|
|
| Sun ONE Directory Server 5.2 配備ガイド |
第 4 章「ディレクトリツリーの設計」では、ディレクトリでのエントリの格納方法について説明しました。Directory Server は膨大な数のエントリを格納できるので、エントリを複数のサーバーに分散して配置しなければならない場合があります。ディレクトリのトポロジは、ディレクトリツリーをどのように複数の物理的な Directory Server に分割するか、およびこれらのサーバーをどのように相互にリンクするかを示します。
この章では、ディレクトリのトポロジの計画について説明します。この章で説明する内容は次のとおりです。
トポロジの概要
第 4 章「ディレクトリツリーの設計」で設計したディレクトリツリーが複数の物理的な Directory Server に分散されている、分散型のディレクトリを構成するように、Sun ONE Directory Server の配置を設計できます。ディレクトリを複数のサーバーに分割する手法は、次のような機能強化を実現するのに役立ちます。
- ディレクトリを使用するアプリケーションに最大限のパフォーマンスを提供する
- ディレクトリの可用性を高める
- ディレクトリの管理を向上させる
データベースは、レプリケーション、バックアップ、データの復元などの作業に使用する基本単位です。
ディレクトリを複数のサーバーに分割すると、各サーバーはディレクトリツリーの一部分だけを処理します。分散されたディレクトリの動作は、DNS ネームスペースの各部分を特定の DNS サーバーに割り当てるドメイン名サービス (DNS) に似ています。DNS と同様に、ディレクトリのネームスペースを複数のサーバーに分散し、クライアント側からは単一のディレクトリツリーを持つ 1 つのディレクトリとして管理させることができます。
Sun ONE Directory Server には、異なるデータベースに格納されているディレクトリデータをリンクするために、リフェラルと連鎖のメカニズムも用意されています。
この章では、データベース、リフェラル、連鎖について、およびデータベースのパフォーマンスを向上するためにインデックスを設計する方法について説明します。
データの分散
データを分散すると、社内の各サーバー上にディレクトリのエントリを物理的に格納することなく、ディレクトリを複数のサーバーにわたって拡張できます。これらのサーバーは、パフォーマンス要件を満たすために複数のマシンに格納することができます。そのため、分散型ディレクトリは、1 つのサーバーで保持できる数よりはるかに多くのエントリを保持できます。
また、分散されていることがユーザーからは見えないようにディレクトリを設定することもできます。ユーザーとアプリケーションからは、ディレクトリへのクエリーに応答する単一のディレクトリがあるようにしか見えません。
次に、データ分散のしくみについて詳しく説明します。
複数のデータベースの使用
Sun ONE Directory Server はデータを LDBM データベースに格納します。LDBM データベースはディスクベースの高パフォーマンスデータベースです。各データベースは、割り当てられたすべてのデータを含む大きなファイルのセットから構成されます。
ディレクトリツリーの異なる部分を別々のデータベースに格納できます。たとえば、図 5-1 のようなディレクトリツリーがあるとします。
図 5-1 3 つのサブサフィックスを持つディレクトリツリー
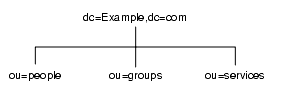
ツリーにある 3 つのサブサフィックスのデータを、図 5-2 のように 3 つの異なるデータベースに格納できます。
図 5-2 3 つの異なるデータベースに格納された 3 つのサブサフィックス
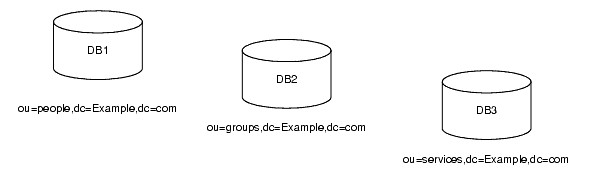
ディレクトリツリーを多数のデータベースに分割すると、それらのデータベースを複数のサーバーに分散できます。通常は、パフォーマンスを向上するために複数のマシンにインストールされた複数のデータベースに分散します。たとえば、ディレクトリツリーの 3 つのサブサフィックスを含めるために作成した 3 つのデータベースを、図 5-1 のように 2 つのサーバーに格納できます。
図 5-3 2 つのサーバー A、B に格納された Example.com の 3 つのデータベース
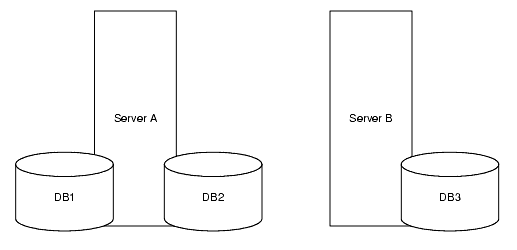
サーバー A にはデータベース DB1 と DB2、サーバー B には DB3 が含まれます。データベースを複数のサーバーに分散すると、各サーバーが処理しなければならない作業量を削減できます。このようにして、1 つのサーバーで保持できる数よりもはるかに多いエントリに対応するようにディレクトリを拡張できます。
さらに、Sun ONE Directory Server ではデータベースをダイナミックに追加できるので、ディレクトリにデータベースが必要になったときに、ディレクトリ全体をオフラインにしなくても新しいデータベースを追加できます。
サフィックスについて
各データベースにはディレクトリサーバーのサフィックスにあるデータが格納されます。サフィックスとサブサフィックスの両方を作成して、ディレクトリツリーの内容を編成できます。サフィックスはツリーのルートにあるエントリです。このサフィックスは、ディレクトリツリーのルートか、またはディレクトリサーバー用に設計したもっと大きなツリーの一部を形成します。
サブサフィックスは、サフィックスの下にある分岐です。サフィックスとサブサフィックスのデータはデータベースに格納されます。
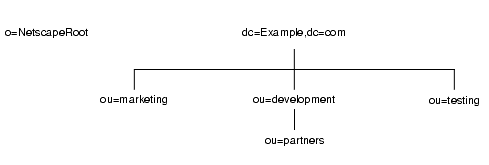
たとえば、ディレクトリデータの分散を表すためにサブサフィックスを作成するとします。Example.com 社のディレクトリツリーは、図 5-4 のようになります。
図 5-4 Example.com 社のディレクトリツリー
Example.com 社が、ディレクトリツリーを図 5-5 のように 5 つの異なるデータベースに分割するとします。
図 5-5 5 つのデータベースに分割された Example.com 社のディレクトリツリー
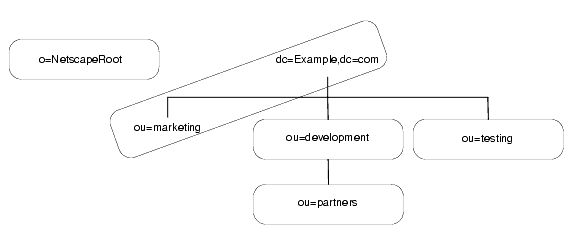
o=NetscapeRoot と dc=Example,dc=com はどちらもサフィックスです。それ以外の ou=testing,dc=Example,dc=com、ou=development,dc=Example,dc=com、ou=partners,ou=development,dc=Example,dc=com の各サフィックスは、どれも dc=Example,dc=com サフィックスのサブサフィックスです。サフィックス dc=Example,dc=com には、元のディレクトリツリーの分岐である ou=marketing のデータが含まれます。
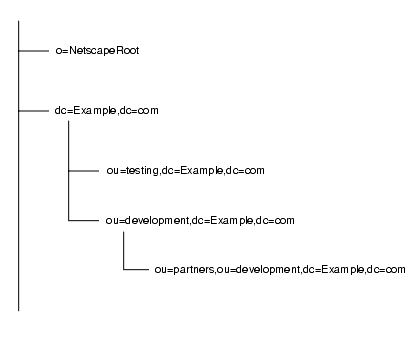
この分割により、サフィックスとサブサフィックスは図 5-6 のようにエントリを格納します。
図 5-6 Example.com 社のサフィックスと関連エントリ
ディレクトリには複数のサフィックスを持たせることができます。たとえば、Example.com という ISP が複数の Web サイトをホスティングし、1 つが独自の Web サイトである Example.com、もう 1 つが HostedExample2.com という別の Web サイトであると仮定します。ISP は、すべてを格納する 1 つのサフィックスを作成するか、同社がホスティングする ISP 部分と Example.com 社の社内データのために 2 つの異なるサフィックスを作成するかを選択できます。
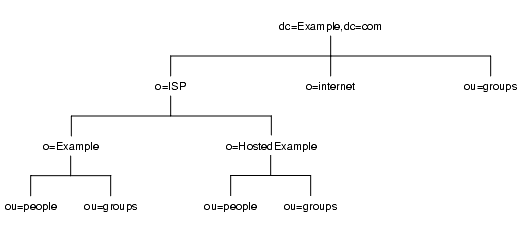
すべてのデータを 1 つのサフィックスに格納するソリューションでは、ディレクトリ情報ツリーは図 5-7 のようになります。
図 5-7 1 つのサフィックスを持つ ISP、Example.com 社のディレクトリツリー
ISP が dc=Example,dc=com という命名コンテキストに対応するサフィックスと、同社の o=ISP 部分に対応するサフィックスの 2 つのサフィックスを作成する 2 番目のソリューションでは、ディレクトリ情報ツリーは図 5-8 のようになります。
図 5-8 Example.com という ISP のディレクトリツリー
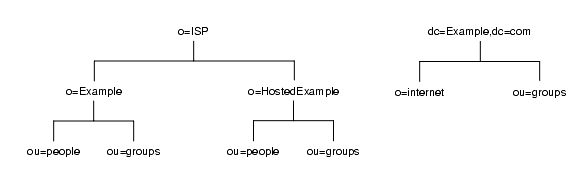
dc=Example,dc=com エントリと o=ISP エントリはサフィックスを表します。ホスティングされる各 ISP のエントリ (o=Example と o=HostedExample) は o=ISP サフィックスのサブサフィックスで、ou=people と ou=groups はホスティングされる各 ISP のサブサフィックスとして分岐します。
リフェラルと連鎖について
データを複数のデータベースに分散したあとは、分散したデータ間の関係を定義する必要があります。これは、別々のデータベースに保持されているディレクトリ情報へのポインタを使用して行います。Sun ONE Directory Server には、分散されたデータを単一のディレクトリツリーとしてリンクするために、リフェラルと連鎖というメカニズムが用意されています。
- リフェラル
サーバーは、要求を完了するために別のサーバーに接続する必要があることを示す情報をクライアントアプリケーションに返します。
- 連鎖
サーバーはクライアントアプリケーションの代わりに別のサーバーに接続し、操作が終了すると、結合した結果をクライアントアプリケーションに返します。
次に、2 つのメカニズムをより詳細に比較します。
リフェラルの使い方
リフェラルはサーバーが返す情報であり、操作要求を完了するために接続する必要があるサーバーをクライアントアプリケーションに指示します。Directory Server は、次の 3 種類のリフェラルをサポートしています。
- デフォルトリフェラル
クライアントアプリケーションが提示した DN に対応するサフィックスがサーバーにない場合、ディレクトリはデフォルトリフェラルを返します。デフォルトリフェラルは、nsslapd-referral 属性を使用してサーバーレベルで設定します。
- サフィックスリフェラル
サフィックスリフェラルはデフォルトリフェラルとは異なり、データベースレベルで格納されるリフェラルです。サフィックスリフェラルは、サフィックスの設定情報として設定されます。サフィックスリフェラルは、サフィックスごと、つまり、一般的にはデータベースごとに設定できます。
- スマートリフェラル
スマートリフェラルは、ディレクトリ自体のエントリに格納されています。このリフェラルは、そのスマートリフェラルが格納されているエントリの DN と一致する DN を持つサブツリーに関する情報を保有している Directory Server をポイントします。
すべてのリフェラルは、LDAP URL (Uniform Resource Locator) の形式で返されます。次に、LDAP リフェラルの構造と、Directory Server がサポートする 3 つのタイプのリフェラルについて説明します。
LDAP リフェラルの構造
LDAP リフェラルには LDAP URL 形式の情報が含まれます。LDAP URL には、次の情報が含まれます。
- 接続先サーバーのホスト名
- サーバーのポート番号
- 検索操作の場合は ベース DN、追加、削除、および変更操作の場合はターゲット DN
たとえば、クライアントアプリケーションが Jensen という姓を持つエントリを dc=Example,dc=com 内で検索するとします。リフェラルは、次の LDAP URL をクライアントアプリケーションに返します。
ldap://europe.Example.com:389/ou=people,l=europe,dc=Example,dc=com
リフェラルは、LDAP ポート 389 のホスト europe.Example.com に接続し、ou=people,l=europe,dc=Example,dc=com にルート設定された検索要求を送信するように、クライアントアプリケーションに指示します。
リフェラルがどのように処理されるかは、使用している LDAP クライアントアプリケーションによって決まります。一部のクライアントアプリケーションは、参照先サーバーに対して自動的に操作を再実行します。別のクライアントアプリケーションは、ユーザーにリフェラル情報を返します。コマンド行ユーティリティなど、Sun ONE Directory Server が提供するほとんどの LDAP クライアントアプリケーションは、自動的にリフェラルを実行します。参照先サーバーへのアクセスには、最初のサーバー要求で指定したバインド証明情報が使用されます。
ほとんどのクライアントアプリケーションは、リフェラルの制限数、あるいはホップ数だけリフェラルを実行します。実行するリフェラル数を制限すると、クライアントアプリケーションがディレクトリ検索要求を完了しようとして費やす時間を短縮でき、また循環リフェラルパターンが原因で発生する処理停止を防ぐのにも役に立ちます。
デフォルトリフェラル
ディレクトリサーバーは、要求されたディレクトリオブジェクトの DN とローカルサーバーでサポートされているディレクトリサフィックスを比較して、デフォルトリフェラルを返すかどうかを決めます。DN とサポートされているサフィックスが一致しない場合はデフォルトリフェラルを返します。
たとえば、ディレクトリクライアントが次のディレクトリエントリを要求したとします。
uid=bjensen,ou=people,dc=Example,dc=com
ところが、サーバーは dc=europe,dc=Example,dc=com サフィックスの下に格納されているエントリしか管理していません。このような場合、ディレクトリは、dc=Example,dc=com サフィックスに格納されているエントリを取得するために接続する必要があるサーバーを示すリフェラルをクライアントに返します。デフォルトリフェラルを受け取ったクライアントは適切なサーバーに接続して、元の要求を再送信します。
デフォルトリフェラルは、ディレクトリの分散に関する情報をより多く保持しているディレクトリサーバーをポイントするように設定します。サーバーのデフォルトリフェラルは、dse.ldif 設定ファイルに格納されている nsslapd-referral 属性で設定します。
デフォルトリフェラルの設定については、『Sun ONE Directory Server 管理ガイド』の「Setting Default Referrals」を参照してください。
サフィックスリフェラル
サフィックスリフェラルを使用することで、リフェラルをサフィックスレベルで設定できます。この機能によりリフェラルの詳細度が向上し、1 つの設定属性を指定して、更新が実際に行われる場所を制御できるようになりました。ディレクトリインストール時の各データベースのデフォルトリフェラルは、dse.ldif 設定ファイル内のマッピングツリーエントリに含まれる nsslapd-referral 属性によっても設定されます。
米国内に 2 つの主要サイトがあり、1 つはニューヨーク、もう 1 つはロサンジェルスに基盤を置いていると仮定します。クライアントアプリケーションは、ニューヨークのサイトを次のように参照します。
uid=bjensen,ou=people,dc=US,dc=Example,dc=com
サフィックスリフェラルを dc=NewYork,dc=US,dc=Example,dc=com と設定することで、dc=NewYork サブツリーを含むサフィックスによって要求が処理されるようになります。
サフィックスは、4 つの異なる状態で稼動するように設定できます。このうち、2 つはサフィックスリフェラルに関するものです。サフィックスリフェラルが必要ない場合は、すべての操作をバックエンドデータベースが処理する nsslapd-referral: backend 状態、または処理を担当するデータベースは存在せず、クライアントアプリケーションからの要求に応じてエラーを返す nsslapd-referral: disabled 状態を選択できます。
しかし、サフィックスリフェラルを設定する場合は、2 つの別の状態を選択できます。nsslapd-referral: referral 状態を選択すると、このサフィックスに対するすべての要求でリフェラルが返されます。nsslapd-referral: referral on update 状態を選択した場合は、すべての操作はデータベースによって行われ、更新要求に対してはリフェラルが返されます。2 番目の referral on update 状態は、レプリケーションが設定された場合に、コンシューマが更新要求を処理しないように内部的に使用されます。ただし、ロードバランスやパフォーマンス上の理由から特定のデータベースに対する読み取り操作のアクセスを制限する必要がある場合は、サフィックスリフェラルのこの設定で解決できることがあります。
サフィックスリフェラルの設定については、『Sun ONE Directory Server 管理ガイド』の「Creating Suffix Referrals」を参照してください。
スマートリフェラル
Directory Server では、スマートリフェラルを使用するようにディレクトリを設定することもできます。スマートリフェラルを使用すると、ディレクトリのエントリまたはディレクトリツリーを特定の LDAP URL に関連付けることができます。ディレクトリのエントリを特定の LDAP URL に関連付けると、次のいずれかに要求を転送できます。
- 異なるサーバー上の同じネームスペース
- ローカルサーバー上の異なるネームスペース
- 同じサーバー上の異なるネームスペース
デフォルトリフェラルとは異なり、スマートリフェラルはディレクトリ自体に格納されます。スマートリフェラルの設定と管理については、『Sun ONE Directory Server 管理ガイド』の「Creating Smart Referrals」を参照してください。
たとえば、Example.com 社の米国支社のディレクトリに、ou=people,dc=Example,dc=com というディレクトリ分岐点があるとします。
ou=people エントリ自体にスマートリフェラルを指定することで、この分岐への要求をすべて Example.com 社のヨーロッパ支社の ou=people 分岐に転送できます。このスマートリフェラルは、次のようになります。
ldap://europe.Example.com:389/ou=people,dc=Example,dc=com
米国支店のディレクトリにある people 分岐への要求はすべて、ヨーロッパのディレクトリに転送されます。図 5-9 は、このスマートリフェラルが、米国のディレクトリに対する要求をヨーロッパのディレクトリに転送する様子を示しています。
図 5-9 米国のディレクトリからヨーロッパのディレクトリへのスマートリフェラル
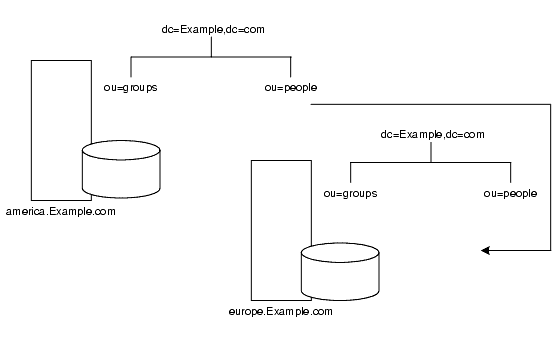
同じメカニズムを使用して、異なるネームスペースを使っている別のサーバーにクエリーを転送できます。たとえば、Example.com 社のイタリア支社の従業員がヨーロッパのディレクトリに米国の Example.com 社員の電話番号を要求したとします。ディレクトリは次のリフェラルを返します。
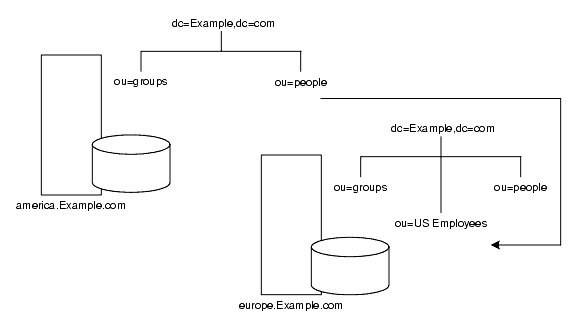
ldap://europe.Example.com:389/ou=US employees,dc=Example,dc=com
図 5-10 は、ヨーロッパ支社のイタリア人従業員が米国支社の米国人従業員の電話番号を要求する場合のスマートリフェラルを示しています。
図 5-10 電話番号要求のスマートリフェラル
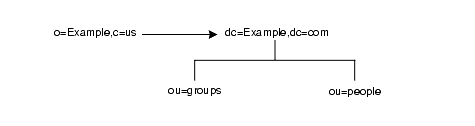
同じサーバー上に複数のサフィックスを設定している場合は、あるネームスペースから同じマシン上の別のネームスペースにクエリーを転送できます。ローカルマシン上の o=Example,c=us に対するすべてのクエリーを dc=Example,dc=com に転送する場合は、o=Example,c=us エントリに次のスマートリフェラルを設定します。
ldap:///dc=Example,dc=com
図 5-11 を参照してください。
図 5-11 スマートリフェラルのトラフィック
1 つのネームスペースからのクエリーを同一マシン上の別のネームスペースに転送するため、通常は URL の 2 番目のスラッシュの後に指定される host:port の情報ペアを指定する必要はありません。URL にこの情報ペアが指定されていないため、同じ Directory Server をポイントする URL には 3 つのスラッシュが含まれます。
注 リフェラルを最大限に活用できるように、リフェラルが設定されている場所の下を検索のベースにしないでください。
LDAP URL の詳細については、『Sun ONE Directory Server Reference Manual』の「LDAP URL」を参照してください。Sun ONE Directory Server のエントリにスマート URL を含める方法については、『Sun ONE Directory Server 管理ガイド』の「Setting Referrals」を参照してください。
スマートリフェラルを設計する際のヒント
スマートリフェラルを使用する前に、次の点を考慮してください。
- 設計を単純にする
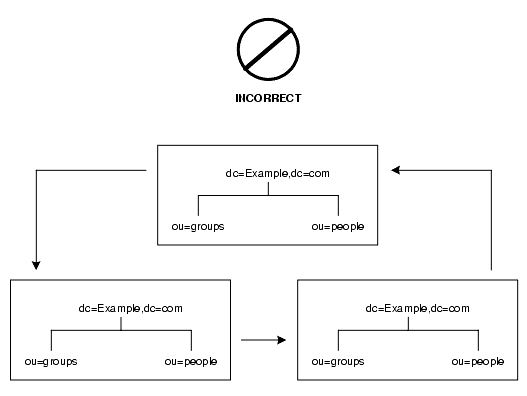
複雑に交錯したリフェラルを使用してディレクトリを運用すると、管理が難しくなります。また、スマートリフェラルを使いすぎると、循環リフェラルパターンを引き起こしてしまう場合もあります。例えば、リフェラルがある LDAP URL をポイントし、その LDAP URL が別の LDAP URL をポイントするといったことが、連鎖のどこかで最後に元のサーバーに戻ってしまうまで続くという状況です。図 5-12 は、循環リフェラルのパターンを示しています。
図 5-12 スマートリフェラルの使いすぎによる循環リフェラルのパターン
- 主要な分岐点で転送する
ディレクトリツリーのサフィックスレベルで転送を処理するように、リフェラルの使用を制限します。スマートリフェラルを使用すると、最下位のエントリ (分岐ではありません) への検索要求を別のサーバーや DN に転送できます。そのため、スマートリフェラルをエイリアスメカニズムとして使用することがよくあり、その結果、ディレクトリ構造の安全保護を複雑で困難なものにしています。リフェラルの使用をディレクトリツリーのサフィックスまたは主要な分岐点に限定することで、管理するリフェラル数が減少し、ディレクトリの管理に伴う負荷を低減できます。
- セキュリティへの影響を考慮する
アクセス制御はリフェラルの境界を越えると機能しません。要求を発信したサーバーがエントリへのアクセスを許可している場合でも、スマートリフェラルがクライアントの要求を別のサーバーに転送したときは、クライアントアプリケーションがアクセスを許可されないこともあります。
また、クライアントが認証されるためには、クライアントは転送先のサーバー上でクライアント証明情報を使用できなければなりません。
連鎖の使用方法
連鎖は要求を別のサーバーに中継する手法の 1 つです。この手法は連鎖サフィックスを介して実行されます。「データの分散」で説明したように、連鎖サフィックスにはデータは含まれていません。連鎖サフィックスは、クライアントアプリケーションの要求をデータがあるリモートサーバーに転送します。
連鎖時に、サーバーは格納されていないデータに対する要求をクライアントアプリケーションから受け取ります。サーバーは連鎖サフィックスを使用して、クライアントアプリケーションの代わりに他のサーバーにアクセスし、結果をクライアントアプリケーションに返します。図 5-13 は、この処理を示しています。
図 5-13 連鎖による処理
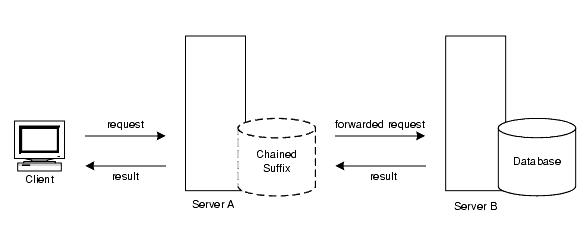
各連鎖サフィックスは、データを保持しているリモートサーバーに関連付けられています。障害が発生したときに連鎖サフィックスが使用する、データのレプリカが入った代替リモートサーバーを設定することもできます。連鎖サフィックスの設定については、『Sun ONE Directory Server 管理ガイド』の「Creating Chained Suffixes」を参照してください。
連鎖サフィックスには次の機能があります。
- リモートデータへの透過的なアクセス
連鎖サフィックスがクライアントからの要求を処理するので、データの分散はクライアントからは見えません。
- 動的な管理
システム全体をクライアントアプリケーションが使用できる状態にしたままで、ディレクトリを部分的にシステムに追加したり、システムから削除したりできます。連鎖サフィックスは、エントリがディレクトリに再分散されるまで、リフェラルを一時的にアプリケーションに返すことができます。サフィックスを使用してこの機能を実装することもできます。サフィックスはクライアントアプリケーションをデータベースに転送するのではなく、リフェラルを返します。
- アクセス制御
連鎖サフィックスは、クライアントアプリケーションに代わって該当する認証情報をリモートサーバーに提示します。アクセス制御を評価する必要がない場合は、リモートサーバーに対するユーザー代行機能を無効にすることができます。アクセス制御と連鎖サフィックスの関係については、『Sun ONE Directory Server 管理ガイド』の「Access Control Through Chained Suffixes」を参照してください。
リフェラルと連鎖の選択
分割されたディレクトリ部分をリンクする場合、どちらの手法にも利点と欠点があります。ディレクトリの要件に応じて、どちらか一方、あるいは両方を組み合わせて使用します。
リフェラルと連鎖の大きな違いは、分散された情報の検索方法を認識するための情報が置かれている場所です。連鎖システムでは、この情報がサーバー内に実装されます。リフェラルを使用するシステムでは、この情報はクライアントアプリケーション内に実装されます。
連鎖では、クライアント側の処理は簡単になりますが、その分サーバー側の処理が複雑になります。連鎖対象のサーバーは、リモートサーバーと協調して結果をディレクトリクライアントに送信する必要があります。
リフェラルでは、クライアントがリフェラルを検索して検索結果を照合する必要があります。ただし、連鎖よりもリフェラルを使用した方がクライアントアプリケーションを柔軟に作成でき、開発者は分散型ディレクトリの進行状況をより適切な形でユーザーにフィードバックできます。
次に、リフェラルと連鎖の違いについて詳しく説明します。
使用方法の違い
リフェラルをサポートしないクライアントアプリケーションもあります。連鎖を使用すると、クライアントアプリケーションは 1 つのサーバーと通信するだけで、多数のサーバーに格納されているデータにアクセスすることができます。企業のネットワークがプロキシを使用している場合は、リフェラルが機能しないことがあります。たとえば、クライアントアプリケーションがファイアウォール内の 1 つのサーバーとだけ通信する権限を持っているとします。クライアントアプリケーションが別のサーバーに転送された場合、クライアントはそのサーバーに正常に接続できません。
また、リフェラルでは、クライアントを認証する必要があります。つまり、クライアントの転送先のサーバーにクライアントの証明情報が格納されている必要があります。連鎖では、クライアント認証は 1 回だけで済みます。要求の連鎖先のサーバーでクライアントを再び認証する必要はありません。
アクセス制御の評価
連鎖は、リフェラルとは異なる方法でアクセス制御を評価します。リフェラルでは、バインド DN エントリがすべての転送先サーバー上に存在しなければなりません。連鎖では、クライアントエントリがすべての転送先サーバー上に存在している必要はありません。
たとえば、クライアントが検索要求をサーバー A に送信する場合を考えてみます。図 5-14 は、リフェラルを使用した場合の動作を示しています。
図 5-14 リフェラルによってサーバー B に転送される、クライアントアプリケーションからサーバー A に対する検索要求
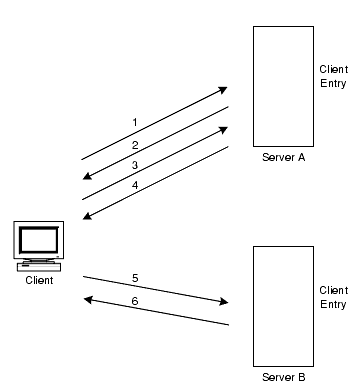
上の図では、クライアントアプリケーションは次の手順を実行します。
- クライアントアプリケーションは、まずサーバー A にバインドします。
- サーバー A は、ユーザー名とパスワードを提供するクライアントのエントリを保持しているので、バインド受け入れメッセージを返します。リフェラルが機能するためには、サーバー A にクライアントエントリが存在する必要があります。
- クライアントアプリケーションがサーバー A に操作要求を送信します。
- しかし、サーバー A には要求された情報が格納されていません。サーバー A は、代わりにリフェラルをクライアントアプリケーションに返し、サーバー B へのアクセスを指示します。
- クライアントアプリケーションが、バインド要求をサーバー B に送信します。サーバー がバインドに成功するには、サーバー B にクライアントアプリケーションのエントリが存在する必要があります。
- バインドに成功したので、クライアントアプリケーションは再び検索操作をサーバー B に送信できます。
この方法では、サーバー A からレプリケートされたクライアントエントリのコピーがサーバー B に必要です。
連鎖では、この問題は発生しません。図 5-15 は、連鎖を使用した場合の検索要求の動作を示しています。
図 5-15 連鎖を使用した検索要求
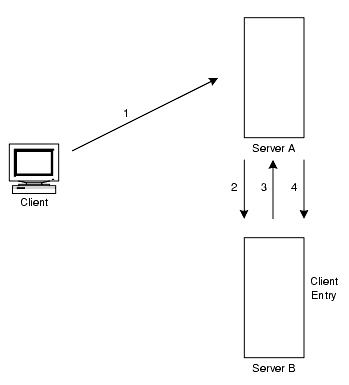
上の図では、次の手順が実行されます。
- クライアントアプリケーションがサーバー A にバインドし、サーバー A はユーザー名とパスワードが正しいことを確認しようとします。
- サーバー A にはクライアントアプリケーションに対応するエントリが存在しません。その代わりに、サーバー A にはクライアントの実際のエントリがあるサーバー B への連鎖サフィックスがあります。サーバー A はバインド要求をサーバー B に送信します。
- サーバー B はサーバー A にバインド受け入れメッセージを返信します。
- サーバー A は連鎖サフィックスを使用してクライアントアプリケーションからの要求を処理します。連鎖サフィックスはサーバー B にあるリモートデータストアに接続して検索操作を処理します。
連鎖システムでは、クライアントアプリケーションに対応するエントリが、クライアントが要求するデータと同じサーバー上にある必要はありません。図 5-16 は、クライアントからの検索要求を処理するために、2 つの連鎖サフィックスを使用する方法を示しています。
図 5-16 クライアントからの検索要求を処理するために 2 つの連鎖サフィックスを使用する連鎖
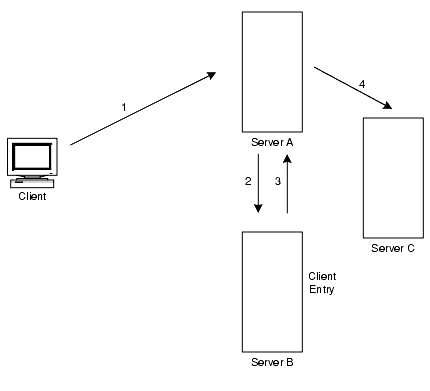
上の図では、次の手順が実行されます。
- クライアントアプリケーションがサーバー A にバインドし、サーバー A はユーザー名とパスワードが正しいことを確認しようとします。
- サーバー A にはクライアントアプリケーションに対応するエントリが存在しません。その代わりに、サーバー A にはクライアントの実際のエントリがあるサーバー B への連鎖サフィックスがあります。サーバー A はバインド要求をサーバー B に送信します。
- サーバー B はサーバー A にバインド受け入れメッセージを返信します。
- サーバー A は別の連鎖サフィックスを使用してクライアントアプリケーションからの要求を処理します。連鎖サフィックスはサーバー C にあるリモートデータストアに接続して検索操作を処理します。
ただし、連鎖サフィックスは、次のアクセス制御をサポートしません。
- ユーザーエントリが別のサーバー上にある場合、そのユーザーエントリの内容にアクセスする必要がある制御はサポートされません。これには、グループ、フィルタ、およびロールに基づくアクセス制御が含まれます。
- クライントの IP アドレスまたは DNS ドメインに基づく制御は拒否される場合があります。これは、連鎖サフィックスがクライアントとしてリモートサーバーに接続するためです。リモートデータベースに IP に基づくアクセス制御が含まれている場合、リモートデータベースは、元のクライアントのドメインではなく、連鎖サフィックスのドメインを使用してアクセス制御を評価します。