|
|
| Sun ONE Directory Server 5.2 配備ガイド |
ディレクトリ情報ツリー (DIT) を使用することで、ディレクトリに格納されているデータを参照することができます。格納した情報のタイプ、企業の地理的な特性、ディレクトリで使用するアプリケーション、および使用するレプリケーションのタイプによって、ディレクトリツリーの設計方法が決まります。この章では、ディレクトリツリーの設計手順について概要を説明します。説明する内容は次のとおりです。
ディレクトリツリーの概要
ディレクトリツリーを使用すると、クライアントアプリケーションからディレクトリデータに名前を付けたり、参照したりできるようになります。ディレクトリツリーは、ディレクトリデータの分散、レプリケート、アクセス制御の方法など、その他の設計判断と緊密に連携します。最初に適切なディレクトリツリーを設計することは、配備後に不適切なディレクトリツリーを設計しなおすより時間的にずっと効率的です。
適切に設計されたディレクトリツリーでは、次のことが可能になります。
- ディレクトリデータの管理を簡単にする
- レプリケーションポリシーとアクセス制御の作成における柔軟性
- ディレクトリを使用するアプリケーションをサポートする
- ユーザーが簡単にディレクトリを操作する
ディレクトリツリーの構造は、階層型の LDAP モデルに従います。ディレクトリツリーでは、たとえば、グループ、ユーザー、あるいは場所ごとにデータを編成できます。また、ディレクトリツリーによって複数のサーバー間でどのようにデータを分散して配置するかが決まります。たとえば、各データベースでは、サフィックスレベルでデータを分割する必要があります。適切なディレクトリツリー構造がなければ、複数のサーバー間で希望どおりにデータを分散することができない場合があります。
これらの留意点のほかに、選択するディレクトリツリー構造の種類によって、設定できるレプリケーションの可能性が制限されることに注意してください。ディレクトリツリーのパーティションは、レプリケーションが正しく機能するように定義する必要があります。ディレクトリツリーの一部だけをレプリケートするのであれば、ディレクトリツリーの設計時にそれを設計に反映させる必要があります。同様に、分岐点にアクセス制御を適用する場合も、ディレクトリツリーの設計時にそれを考慮する必要があります。
ディレクトリツリーの設計
この節では、ディレクトリツリーの設計段階で決定する事柄について説明します。ディレクトリツリーの設計では、データを格納するサフィックスの選択、データエントリ間の階層関係の決定、ディレクトリツリー階層内のエントリのネーミングを行います。次に、ディレクトリツリー設計の各段階について詳しく説明します。
サフィックスの選択
サフィックスは、ツリーのルートにあるエントリの名前です。サフィックスの下にディレクトリデータが格納されます。ディレクトリには複数のサフィックスを持たせることができます。一般的なルートポイントを持たない情報のディレクトリツリーが複数ある場合、複数のサフィックスを使用することもできます。
デフォルトでは、Sun ONE Directory Server を標準的な設定で配備すると、データの格納用に 1 つのサフィックスが、設定情報やディレクトリのスキーマなど、ディレクトリの内部処理に必要なデータ用に複数のサフィックスが使用されます。これらの標準ディレクトリサフィックスについては、『Sun ONE Directory Server 管理ガイド』の第 3 章「Creating Your Directory Tree」を参照してください。
サフィックスの命名規則
ディレクトリ内のすべてのエントリは、サフィックスと呼ばれる共通のベースエントリの下に格納する必要があります。ディレクトリには複数のサフィックスを持たせることができます。ディレクトリサフィックスに名前を付けるときは、次の推奨事項に注意してください。
- グローバルに一意の名前にする
- 変更しない、あるいはまれにしか変更しないようにする
- そのサフィックスの下にあるエントリが画面上で読みやすいように短い名前にする
- ユーザーが容易に入力および記憶できるものにする
1 つの企業環境では、企業の DNS 名またはインターネットドメイン名に合わせてディレクトリのサフィックスを選択します。たとえば、企業が Example.com というドメイン名を所有している場合は、次のようなディレクトリサフィックスを使用します。
dc=example,dc=com
dc (domainComponent) 属性は、ドメイン名をコンポーネントに分割してサフィックスを表します。
通常、サフィックスの名前を付けるときには、任意の属性を使用できます。ただし、ホスティングサービス事業者環境では、サフィックスに使用する属性は次のものに限定することをお勧めします。
- c (countryName)
ISO の定義に準拠した、国名を表す 2 桁のコードを含めます。
- l (localityName)
エントリが存在する、あるいはエントリに関連付けられた国や都市などの地域を示します。
- st (stateOrProvinceName)
エントリがある州または県を示します。
- o (organizationName)
エントリが属する組織の名前を示します。
これらの属性がサフィックスに含まれていると、顧客のアプリケーションとの相互運用性が高まります。たとえば、ホスティングサービス事業者がこれらの属性を使用して、クライアントの Example.com に、次のようなルートサフィックスを作成する場合を考えてみます。
o=Example.com,st=Washington,c=US
これらの属性については、表 4-1 を参照してください。
組織名のあとに国名コードを使用する指定方法は、X.500 のサフィックスの命名規則に従っています。
複数のサフィックスの命名
ディレクトリで使用する各サフィックスが、それぞれ固有のディレクトリツリーを示します。複数のディレクトリツリーを作成し、各ディレクトリツリーを Directory Server によって提供される別々のデータベースに格納することができます。たとえば、図 4-1 に示すように Example.com と Example2.com 用に別々のサフィックスを作成し、それぞれを異なるデータベースに格納できます。
図 4-1 2 つの異なるデータベースに格納される 2 つのサフィックス

データベースは、リソースの制限に応じて 1 つのサーバーまたは複数のサーバーに格納できます。
ディレクトリツリー構造の作成
ツリーの構造をフラットなものにするか階層型にするかを決定する必要があります。一般には、ディレクトリツリーはできるだけフラットにします。ただし、あとで複数のデータベース間にデータを分散したり、レプリケートできるようにしたり、アクセス制御を設定したりする場合は、ある程度階層化することも必要です。
ツリー構造を決定するには、次の手順と検討事項に従います。
ディレクトリの分岐点の作成
階層を設計するときは問題の生じる名前の変更を避けるようにします。ネームスペースがフラットなほど、名前を変更する確率は低くなります。名前を変更する確率は、名前が変更される可能性があるコンポーネントが、ネームスペース内に多く含まれているほど高くなります。ディレクトリツリーの階層が深いほどネームスペース内のコンポーネントは多くなり、名前を変更する確率が高くなります。
次に、ディレクトリツリーの階層設計に適用されるガイドラインを示します。
- 企業組織内でもっとも大きい部門区分のみを表すようにツリーを分岐させる
このような分岐点は、部門 (企業情報サービス、カスタマサポート、販売サービス、専門サービスなど) だけを表します。ディレクトリツリーを分岐させる部門は、安定したものにします。組織変更が頻繁に行われる場合は、この種の分岐は使用しないようにします。
- 分岐点には組織の実際の名前ではなく、機能を表す名前または一般的な名前を使用する
組織名は変更されることが考えられます。会社が部門の名前を変更するたびにディレクトリツリーを変更する必要に迫られるのでは困ります。代わりに、組織の機能を表す一般的な名前を使用します (たとえば、「Widget 研究開発」ではなく「エンジニアリング」を使用します)。
- 似たような機能を持つ組織が複数ある場合は、部門の構成に基づいて分岐点を作成するのではなく、その機能を表す分岐点を 1 つ作成する
たとえば、特定の製品ラインを担当する複数のマーケティング部門がある場合でも、1 つのマーケティング サブツリーのみを作成します。すべてのマーケティングエントリは、そのツリーに所属させます。
次に、会社とホスト環境に固有のガイドラインを示します。
企業環境での分岐点の作成
変更される可能性の低い情報に基づいてディレクトリ構造を決定すれば、名前の変更を避けられます。たとえば、組織ではなくツリー内のオブジェクトのタイプに基づいて構造を定義します。次に、ツリー構造の定義に使用するオブジェクトの例を示します。
- ou=people
- ou=groups
- ou=contracts
- ou=employees
- ou=services
図 4-2 は、これらのオブジェクトを使用した Example.com 社のディレクトリツリーの構造例を示しています。
図 4-2 5 つの分岐点を持つディレクトリ情報ツリーの例
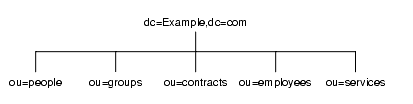
よく使用されている従来型の属性だけを使用することをお勧めします (表 4-1 を参照)。従来からある属性を使用すると、サードパーティの LDAP クライアントアプリケーションとの互換性が保たれる可能性が高くなります。また、従来からある属性は、デフォルトのディレクトリスキーマで認識可能なので、分岐 DN のエントリを作成しやすくなります。
表 4-1 従来からある DN 分岐点の属性
属性名
定義
c
国名
o
組織名。通常、この属性は、企業の部門、教育機関での学部 (人文学部、理学部など)、子会社、企業内の主要部門など、大きな部門を表すために使用する。また、「サフィックスの命名規則」で説明したように、ドメイン名を表す場合もこの属性を使用する必要がある
ou
組織の構成単位。通常この属性は、組織よりも小さな組織内の部門を表すために使用する。組織単位は、一般にすぐ上の組織に属する
st
州あるいは県の名前
l
地域 (都市、地方、オフィス、施設名など)
dc
「サフィックスの命名規則」で説明されているドメインのコンポーネント
ホスト環境での分岐点の作成
ホスト環境では、organization(o) オブジェクトクラスの 2 つのエントリと organizationalUnit(ou) オブジェクトクラスの 1 つのエントリをルートサフィックスの下に含むツリーを作成します。図 4-3 は、ISP である Example.com のディレクトリ分岐の例を示しています。
図 4-3 ISP Example.com のディレクトリ情報ツリー
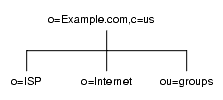
分岐点の特定
ディレクトリツリーをどのように分岐させるかを決めるには、その分岐点を特定するために使用する属性を決定することが必要になります。DN は、属性とデータのペアで構成される一意の文字列です。たとえば、Example.com 社の社員 Barbara Jensen 用のエントリの DN は次のようになります。
cn=Barbara Jensen,ou=people,dc=example,dc=com
各属性とデータのペアは、ディレクトリツリーの分岐点を表します。図 4-4 は、Example.com という企業のディレクトリツリーの例を示しています。
図 4-4 Example.com 社のディレクトリ情報ツリー
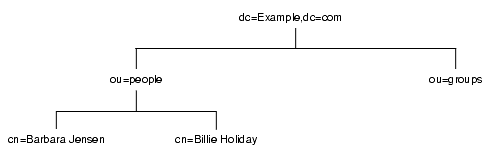
図 4-5 は、インターネットホストを持つ ExampleHost.com 社のディレクトリツリーを示しています。
図 4-5 ExampleHost.com 社のインターネットホストディレクトリ情報ツリー
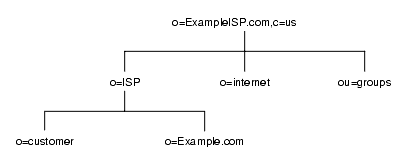
サフィックスのエントリ o=ExampleHost.com,c=US の下で、ツリーは 3 つに分岐しています。ISP の分岐には、顧客データと Example.com の社内情報が含まれています。internet の分岐は、ドメインのツリーです。groups の分岐には、管理グループに関する情報が含まれています。
分岐点の属性を選択するときは、一貫性を持たせることが重要です。ディレクトリツリー全体で識別名 (DN) の形式が統一されていないと、一部の LDAP アプリケーションで混乱が生じる可能性があります。つまり、ディレクトリツリーのある部分で l (localityName) が o (organizationName) の下位にある場合、ディレクトリのほかの部分でも l が o の下位にあることを確認してください。
注 よくある間違いに、識別名で使用されている属性に基づいてディレクトリを検索してしまうことがあります。識別名はディレクトリエントリをほかと識別するだけのもので、これを検索対象にすることはできません。ただし、エントリ自体に格納された属性とデータのペアに基づいてエントリを検索することは可能です。
レプリケーションに関する検討事項
ディレクトリツリーの設計時に、レプリケートするエントリを検討します。エントリセットをレプリケートする場合は、サブツリーの頂点で識別名 (DN) を指定し、その下にあるエントリをすべてレプリケートするのが自然な方法です。また、このサブツリーは、ディレクトリデータの一部を含むディレクトリパーティションである、データベースに対応します。
たとえば、企業環境では自社内のネットワーク名に対応させてディレクトリツリーを編成できます。ネットワーク名が変更されることはほとんどないので、ディレクトリツリー構造は安定したものになります。また、レプリケーションを使用して別のディレクトリサーバーを連動させる場合は、ネットワーク名を使用してディレクトリツリーの最上位の分岐点を作成する方法が有効です。
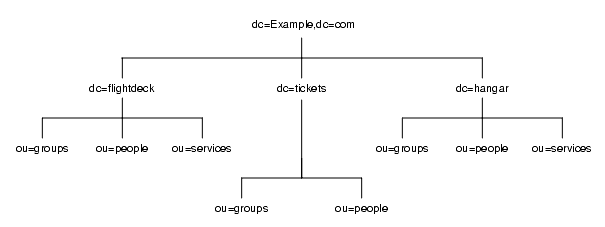
たとえば、Example.com 社に flightdeck.Example.com、 tickets.Example.com、hanger.Example.com という 3 つのプライマリネットワークがあるとします。図 4-6 は、このディレクトリツリーの最初の分岐を示しています。
図 4-6 Example.com 社 DIT の 3 つの主要ネットワーク

ツリーの最初の構造を作成した後、ネットワークをさらに図 4-7 のように分岐させています。
図 4-7 Example.com 社 DIT の 3 つの主要ネットワークの詳細
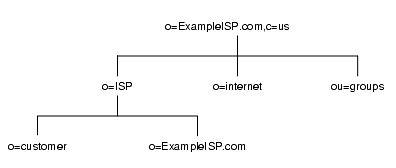
もう一つ例を示します。図 4-8 は、ISP 企業である ExampleISP.com のディレクトリ分岐を示しています。
図 4-8 ExampleISP.com 社のディレクトリ情報ツリー
ディレクトリツリーの最初の構造を作成した後、ネットワークをさらに図 4-9 のように分岐させています。
図 4-9 ExampleISP.com 社の詳細な DIT
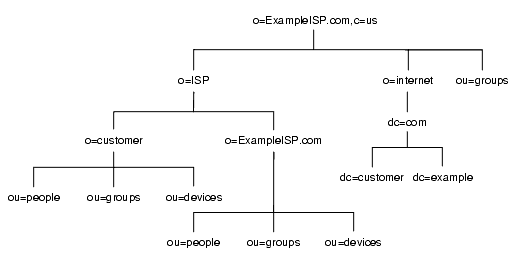
どちらの企業も、あまり変更されることのない情報に基づいてデータ階層を設計しています。
アクセス制御に関する検討事項
ディレクトリツリーを階層化すると、特定のタイプのアクセス制御を使用できるようになります。レプリケーションの場合と同様に、類似したエントリをグループ化すると、それらのエントリを 1 つの分岐点から簡単に管理できます。
また、ディレクトリツリー階層で管理を分散させることができます。たとえば、営業部の管理者に営業のエントリへのアクセス権を与え、マーケティング部の管理者にマーケティングのエントリへのアクセス権を与える場合は、ディレクトリツリーの設計を通じてアクセス権を付与することができます。
ディレクトリツリーではなくディレクトリの内容に基づいてアクセス制御を設定することができます。ACI フィルタを適用するターゲットメカニズムを使用すると、ディレクトリエントリが特定の属性値を含むすべてのエントリへのアクセスを持つように規定した、1 つのアクセス制御規則を定義できます。たとえば、ou=Sales という属性を含むすべてのエントリへのアクセス権を営業部の管理者に与える ACI フィルタを設定できます。
ただし、ACI フィルタは管理が簡単ではありません。ディレクトリツリー階層で組織に対応した分岐を作成する、ACI フィルタを適用する、あるいは両者を組み合わせるなどして、ディレクトリにもっとも適したアクセス制御方法を決める必要があります。ディレクトリで ACI を管理できるように、Sun ONE Directory Server 5.2 には getEffectiveRights という機能が用意されています。この機能は、指定したユーザーがディレクトリのエントリと属性に対して持つアクセス制御権を要求、取得します。getEffectiveRights 機能を使用することで、ユーザーの管理、アクセス制御ポリシーの検証、デバッグを簡単に実行できます。詳細については、第 7 章「安全なディレクトリの設計」で説明します。
エントリのネーミング
ディレクトリツリー階層を設計したあとは、ツリー構造内のエントリに名前を付けるときに使用する属性を決定する必要があります。一般に、名前は 1 つ以上の属性値を選び、相対識別名 (RDN) を形成して作成します。RDN とは、一番左の DN 属性値のことです。名前を付けるエントリのタイプによって使用する属性が変わります。
エントリの名前は、次の規則に従って付ける必要があります。
- 変更される可能性の低い属性を選んで名前を付ける
- 名前はディレクトリ全体で一意でなければならない。名前を一意にすると、DN によってディレクトリ内の複数のエントリが参照されることがなくなる
エントリを作成するときは、エントリ内で RDN を定義します。エントリ内で少なくとも RDN を定義しておけば、簡単にエントリを検出できます。これは、検索が実際の DN を対象にして実行されるのではなく、エントリ自体に格納されている属性値を対象に実行されるからです。
属性名には意味があるので、属性が表すエントリのタイプに合った属性名を使用するようにします。たとえば、組織を表すために l (locality) を使用したり、組織の構成単位を表すために c (country) を使用したりしないでください。
エントリに名前を付けるときの手法について、次の項目ごとに説明します。
人のエントリのネーミング
人のエントリの名前 (DN) は一意である必要があります。従来、識別名ではその人のエントリに名前を付けるときに、commonName または cn 属性を使用しています。つまり、Babs Jensen という名前のユーザーのエントリには、次のような識別名が付けられます。
cn=Babs Jensen,dc=example,dc=com
このエントリと関連付けられているユーザーを識別するのは簡単ですが、同じ名前のユーザーが組織に 2 人いる場合は一意にならない場合があります。この場合、DN の名前の衝突として知られている、複数のエントリが同じ識別名を持つ問題が生じます。
共通名の衝突は、一意の識別子を共通名に追加することで避けられます。たとえば、次のようにします。
cn=Babs Jensen+employeeNumber=23,dc=example,dc=com
ただし、大きなディレクトリの場合は、扱いにくい共通名となり、管理が難しくなります。
より良い方法は、cn 以外の属性で人のエントリを特定することです。次のいずれかの属性を使用することを検討してください。
- uid
Uid (userID) 属性を使用して、個人に固有な値を指定します。たとえば、ユーザーのログイン ID や社員番号などが使用できます。ホスト環境の加入者は、uid 属性で識別する必要があります。
mail 属性を使用して、個人の電子メールアドレスの値を追加します。この方法でも、重複した属性値を含む扱いにくい DN になる場合があるので (たとえば mail=bjensen@Example.com, dc=example,dc=com)、Uid 属性で使用可能な一意の値がなかった場合にのみ、この方法を使用します。たとえば、会社が社員番号やユーザー ID を臨時社員や契約社員に割り当てない場合は、Uid 属性の代わりに mail 属性を使用します。
- employeeNumber
inetOrgPerson オブジェクトクラスの社員には、employeeNumber などの会社側が割り当てた属性値を使用することを検討します。
人のエントリの RDN の属性とデータのペアにどのような属性値を使用する場合でも、必ず一意で永続的な値を使用します。
ホストされる環境での人のエントリに関する検討事項
ユーザーがサービスの加入者の場合、そのエントリは inetUser オブジェクトクラスにし、Uid 属性を含める必要があります。属性は顧客のサブツリーで一意である必要があります。
ユーザーがホスティングサービス事業者に属している場合は、nsManagedPerson オブジェクトクラスの inetOrgPerson として表します。
DIT 内への人のエントリの配置
次に、ディレクトリツリーに人のエントリを配置する場合のガイドラインを示します。
- 企業内のユーザーのエントリは、組織のエントリの下にあるディレクトリツリーに配置する必要がある
- ホスティングサービス事業者の加入者は、ホストされる組織の ou=people 分岐の下に配置する必要がある
組織エントリのネーミング
組織エントリ名は、ほかのエントリと同様に一意である必要があります。ほかの属性値と組織の法的な名前を組み合わせて使用すると、名前は確実に一意になります。たとえば、次のように組織エントリに名前を付けます。
o=Example.com+st=Washington,o=ISP,c=US
登録商標を使用することもできますが、一意である保証はありません。
ホスト環境では、組織エントリに次の属性を含ませる必要があります。
- o (organizationName)
- top、organization、および nsManagedDomain の値を持つ objectClass
その他のエントリのネーミング
地域、州、国、デバイス、サーバー、ネットワーク情報、その他のタイプのデータなど、ディレクトリには多くのものを表すエントリが含まれています。
これらのタイプのエントリには、可能な場合は RDN 内で commonName (cn) 属性を使用してください。たとえば、グループエントリに名前を付ける場合は、次のように名前を付けます。
cn=allAdministrators,dc=example,dc=com
ただし、commonName 属性がサポートされていないオブジェクトクラスを持つエントリに名前を付けなければならないこともあります。この場合は、エントリのオブジェクトクラスでサポートされている属性を使用します。
エントリの DN で使用される属性とエントリ内で実際に使用されている属性が対応している必要はありません。ただし、指定する属性を DNで見えるようにすると、ディレクトリツリーを簡単に管理できます。
ディレクトリエントリのグループ化と属性の管理
ディレクトリツリーは、エントリの情報を階層構造で構成します。階層もグループ化メカニズムの 1 つですが、分散しているエントリの関連付け、頻繁に変更される組織、または多数のエントリで繰り返されるデータには適していません。Directory Server には、グループ化メカニズムとしてグループとロールも提供しています。こちらのほうがエントリ間の関係を柔軟に定義できます。
これらのグループ化メカニズムのほかに、Directory Server ではサービスクラス (CoS) というメカニズムを利用できます。これは、アプリケーションの介入なしでエントリ間で属性を共有できるように、属性を管理するメカニズムです。ロールメカニズムと同様に、エントリが検出されると、CoS がそのエントリに対して仮想属性を生成します。ただし、CoS はメンバーを定義するのではなく、一貫性の保持と容量の節約のために、関連するエントリがデータを共有できるようにします。
次に、エントリのグループ化と属性管理のメカニズム、およびそれぞれの利点と制限について説明します。
- スタティックグループとダイナミックグループ
- 管理されているロール、フィルタを適用したロール、入れ子のロール
- ロールの列挙とロールメンバーシップの列挙
- ロールの範囲
- ロールの制限事項
- グループとロールのどちらを使用するかの決定
- サービスクラス (CoS) による属性の管理
- CoS について
- CoS 定義エントリと CoS テンプレートエントリ
- CoS の優先順位
- ポインタ CoS、間接 CoS、クラシック CoS
- CoS の制限事項
スタティックグループとダイナミックグループ
グループとは、そのメンバーであるほかのエントリを特定するエントリです。グループのメンバーの範囲は、ディレクトリ全体です。グループ定義エントリの場所は関係しません。グループ定義エントリは、特に変更を頻繁に行う企業では、グループ化メカニズムに柔軟性を与えてくれます。グループ名がわかっている場合は、そのすべてのメンバーエントリを簡単に検索できます。次に、スタティックグループとダイナミックグループの特徴について説明します。どのような場合にどちらのグループを使用するべきかを理解してください。
- スタティックグループは、そのメンバーエントリの名前を明示的に指定します。スタティックグループを定義するエントリは、groupOfNames または groupOfUniqueNames オブジェクトクラスを使用し、各メンバーの DN をそれぞれ member または uniqueMember の属性値として含みます。member 属性には、サーバーがグループのメンバーシップを確立するときにチェックする DN が含まれ、uniqueMember 属性には、DN とオプションとして一意の識別子が続く構文が含まれます。メンバーシップのチェックは、この構文に対して行われます。ただし現時点では、Directory Server はネイティブアクセス制御処理の groupOfNames (member 属性) だけをサポートしています。uniqueMember 属性の構文については、『RFC 2256: A Summary of the X.500(96) User Schema for use with LDAPv3』 (http://www.ietf.org/rfc/rfc2256.txt) を参照してください。
- スタティックグループは、ディレクトリ管理者のグループのようにメンバーの少ないグループに適しており、数千のメンバーが含まれるグループには適していません。パフォーマンスが著しく低下するため、メンバー数が 20,000 を超えるスタティックグループを作成することは避けてください。これ以上のサイズのグループには、ダイナミックグループまたはロールを使用することをお勧めします。メンバー数が 20,000 を超えるグループを定義するためにスタティックグループを使用する必要がある場合は、1 つの大きなスタティックグループを使用するのではなく、グループのグループ化を使います。
- ダイナミックグループはフィルタを指定し、そのフィルタと一致するすべてのエントリがグループのメンバーとなります。このようなグループは、フィルタが評価されるたびにメンバーが定義されるため、ダイナミックグループと呼ばれます。ダイナミックグループの定義エントリは、groupOfUniqueNames および groupOfURLs オブジェクトクラスに属します。グループメンバーシップは、memberURL 属性の LDAP URL 値として表現される 1 つまたは複数のフィルタ、または uniqueMember 属性の値として表現される 1 つまたは複数の DN としてリストされます。
注 別のグループの DN をダイナミックグループの uniqueMember 属性に挿入することで、グループ内に別のグループを入れ子にすることができます。
どちらのグループも、ディレクトリ内のどこにいるメンバーでも識別できますが、グループ定義自体は、ou=Groups などの適切な名前のノードに格納することをお勧めします。たとえば、このように格納することで、バインドの証明情報がグループのメンバーである場合に、アクセスを許可または制限するアクセス制御命令 (ACI) を定義するときに、検索が簡単になります。
管理されているロール、フィルタを適用したロール、入れ子のロール
ロールはエントリをグループ化する新しいメカニズムで、エントリがメンバーとなっているすべてのロールを自動的に特定します。各ロールはメンバー (そのロールを所有するエントリ) を持ちます。グループと同じようにロールのメンバーを明示的またはダイナミックに指定できます。ディレクトリ内のエントリを取得するときに、そのエントリがメンバーとして属するすべてのロール定義の DN を含む nsRole 属性がロールメカニズムによって自動的に生成されるため、そのエントリがどのロールに属するかを直ちに知ることができます。これにより、グループ化メカニズムの主な欠点が解消されます。
ディレクトリがすべてのロールのメンバーを自動的に算出するため、ロールメカニズムはクライアントから非常に簡単に使用できます。ロールに属しているすべてのエントリに nsRole 仮想属性が指定されます。この属性の値は、そのエントリがメンバーになっているすべてのロールの DN です。nsRole が仮想属性であるのは、実行中にサーバーによって生成され、実際にはディレクトリに格納されないためです。つまり、ロールを使って処理を実行すると、グループを使う場合よりもサーバー側でより多くのリソースが消費されます。これは、クライアントアプリケーションのためにサーバーがその処理を実行するためです。ただし、ロールのメンバーの検査方法は一貫しており、サーバー側で透過的に実行されます。
Sun ONE Directory Server は、次の 3 種類のロールをサポートしています。
- 管理されているロール : 明示的にメンバーエントリにロールを割り当てる
- フィルタを適用したロール : 指定した LDAP フィルタと一致するエントリを割り当てる。このため、ロールは各エントリに含まれている属性によって異なる
- 入れ子のロール : ほかのロールを含むロールを作成できる
管理されているロール
管理されているロールは、メンバーがロール定義エントリではなく各メンバーエントリ内で定義されていることを除いて、スタティックグループと似ています。管理されているロールを使用すると、管理者は、対象となるエントリに nsRoleDN 属性を追加することにより、特定のロールを割り当てることができます。この属性の値は、ロール定義エントリの DN です。スタティックロールの定義エントリは、対象の範囲だけを定義します。そのロールのメンバーは指定範囲内で、nsRoleDN 属性がロール定義エントリの DN を指定しているエントリです。
フィルタを適用したロール
フィルタを適用したロールはダイナミックグループと似ており、ロールのメンバーを決定するフィルタを定義します。nsRoleFilter 属性の値は、フィルタを適用したロールを定義します。サーバーが、フィルタ文字列と一致する、フィルタを適用したロールの適用範囲内のエントリを返す場合、そのエントリにはロールを識別する nsRole 属性が常に含まれています。
入れ子のロール
入れ子のロールはほかのロールの定義エントリをリストし、それらのロールのすべてのメンバーを組み合わせます。つまり、あるエントリが入れ子のロールにリストされているロールのメンバーである場合、そのエントリは入れ子のロールのメンバーでもあることになります。入れ子のロールを使用して、別のロールを含むロールを作成できます。
ロールの列挙とロールメンバーシップの列挙
ロールの列挙
nsRole 属性はほかの属性と同様に読み取られます。クライアントはこの属性を使用して、任意のエントリが属しているすべてのロールを列挙することができます。ロールメカニズムで使用されるのは、nsRole 属性だけで、この属性はすべての変更操作から保護されています。ただし、読み取りは可能なので、ロールメンバーシップへの読み取りアクセスがセキュリティ要件で禁じられている場合は、アクセス制御を定義して読み取りから保護してください。
ロールメンバーシップの列挙
Directory Server の従来のリリースでは実行できなかった仮想属性に対する検索が可能になりました。これにより、nsRole 属性を検索し、ロールのメンバーを列挙することができます。ただし、検索操作でインデックスが付けられていない属性は、パフォーマンスに大きな影響を与える可能性があるため、注意が必要です。等価フィルタに基づく検索の多くにはインデックスが付けられるため効率的ですが、たとえば否定検索にはインデックスが付けられず、パフォーマンスの低下を招くことになります。nsRoleDN 属性にはデフォルトでインデックスが付けられるので、管理されているロールに対する検索は比較的効率的です。ただし、フィルタを適用したロールと入れ子のロールでは、インデックスが付けられた属性と付けられていない属性の両方がフィルタに含まれている可能性があるため、インデックスが付けられていない検索を行わないように、少なくとも 1 つのインデックス付き属性がフィルタに含まれていることを確認する必要があります。
ロールの範囲
Directory Server の従来のリリースでは、ロールの範囲はロール定義のサブツリーに限定されていました。異なるサブツリーの間でロールを共有するには、そのサブツリーがツリーのルートにある必要があったため、複数のサブツリーにまたがるロールは限定され、管理も複雑でした。Example.com という大企業のエンジニアリング部門に勤務するエンジニアが、販売部門によって制御されるアプリケーションにアクセスしなければならない場合を考えてください。ロールが販売部門の管理者のために作成され、販売サブツリー内のこのアプリケーションへのアクセスを制御している場合、エンジニアリングサブツリーには属しているが、販売サブツリーには属さないこのエンジニアは、ロールの範囲がサブツリーに限定されているため、そのアプリケーションにアクセスすることはできません。グループに同じ範囲制限が適用された場合 (現在でも適用されます)、それを解決するには、そのアプリケーションにアクセスできる販売部門のユーザーのグループにエンジニアを追加する必要がありました。しかし、この解決策はグループベースであり、結果としてロールメカニズムの利点は失われます。
Sun ONE Directory Server 5.2 では、ロールの範囲をロール定義エントリのサブツリーを超えて拡張するための新しい属性を使用できます。これは、nsRoleScopeDN という 1 つの値を属性で、既存のロールに追加する範囲の DN を含みます。
注 範囲拡張のための新しい nsRoleScopeDN 属性を追加できるのは、入れ子のロールだけです。
販売アプリケーションにアクセスする必要のある、前述の Example.com のエンジニアの例で、ロールの範囲をどのように拡張できるかについて説明します。Example.com のディレクトリツリーには、エンジニアリングサブツリー用の o=eng,dc=example,dc=com と、販売サブツリー用の o=sales, dc=example,dc=com という 2 つのサブツリーがあると仮定します。販売アプリケーションへのアクセスを管理する SalesAppManagedRole という販売サブツリーロールの範囲を拡張し、エンジニアリングサブツリーの 1 人のユーザーを含めるには、次の手順を実行します。
- エンジニアリングサブツリーに、たとえば EngineerManagedRole のようにエンジニアユーザーのロールを作成します。(前述の例では管理されているロールを作成しているが、フィルタを適用したロールでも、入れ子のロールでも構わない。)
- 販売サブツリーに、たとえば SalesAppPlusEngNestedRole のような入れ子のロールを作成し、新たに作成した EngineerManagedRole ロールと、当初からの SalesAppManagedRole ロールを格納します。
- 新しい SalesAppPlusEngNestedRole 入れ子ロールに nsRoleScopeDN 属性を追加します。属性値には、追加するエンジニアリングサブツリーの範囲の DN を指定します。この例では、o=eng,dc=example,dc=com を指定します。
新しい SalesAppPlusEngNestedRole 入れ子ロールは、次のようになります。
dn:cn=SalesAppPlusEngNestedRole,dc=example,dc=com
objectclass: LDAPsubentry
objectclass:nsRoleDefinition
objectclass:nsComplexRoleDefinition
objectclass:nsNestedRoleDefinition
nsRoleDN:cn=SalesAppManagedRole,o=sales,dc=example,dc=com
nsRoleDN:cn=EngineerManagedRole,o=eng,dc=example,dc=com
nsRoleScopeDN:o=eng,dc=example,dc=com
アクセス制御の点から見ると、販売アプリケーションにアクセスするエンジニアリングユーザーには、SalesAppPlusEngNestedRole ロールおよび実際の販売アプリケーションにアクセスするための適切なアクセス権を与えることが重要です。同様に、レプリケーションの面から考えると、ロールの範囲全体をレプリケートする必要があります。これは、拡張された範囲をレプリケートしない場合に問題が発生するためです。
注 範囲の拡張は入れ子のロールに限定されているため、これまで 1 つのドメインのロールを管理していた管理者は、その他のドメインにすでに存在するロールを使用する権限だけを持つことになり、その他のドメインで任意のユーザーの任意のロールを作成することはできなくなります。
ロールの制限事項
ディレクトリサービスをサポートするロールを作成する場合は、次の制限事項を考慮する必要があります。
- ロールと連鎖
連鎖機能を使用してディレクトリツリーを複数のサーバーに分散している場合は、ロールを定義するエントリをそれらのロールを所有するエントリと同じサーバーに配置する必要があります。連鎖を介して、サーバー A が別のサーバー B からエントリを受け取る場合は、それらのエントリにはサーバー B で定義されたロールが含まれますが、サーバー A で定義されたロールは割り当てられません。
- フィルタを適用したロールは CoS によって生成された属性を使用できない
フィルタを適用したロールでは、CoS 仮想属性の値に基づくフィルタ文字列を使用できません。詳細は、「CoS について」を参照してください。ただし、CoS 定義の指示子属性は、ロール定義によって生成された nsRole 属性を参照できます。ロールベースの属性の作成については、『Sun ONE Directory Server 管理ガイド』の第 5 章に記載されている「Creating Role-Based Attributes」を参照してください。
- ロールの範囲拡張
ロールの範囲は、同一サーバーインスタンス上の異なるサブツリーに限定されます。ロールの範囲を別のサーバーにまで拡張すると、予期せぬ動作が生じることがあります。
グループとロールのどちらを使用するかの決定
グループとロールのメカニズムは機能の一部が重複しているため、あいまいさを招く可能性があります。エントリをグループ化するどちらの方法にも、利点と欠点があります。一般に、より新しく設計されたロールメカニズムのほうが、頻繁に必要となる機能を効率的に提供できるように設計されています。しかし、グループ化メカニズムは、サーバーの複雑さに影響を及ぼし、クライアントによるメンバー情報の処理方法を決めるため、グループ化メカニズムは慎重に計画する必要があります。どのメカニズムが適しているかを判断するには、メンバーシップクエリーと、実行する必要のある管理操作の種類を理解する必要があります。次の 2 つの項目では、設計時の選択に役立てられるように、両方のメカニズムの長所と短所について説明します。管理者がグループ化ポリシーを後から一貫して維持できるように、選択内容を文書化しておくことを強くお勧めします。
この節には、次の項目があります。
グループメカニズムの利点
- メンバーシップが 20,000 以下の場合にメンバーを列挙するには、スタティックグループが適している
特定セットのメンバーを列挙するだけであれば、スタティックグループを使用するほうが負担が少なくなります。ただし、20,000 を超えるメンバーを含むスタティックグループはパフォーマンスを低下させるため、メンバー数が 20,000 以下であることが前提となります。member 属性を取得してスタティックグループのメンバーを列挙することは、同じロールを共有するすべてのエントリを調べるより簡単であるため、メンバーの列挙操作により適しています。
- メンバーの割り当てと削除などの管理操作には、スタティックグループが適している
グループにユーザーを追加する上で、特別なアクセス権を追加する必要がないため、メンバーの割り当てと削除を行う場合の最適なグループ化メカニズムは、スタティックグループとなります。
グループエントリを作成する権限を持つということは、グループにメンバーを割り当てる権限を持つということになります。これに対して、管理されているロールとフィルタが適用されたロールでは、管理者はユーザーエントリに nsroledn 属性を書き込む権限も持つ必要があります。このアクセス権の制限は、入れ子のロールにも間接的に適用されます。これは、入れ子のロールを作成するということは、すでに定義されているその他のロールをまとめる権限が必要であることを意味するためです。
- フィルタベースの ACI で使用するには、ダイナミックグループが適している
ACI でのバインドルールの指定など、フィルタに基づいてすべてのメンバーを検索するだけの場合は、ダイナミックグループを使用します。フィルタを適用したロールはダイナミックグループと似ていますが、nsRole 仮想属性を生成するロールメカニズムを開始します。クライアントが nsRole 値を必要としない場合は、ダイナミックグループを選択することで、この計算のオーバーヘッドを回避できます。
- 既存のセットに対してセットの追加や削除を行うときは、グループが適している
既存のセットに対してセットの追加や削除を行う場合は、入れ子の制限がないため、グループメカニズムが最も適しています。ロールメカニズムでは、他のロールを受け入れられるのは入れ子のロールに限られています。
- グループ化範囲の自由度が配備で重要になる場合は、グループが適している
グループのメンバー範囲は、グループ定義エントリの場所に関係なくディレクトリ全体であるため、範囲の面ではグループには柔軟性があります。ロールでも、特定のサブツリーを超えて範囲を拡張することができますが、入れ子のロールに範囲拡張属性 nsRoleScopeDN を追加する必要があるため、範囲拡張には制限があります。
ロールメカニズムの利点
- 指定セットのメンバーを列挙し、指定エントリのすべてのメンバーを検索する場合は、ロールが適している
指定セットのメンバーを列挙し、指定エントリのすべてのメンバーを検索する場合は、ロールメカニズムが最も適しています。ロールはこの情報をユーザーエントリにプッシュします。そこでは情報をキャッシュできるので、以後のメンバーシップのテストをより効率的に行えます。サーバーがすべての計算を実行し、クライアントは nsRole 属性の値を読み取るだけです。さらに、この属性にすべてのタイプのロールが含まれ、クライアントはすべてのロールを均等に処理できます。一般に、グループよりもロールの方が、両方の処理をより効率よく実行でき、クライアント側での処理が簡単になります。
- CoS、パスワードポリシー、アカウントの無効化、ACI など、Directory Server の既存のグループ化メカニズムを統合する場合は、ロールが適している
サーバー上のセットのメンバーシップを「自然に」使用する、つまり、メンバーシップに関する計算をサーバーが自動的に行う利点を活用する場合は、ロールメカニズムが最適です。これはロールが設計された目的でもあります。ロールは、リソース指向の ACIで、CoS のベースとして、より複雑な検索フィルタ、パスワードポリシー、アカウントの無効化などの一部として使用することができます。グループを使用してこのような統合を行うことはできません。
サービスクラス (CoS) による属性の管理
ディレクトリエントリのグループ化と属性の管理に関する節の冒頭でも説明したように、サービスクラス (CoS) メカニズムを使用することで、アプリケーションによる介入なしでエントリ間で属性を共有することができます。CoS は、ロールメカニズムと同じように、エントリの取得時にエントリの仮想属性を生成します。CoS は、メンバーシップを定義しません。ロールメカニズムのようにエントリをグループ化するのではなく、一貫性の保持と容量の節約のために、関連するエントリがデータを共有できるようにします。ここでは、CoS メカニズムの詳細について説明します。説明する内容は次のとおりです。
CoS について
facsimileTelephoneNumber 属性の値が等しい何千ものエントリがディレクトリに格納されているとします。従来のやり方で FAX 番号を変更するには、各エントリを個別に更新する必要がありました。これは管理者にとって大きな負担であり、時間がかかるというだけでなく、全てのエントリが更新されないという危険がありました。CoS を使用すると、FAX 番号は 1 か所に保存され、Directory Server は、エントリが返されるときに、関係のあるすべてのエントリに対して facsimileTelephoneNumber 属性を自動的に生成します。
クライアントアプリケーションでは、生成された CoS 属性はほかの属性と同じように検出されます。ただし、ディレクトリ管理者が管理するのは 1 つの FAX 番号値だけです。さらに、実際にディレクトリに格納される値が少ないため、データベースが使用するデータ領域が少なくて済みます。また、CoS メカニズムを使用すると、生成された値をエントリで上書きすることも、同じ属性に対して複数の値を生成することも可能です。
注 CoS 仮想属性にはインデックスが付けられないため、LDAP 検索フィルタで参照した場合、パフォーマンスに影響が生じる可能性があります。
生成される CoS 属性には、複数のテンプレートにより複数の値が設定されている場合があります。指示子が複数のテンプレートエントリを指定する場合もあれば、同じ属性に複数の CoS 定義がある場合もあります。また、選択したすべてのテンプレートから 1 つの値だけが生成されるように、テンプレートの優先順位を指定することもできます。詳細については、『Sun ONE Directory Server 管理ガイド』の第 5 章に記載されている「Defining Class of Service (CoS)」を参照してください。
ロールとクラシック CoS を組み合わせて使用すると、ロールベースの属性を指定できます。エントリは関連付けられたサービスクラステンプレートを持つ特定のロールを所有しているため、これらの属性がエントリ上に現れます。たとえば、ロールに基づいた属性を使用して、ロール単位で検索制限を設定できます。
CoS の機能は再帰的に使用できます。つまり、Directory Server では、CoS で生成されたほかの属性によって指定される CoS から属性を生成できます。CoS スキーマを複雑にすると、クライアントアプリケーションから情報へのアクセスが単純化され、繰り返し使用する属性を簡単に管理できるようになりますが、同時に管理が複雑になり、サーバーのパフォーマンスが低下します。極端に複雑な CoS スキーマは避けてください。たとえば、多くの間接 CoS スキーマは、クラシック CoS またはポインタ CoS として再定義することができます。
最後に、必要以上に CoS 定義を変更しないようにすることが非常に重要です。サーバーは CoS 情報をキャッシュに保存するため、CoS 定義への変更がすぐには反映されません。キャッシュを利用することで、生成された属性エントリに高速にアクセスできるようになりますが、CoS 情報が変更されると、サーバーはキャッシュを再構築しなくてはなりません。これは、多少時間のかかるタスク (通常は数秒) です。キャッシュの再構築中は、読み取り操作は新たに変更された情報ではなく、古いキャッシュに残されされている情報に対して行われます。このため、CoS 定義を頻繁に変更した場合、古くなったデータにアクセスする可能性が高くなります。
CoS 定義エントリと CoS テンプレートエントリ
CoS メカニズムは、CoS 定義エントリと CoS テンプレートエントリという 2 種類の支援エントリに依存します。ここでは、2 つのエントリの詳細について説明します。説明する内容は次のとおりです。
CoS 定義エントリ
CoS 定義エントリは、使用中の CoS のタイプおよび生成される CoS 属性の名前を特定します。このエントリは、ロール定義エントリと同様に、LDAPsubentry オブジェクトクラスから継承されます。CoS 偏差の範囲は、定義エントリの格納場所によって決定されます。この範囲は、CoS 定義エントリの親の下にあるサブツリー全体となります。定義エントリの親の分岐内のすべてのエントリを CoS 定義のターゲットエントリと呼びます。同じ CoS 属性に複数の定義が存在することもあります。この場合は、複数の値が含まれます。
CoS 定義エントリは、cosSuperDefinition オブジェクトクラスのインスタンスです。CoS 定義エントリは、CoS のタイプを指定する、次のオブジェクトクラスのいずれかから継承されます。
- cosPointerDefinition
- cosIndirectDefinition
- cosClassicDefinition
CoS 定義エントリには、必要に応じて、仮想 CoS 属性、テンプレート DN、およびターゲットエントリの指示子属性を指定できるように、CoS のそれぞれのタイプに固有の属性が含まれています。デフォルトでは、CoS メカニズムは、CoS 属性と同じ名前を持つ既存の属性の値を上書きしません。ただし、CoS 定義エントリの構文を使用することで、この動作を制御できます。
注 スキーマ検査が有効になっている場合は、その CoS 属性を設定できるすべてのターゲットエントリにこの属性が生成されます。スキーマ検査が無効になっている場合は、すべてのターゲットエントリに CoS 属性が生成されます。
CoS テンプレートエントリ
CoS テンプレートエントリには、CoS 属性について生成される値が含まれます。CoS の適用範囲内のすべてのエントリで、ここに定義された値が使用されます。それぞれが異なる値を持つ複数のテンプレートが存在することもあります。この場合、生成される属性は複数の値を持ちます。CoS メカニズムは、定義エントリとターゲットエントリの内容に基づいていずれかの値を選択します。
CoS テンプレートエントリは、cosTemplate オブジェクトクラスのインスタンスです。CoS テンプレートエントリには、CoS メカニズムによって生成された 1 つ以上の値が含まれます。特定の CoS 用のテンプレートエントリは、その CoS 定義と同じレベルのディレクトリツリー内に格納されます。
注 管理を容易にするため、定義エントリとテンプレートエントリはできるだけ同じ場所に格納してください。また、それが提供する機能を説明するような名前を付けることをお勧めします。たとえば、定義エントリ DN に "cn=classicCosGenerateEmployeeType,ou=People,dc=example,dc=com" などの名前を付けると、"cn=ClassicCos1,ou=People,dc=example,dc=com" よりもわかりやすくなります。CoS の各タイプに関連するオブジェクトクラスと属性については、『Sun ONE Directory Server 管理ガイド』の第 5 章に記載されている「Defining Class of Service (CoS)」を参照してください。
CoS の優先順位
属性値を得る上で互いに競合する CoS スキームが作成される場合があります。たとえば、CoS 定義エントリに複数の値を持つ cosSpecifier があると仮定します。このような場合、どのテンプレートが属性値を提供するかを決定するために、各テンプレートエントリにテンプレート優先順位を指定することができます。テンプレート優先順位の設定には、cosPriority 属性を使用します。この属性は、特定のテンプレートのグローバルな優先順位を数字で表します。優先順位 0 は、優先順位が最も高いことを示します。
cosPriority 属性を持たないテンプレートは、優先順位が最も低いとみなされます。2 つ以上のテンプレートが属性値を提供する状況で、その優先順位が同じまたは設定されていない場合は、任意の値が選択されます。
次に、CoS テンプレートエントリの例を示します。
dn: cn=exampleUS,cn=data
objectclass:top
objectclass: cosTemplate
postalCode: 44438
cosPriority: 0このテンプレートエントリには、postalCode 属性の値が含まれます。優先順位にはゼロが指定されているため、別の postalCode 値を持つ競合テンプレートに優先して適用されます。
ポインタ CoS、間接 CoS、クラシック CoS
テンプレートの選択方法が異なり、それによって生成される値が異なる 3 つのタイプの CoS があります。次に、これらの 3 種類の CoS について詳しく説明します。
ポインタ CoS
ポインタ CoS はもっとも単純です。ポインタ CoS 定義エントリによって、cosTemplate オブジェクトクラスの特定のテンプレートエントリの DN が決定されます。すべてのターゲットエントリに、このテンプレートで定義されているものと同じ CoS 属性値が設定されます。
ポインタ CoS の例
この例では、dc=example,dc=com の下に格納されるすべてのエントリに共通の郵便番号を定義する CoS を示します。図 4-10 は、この例の 3 つのエントリ (CoS 定義エントリ、CoS テンプレートエントリ、ターゲットエントリ) を示しています。
図 4-10 ポインタ CoS の定義とテンプレートの例
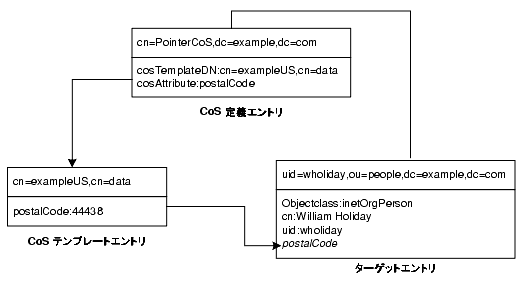
テンプレートエントリは、CoS 定義エントリ内の DN (cn=exampleUS,cn=data) によって特定されます。エントリ dc=example,dc=com で postalCode 属性が照会されるたびに、Directory Server は、テンプレートエントリ cn=exampleUS,cn=data 内の使用可能な値を返します。したがって、郵便コードは、エントリ uid=wholiday,ou=people,dc=example,dc=com と一緒に表示されますが、このエントリには格納されません。エントリ内に実際に存在する属性の代わりに、CoS によって生成されるいくつかの属性が数千または数百万のエントリで共有される例を考えると、CoS を利用することで節約できる格納のための容量とパフォーマンスの向上を理解することができます。
間接 CoS
間接 CoS を使用すると、ディレクトリ内の任意のエントリをテンプレートにして、CoS 値を指定することができます。間接 CoS 定義エントリは、間接指示子と呼ばれる属性を識別します。ターゲットエントリに含まれるこの属性の値によって、そのエントリで使用されるテンプレートが決定されます。ターゲットエントリ内の間接指示子属性には、DN が含まれています。間接 CoS を使用することで、各ターゲットエントリで異なるテンプレートを使用できるため、CoS 属性に異なる値を指定することができます。
たとえば、departmentNumber 属性を生成する間接 CoS では、指示子として社員の上司を使用できます。ターゲットエントリを検索する場合、CoS メカニズムはテンプレートとして manager 属性の DN 値を使用します。そして、上司の部門番号と同じ値を使用して、社員の departmentNumber 属性を生成します。
間接 CoS の例
次の間接 CoS の例では、ターゲットエントリの manager 属性を使用してテンプレートエントリを特定しています。CoS メカニズムでは、この方法で、すべての従業員に対して上司と同じ departmentNumber 属性を生成することにより、常に最新の状態を維持できます。図 4-11 は、この例の 3 つのエントリを示しています。
図 4-11 間接 CoS の定義とテンプレートの例
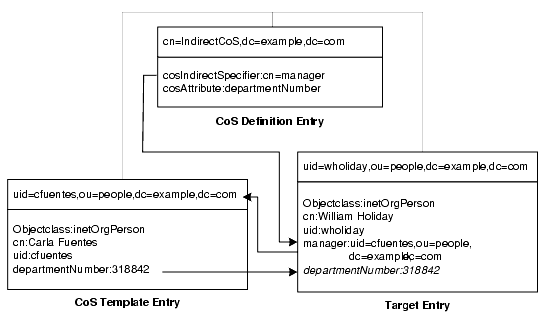
間接 CoS の定義エントリは、指示子属性の名前を指定します。この例では、manager 属性です。William Holiday のエントリは、この CoS のターゲット エントリの 1 つであり、その manager 属性には、cn=Carla Fuentes,ou=people,dc=example,dc=com の DN が含まれます。したがって、Carla Fuentes のエントリは、departmentNumber 属性値 318842 を提供するテンプレートです。
クラシック CoS
クラシック Cos は、ポインタ CoS と間接 Cos の動作を組み合わせたものです。クラシック CoS の定義エントリは、テンプレートのベース DN と指示子属性を特定します。次のように、ターゲットエントリの指示子属性の値は、テンプレートエントリの DN の構築に使用されます。
cn=specifierValue,baseDN
CoS 値を含むテンプレートは、ターゲットエントリの指示子属性の RDN (relative domain name) 値とテンプレートのベース DN を組み合わせることで決定されます。
クラシック CoS テンプレートは、任意の間接 CoS テンプレートに関連するパフォーマンスの問題を回避するための、cosTemplate オブジェクトクラスのエントリです。
クラシック CoS の例
クラシック CoS メカニズムでは、定義エントリで指定されたベース DN とターゲットエントリの指示子属性からテンプレートの DN が決定されます。指示子属性の値は、テンプレート DN の cn 値として使用されます。したがって、クラシック CoS のテンプレート DN は、次のような構造になります。
cn=specifierValue,baseDN
図 4-12 の例は、郵便番号属性の値を生成するクラシック CoS の定義を示しています。
図 4-12 クラシック CoS の定義とテンプレートの例
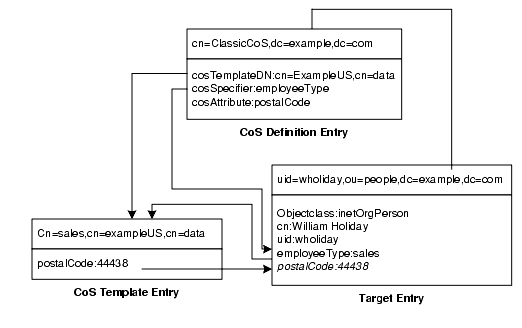
この例では、CoS 定義エントリの cosSpecifier 属性が、employeeType 属性を指定します。この属性とテンプレート DN を組み合わせると、テンプレートエントリを cn=sales,cn=exampleUS,cn=data として識別できます。このテンプレートエントリは、postalCode 属性の値をターゲットエントリに与えます。
CoS の制限事項
CoS 機能は、複雑なメカニズムであり、パフォーマンスおよびセキュリティ上の理由から次の制限事項が適用されます。
- サブツリーの制限
cn=config サブツリーと cn=schema サブツリーには、CoS 定義を作成できません。
- 属性が CoS 生成属性として宣言されているサフィックスの検索は、インデックスが付けられていない検索となる
属性が CoS 生成属性として宣言されているサフィックスの検索は、インデックスが付けられていない検索となります。これは、パフォーマンスに重大な影響を生じる可能性があります。同じ属性が CoS 属性として宣言されていないサフィックスでは、検索にインデックスが付けられます。
- 属性タイプの制限
次の属性タイプは、同じ名前の実際の属性と動作が異なるため、CoS メカニズムでは生成できません。
- userPassword : CoS で生成されたパスワード値は、ディレクトリサーバーへのバインドに使用できない
- aci : Directory Server では、CoS によって定義された仮想 ACI 値の内容に基づいてアクセス制御を適用しない
- objectclass : Directory Server では、CoS によって定義された仮想オブジェクトクラスの値を検査するスキーマが実行されない
- nsRoleDN : CoS によって生成された nsRoleDN 値は、サーバーによるロールの生成に使用されない
- すべてのテンプレートをローカルに配置する必要がある
CoS 定義またはターゲットエントリの指示子に指定されているテンプレートエントリの DN は、ディレクトリ内のローカルエントリを参照する必要があります。テンプレートとそこに含まれる値は、ディレクトリ連鎖またはリフェラルからは取得できません。
- CoS 仮想値と実際の値と組み合わせることはできない
CoS 属性の値では、エントリの実際の値とテンプレートの仮想値を組み合わせることはできません。CoS により実際の属性値が上書きされると、実際の値はすべてテンプレートの値に置き換えられます。ただし、『Sun ONE Directory Server 管理ガイド』の「CoS Limitations」で説明しているように、CoS メカニズムでは、複数の CoS 定義の仮想値を組み合わせることができます。
- フィルタが適用されたロールは CoS によって生成される属性を使用できない
フィルタを適用したロールでは、CoS 仮想属性の値に基づくフィルタ文字列を使用できません。ただし、CoS 定義の指示子属性は、ロール定義によって生成された nsRole 属性を参照できます。詳細については、『Sun ONE Directory Server 管理ガイド』の「Creating Role-Based Attributes」を参照してください。
- アクセス制御命令 (ACI)
格納されている通常の属性へのアクセスと同様に、CoS によって生成された属性へのアクセスが制御されます。ただし、CoS によって生成された属性値に依存するアクセス制御規則は、「属性タイプの制限」で説明されている条件に従います。
- CoS キャッシュの応答時間
CoS キャッシュは、パフォーマンスを向上させるためにすべての CoS データをメモリに保持する Directory Server の内部構造です。このキャッシュは、仮想属性の算出時に使用される CoS データの取得用に最適化されており、CoS 定義エントリおよびテンプレートエントリの更新中でも使用できます。したがって、定義エントリおよびテンプレートエントリを追加または変更すると、変更内容が反映されるまでわずかに時間がかかる場合があります。この遅延時間は、CoS 定義の数と複雑さ、および現在のサーバーの負荷によって異なりますが、通常は、数秒間かかります。複雑な CoS 設定を行うときは、この遅延時間に留意してください。
ディレクトリツリーの設計例
次に、フラットな階層をサポートするディレクトリツリーの設計例と、より複雑な階層を含む設計例を示します。
国際企業向けのディレクトリツリー
国際企業の要件に対応するには、ディレクトリツリーのルートをインターネットのドメイン名に設定し、そのルートポイントのすぐ下で、企業が事業を展開している国ごとにツリーを分岐させます。「サフィックスの命名規則」では、国名指示子をディレクトリツリーのルートとして設定しないように勧めています。これは、企業が国際的な組織である場合には、特に当てはまります。
LDAP は DN 内の属性の順序については何の規制も設けていないため、図 4-13 のように c (countryName) 属性を使用して各国の分岐を表すことができます。
図 4-13 c (countryName) 属性を使用してディレクトリツリーで国を表現した例

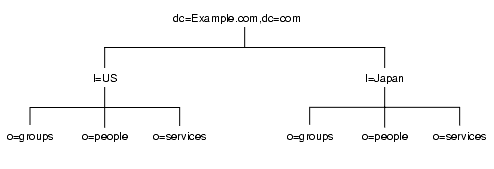
ただし、この方法ではスタイルに統一感がないと感じる管理者もいるので、代わりに l (locality) 属性を使用して、各国を次のように表すこともできます。
図 4-14 l (locality) 属性を使用してディレクトリツリーで国を表現した例
ISP 向けのディレクトリツリー
IPS (インターネットサービスプロバイダ) は、ディレクトリを通じて複数の企業をサポートする可能性があります。ISP の場合は、各顧客を個別の企業とみなし、ディレクトリツリーを設計します。セキュリティ上の理由から、それぞれが一意のサフィックスを持つ個別のディレクトリツリーをアカウントごとに提供し、各ディレクトリツリーに適した個別のセキュリティポリシーを設定します。
各顧客に別々のデータベースを割り当て、別々のサーバーにこれらのデータベースを格納することもできます。各ディレクトリツリーを専用のデータベース内に置けば、ほかの顧客に影響を与えずに各ディレクトリツリーにあるデータをバックアップしたり復元したりできます。
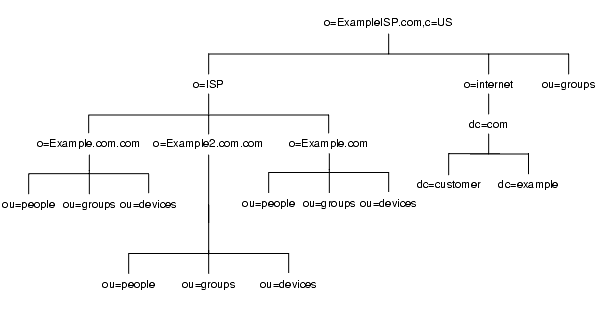
また、データを分散して配置することにより、ディスクの競合に起因するパフォーマンス上の問題を減らし、ディスク障害によって影響を受けるアカウントの数を減らすこともできます。次の図 4-15 は、ISP 企業である Example.com のディレクトリツリーを示しています。
図 4-15 Example.com という ISP のディレクトリツリー
その他のディレクトリツリー関連資料
ディレクトリツリーの設計については、次のリンクを参照してください。
- RFC 2247:Using Domains in LDAP/X.500 Distinguished Names (LDAP/X.500 識別名でドメインを使用する方法)
http://www.ietf.org/rfc/rfc2247.txt
- RFC 2253:LDAPv3, UTF-8 String Representation of Distinguished Names (LDAPv3、識別名をUTF-8 文字列で表す方法)
http://www.ietf.org/rfc/rfc2253.txt