a tablespace.
Signatures.
setTablespace() can be invoked in either of
two ways, listed here:
Using the name of the tablespace, as shown here:
void setTablespace ( const char*name)Using a reference to a
Tablespaceobject.void setTablespace ( const class Tablespace&tablespace)
Parameters. This method takes a single parameter, which can be either one of the following:
The
nameof the tablespace (as a character pointer).A reference
tablespaceto the correspondingTablespaceobject.
Return value. None.
Abstract
This section describes the Dictionary class.
Parent class. NdbDictionary
Child classes. List
Description. This is used for defining and retrieving data object metadata. It also includes methods for creating and dropping database objects.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
Dictionary() | Class constructor method |
~Dictionary() | Destructor method |
getTable() | Gets the table having the given name |
getIndex() | Gets the index having the given name |
getEvent() | Gets the event having the given name |
getTablespace() | Gets the tablespace having the given name |
getLogfileGroup() | Gets the logfile group having the given name |
getDatafile() | Gets the datafile having the given name |
getUndofile() | Gets the undofile having the given name |
getNdbError() | Retrieves the latest error |
createTable() | Creates a table |
createIndex() | Creates an index |
createEvent() | Creates an event |
createTablespace() | Creates a tablespace |
createLogfileGroup() | Creates a logfile group |
createDatafile() | Creates a datafile |
createUndofile() | Creates an undofile |
dropTable() | Drops a table |
dropIndex() | |
dropEvent() | Drops an index |
dropTablespace() | Drops a tablespace |
dropLogfileGroup() | Drops a logfile group |
dropDatafile() | Drops a datafile |
dropUndofile() | Drops an undofile |
invalidateTable() | Invalidates a table object |
listObjects() | Fetches a list of the objects in the dictionary |
listIndexes() | Fetches a list of the indexes defined on a given table |
listEvents() | Fetches a list of the events defined in the dictionary |
removeCachedTable() | Removes a table from the local cache |
removeCachedIndex() | Removes an index from the local cache |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.3.1, “Dictionary Methods”.
Objects created using the
Dictionary::create
methods are not visible from the MySQL Server. For this reason, it
is usually preferable to avoid using them.
*()
The Dictionary class does not have any methods for working
directly with columns. You must use Column
class methods for this purpose—see
Section 2.3.1, “The Column Class”, for details.
Types.
See Section 2.3.7, “The List Class”, and Section 2.3.27, “The Element Structure”.
Dictionary Class and Subclass Diagram.
This diagram shows all the public members of the
Dictionary class and its subclasses:
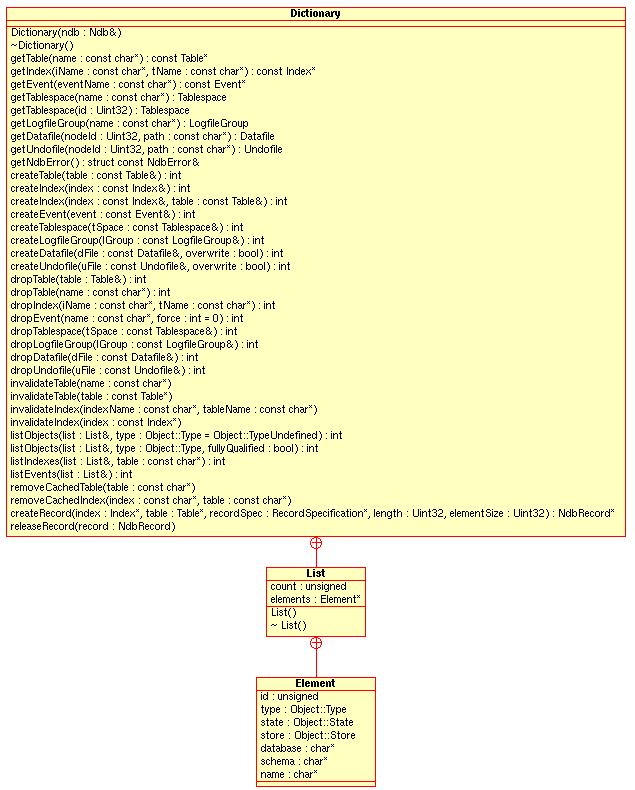
- 2.3.3.1.1.
DictionaryClass Constructor - 2.3.3.1.2.
Dictionary::getTable() - 2.3.3.1.3.
Dictionary::getIndex() - 2.3.3.1.4.
Dictionary::getEvent() - 2.3.3.1.5.
Dictionary::getTablespace() - 2.3.3.1.6.
Dictionary::getLogfileGroup() - 2.3.3.1.7.
Dictionary::getDatafile() - 2.3.3.1.8.
Dictionary::getUndofile() - 2.3.3.1.9.
Dictionary::getNdbError() - 2.3.3.1.10.
Dictionary::createTable() - 2.3.3.1.11.
Dictionary::createIndex() - 2.3.3.1.12.
Dictionary::createEvent() - 2.3.3.1.13.
Dictionary::createTablespace() - 2.3.3.1.14.
Dictionary::createLogfileGroup() - 2.3.3.1.15.
Dictionary::createDatafile() - 2.3.3.1.16.
Dictionary::createRecord() - 2.3.3.1.17.
Dictionary::createUndofile() - 2.3.3.1.18.
Dictionary::dropTable() - 2.3.3.1.19.
Dictionary::dropIndex() - 2.3.3.1.20.
Dictionary::dropEvent() - 2.3.3.1.21.
Dictionary::dropTablespace() - 2.3.3.1.22.
Dictionary::dropLogfileGroup() - 2.3.3.1.23.
Dictionary::dropDatafile() - 2.3.3.1.24.
Dictionary::dropUndofile() - 2.3.3.1.25.
DIctionary::invalidateTable() - 2.3.3.1.26.
DIctionary::invalidateIndex() - 2.3.3.1.27.
Dictionary::listObjects() - 2.3.3.1.28.
Dictionary::listIndexes() - 2.3.3.1.29.
Dictionary::listEvents() - 2.3.3.1.30.
Dictionary::releaseRecord() - 2.3.3.1.31.
Dictionary::removeCachedTable() - 2.3.3.1.32.
Dictionary::removeCachedIndex()
Abstract
This section details all of the public methods of the
Dictionary class.
Description.
This method creates a new instance of the
Dictionary class.
Both the constructor and destructor for this class are protected methods, rather than public.
Signature.
protected Dictionary
(
Ndb& ndb
)
Parameters.
An Ndb object. See
Section 2.3.8, “The Ndb Class”.
Return value.
A Dictionary object.
Destructor. The destructor takes no parameters and returns nothing.
protected ~Dictionary
(
void
)
Description.
This method can be used to access the table with a known name.
See Section 2.3.21, “The Table Class”.
Signature.
const Table* getTable
(
const char* name
) const
Parameters.
The name of the table.
Return value.
A pointer to the table, or NULL if there is
no table with the name supplied.
Description. This method retrieves a pointer to an index, given the name of the index and the name of the table to which the table belongs.
Signature.
const Index* getIndex
(
const char* iName,
const char* tName
) const
Parameters. Two parameters are required:
The name of the index (
iName)The name of the table to which the index belongs (
tName)
Both of these are string values, represented by character pointers.
Return value.
A pointer to an Index. See
Section 2.3.5, “The Index Class”, for information about this
object.
Description.
This method is used to obtain an Event
object, given the event's name.
Signature.
const Event* getEvent
(
const char* eventName
)
Parameters.
The eventName, a string (character
pointer).
Return value.
A pointer to an Event object. See
Section 2.3.4, “The Event Class”, for more information.
Description.
Given either the name or ID of a tablespace, this method
returns the corresponding Tablespace
object.
Signatures. This method can be invoked in either of ways, as show here:
Using the tablespace name:
Tablespace getTablespace ( const char*name)Using the tablespace ID:
Tablespace getTablespace ( Uint32id)
Parameters. Either one of the following:
The
nameof the tablespace, a string (as a character pointer)The unsigned 32-bit integer
idof the tablespace
Return value.
A Tablespace object, as discussed in
Section 2.3.22, “The Tablespace Class”.
Description.
This method gets a LogfileGroup object,
given the name of the logfile group.
Signature.
LogfileGroup getLogfileGroup
(
const char* name
)
Parameters.
The name of the logfile group.
Return value.
An instance of LogfileGroup; see
Section 2.3.6, “The LogfileGroup Class”, for more information.
Description.
This method is used to retrieve a Datafile
object, given the node ID of the data node where a datafile is
located and the path to the datafile on that node's file
system.
Signature.
Datafile getDatafile
(
Uint32 nodeId,
const char* path
)
Parameters. This method must be invoked using two arguments, as shown here:
The 32-bit unsigned integer
nodeIdof the data node where the datafile is locatedThe
pathto the datafile on the node's file system (string as character pointer)
Return value.
A Datafile object—see
Section 2.3.2, “The Datafile Class”, for details.
Description.
This method gets an Undofile object, given
the ID of the node where an undofile is located and the file
system path to the file.
Signature.
Undofile getUndofile
(
Uint32 nodeId,
const char* path
)
Parameters. This method requires the following two arguments:
The
nodeIdof the data node where the undofile is located; this value is passed as a 32-bit unsigned integerThe
pathto the undofile on the node's file system (string as character pointer)
Return value.
An instance of Undofile. For more
information, see Section 2.3.23, “The Undofile Class”.
Description.
This method retrieves the most recent NDB
API error.
Signature.
const struct NdbError& getNdbError
(
void
) const
Parameters. None.
Return value.
A reference to an NdbError object. See
Section 2.3.31, “The NdbError Structure”.
Description.
Creates a table given an instance of Table.
Signature.
int createTable
(
const Table& table
)
Parameters.
An instance of Table. See
Section 2.3.21, “The Table Class”, for more information.
Return value.
0 on success, -1 on
failure.
Description.
This method creates an index given an instance of
Index and possibly an optional instance of
Table.
Signature. This method can be invoked with or without a reference to a table object:
int createIndex
(
const Index& index
)
int createIndex
(
const Index& index,
const Table& table
)
Parameters.
Required: A reference to an
Index object.
Optional: A reference to a
Table object.
Return value.
0 on success, -1 on
failure.
Description.
Creates an event, given a reference to an
Event object.
Signature.
int createEvent
(
const Event& event
)
Parameters.
A reference event to an
Event object.
Return value.
0 on success, -1 on
failure.
Description.
This method creates a new tablespace, given a
Tablespace object.
Signature.
int createTablespace
(
const Tablespace& tSpace
)
Parameters.
This method requires a single argument—a reference to an
instance of Tablespace.
Return value.
0 on success, -1 on
failure.
Description.
This method creates a new logfile group, given an instance of
LogfileGroup.
Signature.
int createLogfileGroup
(
const LogfileGroup& lGroup
)
Parameters.
A single argument, a reference to a
LogfileGroup object, is required.
Return value.
0 on success, -1 on
failure.
Description.
This method creates a new datafile, given a
Datafile object.
Signature.
int createDatafile
(
const Datafile& dFile
)
Parameters.
A single argument—a reference to an instance of
Datafile—is required.
Return value.
0 on success, -1 on
failure.
Description.
This method is used to create an NdbRecord
object for use in table or index scanning operations. (See
Section 2.3.25, “The NdbRecord Interface”.)
Dctionary::createRecord() is available
beginning with MySQL Cluster NDB 6.2.3.
Signature. The signature of this method depends on whether the resulting NdbRecord is to be used in table or index operations:
To create an NdbRecord for use in table
operations, use the following:
NdbRecord* createRecord
(
const Table* table,
const RecordSpecification* recordSpec,
Uint32 length,
Uint32 elementSize
)
To create an NdbRecord for use in index
operations, you can use either of the following:
NdbRecord* createRecord
(
const Index* index,
const Table* table,
const RecordSpecification* recordSpec,
Uint32 length,
Uint32 elementSize
)
or
NdbRecord* createRecord
(
const Index* index,
const RecordSpecification* recordSpec,
Uint32 length,
Uint32 elementSize
)
Parameters.
Dictionary::createRecord() takes the
following parameters:
If this
NdbRecordis to be used with an index, a pointer to the correspondingIndexobject. If theNdbRecordis to be used with a table, this parameter is omitted. (See Section 2.3.5, “TheIndexClass”.)A pointer to a
Tableobject representing the table to be scanned. If theNdbrecordproduced is to be used with an index, then this optionally specifies the table containing that index. (See Section 2.3.21, “TheTableClass”.)A
RecordSpecificationused to describe a column. (See Section 2.3.34, “TheRecordSpecificationStructure”.The
lengthof the record.The size of the elements making up this record.
Return value.
An NdbRecord for use in operations
involving the given table or index.
Example.
See Section 2.3.25, “The NdbRecord Interface”.
Description.
This method creates a new undofile, given an
Undofile object.
Signature.
int createUndofile
(
const Undofile& uFile
)
Parameters.
This method requires one argument: a reference to an instance
of Undofile.
Return value.
0 on success, -1 on
failure.
Description.
Drops a table given an instance of Table.
Signature.
int dropTable
(
const Table& table
)
Parameters.
An instance of Table. See
Section 2.3.21, “The Table Class”, for more information.
Return value.
0 on success, -1 on
failure.
Description.
This method drops an index given an instance of
Index, and possibly an optional instance of
Table.
Signature.
int dropIndex
(
const Index& index
)
int dropIndex
(
const Index& index,
const Table& table
)
Parameters. This method takes two parameters, one of which is optional:
Required. A reference to an
Indexobject.Optional. A reference to a
Tableobject.
Return value.
0 on success, -1 on
failure.
Description.
This method drops an event, given a reference to an
Event object.
Signature.
int dropEvent
(
const char* name,
int force = 0
)
Parameters. This method takes two parameters:
The
nameof the event to be dropped, as a string.By default,
dropEvent()fails if the event specified does not exist. You can override this behavior by passing any nonzero value for the (optional)forceargument; in this case no check is made as to whether there actually is such an event, and an error is returned only if the event exists but it was for whatever reason not possible to drop it.
Return value.
0 on success, -1 on
failure.
Description.
This method drops a tablespace, given a
Tablespace object.
Signature.
int dropTablespace
(
const Tablespace& tSpace
)
Parameters.
This method requires a single argument—a reference to an
instance of Tablespace.
Return value.
0 on success, -1 on
failure.
Description.
Given an instance of LogfileGroup, this
method drops the corresponding log file group.
Signature.
int dropLogfileGroup
(
const LogfileGroup& lGroup
)
Parameters.
A single argument, a reference to a
LogfileGroup object, is required.
Return value.
0 on success, -1 on
failure.
Description.
This method drops a data file, given a
Datafile object.
Signature.
int dropDatafile
(
const Datafile& dFile
)
Parameters.
A single argument—a reference to an instance of
Datafile—is required.
Return value.
0 on success, -1 on
failure.
Description.
This method drops an undo file, given an
Undofile object.
Signature.
int dropUndofile
(
const Undofile& uFile
)
Parameters.
This method requires one argument: a reference to an instance
of Undofile.
Return value.
0 on success, -1 on
failure.
Description. This method is used to invalidate a cached table object.
Signature.
void invalidateTable
(
const char* name
)
Beginning with MySQL Cluster NDB 6.3.39, MySQL Cluster NDB
7.0.20, and MySQL Cluster NDB 7.1.9, an alternative way of
calling this method is supported, using a
Table object rather than the name of the
table, as shown here:
void invalidateTable
(
const Table* table
)
Parameters.
The name of the table to be removed
from the table cache, or a pointer to the corresponding
Table object.
Return value. None.
Description. This method is used to invalidate a cached index object.
This method is supported beginning with MySQL Cluster NDB 6.3.39, MySQL Cluster NDB 7.0.20, and MySQL Cluster NDB 7.1.9.
Signature.
The index invalidated by this method can be referenced either
as an Index object (using a pointer), or by
index name and table name, as shown here:
void invalidateIndex
(
const char* indexName,
const char* tableName
)
void invalidateIndex
(
const Index* index
)
Parameters.
The names of the index to be removed from the cache and the
table to which it belongs
(indexName and
tableName, respectively), or a
pointer to the corresponding Index object.
Return value. None.
Description. This method is used to obtain a list of objects in the dictionary. It is possible to get all of the objects in the dictionary, or to restrict the list to objects of a single type.
Signature. Prior to MySQL Cluster NDB 6.2.19, MySQL Cluster NDB 6.3.29, and MySQL Cluster NDB 7.0.10, this method had only the following signature:
int listObjects
(
List& list,
Object::Type type = Object::TypeUndefined
) const
Beginning with MySQL Cluster NDB 6.2.19, MySQL Cluster NDB 6.3.29, and MySQL Cluster NDB 7.0.10 (see Bug#48851), this method has the following additional signature:
int listObjects
(
List& list,
Object::Type type,
bool fullyQualified
) const
A non-const version of this method, shown
here, was removed in MySQL Cluster NDB 6.2.19, MySQL Cluster
NDB 6.3.28, and MySQL Cluster NDB 7.0.9 (see Bug#47798):
int listObjects
(
List& list,
Object::Type type = Object::TypeUndefined
)
Parameters.
A reference to a List object is
required—this is the list that contains the dictionary's
objects after listObjects() is called. (See
Section 2.3.7, “The List Class”.) An optional second argument
type may be used to restrict the
list to only those objects of the given type—that is, of
the specified Object::Type. (See
Section 2.3.20.1.5, “The Object::Type Type”.) If
type is not given, then the list
contains all of the dictionary's objects.
Beginning with MySQL Cluster NDB 6.2.19, MySQL Cluster NDB
6.3.29, and MySQL Cluster NDB 7.0.10, you can also specify
whether or not the object names in the
list are fully qualified (that is,
whether the object name includes the database, schema, and
possibly the table name). If you specify
fullyQualified, then you must also
specify the type.
Return value.
0 on success, -1 on
failure.
Description.
This method is used to obtain a List of all
the indexes on a table, given the table's name. (See
Section 2.3.7, “The List Class”.)
Signature.
int listIndexes
(
List& list,
const char* table
) const
The non-const version of this method, shown
here, was removed in MySQL Cluster NDB 6.2.19, MySQL Cluster
NDB 6.3.28, and MySQL Cluster NDB 7.0.9 (see Bug#47798):
int listIndexes
(
List& list,
const char* table
)
Parameters.
listIndexes() takes two arguments, both of
which are required:
A reference to the
Listthat contains the indexes following the call to the methodThe name of the
tablewhose indexes are to be listed
Return value.
0 on success, -1 on
failure.
Description. This method returns a list of all events defined within the dictionary.
This method was added in MySQL Cluster NDB 6.1.13.
Signature.
int listEvents
(
List& list
)
The non-const version of this method, shown
here, was removed in MySQL Cluster NDB 6.2.19, MySQL Cluster
NDB 6.3.28, and MySQL Cluster NDB 7.0.9 (see Bug#47798):
int listEvents
(
List& list
) const
Parameters.
A reference to a List object. (See
Section 2.3.7, “The List Class”.)
Return value.
0 on success; -1 on
failure.
Description.
This method is used to free an NdbRecord
after it is no longer needed.
Signature.
void releaseRecord
(
NdbRecord* record
)
Parameters.
The NdbRecord to be cleaned up.
Return value. None.
Example.
See Section 2.3.25, “The NdbRecord Interface”.
Description. This method removes the specified table from the local cache.
Signature.
void removeCachedTable
(
const char* table
)
Parameters.
The name of the table to be removed
from the cache.
Return value. None.
Description. This method removes the specified index from the local cache.
Signature.
void removeCachedIndex
(
const char* index,
const char* table
)
Parameters.
The removeCachedIndex() requires two
arguments:
The name of the
indexto be removed from the cacheThe name of the
tablein which the index is found
Return value. None.
Abstract
This section discusses the Event class, its
methods and defined types.
Parent class. NdbDictionary
Child classes. None
Description. This class represents a database event in a MySQL Cluster.
Methods.
The following table lists the public methods of the
Event class and the purpose or use of each
method:
| Method | Purpose / Use |
|---|---|
Event() | Class constructor |
~Event() | Destructor |
getName() | Gets the event's name |
getTable() | Gets the Table object on which the event is defined |
getTableName() | Gets the name of the table on which the event is defined |
getTableEvent() | Checks whether an event is to be detected |
getDurability() | Gets the event's durability |
getReport() | Gets the event's reporting options |
getNoOfEventColumns() | Gets the number of columns for which an event is defined |
getEventColumn() | Gets a column for which an event is defined |
getObjectStatus() | Gets the event's object status |
getObjectVersion() | Gets the event's object version |
getObjectId() | Gets the event's object ID |
setName() | Sets the event's name |
setTable() | Sets the Table object on which the event is defined |
addTableEvent() | Adds the type of event that should be detected |
setDurability() | Sets the event's durability |
setReport() | The the event's reporting options |
addEventColumn() | Adds a column on which events should be detected |
addEventColumns() | Adds multiple columns on which events should be detected |
mergeEvents() | Sets the event's merge flag |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.4.2, “Event Methods”.
Types.
These are the public types of the Event class:
| Type | Purpose / Use |
|---|---|
TableEvent | Represents the type of a table event |
EventDurability | Specifies an event's scope, accessibility, and lifetime |
EventReport | Specifies the reporting option for a table event |
For a discussion of each of these types, along with its possible
values, see Section 2.3.4.1, “Event Types”.
Class diagram.
This diagram shows all the available methods and enumerated types
of the Event class:

Abstract
This section details the public types belonging to the
Event class.
Abstract
This section describes TableEvent, a type
defined by the Event class.
Description.
TableEvent is used to classify the types of
events that may be associated with tables in the NDB API.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
TE_INSERT | Insert event on a table |
TE_DELETE | Delete event on a table |
TE_UPDATE | Update event on a table |
TE_DROP | Occurs when a table is dropped |
TE_ALTER | Occurs when a table definition is changed |
TE_CREATE | Occurs when a table is created |
TE_GCP_COMPLETE | Occurs on the completion of a global checkpoint |
TE_CLUSTER_FAILURE | Occurs on Cluster failures |
TE_STOP | Occurs when an event operation is stopped |
TE_NODE_FAILURE | Occurs when a Cluster node fails |
TE_SUBSCRIBE | Occurs when a cluster node subscribes to an event |
TE_UNSUBSCRIBE | Occurs when a cluster node unsubscribes from an event |
TE_ALL | Occurs when any event occurs on a table (not relevant when a specific event is received) |
Abstract
This section discusses EventDurability, a
type defined by the Event class.
Description. The values of this type are used to describe an event's lifetime or persistence as well as its scope.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
ED_UNDEFINED | The event is undefined or of an unsupported type. |
ED_SESSION | This event persists only for the duration of the current session, and is
available only to the current application. It is deleted
after the application disconnects or following a cluster
restart.
Important
The value |
ED_TEMPORARY | Any application may use the event, but it is deleted following a cluster
restart.
Important
The value |
ED_PERMANENT | Any application may use the event, and it persists until deleted by an
application—even following a cluster. restart
Important
The value |
Abstract
This section discusses EventReport, a type
defined by the Event class.
Description. The values of this type are used to specify reporting options for table events.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
ER_UPDATED | Reporting of update events |
ER_ALL | Reporting of all events, except for those not resulting in any updates
to the inline parts of BLOB columns |
ER_SUBSCRIBE | Reporting of subscription events |
ER_DDL | Reporting of DDL events (added in MySQL Cluster NDB 6.3.34,
7.0.15, and 7.1.4; see
Section 2.3.4.2.17, “Event::setReport()”, for more
information) |
- 2.3.4.2.1.
EventConstructor - 2.3.4.2.2.
Event::getName() - 2.3.4.2.3.
Event::getTable() - 2.3.4.2.4.
Event::getTableName() - 2.3.4.2.5.
Event::getTableEvent() - 2.3.4.2.6.
Event::getDurability() - 2.3.4.2.7.
Event::getReport() - 2.3.4.2.8.
Event::getNoOfEventColumns() - 2.3.4.2.9.
Event::getEventColumn() - 2.3.4.2.10.
Event::getObjectStatus() - 2.3.4.2.11.
Event::getObjectVersion() - 2.3.4.2.12.
Event::getObjectId() - 2.3.4.2.13.
Event::setName() - 2.3.4.2.14.
Event::setTable() - 2.3.4.2.15.
Event::addTableEvent() - 2.3.4.2.16.
Event::setDurability() - 2.3.4.2.17.
Event::setReport() - 2.3.4.2.18.
Event::addEventColumn() - 2.3.4.2.19.
Event::addEventColumns() - 2.3.4.2.20.
Event::mergeEvents()
Description.
The Event constructor creates a new
instance with a given name, and optionally associated with a
table.
Signatures. It is possible to invoke this method in either of two ways, the first of these being by name only, as shown here:
Event
(
const char* name
)
Alternatively, you can use the event name and an associated table, like this:
Event
(
const char* name,
const NdbDictionary::Table& table
)
Parameters.
At a minimum, a name (as a constant
character pointer) for the event is required. Optionally, an
event may also be associated with a table; this argument, when
present, is a reference to a Table object
(see Section 2.3.21, “The Table Class”).
Return value.
A new instance of Event.
Destructor.
A destructor for this class is supplied as a virtual method
which takes no arguments and whose return type is
void.
Description. This method obtains the name of the event.
Signature.
const char* getName
(
void
) const
Parameters. None.
Return value. The name of the event, as a character pointer.
Description.
This method is used to find the table with which an event is
associated. It returns a reference to the corresponding
Table object. You may also obtain the name
of the table directly using getTableName(). (For details, see
Section 2.3.4.2.4, “Event::getTableName()”.)
Signature.
const NdbDictionary::Table* getTable
(
void
) const
Parameters. None.
Return value.
The table with which the event is associated—if there is
one—as a pointer to a Table object;
otherwise, this method returns NULL. (See
Section 2.3.21, “The Table Class”.)
Description.
This method obtains the name of the table with which an event
is associated, and can serve as a convenient alternative to
getTable(). (See
Section 2.3.4.2.3, “Event::getTable()”.)
Signature.
const char* getTableName
(
void
) const
Parameters. None.
Return value. The name of the table associated with this event, as a character pointer.
Description. This method is used to check whether a given table event will be detected.
Signature.
bool getTableEvent
(
const TableEvent te
) const
Parameters.
This method takes a single parameter, the table event's
type—that is, a TableEvent value. See
Section 2.3.4.1.1, “The Event::TableEvent Type”, for the list of
possible values.
Return value.
This method returns true if events of
TableEvent type
te will be detected. Otherwise, the
return value is false.
Description.
This method gets the event's lifetime and scope (that is, its
EventDurability).
Signature.
EventDurability getDurability
(
void
) const
Parameters. None.
Return value.
An EventDurability value. See
Section 2.3.4.1.2, “The Event::EventDurability Type”, for possible
values.
Description. This method is used to obtain the reporting option in force for this event.
Signature.
EventReport getReport
(
void
) const
Parameters. None.
Return value.
One of the reporting options specified in
Section 2.3.4.1.3, “The Event::EventReport Type”.
Description. This method obtains the number of columns on which an event is defined.
Signature.
int getNoOfEventColumns
(
void
) const
Parameters. None.
Return value.
The number of columns (as an integer), or
-1 in the case of an error.
Description. This method is used to obtain a specific column from among those on which an event is defined.
Signature.
const Column* getEventColumn
(
unsigned no
) const
Parameters.
The number (no) of the column, as
obtained using getNoOfColumns() (see
Section 2.3.4.2.8, “Event::getNoOfEventColumns()”).
Return value.
A pointer to the Column corresponding to
no.
Description. This method gets the object status of the event.
Signature.
virtual Object::Status getObjectStatus
(
void
) const
Parameters. None.
Return value.
The object status of the event. For possible values, see
Section 2.3.20.1.3, “The Object::Status Type”.
Description. This method gets the event's object version.
Signature.
virtual int getObjectVersion
(
void
) const
Parameters. None.
Return value. The object version of the event, as an integer.
Description. This method retrieves an event's object ID.
Signature.
virtual int getObjectId
(
void
) const
Parameters. None.
Return value. The object ID of the event, as an integer.
Description.
This method is used to set the name of an event. The name must
be unique among all events visible from the current
application (see Section 2.3.4.2.6, “Event::getDurability()”).
You can also set the event's name when first creating it. See
Section 2.3.4.2.1, “Event Constructor”.
Signature.
void setName
(
const char* name
)
Parameters.
The name to be given to the event
(as a constant character pointer).
Return value. None.
Description. This method defines a table on which events are to be detected.
By default, event detection takes place on all columns in the
table. Use addEventColumn() to override
this behavior. For details, see
Section 2.3.4.2.18, “Event::addEventColumn()”.
Signature.
void setTable
(
const NdbDictionary::Table& table
)
Parameters.
This method requires a single parameter, a reference to the
table (see Section 2.3.21, “The Table Class”) on which events are to
be detected.
Return value. None.
Description. This method is used to add types of events that should be detected.
Signature.
void addTableEvent
(
const TableEvent te
)
Parameters.
This method requires a TableEvent value.
See Section 2.3.4.1.1, “The Event::TableEvent Type” for possible
values.
Return value. None.
Description. This method sets an event's durability—that is, its lifetime and scope.
Signature.
void setDurability(EventDurability ed)
Parameters.
This method requires a single
EventDurability value as a parameter. See
Section 2.3.4.1.2, “The Event::EventDurability Type”, for possible
values.
Return value. None.
Description.
This method is used to set a reporting option for an event.
Possible option values may be found in
Section 2.3.4.1.3, “The Event::EventReport Type”.
Reporting of DDL events.
Prior to MySQL Cluster NDB 6.3.34, 7.0.15, and 7.1.4, it was
not necessary to set a specific reporting option in order to
receive DDL events from alter table and drop table events.
Beginning with MySQL Cluster NDB 6.3.34, 7.0.15, and 7.1.4,
this is no longer the case; in these and later versions, you
must call setReport() using the new
EventReport value ER_DDL
(added in the same MySQL Cluster versions).
For example, to enable DDL event reporting in MySQL Cluster NDB
6.3.34, 7.0.15, and 7.1.4, and later on an
Event object named
myEvent, you must invoke this method as shown
here:
myEvent.setReport(NdbDictionary::Event::ER_DDL);
When upgrading to MySQL CLuster NDB 6.3.34, 7.0.15, or 7.1.4
from a version that supports automatic reporting of DDL events
where you wish to retain this behavior, you must add the
indicated setReport() call or calls, then
recompile, following the upgrade. If you merely replace the
old version of the libndbclient library
with the library included with the new MySQL Cluster version,
DDL events are no longer reported by default.
Signature.
void setReport
(
EventReport er
)
Parameters.
An EventReport option value.
Return value. None.
Description. This method is used to add a column on which events should be detected. The column may be indicated either by its ID or its name.
You must invoke Dictionary::createEvent()
before any errors will be detected. See
Section 2.3.3.1.12, “Dictionary::createEvent()”.
If you know several columns by name, you can enable event
detection on all of them at one time by using
addEventColumns(). See
Section 2.3.4.2.19, “Event::addEventColumns()”.
Signature. Identifying the event using its column ID:
void addEventColumn
(
unsigned attrId
)
Identifying the column by name:
void addEventColumn
(
const char* columnName
)
Parameters. This method takes a single argument, which may be either one of the following:
The column ID (
attrId), which should be an integer greater than or equal to0, and less than the value returned bygetNoOfEventColumns().The column's
name(as a constant character pointer).
Return value. None.
Description. This method is used to enable event detection on several columns at the same time. You must use the names of the columns.
As with addEventColumn(), you must invoke
Dictionary::createEvent() before any errors
will be detected. See
Section 2.3.3.1.12, “Dictionary::createEvent()”.
Signature.
void addEventColumns
(
int n,
const char** columnNames
)
Parameters. This method requires two arguments, listed here:
The number of columns
n(an integer).The names of the columns
columnNames—this must be passed as a pointer to a character pointer.
Return value. None.
Description.
This method is used to set the merge events
flag, which is false by
default. Setting it to true implies that
events are merged as follows:
For a given
NdbEventOperationassociated with this event, events on the same primary key within the same global checkpoint index (GCI) are merged into a single event.A blob table event is created for each blob attribute, and blob events are handled as part of main table events.
Blob post/pre data from blob part events can be read via
NdbBlobmethods as a single value.
Currently this flag is not inherited by
NdbEventOperation, and must be set on
NdbEventOperation explicitly. See
Section 2.3.11, “The NdbEventOperation Class”.
Signature.
void mergeEvents
(
bool flag
)
Parameters.
A Boolean flag value.
Return value. None.
Abstract
This section provides a reference to the Index
class and its public members.
Parent class. NdbDictionary
Child classes. None
Description.
This class represents an index on an NDB
Cluster table column. It is a descendant of the
NdbDictionary class, using the
Object class. For information on these, see
Section 2.3.10, “The NdbDictionary Class”, and
Section 2.3.20, “The Object Class”.
Methods.
The following table lists the public methods of
Index and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
Index() | Class constructor |
~Index() | Destructor |
getName() | Gets the name of the index |
getTable() | Gets the name of the table being indexed |
getNoOfColumns() | Gets the number of columns belonging to the index |
getColumn() | Gets a column making up (part of) the index |
getType() | Gets the index type |
getLogging() | Checks whether the index is logged to disk |
getObjectStatus() | Gets the index object status |
getObjectVersion() | Gets the index object status |
getObjectId() | Gets the index object ID |
setName() | Sets the name of the index |
setTable() | Sets the name of the table to be indexed |
addColumn() | Adds a Column object to the index |
addColumnName() | Adds a column by name to the index |
addColumnNames() | Adds multiple columns by name to the index |
setType() | Set the index type |
setLogging() | Enable/disable logging of the index to disk |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.5.2, “Index Methods”.
Types.
Index has one public type, the Type type. For a
discussion of Type, see
Section 2.3.5.1, “The Index::Type Type”.
Class diagram.
This diagram shows all the available methods and enumerated types
of the Index class:

Description.
This is an enumerated type which describes the sort of column
index represented by a given instance of
Index.
Do not confuse this enumerated type with
Object::Type, which is discussed in
Section 2.3.20.1.5, “The Object::Type Type”, or with
Table::Type or
Column::Type.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
Undefined | Undefined object type (initial/default value) |
UniqueHashIndex | Unique unordered hash index (only index type currently supported) |
OrderedIndex | Nonunique, ordered index |
- 2.3.5.2.1.
IndexClass Constructor - 2.3.5.2.2.
Index::getName() - 2.3.5.2.3.
Index::getTable() - 2.3.5.2.4.
Index::getNoOfColumns() - 2.3.5.2.5.
Index::getColumn() - 2.3.5.2.6.
Index::getType() - 2.3.5.2.7.
Index::getLogging() - 2.3.5.2.8.
Index::getObjectStatus() - 2.3.5.2.9.
Index::getObjectVersion() - 2.3.5.2.10.
Index::getObjectId() - 2.3.5.2.11.
Index::setName() - 2.3.5.2.12.
Index::setTable() - 2.3.5.2.13.
Index::addColumn() - 2.3.5.2.14.
Index::addColumnName() - 2.3.5.2.15.
Index::addColumnNames() - 2.3.5.2.16.
Index::setType() - 2.3.5.2.17.
Index::setLogging
Abstract
This section contain descriptions of all public methods of the
Index class. This class has relatively few
methods (compared to, say, Table), which are
fairly straightforward to use.
If you create or change indexes using the NDB
API, these modifications cannot be seen by MySQL. The only
exception to this is renaming the index using
Index::setName().
Description.
This is used to create an new instance of
Index.
Indexes created using the NDB API cannot be seen by the MySQL Server.
Signature.
Index
(
const char* name = ""
)
Parameters.
The name of the new index. It is possible to create an index
without a name, and then assign a name to it later using
setName(). See
Section 2.3.5.2.11, “Index::setName()”.
Return value.
A new instance of Index.
Destructor.
The destructor (~Index()) is supplied as a
virtual method.
Description. This method is used to obtain the name of an index.
Signature.
const char* getName
(
void
) const
Parameters. None.
Return value. The name of the index, as a constant character pointer.
Description. This method can be used to obtain the name of the table to which the index belongs.
Signature.
const char* getTable
(
void
) const
Parameters. None.
Return value. The name of the table, as a constant character pointer.
Description. This method is used to obtain the number of columns making up the index.
Signature.
unsigned getNoOfColumns
(
void
) const
Parameters. None.
Return value. An unsigned integer representing the number of columns in the index.
Description. This method retrieves the column at the specified position within the index.
Signature.
const Column* getColumn
(
unsigned no
) const
Parameters.
The ordinal position number no of
the column, as an unsigned integer. Use the
getNoOfColumns() method to determine how
many columns make up the index—see
Section 2.3.5.2.4, “Index::getNoOfColumns()”, for details.
Return value.
The column having position no in
the index, as a pointer to an instance of
Column. See Section 2.3.1, “The Column Class”.
Description. This method can be used to find the type of index.
Signature.
Type getType
(
void
) const
Parameters. None.
Return value.
An index type. See Section 2.3.5.1, “The Index::Type Type”, for
possible values.
Description. Use this method to determine whether logging to disk has been enabled for the index.
Indexes which are not logged are rebuilt when the cluster is started or restarted.
Ordered indexes currently do not support logging to disk; they are rebuilt each time the cluster is started. (This includes restarts.)
Signature.
bool getLogging
(
void
) const
Parameters. None.
Return value. A Boolean value:
true: The index is being logged to disk.false: The index is not being logged.
Description. This method gets the object status of the index.
Signature.
virtual Object::Status getObjectStatus
(
void
) const
Parameters. None.
Return value.
A Status value—see
Section 2.3.20.1.3, “The Object::Status Type”, for more information.
Description. This method gets the object version of the index.
Signature.
virtual int getObjectVersion
(
void
) const
Parameters. None.
Return value. The object version for the index, as an integer.
Description. This method is used to obtain the object ID of the index.
Signature.
virtual int getObjectId
(
void
) const
Parameters. None.
Return value. The object ID, as an integer.
Description. This method sets the name of the index.
This is the only
Index::set
method whose result is visible to a MySQL Server.
*()
Signature.
void setName
(
const char* name
)
Parameters.
The desired name for the index, as
a constant character pointer.
Return value. None.
Description. This method sets the table that is to be indexed. The table is referenced by name.
Signature.
void setTable
(
const char* name
)
Parameters.
The name of the table to be
indexed, as a constant character pointer.
Return value. None.
Description. This method may be used to add a column to an index.
The order of the columns matches the order in which they are added to the index. However, this matters only with ordered indexes.
Signature.
void addColumn
(
const Column& c
)
Parameters.
A reference c to the column which
is to be added to the index.
Return value. None.
Description.
This method works in the same way as
addColumn(), except that it takes the name
of the column as a parameter. See
Section 2.3.5.2.5, “Index::getColumn()”.
Signature.
void addColumnName
(
const char* name
)
Parameters.
The name of the column to be added
to the index, as a constant character pointer.
Return value. None.
Description. This method is used to add several column names to an index definition at one time.
As with the addColumn() and
addColumnName() methods, the indexes are
numbered in the order in which they were added. (However, this
matters only for ordered indexes.)
Signature.
void addColumnNames
(
unsigned noOfNames,
const char** names
)
Parameters. This method takes two parameters, listed here:
The number of columns and names
noOfNamesto be added to the index.The
namesto be added (as a pointer to a pointer).
Return value. None.
Description. This method is used to set the index type.
Signature.
void setType
(
Type type
)
Parameters.
The type of index. For possible
values, see Section 2.3.5.1, “The Index::Type Type”.
Return value. None.
Description. This method is used to enable or disable logging of the index to disk.
Signature.
void setLogging
(
bool enable
)
Parameters.
setLogging() takes a single Boolean
parameter enable. If
enable is true,
then logging is enabled for the index; if false, then logging
of this index is disabled.
Return value. None.
Abstract
This section discusses the LogfileGroup class,
which represents a MySQL Cluster Disk Data logfile group.
Parent class. NdbDictionary
Child classes. None
Description. This class represents a MySQL Cluster Disk Data logfile group, which is used for storing Disk Data undofiles. For general information about logfile groups and undofiles, see the MySQL Cluster Disk Data Tables, in the MySQL Manual.
In MySQL 5.1, only unindexed column data can be stored on disk. Indexes and indexes columns continue to be stored in memory as with previous versions of MySQL Cluster.
Versions of MySQL prior to 5.1 do not support Disk Data storage
and so do not support logfile groups; thus the
LogfileGroup class is unavailable for NDB API
applications written against these MySQL versions.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
LogfileGroup() | Class constructor |
~LogfileGroup() | Virtual destructor |
getName() | Retrieves the logfile group's name |
getUndoBufferSize() | Gets the size of the logfile group's UNDO buffer |
getAutoGrowSpecification() | Gets the logfile group's AutoGrowSpecification values |
getUndoFreeWords() | Retrieves the amount of free space in the UNDO buffer |
getObjectStatus() | Gets the logfile group's object status value |
getObjectVersion() | Retrieves the logfile group's object version |
getObjectId() | Get the object ID of the logfile group |
setName() | Sets the name of the logfile group |
setUndoBufferSize() | Sets the size of the logfile group's UNDO buffer. |
setAutoGrowSpecification() | Sets AutoGrowSpecification values for the logfile
group |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.6.1, “LogfileGroup Methods”.
Types.
The LogfileGroup class does not itself define
any public types. However, two of its methods make use of the
AutoGrowSpecification data structure as a
parameter or return value. For more information, see
Section 2.3.26, “The AutoGrowSpecification Structure”.
Class diagram.
This diagram shows all the available public methods of the
LogfileGroup class:
- 2.3.6.1.1.
LogfileGroupConstructor - 2.3.6.1.2.
LogfileGroup::getName() - 2.3.6.1.3.
LogfileGroup::getUndoBufferSize() - 2.3.6.1.4.
LogfileGroup::getAutoGrowSpecification() - 2.3.6.1.5.
LogfileGroup::getUndoFreeWords() - 2.3.6.1.6.
LogfileGroup::getObjectStatus() - 2.3.6.1.7.
LogfileGroup::getObjectVersion() - 2.3.6.1.8.
LogfileGroup::getObjectId() - 2.3.6.1.9.
LogfileGroup::setName() - 2.3.6.1.10.
LogfileGroup::setUndoBufferSize() - 2.3.6.1.11.
LogfileGroup::setAutoGrowSpecification()
Abstract
This section provides descriptions for the public methods of the
LogfileGroup class.
Description. The LogfileGroup class has two public constructors, one of which takes no arguments and creates a completely new instance. The other is a copy constructor.
The Dictionary class also supplies methods
for creating and destroying LogfileGroup
objects. See Section 2.3.3, “The Dictionary Class”.
Signatures. New instance:
LogfileGroup
(
void
)
Copy constructor:
LogfileGroup
(
const LogfileGroup& logfileGroup
)
Parameters.
When creating a new instance, the constructor takes no
parameters. When copying an existing instance, the constructor
is passed a reference to the LogfileGroup
instance to be copied.
Return value.
A LogfileGroup object.
Destructor.
virtual ~LogfileGroup
(
void
)
Examples.
[To be supplied...]
Description. This method gets the name of the logfile group.
Signature.
const char* getName
(
void
) const
Parameters. None.
Return value. The logfile group's name, a string (as a character pointer).
Description.
This method retrieves the size of the logfile group's
UNDO buffer.
Signature.
Uint32 getUndoBufferSize
(
void
) const
Parameters. None.
Return value.
The size of the UNDO buffer, in bytes.
Description.
This method retrieves the
AutoGrowSpecification associated with the
logfile group.
Signature.
const AutoGrowSpecification& getAutoGrowSpecification
(
void
) const
Parameters. None.
Return value.
An AutoGrowSpecification data structure.
See Section 2.3.26, “The AutoGrowSpecification Structure”, for details.
Description.
This method retrieves the number of bytes unused in the
logfile group's UNDO buffer.
Signature.
Uint64 getUndoFreeWords
(
void
) const
Parameters. None.
Return value. The number of bytes free, as a 64-bit integer.
Description.
This method is used to obtain the object status of the
LogfileGroup.
Signature.
virtual Object::Status getObjectStatus
(
void
) const
Parameters. None.
Return value.
The logfile group's Status—see
Section 2.3.20.1.3, “The Object::Status Type” for possible values.
Description. This method gets the logfile group's object version.
Signature.
virtual int getObjectVersion
(
void
) const
Parameters. None.
Return value. The object version of the logfile group, as an integer.
Description. This method is used to retrieve the object ID of the logfile group.
Signature.
virtual int getObjectId
(
void
) const
Parameters. None.
Return value. The logfile group's object ID (an integer value).
Description. This method is used to set a name for the logfile group.
Signature.
void setName
(
const char* name
)
Parameters.
The name to be given to the logfile
group (character pointer).
Return value. None.
Description.
This method can be used to set the size of the logfile group's
UNDO buffer.
Signature.
void setUndoBufferSize
(
Uint32 size
)
Parameters.
The size in bytes for the
UNDO buffer (using a 32-bit unsigned
integer value).
Return value. None.
Description.
This method sets to the
AutoGrowSpecification data for the logfile
group.
Signature.
void setAutoGrowSpecification
(
const AutoGrowSpecification& autoGrowSpec
)
Parameters.
The data is passed as a single parameter, an
AutoGrowSpecification data
structure—see
Section 2.3.26, “The AutoGrowSpecification Structure”.
Return value. None.
Abstract
This section covers the List class.
Parent class. Dictionary
Child classes. None
Description.
The List class is a
Dictionary subclass that is used for
representing lists populated by the methods
Dictionary::listObjects(),
Dictionary::listIndexes(), and
Dictionary::listEvents(). (See
Section 2.3.3.1.27, “Dictionary::listObjects()”,
Section 2.3.3.1.28, “Dictionary::listIndexes()”, and
Section 2.3.3.1.29, “Dictionary::listEvents()”, for more information
about these methods.)
Class Methods. This class has only two methods, a constructor and a destructor. Neither method takes any arguments.
Constructor.
Calling the List constructor creates a new
List whose count and
elements attributes are both set equal to
0.
Destructor.
The destructor ~List() is simply defined in
such a way as to remove all elements and their properties. You can
find its definition in the file
/storage/ndb/include/ndbapi/NdbDictionary.hpp.
Attributes.
A List has the following two attributes:
count, an unsigned integer, which stores the number of elements in the list.elements, a pointer to an array ofElementdata structures contained in the list. See Section 2.3.27, “TheElementStructure”.
Types.
The List class also defines an
Element structure; see
Section 2.3.27, “The Element Structure”, for more information.
For a graphical representation of this class and its parent-child
relationships, see Section 2.3.3, “The Dictionary Class”.
Abstract
This class represents the NDB kernel; it is the
primary class of the NDB API.
Parent class. None
Child classes. None
Description.
Any nontrivial NDB API program makes use of at least one instance
of Ndb. By using several Ndb
objects, it is possible to implement a multi-threaded application.
You should remember that one Ndb object cannot
be shared between threads; however, it is possible for a single
thread to use multiple Ndb objects. A single
application process can support a maximum of 128
Ndb objects.
The Ndb object is multi-thread safe in that each
Ndb object can be handled by one thread at a
time. If an Ndb object is handed over to
another thread, then the application must ensure that a memory
barrier is used to ensure that the new thread sees all updates
performed by the previous thread.
Semaphores and mutexes are examples of easy ways to provide memory barriers without having to bother about the memory barrier concept.
It is also possible to use multiple Ndb objects
to perform operations on different clusters in a single application.
See the Note on
Application-Level Partitioning for conditions and
restrictions applying to such usage.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
Ndb() | Class constructor; represents a connection to a MySQL Cluster. |
~Ndb() | Class destructor; terminates a Cluster connection when it is no longer to be used |
init() | Initialises an Ndb object and makes it ready for use. |
getDictionary() | Gets a dictionary, which is used for working with database schema information. |
getDatabaseName() | Gets the name of the current database. |
setDatabaseName() | Sets the name of the current database. |
getDatabaseSchemaName() | Gets the name of the current database schema. |
setDatabaseSchemaName() | Sets the name of the current database schema. |
startTransaction() | Begins a transaction. (See Section 2.3.19, “The NdbTransaction Class”.) |
closeTransaction() | Closes a transaction. |
computeHash() | Computes a distribution hash value. |
createEventOperation() | Creates a subscription to a database event. (See
Section 2.3.11, “The NdbEventOperation Class”.) |
dropEventOperation() | Drops a subscription to a database event. |
pollEvents() | Waits for an event to occur. |
getNdbError() | Retrieves an error. (See Section 2.3.31, “The NdbError Structure”.) |
getNdbErrorDetail() | Retrieves extra error details. Added in MySQL Cluster NDB 6.2.19, MySQL Cluster NDB 6.3.29, and MySQL Cluster NDB 7.0.10. |
getReference() | Retrieves a reference or identifier for the Ndb
object instance. |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.8.1, “Ndb Methods”.
Class diagram.
This diagram shows all the available members of the
Ndb class:
- 2.3.8.1.1.
NdbClass Constructor - 2.3.8.1.2.
Ndb::init() - 2.3.8.1.3.
Ndb::getDictionary() - 2.3.8.1.4.
Ndb::getDatabaseName() - 2.3.8.1.5.
Ndb::setDatabaseName() - 2.3.8.1.6.
Ndb::getDatabaseSchemaName() - 2.3.8.1.7.
Ndb::setDatabaseSchemaName() - 2.3.8.1.8.
Ndb::startTransaction() - 2.3.8.1.9.
Ndb::closeTransaction() - 2.3.8.1.10.
Ndb::computeHash() - 2.3.8.1.11.
Ndb::createEventOperation - 2.3.8.1.12.
Ndb::dropEventOperation() - 2.3.8.1.13.
Ndb::pollEvents() - 2.3.8.1.14.
Ndb::nextEvent() - 2.3.8.1.15.
Ndb::getNdbError() - 2.3.8.1.16.
Ndb::getNdbErrorDetail() - 2.3.8.1.17.
Ndb::getReference()
Abstract
The sections that follow discuss the public methods of the
Ndb class.
Description.
This creates an instance of Ndb, which
represents a connection to the MySQL Cluster. All NDB API
applications should begin with the creation of at least one
Ndb object. This requires the creation of
at least one instance of
Ndb_cluster_connection, which serves as a
container for a cluster connectstring.
Signature.
Ndb
(
Ndb_cluster_connection* ndb_cluster_connection,
const char* catalogName = "",
const char* schemaName = "def"
)
Parameters.
The Ndb class constructor can take up to 3
parameters, of which only the first is required:
ndb_cluster_connectionis an instance ofNdb_cluster_connection, which represents a cluster connectstring. (See Section 2.3.24, “TheNdb_cluster_connectionClass”.)catalogNameis an optional parameter providing a namespace for the tables and indexes created in any connection from theNdbobject.This is equivalent to what mysqld considers “the database”.
The default value for this parameter is an empty string.
The optional
schemaNameprovides an additional namespace for the tables and indexes created in a given catalog.The default value for this parameter is the string “def”.
Return value.
An Ndb object.
~Ndb() (Class Destructor).
The destructor for the Ndb class should be
called in order to terminate an instance of
Ndb. It requires no arguments, nor any
special handling.
Description.
This method is used to initialise an Ndb
object.
Signature.
int init
(
int maxNoOfTransactions = 4
)
Parameters.
The init() method takes a single parameter
maxNoOfTransactions of type
integer. This parameter specifies the maximum number of
parallel NdbTransaction objects that can be
handled by this instance of Ndb. The
maximum permitted value for
maxNoOfTransactions is 1024; if not
specified, it defaults to 4.
Each scan or index operation uses an extra
NdbTransaction object. See
Section 2.3.19, “The NdbTransaction Class”.
Return value.
This method returns an int, which can be
either of the following two values:
0: indicates that the
Ndbobject was initialised successfully.-1: indicates failure.
Description.
This method is used to obtain an object for retrieving or
manipulating database schema information. This
Dictionary object contains meta-information
about all tables in the cluster.
The dictionary returned by this method operates independently
of any transaction. See Section 2.3.3, “The Dictionary Class”, for
more information.
Signature.
NdbDictionary::Dictionary* getDictionary
(
void
) const
Parameters. None.
Return value.
An instance of the Dictionary class.
Description. This method can be used to obtain the name of the current database.
Signature.
const char* getDatabaseName
(
void
)
Parameters. None.
Return value. The name of the current database.
Description. This method is used to set the name of the current database.
Signature.
void setDatabaseName
(
const char *databaseName
)
Parameters.
setDatabaseName() takes a single, required
parameter, the name of the new database to be set as the
current database.
Return value. N/A.
Description. This method can be used to obtain the current database schema name.
Signature.
const char* getDatabaseSchemaName
(
void
)
Parameters. None.
Return value. The name of the current database schema.
Description. This method sets the name of the current database schema.
Signature.
void setDatabaseSchemaName
(
const char *databaseSchemaName
)
Parameters. The name of the database schema.
Return value. N/A.
Description. This method is used to begin a new transaction. There are three variants, the simplest of these using a table and a partition key or partition ID to specify the transaction coordinator (TC). The third variant makes it possible for you to specify the TC by means of a pointer to the data of the key.
When the transaction is completed it must be closed using
NdbTransaction::close() or
Ndb::closeTransaction(). Failure to do so
aborts the transaction. This must be done regardless of the
transaction's final outcome, even if it fails due to an error.
See Section 2.3.8.1.9, “Ndb::closeTransaction()”, and
Section 2.3.19.2.7, “NdbTransaction::close()”, for more
information.
Signature.
NdbTransaction* startTransaction
(
const NdbDictionary::Table* table = 0,
const char* keyData = 0,
Uint32* keyLen = 0
)
Parameters. This method takes the following three parameters:
table: A pointer to aTableobject. (See Section 2.3.21, “TheTableClass”.) This is used to determine on which node the transaction coordinator should run.keyData: A pointer to a partition key corresponding totable.keyLen: The length of the partition key, expressed in bytes.
Distribution-aware forms of startTransaction().
Beginning with MySQL Cluster NDB 6.1.4, it is possible to
employ distribution awareness with this
method; that is, to suggest which node should act as the
transaction coordinator.
Signature.
NdbTransaction* startTransaction
(
const NdbDictionary::Table* table,
const struct Key_part_ptr* keyData,
void* xfrmbuf = 0,
Uint32 xfrmbuflen = 0
)
Parameters. When specifying the transaction coordinator, this method takes the four parameters listed here:
A pointer to a
table(NdbDictionary::Tableobject) used for deciding which node should act as the transaction coordinator.A null-terminated array of pointers to the values of the distribution key columns. The length of the key part is read from metadata and checked against the passed value.
A
Key_part_ptris defined as shown in Section 2.3.30, “TheKey_part_ptrStructure”.A pointer to a temporary buffer, used to calculate the hash value.
The length of the buffer.
If xfrmbuf is NULL
(the default), then a call to malloc() or
free() is made automatically, as appropriate.
startTransaction() fails if
xfrmbuf is not NULL and
xfrmbuflen is too small.
Example.
Suppose that the table's partition key is a single
BIGINT column. Then you would declare the
distribution key array as shown here:
Key_part_ptr distkey[2];
The value of the distribution key would be defined as shown here:
unsigned long long distkeyValue= 23;
The pointer to the distribution key array would be set as follows:
distkey[0].ptr= (const void*) &distkeyValue;
The length of this pointer would be set accordingly:
distkey[0].len= sizeof(distkeyValue);
The distribution key array must terminate with a
NULL element. This is necessary to avoid to
having an additional parameter providing the number of columns
in the distribution key:
distkey[1].ptr= NULL; distkey[1].len= NULL;
Setting the buffer to NULL permits
startTransaction() to allocate and free
memory automatically:
xfrmbuf= NULL; xfrmbuflen= 0;
You can also specify a buffer to save having to make explicit
malloc() and free()
calls, but calculating an appropriate size for this buffer is
not a simple matter; if the buffer is not
NULL but its length is too short, then the
startTransaction() call fails. However, if you choose to
specify the buffer, 1 MB is usually a sufficient size.
Now, when you start the transaction, you can access the node that contains the desired information directly.
In MySQL Cluster NDB 6.2 and later, another distribution-aware version of this method is available. This variant makes it possible for you to specify a table and partition (using the partition ID) as a hint for selecting the transaction coordinator, and is defined as shown here:
NdbTransaction* startTransaction
(
const NdbDictionary::Table* table,
Uint32 partitionId
)
In the event that the cluster has the same number of data nodes
as it has replicas, specifying the transaction coordinator gains
no improvement in performance, since each data node contains the
entire database. However, where the number of data nodes is
greater than the number of replicas (for example, where
NoOfReplicas is set equal to 2 in a cluster
with 4 data nodes), you should see a marked improvement in
performance by using the distribution-aware version of this
method.
It is still possible to use this method as before, without
specifying the transaction coordinator. In either case, you must
still explicitly close the transaction, whether or not the call
to startTransaction() was successful.
Return value.
On success, an NdbTransaction object (see
Section 2.3.19, “The NdbTransaction Class”). In the event of
failure, NULL is returned.
Description.
This is one of two NDB API methods provided for closing a
transaction (the other being
NdbTransaction::close()—see
Section 2.3.19.2.7, “NdbTransaction::close()”). You must call one
of these two methods to close the transaction once it has been
completed, whether or not the transaction succeeded.
If the transaction has not yet been committed, it is aborted
when this method is called. See
Section 2.3.8.1.8, “Ndb::startTransaction()”.
Signature.
void closeTransaction
(
NdbTransaction *transaction
)
Parameters.
This method takes a single argument, a pointer to the
NdbTransaction to be closed.
Return value. N/A.
Description. This method can be used to compute a distribution hash value, given a table and its keys.
computeHash() can be used onlyt for tables
that use native NDB partitioning.
Signature.
static int computeHash
(
Uint32* hashvalueptr,
const NdbDictionary::Table* table,
const struct Key_part_ptr* keyData,
void* xfrmbuf = 0,
Uint32 xfrmbuflen = 0
)
Parameters. This method takes the following parameters:
If the method call is successful,
hashvalueptris set to the computed hash value.A pointer to a
table(see Section 2.3.21, “TheTableClass”).keyDatais a null-terminated array of pointers to the key parts that are part of the table's distribution key. The length of each key part is read from metadata and checked against the passed value (see Section 2.3.30, “TheKey_part_ptrStructure”).xfrmbufis a pointer to temporary buffer used to calculate the hash value.xfrmbuflenis the length of this buffer.NoteIf
xfrmbufisNULL(the default), then a call tomalloc()orfree()is made automatically, as appropriate.computeHash()fails ifxfrmbufis notNULLandxfrmbuflenis too small.
Return value.
0 on success, an error code on failure. (If the method call
succeeds, the computed hash value is made available via
hashvalueptr.)
Description. This method creates a subscription to a database event.
Signature.
NdbEventOperation* createEventOperation
(
const char *eventName
)
Parameters.
This method takes a single argument, the unique
eventName identifying the event to
which you wish to subscribe.
Return value.
A pointer to an NdbEventOperation object
(or NULL, in the event of failure). See
Section 2.3.11, “The NdbEventOperation Class”.
Description.
This method drops a subscription to a database event
represented by an NdbEventOperation object.
Signature.
int dropEventOperation
(
NdbEventOperation *eventOp
)
Parameters.
This method requires a single input parameter, a pointer to an
instance of NdbEventOperation.
Return value.
0 on success; any other result
indicates failure.
Description. This method waits for a GCP to complete. It is used to determine whether any events are available in the subscription queue.
Beginning with MySQL Cluster NDB 6.2.5, this method waits for
the next epoch, rather than the next GCP.
See Section 2.3.11, “The NdbEventOperation Class”, for more
information about the differences in event handling for this and
later MySQL Cluster NDB 6.X and 7.X releases. releases.
Signature.
int pollEvents
(
int maxTimeToWait,
Uint64* latestGCI = 0
)
Parameters. This method takes the two parameters listed here:
The maximum time to wait, in milliseconds, before “giving up” and reporting that no events were available (that is, before the method automatically returns
0).The index of the most recent global checkpoint. Normally, this may safely be permitted to assume its default value, which is
0.
Return value.
pollEvents() returns a value of type
int, which may be interpreted as follows:
> 0: There are events available in the queue.0: There are no events available.< 0: Indicates failure (possible error).
Description. Returns the next event operation having data from a subscription queue.
Signature.
NdbEventOperation* nextEvent
(
void
)
Parameters. None.
Return value.
This method returns an NdbEventOperation
object representing the next event in a subscription queue, if
there is such an event. If there is no event in the queue, it
returns NULL instead. (See
Section 2.3.11, “The NdbEventOperation Class”.)
Description.
This method provides you with two different ways to obtain an
NdbError object representing an error
condition. For more detailed information about error handling
in the NDB API, see Chapter 5, MySQL Cluster API Errors.
Signature.
The getNdbError() method actually has two
variants.
The first of these simply gets the most recent error to have occurred:
const NdbError& getNdbError
(
void
)
The second variant returns the error corresponding to a given error code:
const NdbError& getNdbError
(
int errorCode
)
Regardless of which version of the method is used, the
NdbError object returned persists until the
next NDB API method is invoked.
Parameters.
To obtain the most recent error, simply call
getNdbError() without any parameters. To
obtain the error matching a specific
errorCode, invoke the method
passing the code (an int) to it as a
parameter. For a listing of NDB API error codes and
corresponding error messages, see
Section 5.2, “NDB API Errors and Error Handling”.
Return value.
An NdbError object containing information
about the error, including its type and, where applicable,
contextual information as to how the error arose. See
Section 2.3.31, “The NdbError Structure”, for details.
Description.
This method, introduced in MySQL Cluster NDB 6.2.19, MySQL
Cluster NDB 6.3.29, and MySQL Cluster NDB 7.0.10, provides an
easier and safer way to access any extra information about an
error. Formerly, it was necessary to read these extra details
from the NdbError object's
details property, which is now deprecated
in favor of getNdbErrorDetail() (Bug#48851). This method enables storage of such details in a
user-supplied buffer, returning a pointer to the beginning of
this buffer. In the event that the string containing the
details exceeds the length of the buffer, it is truncated to
fit.
getErrorDetail() makes it much simpler to
determine the source of an error than reading
NdbError.details, because this method
provides the information in the form of a string. For example,
in the case of a unique constraint violation (error 893), this
string supplies the fully qualified name of the index where the
problem originated, in the format
database-name/schema-name/table-name/index-name,
(NdbError.details, on the other hand,
supplies only an index ID, and it is often not readily apparent
to which table this index belongs.) Regardless of the type of
error and details concerning this error, the string retrieved by
getErrorDetail() is always null-terminated.
Signature.
The getNdbErrorDetail() method has the
following signature:
const char* getNdbErrorDetail
(
const NdbError& error,
char* buffer,
Uint32 bufferLength
) const
Parameters.
To obtain detailed information about an error, call
getNdbErrorDetail() with a reference to the
corresponding NdbError object, a
buffer, and the length of this
buffer (expressed as an unsigned 32-bit integer).
Return value.
When extra details about the error
are available, this method returns a pointer to the beginning
of the buffer supplied. As stated
previously, if the string containing the details is longer
than bufferLength, the string is
truncated to fit. In the event that no addition details are
available, getNdbErrorDetail() returns
NULL.
Description.
This method can be used to obtain a reference to a given
Ndb object. This is the same value that is
returned for a given operation corresponding to this object in
the output of DUMP 2350. (See
Section 6.2.3.9, “DUMP 2350”, for an
example.)
Signature.
Uint32 getReference
(
void
)
Parameters. None.
Return value. A 32-bit unsigned integer.
Abstract
This class represents a handle to a BLOB column
and provides read and write access to BLOB
column values. This object has a number of different states and
provides several modes of access to BLOB data;
these are also described in this section.
Parent class. None
Child classes. None
Description.
An instance of NdbBlob is created using the
NdbOperation::getBlobHandle() method during the
operation preparation phase. (See
Section 2.3.15, “The NdbOperation Class”.) This object acts as a handle
on a BLOB column.
BLOB Data Storage.
BLOB data is stored in 2 locations:
The header and inline bytes are stored in the blob attribute.
The blob's data segments are stored in a separate table named
NDB$BLOB_, wheretid_cidtidis the table ID, andcidis the blob column ID.
The inline and data segment sizes can be set using the appropriate
NdbDictionary::Column() methods when the table is
created. See Section 2.3.1, “The Column Class”, for more information
about these methods.
Data Access Types.
NdbBlob supports 3 types of data access: These
data access types can be applied in combination, provided that
they are used in the order given above.
In the preparation phase, the
NdbBlobmethodsgetValue()andsetValue()are used to prepare a read or write of aBLOBvalue of known size.Also in the preparation phase,
setActiveHook()is used to define a routine which is invoked as soon as the handle becomes active.In the active phase,
readData()andwriteData()are used to read and writeBLOBvalues having arbitrary sizes.
BLOB Operations.
BLOB operations take effect when the next
transaction is executed. In some cases, NdbBlob
is forced to perform implicit execution. To avoid this, you should
always operate on complete blob data segments, and use
NdbTransaction::executePendingBlobOps() to
flush reads and writes. There is no penalty for doing this if
nothing is pending. It is not necessary to do so following
execution (obviously) or after next scan result is obtained.
NdbBlob also supports reading post- or pre-blob
data from events. The handle can be read after the next event on
the main table has been retrieved. The data becomes available
immediately. (See Section 2.3.11, “The NdbEventOperation Class”.)
BLOBs and NdbOperations.
NdbOperation methods acting on
NdbBlob objects have the following
characteristics: See Section 2.3.15, “The NdbOperation Class”.
NdbOperation::insertTuple()must useNdbBlob::setValue()if theBLOBattribute is nonnullable.NdbOperation::readTuple()used with any lock mode can read but not write blob values.When the
LM_CommittedReadlock mode is used withreadTuple(), the lock mode is automatically upgraded toLM_Readwhenever blob attributes are accessed.NdbOperation::updateTuple()can either overwrite an existing value usingNdbBlob::setValue(), or update it during the active phase.NdbOperation::writeTuple()always overwrites blob values, and must useNdbBlob::setValue()if theBLOBattribute is nonnullable.NdbOperation::deleteTuple()creates implicit, nonaccessibleBLOBhandles.A scan with any lock mode can use its blob handles to read blob values but not write them.
A scan using the
LM_Exclusivelock mode can update row and blob values usingupdateCurrentTuple(); the operation returned must explicitly create its own blob handle.A scan using the
LM_Exclusivelock mode can delete row values (and therefore blob values) usingdeleteCurrentTuple(); this create implicit nonaccessible blob handles.An operation which is returned by
lockCurrentTuple()cannot update blob values.
Known Issues.
The following are known issues or limitations encountered when
working with NdbBlob objects:
Too many pending
BLOBoperations can overflow the I/O buffers.The table and its
BLOBdata segment tables are not created atomically.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
getState() | Gets the state of an NdbBlob object |
getValue() | Prepares to read a blob value |
setValue() | Prepares to insert or update a blob value |
setActiveHook() | Defines a callback for blob handle activation |
getVersion() | Checks whether a blob is statement-based or event-based |
getNull() | Checks whether a blob value is NULL |
setNull() | Sets a blob to NULL |
getLength() | Gets the length of a blob, in bytes |
truncate() | Truncates a blob to a given length |
getPos() | Gets the current position for reading/writing |
setPos() | Sets the position at which to begin reading/writing |
readData() | Reads data from a blob |
writeData() | Writes blob data |
getColumn() | Gets a blob column. |
getNdbError() | Gets an error (an NdbError object) |
blobsFirstBlob() | Gets the first blob in a list. |
blobsNextBlob() | Gets the next blob in a list |
getBlobEventName() | Gets a blob event name |
getBlobTableName() | Gets a blob data segment's table name. |
getNdbOperation() | Get a pointer to the operation (NdbOperation object)
to which this NdbBlob object belonged
when created. |
getBlobTableName() and
getBlobEventName() are static methods.
Most NdbBlob methods (nearly all of those whose
return type is int) return 0
on success and -1 in the event of failure.
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.9.2, “NdbBlob Methods”.
Types.
The public types defined by NdbBlob are shown
here:
| Type | Purpose / Use |
|---|---|
ActiveHook | Callback for NdbBlob::setActiveHook() |
State | Represents the states that may be assumed by the
NdbBlob. |
For a discussion of each of these types, along with its possible
values, see Section 2.3.9.1, “NdbBlob Types”.
Class diagram.
This diagram shows all the available methods and types of the
NdbBlob class:
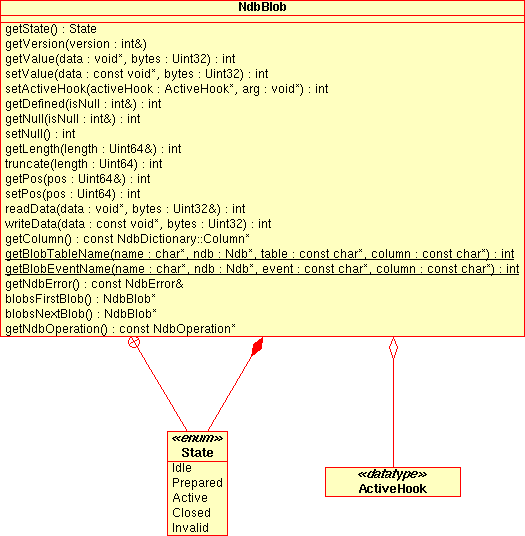
Abstract
This section details the public types belonging to the
NdbBlob class.
Abstract
ActiveHook is a data type defined for use as a callback for
the setActiveHook() method. (See
Section 2.3.9.2.4, “NdbBlob::setActiveHook()”.)
Definition.
ActiveHook is a custom data type defined as
shown here:
typedef int ActiveHook
(
NdbBlob* me,
void* arg
)
Description.
This is a callback for
NdbBlob::setActiveHook(), and is invoked
immediately once the prepared operation has been executed (but
not committed). Any calls to getValue() or
setValue() are performed first. The
BLOB handle is active so
readData() or
writeData() can be used to manipulate the
BLOB value. A user-defined argument is
passed along with the NdbBlob.
ActiveHook() returns a nonzero value in the
event of an error.
Abstract
This is an enumerated data type which represents the possible
states of an NdbBlob instance.
Description.
An NdbBlob may assume any one of these
states
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
Idle | The NdbBlob has not yet been prepared for use with
any operations. |
Prepared | This is the state of the NdbBlob prior to operation
execution. |
Active | This is the BLOB handle's state following execution
or the fetching of the next result, but before the
transaction is committed. |
Closed | This state occurs after the transaction has been committed. |
Invalid | This follows a rollback or the close of a transaction. |
- 2.3.9.2.1.
NdbBlob::getState() - 2.3.9.2.2.
NdbBlob::getValue() - 2.3.9.2.3.
NdbBlob::setValue() - 2.3.9.2.4.
NdbBlob::setActiveHook() - 2.3.9.2.5.
NdbBlob::getVersion() - 2.3.9.2.6.
NdbBlob::getNull() - 2.3.9.2.7.
NdbBlob::setNull() - 2.3.9.2.8.
NdbBlob::getLength() - 2.3.9.2.9.
NdbBlob::truncate() - 2.3.9.2.10.
NdbBlob::getPos() - 2.3.9.2.11.
NdbBlob::setPos() - 2.3.9.2.12.
NdbBlob::readData() - 2.3.9.2.13.
NdbBlob::writeData() - 2.3.9.2.14.
NdbBlob::getColumn() - 2.3.9.2.15.
NdbBlob::getNdbError() - 2.3.9.2.16.
NdbBlob::blobsFirstBlob() - 2.3.9.2.17.
NdbBlob::blobsNextBlob() - 2.3.9.2.18.
NdbBlob::getBlobEventName() - 2.3.9.2.19.
NdbBlob::getBlobTableName() - 2.3.9.2.20.
NdbBlob::getNdbOperation()
Abstract
This section discusses the public methods available in the
NdbBlob class.
This class has no public constructor. You can obtain a blob
handle using
NdbEventOperation::getBlobHandle().
Description.
This method gets the current state of the
NdbBlob object for which it is invoked.
Possible states are described in
Section 2.3.9.1.2, “The NdbBlob::State Type”.
Signature.
State getState
(
void
)
Parameters. None.
Return value.
A State value. For possible values, see
Section 2.3.9.1.2, “The NdbBlob::State Type”.
Description.
Use this method to prepare to read a blob value; the value is
available following invocation. Use
getNull() to check for a
NULL value; use
getLength() to get the actual length of the
blob, and to check for truncation.
getValue() sets the current read/write
position to the point following the end of the data which was
read.
Signature.
int getValue
(
void* data,
Uint32 bytes
)
Parameters.
This method takes two parameters. The first of these is a
pointer to the data to be read; the
second is the number of bytes to be
read.
Return value.
0 on success, -1 on
failure.
Description.
This method is used to prepare for inserting or updating a
blob value. Any existing blob data that is longer than the new
data is truncated. The data buffer must remain valid until the
operation has been executed. setValue()
sets the current read/write position to the point following
the end of the data. You can set
data to a null pointer
(0) in order to create a
NULL value.
Signature.
int setValue
(
const void* data,
Uint32 bytes
)
Parameters. This method takes the two parameters listed here:
The
datathat is to be inserted or used to overwrite the blob value.The number of
bytes—that is, the length—of thedata.
Return value.
0 on success, -1 on
failure.
Description.
This method defines a callback for blob handle activation. The
queue of prepared operations will be executed in no-commit
mode up to this point; then, the callback is invoked. For
additional information, see
Section 2.3.9.1.1, “The NdbBlob::ActiveHook Type”.
Signature.
int setActiveHook
(
ActiveHook* activeHook,
void* arg
)
Parameters. This method requires the two parameters listed here:
A pointer to an
ActiveHookvalue; this is a callback as explained in Section 2.3.9.1.1, “TheNdbBlob::ActiveHookType”.A pointer to
void, for any data to be passed to the callback.
Return value.
0 on success, -1 on
failure.
Description. This method is used to distinguish whether a blob operation is statement-based or event-based.
Signature.
void getVersion
(
int& version
)
Parameters. This method takes a single parameter, an integer reference to the blob version (operation type).
Return value. One of the following three values:
-1: This is a “normal” (statement-based) blob.0: This is an event-operation based blob, following a change in its data.1: This is an event-operation based blob, prior to any change in its data.
getVersion() is always successful, assuming
that it is invoked as a method of a valid
NdbBlob instance.
Description.
This method checks whether the blob's value is
NULL.
Signature.
int getNull
(
int& isNull
)
Parameters.
A reference to an integer isNull.
Following invocation, this parameter has one of the following
values, interpreted as shown here:
-1: The blob is undefined. If this is a nonevent blob, this result causes a state error.0: The blob has a nonnull value.1: The blob's value isNULL.
Return value. None.
Description.
This method sets the value of a blob to
NULL.
Signature.
int setNull
(
void
)
Parameters. None.
Return value.
0 on success; -1 on
failure.
Description. This method gets the blob's current length in bytes.
Signature.
int getLength
(
Uint64& length
)
Parameters. A reference to the length.
Return value.
The blob's length in bytes. For a NULL
blob, this method returns 0. to distinguish
between a blob whose length is 0 blob and
one which is NULL, use the
getNull() method.
Description. This method is used to truncate a blob to a given length.
Signature.
int truncate
(
Uint64 length = 0
)
Parameters.
truncate() takes a single parameter which
specifies the new length to which
the blob is to be truncated. This method has no effect if
length is greater than the blob's
current length (which you can check using
getLength()).
Return value.
0 on success, -1 on
failure.
Description. This method gets the current read/write position in a blob.
Signature.
int getPos
(
Uint64& pos
)
Parameters. One parameter, a reference to the position.
Return value.
Returns 0 on success, or
-1 on failure. (Following a successful
invocation, pos will hold the
current read/write position within the blob, as a number of
bytes from the beginning.)
Description. This method sets the position within the blob at which to read or write data.
Signature.
int setPos
(
Uint64 pos
)
Parameters.
The setPos() method takes a single parameter
pos (an unsigned 64-bit integer),
which is the position for reading or writing data. The value
of pos must be between
0 and the blob's current length.
“Sparse” blobs are not supported in the NDB API; in other words, there can be no unused data positions within a blob.
Return value.
0 on success, -1 on
failure.
Description. This method is used to read data from a blob.
Signature.
int readData
(
void* data,
Uint32& bytes
)
Parameters.
readData() accepts a pointer to the
data to be read, and a reference to
the number of bytes read.
Return value.
Returns 0 on success, -1
on failure. Following a successful invocation,
data points to the data that was
read, and bytes holds the number of
bytes read.
Description.
This method is used to write data to an
NdbBlob. After a successful invocation, the
read/write position will be at the first byte following the
data that was written to the blob.
A write past the current end of the blob data extends the blob automatically.
Signature.
int writeData
(
const void* data,
Uint32 bytes
)
Parameters.
This method takes two parameters, a pointer to the
data to be written, and the number
of bytes to write.
Return value.
0 on success, -1 on
failure.
Description.
Use this method to get the BLOB column to
which the NdbBlob belongs.
Signature.
const Column* getColumn
(
void
)
Parameters. None.
Return value.
A Column object. (See Section 2.3.1, “The Column Class”.)
Description. Use this method to obtain an error object. The error may be blob-specific or may be copied from a failed implicit operation. The error code is copied back to the operation unless the operation already has a nonzero error code.
Signature.
const NdbError& getNdbError
(
void
) const
Parameters. None.
Return value.
An NdbError object. See
Section 2.3.31, “The NdbError Structure”.
Description. This method initialises a list of blobs belonging to the current operation and returns the first blob in the list.
Signature.
NdbBlob* blobsFirstBlob
(
void
)
Parameters. None.
Return value. A pointer to the desired blob.
Description.
Use the method to obtain the next in a list of blobs that was
initialised using blobsFirstBlob(). See
Section 2.3.9.2.16, “NdbBlob::blobsFirstBlob()”.
Signature.
NdbBlob* blobsNextBlob
(
void
)
Parameters. None.
Return value. A pointer to the desired blob.
Description. This method gets a blob event name. The blob event is created if the main event monitors the blob column. The name includes the main event name.
Signature.
static int getBlobEventName
(
char* name,
Ndb* ndb,
const char* event,
const char* column
)
Parameters. This method takes the four parameters listed here:
name: The name of the blob event.ndb: The relevantNdbobject.event: The name of the main event.column: The blob column.
Return value.
0 on success, -1 on
failure.
Description. This method gets the blob data segment table name.
This method is generally of use only for testing and debugging purposes.
Signature.
static int getBlobTableName
(
char* name,
Ndb* ndb,
const char* table,
const char* column
)
Parameters. This method takes the four parameters listed here:
name: The name of the blob data segment table.ndb: The relevantNdbobject.table: The name of the main table.column: The blob column.
Return value.
Returns 0 on success, -1
on failure.
Description.
This method can be used to find the operation with which the
handle for this NdbBlob is associated.
NdbBlob::getNdbOperation() is available
beginning with MySQL Cluster NDB 6.2.17 and MySQL Cluster NDB
6.3.19.
Signature.
const NdbOperation* getNdbOperation
(
void
) const
Parameters. None.
Return value. A pointer to an operation.
The operation referenced by the pointer retruned by this
method may be represented by either an
NdbOperation or
NdbScanOperation object.
See Section 2.3.15, “The NdbOperation Class”, and
Section 2.3.18, “The NdbScanOperation Class”, for more information.
Abstract
This class provides meta-information about database objects, such as tables, columns, and indexes.
While the preferred method of database object creation and
deletion is through the MySQL Server,
NdbDictionary also permits the developer to
perform these tasks through the NDB API.
Parent class. None
Child classes. Dictionary, Column, Object
Description. This is a data dictionary class that supports enquiries about tables, columns, and indexes. It also provides ways to define these database objects and to remove them. Both sorts of functionality are supplied using inner classes that model these objects. These include the following inner classes:
NdbDictionary::Object::Tablefor working with tablesNdbDictionary::Columnfor creating table columnsNdbDictionary::Object::Indexfor working with secondary indexesNdbDictionary::Dictionaryfor creating database objects and making schema enquiriesNdbDictionary::Object::Eventfor working with events in the cluster.
Additional NdbDictionary::Object subclasses model
the tablespaces, logfile groups, datafiles, and undofiles required
for working with MySQL Cluster Disk Data tables (introduced in MySQL
5.1).
Tables and indexes created using NdbDictionary
cannot be viewed from the MySQL Server.
Dropping indexes through the NDB API that were created originally from a MySQL Cluster causes inconsistencies. It is possible that a table from which one or more indexes have been dropped using the NDB API will no longer be usable by MySQL following such operations. In this event, the table must be dropped, and then re-created using MySQL to make it accessible to MySQL once more.
Methods.
NdbDictionary itself has no public methods. All
work is accomplished by accessing its subclasses and their public
members.
NdbDictionary Subclass Hierarchy.
This diagram shows the hierarchy made up of the
NdbDictionary class, its subclasses, and their
enumerated data types:
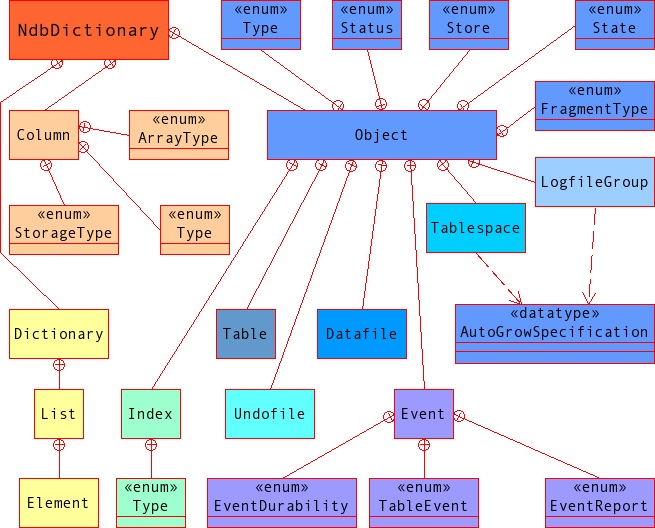
The next several sections discuss NdbDictionary's
subclasses and their public members in detail. The organisation of
these sections reflects that of the NdbDictionary
class hierarchy.
For the numeric equivalents to enumerations of
NdbDictionary subclasses, see the file
/storage/ndb/include/ndbapi/NdbDictionary.hpp
in the MySQL Cluster source tree.
Abstract
This section describes the NdbEventOperation
class, which is used to monitor changes (events) in a database. It
provides the core functionality used to implement MySQL Cluster
Replication.
Parent class. None
Child classes. None
Description.
NdbEventOperation represents a database event.
Creating an Instance of NdbEventOperation.
This class has no public constructor or destructor. Instead,
instances of NdbEventOperation are created as
the result of method calls on Ndb and
NdbDictionary objects, subject to the following
conditions:
There must exist an event which was created using
Dictionary::createEvent(). This method returns an instance of theNdbDictionary::Eventclass. See Section 2.3.3.1.12, “Dictionary::createEvent()”.An
NdbEventOperationobject is instantiated usingNdb::createEventOperation(), which acts on instance ofNdbDictionary::Event. See Section 2.3.8.1.11, “Ndb::createEventOperation”.
See also Section 2.3.4, “The Event Class”.
An instance of this class is removed by invoking
Ndb::dropEventOperation. See
Section 2.3.8.1.12, “Ndb::dropEventOperation()”, for more information.
A detailed example demonstrating creation and removal of event operations is provided in Section 2.4.8, “NDB API Event Handling Example”.
Known Issues. The following issues may be encountered when working with event operations in the NDB API:
The maximum number of active
NdbEventOperationobjects is currently fixed at compile time at2 * MaxNoOfTables.Currently, all
INSERT,DELETE, andUPDATEevents—as well as all attribute changes—are sent to the API, even if only some attributes have been specified. However, these are hidden from the user and only relevant data is shown after callingNdb::nextEvent().Note that false exits from
Ndb::pollEvents()may occur, and thus the followingnextEvent()call returns zero, since there was no available data. In such cases, simply callpollEvents()again.See Section 2.3.8.1.13, “
Ndb::pollEvents()”, and Section 2.3.8.1.14, “Ndb::nextEvent()”.Event code does not check the table schema version. When a table is dropped, make sure that you drop any associated events.
If you have received a complete epoch, events from this epoch are not re-sent, even in the event of a node failure. However, if a node failure has occurred, subsequent epochs may contain duplicate events, which can be identified by duplicated primary keys.
In the MySQL Cluster replication code, duplicate primary keys on
INSERToperations are normally handled by treating such inserts asREPLACEoperations.
To view the contents of the system table containing created events, you can use the ndb_select_all utility as shown here:
ndb_select_all -d sys 'NDB$EVENTS_0'
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
getState() | Gets the current state of the event operation |
getEventType() | Gets the event type |
getValue() | Retrieves an attribute value |
getPreValue() | Retrieves an attribute's previous value |
getBlobHandle() | Gets a handle for reading blob attributes |
getPreBlobHandle() | Gets a handle for reading the previous blob attribute |
getGCI() | Retrieves the GCI of the most recently retrieved event |
getLatestGCI() | Retrieves the most recent GCI (whether or not the corresponding event has been retrieved) |
getNdbError() | Gets the most recent error |
isConsistent() | Detects event loss caused by node failure |
tableNameChanged() | Checks to see whether the name of a table has changed |
tableFrmChanged() | Checks to see whether a table .FRM file has changed |
tableFragmentationChanged() | Checks to see whether the fragmentation for a table has changed |
tableRangeListChanged() | Checks to see whether a table range partition list name has changed |
mergeEvents() | Makes it possible for events to be merged |
execute() | Activates the NdbEventOperation |
For detailed descriptions, signatures, and examples of use for each
of these methods, see
Section 2.3.11.2, “NdbEventOperation Methods”.
Types.
NdbEventOperation defines one enumerated type.
See Section 2.3.11.1, “The NdbEventOperation::State Type”, for details.
Class diagram.
This diagram shows all the available members of the
NdbEventOperation class:

Description. This type describes the event operation's state.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
EO_CREATED | The event operation has been created, but execute()
has not yet been called. |
EO_EXECUTING | The execute() method has been invoked for this event
operation. |
EO_DROPPED | The event operation is waiting to be deleted, and is no longer usable. |
EO_ERROR | An error has occurred, and the event operation is unusable. |
A State value is returned by the
getState() method. See
Section 2.3.11.2.1, “NdbEventOperation::getState()”, for more
information.
- 2.3.11.2.1.
NdbEventOperation::getState() - 2.3.11.2.2.
NdbEventOperation::getEventType() - 2.3.11.2.3.
NdbEventOperation::getValue() - 2.3.11.2.4.
NdbEventOperation::getPreValue() - 2.3.11.2.5.
NdbEventOperation::getBlobHandle() - 2.3.11.2.6.
NdbEventOperation::getPreBlobHandle() - 2.3.11.2.7.
NdbEventOperation::getGCI() - 2.3.11.2.8.
NdbEventOperation::getLatestGCI() - 2.3.11.2.9.
NdbEventOperation::getNdbError() - 2.3.11.2.10.
NdbEventOperation::isConsistent() - 2.3.11.2.11.
NdbEventOperation::tableNameChanged() - 2.3.11.2.12.
NdbEventOperation::tableFrmChanged() - 2.3.11.2.13.
NdbEventOperation::tableFragmentationChanged() - 2.3.11.2.14.
NdbEventOperation::tableRangeListChanged() - 2.3.11.2.15.
NdbEventOperation::mergeEvents() - 2.3.11.2.16.
NdbEventOperation::execute()
Abstract
This section contains definitions and descriptions of the public
methods of the NdbEventOperation class.
Description. This method gets the event operation's current state.
Signature.
State getState
(
void
)
Parameters. None.
Return value.
A State value. See
Section 2.3.11.1, “The NdbEventOperation::State Type”.
Description.
This method is used to obtain the event's type
(TableEvent).
Signature.
NdbDictionary::Event::TableEvent getEventType
(
void
) const
Parameters. None.
Return value.
A TableEvent value. See
Section 2.3.4.1.1, “The Event::TableEvent Type”.
Description.
This method defines the retrieval of an attribute value. The
NDB API allocates memory for the NdbRecAttr
object that is to hold the returned attribute value.
This method does not fetch the attribute
value from the database, and the NdbRecAttr
object returned by this method is not readable or printable
before calling the execute() method and
Ndb::nextEvent() has returned a
non-NULL value.
If a specific attribute has not changed, the corresponding
NdbRecAttr will be in the state
UNDEFINED. This can be checked by using
NdbRecAttr::isNULL() which in such cases
returns -1.
value Buffer Memory Allocation.
It is the application's responsibility to allocate sufficient
memory for the value buffer (if not
NULL), and this buffer must be aligned
appropriately. The buffer is used directly (thus avoiding a
copy penalty) only if it is aligned on a 4-byte boundary and
the attribute size in bytes (calculated as
NdbRecAttr::attrSize() times
NdbRecAttr::arraySize()) is a multiple of
4.
getValue() retrieves the current value. Use
getPreValue() for retrieving the previous
value. See
Section 2.3.11.2.4, “NdbEventOperation::getPreValue()”.
Signature.
NdbRecAttr* getValue
(
const char* name,
char* value = 0
)
Parameters. This method takes the two parameters listed here:
The
nameof the attribute (as a constant character pointer).A pointer to a
value, such that:If the attribute value is not
NULL, then the attribute value is returned in this parameter.If the attribute value is
NULL, then the attribute value is stored only in theNdbRecAttrobject returned by this method.
See
valueBuffer Memory Allocation for more information regarding this parameter.
Return value.
An NdbRecAttr object to hold the value of
the attribute, or a NULL pointer indicating
that an error has occurred. See
Section 2.3.16, “The NdbRecAttr Class”.
Description.
This method performs identically to getValue(), except that it
is used to define a retrieval operation of an attribute's
previous value rather than the current value. See
Section 2.3.11.2.3, “NdbEventOperation::getValue()”, for details.
Signature.
NdbRecAttr* getPreValue
(
const char* name,
char* value = 0
)
Parameters. This method takes the two parameters listed here:
The
nameof the attribute (as a constant character pointer).A pointer to a
value, such that:If the attribute value is not
NULL, then the attribute value is returned in this parameter.If the attribute value is
NULL, then the attribute value is stored only in theNdbRecAttrobject returned by this method.
See
valueBuffer Memory Allocation for more information regarding this parameter.
Return value.
An NdbRecAttr object to hold the value of
the attribute, or a NULL pointer indicating
that an error has occurred. See
Section 2.3.16, “The NdbRecAttr Class”.
Description.
This method is used in place of getValue()
for blob attributes. The blob handle
(NdbBlob) returned by this method supports
read operations only.
To obtain the previous value for a blob attribute, use
getPreBlobHandle().
Signature.
NdbBlob* getBlobHandle
(
const char* name
)
Parameters.
The name of the blob attribute.
Return value.
A pointer to an NdbBlob object. See
Section 2.3.9, “The NdbBlob Class”.
Description.
This function is the same as
getBlobHandle(), except that it is used to
access the previous value of the blob attribute. See
Section 2.3.11.2.5, “NdbEventOperation::getBlobHandle()”.
Signature.
NdbBlob* getPreBlobHandle
(
const char* name
)
Parameters.
The name of the blob attribute.
Return value.
A pointer to an NdbBlob. See
Section 2.3.9, “The NdbBlob Class”.
Description. This method retrieves the GCI for the most recently retrieved event.
Signature.
Uint64 getGCI
(
void
) const
Parameters. None.
Return value. The global checkpoint index of the most recently retrieved event (an integer).
Description. This method retrieves the most recent GCI.
Beginning with MySQL Cluster NDB 6.2.5, this method actually returns the latest epoch number, and all references to GCIs in the documentation for this method when using this or a later MySQL Cluster NDB version should be taken to mean epoch numbers instead. This is a consequence of the implementation for micro-CGPs.
The GCI obtained using this method is not necessarily associated with an event.
Signature.
Uint64 getLatestGCI
(
void
) const
Parameters. None.
Return value. The index of the latest global checkpoint, an integer.
Description. This method retrieves the most recent error.
Signature.
const struct NdbError& getNdbError
(
void
) const
Parameters. None.
Return value.
A reference to an NdbError structure. See
Section 2.3.31, “The NdbError Structure”.
Description. This method is used to determine whether event loss has taken place following the failure of a node.
Signature.
bool isConsistent
(
void
) const
Parameters. None.
Return value.
If event loss has taken place, then this method returns
false; otherwise, it returns
true.
Description.
This method tests whether a table name has changed as the
result of a TE_ALTER table event. (See
Section 2.3.4.1.1, “The Event::TableEvent Type”.)
Signature.
bool tableNameChanged
(
void
) const
Prior to MySQL Cluster NDB 7.1.0, this method used
const bool as its return type (see
Bug#44840).
Parameters. None.
Return value.
Returns true if the name of the table has
changed; otherwise, the method returns
false.
Description.
Use this method to determine whether a table
.FRM file has changed in connection with
a TE_ALTER event. (See
Section 2.3.4.1.1, “The Event::TableEvent Type”.)
Signature.
bool tableFrmChanged
(
void
) const
Prior to MySQL Cluster NDB 7.1.0, this method used
const bool as its return type (see
Bug#44840)-
Parameters. None.
Return value.
Returns true if the table
.FRM file has changed; otherwise, the
method returns false.
Description.
This method is used to test whether a table's fragmentation
has changed in connection with a TE_ALTER
event. (See Section 2.3.4.1.1, “The Event::TableEvent Type”.)
Signature.
bool tableFragmentationChanged
(
void
) const
Prior to MySQL Cluster NDB 7.1.0, this method used
const bool as its return type (see
Bug#44840).
Parameters. None.
Return value.
Returns true if the table's fragmentation
has changed; otherwise, the method returns
false.
Description.
Use this method to check whether a table range partition list
name has changed in connection with a
TE_ALTER event.
Signature.
bool tableRangeListChanged
(
void
) const
Prior to MySQL Cluster NDB 7.1.0, this method used
const bool as its return type (see
Bug#44840).
Parameters. None.
Return value.
This method returns true if range or list
partition name has changed; otherwise it returns
false.
Description.
This method is used to set the merge events flag. For
information about event merging, see
Section 2.3.4.2.20, “Event::mergeEvents()”.
The merge events flag is false by default.
Signature.
void mergeEvents
(
bool flag
)
Parameters.
A Boolean flag.
Return value. None.
Description.
Activates the NdbEventOperation, so that it
can begin receiving events. Changed attribute values may be
retrieved after Ndb::nextEvent() has
returned a value other than NULL.
One of getValue(),
getPreValue(),
getBlobValue(), or
getPreBlobValue() must be called before
invoking execute().
Before attempting to use this method, you should have read the
explanations provided in Section 2.3.8.1.14, “Ndb::nextEvent()”,
and Section 2.3.11.2.3, “NdbEventOperation::getValue()”. Also see
Section 2.3.11, “The NdbEventOperation Class”.
Signature.
int execute
(
void
)
Parameters. None.
Return value.
This method returns 0 on success and
-1 on failure.
Abstract
This section describes the NdbIndexOperation
class and its public methods.
Parent class. NdbOperation
Child classes. None
Description.
NdbIndexOperation represents an index operation
for use in transactions. This class inherits from
NdbOperation; see
Section 2.3.15, “The NdbOperation Class”, for more information.
NdbIndexOperation can be used only with unique
hash indexes; to work with ordered indexes, use
NdbIndexScanOperation. See
Section 2.3.13, “The NdbIndexScanOperation Class”.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
getIndex() | Gets the index used by the operation |
readTuple() | Reads a tuple from a table |
updateTuple() | Updates an existing tuple in a table |
deleteTuple() | Removes a tuple from a table |
Index operations are not permitted to insert tuples.
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.15.2, “NdbOperation Methods”.
Types.
The NdbIndexOperation class defines no public
types of its own.
Class diagram.
This diagram shows all the available methods of the
NdbIndexOperation class:
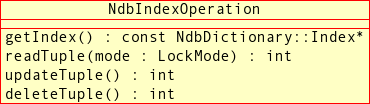
For more information about the use of
NdbIndexOperation, see
Section 1.3.2.3.1, “Single-row operations”.
Abstract
This section lists and describes the public methods of the
NdbIndexOperation class.
This class has no public constructor. To create an instance of
NdbIndexOperation, it is necessary to use the
NdbTransaction::getNdbIndexOperation()
method. See
Section 2.3.19.2.4, “NdbTransaction::getNdbIndexOperation()”.
Description. Gets the index, given an index operation.
Signature.
const NdbDictionary::Index* getIndex
(
void
) const
Parameters. None.
Return value.
A pointer to an Index object. See
Section 2.3.5, “The Index Class”.
Description.
This method define the NdbIndexOperation as
a READ operation. When the
NdbTransaction::execute() method is
invoked, the operation reads a tuple. See
Section 2.3.19.2.5, “NdbTransaction::execute()”.
Signature.
int readTuple
(
LockMode mode
)
Parameters.
mode specifies the locking mode
used by the read operation. See
Section 2.3.15.1.3, “The NdbOperation::LockMode Type”, for possible
values.
Return value.
0 on success, -1 on
failure.
Description.
This method defines the NdbIndexOperation
as an UPDATE operation. When the
NdbTransaction::execute() method is
invoked, the operation updates a tuple found in the table. See
Section 2.3.19.2.5, “NdbTransaction::execute()”.
Signature.
int updateTuple
(
void
)
Parameters. None.
Return value.
0 on success, -1 on
failure.
Description.
This method defines the NdbIndexOperation
as a DELETE operation. When the
NdbTransaction::execute() method is
invoked, the operation deletes a tuple from the table. See
Section 2.3.19.2.5, “NdbTransaction::execute()”.
Signature.
int deleteTuple
(
void
)
Parameters. None.
Return value.
0 on success, -1 on
failure.
Abstract
This section discusses the
NdbIndexScanOperation class and its public
members.
Parent class. NdbScanOperation
Child classes. None
Description.
The NdbIndexScanOperation class represents a
scan operation using an ordered index. This class inherits from
NdbScanOperation and
NdbOperation. See
Section 2.3.18, “The NdbScanOperation Class”, and
Section 2.3.15, “The NdbOperation Class”, for more information about
these classes.
NdbIndexScanOperation is for use with ordered
indexes only; to work with unique hash indexes, use
NdbIndexOperation.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
get_range_no() | Gets the range number for the current row |
getSorted() | Checks whether the current scan is sorted |
getDescending() | Checks whether the current scan is sorted |
readTuples() | Reads tuples using an ordered index |
setBound() | Defines a bound on the index key for a range scan |
reset_bounds() | Resets bounds, puts the operation in the send queue |
end_of_bound() | Marks the end of a bound |
For detailed descriptions, signatures, and examples of use for each
of these methods, see
Section 2.3.13.2, “NdbIndexScanOperation Methods”.
Types.
The NdbIndexScanOperation class defines one
public type. See
Section 2.3.13.1, “The NdbIndexScanOperation::BoundType Type”.
Beginning with MySQL Cluster NDB 6.2.3, this class defines an
additional struct for use with operations
employing NdbRecord; see
Section 2.3.29, “The IndexBound Structure”, and
Section 2.3.25, “The NdbRecord Interface”, for more information.
Class diagram.
This diagram shows all the public members of the
NdbIndexScanOperation class:
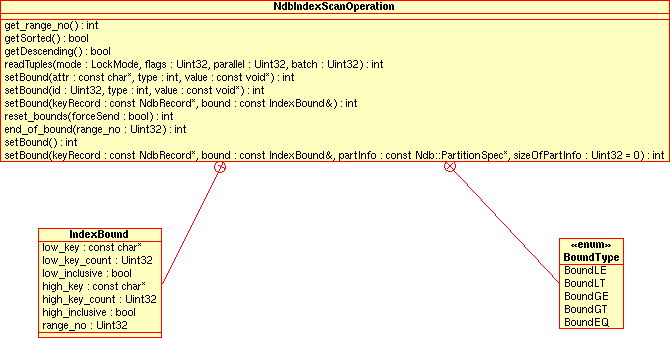
For more information about the use of
NdbIndexScanOperation, see
Section 1.3.2.3.2, “Scan Operations”, and
Section 1.3.2.3.3, “Using Scans to Update or Delete Rows”
Description. This type is used to describe an ordered key bound.
The numeric values are fixed in the API and can be used explicitly; in other words, it is “safe” to calculate the values and use them.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Numeric Value | Description |
|---|---|---|
BoundLE | 0 | Lower bound |
BoundLT | 1 | Strict lower bound |
BoundGE | 2 | Upper bound |
BoundGT | 3 | Strict upper bound |
BoundEQ | 4 | Equality |
- 2.3.13.2.1.
NdbIndexScanOperation::get_range_no() - 2.3.13.2.2.
NdbIndexScanOperation::getSorted() - 2.3.13.2.3.
NdbIndexScanOperation::getDescending() - 2.3.13.2.4.
NdbIndexScanOperation::readTuples() - 2.3.13.2.5.
NdbIndexScanOperation::setBound - 2.3.13.2.6.
NdbIndexScanOperation::reset_bounds() - 2.3.13.2.7.
NdbIndexScanOperation::end_of_bound()
Abstract
This section lists and describes the public methods of the
NdbIndexScanOperation class.
Description. This method returns the range number for the current row.
Signature.
int get_range_no
(
void
)
Parameters. None.
Return value. The range number (an integer).
Description. This method is used to check whether the scan is sorted.
Signature.
bool getSorted
(
void
) const
Parameters. None.
Return value.
true if the scan is sorted, otherwise
false.
Description. This method is used to check whether the scan is descending.
Signature.
bool getDescending
(
void
) const
Parameters. None.
Return value.
This method returns true if the scan is
sorted in descending order; otherwise, it returns
false.
Description. This method is used to read tuples, using an ordered index.
Signature.
virtual int readTuples
(
LockMode mode = LM_Read,
Uint32 flags = 0,
Uint32 parallel = 0,
Uint32 batch = 0
)
Parameters.
The readTuples() method takes the three
parameters listed here:
The lock
modeused for the scan. This is aLockModevalue; see Section 2.3.15.1.3, “TheNdbOperation::LockModeType” for more information, including permitted values.One or more scan flags; multiple
flagsareOR'ed together as they are when used withNdbScanOperation::readTuples(). See Section 2.3.18.1, “TheNdbScanOperation::ScanFlagType” for possible values.The number of fragments to scan in
parallel; use0to specify the maximum automatically.The
batchparameter specifies how many records will be returned to the client from the server by the nextNdbScanOperation::nextResult(true)method call. Use0to specify the maximum automatically.NoteThis parameter was ignored prior to MySQL 5.1.12, and the maximum was used.(Bug#20252)
Return value.
An integer: 0 indicates success;
-1 indicates failure.
Description.
This method defines a bound on an index key used in a range
scan. In MySQL Cluster NDB 6.2.3 and later, it is also sets
bounds for index scans defined using
NdbRecord.
“Old” API usage (prior to introduction of
NdbRecord).
Each index key can have a lower bound, upper bound, or both.
Setting the key equal to a value defines both upper and lower
bounds. Bounds can be defined in any order. Conflicting
definitions gives rise to an error.
Bounds must be set on initial sequences of index keys, and all but possibly the last bound must be nonstrict. This means, for example, that “a >= 2 AND b > 3” is permissible, but “a > 2 AND b >= 3” is not.
The scan may currently return tuples for which the bounds are
not satisfied. For example, a <= 2 && b
<= 3 not only scans the index up to (a=2,
b=3), but also returns any (a=1,
b=4) as well.
When setting bounds based on equality, it is better to use
BoundEQ instead of the equivalent pair
BoundLE and BoundGE. This
is especially true when the table partition key is a prefix of
the index key.
NULL is considered less than any
non-NULL value and equal to another
NULL value. To perform comparisons with
NULL, use setBound() with
a null pointer (0).
An index also stores all-NULL keys as well,
and performing an index scan with an empty bound set returns all
tuples from the table.
Signature (“Old” API). Using the “old” API, this method could be called in either of two ways. Both of these use the bound type and value; the first also uses the name of the bound, as shown here:
int setBound
(
const char* name,
int type,
const void* value
)
The second way to invoke this method under the “old” API uses the bound's ID rather than the name, as shown here:
int setBound
(
Uint32 id,
int type,
const void* value
)
Parameters (“Old” API). This method takes 3 parameters:
Either the
nameor theidof the attribute on which the bound is to be set.The bound
type—see Section 2.3.13.1, “TheNdbIndexScanOperation::BoundTypeType”.A pointer to the bound
value(use0forNULL).
As used with NdbRecord (MySQL Cluster NDB 6.2.3 and
later).
This method is called to add a range to an
IndexScan operation which has been defined
with a call to NdbTransaction::scanIndex().
To add more than one range, the index scan operation must have
been defined with the SF_MultiRange flag
set. (See Section 2.3.18.1, “The NdbScanOperation::ScanFlag Type”.)
Where multiple numbered ranges are defined with multiple calls
to setBound(), and the scan is ordered, the
range number for each range must be larger than the range
number for the previously defined range.
Signature (when used with NdbRecord).
MySQL Cluster NDB 6.2.3 and later:
int setBound
(
const NdbRecord* keyRecord,
const IndexBound& bound
)
Parameters.
As used with NdbRecord in MySQL Cluster NDB
6.2.3 and later, this method takes 2 parameters, listed here:
keyRecord: This is anNdbRecordstructure corresponding to the key on which the index is defined.The
boundto add (see Section 2.3.29, “TheIndexBoundStructure”).
Starting with MySQL Cluster NDB 6.3.24 and NDB 7.0.4, an
additional version of this method is available, which can be
used when the application knows that rows in-range will be found
only within a particular partition. This is the same as that
shown previously, except for the addition of a
PartitionSpecification. Doing so limits the
scan to a single partition, improving system efficiency.
Signature (when specifying a partition).
int setBound
(
const NdbRecord* keyRecord,
const IndexBound& bound,
const Ndb::PartitionSpec* partInfo,
Uint32 sizeOfPartInfo = 0
)
Parameters (when specifying a partition). Beginning with MySQL Cluster NDB 6.3.24 and MySQL Cluster NDB 7.0.4, this method can be invoked with the following four parameters:
keyRecord: This is anNdbRecordstructure (see Section 2.3.25, “TheNdbRecordInterface”) corresponding to the key on which the index is defined.The
boundto be added to the scan (see Section 2.3.29, “TheIndexBoundStructure”).partInfo: This is a pointer to anNdb::PartitionSpec, which provides extra information making it possible to scan a reduced set of partitions. See Section 2.3.33, “ThePartitionSpecStructure”, for more information.sizeOfPartInfo: The length of the partition specification.
keyRecord and
bound are defined and used in the
same way as with the 2-parameter version of this method.
Return value.
Returns 0 on success, -1
on failure.
Description.
Resets the bounds, and puts the operation into the list that
will be sent on the next
NdbTransaction::execute() call.
Signature.
int reset_bounds
(
bool forceSend = false
)
Parameters.
Set forceSend to
true in order to force the operation to be
sent immediately.
Return value.
Returns 0 on success, -1
on failure.
Description. This method is used to mark the end of a bound; it is used when batching index reads (that is, when employing multiple ranges).
Signature.
int end_of_bound
(
Uint32 range_no
)
Parameters. The number of the range on which the bound occurs.
Return value.
0 indicates success; -1
indicates failure.
Abstract
This section discusses the NdbInterpretedCode
class, which can be used to prepare and execute an NDB interpreted
program.
Beginning with MySQL Cluster NDB 6.2.14 and MySQL Cluster 6.3.12,
you must use the
NdbInterpretedCode class (rather than
NdbScanOperation) to write interpreted programs
used for scans.
Parent class. None.
Child classes. None.
Description.
NdbInterpretedCode represents an interpreted
program for use in operations created using
NdbRecord (see
Section 2.3.25, “The NdbRecord Interface”), or with scans created using the
old API. The NdbScanFilter class can also be
used to generate an NDB interpreted program using this class. (See
Section 2.3.17, “The NdbScanFilter Class”.) This class was added in
MySQL Cluster NDB 6.2.14 and 6.3.12.
This interface is still under development, and so is subject to
change without notice. The NdbScanFilter API is
a more stable API for defining scanning and filtering programs.
See Section 2.3.17, “The NdbScanFilter Class”, for more information.
Using NdbInterpretedCode.
To create an NdbInterpretedCode object, invoke
the constructor, optionally supplying a table for the program to
operate on, and a buffer for program storage and finalization. If
no table is supplied, then only instructions which do not access
table attributes can be used.
Each NDB API operation applies to one table, and so does any
NdbInterpretedCode program attached to that
operation.
If no buffer is supplied, then an internal buffer is dynamically
allocated and extended as necessary. Once the
NdbInterpretedCode object is created, you can add
instructions and labels to it by calling the appropriate methods as
described later in this section. When the program has completed,
finalize it by calling the finalise() method,
which resolves any remaining internal branches and calls to label
and subroutine offsets.
A single finalized NdbInterpretedCode program
can be used by more than one operation. It need not be re-prepared
for successive operations.
To use the program with NdbRecord operations and
scans, pass it at operation definition time using the
OperationOptions or
ScanOptions parameter. Alternatively, you can use
the program with old-style API scans by passing it using the
setInterpretedProgram() method. When the program
is no longer required, the NdbInterpretedCode
object can be deleted, along with any user-supplied buffer.
Error checking. For reasons of efficiency, methods of this class provide minimal error checking.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
NdbInterpretedCode() | Class constructor |
load_const_null() | Load a NULL value into a register |
load_const_u16() | Load a 16-bit numeric value into a register |
load_const_u32() | Load a 32-bit numeric value into a register |
load_const_u64() | Load a 64-bit numeric value into a register |
read_attr() | Read a register value into a table column |
write_attr() | Write a table column value into a register |
add_reg() | Add two register values and store the result in a third register |
sub_reg() | Subtract two register values and store the result in a third register |
def_label() | Create a label for use within the interpreted program |
branch_label() | Unconditional jump to a label |
branch_ge() | Jump if one register value is greater than or equal to another |
branch_gt() | Jump if one register value is greater than another |
branch_le() | Jump if one register value is less than or equal to another |
branch_lt() | Jump if one register value is less than another |
branch_eq() | Jump if one register value is equal to another |
branch_ne() | Jump if one register value is not equal to another |
branch_ne_null() | Jump if a register value is not NULL |
branch_eq_null() | Jump if a register value is NULL |
branch_col_eq() | Jump if a column value is equal to another |
branch_col_ne() | Jump if a column value is not equal to another |
branch_col_lt() | Jump if a column value is less than another |
branch_col_le() | Jump if a column value is less than or equal to another |
branch_col_gt() | Jump if a column value is greater than another |
branch_col_ge() | Jump if a column value is greater than or equal to another |
branch_col_eq_null() | Jump if a column value is NULL |
branch_col_ne_null() | Jump if a column value is not NULL |
branch_col_like() | Jump if a column value matches a pattern |
branch_col_notlike() | Jump if a column value does not match a pattern |
branch_col_and_mask_eq_mask() | Jump if a column value ANDed with a bitmask is equal
to the bitmask |
branch_col_and_mask_ne_mask() | Jump if a column value ANDed with a bitmask is not
equal to the bitmask |
branch_col_and_mask_eq_zero() | Jump if a column value ANDed with a bitmask is equal
to 0 |
branch_col_and_mask_ne_zero() | Jump if a column value ANDed with a bitmask is not
equal to 0 |
interpret_exit_ok() | Return a row as part of the result |
interpret_exit_nok() | Do not return a row as part of the result |
interpret_exit_last_row() | Return a row as part of the result, and do not check any more rows in this fragment |
add_val() | Add a value to a table column value |
sub_val() | Subtract a value from a table column value |
def_sub() | Define a subroutine |
call_sub() | Call a subroutine |
ret_sub() | Return from a subroutine |
finalise() | Completes interpreted program and prepares it for use |
getTable() | Gets the table on which the program is defined |
getNdbError() | Gets the most recent error associated with this
NdbInterpretedCode object |
getWordsUsed() | Gets the number of words used in the buffer |
For detailed descriptions, signatures, and examples of use for each
of these methods, see
Section 2.3.14.1, “NdbInterpretedCode Methods”.
Types. This class defines no public types.
Class diagram.
This diagram shows all the available methods of the
NdbInterpretedCode class:
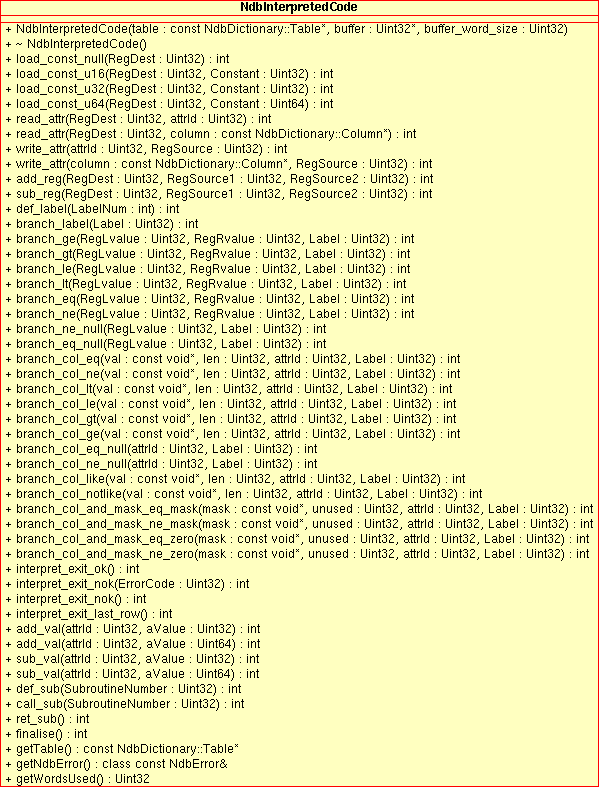
- 2.3.14.1.1.
NdbInterpretedCodeConstructor - 2.3.14.1.2.
NdbInterpretedCodeMethods for Loading Values into Registers - 2.3.14.1.3.
NdbInterpretedCodeMethods for Copying Values Between Registers and Table Columns - 2.3.14.1.4.
NdbInterpretedCodeRegister Arithmetic Methods - 2.3.14.1.5.
NdbInterpretedCode: Labels and Branching - 2.3.14.1.6.
NdbInterpretedCode::def_label() - 2.3.14.1.7.
NdbInterpretedCode::branch_label() - 2.3.14.1.8. Register-Based
NdbInterpretedCodeBranch Operations - 2.3.14.1.9. Column-Based
NdbInterpretedCodeBranch Operations - 2.3.14.1.10. Pattern-Based
NdbInterpretedCodeBranch Operations - 2.3.14.1.11.
NdbInterpretedCodeBitwise Comparison Operations - 2.3.14.1.12.
NdbInterpretedCodeResult Handling Methods - 2.3.14.1.13.
NdbInterpretedCodeConvenience Methods - 2.3.14.1.14. Using Subroutines with
NdbInterpretedCode - 2.3.14.1.15.
NdbInterpretedCodeUtility Methods
This section provides information about the public methods of the
NdbInterpretedCode class, grouped together by
function.
Description.
This is the NdbInterpretedCode class
constuctor.
Signature.
NdbInterpretedCode
(
const NdbDictionary::Table* table = 0,
Uint32* buffer = 0,
Uint32 buffer_word_size = 0
)
Parameters.
The NdbInterpretedCode constructor takes
three parameters, as described here:
The
tableagainst which which this program is to be be run. This parameter must be supplied if the program is table-specific—that is, if it reads from or writes to columns in a table.A pointer to a
bufferof 32-bit words used to store the program.buffer_word_sizeis the length of the buffer passed in. If the program exceeds this length then adding new instructions will fail with error 4518 Too many instructions in interpreted program.Alternatively, if no buffer is passed, a buffer will be dynamically allocated internally and extended to cope as instructions are added.
Return value.
An instance of NdbInterpretedCode.
The methods described in this section are used to load constant
values into NdbInterpretedCode program
registers. The space required by each of these methods is shown
in the following table:
| Method | Buffer (words) | Request message (words) |
|---|---|---|
load_const_null() | 1 | 1 |
load_const_u16() | 1 | 1 |
load_const_u32() | 2 | 2 |
load_const_u64() | 3 | 3 |
Description.
This method is used to load a NULL value
into a register.
Signature.
int load_const_null
(
Uint32 RegDest
)
Parameters.
This method takes a single parameter, the register into
which to place the NULL.
Return value.
Returns 0 on success,
-1 otherwise.
Description. This method loads a 16-bit value into the specified interpreter register.
Signature.
int load_const_u16
(
Uint32 RegDest,
Uint32 Constant
)
Parameters. This method takes the following two parameters:
RegDest: The register into which the value should be loaded.A
Constantvalue to be loaded
Return value.
Returns 0 on success,
-1 otherwise.
Description. This method loads a 32-bit value into the specified interpreter register.
Signature.
int load_const_u32
(
Uint32 RegDest,
Uint32 Constant
)
Parameters. This method takes the following two parameters:
RegDest: The register into which the value should be loaded.A
Constantvalue to be loaded
Return value.
Returns 0 on success,
-1 otherwise.
Description. This method loads a 64-bit value into the specified interpreter register.
Signature.
int load_const_u64
(
Uint32 RegDest,
Uint64 Constant
)
Parameters. This method takes the following two parameters:
RegDest: The register into which the value should be loaded.A
Constantvalue to be loaded
Return value.
Returns 0 on success,
-1 otherwise.
This class provides two methods for copying values between a
column in the current table row and a program register. The
read_attr() method is used to copy a table
column value into a program register;
write_attr() is used to copy a value from a
program register into a table column. Both of these methods
require that the table being operated on was specified when
creating the NdbInterpretedCode object for
which they are called.
The space required by each of these methods is shown in the following table:
| Method | Buffer (words) | Request message (words) |
|---|---|---|
read_attr() | 1 | 1 |
write_attr() | 1 | 1 |
More detailed information may be found in the next two sections.
Description.
The read_attr() method is used to read a
table column value into a program register. The column may
be specified either by using its attribute ID or as a
pointer to a Column object
(Section 2.3.1, “The Column Class”).
Signature. This method can be called in either of two ways. The first of these is by referencing the column by its attribute ID, as shown here:
int read_attr
(
Uint32 RegDest,
Uint32 attrId
)
Alternatively, you can referencing the column as a
Column object, as shown here:
int read_attr
(
Uint32 RegDest,
const NdbDictionary::Column* column
)
Parameters. This method takes two parameters, as described here:
The register to which the column value is to be copied (
RegDest).Either of the following references to the table column whose value is to be copied:
The table column's attribute ID (
attrId)A pointer to a
column—that is, a pointer to anNdbDictionary::Columnobject referencing the table column
Return value.
Returns 0 on success, and
-1 on failure.
Description.
This method is used to copy a register value to a table
column. The column may be specified either by using its
attribute ID or as a pointer to a Column
object (Section 2.3.1, “The Column Class”).
Signature. This method can be invoked in either of two ways. The first of these is requires referencing the column by its attribute ID, as shown here:
int read_attr
(
Uint32 attrId,
Uint32 RegSource
)
You can also reference the column as a
Column object instead, like this:
int read_attr
(
const NdbDictionary::Column* column,
Uint32 RegSource
)
Parameters. This method takes two parameters as follows:
A reference to the table column to which the register value is to be copied. This can be either of the following:
The table column's attribute ID (
attrId)A pointer to a
column—that is, a pointer to anNdbDictionary::Columnobject referencing the table column
The register whose value is to be copied (
RegSource).
Return value.
Returns 0 on success;
-1 on failure.
This class provides two methods for performing arithmetic
operations on registers. Using add_reg(), you
can load the sum of two registers into another register;
sub_reg() lets you load the difference of two
registers into another register.
The space required by each of these methods is shown in the following table:
| Method | Buffer (words) | Request message (words) |
|---|---|---|
add_reg() | 1 | 1 |
sub_reg() | 1 | 1 |
More information about these methods is presented in the next two sections.
Description. This method sums the values stored in any two given registers and stores the result in a third register.
Signature.
int add_reg
(
Uint32 RegDest,
Uint32 RegSource1,
Uint32 RegSource2
)
Parameters.
This method takes three parameters. The first of these is
the register in which the result is to be stored
(RegDest). The second and third
parameters (RegSource1 and
RegSource2) are the registers
whose values are to be summed.
It is possible to re-use for storing the result one of the
registers whose values are summed; that is,
RegDest can be the same as
RegSource1 or
RegSource2.
Return value.
Returns 0 on success,
-1 on failure.
Description. This method gets the difference between the values stored in any two given registers and stores the result in a third register.
Signature.
int sub_reg
(
Uint32 RegDest,
Uint32 RegSource1,
Uint32 RegSource2
)
Parameters.
This method takes three parameters. The first of these is
the register in which the result is to be stored
(RegDest). The second and third
parameters (RegSource1and
RegSource2) are the registers
whose values are to be subtracted. In other words, the value
of register RegDest is calculated
as the value of the expression shown here:
(value in registerRegSource1) – (value in registerRegSource2)
It is possible to re-use one of the registers whose values
are subtracted for storing the result; that is,
RegDest can be the same as
RegSource1 or
RegSource2.
Return value.
0 on success; -1 on
failure.
The NdbInterpretedCode class lets you define
labels within interpreted programs and provides a number of
methods for performing jumps to these labels based on any of the
following types of conditions:
Comparison between two register values
Comparison between a column value and a given constant
Whether or not a column value matches a given pattern
To define a label, use the def_label()
method. See Section 2.3.14.1.6, “NdbInterpretedCode::def_label()”.
To perform an unconditional jump to a label, use the
branch_label() method. See
Section 2.3.14.1.7, “NdbInterpretedCode::branch_label()”.
To perform a jump to a given label based on a comparison of
register values, use one of the
branch_ methods
(*()branch_ge(), branch_gt(),
branch_le(), branch_lt(),
branch_eq(), branch_ne(),
branch_ne_null(), or
branch_eq_null()). See
Section 2.3.14.1.8, “Register-Based NdbInterpretedCode Branch Operations”.
To perform a jump to a given label based on a comparison of
table column values, use one of the
branch_col_
methods (*()branch_col_ge(),
branch_col_gt(),
branch_col_le(),
branch_col_lt(),
branch_col_eq(),
branch_col_ne(),
branch_col_ne_null(), or
branch_col_eq_null()). See
Section 2.3.14.1.9, “Column-Based NdbInterpretedCode Branch Operations”.
To perform a jump based on pattern-matching of a table column
value, use one of the methods
branch_col_like() or
branch_col_notlike(). See
Section 2.3.14.1.10, “Pattern-Based NdbInterpretedCode Branch Operations”.
Description. This method defines a label to be used as the target of one or more jumps in an interpreted program.
def_label() uses a 2-word buffer and requires
no space for request messages.
Signature.
int def_label
(
int LabelNum
)
Parameters.
This method takes a single parameter
LabelNum, whose value must be
unique among all values used for labels within the interpreted
program.
Return value.
0 on success; -1 on
failure.
Description.
This method performs an unconditional jump to an interpreted
program label (see
Section 2.3.14.1.6, “NdbInterpretedCode::def_label()”).
Signature.
int branch_label
(
Uint32 Label
)
Parameters.
This method takes a single parameter, an interpreted program
Label defined using
def_label().
Return value.
0 on success, -1 on
failure.
- 2.3.14.1.8.1.
NdbInterpretedCode::branch_ge() - 2.3.14.1.8.2.
NdbInterpretedCode::branch_gt() - 2.3.14.1.8.3.
NdbInterpretedCode::branch_le() - 2.3.14.1.8.4.
NdbInterpretedCode::branch_lt() - 2.3.14.1.8.5.
NdbInterpretedCode::branch_eq() - 2.3.14.1.8.6.
NdbInterpretedCode::branch_ne() - 2.3.14.1.8.7.
NdbInterpretedCode::branch_ne_null() - 2.3.14.1.8.8.
NdbInterpretedCode::branch_eq_null()
Most of the methods discussed in this section are used to branch
based on the results of register-to-register comparisons. There
are also two methods used to compare a register value with
NULL. All of these methods require as a
parameter a label defined using the
def_label() method (see
Section 2.3.14.1.6, “NdbInterpretedCode::def_label()”).
These methods can be thought of as performing the following logic:
if(register_value1conditionregister_value2) gotoLabel
The space required by each of these methods is shown in the following table:
| Method | Buffer (words) | Request message (words) |
|---|---|---|
branch_ge() | 1 | 1 |
branch_gt() | 1 | 1 |
branch_le() | 1 | 1 |
branch_lt() | 1 | 1 |
branch_eq() | 1 | 1 |
branch_ne() | 1 | 1 |
branch_ne_null() | 1 | 1 |
branch_eq_null() | 1 | 1 |
Description. This method compares two register values; if the first is greater than or equal to the second, the interpreted program jumps to the specified label.
Signature.
int branch_ge
(
Uint32 RegLvalue,
Uint32 RegRvalue,
Uint32 Label
)
Parameters.
This method takes three parameters, the registers whose
values are to be
compared—RegLvalue and
RegRvalue—and the program
Label to jump to if
RegLvalue is greater than or
equal to RegRvalue.
Label must have been defined
previously using def_label() (see
Section 2.3.14.1.6, “NdbInterpretedCode::def_label()”).
Return value.
0 on success, -1 on
failure.
Description. This method compares two register values; if the first is greater than the second, the interpreted program jumps to the specified label.
Signature.
int branch_gt
(
Uint32 RegLvalue,
Uint32 RegRvalue,
Uint32 Label
)
Parameters.
This method takes three parameters, the registers whose
values are to be
compared—RegLvalue and
RegRvalue—and the program
Label to jump to if
RegLvalue is greater than
RegRvalue.
Label must have been defined
previously using def_label() (see
Section 2.3.14.1.6, “NdbInterpretedCode::def_label()”).
Return value.
0 on success, -1 on
failure.
Description. This method compares two register values; if the first is less than or equal to the second, the interpreted program jumps to the specified label.
Signature.
int branch_le
(
Uint32 RegLvalue,
Uint32 RegRvalue,
Uint32 Label
)
Parameters.
This method takes three parameters, the registers whose
values are to be
compared—RegLvalue and
RegRvalue—and the program
Label to jump to if
RegLvalue is less than or equal
to RegRvalue.
Label must have been defined
previously using def_label() (see
Section 2.3.14.1.6, “NdbInterpretedCode::def_label()”).
Return value.
0 on success, -1 on
failure.
Description. This method compares two register values; if the first is less than the second, the interpreted program jumps to the specified label.
Signature.
int branch_lt
(
Uint32 RegLvalue,
Uint32 RegRvalue,
Uint32 Label
)
Parameters.
This method takes three parameters, the registers whose
values are to be
compared—RegLvalue and
RegRvalue—and the program
Label to jump to if
RegLvalue is less than
RegRvalue.
Label must have been defined
previously using def_label() (see
Section 2.3.14.1.6, “NdbInterpretedCode::def_label()”).
Return value.
0 on success, -1 on
failure.
Description. This method compares two register values; if they equal, then the interpreted program jumps to the specified label.
Signature.
int branch_eq
(
Uint32 RegLvalue,
Uint32 RegRvalue,
Uint32 Label
)
Parameters.
This method takes three parameters, the registers whose
values are to be
compared—RegLvalue and
RegRvalue—and the program
Label to jump to if they are
equal. Label must have been
defined previously using def_label() (see
Section 2.3.14.1.6, “NdbInterpretedCode::def_label()”).
Return value.
0 on success, -1 on
failure.
Description. This method compares two register values; if they are not equal, then the interpreted program jumps to the specified label.
Signature.
int branch_ne
(
Uint32 RegLvalue,
Uint32 RegRvalue,
Uint32 Label
)
Parameters.
This method takes three parameters, the registers whose
values are to be
compared—RegLvalue and
RegRvalue—and the program
Label to jump they are not equal.
Label must have been defined
previously using def_label() (see
Section 2.3.14.1.6, “NdbInterpretedCode::def_label()”).
Return value.
0 on success, -1 on
failure.
Description.
This method compares a register value with
NULL; if the value is not null, then the
interpreted program jumps to the specified label.
Signature.
int branch_ne_null
(
Uint32 RegLvalue,
Uint32 Label
)
Parameters.
This method takes two parameters, the register whose value
is to be compared with NULL
(RegLvalue) and the program
Label to jump to if
RegLvalue is not null.
Label must have been defined
previously using def_label() (see
Section 2.3.14.1.6, “NdbInterpretedCode::def_label()”).
Return value.
0 on success, -1 on
failure.
Description.
This method compares a register value with
NULL; if the register value is null, then
the interpreted program jumps to the specified label.
Signature.
int branch_eq_null
(
Uint32 RegLvalue,
Uint32 Label
)
Parameters.
This method takes two parameters, the register whose value
is to be compared with NULL
(RegLvalue) and the program
Label to jump to if
RegLvalue is null.
Label must have been defined
previously using def_label() (see
Section 2.3.14.1.6, “NdbInterpretedCode::def_label()”).
Return value.
0 on success, -1 on
failure.
- 2.3.14.1.9.1.
NdbInterpretedCode::branch_col_eq() - 2.3.14.1.9.2.
NdbInterpretedCode::branch_col_ne() - 2.3.14.1.9.3.
NdbInterpretedCode::branch_col_lt() - 2.3.14.1.9.4.
NdbInterpretedCode::branch_col_le() - 2.3.14.1.9.5.
NdbInterpretedCode::branch_col_gt() - 2.3.14.1.9.6.
NdbInterpretedCode::branch_col_ge() - 2.3.14.1.9.7.
NdbInterpretedCode::branch_col_eq_null() - 2.3.14.1.9.8.
NdbInterpretedCode::branch_col_ne_null()
The methods described in this section are used to perform
branching based on a comparison between a table column value and
a given constant value. Each of these methods expects the
attribute ID of the column whose value is to be tested rather
than a reference to a Column object.
These methods, with the exception of
branch_col_eq_null() and
branch_col_ne_null(), can be thought of as
performing the following logic:
if(constant_valueconditioncolumn_value) gotoLabel
In each case (once again excepting
branch_col_eq_null() and
branch_col_ne_null()), the arbitrary constant
is the first parameter passed to the method.
The space requirements for each of these methods is shown in the
following table, where L represents
the length of the constant value:
| Method | Buffer (words) | Request message (words) |
|---|---|---|
branch_col_eq_null() | 2 | 2 |
branch_col_ne_null() | 2 | 2 |
branch_col_eq() | 2 | 2 + CEIL( |
branch_col_ne() | 2 | 2 + CEIL( |
branch_col_lt() | 2 | 2 + CEIL( |
branch_col_le() | 2 | 2 + CEIL( |
branch_col_gt() | 2 | 2 + CEIL( |
branch_col_ge() | 2 | 2 + CEIL( |
The expression CEIL( is the number of whole 8-byte words required to
hold the constant value to be compared.
L /
8)
Description. This method compares a table column value with an arbitrary constant and jumps to the specified program label if the values are equal.
Signature.
int branch_col_eq
(
const void* val,
Uint32 len,
Uint32 attrId,
Uint32 Label
)
Parameters. This method takes the following four parameters:
A constant value (
val)The length of the value (in bytes)
The attribute ID of the table column whose value is to be compared with
valA
Label(previously defined usingdef_label()) to jump to if the compared values are equal
Return value.
Returns 0 on success,
-1 on failure.
Description. This method compares a table column value with an arbitrary constant and jumps to the specified program label if the two values are not equal.
Signature.
int branch_col_ne
(
const void* val,
Uint32 len,
Uint32 attrId,
Uint32 Label
)
Parameters. This method takes the four parameters listed here:
A constant value (
val)The length of the value (in bytes)
The attribute ID of the table column whose value is to be compared with
valA
Label(previously defined usingdef_label()) to jump to if the compared values are unequal
Return value.
Returns 0 on success,
-1 on failure.
Description. This method compares a table column value with an arbitrary constant and jumps to the specified program label if the constant is less than the column value.
Signature.
int branch_col_lt
(
const void* val,
Uint32 len,
Uint32 attrId,
Uint32 Label
)
Parameters. This method takes the following four parameters:
A constant value (
val)The length of the value (in bytes)
The attribute ID of the table column whose value is to be compared with
valA
Label(previously defined usingdef_label()) to jump to if the constant value is less than the column value
Return value.
0 on success, -1 on
failure.
Description. This method compares a table column value with an arbitrary constant and jumps to the specified program label if the constant is less than or equal to the column value.
Signature.
int branch_col_le
(
const void* val,
Uint32 len,
Uint32 attrId,
Uint32 Label
)
Parameters. This method takes the four parameters listed here:
A constant value (
val)The length of the value (in bytes)
The attribute ID of the table column whose value is to be compared with
valA
Label(previously defined usingdef_label()) to jump to if the constant value is less than or equal to the column value
Return value.
Returns 0 on success,
-1 on failure.
Description. This method compares a table column value with an arbitrary constant and jumps to the specified program label if the constant is greater than the column value.
Signature.
int branch_col_gt
(
const void* val,
Uint32 len,
Uint32 attrId,
Uint32 Label
)
Parameters. This method takes the following four parameters:
A constant value (
val)The length of the value (in bytes)
The attribute ID of the table column whose value is to be compared with
valA
Label(previously defined usingdef_label()) to jump to if the constant value is greater than the column value
Return value.
Returns 0 on success,
-1 on failure.
Description. This method compares a table column value with an arbitrary constant and jumps to the specified program label if the constant is greater than or equal to the column value.
Signature.
int branch_col_ge
(
const void* val,
Uint32 len,
Uint32 attrId,
Uint32 Label
)
Parameters. This method takes the four parameters listed here:
A constant value (
val)The length of the value (in bytes)
The attribute ID of the table column whose value is to be compared with
valA
Label(previously defined usingdef_label()) to jump to if the constant value is greater than or equal to the column value
Return value.
Returns 0 on success,
-1 on failure.
Description.
This method tests the value of a table column and jumps to
the indicated program label if the column value is
NULL.
Signature.
int branch_col_eq_null
(
Uint32 attrId,
Uint32 Label
)
Parameters. This method requires the following two parameters:
The attribute ID of the table column
The program label to jump to if the column value is
NULL
Return value.
Returns 0 on success,
-1 on failure.
Description.
This method tests the value of a table column and jumps to
the indicated program label if the column value is not
NULL.
Signature.
int branch_col_ne_null
(
Uint32 attrId,
Uint32 Label
)
Parameters. This method requires the following two parameters:
The attribute ID of the table column
The program label to jump to if the column value is not
NULL
Return value.
Returns 0 on success,
-1 on failure.
The NdbInterpretedCode class provides two
methods which can be used to branch based on a comparison
between a column containing character data (that is, a
CHAR, VARCHAR,
BINARY, or VARBINARY
column) and a regular expression pattern.
The pattern syntax supported by the regular expression is the
same as that supported by the MySQL Server's
LIKE and NOT LIKE
operators, including the _ and
% metacharacters. For more information about
these, see String Comparison Functions.
This is the same regular expression pattern syntax that is
supported by NdbScanFilter; see
Section 2.3.17.2.6, “NdbScanFilter::cmp()”, for more information.
The table being operated upon must be supplied when the
NdbInterpretedCode object is instantiated.
The regular expression pattern should be in plain
CHAR format, even if the column is actually a
VARCHAR (in other words, there should be no
leading length bytes).
These functions behave as shown here:
if (column_value[NOT] LIKEpattern) gotoLabel;
The space requirements for these methods are shown in the
following table, where L represents
the length of the constant value:
| Method | Buffer (words) | Request message (words) |
|---|---|---|
branch_col_like() | 2 | 2 + CEIL( |
branch_col_notlike() | 2 | 2 + CEIL( |
The expression CEIL( is the number of whole 8-byte words required to
hold the constant value to be compared.
L /
8)
Description. This method tests a table column value against a regular expression pattern and jumps to the indicated program label if they match.
Signature.
int branch_col_like
(
const void* val,
Uint32 len,
Uint32 attrId,
Uint32 Label
)
Parameters. This method takes four parameters, which are listed here:
A regular expression pattern (
val); see Section 2.3.14.1.10, “Pattern-BasedNdbInterpretedCodeBranch Operations”, for the syntax supportedLength of the pattern (in bytes)
The attribute ID for the table column being tested
The program label to jump to if the table column value matches the pattern
Return value.
0 on success, -1 on
failure
Description.
This method is similar to
branch_col_like() in that it tests a
table column value against a regular expression pattern;
however it jumps to the indicated program label only if the
pattern and the column value do not
match.
Signature.
int branch_col_notlike
(
const void* val,
Uint32 len,
Uint32 attrId,
Uint32 Label
)
Parameters. This method takes the following four parameters:
A regular expression pattern (
val); see Section 2.3.14.1.10, “Pattern-BasedNdbInterpretedCodeBranch Operations”, for the syntax supportedLength of the pattern (in bytes)
The attribute ID for the table column being tested
The program label to jump to if the table column value does not match the pattern
Return value.
Returns 0 on success,
-1 on failure
These instructions are available beginning with MySQL Cluster
NDB 6.3.20. They are used to branch based on the result of a
logical AND comparison between a
BIT column value and a bitmask pattern.
Use of these methods requires that the table being operated upon
was supplied when the NdbInterpretedCode
object was constructed. The mask value should be the same size
as the bit column being compared. BIT values
are passed into and out of the NDB API as 32-bit words with bits
set in order from the least significant bit to the most
significant bit. The endianness of the platform on which the
instructions are executed controls which byte contains the least
significant bits. On x86, this is the first byte (byte 0); on
SPARC and PPC, it is the last byte.
The buffer length and request length for each of these methods each requires an amount of space equal to 2 words plus the column width rounded (up) to the nearest whole word.
Description.
This method is used to compare a BIT
column value with a bitmask; if the column value
ANDed together with the bitmask is equal
to the bitmask, then execution jumps to a specified label
specified in the method call.
Signature.
int branch_col_and_mask_eq_mask
(
const void* mask,
Uint32 unused,
Uint32 attrId,
Uint32 Label
)
Parameters. This method can accept four parameters, of which three are actually used. These are described in the following list:
A pointer to a constant
maskto compare the column value toA
Uint32value which is currentlyunused.The
attrIdof the column to be compared.A program
Labelto jump to if the condition is true.
Return value.
This method returns 0 on success and
-1 on failure.
Description.
This method is used to compare a BIT
column value with a bitmask; if the column value
ANDed together with the bitmask is not
equal to the bitmask, then execution jumps to a specified
label specified in the method call.
Signature.
int branch_col_and_mask_ne_mask
(
const void* mask,
Uint32 unused,
Uint32 attrId,
Uint32 Label
)
Parameters. This method accepts four parameters, of which three are actually used. These described in the following list:
A pointer to a constant
maskto compare the column value to.A
Uint32value which is currentlyunused.The
attrIdof the column to be compared.A program
Labelto jump to if the condition is true.
Return value.
This method returns 0 on success and
-1 on failure.
Description.
This method is used to compare a BIT
column value with a bitmask; if the column value
ANDed together with the bitmask is equal
to 0, then execution jumps to a specified
label specified in the method call.
Signature.
int branch_col_and_mask_eq_zero
(
const void* mask,
Uint32 unused,
Uint32 attrId,
Uint32 Label
)
Parameters. This method can accept the following four parameters, of which three are actually used:
A pointer to a constant
maskto compare the column value to.A
Uint32value which is currentlyunused.The
attrIdof the column to be compared.A program
Labelto jump to if the condition is true.
Return value.
This method returns 0 on success and
-1 on failure.
Description.
This method is used to compare a BIT
column value with a bitmask; if the column value
ANDed together with the bitmask is not
equal to 0, then execution jumps to a
specified label specified in the method call.
Signature.
int branch_col_and_mask_ne_zero
(
const void* mask,
Uint32 unused,
Uint32 attrId,
Uint32 Label
)
Parameters. This method accepts the following four parameters, of which three are actually used:
A pointer to a constant
maskto compare the column value to.A
Uint32value which is currentlyunused.The
attrIdof the column to be compared.A program
Labelto jump to if the condition is true.
Return value.
This method returns 0 on success and
-1 on failure.
The methods described in this section are used to tell the interpreter that processing of the current row is complete, and—in the case of scans—whether or not to include this row in the results of the scan.
The space requirements for these methods are shown in the
following table, where L represents
the length of the constant value:
| Method | Buffer (words) | Request message (words) |
|---|---|---|
interpret_exit_ok() | 1 | 1 |
interpret_exit_nok() | 1 | 1 |
interpret_exit_last_row() | 1 | 1 |
Description. For a scanning operation, this method indicates that the current row should be returned as part of the results of the scan and that the program should move on to the next row. For other operations, calling this method causes the interpreted program to exit.
Signature.
int interpret_exit_ok
(
void
)
Parameters. None.
Return value.
Returns 0 on success,
-1 on failure.
Description. For scanning operations, this method is used to indicate that the current row should not be returned as part of the scan, and to cause the program should move on to the next row. It causes other types of operations to be aborted.
Signature.
int interpret_exit_nok
(
Uint32 ErrorCode = 899
)
Parameters.
This method takes a single (optional) parameter
ErrorCode which defaults to NDB
error code 899 (Rowid
already allocated). For a complete listing of
NDB error codes, see Section 5.2.2, “NDB Error Codes and Messages”.
Return value.
Returns 0 on success,
-1 on failure.
Description. For a scanning operation, invoking this method indicates that this row should be returned as part of the scan, and that no more rows in this fragment should be scanned. For other types of operations, the method causes the operation to be aborted.
Signature.
int interpret_exit_last_row
(
void
)
Parameters. None.
Return value.
Returns 0 if successful,
-1 otherwise.
The methods described in this section can be used to insert multiple instructions (using specific registers) into an interpreted program.
In addition to updating the table column, these methods use
interpreter registers 6 and 7, replacing any existing contents
of register 6 with the original column value and any existing
contents of register 7 with the modified column value. The
table itself must be previously defined when instantiating the
NdbInterpretedCode object for which the
method is invoked.
The space requirements for these methods are shown in the
following table, where L represents
the length of the constant value:
| Method | Buffer (words) | Request message (words) |
|---|---|---|
add_value() | 4 | 1; if the supplied value >= 216: 2; if >= 232: 3 |
sub_value() | 4 | 1; if the supplied value >= 216: 2; if >= 232: 3 |
Description.
This method adds a specified value to the value of a given
table column, and places the original and modified column
values in registers 6 and 7. It is equivalent to the
following series of NdbInterpretedCode
method calls, where attrId is the
table column' attribute ID and
aValue is the value to be added:
read_attr(6,attrId); load_const_u32(7,aValue); add_reg(7,6,7); write_attr(attrId, 7);
aValue can be a 32-bit or 64-bit
integer.
Signature.
This method can be invoked in either of two ways, depending
on whether aValue is 32-bit or
64-bit.
32-bit aValue:
int add_val
(
Uint32 attrId,
Uint32 aValue
)
64-bit aValue:
int add_val
(
Uint32 attrId,
Uint64 aValue
)
Parameters. A table column attribute ID and a 32-bit or 64-bit integer value to be added to this column value.
Return value.
Returns 0 on success,
-1 on failure.
Description.
This method subtracts a specified value from the value of a
given table column, and places the original and modified
column values in registers 6 and 7. It is equivalent to the
following series of NdbInterpretedCode
method calls, where attrId is the
table column' attribute ID and
aValue is the value to be
subtracted:
read_attr(6,attrId); load_const_u32(7,aValue); sub_reg(7,6,7); write_attr(attrId, 7);
aValue can be a 32-bit or 64-bit
integer.
Signature.
This method can be invoked in either of two ways, depending
on whether aValue is 32-bit or
64-bit.
32-bit aValue:
int sub_val
(
Uint32 attrId,
Uint32 aValue
)
64-bit aValue:
int sub_val
(
Uint32 attrId,
Uint64 aValue
)
Parameters. A table column attribute ID and a 32-bit or 64-bit integer value to be subtracted from this column value.
Return value.
Returns 0 on success,
-1 on failure.
NdbInterpretedCode supports subroutines which
can be invoked from within interpreted programs, with each
subroutine being identified by a unique number. Subroutines can
be defined only following all main program instructions.
Numbers used to identify subroutines must be contiguous; however, they do not have to be in any particular order.
The beginning of a subroutine is indicated by invoking the
def_sub() method; all instructions after this
belong to this subroutine until the subroutine is terminated
with ret_sub(). A subroutine is called using
call_sub().
Once the subroutine has completed, the program resumes execution with the instruction immediately following the one which invoked the subroutine. Subroutines can also be invoked from other subroutines; currently, the maximum subroutine stack depth is 32.
Description.
This method is used to mark the start of a subroutine. See
Section 2.3.14.1.14, “Using Subroutines with NdbInterpretedCode”, for
more information.
Signature.
int def_sub
(
Uint32 SubroutineNumber
)
Parameters. A single parameter, a number used to identify the subroutine.
Return value.
Returns 0 on success,
-1 otherwise.
This section provides information about some utility methods
supplied by NdbInterepretedCode.
Description.
This method prepares an interpreted program, including any
subroutines it might have, by resolving all branching
instructions and calls to subroutines. It must be called
before using the program, and can be invoked only once for
any given NdbInterpretedCode object.
If no instructions have been defined, this method attempts to
insert a single interpret_exit_ok() method
call prior to finalization.
Signature.
int finalise
(
void
)
Parameters. None.
Return value.
Returns 0 on success,
-1 otherwise.
Description.
This method can be used to obtain a reference to the table
for which the NdbInterpretedCode object
was defined.
Signature.
const NdbDictionary::Table* getTable
(
void
) const
Parameters. None.
Return value.
A pointer to a Table object. Returns
NULL if no table object was supplied when
the NdbInterpretedCode was instantiated.
Description.
This method returns the most recent error associated with
this NdbInterpretedCode object.
Signature.
const class NdbError& getNdbError
(
void
) const
Parameters. None.
Return value.
A reference to an NdbError object. See
Section 2.3.31, “The NdbError Structure”, for more information.
Abstract
This section discusses the NdbOperation class.
Parent class. None
Child classes. NdbIndexOperation, NdbScanOperation
NdbOperation Subclasses.
The following diagram shows the relationships of
NdbOperation, its subclasses, and their public
types:
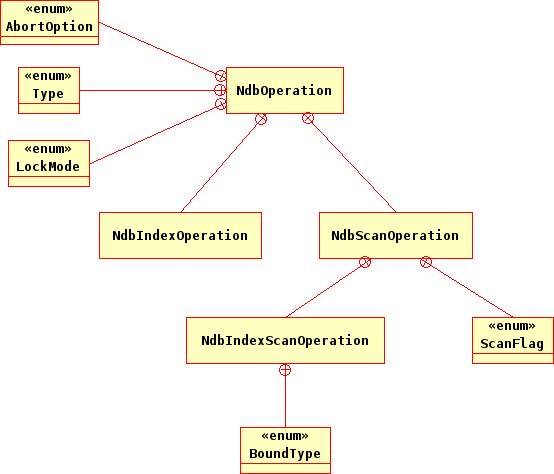
Description.
NdbOperation represents a
“generic” data operation. Its subclasses represent
more specific types of operations. See
Section 2.3.15.1.2, “The NdbOperation::Type Type” for a listing of operation
types and their corresponding NdbOperation
subclasses.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
getValue() | Allocates an attribute value holder for later access |
getBlobHandle() | Used to access blob attributes |
getTableName() | Gets the name of the table used for this operation |
getTable() | Gets the table object used for this operation |
getNdbError() | Gets the latest error |
getNdbErrorLine() | Gets the number of the method where the latest error occurred |
getType() | Gets the type of operation |
getLockMode() | Gets the operation's lock mode |
getNdbTransaction() | Gets the NdbTransaction object for this operation |
equal() | Defines a search condition using equality |
setValue() | Defines an attribute to set or update |
insertTuple() | Adds a new tuple to a table |
updateTuple() | Updates an existing tuple in a table |
readTuple() | Reads a tuple from a table |
writeTuple() | Inserts or updates a tuple |
deleteTuple() | Removes a tuple from a table |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.15.2, “NdbOperation Methods”.
Types.
The NdbOperation class defines three public
types, shown in the following table:
| Type | Purpose / Use |
|---|---|
AbortOption | Determines whether a failed operation causes failure of the transaction of which it is part |
Type | Operation access types |
LockMode | The type of lock used when performing a read operation |
For a discussion of each of these types, along with its possible
values, see Section 2.3.15.1, “NdbOperation Types”.
Class diagram.
The following diagram shows all the available methods and
enumerated types of the NdbOperation class:

For more information about the use of
NdbOperation, see
Section 1.3.2.3.1, “Single-row operations”.
Abstract
This section details the public types belonging to the
NdbOperation class.
Description.
This type is used to determine whether failed operations
should force a transaction to be aborted. It is used as an
argument to the execute() method—see
Section 2.3.19.2.5, “NdbTransaction::execute()”, for more
information.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
AbortOnError | A failed operation causes the transaction to abort. |
AO_IgnoreOnError | Failed operations are ignored; the transaction continues to execute. |
DefaultAbortOption | The AbortOption value is set according to the
operation type:
|
DefaultAbortOperation is available beginning
with MySQL Cluster NDB 6.2.0. See
Section 2.3.19.2.5, “NdbTransaction::execute()”, for more
information.
Previous to MySQL Cluster NDB 6.2.0, this type belonged to the
NdbTransaction class.
Description.
Type is used to describe the operation
access type. Each access type is supported by
NdbOperation or one of its subclasses, as
shown in the following table:
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description | Class |
|---|---|---|
PrimaryKeyAccess | A read, insert, update, or delete operation using the table's primary key | NdbOperation |
UniqueIndexAccess | A read, update, or delete operation using a unique index | NdbIndexOperation |
TableScan | A full table scan | NdbScanOperation |
OrderedIndexScan | An ordered index scan | NdbIndexScanOperation |
Description. This type describes the lock mode used when performing a read operation.
Enumeration values. Possible values for this type are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
LM_Read | Read with shared lock |
LM_Exclusive | Read with exclusive lock |
LM_CommittedRead | Ignore locks; read last committed |
LM_SimpleRead | Read with shared lock, but release lock directly |
There is also support for dirty reads
(LM_Dirty), but this is normally for
internal purposes only, and should not be used for
applications deployed in a production setting.
- 2.3.15.2.1.
NdbOperation::getValue() - 2.3.15.2.2.
NdbOperation::getBlobHandle() - 2.3.15.2.3.
NdbOperation::getTableName() - 2.3.15.2.4.
NdbOperation::getTable() - 2.3.15.2.5.
NdbOperation::getNdbError() - 2.3.15.2.6.
NdbOperation::getNdbErrorLine() - 2.3.15.2.7.
NdbOperation::getType() - 2.3.15.2.8.
NdbOperation::getLockMode() - 2.3.15.2.9.
NdbOperation::getNdbTransaction() - 2.3.15.2.10.
NdbOperation::equal() - 2.3.15.2.11.
NdbOperation::setValue() - 2.3.15.2.12.
NdbOperation::insertTuple() - 2.3.15.2.13.
NdbOperation::readTuple() - 2.3.15.2.14.
NdbOperation::writeTuple() - 2.3.15.2.15.
NdbOperation::updateTuple() - 2.3.15.2.16.
NdbOperation::deleteTuple()
Abstract
This section lists and describes the public methods of the
NdbOperation class.
This class has no public constructor. To create an instance of
NdbOperation, you must use
NdbTransaction::getNdbOperation(). See
Section 2.3.19.2.1, “NdbTransaction::getNdbOperation()”, for more
information.
Description.
This method prepares for the retrieval of an attribute value.
The NDB API allocates memory for an
NdbRecAttr object that is later used to
obtain the attribute value. This can be done by using one of
the many NdbRecAttr accessor methods, the
exact method to be used depending on the attribute's data
type. (This includes the generic
NdbRecAttr::aRef() which retrieves the data
as char*, regardless of its actual type.
However, this is not type-safe, and requires a cast from the
user.) See Section 2.3.16, “The NdbRecAttr Class”, and
Section 2.3.16.1.19, “NdbRecAttr::aRef()”, for more information.
This method does not fetch the attribute
value from the database; the NdbRecAttr
object returned by this method is not readable or printable
before calling NdbTransaction::execute().
If a specific attribute has not changed, the corresponding
NdbRecAttr has the state
UNDEFINED. This can be checked by using
NdbRecAttr::isNULL(), which in such cases
returns -1.
See Section 2.3.19.2.5, “NdbTransaction::execute()”, and
Section 2.3.16.1.4, “NdbRecAttr::isNULL()”.
Signature. There are three versions of this method, each having different parameters:
NdbRecAttr* getValue
(
const char* name,
char* value = 0
)
NdbRecAttr* getValue
(
Uint32 id,
char* value = 0
)
NdbRecAttr* getValue
(
const NdbDictionary::Column* col,
char* value = 0
)
Parameters.
All three forms of this method have two parameters, the second
parameter being optional (defaults to 0).
They differ only with regard to the type of the first
parameter, which can be any one of the following:
The attribute
nameThe attribute
idThe
columnon which the attribute is defined
In all three cases, the second parameter is a character buffer
in which a non-NULL attribute value is
returned. In the event that the attribute is
NULL, is it stored only in the
NdbRecAttr object returned by this method.
If no value is specified in the
getValue() method call, or if 0 is passed as
the value, then the NdbRecAttr object
provides memory management for storing the received data. If the
maximum size of the received data is above a small fixed size,
malloc() is used to store it: For small
sizes, a small, fixed internal buffer (32 bytes in extent) is
provided. This storage is managed by the
NdbRecAttr instance; it is freed when the
operation is released, such as at transaction close time; any
data written here that you wish to preserve should be copied
elsewhere before this freeing of memory takes place.
If you pass a non-zero pointer for
value, then it is assumed that this
points to an portion of memory which is large enough to hold the
maximum value of the column; any returned data is written to
that location. The pointer should be at least 32-bit aligned.
Return value.
A pointer to an NdbRecAttr object to hold
the value of the attribute, or a NULL
pointer, indicating an error.
Retrieving integers.
Integer values can be retrieved from both the
value buffer passed as this
method's second parameter, and from the
NdbRecAttr object itself. On the other
hand, character data is available from
NdbRecAttr if no buffer has been passed in
to getValue() (see
Section 2.3.16.1.19, “NdbRecAttr::aRef()”). However, character
data is written to the buffer only if one is provided, in
which case it cannot be retrieved from the
NdbRecAttr object that was returned. In the
latter case, NdbRecAttr::aRef() returns a
buffer pointing to an empty string.
Accessing bit values.
The following example shows how to check a given bit from the
value buffer. Here,
op is an operation
(NdbOperation object),
name is the name of the column from which
to get the bit value, and trans is an
NdbTransaction object:
Uint32 buf[];
op->getValue(name, buf); /* bit column */
trans->execute();
if(buf[X/32] & 1 << (X & 31)) /* check bit X */
{
/* bit X set */
}
Description.
This method is used in place of getValue()
or setValue() for blob attributes. It
creates a blob handle (NdbBlob object). A
second call with the same argument returns the previously
created handle. The handle is linked to the operation and is
maintained automatically. See Section 2.3.9, “The NdbBlob Class”,
for details.
Signature. This method has two forms, depending on whether it is called with the name or the ID of the blob attribute:
virtual NdbBlob* getBlobHandle
(
const char* name
)
or
virtual NdbBlob* getBlobHandle
(
Uint32 id
)
Parameters. This method takes a single parameter, which can be either one of the following:
The
nameof the attributeThe
idof the attribute
Return value.
Regardless of parameter type used, this method return a
pointer to an instance of NdbBlob.
Description. This method retrieves the name of the table used for the operation.
Signature.
const char* getTableName
(
void
) const
Parameters. None.
Return value. The name of the table.
Description. This method is used to retrieve the table object associated with the operation.
Signature.
const NdbDictionary::Table* getTable
(
void
) const
Parameters. None.
Return value.
Apointer to an instance of Table. For more
information, see Section 2.3.21, “The Table Class”.
Description.
This method gets the most recent error (an
NdbError object).
Signature.
const NdbError& getNdbError
(
void
) const
Parameters. None.
Return value.
An NdbError object. See
Section 2.3.31, “The NdbError Structure”.
Description. This method retrieves the method number in which the latest error occurred.
Signature. Beginning with MySQL Cluster NDB 6.2.17 and MySQL Cluster NDB 6.3.19, this method can (and should) be used as shown here:
int getNdbErrorLine
(
void
) const
The non-const version of this method, shown
here, was removed in MySQL Cluster NDB 6.2.19, MySQL Cluster NDB
6.3.28, and MySQL Cluster NDB 7.0.9 (see Bug#47798):
int getNdbErrorLine
(
void
)
Parameters. None.
Return value. The method number (an integer).
Description. This method is used to retrieve the access type for this operation.
Signature.
Type getType
(
void
) const
Parameters. None.
Prior to MySQL Cluster NDB 7.1.0, this method used
const Type as its return type (see
Bug#44840).
Return value.
A Type value. See
Section 2.3.15.1.2, “The NdbOperation::Type Type”.
Description. This method gets the operation's lock mode.
Signature.
LockMode getLockMode
(
void
) const
Parameters. None.
Return value.
A LockMode value. See
Section 2.3.15.1.3, “The NdbOperation::LockMode Type”.
Description.
Gets the NdbTransaction object for this
operation. Available beginning with MySQL Cluster NDB 6.2.17
and MySQL Cluster NDB 6.3.19.
Signature.
virtual NdbTransaction* getNdbTransaction
(
void
) const
Parameters. None.
Return value.
A pointer to an NdbTransaction object. See
Section 2.3.19, “The NdbTransaction Class”.
Description.
This method defines a search condition with an equality. The
condition is true if the attribute has the given value. To set
search conditions on multiple attributes, use several calls to
equal(); in such cases all of them must be
satisfied for the tuple to be selected.
If the attribute is of a fixed size, its value must include
all bytes. In particular a Char value must
be native-space padded. If the attribute is of variable size,
its value must start with 1 or 2 little-endian length bytes (2
if its type is Long*).
When using insertTuple(), you may also
define the search key with setValue(). See
Section 2.3.15.2.11, “NdbOperation::setValue()”.
Signature.
There are 10 versions of equal(), each
having slightly different parameters. All of these are listed
here:
int equal
(
const char* name,
const char* value
)
int equal
(
const char* name,
Int32 value
)
int equal
(
const char* name,
Uint32 value
)
int equal
(
const char* name,
Int64 value
)
int equal
(
const char* name,
Uint64 value
)
int equal
(
Uint32 id,
const char* value
)
int equal
(
Uint32 id,
Int32 value
)
int equal
(
Uint32 id,
Uint32 value
)
int equal
(
Uint32 id,
Int64 value
)
int equal
(
Uint32 id,
Uint64 value
)
Parameters. This method requires two parameters:
The first parameter can be either of the following:
The
nameof the attribute (a string)The
idof the attribute (an unsigned 32-bit integer)
The second parameter is the attribute
valueto be tested. This value can be any one of the following 5 types:String
32-bit integer
Unsigned 32-bit integer
64-bit integer
Unsigned 64-bit integer
Return value.
Returns -1 in the event of an error.
Description. This method defines an attribute to be set or updated.
There are a number of
NdbOperation::setValue() methods that take a
certain type as input (pass by value rather than passing a
pointer). It is the responsibility of the application programmer
to use the correct types.
However, the NDB API does check that the application sends a
correct length to the interface as given in the length
parameter. A char* value can contain any data
type or any type of array. If the length is not provided, or if
it is set to zero, then the API assumes that the pointer is
correct, and does not check it.
To set a NULL value, use the following
construct:
setValue("ATTR_NAME", (char*)NULL);
When you use insertTuple(), the NDB API
automatically detects that it is supposed to use
equal() instead.
In addition, it is not necessary when using
insertTuple() to use
setValue() on key attributes before other
attributes.
Signature.
There are 14 versions of
NdbOperation::setValue(), each with
slightly different parameters, as listed here (and summarised
in the Parameters section following):
int setValue
(
const char* name,
const char* value
)
int setValue
(
const char* name,
Int32 value
)
int setValue
(
const char* name,
Uint32 value
)
int setValue
(
const char* name,
Int64 value
)
int setValue
(
const char* name,
Uint64 value
)
int setValue
(
const char* name,
float value
)
int setValue
(
const char* name,
double value
)
int setValue
(
Uint32 id,
const char* value
)
int setValue
(
Uint32 id,
Int32 value
)
int setValue
(
Uint32 id,
Uint32 value
)
int setValue
(
Uint32 id,
Int64 value
)
int setValue
(
Uint32 id,
Uint64 value
)
int setValue
(
Uint32 id,
float value
)
int setValue
(
Uint32 id,
double value
)
Parameters. This method requires the following two parameters:
The first parameter identified the attribute to be set, and may be either one of the following:
The attribute
name(a string)The attribute
id(an unsigned 32-bit integer)
The second parameter is the
valueto which the attribute is to be set; its type may be any one of the following 7 types:String (
const char*)32-bit integer
Unsigned 32-bit integer
64-bit integer
Unsigned 64-bit integer
Double
Float
See Section 2.3.15.2.10, “NdbOperation::equal()”, for important
information regarding the value's format and length.
Return value.
Returns -1 in the event of failure.
Description.
This method defines the NdbOperation to be
an INSERT operation. When the
NdbTransaction::execute() method is called,
this operation adds a new tuple to the table. See
Section 2.3.19.2.5, “NdbTransaction::execute()”.
Signature.
virtual int insertTuple
(
void
)
Parameters. None.
Return value.
Returns 0 on success, -1
on failure.
Description.
This method defines the NdbOperation as a
READ operation. When the
NdbTransaction::execute() method is
invoked, the operation reads a tuple. See
Section 2.3.19.2.5, “NdbTransaction::execute()”.
Signature.
virtual int readTuple
(
LockMode mode
)
Parameters.
mode specifies the locking mode
used by the read operation. See
Section 2.3.15.1.3, “The NdbOperation::LockMode Type”, for possible
values.
Return value.
Returns 0 on success, -1
on failure.
Description.
This method defines the NdbOperation as a
WRITE operation. When the
NdbTransaction::execute() method is
invoked, the operation writes a tuple to the table. If the
tuple already exists, it is updated; otherwise an insert takes
place. See Section 2.3.19.2.5, “NdbTransaction::execute()”.
Signature.
virtual int writeTuple
(
void
)
Parameters. None.
Return value.
Returns 0 on success, -1
on failure.
Description.
This method defines the NdbOperation as an
UPDATE operation. When the
NdbTransaction::execute() method is
invoked, the operation updates a tuple found in the table. See
Section 2.3.19.2.5, “NdbTransaction::execute()”.
Signature.
virtual int updateTuple
(
void
)
Parameters. None.
Return value.
Returns 0 on success, -1
on failure.
Description.
This method defines the NdbOperation as a
DELETE operation. When the
NdbTransaction::execute() method is
invoked, the operation deletes a tuple from the table. See
Section 2.3.19.2.5, “NdbTransaction::execute()”.
Signature.
virtual int deleteTuple
(
void
)
Parameters. None.
Return value.
Returns 0 on success, -1
on failure.
Abstract
The section describes the NdbRecAttr class and
its public methods.
Parent class. None
Child classes. None
Description.
NdbRecAttr contains the value of an attribute.
An NdbRecAttr object is used to store an
attribute value after it has been retrieved the
NDB Cluster using the
NdbOperation::getValue(). This object is
allocated by the NDB API. A brief example is shown here:
MyRecAttr = MyOperation->getValue("ATTR2", NULL);
if(MyRecAttr == NULL)
goto error;
if(MyTransaction->execute(Commit) == -1)
goto error;
ndbout << MyRecAttr->u_32_value();
For additional examples, see Section 2.4.1, “Using Synchronous Transactions”.
An NdbRecAttr object is instantiated with its
value only when NdbTransaction::execute() is
invoked. Prior to this, the value is undefined. (Use
NdbRecAttr::isNULL() to check whether the value
is defined.) This means that an NdbRecAttr
object has valid information only between the times that
NdbTransaction::execute() and
Ndb::closeTransaction() are called. The value
of the NULL indicator is -1
until the NdbTransaction::execute() method is
invoked.
Methods.
NdbRecAttr has a number of methods for
retrieving values of various simple types directly from an
instance of this class.
It is also possible to obtain a reference to the value regardless
of its actual type, by using
NdbRecAttr::aRef(); however, you should be
aware that this is not type-safe, and requires a cast from the
user. See Section 2.3.16.1.19, “NdbRecAttr::aRef()”, for more
information.
The following table lists all of the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
getColumn() | Gets the column to which the attribute belongs |
getType() | Gets the attribute's type (Column::Type) |
get_size_in_bytes() | Gets the size of the attribute, in bytes |
isNULL() | Tests whether the attribute is NULL |
int64_value() | Retrieves a Bigint attribute value, as a 64-bit
integer |
int32_value() | Retrieves an Int attribute value, as a 32-bit integer |
medium_value() | Retrieves a Mediumint attribute value, as a 32-bit
integer |
short_value() | Retrieves a Smallint attribute value, as a 16-bit
integer |
char_value() | Retrieves a Char attribute value |
int8_value() | Retrieves a Tinyint attribute value, as an 8-bit
integer |
u_64_value() | Retrieves a Bigunsigned attribute value, as an
unsigned 64-bit integer |
u_32_value() | Retrieves an Unsigned attribute value, as an unsigned
32-bit integer |
u_medium_value() | Retrieves a Mediumunsigned attribute value, as an
unsigned 32-bit integer |
u_short_value() | Retrieves a Smallunsigned attribute value, as an
unsigned 16-bit integer |
u_char_value() | Retrieves a Char attribute value, as an unsigned
char |
u_8_value() | Retrieves a Tinyunsigned attribute value, as an
unsigned 8-bit integer |
float_value() | Retrieves a Float attribute value, as a float (4
bytes) |
double_value() | Retrieves a Double attribute value, as a double (8
bytes) |
aRef() | Gets a pointer to the attribute value |
clone() | Makes a deep copy of the RecAttr object |
~NdbRecAttr() | Destructor method |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.16.1, “NdbRecAttr Methods”.
Types.
The NdbRecAttr class defines no public types.
Class diagram.
This diagram shows all the available methods of the
NdbRecAttr class:

- 2.3.16.1.1.
NdbRecAttr::getColumn() - 2.3.16.1.2.
NdbRecAttr::getType() - 2.3.16.1.3.
NdbRecAttr::get_size_in_bytes() - 2.3.16.1.4.
NdbRecAttr::isNULL() - 2.3.16.1.5.
NdbRecAttr::int64_value() - 2.3.16.1.6.
NdbRecAttr::int32_value() - 2.3.16.1.7.
NdbRecAttr::medium_value() - 2.3.16.1.8.
NdbRecAttr::short_value() - 2.3.16.1.9.
NdbRecAttr::char_value() - 2.3.16.1.10.
NdbRecAttr::int8_value() - 2.3.16.1.11.
NdbRecAttr::u_64_value() - 2.3.16.1.12.
NdbRecAttr::u_32_value() - 2.3.16.1.13.
NdbRecAttr::u_medium_value() - 2.3.16.1.14.
NdbRecAttr::u_short_value() - 2.3.16.1.15.
NdbRecAttr::u_char_value() - 2.3.16.1.16.
NdbRecAttr::u_8_value() - 2.3.16.1.17.
NdbRecAttr::float_value() - 2.3.16.1.18.
NdbRecAttr::double_value() - 2.3.16.1.19.
NdbRecAttr::aRef() - 2.3.16.1.20.
NdbRecAttr::clone() - 2.3.16.1.21.
~NdbRecAttr()
Abstract
This section lists and describes the public methods of the
NdbRecAttr class.
Constructor and Destructor.
The NdbRecAttr class has no public
constructor; an instance of this object is created using
NdbTransaction::execute(). The destructor
method, which is public, is discussed in
Section 2.3.16.1.21, “~NdbRecAttr()”.
Description. This method is used to obtain the column to which the attribute belongs.
Signature.
const NdbDictionary::Column* getColumn
(
void
) const
Parameters. None.
Return value.
A pointer to a Column object. See
Section 2.3.1, “The Column Class”.
Description. This method is used to obtain the column's data type.
Signature.
NdbDictionary::Column::Type getType
(
void
) const
Parameters. None.
Return value.
An NdbDictionary::Column::Type value. See
Section 2.3.1.1.3, “Column::Type” for more information,
including permitted values.
Description. You can use this method to obtain the size of an attribute (element).
Signature.
Uint32 get_size_in_bytes
(
void
) const
Parameters. None.
Return value. The attribute size in bytes, as an unsigned 32-bit integer.
Description.
This method checks whether an attribute value is
NULL.
Signature.
int isNULL
(
void
) const
Parameters. None.
Return value. One of the following three values:
-1: The attribute value is not defined due to an error.0: The attribute value is defined, but is notNULL.1: The attribute value is defined and isNULL.
In the event that NdbTransaction::execute()
has not yet been called, the value returned by
isNull() is not determined.
Description.
This method gets a Bigint value stored in
an NdbRecAttr object, and returns it as a
64-bit signed integer.
Signature.
Int64 int64_value
(
void
) const
Parameters. None.
Return value. A 64-bit signed integer.
Description.
This method gets an Int value stored in an
NdbRecAttr object, and returns it as a
32-bit signed integer.
Signature.
Int32 int32_value
(
void
) const
Parameters. None.
Return value. A 32-bit signed integer.
Description.
Gets the value of a Mediumint value stored
in an NdbRecAttr object, and returns it as
a 32-bit signed integer.
Signature.
Int32 medium_value
(
void
) const
Parameters. None.
Return value. A 32-bit signed integer.
Description.
This method gets a Smallint value stored in
an NdbRecAttr object, and returns it as a
16-bit signed integer (short).
Signature.
short short_value
(
void
) const
Parameters. None.
Return value. A 16-bit signed integer.
Description.
This method gets a Char value stored in an
NdbRecAttr object, and returns it as a
char.
Signature.
char char_value
(
void
) const
Parameters. None.
Return value.
A char value.
Description.
This method gets a Small value stored in an
NdbRecAttr object, and returns it as an
8-bit signed integer.
Signature.
Int8 int8_value
(
void
) const
Parameters. None.
Return value. An 8-bit signed integer.
Description.
This method gets a Bigunsigned value stored
in an NdbRecAttr object, and returns it as
a 64-bit unsigned integer.
Signature.
Uint64 u_64_value
(
void
) const
Parameters. None.
Return value. A 64-bit unsigned integer.
Description.
This method gets an Unsigned value stored
in an NdbRecAttr object, and returns it as
a 32-bit unsigned integer.
Signature.
Uint32 u_32_value
(
void
) const
Parameters. None.
Return value. A 32-bit unsigned integer.
Description.
This method gets an Mediumunsigned value
stored in an NdbRecAttr object, and returns
it as a 32-bit unsigned integer.
Signature.
Uint32 u_medium_value
(
void
) const
Parameters. None.
Return value. A 32-bit unsigned integer.
Description.
This method gets a Smallunsigned value
stored in an NdbRecAttr object, and returns
it as a 16-bit (short) unsigned integer.
Signature.
Uint16 u_short_value
(
void
) const
Parameters. None.
Return value. A short (16-bit) unsigned integer.
Description.
This method gets a Char value stored in an
NdbRecAttr object, and returns it as an
unsigned char.
Signature.
Uint8 u_char_value
(
void
) const
Parameters. None.
Return value.
An 8-bit unsigned char value.
Description.
This method gets a Smallunsigned value
stored in an NdbRecAttr object, and returns
it as an 8-bit unsigned integer.
Signature.
Uint8 u_8_value
(
void
) const
Parameters. None.
Return value. An 8-bit unsigned integer.
Description.
This method gets a Float value stored in an
NdbRecAttr object, and returns it as a
float.
Signature.
float float_value
(
void
) const
Parameters. None.
Return value. A float (4 bytes).
Description.
This method gets a Double value stored in
an NdbRecAttr object, and returns it as a
double.
Signature.
double double_value
(
void
) const
Parameters. None.
Return value. A double (8 bytes).
Description.
This method is used to obtain a reference to an attribute
value, as a char pointer. This pointer is
aligned appropriately for the data type. The memory is
released by the NDB API when
NdbTransaction::closeTransaction() is
executed on the transaction which read the value.
Signature.
char* aRef
(
void
) const
Parameters.
A pointer to the attribute value. Because this pointer is
constant, this method can be called anytime after
NdbOperation::getValue()
has been called.
Return value. None.
Description.
This method creates a deep copy of an
NdbRecAttr object.
The copy created by this method should be deleted by the application when no longer needed.
Signature.
NdbRecAttr* clone
(
void
) const
Parameters. None.
Return value.
An NdbRecAttr object. This is a complete
copy of the original, including all data.
Description.
The NdbRecAttr class destructor method.
You should delete only copies of NdbRecAttr
objects that were created in your application using the
clone() method. See
Section 2.3.16.1.20, “NdbRecAttr::clone()”.
Signature.
~NdbRecAttr
(
void
)
Parameters. None.
Return value. None.
Abstract
This section discusses the NdbScanFilter class
and its public members.
Parent class. None
Child classes. None
Description.
NdbScanFilter provides an alternative means of
specifying filters for scan operations.
Prior to MySQL 5.1.14, the comparison methods of this class did
not work with BIT values (see Bug#24503).
Development of this interface continues in MySQL 5.1, and the charcateristics of the NdbScanFilter class are likely to change further in future releases.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
NdbScanFilter() | Constructor method |
~NdbScanFilter() | Destructor method |
begin() | Begins a compound (set of conditions) |
end() | Ends a compound |
istrue() | Defines a term in a compound as TRUE |
isfalse() | Defines a term in a compound as FALSE |
cmp() | Compares a column value with an arbitrary value |
eq() | Tests for equality |
ne() | Tests for inequality |
lt() | Tests for a less-than condition |
le() | Tests for a less-than-or-equal condition |
gt() | Tests for a greater-than condition |
ge() | Tests for a greater-than-or-equal condition |
isnull() | Tests whether a column value is NULL |
isnotnull() | Tests whether a column value is not NULL |
getNdbError() | Provides access to error information |
getNdbOperation() | Gets the associated NdbOperation |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.17.2, “NdbScanFilter Methods”.
Types.
The NdbScanFilter class defines two public
types:
BinaryCondition: The type of condition, such as lower bound or upper bound.Group: A logical grouping operator, such asANDorOR.
For discussions of each of these types, along with its possible
values, see Section 2.3.17.1, “NdbScanFilter Types”.
Class diagram.
This diagram shows all the public members of the
NdbScanFilter class:
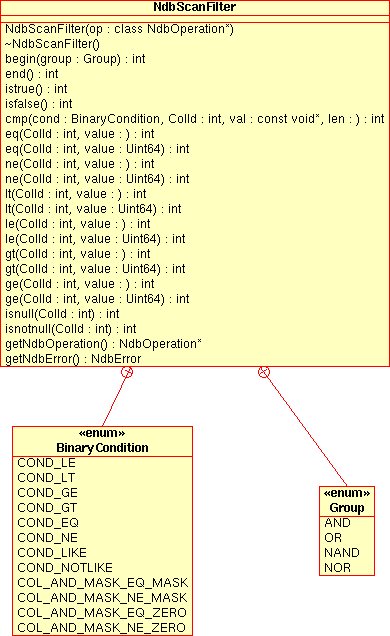
Abstract
This section details the public types belonging to the
NdbScanFilter class.
Description.
This type represents a condition based on the comparison of a
column value with some arbitrary value—that is, a bound
condition. A value of this type is used as the first argument
to NdbScanFilter::cmp().
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Enumeration value | Description | Type of column values compared |
|---|---|---|
COND_LE | Lower bound (<=) | integer |
COND_LT | Strict lower bound (<) | integer |
COND_GE | Upper bound (>=) | integer |
COND_GT | Strict upper bound (>) | integer |
COND_EQ | Equality (=) | integer |
COND_NE | Inequality (<> or !=) | integer |
COND_LIKE | LIKE condition | string |
COND_NOTLIKE | NOT LIKE condition | string |
COL_AND_MASK_EQ_MASK | Column value is equal to column value ANDed with
bitmask | BIT |
COL_AND_MASK_NE_MASK | Column value is not equal to column value ANDed with
bitmask | BIT |
COL_AND_MASK_EQ_ZERO | Column value ANDed with bitmask is equal to zero | BIT |
COL_AND_MASK_NE_ZERO | Column value ANDed with bitmask is not equal to zero | BIT |
String comparisons.
Strings compared using COND_LIKE and
COND_NOTLIKE can use the pattern
metacharacters % and _.
See Section 2.3.17.2.6, “NdbScanFilter::cmp()”, for more
information.
BIT comparisons.
The BIT comparison operators
COL_AND_MASK_EQ_MASK,
COL_AND_MASK_NE_MASK,
COL_AND_MASK_EQ_ZERO, and
COL_AND_MASK_NE_ZERO were added in MySQL
Cluster NDB 6.3.20. Corresponding methods are also available
for NdbInterpretedCode and
NdbOperation beginning with MySQL Cluster
NDB 6.3.20; for more information about these methods, see
Section 2.3.14.1.11, “NdbInterpretedCode Bitwise Comparison Operations”.
Description.
This type is used to describe logical (grouping) operators,
and is used with the begin() method. (See
Section 2.3.17.2.2, “NdbScanFilter::begin()”.)
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
AND | Logical AND: |
OR | Logical OR: |
NAND | Logical NOT AND: NOT
( |
NOR | Logical NOT OR: NOT
( |
- 2.3.17.2.1.
NdbScanFilterClass Constructor - 2.3.17.2.2.
NdbScanFilter::begin() - 2.3.17.2.3.
NdbScanFilter::end() - 2.3.17.2.4.
NdbScanFilter::istrue() - 2.3.17.2.5.
NdbScanFilter::isfalse() - 2.3.17.2.6.
NdbScanFilter::cmp() - 2.3.17.2.7.
NdbScanFilterInteger Comparison Methods - 2.3.17.2.8.
NdbScanFilter::isnull() - 2.3.17.2.9.
NdbScanFilter::isnotnull() - 2.3.17.2.10.
NdbScanFilter::getNdbError() - 2.3.17.2.11.
NdbScanFilter::getNdbOperation()
Abstract
This section lists and describes the public methods of the
NdbScanFilter class.
Description.
This is the constructor method for
NdbScanFilter, and creates a new instance
of the class.
Signature.
NdbScanFilter
(
class NdbOperation* op
)
Parameters.
This method takes a single parameter, a pointer to the
NdbOperation to which the filter applies.
Return value.
A new instance of NdbScanFilter.
Destructor.
The destructor takes no arguments and does not return a value.
It should be called to remove the
NdbScanFilter object when it is no longer
needed.
Description.
This method is used to start a compound, and specifies the
logical operator used to group the conditions making up the
compound. The default is AND.
Signature.
int begin
(
Group group = AND
)
Parameters.
A Group value: one of
AND, OR,
NAND, or NOR. See
Section 2.3.17.1.2, “The NdbScanFilter::Group Type”, for additional
information.
Return value.
0 on success, -1 on
failure.
Description. This method completes a compound, signalling that there are no more conditions to be added to it.
Signature.
int end
(
void
)
Parameters. None.
Return value.
Returns 0 on success, or
-1 on failure.
Description.
Defines a term of the current group as
TRUE.
Signature.
int istrue
(
void
)
Parameters. None.
Return value.
Returns 0 on success, -1
on failure.
Description.
Defines a term of the current group as
FALSE.
Signature.
int isfalse
(
void
)
Parameters. None.
Return value.
0 on success, or -1 on
failure.
Description. This method is used to perform a comparison between a given value and the value of a column.
In many cases, where the value to be compared is an integer,
you can instead use one of several convenience methods
provided by NdbScanFilter for this purpose.
See
Section 2.3.17.2.7, “NdbScanFilter Integer Comparison Methods”.
Signature.
int cmp
(
BinaryCondition condition,
int columnId,
const void* value,
Uint32 length = 0
)
Parameters. This method takes the following parameters:
condition: This represents the condition to be tested which compares the value of the column having the column IDcolumnIDwith some arbitrary value. Theconditionis aBinaryConditionvalue; for permitted values and the relations that they represent, see Section 2.3.17.1.1, “TheNdbScanFilter::BinaryConditionType”.The
conditionvaluesCOND_LIKEorCOND_NOTLIKEare used to compare a column value with a string pattern.columnId: This is the column's identifier, which can be obtained using theColumn::getColumnNo()method (see Section 2.3.1.2.5, “Column::getColumnNo()”, for details).value: The value to be compared, repesented as a pointer tovoid.Using using a
COND_LIKEorCOND_NOTLIKEcomparison condition, thevalueis treated as a string pattern which can include the pattern metacharacters or “wildcard” characters%and_, which have the meanings shown here:Metacharacter Description %Matches zero or more characters _Matches exactly one character To match against a literal “%” or “_” character, use the backslash (
\) as an escape character. To match a literal “\” character, use\\.NoteThese are the same wildcard characters that are supported by the SQL
LIKEandNOT LIKEoperators, and are interpreted in the same way. See String Comparison Functions, for more information.length: The length of the value to be compared. The default value is0. Using0for thelengthhas the same effect as comparing toNULL, that is using theisnull()method (see Section 2.3.17.2.8, “NdbScanFilter::isnull()”).
Return value. This method returns an integer whose possible values are listed here:
0: The comparison is true.-1: The comparison is false.
This section provides information about several convenience
methods which can be used in lieu of the
NdbScanFilter::cmp() method when the
arbitrary value to be compared is an integer. Each of these
methods is essentially a wrapper for cmp()
that includes an appropriate value of
BinaryCondition for that method's
condition parameter; for example,
NdbScanFilter::eq() is defined like this:
int eq(intcolumnId, Uint32value) { return cmp(BinaryCondition::COND_EQ,columnId,&value, 4); }
For more information about the cmp() method,
see Section 2.3.17.2.6, “NdbScanFilter::cmp()”.
Description. This method is used to perform an equality test on a column value and an integer.
Signature.
int eq
(
int ColId,
Uint32 value
)
or
int eq
(
int ColId,
Uint64 value
)
Parameters. This method takes two parameters, listed here:
The ID (
ColId) of the column whose value is to be testedAn integer with which to compare the column value; this integer may be either 32-bit or 64-bit, and is unsigned in either case.
Return value.
Returns 0 on success, or
-1 on failure.
Description. This method is used to perform an inequality test on a column value and an integer.
Signature. This method has 32-bit and 64-bit variants, as shown here:
int ne
(
int ColId,
Uint32 value
)
int ne
(
int ColId,
Uint64 value
)
Parameters.
Like eq() and the other
NdbScanFilter methods of this type, this
method takes two parameters:
The ID (
ColId) of the column whose value is to be testedAn integer with which to compare the column value; this integer may be either 32-bit or 64-bit, and is unsigned in either case.
Return value.
Returns 0 on success, or
-1 on failure.
Description. This method is used to perform a less-than (strict lower bound) test on a column value and an integer.
Signature. This method has 32-bit and 64-bit variants, as shown here:
int lt
(
int ColId,
Uint32 value
)
int lt
(
int ColId,
Uint64 value
)
Parameters.
Like eq(), ne(), and
the other NdbScanFilter methods of this
type, this method takes two parameters, listed here:
The ID (
ColId) of the column whose value is to be testedAn integer with which to compare the column value; this integer may be either 32-bit or 64-bit, and is unsigned in either case.
Return value.
Retrturns 0 on success, or
-1 on failure.
Description. This method is used to perform a less-than-or-equal test on a column value and an integer.
Signature. This method has two variants, to accomodate 32-bit and 64-bit values:
int le
(
int ColId,
Uint32 value
)
int le
(
int ColId,
Uint64 value
)
Parameters.
Like the other NdbScanFilter methods of
this type, this method takes two parameters:
The ID (
ColId) of the column whose value is to be testedAn integer with which to compare the column value; this integer may be either 32-bit or 64-bit, and is unsigned in either case.
Return value.
Returns 0 on success, or
-1 on failure.
Description. This method is used to perform a greater-than (strict upper bound) test on a column value and an integer.
Signature. This method accomodates both 32-bit and 64-bit values:
int gt
(
int ColId,
Uint32 value
)
int gt
(
int ColId,
Uint64 value
)
Parameters.
Like the other NdbScanFilter methods of
this type, this method takes two parameters:
The ID (
ColId) of the column whose value is to be testedAn integer with which to compare the column value; this integer may be either 32-bit or 64-bit, and is unsigned in either case.
Return value.
0 on success; -1 on
failure.
Description. This method is used to perform a greater-than-or-equal test on a column value and an integer.
Signature. This method accepts both 32-bit and 64-bit values, as shown here:
int ge
(
int ColId,
Uint32 value
)
int ge
(
int ColId,
Uint64 value
)
Parameters.
Like eq(), lt(),
le(), and the other
NdbScanFilter methods of this type, this
method takes two parameters:
The ID (
ColId) of the column whose value is to be testedAn integer with which to compare the column value; this integer may be either 32-bit or 64-bit, and is unsigned in either case.
Return value.
0 on success; -1 on
failure.
Description.
This method is used to check whether a column value is
NULL.
Signature.
int isnull
(
int ColId
)
Parameters. The ID of the column whose value is to be tested.
Return value.
Returns 0, if the column value is
NULL.
Description.
This method is used to check whether a column value is not
NULL.
Signature.
int isnotnull
(
int ColId
)
Parameters. The ID of the column whose value is to be tested.
Return value.
Returns 0, if the column value is not
NULL.
Description.
Because errors encountered when building an
NdbScanFilter do not propagate to any
involved NdbOperation object, it is
necessary to use this method to access error information.
Signature.
const NdbError& getNdbError
(
void
)
Parameters. None.
Return value.
A reference to an NdbError. See
Section 2.3.31, “The NdbError Structure”, for more information.
Description.
If the NdbScanFilter was constructed with
an NdbOperation, this method can be used to
obtain a pointer to that NdbOperation
object.
Signature.
NdbOperation* getNdbOperation
(
void
)
Parameters. None.
Return value.
A pointer to the NdbOperation associated
with this NdbScanFilter, if there is one.
Otherwise, NULL.
Abstract
This section describes the NdbScanOperation
class and its class members.
Parent class. NdbOperation
Child classes. NdbIndexScanOperation
Description.
The NdbScanOperation class represents a
scanning operation used in a transaction. This class inherits from
NdbOperation. For more information, see
Section 2.3.15, “The NdbOperation Class”.
Beginning with MySQL Cluster NDB 6.2.14 and MySQL Cluster 6.3.12,
you must use the NdbInterpretedCode class
instead of NdbScanOperation when writing
interpreted programs used for scans. See
Section 2.3.14, “The NdbInterpretedCode Class”, for more information.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
readTuples() | Reads tuples |
nextResult() | Gets the next tuple |
close() | Closes the scan |
lockCurrentTuple() | Locks the current tuple |
updateCurrentTuple() | Updates the current tuple |
deleteCurrentTuple() | Deletes the current tuple |
restart() | Restarts the scan |
getNdbTransaction() | Gets the NdbTransaction object for this scan |
getPruned() | Used to find out whether this scan is pruned to a single partition |
For detailed descriptions, signatures, and examples of use for each
of these methods, see
Section 2.3.18.2, “NdbScanOperation Methods”.
Types.
This class defines a single public type
ScanFlag. See
Section 2.3.18.1, “The NdbScanOperation::ScanFlag Type”, for details.
Class diagram.
This diagram shows all the available members of the
NdbScanOperation class:

For more information about the use of
NdbScanOperation, see
Section 1.3.2.3.2, “Scan Operations”, and
Section 1.3.2.3.3, “Using Scans to Update or Delete Rows”.
Multi-Range Read (MRR) scans using
NdbScanOperation are not supported using MySQL
Cluster NDB 6.2. They are supported for MySQL Cluster NDB 6.3 (and
later) beginning with 6.3.17 (see Bug#38791). Both NDB 6.2 and NDB
6.3 (as well as later MySQL Cluster releases) support MRR scans
using the
NdbRecord
interface.
Description.
Values of this type are the scan flags used with the
readTuples() method. More than one may be
used, in which case, they are OR'ed together
as the second argument to that method. See
Section 2.3.18.2.1, “NdbScanOperation::readTuples()”, for
more information.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
SF_TupScan | TUP scan |
SF_OrderBy | Ordered index scan (ascending) |
SF_Descending | Ordered index scan (descending) |
SF_ReadRangeNo | Enables NdbIndexScanOperation::get_range_no() |
SF_KeyInfo | Requests KeyInfo to be sent back to the caller |
- 2.3.18.2.1.
NdbScanOperation::readTuples() - 2.3.18.2.2.
NdbScanOperation::nextResult() - 2.3.18.2.3.
NdbScanOperation::close() - 2.3.18.2.4.
NdbScanOperation::lockCurrentTuple() - 2.3.18.2.5.
NdbScanOperation::updateCurrentTuple() - 2.3.18.2.6.
NdbScanOperation::deleteCurrentTuple() - 2.3.18.2.7.
NdbScanOperation::restart() - 2.3.18.2.8.
NdbScanOperation::getNdbTransaction() - 2.3.18.2.9.
NdbScanOperation::getPruned()
Abstract
This section lists and describes the public methods of the
NdbScanOperation class.
This class has no public constructor. To create an instance of
NdbScanOperation, it is necessary to use the
NdbTransaction::getNdbScanOperation() method.
See Section 2.3.19.2.2, “NdbTransaction::getNdbScanOperation()”.
Description. This method is used to perform a scan.
Signature.
virtual int readTuples
(
LockMode mode = LM_Read,
Uint32 flags = 0,
Uint32 parallel = 0,
Uint32 batch = 0
)
Parameters. This method takes the four parameters listed here:
The lock
mode; this is aLockModevalue as described in Section 2.3.15.1.3, “TheNdbOperation::LockModeType”.CautionWhen scanning with an exclusive lock, extra care must be taken due to the fact that, if two threads perform this scan simultaneously over the same range, then there is a significant probability of causing a deadlock. The likelihood of a deadlock is increased if the scan is also ordered (that is, using
SF_OrderByorSF_Descending).The
NdbIndexScanOperation::close()method is also affected by this deadlock, since all outstanding requests are serviced before the scan is actually closed.One or more
ScanFlagvalues. Multiple values areOR'ed togetherThe number of fragments to scan in
parallel; use0to require that the maximum possible number be used.The
batchparameter specifies how many records will be returned to the client from the server by the nextNdbScanOperation::nextResult(true)method call. Use0to specify the maximum automatically.NoteThis parameter was ignored prior to MySQL 5.1.12, and the maximum was used (see Bug#20252).
Return value.
Returns 0 on success, -1
on failure.
Description.
This method is used to fetch the next tuple in a scan
transaction. Following each call to
nextResult(), the buffers and
NdbRecAttr objects defined in
NdbOperation::getValue() are updated with
values from the scanned tuple.
Signature. This method can be invoked in one of two ways. The first of these, shown here, is available beginning in MySQL 5.1:
int nextResult
(
bool fetchAllowed = true,
bool forceSend = false
)
Beginning with MySQL Cluster NDB 6.2.3, it is also possible to use this method as shown here:
int nextResult
(
const char*& outRow,
bool fetchAllowed = true,
bool forceSend = false
)
Parameters (2-parameter version). This method takes the following two parameters:
Normally, the NDB API contacts the
NDBkernel for more tuples whenever it is necessary; settingfetchAllowedtofalsekeeps this from happening.Disabling
fetchAllowedby setting it tofalseforcesNDBto process any records it already has in its caches. When there are no more cached records it returns2. You must then callnextResult()withfetchAllowedequal totruein order to contactNDBfor more records.While
nextResult(false)returns0, you should transfer the record to another transaction. WhennextResult(false)returns2, you must execute and commit the other transaction. This causes any locks to be transferred to the other transaction, updates or deletes to be made, and then, the locks to be released. Following this, callnextResult(true)—this fetches more records and caches them in the NDB API.NoteIf you do not transfer the records to another transaction, the locks on those records will be released the next time that the
NDBKernel is contacted for more records.Disabling
fetchAllowedcan be useful when you want to update or delete all of the records obtained in a given transaction, as doing so saves time and speeds up updates or deletes of scanned records.forceSenddefaults tofalse, and can normally be omitted. However, setting this parameter totruemeans that transactions are sent immediately. See Section 1.3.4, “The Adaptive Send Algorithm”, for more information.
Parameters (3-parameter version). Beginning with MySQL Cluster NDB 6.2.3, this method can also be called with the following three parameters:
Calling
nextResult()sets a pointer to the next row inoutRow(if returning 0). This pointer is valid (only) until the next call tonextResult()whenfetchAllowedis true. TheNdbRecordobject defining the row format must be specified beforehand usingNdbTransaction::scanTable()(orNdbTransaction::scanIndex().When false,
fetchAllowedforcesNDBto process any records it already has in its caches. See the description for this parameter in the previous Parameters subsection for more details.Setting
forceSendtotruemeans that transactions are sent immediately, as described in the previous Parameters subsection, as well as in Section 1.3.4, “The Adaptive Send Algorithm”.
Return value. This method returns one of the following 4 integer values, interpreted as shown in the following list:
-1: Indicates that an error has occurred.0: Another tuple has been received.1: There are no more tuples to scan.2: There are no more cached records (invokenextResult(true)to fetch more records).
Example. See Section 2.4.4, “Basic Scanning Example”.
Description. Calling this method closes a scan.
See Scans and exclusive locks for information about multiple threads attempting to perform the same scan with an exclusive lock and how this can affect closing the scans..
Signature.
void close
(
bool forceSend = false,
bool releaseOp = false
)
Parameters. This method takes the two parameters listed here:
forceSenddefaults tofalse; callclose()with this parameter set totruein order to force transactions to be sent.releaseOpalso defaults tofalse; set totruein order to release the operation.
Return value. None.
Description. This method locks the current tuple.
Signature. In MySQL 5.1 and later, this method can be called with an optional single parameter, in either of the two ways shown here:
NdbOperation* lockCurrentTuple
(
void
)
NdbOperation* lockCurrentTuple
(
NdbTransaction* lockTrans
)
Beginning with MySQL Cluster NDB 6.2.3, the following signature
is also supported for this method, when using
NdbRecord:
NdbOperation *lockCurrentTuple
(
NdbTransaction* takeOverTrans,
const NdbRecord* record,
char* row = 0,
const unsigned char* mask = 0
)
Parameters (original). This method takes a single, optional parameter—the transaction that should perform the lock. If this is omitted, the transaction is the current one.
Parameters (when using NdbRecord).
When using the NdbRecord interface (see
Section 2.3.25, “The NdbRecord Interface”), this method
takes these parameters, as described in the following list:
The transaction (
takeOverTrans) that should perform the lock; when usingNdbRecordwith scans, this parameter is not optional.The
NdbRecordreferenced by the scan. This is required, even if no records are being read.The
rowfrom which to read. Set this toNULLif no read is to occur.The
maskpointer is optional. If it is present, then only columns for which the corresponding bit in the mask is set are retrieved by the scan.
Calling an NdbRecord scan lock takeover on
an NdbRecAttr-style scan is not valid, nor
is calling an NdbRecAttr-style scan lock
takeover on an NdbRecord-style scan.
Return value.
This method returns a pointer to an
NdbOperation object, or
NULL. (See
Section 2.3.15, “The NdbOperation Class”.)
Description. This method is used to update the current tuple.
Signature. Originally, this method could be called with a single. optional parameter, in either of the ways shown here:
NdbOperation* updateCurrentTuple
(
void
)
NdbOperation* updateCurrentTuple
(
NdbTransaction* updateTrans
)
Beginning with MySQL Cluster NDB 6.2.3, it is also possible to
employ this method, when using NdbRecord with
scans, as shown here:
NdbOperation* updateCurrentTuple
(
NdbTransaction* takeOverTrans,
const NdbRecord* record,
const char* row,
const unsigned char* mask = 0
)
See Section 2.3.25, “The NdbRecord Interface”, for more information.
Parameters (original). This method takes a single, optional parameter—the transaction that should perform the lock. If this is omitted, the transaction is the current one.
Parameters (when using NdbRecord).
When using the NdbRecord interface
(beginning with MySQL Cluster NDB 6.2.3), this method takes
the following parameters, as described in the following list:
The takeover transaction (
takeOverTrans).The
record(NdbRecordobject) referencing the column used for the scan.The
rowto read from. If no attributes are to be read, set this equal toNULL.The
maskpointer is optional. If it is present, then only columns for which the corresponding bit in the mask is set are retrieved by the scan.
Return value.
This method returns an NdbOperation object
or NULL. (See
Section 2.3.15, “The NdbOperation Class”.)
Description. This method is used to delete the current tuple.
Signature.
Originally (prior to the introduction of
NdbRecord), this method could be invoked
with a single optional parameter, in either of the ways shown
here:
int deleteCurrentTuple
(
void
)
int deleteCurrentTuple
(
NdbTransaction* takeOverTransaction
)
Beginning with MySQL Cluster NDB 6.2.3, this method's signature
when performing NdbRecord-style scans is
shown here:
const NdbOperation* deleteCurrentTuple
(
NdbTransaction* takeOverTrans,
const NdbRecord* record,
char* row = 0,
const unsigned char* mask = 0,
const NdbOperation::OperationOptions* opts = 0,
Uint32 sizeOfOpts = 0
)
For more information, see Section 2.3.25, “The NdbRecord Interface”.
Parameters. This method takes a single, optional parameter—the transaction that should perform the lock. If this is omitted, the transaction is the current one.
Parameters when using NdbRecord.
When used with the NdbRecord interface
(beginning with MySQL Cluster NDB 6.2.3), this method takes
the parameters listed here:
The transaction (
takeOverTrans) that should perform the lock; when usingNdbRecordwith scans, this parameter is not optional.The
NdbRecordreferenced by the scan. Thisrecordvalue is required, even if no records are being read.The
rowfrom which to read. Set this toNULLif no read is to occur.The
maskpointer is optional. If it is present, then only columns for which the corresponding bit in the mask is set are retrieved by the scan.OperationOptions(opts) can be used to provide more finely-grained control of operation definitions. AnOperationOptionsstructure is passed with flags indicating which operation definition options are present. Not all operation types support all operation options; the options supported for each type of operation are shown in the following table:Operation type (Method) OperationOptionsFlags SupportedreadTuple()OO_ABORTOPTION,OO_GETVALUE,OO_PARTITION_ID,OO_INTERPRETEDinsertTuple()OO_ABORTOPTION,OO_SETVALUE,OO_PARTITION_ID,OO_ANYVALUEupdateTuple()OO_ABORTOPTION,OO_SETVALUE,OO_PARTITION_ID,OO_INTERPRETED,OO_ANYVALUEwriteTuple()OO_ABORTOPTION,OO_SETVALUE,OO_PARTITION_ID,OO_ANYVALUEdeleteTuple()OO_ABORTOPTION,OO_GETVALUE,OO_PARTITION_ID,OO_INTERPRETED,OO_ANYVALUEThe optional
sizeOfOptionsparameter is used to preserve backward compatibility of this interface with previous definitions of theOperationOptionsstructure. If an unusual size is detected by the interface implementation, it can use this to determine how to interpret the passedOperationOptionsstructure. To enable this functionality, the caller should passsizeof(NdbOperation::OperationOptions)for the value of this argument.If options are specified, their length (
sizeOfOpts) must be specified as well.
Return value.
Returns 0 on success, or
-1 on failure.
Description.
Use this method to restart a scan without changing any of its
getValue() calls or search conditions.
Signature.
int restart
(
bool forceSend = false
)
Parameters.
Call this method with forceSend set
to true in order to force the transaction
to be sent.
Return value.
0 on success; -1 on
failure.
Description.
Gets the NdbTransaction object for this
scan. This method is available beginning with MySQL Cluster
NDB 6.2.17 and MySQL Cluster NDB 6.3.19.
Signature.
NdbTransaction* getNdbTransaction
(
void
) const
Parameters. None.
Return value.
A pointer to an NdbTransaction object. See
Section 2.3.19, “The NdbTransaction Class”.
Description.
This method is used to determine whether or not a given scan
operation has been pruned to a single partition. For scans
defined using NdbRecord, this method can be called before or
after the scan is executed. For scans not defined using
NdbRecord, getPruned()
is valid only after the scan has been executed.
Signature.
bool getPruned
(
void
) const
Parameters. None.
Return value.
Returns true, if the scan is pruned to a
single table partition.
Abstract
This section describes the NdbTransaction class
and its public members.
Parent class. None
Child classes. None
Description.
A transaction is represented in the NDB API by an
NdbTransaction object, which belongs to an
Ndb object and is created using
Ndb::startTransaction(). A transaction consists
of a list of operations represented by the
NdbOperation class, or by one of its
subclasses—NdbScanOperation,
NdbIndexOperation, or
NdbIndexScanOperation (see
Section 2.3.15, “The NdbOperation Class”). Each operation access exactly
one table.
Using Transactions.
After obtaining an NdbTransaction object, it is
employed as follows:
An operation is allocated to the transaction using any one of the following methods:
getNdbOperation()getNdbScanOperation()getNdbIndexOperation()getNdbIndexScanOperation()
Calling one of these methods defines the operation. Several operations can be defined on the same
NdbTransactionobject, in which case they are executed in parallel. When all operations are defined, theexecute()method sends them to theNDBkernel for execution.The
execute()method returns when theNDBkernel has completed execution of all operations previously defined.ImportantAll allocated operations should be properly defined before calling the
execute()method.execute()operates in one of the three modes listed here:NdbTransaction::NoCommit: Executes operations without committing them.NdbTransaction::Commit: Executes any remaining operation and then commits the complete transaction.NdbTransaction::Rollback: Rolls back the entire transaction.
execute()is also equipped with an extra error handling parameter, which provides the two alternatives listed here:NdbOperation::AbortOnError: Any error causes the transaction to be aborted. This is the default behavior.NdbOperation::AO_IgnoreError: The transaction continues to be executed even if one or more of the operations defined for that transaction fails.
NoteIn MySQL 5.1.15 and earlier, these values were
NdbTransaction::AbortOnErrorandNdbTransaction::AO_IgnoreError.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
getNdbOperation() | Gets an NdbOperation |
getNdbScanOperation() | Gets an NdbScanOperation |
getNdbIndexScanOperation() | Gets an NdbIndexScanOperation |
getNdbIndexOperation() | Gets an NdbIndexOperation |
execute | Executes a transaction |
refresh() | Keeps a transaction from timing out |
close() | Closes a transaction |
getGCI() | Gets a transaction's global checkpoint ID (GCI) |
getTransactionId() | Gets the transaction ID |
commitStatus() | Gets the transaction's commit status |
getNdbError() | Gets the most recent error |
getNdbErrorOperation() | Gets the most recent operation which caused an error |
getNdbErrorLine() | Gets the line number where the most recent error occurred |
getNextCompletedOperation() | Gets operations that have been executed; used for finding errors |
readTuple() | Read a tuple using NdbRecord |
insertTuple() | Insert a tuple using NdbRecord |
updateTuple() | Update a tuple using NdbRecord |
writeTuple() | Write a tuple using NdbRecord |
deleteTuple() | Delete a tuple using NdbRecord |
scanTable() | Perform a table scan using NdbRecord |
scanIndex() | Perform an index scan using NdbRecord |
The methods readTuple(),
insertTuple(),
updateTuple(), writeTuple(),
deleteTuple(), scanTable(),
and scanIndex() require the use of
NdbRecord, which is available beginning with
MySQL Cluster NDB 6.2.3.
These methods were updated in MySQL Cluster NDB 6.2.15 and NDB 6.3.15, but remain backward-compatible with their older versions.
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.19.2, “NdbTransaction Methods”.
Types.
NdbTransaction defines 3 public types as shown
in the following table:
| Type | Purpose / Use |
|---|---|
AbortOption | Determines whether failed operations cause a transaction to abort |
CommitStatusType | Describes the transaction's commit status |
ExecType | Determines whether the transaction should be committed or rolled back |
For a discussion of each of these types, along with its possible
values, see Section 2.3.19.1, “NdbTransaction Types”.
Class diagram.
This diagram shows all the available methods and enumerated types
of the NdbTransaction class:
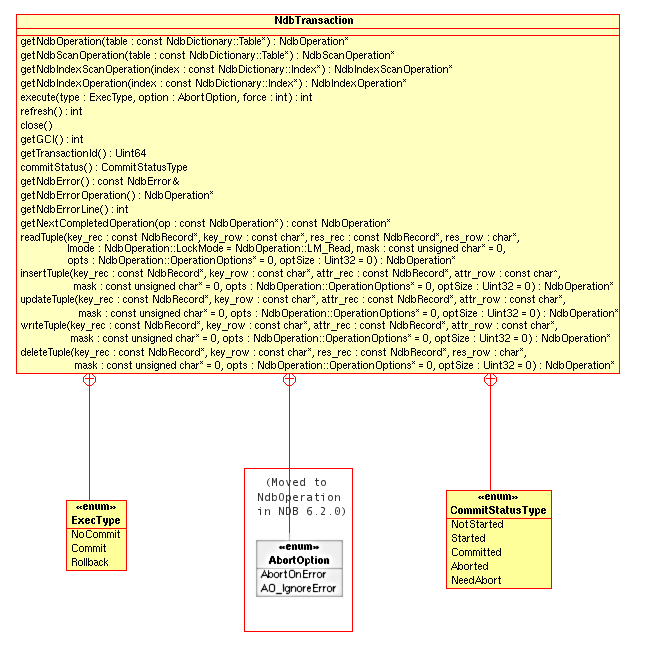
Abstract
This section details the public types belonging to the
NdbTransaction class.
Description.
This type is used to determine whether failed operations
should force a transaction to be aborted. It is used as an
argument to the execute() method—see
Section 2.3.19.2.5, “NdbTransaction::execute()”, for more
information.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
AbortOnError | A failed operation causes the transaction to abort. |
AO_IgnoreOnError | Failed operations are ignored; the transaction continues to execute. |
Beginning with MySQL Cluster NDB 6.2.0, this type belongs to
the NdbOperation class and its possible
values and default behavior have changed. NDB API application
code written against previous versions of MySQL Cluster that
refers explicitly to
NdbTransaction::AbortOption values must be
modified to work with MySQL Cluster NDB 6.2.0 or later.
In particular, this effects the use of
NdbTransaction::execute() in MySQL Cluster
NDB 6.2.0 and later. See
Section 2.3.15.1.1, “The NdbOperation::AbortOption Type”, and
Section 2.3.19.2.5, “NdbTransaction::execute()”, for more
information.
Description. This type is used to describe a transaction's commit status.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
NotStarted | The transaction has not yet been started. |
Started | The transaction has started, but is not yet committed. |
Committed | The transaction has completed, and has been committed. |
Aborted | The transaction was aborted. |
NeedAbort | The transaction has encountered an error, but has not yet been aborted. |
A transaction's commit status ca be read using the
commitStatus() method. See
Section 2.3.19.2.10, “NdbTransaction::commitStatus()”.
Description.
This type sets the transaction's execution type; that is,
whether it should execute, execute and commit, or abort. It is
used as a parameter to the execute()
method. (See Section 2.3.19.2.5, “NdbTransaction::execute()”.)
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
NoCommit | The transaction should execute, but not commit. |
Commit | The transaction should execute and be committed. |
Rollback | The transaction should be rolled back. |
- 2.3.19.2.1.
NdbTransaction::getNdbOperation() - 2.3.19.2.2.
NdbTransaction::getNdbScanOperation() - 2.3.19.2.3.
NdbTransaction::getNdbIndexScanOperation() - 2.3.19.2.4.
NdbTransaction::getNdbIndexOperation() - 2.3.19.2.5.
NdbTransaction::execute() - 2.3.19.2.6.
NdbTransaction::refresh() - 2.3.19.2.7.
NdbTransaction::close() - 2.3.19.2.8.
NdbTransaction::getGCI() - 2.3.19.2.9.
NdbTransaction::getTransactionId() - 2.3.19.2.10.
NdbTransaction::commitStatus() - 2.3.19.2.11.
NdbTransaction::getNdbError() - 2.3.19.2.12.
NdbTransaction::getNdbErrorOperation() - 2.3.19.2.13.
NdbTransaction::getNdbErrorLine() - 2.3.19.2.14.
NdbTransaction::getNextCompletedOperation() - 2.3.19.2.15.
NdbTransaction::readTuple() - 2.3.19.2.16.
NdbTransaction::insertTuple() - 2.3.19.2.17.
NdbTransaction::updateTuple() - 2.3.19.2.18.
NdbTransaction::writeTuple() - 2.3.19.2.19.
NdbTransaction::deleteTuple() - 2.3.19.2.20.
NdbTransaction::scanTable() - 2.3.19.2.21.
NdbTransaction::scanIndex()
Abstract
This section lists and describes the public methods of the
NdbTransaction class.
Description.
This method is used to create an
NdbOperation associated with a given table.
All operations within the same transaction must be initialised with this method. Operations must be defined before they are executed.
Signature.
NdbOperation* getNdbOperation
(
const NdbDictionary::Table* table
)
Parameters.
The Table object on which the operation is
to be performed. See Section 2.3.21, “The Table Class”.
Return value.
A pointer to the new NdbOperation. See
Section 2.3.15, “The NdbOperation Class”.
Description.
This method is used to create an
NdbScanOperation associated with a given
table.
All scan operations within the same transaction must be initialised with this method. Operations must be defined before they are executed.
Signature.
NdbScanOperation* getNdbScanOperation
(
const NdbDictionary::Table* table
)
Parameters.
The Table object on which the operation is
to be performed. See Section 2.3.21, “The Table Class”.
Return value.
A pointer to the new NdbScanOperation. See
Section 2.3.18, “The NdbScanOperation Class”.
Description.
This method is used to create an
NdbIndexScanOperation associated with a
given table.
All index scan operations within the same transaction must be initialised with this method. Operations must be defined before they are executed.
Signature.
NdbIndexScanOperation* getNdbIndexScanOperation
(
const NdbDictionary::Index* index
)
Parameters.
The Index object on which the operation is
to be performed. See Section 2.3.5, “The Index Class”.
Return value.
A pointer to the new NdbIndexScanOperation.
See Section 2.3.13, “The NdbIndexScanOperation Class”.
Description.
This method is used to create an
NdbIndexOperation associated with a given
table.
All index operations within the same transaction must be initialised with this method. Operations must be defined before they are executed.
Signature.
NdbIndexOperation* getNdbIndexOperation
(
const NdbDictionary::Index* index
)
Parameters.
The Index object on which the operation is
to be performed. See Section 2.3.5, “The Index Class”.
Return value.
A pointer to the new NdbIndexOperation. See
Section 2.3.12, “The NdbIndexOperation Class”.
Description. This method is used to execute a transaction.
Signature.
int execute
(
ExecType execType,
NdbOperation::AbortOption abortOption = NdbOperation::DefaultAbortOption,
int force = 0
)
Parameters. The execute method takes the three parameters listed here:
The execution type (
ExecTypevalue); see Section 2.3.19.1.3, “TheNdbTransaction::ExecTypeType”, for more information and possible values.An abort option (
NdbOperation::AbortOptionvalue).NotePrior to MySQL Cluster NDB 6.2.0,
abortOptionwas of typeNdbTransaction::AbortOption; theAbortOptiontype became a member ofNdbOperationin MySQL Cluster NDB 6.2.0), and its default value wasNdbTransaction::AbortOnError. See Section 2.3.15.1.1, “TheNdbOperation::AbortOptionType”, for more information.Beginning with MySQL Cluster NDB 6.2.0, errors arising from this method are found with
NdbOperation::getNdbError()rather thanNdbTransaction::getNdbError(). See Section 2.3.15.2.5, “NdbOperation::getNdbError()”, for more information.A
forceparameter, which determines when operations should be sent to theNDBKernel. It takes ones of the values listed here:0: Nonforced; detected by the adaptive send algorithm.1: Forced; detected by the adaptive send algorithm.2: Nonforced; not detected by the adaptive send algorithm.
See Section 1.3.4, “The Adaptive Send Algorithm”, for more information.
Return value.
Returns 0 on success, or
-1 on failure. The fact that the
transaction did not abort does not necessarily mean that each
operation was successful; you must check each operation
individually for errors.
In MySQL 5.1.15 and earlier versions, this method returned
-1 for some errors even when the trasnsaction
itself was not aborted; beginning with MySQL 5.1.16, this method
reports a failure if and only if the
transaction was aborted. (This change was made due to the fact
it had been possible to construct cases where there was no way
to determine whether or not a transaction was actually aborted.)
However, the transaction's error information is still set in
such cases to reflect the actual error code and category.
This means, in the case where a NoDataFound error is a possibility, you must now check for it explicitly, as shown in this example:
Ndb_cluster_connection myConnection;
if( myConnection.connect(4, 5, 1) )
{
cout << "Unable to connect to cluster within 30 secs." << endl;
exit(-1);
}
Ndb myNdb(&myConnection, "test");
// define operations...
myTransaction = myNdb->startTransaction();
if(myTransaction->getNdbError().classification == NdbError:NoDataFound)
{
cout << "No records found." << endl;
// ...
}
myNdb->closeTransaction(myTransaction);
Description. This method updates the transaction's timeout counter, and thus avoids aborting due to transaction timeout.
Prior to MySQL Cluster NDB 6.3.36, MySQL Cluster NDB 7.0.17,
and MySQL Cluster NDB 7.1.6, this method did not update the
counter used to track
TransactionInactiveTimeout
(see Bug#54724).
It is not advisable to take a lock on a record and maintain it for a extended time since this can impact other transactions.
Signature.
int refresh
(
void
)
Parameters. None.
Return value.
Returns 0 on success, -1
on failure.
Description.
This method closes a transaction. It is equivalent to calling
Ndb::closeTransaction() (see
Section 2.3.8.1.9, “Ndb::closeTransaction()”).
If the transaction has not yet been committed, it is aborted
when this method is called. See
Section 2.3.8.1.8, “Ndb::startTransaction()”.
Signature.
void close
(
void
)
Parameters. None.
Return value. None.
Description. This method retrieves the transaction's global checkpoint ID (GCI).
Each committed transaction belongs to a GCI. The log for the committed transaction is saved on disk when a global checkpoint occurs.
By comparing the GCI of a transaction with the value of the latest GCI restored in a restarted NDB Cluster, you can determine whether or not the transaction was restored.
Whether or not the global checkpoint with this GCI has been saved on disk cannot be determined by this method.
The GCI for a scan transaction is undefined, since no updates are performed in scan transactions.
Signature.
int getGCI
(
void
)
Parameters. None.
Return value.
The transaction's GCI, or -1 if none is
available.
No GCI is available until execute() has
been called with ExecType::Commit.
Description. This method is used to obtain the transaction ID.
Signature.
Uint64 getTransactionId
(
void
)
Parameters. None.
Return value. The transaction ID, as an unsigned 64-bit integer.
Description. This method gets the transaction's commit status.
Signature.
CommitStatusType commitStatus
(
void
)
Parameters. None.
Return value.
The commit status of the transaction, a
CommitStatusType value. See
Section 2.3.19.1.2, “The NdbTransaction::CommitStatusType Type”.
Description.
This method is used to obtain the most recent error
(NdbError).
Signature.
const NdbError& getNdbError
(
void
) const
Parameters. None.
Return value.
A reference to an NdbError object. See
Section 2.3.31, “The NdbError Structure”.
For additional information about handling errors in transactions, see Section 1.3.2.3.5, “Error Handling”.
Description. This method retrieves the operation that caused an error.
To obtain more information about the actual error, use the
NdbOperation::getNdbError() method of the
NdbOperation object returned by
getNdbErrorOperation(). (See
Section 2.3.15.2.5, “NdbOperation::getNdbError()”.)
Signature.
NdbOperation* getNdbErrorOperation
(
void
)
Parameters. None.
Return value.
A pointer to an NdbOperation.
For additional information about handling errors in transactions, see Section 1.3.2.3.5, “Error Handling”.
Description. This method return the line number where the most recent error occurred.
Signature.
int getNdbErrorLine
(
void
)
Parameters. None.
Return value. The line number of the most recent error.
For additional information about handling errors in transactions, see Section 1.3.2.3.5, “Error Handling”.
Description. This method is used to retrieve a transaction's completed operations. It is typically used to fetch all operations belonging to a given transaction to check for errors.
NdbTransaction::getNextCompletedOperation(NULL)
returns the transaction's first NdbOperation
object;
NdbTransaction::getNextCompletedOperation(
returns the myOp)NdbOperation object defined after
NdbOperation myOp.
This method should only be used after the transaction has been executed, but before the transaction has been closed.
Signature.
const NdbOperation* getNextCompletedOperation
(
const NdbOperation* op
) const
Parameters.
This method requires a single parameter
op, which is an operation
(NdbOperation object), or
NULL.
Return value.
The operation following op, or the
first operation defined for the transaction if
getNextCompletedOperation() was called
using NULL.
Description.
This method reads a tuple using NdbRecord
objects.
Signature.
const NdbOperation* readTuple
(
const NdbRecord* key_rec,
const char* key_row,
const NdbRecord* result_rec,
char* result_row,
NdbOperation::LockMode lock_mode = NdbOperation::LM_Read,
const unsigned char* result_mask = 0,
const NdbOperation::OperationOptions* opts = 0,
Uint32 sizeOfOptions = 0
)
Parameters. This method takes the following parameters:
key_recis a pointer to anNdbRecordfor either a table or an index. If on a table, then the operation uses a primary key; if on an index, then the operation uses a unique key. In either case, thekey_recmust include all columns of the key.The
key_rowpassed to this method defines the primary or unique key of the affected tuple, and must remain valid untilexecute()is called.result_recis a pointer to anNdbRecordused to hold the resultresult_rowdefines a buffer for the result data.lock_modespecifies the lock mode in effect for the operation. See Section 2.3.15.1.3, “TheNdbOperation::LockModeType”, for permitted values and other information.result_maskdefines a subset of attributes to read. Only ifmask[attrId >> 3] & (1<<(attrId & 7))is set is the column affected. The mask is copied, and so need not remain valid after the method call returns.OperationOptions(opts) can be used to provide more finely-grained control of operation definitions. AnOperationOptionsstructure is passed with flags indicating which operation definition options are present. Not all operation types support all operation options; the options supported for each type of operation are shown in the following table:Operation type (Method) OperationOptionsFlags SupportedreadTuple()OO_ABORTOPTION,OO_GETVALUE,OO_PARTITION_ID,OO_INTERPRETEDinsertTuple()OO_ABORTOPTION,OO_SETVALUE,OO_PARTITION_ID,OO_ANYVALUEupdateTuple()OO_ABORTOPTION,OO_SETVALUE,OO_PARTITION_ID,OO_INTERPRETED,OO_ANYVALUEwriteTuple()OO_ABORTOPTION,OO_SETVALUE,OO_PARTITION_ID,OO_ANYVALUEdeleteTuple()OO_ABORTOPTION,OO_GETVALUE,OO_PARTITION_ID,OO_INTERPRETED,OO_ANYVALUEThe optional
sizeOfOptionsparameter is used to preserve backward compatibility of this interface with previous definitions of theOperationOptionsstructure. If an unusual size is detected by the interface implementation, it can use this to determine how to interpret the passedOperationOptionsstructure. To enable this functionality, the caller should passsizeof(NdbOperation::OperationOptions)for the value of this argument.
Return value.
A pointer to the
NdbOperation
representing this read operation (this can be used to check
for errors).
Signature (“old” version). Prior to MySQL Cluster NDB 6.2.15 and 6.3.15, this method was defined as shown here:
NdbOperation* readTuple
(
const NdbRecord* key_rec,
const char* key_row,
const NdbRecord* result_rec,
char* result_row,
NdbOperation::LockMode lock_mode = NdbOperation::LM_Read,
const unsigned char* result_mask = 0
)
Parameters (“old” version). Prior to MySQL Cluster NDB 6.2.15 and 6.3.15, this method took the following parameters:
key_recis a pointer to anNdbRecordfor either a table or an index. If on a table, then the operation uses a primary key; if on an index, then the operation uses a unique key. In either case, thekey_recmust include all columns of the key.The
key_rowpassed to this method defines the primary or unique key of the affected tuple, and must remain valid untilexecute()is called.result_recis a pointer to anNdbRecordused to hold the resultresult_rowdefines a buffer for the result data.lock_modespecifies the lock mode in effect for the operation. See Section 2.3.15.1.3, “TheNdbOperation::LockModeType”, for permitted values and other information.result_maskdefines a subset of attributes to read. Only ifmask[attrId >> 3] & (1<<(attrId & 7))is set is the column affected. The mask is copied, and so need not remain valid after the method call returns.
Return value (“old” version).
A pointer to the NdbOperation representing
this operation (this can be used to check for errors).
Description.
Inserts a tuple using NdbRecord.
Signature.
const NdbOperation* insertTuple
(
const NdbRecord* key_rec,
const char* key_row,
const NdbRecord* attr_rec,
const char* attr_row,
const unsigned char* mask = 0,
const NdbOperation::OperationOptions* opts = 0,
Uint32 sizeOfOptions = 0
)
const NdbOperation* insertTuple
(
const NdbRecord* combined_rec,
const char* combined_row,
const unsigned char* mask = 0,
const NdbOperation::OperationOptions* opts = 0,
Uint32 sizeOfOptions = 0
)
Parameters.
insertTuple() takes the following
parameters:
A pointer to an
NdbRecordindicating the record (key_rec) to be inserted.A row (
key_row) of data to be inserted.A pointer to an
NdbRecordindicating an attribute (attr_rec) to be inserted.A row (
attr_row) of data to be inserted as the attribute.A
maskwhich can be used to filter the columns to be inserted.OperationOptions(opts) can be used to provide more finely-grained control of operation definitions. AnOperationOptionsstructure is passed with flags indicating which operation definition options are present. Not all operation types support all operation options; for the options supported by each type of operation, see Section 2.3.19.2.15, “NdbTransaction::readTuple()”.The optional
sizeOfOptionsparameter is used to preserve backward compatibility of this interface with previous definitions of theOperationOptionsstructure. If an unusual size is detected by the interface implementation, it can use this to determine how to interpret the passedOperationOptionsstructure. To enable this functionality, the caller should passsizeof(NdbOperation::OperationOptions)for the value of this argument.
This method can also be called using a single
NdbRecord
pointer and single char pointer
(combined_rec,
combined_row) where the single
NdbRecord represents record and attribute and data.
Return value.
A const pointer to the
NdbOperation
representing this insert operation.
Signature (“old” version). Prior to MySQL Cluster NDB 6.2.15 and MySQL Cluster NDB 6.3.15, this method was defined as follows:
NdbOperation* insertTuple
(
const NdbRecord* record,
const char* row,
const unsigned char* mask = 0
)
Parameters (“old” version).
Prior to MySQL Cluster NDB 6.2.15 and 6.3.15,
insertTuple() took the following
parameters:
A pointer to an
NdbRecordindicating therecordto be inserted.A
rowof data to be inserted.A
maskwhich can be used to filter the columns to be inserted.
Return Value (“old” version).
Prior to MySQL Cluster NDB 6.2.15 and 6.3.15, this method
returned a pointer to the NdbOperation
representing the insert operation.
Description.
Updates a tuple using an NdbRecord object.
Signature.
const NdbOperation* updateTuple
(
const NdbRecord* key_rec,
const char* key_row,
const NdbRecord* attr_rec,
const char* attr_row,
const unsigned char* mask = 0,
const NdbOperation::OperationOptions* opts = 0,
Uint32 sizeOfOptions = 0
)
Parameters.
updateTuple() takes the following
parameters:
key_recis a pointer to anNdbRecordfor either a table or an index. If on a table, then the operation uses a primary key; if on an index, then the operation uses a unique key. In either case, thekey_recmust include all columns of the key.The
key_rowpassed to this method defines the primary or unique key of the affected tuple, and must remain valid untilexecute()is called.attr_recis anNdbRecordreferencing the attribute to be updated.NoteFor unique index operations, the
attr_recmust refer to the underlying table of the index, not to the index itself.attr_rowis a buffer containing the new data for the update.The
mask, if notNULL, defines a subset of attributes to be updated. The mask is copied, and so does not need to remain valid after the call to this method returns.OperationOptions(opts) can be used to provide more finely-grained control of operation definitions. AnOperationOptionsstructure is passed with flags indicating which operation definition options are present. Not all operation types support all operation options; for the options supported by each type of operation, see Section 2.3.19.2.15, “NdbTransaction::readTuple()”.The optional
sizeOfOptionsparameter is used to preserve backward compatibility of this interface with previous definitions of theOperationOptionsstructure. If an unusual size is detected by the interface implementation, it can use this to determine how to interpret the passedOperationOptionsstructure. To enable this functionality, the caller should passsizeof(NdbOperation::OperationOptions)for the value of this argument.
Return value.
The NdbOperation representing this
operation (can be used to check for errors).
Old version. Prior to MySQL Cluster NDB 6.2.15 and 6.3.15, this method was defined as follows:
NdbOperation* updateTuple
(
const NdbRecord* key_rec,
const char* key_row,
const NdbRecord* attr_rec,
const char* attr_row,
const unsigned char* mask = 0
)
Parameters (“old” version).
Prior to MySQL Cluster NDB 6.2.15 and 6.3.15,
updateTuple() took the following
parameters:
key_recis a pointer to anNdbRecordfor either a table or an index. If on a table, then the operation uses a primary key; if on an index, then the operation uses a unique key. In either case, thekey_recmust include all columns of the key.The
key_rowpassed to this method defines the primary or unique key of the affected tuple, and must remain valid untilexecute()is called.attr_recis anNdbRecordreferencing the attribute to be updated.NoteFor unique index operations, the
attr_recmust refer to the underlying table of the index, not to the index itself.attr_rowis a buffer containing the new data for the update.The
mask, if notNULL, defines a subset of attributes to be updated. The mask is copied, and so does not need to remain valid after the call to this method returns.
Return Value (“old” version).
Prior to MySQL Cluster NDB 6.2.15 and 6.3.15, this method
returned a pointer to the NdbOperation
representing this operation (which could be used to check for
errors).
Description.
This method is used with NdbRecord to write
a tuple of data.
Signature.
const NdbOperation* writeTuple
(
const NdbRecord* key_rec,
const char* key_row,
const NdbRecord* attr_rec,
const char* attr_row,
const unsigned char* mask = 0,
const NdbOperation::OperationOptions* opts = 0,
Uint32 sizeOfOptions = 0
)
Parameters. This method takes the following parameters:
key_recis a pointer to anNdbRecordfor either a table or an index. If on a table, then the operation uses a primary key; if on an index, then the operation uses a unique key. In either case, thekey_recmust include all columns of the key.The
key_rowpassed to this method defines the primary or unique key of the tuple to be written, and must remain valid untilexecute()is called.attr_recis anNdbRecordreferencing the attribute to be written.NoteFor unique index operations, the
attr_recmust refer to the underlying table of the index, not to the index itself.attr_rowis a buffer containing the new data.The
mask, if notNULL, defines a subset of attributes to be written. The mask is copied, and so does not need to remain valid after the call to this method returns.OperationOptions(opts) can be used to provide more finely-grained control of operation definitions. AnOperationOptionsstructure is passed with flags indicating which operation definition options are present. Not all operation types support all operation options; for the options supported by each type of operation, see Section 2.3.19.2.15, “NdbTransaction::readTuple()”.The optional
sizeOfOptionsparameter is used to provide backward compatibility of this interface with previous definitions of theOperationOptionsstructure. If an unusual size is detected by the interface implementation, it can use this to determine how to interpret the passedOperationOptionsstructure. To enable this functionality, the caller should passsizeof(NdbOperation::OperationOptions)for the value of this argument.
Return value.
A const pointer to the
NdbOperation representing this write
operation. The operation can be checked for errors if and as
necessary.
Signature (“old” version). Prior to MySQL Cluster NDB 6.2.15 and 6.3.15, this method was defined as shown here:
NdbOperation* writeTuple
(
const NdbRecord* key_rec,
const char* key_row,
const NdbRecord* attr_rec,
const char* attr_row,
const unsigned char* mask = 0
)
Parameters (“old” version). Prior to MySQL Cluster NDB 6.2.15 and 6.3.15, this method took the following parameters:
key_recis a pointer to anNdbRecordfor either a table or an index. If on a table, then the operation uses a primary key; if on an index, then the operation uses a unique key. In either case, thekey_recmust include all columns of the key.The
key_rowpassed to this method defines the primary or unique key of the tuple to be written, and must remain valid untilexecute()is called.attr_recis anNdbRecordreferencing the attribute to be written.NoteFor unique index operations, the
attr_recmust refer to the underlying table of the index, not to the index itself.attr_rowis a buffer containing the new data.The
mask, if notNULL, defines a subset of attributes to be written. The mask is copied, and so does not need to remain valid after the call to this method returns.
Return Value (“old” version).
Prior to MySQL Cluster NDB 6.2.15 and 6.3.15, this method
returned a pointer to the NdbOperation
representing this write operation. The operation could be
checked for errors if and as necessary.
Description.
Deletes a tuple using NdbRecord.
Signature.
const NdbOperation* deleteTuple
(
const NdbRecord* key_rec,
const char* key_row,
const NdbRecord* result_rec,
char* result_row,
const unsigned char* result_mask = 0,
const NdbOperation::OperationOptions* opts = 0,
Uint32 sizeOfOptions = 0
)
Parameters. This method takes the following parameters:
key_recis a pointer to anNdbRecordfor either a table or an index. If on a table, then the delete operation uses a primary key; if on an index, then the operation uses a unique key. In either case, thekey_recmust include all columns of the key.The
key_rowpassed to this method defines the primary or unique key of the tuple to be deleted, and must remain valid untilexecute()is called.The
result_mask, if notNULL, defines a subset of attributes to be written. The mask is copied, and so does not need to remain valid after the call to this method returns.OperationOptions(opts) can be used to provide more finely-grained control of operation definitions. AnOperationOptionsstructure is passed with flags indicating which operation definition options are present. Not all operation types support all operation options; for the options supported by each type of operation, see Section 2.3.19.2.15, “NdbTransaction::readTuple()”.The optional
sizeOfOptionsparameter provides backward compatibility of this interface with previous definitions of theOperationOptionsstructure. If an unusual size is detected by the interface implementation, it can use this to determine how to interpret the passedOperationOptionsstructure. To enable this functionality, the caller should passsizeof(NdbOperation::OperationOptions)for the value of this argument.
Return value.
A const pointer to the
NdbOperation representing this write
operation. The operation can be checked for errors if
necessary.
Signature (“old” version). Prior to MySQL Cluster NDB 6.2.15 and 6.3.15, this method was defined as shown here:
NdbOperation* deleteTuple
(
const NdbRecord* key_rec,
const char* key_row
)
Parameters (“old” version). Prior to MySQL Cluster NDB 6.2.15 and 6.3.15, this method took the following parameters:
key_recis a pointer to anNdbRecordfor either a table or an index. If on a table, then the delete operation uses a primary key; if on an index, then the operation uses a unique key. In either case, thekey_recmust include all columns of the key.The
key_rowpassed to this method defines the primary or unique key of the tuple to be deleted, and must remain valid untilexecute()is called.
Return Value (“old” version).
A pointer to the NdbOperation representing
this write operation. The operation can be checked for errors
if necessary.
Description.
This method performs a table scan, using an
NdbRecord object to read out column data.
Signature.
NdbScanOperation* scanTable
(
const NdbRecord* result_record,
NdbOperation::LockMode lock_mode = NdbOperation::LM_Read,
const unsigned char* result_mask = 0,
Uint32 scan_flags = 0,
Uint32 parallel = 0,
Uint32 batch = 0
)
Parameters.
The scanTable() method takes the following
parameters:
A pointer to an
NdbRecordfor storing the result. Thisresult_recordmust remain valid until after theexecute()call has been made.The
lock_modein effect for the operation. See Section 2.3.15.1.3, “TheNdbOperation::LockModeType”, for permitted values and other information.The
result_maskpointer is optional. If it is present, only columns for which the corresponding bit (by attribute ID order) inresult_maskis set will be retrieved in the scan. Theresult_maskis copied internally, so in contrast toresult_recordneed not be valid whenexecute()is invoked.scan_flagscan be used to impose ordering and sorting conditions for scans. See Section 2.3.18.1, “TheNdbScanOperation::ScanFlagType”, for a list of permitted values.The
parallelargument is the desired parallelism, or0for maximum parallelism (receiving rows from all fragments in parallel), which is the default.batchdetermines whether batching is employed. The default is 0 (off).
Return value.
A pointer to the NdbScanOperation
representing this scan. The operation can be checked for
errors if necessary.
Description.
This method is used to perform an index scan of a table, using
NdbRecord. The scan may optionally be
ordered.
Signature.
NdbIndexScanOperation* scanIndex
(
const NdbRecord* key_record,
const char* low_key,
Uint32 low_key_count,
bool low_inclusive,
const char* high_key,
Uint32 high_key_count,
bool high_inclusive,
const NdbRecord* result_record,
NdbOperation::LockMode lock_mode = NdbOperation::LM_Read,
const unsigned char* result_mask = 0,
Uint32 scan_flags = 0,
Uint32 parallel = 0,
Uint32 batch = 0
)
For multi-range scans, the low_key
and high_key pointers must be
unique. In other words, it is not permissible to reuse the
same row buffer for several different range bounds within a
single scan. However, it is permissible to use the same row
pointer as low_key and
high_key in order to specify an
equals bound; it is also permissible to reuse the rows after
the scanIndex() method
returns—thatis, they need not remain valid until
execute() time (unlike the
NdbRecord pointers).
Parameters. This method takes the following parameters:
The
key_recorddescribes the index to be scanned. It must be a key record on the index; that is, the columns which it specifies must include all of the key columns of the index. It must be created from the index to be scanned, and not from the underlying table.low_keydetermines the lower bound for a range scan.low_key_countdetermines the number of columns used for the lower bound when specifying a partial prefix for the scan.low_inclusivedetermines whether the lower bound is considered as a>=or>relation.high_keydetermines the upper bound for a range scan.high_key_countdetermines the number of columns used for the higher bound when specifying a partial prefix for the scan.high_inclusivedetermines whether the lower bound is considered as a<=or<relation.The
result_recorddescribes the rows to be returned from the scan. For an ordered index scan,result_recordbe a key record on the index; that is, the columns which it specifies must include all of the key columns of the index. This is because the index key is needed for merge sorting of the scans returned from each fragment.The
lock_modefor the scan must be one of the values specified in Section 2.3.15.1.3, “TheNdbOperation::LockModeType”.The
result_maskpointer is optional. If it is present, only columns for which the corresponding bit (by attribute ID order) inresult_maskis set will be retrieved in the scan. Theresult_maskis copied internally, so in contrast toresult_recordneed not be valid whenexecute()is invoked.scan_flagscan be used to impose ordering and sorting conditions for scans. See Section 2.3.18.1, “TheNdbScanOperation::ScanFlagType”, for a list of permitted values.The
parallelargument is the desired parallelism, or0for maximum parallelism (receiving rows from all fragments in parallel), which is the default.batchdetermines whether batching is employed. The default is 0 (off).
Return value.
The current NdbIndexScanOperation, which
can be used for error checking.
Abstract
This class provides meta-information about database objects such
as tables and indexes. Object subclasses model
these and other database objects.
Parent class. NdbDictionary
Child classes. Datafile, Event, Index, LogfileGroup, Table, Tablespace, Undofile
Methods.
The following table lists the public methods of the
Object class and the purpose or use of each
method:
| Method | Purpose / Use |
|---|---|
getObjectStatus() | Gets an object's status |
getObjectVersion() | Gets the version of an object |
getObjectId() | Gets an object's ID |
For a detailed discussion of each of these methods, see
Section 2.3.20.2, “Object Methods”.
Types.
These are the public types of the Object class:
| Type | Purpose / Use |
|---|---|
FragmentType | Fragmentation type used by the object (a table or index) |
State | The object's state (whether it is usable) |
Status | The object's state (whether it is available) |
Store | Whether the object has been temporarily or permanently stored |
Type | The object's type (what sort of table, index, or other database object
the Object represents) |
For a discussion of each of these types, along with its possible
values, see Section 2.3.20.1, “Object Class Enumerated Types”.
This diagram shows all public members of the
Object class:

For a visual representation of Object's
subclasses, see Section 2.3.10, “The NdbDictionary Class”.
Abstract
This section details the public enumerated types belonging to
the Object class.
Abstract
This type describes the Object's
fragmentation type.
Description.
This parameter specifies how data in the table or index is
distributed among the cluster's storage nodes, that is, the
number of fragments per node. The larger the table, the larger
the number of fragments that should be used. Note that all
replicas count as a single fragment. For a table, the default
is FragAllMedium. For a unique hash index,
the default is taken from the underlying table and cannot
currently be changed.
Enumeration values.
Possible values for FragmentType are shown,
along with descriptions, in the following table:
| Value | Description |
|---|---|
FragUndefined | The fragmentation type is undefined or the default |
FragAllMedium | Two fragments per node |
FragAllLarge | Four fragments per node |
Abstract
This type describes the state of the
Object.
Description. This parameter provides us with the object's state. By state, we mean whether or not the object is defined and is in a usable condition.
Enumeration values.
Possible values for State are shown, along
with descriptions, in the following table:
| Value | Description |
|---|---|
StateUndefined | Undefined |
StateOffline | Offline, not useable |
StateBuilding | Building (e.g. restore?), not useable(?) |
StateDropping | Going offline or being dropped; not usable |
StateOnline | Online, usable |
StateBackup | Online, being backed up, usable |
StateBroken | Broken; should be dropped and re-created |
Abstract
This type describes the Object's status.
Description.
Reading an object's Status tells whether or
not it is available in the NDB kernel.
Enumeration values.
Possible values for Status are shown, along
with descriptions, in the following table:
| Value | Description |
|---|---|
New | The object exists only in memory, and has not yet been created in the
NDB kernel |
Changed | The object has been modified in memory, and must be committed in the
NDB Kernel for changes to take effect |
Retrieved | The object exists, and has been read into main memory from the
NDB Kernel |
Invalid | The object has been invalidated, and should no longer be used |
Altered | The table has been altered in the NDB kernel, but is
still available for use |
Abstract
This type describes the Object's
persistence.
Description. Reading this value tells us is the object is temporary or permanent.
Enumeration values.
Possible values for Store are shown, along
with descriptions, in the following table:
| Value | Description |
|---|---|
StoreUndefined | The object is undefined |
StoreTemporary | Temporary storage; the object or data will be deleted on system restart |
StorePermanent | The object or data is permanent; it has been logged to disk |
Abstract
This type describes the Object's type.
Description.
The Type of the object can be one of
several different sorts of index, trigger, tablespace, and so
on.
Enumeration values.
Possible values for Type are shown, along
with descriptions, in the following table:
| Value | Description |
|---|---|
TypeUndefined | Undefined |
SystemTable | System table |
UserTable | User table (may be temporary) |
UniqueHashIndex | Unique (but unordered) hash index |
OrderedIndex | Ordered (but not unique) index |
HashIndexTrigger | Index maintenance (internal) |
IndexTrigger | Index maintenance (internal) |
SubscriptionTrigger | Backup or replication (internal) |
ReadOnlyConstraint | Trigger (internal) |
Tablespace | Tablespace |
LogfileGroup | Logfile group |
Datafile | Datafile |
Undofile | Undofile |
Abstract
The sections that follow describe each of the public methods of
the Object class.
All 3 of these methods are pure virtual methods, and are
reimplemented in the Table,
Index, and Event
subclasses where needed. See Section 2.3.21, “The Table Class”,
Section 2.3.5, “The Index Class”, and Section 2.3.4, “The Event Class”.
Description. This method retrieves the status of the object for which it is invoked.
Signature.
virtual Status getObjectStatus
(
void
) const
Parameters. None.
Return value.
Returns the current Status of the
Object. For possible values, see
Section 2.3.20.1.3, “The Object::Status Type”.
Abstract
This section describes the Table class, which
models a database table in the NDB API.
Parent class. NdbDictionary
Child classes. None
Description.
The Table class represents a table in a MySQL
Cluster database. This class extends the Object
class, which in turn is an inner class of the
NdbDictionary class.
It is possible using the NDB API to create tables independently of
the MySQL server. However, it is usually not advisable to do so,
since tables created in this fashion cannot be seen by the MySQL
server. Similarly, it is possible using Table
methods to modify existing tables, but these changes (except for
renaming tables) are not visible to MySQL.
Calculating Table Sizes. When calculating the data storage one should add the size of all attributes (each attribute consuming a minimum of 4 bytes) and well as 12 bytes overhead. Variable size attributes have a size of 12 bytes plus the actual data storage parts, with an additional overhead based on the size of the variable part. For example, consider a table with 5 attributes: one 64-bit attribute, one 32-bit attribute, two 16-bit attributes, and one array of 64 8-bit attributes. The amount of memory consumed per record by this table is the sum of the following:
8 bytes for the 64-bit attribute
4 bytes for the 32-bit attribute
8 bytes for the two 16-bit attributes, each of these taking up 4 bytes due to right-alignment
64 bytes for the array (64 * 1 byte per array element)
12 bytes overhead
This totals 96 bytes per record. In addition, you should assume an overhead of about 2% for the allocation of page headers and wasted space. Thus, 1 million records should consume 96 MB, and the additional page header and other overhead comes to approximately 2 MB. Rounding up yields 100 MB.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
Table() | Class constructor |
~Table() | Destructor |
getName() | Gets the table's name |
getTableId() | Gets the table's ID |
getColumn() | Gets a column (by name) from the table |
getLogging() | Checks whether logging to disk is enabled for this table |
getFragmentType() | Gets the table's FragmentType |
getKValue() | Gets the table's KValue |
getMinLoadFactor() | Gets the table's minimum load factor |
getMaxLoadFactor() | Gets the table's maximum load factor |
getNoOfColumns() | Gets the number of columns in the table |
getNoOfPrimaryKeys() | Gets the number of columns in the table's primary key. |
getPrimaryKey() | Gets the name of the table's primary key |
equal() | Compares the table with another table |
getFrmData() | Gets the data from the table .FRM file |
getFrmLength() | Gets the length of the table's .FRM file |
getFragmentData() | Gets table fragment data (ID, state, and node group) |
getFragmentDataLen() | Gets the length of the table fragment data |
getRangeListData() | Gets a RANGE or LIST array |
getRangeListDataLen() | Gets the length of the table RANGE or
LIST array |
getTablespaceData() | Gets the ID and version of the tablespace containing the table |
getTablespaceDataLen() | Gets the length of the table's tablespace data |
getLinearFlag() | Gets the current setting for the table's linear hashing flag |
getFragmentCount() | Gets the number of fragments for this table |
getFragmentNodes() | Gets IDs of data nodes on which fragments are located |
getTablespace() | Gets the tablespace containing this table |
getTablespaceNames() | |
getObjectType() | Gets the table's object type (Object::Type as opposed
to Table::Type) |
getObjectStatus() | Gets the table's object status |
getObjectVersion() | Gets the table's object version |
getObjectId() | Gets the table's object ID |
getMaxRows() | Gets the maximum number of rows that this table may contain |
getDefaultNoPartitionsFlag() | Checks whether the default number of partitions is being used |
getRowGCIIndicator() | |
getRowChecksumIndicator() | |
setName() | Sets the table's name |
addColumn() | Adds a column to the table |
setLogging() | Toggle logging of the table to disk |
setLinearFlag() | Sets the table's linear hashing flag |
setFragmentCount() | Sets the number of fragments for this table |
setFragmentType() | Sets the table's FragmentType |
setKValue() | Set the KValue |
setMinLoadFactor() | Set the table's minimum load factor (MinLoadFactor) |
setMaxLoadFactor() | Set the table's maximum load factor (MaxLoadFactor) |
setTablespace() | Set the tablespace to use for this table |
setStatusInvalid() | |
setMaxRows() | Sets the maximum number of rows in the table |
setDefaultNoPartitionsFlag() | Toggles whether the default number of partitions should be used for the table |
setFrm() | Sets the .FRM file to be used for this table |
setFragmentData() | Sets the fragment ID, node group ID, and fragment state |
setTablespaceNames() | Sets the tablespace names for fragments |
setTablespaceData() | Sets the tablespace ID and version |
setRangeListData() | Sets LIST and RANGE partition data |
setObjectType() | Sets the table's object type |
setRowGCIIndicator() | Documentation not yet available. |
setRowChecksumIndicator() | Documentation not yet available. |
aggregate() | Computes aggregate data for the table |
validate() | Validates the definition for a new table prior to creating it |
hasDefaultValues() | Determine whether table has any columns using default values |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.21.2, “Table Methods”.
Types.
The Table class defines a single public type
SingleUserMode. For more information, see
Section 2.3.21.1, “The Table::SingleUserMode Type”.
Class diagram.
This diagram shows all the available methods of the
Table class:
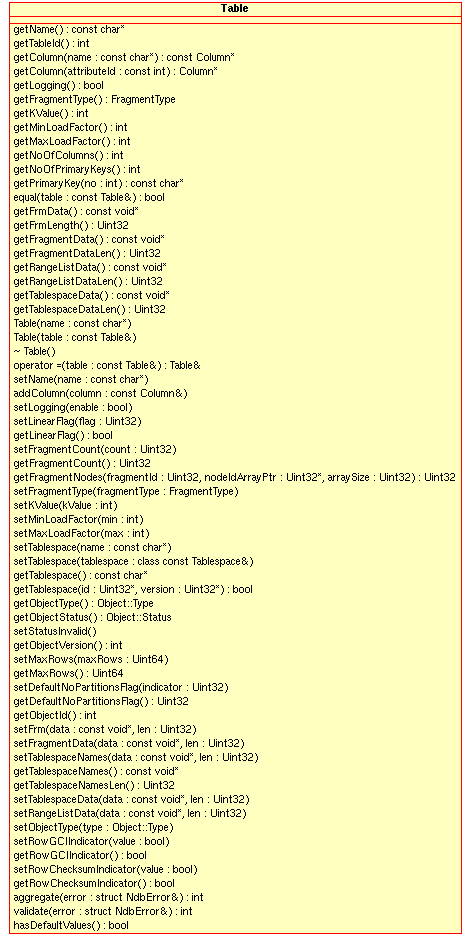
Description. Single user mode specifies access rights to the table when single user mode is in effect.
Enumeration values.
Possible values for SingleUserMode are shown,
along with descriptions, in the following table:
| Value | Description |
|---|---|
SingleUserModeLocked | The table is locked (unavailable). |
SingleUserModeReadOnly | The table is available in read-only mode. |
SingleUserModeReadWrite | The table is available in read-write mode. |
- 2.3.21.2.1.
TableConstructor - 2.3.21.2.2.
Table:getName() - 2.3.21.2.3.
Table::getTableId() - 2.3.21.2.4.
Table::getColumn() - 2.3.21.2.5.
Table::getLogging() - 2.3.21.2.6.
Table::getFragmentType() - 2.3.21.2.7.
Table::getKValue() - 2.3.21.2.8.
Table::getMinLoadFactor() - 2.3.21.2.9.
Table::getMaxLoadFactor() - 2.3.21.2.10.
Table::getNoOfCOlumns() - 2.3.21.2.11.
Table::getNoOfPrimaryKeys() - 2.3.21.2.12.
Table::getPrimaryKey() - 2.3.21.2.13.
Table::equal() - 2.3.21.2.14.
Table::getFrmData() - 2.3.21.2.15.
Table::getFrmLength() - 2.3.21.2.16.
Table::getFragmentData() - 2.3.21.2.17.
Table::getFragmentDataLen() - 2.3.21.2.18.
Table::getRangeListData() - 2.3.21.2.19.
Table::getRangeListDataLen() - 2.3.21.2.20.
Table::getTablespaceData() - 2.3.21.2.21.
Table::getTablespaceDataLen() - 2.3.21.2.22.
Table::getLinearFlag() - 2.3.21.2.23.
Table::getFragmentCount() - 2.3.21.2.24.
Table::getFragmentNodes() - 2.3.21.2.25.
Table::getTablespace() - 2.3.21.2.26.
Table::getObjectType() - 2.3.21.2.27.
Table::getObjectStatus() - 2.3.21.2.28.
Table::getObjectVersion() - 2.3.21.2.29.
Table::getMaxRows() - 2.3.21.2.30.
Table::getDefaultNoPartitionsFlag() - 2.3.21.2.31.
Table::getObjectId() - 2.3.21.2.32.
Table::getTablespaceNames() - 2.3.21.2.33.
Table::getTablespaceNamesLen() - 2.3.21.2.34.
Table::getRowGCIIndicator() - 2.3.21.2.35.
Table::getRowChecksumIndicator() - 2.3.21.2.36.
Table::setName() - 2.3.21.2.37.
Table::addColumn() - 2.3.21.2.38.
Table::setLogging() - 2.3.21.2.39.
Table::setLinearFlag() - 2.3.21.2.40.
Table::setFragmentCount() - 2.3.21.2.41.
Table::setFragmentType() - 2.3.21.2.42.
Table::setKValue() - 2.3.21.2.43.
Table::setMinLoadFactor() - 2.3.21.2.44.
Table::setMaxLoadFactor() - 2.3.21.2.45.
Table::setTablespace() - 2.3.21.2.46.
Table::setMaxRows() - 2.3.21.2.47.
Table::setDefaultNoPartitionsFlag() - 2.3.21.2.48.
Table::setFrm() - 2.3.21.2.49.
Table::setFragmentData() - 2.3.21.2.50.
Table::setTablespaceNames() - 2.3.21.2.51.
Table::setTablespaceData() - 2.3.21.2.52.
Table::setRangeListData() - 2.3.21.2.53.
Table::setObjectType() - 2.3.21.2.54.
Table::setRowGCIIndicator() - 2.3.21.2.55.
Table::setRowChecksumIndicator() - 2.3.21.2.56.
Table::setStatusInvalid() - 2.3.21.2.57.
Table::aggregate() - 2.3.21.2.58.
Table::validate() - 2.3.21.2.59.
Table::hasDefaultValues()
Abstract
This section discusses the public methods of the
Table class.
The assignment (=) operator is overloaded for
this class, so that it always performs a deep copy.
As with other database objects, Table object
creation and attribute changes to existing tables done using the
NDB API are not visible from MySQL. For example, if you add a
new column to a table using
Table::addColumn(), MySQL will not see the
new column. The only exception to this rule with regard to
tables is that you can change the name of an existing table
using Table::setName().
Description.
Creates a Table instance. There are two
version of the Table constructor, one for
creating a new instance, and a copy constructor.
Tables created in the NDB API using this method are not accessible from MySQL.
Signature. New instance:
Table
(
const char* name = ""
)
Copy constructor:
Table
(
const Table& table
)
Parameters. For a new instance, the name of the table to be created. For a copy, a reference to the table to be copied.
Return value.
A Table object.
Destructor.
virtual ~Table()
Description. Gets the name of a table.
Signature.
const char* getName
(
void
) const
Parameters. None.
Return value. The name of the table (a string).
Description. This method gets a table's ID.
Signature.
int getTableId
(
void
) const
Parameters. None.
Return value. An integer.
Description. This method is used to obtain a column definition, given either the index or the name of the column.
Signature. This method can be invoked using either the column ID or column name, as shown here:
Column* getColumn
(
const int AttributeId
)
Column* getColumn
(
const char* name
)
Parameters.
Either of: the column's index in the table (as it would be
returned by the column's getColumnNo()
method), or the name of the column.
Return value.
A pointer to the column with the specified index or name. If
there is no such column, then this method returns
NULL.
Description. This class is used to check whether a table is logged to disk—that is, whether it is permanent or temporary.
Signature.
bool getLogging
(
void
) const
Parameters. None.
Return value.
Returns a Boolean value. If this method returns
true, then full checkpointing and logging
are done on the table. If false, then the
table is a temporary table and is not logged to disk; in the
event of a system restart the table still exists and retains
its definition, but it will be empty. The default logging
value is true.
Description. This method gets the table's fragmentation type.
Signature.
FragmentType getFragmentType
(
void
) const
Parameters. None.
Return value.
A FragmentType value, as defined in
Section 2.3.20.1.1, “The Object::FragmentType Type”.
Description.
This method gets the KValue, a hashing parameter which is
currently restricted to the value 6. In a
future release, it may become feasible to set this parameter
to other values.
Signature.
int getKValue
(
void
) const
Parameters. None.
Return value.
An integer (currently always 6).
Description.
This method gets the value of the load factor when reduction
of the hash table begins. This should always be less than the
value returned by getMaxLoadFactor().
Signature.
int getMinLoadFactor
(
void
) const
Parameters. None.
Return value.
An integer (actually, a percentage expressed as an integer;
see Section 2.3.21.2.9, “Table::getMaxLoadFactor()”).
Description. This method returns the load factor (a hashing parameter) when splitting of the containers in the local hash tables begins.
Signature.
int getMaxLoadFactor
(
void
) const
Parameters. None.
Return value. An integer whose maximum value is 100. When the maximum value is returned, this means that memory usage is optimised. Smaller values indicate that less data is stored in each container, which means that keys are found more quickly; however, this also consumes more memory.
Description. This method is used to obtain the number of columns in a table.
Signature.
int getNoOfColumns
(
void
) const
Parameters. None.
Return value. An integer representing the number of columns in the table.
Description. This method finds the number of primary key columns in the table.
Signature.
int getNoOfPrimaryKeys
(
void
) const
Parameters. None.
Return value. An integer representing the number of primary key columns in the table.
Description. This method is used to obtain the name of the table's primary key.
Signature.
const char* getPrimaryKey
(
int no
) const
Parameters. None.
Return value. The name of the primary key, a string (character pointer).
Description.
This method is used to compare one instance of
Table with another.
Signature.
bool equal
(
const Table& table
) const
Parameters.
A reference to the Table object with which
the current instance is to be compared.
Return value.
true if the two tables are the same,
otherwise false.
Description.
The the data from the .FRM file
associated with the table.
Signature.
const void* getFrmData
(
void
) const
Parameters. None.
Return value.
A pointer to the .FRM data.
Description.
Gets the length of the table's .FRM file
data, in bytes.
Signature.
Uint32 getFrmLength
(
void
) const
Parameters. None.
Return value.
The length of the .FRM file data (an
unsigned 32-bit integer).
Description. This method gets the table's fragment data (ID, state, and node group).
Signature.
const void* getFragmentData
(
void
) const
Parameters. None.
Return value. A pointer to the data to be read.
Description. Gets the length of the table fragment data to be read, in bytes.
Signature.
Uint32 getFragmentDataLen
(
void
) const
Parameters. None.
Return value. The number of bytes to be read, as an unsigned 32-bit integer.
Description. This method gets the range or list data associated with the table.
Signature.
const void* getRangeListData
(
void
) const
Parameters. None.
Return value. A pointer to the data.
Description. This method gets the size of the table's range or list array.
Signature.
Uint32 getRangeListDataLen
(
void
) const
Parameters. None.
Return value. The length of the list or range array, as an integer.
Description. This method gets the table's tablespace data (ID and version).
Signature.
const void* getTablespaceData
(
void
) const
Parameters. None.
Return value. A pointer to the data.
Description. This method is used to get the length of the table's tablespace data.
Signature.
Uint32 getTablespaceDataLen
(
void
) const
Parameters. None.
Return value. The length of the data, as a 32-bit unsigned integer.
Description. This method retrieves the value of the table's linear hashing flag.
Signature.
bool getLinearFlag
(
void
) const
Parameters. None.
Return value.
true if the flag is set, and
false if it is not.
Description. This method gets the number of fragments in the table.
Signature.
Uint32 getFragmentCount
(
void
) const
Parameters. None.
Return value. The number of table fragments, as a 32-bit unsigned integer.
Description. This method retrieves a list of nodes storing a given fragment.
Signature.
Uint32 getFragmentNodes
(
Uint32 fragmentId,
Uint32* nodeIdArrayPtr,
Uint32 arraySize
) const
Parameters. This method takes the following three parameters:
fragmentId: The ID of the desired fragment.nodeIdArrayPtr: Pointer to an array of node IDs of the nodes containing this fragment.NoteNormally, the primary fragment is entry 0 in this array.
arraySize: The size of the array containing the node IDs. If this is less than the number of fragments, then only the firstarraySizeentries are written to this array.
Return value.
A return value of 0 indicates an error;
otherwise, this is the number of table fragments, as a 32-bit
unsigned integer.
This method was added in MySQL Cluster NDB 6.2.19, MySQL Cluster NDB 6.3.33, MySQL Cluster NDB 7.0.14, and MySQL Cluster NDB 7.1.2.
Description. This method is used in two ways: to obtain the name of the tablespace to which this table is assigned; to verify that a given tablespace is the one being used by this table.
Signatures. To obtain the name of the tablespace, invoke without any arguments:
const char* getTablespace
(
void
) const
To determine whether the tablespace is the one indicated by the given ID and version, supply these as arguments, as shown here:
bool getTablespace
(
Uint32* id = 0,
Uint32* version = 0
) const
Parameters. The number and types of parameters depend on how this method is being used:
When used to obtain the name of the tablespace in use by the table, it is called without any arguments.
When used to determine whether the given tablespace is the one being used by this table, then getTablespace() takes two parameters:
The tablespace
id, given as a pointer to a 32-bit unsigned integerThe tablespace
version, also given as a pointer to a 32-bit unsigned integer
The default value for both
idandversionis0.
Return value. The return type depends on how the method is called.
When
getTablespace()is called without any arguments, it returns aTablespaceobject instance. See Section 2.3.22, “TheTablespaceClass”, for more information.When called with two arguments, it returns
trueif the tablespace is the same as the one having the ID and version indicated; otherwise, it returnsfalse.
Description.
This method is used to obtain the table's type—that is,
its Object::Type value
Signature.
Object::Type getObjectType
(
void
) const
Parameters. None.
Return value.
Returns a Type value. For possible values,
see Section 2.3.20.1.5, “The Object::Type Type”.
Description.
This method gets the table's status—that is, its
Object::Status.
Signature.
virtual Object::Status getObjectStatus
(
void
) const
Parameters. None.
Return value.
A Status value. For possible values, see
Section 2.3.20.1.3, “The Object::Status Type”.
Description. This method gets the table's object version.
Signature.
virtual int getObjectVersion
(
void
) const
Parameters. None.
Return value. The table's object version, as an integer.
Description. This method gets the maximum number of rows that the table can hold. This is used for calculating the number of partitions.
Signature.
Uint64 getMaxRows
(
void
) const
Parameters. None.
Return value. The maximum number of table rows, as a 64-bit unsigned integer.
Description. This method is used to find out whether the default number of partitions is used for the table.
Signature.
Uint32 getDefaultNoPartitionsFlag
(
void
) const
Parameters. None.
Return value. A 32-bit unsigned integer.
Description. This method gets the table's object ID.
Signature.
virtual int getObjectId
(
void
) const
Parameters. None.
Return value. The object ID is returned as an integer.
Description. This method gets a pointer to the names of the tablespaces used in the table fragments.
Signature.
const void* getTablespaceNames
(
void
)
Parameters. None.
Return value. Returns a pointer to the tablespace name data.
Description.
This method gets the length of the tablespace name data
returned by getTablespaceNames(). (See
Section 2.3.21.2.32, “Table::getTablespaceNames()”.)
Signature.
Uint32 getTablespaceNamesLen
(
void
) const
Parameters. None.
Return value. Returns the length of the name data, in bytes, as a 32-but unsigned integer.
Description. Checks whether the the row GCI indicator has been set.
Signature.
bool getRowGCIIndicator
(
void
) const
Parameters. None.
Return value.
A true or false value.
Description. Check whether the row checksum indicator has been set.
Signature.
bool getRowChecksumIndicator
(
void
) const
Parameters. None.
Return value.
A true or false value.
Description. This method sets the name of the table.
This is the only
set method of
*()Table whose effects are visible to MySQL.
Signature.
void setName
(
const char* name
)
Parameters.
name is the (new) name of the
table.
Return value. None.
Description. Adds a column to a table.
Signature.
void addColumn
(
const Column& column
)
Parameters. A reference to the column which is to be added to the table.
Return value.
None; however, it does create a copy of
the original Column object.
Description.
Toggles the table's logging state. See
Section 2.3.21.2.5, “Table::getLogging()”.
Signature.
void setLogging
(
bool enable
)
Parameters.
If enable is
true, then logging for this table is
enabled; if it is false, then logging is
disabled.
Return value. None.
Description.
Signature.
void setLinearFlag
(
Uint32 flag
)
Parameters.
The flag is a 32-bit unsigned
integer.
Return value. None.
Description. Sets the number of table fragments.
Signature.
void setFragmentCount
(
Uint32 count
)
Parameters.
count is the number of fragments to
be used for the table.
Return value. None.
Description. This method sets the table's fragmentation type.
Signature.
void setFragmentType
(
FragmentType fragmentType
)
Parameters.
This method takes one argument, a
FragmentType value. See
Section 2.3.20.1.1, “The Object::FragmentType Type”, for more
information.
Return value. None.
Description.
This sets the KValue, a hashing parameter.
Signature.
void setKValue
(
int kValue
)
Parameters.
kValue is an integer. Currently the
only permitted value is 6. In a future
version this may become a variable parameter.
Return value. None.
Description. This method sets the minimum load factor when reduction of the hash table begins.
Signature.
void setMinLoadFactor
(
int min
)
Parameters.
This method takes a single parameter
min, an integer representation of a
percentage (for example, 45 represents 45
percent). For more information, see
Section 2.3.21.2.8, “Table::getMinLoadFactor()”.
Return value. None.
Description. This method sets the maximum load factor when splitting the containers in the local hash tables.
Signature.
void setMaxLoadFactor
(
int max
)
Parameters.
This method takes a single parameter
max, an integer representation of a
percentage (for example, 45 represents 45
percent). For more information, see
Section 2.3.21.2.9, “Table::getMaxLoadFactor()”.
This should never be greater than the minimum load factor.
Return value. None.
Description. This method sets the tablespace for the table.
Signatures. Using the name of the tablespace:
void setTablespace
(
const char* name
)
Using a Tablespace object:
void setTablespace
(
const class Tablespace& tablespace
)
Parameters. This method can be called with a single argument, which can be of either one of these two types:
The
nameof the tablespace (a string).A reference to an existing
Tablespaceinstance.
See Section 2.3.22, “The Tablespace Class”.
Return value. None.
Description. This method sets the maximum number of rows that can be held by the table.
Signature.
void setMaxRows
(
Uint64 maxRows
)
Parameters.
maxRows is a 64-bit unsigned
integer that represents the maximum number of rows to be held
in the table.
Return value. None.
Description. This method sets an indicator that determines whether the default number of partitions is used for the table.
Signature.
void setDefaultNoPartitionsFlag
(
Uint32 indicator
) const
Parameters.
This method takes a single argument
indicator, a 32-bit unsigned
integer.
Return value. None.
Description.
This method is used to write data to this table's
.FRM file.
Signature.
void setFrm
(
const void* data,
Uint32 len
)
Parameters. This method takes the following two arguments:
A pointer to the
datato be written.The length (
len) of the data.
Return value. None.
Description. This method writes an array containing the following fragment information:
Fragment ID
Node group ID
Fragment State
Signature.
void setFragmentData
(
const void* data,
Uint32 len
)
Parameters. This method takes the following two parameters:
A pointer to the fragment
datato be writtenThe length (
len) of this data, in bytes, as a 32-bit unsigned integer
Return value. None.
Description. Sets the names of the tablespaces used by the table fragments.
Signature.
void setTablespaceNames
(
const void* data
Uint32 len
)
Parameters. This method takes the following two parameters:
A pointer to the tablespace names
dataThe length (
len) of the names data, as a 32-bit unsigned integer.
Return value. None.
Description. This method sets the tablespace information for each fragment, and includes a tablespace ID and a tablespace version.
Signature.
void setTablespaceData
(
const void* data,
Uint32 len
)
Parameters. This method requires the following two parameters:
A pointer to the
datacontaining the tablespace ID and versionThe length (
len) of this data, as a 32-bit unsigned integer.
Return value. None.
Description. This method sets an array containing information that maps range values and list values to fragments. This is essentially a sorted map consisting of fragment-ID/value pairs. For range partitions there is one pair per fragment. For list partitions it could be any number of pairs, but at least as many pairs as there are fragments.
Signature.
void setRangeListData
(
const void* data,
Uint32 len
)
Parameters. This method requires the following two parameters:
A pointer to the range or list
datacontaining the ID/value pairsThe length (
len) of this data, as a 32-bit unsigned integer.
Return value. None.
Description. This method sets the table's object type.
Signature.
void setObjectType
(
Object::Type type
)
Parameters.
The desired object type. This must
be one of the Type values listed in
Section 2.3.20.1.5, “The Object::Type Type”.
Return value. None.
Description. Documentation not yet available
Signature.
void setRowGCIIndicator
(
bool value
) const
Parameters.
A true/false
value.
Return value. None.
Description. Documentation not yet available
Signature.
void setRowChecksumIndicator
(
bool value
) const
Parameters.
A true/false
value.
Return value. None.
Description. Forces the table's status to be invalidated.
Signature.
void setStatusInvalid
(
void
) const
Parameters. None.
Return value. None.
Description.
This method computes aggregate data for the table. It is
required in order for aggregate methods such as
getNoOfPrimaryKeys() to work properly
before the table has been created and retrieved via
getTable().
This method was added in MySQL 5.1.12 (see Bug#21690).
Signature.
int aggregate
(
struct NdbError& error
)
Parameters.
A reference to an NdbError object.
Return value.
An integer, whose value is 0 on success,
and -1 if the table is in an inconsistent
state. In the latter case, the
error is also set.
Description.
This method validates the definition for a new table prior to
its being created, and executes the
Table::aggregate() method, as well as
performing additional checks. validate() is
called automatically when a table is created or retrieved. For
this reason, it is usually not necessary to call
aggregate() or
validate() directly.
Even after the validate() method is called,
there may still exist errors which can be detected only by the
NDB kernel when the table is actually
created.
This method was added in MySQL 5.1.12 (see Bug#21690).
Signature.
int validate
(
struct NdbError& error
)
Parameters.
A reference to an NdbError object.
Return value.
An integer, whose value is 0 on success,
and -1 if the table is in an inconsistent
state. In the latter case, the
error is also set.
Description.
Used to determine whether the table has any columns that are
defined with non-NULL default values.
This method was added in MySQL Cluster NDB 7.0.15 and MySQL Cluster NDB 7.1.4.
To read and write default column values, use
Column::getDefaultValue()
and
Column::setDefaultValue().
Signature.
bool hasDefaultValues
(
void
) const
Parameters. None.
Return value.
Returns true if the table has any
non-NULL columns with default values,
otherwise false.
Abstract
This section discusses the Tablespace class and
its public members.
Parent class. NdbDictionary
Child classes. None
Description.
The Tablespace class models a MySQL Cluster
Disk Data tablespace, which contains the datafiles used to store
Cluster Disk Data. For an overview of Cluster Disk Data and their
characteristics, see CREATE TABLESPACE Syntax, in the
MySQL Manual.
In MySQL 5.1, only unindexed column data can be stored on disk. Indexes and indexes columns continue to be stored in memory as with previous versions of MySQL Cluster. (This is also true for MySQL Cluster NDB 6.2, MySQL Cluster NDB 6.3, MySQL Cluster NDB 7.0, and MySQL Cluster NDB 7.1.)
Versions of MySQL prior to 5.1 do not support Disk Data storage
and so do not support tablespaces; thus the
Tablespace class is unavailable for NDB API
applications written against these MySQL versions.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
Tablespace() | Class constructor |
~Tablespace() | Virtual destructor method |
getName() | Gets the name of the tablespace |
getExtentSize() | Gets the extent size used by the tablespace |
getAutoGrowSpecification() | Used to obtain the AutoGrowSpecification structure associated with the tablespace |
getDefaultLogfileGroup() | Gets the name of the tablespace's default log file group |
getDefaultLogfileGroupId() | Gets the ID of the tablespace's default log file group |
getObjectStatus() | Used to obtain the Object::Status of the
Tablespace instance for which it is
called |
getObjectVersion() | Gets the object version of the Tablespace object for
which it is invoked |
getObjectId() | Gets the object ID of a Tablespace instance |
setName() | Sets the name for the tablespace |
setExtentSize() | Sets the size of the extents used by the tablespace |
setAutoGrowSpecification() | Used to set the auto-grow characteristics of the tablespace |
setDefaultLogfileGroup() | Sets the tablespace's default log file group |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.22.1, “Tablespace Methods”.
Types.
The Tablespace class defines no public types of its own; however,
two of its methods make use of the
AutoGrowSpecification data structure.
Information about this structure can be found in
Section 2.3.26, “The AutoGrowSpecification Structure”.
Class diagram.
This diagram shows all the available methods and enumerated types
of the Tablespace class:
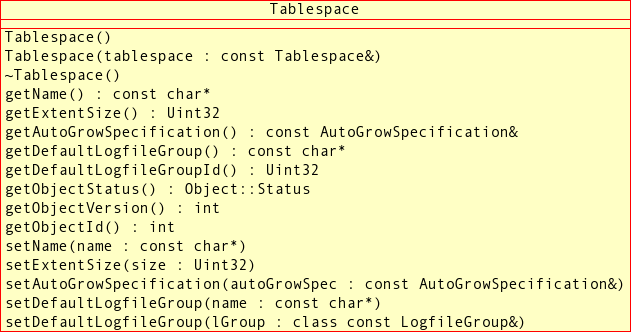
- 2.3.22.1.1.
TablespaceConstructor - 2.3.22.1.2.
Tablespace::getName() - 2.3.22.1.3.
Tablespace::getExtentSize() - 2.3.22.1.4.
Tablespace::getAutoGrowSpecification() - 2.3.22.1.5.
Tablespace::getDefaultLogfileGroup() - 2.3.22.1.6.
Tablespace::getDefaultLogfileGroupId() - 2.3.22.1.7.
Tablespace::getObjectStatus() - 2.3.22.1.8.
Tablespace::getObjectVersion() - 2.3.22.1.9.
Tablespace::getObjectId() - 2.3.22.1.10.
Tablespace::setName() - 2.3.22.1.11.
Tablespace::setExtentSize() - 2.3.22.1.12.
Tablespace::setAutoGrowSpecification() - 2.3.22.1.13.
Tablespace::setDefaultLogfileGroup()
Abstract
This section provides details of the public members of the NDB
API's Tablespace class.
Description.
These methods are used to create a new instance of
Tablespace, or to copy an existing one.
The NdbDictionary::Dictionary class also
supplies methods for creating and dropping tablespaces. See
Section 2.3.3, “The Dictionary Class”.
Signatures. New instance:
Tablespace
(
void
)
Copy constructor:
Tablespace
(
const Tablespace& tablespace
)
Parameters.
New instance: None. Copy constructor: a
reference to an existing Tablespace
instance.
Return value.
A Tablespace object.
Destructor.
The class defines a virtual destructor
~Tablespace() which takes no arguments and
returns no value.
Description. This method retrieves the name of the tablespace.
Signature.
const char* getName
(
void
) const
Parameters. None.
Return value. The name of the tablespace, a string value (as a character pointer).
Description. This method is used to retrieve the extent size—that is the size of the memory allocation units—used by the tablespace.
The same extent size is used for all datafiles contained in a given tablespace.
Signature.
Uint32 getExtentSize
(
void
) const
Parameters. None.
Return value. The tablespace's extent size in bytes, as an unsigned 32-bit integer.
Description.
Signature.
const AutoGrowSpecification& getAutoGrowSpecification
(
void
) const
Parameters. None.
Return value.
A reference to the structure which describes the tablespace
auto-grow characteristics; for details, see
Section 2.3.26, “The AutoGrowSpecification Structure”.
Description. This method retrieves the name of the tablespace's default log file group.
Alternatively, you may wish to obtain the ID of the default
log file group; see
Section 2.3.22.1.6, “Tablespace::getDefaultLogfileGroupId()”.
Signature.
const char* getDefaultLogfileGroup
(
void
) const
Parameters. None.
Return value. The name of the log file group (string value as character pointer).
Description. This method retrieves the ID of the tablespace's default log file group.
You can also obtain directly the name of the default log file
group rather than its ID; see
Section 2.3.22.1.5, “Tablespace::getDefaultLogfileGroup()”, for
more information.
Signature.
Uint32 getDefaultLogfileGroupId
(
void
) const
Parameters. None.
Return value. The ID of the log file group, as an unsigned 32-bit integer.
Description. This method is used to retrieve the object status of a tablespace.
Signature.
virtual Object::Status getObjectStatus
(
void
) const
Parameters. None.
Return value.
An Object::Status value; see
Section 2.3.20.1.3, “The Object::Status Type”, for details.
Description. This method gets the tablespace object version.
Signature.
virtual int getObjectVersion
(
void
) const
Parameters. None.
Return value. The object version, as an integer.
Description. This method retrieves the tablespace's object ID.
Signature.
virtual int getObjectId
(
void
) const
Parameters. None.
Return value. The object ID, as an integer.
Description. This method sets the name of the tablespace.
Signature.
void setName
(
const char* name
) const
Parameters.
The name of the tablespace, a
string (character pointer).
Return value. None.
Description. This method sets the tablespace's extent size.
Signature.
void setExtentSize
(
Uint32 size
)
Parameters.
The size to be used for this
tablespace's extents, in bytes.
Return value. None.
Description. This method is used to set the auto-grow characteristics of the tablespace.
Signature.
void setAutoGrowSpecification
(
const AutoGrowSpecification& autoGrowSpec
)
Parameters.
This method takes a single parameter, an
AutoGrowSpecification data structure. See
Section 2.3.26, “The AutoGrowSpecification Structure”.
Return value. None.
Description. This method is used to set a tablespace's default log file group.
Signature. This method can be called in two different ways. The first of these uses the name of the log file group, as shown here:
void setDefaultLogfileGroup
(
const char* name
)
This method can also be called by passing it a reference to a
LogfileGroup object:
void setDefaultLogfileGroup
(
const class LogfileGroup& lGroup
)
There is no method for setting a log file group as the default
for a tablespace by referencing the log file group's ID. (In
other words, there is no
set method
corresponding to
*()getDefaultLogfileGroupId().)
Parameters.
Either the name of the log file
group to be assigned to the tablespace, or a reference
lGroup to this log file group.
Return value. None.
Abstract
The section discusses the Undofile class and
its public methods.
Parent class. NdbDictionary
Child classes. None
Description.
The Undofile class models a Cluster Disk Data
undofile, which stores data used for rolling back transactions.
In MySQL 5.1, only unindexed column data can be stored on disk. Indexes and indexes columns continue to be stored in memory as with previous versions of MySQL Cluster. (This is also true for MySQL Cluster NDB 6.2, MySQL Cluster NDB 6.3, MySQL Cluster NDB 7.0, and MySQL Cluster NDB 7.1.)
Versions of MySQL prior to 5.1 do not support Disk Data storage
and so do not support undo files; thus the
Undofile class is unavailable for NDB API
applications written against these MySQL versions.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
Undofile() | Class constructor |
~Undofile() | Virtual destructor |
getPath() | Gets the undo file's file system path |
getSize() | Gets the size of the undo file |
getLogfileGroup() | Gets the name of the log file group to which the undo file belongs |
getLogfileGroupId() | Gets the ID of the log file group to which the undo file belongs |
getNode() | Gets the node where the undo file is located |
getFileNo() | Gets the number of the undo file in the log file group |
getObjectStatus() | Gets the undo file's Status |
getObjectVersion() | Gets the undo file's object version |
getObjectId() | Gets the undo file's object ID |
setPath() | Sets the file system path for the undo file |
setSize() | Sets the undo file's size |
setLogfileGroup() | Sets the undo file's log file group using the name of the log file group
or a reference to the corresponding
LogfileGroup object |
setNode() | Sets the node on which the undo file is located |
For detailed descriptions, signatures, and examples of use for each
of these methods, see Section 2.3.23.1, “Undofile Methods”.
Types.
The undo file class defines no public types.
Class diagram.
This diagram shows all the available methods of the
Undofile class:
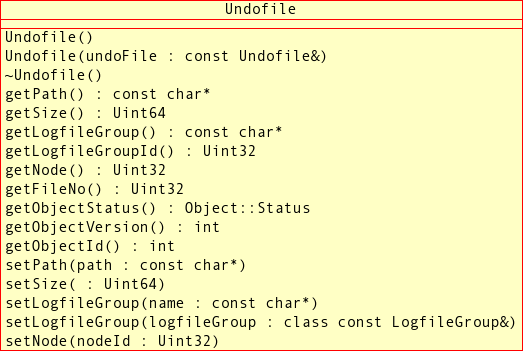
- 2.3.23.1.1.
UndofileConstructor - 2.3.23.1.2.
Undofile::getPath() - 2.3.23.1.3.
Undofile::getSize() - 2.3.23.1.4.
Undofile::getLogfileGroup() - 2.3.23.1.5.
Undofile::getLogfileGroupId() - 2.3.23.1.6.
Undofile::getNode() - 2.3.23.1.7.
Undofile::getFileNo() - 2.3.23.1.8.
Undofile::getObjectStatus() - 2.3.23.1.9.
Undofile::getObjectVersion() - 2.3.23.1.10.
Undofile::getObjectId() - 2.3.23.1.11.
Undofile::setPath() - 2.3.23.1.12.
Undofile::setSize() - 2.3.23.1.13.
Undofile::setLogfileGroup() - 2.3.23.1.14.
Undofile::setNode()
Abstract
This section details the public methods of the
Undofile class.
Description.
The class constructor can be used to create a new
Undofile instance, or to copy an existing
one.
Signatures. Creates a new instance:
Undofile
(
void
)
Copy constructor:
Undofile
(
const Undofile& undoFile
)
Parameters.
New instance: None. The copy constructor
takes a single argument—a reference to the
Undofile object to be copied.
Return value.
An Undofile object.
Destructor.
The class defines a virtual destructor which takes no
arguments and has the return type void.
Description. This method retrieves the path matching the location of the undo file on the data node's file system.
Signature.
const char* getPath
(
void
) const
Parameters. None.
Return value. The file system path, a string (as a character pointer).
Description. This method gets the size of the undo file in bytes.
Signature.
Uint64 getSize
(
void
) const
Parameters. None.
Return value. The size in bytes of the undo file, as an unsigned 64-bit integer.
Description. This method retrieves the name of the log file group to which the undo file belongs.
Signature.
const char* getLogfileGroup
(
void
) const
Parameters. None.
Return value. The name of the log file group, a string value (as a character pointer).
Description. This method retrieves the ID of the log file group to which the undo file belongs.
It is also possible to obtain the name of the log file group
directly. See Section 2.3.23.1.4, “Undofile::getLogfileGroup()”
Signature.
Uint32 getLogfileGroupId
(
void
) const
Parameters. None.
Return value. The ID of the log file group, as an unsigned 32-bit integer.
Description. This method is used to retrieve the node ID of the node where the undo file is located.
Signature.
Uint32 getNode
(
void
) const
Parameters. None.
Return value. The node ID, as an unsigned 32-bit integer.
Description.
The getFileNo() method gets the number of
the undo file in the log file group to which it belongs.
Signature.
Uint32 getFileNo
(
void
) const
Parameters. None.
Return value. The number of the undo file, as an unsigned 32-bit integer.
Description. This method is used to retrieve the object status of an undo file.
Signature.
virtual Object::Status getObjectStatus
(
void
) const
Parameters. None.
Return value.
An Object::Status value; see
Section 2.3.20.1.3, “The Object::Status Type”, for more information.
Description. This method gets the undo file's object version.
Signature.
virtual int getObjectVersion
(
void
) const
Parameters. None.
Return value. The object version, as an integer.
Description. This method retrieves the undo file's object ID.
Signature.
virtual int getObjectId
(
void
) const
Parameters. None.
Return value. The object ID, as an integer.
Description. This method is used to set the file system path of the undo file on the data node where it resides.
Signature.
void setPath
(
const char* path
)
Parameters.
The desired path to the undo file.
Return value. None.
Description. Sets the size of the undo file in bytes.
Signature.
void setSize
(
Uint64 size
)
Parameters.
The intended size of the undo file
in bytes, as an unsigned 64-bit integer.
Return value. None.
Description.
Given either a name or an object reference to a log file
group, the setLogfileGroup() method assigns
the undo file to that log file group.
Signature. Using a log file group name:
void setLogfileGroup
(
const char* name
)
Using a reference to an instance of
LogfileGroup:
void setLogfileGroup
(
const class LogfileGroup & logfileGroup
)
Parameters.
The name of the log file group (a
character pointer), or a reference to a
LogfileGroup instance.
Return value. None.
Abstract
This class represents a connection to a cluster of data nodes.
Parent class. None
Child classes. None
Description.
An NDB application program should begin with the creation of a
single Ndb_cluster_connection object, and
typically makes use of a single
Ndb_cluster_connection. The application
connects to a cluster management server when this object's
connect() method is called. By using the
wait_until_ready() method it is possible to
wait for the connection to reach one or more data nodes.
Application-level partitioning.
There is no restriction against instantiating multiple
Ndb_cluster_connection objects representing
connections to different management servers in a single
application, nor against using these for creating multiple
instances of the Ndb class. Such
Ndb_cluster_connection objects (and the
Ndb instances based on them) are not required
even to connect to the same cluster.
For example, it is entirely possible to perform
application-level partitioning of data in
such a manner that data meeting one set of criteria are
“handed off” to one cluster using an
Ndb object that makes use of an
Ndb_cluster_connection object representing a
connection to that cluster, while data not meeting those criteria
(or perhaps a different set of criteria) can be sent to a different
cluster through a different instance of Ndb that makes use of an
Ndb_cluster_connection “pointing” to
the second cluster.
It is possible to extend this scenario to develop a single application that accesses an arbitrary number of clusters. However, in doing so, the following conditions and requirements must be kept in mind:
A cluster management server (ndb_mgmd) can connect to one and only one cluster without being restarted and reconfigured, as it must read the data telling it which data nodes make up the cluster from a configuration file (
config.ini).An
Ndb_cluster_connectionobject “belongs” to a single management server whose host name or IP address is used in instantiating this object (passed as theconnectstringargument to its constructor); once the object is created, it cannot be used to initiate a connection to a different management server.(See Section 2.3.24.1.1, “
Ndb_cluster_connectionClass Constructor”.)An
Ndbobject making use of this connection (Ndb_cluster_connection) cannot be re-used to connect to a different cluster management server (and thus to a different collection of data nodes making up a cluster). Any given instance ofNdbis bound to a specificNdb_cluster_connectionwhen created, and thatNdb_cluster_connectionis in turn bound to a single and unique management server when it is instantiated.The bindings described above persist for the lifetimes of the
NdbandNdb_cluster_connectionobjects in question.
Therefore, it is imperative in designing and implementing any
application that accesses multiple clusters in a single session,
that a separate set of Ndb_cluster_connection and
Ndb objects be instantiated for connecting to
each cluster management server, and that no confusion arises as to
which of these is used to access which MySQL Cluster.
It is also important to keep in mind that no direct “sharing” of data or data nodes between different clusters is possible. A data node can belong to one and only one cluster, and any movement of data between clusters must be accomplished on the application level.
For examples demonstrating how connections to two different clusters can be made and used in a single application, see Section 2.4.2, “Using Synchronous Transactions and Multiple Clusters”, and Section 3.5.2, “MGM API Event Handling with Multiple Clusters”.
Methods. The following table lists the public methods of this class and the purpose or use of each method:
| Method | Purpose / Use |
|---|---|
Ndb_cluster_connection() | Constructor; creates a connection to a cluster of data nodes. |
set_name() | Provides a name for the connection |
set_timeout() | Sets a connection timeout |
connect() | Connects to a cluster management server. |
wait_until_ready() | Waits until a connection with one or more data nodes is successful. |
set_optimized_node_selection() | Used to control node-selection behavior. |
lock_ndb_objects() |
Disables the creation of new |
unlock_ndb_objects() |
Enables the creation of new |
get_next_ndb_object() |
Used to iterate through multiple |
set_auto_reconnect() |
Enables or disables auto-reconnection of API nodes using
this |
get_auto_reconnect() |
Gets the auto-reconnection setting for API nodes using
this |
For detailed descriptions, signatures, and examples of use for each
of these methods, see
Section 2.3.24.1, “Ndb_cluster_connection Methods”.
Class diagram.
This diagram shows all the available methods of the
Ndb_cluster_connection class:

- 2.3.24.1.1.
Ndb_cluster_connectionClass Constructor - 2.3.24.1.2.
Ndb_cluster_connection::set_name() - 2.3.24.1.3.
Ndb_cluster_connection::set_timeout() - 2.3.24.1.4.
Ndb_cluster_connection::connect() - 2.3.24.1.5.
Ndb_cluster_connection::wait_until_ready() - 2.3.24.1.6.
Ndb_cluster_connection::set_optimized_node_selection() - 2.3.24.1.7.
ndb_cluster_connection::get_next_ndb_object() - 2.3.24.1.8.
ndb_cluster_connection::lock_ndb_objects() - 2.3.24.1.9.
ndb_cluster_connection::unlock_ndb_objects() - 2.3.24.1.10.
Ndb_cluster_connection::set_auto_reconnect() - 2.3.24.1.11.
Ndb_cluster_connection::get_auto_reconnect() - 2.3.24.1.12.
Ndb_cluster_connection::get_latest_error() - 2.3.24.1.13.
Ndb_cluster_connection::get_latest_error_msg()
This section describes the methods belonging to the
Ndb_cluster_connection class.
Description.
This method creates a connection to a MySQL cluster, that is,
to a cluster of data nodes. The object returned by this method
is required in order to instantiate an Ndb
object. (See Section 2.3.8, “The Ndb Class”.) Thus, every NDB API
application requires the use of an
Ndb_cluster_connection.
Prior to MySQL Cluster NDB 7.0.15 and MySQL Cluster NDB 7.1.4,
Ndb_cluster_connection had a single
constructor, whose signature is shown here:
Signature.
Ndb_cluster_connection
(
const char* connectstring = 0
)
Parameters.
This version of the constructor requires a single
connectstring parameter, pointing
to the location of the management server.
Beginning with MySQL Cluster NDB 7.0.15 and MySQL Cluster NDB 7.1.4, a second constructor is provided which takes a node ID in addition to the connectstring argument. Its signature and parameters are shown here:
Signature.
Ndb_cluster_connection
(
const char* connectstring,
int force_api_nodeid
)
Parameters.
This version of the constructor takes two arguments, a
connectstring and the node ID
(force_api_nodeid) to be used by
this API node. This node ID overrides any node ID value set in
the connectstring argument.
Return value.
(Both versions:) An instance of
Ndb_cluster_connection.
Description. Sets a name for the connection. If the name is specified, it is reported in the cluster log.
Signature.
void set_name
(
const char* name
)
Parameters.
The name to be used as an
identifier for the connection.
Return value. None.
Description. Used to set a timeout for the connection, to limit the amount of time that we may block when connecting.
This method is actually a wrapper for the function
ndb_mgm_set_timeout(). For more information,
see Section 3.2.4.12, “ndb_mgm_set_timeout()”.
Signature.
int set_timeout
(
int timeout_ms
)
Parameters.
The length of the timeout, in milliseconds
(timeout_ms). Currently, only
multiples of 1000 are accepted.
Return value. 0 on success; any other value indicates failure.
Description. This method connects to a cluster management server.
Signature.
int connect
(
int retries = 0,
int delay = 1,
int verbose = 0
)
Parameters. This method takes three parameters, all of which are optional:
retriesspecifies the number of times to retry the connection in the event of failure. The default value (0) means that no additional attempts to connect will be made in the event of failure; a negative value forretriesresults in the connection attempt being repeated indefinitely.The
delayrepresents the number of seconds between reconnect attempts; the default is1second.verboseindicates whether the method should output a report of its progress, with1causing this reporting to be enabled; the default is0(reporting disabled).
Return value.
This method returns an int, which can have
one of the following 3 values:
0: The connection attempt was successful.
1: Indicates a recoverable error.
-1: Indicates an unrecoverable error.
Description. This method waits until the requested connection with one or more data nodes is successful.
Signature.
int wait_until_ready
(
int timeoutBefore,
int timeoutAfter
)
Parameters. This method takes two parameters:
timeoutBeforedetermines the number of seconds to wait until the first “live” node is detected. If this amount of time is exceeded with no live nodes detected, then the method immediately returns a negative value.timeoutAfterdetermines the number of seconds to wait after the first “live” node is detected for all nodes to become active. If this amount of time is exceeded without all nodes becoming active, then the method immediately returns a value greater than zero.
If this method returns 0, then all nodes are
“live”.
Return value.
wait_until_ready() returns an
int, whose value is interpreted as follows:
= 0: All nodes are “live”.> 0: At least one node is “live” (however, it is not known whether all nodes are “live”).< 0: An error occurred.
Description.
This method can be used to override the
connect() method's default behavior as
regards which node should be connected to first.
Signature.
void set_optimized_node_selection
(
int value
)
Parameters.
An integer value.
Return value. None.
Description.
This method is used to iterate over a set of
Ndb objects, retrieving them one at a time.
Signature.
const Ndb* get_next_ndb_object
(
const Ndb* p
)
Parameters.
This method takes a single parameter, a pointer to the last
Ndb object to have been retrieved or
NULL.
Return value.
Returns the next Ndb object, or
NULL if no more Ndb
objects are available.
Iterating over Ndb objects.
To retrieve all existing Ndb objects,
perform the following three steps:
Invoke the
lock_ndb_objects()method. This prevents the creation of any new instances ofNdbuntil theunlock_ndb_objects()method is called.Retrieve the first available
Ndbobject by passingNULLtoget_next_ndb_object(). You can retrieve the secondNdbobject by passing the pointer retrieved by the first call to the nextget_next_ndb_object()call, and so on. When a pointer to the last availableNdbinstance is used, the method returnsNULL.After you have retrieved all desired
Ndbobjects, you should re-enableNdbobject creation by calling theunlock_ndb_objects()method.
See also
Section 2.3.24.1.8, “ndb_cluster_connection::lock_ndb_objects()”,
and
Section 2.3.24.1.9, “ndb_cluster_connection::unlock_ndb_objects()”.
Description.
Calling this method prevents the creation of new instances of
the Ndb class. This method must be called
prior to iterating over multiple Ndb
objects using get_next_ndb_object().
Signature.
void lock_ndb_objects
(
void
)
Parameters. None.
Return value. None.
This method was added in MySQL Cluster NDB 6.1.4. For more
information, see
Section 2.3.24.1.7, “ndb_cluster_connection::get_next_ndb_object()”.
Description.
This method undoes the effects of the
lock_ndb_objects() method, making it
possible to create new instances of Ndb.
unlock_ndb_objects() should be called after
you have finished retrieving Ndb objects
using the get_next_ndb_object() method.
Signature.
void unlock_ndb_objects
(
void
)
Parameters. None.
Return value. None.
For more information, see
Section 2.3.24.1.7, “ndb_cluster_connection::get_next_ndb_object()”.
Description.
Prior to MySQL Cluster NDB 6.3.26 and MySQL Cluster NDB 7.0.7,
an API node that was disconnected from the cluster tried to
re-use an existing Ndb_cluster_connection
object when reconnecting; however, it was discovered that
permitting this also sometimes made it possible for multiple
API nodes to try to connect using the same node ID during a
restart of the cluster. (Bug#45921) Beginning with these
versions, API nodes are instead forced to use a new connection
object, unless this behavior is overridden by setting
AutoReconnect = 1 in the
config.ini file or calling this method
with 1 as the input value. Calling the method with 0 for the
value has the same effect as setting the
AutoReconnect configuration parameter (also
introduced in those MySQL Cluster versions) to 0; that is, API
nodes are forced to create new connections.
When called, this method overrides any setting for
AutoReconnect made in the
config.ini file.
For information about AutoReconnect, see
Defining SQL and Other API Nodes in a MySQL Cluster.
Signature.
void set_auto_reconnect
(
int value
)
Parameters.
A value of 0 or 1 which determines
API node reconnection behavior. 0 forces API nodes to use new
connections (Ndb_cluster_connection
objects); 1 permits API nodes to re-use existing connections
to the cluster.
Return value. None.
Description.
Introduced in MySQL Cluster NDB 6.3.26 and MySQL Cluster NDB
7.0.7, this method retrieves the current
AutoReconnect setting for a given
Ndb_cluster_connection. For more detailed
information, see
Section 2.3.24.1.10, “Ndb_cluster_connection::set_auto_reconnect()”.
Signature.
int get_auto_reconnect
(
void
)
Parameters. None.
Return value.
An integer value 0 or 1,
corresponding to the current AutoReconnect
setting in effect for for this connection.
0 forces API nodes to use new connections
to the cluster, while 1 enables API nodes
to re-use existing connections.
Description.
This method was introduced in MySQL Cluster NDB 6.3.20 and
MySQL Cluster NDB 6.4.0. It can be used to determine whether
or not the most recent connect() attempt
made by this Ndb_cluster_connection
succeeded (see
Section 2.3.24.1.4, “Ndb_cluster_connection::connect()”). If the
connection succeeded, get_latest_error()
returns 0; otherwise, it returns
1. If the connection attempt failed, use
Ndb_cluster_connection::get_latest_error_msg()
to obtain an error message giving the reason for the failure.
Signature.
int get_latest_error
(
void
) const
Parameters. None.
Return value.
1 or 0. A return value
of 1 indicates that the latest attempt to
connect failed; if the attempt succeeded, a
0 is returned.
Description.
If the most recent connection attempt by this
Ndb_cluster_connection failed (as
determined by calling
get_latest_error()),
this method provides an error message supplying information
about the reason for the failure.
Signature.
const char* get_latest_error_msg
(
void
) const
Parameters. None.
Return value.
A string containing an error message describing a failure by
Ndb_cluster_connection::connect().
If the most recent connection attempt succeeded, an empty
string is returned.
NdbRecord is an interface which provides a
mapping to a full or a partial record stored in
NDB. In the latter case, it can be used in
conjunction with a bitmap to assist in access.
NdbRecord is available beginning with MySQL
Cluster NDB 6.2.3.
NdbRecord has no API methods of its own; rather
it acts as a handle that can be passed between various method calls
for use in many different sorts of operations, including the
following operation types:
Unique key reads and primary key reads
Table scans and index scans
DML operations involving unique keys or primary keys
Operations involving index bounds
The same NdbRecord can be used simultaneously in
multiple operations, transactions, and threads.
An NdbRecord can be created in NDB API programs
by calling the createRecord() method of the
NdbDictionary class. In addition, a number of NDB
API methods have additional declarations in MySQL Cluster NDB 6.2.3
and later MySQL Cluster releases that enable the programmer to
leverage NdbRecord:
In addition, new members of NdbIndexScanOperation
and NdbDictionary are introduced in MySQL Cluster
NDB 6.2.3 for use with NdbRecord scans:
NdbIndexScanOperation::IndexBoundis a structure used to describe index scan bounds. See Section 2.3.29, “TheIndexBoundStructure”.NdbDictionary::RecordSpecificationis a structure used to specify columns and range offsets. See Section 2.3.34, “TheRecordSpecificationStructure”.
Beginning with MySQL Cluster NDB 6.3.24 and MySQL Cluster NDB 7.0.4,
you can also use NdbRecord in conjunction with
the new Ndb::PartitionSpec structure to perform
scans that take advantage of partition pruning, by means of a
variant of NdbIndexScanOperation::setBound() that
was added in the same MySQL Cluster releases. For more information,
see Section 2.3.13.2.5, “NdbIndexScanOperation::setBound”, and
Section 2.3.33, “The PartitionSpec Structure”.
Abstract
This section describes the
AutoGrowSpecification structure.
Parent class. NdbDictionary
Description.
The AutoGrowSpecification is a data structure
defined in the NdbDictionary class, and is used
as a parameter to or return value of some of the methods of the
Tablespace and LogfileGroup
classes. See Section 2.3.22, “The Tablespace Class”, and
Section 2.3.6, “The LogfileGroup Class”, for more information.
Methods.
AutoGrowSpecification has the following
members, whose types are as shown in the following diagram:
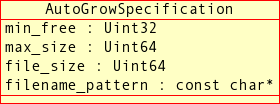
The purpose and use of each member can be found in the following table:
| Name | Description |
|---|---|
min_free | ??? |
max_size | ??? |
file_size | ??? |
filename_pattern | ??? |
Abstract
This section discusses the Element structure.
Parent class. List
Description.
The Element structure models an element of a
list; it is used to store an object in a List
populated by the Dictionary methods
listObjects(),
listIndexes(), and
listEvents().
Attributes.
An Element has the attributes shown in the
following table:
| Attribute | Type | Initial Value | Description |
|---|---|---|---|
id | unsigned int | 0 | The object's ID |
type | Object::Type | Object::TypeUndefined | The object's type—see Section 2.3.20.1.5, “The Object::Type Type” for
possible values |
state | Object::State | Object::StateUndefined | The object's state—see Section 2.3.20.1.2, “The Object::State Type” for
possible values |
store | Object::Store | Object::StoreUndefined | How the object is stored—see Section 2.3.20.1.4, “The Object::Store Type”
for possible values |
database | char* | 0 | The database in which the object is found |
schema | char* | 0 | The schema in which the object is found |
name | char* | 0 | The object's name |
For a graphical representation of this class and its parent-child
relationships, see Section 2.3.3, “The Dictionary Class”.
Parent class. NdbOperation
Description.
This structure is used to specify an extra value to obtain as part
of an
NdbRecord
operation.
Members. The makeup of this structure is shown here:
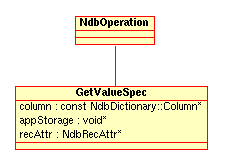
The individual members are described in more detail in the following table:
| Name | Type | Description |
|---|---|---|
column | const
| To specify an extra value to read, the caller must provide this, as well
as (optionally NULL)
appStorage pointer. |
appStorage | void* | If this pointer is null, then the received value is stored in memory
managed by the
NdbRecAttr
object. Otherwise, the received value is stored at the
location pointed to (and is still accessable using the
NdbRecAttr
object).
Important It is the caller's responsibility to ensure that the following conditions are met:
|
recAttr | NdbRecAttr* | After the operation is defined, recAttr
contains a pointer to the NdbRecAttr
object for receiving the data. |
Currently, blob reads cannot be specified using
GetValueSpec.
For more information, see Section 2.3.25, “The NdbRecord Interface”.
Parent class. NdbIndexScanOperation
Description.
IndexBound is a structure used to describe
index scan bounds for NdbRecord scans. It is
available beginning with MySQL Cluster NDB 6.2.3.
Members. These are shown in the following table:
| Name | Type | Description |
|---|---|---|
low_key | const char* | Row containing lower bound for scan (or NULL for scan
from the start). |
low_key_count | Uint32 | Number of columns in lower bound (for bounding by partial prefix). |
low_inclusive | bool | True for <= relation, false for
<. |
high_key | const char* | Row containing upper bound for scan (or NULL for scan
to the end). |
high_key_count | Uint32 | Number of columns in upper bound (for bounding by partial prefix). |
high_inclusive | bool | True for >= relation, false for
>. |
range_no | Uint32 | Value to identify this bound; may be read using the
get_range_no() method (see
Section 2.3.13.2.1, “NdbIndexScanOperation::get_range_no()”).
This value must be less than 8192 (set to zero if it is not
being used). For ordered scans, range_no
must be strictly increasing for each range, or else the
result set will not be sorted correctly. |
For more information, see Section 2.3.25, “The NdbRecord Interface”.
Abstract
This section describes the Key_part_ptr
structure.
Parent class. Ndb
Description.
Key_part_ptr provides a convenient way to
define key-part data when starting transactions and computing hash
values, by passing in pointers to distribution key values. When
the distribution key has multiple parts, they should be passed as
an array, with the last part's pointer set equal to
NULL. See
Section 2.3.8.1.8, “Ndb::startTransaction()”, and
Section 2.3.8.1.10, “Ndb::computeHash()”, for more information about
how this structure is used.
Attributes.
A Key_part_ptr has the attributes shown in the
following table:
| Attribute | Type | Initial Value | Description |
|---|---|---|---|
ptr | const void* | none | Pointer to one or more distribution key values |
len | unsigned | none | The length of the pointer |
Abstract
This section discusses the NdbError data
structure, which contains status and other information about
errors, including error codes, classifications, and messages.
Description.
An NdbError consists of six parts, listed here,
of which one is deprecated as of MySQL Cluster NDB 6.2.19, MySQL
Cluster NDB 6.3.29, and MySQL Cluster NDB 7.0.10:
Error status: This describes the impact of an error on the application, and reflects what the application should do when the error is encountered.
The error status is described by a value of the
Statustype. See Section 2.3.31.1.1, “TheNdbError::StatusType”, for possibleStatusvalues and how they should be interpreted.Error classification: This represents a logical error type or grouping.
The error classification is described by a value of the
Classificationtype. See Section 2.3.31.1.2, “TheNdbError::ClassificationType”, for possible classifications and their interpretation. Additional information is provided in Section 5.2.3, “NDB Error Classifications”.Error code: This is an NDB API internal error code which uniquely identifies the error.
ImportantIt is not recommended to write application programs which are dependent on specific error codes. Instead, applications should check error status and classification. More information about errors can also be obtained by checking error messages and (when available) error detail messages. However—like error codes—these error messages and error detail messages are subject to change.
A listing of current error codes, broken down by classification, is provided in Section 5.2.2, “NDB Error Codes and Messages”. This listing will be updated periodically, or you can check the file
storage/ndb/src/ndbapi/ndberror.cin the MySQL 5.1 sources.MySQL Error code: This is the corresponding MySQL Server error code. MySQL error codes are not discussed in this document; please see Server Error Codes and Messages, in the MySQL Manual, for information about these.
Error message: This is a generic, context-independent description of the error.
Error details: This can often provide additional information (not found in the error message) about an error, specific to the circumstances under which the error is encountered. However, it is not available in all cases.
Where not specified, the error detail message is
NULL.NoteThis property is deprecated as of MySQL Cluster NDB 6.2.19, MySQL Cluster NDB 6.3.29, and MySQL Cluster NDB 7.0.10. Beginning with these MySQL Cluster releases, for obtaining error details, you should use the
Ndb::getNdbErrorDetail()method instead. See Section 2.3.8.1.16, “Ndb::getNdbErrorDetail()”, for more information.
Specific NDB API error codes, messages, and detail messages are subject to change without notice.
Definition. The NdbError structure contains the following members, whose types are as shown here:
Status status: The error status.Classification classification: The error type (classification).int code: The NDB API error code.int mysql_code: The MySQL error code.const char* message: The error message.char* details: The error detail message.Notedetailsis deprecated as of MySQL Cluster NDB 6.2.19, MySQL Cluster NDB 6.3.29, and MySQL Cluster NDB 7.0.10. Beginning with these MySQL Cluster releases, for obtaining error details, you should use theNdb::getNdbErrorDetail()method instead. See Section 2.3.8.1.16, “Ndb::getNdbErrorDetail()”, for more information. (Bug#48851)
See the Description for more information about these members and their types.
Types.
NdbError defines the two data types listed
here:
Status: The error status. See Section 2.3.31.1.1, “TheNdbError::StatusType”.Classification: The type of error or the logical grouping to which it belongs. See Section 2.3.31.1.2, “TheNdbError::ClassificationType”.
Structure Diagram.
This diagram shows all the available members and types of the
NdbError structure:
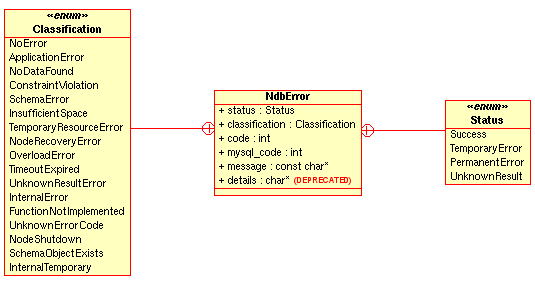
Abstract
This section discusses the Status and
Classification data types defined by
NdbError.
Description. This type is used to describe an error's status.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
Success | No error has occurred |
TemporaryError | A temporary and usually recoverable error; the application should retry the operation giving rise to the error |
PermanentError | Permanent error; not recoverable |
UnknownResult | The operation's result or status is unknown |
Related information specific to certain error conditions may be found in Section 5.2.3, “NDB Error Classifications”.
Description. This type describes the type of error, or the logical group to which it belongs.
Enumeration values. Possible values are shown, along with descriptions, in the following table:
| Value | Description |
|---|---|
NoError | Indicates success (no error occurred) |
ApplicationError | An error occurred in an application program |
NoDataFound | A read operation failed due to one or more missing records. |
ConstraintViolation | A constraint violation occurred, such as attempting to insert a tuple having a primary key value already in use in the target table. |
SchemaError | An error took place when trying to create or use a table. |
InsufficientSpace | There was insufficient memory for data or indexes. |
TemporaryResourceError | This type of error is typically encountered when there are too many active transactions. |
NodeRecoveryError | This is a temporary failure which was likely caused by a node recovery
in progress, some examples being when information sent
between an application and NDB is
lost, or when there is a distribution change. |
OverloadError | This type of error is often caused when there is insufficient logfile space. |
TimeoutExpired | A timeout, often caused by a deadlock. |
UnknownResultError | It is not known whether a transaction was committed. |
InternalError | A serious error has occurred in NDB itself. |
FunctionNotImplemented | The application attempted to use a function which is not yet implemented. |
UnknownErrorCode | This is seen where the NDB error handler cannot
determine the correct error code to report. |
NodeShutdown | This is caused by a node shutdown. |
SchemaObjectExists | The application attempted to create a schema object that already exists. |
InternalTemporary | A request was sent to a node other than the master. |
Related information specific to certain error conditions may be found in Section 5.2.2, “NDB Error Codes and Messages”, and in Section 5.2.3, “NDB Error Classifications”.
Parent class. NdbOperation
Description.
These options are passed to the
NdbRecord-based
primary key and scan takeover operation methods defined in the
NdbTransaction
and
NdbScanOperation
classes.
Most NdbTransaction::*Tuple() methods take a
supplementary sizeOfOptions parameter.
This is optional, and is intended to permit the interface
implementation to remain backward compatible with older
un-recompiled clients that may pass an older (smaller) version of
the OperationOptions structure. This effect is
achieved by passing sizeof(OperationOptions)
into this parameter.
Each option type is marked as present by setting the corresponding
bit in optionsPresent. (Only the option
types marked in optionsPresent need have
sensible data.) All data is copied out of the
OperationOptions structure (and any subtended
structures) at operation definition time. If no options are
required, then NULL may be passed instead.
Members. The makeup of this structure is shown here:

The individual members are described in more detail in the following table:
| Name | Type | Description |
|---|---|---|
optionsPresent | Uint64 | Which flags are present. |
| [...] | Flags:
The accepted names and values are shown in the following list:
| Type of flags. |
abortOption | AbortOption | An operation-specific abort option; necessary only if the default abortoption behavior is not satisfactory. |
extraGetValues | GetValueSpec* | Extra column values to be read. |
numExtraGetValues | Uint32 | Number of extra column values to be read. |
extraSetValues | SetValueSpec* | Extra column values to be set. |
numExtraSetValues | Uint32 | Number of extra column values to be set. |
partitionId | Uint32 | Limit the scan to the partition having this ID; alternatively, you can
supply an
Ndb::PartitionSpec
here. For index scans, partitioning information can be
supplied for each range. |
interpretedCode | const
NdbInterpretedCode* | Interpeted code to execute as part of the scan. |
anyValue | Uint32 | An anyValue to be used with this operation. This is
used by MySQL Cluster Replication to store the SQL
node's server ID. Beginning with MySQL Cluster NDB
7.0.17 and MySQL Cluster NDB 7.1.6, it is possible to start
the SQL node with the
--server-id-bits option,
which causes only some of the
server_id's bits to be
used for uniquely identifying it; if this option is set to
less than 32, the remaining bits can be used to store user
data |
customData | void* | Data pointer to associate with this operation. |
partitionInfo | const
Ndb::PartitionSpec* | Partition information for bounding this scan. |
sizeOfPartInfo | Uint32 | Size of the bounding partition information. |
For more information, see Section 2.3.25, “The NdbRecord Interface”.
Abstract
This section describes the PartitionSpec
structure.
Parent class. Ndb
Description.
PartitionSpec is a structure available in MySQL
Cluster NDB 6.3.24 and later. A given
PartitionSpec is used for describing a table
partition in terms of any one of the following criteria:
A specific partition ID for a table with user-defined partitioning.
An array made up of a table's distribution key values for a table with native partitioning.
(MySQL Cluster NDB 7.0.4 and later:) A row in
NdbRecordformat containing a natively partitioned table's distribution key values.
Attributes.
A PartitionSpec has two attributes, a
SpecType and a Spec which is
a data structure corresponding to that
SpecType, as shown in the following table:
SpecType Enumeration | SpecType Value (Uint32) | Data Structure | Description |
|---|---|---|---|
PS_NONE | 0 | none | No partitioning information is provided. |
PS_USER_DEFINED | 1 | UserDefined | For a table having user-defined partitioning, a specific partition is identified by its partition ID. |
PS_DISTR_KEY_PART_PTR | 2 | KeyPartPtr | For a table having native partitioning, an array containing the table's distribution key values is used to identify the partition. |
(MySQL Cluster NDB 7.0.4 and later:)
PS_DISTR_KEY_RECORD | 3 | KeyRecord | The partition is identified using a natively partitioned table's
distribution key values, as contained in a row given in
NdbRecord format. |
UserDefined structure.
This structure is used when the SpecType is
PS_USER_DEFINED.
| Attribute | Type | Description |
|---|---|---|
partitionId | Uint32 | The partition ID for the desired table. |
KeyPartPtr structure.
This structure is used when the SpecType is
PS_DISTR_KEY_PART_PTR.
| Attribute | Type | Description |
|---|---|---|
tableKeyParts | const Key_part_ptr* (see
Section 2.3.30, “The Key_part_ptr Structure”) | Pointer to the distribution key values for a table having native partitioning. |
xfrmbuf | void* | Pointer to a temporary buffer used for performing calculations. |
xfrmbuflen | Uint32 | Length of the temporary buffer. |
KeyRecord structure.
(MySQL Cluster NDB 7.0.4 and later:) This
structure is used when the SpecType is
PS_DISTR_KEY_RECORD.
| Attribute | Type | Description |
|---|---|---|
keyRecord | const NdbRecord* (see
Section 2.3.25, “The NdbRecord Interface”) | A row in NdbRecord format, containing a table's
distribution keys. |
keyRow | const char* | The distribution key data. |
xfrmbuf | void* | Pointer to a temporary buffer used for performing calculations. |
xfrmbuflen | Uint32 | Length of the temporary buffer. |
Definition from Ndb.hpp.
Because this is a fairly complex structure, we here provide the
original source-code definition of
PartitionSpec, as given in
storage/ndb/include/ndbapi/Ndb.hpp:
struct PartitionSpec
{
enum SpecType
{
PS_NONE = 0,
PS_USER_DEFINED = 1,
PS_DISTR_KEY_PART_PTR = 2
/* MySQL Cluster NDB 7.0.4 and later: */
,
PS_DISTR_KEY_RECORD = 3
};
Uint32 type;
union
{
struct {
Uint32 partitionId;
} UserDefined;
struct {
const Key_part_ptr* tableKeyParts;
void* xfrmbuf;
Uint32 xfrmbuflen;
} KeyPartPtr;
/* MySQL Cluster NDB 7.0.4 and later: */
struct {
const NdbRecord* keyRecord;
const char* keyRow;
void* xfrmbuf;
Uint32 xfrmbuflen;
} KeyRecord;
};
};
Parent class. NdbDictionary
Description.
This structure is used to specify columns and range offsets when
creating NdbRecord objects.
Members. The makeup of this structure is shown here:
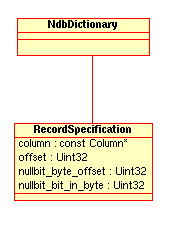
The individual members are described in more detail in the following table:
| Name | Type | Description |
|---|---|---|
column | const Column * | The column described by this entry (the column's maximum size defines
the field size for the row). Even when creating an
NdbRecord for an index, this must point
to a column obtained from the underlying table, and not from
the index itself. |
offset | Uint32 | The offset of data from the beginning of a row. For reading blobs, the
blob handle (NdbBlob*), rather than the
actual blob data, is written into the row. This means that
there must be at least sizeof(NdbBlob*)
must be available in the row. |
nullbit_byte_offset | Uint32 | The offset from the beginning of the row of the byte containing the
NULL bit. |
nullbit_bit_in_byte | Uint32 | NULL bit (0-7). |
nullbit_byte_offset and
nullbit_bit_in_byte are not used for
non-NULLable columns.
For more information, see Section 2.3.25, “The NdbRecord Interface”.
Parent class. NdbScanOperation
Description.
This data structure is used to pass options to the
NdbRecord-based
scanTable() and scanIndex()
methods of the NdbTransaction class (see
Section 2.3.19.2.20, “NdbTransaction::scanTable()”, and
Section 2.3.19.2.21, “NdbTransaction::scanIndex()”). Each option type
is marked as present by setting the corresponding bit in the
optionsPresent field. Only the option types
marked in the optionsPresent field need have
sensible data.
All data is copied out of the ScanOptions
structure (and any subtended structures) at operation definition
time. If no options are required, then NULL may
be passed as the ScanOptions pointer.
Members. The makeup of this structure is shown here:
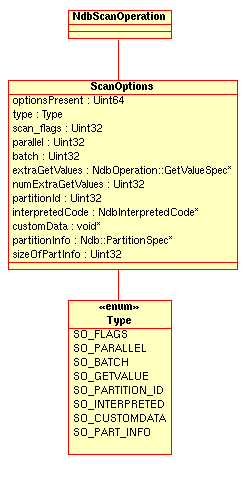
The individual members are described in more detail in the following table:
| Name | Type | Description |
|---|---|---|
optionsPresent | Uint64 | Which options are present. |
| [...] | Type:
| Type of options. |
scan_flags | Uint32 | Flags controlling scan behavior; see
Section 2.3.18.1, “The NdbScanOperation::ScanFlag Type”, for more
information. |
parallel | Uint32 | Scan parallelism; 0 (the default) sets maximum parallelism. |
batch | Uint32 | Batch size for transfers from data nodes to API nodes; 0 (the default) enables this to be selected automatically. |
extraGetValues | NdbOperation::GetValueSpec* | Extra values to be read for each row matching the sdcan criteria. |
numExtraGetValues | Uint32 | Number of extra values to be read. |
partitionId | Uint32 | Limit the scan to the partition having this ID; alternatively, you can
supply an
Ndb::PartitionSpec
here. For index scans, partitioning information can be
supplied for each range. |
interpretedCode | const
NdbInterpretedCode* | Interpeted code to execute as part of the scan. |
customData | void* | Data pointer to associate with this scan operation. |
partitionInfo | const
Ndb::PartitionSpec* | Partition information for bounding this scan. |
sizeOfPartInfo | Uint32 | Size of the bounding partition information. |
For more information, see Section 2.3.25, “The NdbRecord Interface”.
Parent class. NdbOperation
Description.
This structure is used to specify an extra value to set as part of
an
NdbRecord
operation.
Members. The makeup of this structure is shown here:
The individual members are described in more detail in the following table:
| Name | Type | Description |
|---|---|---|
column | const
| To specify an extra value to read, the caller must provide this, as well
as (optionally NULL)
appStorage pointer. |
value | void* | This must point to the value to be set, or to NULL if
the attribute is to be set to NULL. The
value pointed to is copied when the operation is defined,
and need not remain in place until execution time. |
Currently, blob values cannot be set using
SetValueSpec.
For more information, see Section 2.3.25, “The NdbRecord Interface”.
- 2.4.1. Using Synchronous Transactions
- 2.4.2. Using Synchronous Transactions and Multiple Clusters
- 2.4.3. Handling Errors and Retrying Transactions
- 2.4.4. Basic Scanning Example
- 2.4.5. Using Secondary Indexes in Scans
- 2.4.6. Using
NdbRecordwith Hash Indexes - 2.4.7. Comparing
RecAttrandNdbRecord - 2.4.8. NDB API Event Handling Example
- 2.4.9. Basic
BLOBHandling Example - 2.4.10. Handling
BLOBs UsingNdbRecord
This section provides code examples illustrating how to accomplish some basic tasks using the NDB API.
All of these examples can be compiled and run as provided, and produce sample output to demonstrate their effects.
This example illustrates the use of synchronous transactions in the NDB API.
The source code for this example can be found in
storage/ndb/ndbapi-examples/ndbapi_simple/ndbapi_simple.cpp
in the MySQL Cluster source tree.
The correct output from this program is as follows:
ATTR1 ATTR2 0 10 1 1 2 12 Detected that deleted tuple doesn't exist! 4 14 5 5 6 16 7 7 8 18 9 9
The program listing follows.
/*
* ndbapi_simple.cpp: Using synchronous transactions in NDB API
*
* Correct output from this program is:
*
* ATTR1 ATTR2
* 0 10
* 1 1
* 2 12
* Detected that deleted tuple doesn't exist!
* 4 14
* 5 5
* 6 16
* 7 7
* 8 18
* 9 9
*
*/
#include <mysql.h>
#include <mysqld_error.h>
#include <NdbApi.hpp>
// Used for cout
#include <stdio.h>
#include <iostream>
static void run_application(MYSQL &, Ndb_cluster_connection &);
#define PRINT_ERROR(code,msg) \
std::cout << "Error in " << __FILE__ << ", line: " << __LINE__ \
<< ", code: " << code \
<< ", msg: " << msg << "." << std::endl
#define MYSQLERROR(mysql) { \
PRINT_ERROR(mysql_errno(&mysql),mysql_error(&mysql)); \
exit(-1); }
#define APIERROR(error) { \
PRINT_ERROR(error.code,error.message); \
exit(-1); }
int main(int argc, char** argv)
{
if (argc != 3)
{
std::cout << "Arguments are <socket mysqld> <connect_string cluster>.\n";
exit(-1);
}
// ndb_init must be called first
ndb_init();
// connect to mysql server and cluster and run application
{
char * mysqld_sock = argv[1];
const char *connectstring = argv[2];
// Object representing the cluster
Ndb_cluster_connection cluster_connection(connectstring);
// Connect to cluster management server (ndb_mgmd)
if (cluster_connection.connect(4 /* retries */,
5 /* delay between retries */,
1 /* verbose */))
{
std::cout << "Cluster management server was not ready within 30 secs.\n";
exit(-1);
}
// Optionally connect and wait for the storage nodes (ndbd's)
if (cluster_connection.wait_until_ready(30,0) < 0)
{
std::cout << "Cluster was not ready within 30 secs.\n";
exit(-1);
}
// connect to mysql server
MYSQL mysql;
if ( !mysql_init(&mysql) ) {
std::cout << "mysql_init failed\n";
exit(-1);
}
if ( !mysql_real_connect(&mysql, "localhost", "root", "", "",
0, mysqld_sock, 0) )
MYSQLERROR(mysql);
// run the application code
run_application(mysql, cluster_connection);
}
ndb_end(0);
return 0;
}
static void create_table(MYSQL &);
static void do_insert(Ndb &);
static void do_update(Ndb &);
static void do_delete(Ndb &);
static void do_read(Ndb &);
static void run_application(MYSQL &mysql,
Ndb_cluster_connection &cluster_connection)
{
/********************************************
* Connect to database via mysql-c *ndb_examples
********************************************/
mysql_query(&mysql, "CREATE DATABASE ndb_examples");
if (mysql_query(&mysql, "USE ndb_examples") != 0) MYSQLERROR(mysql);
create_table(mysql);
/********************************************
* Connect to database via NdbApi *
********************************************/
// Object representing the database
Ndb myNdb( &cluster_connection, "ndb_examples" );
if (myNdb.init()) APIERROR(myNdb.getNdbError());
/*
* Do different operations on database
*/
do_insert(myNdb);
do_update(myNdb);
do_delete(myNdb);
do_read(myNdb);
}
/*********************************************************
* Create a table named api_simple if it does not exist *
*********************************************************/
static void create_table(MYSQL &mysql)
{
while (mysql_query(&mysql,
"CREATE TABLE"
" api_simple"
" (ATTR1 INT UNSIGNED NOT NULL PRIMARY KEY,"
" ATTR2 INT UNSIGNED NOT NULL)"
" ENGINE=NDB"))
{
if (mysql_errno(&mysql) == ER_TABLE_EXISTS_ERROR)
{
std::cout << "MySQL Cluster already has example table: api_simple. "
<< "Dropping it..." << std::endl;
mysql_query(&mysql, "DROP TABLE api_simple");
}
else MYSQLERROR(mysql);
}
}
/**************************************************************************
* Using 5 transactions, insert 10 tuples in table: (0,0),(1,1),...,(9,9) *
**************************************************************************/
static void do_insert(Ndb &myNdb)
{
const NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_simple");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
for (int i = 0; i < 5; i++) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->insertTuple();
myOperation->equal("ATTR1", i);
myOperation->setValue("ATTR2", i);
myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->insertTuple();
myOperation->equal("ATTR1", i+5);
myOperation->setValue("ATTR2", i+5);
if (myTransaction->execute( NdbTransaction::Commit ) == -1)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
}
}
/*****************************************************************
* Update the second attribute in half of the tuples (adding 10) *
*****************************************************************/
static void do_update(Ndb &myNdb)
{
const NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_simple");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
for (int i = 0; i < 10; i+=2) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->updateTuple();
myOperation->equal( "ATTR1", i );
myOperation->setValue( "ATTR2", i+10);
if( myTransaction->execute( NdbTransaction::Commit ) == -1 )
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
}
}
/*************************************************
* Delete one tuple (the one with primary key 3) *
*************************************************/
static void do_delete(Ndb &myNdb)
{
const NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_simple");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->deleteTuple();
myOperation->equal( "ATTR1", 3 );
if (myTransaction->execute(NdbTransaction::Commit) == -1)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
}
/*****************************
* Read and print all tuples *
*****************************/
static void do_read(Ndb &myNdb)
{
const NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_simple");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
std::cout << "ATTR1 ATTR2" << std::endl;
for (int i = 0; i < 10; i++) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->readTuple(NdbOperation::LM_Read);
myOperation->equal("ATTR1", i);
NdbRecAttr *myRecAttr= myOperation->getValue("ATTR2", NULL);
if (myRecAttr == NULL) APIERROR(myTransaction->getNdbError());
if(myTransaction->execute( NdbTransaction::Commit ) == -1)
APIERROR(myTransaction->getNdbError());
if (myTransaction->getNdbError().classification == NdbError::NoDataFound)
if (i == 3)
std::cout << "Detected that deleted tuple doesn't exist!" << std::endl;
else
APIERROR(myTransaction->getNdbError());
if (i != 3) {
printf(" %2d %2d\n", i, myRecAttr->u_32_value());
}
myNdb.closeTransaction(myTransaction);
}
}
This example demonstrates synchronous transactions and connecting to multiple clusters in a single NDB API application.
The source code for this program may be found in the MySQL Cluster
source tree, in the file
storage/ndb/ndbapi-examples/ndbapi_simple_dual/main.cpp.
The example file was formerly named
ndbapi_simple_dual.cpp.
/*
* ndbapi_simple_dual: Using synchronous transactions in NDB API
*
* Correct output from this program is:
*
* ATTR1 ATTR2
* 0 10
* 1 1
* 2 12
* Detected that deleted tuple doesn't exist!
* 4 14
* 5 5
* 6 16
* 7 7
* 8 18
* 9 9
* ATTR1 ATTR2
* 0 10
* 1 1
* 2 12
* Detected that deleted tuple doesn't exist!
* 4 14
* 5 5
* 6 16
* 7 7
* 8 18
* 9 9
*
*/
#include <mysql.h>
#include <NdbApi.hpp>
// Used for cout
#include <stdio.h>
#include <iostream>
static void run_application(MYSQL &, Ndb_cluster_connection &, const char* table, const char* db);
#define PRINT_ERROR(code,msg) \
std::cout << "Error in " << __FILE__ << ", line: " << __LINE__ \
<< ", code: " << code \
<< ", msg: " << msg << "." << std::endl
#define MYSQLERROR(mysql) { \
PRINT_ERROR(mysql_errno(&mysql),mysql_error(&mysql)); \
exit(-1); }
#define APIERROR(error) { \
PRINT_ERROR(error.code,error.message); \
exit(-1); }
int main(int argc, char** argv)
{
if (argc != 5)
{
std::cout << "Arguments are <socket mysqld1> <connect_string cluster 1> <socket mysqld2> <connect_string cluster 2>.\n";
exit(-1);
}
// ndb_init must be called first
ndb_init();
{
char * mysqld1_sock = argv[1];
const char *connectstring1 = argv[2];
char * mysqld2_sock = argv[3];
const char *connectstring2 = argv[4];
// Object representing the cluster 1
Ndb_cluster_connection cluster1_connection(connectstring1);
MYSQL mysql1;
// Object representing the cluster 2
Ndb_cluster_connection cluster2_connection(connectstring2);
MYSQL mysql2;
// connect to mysql server and cluster 1 and run application
// Connect to cluster 1 management server (ndb_mgmd)
if (cluster1_connection.connect(4 /* retries */,
5 /* delay between retries */,
1 /* verbose */))
{
std::cout << "Cluster 1 management server was not ready within 30 secs.\n";
exit(-1);
}
// Optionally connect and wait for the storage nodes (ndbd's)
if (cluster1_connection.wait_until_ready(30,0) < 0)
{
std::cout << "Cluster 1 was not ready within 30 secs.\n";
exit(-1);
}
// connect to mysql server in cluster 1
if ( !mysql_init(&mysql1) ) {
std::cout << "mysql_init failed\n";
exit(-1);
}
if ( !mysql_real_connect(&mysql1, "localhost", "root", "", "",
0, mysqld1_sock, 0) )
MYSQLERROR(mysql1);
// connect to mysql server and cluster 2 and run application
// Connect to cluster management server (ndb_mgmd)
if (cluster2_connection.connect(4 /* retries */,
5 /* delay between retries */,
1 /* verbose */))
{
std::cout << "Cluster 2 management server was not ready within 30 secs.\n";
exit(-1);
}
// Optionally connect and wait for the storage nodes (ndbd's)
if (cluster2_connection.wait_until_ready(30,0) < 0)
{
std::cout << "Cluster 2 was not ready within 30 secs.\n";
exit(-1);
}
// connect to mysql server in cluster 2
if ( !mysql_init(&mysql2) ) {
std::cout << "mysql_init failed\n";
exit(-1);
}
if ( !mysql_real_connect(&mysql2, "localhost", "root", "", "",
0, mysqld2_sock, 0) )
MYSQLERROR(mysql2);
// run the application code
run_application(mysql1, cluster1_connection, "api_simple_dual_1", "ndb_examples");
run_application(mysql2, cluster2_connection, "api_simple_dual_2", "ndb_examples");
}
// Note: all connections must have been destroyed before calling ndb_end()
ndb_end(0);
return 0;
}
static void create_table(MYSQL &, const char* table);
static void do_insert(Ndb &, const char* table);
static void do_update(Ndb &, const char* table);
static void do_delete(Ndb &, const char* table);
static void do_read(Ndb &, const char* table);
static void run_application(MYSQL &mysql,
Ndb_cluster_connection &cluster_connection,
const char* table,
const char* db)
{
/********************************************
* Connect to database via mysql-c *
********************************************/
char db_stmt[256];
sprintf(db_stmt, "CREATE DATABASE %s\n", db);
mysql_query(&mysql, db_stmt);
sprintf(db_stmt, "USE %s", db);
if (mysql_query(&mysql, db_stmt) != 0) MYSQLERROR(mysql);
create_table(mysql, table);
/********************************************
* Connect to database via NdbApi *
********************************************/
// Object representing the database
Ndb myNdb( &cluster_connection, db );
if (myNdb.init()) APIERROR(myNdb.getNdbError());
/*
* Do different operations on database
*/
do_insert(myNdb, table);
do_update(myNdb, table);
do_delete(myNdb, table);
do_read(myNdb, table);
/*
* Drop the table
*/
mysql_query(&mysql, db_stmt);
}
/*********************************************************
* Create a table named by table if it does not exist *
*********************************************************/
static void create_table(MYSQL &mysql, const char* table)
{
char create_stmt[256];
sprintf(create_stmt, "CREATE TABLE %s \
(ATTR1 INT UNSIGNED NOT NULL PRIMARY KEY,\
ATTR2 INT UNSIGNED NOT NULL)\
ENGINE=NDB", table);
if (mysql_query(&mysql, create_stmt))
MYSQLERROR(mysql);
}
/**************************************************************************
* Using 5 transactions, insert 10 tuples in table: (0,0),(1,1),...,(9,9) *
**************************************************************************/
static void do_insert(Ndb &myNdb, const char* table)
{
const NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable(table);
if (myTable == NULL)
APIERROR(myDict->getNdbError());
for (int i = 0; i < 5; i++) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->insertTuple();
myOperation->equal("ATTR1", i);
myOperation->setValue("ATTR2", i);
myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->insertTuple();
myOperation->equal("ATTR1", i+5);
myOperation->setValue("ATTR2", i+5);
if (myTransaction->execute( NdbTransaction::Commit ) == -1)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
}
}
/*****************************************************************
* Update the second attribute in half of the tuples (adding 10) *
*****************************************************************/
static void do_update(Ndb &myNdb, const char* table)
{
const NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable(table);
if (myTable == NULL)
APIERROR(myDict->getNdbError());
for (int i = 0; i < 10; i+=2) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->updateTuple();
myOperation->equal( "ATTR1", i );
myOperation->setValue( "ATTR2", i+10);
if( myTransaction->execute( NdbTransaction::Commit ) == -1 )
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
}
}
/*************************************************
* Delete one tuple (the one with primary key 3) *
*************************************************/
static void do_delete(Ndb &myNdb, const char* table)
{
const NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable(table);
if (myTable == NULL)
APIERROR(myDict->getNdbError());
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->deleteTuple();
myOperation->equal( "ATTR1", 3 );
if (myTransaction->execute(NdbTransaction::Commit) == -1)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
}
/*****************************
* Read and print all tuples *
*****************************/
static void do_read(Ndb &myNdb, const char* table)
{
const NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable(table);
if (myTable == NULL)
APIERROR(myDict->getNdbError());
std::cout << "ATTR1 ATTR2" << std::endl;
for (int i = 0; i < 10; i++) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->readTuple(NdbOperation::LM_Read);
myOperation->equal("ATTR1", i);
NdbRecAttr *myRecAttr= myOperation->getValue("ATTR2", NULL);
if (myRecAttr == NULL) APIERROR(myTransaction->getNdbError());
if(myTransaction->execute( NdbTransaction::Commit ) == -1)
if (i == 3) {
std::cout << "Detected that deleted tuple doesn't exist!" << std::endl;
} else {
APIERROR(myTransaction->getNdbError());
}
if (i != 3) {
printf(" %2d %2d\n", i, myRecAttr->u_32_value());
}
myNdb.closeTransaction(myTransaction);
}
}
This program demonstrates handling errors and retrying failed transactions using the NDB API.
The source code for this example can be found in
storage/ndb/ndbapi-examples/ndbapi_retries/ndbapi_retries.cpp
in the MySQL Cluster source tree.
There are many ways to program using the NDB API. In this example,
we perform two inserts in the same transaction using
NdbConnection::execute(NoCommit).
In NDB API applications, there are two types of failures to be taken into account:
Transaction failures: If nonpermanent, these can be handled by re-executing the transaction.
Application errors: These are indicated by
APIERROR; they must be handled by the application programmer.
//
// ndbapi_retries.cpp: Error handling and transaction retries
//
// There are many ways to program using the NDB API. In this example
// we execute two inserts in the same transaction using
// NdbConnection::execute(NoCommit).
//
// Transaction failing is handled by re-executing the transaction
// in case of non-permanent transaction errors.
// Application errors (i.e. errors at points marked with APIERROR)
// should be handled by the application programmer.
#include <mysql.h>
#include <mysqld_error.h>
#include <NdbApi.hpp>
// Used for cout
#include <iostream>
// Used for sleep (use your own version of sleep)
#include <unistd.h>
#define TIME_TO_SLEEP_BETWEEN_TRANSACTION_RETRIES 1
#define PRINT_ERROR(code,msg) \
std::cout << "Error in " << __FILE__ << ", line: " << __LINE__ \
<< ", code: " << code \
<< ", msg: " << msg << "." << std::endl
#define MYSQLERROR(mysql) { \
PRINT_ERROR(mysql_errno(&mysql),mysql_error(&mysql)); \
exit(-1); }
//
// APIERROR prints an NdbError object
//
#define APIERROR(error) \
{ std::cout << "API ERROR: " << error.code << " " << error.message \
<< std::endl \
<< " " << "Status: " << error.status \
<< ", Classification: " << error.classification << std::endl\
<< " " << "File: " << __FILE__ \
<< " (Line: " << __LINE__ << ")" << std::endl \
; \
}
//
// TRANSERROR prints all error info regarding an NdbTransaction
//
#define TRANSERROR(ndbTransaction) \
{ NdbError error = ndbTransaction->getNdbError(); \
std::cout << "TRANS ERROR: " << error.code << " " << error.message \
<< std::endl \
<< " " << "Status: " << error.status \
<< ", Classification: " << error.classification << std::endl \
<< " " << "File: " << __FILE__ \
<< " (Line: " << __LINE__ << ")" << std::endl \
; \
printTransactionError(ndbTransaction); \
}
void printTransactionError(NdbTransaction *ndbTransaction) {
const NdbOperation *ndbOp = NULL;
int i=0;
/****************************************************************
* Print NdbError object of every operations in the transaction *
****************************************************************/
while ((ndbOp = ndbTransaction->getNextCompletedOperation(ndbOp)) != NULL) {
NdbError error = ndbOp->getNdbError();
std::cout << " OPERATION " << i+1 << ": "
<< error.code << " " << error.message << std::endl
<< " Status: " << error.status
<< ", Classification: " << error.classification << std::endl;
i++;
}
}
//
// Example insert
// @param myNdb Ndb object representing NDB Cluster
// @param myTransaction NdbTransaction used for transaction
// @param myTable Table to insert into
// @param error NdbError object returned in case of errors
// @return -1 in case of failures, 0 otherwise
//
int insert(int transactionId, NdbTransaction* myTransaction,
const NdbDictionary::Table *myTable) {
NdbOperation *myOperation; // For other operations
myOperation = myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) return -1;
if (myOperation->insertTuple() ||
myOperation->equal("ATTR1", transactionId) ||
myOperation->setValue("ATTR2", transactionId)) {
APIERROR(myOperation->getNdbError());
exit(-1);
}
return myTransaction->execute(NdbTransaction::NoCommit);
}
//
// Execute function which re-executes (tries 10 times) the transaction
// if there are temporary errors (e.g. the NDB Cluster is overloaded).
// @return -1 failure, 1 success
//
int executeInsertTransaction(int transactionId, Ndb* myNdb,
const NdbDictionary::Table *myTable) {
int result = 0; // No result yet
int noOfRetriesLeft = 10;
NdbTransaction *myTransaction; // For other transactions
NdbError ndberror;
while (noOfRetriesLeft > 0 && !result) {
/*********************************
* Start and execute transaction *
*********************************/
myTransaction = myNdb->startTransaction();
if (myTransaction == NULL) {
APIERROR(myNdb->getNdbError());
ndberror = myNdb->getNdbError();
result = -1; // Failure
} else if (insert(transactionId, myTransaction, myTable) ||
insert(10000+transactionId, myTransaction, myTable) ||
myTransaction->execute(NdbTransaction::Commit)) {
TRANSERROR(myTransaction);
ndberror = myTransaction->getNdbError();
result = -1; // Failure
} else {
result = 1; // Success
}
/**********************************
* If failure, then analyze error *
**********************************/
if (result == -1) {
switch (ndberror.status) {
case NdbError::Success:
break;
case NdbError::TemporaryError:
std::cout << "Retrying transaction..." << std::endl;
sleep(TIME_TO_SLEEP_BETWEEN_TRANSACTION_RETRIES);
--noOfRetriesLeft;
result = 0; // No completed transaction yet
break;
case NdbError::UnknownResult:
case NdbError::PermanentError:
std::cout << "No retry of transaction..." << std::endl;
result = -1; // Permanent failure
break;
}
}
/*********************
* Close transaction *
*********************/
if (myTransaction != NULL) {
myNdb->closeTransaction(myTransaction);
}
}
if (result != 1) exit(-1);
return result;
}
/*********************************************************
* Create a table named api_retries if it does not exist *
*********************************************************/
static void create_table(MYSQL &mysql)
{
while(mysql_query(&mysql,
"CREATE TABLE "
" api_retries"
" (ATTR1 INT UNSIGNED NOT NULL PRIMARY KEY,"
" ATTR2 INT UNSIGNED NOT NULL)"
" ENGINE=NDB"))
{
if (mysql_errno(&mysql) == ER_TABLE_EXISTS_ERROR)
{
std::cout << "MySQL Cluster already has example table: api_scan. "
<< "Dropping it..." << std::endl;
mysql_query(&mysql, "DROP TABLE api_retries");
}
else MYSQLERROR(mysql);
}
}
int main(int argc, char** argv)
{
if (argc != 3)
{
std::cout << "Arguments are <socket mysqld> <connect_string cluster>.\n";
exit(-1);
}
char * mysqld_sock = argv[1];
const char *connectstring = argv[2];
ndb_init();
Ndb_cluster_connection *cluster_connection=
new Ndb_cluster_connection(connectstring); // Object representing the cluster
int r= cluster_connection->connect(5 /* retries */,
3 /* delay between retries */,
1 /* verbose */);
if (r > 0)
{
std::cout
<< "Cluster connect failed, possibly resolved with more retries.\n";
exit(-1);
}
else if (r < 0)
{
std::cout
<< "Cluster connect failed.\n";
exit(-1);
}
if (cluster_connection->wait_until_ready(30,30))
{
std::cout << "Cluster was not ready within 30 secs." << std::endl;
exit(-1);
}
// connect to mysql server
MYSQL mysql;
if ( !mysql_init(&mysql) ) {
std::cout << "mysql_init failed\n";
exit(-1);
}
if ( !mysql_real_connect(&mysql, "localhost", "root", "", "",
0, mysqld_sock, 0) )
MYSQLERROR(mysql);
/********************************************
* Connect to database via mysql-c *
********************************************/
mysql_query(&mysql, "CREATE DATABASE ndb_examples");
if (mysql_query(&mysql, "USE ndb_examples") != 0) MYSQLERROR(mysql);
create_table(mysql);
Ndb* myNdb= new Ndb( cluster_connection,
"ndb_examples" ); // Object representing the database
if (myNdb->init() == -1) {
APIERROR(myNdb->getNdbError());
exit(-1);
}
const NdbDictionary::Dictionary* myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_retries");
if (myTable == NULL)
{
APIERROR(myDict->getNdbError());
return -1;
}
/************************************
* Execute some insert transactions *
************************************/
std::cout << "Ready to insert rows. You will see notices for temporary "
"errors, permenant errors, and retries. \n";
for (int i = 10000; i < 20000; i++) {
executeInsertTransaction(i, myNdb, myTable);
}
std::cout << "Done.\n";
delete myNdb;
delete cluster_connection;
ndb_end(0);
return 0;
}
This example illustrates how to use the NDB scanning API. It shows
how to perform a scan, how to scan for an update, and how to scan
for a delete, making use of the NdbScanFilter
and NdbScanOperation classes.
(See Section 2.3.17, “The NdbScanFilter Class”, and
Section 2.3.18, “The NdbScanOperation Class”.)
The source code for this example may found in the MySQL Cluster
source tree, in the file
storage/ndb/ndbapi-examples/ndbapi_scan/ndbapi_scan.cpp.
This example makes use of the following classes and methods:
Ndb_cluster_connection:connect()wait_until_ready()
Ndb:init()getDictionary()startTransaction()closeTransaction()
NdbTransaction:getNdbScanOperation()execute()
NdbOperation:insertTuple()equal()setValue()
NdbScanOperation:getValue()readTuples()nextResult()deleteCurrentTuple()updateCurrentTuple()
NdbDictionary:Dictionary::getTable()Table::getColumn()Column::getLength()
NdbScanFilter:begin()eq()end()
/*
* ndbapi_scan.cpp:
* Illustrates how to use the scan api in the NDBAPI.
* The example shows how to do scan, scan for update and scan for delete
* using NdbScanFilter and NdbScanOperation
*
* Classes and methods used in this example:
*
* Ndb_cluster_connection
* connect()
* wait_until_ready()
*
* Ndb
* init()
* getDictionary()
* startTransaction()
* closeTransaction()
*
* NdbTransaction
* getNdbScanOperation()
* execute()
*
* NdbScanOperation
* getValue()
* readTuples()
* nextResult()
* deleteCurrentTuple()
* updateCurrentTuple()
*
* const NdbDictionary::Dictionary
* getTable()
*
* const NdbDictionary::Table
* getColumn()
*
* const NdbDictionary::Column
* getLength()
*
* NdbOperation
* insertTuple()
* equal()
* setValue()
*
* NdbScanFilter
* begin()
* eq()
* end()
*
*/
#include <mysql.h>
#include <mysqld_error.h>
#include <NdbApi.hpp>
// Used for cout
#include <iostream>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
/**
* Helper sleep function
*/
static void
milliSleep(int milliseconds){
struct timeval sleeptime;
sleeptime.tv_sec = milliseconds / 1000;
sleeptime.tv_usec = (milliseconds - (sleeptime.tv_sec * 1000)) * 1000000;
select(0, 0, 0, 0, &sleeptime);
}
/**
* Helper debugging macros
*/
#define PRINT_ERROR(code,msg) \
std::cout << "Error in " << __FILE__ << ", line: " << __LINE__ \
<< ", code: " << code \
<< ", msg: " << msg << "." << std::endl
#define MYSQLERROR(mysql) { \
PRINT_ERROR(mysql_errno(&mysql),mysql_error(&mysql)); \
exit(-1); }
#define APIERROR(error) { \
PRINT_ERROR(error.code,error.message); \
exit(-1); }
struct Car
{
/**
* Note memset, so that entire char-fields are cleared
* as all 20 bytes are significant (as type is char)
*/
Car() { memset(this, 0, sizeof(* this)); }
unsigned int reg_no;
char brand[20];
char color[20];
};
/**
* Function to drop table
*/
void drop_table(MYSQL &mysql)
{
if (mysql_query(&mysql, "DROP TABLE IF EXISTS api_scan"))
MYSQLERROR(mysql);
}
/**
* Function to create table
*/
void create_table(MYSQL &mysql)
{
while (mysql_query(&mysql,
"CREATE TABLE"
" api_scan"
" (REG_NO INT UNSIGNED NOT NULL,"
" BRAND CHAR(20) NOT NULL,"
" COLOR CHAR(20) NOT NULL,"
" PRIMARY KEY USING HASH (REG_NO))"
" ENGINE=NDB"))
{
if (mysql_errno(&mysql) != ER_TABLE_EXISTS_ERROR)
MYSQLERROR(mysql);
std::cout << "MySQL Cluster already has example table: api_scan. "
<< "Dropping it..." << std::endl;
drop_table(mysql);
}
}
int populate(Ndb * myNdb)
{
int i;
Car cars[15];
const NdbDictionary::Dictionary* myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_scan");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
/**
* Five blue mercedes
*/
for (i = 0; i < 5; i++)
{
cars[i].reg_no = i;
sprintf(cars[i].brand, "Mercedes");
sprintf(cars[i].color, "Blue");
}
/**
* Five black bmw
*/
for (i = 5; i < 10; i++)
{
cars[i].reg_no = i;
sprintf(cars[i].brand, "BMW");
sprintf(cars[i].color, "Black");
}
/**
* Five pink toyotas
*/
for (i = 10; i < 15; i++)
{
cars[i].reg_no = i;
sprintf(cars[i].brand, "Toyota");
sprintf(cars[i].color, "Pink");
}
NdbTransaction* myTrans = myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
for (i = 0; i < 15; i++)
{
NdbOperation* myNdbOperation = myTrans->getNdbOperation(myTable);
if (myNdbOperation == NULL)
APIERROR(myTrans->getNdbError());
myNdbOperation->insertTuple();
myNdbOperation->equal("REG_NO", cars[i].reg_no);
myNdbOperation->setValue("BRAND", cars[i].brand);
myNdbOperation->setValue("COLOR", cars[i].color);
}
int check = myTrans->execute(NdbTransaction::Commit);
myTrans->close();
return check != -1;
}
int scan_delete(Ndb* myNdb,
int column,
const char * color)
{
// Scan all records exclusive and delete
// them one by one
int retryAttempt = 0;
const int retryMax = 10;
int deletedRows = 0;
int check;
NdbError err;
NdbTransaction *myTrans;
NdbScanOperation *myScanOp;
const NdbDictionary::Dictionary* myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_scan");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
/**
* Loop as long as :
* retryMax not reached
* failed operations due to TEMPORARY erros
*
* Exit loop;
* retyrMax reached
* Permanent error (return -1)
*/
while (true)
{
if (retryAttempt >= retryMax)
{
std::cout << "ERROR: has retried this operation " << retryAttempt
<< " times, failing!" << std::endl;
return -1;
}
myTrans = myNdb->startTransaction();
if (myTrans == NULL)
{
const NdbError err = myNdb->getNdbError();
if (err.status == NdbError::TemporaryError)
{
milliSleep(50);
retryAttempt++;
continue;
}
std::cout << err.message << std::endl;
return -1;
}
/**
* Get a scan operation.
*/
myScanOp = myTrans->getNdbScanOperation(myTable);
if (myScanOp == NULL)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
/**
* Define a result set for the scan.
*/
if(myScanOp->readTuples(NdbOperation::LM_Exclusive) != 0)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
/**
* Use NdbScanFilter to define a search critera
*/
NdbScanFilter filter(myScanOp) ;
if(filter.begin(NdbScanFilter::AND) < 0 ||
filter.cmp(NdbScanFilter::COND_EQ, column, color, 20) < 0 ||
filter.end() < 0)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
/**
* Start scan (NoCommit since we are only reading at this stage);
*/
if(myTrans->execute(NdbTransaction::NoCommit) != 0){
err = myTrans->getNdbError();
if(err.status == NdbError::TemporaryError){
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
milliSleep(50);
continue;
}
std::cout << err.code << std::endl;
std::cout << myTrans->getNdbError().code << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
/**
* start of loop: nextResult(true) means that "parallelism" number of
* rows are fetched from NDB and cached in NDBAPI
*/
while((check = myScanOp->nextResult(true)) == 0){
do
{
if (myScanOp->deleteCurrentTuple() != 0)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
deletedRows++;
/**
* nextResult(false) means that the records
* cached in the NDBAPI are modified before
* fetching more rows from NDB.
*/
} while((check = myScanOp->nextResult(false)) == 0);
/**
* NoCommit when all cached tuple have been marked for deletion
*/
if(check != -1)
{
check = myTrans->execute(NdbTransaction::NoCommit);
}
/**
* Check for errors
*/
err = myTrans->getNdbError();
if(check == -1)
{
if(err.status == NdbError::TemporaryError)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
milliSleep(50);
continue;
}
}
/**
* End of loop
*/
}
/**
* Commit all prepared operations
*/
if(myTrans->execute(NdbTransaction::Commit) == -1)
{
if(err.status == NdbError::TemporaryError){
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
milliSleep(50);
continue;
}
}
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return 0;
}
if(myTrans!=0)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
}
return -1;
}
int scan_update(Ndb* myNdb,
int update_column,
const char * before_color,
const char * after_color)
{
// Scan all records exclusive and update
// them one by one
int retryAttempt = 0;
const int retryMax = 10;
int updatedRows = 0;
int check;
NdbError err;
NdbTransaction *myTrans;
NdbScanOperation *myScanOp;
const NdbDictionary::Dictionary* myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_scan");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
/**
* Loop as long as :
* retryMax not reached
* failed operations due to TEMPORARY erros
*
* Exit loop;
* retryMax reached
* Permanent error (return -1)
*/
while (true)
{
if (retryAttempt >= retryMax)
{
std::cout << "ERROR: has retried this operation " << retryAttempt
<< " times, failing!" << std::endl;
return -1;
}
myTrans = myNdb->startTransaction();
if (myTrans == NULL)
{
const NdbError err = myNdb->getNdbError();
if (err.status == NdbError::TemporaryError)
{
milliSleep(50);
retryAttempt++;
continue;
}
std::cout << err.message << std::endl;
return -1;
}
/**
* Get a scan operation.
*/
myScanOp = myTrans->getNdbScanOperation(myTable);
if (myScanOp == NULL)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
/**
* Define a result set for the scan.
*/
if( myScanOp->readTuples(NdbOperation::LM_Exclusive) )
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
/**
* Use NdbScanFilter to define a search critera
*/
NdbScanFilter filter(myScanOp) ;
if(filter.begin(NdbScanFilter::AND) < 0 ||
filter.cmp(NdbScanFilter::COND_EQ, update_column, before_color, 20) <0||
filter.end() <0)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
/**
* Start scan (NoCommit since we are only reading at this stage);
*/
if(myTrans->execute(NdbTransaction::NoCommit) != 0)
{
err = myTrans->getNdbError();
if(err.status == NdbError::TemporaryError){
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
milliSleep(50);
continue;
}
std::cout << myTrans->getNdbError().code << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
/**
* start of loop: nextResult(true) means that "parallelism" number of
* rows are fetched from NDB and cached in NDBAPI
*/
while((check = myScanOp->nextResult(true)) == 0){
do {
/**
* Get update operation
*/
NdbOperation * myUpdateOp = myScanOp->updateCurrentTuple();
if (myUpdateOp == 0)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
updatedRows++;
/**
* do the update
*/
myUpdateOp->setValue(update_column, after_color);
/**
* nextResult(false) means that the records
* cached in the NDBAPI are modified before
* fetching more rows from NDB.
*/
} while((check = myScanOp->nextResult(false)) == 0);
/**
* NoCommit when all cached tuple have been updated
*/
if(check != -1)
{
check = myTrans->execute(NdbTransaction::NoCommit);
}
/**
* Check for errors
*/
err = myTrans->getNdbError();
if(check == -1)
{
if(err.status == NdbError::TemporaryError){
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
milliSleep(50);
continue;
}
}
/**
* End of loop
*/
}
/**
* Commit all prepared operations
*/
if(myTrans->execute(NdbTransaction::Commit) == -1)
{
if(err.status == NdbError::TemporaryError){
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
milliSleep(50);
continue;
}
}
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return 0;
}
if(myTrans!=0)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
}
return -1;
}
int scan_print(Ndb * myNdb)
{
// Scan all records exclusive and update
// them one by one
int retryAttempt = 0;
const int retryMax = 10;
int fetchedRows = 0;
int check;
NdbError err;
NdbTransaction *myTrans;
NdbScanOperation *myScanOp;
/* Result of reading attribute value, three columns:
REG_NO, BRAND, and COLOR
*/
NdbRecAttr * myRecAttr[3];
const NdbDictionary::Dictionary* myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_scan");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
/**
* Loop as long as :
* retryMax not reached
* failed operations due to TEMPORARY erros
*
* Exit loop;
* retyrMax reached
* Permanent error (return -1)
*/
while (true)
{
if (retryAttempt >= retryMax)
{
std::cout << "ERROR: has retried this operation " << retryAttempt
<< " times, failing!" << std::endl;
return -1;
}
myTrans = myNdb->startTransaction();
if (myTrans == NULL)
{
const NdbError err = myNdb->getNdbError();
if (err.status == NdbError::TemporaryError)
{
milliSleep(50);
retryAttempt++;
continue;
}
std::cout << err.message << std::endl;
return -1;
}
/*
* Define a scan operation.
* NDBAPI.
*/
myScanOp = myTrans->getNdbScanOperation(myTable);
if (myScanOp == NULL)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
/**
* Read without locks, without being placed in lock queue
*/
if( myScanOp->readTuples(NdbOperation::LM_CommittedRead) == -1)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
/**
* Define storage for fetched attributes.
* E.g., the resulting attributes of executing
* myOp->getValue("REG_NO") is placed in myRecAttr[0].
* No data exists in myRecAttr until transaction has commited!
*/
myRecAttr[0] = myScanOp->getValue("REG_NO");
myRecAttr[1] = myScanOp->getValue("BRAND");
myRecAttr[2] = myScanOp->getValue("COLOR");
if(myRecAttr[0] ==NULL || myRecAttr[1] == NULL || myRecAttr[2]==NULL)
{
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
/**
* Start scan (NoCommit since we are only reading at this stage);
*/
if(myTrans->execute(NdbTransaction::NoCommit) != 0){
err = myTrans->getNdbError();
if(err.status == NdbError::TemporaryError){
std::cout << myTrans->getNdbError().message << std::endl;
myNdb->closeTransaction(myTrans);
milliSleep(50);
continue;
}
std::cout << err.code << std::endl;
std::cout << myTrans->getNdbError().code << std::endl;
myNdb->closeTransaction(myTrans);
return -1;
}
/**
* start of loop: nextResult(true) means that "parallelism" number of
* rows are fetched from NDB and cached in NDBAPI
*/
while((check = myScanOp->nextResult(true)) == 0){
do {
fetchedRows++;
/**
* print REG_NO unsigned int
*/
std::cout << myRecAttr[0]->u_32_value() << "\t";
/**
* print BRAND character string
*/
std::cout << myRecAttr[1]->aRef() << "\t";
/**
* print COLOR character string
*/
std::cout << myRecAttr[2]->aRef() << std::endl;
/**
* nextResult(false) means that the records
* cached in the NDBAPI are modified before
* fetching more rows from NDB.
*/
} while((check = myScanOp->nextResult(false)) == 0);
}
myNdb->closeTransaction(myTrans);
return 1;
}
return -1;
}
int main(int argc, char** argv)
{
if (argc != 3)
{
std::cout << "Arguments are <socket mysqld> <connect_string cluster>.\n";
exit(-1);
}
char * mysqld_sock = argv[1];
const char *connectstring = argv[2];
ndb_init();
MYSQL mysql;
/**************************************************************
* Connect to mysql server and create table *
**************************************************************/
{
if ( !mysql_init(&mysql) ) {
std::cout << "mysql_init failed\n";
exit(-1);
}
if ( !mysql_real_connect(&mysql, "localhost", "root", "", "",
0, mysqld_sock, 0) )
MYSQLERROR(mysql);
mysql_query(&mysql, "CREATE DATABASE ndb_examples");
if (mysql_query(&mysql, "USE ndb_examples") != 0) MYSQLERROR(mysql);
create_table(mysql);
}
/**************************************************************
* Connect to ndb cluster *
**************************************************************/
Ndb_cluster_connection cluster_connection(connectstring);
if (cluster_connection.connect(4, 5, 1))
{
std::cout << "Unable to connect to cluster within 30 secs." << std::endl;
exit(-1);
}
// Optionally connect and wait for the storage nodes (ndbd's)
if (cluster_connection.wait_until_ready(30,0) < 0)
{
std::cout << "Cluster was not ready within 30 secs.\n";
exit(-1);
}
Ndb myNdb(&cluster_connection,"ndb_examples");
if (myNdb.init(1024) == -1) { // Set max 1024 parallel transactions
APIERROR(myNdb.getNdbError());
exit(-1);
}
/*******************************************
* Check table definition *
*******************************************/
int column_color;
{
const NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *t= myDict->getTable("api_scan");
if(t == NULL)
{
std::cout << "Dictionary::getTable() failed.";
exit(-1);
}
Car car;
if (t->getColumn("COLOR")->getLength() != sizeof(car.color) ||
t->getColumn("BRAND")->getLength() != sizeof(car.brand))
{
std::cout << "Wrong table definition" << std::endl;
exit(-1);
}
column_color= t->getColumn("COLOR")->getColumnNo();
}
if(populate(&myNdb) > 0)
std::cout << "populate: Success!" << std::endl;
if(scan_print(&myNdb) > 0)
std::cout << "scan_print: Success!" << std::endl << std::endl;
std::cout << "Going to delete all pink cars!" << std::endl;
{
/**
* Note! color needs to be of exact the same size as column defined
*/
Car tmp;
sprintf(tmp.color, "Pink");
if(scan_delete(&myNdb, column_color, tmp.color) > 0)
std::cout << "scan_delete: Success!" << std::endl << std::endl;
}
if(scan_print(&myNdb) > 0)
std::cout << "scan_print: Success!" << std::endl << std::endl;
{
/**
* Note! color1 & 2 need to be of exact the same size as column defined
*/
Car tmp1, tmp2;
sprintf(tmp1.color, "Blue");
sprintf(tmp2.color, "Black");
std::cout << "Going to update all " << tmp1.color
<< " cars to " << tmp2.color << " cars!" << std::endl;
if(scan_update(&myNdb, column_color, tmp1.color, tmp2.color) > 0)
std::cout << "scan_update: Success!" << std::endl << std::endl;
}
if(scan_print(&myNdb) > 0)
std::cout << "scan_print: Success!" << std::endl << std::endl;
/**
* Drop table
*/
drop_table(mysql);
return 0;
}
This program illustrates how to use secondary indexes in the NDB API.
The source code for this example may be found in the MySQL Cluster
source tree, in
storage/ndb/ndbapi-examples/ndbapi_simple_index/main.cpp.
This file was previously named
ndbapi_simple_index.cpp.
The correct output from this program is shown here:
ATTR1 ATTR2 0 10 1 1 2 12 Detected that deleted tuple doesn't exist! 4 14 5 5 6 16 7 7 8 18 9 9
The listing for this program is shown here:
#include <mysql.h>
#include <mysqld_error.h>
#include <NdbApi.hpp>
// Used for cout
#include <stdio.h>
#include <iostream>
#define PRINT_ERROR(code,msg) \
std::cout << "Error in " << __FILE__ << ", line: " << __LINE__ \
<< ", code: " << code \
<< ", msg: " << msg << "." << std::endl
#define MYSQLERROR(mysql) { \
PRINT_ERROR(mysql_errno(&mysql),mysql_error(&mysql)); \
exit(-1); }
#define APIERROR(error) { \
PRINT_ERROR(error.code,error.message); \
exit(-1); }
int main(int argc, char** argv)
{
if (argc != 3)
{
std::cout << "Arguments are <socket mysqld> <connect_string cluster>.\n";
exit(-1);
}
char * mysqld_sock = argv[1];
const char *connectstring = argv[2];
ndb_init();
MYSQL mysql;
/**************************************************************
* Connect to mysql server and create table *
**************************************************************/
{
if ( !mysql_init(&mysql) ) {
std::cout << "mysql_init failed\n";
exit(-1);
}
if ( !mysql_real_connect(&mysql, "localhost", "root", "", "",
0, mysqld_sock, 0) )
MYSQLERROR(mysql);
mysql_query(&mysql, "CREATE DATABASE ndb_examples_1");
if (mysql_query(&mysql, "USE ndb_examples") != 0) MYSQLERROR(mysql);
while (mysql_query(&mysql,
"CREATE TABLE"
" api_simple_index"
" (ATTR1 INT UNSIGNED,"
" ATTR2 INT UNSIGNED NOT NULL,"
" PRIMARY KEY USING HASH (ATTR1),"
" UNIQUE MYINDEXNAME USING HASH (ATTR2))"
" ENGINE=NDB"))
{
if (mysql_errno(&mysql) == ER_TABLE_EXISTS_ERROR)
{
std::cout << "MySQL Cluster already has example table: api_scan. "
<< "Dropping it..." << std::endl;
mysql_query(&mysql, "DROP TABLE api_simple_index");
}
else MYSQLERROR(mysql);
}
}
/**************************************************************
* Connect to ndb cluster *
**************************************************************/
Ndb_cluster_connection *cluster_connection=
new Ndb_cluster_connection(connectstring); // Object representing the cluster
if (cluster_connection->connect(5,3,1))
{
std::cout << "Connect to cluster management server failed.\n";
exit(-1);
}
if (cluster_connection->wait_until_ready(30,30))
{
std::cout << "Cluster was not ready within 30 secs.\n";
exit(-1);
}
Ndb* myNdb = new Ndb( cluster_connection,
"ndb_examples" ); // Object representing the database
if (myNdb->init() == -1) {
APIERROR(myNdb->getNdbError());
exit(-1);
}
const NdbDictionary::Dictionary* myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_simple_index");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
const NdbDictionary::Index *myIndex= myDict->getIndex("MYINDEXNAME$unique","api_simple_index");
if (myIndex == NULL)
APIERROR(myDict->getNdbError());
/**************************************************************************
* Using 5 transactions, insert 10 tuples in table: (0,0),(1,1),...,(9,9) *
**************************************************************************/
for (int i = 0; i < 5; i++) {
NdbTransaction *myTransaction= myNdb->startTransaction();
if (myTransaction == NULL) APIERROR(myNdb->getNdbError());
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->insertTuple();
myOperation->equal("ATTR1", i);
myOperation->setValue("ATTR2", i);
myOperation = myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->insertTuple();
myOperation->equal("ATTR1", i+5);
myOperation->setValue("ATTR2", i+5);
if (myTransaction->execute( NdbTransaction::Commit ) == -1)
APIERROR(myTransaction->getNdbError());
myNdb->closeTransaction(myTransaction);
}
/*****************************************
* Read and print all tuples using index *
*****************************************/
std::cout << "ATTR1 ATTR2" << std::endl;
for (int i = 0; i < 10; i++) {
NdbTransaction *myTransaction= myNdb->startTransaction();
if (myTransaction == NULL) APIERROR(myNdb->getNdbError());
NdbIndexOperation *myIndexOperation=
myTransaction->getNdbIndexOperation(myIndex);
if (myIndexOperation == NULL) APIERROR(myTransaction->getNdbError());
myIndexOperation->readTuple(NdbOperation::LM_Read);
myIndexOperation->equal("ATTR2", i);
NdbRecAttr *myRecAttr= myIndexOperation->getValue("ATTR1", NULL);
if (myRecAttr == NULL) APIERROR(myTransaction->getNdbError());
if(myTransaction->execute( NdbTransaction::Commit,
NdbOperation::AbortOnError ) != -1)
printf(" %2d %2d\n", myRecAttr->u_32_value(), i);
myNdb->closeTransaction(myTransaction);
}
/*****************************************************************
* Update the second attribute in half of the tuples (adding 10) *
*****************************************************************/
for (int i = 0; i < 10; i+=2) {
NdbTransaction *myTransaction= myNdb->startTransaction();
if (myTransaction == NULL) APIERROR(myNdb->getNdbError());
NdbIndexOperation *myIndexOperation=
myTransaction->getNdbIndexOperation(myIndex);
if (myIndexOperation == NULL) APIERROR(myTransaction->getNdbError());
myIndexOperation->updateTuple();
myIndexOperation->equal( "ATTR2", i );
myIndexOperation->setValue( "ATTR2", i+10);
if( myTransaction->execute( NdbTransaction::Commit ) == -1 )
APIERROR(myTransaction->getNdbError());
myNdb->closeTransaction(myTransaction);
}
/*************************************************
* Delete one tuple (the one with primary key 3) *
*************************************************/
{
NdbTransaction *myTransaction= myNdb->startTransaction();
if (myTransaction == NULL) APIERROR(myNdb->getNdbError());
NdbIndexOperation *myIndexOperation=
myTransaction->getNdbIndexOperation(myIndex);
if (myIndexOperation == NULL) APIERROR(myTransaction->getNdbError());
myIndexOperation->deleteTuple();
myIndexOperation->equal( "ATTR2", 3 );
if (myTransaction->execute(NdbTransaction::Commit) == -1)
APIERROR(myTransaction->getNdbError());
myNdb->closeTransaction(myTransaction);
}
/*****************************
* Read and print all tuples *
*****************************/
{
std::cout << "ATTR1 ATTR2" << std::endl;
for (int i = 0; i < 10; i++) {
NdbTransaction *myTransaction= myNdb->startTransaction();
if (myTransaction == NULL) APIERROR(myNdb->getNdbError());
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->readTuple(NdbOperation::LM_Read);
myOperation->equal("ATTR1", i);
NdbRecAttr *myRecAttr= myOperation->getValue("ATTR2", NULL);
if (myRecAttr == NULL) APIERROR(myTransaction->getNdbError());
if(myTransaction->execute( NdbTransaction::Commit,
NdbOperation::AbortOnError ) == -1)
if (i == 3) {
std::cout << "Detected that deleted tuple doesn't exist!\n";
} else {
APIERROR(myTransaction->getNdbError());
}
if (i != 3) {
printf(" %2d %2d\n", i, myRecAttr->u_32_value());
}
myNdb->closeTransaction(myTransaction);
}
}
delete myNdb;
delete cluster_connection;
ndb_end(0);
return 0;
}
This program illustrates how to use secondary indexes in the NDB API with the aid of the NdbRecord interface introduced in MySQL-5.1.18-6.2.3..
The source code for this example may be found in the MySQL Cluster
source trees, in the file
storage/ndb/ndbapi-examples/ndbapi_s_i_ndbrecord/main.cpp.
When run on a cluster having 2 data nodes, the correct output from this program is as shown here:
ATTR1 ATTR2 0 0 (frag=0) 1 1 (frag=1) 2 2 (frag=1) 3 3 (frag=0) 4 4 (frag=1) 5 5 (frag=1) 6 6 (frag=0) 7 7 (frag=0) 8 8 (frag=1) 9 9 (frag=0) ATTR1 ATTR2 0 10 1 1 2 12 Detected that deleted tuple doesn't exist! 4 14 5 5 6 16 7 7 8 18 9 9
The program listing is shown here:
//
// ndbapi_simple_index_ndbrecord.cpp: Using secondary unique hash indexes
// in NDB API, utilising the NdbRecord interface.
//
// Correct output from this program is (from a two-node cluster):
//
// ATTR1 ATTR2
// 0 0 (frag=0)
// 1 1 (frag=1)
// 2 2 (frag=1)
// 3 3 (frag=0)
// 4 4 (frag=1)
// 5 5 (frag=1)
// 6 6 (frag=0)
// 7 7 (frag=0)
// 8 8 (frag=1)
// 9 9 (frag=0)
// ATTR1 ATTR2
// 0 10
// 1 1
// 2 12
// Detected that deleted tuple doesn't exist!
// 4 14
// 5 5
// 6 16
// 7 7
// 8 18
// 9 9
#include <mysql.h>
#include <NdbApi.hpp>
// Used for cout
#include <stdio.h>
#include <iostream>
#define PRINT_ERROR(code,msg) \
std::cout << "Error in " << __FILE__ << ", line: " << __LINE__ \
<< ", code: " << code \
<< ", msg: " << msg << "." << std::endl
#define MYSQLERROR(mysql) { \
PRINT_ERROR(mysql_errno(&mysql),mysql_error(&mysql)); \
exit(1); }
#define APIERROR(error) { \
PRINT_ERROR(error.code,error.message); \
exit(1); }
/* C struct representing layout of data from table
* api_s_i_ndbrecord in memory
* This can make it easier to work with rows in the application,
* but is not necessary - NdbRecord can map columns to any
* pattern of offsets.
* In this program, the same row offsets are used for columns
* specified as part of a key, and as part of an attribute or
* result. This makes the example simpler, but is not
* essential.
*/
struct MyTableRow
{
unsigned int attr1;
unsigned int attr2;
};
int main(int argc, char** argv)
{
if (argc != 3)
{
std::cout << "Arguments are <socket mysqld> <connect_string cluster>.\n";
exit(1);
}
char * mysqld_sock = argv[1];
const char *connectstring = argv[2];
ndb_init();
MYSQL mysql;
/**************************************************************
* Connect to mysql server and create table *
**************************************************************/
{
if ( !mysql_init(&mysql) ) {
std::cout << "mysql_init failed\n";
exit(1);
}
if ( !mysql_real_connect(&mysql, "localhost", "root", "", "",
0, mysqld_sock, 0) )
MYSQLERROR(mysql);
mysql_query(&mysql, "CREATE DATABASE ndb_examples");
if (mysql_query(&mysql, "USE ndb_examples") != 0)
MYSQLERROR(mysql);
mysql_query(&mysql, "DROP TABLE api_s_i_ndbrecord");
if (mysql_query(&mysql,
"CREATE TABLE"
" api_s_i_ndbrecord"
" (ATTR1 INT UNSIGNED,"
" ATTR2 INT UNSIGNED NOT NULL,"
" PRIMARY KEY USING HASH (ATTR1),"
" UNIQUE MYINDEXNAME USING HASH (ATTR2))"
" ENGINE=NDB"))
MYSQLERROR(mysql);
}
/**************************************************************
* Connect to ndb cluster *
**************************************************************/
Ndb_cluster_connection *cluster_connection=
new Ndb_cluster_connection(connectstring); // Object representing the cluster
if (cluster_connection->connect(5,3,1))
{
std::cout << "Connect to cluster management server failed.\n";
exit(1);
}
if (cluster_connection->wait_until_ready(30,30))
{
std::cout << "Cluster was not ready within 30 secs.\n";
exit(1);
}
Ndb* myNdb = new Ndb( cluster_connection,
"ndb_examples" ); // Object representing the database
if (myNdb->init() == -1) {
APIERROR(myNdb->getNdbError());
exit(1);
}
NdbDictionary::Dictionary* myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_s_i_ndbrecord");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
const NdbDictionary::Index *myIndex= myDict->getIndex("MYINDEXNAME$unique","api_s_i_ndbrecord");
if (myIndex == NULL)
APIERROR(myDict->getNdbError());
/* Create NdbRecord descriptors. */
const NdbDictionary::Column *col1= myTable->getColumn("ATTR1");
if (col1 == NULL)
APIERROR(myDict->getNdbError());
const NdbDictionary::Column *col2= myTable->getColumn("ATTR2");
if (col2 == NULL)
APIERROR(myDict->getNdbError());
/* NdbRecord for primary key lookup. */
NdbDictionary::RecordSpecification spec[2];
spec[0].column= col1;
spec[0].offset= offsetof(MyTableRow, attr1);
// So that it goes nicely into the struct
spec[0].nullbit_byte_offset= 0;
spec[0].nullbit_bit_in_byte= 0;
const NdbRecord *pk_record=
myDict->createRecord(myTable, spec, 1, sizeof(spec[0]));
if (pk_record == NULL)
APIERROR(myDict->getNdbError());
/* NdbRecord for all table attributes (insert/read). */
spec[0].column= col1;
spec[0].offset= offsetof(MyTableRow, attr1);
spec[0].nullbit_byte_offset= 0;
spec[0].nullbit_bit_in_byte= 0;
spec[1].column= col2;
spec[1].offset= offsetof(MyTableRow, attr2);
spec[1].nullbit_byte_offset= 0;
spec[1].nullbit_bit_in_byte= 0;
const NdbRecord *attr_record=
myDict->createRecord(myTable, spec, 2, sizeof(spec[0]));
if (attr_record == NULL)
APIERROR(myDict->getNdbError());
/* NdbRecord for unique key lookup. */
spec[0].column= col2;
spec[0].offset= offsetof(MyTableRow, attr2);
spec[0].nullbit_byte_offset= 0;
spec[0].nullbit_bit_in_byte= 0;
const NdbRecord *key_record=
myDict->createRecord(myIndex, spec, 1, sizeof(spec[0]));
if (key_record == NULL)
APIERROR(myDict->getNdbError());
MyTableRow row;
/**************************************************************************
* Using 5 transactions, insert 10 tuples in table: (0,0),(1,1),...,(9,9) *
**************************************************************************/
for (int i = 0; i < 5; i++) {
NdbTransaction *myTransaction= myNdb->startTransaction();
if (myTransaction == NULL) APIERROR(myNdb->getNdbError());
/*
We initialise the row data and pass to each insertTuple operation
The data is copied in the call to insertTuple and so the original
row object can be reused for the two operations.
*/
row.attr1= row.attr2= i;
const NdbOperation *myOperation=
myTransaction->insertTuple(attr_record, (const char*)&row);
if (myOperation == NULL)
APIERROR(myTransaction->getNdbError());
row.attr1= row.attr2= i+5;
myOperation=
myTransaction->insertTuple(attr_record, (const char*)&row);
if (myOperation == NULL)
APIERROR(myTransaction->getNdbError());
if (myTransaction->execute( NdbTransaction::Commit ) == -1)
APIERROR(myTransaction->getNdbError());
myNdb->closeTransaction(myTransaction);
}
/*****************************************
* Read and print all tuples using index *
*****************************************/
std::cout << "ATTR1 ATTR2" << std::endl;
for (int i = 0; i < 10; i++) {
NdbTransaction *myTransaction= myNdb->startTransaction();
if (myTransaction == NULL)
APIERROR(myNdb->getNdbError());
/* The optional OperationOptions parameter to NdbRecord methods
* can be used to specify extra reads of columns which are not in
* the NdbRecord specification, which need to be stored somewhere
* other than specified in the NdbRecord specification, or
* which cannot be specified as part of an NdbRecord (pseudo
* columns)
*/
Uint32 frag;
NdbOperation::GetValueSpec getSpec[1];
getSpec[0].column=NdbDictionary::Column::FRAGMENT;
getSpec[0].appStorage=&frag;
NdbOperation::OperationOptions options;
options.optionsPresent = NdbOperation::OperationOptions::OO_GETVALUE;
options.extraGetValues = &getSpec[0];
options.numExtraGetValues = 1;
/* We're going to read using the secondary unique hash index
* Set the value of its column
*/
row.attr2= i;
MyTableRow resultRow;
unsigned char mask[1]= { 0x01 }; // Only read ATTR1 into resultRow
const NdbOperation *myOperation=
myTransaction->readTuple(key_record, (const char*) &row,
attr_record, (char*) &resultRow,
NdbOperation::LM_Read, mask,
&options,
sizeof(NdbOperation::OperationOptions));
if (myOperation == NULL)
APIERROR(myTransaction->getNdbError());
if (myTransaction->execute( NdbTransaction::Commit,
NdbOperation::AbortOnError ) != -1)
{
printf(" %2d %2d (frag=%u)\n", resultRow.attr1, i, frag);
}
myNdb->closeTransaction(myTransaction);
}
/*****************************************************************
* Update the second attribute in half of the tuples (adding 10) *
*****************************************************************/
for (int i = 0; i < 10; i+=2) {
NdbTransaction *myTransaction= myNdb->startTransaction();
if (myTransaction == NULL)
APIERROR(myNdb->getNdbError());
/* Specify key column to lookup in secondary index */
row.attr2= i;
/* Specify new column value to set */
MyTableRow newRowData;
newRowData.attr2= i+10;
unsigned char mask[1]= { 0x02 }; // Only update ATTR2
const NdbOperation *myOperation=
myTransaction->updateTuple(key_record, (const char*)&row,
attr_record,(char*) &newRowData, mask);
if (myOperation == NULL)
APIERROR(myTransaction->getNdbError());
if ( myTransaction->execute( NdbTransaction::Commit ) == -1 )
APIERROR(myTransaction->getNdbError());
myNdb->closeTransaction(myTransaction);
}
/*************************************************
* Delete one tuple (the one with unique key 3) *
*************************************************/
{
NdbTransaction *myTransaction= myNdb->startTransaction();
if (myTransaction == NULL)
APIERROR(myNdb->getNdbError());
row.attr2= 3;
const NdbOperation *myOperation=
myTransaction->deleteTuple(key_record, (const char*) &row,
attr_record);
if (myOperation == NULL)
APIERROR(myTransaction->getNdbError());
if (myTransaction->execute(NdbTransaction::Commit) == -1)
APIERROR(myTransaction->getNdbError());
myNdb->closeTransaction(myTransaction);
}
/*****************************
* Read and print all tuples *
*****************************/
{
std::cout << "ATTR1 ATTR2" << std::endl;
for (int i = 0; i < 10; i++) {
NdbTransaction *myTransaction= myNdb->startTransaction();
if (myTransaction == NULL)
APIERROR(myNdb->getNdbError());
row.attr1= i;
/* Read using pk. Note the same row space is used as
* key and result storage space
*/
const NdbOperation *myOperation=
myTransaction->readTuple(pk_record, (const char*) &row,
attr_record, (char*) &row);
if (myOperation == NULL)
APIERROR(myTransaction->getNdbError());
if (myTransaction->execute( NdbTransaction::Commit,
NdbOperation::AbortOnError ) == -1)
if (i == 3) {
std::cout << "Detected that deleted tuple doesn't exist!\n";
} else {
APIERROR(myTransaction->getNdbError());
}
if (i != 3)
printf(" %2d %2d\n", row.attr1, row.attr2);
myNdb->closeTransaction(myTransaction);
}
}
delete myNdb;
delete cluster_connection;
ndb_end(0);
return 0;
}
This example illustrates the key differences between the old-style RecAttr API and the newer approach using NdbRecord when performing some common tasks in an NDB API application.
The source code can be found can be found in the file
storage/ndb/ndbapi-examples/ndbapi_recattr_vs_record/main.cpp
in the MySQL Cluster source tree.
#include <mysql.h>
#include <NdbApi.hpp>
// Used for cout
#include <stdio.h>
#include <iostream>
// Do we use old-style (NdbRecAttr?) or new style (NdbRecord?)
enum ApiType {api_attr, api_record};
static void run_application(MYSQL &, Ndb_cluster_connection &, ApiType);
#define PRINT_ERROR(code,msg) \
std::cout << "Error in " << __FILE__ << ", line: " << __LINE__ \
<< ", code: " << code \
<< ", msg: " << msg << "." << std::endl
#define MYSQLERROR(mysql) { \
PRINT_ERROR(mysql_errno(&mysql),mysql_error(&mysql)); \
exit(-1); }
#define APIERROR(error) { \
PRINT_ERROR(error.code,error.message); \
exit(-1); }
int main(int argc, char** argv)
{
if (argc != 4)
{
std::cout << "Arguments are <socket mysqld> <connect_string cluster> <attr|record>.\n";
exit(-1);
}
// ndb_init must be called first
ndb_init();
// connect to mysql server and cluster and run application
{
char * mysqld_sock = argv[1];
const char *connectstring = argv[2];
ApiType accessType=api_attr;
// Object representing the cluster
Ndb_cluster_connection cluster_connection(connectstring);
// Connect to cluster management server (ndb_mgmd)
if (cluster_connection.connect(4 /* retries */,
5 /* delay between retries */,
1 /* verbose */))
{
std::cout << "Cluster management server was not ready within 30 secs.\n";
exit(-1);
}
// Optionally connect and wait for the storage nodes (ndbd's)
if (cluster_connection.wait_until_ready(30,0) < 0)
{
std::cout << "Cluster was not ready within 30 secs.\n";
exit(-1);
}
// connect to mysql server
MYSQL mysql;
if ( !mysql_init(&mysql) ) {
std::cout << "mysql_init failed\n";
exit(-1);
}
if ( !mysql_real_connect(&mysql, "localhost", "root", "", "",
0, mysqld_sock, 0) )
MYSQLERROR(mysql);
if (0==strncmp("attr", argv[3], 4))
{
accessType=api_attr;
}
else if (0==strncmp("record", argv[3], 6))
{
accessType=api_record;
}
else
{
std::cout << "Bad access type argument : "<< argv[3] << "\n";
exit(-1);
}
// run the application code
run_application(mysql, cluster_connection, accessType);
}
ndb_end(0);
return 0;
}
static void init_ndbrecord_info(Ndb &);
static void create_table(MYSQL &);
static void do_insert(Ndb &, ApiType);
static void do_update(Ndb &, ApiType);
static void do_delete(Ndb &, ApiType);
static void do_read(Ndb &, ApiType);
static void do_mixed_read(Ndb &);
static void do_mixed_update(Ndb &);
static void do_scan(Ndb &, ApiType);
static void do_mixed_scan(Ndb &);
static void do_indexScan(Ndb &, ApiType);
static void do_mixed_indexScan(Ndb&);
static void do_read_and_delete(Ndb &);
static void do_scan_update(Ndb&, ApiType);
static void do_scan_delete(Ndb&, ApiType);
static void do_scan_lock_reread(Ndb&, ApiType);
static void do_all_extras_read(Ndb &myNdb);
static void do_secondary_indexScan(Ndb &myNdb, ApiType accessType);
static void do_secondary_indexScanEqual(Ndb &myNdb, ApiType accessType);
static void do_interpreted_update(Ndb &myNdb, ApiType accessType);
static void do_interpreted_scan(Ndb &myNdb, ApiType accessType);
static void do_read_using_default(Ndb &myNdb);
/* This structure is used describe how we want data read using
* NDBRecord to be placed into memory. This can make it easier
* to work with data, but is not essential.
*/
struct RowData
{
int attr1;
int attr2;
int attr3;
};
/* Handy struct for representing the data in the
* secondary index
*/
struct IndexRow
{
unsigned int attr3;
unsigned int attr2;
};
static void run_application(MYSQL &mysql,
Ndb_cluster_connection &cluster_connection,
ApiType accessType)
{
/********************************************
* Connect to database via mysql-c *
********************************************/
mysql_query(&mysql, "CREATE DATABASE ndb_examples");
if (mysql_query(&mysql, "USE ndb_examples") != 0) MYSQLERROR(mysql);
create_table(mysql);
/********************************************
* Connect to database via NdbApi *
********************************************/
// Object representing the database
Ndb myNdb( &cluster_connection, "ndb_examples" );
if (myNdb.init()) APIERROR(myNdb.getNdbError());
init_ndbrecord_info(myNdb);
/*
* Do different operations on database
*/
do_insert(myNdb, accessType);
do_update(myNdb, accessType);
do_delete(myNdb, accessType);
do_read(myNdb, accessType);
do_mixed_read(myNdb);
do_mixed_update(myNdb);
do_read(myNdb, accessType);
do_scan(myNdb, accessType);
do_mixed_scan(myNdb);
do_indexScan(myNdb, accessType);
do_mixed_indexScan(myNdb);
do_read_and_delete(myNdb);
do_scan_update(myNdb, accessType);
do_scan_delete(myNdb, accessType);
do_scan_lock_reread(myNdb, accessType);
do_all_extras_read(myNdb);
do_secondary_indexScan(myNdb, accessType);
do_secondary_indexScanEqual(myNdb, accessType);
do_scan(myNdb, accessType);
do_interpreted_update(myNdb, accessType);
do_interpreted_scan(myNdb, accessType);
do_read_using_default(myNdb);
do_scan(myNdb, accessType);
}
/*********************************************************
* Create a table named api_recattr_vs_record if it does not exist *
*********************************************************/
static void create_table(MYSQL &mysql)
{
if (mysql_query(&mysql,
"DROP TABLE IF EXISTS"
" api_recattr_vs_record"))
MYSQLERROR(mysql);
if (mysql_query(&mysql,
"CREATE TABLE"
" api_recattr_vs_record"
" (ATTR1 INT UNSIGNED NOT NULL PRIMARY KEY,"
" ATTR2 INT UNSIGNED NOT NULL,"
" ATTR3 INT UNSIGNED NOT NULL)"
" ENGINE=NDB"))
MYSQLERROR(mysql);
/* Add ordered secondary index on 2 attributes, in reverse order */
if (mysql_query(&mysql,
"CREATE INDEX"
" MYINDEXNAME"
" ON api_recattr_vs_record"
" (ATTR3, ATTR2)"))
MYSQLERROR(mysql);
}
/* Clunky statics for shared NdbRecord stuff */
static const NdbDictionary::Column *pattr1Col;
static const NdbDictionary::Column *pattr2Col;
static const NdbDictionary::Column *pattr3Col;
static const NdbRecord *pkeyColumnRecord;
static const NdbRecord *pallColsRecord;
static const NdbRecord *pkeyIndexRecord;
static const NdbRecord *psecondaryIndexRecord;
static int attr1ColNum;
static int attr2ColNum;
static int attr3ColNum;
/**************************************************************
* Initialise NdbRecord structures for table and index access *
**************************************************************/
static void init_ndbrecord_info(Ndb &myNdb)
{
/* Here we create various NdbRecord structures for accessing
* data using the tables and indexes on api_recattr_vs_record
* We could use the default NdbRecord structures, but then
* we wouldn't have the nice ability to read and write rows
* to and from the RowData and IndexRow structs
*/
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_recattr_vs_record");
NdbDictionary::RecordSpecification recordSpec[3];
if (myTable == NULL)
APIERROR(myDict->getNdbError());
pattr1Col = myTable->getColumn("ATTR1");
if (pattr1Col == NULL) APIERROR(myDict->getNdbError());
pattr2Col = myTable->getColumn("ATTR2");
if (pattr2Col == NULL) APIERROR(myDict->getNdbError());
pattr3Col = myTable->getColumn("ATTR3");
if (pattr3Col == NULL) APIERROR(myDict->getNdbError());
attr1ColNum = pattr1Col->getColumnNo();
attr2ColNum = pattr2Col->getColumnNo();
attr3ColNum = pattr3Col->getColumnNo();
// ATTR 1
recordSpec[0].column = pattr1Col;
recordSpec[0].offset = offsetof(RowData, attr1);
recordSpec[0].nullbit_byte_offset = 0; // Not nullable
recordSpec[0].nullbit_bit_in_byte = 0;
// ATTR 2
recordSpec[1].column = pattr2Col;
recordSpec[1].offset = offsetof(RowData, attr2);
recordSpec[1].nullbit_byte_offset = 0; // Not nullable
recordSpec[1].nullbit_bit_in_byte = 0;
// ATTR 3
recordSpec[2].column = pattr3Col;
recordSpec[2].offset = offsetof(RowData, attr3);
recordSpec[2].nullbit_byte_offset = 0; // Not nullable
recordSpec[2].nullbit_bit_in_byte = 0;
/* Create table record with just the primary key column */
pkeyColumnRecord =
myDict->createRecord(myTable, recordSpec, 1, sizeof(recordSpec[0]));
if (pkeyColumnRecord == NULL) APIERROR(myDict->getNdbError());
/* Create table record with all the columns */
pallColsRecord =
myDict->createRecord(myTable, recordSpec, 3, sizeof(recordSpec[0]));
if (pallColsRecord == NULL) APIERROR(myDict->getNdbError());
/* Create NdbRecord for primary index access */
const NdbDictionary::Index *myPIndex= myDict->getIndex("PRIMARY", "api_recattr_vs_record");
if (myPIndex == NULL)
APIERROR(myDict->getNdbError());
pkeyIndexRecord =
myDict->createRecord(myPIndex, recordSpec, 1, sizeof(recordSpec[0]));
if (pkeyIndexRecord == NULL) APIERROR(myDict->getNdbError());
/* Create Index NdbRecord for secondary index access
* Note that we use the columns from the table to define the index
* access record
*/
const NdbDictionary::Index *mySIndex= myDict->getIndex("MYINDEXNAME", "api_recattr_vs_record");
recordSpec[0].column= pattr3Col;
recordSpec[0].offset= offsetof(IndexRow, attr3);
recordSpec[0].nullbit_byte_offset=0;
recordSpec[0].nullbit_bit_in_byte=0;
recordSpec[1].column= pattr2Col;
recordSpec[1].offset= offsetof(IndexRow, attr2);
recordSpec[1].nullbit_byte_offset=0;
recordSpec[1].nullbit_bit_in_byte=1;
/* Create NdbRecord for accessing via secondary index */
psecondaryIndexRecord =
myDict->createRecord(mySIndex,
recordSpec,
2,
sizeof(recordSpec[0]));
if (psecondaryIndexRecord == NULL)
APIERROR(myDict->getNdbError());
}
/**************************************************************************
* Using 5 transactions, insert 10 tuples in table: (0,0),(1,1),...,(9,9) *
**************************************************************************/
static void do_insert(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_recattr_vs_record");
std::cout << "Running do_insert\n";
if (myTable == NULL)
APIERROR(myDict->getNdbError());
for (int i = 0; i < 5; i++) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
switch (accessType)
{
case api_attr :
{
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->insertTuple();
myOperation->equal("ATTR1", i);
myOperation->setValue("ATTR2", i);
myOperation->setValue("ATTR3", i);
myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->insertTuple();
myOperation->equal("ATTR1", i+5);
myOperation->setValue("ATTR2", i+5);
myOperation->setValue("ATTR3", i+5);
break;
}
case api_record :
{
RowData row;
row.attr1= row.attr2= row.attr3= i;
const NdbOperation *pop1=
myTransaction->insertTuple(pallColsRecord, (char *) &row);
if (pop1 == NULL) APIERROR(myTransaction->getNdbError());
row.attr1= row.attr2= row.attr3= i+5;
const NdbOperation *pop2=
myTransaction->insertTuple(pallColsRecord, (char *) &row);
if (pop2 == NULL) APIERROR(myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if (myTransaction->execute( NdbTransaction::Commit ) == -1)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
}
std::cout << "-------\n";
}
/*****************************************************************
* Update the second attribute in half of the tuples (adding 10) *
*****************************************************************/
static void do_update(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_recattr_vs_record");
std::cout << "Running do_update\n";
for (int i = 0; i < 10; i+=2) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
switch (accessType)
{
case api_attr :
{
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->updateTuple();
myOperation->equal( "ATTR1", i );
myOperation->setValue( "ATTR2", i+10);
myOperation->setValue( "ATTR3", i+20);
break;
}
case api_record :
{
RowData row;
row.attr1=i;
row.attr2=i+10;
row.attr3=i+20;
/* Since we're using an NdbRecord with all columns in it to
* specify the updated columns, we need to create a mask to
* indicate that we are only updating attr2 and attr3.
*/
unsigned char attrMask=(1<<attr2ColNum) | (1<<attr3ColNum);
const NdbOperation *pop =
myTransaction->updateTuple(pkeyColumnRecord, (char*) &row,
pallColsRecord, (char*) &row,
&attrMask);
if (pop==NULL) APIERROR(myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if( myTransaction->execute( NdbTransaction::Commit ) == -1 )
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
}
std::cout << "-------\n";
};
/*************************************************
* Delete one tuple (the one with primary key 3) *
*************************************************/
static void do_delete(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_recattr_vs_record");
std::cout << "Running do_delete\n";
if (myTable == NULL)
APIERROR(myDict->getNdbError());
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
switch (accessType)
{
case api_attr :
{
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->deleteTuple();
myOperation->equal( "ATTR1", 3 );
break;
}
case api_record :
{
RowData keyInfo;
keyInfo.attr1=3;
const NdbOperation *pop=
myTransaction->deleteTuple(pkeyColumnRecord,
(char*) &keyInfo,
pallColsRecord);
if (pop==NULL) APIERROR(myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if (myTransaction->execute(NdbTransaction::Commit) == -1)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/*****************************************************************
* Update the second attribute in half of the tuples (adding 10) *
*****************************************************************/
static void do_mixed_update(Ndb &myNdb)
{
/* This method performs an update using a mix of NdbRecord
* supplied attributes, and extra setvalues provided by
* the OperationOptions structure.
*/
std::cout << "Running do_mixed_update (NdbRecord only)\n";
for (int i = 0; i < 10; i+=2) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
RowData row;
row.attr1=i;
row.attr2=i+30;
/* Only attr2 is updated via NdbRecord */
unsigned char attrMask= (1<<attr2ColNum);
NdbOperation::SetValueSpec setvalspecs[1];
/* Value to set attr3 to */
Uint32 dataSource= i + 40;
setvalspecs[0].column = pattr3Col;
setvalspecs[0].value = &dataSource;
NdbOperation::OperationOptions opts;
opts.optionsPresent= NdbOperation::OperationOptions::OO_SETVALUE;
opts.extraSetValues= &setvalspecs[0];
opts.numExtraSetValues= 1;
// Define mixed operation in one call to NDBAPI
const NdbOperation *pop =
myTransaction->updateTuple(pkeyColumnRecord, (char*) &row,
pallColsRecord, (char*) &row,
&attrMask,
&opts);
if (pop==NULL) APIERROR(myTransaction->getNdbError());
if( myTransaction->execute( NdbTransaction::Commit ) == -1 )
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
}
std::cout << "-------\n";
}
/*********************************************
* Read and print all tuples using PK access *
*********************************************/
static void do_read(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_recattr_vs_record");
std::cout << "Running do_read\n";
if (myTable == NULL)
APIERROR(myDict->getNdbError());
std::cout << "ATTR1 ATTR2 ATTR3" << std::endl;
for (int i = 0; i < 10; i++) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
RowData rowData;
NdbRecAttr *myRecAttr;
NdbRecAttr *myRecAttr2;
switch (accessType)
{
case api_attr :
{
NdbOperation *myOperation= myTransaction->getNdbOperation(myTable);
if (myOperation == NULL) APIERROR(myTransaction->getNdbError());
myOperation->readTuple(NdbOperation::LM_Read);
myOperation->equal("ATTR1", i);
myRecAttr= myOperation->getValue("ATTR2", NULL);
if (myRecAttr == NULL) APIERROR(myTransaction->getNdbError());
myRecAttr2=myOperation->getValue("ATTR3", NULL);
if (myRecAttr2 == NULL) APIERROR(myTransaction->getNdbError());
break;
}
case api_record :
{
rowData.attr1=i;
const NdbOperation *pop=
myTransaction->readTuple(pkeyColumnRecord,
(char*) &rowData,
pallColsRecord, // Read PK+ATTR2+ATTR3
(char*) &rowData);
if (pop==NULL) APIERROR(myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::Commit ) == -1)
APIERROR(myTransaction->getNdbError());
if (myTransaction->getNdbError().classification == NdbError::NoDataFound)
if (i == 3)
std::cout << "Detected that deleted tuple doesn't exist!" << std::endl;
else
APIERROR(myTransaction->getNdbError());
switch (accessType)
{
case api_attr :
{
if (i != 3) {
printf(" %2d %2d %2d\n",
i,
myRecAttr->u_32_value(),
myRecAttr2->u_32_value());
}
break;
}
case api_record :
{
if (i !=3) {
printf(" %2d %2d %2d\n",
i,
rowData.attr2,
rowData.attr3);
}
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
myNdb.closeTransaction(myTransaction);
}
std::cout << "-------\n";
}
/*****************************
* Read and print all tuples *
*****************************/
static void do_mixed_read(Ndb &myNdb)
{
std::cout << "Running do_mixed_read (NdbRecord only)\n";
std::cout << "ATTR1 ATTR2 ATTR3 COMMIT_COUNT" << std::endl;
for (int i = 0; i < 10; i++) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
RowData rowData;
NdbRecAttr *myRecAttr3, *myRecAttrCC;
/* Start with NdbRecord read of ATTR2, and then add
* getValue NdbRecAttr read of ATTR3 and Commit count
*/
NdbOperation::GetValueSpec extraCols[2];
extraCols[0].column=pattr3Col;
extraCols[0].appStorage=NULL;
extraCols[0].recAttr=NULL;
extraCols[1].column=NdbDictionary::Column::COMMIT_COUNT;
extraCols[1].appStorage=NULL;
extraCols[1].recAttr=NULL;
NdbOperation::OperationOptions opts;
opts.optionsPresent = NdbOperation::OperationOptions::OO_GETVALUE;
opts.extraGetValues= &extraCols[0];
opts.numExtraGetValues= 2;
/* We only read attr2 using the normal NdbRecord access */
unsigned char attrMask= (1<<attr2ColNum);
// Set PK search criteria
rowData.attr1= i;
const NdbOperation *pop=
myTransaction->readTuple(pkeyColumnRecord,
(char*) &rowData,
pallColsRecord, // Read all with mask
(char*) &rowData,
NdbOperation::LM_Read,
&attrMask, // result_mask
&opts);
if (pop==NULL) APIERROR(myTransaction->getNdbError());
myRecAttr3= extraCols[0].recAttr;
myRecAttrCC= extraCols[1].recAttr;
if (myRecAttr3 == NULL) APIERROR(myTransaction->getNdbError());
if (myRecAttrCC == NULL) APIERROR(myTransaction->getNdbError());
if(myTransaction->execute( NdbTransaction::Commit ) == -1)
APIERROR(myTransaction->getNdbError());
if (myTransaction->getNdbError().classification == NdbError::NoDataFound)
if (i == 3)
std::cout << "Detected that deleted tuple doesn't exist!" << std::endl;
else
APIERROR(myTransaction->getNdbError());
if (i !=3) {
printf(" %2d %2d %2d %d\n",
rowData.attr1,
rowData.attr2,
myRecAttr3->u_32_value(),
myRecAttrCC->u_32_value()
);
}
myNdb.closeTransaction(myTransaction);
}
std::cout << "-------\n";
}
/********************************************
* Read and print all tuples via table scan *
********************************************/
static void do_scan(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_recattr_vs_record");
std::cout << "Running do_scan\n";
if (myTable == NULL)
APIERROR(myDict->getNdbError());
std::cout << "ATTR1 ATTR2 ATTR3" << std::endl;
NdbTransaction *myTransaction=myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbScanOperation *psop;
NdbRecAttr *recAttrAttr1;
NdbRecAttr *recAttrAttr2;
NdbRecAttr *recAttrAttr3;
switch (accessType)
{
case api_attr :
{
psop=myTransaction->getNdbScanOperation(myTable);
if (psop == NULL) APIERROR(myTransaction->getNdbError());
if (psop->readTuples(NdbOperation::LM_Read) != 0) APIERROR (myTransaction->getNdbError());
recAttrAttr1=psop->getValue("ATTR1");
recAttrAttr2=psop->getValue("ATTR2");
recAttrAttr3=psop->getValue("ATTR3");
break;
}
case api_record :
{
/* Note that no row ptr is passed to the NdbRecord scan operation
* The scan will fetch a batch and give the user a series of pointers
* to rows in the batch in nextResult() below
*/
psop=myTransaction->scanTable(pallColsRecord,
NdbOperation::LM_Read);
if (psop == NULL) APIERROR(myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
switch (accessType)
{
case api_attr :
{
while (psop->nextResult(true) == 0)
{
printf(" %2d %2d %2d\n",
recAttrAttr1->u_32_value(),
recAttrAttr2->u_32_value(),
recAttrAttr3->u_32_value());
}
psop->close();
break;
}
case api_record :
{
RowData *prowData; // Ptr to point to our data
int rc=0;
/* Ask nextResult to update out ptr to point to the next
* row from the scan
*/
while ((rc = psop->nextResult((const char**) &prowData,
true,
false)) == 0)
{
printf(" %2d %2d %2d\n",
prowData->attr1,
prowData->attr2,
prowData->attr3);
}
if (rc != 1) APIERROR(myTransaction->getNdbError());
psop->close(true);
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::Commit ) !=0)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/***********************************************************
* Read and print all tuples via table scan and mixed read *
***********************************************************/
static void do_mixed_scan(Ndb &myNdb)
{
std::cout << "Running do_mixed_scan(NdbRecord only)\n";
std::cout << "ATTR1 ATTR2 ATTR3" << std::endl;
NdbTransaction *myTransaction=myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbScanOperation *psop;
NdbRecAttr *recAttrAttr3;
/* Set mask so that NdbRecord scan reads attr1 and attr2 only */
unsigned char attrMask=((1<<attr1ColNum) | (1<<attr2ColNum));
/* Define extra get value to get attr3 */
NdbOperation::GetValueSpec extraGets[1];
extraGets[0].column = pattr3Col;
extraGets[0].appStorage= 0;
extraGets[0].recAttr= 0;
NdbScanOperation::ScanOptions options;
options.optionsPresent= NdbScanOperation::ScanOptions::SO_GETVALUE;
options.extraGetValues= &extraGets[0];
options.numExtraGetValues= 1;
psop=myTransaction->scanTable(pallColsRecord,
NdbOperation::LM_Read,
&attrMask,
&options,
sizeof(NdbScanOperation::ScanOptions));
if (psop == NULL) APIERROR(myTransaction->getNdbError());
/* RecAttr for the extra get has been set by the operation definition */
recAttrAttr3 = extraGets[0].recAttr;
if (recAttrAttr3 == NULL) APIERROR(myTransaction->getNdbError());
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
RowData *prowData; // Ptr to point to our data
int rc=0;
while ((rc = psop->nextResult((const char**) &prowData,
true,
false)) == 0)
{
printf(" %2d %2d %2d\n",
prowData->attr1,
prowData->attr2,
recAttrAttr3->u_32_value());
}
if (rc != 1) APIERROR(myTransaction->getNdbError());
psop->close(true);
if(myTransaction->execute( NdbTransaction::Commit ) !=0)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/************************************************************
* Read and print all tuples via primary ordered index scan *
************************************************************/
static void do_indexScan(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Index *myPIndex= myDict->getIndex("PRIMARY", "api_recattr_vs_record");
std::cout << "Running do_indexScan\n";
if (myPIndex == NULL)
APIERROR(myDict->getNdbError());
std::cout << "ATTR1 ATTR2 ATTR3" << std::endl;
NdbTransaction *myTransaction=myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbIndexScanOperation *psop;
/* RecAttrs for NdbRecAttr Api */
NdbRecAttr *recAttrAttr1;
NdbRecAttr *recAttrAttr2;
NdbRecAttr *recAttrAttr3;
switch (accessType)
{
case api_attr :
{
psop=myTransaction->getNdbIndexScanOperation(myPIndex);
if (psop == NULL) APIERROR(myTransaction->getNdbError());
/* Multi read range is not supported for the NdbRecAttr scan
* API, so we just read one range.
*/
Uint32 scanFlags=
NdbScanOperation::SF_OrderBy |
NdbScanOperation::SF_MultiRange |
NdbScanOperation::SF_ReadRangeNo;
if (psop->readTuples(NdbOperation::LM_Read,
scanFlags,
(Uint32) 0, // batch
(Uint32) 0) != 0) // parallel
APIERROR (myTransaction->getNdbError());
/* Add a bound
* Tuples where ATTR1 >=2 and < 4
* 2,[3 deleted]
*/
Uint32 low=2;
Uint32 high=4;
if (psop->setBound("ATTR1", NdbIndexScanOperation::BoundLE, (char*)&low))
APIERROR(myTransaction->getNdbError());
if (psop->setBound("ATTR1", NdbIndexScanOperation::BoundGT, (char*)&high))
APIERROR(myTransaction->getNdbError());
if (psop->end_of_bound(0))
APIERROR(psop->getNdbError());
/* Second bound
* Tuples where ATTR1 > 5 and <=9
* 6,7,8,9
*/
low=5;
high=9;
if (psop->setBound("ATTR1", NdbIndexScanOperation::BoundLT, (char*)&low))
APIERROR(myTransaction->getNdbError());
if (psop->setBound("ATTR1", NdbIndexScanOperation::BoundGE, (char*)&high))
APIERROR(myTransaction->getNdbError());
if (psop->end_of_bound(1))
APIERROR(psop->getNdbError());
/* Read all columns */
recAttrAttr1=psop->getValue("ATTR1");
recAttrAttr2=psop->getValue("ATTR2");
recAttrAttr3=psop->getValue("ATTR3");
break;
}
case api_record :
{
/* NdbRecord supports scanning multiple ranges using a
* single index scan operation
*/
Uint32 scanFlags =
NdbScanOperation::SF_OrderBy |
NdbScanOperation::SF_MultiRange |
NdbScanOperation::SF_ReadRangeNo;
NdbScanOperation::ScanOptions options;
options.optionsPresent=NdbScanOperation::ScanOptions::SO_SCANFLAGS;
options.scan_flags=scanFlags;
psop=myTransaction->scanIndex(pkeyIndexRecord,
pallColsRecord,
NdbOperation::LM_Read,
NULL, // no mask - read all columns in result record
NULL, // bound defined later
&options,
sizeof(NdbScanOperation::ScanOptions));
if (psop == NULL) APIERROR(myTransaction->getNdbError());
/* Add a bound
* Tuples where ATTR1 >=2 and < 4
* 2,[3 deleted]
*/
Uint32 low=2;
Uint32 high=4;
NdbIndexScanOperation::IndexBound bound;
bound.low_key=(char*)&low;
bound.low_key_count=1;
bound.low_inclusive=true;
bound.high_key=(char*)&high;
bound.high_key_count=1;
bound.high_inclusive=false;
bound.range_no=0;
if (psop->setBound(pkeyIndexRecord, bound))
APIERROR(myTransaction->getNdbError());
/* Second bound
* Tuples where ATTR1 > 5 and <=9
* 6,7,8,9
*/
low=5;
high=9;
bound.low_key=(char*)&low;
bound.low_key_count=1;
bound.low_inclusive=false;
bound.high_key=(char*)&high;
bound.high_key_count=1;
bound.high_inclusive=true;
bound.range_no=1;
if (psop->setBound(pkeyIndexRecord, bound))
APIERROR(myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
if (myTransaction->getNdbError().code != 0)
APIERROR(myTransaction->getNdbError());
switch (accessType)
{
case api_attr :
{
while (psop->nextResult(true) == 0)
{
printf(" %2d %2d %2d Range no : %2d\n",
recAttrAttr1->u_32_value(),
recAttrAttr2->u_32_value(),
recAttrAttr3->u_32_value(),
psop->get_range_no());
}
psop->close();
break;
}
case api_record :
{
RowData *prowData; // Ptr to point to our data
int rc=0;
while ((rc = psop->nextResult((const char**) &prowData,
true,
false)) == 0)
{
// printf(" PTR : %d\n", (int) prowData);
printf(" %2d %2d %2d Range no : %2d\n",
prowData->attr1,
prowData->attr2,
prowData->attr3,
psop->get_range_no());
}
if (rc != 1) APIERROR(myTransaction->getNdbError());
psop->close(true);
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::Commit ) !=0)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/*************************************************************************
* Read and print all tuples via index scan using mixed NdbRecord access *
*************************************************************************/
static void do_mixed_indexScan(Ndb &myNdb)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Index *myPIndex= myDict->getIndex("PRIMARY", "api_recattr_vs_record");
std::cout << "Running do_mixed_indexScan\n";
if (myPIndex == NULL)
APIERROR(myDict->getNdbError());
std::cout << "ATTR1 ATTR2 ATTR3" << std::endl;
NdbTransaction *myTransaction=myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbIndexScanOperation *psop;
NdbRecAttr *recAttrAttr3;
Uint32 scanFlags =
NdbScanOperation::SF_OrderBy |
NdbScanOperation::SF_MultiRange |
NdbScanOperation::SF_ReadRangeNo;
/* We'll get Attr3 via ScanOptions */
unsigned char attrMask=((1<<attr1ColNum) | (1<<attr2ColNum));
NdbOperation::GetValueSpec extraGets[1];
extraGets[0].column= pattr3Col;
extraGets[0].appStorage= NULL;
extraGets[0].recAttr= NULL;
NdbScanOperation::ScanOptions options;
options.optionsPresent=
NdbScanOperation::ScanOptions::SO_SCANFLAGS |
NdbScanOperation::ScanOptions::SO_GETVALUE;
options.scan_flags= scanFlags;
options.extraGetValues= &extraGets[0];
options.numExtraGetValues= 1;
psop=myTransaction->scanIndex(pkeyIndexRecord,
pallColsRecord,
NdbOperation::LM_Read,
&attrMask, // mask
NULL, // bound defined below
&options,
sizeof(NdbScanOperation::ScanOptions));
if (psop == NULL) APIERROR(myTransaction->getNdbError());
/* Grab RecAttr now */
recAttrAttr3= extraGets[0].recAttr;
/* Add a bound
* ATTR1 >= 2, < 4
* 2,[3 deleted]
*/
Uint32 low=2;
Uint32 high=4;
NdbIndexScanOperation::IndexBound bound;
bound.low_key=(char*)&low;
bound.low_key_count=1;
bound.low_inclusive=true;
bound.high_key=(char*)&high;
bound.high_key_count=1;
bound.high_inclusive=false;
bound.range_no=0;
if (psop->setBound(pkeyIndexRecord, bound))
APIERROR(myTransaction->getNdbError());
/* Second bound
* ATTR1 > 5, <= 9
* 6,7,8,9
*/
low=5;
high=9;
bound.low_key=(char*)&low;
bound.low_key_count=1;
bound.low_inclusive=false;
bound.high_key=(char*)&high;
bound.high_key_count=1;
bound.high_inclusive=true;
bound.range_no=1;
if (psop->setBound(pkeyIndexRecord, bound))
APIERROR(myTransaction->getNdbError());
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
RowData *prowData; // Ptr to point to our data
int rc=0;
while ((rc = psop->nextResult((const char**) &prowData,
true,
false)) == 0)
{
printf(" %2d %2d %2d Range no : %2d\n",
prowData->attr1,
prowData->attr2,
recAttrAttr3->u_32_value(),
psop->get_range_no());
}
if (rc != 1) APIERROR(myTransaction->getNdbError());
psop->close(true);
if(myTransaction->execute( NdbTransaction::Commit ) !=0)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/********************************************************
* Read + Delete one tuple (the one with primary key 8) *
********************************************************/
static void do_read_and_delete(Ndb &myNdb)
{
/* This procedure performs a single operation, single round
* trip read and then delete of a tuple, specified by
* primary key
*/
std::cout << "Running do_read_and_delete (NdbRecord only)\n";
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
RowData row;
row.attr1=8;
row.attr2=0; // Don't care
row.attr3=0; // Don't care
/* We'll also read some extra columns while we're
* reading + deleting
*/
NdbOperation::OperationOptions options;
NdbOperation::GetValueSpec extraGets[2];
extraGets[0].column = pattr3Col;
extraGets[0].appStorage = NULL;
extraGets[0].recAttr = NULL;
extraGets[1].column = NdbDictionary::Column::COMMIT_COUNT;
extraGets[1].appStorage = NULL;
extraGets[1].recAttr = NULL;
options.optionsPresent= NdbOperation::OperationOptions::OO_GETVALUE;
options.extraGetValues= &extraGets[0];
options.numExtraGetValues= 2;
unsigned char attrMask = (1<<attr2ColNum); // Only read Col2 into row
const NdbOperation *pop=
myTransaction->deleteTuple(pkeyColumnRecord, // Spec of key used
(char*) &row, // Key information
pallColsRecord, // Spec of columns to read
(char*) &row, // Row to read values into
&attrMask, // Columns to read as part of delete
&options,
sizeof(NdbOperation::OperationOptions));
if (pop==NULL) APIERROR(myTransaction->getNdbError());
if (myTransaction->execute(NdbTransaction::Commit) == -1)
APIERROR(myTransaction->getNdbError());
std::cout << "ATTR1 ATTR2 ATTR3 COMMITS" << std::endl;
printf(" %2d %2d %2d %2d\n",
row.attr1,
row.attr2,
extraGets[0].recAttr->u_32_value(),
extraGets[1].recAttr->u_32_value());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/* Some handy consts for scan control */
static const int GOT_ROW= 0;
static const int NO_MORE_ROWS= 1;
static const int NEED_TO_FETCH_ROWS= 2;
/*********************************************
* Read and update all tuples via table scan *
*********************************************/
static void do_scan_update(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_recattr_vs_record");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
std::cout << "Running do_scan_update\n";
NdbTransaction *myTransaction=myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbScanOperation *psop;
NdbRecAttr *recAttrAttr1;
NdbRecAttr *recAttrAttr2;
NdbRecAttr *recAttrAttr3;
switch (accessType)
{
case api_attr :
{
psop=myTransaction->getNdbScanOperation(myTable);
if (psop == NULL) APIERROR(myTransaction->getNdbError());
/* When we want to operate on the tuples returned from a
* scan, we need to request the the tuple's keyinfo is
* returned, with SF_KeyInfo
*/
if (psop->readTuples(NdbOperation::LM_Read,
NdbScanOperation::SF_KeyInfo) != 0)
APIERROR (myTransaction->getNdbError());
recAttrAttr1=psop->getValue("ATTR1");
recAttrAttr2=psop->getValue("ATTR2");
recAttrAttr3=psop->getValue("ATTR3");
break;
}
case api_record :
{
NdbScanOperation::ScanOptions options;
options.optionsPresent= NdbScanOperation::ScanOptions::SO_SCANFLAGS;
options.scan_flags= NdbScanOperation::SF_KeyInfo;
psop=myTransaction->scanTable(pallColsRecord,
NdbOperation::LM_Read,
NULL, // mask - read all columns
&options,
sizeof(NdbScanOperation::ScanOptions));
if (psop == NULL) APIERROR(myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
switch (accessType)
{
case api_attr :
{
int result= NEED_TO_FETCH_ROWS;
Uint32 processed= 0;
while (result == NEED_TO_FETCH_ROWS)
{
bool fetch=true;
while ((result = psop->nextResult(fetch)) == GOT_ROW)
{
fetch= false;
Uint32 col2Value=recAttrAttr2->u_32_value();
NdbOperation *op=psop->updateCurrentTuple();
if (op==NULL)
APIERROR(myTransaction->getNdbError());
op->setValue("ATTR2", (10*col2Value));
processed++;
}
if (result < 0)
APIERROR(myTransaction->getNdbError());
if (processed !=0)
{
// Need to execute
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
processed=0;
}
}
psop->close();
break;
}
case api_record :
{
RowData *prowData; // Ptr to point to our data
int result= NEED_TO_FETCH_ROWS;
Uint32 processed=0;
while (result == NEED_TO_FETCH_ROWS)
{
bool fetch= true;
while ((result = psop->nextResult((const char**) &prowData,
fetch, false)) == GOT_ROW)
{
fetch= false;
/* Copy row into a stack variable */
RowData r= *prowData;
/* Modify attr2 */
r.attr2*= 10;
/* Update it */
const NdbOperation *op = psop->updateCurrentTuple(myTransaction,
pallColsRecord,
(char*) &r);
if (op==NULL)
APIERROR(myTransaction->getNdbError());
processed ++;
}
if (result < 0)
APIERROR(myTransaction->getNdbError());
if (processed !=0)
{
/* To get here, there are no more cached scan results,
* and some row updates that we've not sent yet.
* Send them before we try to get another batch, or
* finish.
*/
if (myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
processed=0;
}
}
psop->close(true);
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::Commit ) !=0)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/**************************************************
* Read all and delete some tuples via table scan *
**************************************************/
static void do_scan_delete(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_recattr_vs_record");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
std::cout << "Running do_scan_delete\n";
NdbTransaction *myTransaction=myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbScanOperation *psop;
NdbRecAttr *recAttrAttr1;
/* Scan, retrieving first column.
* Delete particular records, based on first column
* Read third column as part of delete
*/
switch (accessType)
{
case api_attr :
{
psop=myTransaction->getNdbScanOperation(myTable);
if (psop == NULL) APIERROR(myTransaction->getNdbError());
/* Need KeyInfo when performing scanning delete */
if (psop->readTuples(NdbOperation::LM_Read,
NdbScanOperation::SF_KeyInfo) != 0)
APIERROR (myTransaction->getNdbError());
recAttrAttr1=psop->getValue("ATTR1");
break;
}
case api_record :
{
NdbScanOperation::ScanOptions options;
options.optionsPresent=NdbScanOperation::ScanOptions::SO_SCANFLAGS;
/* Need KeyInfo when performing scanning delete */
options.scan_flags=NdbScanOperation::SF_KeyInfo;
psop=myTransaction->scanTable(pkeyColumnRecord,
NdbOperation::LM_Read,
NULL, // mask
&options,
sizeof(NdbScanOperation::ScanOptions));
if (psop == NULL) APIERROR(myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
switch (accessType)
{
case api_attr :
{
int result= NEED_TO_FETCH_ROWS;
Uint32 processed=0;
while (result == NEED_TO_FETCH_ROWS)
{
bool fetch=true;
while ((result = psop->nextResult(fetch)) == GOT_ROW)
{
fetch= false;
Uint32 col1Value=recAttrAttr1->u_32_value();
if (col1Value == 2)
{
/* Note : We cannot do a delete pre-read via
* the NdbRecAttr interface. We can only
* delete here.
*/
if (psop->deleteCurrentTuple())
APIERROR(myTransaction->getNdbError());
processed++;
}
}
if (result < 0)
APIERROR(myTransaction->getNdbError());
if (processed !=0)
{
/* To get here, there are no more cached scan results,
* and some row deletes that we've not sent yet.
* Send them before we try to get another batch, or
* finish.
*/
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
processed=0;
}
}
psop->close();
break;
}
case api_record :
{
RowData *prowData; // Ptr to point to our data
int result= NEED_TO_FETCH_ROWS;
Uint32 processed=0;
while (result == NEED_TO_FETCH_ROWS)
{
bool fetch=true;
const NdbOperation* theDeleteOp;
RowData readRow;
NdbRecAttr* attr3;
NdbRecAttr* commitCount;
while ((result = psop->nextResult((const char**) &prowData,
fetch,
false)) == GOT_ROW)
{
fetch = false;
/* Copy latest row to a stack local */
RowData r;
r= *prowData;
if (r.attr1 == 2)
{
/* We're going to perform a read+delete on this
* row. We'll read attr1 and attr2 via NdbRecord
* and Attr3 and the commit count via extra
* get values.
*/
NdbOperation::OperationOptions options;
NdbOperation::GetValueSpec extraGets[2];
extraGets[0].column = pattr3Col;
extraGets[0].appStorage = NULL;
extraGets[0].recAttr = NULL;
extraGets[1].column = NdbDictionary::Column::COMMIT_COUNT;
extraGets[1].appStorage = NULL;
extraGets[1].recAttr = NULL;
options.optionsPresent= NdbOperation::OperationOptions::OO_GETVALUE;
options.extraGetValues= &extraGets[0];
options.numExtraGetValues= 2;
// Read cols 1 + 2 via NdbRecord
unsigned char attrMask = (1<<attr1ColNum) | (1<<attr2ColNum);
theDeleteOp = psop->deleteCurrentTuple(myTransaction,
pallColsRecord,
(char*) &readRow,
&attrMask,
&options,
sizeof(NdbOperation::OperationOptions));
if (theDeleteOp==NULL)
APIERROR(myTransaction->getNdbError());
/* Store extra Get RecAttrs */
attr3= extraGets[0].recAttr;
commitCount= extraGets[1].recAttr;
processed ++;
}
}
if (result < 0)
APIERROR(myTransaction->getNdbError());
if (processed !=0)
{
/* To get here, there are no more cached scan results,
* and some row deletes that we've not sent yet.
* Send them before we try to get another batch, or
* finish.
*/
if (myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
processed=0;
// Let's look at the data just read
printf("Deleted data\n");
printf("ATTR1 ATTR2 ATTR3 COMMITS\n");
printf(" %2d %2d %2d %2d\n",
readRow.attr1,
readRow.attr2,
attr3->u_32_value(),
commitCount->u_32_value());
}
}
psop->close(true);
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::Commit ) !=0)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/***********************************************************
* Read all tuples via scan, reread one with lock takeover *
***********************************************************/
static void do_scan_lock_reread(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_recattr_vs_record");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
std::cout << "Running do_scan_lock_reread\n";
NdbTransaction *myTransaction=myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbScanOperation *psop;
NdbRecAttr *recAttrAttr1;
switch (accessType)
{
case api_attr :
{
psop=myTransaction->getNdbScanOperation(myTable);
if (psop == NULL) APIERROR(myTransaction->getNdbError());
/* Need KeyInfo for lock takeover */
if (psop->readTuples(NdbOperation::LM_Read,
NdbScanOperation::SF_KeyInfo) != 0)
APIERROR (myTransaction->getNdbError());
recAttrAttr1=psop->getValue("ATTR1");
break;
}
case api_record :
{
NdbScanOperation::ScanOptions options;
options.optionsPresent= NdbScanOperation::ScanOptions::SO_SCANFLAGS;
/* Need KeyInfo for lock takeover */
options.scan_flags= NdbScanOperation::SF_KeyInfo;
psop=myTransaction->scanTable(pkeyColumnRecord,
NdbOperation::LM_Read,
NULL, // mask
&options,
sizeof(NdbScanOperation::ScanOptions));
if (psop == NULL) APIERROR(myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
switch (accessType)
{
case api_attr :
{
int result= NEED_TO_FETCH_ROWS;
Uint32 processed=0;
NdbRecAttr *attr1, *attr2, *attr3, *commitCount;
while (result == NEED_TO_FETCH_ROWS)
{
bool fetch=true;
while ((result = psop->nextResult(fetch)) == GOT_ROW)
{
fetch= false;
Uint32 col1Value=recAttrAttr1->u_32_value();
if (col1Value == 9)
{
/* Let's read the rest of the info for it with
* a separate operation
*/
NdbOperation *op= psop->lockCurrentTuple();
if (op==NULL)
APIERROR(myTransaction->getNdbError());
attr1=op->getValue("ATTR1");
attr2=op->getValue("ATTR2");
attr3=op->getValue("ATTR3");
commitCount=op->getValue(NdbDictionary::Column::COMMIT_COUNT);
processed++;
}
}
if (result < 0)
APIERROR(myTransaction->getNdbError());
if (processed !=0)
{
// Need to execute
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
processed=0;
// Let's look at the whole row...
printf("Locked and re-read data:\n");
printf("ATTR1 ATTR2 ATTR3 COMMITS\n");
printf(" %2d %2d %2d %2d\n",
attr1->u_32_value(),
attr2->u_32_value(),
attr3->u_32_value(),
commitCount->u_32_value());
}
}
psop->close();
break;
}
case api_record :
{
RowData *prowData; // Ptr to point to our data
int result= NEED_TO_FETCH_ROWS;
Uint32 processed=0;
RowData rereadData;
NdbRecAttr *attr3, *commitCount;
while (result == NEED_TO_FETCH_ROWS)
{
bool fetch=true;
while ((result = psop->nextResult((const char**) &prowData,
fetch,
false)) == GOT_ROW)
{
fetch = false;
/* Copy row to stack local */
RowData r;
r=*prowData;
if (r.attr1 == 9)
{
/* Perform extra read of this row via lockCurrentTuple
* Read all columns using NdbRecord for attr1 + attr2,
* and extra get values for attr3 and the commit count
*/
NdbOperation::OperationOptions options;
NdbOperation::GetValueSpec extraGets[2];
extraGets[0].column = pattr3Col;
extraGets[0].appStorage = NULL;
extraGets[0].recAttr = NULL;
extraGets[1].column = NdbDictionary::Column::COMMIT_COUNT;
extraGets[1].appStorage = NULL;
extraGets[1].recAttr = NULL;
options.optionsPresent=NdbOperation::OperationOptions::OO_GETVALUE;
options.extraGetValues=&extraGets[0];
options.numExtraGetValues=2;
// Read cols 1 + 2 via NdbRecord
unsigned char attrMask = (1<<attr1ColNum) | (1<<attr2ColNum);
const NdbOperation *lockOp = psop->lockCurrentTuple(myTransaction,
pallColsRecord,
(char *) &rereadData,
&attrMask,
&options,
sizeof(NdbOperation::OperationOptions));
if (lockOp == NULL)
APIERROR(myTransaction->getNdbError());
attr3= extraGets[0].recAttr;
commitCount= extraGets[1].recAttr;
processed++;
}
}
if (result < 0)
APIERROR(myTransaction->getNdbError());
if (processed !=0)
{
// Need to execute
if (myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
processed=0;
// Let's look at the whole row...
printf("Locked and re-read data:\n");
printf("ATTR1 ATTR2 ATTR3 COMMITS\n");
printf(" %2d %2d %2d %2d\n",
rereadData.attr1,
rereadData.attr2,
attr3->u_32_value(),
commitCount->u_32_value());
}
}
psop->close(true);
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::Commit ) !=0)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/***************************************************************
* Read all tuples via primary key, using only extra getValues *
***************************************************************/
static void do_all_extras_read(Ndb &myNdb)
{
std::cout << "Running do_all_extras_read(NdbRecord only)\n";
std::cout << "ATTR1 ATTR2 ATTR3 COMMIT_COUNT" << std::endl;
for (int i = 0; i < 10; i++) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
RowData rowData;
NdbRecAttr *myRecAttr1, *myRecAttr2, *myRecAttr3, *myRecAttrCC;
/* We read nothing via NdbRecord, and everything via
* 'extra' reads
*/
NdbOperation::GetValueSpec extraCols[4];
extraCols[0].column=pattr1Col;
extraCols[0].appStorage=NULL;
extraCols[0].recAttr=NULL;
extraCols[1].column=pattr2Col;
extraCols[1].appStorage=NULL;
extraCols[1].recAttr=NULL;
extraCols[2].column=pattr3Col;
extraCols[2].appStorage=NULL;
extraCols[2].recAttr=NULL;
extraCols[3].column=NdbDictionary::Column::COMMIT_COUNT;
extraCols[3].appStorage=NULL;
extraCols[3].recAttr=NULL;
NdbOperation::OperationOptions opts;
opts.optionsPresent = NdbOperation::OperationOptions::OO_GETVALUE;
opts.extraGetValues=&extraCols[0];
opts.numExtraGetValues=4;
unsigned char attrMask= 0; // No row results required.
// Set PK search criteria
rowData.attr1= i;
const NdbOperation *pop=
myTransaction->readTuple(pkeyColumnRecord,
(char*) &rowData,
pkeyColumnRecord,
NULL, // null result row
NdbOperation::LM_Read,
&attrMask,
&opts);
if (pop==NULL) APIERROR(myTransaction->getNdbError());
myRecAttr1=extraCols[0].recAttr;
myRecAttr2=extraCols[1].recAttr;
myRecAttr3=extraCols[2].recAttr;
myRecAttrCC=extraCols[3].recAttr;
if (myRecAttr1 == NULL) APIERROR(myTransaction->getNdbError());
if (myRecAttr2 == NULL) APIERROR(myTransaction->getNdbError());
if (myRecAttr3 == NULL) APIERROR(myTransaction->getNdbError());
if (myRecAttrCC == NULL) APIERROR(myTransaction->getNdbError());
if(myTransaction->execute( NdbTransaction::Commit ) == -1)
APIERROR(myTransaction->getNdbError());
bool deleted= (myTransaction->getNdbError().classification ==
NdbError::NoDataFound);
if (deleted)
printf("Detected that deleted tuple %d doesn't exist!\n", i);
else
{
printf(" %2d %2d %2d %d\n",
myRecAttr1->u_32_value(),
myRecAttr2->u_32_value(),
myRecAttr3->u_32_value(),
myRecAttrCC->u_32_value()
);
}
myNdb.closeTransaction(myTransaction);
}
std::cout << "-------\n";
}
/******************************************************************
* Read and print some tuples via bounded scan of secondary index *
******************************************************************/
static void do_secondary_indexScan(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Index *mySIndex= myDict->getIndex("MYINDEXNAME", "api_recattr_vs_record");
std::cout << "Running do_secondary_indexScan\n";
std::cout << "ATTR1 ATTR2 ATTR3" << std::endl;
NdbTransaction *myTransaction=myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbIndexScanOperation *psop;
NdbRecAttr *recAttrAttr1;
NdbRecAttr *recAttrAttr2;
NdbRecAttr *recAttrAttr3;
Uint32 scanFlags =
NdbScanOperation::SF_OrderBy |
NdbScanOperation::SF_Descending |
NdbScanOperation::SF_MultiRange |
NdbScanOperation::SF_ReadRangeNo;
switch (accessType)
{
case api_attr :
{
psop=myTransaction->getNdbIndexScanOperation(mySIndex);
if (psop == NULL) APIERROR(myTransaction->getNdbError());
if (psop->readTuples(NdbOperation::LM_Read,
scanFlags,
(Uint32) 0, // batch
(Uint32) 0) != 0) // parallel
APIERROR (myTransaction->getNdbError());
/* Bounds :
* > ATTR3=6
* < ATTR3=42
*/
Uint32 low=6;
Uint32 high=42;
if (psop->setBound("ATTR3", NdbIndexScanOperation::BoundLT, (char*)&low))
APIERROR(psop->getNdbError());
if (psop->setBound("ATTR3", NdbIndexScanOperation::BoundGT, (char*)&high))
APIERROR(psop->getNdbError());
recAttrAttr1=psop->getValue("ATTR1");
recAttrAttr2=psop->getValue("ATTR2");
recAttrAttr3=psop->getValue("ATTR3");
break;
}
case api_record :
{
NdbScanOperation::ScanOptions options;
options.optionsPresent=NdbScanOperation::ScanOptions::SO_SCANFLAGS;
options.scan_flags=scanFlags;
psop=myTransaction->scanIndex(psecondaryIndexRecord,
pallColsRecord,
NdbOperation::LM_Read,
NULL, // mask
NULL, // bound
&options,
sizeof(NdbScanOperation::ScanOptions));
if (psop == NULL) APIERROR(myTransaction->getNdbError());
/* Bounds :
* > ATTR3=6
* < ATTR3=42
*/
Uint32 low=6;
Uint32 high=42;
NdbIndexScanOperation::IndexBound bound;
bound.low_key=(char*)&low;
bound.low_key_count=1;
bound.low_inclusive=false;
bound.high_key=(char*)&high;
bound.high_key_count=1;
bound.high_inclusive=false;
bound.range_no=0;
if (psop->setBound(psecondaryIndexRecord, bound))
APIERROR(myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
// Check rc anyway
if (myTransaction->getNdbError().status != NdbError::Success)
APIERROR(myTransaction->getNdbError());
switch (accessType)
{
case api_attr :
{
while (psop->nextResult(true) == 0)
{
printf(" %2d %2d %2d Range no : %2d\n",
recAttrAttr1->u_32_value(),
recAttrAttr2->u_32_value(),
recAttrAttr3->u_32_value(),
psop->get_range_no());
}
psop->close();
break;
}
case api_record :
{
RowData *prowData; // Ptr to point to our data
int rc=0;
while ((rc = psop->nextResult((const char**) &prowData,
true,
false)) == 0)
{
// printf(" PTR : %d\n", (int) prowData);
printf(" %2d %2d %2d Range no : %2d\n",
prowData->attr1,
prowData->attr2,
prowData->attr3,
psop->get_range_no());
}
if (rc != 1) APIERROR(myTransaction->getNdbError());
psop->close(true);
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::Commit ) !=0)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/***********************************************************************
* Index scan to read tuples from secondary index using equality bound *
***********************************************************************/
static void do_secondary_indexScanEqual(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Index *mySIndex= myDict->getIndex("MYINDEXNAME", "api_recattr_vs_record");
std::cout << "Running do_secondary_indexScanEqual\n";
std::cout << "ATTR1 ATTR2 ATTR3" << std::endl;
NdbTransaction *myTransaction=myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbIndexScanOperation *psop;
NdbRecAttr *recAttrAttr1;
NdbRecAttr *recAttrAttr2;
NdbRecAttr *recAttrAttr3;
Uint32 scanFlags = NdbScanOperation::SF_OrderBy;
Uint32 attr3Eq= 44;
switch (accessType)
{
case api_attr :
{
psop=myTransaction->getNdbIndexScanOperation(mySIndex);
if (psop == NULL) APIERROR(myTransaction->getNdbError());
if (psop->readTuples(NdbOperation::LM_Read,
scanFlags,
(Uint32) 0, // batch
(Uint32) 0) != 0) // parallel
APIERROR (myTransaction->getNdbError());
if (psop->setBound("ATTR3", NdbIndexScanOperation::BoundEQ, (char*)&attr3Eq))
APIERROR(myTransaction->getNdbError());
recAttrAttr1=psop->getValue("ATTR1");
recAttrAttr2=psop->getValue("ATTR2");
recAttrAttr3=psop->getValue("ATTR3");
break;
}
case api_record :
{
NdbScanOperation::ScanOptions options;
options.optionsPresent= NdbScanOperation::ScanOptions::SO_SCANFLAGS;
options.scan_flags=scanFlags;
psop=myTransaction->scanIndex(psecondaryIndexRecord,
pallColsRecord, // Read all table rows back
NdbOperation::LM_Read,
NULL, // mask
NULL, // bound specified below
&options,
sizeof(NdbScanOperation::ScanOptions));
if (psop == NULL) APIERROR(myTransaction->getNdbError());
/* Set equality bound via two inclusive bounds */
NdbIndexScanOperation::IndexBound bound;
bound.low_key= (char*)&attr3Eq;
bound.low_key_count= 1;
bound.low_inclusive= true;
bound.high_key= (char*)&attr3Eq;
bound.high_key_count= 1;
bound.high_inclusive= true;
bound.range_no= 0;
if (psop->setBound(psecondaryIndexRecord, bound))
APIERROR(myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
// Check rc anyway
if (myTransaction->getNdbError().status != NdbError::Success)
APIERROR(myTransaction->getNdbError());
switch (accessType)
{
case api_attr :
{
int res;
while ((res= psop->nextResult(true)) == GOT_ROW)
{
printf(" %2d %2d %2d\n",
recAttrAttr1->u_32_value(),
recAttrAttr2->u_32_value(),
recAttrAttr3->u_32_value());
}
if (res != NO_MORE_ROWS)
APIERROR(psop->getNdbError());
psop->close();
break;
}
case api_record :
{
RowData *prowData; // Ptr to point to our data
int rc=0;
while ((rc = psop->nextResult((const char**) &prowData,
true, // fetch
false)) // forceSend
== GOT_ROW)
{
printf(" %2d %2d %2d\n",
prowData->attr1,
prowData->attr2,
prowData->attr3);
}
if (rc != NO_MORE_ROWS)
APIERROR(myTransaction->getNdbError());
psop->close(true);
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::Commit ) !=0)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/**********************
* Interpreted update *
**********************/
static void do_interpreted_update(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_recattr_vs_record");
const NdbDictionary::Index *myPIndex= myDict->getIndex("PRIMARY", "api_recattr_vs_record");
std::cout << "Running do_interpreted_update\n";
if (myTable == NULL)
APIERROR(myDict->getNdbError());
if (myPIndex == NULL)
APIERROR(myDict->getNdbError());
std::cout << "ATTR1 ATTR2 ATTR3" << std::endl;
NdbTransaction *myTransaction=myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbRecAttr *recAttrAttr1;
NdbRecAttr *recAttrAttr2;
NdbRecAttr *recAttrAttr3;
NdbRecAttr *recAttrAttr11;
NdbRecAttr *recAttrAttr12;
NdbRecAttr *recAttrAttr13;
RowData rowData;
RowData rowData2;
/* Register aliases */
const Uint32 R1=1, R2=2, R3=3, R4=4, R5=5, R6=6;
switch (accessType)
{
case api_attr :
{
NdbOperation *pop;
pop=myTransaction->getNdbOperation(myTable);
if (pop == NULL) APIERROR(myTransaction->getNdbError());
if (pop->interpretedUpdateTuple())
APIERROR (pop->getNdbError());
/* Interpreted update on row where ATTR1 == 4 */
if (pop->equal("ATTR1", 4) != 0)
APIERROR (pop->getNdbError());
/* First, read the values of all attributes in the normal way */
recAttrAttr1=pop->getValue("ATTR1");
recAttrAttr2=pop->getValue("ATTR2");
recAttrAttr3=pop->getValue("ATTR3");
/* Now define interpreted program which will run after the
* values have been read
* This program is rather tortuous and doesn't achieve much other
* than demonstrating control flow, register and some column
* operations
*/
// R5= 3
if (pop->load_const_u32(R5, 3) != 0)
APIERROR (pop->getNdbError());
// R1= *ATTR1; R2= *ATTR2; R3= *ATTR3
if (pop->read_attr("ATTR1", R1) != 0)
APIERROR (pop->getNdbError());
if (pop->read_attr("ATTR2", R2) != 0)
APIERROR (pop->getNdbError());
if (pop->read_attr("ATTR3", R3) != 0)
APIERROR (pop->getNdbError());
// R3= R3-R5
if (pop->sub_reg(R3, R5, R3) != 0)
APIERROR (pop->getNdbError());
// R2= R1+R2
if (pop->add_reg(R1, R2, R2) != 0)
APIERROR (pop->getNdbError());
// *ATTR2= R2
if (pop->write_attr("ATTR2", R2) != 0)
APIERROR (pop->getNdbError());
// *ATTR3= R3
if (pop->write_attr("ATTR3", R3) != 0)
APIERROR (pop->getNdbError());
// *ATTR3 = *ATTR3 - 30
if (pop->subValue("ATTR3", (Uint32)30) != 0)
APIERROR (pop->getNdbError());
Uint32 comparisonValue= 10;
// if *ATTR3 > comparisonValue, goto Label 0
if (pop->branch_col_lt(pattr3Col->getColumnNo(),
&comparisonValue,
sizeof(Uint32),
false,
0) != 0)
APIERROR (pop->getNdbError());
// assert(false)
// Fail the operation with error 627 if we get here.
if (pop->interpret_exit_nok(627) != 0)
APIERROR (pop->getNdbError());
// Label 0
if (pop->def_label(0) != 0)
APIERROR (pop->getNdbError());
Uint32 comparisonValue2= 344;
// if *ATTR2 == comparisonValue, goto Label 1
if (pop->branch_col_eq(pattr2Col->getColumnNo(),
&comparisonValue2,
sizeof(Uint32),
false,
1) != 0)
APIERROR (pop->getNdbError());
// assert(false)
// Fail the operation with error 628 if we get here
if (pop->interpret_exit_nok(628) != 0)
APIERROR (pop->getNdbError());
// Label 1
if (pop->def_label(1) != 1)
APIERROR (pop->getNdbError());
// Optional infinite loop
//if (pop->branch_label(0) != 0)
// APIERROR (pop->getNdbError());
// R1 = 10
if (pop->load_const_u32(R1, 10) != 0)
APIERROR (pop->getNdbError());
// R3 = 2
if (pop->load_const_u32(R3, 2) != 0)
APIERROR (pop->getNdbError());
// Now call subroutine 0
if (pop->call_sub(0) != 0)
APIERROR (pop->getNdbError());
// *ATTR2= R2
if (pop->write_attr("ATTR2", R2) != 0)
APIERROR (pop->getNdbError());
// Return ok, we'll move onto an update.
if (pop->interpret_exit_ok() != 0)
APIERROR (pop->getNdbError());
/* Define a final read of the columns after the update */
recAttrAttr11= pop->getValue("ATTR1");
recAttrAttr12= pop->getValue("ATTR2");
recAttrAttr13= pop->getValue("ATTR3");
// Define any subroutines called by the 'main' program
// Subroutine 0
if (pop->def_subroutine(0) != 0)
APIERROR (pop->getNdbError());
// R4= 1
if (pop->load_const_u32(R4, 1) != 0)
APIERROR (pop->getNdbError());
// Label 2
if (pop->def_label(2) != 2)
APIERROR (pop->getNdbError());
// R3= R3-R4
if (pop->sub_reg(R3, R4, R3) != 0)
APIERROR (pop->getNdbError());
// R2= R2 + R1
if (pop->add_reg(R2, R1, R2) != 0)
APIERROR (pop->getNdbError());
// Optional infinite loop
// if (pop->branch_label(2) != 0)
// APIERROR (pop->getNdbError());
// Loop, subtracting 1 from R4 until R4 < 1
if (pop->branch_ge(R4, R3, 2) != 0)
APIERROR (pop->getNdbError());
// Jump to label 3
if (pop->branch_label(3) != 0)
APIERROR (pop->getNdbError());
// assert(false)
// Fail operation with error 629
if (pop->interpret_exit_nok(629) != 0)
APIERROR (pop->getNdbError());
// Label 3
if (pop->def_label(3) != 3)
APIERROR (pop->getNdbError());
// Nested subroutine call to sub 2
if (pop->call_sub(2) != 0)
APIERROR (pop->getNdbError());
// Return from subroutine 0
if (pop->ret_sub() !=0)
APIERROR (pop->getNdbError());
// Subroutine 1
if (pop->def_subroutine(1) != 1)
APIERROR (pop->getNdbError());
// R6= R1+R2
if (pop->add_reg(R1, R2, R6) != 0)
APIERROR (pop->getNdbError());
// Return from subrouine 1
if (pop->ret_sub() !=0)
APIERROR (pop->getNdbError());
// Subroutine 2
if (pop->def_subroutine(2) != 2)
APIERROR (pop->getNdbError());
// Call backwards to subroutine 1
if (pop->call_sub(1) != 0)
APIERROR (pop->getNdbError());
// Return from subroutine 2
if (pop->ret_sub() !=0)
APIERROR (pop->getNdbError());
break;
}
case api_record :
{
const NdbOperation *pop;
rowData.attr1= 4;
/* NdbRecord does not support an updateTuple pre-read or post-read, so
* we use separate operations for these.
* Note that this assumes that a operations are executed in
* the order they are defined by NDBAPI, which is not guaranteed. To ensure
* execution order, the application should perform a NoCommit execute between
* operations.
*/
const NdbOperation *op0= myTransaction->readTuple(pkeyColumnRecord,
(char*) &rowData,
pallColsRecord,
(char*) &rowData);
if (op0 == NULL)
APIERROR (myTransaction->getNdbError());
/* Allocate some space to define an Interpreted program */
const Uint32 numWords= 64;
Uint32 space[numWords];
NdbInterpretedCode stackCode(myTable,
&space[0],
numWords);
NdbInterpretedCode *code= &stackCode;
/* Similar program as above, with tortuous control flow and little
* purpose. Note that for NdbInterpretedCode, some instruction
* arguments are in different orders
*/
// R5= 3
if (code->load_const_u32(R5, 3) != 0)
APIERROR(code->getNdbError());
// R1= *ATTR1; R2= *ATTR2; R3= *ATTR3
if (code->read_attr(R1, pattr1Col) != 0)
APIERROR (code->getNdbError());
if (code->read_attr(R2, pattr2Col) != 0)
APIERROR (code->getNdbError());
if (code->read_attr(R3, pattr3Col) != 0)
APIERROR (code->getNdbError());
// R3= R3-R5
if (code->sub_reg(R3, R3, R5) != 0)
APIERROR (code->getNdbError());
// R2= R1+R2
if (code->add_reg(R2, R1, R2) != 0)
APIERROR (code->getNdbError());
// *ATTR2= R2
if (code->write_attr(pattr2Col, R2) != 0)
APIERROR (code->getNdbError());
// *ATTR3= R3
if (code->write_attr(pattr3Col, R3) != 0)
APIERROR (code->getNdbError());
// *ATTR3 = *ATTR3 - 30
if (code->sub_val(pattr3Col->getColumnNo(), (Uint32)30) != 0)
APIERROR (code->getNdbError());
Uint32 comparisonValue= 10;
// if comparisonValue < *ATTR3, goto Label 0
if (code->branch_col_lt(&comparisonValue,
sizeof(Uint32),
pattr3Col->getColumnNo(),
0) != 0)
APIERROR (code->getNdbError());
// assert(false)
// Fail operation with error 627
if (code->interpret_exit_nok(627) != 0)
APIERROR (code->getNdbError());
// Label 0
if (code->def_label(0) != 0)
APIERROR (code->getNdbError());
Uint32 comparisonValue2= 344;
// if *ATTR2 == comparisonValue, goto Label 1
if (code->branch_col_eq(&comparisonValue2,
sizeof(Uint32),
pattr2Col->getColumnNo(),
1) != 0)
APIERROR (code->getNdbError());
// assert(false)
// Fail operation with error 628
if (code->interpret_exit_nok(628) != 0)
APIERROR (code->getNdbError());
// Label 1
if (code->def_label(1) != 0)
APIERROR (code->getNdbError());
// R1= 10
if (code->load_const_u32(R1, 10) != 0)
APIERROR (code->getNdbError());
// R3= 2
if (code->load_const_u32(R3, 2) != 0)
APIERROR (code->getNdbError());
// Call subroutine 0 to effect
// R2 = R2 + (R1*R3)
if (code->call_sub(0) != 0)
APIERROR (code->getNdbError());
// *ATTR2= R2
if (code->write_attr(pattr2Col, R2) != 0)
APIERROR (code->getNdbError());
// Return ok
if (code->interpret_exit_ok() != 0)
APIERROR (code->getNdbError());
// Subroutine 0
if (code->def_sub(0) != 0)
APIERROR (code->getNdbError());
// R4= 1
if (code->load_const_u32(R4, 1) != 0)
APIERROR (code->getNdbError());
// Label 2
if (code->def_label(2) != 0)
APIERROR (code->getNdbError());
// R3= R3-R4
if (code->sub_reg(R3, R3, R4) != 0)
APIERROR (code->getNdbError());
// R2= R2+R1
if (code->add_reg(R2, R2, R1) != 0)
APIERROR (code->getNdbError());
// Loop, subtracting 1 from R4 until R4>1
if (code->branch_ge(R3, R4, 2) != 0)
APIERROR (code->getNdbError());
// Jump to label 3
if (code->branch_label(3) != 0)
APIERROR (code->getNdbError());
// Fail operation with error 629
if (code->interpret_exit_nok(629) != 0)
APIERROR (code->getNdbError());
// Label 3
if (code->def_label(3) != 0)
APIERROR (code->getNdbError());
// Call sub 2
if (code->call_sub(2) != 0)
APIERROR (code->getNdbError());
// Return from sub 0
if (code->ret_sub() != 0)
APIERROR (code->getNdbError());
// Subroutine 1
if (code->def_sub(1) != 0)
APIERROR (code->getNdbError());
// R6= R1+R2
if (code->add_reg(R6, R1, R2) != 0)
APIERROR (code->getNdbError());
// Return from subroutine 1
if (code->ret_sub() !=0)
APIERROR (code->getNdbError());
// Subroutine 2
if (code->def_sub(2) != 0)
APIERROR (code->getNdbError());
// Call backwards to subroutine 1
if (code->call_sub(1) != 0)
APIERROR (code->getNdbError());
// Return from subroutine 2
if (code->ret_sub() !=0)
APIERROR (code->getNdbError());
/* Finalise code object
* This step is essential for NdbInterpretedCode objects
* and must be done before they can be used.
*/
if (code->finalise() !=0)
APIERROR (code->getNdbError());
/* Time to define the update operation to use the
* InterpretedCode object. The same finalised object
* could be used with multiple operations or even
* multiple threads
*/
NdbOperation::OperationOptions oo;
oo.optionsPresent=
NdbOperation::OperationOptions::OO_INTERPRETED;
oo.interpretedCode= code;
unsigned char mask= 0;
pop= myTransaction->updateTuple(pkeyColumnRecord,
(char*) &rowData,
pallColsRecord,
(char*) &rowData,
(const unsigned char *) &mask, // mask - update nothing
&oo,
sizeof(NdbOperation::OperationOptions));
if (pop == NULL)
APIERROR (myTransaction->getNdbError());
// NoCommit execute so we can read the 'after' data.
if (myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
/* Second read op as we can't currently do a 'read after
* 'interpreted code' read as part of NdbRecord.
* We are assuming that the order of op definition == order
* of execution on a single row, which is not guaranteed.
*/
const NdbOperation *pop2=
myTransaction->readTuple(pkeyColumnRecord,
(char*) &rowData,
pallColsRecord,
(char*) &rowData2);
if (pop2 == NULL)
APIERROR (myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
// Check return code
if (myTransaction->getNdbError().status != NdbError::Success)
APIERROR(myTransaction->getNdbError());
switch (accessType)
{
case api_attr :
{
printf(" %2d %2d %2d Before\n"
" %2d %2d %2d After\n",
recAttrAttr1->u_32_value(),
recAttrAttr2->u_32_value(),
recAttrAttr3->u_32_value(),
recAttrAttr11->u_32_value(),
recAttrAttr12->u_32_value(),
recAttrAttr13->u_32_value());
break;
}
case api_record :
{
printf(" %2d %2d %2d Before\n"
" %2d %2d %2d After\n",
rowData.attr1,
rowData.attr2,
rowData.attr3,
rowData2.attr1,
rowData2.attr2,
rowData2.attr3);
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::Commit ) !=0)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/******************************************************
* Read and print selected rows with interpreted code *
******************************************************/
static void do_interpreted_scan(Ndb &myNdb, ApiType accessType)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_recattr_vs_record");
std::cout << "Running do_interpreted_scan\n";
if (myTable == NULL)
APIERROR(myDict->getNdbError());
std::cout << "ATTR1 ATTR2 ATTR3" << std::endl;
NdbTransaction *myTransaction=myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
NdbScanOperation *psop;
NdbRecAttr *recAttrAttr1;
NdbRecAttr *recAttrAttr2;
NdbRecAttr *recAttrAttr3;
/* Create some space on the stack for the program */
const Uint32 numWords= 64;
Uint32 space[numWords];
NdbInterpretedCode stackCode(myTable,
&space[0],
numWords);
NdbInterpretedCode *code= &stackCode;
/* RecAttr and NdbRecord scans both use NdbInterpretedCode
* Let's define a small scan filter of sorts
*/
Uint32 comparisonValue= 10;
// Return rows where 10 > ATTR3 (ATTR3 <10)
if (code->branch_col_gt(&comparisonValue,
sizeof(Uint32),
pattr3Col->getColumnNo(),
0) != 0)
APIERROR (myTransaction->getNdbError());
/* If we get here then we don't return this row */
if (code->interpret_exit_nok() != 0)
APIERROR (myTransaction->getNdbError());
/* Label 0 */
if (code->def_label(0) != 0)
APIERROR (myTransaction->getNdbError());
/* Return this row */
if (code->interpret_exit_ok() != 0)
APIERROR (myTransaction->getNdbError());
/* Finalise the Interpreted Program */
if (code->finalise() != 0)
APIERROR (myTransaction->getNdbError());
switch (accessType)
{
case api_attr :
{
psop=myTransaction->getNdbScanOperation(myTable);
if (psop == NULL) APIERROR(myTransaction->getNdbError());
if (psop->readTuples(NdbOperation::LM_Read) != 0) APIERROR (myTransaction->getNdbError());
if (psop->setInterpretedCode(code) != 0)
APIERROR (myTransaction->getNdbError());
recAttrAttr1=psop->getValue("ATTR1");
recAttrAttr2=psop->getValue("ATTR2");
recAttrAttr3=psop->getValue("ATTR3");
break;
}
case api_record :
{
NdbScanOperation::ScanOptions so;
so.optionsPresent = NdbScanOperation::ScanOptions::SO_INTERPRETED;
so.interpretedCode= code;
psop=myTransaction->scanTable(pallColsRecord,
NdbOperation::LM_Read,
NULL, // mask
&so,
sizeof(NdbScanOperation::ScanOptions));
if (psop == NULL) APIERROR(myTransaction->getNdbError());
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::NoCommit ) != 0)
APIERROR(myTransaction->getNdbError());
switch (accessType)
{
case api_attr :
{
while (psop->nextResult(true) == 0)
{
printf(" %2d %2d %2d\n",
recAttrAttr1->u_32_value(),
recAttrAttr2->u_32_value(),
recAttrAttr3->u_32_value());
}
psop->close();
break;
}
case api_record :
{
RowData *prowData; // Ptr to point to our data
int rc=0;
while ((rc = psop->nextResult((const char**) &prowData,
true,
false)) == GOT_ROW)
{
printf(" %2d %2d %2d\n",
prowData->attr1,
prowData->attr2,
prowData->attr3);
}
if (rc != NO_MORE_ROWS) APIERROR(myTransaction->getNdbError());
psop->close(true);
break;
}
default :
{
std::cout << "Bad branch : " << accessType << "\n";
exit(-1);
}
}
if(myTransaction->execute( NdbTransaction::Commit ) !=0)
APIERROR(myTransaction->getNdbError());
myNdb.closeTransaction(myTransaction);
std::cout << "-------\n";
}
/******************************************************
* Read some data using the default NdbRecord objects *
******************************************************/
static void do_read_using_default(Ndb &myNdb)
{
NdbDictionary::Dictionary* myDict= myNdb.getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_recattr_vs_record");
const NdbRecord* tableRec= myTable->getDefaultRecord();
if (myTable == NULL)
APIERROR(myDict->getNdbError());
std::cout << "Running do_read_using_default_record (NdbRecord only)\n";
std::cout << "ATTR1 ATTR2 ATTR3" << std::endl;
/* Allocate some space for the rows to be read into */
char* buffer= (char*)malloc(NdbDictionary::getRecordRowLength(tableRec));
if (buffer== NULL)
{
printf("Allocation failed\n");
exit(-1);
}
for (int i = 0; i < 10; i++) {
NdbTransaction *myTransaction= myNdb.startTransaction();
if (myTransaction == NULL) APIERROR(myNdb.getNdbError());
char* attr1= NdbDictionary::getValuePtr(tableRec,
buffer,
attr1ColNum);
*((unsigned int*)attr1)= i;
const NdbOperation *pop=
myTransaction->readTuple(tableRec,
buffer,
tableRec, // Read everything
buffer);
if (pop==NULL) APIERROR(myTransaction->getNdbError());
if(myTransaction->execute( NdbTransaction::Commit ) == -1)
APIERROR(myTransaction->getNdbError());
NdbError err= myTransaction->getNdbError();
if (err.code != 0)
{
if (err.classification == NdbError::NoDataFound)
std::cout << "Detected that tuple " << i << " doesn't exist!" << std::endl;
else
APIERROR(myTransaction->getNdbError());
}
else
{
printf(" %2d %2d %2d\n",
i,
*((unsigned int*) NdbDictionary::getValuePtr(tableRec,
buffer,
attr2ColNum)),
*((unsigned int*) NdbDictionary::getValuePtr(tableRec,
buffer,
attr3ColNum)));
}
myNdb.closeTransaction(myTransaction);
}
free(buffer);
std::cout << "-------\n";
}
This example demonstrates NDB API event handling.
The source code for this program may be found in the MySQL Cluster
source tree, in the file
storage/ndb/ndbapi-examples/ndbapi_event/ndbapi_event.cpp.
#include <NdbApi.hpp>
// Used for cout
#include <stdio.h>
#include <iostream>
#include <unistd.h>
#ifdef VM_TRACE
#include <my_global.h>
#endif
#ifndef assert
#include <assert.h>
#endif
/**
* Assume that there is a table which is being updated by
* another process (e.g. flexBench -l 0 -stdtables).
* We want to monitor what happens with column values.
*
* Or using the mysql client:
*
* shell> mysql -u root
* mysql> create database ndb_examples;
* mysql> use ndb_examples;
* mysql> create table t0
(c0 int, c1 int, c2 char(4), c3 char(4), c4 text,
primary key(c0, c2)) engine ndb charset latin1;
*
* In another window start ndbapi_event, wait until properly started
insert into t0 values (1, 2, 'a', 'b', null);
insert into t0 values (3, 4, 'c', 'd', null);
update t0 set c3 = 'e' where c0 = 1 and c2 = 'a'; -- use pk
update t0 set c3 = 'f'; -- use scan
update t0 set c3 = 'F'; -- use scan update to 'same'
update t0 set c2 = 'g' where c0 = 1; -- update pk part
update t0 set c2 = 'G' where c0 = 1; -- update pk part to 'same'
update t0 set c0 = 5, c2 = 'H' where c0 = 3; -- update full PK
delete from t0;
insert ...; update ...; -- see events w/ same pk merged (if -m option)
delete ...; insert ...; -- there are 5 combinations ID IU DI UD UU
update ...; update ...;
-- text requires -m flag
set @a = repeat('a',256); -- inline size
set @b = repeat('b',2000); -- part size
set @c = repeat('c',2000*30); -- 30 parts
-- update the text field using combinations of @a, @b, @c ...
* you should see the data popping up in the example window
*
*/
#define APIERROR(error) \
{ std::cout << "Error in " << __FILE__ << ", line:" << __LINE__ << ", code:" \
<< error.code << ", msg: " << error.message << "." << std::endl; \
exit(-1); }
int myCreateEvent(Ndb* myNdb,
const char *eventName,
const char *eventTableName,
const char **eventColumnName,
const int noEventColumnName,
bool merge_events);
int main(int argc, char** argv)
{
if (argc < 3)
{
std::cout << "Arguments are <connect_string cluster> <timeout> [m(merge events)|d(debug)].\n";
exit(-1);
}
const char *connectstring = argv[1];
int timeout = atoi(argv[2]);
ndb_init();
bool merge_events = argc > 3 && strchr(argv[3], 'm') != 0;
#ifdef VM_TRACE
bool dbug = argc > 3 && strchr(argv[3], 'd') != 0;
if (dbug) DBUG_PUSH("d:t:");
if (dbug) putenv("API_SIGNAL_LOG=-");
#endif
Ndb_cluster_connection *cluster_connection=
new Ndb_cluster_connection(connectstring); // Object representing the cluster
int r= cluster_connection->connect(5 /* retries */,
3 /* delay between retries */,
1 /* verbose */);
if (r > 0)
{
std::cout
<< "Cluster connect failed, possibly resolved with more retries.\n";
exit(-1);
}
else if (r < 0)
{
std::cout
<< "Cluster connect failed.\n";
exit(-1);
}
if (cluster_connection->wait_until_ready(30,30))
{
std::cout << "Cluster was not ready within 30 secs." << std::endl;
exit(-1);
}
Ndb* myNdb= new Ndb(cluster_connection,
"ndb_examples"); // Object representing the database
if (myNdb->init() == -1) APIERROR(myNdb->getNdbError());
const char *eventName= "CHNG_IN_t0";
const char *eventTableName= "t0";
const int noEventColumnName= 5;
const char *eventColumnName[noEventColumnName]=
{"c0",
"c1",
"c2",
"c3",
"c4"
};
// Create events
myCreateEvent(myNdb,
eventName,
eventTableName,
eventColumnName,
noEventColumnName,
merge_events);
// Normal values and blobs are unfortunately handled differently..
typedef union { NdbRecAttr* ra; NdbBlob* bh; } RA_BH;
int i, j, k, l;
j = 0;
while (j < timeout) {
// Start "transaction" for handling events
NdbEventOperation* op;
printf("create EventOperation\n");
if ((op = myNdb->createEventOperation(eventName)) == NULL)
APIERROR(myNdb->getNdbError());
op->mergeEvents(merge_events);
printf("get values\n");
RA_BH recAttr[noEventColumnName];
RA_BH recAttrPre[noEventColumnName];
// primary keys should always be a part of the result
for (i = 0; i < noEventColumnName; i++) {
if (i < 4) {
recAttr[i].ra = op->getValue(eventColumnName[i]);
recAttrPre[i].ra = op->getPreValue(eventColumnName[i]);
} else if (merge_events) {
recAttr[i].bh = op->getBlobHandle(eventColumnName[i]);
recAttrPre[i].bh = op->getPreBlobHandle(eventColumnName[i]);
}
}
// set up the callbacks
printf("execute\n");
// This starts changes to "start flowing"
if (op->execute())
APIERROR(op->getNdbError());
NdbEventOperation* the_op = op;
i= 0;
while (i < timeout) {
// printf("now waiting for event...\n");
int r = myNdb->pollEvents(1000); // wait for event or 1000 ms
if (r > 0) {
// printf("got data! %d\n", r);
while ((op= myNdb->nextEvent())) {
assert(the_op == op);
i++;
switch (op->getEventType()) {
case NdbDictionary::Event::TE_INSERT:
printf("%u INSERT", i);
break;
case NdbDictionary::Event::TE_DELETE:
printf("%u DELETE", i);
break;
case NdbDictionary::Event::TE_UPDATE:
printf("%u UPDATE", i);
break;
default:
abort(); // should not happen
}
printf(" gci=%d\n", (int)op->getGCI());
for (k = 0; k <= 1; k++) {
printf(k == 0 ? "post: " : "pre : ");
for (l = 0; l < noEventColumnName; l++) {
if (l < 4) {
NdbRecAttr* ra = k == 0 ? recAttr[l].ra : recAttrPre[l].ra;
if (ra->isNULL() >= 0) { // we have a value
if (ra->isNULL() == 0) { // we have a non-null value
if (l < 2)
printf("%-5u", ra->u_32_value());
else
printf("%-5.4s", ra->aRef());
} else
printf("%-5s", "NULL");
} else
printf("%-5s", "-"); // no value
} else if (merge_events) {
int isNull;
NdbBlob* bh = k == 0 ? recAttr[l].bh : recAttrPre[l].bh;
bh->getDefined(isNull);
if (isNull >= 0) { // we have a value
if (! isNull) { // we have a non-null value
Uint64 length = 0;
bh->getLength(length);
// read into buffer
unsigned char* buf = new unsigned char [length];
memset(buf, 'X', length);
Uint32 n = length;
bh->readData(buf, n); // n is in/out
assert(n == length);
// pretty-print
bool first = true;
Uint32 i = 0;
while (i < n) {
unsigned char c = buf[i++];
Uint32 m = 1;
while (i < n && buf[i] == c)
i++, m++;
if (! first)
printf("+");
printf("%u%c", m, c);
first = false;
}
printf("[%u]", n);
delete [] buf;
} else
printf("%-5s", "NULL");
} else
printf("%-5s", "-"); // no value
}
}
printf("\n");
}
}
} // else printf("timed out (%i)\n", timeout);
}
// don't want to listen to events anymore
if (myNdb->dropEventOperation(the_op)) APIERROR(myNdb->getNdbError());
the_op = 0;
j++;
}
{
NdbDictionary::Dictionary *myDict = myNdb->getDictionary();
if (!myDict) APIERROR(myNdb->getNdbError());
// remove event from database
if (myDict->dropEvent(eventName)) APIERROR(myDict->getNdbError());
}
delete myNdb;
delete cluster_connection;
ndb_end(0);
return 0;
}
int myCreateEvent(Ndb* myNdb,
const char *eventName,
const char *eventTableName,
const char **eventColumnNames,
const int noEventColumnNames,
bool merge_events)
{
NdbDictionary::Dictionary *myDict= myNdb->getDictionary();
if (!myDict) APIERROR(myNdb->getNdbError());
const NdbDictionary::Table *table= myDict->getTable(eventTableName);
if (!table) APIERROR(myDict->getNdbError());
NdbDictionary::Event myEvent(eventName, *table);
myEvent.addTableEvent(NdbDictionary::Event::TE_ALL);
// myEvent.addTableEvent(NdbDictionary::Event::TE_INSERT);
// myEvent.addTableEvent(NdbDictionary::Event::TE_UPDATE);
// myEvent.addTableEvent(NdbDictionary::Event::TE_DELETE);
myEvent.addEventColumns(noEventColumnNames, eventColumnNames);
myEvent.mergeEvents(merge_events);
// Add event to database
if (myDict->createEvent(myEvent) == 0)
myEvent.print();
else if (myDict->getNdbError().classification ==
NdbError::SchemaObjectExists) {
printf("Event creation failed, event exists\n");
printf("dropping Event...\n");
if (myDict->dropEvent(eventName)) APIERROR(myDict->getNdbError());
// try again
// Add event to database
if ( myDict->createEvent(myEvent)) APIERROR(myDict->getNdbError());
} else
APIERROR(myDict->getNdbError());
return 0;
}
This example illustrates the manipulation of a
BLOB column in the NDB API.
It demonstrates how to perform insert, read, and update
operations, using both inline value buffers as well as read and
write methods.
The source code can be found can be found in the file
storage/ndb/ndbapi-examples/ndbapi_blob/ndbapi_blob.cpp
in the MySQL Cluster source tree.
While the MySQL data type used in the example is actually
TEXT, the same principles apply
#include <mysql.h>
#include <mysqld_error.h>
#include <NdbApi.hpp>
/* Used for cout. */
#include <iostream>
#include <stdio.h>
#include <ctype.h>
/**
* Helper debugging macros
*/
#define PRINT_ERROR(code,msg) \
std::cout << "Error in " << __FILE__ << ", line: " << __LINE__ \
<< ", code: " << code \
<< ", msg: " << msg << "." << std::endl
#define MYSQLERROR(mysql) { \
PRINT_ERROR(mysql_errno(&mysql),mysql_error(&mysql)); \
exit(-1); }
#define APIERROR(error) { \
PRINT_ERROR(error.code,error.message); \
exit(-1); }
/* Quote taken from Project Gutenberg. */
const char *text_quote=
"Just at this moment, somehow or other, they began to run.\n"
"\n"
" Alice never could quite make out, in thinking it over\n"
"afterwards, how it was that they began: all she remembers is,\n"
"that they were running hand in hand, and the Queen went so fast\n"
"that it was all she could do to keep up with her: and still the\n"
"Queen kept crying 'Faster! Faster!' but Alice felt she COULD NOT\n"
"go faster, though she had not breath left to say so.\n"
"\n"
" The most curious part of the thing was, that the trees and the\n"
"other things round them never changed their places at all:\n"
"however fast they went, they never seemed to pass anything. 'I\n"
"wonder if all the things move along with us?' thought poor\n"
"puzzled Alice. And the Queen seemed to guess her thoughts, for\n"
"she cried, 'Faster! Don't try to talk!'\n"
"\n"
" Not that Alice had any idea of doing THAT. She felt as if she\n"
"would never be able to talk again, she was getting so much out of\n"
"breath: and still the Queen cried 'Faster! Faster!' and dragged\n"
"her along. 'Are we nearly there?' Alice managed to pant out at\n"
"last.\n"
"\n"
" 'Nearly there!' the Queen repeated. 'Why, we passed it ten\n"
"minutes ago! Faster!' And they ran on for a time in silence,\n"
"with the wind whistling in Alice's ears, and almost blowing her\n"
"hair off her head, she fancied.\n"
"\n"
" 'Now! Now!' cried the Queen. 'Faster! Faster!' And they\n"
"went so fast that at last they seemed to skim through the air,\n"
"hardly touching the ground with their feet, till suddenly, just\n"
"as Alice was getting quite exhausted, they stopped, and she found\n"
"herself sitting on the ground, breathless and giddy.\n"
"\n"
" The Queen propped her up against a tree, and said kindly, 'You\n"
"may rest a little now.'\n"
"\n"
" Alice looked round her in great surprise. 'Why, I do believe\n"
"we've been under this tree the whole time! Everything's just as\n"
"it was!'\n"
"\n"
" 'Of course it is,' said the Queen, 'what would you have it?'\n"
"\n"
" 'Well, in OUR country,' said Alice, still panting a little,\n"
"'you'd generally get to somewhere else--if you ran very fast\n"
"for a long time, as we've been doing.'\n"
"\n"
" 'A slow sort of country!' said the Queen. 'Now, HERE, you see,\n"
"it takes all the running YOU can do, to keep in the same place.\n"
"If you want to get somewhere else, you must run at least twice as\n"
"fast as that!'\n"
"\n"
" 'I'd rather not try, please!' said Alice. 'I'm quite content\n"
"to stay here--only I AM so hot and thirsty!'\n"
"\n"
" -- Lewis Carroll, 'Through the Looking-Glass'.";
/*
Function to drop table.
*/
void drop_table(MYSQL &mysql)
{
if (mysql_query(&mysql, "DROP TABLE api_blob"))
MYSQLERROR(mysql);
}
/*
Functions to create table.
*/
int try_create_table(MYSQL &mysql)
{
return mysql_query(&mysql,
"CREATE TABLE"
" api_blob"
" (my_id INT UNSIGNED NOT NULL,"
" my_text TEXT NOT NULL,"
" PRIMARY KEY USING HASH (my_id))"
" ENGINE=NDB");
}
void create_table(MYSQL &mysql)
{
if (try_create_table(mysql))
{
if (mysql_errno(&mysql) != ER_TABLE_EXISTS_ERROR)
MYSQLERROR(mysql);
std::cout << "MySQL Cluster already has example table: api_blob. "
<< "Dropping it..." << std::endl;
/******************
* Recreate table *
******************/
drop_table(mysql);
if (try_create_table(mysql))
MYSQLERROR(mysql);
}
}
int populate(Ndb *myNdb)
{
const NdbDictionary::Dictionary *myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_blob");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
NdbTransaction *myTrans= myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
NdbOperation *myNdbOperation= myTrans->getNdbOperation(myTable);
if (myNdbOperation == NULL)
APIERROR(myTrans->getNdbError());
myNdbOperation->insertTuple();
myNdbOperation->equal("my_id", 1);
NdbBlob *myBlobHandle= myNdbOperation->getBlobHandle("my_text");
if (myBlobHandle == NULL)
APIERROR(myNdbOperation->getNdbError());
myBlobHandle->setValue(text_quote, strlen(text_quote));
int check= myTrans->execute(NdbTransaction::Commit);
myTrans->close();
return check != -1;
}
int update_key(Ndb *myNdb)
{
/*
Uppercase all characters in TEXT field, using primary key operation.
Use piece-wise read/write to avoid loading entire data into memory
at once.
*/
const NdbDictionary::Dictionary *myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_blob");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
NdbTransaction *myTrans= myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
NdbOperation *myNdbOperation= myTrans->getNdbOperation(myTable);
if (myNdbOperation == NULL)
APIERROR(myTrans->getNdbError());
myNdbOperation->updateTuple();
myNdbOperation->equal("my_id", 1);
NdbBlob *myBlobHandle= myNdbOperation->getBlobHandle("my_text");
if (myBlobHandle == NULL)
APIERROR(myNdbOperation->getNdbError());
/* Execute NoCommit to make the blob handle active. */
if (-1 == myTrans->execute(NdbTransaction::NoCommit))
APIERROR(myTrans->getNdbError());
Uint64 length= 0;
if (-1 == myBlobHandle->getLength(length))
APIERROR(myBlobHandle->getNdbError());
/*
A real application should use a much larger chunk size for
efficiency, preferably much larger than the part size, which
defaults to 2000. 64000 might be a good value.
*/
#define CHUNK_SIZE 100
int chunk;
char buffer[CHUNK_SIZE];
for (chunk= (length-1)/CHUNK_SIZE; chunk >=0; chunk--)
{
Uint64 pos= chunk*CHUNK_SIZE;
Uint32 chunk_length= CHUNK_SIZE;
if (pos + chunk_length > length)
chunk_length= length - pos;
/* Read from the end back, to illustrate seeking. */
if (-1 == myBlobHandle->setPos(pos))
APIERROR(myBlobHandle->getNdbError());
if (-1 == myBlobHandle->readData(buffer, chunk_length))
APIERROR(myBlobHandle->getNdbError());
int res= myTrans->execute(NdbTransaction::NoCommit);
if (-1 == res)
APIERROR(myTrans->getNdbError());
/* Uppercase everything. */
for (Uint64 j= 0; j < chunk_length; j++)
buffer[j]= toupper(buffer[j]);
if (-1 == myBlobHandle->setPos(pos))
APIERROR(myBlobHandle->getNdbError());
if (-1 == myBlobHandle->writeData(buffer, chunk_length))
APIERROR(myBlobHandle->getNdbError());
/* Commit on the final update. */
if (-1 == myTrans->execute(chunk ?
NdbTransaction::NoCommit :
NdbTransaction::Commit))
APIERROR(myTrans->getNdbError());
}
myNdb->closeTransaction(myTrans);
return 1;
}
int update_scan(Ndb *myNdb)
{
/*
Lowercase all characters in TEXT field, using a scan with
updateCurrentTuple().
*/
char buffer[10000];
const NdbDictionary::Dictionary *myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_blob");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
NdbTransaction *myTrans= myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
NdbScanOperation *myScanOp= myTrans->getNdbScanOperation(myTable);
if (myScanOp == NULL)
APIERROR(myTrans->getNdbError());
myScanOp->readTuples(NdbOperation::LM_Exclusive);
NdbBlob *myBlobHandle= myScanOp->getBlobHandle("my_text");
if (myBlobHandle == NULL)
APIERROR(myScanOp->getNdbError());
if (myBlobHandle->getValue(buffer, sizeof(buffer)))
APIERROR(myBlobHandle->getNdbError());
/* Start the scan. */
if (-1 == myTrans->execute(NdbTransaction::NoCommit))
APIERROR(myTrans->getNdbError());
int res;
for (;;)
{
res= myScanOp->nextResult(true);
if (res==1)
break; // Scan done.
else if (res)
APIERROR(myScanOp->getNdbError());
Uint64 length= 0;
if (myBlobHandle->getLength(length) == -1)
APIERROR(myBlobHandle->getNdbError());
/* Lowercase everything. */
for (Uint64 j= 0; j < length; j++)
buffer[j]= tolower(buffer[j]);
NdbOperation *myUpdateOp= myScanOp->updateCurrentTuple();
if (myUpdateOp == NULL)
APIERROR(myTrans->getNdbError());
NdbBlob *myBlobHandle2= myUpdateOp->getBlobHandle("my_text");
if (myBlobHandle2 == NULL)
APIERROR(myUpdateOp->getNdbError());
if (myBlobHandle2->setValue(buffer, length))
APIERROR(myBlobHandle2->getNdbError());
if (-1 == myTrans->execute(NdbTransaction::NoCommit))
APIERROR(myTrans->getNdbError());
}
if (-1 == myTrans->execute(NdbTransaction::Commit))
APIERROR(myTrans->getNdbError());
myNdb->closeTransaction(myTrans);
return 1;
}
struct ActiveHookData {
char buffer[10000];
Uint32 readLength;
};
int myFetchHook(NdbBlob* myBlobHandle, void* arg)
{
ActiveHookData *ahd= (ActiveHookData *)arg;
ahd->readLength= sizeof(ahd->buffer) - 1;
return myBlobHandle->readData(ahd->buffer, ahd->readLength);
}
int fetch_key(Ndb *myNdb)
{
/*
Fetch and show the blob field, using setActiveHook().
*/
const NdbDictionary::Dictionary *myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_blob");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
NdbTransaction *myTrans= myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
NdbOperation *myNdbOperation= myTrans->getNdbOperation(myTable);
if (myNdbOperation == NULL)
APIERROR(myTrans->getNdbError());
myNdbOperation->readTuple();
myNdbOperation->equal("my_id", 1);
NdbBlob *myBlobHandle= myNdbOperation->getBlobHandle("my_text");
if (myBlobHandle == NULL)
APIERROR(myNdbOperation->getNdbError());
struct ActiveHookData ahd;
if (myBlobHandle->setActiveHook(myFetchHook, &ahd) == -1)
APIERROR(myBlobHandle->getNdbError());
/*
Execute Commit, but calling our callback set up in setActiveHook()
before actually committing.
*/
if (-1 == myTrans->execute(NdbTransaction::Commit))
APIERROR(myTrans->getNdbError());
myNdb->closeTransaction(myTrans);
/* Our fetch callback will have been called during the execute(). */
ahd.buffer[ahd.readLength]= '\0';
std::cout << "Fetched data:" << std::endl << ahd.buffer << std::endl;
return 1;
}
int update2_key(Ndb *myNdb)
{
char buffer[10000];
/* Simple setValue() update. */
const NdbDictionary::Dictionary *myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_blob");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
NdbTransaction *myTrans= myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
NdbOperation *myNdbOperation= myTrans->getNdbOperation(myTable);
if (myNdbOperation == NULL)
APIERROR(myTrans->getNdbError());
myNdbOperation->updateTuple();
myNdbOperation->equal("my_id", 1);
NdbBlob *myBlobHandle= myNdbOperation->getBlobHandle("my_text");
if (myBlobHandle == NULL)
APIERROR(myNdbOperation->getNdbError());
memset(buffer, ' ', sizeof(buffer));
if (myBlobHandle->setValue(buffer, sizeof(buffer)) == -1)
APIERROR(myBlobHandle->getNdbError());
if (-1 == myTrans->execute(NdbTransaction::Commit))
APIERROR(myTrans->getNdbError());
myNdb->closeTransaction(myTrans);
return 1;
}
int delete_key(Ndb *myNdb)
{
/* Deletion of blob row. */
const NdbDictionary::Dictionary *myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_blob");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
NdbTransaction *myTrans= myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
NdbOperation *myNdbOperation= myTrans->getNdbOperation(myTable);
if (myNdbOperation == NULL)
APIERROR(myTrans->getNdbError());
myNdbOperation->deleteTuple();
myNdbOperation->equal("my_id", 1);
if (-1 == myTrans->execute(NdbTransaction::Commit))
APIERROR(myTrans->getNdbError());
myNdb->closeTransaction(myTrans);
return 1;
}
int main(int argc, char**argv)
{
if (argc != 3)
{
std::cout << "Arguments are <socket mysqld> <connect_string cluster>.\n";
exit(-1);
}
char *mysqld_sock = argv[1];
const char *connectstring = argv[2];
ndb_init();
MYSQL mysql;
/* Connect to mysql server and create table. */
{
if ( !mysql_init(&mysql) ) {
std::cout << "mysql_init failed.\n";
exit(-1);
}
if ( !mysql_real_connect(&mysql, "localhost", "root", "", "",
0, mysqld_sock, 0) )
MYSQLERROR(mysql);
mysql_query(&mysql, "CREATE DATABASE ndb_examples");
if (mysql_query(&mysql, "USE ndb_examples") != 0)
MYSQLERROR(mysql);
create_table(mysql);
}
/* Connect to ndb cluster. */
Ndb_cluster_connection cluster_connection(connectstring);
if (cluster_connection.connect(4, 5, 1))
{
std::cout << "Unable to connect to cluster within 30 secs." << std::endl;
exit(-1);
}
/* Optionally connect and wait for the storage nodes (ndbd's). */
if (cluster_connection.wait_until_ready(30,0) < 0)
{
std::cout << "Cluster was not ready within 30 secs.\n";
exit(-1);
}
Ndb myNdb(&cluster_connection,"ndb_examples");
if (myNdb.init(1024) == -1) { // Set max 1024 parallel transactions
APIERROR(myNdb.getNdbError());
exit(-1);
}
if(populate(&myNdb) > 0)
std::cout << "populate: Success!" << std::endl;
if(update_key(&myNdb) > 0)
std::cout << "update_key: Success!" << std::endl;
if(update_scan(&myNdb) > 0)
std::cout << "update_scan: Success!" << std::endl;
if(fetch_key(&myNdb) > 0)
std::cout << "fetch_key: Success!" << std::endl;
if(update2_key(&myNdb) > 0)
std::cout << "update2_key: Success!" << std::endl;
if(delete_key(&myNdb) > 0)
std::cout << "delete_key: Success!" << std::endl;
return 0;
}
This example illustrates the manipulation of a
BLOB column in the NDB API using the
NdbRecord interface available beginning with
MySQL Cluster NDB 6.2.3. It demonstrates how to perform insert,
read, and update operations, using both inline value buffers as
well as read and write methods. It can be found in the file
storage/ndb/ndbapi-examples/ndbapi_blob_ndbrecord/main.cpp
in the MySQL Cluster source trees.
While the MySQL data type used in the example is actually
TEXT, the same principles apply
#include <ndb_global.h>
#include <mysql.h>
#include <mysqld_error.h>
#include <NdbApi.hpp>
/* Used for cout. */
#include <iostream>
#include <stdio.h>
#include <ctype.h>
/**
* Helper debugging macros
*/
#define PRINT_ERROR(code,msg) \
std::cout << "Error in " << __FILE__ << ", line: " << __LINE__ \
<< ", code: " << code \
<< ", msg: " << msg << "." << std::endl
#define MYSQLERROR(mysql) { \
PRINT_ERROR(mysql_errno(&mysql),mysql_error(&mysql)); \
exit(-1); }
#define APIERROR(error) { \
PRINT_ERROR(error.code,error.message); \
exit(-1); }
/* Quote taken from Project Gutenberg. */
const char *text_quote=
"Just at this moment, somehow or other, they began to run.\n"
"\n"
" Alice never could quite make out, in thinking it over\n"
"afterwards, how it was that they began: all she remembers is,\n"
"that they were running hand in hand, and the Queen went so fast\n"
"that it was all she could do to keep up with her: and still the\n"
"Queen kept crying 'Faster! Faster!' but Alice felt she COULD NOT\n"
"go faster, though she had not breath left to say so.\n"
"\n"
" The most curious part of the thing was, that the trees and the\n"
"other things round them never changed their places at all:\n"
"however fast they went, they never seemed to pass anything. 'I\n"
"wonder if all the things move along with us?' thought poor\n"
"puzzled Alice. And the Queen seemed to guess her thoughts, for\n"
"she cried, 'Faster! Don't try to talk!'\n"
"\n"
" Not that Alice had any idea of doing THAT. She felt as if she\n"
"would never be able to talk again, she was getting so much out of\n"
"breath: and still the Queen cried 'Faster! Faster!' and dragged\n"
"her along. 'Are we nearly there?' Alice managed to pant out at\n"
"last.\n"
"\n"
" 'Nearly there!' the Queen repeated. 'Why, we passed it ten\n"
"minutes ago! Faster!' And they ran on for a time in silence,\n"
"with the wind whistling in Alice's ears, and almost blowing her\n"
"hair off her head, she fancied.\n"
"\n"
" 'Now! Now!' cried the Queen. 'Faster! Faster!' And they\n"
"went so fast that at last they seemed to skim through the air,\n"
"hardly touching the ground with their feet, till suddenly, just\n"
"as Alice was getting quite exhausted, they stopped, and she found\n"
"herself sitting on the ground, breathless and giddy.\n"
"\n"
" The Queen propped her up against a tree, and said kindly, 'You\n"
"may rest a little now.'\n"
"\n"
" Alice looked round her in great surprise. 'Why, I do believe\n"
"we've been under this tree the whole time! Everything's just as\n"
"it was!'\n"
"\n"
" 'Of course it is,' said the Queen, 'what would you have it?'\n"
"\n"
" 'Well, in OUR country,' said Alice, still panting a little,\n"
"'you'd generally get to somewhere else--if you ran very fast\n"
"for a long time, as we've been doing.'\n"
"\n"
" 'A slow sort of country!' said the Queen. 'Now, HERE, you see,\n"
"it takes all the running YOU can do, to keep in the same place.\n"
"If you want to get somewhere else, you must run at least twice as\n"
"fast as that!'\n"
"\n"
" 'I'd rather not try, please!' said Alice. 'I'm quite content\n"
"to stay here--only I AM so hot and thirsty!'\n"
"\n"
" -- Lewis Carroll, 'Through the Looking-Glass'.";
/* NdbRecord objects. */
const NdbRecord *key_record; // For specifying table key
const NdbRecord *blob_record; // For accessing blob
const NdbRecord *full_record; // All columns, for insert
/* C struct representing the row layout */
struct MyRow
{
unsigned int myId;
/* Pointer to Blob handle for operations on the blob column
* Space must be left for it in the row, but a pointer to the
* blob handle can also be obtained via calls to
* NdbOperation::getBlobHandle()
*/
NdbBlob* myText;
};
static void setup_records(Ndb *myNdb)
{
NdbDictionary::RecordSpecification spec[2];
NdbDictionary::Dictionary *myDict= myNdb->getDictionary();
const NdbDictionary::Table *myTable= myDict->getTable("api_blob_ndbrecord");
if (myTable == NULL)
APIERROR(myDict->getNdbError());
const NdbDictionary::Column *col1= myTable->getColumn("my_id");
if (col1 == NULL)
APIERROR(myDict->getNdbError());
const NdbDictionary::Column *col2= myTable->getColumn("my_text");
if (col2 == NULL)
APIERROR(myDict->getNdbError());
spec[0].column= col1;
spec[0].offset= offsetof(MyRow, myId);
spec[0].nullbit_byte_offset= 0;
spec[0].nullbit_bit_in_byte= 0;
spec[1].column= col2;
spec[1].offset= offsetof(MyRow, myText);
spec[1].nullbit_byte_offset= 0;
spec[1].nullbit_bit_in_byte= 0;
key_record= myDict->createRecord(myTable, &spec[0], 1, sizeof(spec[0]));
if (key_record == NULL)
APIERROR(myDict->getNdbError());
blob_record= myDict->createRecord(myTable, &spec[1], 1, sizeof(spec[0]));
if (blob_record == NULL)
APIERROR(myDict->getNdbError());
full_record= myDict->createRecord(myTable, &spec[0], 2, sizeof(spec[0]));
if (full_record == NULL)
APIERROR(myDict->getNdbError());
}
/*
Function to drop table.
*/
void drop_table(MYSQL &mysql)
{
if (mysql_query(&mysql, "DROP TABLE api_blob_ndbrecord"))
MYSQLERROR(mysql);
}
/*
Functions to create table.
*/
int try_create_table(MYSQL &mysql)
{
return mysql_query(&mysql,
"CREATE TABLE"
" api_blob_ndbrecord"
" (my_id INT UNSIGNED NOT NULL,"
" my_text TEXT NOT NULL,"
" PRIMARY KEY USING HASH (my_id))"
" ENGINE=NDB");
}
void create_table(MYSQL &mysql)
{
if (try_create_table(mysql))
{
if (mysql_errno(&mysql) != ER_TABLE_EXISTS_ERROR)
MYSQLERROR(mysql);
std::cout << "MySQL Cluster already has example table: api_blob_ndbrecord. "
<< "Dropping it..." << std::endl;
/******************
* Recreate table *
******************/
drop_table(mysql);
if (try_create_table(mysql))
MYSQLERROR(mysql);
}
}
int populate(Ndb *myNdb)
{
MyRow row;
NdbTransaction *myTrans= myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
row.myId= 1;
const NdbOperation *myNdbOperation= myTrans->insertTuple(full_record, (const char*) &row);
if (myNdbOperation == NULL)
APIERROR(myTrans->getNdbError());
NdbBlob *myBlobHandle= myNdbOperation->getBlobHandle("my_text");
if (myBlobHandle == NULL)
APIERROR(myNdbOperation->getNdbError());
myBlobHandle->setValue(text_quote, strlen(text_quote));
int check= myTrans->execute(NdbTransaction::Commit);
myTrans->close();
return check != -1;
}
int update_key(Ndb *myNdb)
{
MyRow row;
/*
Uppercase all characters in TEXT field, using primary key operation.
Use piece-wise read/write to avoid loading entire data into memory
at once.
*/
NdbTransaction *myTrans= myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
row.myId= 1;
const NdbOperation *myNdbOperation=
myTrans->updateTuple(key_record,
(const char*) &row,
blob_record,
(const char*) &row);
if (myNdbOperation == NULL)
APIERROR(myTrans->getNdbError());
NdbBlob *myBlobHandle= myNdbOperation->getBlobHandle("my_text");
if (myBlobHandle == NULL)
APIERROR(myNdbOperation->getNdbError());
/* Execute NoCommit to make the blob handle active so
* that we can determine the actual Blob length
*/
if (-1 == myTrans->execute(NdbTransaction::NoCommit))
APIERROR(myTrans->getNdbError());
Uint64 length= 0;
if (-1 == myBlobHandle->getLength(length))
APIERROR(myBlobHandle->getNdbError());
/*
A real application should use a much larger chunk size for
efficiency, preferably much larger than the part size, which
defaults to 2000. 64000 might be a good value.
*/
#define CHUNK_SIZE 100
int chunk;
char buffer[CHUNK_SIZE];
for (chunk= (length-1)/CHUNK_SIZE; chunk >=0; chunk--)
{
Uint64 pos= chunk*CHUNK_SIZE;
Uint32 chunk_length= CHUNK_SIZE;
if (pos + chunk_length > length)
chunk_length= length - pos;
/* Read from the end back, to illustrate seeking. */
if (-1 == myBlobHandle->setPos(pos))
APIERROR(myBlobHandle->getNdbError());
if (-1 == myBlobHandle->readData(buffer, chunk_length))
APIERROR(myBlobHandle->getNdbError());
int res= myTrans->execute(NdbTransaction::NoCommit);
if (-1 == res)
APIERROR(myTrans->getNdbError());
/* Uppercase everything. */
for (Uint64 j= 0; j < chunk_length; j++)
buffer[j]= toupper(buffer[j]);
if (-1 == myBlobHandle->setPos(pos))
APIERROR(myBlobHandle->getNdbError());
if (-1 == myBlobHandle->writeData(buffer, chunk_length))
APIERROR(myBlobHandle->getNdbError());
/* Commit on the final update. */
if (-1 == myTrans->execute(chunk ?
NdbTransaction::NoCommit :
NdbTransaction::Commit))
APIERROR(myTrans->getNdbError());
}
myNdb->closeTransaction(myTrans);
return 1;
}
int update_scan(Ndb *myNdb)
{
/*
Lowercase all characters in TEXT field, using a scan with
updateCurrentTuple().
*/
char buffer[10000];
NdbTransaction *myTrans= myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
NdbScanOperation *myScanOp=
myTrans->scanTable(blob_record, NdbOperation::LM_Exclusive);
if (myScanOp == NULL)
APIERROR(myTrans->getNdbError());
NdbBlob *myBlobHandle= myScanOp->getBlobHandle("my_text");
if (myBlobHandle == NULL)
APIERROR(myScanOp->getNdbError());
if (myBlobHandle->getValue(buffer, sizeof(buffer)))
APIERROR(myBlobHandle->getNdbError());
/* Start the scan. */
if (-1 == myTrans->execute(NdbTransaction::NoCommit))
APIERROR(myTrans->getNdbError());
const MyRow *out_row;
int res;
for (;;)
{
res= myScanOp->nextResult((const char**)&out_row, true, false);
if (res==1)
break; // Scan done.
else if (res)
APIERROR(myScanOp->getNdbError());
Uint64 length= 0;
if (myBlobHandle->getLength(length) == -1)
APIERROR(myBlobHandle->getNdbError());
/* Lowercase everything. */
for (Uint64 j= 0; j < length; j++)
buffer[j]= tolower(buffer[j]);
/* 'Take over' the row locks from the scan to a separate
* operation for updating the tuple
*/
const NdbOperation *myUpdateOp=
myScanOp->updateCurrentTuple(myTrans,
blob_record,
(const char*)out_row);
if (myUpdateOp == NULL)
APIERROR(myTrans->getNdbError());
NdbBlob *myBlobHandle2= myUpdateOp->getBlobHandle("my_text");
if (myBlobHandle2 == NULL)
APIERROR(myUpdateOp->getNdbError());
if (myBlobHandle2->setValue(buffer, length))
APIERROR(myBlobHandle2->getNdbError());
if (-1 == myTrans->execute(NdbTransaction::NoCommit))
APIERROR(myTrans->getNdbError());
}
if (-1 == myTrans->execute(NdbTransaction::Commit))
APIERROR(myTrans->getNdbError());
myNdb->closeTransaction(myTrans);
return 1;
}
struct ActiveHookData {
char buffer[10000];
Uint32 readLength;
};
int myFetchHook(NdbBlob* myBlobHandle, void* arg)
{
ActiveHookData *ahd= (ActiveHookData *)arg;
ahd->readLength= sizeof(ahd->buffer) - 1;
return myBlobHandle->readData(ahd->buffer, ahd->readLength);
}
int fetch_key(Ndb *myNdb)
{
/* Fetch a blob without specifying how many bytes
* to read up front, in one execution using
* the 'ActiveHook' mechanism.
* The supplied ActiveHook procedure is called when
* the Blob handle becomes 'active'. At that point
* the length of the Blob can be obtained, and buffering
* arranged, and the data read requested.
*/
/* Separate rows used to specify key and hold result */
MyRow key_row;
MyRow out_row;
/*
Fetch and show the blob field, using setActiveHook().
*/
NdbTransaction *myTrans= myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
key_row.myId= 1;
out_row.myText= NULL;
const NdbOperation *myNdbOperation=
myTrans->readTuple(key_record,
(const char*) &key_row,
blob_record,
(char*) &out_row);
if (myNdbOperation == NULL)
APIERROR(myTrans->getNdbError());
/* This time, we'll get the blob handle from the row, because
* we can. Alternatively, we could use the normal mechanism
* of calling getBlobHandle().
*/
NdbBlob *myBlobHandle= out_row.myText;
if (myBlobHandle == NULL)
APIERROR(myNdbOperation->getNdbError());
struct ActiveHookData ahd;
if (myBlobHandle->setActiveHook(myFetchHook, &ahd) == -1)
APIERROR(myBlobHandle->getNdbError());
/*
Execute Commit, but calling our callback set up in setActiveHook()
before actually committing.
*/
if (-1 == myTrans->execute(NdbTransaction::Commit))
APIERROR(myTrans->getNdbError());
myNdb->closeTransaction(myTrans);
/* Our fetch callback will have been called during the execute(). */
ahd.buffer[ahd.readLength]= '\0';
std::cout << "Fetched data:" << std::endl << ahd.buffer << std::endl;
return 1;
}
int update2_key(Ndb *myNdb)
{
char buffer[10000];
MyRow row;
/* Simple setValue() update specified before the
* Blob handle is made active
*/
NdbTransaction *myTrans= myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
row.myId= 1;
const NdbOperation *myNdbOperation=
myTrans->updateTuple(key_record,
(const char*)&row,
blob_record,
(char*) &row);
if (myNdbOperation == NULL)
APIERROR(myTrans->getNdbError());
NdbBlob *myBlobHandle= myNdbOperation->getBlobHandle("my_text");
if (myBlobHandle == NULL)
APIERROR(myNdbOperation->getNdbError());
memset(buffer, ' ', sizeof(buffer));
if (myBlobHandle->setValue(buffer, sizeof(buffer)) == -1)
APIERROR(myBlobHandle->getNdbError());
if (-1 == myTrans->execute(NdbTransaction::Commit))
APIERROR(myTrans->getNdbError());
myNdb->closeTransaction(myTrans);
return 1;
}
int delete_key(Ndb *myNdb)
{
MyRow row;
/* Deletion of row containing blob via primary key. */
NdbTransaction *myTrans= myNdb->startTransaction();
if (myTrans == NULL)
APIERROR(myNdb->getNdbError());
row.myId= 1;
const NdbOperation *myNdbOperation= myTrans->deleteTuple(key_record,
(const char*)&row,
full_record);
if (myNdbOperation == NULL)
APIERROR(myTrans->getNdbError());
if (-1 == myTrans->execute(NdbTransaction::Commit))
APIERROR(myTrans->getNdbError());
myNdb->closeTransaction(myTrans);
return 1;
}
int main(int argc, char**argv)
{
if (argc != 3)
{
std::cout << "Arguments are <socket mysqld> <connect_string cluster>.\n";
exit(-1);
}
char *mysqld_sock = argv[1];
const char *connectstring = argv[2];
ndb_init();
MYSQL mysql;
/* Connect to mysql server and create table. */
{
if ( !mysql_init(&mysql) ) {
std::cout << "mysql_init failed.\n";
exit(-1);
}
if ( !mysql_real_connect(&mysql, "localhost", "root", "", "",
0, mysqld_sock, 0) )
MYSQLERROR(mysql);
mysql_query(&mysql, "CREATE DATABASE ndb_examples");
if (mysql_query(&mysql, "USE ndb_examples") != 0)
MYSQLERROR(mysql);
create_table(mysql);
}
/* Connect to ndb cluster. */
Ndb_cluster_connection cluster_connection(connectstring);
if (cluster_connection.connect(4, 5, 1))
{
std::cout << "Unable to connect to cluster within 30 secs." << std::endl;
exit(-1);
}
/* Optionally connect and wait for the storage nodes (ndbd's). */
if (cluster_connection.wait_until_ready(30,0) < 0)
{
std::cout << "Cluster was not ready within 30 secs.\n";
exit(-1);
}
Ndb myNdb(&cluster_connection,"ndb_examples");
if (myNdb.init(1024) == -1) { // Set max 1024 parallel transactions
APIERROR(myNdb.getNdbError());
exit(-1);
}
setup_records(&myNdb);
if(populate(&myNdb) > 0)
std::cout << "populate: Success!" << std::endl;
if(update_key(&myNdb) > 0)
std::cout << "update_key: Success!" << std::endl;
if(update_scan(&myNdb) > 0)
std::cout << "update_scan: Success!" << std::endl;
if(fetch_key(&myNdb) > 0)
std::cout << "fetch_key: Success!" << std::endl;
if(update2_key(&myNdb) > 0)
std::cout << "update2_key: Success!" << std::endl;
if(delete_key(&myNdb) > 0)
std::cout << "delete_key: Success!" << std::endl;
return 0;
}