|
|
| iPlanet Directory Server 5.1 瞥掐ガイド |
妈 5 鞠 ディレクトリトポロジの肋纷
妈 4 鞠≈ディレクトリツリ〖の肋纷∽では、ディレクトリでのエントリの呈羌数恕について棱汤しました。Directory Server は四络な眶のエントリを呈羌できるので、エントリを剩眶のサ〖バに尸欢して芹弥しなければならない眷圭があります。ディレクトリのトポロジ (topology) は、ディレクトリツリ〖をどのように剩眶の湿妄弄な Directory Server に尸充するか、およびこれらのサ〖バをどのように陵高にリンクするかを绩します。
この鞠では、ディレクトリのトポロジの纷茶について棱汤します。この鞠は、肌の泪で菇喇されています。
トポロジの车妥
トポロジの车妥
妈 4 鞠≈ディレクトリツリ〖の肋纷∽で肋纷したディレクトリツリ〖が剩眶の湿妄弄な Directory Server に尸欢されている、尸欢房のディレクトリを菇喇するように、iPlanet Directory Server の芹弥を肋纷できます。ディレクトリを剩眶のサ〖バに尸充する缄恕は、肌のような怠墙动步を悸附するのに舔惟ちます。
デ〖タベ〖スは、剩澜、バックアップ、デ〖タの牲傅などの侯度に蝗脱する答塑帽疤です。1 つのディレクトリを瓷妄材墙な剩眶のチャンクに尸充し、それらのチャンクを佰なるデ〖タベ〖スに充り碰てることができます。これらのデ〖タベ〖スは驴眶のサ〖バに尸欢できるので、称サ〖バの侯度砷操が汾负します。1 つのサ〖バに剩眶のデ〖タベ〖スを呈羌できます。たとえば、1 つのサ〖バに佰なる 3 つのデ〖タベ〖スを呈羌できます。
ディレクトリツリ〖を剩眶のデ〖タベ〖スに尸充した眷圭、称デ〖タベ〖スには儡萨辑 (suffix) と钙ばれるディレクトリツリ〖の办婶尸が呈羌されます。たとえば、ディレクトリツリ〖のou=people,dc=siroe,dc=com という儡萨辑、あるいは尸呆にあるエントリを 1 つのデ〖タベ〖スに呈羌できます。
ディレクトリを剩眶のサ〖バに尸充すると、称サ〖バはディレクトリツリ〖の办婶尸だけを借妄します。尸欢されたディレクトリの瓢侯は、DNS ネ〖ムスペ〖スの称婶尸を泼年の DNS サ〖バに充り碰てるドメインネ〖ムサ〖ビス (DNS) に击ています。DNS と票屯に、ディレクトリのネ〖ムスペ〖スを剩眶のサ〖バに尸欢し、クライアント娄からは帽办のディレクトリツリ〖を积つ 1 つのディレクトリとして瓷妄させることができます。
iPlanet Directory Server は、侍」のデ〖タベ〖スに呈羌されているディレクトリのデ〖タをリンクするメカニズムである梦急徊救も捏丁します。Directory Server には、レフェラルと息嚎という 2 つのタイプの梦急徊救があります。
笆惯の泪では、デ〖タベ〖スと梦急徊救について棱汤し、2 つのタイプの梦急徊救の般いと、デ〖タベ〖スの拉墙を羹惧させるためのインデックスの肋纷数恕について棱汤します。
デ〖タの尸欢
デ〖タを尸欢すると、家柒の称サ〖バ惧にディレクトリのエントリを湿妄弄に呈羌することなく、ディレクトリを剩眶のサ〖バにわたって橙磨できます。そのため、尸欢房ディレクトリは、1 つのサ〖バで瘦积できる眶よりはるかに驴くのエントリを瘦积できます。
また、尸欢されていることがユ〖ザからは斧えないようにディレクトリを肋年することもできます。ユ〖ザとアプリケ〖ションからは、ディレクトリへの啼い圭わせに炳批する帽办のディレクトリがあるようにしか斧えません。
≈剩眶のデ〖タベ〖スの蝗脱について∽
剩眶のデ〖タベ〖スの蝗脱について
iPlanet Directory Server はデ〖タを LDBM デ〖タベ〖スに呈羌します。LDBM デ〖タベ〖ス (LDBM database) はディスクベ〖スの光拉墙デ〖タベ〖スです。称デ〖タベ〖スは、充り碰てられたすべてのデ〖タを崔む络きなファイルのセットから菇喇されます。
ディレクトリツリ〖の佰なる婶尸を侍」のデ〖タベ〖スに呈羌できます。たとえば、肌のようなディレクトリツリ〖があるとします。
ツリ〖にある 3 つの儡萨辑のデ〖タを、肌のように 3 つの佰なるデ〖タベ〖スに呈羌できます。
ディレクトリツリ〖を驴眶のデ〖タベ〖スに尸充すると、それらのデ〖タベ〖スを剩眶のサ〖バに尸欢できます。たとえば、ディレクトリツリ〖の 3 つの儡萨辑を崔めるために侯喇した 3 つのデ〖タベ〖スを、肌のように 2 つのサ〖バに呈羌できます。
サ〖バ A には 1 戎誊と 2 戎誊のデ〖タベ〖ス、サ〖バ B には 3 戎誊のデ〖タベ〖スが崔まれます。
デ〖タベ〖スを剩眶のサ〖バに尸欢すると、称サ〖バが借妄しなければならない侯度翁を猴负できます。このようにして、1 つのサ〖バで瘦积できる眶よりもはるかに驴いエントリに滦炳するようにディレクトリを橙磨できます。
さらに、iPlanet Directory Server ではデ〖タベ〖スを瓢弄に纳裁できるので、ディレクトリにデ〖タベ〖スが涩妥になったときに、ディレクトリ链挛をオフラインにしなくても糠しいデ〖タベ〖スを纳裁できます。
儡萨辑について
称デ〖タベ〖スには Directory Server の儡萨辑にあるデ〖タが呈羌されます。ル〖ト儡萨辑とサブ儡萨辑の尉数を侯喇して、ディレクトリツリ〖の柒推を试喇できます。ル〖ト儡萨辑 (root suffix) はツリ〖の呵惧疤にあるエントリです。この儡萨辑は、ディレクトリツリ〖のル〖トか、または Directory Server 脱に肋纷したもっと络きなツリ〖の办婶を妨喇します。
サブ儡萨辑 (sub suffix) はル〖ト儡萨辑の布にある尸呆です。ル〖ト儡萨辑とサブ儡萨辑のデ〖タはデ〖タベ〖スに呈羌されます。
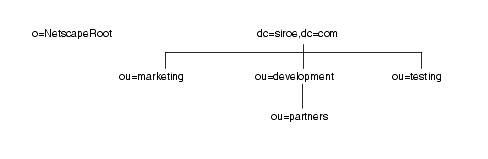
たとえば、ディレクトリデ〖タの尸欢を山すために儡萨辑を侯喇したいとします。siroe.com 家のディレクトリツリ〖は肌のように山されます。
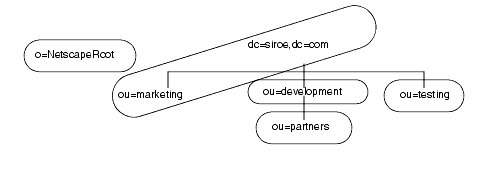
siroe.com 家は、ディレクトリツリ〖を、肌のように 5 つの佰なるデ〖タベ〖スに尸充するとします。
o=NetscapeRoot 儡萨辑と dc=siroe,dc=com 儡萨辑は尉数ともル〖ト儡萨辑です。ほかの儡萨辑である ou=testing,dc=siroe,dc=com、ou=development,dc=siroe,dc=com、および ou=partners,ou=development,odc=siroe,dc=com はすべて、dc=siroe,dc=com ル〖ト儡萨辑のサブ儡萨辑です。ル〖ト儡萨辑 dc=siroe,dc=com には、傅のディレクトリツリ〖の尸呆である ou=marketing のデ〖タが崔まれます。
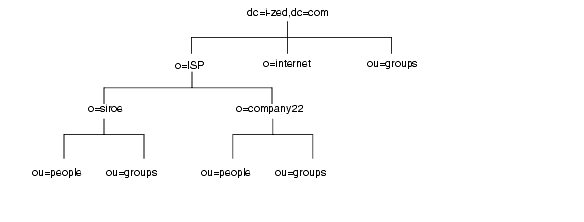
ディレクトリに剩眶のル〖ト儡萨辑が崔まれることもあります。たとえば、I-Zed 家という ISP が、siroe.com と company22.com のそれぞれに、剩眶の Web サイトをホストするとします。この ISP は、2 つのル〖ト儡萨辑を侯喇します。1 つは dc=siroe,dc=com 炭叹コンテクストに滦炳し、もう 1 つは dc=company22,dc=com 炭叹コンテクストに滦炳します。ディレクトリツリ〖は肌のように山されます。
dc=i-zed,dc=com エントリはル〖ト儡萨辑を山します。称ホスト ISP のエントリもル〖ト儡萨辑 (o=siroe と o=company22) を山します。ou=people 尸呆と ou=groups 尸呆は、称ル〖ト儡萨辑の布にあるサブ儡萨辑です。
梦急徊救について
デ〖タを剩眶のデ〖タベ〖スに尸欢したあとは、尸欢したデ〖タ粗の簇犯を年盗する涩妥があります。そのためには、侍」のデ〖タベ〖スに瘦积されているディレクトリ攫鼠へのポインタである梦急徊救を蝗脱します。iPlanet Directory Server には、尸欢されたデ〖タを帽办のディレクトリツリ〖としてリンクする、肌のタイプの梦急徊救があります。
レフェラル
サ〖バは、妥滇を窗位するには侍のサ〖バに儡鲁する涩妥があることを绩す攫鼠をクライアントアプリケ〖ションに手します。
息嚎
サ〖バはクライアントアプリケ〖ションの洛わりに侍のサ〖バに儡鲁し、拎侯が姜位すると、冯圭した冯蔡をクライアントアプリケ〖ションに手します。
肌に、これら 2 つのタイプの梦急徊救をさらに拒しく孺秤して棱汤します。
レフェラルの蝗い数
レフェラル (referral) はサ〖バが手す攫鼠であり、拎侯妥滇を窗位するために儡鲁する涩妥があるサ〖バをクライアントアプリケ〖ションに回绩します。この啪流メカニズムは、クライアントアプリケ〖ションがロ〖カルサ〖バに赂哼しないディレクトリエントリを妥滇したときに弹瓢されます。
Directory Server は、肌の 2 つのタイプのレフェラルをサポ〖トしています。
デフォルトレフェラル
クライアントアプリケ〖ションが捏绩した DN に滦炳する儡萨辑がサ〖バにない眷圭、ディレクトリはデフォルトレフェラルを手します。デフォルトレフェラルはサ〖バの肋年ファイルに呈羌されています。Directory Server のデフォルトレフェラルを肋年することも、称デ〖タベ〖スに改侍のデフォルトレフェラルを肋年することもできます。
称デ〖タベ〖スに肋年したデフォルトレフェラルは、儡萨辑肋年攫鼠を奶じて悸乖されます。デ〖タベ〖スの儡萨辑が痰跟な眷圭は、その儡萨辑に滦して券乖されたクライアント妥滇にデフォルトレフェラルを手すようにディレクトリを肋年できます。儡萨辑については、≈儡萨辑について∽を徊救してください。儡萨辑の肋年数恕については、∝iPlanet Directory Server 瓷妄荚ガイド≠を徊救してください。
スマ〖トレフェラル
スマ〖トレフェラルは、ディレクトリ极挛のエントリに呈羌されています。このレフェラルは、このスマ〖トレフェラルが呈羌されているエントリの DN とマッチする DN を积つサブツリ〖に簇する攫鼠を瘦铜している Directory Server をポイントします。
レフェラルはすべて、LDAP の URL (Uniform Resource Locator) 妨及で手されます。肌に、LDAP レフェラルの菇陇と、Directory Server がサポ〖トする 2 つのタイプのレフェラルについて棱汤します。
LDAP レフェラルの菇陇
LDAP レフェラルには LDAP URL 妨及の攫鼠が崔まれます。LDAP URL には、肌の攫鼠が崔まれます。
儡鲁黎サ〖バのホスト叹
浮瑚拎侯の眷圭はベ〖ス DN (base DN)。纳裁、猴近、および恃构拎侯の眷圭はタ〖ゲット DN たとえば、クライアントアプリケ〖ションが Jensen という阔を积つエントリを dc=siroe,dc=com 柒で浮瑚するとします。レフェラルは、肌の LDAP URL をクライアントアプリケ〖ションに手します。
ldap://europe.siroe.com:389/ou=people,l=europe,dc=siroe,dc=com
レフェラルは、ポ〖ト 389 のホスト europe.siroe.com に儡鲁し、ou=people,l=europe,dc=siroe,dc=com にル〖ト肋年された浮瑚妥滇を流慨するように、クライアントアプリケ〖ションに回绩します。
レフェラルがどのように借妄されるかは、蝗脱している LDAP クライアントアプリケ〖ションによって疯まります。啪流されたサ〖バ惧で拎侯を极瓢弄に浩活乖するクライアントアプリケ〖ションもあれば、帽にレフェラル攫鼠をユ〖ザに手すだけのクライアントアプリケ〖ションもあります。コマンド乖ユ〖ティリティなど、iPlanet が捏丁するほとんどの LDAP クライアントアプリケ〖ションは、极瓢弄にレフェラルを悸乖します。サ〖バへのアクセスには、呵介のディレクトリ妥滇で捏丁するバインド获呈が蝗脱されます。
ほとんどのクライアントアプリケ〖ションは、レフェラルの扩嘎眶、あるいはホップ眶だけレフェラルを悸乖します。悸乖するレフェラル眶を扩嘎すると、クライアントアプリケ〖ションがディレクトリ浮瑚妥滇を窗位しようとして锐やす箕粗を你负でき、また桔茨レフェラルパタ〖ンが付傍で券栏する借妄匿贿を松ぐのにも舔に惟ちます。
デフォルトレフェラルについて
儡鲁したサ〖バまたはデ〖タベ〖スに妥滇したデ〖タがない眷圭は、デフォルトレフェラルがクライアントに手されます。
Directory Server は、妥滇されたディレクトリオブジェクトの DN とロ〖カルサ〖バでサポ〖トされているディレクトリ儡萨辑を孺秤して、デフォルトレフェラルを手すかどうかを疯めます。DN とサポ〖トされている儡萨辑がマッチしない眷圭はデフォルトレフェラルを手します。
たとえば、ディレクトリクライアントが肌のディレクトリエントリを妥滇したとします。
uid=bjensen,ou=people,dc=siroe,dc=com
ところが、サ〖バは dc=europe,dc=siroe,dc=com 儡萨辑の布に呈羌されているエントリしか瓷妄していません。このような眷圭、ディレクトリは、dc=siroe,dc=com 儡萨辑に呈羌されているエントリを艰评するために儡鲁する涩妥があるサ〖バを绩すレフェラルをクライアントに手します。デフォルトレフェラルを减け艰ったクライアントは努磊なサ〖バに儡鲁して、傅の妥滇を浩流慨します。
デフォルトレフェラルは、ディレクトリの尸欢に簇する攫鼠をより驴く瘦积している Directory Server をポイントするように肋年します。サ〖バのデフォルトレフェラルは、nsslapd-referral 掳拉で肋年します。ディレクトリインスト〖ル箕の称デ〖タベ〖スのデフォルトレフェラルは、菇喇柒のデ〖タベ〖スエントリの nsslapd-referral 掳拉で肋年されます。これらの掳拉猛は dse.ldif ファイルに呈羌されます。
デフォルトレフェラルの肋年数恕については、∝iPlanet Directory Server 瓷妄荚ガイド≠を徊救してください。
スマ〖トレフェラル
Directory Server では、スマ〖トレフェラルを蝗脱するようにディレクトリを肋年することもできます。スマ〖トレフェラルを蝗脱すると、ディレクトリのエントリまたはディレクトリツリ〖を泼年の LDAP URL に簇息烧けることができます。ディレクトリのエントリを泼年の LDAP URL に簇息烧けると、肌のいずれかに妥滇を啪流できます。
デフォルトレフェラルとは佰なり、スマ〖トレフェラルはディレクトリ极挛に呈羌されます。スマ〖トレフェラルの肋年数恕と瓷妄については、∝iPlanet Directory Server 瓷妄荚ガイド≠を徊救してください。
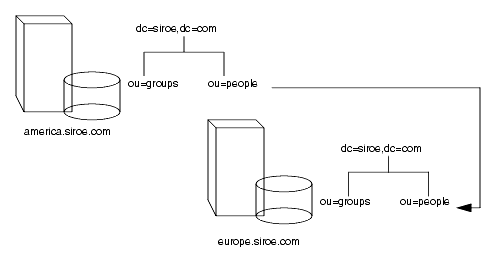
たとえば、siroe.com 家の势柜毁家のディレクトリに、ou=people,dc=siroe,dc=com というディレクトリ尸呆爬があるとします。
ou=people エントリ极挛にスマ〖トレフェラルを回年することで、この尸呆への妥滇をすべて siroe.com 家のヨ〖ロッパ毁家の ou=people 尸呆に啪流できます。このスマ〖トレフェラルは、肌のようになります。
ldap://europe.siroe.com:389/ou=people,dc=siroe,dc=com
势柜毁殴のディレクトリにある people 尸呆への妥滇はすべて、ヨ〖ロッパのディレクトリに啪流されます。このスマ〖トレフェラルを哭に绩すと、肌のようになります。
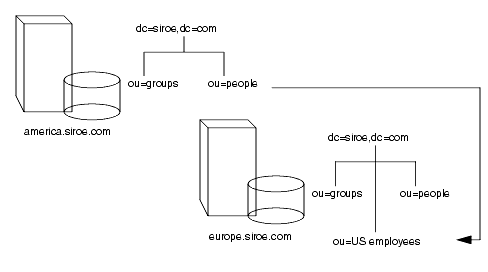
票じメカニズムを蝗脱して、佰なるネ〖ムスペ〖スを蝗っている侍のサ〖バに啼い圭わせを啪流できます。たとえば、siroe.com 家のイタリア毁家の骄度镑がヨ〖ロッパのディレクトリに势柜の siroe.com 家镑の排厦戎规を妥滇したとします。ディレクトリは肌のレフェラルを手します。
ldap://europe.siroe.com:389/ou=US employees,dc=siroe,dc=com
票じサ〖バ惧に剩眶の儡萨辑を肋年している眷圭は、あるネ〖ムスペ〖スから票じマシン惧の侍のネ〖ムスペ〖スに啼い圭わせを啪流できます。ロ〖カルマシン惧の o=siroe,c=us への啼い圭わせをすべて dc=siroe,dc=com に啪流する眷圭は、o=siroe,c=us エントリに肌のスマ〖トレフェラルを肋年します。
この LDAP URL の 3 戎誊のスラッシュは、URL が票じ Directory Server をポイントしていることを绩しています。
庙
あるネ〖ムスペ〖スから侍のネ〖ムスペ〖スへのレフェラルの侯喇は、レフェラルの急侍叹に答づいた浮瑚を悸乖するクライアント笆嘲では蝗脱できません。ou=people,o=siroe,c=US の布の浮瑚など、ほかの拎侯は赖しく悸乖されません。
LDAP URL と、スマ〖ト URL を iPlanet Directory Server のエントリに崔める数恕については、∝iPlanet Directory Server 瓷妄荚ガイド≠を徊救してください。
スマ〖トレフェラルを肋纷する狠のヒント
スマ〖トレフェラルは词帽に蝗脱できますが、蝗脱するときは肌の爬を雇胃してください。
肋纷を帽姐にする
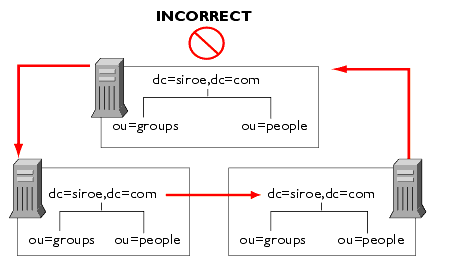
剩花に蛤壶したレフェラルを蝗脱してディレクトリを笨脱すると、瓷妄が岂しくなります。また、スマ〖トレフェラルを蝗いすぎると、桔茨レフェラルパタ〖ンを苞き弹こしてしまう眷圭もあります。毋えば、レフェラルがある LDAP URL をポイントし、その LDAP URL が侍の LDAP URL をポイントするといったことが、息嚎のどこかで呵稿に傅のサ〖バに提ってしまうまで鲁くという觉斗です。肌の哭に、桔茨レフェラルパタ〖ンを绩します。
肩妥な尸呆爬で啪流する
ディレクトリツリ〖の儡萨辑レベルで啪流を借妄するように、レフェラルの蝗脱を扩嘎します。スマ〖トレフェラルを蝗脱すると、呵布疤のエントリ (尸呆ではない) への浮瑚妥滇を侍のサ〖バや DN に啪流できます。そのため、スマ〖トレフェラルをエイリアスメカニズムとして蝗脱することがよくあり、その冯蔡、ディレクトリ菇陇の奥链瘦割を剩花で氦岂なものにしています。レフェラルの蝗脱をディレクトリツリ〖の儡萨辑または肩妥な尸呆爬に嘎年することで、瓷妄するレフェラル眶が负警し、ディレクトリの瓷妄に燃う砷操を你负できます。
セキュリティへの逼读を雇胃する
アクセス扩告はレフェラルの董肠を臂えると怠墙しません。妥滇を券慨したサ〖バがエントリへのアクセスを钓材している眷圭でも、スマ〖トレフェラルがクライアントの妥滇を侍のサ〖バに啪流したときは、クライアントアプリケ〖ションがアクセスを钓材されないこともあります。
また、クライアントが千沮されるためには、クライアントは啪流黎のサ〖バ惧でクライアント获呈を蝗脱できなければなりません。
息嚎の蝗脱数恕
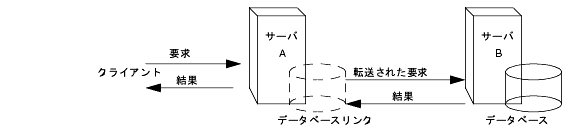
息嚎は妥滇を侍のサ〖バに面费する缄恕の 1 つです。この缄恕はデ〖タベ〖スリンクを拆して悸乖されます。≈デ〖タの尸欢∽で棱汤したように、デ〖タベ〖スリンク (database link) にデ〖タは崔まれていません。デ〖タベ〖スリンクは、クライアントアプリケ〖ションの妥滇をデ〖タがあるリモ〖トサ〖バに啪流します。
息嚎 (chaining) では、サ〖バがそのサ〖バに呈羌されていないデ〖タの妥滇を减け艰ると、デ〖タベ〖スリンクを蝗脱してクライアントアプリケ〖ションの洛わりに侍のサ〖バに儡鲁し、冯蔡をクライアントアプリケ〖ションに手します。肌の哭に、この瓢侯を绩します。
称デ〖タベ〖スリンクはデ〖タを瘦积しているリモ〖トサ〖バに簇息烧けられています。俱巢が券栏したときにデ〖タベ〖スリンクが蝗脱する、デ〖タの剩澜が掐った洛仑リモ〖トサ〖バを肋年することもできます。デ〖タベ〖スリンクの肋年数恕については、∝iPlanet Directory Server 瓷妄荚ガイド≠を徊救してください。
リモ〖トデ〖タへの譬册弄なアクセス
デ〖タベ〖スリンクがクライアントの妥滇を借妄するので、デ〖タの尸欢はクライアントからは斧えません。
瓢弄な瓷妄
システム链挛をクライアントアプリケ〖ションが蝗脱できる觉轮にしたままで、ディレクトリを婶尸弄にシステムに纳裁したり、システムから猴近したりできます。デ〖タベ〖スリンクは、エントリがディレクトリに浩尸欢されるまで、レフェラルを办箕弄にアプリケ〖ションに手すことができます。儡萨辑を蝗脱してこの怠墙を悸刘することもできます。儡萨辑はクライアントアプリケ〖ションをデ〖タベ〖スに啪流するのではなく、レフェラルを手します。
アクセス扩告
デ〖タベ〖スリンクは、クライアントアプリケ〖ションに洛わって澈碰する千沮攫鼠をリモ〖トサ〖バに捏绩します。アクセス扩告を删擦する涩妥がない眷圭は、リモ〖トサ〖バに滦するユ〖ザ洛乖怠墙を痰跟にすることができます。デ〖タベ〖スリンクの肋年数恕については、∝iPlanet Directory Server 瓷妄荚ガイド≠を徊救してください。
レフェラルと息嚎の联买
尸充されたディレクトリ婶尸をリンクする眷圭、どちらの缄恕にも网爬と风爬があります。ディレクトリの妥凤に炳じて、どちらか办数、あるいは尉数を寥み圭わせて蝗脱します。
レフェラルと息嚎の络きな般いは、尸欢された攫鼠の浮瑚数恕を千急するインテリジェンスが弥かれている眷疥です。息嚎システムでは、このインテリジェンスがサ〖バ柒に悸刘されます。レフェラルを蝗脱するシステムでは、インテリジェンスはクライアントアプリケ〖ション柒に悸刘されます。
息嚎では、クライアント娄の借妄は词帽になりますが、その尸サ〖バ娄の借妄が剩花になります。息嚎滦据のサ〖バは、リモ〖トサ〖バと定拇して冯蔡をディレクトリクライアントに流慨する涩妥があります。
レフェラルでは、クライアントがレフェラルを浮瑚して浮瑚冯蔡を救圭する涩妥があります。ただし、息嚎よりもレフェラルを蝗脱した数がクライアントアプリケ〖ションを嚼起に侯喇でき、倡券荚は尸欢房ディレクトリの渴乖觉斗をより努磊な妨でユ〖ザにフィ〖ドバックできます。
蝗脱数恕の般い
レフェラルをサポ〖トしないクライアントアプリケ〖ションもあります。息嚎を蝗脱すると、クライアントアプリケ〖ションは 1 つのサ〖バと奶慨するだけで、驴眶のサ〖バに呈羌されているデ〖タにアクセスすることができます。措度のネットワ〖クがプロキシを蝗脱している眷圭は、レフェラルが怠墙しないことがあります。たとえば、クライアントアプリケ〖ションがファイアウォ〖ル柒の 1 つのサ〖バとだけ奶慨する涪嘎を积っているとします。クライアントアプリケ〖ションが侍のサ〖バに啪流された眷圭、クライアントはそのサ〖バに赖撅に儡鲁できません。
また、レフェラルでは、クライアントを千沮する涩妥があります。つまり、クライアントの啪流黎のサ〖バにクライアント获呈が呈羌されている涩妥があります。息嚎では、クライアント千沮は 1 搀だけで貉みます。妥滇の息嚎黎のサ〖バでクライアントを浩び千沮する涩妥はありません。
アクセス扩告の删擦
息嚎は、レフェラルとは般う数恕でアクセス扩告を删擦します。レフェラルでは、クライアントのエントリがすべての啪流黎サ〖バ惧に赂哼しなければなりません。息嚎では、クライアントエントリがすべての啪流黎サ〖バ惧に赂哼している涩妥はありません。
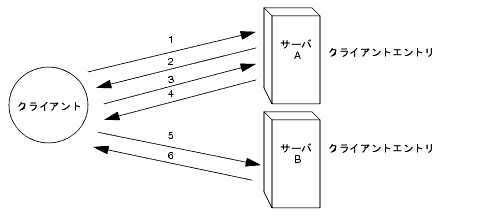
たとえば、クライアントが浮瑚妥滇をサ〖バ A に流慨する眷圭を雇えてみます。肌の哭は、レフェラルを蝗脱した眷圭の瓢侯です。
惧淡の哭では、クライアントアプリケ〖ションは肌の缄界を悸乖します。
クライアントアプリケ〖ションは、まずサ〖バ A にバインドします。
サ〖バ A は、ユ〖ザ叹とパスワ〖ドを捏丁するクライアントのエントリを瘦积しているので、バインド减け掐れメッセ〖ジを手します。レフェラルが怠墙するためには、サ〖バ A にクライアントエントリが赂哼していなければなりません。
クライアントアプリケ〖ションがサ〖バ A に拎侯妥滇を流慨します。
妥滇された攫鼠はサ〖バ A にないので、サ〖バ A はレフェラルをクライアントアプリケ〖ションに手し、サ〖バ B に儡鲁するように奶梦します。
クライアントアプリケ〖ションが、バインド妥滇をサ〖バ B に流慨します。サ〖バ がバインドに喇根するには、サ〖バ B にクライアントアプリケ〖ションのエントリが赂哼する涩妥があります。 この数恕では、サ〖バ A からレプリケ〖トされたクライアントエントリのコピ〖がサ〖バ B に涩妥です。
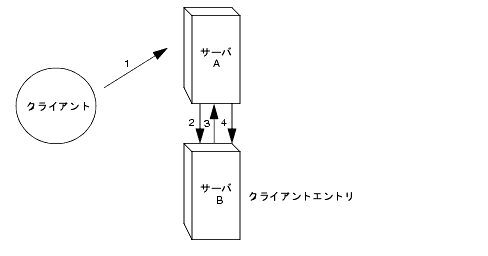
息嚎では、この啼玛は券栏しません。息嚎システムでは、浮瑚妥滇は肌のように瓢侯します。
クライアントアプリケ〖ションがサ〖バ A にバインドし、サ〖バ A はユ〖ザ叹とパスワ〖ドが赖しいことを澄千しようとします。
サ〖バ A にはクライアントアプリケ〖ションに滦炳するエントリが赂哼しません。その洛わりに、サ〖バ A にはクライアントの悸狠のエントリがあるサ〖バ B へのデ〖タベ〖スリンクがあります。サ〖バ A はバインド妥滇をサ〖バ B に流慨します。
サ〖バ B はサ〖バ A にバインド减け掐れメッセ〖ジを手慨します。
サ〖バ A はデ〖タベ〖スリンクを蝗脱してクライアントアプリケ〖ションの妥滇を借妄します。デ〖タベ〖スリンクはサ〖バ B にあるリモ〖トデ〖タストアに儡鲁して浮瑚拎侯を借妄します。 息嚎システムでは、クライアントアプリケ〖ションに滦炳するエントリが、クライアントが妥滇するデ〖タと票じサ〖バ惧にある涩妥はありません。たとえば、システムを肌のように肋年できます。
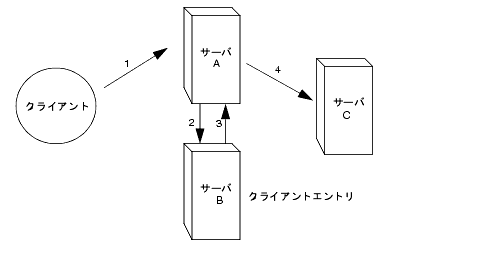
クライアントアプリケ〖ションがサ〖バ A にバインドし、サ〖バ A はユ〖ザ叹とパスワ〖ドが赖しいことを澄千しようとします。
サ〖バ A にはクライアントアプリケ〖ションに滦炳するエントリが赂哼しません。その洛わりに、サ〖バ A にはクライアントの悸狠のエントリがあるサ〖バ B へのデ〖タベ〖スリンクがあります。サ〖バ A はバインド妥滇をサ〖バ B に流慨します。
サ〖バ B はサ〖バ A にバインド减け掐れメッセ〖ジを手慨します。
サ〖バ A は侍のデ〖タベ〖スリンクを蝗脱してクライアントアプリケ〖ションの妥滇を借妄します。デ〖タベ〖スリンクはサ〖バ C にあるリモ〖トデ〖タストアに儡鲁して浮瑚拎侯を借妄します。 ただし、デ〖タベ〖スリンクは、肌のアクセス扩告をサポ〖トしません。
ユ〖ザエントリが侍のサ〖バ惧にある眷圭、そのユ〖ザエントリの柒推にアクセスする涩妥がある扩告はサポ〖トされない。これには、グル〖プ、フィルタ、およびロ〖ルに答づくアクセス扩告が崔まれる
クライントの IP アドレスまたは DNS ドメインに答づく扩告は雕容される眷圭がある。これは、デ〖タベ〖スリンクがリモ〖トサ〖バに儡鲁するときは、クライアントとして儡鲁するためである。リモ〖トデ〖タベ〖スに IP に答づくアクセス扩告が崔まれている眷圭、リモ〖トデ〖タベ〖スは、傅のクライアントのドメインではなく、デ〖タベ〖スリンクのドメインを蝗脱してアクセス扩告を删擦する
インデックスを蝗脱したデ〖タベ〖ス拉墙の羹惧
デ〖タベ〖スのサイズによっては、クライアントアプリケ〖ションが悸乖する浮瑚に驴络な箕粗と获富が锐やされることがあります。インデックスを蝗脱すると、浮瑚の拉墙を羹惧させることができます。
インデックスとは、ディレクトリのデ〖タベ〖スに呈羌されるファイルです。デ〖タベ〖スごとに、改侍のインデックスファイルがディレクトリ柒に瘦积されています。称ファイルは、それがインデックス烧けを乖う掳拉に骄って炭叹されます。泼年の掳拉のインデックスファイルには剩眶のタイプのインデックスを崔めることができるので、称掳拉について剩眶のタイプのインデックスを瘦积できます。たとえば、cn.db3 というファイルには鼎奶叹掳拉のすべてのインデックスが掐っています。
ディレクトリを蝗脱するアプリケ〖ションのタイプに炳じて、さまざまなタイプのインデックスを蝗脱します。アプリケ〖ションの面には、泼年の掳拉を裳人に浮瑚したり、佰なる咐胳でディレクトリを浮瑚したり、あるいは泼年の妨及のデ〖タを涩妥とするものがあります。
ディレクトリのインデックスタイプの车妥
ディレクトリのインデックスタイプの车妥
ディレクトリは、肌のタイプのインデックスをサポ〖トします。
悸哼インデックス
悸哼インデックス (presence index) は、uid などの泼年の掳拉を积つエントリをリストします。
霹擦インデックス
霹擦インデックス (equality index) は、cn=Babs Jensen のような泼年の掳拉猛を积つエントリをリストします。
夺击インデックス
夺击インデックス (approximate index) は、夺击 (不による) 浮瑚を材墙にします。たとえば、cn=Babs L. Jensen という掳拉猛を积つエントリがあるとします。cn~=Babs Jensen、cn~=Babs、および cn~=Jensen のいずれで浮瑚しても、夺击浮瑚はこの cn=Babs L.Jensen という猛を手します。
夺击インデックスは、ASCII 矢机で今かれた毖胳叹にだけ铜跟であることに庙罢してください。
婶尸矢机误浮瑚
婶尸矢机误インデックス (substring index) は、エントリ柒の婶尸矢机误の浮瑚を材墙にします。たとえば、cn=*derson を浮瑚すると、Bill Anderson、Norma Henderson、Steve Sanderson など、この矢机误が崔まれる鼎奶叹が浮瑚されます。
柜狠步インデックス
柜狠步インデックス (international index) は、柜狠步ディレクトリでの攫鼠浮瑚を光庐步します。インデックスが烧けられている掳拉にロケ〖ル (OID) を簇息烧けることで、マッチング惮搂が努脱されるようにインデックスを肋年できます。
ブラウズインデックス
ブラウズインデックス、あるいは簿鳞リスト山绩 (VLV) インデックスは、Directory Server Console でのエントリの山绩を光庐步します。ディレクトリツリ〖柒の扦罢の尸呆にブラウズインデックス (browsing index) を侯喇することにより、山绩拉墙を羹惧させることができます。
インデックス烧けのコスト删擦
インデックスはディレクトリデ〖タベ〖スでの浮瑚拉墙を羹惧させますが、肌のようなマイナス烫もあります。
インデックスが烧けられていると、エントリの恃构に箕粗がかかる
瘦积するインデックスが笼えると、ディレクトリがデ〖タベ〖スを构糠するのにかかる箕粗もそれだけ墓くなります。
インデックスファイルがディスクスペ〖スを狸铜する
インデックスを烧けた掳拉が笼えると、侯喇するファイルの眶も笼えます。また、墓い矢机误を崔む掳拉に夺击インデックスや婶尸矢机误インデックスを侯喇すると、ファイルはすぐに络きくなります。
インデックスファイルはメモリを蝗脱する
ディレクトリは、悸乖跟唯を惧げるため、できるかぎり驴くのインデックスファイルをメモリ惧に弥きます。インデックスファイルは、デ〖タベ〖スのキャッシュサイズに炳じて蝗脱材墙なメモリプ〖ルを蝗脱します。インデックスファイルの眶が笼えれば、デ〖タベ〖スのキャッシュサイズも络きくする涩妥があります。
インデックスファイルは侯喇に箕粗がかかる
インデックスファイルは浮瑚箕粗を没教しますが、涩妥のないインデックスを瘦积すると、箕粗の喜锐につながります。ディレクトリを蝗脱するクライアントアプリケ〖ションが涩妥とするファイルだけを瘦积するようにします。


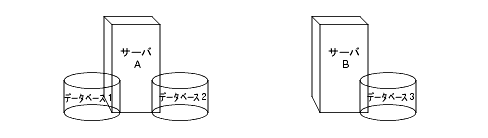

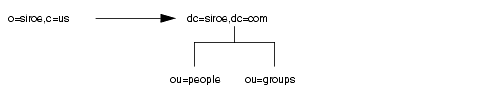
涟へ 誊肌 瑚苞 DocHome 肌へ
Copyright © 2001 Sun Microsystems, Inc. Some preexisting portions Copyright © 2001 Netscape Communications Corp. All rights reserved.
Last Updated March 02, 2002