|
| |
| Sun Java System Application Server Enterprise Edition 8.1 2005Q1 High Availability Administration Guide | |
Chapter 2
Installing and Setting Up High Availability DatabaseThis chapter covers the following topics:
Overview of High-Availability DatabaseThis section introduces the high-availability database (HADB) used to store HTTP and stateful session bean (SFSB) session information. Without a session persistence mechanism, the HTTP or SFSB session state, including the passivated session state, is lost when a web or EJB container fails over to another. Use of the HADB for session persistence overcomes this situation.
This section contains procedures for setting up and configuring the HADB database for use by the Application Server.
About Highly Available Clusters
A highly available cluster in the Sun Java System Application Server Enterprise Edition integrates a state replication service with the clusters and load balancer.
HADB is a high availability database for storing session state. HttpSession objects and Stateful Session Bean state is stored in the HADB. This horizontally scalable state management service can be managed independently of the application server tier. It is designed to support up to 99.999% service and data availability with load balancing, failover and state recovery capabilities.
Keeping state management responsibilities separated from Application Server has significant benefits. Application Server instances spend their cycles performing as a scalable and high performance Java™ 2 Platform, Enterprise Edition (J2EE™ platform) containers delegating state replication to an external high availability state service. Due to this loosely coupled architecture, application server instances can be very easily added to or deleted from a cluster. The HADB state replication service can be independently scaled for optimum availability and performance. When an application server instance also performs replication, the performance of J2EE applications can suffer and can be subject to longer garbage collection pauses.
HADB Server Architecture
High availability means availability despite planned outages for upgrades or unplanned outages caused by hardware or software failures. The HADB is based on a simple data model and the Always-On technology. The HADB offers an ideal platform for delivering all types of session state persistence within a high performance enterprise application server environment.
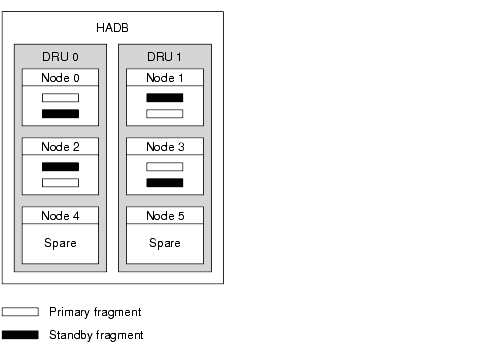
The following figure shows the architecture of a database with four active nodes and two spare nodes. Nodes 0 and 1 are a mirror node pair, as are nodes 2 and 3.
Figure 2-1 HADB Architecture
The HADB achieves high data availability through fragmentation and replication of data. All tables in the database are partitioned to create subsets of approximately the same size called fragments. This process of fragmentation is based on a hash function. This hash function fragments and evenly distributes the data among the nodes of the database. Each fragment is stored twice in the database, in mirror nodes. This ensures fault tolerance and fast recovery of data. In addition, if a node fails, or is shut down, a spare node can take over until the node is active again.
HADB nodes are organized into two Data Redundancy Units (DRUs), which mirror each other. Each DRU consists of half of the active and spare nodes, and contains one complete copy of the data. To ensure fault tolerance, the computers that support one DRU must be completely self-supported with respect to power (use of uninterruptible power supplies is recommended), processing units, and storage. If a power failure occurs in one DRU, the nodes in the other DRU can continue servicing requests until the power returns.
Without a session persistence mechanism, the HTTP or SFSB session state, including the passivated session state, is lost when one web or EJB container fails over to another. Use of the HADB for session persistence overcomes this situation. The HADB stores and retrieves state information in a separate but well-integrated persistent storage tier.
The HADB reclaims space when session data is deleted. The HADB places session data records in fixed size blocks. When all records of a block are deleted, the block is freed. Records of a block can be deleted randomly, creating holes in the block. When a new record is inserted into a block and contiguous space is needed, the holes are removed and thus the block is compacted.
This is a brief summary of the architecture. For details, see the Sun Java System Application Server Enterprise Edition Deployment Planning Guide.
HADB Nodes
A database node consists of a set of processes, a dedicated area of shared memory, and one or more secondary storage devices. It is used for storing and updating session data. Each node must have a mirror node, therefore nodes occur in pairs. In addition, to maximize availability, include two or more spare nodes, one in each DRU, so if a node fails a spare can take over while the node is repaired.
For an explanation of node topology alternatives, see the Sun Java System Application Server System Deployment Guide.
New Features and Improvements
The version of HADB provided with Sun Java System Application Server Enterprise Edition 8.1 has many new features and improvements.
HADB management is improved by changing the underlying components of the management system. The old hadbm interface functions are maintained with minor modifications. These changes also remove the dependency on SSH/RSH.
The management agent server process (ma) constitutes a domain and keeps the database configuration in a repository. The repository information is distributed among all agents.
The following topics provide more details:
General Improvements
This version of HADB has the following general improvements:
- HADB no longer requires SSH/RSH.
- Administrator password for HADB management enhances security.
- Automatic online upgrade to future versions.
- Dependency on a single host is removed.
- Heterogeneous configurations of the database is supported. The device paths and history paths can be set individually.
- Ability to manage multi-platforms uniformly.
Specific Changes
This version of HADB includes the following changes from the previous version.
- UDP multicast is now required for network configuration.
- The management agent, ma, is now required to be running on all HADB hosts.
- New hadbm commands for domain management:
- All hadbm commands have the following new options:
- Changes made to hadbm create:
- Changes made to hadbm startnode and hadbm restartnode.
- Changes made to hadbm addnodes.
- Changes made to hadbm get and hadbm set.
Using Customer Support for HADB
Before calling customer support about HADB issues, gather as much of the following information as possible:
Preparing for HADB SetupThis section discusses the following topics:
After performing these tasks, see Chapter 3, "Administering High Availability Database," for information on configuring and managing HADB.
For the latest information on HADB, see the Sun Java System Application System Enterprise Edition Release Notes.
Prerequisites
Before setting up and configuring HADB, make sure your environment meets the following requirements:
- HADB supports IPv4 only. Disable IPv6 on the interfaces being used for HADB.
- The network (routers, switches, and network interfaces on the hosts) must be configured for User Datagram Protocol (UDP) multicast. If HADB hosts span multiple subnets, configure routers between the subnets to forward UDP multicast messages between the subnets.
- Configure any firewalls located between HADB hosts, or between HADB and Application Server hosts to allow all UDP traffic, both ordinary and multicast.
- Do not use dynamic IP addresses (assigned by Dynamic Host Configuration Protocol, or DHCP) for hosts that are part of hadbm createdomain, hadbm extenddomain, hadbm create, or hadbm addnodes commands.
Configuring Network Redundancy
Configuring a redundant network will enable HADB to remain available, even if there is a single network failure. You can configure a redundant network in two ways:
Setting Up Network Multipathing
Before setting up network multipathing, refer to the Administering Network Multipathing section of the IP Network Multipathing Administration Guide at http://docs.sun.com/doc/816-5249.
If the HADB host machines already use IP multipathing, configure them as follows:
For HADB to properly support multipathing failover, the network interface failure detection time must not exceed one second (1000 milliseconds), as specified by the FAILURE_DETECTION_TIME parameter in /etc/default/mpathd. Edit the file and change the value of this parameter to 1000 if the original value is higher:
FAILURE_DETECTION_TIME=1000
To put the change into effect, use this command:
pkill -HUP in.mpathd
As described in the IP Network Multipathing Administration Guide, multipathing involves grouping physical network interfaces into multipath interface groups. Each physical interface in such a group has two IP addresses associated with it:
Specify only one physical interface address from the multipath group when you use hadbm create --hosts.
For example, if Host 1 and Host 2 have two physical network interfaces each, then on each host, these two interfaces are set up as a multipath group. Running ifconfig -a yields the following:
Host 1:
bge0: flags=1000843<UP,BROADCAST,RUNNING,MULTICAST,IPv4> mtu 1500 index 5 inet 129.159.115.10 netmask ffffff00 broadcast 129.159.115.255 groupname mp0
bge0:1: flags=9040843<UP,BROADCAST,RUNNING,MULTICAST,DEPRECATED,IPv4,NOFAILOVER > mtu 1500 index 5 inet 129.159.115.11 netmask ffffff00 broadcast 129.159.115.255
bge1: flags=1000843<UP,BROADCAST,RUNNING,MULTICAST,IPv4> mtu 1500 index 6 inet 129.159.115.12 netmask ffffff00 broadcast 129.159.115.255 groupname mp0
bge1:1: flags=9040843<UP,BROADCAST,RUNNING,MULTICAST,DEPRECATED,IPv4,NOFAILOVER > mtu 1500 index 6 inet 129.159.115.13 netmask ff000000 broadcast 129.159.115.255
Host 2:
bge0: flags=1000843<UP,BROADCAST,RUNNING,MULTICAST,IPv4> mtu 1500 index 3 inet 129.159.115.20 netmask ffffff00 broadcast 129.159.115.255 groupname mp0
bge0:1: flags=9040843<UP,BROADCAST,RUNNING,MULTICAST,DEPRECATED,IPv4,NOFAILOVER > mtu 1500 index 3 inet 129.159.115.21 netmask ff000000 broadcast 129.159.115.255
bge1: flags=1000843<UP,BROADCAST,RUNNING,MULTICAST,IPv4> mtu 1500 index 4 inet 129.159.115.22 netmask ffffff00 broadcast 129.159.115.255 groupname mp0
bge1:1: flags=9040843<UP,BROADCAST,RUNNING,MULTICAST,DEPRECATED,IPv4,NOFAILOVER > mtu 1500 index 4 inet 129.159.115.23 netmask ff000000 broadcast 129.159.115.255
In this example, the physical network interfaces on both hosts are the ones listed as bge0 and bge1. The ones listed as bge0:1 and bge1:1 are multipath test interfaces (marked DEPRECATED in the ifconfig output), as described in the IP Network Multipathing Administration Guide.
To set up HADB in this environment, select one physical interface address from each host. In this example, the IP address 129.159.115.10 from host 1 and 129.159.115.20 from host 2 are selected for the use of HADB. To create a database with one database node per host, use the --host argument to hadbm create. For example
hadbm create --host 129.159.115.10,129.159.115.20
To create a database with two database nodes on each host, use the following argument:
hadbm create --host 129.159.115.10,129.159.115.20,
129.159.115.10,129.159.115.20In both cases, you must configure the agents on Host 1 and Host 2 with separate parameters to specify which interface on the machines the agents should use:
Host 1: ma.server.mainternal.interfaces=129.159.115.10
Host 2: ma.server.mainternal.interfaces=129.159.115.20For information on the ma.server.mainternal.interfaces variable, see Table 3-2.
Configuring Double Networks
To allow HADB to tolerate single network failures, use IP multipathing if the operating system (for example, Solaris) supports it.
If your operating system is not configured for IP multipathing, and the HADB hosts are equipped with two NICs, you can configure HADB to use double networks. For every host, the IP addresses of each of the network interface card (NIC) must be on separate IP subnets.
Note
Routers between the subnets must be configured to forward UDP multicast messages between subnets.
When creating an HADB database, specify two IP addresses or host names for each node: one for each NIC IP address, using the --hosts option. For each node, the first IP address is on net-0 and the second on net-1. The syntax is as follows, with host names for the same node separated by a plus sign (+):
--hosts=node0net0name+node0net1name,node1net0name+node1net1name,node2net0name+node2net1name, ...
For example, the following argument creates two nodes, each with two network interfaces. The network addresses for node 0 are 10.10.116.61 and 10.10.124.61, and the network addresses for node 1 are 10.10.116.62 and 10.10.124.62. The addresses 10.10.116.61 and 10.10.116.62 are on the same subnet, and the addresses 10.10.124.61 and 10.10.124.62 are on the same subnet. The following host option is used to create these nodes:
--hosts 10.10.116.61+10.10.124.61,10.10.116.62+10.10.124.62
Within a database, all nodes must be connected to a single network, or all nodes must be connected to two networks.
For the example above, the management agents must use the same subnet. Thus, the configuration variable ma.server.mainternal.interfaces must be set to, for example, 10.10.116.0/24. This setting can be used on both agents in this example.
Configuring Shared Memory and Semaphores
You must configure shared memory and semaphores before installing HADB. The procedure depends on your operating system.
Procedure for Solaris
Follow this procedure to configure shared memory and semaphores:
- Log in as root.
- Set the shmmax value to the size of the physical memory on the HADB host machine. The maximum shared memory segment size must be larger than the size of the HADB database buffer pool. For a machine with a 2 GByte (0x8000000 hexadecimal) main memory, add the following to the /etc/system file:
set shmsys:shminfo_shmmax=0x80000000
set shmsys:shminfo_shmseg=20
- Check the /etc/system file for semaphore configuration entries. This file might already contain semmni, semmns, and semmnu entries. For example:
set semsys:seminfo_semmni=10
set semsys:seminfo_semmns=60
set semsys:seminfo_semmnu=30If the entries are present, increment the values by adding 16, 128, and 1000 respectively. The entries in the example above would change to:
set semsys:seminfo_semmni=26
set semsys:seminfo_semmns=188
set semsys:seminfo_semmnu=1030If the /etc/system file does not contain the above mentioned entries, add these entries at the end of the file:
set semsys:seminfo_semmni=16
set semsys:seminfo_semmns=128
set semsys:seminfo_semmnu=1000This is sufficient to run up to 16 HADB nodes on the computer. For information on setup for more than 16 nodes, see the HADB chapter in the Sun Java System Application Server Enterprise Edition 8.1 2005Q1 Performance Tuning Guide.
- Reboot the machine.
Procedure for Linux
Follow this procedure to configure shared memory and semaphores:
- Log in as root.
- Edit the file /etc/sysctl.conf
- The kernel.shmax parameter defines the maximum size in bytes for a shared memory segment. The kernel.shmall parameter sets the total amount of shared memory in pages that can be used at one time on the system. Set the value of both of these parameters to the amount physical memory on the machine. Specify the value as a decimal number of bytes. For example, for a machine having 512 Mbytes of physical memory:
kernel.shmmax=536870912
kernel.shmall=536870912- Reboot the machine. using this command:
sync; sync; reboot
Synchronizing System Clocks
You must synchronize clocks on HADB hosts, because HADB uses time stamps based on the system clock. HADB uses the system clock to manage timeouts. Also, HADB includes time stamps in events it logs to history files. For troubleshooting, you must analyze all the history files together, since HADB is a distributed system. So, it is important that all the hosts' clocks be synchronized
Do not adjust system clocks on a running HADB system. Doing so can cause problems in the operating system or other software components that can in turn cause problems such as hangs or restarts of HADB nodes. Adjusting the clock backward can cause some HADB server processes to hang as the clock is adjusted.
To synchronize clocks, use:
If HADB detects a clock adjustment of more than one second, it logs it to the node history file, for example:
NSUP INF 2003-08-26 17:46:47.975 Clock adjusted.
Leap is +195.075046 seconds.File System Support
HADB has some restrictions with certain file systems.
Red Hat Enterprise Linux
HADB supports the ext2 and ext3 file systems on Red Hat Enterprise Linux 3.0. For Red Hat Enterprise Linux 2.1, HADB supports the ext2 file system.
Veritas File System
When using the Veritas File System on Solaris, HADB writes the message WRN: Direct disk I/O mapping failed to the history files. This message indicates that HADB cannot turn on direct input/output (I/O) for the data and log devices. Direct I/O reduces the CPU cost of writing disk pages. It also reduces overhead of administering "dirty" data pages in the operating system.
To use direct I/O with Veritas File System, do one of the following:
- Create the data and log devices on a file system that is mounted with the option mincache=direct. This option applies to all files created on the file system. Check the mount_vxfs(1M) command for details.
- Use the Veritas Quick I/O facility to perform raw I/O to file system files. For details, see the VERITAS File System 4.0 Administrator's Guide for Solaris.
InstallationIn general, you can install HADB on the same system as Application Server (co-located topology) or on separate hosts (separate tier topology). For more information on these two options, see the Sun Java System Application Server Performance Tuning Guide. However, you must install the HADB management client to be able to set up high availability with the asadmin ha-config-cluster command. When using the Java Enterprise System installer, you must install an entire HADB instance to install the management client, even if the nodes are to be installed on a separate tier.
HADB Installation
On a single or dual CPU system, you can install both HADB and Application Server if the system has at least two Gbytes of memory. If not, install HADB on a separate system or use additional hardware. To use the asadmin ha-configure-cluster command, you must install both HADB and Application Server.
Each HADB node requires 512 Mbytes of memory, so a machine needs one Gbyte of memory to run two HADB nodes. If the machine has less memory, set up each node on a different machine. For example, you can install two nodes on:
You can install HADB with either the Java Enterprise System installer or the Application Server standalone installer. In either installer, choose the option to install HADB (called High Availability Session Store in Java ES) in the Component Selection page. Complete the installation on your hosts. If you are using the Application Server standalone installer, and choose two separate machines to run HADB, you must choose an identical installation directory on both machines.
Default Installation Directories
Throughout this manual, HADB_install_dir represents the directory in which HADB is installed. The default installation directory depends on whether you install HADB as part of the Java Enterprise System. For Java Enterprise System, the default installation directory is /opt/SUNWhadb/4. For the standalone Application Server installer, it is /opt/SUNWappserver/hadb/4.
Setting Root Privileges for Node Supervisor Processes
The node supervisor processes (NSUP) ensure the availability of the HADB by exchanging "I'm alive" messages with each other. The NSUP executable files must have root privileges so that they can respond with real-time priority, as quickly as possible.
Symptoms
If NSUP executables do not have the proper privilege, you might notice symptoms of resource starvation such as:
Procedure
To avoid resource starvation, follow this procedure:
This starts the clu_nsup_srv process as the user root, and enables the process to give itself realtime priority. The clu_nsup_srv process does not consume significant CPU resources, has a small footprint, and running it with real-time priority does not affect performance.
To avoid any security impact, the real-time priority is set immediately after the process is started and the process falls back to the effective UID once the priority has been changed. Other HADB processes run with normal priority.
Restrictions
If NSUP cannot set the real-time priority errno is set to EPERM on Solaris and Linux. The error is written to the ma.log file, and the process continues without real-time priority.
Setting real-time priorities is not possible when:
- HADB is installed in Solaris 10 non-global zones
- PRIV_PROC_LOCK_MEMORY (allow a process to lock pages in physical memory) and/or PRIV_PROC_PRIOCNTL privileges are revoked in Solaris 10
- Users turn off setuid permission
- Users install the software as tar files (the non-root installation option for the Application Server)
Setting up High AvailabilityThis section provides the steps for creating a highly available cluster, and testing HTTP session persistence.
This section discusses the following topics:
Prerequisites
Before configuring HADB, do the following:
- Install Application Server instances and the Load Balancer Plug-in.
For more information, see the Java Enterprise System Installation Guide (if you are using Java ES) or the Application Server Installation Guide (if you are using the standalone Application Server installer).
- Create Application Server domains and clusters.
For more information, see the Sun Java System Application Server Administration Guide.
- Install and configure your web server software.
For more information, see "Configuring Web Servers for HTTP Load Balancing" on page 24.
- Setup and configure load balancing.
For more information, see "Configuring the Load Balancer" on page 32.
Starting the HADB Management Agent
The management agent, ma, executes management commands on HADB hosts and ensures availability of the HADB node supervisor processes by restarting them if they fail.
For a production deployment, start the management agent as a service to ensure its availability. This section provides abbreviated instructions for starting the management agent as a service with its default configuration.
For more details, including instructions on starting the management agent in console mode for testing or evaluation and information on customizing its configuration, see Using the HADB Management Agent.
Procedure for Java Enterprise System
This section describes how to start the management agent as a service with default configuration when using Java Enterprise System.
To deactivate automatic start and stop of the agent, remove the links or change the letters K and S in the link names to lowercase.
Procedure for Standalone Application Server
This section describes how to start the management agent as a service when using the standalone Application Server.
To start the management agent as a service:
- In a shell, change your current directory to HADB_install_dir/lib.
- Edit the shell script ma-initd and replace the default values of HADB_ROOT and HADB_MA_CFG in the script to reflect your installation:
- HADB_ROOT is the HADB installation directory, HADB_install_dir.
- HADB_MA_CFG is the location of the management agent configuration file. For more information, see Customizing Management Agent Configuration.
- Copy ma-initd to the directory /etc/init.d
- Create the following soft links to the file /etc/init.d/ma-initd:
/etc/rc0.d/K20ma-initd
/etc/rc1.d/K20ma-initd
/etc/rc2.d/K20ma-initd
/etc/rc3.d/S99ma-initd
/etc/rc5.d/S99ma-initd
/etc/rcS.d/K20ma-initdConfiguring a Cluster for High Availability
Before starting this section, you must have created one or more Application Server clusters. For information on how to create a cluster, see Sun Java System Application Server Administration Guide.
From the machine on which the Domain Administration Server is running, configure the cluster to use HADB using this command:
asadmin configure-ha-cluster --user admin --hosts hadb_hostname,hadb_hostname --devicesize 256 clusterName
Replace hadb_hostname with the host name of the machine where HADB is running, and clusterName with the name of the cluster. If you are using just one machine, you must provide the host name twice.
This simplified example runs two nodes of HADB on the same machine. In production settings, using more than one machine is recommended.
Configuring an Application for High Availability
In Admin Console, select the application under Applications > Enterprise Applications. Set Availability Enabled and then click Save.
Restarting the Cluster
To restart a cluster in Admin Console, choose Clusters > cluster-name. Click Stop Instances. Once the instances have stopped, click "Start Instances."
Alternatively, use these asadmin commands:
asadmin stop-cluster --user admin cluster-name
asadmin start-cluster --user admin cluster-name
For more information on these commands, see the Sun Java System Application Server System Reference Manual.
Upgrading HADBHADB is designed to provide "always on" service that is uninterrupted by upgrading the software. This section describes how to upgrade to a new version of HADB without taking the database offline or incurring any loss of avaiability.
The following sections describe how to upgrade your HADB installation:
Procedure
To upgrade your HADB Installation to a newer version, follow these steps:
- Install new version of HADB.
- Unregister your existing HADB installationas described in Unregistering HADB Packages.
- Register the new HADB version, as described in Registering HADB Packages.
Registering the HADB package in the HADB management domain makes it easy to upgrade or change HADB packages. The management agent keeps track of where the software packages are located, as well as the version information for the hosts in the domain. The default package name is a string starting with V and containing the version number of the hadbm program.
- If neccessary, replace the management agent startup script. For more information, see Replacing the Management Agent Startup Script.
Registering HADB Packages
Use the hadbm registerpackage command to register the HADB packages that are installed on the hosts in the management domain. HADB packages can also be registered when creating a database with hadbm create.
Before using the hadm registerpackage command, ensure that all management agents are configured and running on all the hosts in the hostlist, the management agent's repository is available for updates, and no software package is already registered with the same package name.
The command syntax is:
hadbm registerpackage
--packagepath=path
[--hosts=hostlist]
[--adminpassword=password | --adminpasswordfile=file]
[--agent=maurl]
[package-name]The package-name operand is the name of the package.
The following table describes the special hadbm registerpackage command option. See Table 3-3 and Table 3-4 for a description of other command options.
For example, the following command registers software package v4 on hosts host1, host2, and host3:
hadbm registerpackage --packagepath=hadb_install_dir/SUNWHadb/4.4 --hosts=host1,host2,host3 v4
The response is:
Package successfully registered.
If you omit the --hosts option, the command registers the package on all enabled hosts in the domain.
Unregistering HADB Packages
Use the hadbm unregisterpackage command to remove HADB packages that are registered with the management domain.
Before using the hadbm unregisterpackage command, ensure that all management agents are configured and running on all the hosts in the hostlist, the management agent's repository is available for updates, the package is registered in the management domain, and no existing databases are configured to run on the package about to be unregistered.
The command syntax is:
hadbm unregisterpackage
--hosts=hostlist
[--adminpassword=password | --adminpasswordfile=file]
[--agent=maurl]
[package-name]The package-name operand is the name of the package.
See Table 2-1 above for a description of the --hosts option. If you omit the --hosts option, the hostlist defaults to the enabled hosts where the package is registered. See Table 3-3 and Table 3-4 for a description of other command options.
For example:
Unregistering a software package, v4, from specific hosts in the domain:
hadbm unregisterpackage --hosts=host1,host2,host3 v4
The response is:
Package successfully unregistered.
Replacing the Management Agent Startup Script
When you install a new version of HADB, you may need to replace the management agent startup script in /etc/init.d/ma-initd. Check the contents of the file, HADB_install_dir/lib/ma-initd. If it is different from the old ma-initd file, replace the old file with the new file.