|
|
| iPlanet Directory Server 5.1 導入ガイド |
第 4 章 ディレクトリツリーの設計
ディレクトリツリー (directory tree) は、ディレクトリに格納されているデータを参照できるようにします。ディレクトリに格納した情報のタイプ、企業の地理的な特性、ディレクトリで使用するアプリケーション、および使用する複製のタイプによって、ディレクトリツリーの設計方法が決まります。
この章では、ディレクトリツリーを設計する手順の概要について説明します。この章は、次の節で構成されています。
ディレクトリツリーの概要
ディレクトリツリーの概要
ディレクトリツリーを使用すると、クライアントアプリケーションからディレクトリデータに名前を付けたり、参照したりできるようになります。ディレクトリツリーの設計は、ディレクトリデータの分散方法、レプリケート方法、あるいはアクセス制御方法など、ディレクトリの設計段階におけるさまざまな決定事項と密接に関係しています。導入前にディレクトリツリーの設計に多くの時間を割けば、ディレクトリを使い始めてからディレクトリツリーに不十分な点を見つけても、頭痛の種を減らすことができます。
適切に設計されたディレクトリツリーでは、次のことが可能になります。
ディレクトリデータの管理を簡単にする ディレクトリツリーの構造は、階層型の LDAP モデルに従います。ディレクトリツリーでは、たとえば、グループ、ユーザ、あるいは場所ごとにデータを編成できます。また、ディレクトリツリーによって複数のサーバ間でどのようにデータを分散して配置するかが決まります。たとえば、各データベースでは、接尾辞レベルでデータを分割する必要があります。適切なディレクトリツリー構造がなければ、複数のサーバ間で希望どおりにデータを分散することができない場合があります。
また、使用するディレクトリツリー構造のタイプによって複製が制約を受けます。複製が機能するように、慎重にデータの分割を定義する必要があります。ディレクトリツリーの一部分だけを複製する場合は、設計段階からそのことを考慮に入れておく必要があります。また、分岐点でアクセス制御を使用したいのであれば、そのこともディレクトリツリーの設計段階で考慮しておきます。
ディレクトリツリーの設計
この節では、ディレクトリツリーの設計段階で決定する事柄について説明します。ディレクトリツリーの設計段階は、次の手順に分けられます。
次に、ディレクトリツリーの設計段階について詳しく説明します。
接尾辞の選択
接尾辞 (suffix) は、ツリーのルートにあるエントリの名前です。接尾辞の下にディレクトリデータが格納されます。ディレクトリには複数の接尾辞を持たせることができます。一般的なルートポイントを持たない情報のディレクトリツリーが複数ある場合、複数の接尾辞を使用することもできます。
デフォルトでは、iPlanet Directory Server を標準的な構成で導入すると、データの格納用に 1 つの接尾辞が、構成情報やディレクトリのスキーマなど、ディレクトリの内部処理に必要なデータ用に複数の接尾辞が使用されます。標準のディレクトリの接尾辞については、『iPlanet Directory Server 管理者ガイド』を参照してください。
接尾辞の命名規則
ディレクトリ内のすべてのエントリは、ルート接尾辞 (root suffix) である共通のベースエントリの下に格納する必要があります。ディレクトリのルート接尾辞に名前を付けるときは、次のことを考慮してください。
1 つの企業環境では、企業の DNS 名またはインターネットドメイン名に合わせてディレクトリの接尾辞を選択します。たとえば、企業が siroe.com というドメイン名を所有している場合は、次のようなディレクトリ接尾辞を使用します。
dc (domainComponent) 属性は、ドメイン名をコンポーネントに分割して接尾辞を表します。
通常、ルート接尾辞の名前を付けるときには、任意の属性を使用できます。ただし、ホスティングサービス事業者環境では、ルート接尾辞に使用する属性は次のものに限定することをお勧めします。
c (countryName)
ISO の定義に準拠した、国名を表す 2 桁のコードを含めます。
l (localityName)
エントリが存在する、あるいはエントリに関連付けられた国や都市などの地域を示します。
st
エントリがある州または県を示します。
o (organizationName)
エントリが属する組織の名前を示します。
これらの属性が接尾辞に含まれていると、顧客のアプリケーションとの相互運用性が高まります。たとえば、ホスティングサービス事業者がこれらの属性を使用して、クライアントの Company22 に、次のようなルート接尾辞を作成する場合を考えてみます。
o=Company222,st=Washington,c=US
組織名のあとに国名コードを使用する指定方法は、X.500 の接尾辞の命名規則に従っています。
複数の接尾辞の命名
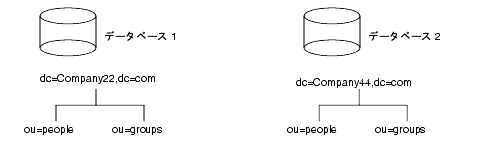
ディレクトリで使用する各接尾辞が、それぞれ固有のディレクトリツリーを示します。ディレクトリに複数のツリーを含めるには、いくつかの方法があります。1 つ目の方法は、複数のディレクトリツリーを作成し、各ディレクトリツリーを Directory Server によって提供される別々のデータベースに格納する方法です。たとえば、次のように Company22 と Company44 用に別々の接尾辞を作成し、それぞれを異なるデータベースに格納できます。
データベースは、資源の制限に応じて 1 つのサーバまたは複数のサーバに格納できます。
ディレクトリツリー構造の作成
ツリーの構造をフラットなものにするか階層型にするかを決定する必要があります。一般には、ディレクトリツリーはできるだけフラットにします。ただし、あとで複数のデータベース間にデータを分散したり、レプリケーションできるようにしたり、アクセス制御を設定したりする場合は、ある程度階層化することも必要です。
「ディレクトリの分岐点の作成」
ディレクトリの分岐点の作成
階層を設計するときは問題の生じる名前の変更を避けるようにします。ネームスペースがフラットなほど、名前を変更する確率は低くなります。名前を変更する確率は、名前が変更される可能性があるコンポーネントが、ネームスペース内に多く含まれているほど高くなります。ディレクトリツリーの階層が深いほどネームスペース内のコンポーネントは多くなり、名前を変更する確率が高くなります。
次に、ディレクトリツリーの階層を設計するときのガイドラインを示します。
企業組織内でもっとも大きい部門区分のみを表すようにツリーを分岐させる
このような分岐点は、部門 (企業情報サービス、カスタマサポート、販売サービス、専門サービスなど) だけを表します。ディレクトリツリーを分岐させる部門は、安定したものにします。組織変更が頻繁に行われる場合は、この種の分岐は使用しないようにします。
分岐点には組織の実際の名前ではなく、機能を表す名前または一般的な名前を使用する
組織名は変更されることが考えられます。会社が部門の名前を変更するたびにディレクトリツリーを変更する必要に迫られるのでは困ります。代わりに、組織の機能を表す一般的な名前を使用します (たとえば、「Widget 研究開発」ではなく「エンジニアリング」を使用する)。
似たような機能を持つ組織が複数ある場合は、部門の構成に基づいて分岐点を作成するのではなく、その機能を表す分岐点を 1 つ作成する
たとえば、特定の製品ラインを担当する複数のマーケティング部門がある場合でも、1 つのマーケティング サブツリーのみを作成し、すべてのマーケティングエントリをそのツリーに所属させます。
次に、会社とホスト環境に固有のガイドラインを示します。
企業環境での分岐点の作成
変更される可能性の低い情報に基づいてディレクトリ構造を決定すれば、名前の変更を避けられます。たとえば、組織ではなくツリー内のオブジェクトのタイプに基づいて構造を定義します。次に、ツリー構造の定義に使用するオブジェクトの例を示します。
これらのオブジェクトを使用して構成されたディレクトリツリーは、次のようになります。
ホスト環境での分岐点の作成
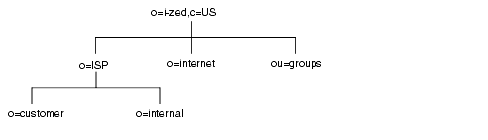
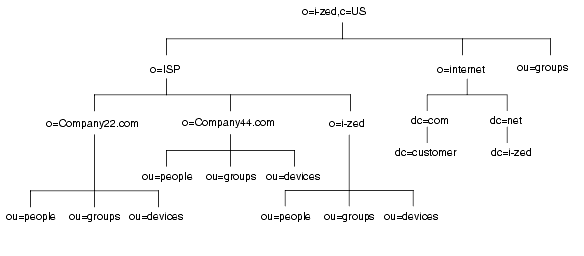
ホスト環境では、organization(o) オブジェクトクラスの 2 つのエントリと organizationalUnit(ou) オブジェクトクラスの 1 つのエントリをルート接尾辞の下に含むツリーを作成します。たとえば、ISP の I-Zed 社では次のようにディレクトリを分岐させます。
分岐点の特定
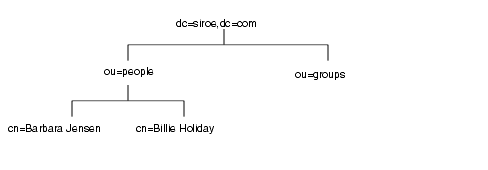
ディレクトリツリーをどのように分岐させるかを決めるには、その分岐点を特定するために使用する属性を決定することが必要になります。DN は、属性とデータのペアで構成される一意の文字列です。たとえば、siroe.com 社の社員 Barbara Jensen 用のエントリの DN は次のようになります。
cn=Barbara Jensen,ou=people,dc=siroe,dc=com
各属性とデータのペアは、ディレクトリツリーの分岐点を表します。たとえば、siroe.com 社という企業のディレクトリツリーは次のようになります。
インターネットのホストである I-Zed 社のディレクトリツリーは、次のようになります。
ルート接尾辞のエントリ o=i-zed,c=US の下で、ツリーは 3 つに分岐しています。ISP の分岐には、顧客データと I-Zed の内部情報が含まれています。internet の分岐は、ドメインのツリーです。groups の分岐には、管理グループに関する情報が含まれています。
分岐点の属性を選択するときは、次のような事柄を検討する必要があります。
一貫性のあるものにする
ディレクトリツリー全体で識別名 (distinguished name) (DN) の形式が統一されていないと、いくつかの LDAP クライアント (LDAP client) アプリケーションが混乱する可能性があります。つまり、ディレクトリツリーのある部分で l が o の下位にある場合、ディレクトリのほかの部分でも l が o の下位にあることを確認してください。
よく使用されている従来型の属性だけを使用する (表 4-1 を参照)
従来からある属性を使用すると、サードパーティの LDAP クライアントアプリケーションとの互換性が保たれる可能性が高くなります。また、従来からある属性は、デフォルトのディレクトリスキーマで認識可能なので、分岐 DN のエントリを作成しやすくなります。
組織名。通常、この属性は、企業の部門、教育機関での学部 (人文学部、理学部など)、子会社、企業内の主要部門など、大きな部門を表すために使用する。また、「接尾辞の命名規則」で説明したように、ドメイン名を表す場合もこの属性を使用する必要がある
組織の構成単位。通常この属性は、組織よりも小さな組織内の部門を表すために使用する。組織単位は、一般にすぐ上の組織に属する
「接尾辞の命名規則」で説明されているドメインのコンポーネント
レプリケーションに関する検討事項
ディレクトリツリーの設計時に、レプリケーションするエントリを検討します。エントリセットをレプリケーションする場合は、サブツリーの頂点で識別名 (distinguished name) (DN) を指定し、その下にあるエントリをすべてレプリケートするのが自然な方法です。また、このサブツリーは、ディレクトリデータの一部を含むディレクトリパーティションである、データベースに対応します。
たとえば、企業環境では自社内のネットワーク名に対応させてディレクトリツリーを編成できます。ネットワーク名が変更されることはほとんどないので、ディレクトリツリー構造は安定したものになります。また、複製を使用して別の Directory Server を連動させる場合は、ネットワーク名を使用してディレクトリツリーの最上位の分岐点を作成する方法が有効です。
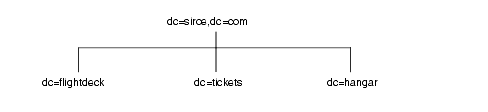
たとえば、siroe.com 社に flightdeck.siroe.com、 tickets.siroe.com、および hanger.siroe.com という 3 つのプライマリネットワークがあるとします。これらのネットワークでは、最初にディレクトリツリーを次のように分岐させています。
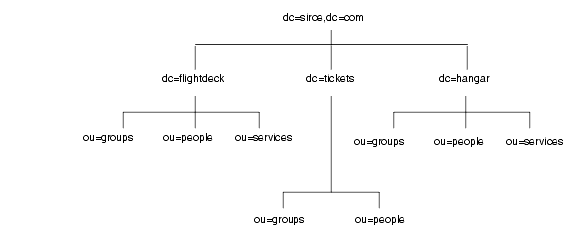
ツリーの最初の構造を作成したあと、ネットワークをさらに次のように分岐させています。
別の例として、ISP の i-zed.com 社は次のようにディレクトリを分岐させています。
ディレクトリツリーの最初の構造を作成したあと、ネットワークをさらに次のように分岐させています。
siroe.com 社と ISP の i-zed.com 社はどちらも、あまり変更されることのない情報に基づいてデータ階層を設計しています。
アクセス制御に関する検討事項
ディレクトリツリーを階層化すると、特定のタイプのアクセス制御を使用できるようになります。複製の場合と同様に、類似したエントリをグループ化すると、それらのエントリを 1 つの分岐点から簡単に管理できます。
また、ディレクトリツリー階層で管理を分散させることができます。たとえば、営業部の管理者に営業のエントリへのアクセス権を与え、マーケティング部の管理者にマーケティングのエントリへのアクセス権を与える場合は、ディレクトリツリーの設計を通じてアクセス権を付与することができます。
ディレクトリツリーではなくディレクトリの内容に基づいてアクセス制御を設定することができます。ACI フィルタを適用するターゲット (target) メカニズムを使用すると、ディレクトリエントリが特定の属性値を含むすべてのエントリへのアクセスを持つように規定した、1 つのアクセス制御規則を定義できます。たとえば、ou=Sales という属性を含むすべてのエントリへのアクセス権を営業部の管理者に与える ACI フィルタを設定できます。
ただし、ACI フィルタは管理が簡単ではありません。ディレクトリツリー階層で組織に対応した分岐を作成する、ACI フィルタを適用する、あるいは両者を組み合わせるなどして、ディレクトリにもっとも適したアクセス制御方法を決める必要があります。
エントリの命名
ディレクトリツリー階層を設計したあとは、ツリー構造内のエントリに名前を付けるときに使用する属性を決定する必要があります。一般に、名前は 1 つ以上の属性値を選び、RDN (相対識別名 (Relative distinguished name)) を形成して作成します。RDN とは、一番左の DN 属性値のことです。名前を付けるエントリのタイプによって使用する属性が変わります。
エントリを作成するときは、エントリ内で RDN を定義します。エントリ内で少なくとも RDN を定義しておけば、簡単にエントリを検出できます。これは、検索が実際の DN を対象にして実行されるのではなく、エントリ自体に格納されている属性値を対象に実行されるからです。
属性名には意味があるので、属性が表すエントリのタイプに合った属性名を使用するようにします。たとえば、組織を表すために l (locality) を使用したり、組織の構成単位を表すために c (country) を使用したりしないでください。
エントリに名前を付けるときの手法について、次の項目ごとに説明します。
ユーザエントリの命名
ユーザエントリの命名
ユーザエントリの名前、DN は一意である必要があります。従来、識別名ではそのユーザエントリに名前を付けるときに、commonName または cn 属性を使用しています。つまり、Babs Jensen という名前のユーザのエントリには、次のような識別名が付けられます。
cn=Babs Jensen,dc=siroe,dc=com
このエントリと関連付けられているユーザを識別するのは簡単ですが、同じ名前のユーザがいる場合は一意にならない場合があります。この場合、DN の 名前の衝突 (name collisions) として知られている、複数のエントリが同じ識別名を持つ問題が生じます。
共通名の衝突は、一意の識別子を共通名に追加することで避けられます。たとえば、次のようにします。
cn=Babs Jensen+employeeNumber=23,dc=siroe,dc=com
ただし、大きなディレクトリの場合は、扱いにくい共通名となり、管理が難しくなります。
より良い方法は、cn 以外の属性でユーザエントリを特定することです。次のいずれかの属性を使用することを検討してください。
uid
uid (userID) 属性を使用して、個人に固有な値を指定します。たとえば、ユーザのログイン ID や社員番号などが使用できます。ホスト環境の加入者は、uid 属性で識別する必要があります。
mail 属性を使用して、個人の電子メールアドレスの値を追加します。この方法でも、重複した属性値を含む扱いにくい DN になる場合があるので (たとえば mail=bjensen@siroe.com, dc=siroe,dc=com)、uid 属性で使用可能な一意の値がなかった場合にのみこの方法を使用します。たとえば、会社が社員番号やユーザ ID を臨時社員や契約社員に割り当てない場合は、uid 属性の代わりに mail 属性を使用します。
employeeNumber
inetOrgPerson オブジェクトクラスの社員には、employeeNumber などの会社側が割り当てた属性値を使用することを検討します。
ユーザエントリの RDN の属性とデータのペアにどのような属性値を使用する場合でも、必ず一意で永続的な値を使用します。また、ユーザエントリの RDN は読みやすいものにします。識別名に基づいてディレクトリエントリを変更する場合など、DN を認識しやすくするとディレクトリのタスクが 簡単になるものがあります。つまり、uid=bjensen, dc=siroe,dc=com の方が uid=b12r56A, dc=siroe,dc=com より適切です。また、ディレクトリのクライアントアプリケーションの中には、uid 属性と cn 属性に人間が読める名前を使用することを前提にしているものもあります。
ホストされる環境でのユーザエントリに関する検討事項
ユーザがサービスの加入者の場合、そのエントリは inetUser オブジェクトクラスにし、uid 属性を含める必要があります。属性は顧客のサブツリーで一意である必要があります。
ユーザがホスティングサービス事業者に属している場合は、nsManagedPerson オブジェクトクラスの inetOrgPerson として表します。
DIT 内へのユーザエントリの配置
次に、ディレクトリツリーにユーザエントリを配置する場合のガイドラインを示します。
組織エントリの命名
組織エントリ名は、ほかのエントリと同様に一意である必要があります。ほかの属性値と組織の法的な名前を組み合わせて使用すると、名前は確実に一意になります。たとえば、次のように組織エントリに名前を付けます。
o=Company22+st=Washington,o=ISP,c=US
登録商標を使用することもできますが、一意である保証はありません。
ホスト環境では、組織エントリに次の属性を含ませる必要があります。
その他のエントリの命名
地域、州、国、デバイス、サーバ、ネットワーク情報、その他のタイプのデータなど、ディレクトリには多くのものを表すエントリが含まれています。
これらのタイプのエントリには、可能な場合は RDN 内で commonName (cn) 属性を使用してください。たとえば、グループエントリに名前を付ける場合は、次のように名前を付けます。
cn=allAdministrators,dc=siroe,dc=com
ただし、commonName 属性がサポートされていないオブジェクトクラスを持つエントリに名前を付けなければならないこともあります。この場合は、エントリのオブジェクトクラスでサポートされている属性を使用します。
エントリの DN で使用される属性とエントリ内で実際に使用されている属性が対応している必要はありません。ただし、指定する属性を DNで見えるようにすると、ディレクトリツリーを簡単に管理できます。
ディレクトリエントリのグループ化
ディレクトリツリーは、エントリの情報を階層構造で構成します。階層もグループ化メカニズムの 1 つですが、分散しているエントリの関連付け、頻繁に変更される組織、または多数のエントリで繰り返されるデータには適していません。グループとロールによってエントリを柔軟に関連付けられるようになり、サービスクラスによってディレクトリの分岐内で共有されるデータを簡単に管理できるようになります。
静的グループと動的グループ
静的グループと動的グループ
グループとは、そのメンバーであるほかのエントリを特定するエントリです。グループ名がわかっている場合は、そのすべてのメンバーエントリを簡単に検索できます。
静的グループは、そのメンバーエントリの名前を明示的に指定する。静的グループを定義するエントリは、groupOfNames または groupOfUniqueNames オブジェクトクラスを使用し、各メンバーの DN をそれぞれ member または uniqueMember の属性値として含む。静的グループは、ディレクトリ管理者のグループなど少人数のグループに適している
静的グループは、メンバーが何千人といるようなグループには適しません。性能が著しく低下するため、メンバー数が 20,000 を超える静的グループを作成することはお勧めできません。これ以上のサイズのグループには、動的グループまたはロールを使用することをお勧めします。メンバー数が 20,000 を超えるグループを定義するために静的グループを使用する必要がある場合は、1 つの大きな静的グループを使用するのではなく、グループのグループ化を使います。
動的グループはフィルタを指定し、一致するすべてのエントリがグループのメンバーとなる。このようなグループは、フィルタが評価されるたびにメンバーが定義されるために動的である。動的グループの定義エントリは groupOfURLs オブジェクトクラスに属し、memberURL 属性の LDAP URL 値として表現される 1 つまたは複数のフィルタを含む 両方のタイプのグループで、ディレクトリ内のあらゆるメンバーを特定できます。グループ定義自体を ou=Groups 分岐の下に配置することをお勧めします。たとえば、バインド資格がグループのメンバーである場合にアクセスを許可または制限する ACI (Access Control Instruction) を定義するときに、これによって検索が簡単になります。
グループの利点は、すべてのメンバーを簡単に検索できることです。静的グループは簡単に一覧表示でき、動的グループのフィルタは簡単に評価できます。グループの欠点は任意のエントリをメンバーにできることです。このため、あるエントリがメンバーとなっているすべてのグループの名前を挙げることは、非常に困難です。
管理されているロール、フィルタを適用したロール、入れ子のロール
ロールはエントリをグループ化する新しいメカニズムで、エントリがメンバーとなっているすべてのロールを自動的に特定します。ディレクトリ内のエントリを検索すると、そのエントリが属しているロールがすぐにわかります。これによって、グループのメカニズムの主な欠点が解消されます。
管理されているロールは、メンバーがロール定義エントリではなく各メンバーエントリ内で定義されていることを除いて、静的グループと同じである。静的なロール定義エントリは、効果の範囲だけを定義し、その範囲はその親エントリの分岐全体である。そのロールのメンバーは分岐内のエントリであり、その nsRoleDN 属性でロール定義エントリの DN を指定している
フィルタを適用したロールは動的グループと非常に似ていて、ロールのメンバーを決めるフィルタを定義する。すべてのロールと同様に、フィルタの範囲はフィルタを適用したロール定義エントリの場所によって定義される
入れ子のロールはほかのロールの定義エントリをリストし、それらのロールのすべてのメンバーを組み合わせる。つまり、あるエントリが入れ子のロール定義のリストにされているロールのメンバーである場合、そのエントリは入れ子のロールのメンバーでもある Directory Server がすべてのロールのメンバーを自動的に算出するため、ロールメカニズムはクライアントからは非常に簡単に使用できます。ロールに属しているすべてのエントリに nsRole 仮想属性が指定されます。この属性の値は、そのエントリがメンバーになっているすべてのロールの DN です。nsRole が仮想属性であるのは、実行中にサーバによって生成され、実際にはディレクトリに格納されないためです。
nsRole 属性はほかの属性と同様に読み取られます。クライアントはこの属性を使用して、任意のエントリが属しているすべてのロールを並べることができます。したがって、指定したエントリが特定のロールに属しているかどうかを簡単に判断できます。
グループとロールのどちらを使用するかの決定
グループとロールのメカニズムは機能の一部が重複しているため、あいまいさを招く可能性があります。エントリをグループ化するどちらの方法にも、利点と欠点があります。とはいえ、新しいロールメカニズムは、頻繁に必要とされる機能を最大限に引き出せるように設計されています。
クライアントがグループまたはロールのすべてのメンバーを検索する必要がある
グループがもっとも効率良く機能するのはこのときです。nsRole は仮想属性であり、フィルタでは使用できないため、ロールのすべてのメンバーを検索するのは困難です。ただし、クライアントは分岐内のすべてのエントリを検索し、nsRole 属性の値を読み取って、すべてのロールメンバーを検索することは可能です。
エントリが特定のグループまたはロールのメンバーであるかどうかをクライアントが知る必要がある
本来、これはコンピュータに大きな負荷がかかるタスクです。さらに、グループをもとにした実装は非常に複雑です。ロールはこの問題を解決するために開発されました。ロール定義の構造と範囲が決まっていれば、サーバはクライアントよりもずっと効率よくメンバーを算出できます。したがって、クライアントがあるタイプのロールのメンバーを検索するときは、生成された nsRole 属性の値を読み取るだけで済みます。
必要に応じて、以下の設計をお勧めします。
メンバー数を算出するだけの場合は、静的グループを使用する。クライアントは静的グループ定義を検索し、すべてのメンバーの DN のリストを簡単に取得できる
ACI でのバインド規則の指定など、フィルタに基づいてすべてのメンバーを検索するだけの場合は、動的グループを使用する。フィルタを適用したロールはフィルタを適用したグループとほとんど同じであるが、nsRole 仮想属性を生成するロールメカニズムが始動する。クライアントが nsRole 値を必要としない場合は、動的グループだけを定義すると計算のオーバーヘッドを回避できる
クライアントが特定のエントリのすべてのメンバー情報を必要とする場合は、ロールを使用する。サーバがすべての計算を実行し、クライアントは nsRole 属性の値を読み取るだけで済む。さらに、この属性にすべてのタイプのロールが現れ、クライアントはすべてのロールを均等に処理できる
エントリのセットがいくつかあり、特定のセットのメンバーを並べること、および特定のエントリがメンバーとなっているすべてのセットを検索することが必要である場合は、ロールだけを使用する。全般的に、グループよりもロールの方が、両方を効率よく、より簡単なクライアントで実行できる
また、ツリー階層を使用して、グループと同等のエントリのセットを作成することもできます。これによって、ロールのメンバーを並べるのが簡単になり、ロールに基づく設計の効率を最大限に引き出すことができます。
グループ化メカニズムは、サーバの複雑さに影響を及ぼし、クライアントによるメンバー情報の処理方法を決めるため、グループ化メカニズムは慎重に計画する必要があります。要件に合うメカニズムを知り、効率よく使用してください。最後に、管理者があとでポリシーの一貫性を維持できるように、選択した設計を文書化しておくことを検討してください。
サービスクラス
サービスクラス (Class of Service) (CoS: Class of Service) メカニズムを使用すると、アプリケーションに見えない方法で、エントリ間で属性を共有できます。ロールメカニズムと同様に、エントリが検出されると、CoS がそのエントリに対して仮想属性を生成します。ただし、CoS はメンバーを定義するのではなく、一貫性の保持と容量の節約のために、関連するエントリがデータを共有できるようにします。
たとえば、ディレクトリには facsimileTelephoneNumber 属性の値が等しい何千ものエントリを格納できます。従来のやり方で FAX 番号を変更するには、各エントリを個別に更新する必要がありました。これは管理者にとって大きな負担であり、全てのエントリが更新されないという危険がありました。CoS を使用すると、FAX 番号は 1 か所に保存され、Directory Server は、エントリが返されるときに、関係のあるすべてのエントリに対して facsimileTelephoneNumber 属性を自動的に生成します。
クライアントアプリケーションでは、生成された CoS 属性はほかの属性と同じように検出されます。ただし、ディレクトリ管理者が管理するのは 1 つの FAX 番号値だけです。さらに、実際にディレクトリに格納される値が少ないため、データベースが使用するデータ領域が少なくて済みます。また、CoS メカニズムを使用すると、生成された値をエントリで上書きすることも、同じ属性に対して複数の値を生成することも可能です。
CoS メカニズムでは、2 つのタイプのヘルパーエントリが使用されます。
CoS 定義エントリは、生成される属性とその値の指定方法を示す。定義エントリの場所によって、CoS 偏差の範囲が決まる。定義エントリの親の分岐内のすべてのエントリが、CoS 定義のターゲットエントリと呼ばれる
スキーマ検査が有効になっている場合は、その CoS 属性を設定できるすべてのターゲットエントリにこの属性が生成されます。スキーマ検査が無効になっている場合は、すべてのターゲットエントリに CoS 属性が生成されます。
CoS テンプレートエントリには、CoS 属性に生成される値が含まれる。値の異なる複数のテンプレートがある可能性がある。CoS メカニズムは、定義エントリとターゲットエントリの内容に基づいてテンプレートを選択する テンプレートの選択方法が異なり、それによって生成される値が異なる 3 つのタイプの CoS があります。
ポインタ CoS はもっとも単純で、定義エントリによって、cosTemplate オブジェクトクラスの特定のテンプレートエントリの DN が決まる。すべてのターゲットエントリに、このテンプレートで定義されているものと同じ CoS 属性値が設定される
間接 CoS を使用すると、ディレクトリ内の任意のエントリをテンプレートにして、CoS 値を指定することができる。定義エントリは、ターゲットエントリにある指示子属性の名前を指定する。この属性には必ず DN が含まれ、その値によって、特定のターゲットに使用されるテンプレートが決まる
たとえば、departmentNumber 属性を生成する間接 CoS では、指示子として社員の上司を使用できます。ターゲットエントリを検索する場合、CoS メカニズムはテンプレートとして manager 属性の DN 値を使用します。そして、上司の部門番号と同じ値を使用して、社員の departmentNumber 属性を生成します。
間接 CoS は使いすぎないようにしてください。ディレクトリツリーの任意の場所にある任意のエントリをテンプレートにすることができるため、アクセスの制御が非常に困難になります。また、特に性能が重視される場所では、間接 CoS の使用は避けてください。
クラシック CoS はポインタ CoS と間接 CoS の動作を組み合わせたもので、 CoS 定義によって、テンプレートのベース DN と指示子属性の名前の両方が指定される。ターゲットエントリの指示子属性の値は、以下に示すようにテンプレートエントリの DN を構築するために使用する
cn=specifierValue,baseDN
クラシック CoS テンプレートは、任意の間接 CoS テンプレートに関連する性能の問題を回避するための、cosTemplate オブジェクトクラスのエントリです。テンプレートを定義エントリと同じ場所に格納し、意味のある名前を付けて、CoS メカニズムを簡単に管理できるようにすることをお勧めします。
生成される CoS 属性には、複数のテンプレートにより複数の値を設定できる場合があります。指示子が複数のテンプレートエントリを指定する場合もあれば、同じ属性に複数の CoS 定義がある場合もあります。また、選択したすべてのテンプレートから 1 つの値だけが生成されるように、テンプレートの優先順位を指定することもできます。詳細は、『iPlanet Directory Server 管理者ガイド』を参照してください。
ロールとクラシック CoS を組み合わせて使用すると、ロールに基づく属性 (role-based attributes) を指定できます。エントリは関連付けられたサービスクラステンプレートを持つ特定のロールを所有しているため、これらの属性がエントリ上に現れます。たとえば、ロールに基づいた属性を使用して、ロール単位で検索制限を設定できます。
CoS の機能は再帰的に使用できます。つまり、iPlanet Directory Server では、CoS で生成されたほかの属性によって指定される CoS から属性を生成できます。CoS スキーマを複雑にすると、クライアントアプリケーションから情報へのアクセスが単純化され、繰り返し使用する属性を簡単に管理できるようになりますが、同時に管理が複雑になり、サーバの性能が低下します。極端に複雑な CoS スキーマは避けてください。たとえば、多くの間接 CoS スキーマは、クラシック CoS またはポインタ CoS として再定義することができます。
最後に、必要以上に CoS 定義を変更しないようにしてください。サーバは CoS 情報をキャッシュに保存するため、CoS 定義への変更がすぐには反映されません。キャッシュに保存することによって、生成される属性エントリへの読み取りアクセスが速くなります。CoS 情報が変更されると、サーバはキャッシュを再構築しなくてはなりません。これは、多少時間のかかるタスク (通常は数秒) です。キャッシュの再構築中は、読み取り処理では新たに変更された情報ではなく、古いキャッシュ情報にアクセスする可能性があります。
ディレクトリツリーの設計例
次に、フラットな階層をサポートするディレクトリツリーの設計例と、より複雑な階層を含む設計例を示します。
国際企業向けのディレクトリツリー
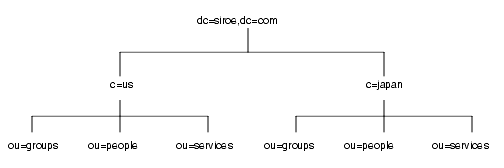
国際企業の要件に対応するには、ディレクトリツリーのルートをインターネットのドメイン名に設定し、そのルートポイントのすぐ下で、企業が事業を展開している国ごとにツリーを分岐させます。「接尾辞の命名規則」では、国名指示子をディレクトリツリーのルートとして設定しないように勧めています。これは、企業が国際的な組織である場合には、特に当てはまります。
LDAP は DN 内の属性の順序については何の規制も設けていないため、次のように c (countryName) 属性を使用して各国の分岐を表すことができます。
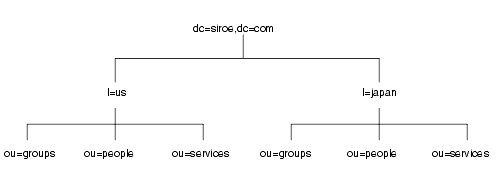
ただし、この方法ではスタイルに統一感がないと感じる管理者もいるので、代わりに l (locality) 属性を使用して、各国を次のように表すこともできます。
ISP 向けのディレクトリツリー
IPS (インターネットサービスプロバイダ) は、ディレクトリを通じて複数の企業をサポートする可能性があります。ISP の場合は、各顧客を個別の企業とみなし、ディレクトリツリーを設計します。セキュリティ上の理由から、それぞれが一意の接尾辞を持つ個別のディレクトリツリーをアカウントごとに提供し、各ディレクトリツリーに適した個別のセキュリティポリシーを設定します。
各顧客に別々のデータベースを割り当て、別々のサーバにこれらのデータベースを格納することもできます。各ディレクトリツリーを専用のデータベース内に置けば、ほかの顧客に影響を与えずに各ディレクトリツリーにあるデータをバックアップしたり復元したりできます。
また、データを分散して配置することにより、ディスクの競合に起因する性能上の問題を減らし、ディスク障害によって影響を受けるアカウントの数を減らすこともできます。
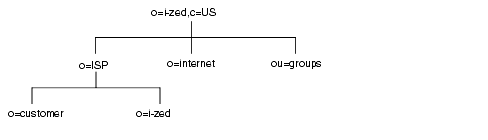
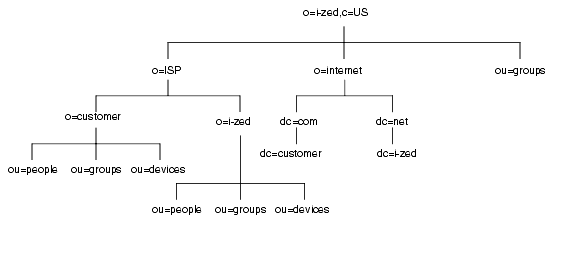
たとえば、ISP の I-Zed 社用のディレクトリツリーは次のようになります。
その他のディレクトリツリー関連資料
ディレクトリツリーの設計については、次のリンクを参照してください。
RFC 2247: Using Domains in LDAP/X.500 Distinguished Names (LDAP/X.500 識別名でドメインを使用する方法)
http://www.ietf.org/rfc/rfc2247.txt
RFC 2253: LDAPv3, UTF-8 String Representation of Distinguished Names (LDAPv3、識別名をUTF-8 文字列で表す方法)
http://www.ietf.org/rfc/rfc2253.txt

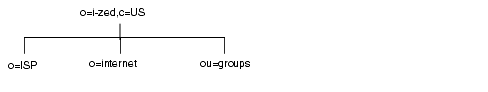
前へ 目次 索引 DocHome 次へ
Copyright © 2001 Sun Microsystems, Inc. Some preexisting portions Copyright © 2001 Netscape Communications Corp. All rights reserved.
Last Updated March 02, 2002