Table of Contents
- 6.1. MySQL Cluster File Systems
- 6.2.
DUMPCommands - 6.2.1.
DUMPCodes 1 to 999 - 6.2.2.
DUMPCodes 1000 to 1999 - 6.2.3.
DUMPCodes 2000 to 2999 - 6.2.4.
DUMPCodes 3000 to 3999 - 6.2.5.
DUMPCodes 4000 to 4999 - 6.2.6.
DUMPCodes 5000 to 5999 - 6.2.7.
DUMPCodes 6000 to 6999 - 6.2.8.
DUMPCodes 7000 to 7999 - 6.2.9.
DUMPCodes 8000 to 8999 - 6.2.10.
DUMPCodes 9000 to 9999 - 6.2.11.
DUMPCodes 10000 to 10999 - 6.2.12.
DUMPCodes 11000 to 11999 - 6.2.13.
DUMPCodes 12000 to 12999
- 6.2.1.
- 6.3. The NDB Protocol
- 6.4.
NDBKernel Blocks - 6.4.1. The
BACKUPBlock - 6.4.2. The
CMVMIBlock - 6.4.3. The
DBACCBlock - 6.4.4. The
DBDICTBlock - 6.4.5. The
DBDIHBlock - 6.4.6.
DBLQHBlock - 6.4.7. The
DBTCBlock - 6.4.8. The
DBTUPBlock - 6.4.9.
DBTUXBlock - 6.4.10. The
DBUTILBlock - 6.4.11. The
LGMANBlock - 6.4.12. The
NDBCNTRBlock - 6.4.13. The
NDBFSBlock - 6.4.14. The
PGMANBlock - 6.4.15. The
QMGRBlock - 6.4.16. The
RESTOREBlock - 6.4.17. The
SUMABlock - 6.4.18. The
TSMANBlock - 6.4.19. The
TRIXBlock
- 6.4.1. The
- 6.5. MySQL Cluster Start Phases
- 6.5.1. Initialization Phase (Phase -1)
- 6.5.2. Configuration Read Phase (
STTORPhase -1) - 6.5.3.
STTORPhase 0 - 6.5.4.
STTORPhase 1 - 6.5.5.
STTORPhase 2 - 6.5.6.
NDB_STTORPhase 1 - 6.5.7.
STTORPhase 3 - 6.5.8.
NDB_STTORPhase 2 - 6.5.9.
STTORPhase 4 - 6.5.10.
NDB_STTORPhase 3 - 6.5.11.
STTORPhase 5 - 6.5.12.
NDB_STTORPhase 4 - 6.5.13.
NDB_STTORPhase 5 - 6.5.14.
NDB_STTORPhase 6 - 6.5.15.
STTORPhase 6 - 6.5.16.
STTORPhase 7 - 6.5.17.
STTORPhase 8 - 6.5.18.
NDB_STTORPhase 7 - 6.5.19.
STTORPhase 9 - 6.5.20.
STTORPhase 101 - 6.5.21. System Restart Handling in Phase 4
- 6.5.22.
START_MEREQHandling
- 6.6.
NDBInternals Glossary
Abstract
This chapter contains information about MySQL Cluster that is not strictly necessary for running the Cluster product, but can prove useful for development and debugging purposes.
This section contains information about the file systems created and used by MySQL Cluster data nodes and management nodes.
This section discusses the files and directories created by MySQL Cluster nodes, their usual locations, and their purpose.
A cluster data node's DataDir contains at a
minimum 3 files. These are named as shown here, where
node_id is the node ID:
ndb_node_id_out.logSample output:
2006-09-12 20:13:24 [ndbd] INFO -- Angel pid: 13677 ndb pid: 13678 2006-09-12 20:13:24 [ndbd] INFO -- NDB Cluster -- DB node 1 2006-09-12 20:13:24 [ndbd] INFO -- Version 5.1.12 (beta) -- 2006-09-12 20:13:24 [ndbd] INFO -- Configuration fetched at localhost port 1186 2006-09-12 20:13:24 [ndbd] INFO -- Start initiated (version 5.1.12) 2006-09-12 20:13:24 [ndbd] INFO -- Ndbd_mem_manager::init(1) min: 20Mb initial: 20Mb WOPool::init(61, 9) RWPool::init(82, 13) RWPool::init(a2, 18) RWPool::init(c2, 13) RWPool::init(122, 17) RWPool::init(142, 15) WOPool::init(41, 8) RWPool::init(e2, 12) RWPool::init(102, 55) WOPool::init(21, 8) Dbdict: name=sys/def/SYSTAB_0,id=0,obj_ptr_i=0 Dbdict: name=sys/def/NDB$EVENTS_0,id=1,obj_ptr_i=1 m_active_buckets.set(0)
ndb_node_id_signal.logThis file contains a log of all signals sent to or from the data node.
NoteThis file is created only if the
SendSignalIdparameter is enabled, which is true only for-debugbuilds.ndb_node_id.pidThis file contains the data node's process ID; it is created when the ndbd process is started.
The location of these files is determined by the value of the
DataDir configuration parameter. See
DataDir.
This directory is named
ndb_,
where nodeid_fsnodeid is the data node's
node ID. It contains the following files and directories:
Files:
data-nodeid.datundo-nodeid.dat
Directories:
LCP: In MySQL Cluster NDB 6.3.8 and later MySQL Cluster releases, this directory holds 2 subdirectories, named0and1, each of which which contain locals checkpoint data files, one per local checkpoint (see Configuring MySQL Cluster Parameters for Local Checkpoints).Prior to MySQL Cluster NDB 6.3.8, this directory contained 3 subdirectories, named
0,1, and2, due to the fact thatNDBsaved 3 local checkpoints to disk (rather than 2) in these earlier versions of MySQL Cluster.These subdirectories each contain a number of files whose names follow the pattern
T, whereNFM.DataNis a table ID and and M is a fragment number. Each data node typically has one primary fragment and one backup fragment. This means that, for a MySQL Cluster having 2 data nodes, and withNoOfReplicas = 2,Mis either 0 to 1. For a 4-node cluster withNoOfReplicas = 2,Mis either 0 or 2 on node group 1, and either 1 or 3 on node group 2.In MySQL Cluster NDB 7.0 and later, when using ndbmtd there may be more than one primary fragment per node. In this case,
Mis a number in the range of 0 to the number of LQH worker threads in the entire cluster, less 1. The number of fragments on each data node is equal to the number of LQH on that node timesNoOfReplicas.NoteIncreasing
MaxNoOfExecutionThreadsdoes not change the number of fragments used by existing tables; only newly-created tables automatically use the new fragment count. To force the new fragment count to be used by an existing table after increasingMaxNoOfExecutionThreads, you must perform anALTER TABLE ... REORGANIZE PARTITIONstatement (just as when adding new node groups in MySQL Cluster NDB 7.0 and later).Directories named
D1andD2, each of which contains 2 subdirectories:DBDICT: Contains data dictionary information. This is stored in:The file
P0.SchemaLogA set of directories
T0,T1,T2, ..., each of which contains anS0.TableListfile.
Directories named
D8,D9,D10, andD11, each of which contains a directory namedDBLQH.In each case, the
DBLQHdirectory containsNfiles namedS0.Fraglog,S1.FragLog,S2.FragLog, ...,S, whereN.FragLogNis equal to the value of theNoOfFragmentLogFilesconfiguration parameter.The
DBLQHdirectories also contain the redo log files.DBDIH: This directory contains the fileP, which records information such as the last GCI, restart status, and node group membership of each node; its structure is defined inX.sysfilestorage/ndb/src/kernel/blocks/dbdih/Sysfile.hppin the MySQL Cluster source tree. In addition, theSfiles keep records of the fragments belonging to each table.X.FragList
MySQL Cluster creates backup files in the directory specified
by the BackupDataDir configuration
parameter, as discussed in
Using The MySQL Cluster Management Client to Create a Backup,
and
Identifying
Data Nodes.
The files created when a backup is performed are listed and described in MySQL Cluster Backup Concepts.
This section applies only to MySQL 5.1 and later. Previous versions of MySQL did not support Disk Data tables.
MySQL Cluster Disk Data files are created (or dropped) by the user by means of SQL statements intended specifically for this purpose. Such files include the following:
One or more undo logfiles associated with a logfile group
One or more datafiles associated with a tablespace that uses the logfile group for undo logging
Both undo logfiles and datafiles are created in the data
directory (DataDir) of each cluster data
node. The relationship of these files with their logfile group
and tablespace are shown in the following diagram:
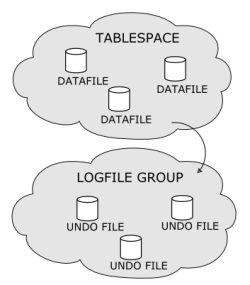
Disk Data files and the SQL commands used to create and drop them are discussed in depth in MySQL Cluster Disk Data Tables.
The files used by a MySQL Cluster management node are discussed in ndb_mgmd.
- 6.2.1.
DUMPCodes 1 to 999 - 6.2.2.
DUMPCodes 1000 to 1999 - 6.2.3.
DUMPCodes 2000 to 2999 - 6.2.4.
DUMPCodes 3000 to 3999 - 6.2.5.
DUMPCodes 4000 to 4999 - 6.2.6.
DUMPCodes 5000 to 5999 - 6.2.7.
DUMPCodes 6000 to 6999 - 6.2.8.
DUMPCodes 7000 to 7999 - 6.2.9.
DUMPCodes 8000 to 8999 - 6.2.10.
DUMPCodes 9000 to 9999 - 6.2.11.
DUMPCodes 10000 to 10999 - 6.2.12.
DUMPCodes 11000 to 11999 - 6.2.13.
DUMPCodes 12000 to 12999
Never use these commands on a production MySQL Cluster except under the express direction of MySQL Technical Support. Oracle will not be held responsible for adverse results arising from their use under any other circumstances!
DUMP commands can be used in the Cluster
management client (ndb_mgm) to dump debugging
information to the Cluster log. They are documented here, rather
than in the MySQL Manual, for the following reasons:
They are intended only for use in troubleshooting, debugging, and similar activities by MySQL developers, QA, and support personnel.
Due to the way in which
DUMPcommands interact with memory, they can cause a running MySQL Cluster to malfunction or even to fail completely when used.The formats, arguments, and even availability of these commands are not guaranteed to be stable. All of this information is subject to change at any time without prior notice.
For the preceding reasons,
DUMPcommands are neither intended nor warranted for use in a production environment by end-users.
General syntax:
ndb_mgm> node_id DUMP code [arguments]
This causes the contents of one or more NDB
registers on the node with ID node_id
to be dumped to the Cluster log. The registers affected are
determined by the value of code. Some
(but not all) DUMP commands accept additional
arguments; these are noted and
described where applicable.
Individual DUMP commands are listed by their
code values in the sections that
follow. For convenience in locating a given
DUMP code, they are divided by thousands.
Each listing includes the following information:
The
codevalueThe relevant
NDBkernel block or blocks (see Section 6.4, “NDBKernel Blocks”, for information about these)The
DUMPcode symbol where defined; if undefined, this is indicated using a triple dash:---.Sample output; unless otherwise stated, it is assumed that each
DUMPcommand is invoked as shown here:ndb_mgm>
2 DUMPcodeGenerally, this is from the cluster log; in some cases, where the output may be generated in the node log instead, this is indicated. Where the DUMP command produces errors, the output is generally taken from the error log.
Where applicable, additional information such as possible extra
arguments, warnings, state or other values returned in theDUMPcommand's output, and so on. Otherwise its absence is indicated with “[N/A]”.
DUMP command codes are not necessarily
defined sequentially. For example, codes 2
through 12 are currently undefined, and so
are not listed. However, individual DUMP code
values are subject to change, and there is no guarantee that a
given code value will continue to be defined for the same
purpose (or defined at all, or undefined) over time.
There is also no guarantee that a given DUMP
code—even if currently undefined—will not have
serious consequences when used on a running MySQL Cluster.
For information concerning other ndb_mgm client commands, see Commands in the MySQL Cluster Management Client.
- 6.2.1.1.
DUMP 1 - 6.2.1.2.
DUMP 13 - 6.2.1.3.
DUMP 14 - 6.2.1.4.
DUMP 15 - 6.2.1.5.
DUMP 16 - 6.2.1.6.
DUMP 17 - 6.2.1.7.
DUMP 18 - 6.2.1.8.
DUMP 20 - 6.2.1.9.
DUMP 21 - 6.2.1.10.
DUMP 22 - 6.2.1.11.
DUMP 23 - 6.2.1.12.
DUMP 24 - 6.2.1.13.
DUMP 25 - 6.2.1.14.
DUMP 70 - 6.2.1.15.
DUMP 400 - 6.2.1.16.
DUMP 401 - 6.2.1.17.
DUMP 402 - 6.2.1.18.
DUMP 403 - 6.2.1.19.
DUMP 404 - 6.2.1.20.
DUMP 908
This section contains information about DUMP
codes 1 through 999, inclusive.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 1 | --- | QMGR |
Description.
Dumps information about cluster start Phase 1 variables (see
Section 6.5.4, “STTOR Phase 1”).
Sample Output.
Node 2: creadyDistCom = 1, cpresident = 2 Node 2: cpresidentAlive = 1, cpresidentCand = 2 (gci: 157807) Node 2: ctoStatus = 0 Node 2: Node 2: ZRUNNING(3) Node 2: Node 3: ZRUNNING(3)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 13 | --- | CMVMI, NDBCNTR |
Description. Dump signal counter.
Sample Output.
Node 2: Cntr: cstartPhase = 9, cinternalStartphase = 8, block = 0 Node 2: Cntr: cmasterNodeId = 2
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 14 | CommitAckMarkersSize | DBLQH, DBTC |
Description.
Dumps free size in commitAckMarkerPool.
Sample Output.
Node 2: TC: m_commitAckMarkerPool: 12288 free size: 12288 Node 2: LQH: m_commitAckMarkerPool: 36094 free size: 36094
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 15 | CommitAckMarkersDump | DBLQH, DBTC |
Description.
Dumps information in commitAckMarkerPool.
Sample Output.
Node 2: TC: m_commitAckMarkerPool: 12288 free size: 12288 Node 2: LQH: m_commitAckMarkerPool: 36094 free size: 36094
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 16 | DihDumpNodeRestartInfo | DBDIH |
Description. Provides node restart information.
Sample Output.
Node 2: c_nodeStartMaster.blockLcp = 0, c_nodeStartMaster.blockGcp = 0, c_nodeStartMaster.wait = 0 Node 2: cstartGcpNow = 0, cgcpStatus = 0 Node 2: cfirstVerifyQueue = -256, cverifyQueueCounter = 0 Node 2: cgcpOrderBlocked = 0, cgcpStartCounter = 5
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 17 | DihDumpNodeStatusInfo | DBDIH |
Description. Dumps node status.
Sample Output.
Node 2: Printing nodeStatus of all nodes Node 2: Node = 2 has status = 1 Node 2: Node = 3 has status = 1
Additional Information. Possible node status values are shown in the following table:
| Value | Name |
|---|---|
| 0 | NOT_IN_CLUSTER |
| 1 | ALIVE |
| 2 | STARTING |
| 3 | DIED_NOW |
| 4 | DYING |
| 5 | DEAD |
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 18 | DihPrintFragmentation | DBDIH |
Description. Prints one entry per table fragment; lists the table number, fragment number, and list of nodes handling this fragment in order of priority.
Sample Output.
Node 2: Printing fragmentation of all tables -- Node 2: Table 0 Fragment 0 - 2 3 Node 2: Table 0 Fragment 1 - 3 2 Node 2: Table 1 Fragment 0 - 2 3 Node 2: Table 1 Fragment 1 - 3 2 Node 2: Table 2 Fragment 0 - 2 3 Node 2: Table 2 Fragment 1 - 3 2 Node 2: Table 3 Fragment 0 - 2 3 Node 2: Table 3 Fragment 1 - 3 2 Node 2: Table 4 Fragment 0 - 2 3 Node 2: Table 4 Fragment 1 - 3 2 Node 2: Table 9 Fragment 0 - 2 3 Node 2: Table 9 Fragment 1 - 3 2 Node 2: Table 10 Fragment 0 - 2 3 Node 2: Table 10 Fragment 1 - 3 2 Node 2: Table 11 Fragment 0 - 2 3 Node 2: Table 11 Fragment 1 - 3 2 Node 2: Table 12 Fragment 0 - 2 3 Node 2: Table 12 Fragment 1 - 3 2
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 20 | --- | BACKUP |
Description.
Prints values of BackupDataBufferSize,
BackupLogBufferSize,
BackupWriteSize, and
BackupMaxWriteSize
Sample Output.
Node 2: Backup: data: 2097152 log: 2097152 min: 32768 max: 262144
Additional Information. This command can also be used to set these parameters, as in this example:
ndb_mgm> 2 DUMP 20 3 3 64 512
Sending dump signal with data:
0x00000014 0x00000003 0x00000003 0x00000040 0x00000200
Node 2: Backup: data: 3145728 log: 3145728 min: 65536 max: 524288
You must set each of these parameters to the same value on
all nodes; otherwise, subsequent issuing of a START
BACKUP command crashes the cluster.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 21 | --- | BACKUP |
Description.
Sends a GSN_BACKUP_REQ signal to the
node, causing that node to initiate a backup.
Sample Output.
Node 2: Backup 1 started from node 2 Node 2: Backup 1 started from node 2 completed StartGCP: 158515 StopGCP: 158518 #Records: 2061 #LogRecords: 0 Data: 35664 bytes Log: 0 bytes
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
22 backup_id | --- | BACKUP |
Description.
Sends a GSN_FSREMOVEREQ signal to the
node. This should remove the backup having backup ID
backup_id from the backup
directory; however, it actually causes the node to
crash.
Sample Output.
Time: Friday 16 February 2007 - 10:23:00 Status: Temporary error, restart node Message: Assertion (Internal error, programming error or missing error message, please report a bug) Error: 2301 Error data: ArrayPool<T>::getPtr Error object: ../../../../../storage/ndb/src/kernel/vm/ArrayPool.hpp line: 395 (block: BACKUP) Program: ./libexec/ndbd Pid: 27357 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.4 Version: Version 5.1.16 (beta)
Additional Information.
It appears that any invocation of
DUMP 22 causes the node or nodes to
crash.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 23 | --- | BACKUP |
Description. Dumps all backup records and file entries belonging to those records.
The example shows a single record with a single file only, but there may be multiple records and multiple file lines within each record.
Sample Output.
With no backup in progress (BackupRecord
shows as 0):
Node 2: BackupRecord 0: BackupId: 5 MasterRef: f70002 ClientRef: 0 Node 2: State: 2 Node 2: file 0: type: 3 flags: H'0
While a backup is in progress (BackupRecord
is 1):
Node 2: BackupRecord 1: BackupId: 8 MasterRef: f40002 ClientRef: 80010001 Node 2: State: 1 Node 2: file 3: type: 3 flags: H'1 Node 2: file 2: type: 2 flags: H'1 Node 2: file 0: type: 1 flags: H'9 Node 2: BackupRecord 0: BackupId: 110 MasterRef: f70002 ClientRef: 0 Node 2: State: 2 Node 2: file 0: type: 3 flags: H'0
Additional Information.
Possible State values are shown in the
following table:
| Value | State | Description |
|---|---|---|
| 0 | INITIAL | |
| 1 | DEFINING | Defining backup content and parameters |
| 2 | DEFINED | DEFINE_BACKUP_CONF signal sent by slave, received on
master |
| 3 | STARTED | Creating triggers |
| 4 | SCANNING | Scanning fragments |
| 5 | STOPPING | Closing files |
| 6 | CLEANING | Freeing resources |
| 7 | ABORTING | Aborting backup |
Types are shown in the following table:
| Value | Name |
|---|---|
| 1 | CTL_FILE |
| 2 | LOG_FILE |
| 3 | DATA_FILE |
| 4 | LCP_FILE |
Flags are shown in the following table:
| Value | Name |
|---|---|
0x01 | BF_OPEN |
0x02 | BF_OPENING |
0x04 | BF_CLOSING |
0x08 | BF_FILE_THREAD |
0x10 | BF_SCAN_THREAD |
0x20 | BF_LCP_META |
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 24 | --- | BACKUP |
Description. Prints backup record pool information.
Sample Output.
Node 2: Backup - dump pool sizes Node 2: BackupPool: 2 BackupFilePool: 4 TablePool: 323 Node 2: AttrPool: 2 TriggerPool: 4 FragmentPool: 323 Node 2: PagePool: 198
Additional Information.
If 2424 is passed as an argument (for
example, 2 DUMP 24 2424), this causes an
LCP.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 25 | NdbcntrTestStopOnError | NDBCNTR |
Description. Kills the data node or nodes.
Sample Output.
Time: Friday 16 February 2007 - 10:26:46 Status: Temporary error, restart node Message: System error, node killed during node restart by other node (Internal error, programming error or missing error message, please report a bug) Error: 2303 Error data: System error 6, this node was killed by node 2 Error object: NDBCNTR (Line: 234) 0x00000008 Program: ./libexec/ndbd Pid: 27665 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.5 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 70 | NdbcntrStopNodes | |
Description.
Sample Output.
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 400 | NdbfsDumpFileStat- | NDBFS |
Description.
Provides NDB file system statistics.
Sample Output.
Node 2: NDBFS: Files: 27 Open files: 10 Node 2: Idle files: 17 Max opened files: 12 Node 2: Max files: 40 Node 2: Requests: 256
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 401 | NdbfsDumpAllFiles | NDBFS |
Description.
Prints NDB file system file handles and
states (OPEN or
CLOSED).
Sample Output.
Node 2: NDBFS: Dump all files: 27 Node 2: 0 (0x87867f8): CLOSED Node 2: 1 (0x8787e70): CLOSED Node 2: 2 (0x8789490): CLOSED Node 2: 3 (0x878aab0): CLOSED Node 2: 4 (0x878c0d0): CLOSED Node 2: 5 (0x878d6f0): CLOSED Node 2: 6 (0x878ed10): OPEN Node 2: 7 (0x8790330): OPEN Node 2: 8 (0x8791950): OPEN Node 2: 9 (0x8792f70): OPEN Node 2: 10 (0x8794590): OPEN Node 2: 11 (0x8795da0): OPEN Node 2: 12 (0x8797358): OPEN Node 2: 13 (0x8798978): OPEN Node 2: 14 (0x8799f98): OPEN Node 2: 15 (0x879b5b8): OPEN Node 2: 16 (0x879cbd8): CLOSED Node 2: 17 (0x879e1f8): CLOSED Node 2: 18 (0x879f818): CLOSED Node 2: 19 (0x87a0e38): CLOSED Node 2: 20 (0x87a2458): CLOSED Node 2: 21 (0x87a3a78): CLOSED Node 2: 22 (0x87a5098): CLOSED Node 2: 23 (0x87a66b8): CLOSED Node 2: 24 (0x87a7cd8): CLOSED Node 2: 25 (0x87a92f8): CLOSED Node 2: 26 (0x87aa918): CLOSED
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 402 | NdbfsDumpOpenFiles | NDBFS |
Description.
Prints list of NDB file system open
files.
Sample Output.
Node 2: NDBFS: Dump open files: 10 Node 2: 0 (0x8792f70): /usr/local/mysql-5.1/cluster/ndb_2_fs/D1/DBDIH/P0.sysfile Node 2: 1 (0x8794590): /usr/local/mysql-5.1/cluster/ndb_2_fs/D2/DBDIH/P0.sysfile Node 2: 2 (0x878ed10): /usr/local/mysql-5.1/cluster/ndb_2_fs/D8/DBLQH/S0.FragLog Node 2: 3 (0x8790330): /usr/local/mysql-5.1/cluster/ndb_2_fs/D9/DBLQH/S0.FragLog Node 2: 4 (0x8791950): /usr/local/mysql-5.1/cluster/ndb_2_fs/D10/DBLQH/S0.FragLog Node 2: 5 (0x8795da0): /usr/local/mysql-5.1/cluster/ndb_2_fs/D11/DBLQH/S0.FragLog Node 2: 6 (0x8797358): /usr/local/mysql-5.1/cluster/ndb_2_fs/D8/DBLQH/S1.FragLog Node 2: 7 (0x8798978): /usr/local/mysql-5.1/cluster/ndb_2_fs/D9/DBLQH/S1.FragLog Node 2: 8 (0x8799f98): /usr/local/mysql-5.1/cluster/ndb_2_fs/D10/DBLQH/S1.FragLog Node 2: 9 (0x879b5b8): /usr/local/mysql-5.1/cluster/ndb_2_fs/D11/DBLQH/S1.FragLog
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 403 | NdbfsDumpIdleFiles | NDBFS |
Description.
Prints list of NDB file system idle file
handles.
Sample Output.
Node 2: NDBFS: Dump idle files: 17 Node 2: 0 (0x8787e70): CLOSED Node 2: 1 (0x87aa918): CLOSED Node 2: 2 (0x8789490): CLOSED Node 2: 3 (0x878d6f0): CLOSED Node 2: 4 (0x878aab0): CLOSED Node 2: 5 (0x878c0d0): CLOSED Node 2: 6 (0x879cbd8): CLOSED Node 2: 7 (0x87a0e38): CLOSED Node 2: 8 (0x87a2458): CLOSED Node 2: 9 (0x879e1f8): CLOSED Node 2: 10 (0x879f818): CLOSED Node 2: 11 (0x87a66b8): CLOSED Node 2: 12 (0x87a7cd8): CLOSED Node 2: 13 (0x87a3a78): CLOSED Node 2: 14 (0x87a5098): CLOSED Node 2: 15 (0x87a92f8): CLOSED Node 2: 16 (0x87867f8): CLOSED
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 404 | --- | NDBFS |
Description. Kills node or nodes.
Sample Output.
Time: Friday 16 February 2007 - 11:17:55 Status: Temporary error, restart node Message: Internal program error (failed ndbrequire) (Internal error, programming error or missing error message, please report a bug) Error: 2341 Error data: ndbfs/Ndbfs.cpp Error object: NDBFS (Line: 1066) 0x00000008 Program: ./libexec/ndbd Pid: 29692 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.7 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 908 | --- | DBDIH, QMGR |
Description.
Causes heartbeat transmission information.to be written to
the data node logs. Useful in conjunction with setting the
HeartbeatOrder parameter (introduced in
MySQL Cluster NDB 6.3.35, MySQL Cluster NDB 7.0.16, and
MySQL Cluster NDB 7.1.5).
Additional Information. [N/A]
This section contain information about DUMP
codes 1000 through 1999, inclusive.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 1000 | DumpPageMemory | DBACC, DBTUP |
Description.
Prints data node mMemory usage (ACC &
TUP), as both a number of data pages, and
the percentage of DataMemory and
IndexMemory used.
Sample Output.
Node 2: Data usage is 8%(54 32K pages of total 640)
Node 2: Index usage is 1%(24 8K pages of total 1312)
Node 2: Resource 0 min: 0 max: 639 curr: 0
When invoked as ALL DUMP 1000, this
command reports memory usage for each data node separately,
in turn.
Additional Information.
Beginning with MySQL Cluster NDB 6.2.3 and MySQL Cluster NDB
6.3.0, you can use the ndb_mgm client
REPORT MEMORYUSAGE to obtain this
information (see
Commands in the MySQL Cluster Management Client).
Beginning with MySQL Cluster NDB 7.1.0, you can also query
the ndbinfo database for this information
(see The ndbinfo memoryusage Table).
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 1223 | --- | DBDICT |
Description. Kills node.
Sample Output.
Time: Friday 16 February 2007 - 11:25:17 Status: Temporary error, restart node Message: Internal program error (failed ndbrequire) (Internal error, programming error or missing error message, please report a bug) Error: 2341 Error data: dbtc/DbtcMain.cpp Error object: DBTC (Line: 464) 0x00000008 Program: ./libexec/ndbd Pid: 742 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.10 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 1224 | --- | DBDICT |
Description. Kills node.
Sample Output.
Time: Friday 16 February 2007 - 11:26:36 Status: Temporary error, restart node Message: Internal program error (failed ndbrequire) (Internal error, programming error or missing error message, please report a bug) Error: 2341 Error data: dbdih/DbdihMain.cpp Error object: DBDIH (Line: 14433) 0x00000008 Program: ./libexec/ndbd Pid: 975 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.11 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 1225 | --- | DBDICT |
Description. Kills node.
Sample Output.
Node 2: Forced node shutdown completed. Initiated by signal 6. Caused by error 2301: 'Assertion(Internal error, programming error or missing error message, please report a bug). Temporary error, restart node'. - Unknown error code: Unknown result: Unknown error code
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 1226 | --- | DBDICT |
Description. Prints pool objects.
Sample Output.
Node 2: c_obj_pool: 1332 1321 Node 2: c_opRecordPool: 256 256 Node 2: c_rope_pool: 4204 4078
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 1332 | LqhDumpAllDefinedTabs | DBACC |
Description.
Prints the states of all tables known by the local query
handler (LQH).
Sample Output.
Node 2: Table 0 Status: 0 Usage: 0 Node 2: frag: 0 distKey: 0 Node 2: frag: 1 distKey: 0 Node 2: Table 1 Status: 0 Usage: 0 Node 2: frag: 0 distKey: 0 Node 2: frag: 1 distKey: 0 Node 2: Table 2 Status: 0 Usage: 0 Node 2: frag: 0 distKey: 0 Node 2: frag: 1 distKey: 0 Node 2: Table 3 Status: 0 Usage: 0 Node 2: frag: 0 distKey: 0 Node 2: frag: 1 distKey: 0 Node 2: Table 4 Status: 0 Usage: 0 Node 2: frag: 0 distKey: 0 Node 2: frag: 1 distKey: 0 Node 2: Table 9 Status: 0 Usage: 0 Node 2: frag: 0 distKey: 0 Node 2: frag: 1 distKey: 0 Node 2: Table 10 Status: 0 Usage: 0 Node 2: frag: 0 distKey: 0 Node 2: frag: 1 distKey: 0 Node 2: Table 11 Status: 0 Usage: 0 Node 2: frag: 0 distKey: 0 Node 2: frag: 1 distKey: 0 Node 2: Table 12 Status: 0 Usage: 0 Node 2: frag: 0 distKey: 0 Node 2: frag: 1 distKey: 0
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 1333 | LqhDumpNoLogPages | DBACC |
Description. Reports redo log buffer usage.
Sample Output.
Node 2: LQH: Log pages : 256 Free: 244
Additional Information. The redo log buffer is measured in 32KB pages, so the sample output can be interpreted as follows:
Redo log buffer total. 8,338KB = ~8.2MB
Redo log buffer free. 7,808KB = ~7.6MB
Redo log buffer used. 384KB = ~0.4MB
- 6.2.3.1.
DUMP 2300 - 6.2.3.2.
DUMP 2301 - 6.2.3.3.
DUMP 2302 - 6.2.3.4.
DUMP 2303 - 6.2.3.5.
DUMP 2304 - 6.2.3.6.
DUMP 2305 - 6.2.3.7.
DUMP 2308 - 6.2.3.8.
DUMP 2315 - 6.2.3.9.
DUMP 2350 - 6.2.3.10.
DUMP 2352 - 6.2.3.11.
DUMP 2400 - 6.2.3.12.
DUMP 2401 - 6.2.3.13.
DUMP 2402 - 6.2.3.14.
DUMP 2403 - 6.2.3.15.
DUMP 2404 - 6.2.3.16.
DUMP 2405 - 6.2.3.17.
DUMP 2406 - 6.2.3.18.
DUMP 2500 - 6.2.3.19.
DUMP 2501 - 6.2.3.20.
DUMP 2502 - 6.2.3.21.
DUMP 2503 - 6.2.3.22.
DUMP 2504 - 6.2.3.23.
DUMP 2505 - 6.2.3.24.
DUMP 2506 - 6.2.3.25.
DUMP 2507 - 6.2.3.26.
DUMP 2508 - 6.2.3.27.
DUMP 2509 - 6.2.3.28.
DUMP 2510 - 6.2.3.29.
DUMP 2511 - 6.2.3.30.
DUMP 2512 - 6.2.3.31.
DUMP 2513 - 6.2.3.32.
DUMP 2514 - 6.2.3.33.
DUMP 2515 - 6.2.3.34.
DUMP 2550 - 6.2.3.35.
DUMP 2600 - 6.2.3.36.
DUMP 2601 - 6.2.3.37.
DUMP 2602 - 6.2.3.38.
DUMP 2603 - 6.2.3.39.
DUMP 2604
This section contains information about DUMP
codes 2000 through 2999, inclusive.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2300 | LqhDumpOneScanRec | DBACC |
Description. [Unknown]
Sample Output. [Not available]
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2301 | LqhDumpAllScanRec | DBACC |
Description. Kills the node.
Sample Output.
Time: Friday 16 February 2007 - 12:35:36 Status: Temporary error, restart node Message: Assertion (Internal error, programming error or missing error message, please report a bug) Error: 2301 Error data: ArrayPool<T>::getPtr Error object: ../../../../../storage/ndb/src/kernel/vm/ArrayPool.hpp line: 345 (block: DBLQH) Program: ./ndbd Pid: 10463 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.22 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2302 | LqhDumpAllActiveScanRec | DBACC |
Description. [Unknown]
Sample Output.
Time: Friday 16 February 2007 - 12:51:14 Status: Temporary error, restart node Message: Assertion (Internal error, programming error or missing error message, please report a bug) Error: 2301 Error data: ArrayPool<T>::getPtr Error object: ../../../../../storage/ndb/src/kernel/vm/ArrayPool.hpp line: 349 (block: DBLQH) Program: ./ndbd Pid: 10539 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.23 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2303 | LqhDumpLcpState | DBACC |
Description. [Unknown]
Sample Output.
Node 2: == LQH LCP STATE == Node 2: clcpCompletedState=0, c_lcpId=3, cnoOfFragsCheckpointed=0 Node 2: lcpState=0 lastFragmentFlag=0 Node 2: currentFragment.fragPtrI=9 Node 2: currentFragment.lcpFragOrd.tableId=4 Node 2: lcpQueued=0 reportEmpty=0 Node 2: m_EMPTY_LCP_REQ=-1077761081
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2304 | --- | DBLQH |
Description.
This command causes all fragment log files and their states
to be written to the data node's out file (in the case of
the data node having the node ID 1, this
would be ndb_1_out.log). The number of
these files is controlled by the
NoFragmentLogFiles configuration
parameter, whose default value is 16 in MySQL 5.1 and later
releases.
Sample Output.
The following is taken from
ndb_1_out.log for a cluster with 2 data
nodes:
LP 2 state: 0 WW_Gci: 1 gcprec: -256 flq: -256 currfile: 32 tailFileNo: 0 logTailMbyte: 1 file 0(32) FileChangeState: 0 logFileStatus: 20 currentMbyte: 1 currentFilepage 55 file 1(33) FileChangeState: 0 logFileStatus: 20 currentMbyte: 0 currentFilepage 0 file 2(34) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 3(35) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 4(36) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 5(37) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 6(38) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 7(39) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 8(40) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 9(41) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 10(42) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 11(43) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 12(44) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 13(45) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 14(46) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 15(47) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 LP 3 state: 0 WW_Gci: 1 gcprec: -256 flq: -256 currfile: 48 tailFileNo: 0 logTailMbyte: 1 file 0(48) FileChangeState: 0 logFileStatus: 20 currentMbyte: 1 currentFilepage 55 file 1(49) FileChangeState: 0 logFileStatus: 20 currentMbyte: 0 currentFilepage 0 file 2(50) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 3(51) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 4(52) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 5(53) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 6(54) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 7(55) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 8(56) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 9(57) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 10(58) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 11(59) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 12(60) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 13(61) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 14(62) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0 file 15(63) FileChangeState: 0 logFileStatus: 1 currentMbyte: 0 currentFilepage 0
Additional Information.
See also Section 6.2.3.6, “DUMP 2305”.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2305 | --- | DBLQH |
Description.
Show the states of all fragment log files (see
Section 6.2.3.5, “DUMP 2304”), then
kills the node.
Sample Output.
Time: Friday 16 February 2007 - 13:11:57 Status: Temporary error, restart node Message: System error, node killed during node restart by other node (Internal error, programming error or missing error message, please report a bug) Error: 2303 Error data: Please report this as a bug. Provide as much info as possible, expecially all the ndb_*_out.log files, Thanks. Shutting down node due to failed handling of GCP_SAVEREQ Error object: DBLQH (Line: 18619) 0x0000000a Program: ./libexec/ndbd Pid: 111 Time: Friday 16 February 2007 - 13:11:57 Status: Temporary error, restart node Message: Error OS signal received (Internal error, programming error or missing error message, please report a bug) Error: 6000 Error data: Signal 6 received; Aborted Error object: main.cpp Program: ./libexec/ndbd Pid: 11138 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.2 Version: Version 5.1.16 (beta)
Additional Information. No error message is written to the cluster log when the node is killed. Node failure is made evident only by subsequent heartbeat failure messages.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2308 | --- | DBLQH |
Description. Kills the node.
Sample Output.
Time: Friday 16 February 2007 - 13:22:06 Status: Temporary error, restart node Message: Internal program error (failed ndbrequire) (Internal error, programming error or missing error message, please report a bug) Error: 2341 Error data: dblqh/DblqhMain.cpp Error object: DBLQH (Line: 18805) 0x0000000a Program: ./libexec/ndbd Pid: 11640 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.1 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2315 | LqhErrorInsert5042 | DBLQH |
Description. [Unknown]
Sample Output. [N/A]
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
data_node_id 2350
operation_filter+ | --- | --- |
Description. Dumps all operations on a given data node or data nodes, according to the type and other parameters defined by the operation filter or filters specified.
Sample Output. Dump all operations on data node 2, from API node 5:
ndb_mgm> 2 DUMP 2350 1 5
2006-10-09 13:16:49 [MgmSrvr] INFO -- Node 2: Starting dump of operations
2006-10-09 13:16:49 [MgmSrvr] INFO -- Node 2: OP[470]:
Tab: 4 frag: 0 TC: 3 API: 5(0x8035)transid: 0x31c 0x3500500 op: SCAN state: InQueue
2006-10-09 13:16:49 [MgmSrvr] INFO -- Node 2: End of operation dump
Additional information. Information about operation filter and operation state values follows.
Operation filter values. The operation filter (or filters) can take on the following values:
| Value | Filter |
|---|---|
| 0 | table ID |
| 1 | API node ID |
| 2 | 2 transaction IDs, defining a range of transactions |
| 3 | transaction coordinator node ID |
In each case, the ID of the object specified follows the specifier. See the sample output for examples.
Operation states. The “normal” states that may appear in the output from this command are listed here:
Transactions:
Prepared: The transaction coordinator is idle, waiting for the API to proceedRunning: The transaction coordinator is currently preparing operationsCommitting,Prepare to commit,Commit sent: The transaction coordinator is committingCompleting: The transaction coordinator is completing the commit (after commit, some cleanup is needed)Aborting: The transaction coordinator is aborting the transactionScanning: The transaction coordinator is scanning
Scan operations:
WaitNextScan: The scan is idle, waiting for APIInQueue: The scan has not yet started, but rather is waiting in queue for other scans to complete
Primary key operations:
In lock queue: The operation is waiting on a lockRunning: The operation is being preparedPrepared: The operation is prepared, holding an appropriate lock, and waiting for commit or rollback to complete
Relation to NDB API.
It is possible to match the output of DUMP
2350 to specific threads or Ndb
objects. First suppose that you dump all operations on data
node 2 from API node 5, using table 4 only, like this:
ndb_mgm> 2 DUMP 2350 1 5 0 4
2006-10-09 13:16:49 [MgmSrvr] INFO -- Node 2: Starting dump of operations
2006-10-09 13:16:49 [MgmSrvr] INFO -- Node 2: OP[470]:
Tab: 4 frag: 0 TC: 3 API: 5(0x8035)transid: 0x31c 0x3500500 op: SCAN state: InQueue
2006-10-09 13:16:49 [MgmSrvr] INFO -- Node 2: End of operation dump
Suppose you are working with an Ndb
instance named MyNdb, to which this
operation belongs. You can see that this is the case by
calling the Ndb object's
getReference() method, like this:
printf("MyNdb.getReference(): 0x%x\n", MyNdb.getReference());
The output from the preceding line of code is:
MyNdb.getReference(): 0x80350005
The high 16 bits of the value shown corresponds to the number
in parentheses from the OP line in the
DUMP command's output (8035). For more
about this method, see Section 2.3.8.1.17, “Ndb::getReference()”.
This command was added in MySQL Cluster NDB 6.1.12 and MySQL Cluster NDB 6.2.2.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
node_id 2352
operation_id | --- | --- |
Description. Gets information about an operation with a given operation ID.
Sample Output.
First, obtain a dump of operations. Here, we use
DUMP 2350 to get a dump of all operations
on data node 2 from API node 5:
ndb_mgm> 2 DUMP 2350 1 5
2006-10-11 13:31:25 [MgmSrvr] INFO -- Node 2: Starting dump of operations
2006-10-11 13:31:25 [MgmSrvr] INFO -- Node 2: OP[3]:
Tab: 3 frag: 1 TC: 2 API: 5(0x8035)transid: 0x3 0x200400 op: INSERT state: Prepared
2006-10-11 13:31:25 [MgmSrvr] INFO -- Node 2: End of operation dump
In this case, there is a single operation reported on node 2,
whose operation ID is 3. To obtain the
transaction ID and primary key, we use the node ID and
operation ID with DUMP 2352 as shown here:
ndb_mgm> 2 dump 2352 3
2006-10-11 13:31:31 [MgmSrvr] INFO -- Node 2: OP[3]: transid: 0x3 0x200400 key: 0x2
Additional Information.
Use DUMP 2350 to obtain an operation ID.
See Section 6.2.3.9, “DUMP 2350”, and
the previous example.
This command was added in MySQL Cluster NDB 6.1.12 and MySQL Cluster NDB 6.2.2.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
2400 record_id | AccDumpOneScanRec | DBACC |
Description.
Dumps the scan record having record ID
record_id.
Sample Output.
For 2 DUMP 1:
Node 2: Dbacc::ScanRec[1]: state=1, transid(0x0, 0x0) Node 2: timer=0, continueBCount=0, activeLocalFrag=0, nextBucketIndex=0 Node 2: scanNextfreerec=2 firstActOp=0 firstLockedOp=0, scanLastLockedOp=0 firstQOp=0 lastQOp=0 Node 2: scanUserP=0, startNoBuck=0, minBucketIndexToRescan=0, maxBucketIndexToRescan=0 Node 2: scanBucketState=0, scanLockHeld=0, userBlockRef=0, scanMask=0 scanLockMode=0
Additional Information.
For dumping all scan records, see
Section 6.2.3.12, “DUMP 2401”.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2401 | AccDumpAllScanRec | DBACC |
Description. Dumps all scan records for the node specified.
Sample Output.
Node 2: ACC: Dump all ScanRec - size: 513 Node 2: Dbacc::ScanRec[1]: state=1, transid(0x0, 0x0) Node 2: timer=0, continueBCount=0, activeLocalFrag=0, nextBucketIndex=0 Node 2: scanNextfreerec=2 firstActOp=0 firstLockedOp=0, scanLastLockedOp=0 firstQOp=0 lastQOp=0 Node 2: scanUserP=0, startNoBuck=0, minBucketIndexToRescan=0, maxBucketIndexToRescan=0 Node 2: scanBucketState=0, scanLockHeld=0, userBlockRef=0, scanMask=0 scanLockMode=0 Node 2: Dbacc::ScanRec[2]: state=1, transid(0x0, 0x0) Node 2: timer=0, continueBCount=0, activeLocalFrag=0, nextBucketIndex=0 Node 2: scanNextfreerec=3 firstActOp=0 firstLockedOp=0, scanLastLockedOp=0 firstQOp=0 lastQOp=0 Node 2: scanUserP=0, startNoBuck=0, minBucketIndexToRescan=0, maxBucketIndexToRescan=0 Node 2: scanBucketState=0, scanLockHeld=0, userBlockRef=0, scanMask=0 scanLockMode=0 Node 2: Dbacc::ScanRec[3]: state=1, transid(0x0, 0x0) Node 2: timer=0, continueBCount=0, activeLocalFrag=0, nextBucketIndex=0 Node 2: scanNextfreerec=4 firstActOp=0 firstLockedOp=0, scanLastLockedOp=0 firstQOp=0 lastQOp=0 Node 2: scanUserP=0, startNoBuck=0, minBucketIndexToRescan=0, maxBucketIndexToRescan=0 Node 2: scanBucketState=0, scanLockHeld=0, userBlockRef=0, scanMask=0 scanLockMode=0 ⋮ Node 2: Dbacc::ScanRec[512]: state=1, transid(0x0, 0x0) Node 2: timer=0, continueBCount=0, activeLocalFrag=0, nextBucketIndex=0 Node 2: scanNextfreerec=-256 firstActOp=0 firstLockedOp=0, scanLastLockedOp=0 firstQOp=0 lastQOp=0 Node 2: scanUserP=0, startNoBuck=0, minBucketIndexToRescan=0, maxBucketIndexToRescan=0 Node 2: scanBucketState=0, scanLockHeld=0, userBlockRef=0, scanMask=0 scanLockMode=0
Additional Information.
If you want to dump a single scan record, given its record
ID, see Section 6.2.3.11, “DUMP 2400”;
for dumping all active scan records, see
Section 6.2.3.13, “DUMP 2402”.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2402 | AccDumpAllActiveScanRec | DBACC |
Description. Dumps all active scan records.
Sample Output.
Node 2: ACC: Dump active ScanRec - size: 513
Additional Information.
To dump all scan records (active or not), see
Section 6.2.3.12, “DUMP 2401”.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
2403 record_id | AccDumpOneOperationRec | DBACC |
Description. [Unknown]
Sample Output.
(For 2 DUMP 1:)
Node 2: Dbacc::operationrec[1]: transid(0x0, 0x7f1) Node 2: elementIsforward=1, elementPage=0, elementPointer=724 Node 2: fid=0, fragptr=0, hashvaluePart=63926 Node 2: hashValue=-2005083304 Node 2: nextLockOwnerOp=-256, nextOp=-256, nextParallelQue=-256 Node 2: nextSerialQue=-256, prevOp=0 Node 2: prevLockOwnerOp=24, prevParallelQue=-256 Node 2: prevSerialQue=-256, scanRecPtr=-256 Node 2: m_op_bits=0xffffffff, scanBits=0
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2404 | AccDumpNumOpRecs | DBACC |
Description. Number the number of operation records (total number, and number free).
Sample Output.
Node 2: Dbacc::OperationRecords: num=69012, free=32918
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2405 | AccDumpFreeOpRecs | |
Description. Unknown: No output results if this command is called without additional arguments; if an extra argument is used, this command crashes the data node.
Sample Output.
(For 2 DUMP 2405 1:)
Time: Saturday 17 February 2007 - 18:33:54 Status: Temporary error, restart node Message: Job buffer congestion (Internal error, programming error or missing error message, please report a bug) Error: 2334 Error data: Job Buffer Full Error object: APZJobBuffer.C Program: ./libexec/ndbd Pid: 27670 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.1 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2406 | AccDumpNotFreeOpRecs | DBACC |
Description. Unknown: No output results if this command is called without additional arguments; if an extra argument is used, this command crashes the data node.
Sample Output.
(For 2 DUMP 2406 1:)
Time: Saturday 17 February 2007 - 18:39:16 Status: Temporary error, restart node Message: Job buffer congestion (Internal error, programming error or missing error message, please report a bug) Error: 2334 Error data: Job Buffer Full Error object: APZJobBuffer.C Program: ./libexec/ndbd Pid: 27956 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.1 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2500 | TcDumpAllScanFragRec | DBTC |
Description. Kills the data node.
Sample Output.
Time: Friday 16 February 2007 - 13:37:11 Status: Temporary error, restart node Message: Assertion (Internal error, programming error or missing error message, please report a bug) Error: 2301 Error data: ArrayPool<T>::getPtr Error object: ../../../../../storage/ndb/src/kernel/vm/ArrayPool.hpp line: 345 (block: CMVMI) Program: ./libexec/ndbd Pid: 13237 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.1 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2501 | TcDumpOneScanFragRec | DBTC |
Description. No output if called without any additional arguments. With additional arguments, it kills the data node.
Sample Output.
(For 2 DUMP 2501 1:)
Time: Saturday 17 February 2007 - 18:41:41 Status: Temporary error, restart node Message: Assertion (Internal error, programming error or missing error message, please report a bug) Error: 2301 Error data: ArrayPool<T>::getPtr Error object: ../../../../../storage/ndb/src/kernel/vm/ArrayPool.hpp line: 345 (block: DBTC) Program: ./libexec/ndbd Pid: 28239 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.1 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2502 | TcDumpAllScanRec | DBTC |
Description. Dumps all scan records.
Sample Output.
Node 2: TC: Dump all ScanRecord - size: 256 Node 2: Dbtc::ScanRecord[1]: state=0nextfrag=0, nofrag=0 Node 2: ailen=0, para=0, receivedop=0, noOprePperFrag=0 Node 2: schv=0, tab=0, sproc=0 Node 2: apiRec=-256, next=2 Node 2: Dbtc::ScanRecord[2]: state=0nextfrag=0, nofrag=0 Node 2: ailen=0, para=0, receivedop=0, noOprePperFrag=0 Node 2: schv=0, tab=0, sproc=0 Node 2: apiRec=-256, next=3 Node 2: Dbtc::ScanRecord[3]: state=0nextfrag=0, nofrag=0 Node 2: ailen=0, para=0, receivedop=0, noOprePperFrag=0 Node 2: schv=0, tab=0, sproc=0 Node 2: apiRec=-256, next=4 ⋮ Node 2: Dbtc::ScanRecord[254]: state=0nextfrag=0, nofrag=0 Node 2: ailen=0, para=0, receivedop=0, noOprePperFrag=0 Node 2: schv=0, tab=0, sproc=0 Node 2: apiRec=-256, next=255 Node 2: Dbtc::ScanRecord[255]: state=0nextfrag=0, nofrag=0 Node 2: ailen=0, para=0, receivedop=0, noOprePperFrag=0 Node 2: schv=0, tab=0, sproc=0 Node 2: apiRec=-256, next=-256 Node 2: Dbtc::ScanRecord[255]: state=0nextfrag=0, nofrag=0 Node 2: ailen=0, para=0, receivedop=0, noOprePperFrag=0 Node 2: schv=0, tab=0, sproc=0 Node 2: apiRec=-256, next=-256
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2503 | TcDumpAllActiveScanRec | DBTC |
Description. Dumps all active scan records.
Sample Output.
Node 2: TC: Dump active ScanRecord - size: 256
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
2504 record_id | TcDumpOneScanRec | DBTC |
Description.
Dumps a single scan record having the record ID
record_id. (For dumping all scan
records, see
Section 6.2.3.20, “DUMP 2502”.)
Sample Output.
(For 2 DUMP 2504 1:)
Node 2: Dbtc::ScanRecord[1]: state=0nextfrag=0, nofrag=0 Node 2: ailen=0, para=0, receivedop=0, noOprePperFrag=0 Node 2: schv=0, tab=0, sproc=0 Node 2: apiRec=-256, next=2
Additional Information. The attributes in the output of this command are described as follows:
ScanRecord. The scan record slot number (same asrecord_id)state. One of the following values (found in asScanStateinDbtc.hpp):Value State 0 IDLE1 WAIT_SCAN_TAB_INFO2 WAIT_AI3 WAIT_FRAGMENT_COUNT4 RUNNING5 CLOSING_SCANnextfrag: ID of the next fragment to be scanned. Used by a scan fragment process when it is ready for the next fragment.nofrag: Total number of fragments in the table being scanned.ailen: Length of the expected attribute information.para: Number of scan frag processes that belonging to this scan.receivedop: Number of operations received.noOprePperFrag: Maximum number of bytes per batch.schv: Schema version used by this scan.tab: The index or table that is scanned.sproc: Index of stored procedure belonging to this scan.apiRec: Reference toApiConnectRecordnext: Index of nextScanRecordin free list
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2505 | TcDumpOneApiConnectRec | DBTC |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2506 | TcDumpAllApiConnectRec | DBTC |
Description. [Unknown]
Sample Output.
Node 2: TC: Dump all ApiConnectRecord - size: 12288 Node 2: Dbtc::ApiConnectRecord[1]: state=0, abortState=0, apiFailState=0 Node 2: transid(0x0, 0x0), apiBref=0x1000002, scanRec=-256 Node 2: ctcTimer=36057, apiTimer=0, counter=0, retcode=0, retsig=0 Node 2: lqhkeyconfrec=0, lqhkeyreqrec=0, tckeyrec=0 Node 2: next=-256 Node 2: Dbtc::ApiConnectRecord[2]: state=0, abortState=0, apiFailState=0 Node 2: transid(0x0, 0x0), apiBref=0x1000002, scanRec=-256 Node 2: ctcTimer=36057, apiTimer=0, counter=0, retcode=0, retsig=0 Node 2: lqhkeyconfrec=0, lqhkeyreqrec=0, tckeyrec=0 Node 2: next=-256 Node 2: Dbtc::ApiConnectRecord[3]: state=0, abortState=0, apiFailState=0 Node 2: transid(0x0, 0x0), apiBref=0x1000002, scanRec=-256 Node 2: ctcTimer=36057, apiTimer=0, counter=0, retcode=0, retsig=0 Node 2: lqhkeyconfrec=0, lqhkeyreqrec=0, tckeyrec=0 Node 2: next=-256 ⋮ Node 2: Dbtc::ApiConnectRecord[12287]: state=7, abortState=0, apiFailState=0 Node 2: transid(0x0, 0x0), apiBref=0xffffffff, scanRec=-256 Node 2: ctcTimer=36308, apiTimer=0, counter=0, retcode=0, retsig=0 Node 2: lqhkeyconfrec=0, lqhkeyreqrec=0, tckeyrec=0 Node 2: next=-256 Node 2: Dbtc::ApiConnectRecord[12287]: state=7, abortState=0, apiFailState=0 Node 2: transid(0x0, 0x0), apiBref=0xffffffff, scanRec=-256 Node 2: ctcTimer=36308, apiTimer=0, counter=0, retcode=0, retsig=0 Node 2: lqhkeyconfrec=0, lqhkeyreqrec=0, tckeyrec=0 Node 2: next=-256
Additional Information. If the default settings are used, the output from this command is likely to exceed the maximum log file size.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2507 | TcSetTransactionTimeout | DBTC |
Description. Apparently requires an extra argument, but is not currently known with certainty.
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2508 | TcSetApplTransactionTimeout | DBTC |
Description. Apparently requires an extra argument, but is not currently known with certainty.
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2509 | StartTcTimer | DBTC |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2510 | StopTcTimer | DBTC |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2511 | StartPeriodicTcTimer | DBTC |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
2512 [delay] | TcStartDumpIndexOpCount | DBTC |
Description.
Dumps the value of
MaxNoOfConcurrentOperations, and the
current resource usage, in a continuous loop. The
delay time between reports can
optionally be specified (in seconds), with the default being
1 and the maximum value being 25 (values greater than 25 are
silently coerced to 25).
Sample Output. (Single report:)
Node 2: IndexOpCount: pool: 8192 free: 8192
Additional Information.
There appears to be no way to disable the repeated checking
of MaxNoOfConcurrentOperations once
started by this command, except by restarting the data node.
It may be preferable for this reason to use DUMP
2513 instead (see
Section 6.2.3.31, “DUMP 2513”).
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2513 | TcDumpIndexOpCount | |
Description.
Dumps the value of
MaxNoOfConcurrentOperations, and the
current resource usage.
Sample Output.
Node 2: IndexOpCount: pool: 8192 free: 8192
Additional Information.
Unlike the continuous checking done by DUMP
2512 the check is performed only once (see
Section 6.2.3.30, “DUMP 2512”).
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2514 | --- | DBTC |
Description. [Unknown]
Sample Output.
Node 2: IndexOpCount: pool: 8192 free: 8192 - Repeated 3 times Node 2: TC: m_commitAckMarkerPool: 12288 free size: 12288 Node 2: LQH: m_commitAckMarkerPool: 36094 free size: 36094 Node 3: TC: m_commitAckMarkerPool: 12288 free size: 12288 Node 3: LQH: m_commitAckMarkerPool: 36094 free size: 36094 Node 2: IndexOpCount: pool: 8192 free: 8192
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2515 | --- | DBTC |
Description. Appears to kill all data nodes in the cluster. Purpose unknown.
Sample Output. From the node for which the command is issued:
Time: Friday 16 February 2007 - 13:52:32 Status: Temporary error, restart node Message: Assertion (Internal error, programming error or missing error message, please report a bug) Error: 2301 Error data: Illegal signal received (GSN 395 not added) Error object: Illegal signal received (GSN 395 not added) Program: ./libexec/ndbd Pid: 14256 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.1 Version: Version 5.1.16 (beta)
From the remaining data nodes:
Time: Friday 16 February 2007 - 13:52:31 Status: Temporary error, restart node Message: System error, node killed during node restart by other node (Internal error, programming error or missing error message, please report a bug) Error: 2303 Error data: System error 0, this node was killed by node 2515 Error object: NDBCNTR (Line: 234) 0x0000000a Program: ./libexec/ndbd Pid: 14261 Trace: /usr/local/mysql-5.1/cluster/ndb_3_trace.log.1 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
data_node_id 2550
transaction_filter+ | --- | --- |
Description.
Dumps all transaction from data node
data_node_id meeting the
conditions established by the transaction filter or filters
specified.
Sample Output. Dump all transactions on node 2 which have been inactive for 30 seconds or longer:
ndb_mgm> 2 DUMP 2550 4 30
2006-10-09 13:16:49 [MgmSrvr] INFO -- Node 2: Starting dump of transactions
2006-10-09 13:16:49 [MgmSrvr] INFO -- Node 2: TRX[123]: API: 5(0x8035) transid: 0x31c 0x3500500 inactive: 42s state:
2006-10-09 13:16:49 [MgmSrvr] INFO -- Node 2: End of transaction dump
Additional Information. The following values may be used for transaction filters. The filter value must be followed by one or more node IDs or, in the case of the last entry in the table, by the time in seconds that transactions have been inactive:
| Value | Filter |
|---|---|
| 1 | API node ID |
| 2 | 2 transaction IDs, defining a range of transactions |
| 4 | time transactions inactive (seconds) |
This command was added in MySQL Cluster NDB 6.1.12 and MySQL Cluster NDB 6.2.2.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 260 | CmvmiDumpConnections | CMVMI |
Description. Shows status of connections between all cluster nodes. When the cluster is operating normally, every connection has the same status.
Sample Output.
Node 3: Connection to 1 (MGM) is connected Node 3: Connection to 2 (MGM) is trying to connect Node 3: Connection to 3 (DB) does nothing Node 3: Connection to 4 (DB) is connected Node 3: Connection to 7 (API) is connected Node 3: Connection to 8 (API) is connected Node 3: Connection to 9 (API) is trying to connect Node 3: Connection to 10 (API) is trying to connect Node 3: Connection to 11 (API) is trying to connect Node 4: Connection to 1 (MGM) is connected Node 4: Connection to 2 (MGM) is trying to connect Node 4: Connection to 3 (DB) is connected Node 4: Connection to 4 (DB) does nothing Node 4: Connection to 7 (API) is connected Node 4: Connection to 8 (API) is connected Node 4: Connection to 9 (API) is trying to connect Node 4: Connection to 10 (API) is trying to connect Node 4: Connection to 11 (API) is trying to connect
Additional Information.
The message is trying to connect actually
means that the node in question was not started. This can
also be seen when there are unused [api]
or [mysql] sections in the
config.ini file nodes
configured—in other words when there are spare slots
for API or SQL nodes.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2601 | CmvmiDumpLongSignalMemory | CMVMI |
Description. [Unknown]
Sample Output.
Node 2: Cmvmi: g_sectionSegmentPool size: 4096 free: 4096
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2602 | CmvmiSetRestartOnErrorInsert | CMVMI |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2603 | CmvmiTestLongSigWithDelay | CMVMI |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 2604 | CmvmiDumpSubscriptions | CMVMI |
Description. Dumps current event subscriptions.
This output appears in the
ndb_
file (local to each data node) and not in the management
server (global) cluster log file.
node_id_out.log
Sample Output.
2007-04-17 17:10:54 [ndbd] INFO -- List subscriptions: 2007-04-17 17:10:54 [ndbd] INFO -- Subscription: 0, nodeId: 1, ref: 0x80000001 2007-04-17 17:10:54 [ndbd] INFO -- Category 0 Level 7 2007-04-17 17:10:54 [ndbd] INFO -- Category 1 Level 7 2007-04-17 17:10:54 [ndbd] INFO -- Category 2 Level 7 2007-04-17 17:10:54 [ndbd] INFO -- Category 3 Level 7 2007-04-17 17:10:54 [ndbd] INFO -- Category 4 Level 7 2007-04-17 17:10:54 [ndbd] INFO -- Category 5 Level 8 2007-04-17 17:10:54 [ndbd] INFO -- Category 6 Level 7 2007-04-17 17:10:54 [ndbd] INFO -- Category 7 Level 7 2007-04-17 17:10:54 [ndbd] INFO -- Category 8 Level 15 2007-04-17 17:10:54 [ndbd] INFO -- Category 9 Level 7 2007-04-17 17:10:54 [ndbd] INFO -- Category 10 Level 7 2007-04-17 17:10:54 [ndbd] INFO -- Category 11 Level 15
Additional Information. The output lists all event subscriptions; for each subscription a header line and a list of categories with their current log levels is printed. The following information is included in the output:
Subscription: The event subscription's internal IDnodeID: Node ID of the subscribing noderef: A block reference, consisting of a block ID fromstorage/ndb/include/kernel/BlockNumbers.hshifted to the left by 4 hexadecimal digits (16 bits) followed by a 4-digit hexadecimal node number. Block id0x8000appears to be a placeholder; it is defined asMIN_API_BLOCK_NO, with the node number part being 1 as expectedCategory: The cluster log category, as listed in Event Reports Generated in MySQL Cluster (see also the filestorage/ndb/include/mgmapi/mgmapi_config_parameters.h).Level: The event level setting (the range being 0 to 15).
This section contains information about DUMP
codes 5000 through 5999, inclusive.
- 6.2.8.1.
DUMP 7000 - 6.2.8.2.
DUMP 7001 - 6.2.8.3.
DUMP 7002 - 6.2.8.4.
DUMP 7003 - 6.2.8.5.
DUMP 7004 - 6.2.8.6.
DUMP 7005 - 6.2.8.7.
DUMP 7006 - 6.2.8.8.
DUMP 7007 - 6.2.8.9.
DUMP 7008 - 6.2.8.10.
DUMP 7009 - 6.2.8.11.
DUMP 7010 - 6.2.8.12.
DUMP 7011 - 6.2.8.13.
DUMP 7012 - 6.2.8.14.
DUMP 7013 - 6.2.8.15.
DUMP 7014 - 6.2.8.16.
DUMP 7015 - 6.2.8.17.
DUMP 7016 - 6.2.8.18.
DUMP 7017 - 6.2.8.19.
DUMP 7018 - 6.2.8.20.
DUMP 7020 - 6.2.8.21.
DUMP 7080 - 6.2.8.22.
DUMP 7090 - 6.2.8.23.
DUMP 7098 - 6.2.8.24.
DUMP 7099 - 6.2.8.25.
DUMP 7901
This section contains information about DUMP
codes 7000 through 7999, inclusive.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7000 | --- | DBDIH |
Description. Prints information on GCP state
Sample Output.
Node 2: ctimer = 299072, cgcpParticipantState = 0, cgcpStatus = 0 Node 2: coldGcpStatus = 0, coldGcpId = 436, cmasterState = 1 Node 2: cmasterTakeOverNode = 65535, ctcCounter = 299072
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7001 | --- | DBDIH |
Description. Prints information on the current LCP state.
Sample Output.
Node 2: c_lcpState.keepGci = 1 Node 2: c_lcpState.lcpStatus = 0, clcpStopGcp = 1 Node 2: cgcpStartCounter = 7, cimmediateLcpStart = 0
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7002 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: cnoOfActiveTables = 4, cgcpDelay = 2000 Node 2: cdictblockref = 16384002, cfailurenr = 1 Node 2: con_lineNodes = 2, reference() = 16121858, creceivedfrag = 0
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7003 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: cfirstAliveNode = 2, cgckptflag = 0 Node 2: clocallqhblockref = 16187394, clocaltcblockref = 16056322, cgcpOrderBlocked = 0 Node 2: cstarttype = 0, csystemnodes = 2, currentgcp = 438
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7004 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: cmasterdihref = 16121858, cownNodeId = 2, cnewgcp = 438 Node 2: cndbStartReqBlockref = 16449538, cremainingfrags = 1268 Node 2: cntrlblockref = 16449538, cgcpSameCounter = 16, coldgcp = 437
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7005 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: crestartGci = 1
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7006 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: clcpDelay = 20, cgcpMasterTakeOverState = 0 Node 2: cmasterNodeId = 2 Node 2: cnoHotSpare = 0, c_nodeStartMaster.startNode = -256, c_nodeStartMaster.wait = 0
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7007 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: c_nodeStartMaster.failNr = 1 Node 2: c_nodeStartMaster.startInfoErrorCode = -202116109 Node 2: c_nodeStartMaster.blockLcp = 0, c_nodeStartMaster.blockGcp = 0
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7008 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: cfirstDeadNode = -256, cstartPhase = 7, cnoReplicas = 2 Node 2: cwaitLcpSr = 0
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7009 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: ccalcOldestRestorableGci = 1, cnoOfNodeGroups = 1 Node 2: cstartGcpNow = 0 Node 2: crestartGci = 1
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7010 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: cminHotSpareNodes = 0, c_lcpState.lcpStatusUpdatedPlace = 9843, cLcpStart = 1 Node 2: c_blockCommit = 0, c_blockCommitNo = 0
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7011 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: c_COPY_GCIREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_COPY_TABREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_CREATE_FRAGREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_DIH_SWITCH_REPLICA_REQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_EMPTY_LCP_REQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_END_TOREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_GCP_COMMIT_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_GCP_PREPARE_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_GCP_SAVEREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_INCL_NODEREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_MASTER_GCPREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_MASTER_LCPREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_START_INFOREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_START_RECREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_START_TOREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_STOP_ME_REQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_TC_CLOPSIZEREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_TCGETOPSIZEREQ_Counter = [SignalCounter: m_count=0 0000000000000000] Node 2: c_UPDATE_TOREQ_Counter = [SignalCounter: m_count=0 0000000000000000]
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7012 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: ParticipatingDIH = 0000000000000000 Node 2: ParticipatingLQH = 0000000000000000 Node 2: m_LCP_COMPLETE_REP_Counter_DIH = [SignalCounter: m_count=0 0000000000000000] Node 2: m_LCP_COMPLETE_REP_Counter_LQH = [SignalCounter: m_count=0 0000000000000000] Node 2: m_LAST_LCP_FRAG_ORD = [SignalCounter: m_count=0 0000000000000000] Node 2: m_LCP_COMPLETE_REP_From_Master_Received = 0
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7013 | DihDumpLCPState | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: lcpStatus = 0 (update place = 9843) Node 2: lcpStart = 1 lcpStopGcp = 1 keepGci = 1 oldestRestorable = 1 Node 2: immediateLcpStart = 0 masterLcpNodeId = 2
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7014 | DihDumpLCPMasterTakeOver | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: c_lcpMasterTakeOverState.state = 0 updatePlace = 11756 failedNodeId = -202116109 Node 2: c_lcpMasterTakeOverState.minTableId = 4092851187 minFragId = 4092851187
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7015 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: Table 1: TabCopyStatus: 0 TabUpdateStatus: 0 TabLcpStatus: 3 Node 2: Fragment 0: noLcpReplicas==0 0(on 2)=1(Idle) 1(on 3)=1(Idle) Node 2: Fragment 1: noLcpReplicas==0 0(on 3)=1(Idle) 1(on 2)=1(Idle) Node 2: Table 2: TabCopyStatus: 0 TabUpdateStatus: 0 TabLcpStatus: 3 Node 2: Fragment 0: noLcpReplicas==0 0(on 2)=0(Idle) 1(on 3)=0(Idle) Node 2: Fragment 1: noLcpReplicas==0 0(on 3)=0(Idle) 1(on 2)=0(Idle) Node 2: Table 3: TabCopyStatus: 0 TabUpdateStatus: 0 TabLcpStatus: 3 Node 2: Fragment 0: noLcpReplicas==0 0(on 2)=0(Idle) 1(on 3)=0(Idle) Node 2: Fragment 1: noLcpReplicas==0 0(on 3)=0(Idle) 1(on 2)=0(Idle) Node 2: Table 4: TabCopyStatus: 0 TabUpdateStatus: 0 TabLcpStatus: 3 Node 2: Fragment 0: noLcpReplicas==0 0(on 2)=0(Idle) 1(on 3)=0(Idle) Node 2: Fragment 1: noLcpReplicas==0 0(on 3)=0(Idle) 1(on 2)=0(Idle)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7016 | DihAllAllowNodeStart | DBDIH |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7017 | DihMinTimeBetweenLCP | DBDIH |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7018 | DihMaxTimeBetweenLCP | DBDIH |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7020 | --- | DBDIH |
Description. This command provides general signal injection functionality. Two additional arguments are always required:
The number of the signal to be sent
The number of the block to which the signal should be sent
In addition some signals permit or require extra data to be sent.
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7080 | EnableUndoDelayDataWrite | DBACC, DBDIH,
DBTUP |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7090 | DihSetTimeBetweenGcp | DBDIH |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7098 | --- | DBDIH |
Description. [Unknown]
Sample Output.
Node 2: Invalid no of arguments to 7098 - startLcpRoundLoopLab - expected 2 (tableId, fragmentId)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 7099 | DihStartLcpImmediately | DBDIH |
Description. Can be used to trigger an LCP manually.
Sample Output.
In this example, node 2 is the master node and controls
LCP/GCP synchronization for the cluster. Regardless of the
node_id specified, only the
master node responds:
Node 2: Local checkpoint 7 started. Keep GCI = 1003 oldest restorable GCI = 947 Node 2: Local checkpoint 7 completed
Additional Information. You may need to enable a higher logging level to have the checkpoint's completion reported, as shown here:
ndb_mgmgt; ALL CLUSTERLOG CHECKPOINT=8
This section contains information about DUMP
codes 8000 through 8999, inclusive.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 8004 | --- | SUMA |
Description. Dumps information about subscription resources.
Sample Output.
Node 2: Suma: c_subscriberPool size: 260 free: 258 Node 2: Suma: c_tablePool size: 130 free: 128 Node 2: Suma: c_subscriptionPool size: 130 free: 128 Node 2: Suma: c_syncPool size: 2 free: 2 Node 2: Suma: c_dataBufferPool size: 1009 free: 1005 Node 2: Suma: c_metaSubscribers count: 0 Node 2: Suma: c_removeDataSubscribers count: 0
Additional Information.
When subscriberPool ... free becomes and
stays very low relative to subscriberPool ...
size, it is often a good idea to increase the
value of the
MaxNoOfTables
configuration parameter (subscriberPool =
2 * MaxNoOfTables). However, there could
also be a problem with API nodes not releasing resources
correctly when they are shut down. DUMP
8004 provides a way to monitor these values.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 8005 | --- | SUMA |
Description. [Unknown]
Sample Output.
Node 2: Bucket 0 10-0 switch gci: 0 max_acked_gci: 2961 max_gci: 0 tail: -256 head: -256 Node 2: Bucket 1 00-0 switch gci: 0 max_acked_gci: 2961 max_gci: 0 tail: -256 head: -256
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 8010 | --- | SUMA |
Description. Writes information about all subscribers and connected nodes to the cluster log.
Sample Output. In this example, node 1 is a management node, nodes 2 and 3 are data nodes, and nodes 4 and 5 are SQL nodes (which both act as replication masters).
2010-10-15 10:08:33 [MgmtSrvr] INFO -- Node 2: c_subscriber_nodes: 0000000000000000000000000000000000000000000000000000000000000030 2010-10-15 10:08:33 [MgmtSrvr] INFO -- Node 2: c_connected_nodes: 0000000000000000000000000000000000000000000000000000000000000032 2010-10-15 10:08:33 [MgmtSrvr] INFO -- Node 3: c_subscriber_nodes: 0000000000000000000000000000000000000000000000000000000000000030 2010-10-15 10:08:33 [MgmtSrvr] INFO -- Node 3: c_connected_nodes: 0000000000000000000000000000000000000000000000000000000000000032
For each data node, this DUMP command
prints two hexadecimal numbers. These are representations of
bitfields having one bit per node ID, starting with node ID 0
for the rightmost bit (0x01).
The subscriber nodes bitmask
(c_subscriber_nodes) has the significant
hexadecimal digits 30 (decimal 48), or
binary 110000, which equates to nodes 4 and
5. The connected nodes bitmask
(c_connected_nodes) has the significant
hexadecimal digits 32 (decimal 50). The
binary representation of this number is
110010, which has 1 as
the second, fifth, and sixth digits (counting from the right),
and so works out to nodes 1, 4, and 5 as the connected nodes.
Additional Information.
This DUMP code was added in MySQL Cluster
NDB 6.2.9.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 8011 | --- | SUMA |
Description. Writes information about all subscribers to the cluster log.
Sample Output. (From cluster log:)
2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 1: -- Starting dump of subscribers -- 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 1: Table: 2 ver: 4294967040 #n: 1 (ref,data,subscription) 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 1: [ 80010004 24 0 ] 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 1: Table: 3 ver: 4294967040 #n: 1 (ref,data,subscription) 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 1: [ 80010004 28 1 ] 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 1: Table: 4 ver: 4294967040 #n: 1 (ref,data,subscription) 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 1: [ 80020004 24 2 ] 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 1: -- Ending dump of subscribers -- 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 2: -- Starting dump of subscribers -- 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 2: Table: 2 ver: 4294967040 #n: 1 (ref,data,subscription) 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 2: [ 80010004 24 0 ] 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 2: Table: 3 ver: 4294967040 #n: 1 (ref,data,subscription) 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 2: [ 80010004 28 1 ] 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 2: Table: 4 ver: 4294967040 #n: 1 (ref,data,subscription) 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 2: [ 80020004 24 2 ] 2007-11-23 13:17:31 [MgmSrvr] INFO -- Node 2: -- Ending dump of subscribers --
Additional Information. Added in MySQL Cluster NDB 6.2.9.
This section contains information about DUMP
codes 9000 through 9999, inclusive.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 9002 | DumpTsman | TSMAN |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 9800 | DumpTsman | TSMAN |
Description. Kills data node.
Sample Output.
Time: Friday 16 February 2007 - 18:32:53 Status: Temporary error, restart node Message: Internal program error (failed ndbrequire) (Internal error, programming error or missing error message, please report a bug) Error: 2341 Error data: tsman.cpp Error object: TSMAN (Line: 1413) 0x0000000a Program: ./libexec/ndbd Pid: 29658 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.1 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 9801 | --- | TSMAN |
Description. Kills data node.
Sample Output.
Time: Friday 16 February 2007 - 18:35:48 Status: Temporary error, restart node Message: Internal program error (failed ndbrequire) (Internal error, programming error or missing error message, please report a bug) Error: 2341 Error data: tsman.cpp Error object: TSMAN (Line: 1844) 0x0000000a Program: ./libexec/ndbd Pid: 30251 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.1 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 9802 | --- | TSMAN |
Description. Kills data node.
Sample Output.
Time: Friday 16 February 2007 - 18:39:30 Status: Temporary error, restart node Message: Internal program error (failed ndbrequire) (Internal error, programming error or missing error message, please report a bug) Error: 2341 Error data: tsman.cpp Error object: TSMAN (Line: 1413) 0x0000000a Program: ./libexec/ndbd Pid: 30482 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.1 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 9803 | --- | TSMAN |
Description. Kills data node.
Sample Output.
Time: Friday 16 February 2007 - 18:41:32 Status: Temporary error, restart node Message: Internal program error (failed ndbrequire) (Internal error, programming error or missing error message, please report a bug) Error: 2341 Error data: tsman.cpp Error object: TSMAN (Line: 2144) 0x0000000a Program: ./libexec/ndbd Pid: 30712 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.1 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
This section contains information about DUMP
codes 10000 through 10999, inclusive.
This section contains information about DUMP
codes 11000 through 11999, inclusive.
This section contains information about DUMP
codes 12000 through 12999, inclusive.
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 12001 | TuxLogToFile | DBTUX |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 12002 | TuxSetLogFlags | DBTUX |
Description. [Unknown]
Sample Output.
...
Additional Information. [N/A]
| Code | Symbol | Kernel Block(s) |
|---|---|---|
| 12009 | TuxMetaDataJunk | DBTUX |
Description. Kills data node.
Sample Output.
Time: Friday 16 February 2007 - 19:49:59 Status: Temporary error, restart node Message: Error OS signal received (Internal error, programming error or missing error message, please report a bug) Error: 6000 Error data: Signal 6 received; Aborted Error object: main.cpp Program: ./libexec/ndbd Pid: 13784 Trace: /usr/local/mysql-5.1/cluster/ndb_2_trace.log.1 Version: Version 5.1.16 (beta)
Additional Information. [N/A]
Abstract
This document discusses the protocol used for communication between data nodes and API nodes in a MySQL Cluster to perform various operations such as data reads and writes, committing and rolling back transactions, and handling of transaction records.
MySQL Cluster data and API nodes communicate with one another by
passing messages to one another. The sending of a message from
one node and its reception by another node is referred to as a
signal; the NDB
Protocol is the set of rules governing the format of these
messages and the manner in which they are passed.
An NDB message is typically either a
request or a
response. A request indicates that an API
node wants to perform an operation involving cluster data (such
as retrieval, insertion, updating, or deletion) or transactions
(commit, roll back, or to fetch or relase a transaction record).
A request is, when necessary, accompanied by key or index
information. The response sent by a data node to this request
indicates whether or not the request succeeded and, where
appropriate, is accompanied by one or more data messages.
Request types.
A request is represented as a REQ message.
Requests can be divided into those handling data and those
handling transactions:
Data requests. Data request operations are of three principal types:
Primary key lookup operations are performed through the exchange of
TCKEYmessages.Unique key lookup operations are performed through the exchange of
TCINDXmessages.Table or index scan operations are performed through the exchange of
SCANTABmessages.
Data request messages are often accompanied by
KEYINFOmessages,ATTRINFOmessages, or both sorts of messages.Transactional requests. These may be divided into two categories:
Commits and rollbacks, which are represented by
TC_COMMITandTCROLLBACKrequest messages, respectively.Transaction record requests, consisting of transaction record acquisition and release, are handled through the use of, respectively,
TCSEIZEandTCRELEASErequest messages.
Response types. A response indicates either the success or the failure of the request to which it is sent in reply:
A response indicating success is represented as a
CONF(confirmation) message, and is often accompanied by data, which is packaged as one or moreTRANSID_AImessages.A response indicating failure is represented as a
REF(refusal) message.
For more information about these message types and their relationship to one another, see Section 6.3.2, “Message Naming Conventions and Structure”.
This section describes the NDB Protocol
message types and their structures.
Naming Conventions. Message names are constructed according to a simple pattern which should be readily apparent from the discussion of request and response types in the previous section. These are shown in the following matrix:
| Operation Type | Request (REQ) | Response/Success (CONF) | Response/Failure (REF) |
|---|---|---|---|
Primary Key Lookup
(TCKEY) | TCKEYREQ | TCKEYCONF | TCKEYREF |
Unique Key Lookup
(TCINDX) | TCINDXREQ | TCINDXCONF | TCINDXREF |
Table or Index Scan
(SCANTAB) | SCANTABREQ | SCANTABCONF | SCANTABREF |
Result Retrieval
(SCAN_NEXT) | SCAN_NEXTREQ | SCANTABCONF | SCANTABREF |
Transaction Record Acquisition
(TCSEIZE) | TCSEIZEREQ | TCSEIZECONF | TCSEIZEREF |
Transaction Record Release
(TCRELEASE) | TCRELEASEREQ | TCRELEASECONF | TCRELEASEREF |
CONF and REF are shorthand
for “confirmed” and “refused”,
respectively.
Three additional types of messages are used in some instances of inter-node communication. These message types are listed here:
A
KEYINFOmessage contains information about the key used in aTCKEYREQorTCINDXREQmessage. It is employed when the key data does not fit within the request message.KEYINFOmessages are also sent for index scan operations in which bounds are employed.An
ATTRINFOmessage contains nonkey attribute values which does not fit within aTCKEYREQ,TCINDXREQ, orSCANTABREQmessage. It is used for:Supplying attribute values for inserts and updates
Designating which attributes are to be read for read operations
Specifying optional values to read for delete operations
A
TRANSID_AImessage contains data returned from a read operation; in other words, it is a result set (or part of one).
In this section we discuss the sequence of message-passing that takes place between a data node and an API node for each of the following operations:
Primary key lookup
Unique key lookup
Table scan or index scan
Explicit commit of a transaction
Rollback of a transaction
Transaction record handling (acquisition and release)
Primary key lookup. An operation using a primary key lookup is performed as shown in the following diagram:
* and + are used here with the meanings “zero or more” and “one or more”, respectively.
The steps making up this process are listed and explained in greater detail here:
The API node sends a
TCKEYREQmessage to the data node. In the event that the necessary information about the key to be used is too large to be contained in theTCKEYREQ, the message may be accompanied by any number ofKEYINFOmessages carrying the remaining key information. If additional attributes are used for the operation and exceed the space available in theTCKEYREQ, or if data is to be sent to the data node as part of a write operation, then these are sent with theTCKEYREQas any number ofATTRINFOmessages.The data node sends a message in response to the request, according to whether the operation succeeded or failed:
If the operation was successful, the data node sends a
TCKEYCONFmessage to the API node. If the request was for a read operation, thenTCKEYCONFis accompanied by aTRANSID_AImessage, which contains actual result data. If there is more data than can be contained in a singleTRANSID_AIcan carry, more than one of these messages may be sent.If the operation failed, then the data node sends a
TCKEYREFmessage back to the API node, and no more signalling takes place until the API node makes a new request.
Unique key lookup. This is performed in a manner similar to that performed in a primary key lookup:
A request is made by the API node using a
TCINDXREQmessage which may be accompanied by zero or moreKEYINFOmessages, zero or moreATTRINFOmessages, or both.The data node returns a response, depending on whether or not the operation succeeded:
If the operation was a success, the message is
TCINDXCONF. For a successful read operation, this message may be accompanied by one or moreTRANSID_AImessages carrying the result data.If the operation failed, the data node returns a
TCINDXREFmessage.
The exchange of messages involved in a unique key lookup is illustrated in the following diagram:
Table scans and index scans. These are similar in many respects to primary key and unique key lookups, as shown here:
A request is made by the API node using a
SCAN_TABREQmessage, along with zero or moreATTRINFOmessages.KEYINFOmessages are also used with index scans in the event that bounds are used.The data node returns a response, according to whether or not the operation succeeded:
If the operation was a success, the message is
SCAN_TABCONF. For a successful read operation, this message may be accompanied by one or moreTRANSID_AImessages carrying the result data. However—unlike the case with lookups based on a primary or unique key—it is often necessary to fetch multiple results from the data node. Requests following the first are signalled by the API node using aSCAN_NEXTREQ, which tells the data node to send the next set of results (if there are more results). This is shown here: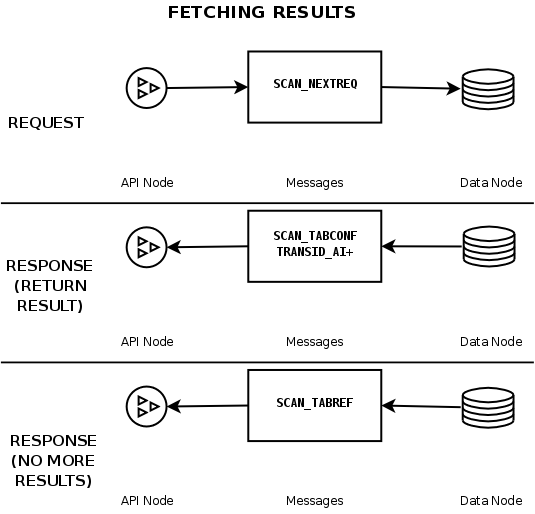
If the operation failed, the data node returns a
SCAN_TABREFmessage.SCAN_TABREFis also used to signal to the API node that all data resulting from a read has been sent.
Committing and rolling back transactions.
The process of performing an explicit commit follows the same
general pattern as shown previously. The API node sends a
TC_COMMITREQ message to the data node,
which responds with either a TC_COMMITCONF
(on success) or a TC_COMMITREF (if the
commit failed). This is shown in the following diagram:
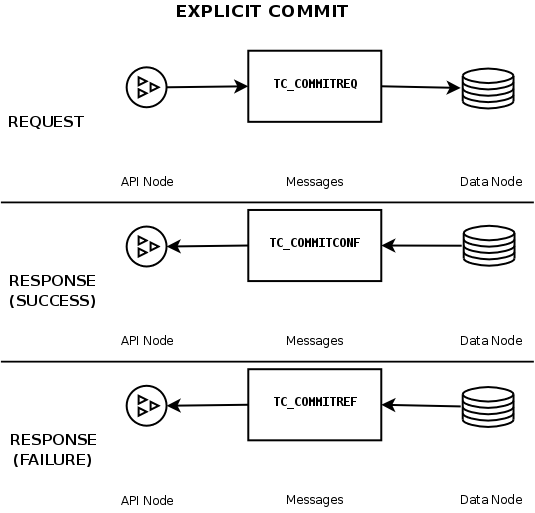
Some operations perform a COMMIT
automatically, so this is not required for every transaction.
Rolling back a transaction also follows this pattern. In this
case, however, the API node sends a
TCROLLBACKTREQ message to the data node.
Either a TCROLLACKCONF or a
TCROLLBACKREF is sent in response, as shown
here:
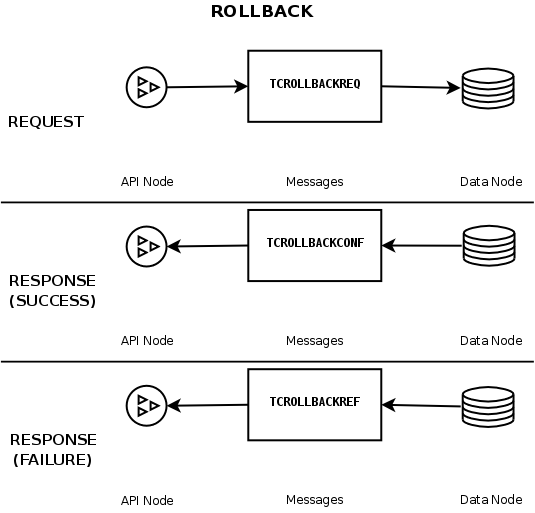
Handling of transaction records.
Acquiring a transaction record is accomplished when an API
node transmits a TCSEIZEREQ message to a
data node and receives a TCSEIZECONF or
TCSEIZEREF in return, depending on whether
or not the request was successful. This is depicted here:
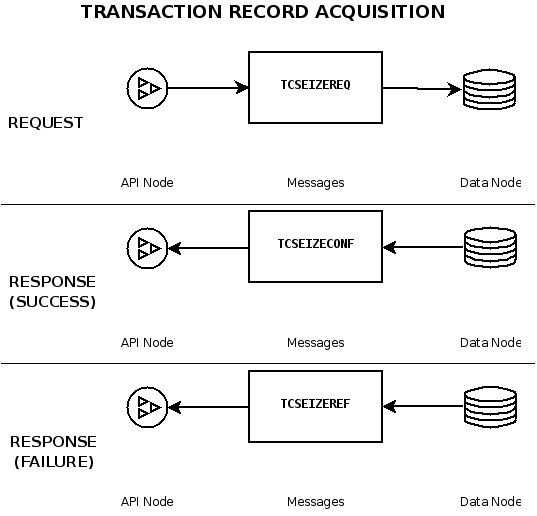
The release of a transaction record is also handled using the
request-response pattern. In this case, the API node's request
contains a TCRELEASEREQ message, and the data
node's response uses either a TCRELEASECONF
(indicating that the record was released) or a
TCRELEASEREF (indicating that the attempt at
release did not succeed). This series of events is illustrated
in the next diagram:
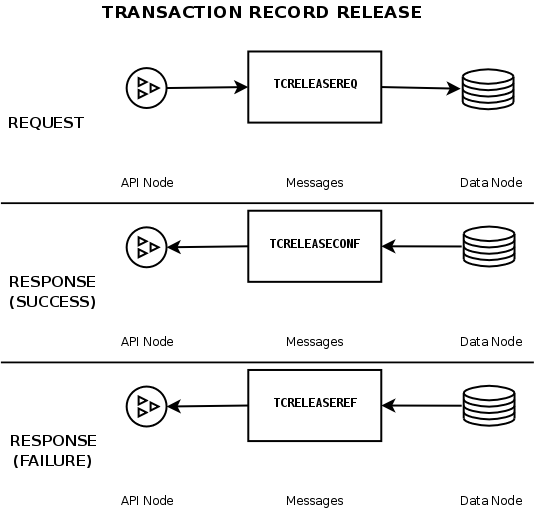
- 6.4.1. The
BACKUPBlock - 6.4.2. The
CMVMIBlock - 6.4.3. The
DBACCBlock - 6.4.4. The
DBDICTBlock - 6.4.5. The
DBDIHBlock - 6.4.6.
DBLQHBlock - 6.4.7. The
DBTCBlock - 6.4.8. The
DBTUPBlock - 6.4.9.
DBTUXBlock - 6.4.10. The
DBUTILBlock - 6.4.11. The
LGMANBlock - 6.4.12. The
NDBCNTRBlock - 6.4.13. The
NDBFSBlock - 6.4.14. The
PGMANBlock - 6.4.15. The
QMGRBlock - 6.4.16. The
RESTOREBlock - 6.4.17. The
SUMABlock - 6.4.18. The
TSMANBlock - 6.4.19. The
TRIXBlock
The following sections list and describe the major kernel blocks
found in the NDB source code. These are found
under the directory
storage/ndb/src/kernel/blocks/ in the MySQL
Cluster source tree.
This block is responsible for handling online backups and
checkpoints. It is found in
storage/ndb/src/kernel/blocks/backup/, and
contains the following files:
Backup.cpp: Defines methods for node signal handing; also provides output methods for backup status messages to user.BackupFormat.hpp: Defines the formats used for backup data,.CTL, and log files.Backup.hpp: Defines theBackupclass.BackupInit.cpp: ActualBackupclass constructor is found here.Backup.txt: Contains a backup signal diagram (text format). Somewhat dated (from 2003), but still potentially useful for understanding the sequence of events that is followed during backups.FsBuffer.hpp: Defines theFsBufferclass, which implements the circular data buffer that is used (together with the NDB file system) for reading and writing backup data and logs.read.cpp: Contains some utility functions for reading log and checkpoint files toSTDOUT.
This block is responsible for configuration management between
the kernel blocks and the NDB virtual
machine, as well as the cluster job que and cluster
transporters. It is found in
storage/ndb/src/kernel/blocks/cmvmi, and
contains these files:
Cmvmi.cpp: Implements communication and reporting methods for the
Cmvmiclass.Cmvmi.hpp: Defines theCmvmiclass.
CMVMI is implemented as the
Cmvmi class, defined in
storage/ndb/src/kernel/blocks/cmvmi/Cmvmi.hpp.
Also referred to as the ACC block, this is
the access control and lock management module, found in
storage/ndb/src/kernel/blocks/dbacc. It
contains the following files:
Dbacc.hpp: Defines theDbaccclass, along with structures for operation, scan, table, and other records.DbaccInit.cpp:Dbaccclass constructor and destructor; methods for initialising data and records.DbaccMain.cpp: ImplementsDbaccclass methods.
The ACC block handles the database index
structures, which are stored in 8K pages. Database locks are
also handled in the ACC block.
When a new tuple is inserted, the TUP block
stores the tuple in a suitable space and returns an index (a
reference to the address of the tuple in memory).
ACC stores both the primary key and this
tuple index of the tuple in a hash table.
Like the TUP block, the
ACC block implements part of the checkpoint
protocol. It also performs undo logging. It is implemented by
the Dbacc class, which is defined in
storage/ndb/src/kernel/blocks/dbacc/DbaccMain.hpp.
See also Section 6.4.8, “The DBTUP Block”.
This block, the data dictionary block, is found in
storage/ndb/src/kernel/blocks/dbdict. Data
dictionary information is replicated to all
DICT blocks in the cluster. This is the only
block other than DBTC to which applications
can send direct requests. DBDICT is
responsible for managing metadata (via the cluster's master
node) such as table and index definitions, as well as many Disk
Data operations. This block contains the following files:
CreateIndex.txt: Contains notes about processes for creating, altering, and dropping indexes and triggers.Dbdict.cpp: Implements structure for event metadata records (forNDB$EVENTS_0), as well as methods for system start and restart, table and schema file handling, and packing table data into pages. Functionality for determining node status and handling node failures is also found here. In addition, this file implements data and other initialisation routines forDbdict.DictLock.txt: Implementation notes: Describes locking of the master node'sDICTagainst schema operations.printSchemaFile.cpp: Contains the source for the ndb_print_schema_file utility, described in ndb_print_schema_file.Slave_AddTable.sfl: A signal log trace of a table creation operation forDBDICTon a nonmaster node.CreateTable.txt: Notes outlining the table creation process (dated).CreateTable.new.txt: Notes outlining the table creation process (updated version ofCreateTable.txt).Dbdict.hpp: Defines theDbdictclass; also creates theNDB$EVENTS_0table. Also defines a number of structures such as table and index records, as well as for table records.DropTable.txt: Implementation notes for the process of dropping a table.Dbdict.txt: Implementation notes for creating and dropping events andNdbEventOperationobjects (see Section 2.3.11, “TheNdbEventOperationClass”).Event.txt: A copy ofDbdict.txt.Master_AddTable.sfl: A signal log trace of a table creation operation forDBDICTon the master node.SchemaFile.hpp: Defines the structure of a schema file.
This block is implemented as the Dbdict
class, defined in
storage/ndb/src/kernel/blocks/dblqh/Dbdict.hpp.
This block provides data distribution (partitioning) management
services. It is responsible for maintaining data fragments and
replicas, handling of local and global checkpoints; it also
manages node and system restarts. It contains the following
files, all found in the directory
storage/ndb/src/kernel/blocks/dbdih:
Dbdih.hpp: This file contains the definition of theDbdihclass, as well as theFileRecordPtrtype, which is used to keep storage information about a fragment and its replicas. If a fragment has more than one backup replica, then a list of the additional ones is attached to this record. This record also stores the status of the fragment, and is 64-byte aligned.DbdihMain.cpp: Contains definitions ofDbdihclass methods.printSysfile/printSysfile.cpp: Older version of theprintSysfile.cppin the maindbdihdirectory.DbdihInit.cpp: InitializesDbdihdata and records; also contains the class destructor.LCP.txt: Contains developer noted about the exchange of messages betweenDIHandLQHthat takes place during a local checkpoint.printSysfile.cpp: This file contains the source code for ndb_print_sys_file. For information about using this utility, see ndb_print_sys_file.Sysfile.hpp: Contains the definition of theSysfilestructure; in other words, the format of anNDBsystem file. See Section 6.1, “MySQL Cluster File Systems”, for more information aboutNDBsystem files.
This block often makes use of BACKUP blocks
on the data nodes to accomplish distributed tasks, such as
global checkpoints and system restarts.
This block is implemented as the Dbdih class,
whose definition may be found in the file
storage/ndb/src/kernel/blocks/dbdih/Dbdih.hpp.
This is the local, low-level query handler block, which manages
data and transactions local to the cluster's data nodes, and
acts as a coordinator of 2-phase commits. It is responsible
(when called on by the transaction coordinator) for performing
operations on tuples, accomplishing this task with help of
DBACC block (which manages the index
structures) and DBTUP (which manages the
tuples). It is made up of the following files, found in
storage/ndb/src/kernel/blocks/dblqh:
Dblqh.hpp: Contains theDblqhclass definition. The code itself includes the following modules:Start/Restart Module. This module handles the following start phases:
Start phase 1. Load block reference and processor ID
Start phase 2. Initiate all records within the block; connect
LQHwithACCandTUPStart phase 4. Connect each
LQHwith every otherLQHin the database system. For an initial start, create the fragment log files. For a system restart or node restart, open the fragment log files and find the end of the log files.
Fragment addition and deletion module. Used by the data dictionary to create new fragments and delete old fragments.
Execution module. This module handles the reception of
LQHKEYREQmessages and all processing of operations on behalf of this request. This also involves reception of various types ofATTRINFOandKEYINFOmessages, as well as communications withACCandTUP.Log module. The log module handles the reading and writing of the log. It is also responsible for handling system restarts, and controls system restart in
TUPandACCas well.Tramsaction module. This module handles the commit and completion phases.
TC failure module. Handles failures in the transaction coordinator.
Scan module. This module contains the code that handles a scan of a particular fragment. It operates under the control of the transaction coordinator and orders
ACCto perform a scan of all tuples in the fragment.TUPperforms the necessary search conditions to insure that only valid tuples are returned to the application.Node recovery module. This is used when a node has failed, copying the effected fragment to a new fragment replica. It also shuts down all connections to the failed node.
LCP module. This module handles execution and control of local checkpoints in
TUPandACC. It also interacts withDIHto determine which global checkpoints are recoverable.Global checkpoint module. Assist
DIHin discovering when GCPs are recoverable. It handles theGCP_SAVEREQmessage requestingLQHto save a given GCP to disk, and to provide a notification of when this has been done.File handling module. This includes a number of sub-modules:
Signal reception
Normal operation
File change
Initial start
System restart, Phase 1
System restart, Phase 2
System restart, Phase 3
System restart, Phase 4
Error
DblqhInit.cpp: InitialisesDblqhrecords and data. Also includes theDblqhclass destructor, used for deallocating these.DblqhMain.cpp: ImplementsDblqhfunctionality (class methods).This directory also has the files listed here in a
redoLogReadersubdirectory containing the sources for the ndb_redo_log_reader utility (see ndbd_redo_log_reader):records.cpprecords.hppredoLogFileReader.cpp
This block also handles redo logging, and helps oversee the
DBACC, DBTUP,
LGMAN, TSMAN,
PGMAN, and BACKUP blocks.
It is implemented as the class Dblqh, defined
in the file
storage/ndb/src/kernel/blocks/dblqh/Dblqh.hpp.
This is the transaction coordinator block, which handles
distributed transactions and other data operations on a global
level (as opposed to DBLQH which deals with
such issues on individual data nodes). In the source code, it is
located in the directory
storage/ndb/src/kernel/blocks/dbtc, which
contains these files:
Dbtc.hpp: Defines theDbtcclass and associated constructs, including the following:Trigger and index data (
TcDefinedTriggerData). A record forming a list of active triggers for each table. These records are managed by a trigger pool, in which a trigger record is seized whenever a trigger is activated, and released when the trigger is deactivated.Fired trigger data (
TcFiredTriggerData). A record forming a list of fired triggers for a given transaction.Index data (
TcIndexData). This record forms lists of active indexes for each table. Such records are managed by an index pool, in which each index record is seized whenever an index is created, and released when the index is dropped.API connection record (
ApiConnectRecord). An API connect record contains the connection record to which the application connects. The application can send one operation at a time. It can send a new operation immediately after sending the previous operation. This means that several operations can be active in a single transaction within the transaction coordinator, which is achieved by using the API connect record. Each active operation is handled by the TC connect record; as soon as the TC connect record has sent the request to the local query handler, it is ready to receive new operations. TheLQHconnect record takes care of waiting for an operation to complete; when an operation has completed on theLQHconnect record, a new operation can be started on the currentLQHconnect record.ApiConnectRecordis always 256-byte aligned.Transaction coordinator connection record (
TcConnectRecord). ATcConnectRecord) keeps all information required for carrying out a transaction; the transaction controller establishes connections to the different blocks needed to carry out the transaction. There can be multiple records for each active transaction. The TC connection record cooperates with the API connection record for communication with the API node, and with theLQHconnection record for communication with any local query handlers involved in the transaction.TcConnectRecord) is permanently connected to a record inDBDICTand another inDIH, and contains a list of activeLQHconnection records and a list of started (but not currently active)LQHconnection records. It also contains a list of all operations that are being executed with the current TC connection record.TcConnectRecordis always 128-byte aligned.Cache record (
CacheRecord). This record is used between reception of aTCKEYREQand sending ofLQHKEYREQ(see Section 6.3.3, “Operations and Signals”) This is a separate record, so as to improve the cache hit rate and as well as to minimize memory storage requirements.Host record (
HostRecord). This record contains the “alive” status of each node in the system, and is 128-byte aligned.Table record (
TableRecord). This record contains the current schema versions of all tables in the system.Scan record (
ScanRecord). Each scan allocates aScanRecordto store information about the current scan.Data buffer (
DatabufRecord). This is a buffer used for general data storage.Attribute information record (
AttrbufRecord). This record can contain one (1)ATTRINFOsignal, which contains a set of 32 attribute information words.Global checkpoint information record (
GcpRecord). This record is used to store the globalcheckpoint number, as well as a counter, during the completion phase of the transaction. AGcpRecordis 32-byte aligned.TC failure record (
TC_FAIL_RECORD). This is used when handling takeover of TC duties from a failed transaction coordinator.
DbtcInit.cpp: Handles allocation and deallocation ofDbtcindexes and data (includes class desctructor).DbtcMain.cpp: ImplementsDbtcmethods.
Any data node may act as the transaction coordinator.
The DBTC block is implemented as the
Dbtc class.
The transaction coordinator is the kernel interface to which applications send their requests. It establishes connections to different blocks in the system to carry out the transaction and decides which node will handle each transaction, sending a confirmation signal on the result to the application so that the application can verify that the result received from the TUP block is correct.
This block also handles unique indexes, which must be co-ordinated across all data nodes simultaneously.
This is the tuple manager, which manages the physical storage of
cluster data. It consists of the following files found in the
directory
storage/ndb/src/kernel/blocks/dbtup:
AttributeOffset.hpp: Defines theAttributeOffsetclass, which models the structure of an attribute, permitting up to 4096 attributes, all of which are nullable.DbtupDiskAlloc.cpp: Handles allocation and deallocation of extents for disk space.DbtupIndex.cpp: Implements methods for reading and writing tuples using ordered indexes.DbtupScan.cpp: Implements methods for tuple scans.tuppage.cpp: Handles allocating pages for writing tuples.tuppage.hpp: Defines structures for fixed and variable size data pages for tuples.DbtupAbort.cpp: Contains routines for terminating failed tuple operations.DbtupExecQuery.cpp: Handles execution of queries for tuples and reading from them.DbtupMeta.cpp: Handle table operations for theDbtupclass.DbtupStoredProcDef.cpp: Module for adding and dropping procedures.DbtupBuffer.cpp: Handles read/write buffers for tuple operations.DbtupFixAlloc.cpp: Allocates and frees fixed-size tuples from the set of pages attatched to a fragment. The fixed size is set per fragment; there can be only one such value per fragment.DbtupPageMap.cpp: Routines used byDbtupto map logical page IDs to physical page IDs. The mapping needs the fragment ID and the logical page ID to provide the physical ID. This part ofDbtupis the exclusive user of a certain set of variables on the fragment record; it is also the exclusive user of the struct for page ranges (thePageRangestruct defined inDbtup.hpp).DbtupTabDesMan.cpp: This file contains the routines making up the table descriptor memory manager. Each table has a descriptor, which is a contiguous array of data words, and which is allocated from a global array using a “buddy” algorithm, with free lists existing for each 2N words.Notes.txt: Contains some developers' implementation notes on tuples, tuple operations, and tuple versioning.Undo_buffer.hpp: Defines theUndo_bufferclass, used for storage of operations that may need to be rolled back.Undo_buffer.cpp: Implements some necessaryUndo_buffermethods.DbtupCommit.cpp: Contains routines used to commit operations on tuples to disk.DbtupGen.cpp: This file containsDbtupinitialization routines.DbtupPagMan.cpp: This file implements the page memory manager's “buddy” algorithm.PagManis invoked when fragments lack sufficient internal page space to accomodate all the data they are requested to store. It is also invoked when fragments deallocate page space back to the free area.DbtupTrigger.cpp: The routines contained in this file perform handling ofNDBinternal triggers.DbtupDebug.cpp: Used for debugging purposes only.Dbtup.hpp: Contains theDbtupclass definition. Also defines a number of essential structures such as tuple scans, disk allocation units, fragment records, and so on.DbtupRoutines.cpp: ImplementsDbtuproutines for reading attributes.DbtupVarAlloc.cpptest_varpage.cpp: Simple test program for verifying variable-size page operations.
This block also monitors changes in tuples.
This kernel block handles the local management of ordered
indexes. It consists of the following files found in the
storage/ndb/src/kernel/blocks/dbtux
directory:
DbtuxCmp.cpp: Implements routines to search by key vs node prefix or entry. The comparison starts at a given attribute position, which is updated by the number of equal initial attributes found. The entry data may be partial, in which caseCmpUnknownmay be returned. The attributes are normalized and have a variable size, given in words.DbtuxGen.cpp: Implements initialization routines used in node starts and restarts.DbtuxMaint.cpp: Contains routines used to maintain indexes.DbtuxNode.cpp: Implements routines for node creation, allocation, and deletion operations. Also assigns lists of scans to nodes.DbtuxSearch.cpp: Provides routines for handling node scan request messages.DbtuxTree.cpp: Routines for performing node tree operations.Times.txt: Contains some (old) performance figures from tests runs on operations using ordered indexes. Of historical interest only.DbtuxDebug.cpp: Debugging code for dumping node states.Dbtux.hpp: ContainsDbtuxclass definition.DbtuxMeta.cpp: Routines for creating, setting, and dropping indexes. Also provides means of aborting these operations in the event of failure.DbtuxScan.cpp: Routines for performing index scans.DbtuxStat.cpp: Implements methods for obtaining node statistics.tuxstatus.html: 2004-01-30 status report on ordered index implementation. Of historical interest only.
This block provides internal interfaces to transaction and data
operations, performing essential operations on signals passed
between nodes. This block implements transactional services
which can then be used by other blocks. It is also used in
building online indexes, and is found in
storage/ndb/src/kernel/blocks/dbutil, which
includes these files:
DbUtil.cpp: ImplementsDbutilclass methodsDbUtil.hpp: Defines theDbutilclass, used to provide transactional services.DbUtil.txt: Implementation notes on utility protocols implemented byDBUTIL.
Among the duties performed by this block is the maintenance of sequences for backup IDs and other distributed identifiers.
This block, the log group manager, is responsible for handling
the undo logs for Disk Data tables. It consists of these files
in the storage/ndb/src/kernel/blocks
directory:
lgman.cpp: ImplementsLgmanfor adding, dropping, and working with log files and file groups.lgman.hpp: Contains the definition for theLgmanclass, used to handle undo log files. Handles allocation of log buffer space.
This is a cluster management block that handles block
initialisation and configuration. During the data node startup
process, it takes over from the QMGR block
and continues the process. It also assist with graceful
(planned) shutdowns of data nodes. Ths block is located in
storage/ndb/src/kernel/blocks/ndbcntr, and
contains these files:
Ndbcntr.hpp: Defines theNdbcntrclass used to implement cluster management functions.NdbcntrInit.cpp: Initializers forNdbcntrdata and records.NdbcntrMain.cpp: Implements methods used for starts, restarts, and reading of configuration data.NdbcntrSysTable.cpp:NDBCNTRcreates and initializes system tables on initial system start. The tables are defined in static structs in this file.
This block provides the NDB file system
abstraction layer, and is located in the directory
storage/ndb/src/kernel/blocks/ndbfs, which
contains the following files:
AsyncFile.hpp: Defines theAsyncFileclass, which represents an asynchronous file. All actions are executed concurrently with the other activities carried out by the process. Because all actions are performed in a separate thread, the result of an action is sent back through a memory channel. For the asyncronous notification of a finished request, each callincludes a request as a parameter. This class is used for writing or reading data to and from disk concurrently with other activities.AsyncFile.cpp: Defines the actions possible for an asynchronous file, and implements them.Filename.hpp: Defines theFilenameclass. Takes a 128-bit value (as a array of four longs) and makes a file name out of it. This file name encodes information about the file, such as whether it is a file or a directory, and if the former, the type of file. Possible types include data file, fragment log, fragment list, table list, schema log, and system file, among others.Filename.cpp: Implementsset()methods for theFilenameclass.MemoryChannelTest/MemoryChannelTest.cpp: Basic program for testing reads from and writes to a memory channel (that is, reading from and writing to a circular buffer).OpenFiles.hpp: Implements anOpenFilesclass, which implements some convenience methods for determining whether or not a given file is already open.VoidFs.cpp: Used for diskless operation. Generates a “dummy” acknowledgment to write operations.CircularIndex.hpp: TheCircularIndexclass, defined in this file, serves as the building block for implementing circular buffers. It increments as a normal index until it reaches maximum size, then resets to zero.CircularIndex.cpp: Contains only a single#define, not actually used at this time.MemoryChannel.hpp: Defines theMemoryChannelandMemoryChannelMultipleWriterclasses, which provide a pointer-based channel for communication between two threads. It does not copy any data into or out of the channel, so the item that is put in can not be used untill the other thread has given it back. There is no support for detecting the return of an item.MemoryChannel.cpp: “Dummy” file, not used at this time.Ndbfs.hpp: Because anNDBsignal request can result in multiple requests toAsyncFile, one class (defined in this file) is responsible for keeping track of all outstanding requests, and when all are finished, reporting the outcome back to the sending block.Ndbfs.cpp: Implements initialization and signal-handling methods for theNdbfsclass.Pool.hpp: Creates and manages a pool of objects for use byNdbfsand other classes in this block.AsyncFileTest/AsyncFileTest.cpp: Test program, used to test and benchmark functionality ofAsyncFile.
This block provides page and buffer management services for Disk Data tables. It includes these files:
diskpage.hpp: Defines theFile_formats,Datafile, andUndofilestructures.diskpage.cpp: Initializes sero page headers; includes some output reoutines for reporting and debugging.pgman.hpp: Defines thePgmanclass implementing a number of page and buffer services, including page entries and requests, page replacement, page lists, page cleanup, and other page processing.pgman.cpp: ImplementsPgmanmethods for initialization and various page management tasks.
This is the logical cluster management block, and handles node
membership in the cluster using heartbeats.
QMGR is responsible for polling the data
nodes when a data node failure occurs and determining that the
node has actually failed and should be dropped from the cluster.
This block contains the following files, found in
storage/ndb/src/kernel/blocks/qmgr:
Qmgr.hpp: Defines the Qmgr class and associated structures, including those used in detection of node failure and cluster partitioning.QmgrInit.cpp: Implements data and record initilization methods forQmgr, as well as its destructor.QmgrMain.cpp: Contains routines for monitoring of heartbeats, detection and handling of “split-brain” problems, and management of some startup phases.timer.hpp: Defines theTimerclass, used byNDBto keep strict timekeeping independent of the system clock.
This block also assists in the early phases of data node startup.
The QMGR block is implemented by the
Qmgr class, whose definition is found in the
file
storage/ndb/src/kernel/blocks/qmgr/Qmgr.hpp.
This block consists of the files
restore.cpp and
restore.hpp, in the
storage/ndb/src/kernel/blocks directory. It
handles restoration of the cluster from online backups.
The cluster subscription manager, which handles event logging
and reporting functions. It also figures prominently in MySQL
CLuster Replication. SUMA consists of the
following files, found in the directory
storage/ndb/src/kernel/blocks/suma/:
Suma.hpp: Defines theSumaclass and interfaces for managing subscriptions and performing necessary communications with otherSUMA(and other) blocks.SumaInit.cpp: Performs initialization ofDICT,DIH, and other interfacesSuma.cpp: Implements subscription-handling routines.Suma.txt: Contains a text-based diagram illustratingSUMAprotocols.
This is the tablespace manager block for Disk Data tables, and
includes the following files from
storage/ndb/src/kernel/blocks:
tsman.hpp: Defines theTsmanclass, as well as structures representing data files and tablespaces.tsman.cpp: ImplementsTsmanmethods.
This kernel block is responsible for the handling of internal
triggers and unique indexes. TRIX, like
DBUTIL, is a utility block containing many
helper functions for building indexes and handling signals
between nodes. It is found in the directory
storage/ndb/src/kernel/blocks/trix, and
includes these files:
Trix.hpp: Defines theTrixclass, along with structures representing subscription data and records (for communicating withSUMA) and node data and ists (needed when communicating with remoteTRIXblocks).Trix.cpp: ImplementsTrixclass methods, including those necessary for taking appropriate action in the event of node failures.
This block is implemented as the Trix class,
defined in
storage/ndb/src/kernel/blocks/trix/Trix.hpp.
- 6.5.1. Initialization Phase (Phase -1)
- 6.5.2. Configuration Read Phase (
STTORPhase -1) - 6.5.3.
STTORPhase 0 - 6.5.4.
STTORPhase 1 - 6.5.5.
STTORPhase 2 - 6.5.6.
NDB_STTORPhase 1 - 6.5.7.
STTORPhase 3 - 6.5.8.
NDB_STTORPhase 2 - 6.5.9.
STTORPhase 4 - 6.5.10.
NDB_STTORPhase 3 - 6.5.11.
STTORPhase 5 - 6.5.12.
NDB_STTORPhase 4 - 6.5.13.
NDB_STTORPhase 5 - 6.5.14.
NDB_STTORPhase 6 - 6.5.15.
STTORPhase 6 - 6.5.16.
STTORPhase 7 - 6.5.17.
STTORPhase 8 - 6.5.18.
NDB_STTORPhase 7 - 6.5.19.
STTORPhase 9 - 6.5.20.
STTORPhase 101 - 6.5.21. System Restart Handling in Phase 4
- 6.5.22.
START_MEREQHandling
Before the data node actually starts, a number of other setup and initialization tasks must be done for the block objects, transporters, and watchdog checks, among others.
This initialization process begins in
storage/ndb/src/kernel/main.cpp with a
series of calls to
globalEmulatorData.theThreadConfig->doStart().
When starting ndbd with the
-n or --nostart option there
is only one call to this method; otherwise, there are two, with
the second call actually starting the data node. The first
invocation of doStart() sends the
START_ORD signal to the
CMVMI block (see
Section 6.4.2, “The CMVMI Block”); the second
call to this method sends a START_ORD signal
to NDBCNTR (see
Section 6.4.12, “The NDBCNTR Block”).
When START_ORD is received by the
NDBCNTR block, the signal is immediately
transferred to NDBCNTR's
MISSRA sub-block, which handles the start
process by sending a READ_CONFIG_REQ signals
to all blocks in order as given in the array
readConfigOrder:
NDBFSDBTUPDBACCDBTCDBLQHDBTUXDBDICTDBDIHNDBCNTRQMGRTRIXBACKUPDBUTILSUMATSMANLGMANPGMANRESTORE
NDBFS is permitted to run before any of the
remaining blocks are contacted, in order to make sure that it
can start the CMVMI block's threads.
The READ_CONFIG_REQ signal provides all
kernel blocks an opportunity to read the configuration data,
which is stored in a global object accessible to all blocks. All
memory allocation in the data nodes takes place during this
phase.
Connections between the kernel blocks and the
NDB file system are also set up during
Phase 0. This is necessary to enable the blocks to communicate
easily which parts of a table structure are to be written to
disk.
NDB performs memory allocations in two
different ways. The first of these is by using the
allocRecord() method (defined in
storage/ndb/src/kernel/vm/SimulatedBlock.hpp).
This is the traditional method whereby records are accessed
using the ptrCheckGuard macros (defined in
storage/ndb/src/kernel/vm/pc.hpp). The
other method is to allocate memory using the
setSize() method defined with the help of the
template found in
storage/ndb/src/kernel/vm/CArray.hpp.
These methods sometimes also initialize the memory, ensuring that both memory allocation and initialization are done with watchdog protection.
Many blocks also perform block-specific initialization, which often entails building linked lists or doubly-linked lists (and in some cases hash tables).
Many of the sizes used in allocation are calculated in the
Configuration::calcSizeAlt() method, found in
storage/ndb/src/kernel/vm/Configuration.cpp.
Some preparations for more intelligent pooling of memory
resources have been made. DataMemory and disk
records already belong to this global memory pool.
Most NDB kernel blocks begin their start
phases at STTOR Phase 1, with the exception
of NDBFS and NDBCNTR,
which begin with Phase 0, as can be seen by inspecting the first
value for each element in the ALL_BLOCKS
array (defined in
src/kernel/blocks/ndbcntr/NdbcntrMain.cpp).
In addition, when the STTOR signal is sent to
a block, the return signal STTORRY always
contains a list of the start phases in which the block has an
interest. Only in those start phases does the block actually
receive a STTOR signal.
STTOR signals are sent out in the order in
which the kernel blocks are listed in the
ALL_BLOCKS array. While
NDBCNTR goes through start phases 0 to 255,
most of these are empty.
Both activities in Phase 0 have to do with initialization of the
NDB file system. First, if necessary,
NDBFS creates the file system directory for
the data node. In the case of an initial start,
NDBCNTR clears any existing files from the
directory of the data node to ensure that the
DBDIH block does not subsequently discover
any system files (if DBDIH were to find any
system files, it would not interpret the start correctly as an
initial start). (See also
Section 6.4.5, “The DBDIH Block”.)
Each time that NDBCNTR completes the sending
of one start phase to all kernel blocks, it sends a
NODE_STATE_REP signal to all blocks, which
effectively updates the NodeState in all
blocks.
Each time that NDBCNTR completes a nonempty
start phase, it reports this to the management server; in most
cases this is recorded in the cluster log.
Finally, after completing all start phases,
NDBCNTR updates the node state in all blocks
using a NODE_STATE_REP signal; it also sends
an event report advising that all start phases are complete. In
addition, all other cluster data nodes are notified that this
node has completed all its start phases to ensure all nodes are
aware of one another's state. Each data node sends a
NODE_START_REP to all blocks; however, this
is significant only for DBDIH, so that it
knows when it can unlock the lock for schema changes on
DBDICT.
In the following table, and throughout this text, we sometimes
refer to STTOR start phases simply as
“start phases” or “Phase
N” (where
N is some number).
NDB_STTOR start phases are always qualified
as such, and so referred to as
“NDB_STTOR start phases” or
“NDB_STTOR phases”.
| Kernel Block | Receptive Start Phases |
|---|---|
NDBFS | 0 |
DBTC | 1 |
DBDIH | 1 |
DBLQH | 1, 4 |
DBACC | 1 |
DBTUP | 1 |
DBDICT | 1, 3 |
NDBCNTR | 0, 1, 2, 3, 4, 5, 6, 8, 9 |
CMVMI | 1 (prior to QMGR), 3, 8 |
QMGR | 1, 7 |
TRIX | 1 |
BACKUP | 1, 3, 7 |
DBUTIL | 1, 6 |
SUMA | 1, 3, 5, 7, 100 (empty), 101 |
DBTUX | 1,3,7 |
TSMAN | 1, 3 (both ignored) |
LGMAN | 1, 2, 3, 4, 5, 6 (all ignored) |
PGMAN | 1, 3, 7 (Phase 7 currently empty) |
RESTORE | 1,3 (only in Phase 1 is any real work done) |
This table was current at the time this text was written, but is likely to change over time. The latest information can be found in the source code.
This is one of the phases in which most kernel blocks
participate (see the table in
Section 6.5.3, “STTOR Phase 0”).
Otherwise, most blocks are involved primarily in the
initialization of data—for example, this is all that
DBTC does.
Many blocks initialize references to other blocks in Phase 1.
DBLQH initializes block references to
DBTUP, and DBACC
initializes block references to DBTUP and
DBLQH. DBTUP initializes
references to the blocks DBLQH,
TSMAN, and LGMAN.
NDBCNTR initializes some variables and sets
up block references to DBTUP,
DBLQH, DBACC,
DBTC, DBDIH, and
DBDICT; these are needed in the special start
phase handling of these blocks using
NDB_STTOR signals, where the bulk of the node
startup process actually takes place.
If the cluster is configured to lock pages (that is, if the
LockPagesInMainMemory configuration parameter
has been set), CMVMI handles this locking.
The QMGR block calls the
initData() method (defined in
storage/ndb/src/kernel/blocks/qmgr/QmgrMain.cpp)
whose output is handled by all other blocks in the
READ_CONFIG_REQ phase (see
Section 6.5.1, “Initialization Phase (Phase -1)”).
Following these initializations, QMGR sends
the DIH_RESTARTREQ signal to
DBDIH, which determines whether a proper
system file exists; if it does, an initial start is not being
performed. After the reception of this signal comes the process
of integrating the node among the other data nodes in the
cluster, where data nodes enter the cluster one at a time. The
first one to enter becomes the master; whenever the master dies
the new master is always the node that has been running for the
longest time from those remaining.
QMGR sets up timers to ensure that inclusion
in the cluster does not take longer than what the cluster's
configuration is set to permit (see
Controlling
Timeouts, Intervals, and Disk Paging for the relevant
configuration parameters), after which communication to all
other data nodes is established. At this point, a
CM_REGREQ signal is sent to all data nodes.
Only the president of the cluster responds to this signal; the
president permits one node at a time to enter the cluster. If no
node responds within 3 seconds then the president becomes the
master. If several nodes start up simultaneously, then the node
with the lowest node ID becomes president. The president sends
CM_REGCONF in response to this signal, but
also sends a CM_ADD signal to all nodes that
are currently alive.
Next, the starting node sends a
CM_NODEINFOREQ signal to all current
“live” data nodes. When these nodes receive that
signal they send a NODE_VERSION_REP signal to
all API nodes that have connected to them. Each data node also
sends a CM_ACKADD to the president to inform
the president that it has heard the
CM_NODEINFOREQ signal from the new node.
Finally, each of the current data nodes sends the
CM_NODEINFOCONF signal in response to the
starting node. When the starting node has received all these
signals, it also sends the CM_ACKADD signal
to the president.
When the president has received all of the expected
CM_ACKADD signals, it knows that all data
nodes (including the newest one to start) have replied to the
CM_NODEINFOREQ signal. When the president
receives the final CM_ACKADD, it sends a
CM_ADD signal to all current data nodes (that
is, except for the node that just started). Upon receiving this
signal, the existing data nodes enable communication with the
new node; they begin sending heartbeats to it and including in
the list of neighbors used by the heartbeat protocol.
The start struct is reset, so that it can
handle new starting nodes, and then each data node sends a
CM_ACKADD to the president, which then sends
a CM_ADD to the starting node after all such
CM_ACKADD signals have been received. The new
node then opens all of its communication channels to the data
nodes that were already connected to the cluster; it also sets
up its own heartbeat structures and starts sending heartbeats.
It also sends a CM_ACKADD message in response
to the president.
The signalling between the starting data node, the already “live” data nodes, the president, and any API nodes attached to the cluster during this phase is shown in the following diagram:
As a final step, QMGR also starts the timer
handling for which it is responsible. This means that it
generates a signal to blocks that have requested it. This signal
is sent 100 times per second even if any one instance of the
signal is delayed..
The BACKUP kernel block also begins sending a
signal periodically. This is to ensure that excessive amounts of
data are not written to disk, and that data writes are kept
within the limits of what has been specified in the cluster
configuration file during and after restarts. The
DBUTIL block initializes the transaction
identity, and DBTUX creates a reference to
the DBTUP block, while
PGMAN initializes pointers to the
LGMAN and DBTUP blocks.
The RESTORE kernel block creates references
to the DBLQH and DBTUP
blocks to enable quick access to those blocks when needed.
The only kernel block that participates in this phase to any
real effect is NDBCNTR.
In this phase NDBCNTR obtains the current
state of each configured cluster data node. Messages are sent to
NDBCNTR from QMGR
reporting the changes in status of any the nodes.
NDBCNTR also sets timers corresponding to the
StartPartialTimeout,
StartPartitionTimeout, and
StartFailureTimeout configuration parameters.
The next step is for a CNTR_START_REQ signal
to be sent to the proposed master node. Normally the president
is also chosen as master. However, during a system restart where
the starting node has a newer global checkpoint than that which
has survived on the president, then this node will take over as
master node, even though it is not recognized as the president
by QMGR. If the starting node is chosen as
the new master, then the other nodes are informed of this using
a CNTR_START_REF signal.
The master withholds the CNTR_START_REQ
signal until it is ready to start a new node, or to start the
cluster for an initial restart or system restart.
When the starting node receives
CNTR_START_CONF, it starts the
NDB_STTOR phases, in the following order:
DBLQHDBDICTDBTUPDBACCDBTCDBDIH
DBDICT, if necessary, initializes the schema
file. DBDIH, DBTC,
DBTUP, and DBLQH
initialize variables. DBLQH also initializes
the sending of statistics on database operations.
DBDICT initializes a variable that keeps
track of the type of restart being performed.
NDBCNTR executes the second of the
NDB_STTOR start phases, with no other
NDBCNTR activity taking place during this
STTOR phase.
The DBLQH block enables its exchange of
internal records with DBTUP and
DBACC, while DBTC permits
its internal records to be exchanged with
DBDIH. The DBDIH kernel
block creates the mutexes used by the NDB
kernel and reads nodes using the
READ_NODESREQ signal. With the data from the
response to this signal, DBDIH can create
node lists, node groups, and so forth. For node restarts and
initial node restarts, DBDIH also asks the
master for permission to perform the restart. The master will
ask all “live” nodes if they are prepared to permit
the new node to join the cluster. If an initial node restart is
to be performed, then all LCPs are invalidated as part of this
phase.
LCPs from nodes that are not part of the cluster at the time of the initial node restart are not invalidated. The reason for this is that there is never any chance for a node to become master of a system restart using any of the LCPs that have been invalidated, since this node must complete a node restart—including a local checkpoint—before it can join the cluster and possibly become a master node.
The CMVMI kernel block activates the sending
of packed signals, which occurs only as part of database
operations. Packing must be enabled prior to beginning any such
operations during the execution of the redo log or node recovery
phases.
The DBTUX block sets the type of start
currently taking place, while the BACKUP
block sets the type of restart to be performed, if any (in each
case, the block actually sets a variable whose value reflects
the type of start or restart). The SUMA block
remains inactive during this phase.
The PGMAN kernel block starts the generation
of two repeated signals, the first handling cleanup. This signal
is sent every 200 milliseconds. The other signal handles
statistics, and is sent once per second.
Only the DBLQH and NDBCNTR
kernel blocks are directly involved in this phase.
DBLQH allocates a record in the
BACKUP block, used in the execution of local
checkpoints using the DEFINE_BACKUP_REQ
signal. NDBCNTR causes
NDB_STTOR to execute NDB_STTOR phase 3; there
is otherwise no other NDBCNTR activity during
this STTOR phase.
The DBLQH block initiates checking of the log
files here. Then it obtains the states of the data nodes using
the READ_NODESREQ signal. Unless an initial
start or an initial node restart is being performed, the
checking of log files is handled in parallel with a number of
other start phases. For initial starts, the log files must be
initialized; this can be a lengthy process and should have some
progress status attached to it.
From this point, there are two parallel paths, one continuing to restart and another reading and determining the state of the redo log files.
The DBDICT block requests information about
the cluster data nodes using the
READ_NODESREQ signal.
DBACC resets the system restart flag if this
is not a system restart; this is used only to verify that no
requests are received from DBTUX during
system restart. DBTC requests information
about all nodes by means of the READ_NODESREQ
signal.
DBDIH sets an internal master state and makes
other preparations exclusive to initial starts. In the case of
an initial start, the nonmaster nodes perform some initial
tasks, the master node doing once all nonmaster nodes have
reported that their tasks are completed. (This delay is actually
unnecessary since there is no reason to wait while initializing
the master node.)
For node restarts and initial node restarts no more work is done in this phase. For initial starts the work is done when all nodes have created the initial restart information and initialized the system file.
For system restarts this is where most of the work is performed,
initiated by sending the NDB_STARTREQ signal
from NDBCNTR to DBDIH in
the master. This signal is sent when all nodes in the system
restart have reached this point in the restart. This we can mark
as our first synchronization point for system restarts,
designated WAITPOINT_4_1.
For a description of the system restart version of Phase 4, see Section 6.5.21, “System Restart Handling in Phase 4”.
After completing execution of the
NDB_STARTREQ signal, the master sends a
CNTR_WAITREP signal with
WAITPOINT_4_2 to all nodes. This ends
NDB_STTOR phase 3 as well as
(STTOR) Phase 4.
All that takes place in Phase 5 is the delivery by
NDBCNTR of NDB_STTOR phase
4; the only block that acts on this signal is
DBDIH that controls most of the part of a
data node start that is database-related.
Some initialization of local checkpoint variables takes place in this phase, and for initial restarts, this is all that happens in this phase.
For system restarts, all required takeovers are also performed.
Currently, this means that all nodes whose states could not be
recovered using the redo log are restarted by copying to them
all the necessary data from the “live” data nodes.
For node restarts and initial node restarts, the master node
performs a number of services, requested to do so by sending the
START_MEREQ signal to it. This phase is
complete when the master responds with a
START_MECONF message, and is described in
Section 6.5.22, “START_MEREQ Handling”.
After ensuring that the tasks assigned to
DBDIH tasks in the NDB_STTOR phase 4 are
complete, NDBCNTR performs some work on its
own. For initial starts, it creates the system table that keeps
track of unique identifiers such as those used for
AUTO_INCREMENT. Following the WAITPOINT_4_1
synchronization point, all system restarts proceed immediately
to NDB_STTOR phase 5, which is handled by the
DBDIH block. See
Section 6.5.13, “NDB_STTOR Phase 5”, for
more information.
For initial starts and system restarts this phase means executing a local checkpoint. This is handled by the master so that the other nodes will return immediately from this phase. Node restarts and initial node restarts perform the copying of the records from the primary replica to the starting replicas in this phase. Local checkpoints are enabled before the copying process is begun.
Copying the data to a starting node is part of the node takeover protocol. As part of this protocol, the node status of the starting node is updated; this is communicated using the global checkpoint protocol. Waiting for these events to take place ensures that the new node status is communicated to all nodes and their system files.
After the node's status has been communicated, all nodes are
signaled that we are about to start the takeover protocol for
this node. Part of this protocol consists of Steps 3 - 9 during
the system restart phase as described below. This means that
restoration of all the fragments, preparation for execution of
the redo log, execution of the redo log, and finally reporting
back to DBDIH when the execution of the redo
log is completed, are all part of this process.
After preparations are complete, copy phase for each fragment in the node must be performed. The process of copying a fragment involves the following steps:
The
DBLQHkernel block in the starting node is informed that the copy process is about to begin by sending it aPREPARE_COPY_FRAGREQsignal.When
DBLQHacknowledges this request aCREATE_FRAGREQsignal is sent to all nodes notify them of the preparation being made to copy data to this replica for this table fragment.After all nodes have acknowledged this, a
COPY_FRAGREQsignal is sent to the node from which the data is to be copied to the new node. This is always the primary replica of the fragment. The node indicated copies all the data over to the starting node in response to this message.After copying has been completed, and a
COPY_FRAGCONFmessage is sent, all nodes are notified of the completion through anUPDATE_TOREQsignal.After all nodes have updated to reflect the new state of the fragment, the
DBLQHkernel block of the starting node is informed of the fact that the copy has been completed, and that the replica is now up-to-date and any failures should now be treated as real failures.The new replica is transformed into a primary replica if this is the role it had when the table was created.
After completing this change another round of
CREATE_FRAGREQmessages is sent to all nodes informing them that the takeover of the fragment is now committed.After this, process is repeated with the next fragment if another one exists.
When there are no more fragments for takeover by the node, all nodes are informed of this by sending an
UPDATE_TOREQsignal sent to all of them.Wait for the next complete local checkpoint to occur, running from start to finish.
The node states are updated, using a complete global checkpoint. As with the local checkpoint in the previous step, the global checkpoint must be permitted to start and then to finish.
When the global checkpoint has completed, it will communicate the successful local checkpoint of this node restart by sending an
END_TOREQsignal to all nodes.A
START_COPYCONFis sent back to the starting node informing it that the node restart has been completed.Receiving the
START_COPYCONFsignal endsNDB_STTORphase 5. This provides another synchronization point for system restarts, designated asWAITPOINT_5_2.
The copy process in this phase can in theory be performed in parallel by several nodes. However, all messages from the master to all nodes are currently sent to single node at a time, but can be made completely parallel. This is likely to be done in the not too distant future.
In an initial and an initial node restart, the
SUMA block requests the subscriptions from
the SUMA master node.
NDBCNTR executes NDB_STTOR
phase 6. No other NDBCNTR activity takes
place.
In this NDB_STTOR phase, both
DBLQH and DBDICT clear
their internal representing the current restart type. The
DBACC block resets the system restart flag;
DBACC and DBTUP start a
periodic signal for checking memory usage once per second.
DBTC sets an internal variable indicating
that the system restart has been completed.
The NDBCNTR block defines the cluster's node
groups, and the DBUTIL block initializes a
number of data structures to facilitate the sending keyed
operations can be to the system tables.
DBUTIL also sets up a single connection to
the DBTC kernel block.
In QMGR the president starts an arbitrator
(unless this feature has been disabled by setting the value of
the ArbitrationRank configuration parameter
to 0 for all nodes—see
Defining a MySQL Cluster Management Server, and
Defining SQL and Other API Nodes in a MySQL Cluster, for more
information; note that this currently can be done only when
using MySQL Cluster Carrier Grade Edition). In addition,
checking of API nodes through heartbeats is activated.
Also during this phase, the BACKUP block sets
the disk write speed to the value used following the completion
of the restart. The master node during initial start also
inserts the record keeping track of which backup ID is to be
used next. The SUMA and
DBTUX blocks set variables indicating start
phase 7 has been completed, and that requests to
DBTUX that occurs when running the redo log
should no longer be ignored.
If this is a system restart, the master node initiates a rebuild
of all indexes from DBDICT during this phase.
The CMVMI kernel block opens communication
channels to the API nodes (including MySQL servers acting as SQL
nodes). Indicate in globalData that the node
is started.
This is the SUMA handover phase, during which
a GCP is negotiated and used as a point of reference for
changing the source of event and replication subscriptions from
existing nodes only to include a newly started node.
This consists of the following steps:
The master sets the latest GCI as the restart GCI, and then synchronizes its system file to all other nodes involved in the system restart.
The next step is to synchronize the schema of all the nodes in the system restart. This is performed in 15 passes. The problem we are trying to solve here occurs when a schema object has been created while the node was up but was dropped while the node was down, and possibly a new object was even created with the same schema ID while that node was unavailable. In order to handle this situation, it is necessary first to re-create all objects that are supposed to exist from the viewpoint of the starting node. After this, any objects that were dropped by other nodes in the cluster while this node was “dead” are dropped; this also applies to any tables that were dropped during the outage. Finally, any tables that have been created by other nodes while the starting node was unavailable are re-created on the starting node. All these operations are local to the starting node. As part of this process, is it also necessary to ensure that all tables that need to be re-created have been created locally and that the proper data structures have been set up for them in all kernel blocks.
After performing the procedure described previously for the master node the new schema file is sent to all other participants in the system restart, and they perform the same synchronization.
All fragments involved in the restart must have proper parameters as derived from
DBDIH. This causes a number ofSTART_FRAGREQsignals to be sent fromDBDIHtoDBLQH. This also starts the restoration of the fragments, which are restored one by one and one record at a time in the course of reading the restore data from disk and applying in parallel the restore data read from disk into main memory. This restores only the main memory parts of the tables.Once all fragments have been restored, a
START_RECREQmessage is sent to all nodes in the starting cluster, and then all undo logs for any Disk Data parts of the tables are applied.After applying the undo logs in
LGMAN, it is necessary to perform some restore work inTSMANthat requires scanning the extent headers of the tablespaces.Next, it is necessary to prepare for execution of the redo log, which log can be performed in up to four phases. For each fragment, execution of redo logs from several different nodes may be required. This is handled by executing the redo logs in different phases for a specific fragment, as decided in
DBDIHwhen sending theSTART_FRAGREQsignal. AnEXEC_FRAGREQsignal is sent for each phase and fragment that requires execution in this phase. After these signals are sent, anEXEC_SRREQsignal is sent to all nodes to tell them that they can start executing the redo log.NoteBefore starting execution of the first redo log, it is necessary to make sure that the setup which was started earlier (in Phase 4) by
DBLQHhas finished, or to wait until it does before continuing.Prior to executing the redo log, it is necessary to calculate where to start reading and where the end of the REDO log should have been reached. The end of the REDO log should be found when the last GCI to restore has been reached.
After completing the execution of the redo logs, all redo log pages that have been written beyond the last GCI to be restore are invalidated. Given the cyclic nature of the redo logs, this could carry the invalidation into new redo log files past the last one executed.
After the completion of the previous step,
DBLQHreport this back toDBDIHusing aSTART_RECCONFmessage.When the master has received this message back from all starting nodes, it sends a
NDB_STARTCONFsignal back toNDBCNTR.The
NDB_STARTCONFmessage signals the end ofSTTORphase 4 toNDBCNTR, which is the only block involved to any significant degree in this phase.
The first step in handling START_MEREQ is to
ensure that no local checkpoint is currently taking place;
otherwise, it is necessary to wait until it is completed. The
next step is to copy all distribution information from the
master DBDIH to the starting
DBDIH. After this, all metadata is
synchronized in DBDICT (see
Section 6.5.21, “System Restart Handling in Phase 4”).
After blocking local checkpoints, and then synchronizing distribution information and metadata information, global checkpoints are blocked.
The next step is to integrate the starting node in the global checkpoint protocol, local checkpoint protocol, and all other distributed protocols. As part of this the node status is also updated.
After completing this step the global checkpoint protocol is
permitted to start again, the START_MECONF
signal is sent to indicate to the starting node that the next
phase may proceed.
This section contains terms and abbreviations that are found in or
useful to understanding the NDB source code.
ACC. ACCelerator or ACCess manager. Handles hash indexes of primary keys, providing fast access to records. See Section 6.4.3, “The
DBACCBlock”.API node. In
NDBterms, this is any application that accesses cluster data using theNDBAPI, including mysqld when functioning as an API node. (MySQL servers acting in this capacity are also referred to as “SQL nodes”). Often abbreviated to “API”.CMVMI. Stands for Cluster Manager Virtual Machine Interface. An
NDBkernel handling nonsignal requests to the operating system, as well as configuration management, interaction with the cluster management server, and interaction between various kernel blocks and theNDBvirtual machine. See Section 6.4.2, “TheCMVMIBlock”, for more information.CNTR. Stands for restart CoordiNaToR. See Section 6.4.12, “The
NDBCNTRBlock”, for more information.DBTC. The transaction coordinator (also sometimes written simply as TC). See Section 6.4.7, “The
DBTCBlock”, for more information.DICT. The
NDBdata DICTionary kernel block. Also DBDICT. See Section 6.4.4, “TheDBDICTBlock”.DIH. DIstribution Handler. An
NDBkernel block. See Section 6.4.5, “TheDBDIHBlock”.LGMAN. The Log Group MANager
NDBkernel block, used for MySQL Cluster Disk Data tables. See Section 6.4.11, “TheLGMANBlock”.LQH. Local Query Handler.
NDBkernel block, discussed in Section 6.4.6, “DBLQHBlock”.MGM. ManaGeMent node (or management server). Implemented as the ndb_mgmd server daemon. Responsible for passing cluster configuration information to data nodes and performing functions such as starting and stopping nodes. Accessed by the user by means of the cluster management client (ndb_mgm). A discussion of management nodes can be found in ndb_mgmd.
QMGR. The cluster management block in the
NDBkernel. It responsibilities include monitoring heartbeats from data and API nodes. See Section 6.4.15, “TheQMGRBlock”, for more information.RBR. Row-Based Replication. MySQL Cluster Replication is row-based replication. See MySQL Cluster Replication.
STTOR. STart Or Restart
SUMA. The cluster SUbscription MAnager. See Section 6.4.17, “The
SUMABlock”.TC
TC. Transaction Coordinator. See Section 6.4.7, “The
DBTCBlock”.TRIX. Stands for TRansactions and IndeXes, which are managed by the
NDBkernel block having this name. See Section 6.4.19, “TheTRIXBlock”.TSMAN. Table space manager. Handles tablespaces for MySQL Cluster Disk Data. See Section 6.4.18, “The
TSMANBlock”, for more information.TUP. TUPle. Unit of data storage. Also used (along with DBTUP) to refer to the
NDBkernel's tuple management block, which is discussed in Section 6.4.8, “TheDBTUPBlock”.