| C ユーザーズガイド |
第 4 章
Sun ANSI/ISO C コードの並列化
C コンパイラは、SPARCTM メモリー共有型マルチプロセッサのマシン上で実行するコードを最適化できます。この最適化処理は「並列化」と呼ばれます。コンパイルされたコードは、システムの複数のプロセッサを使用して並列して実行できます。
この章では、このコンパイラの並列化機能を利用する方法について説明します。説明事項は次のとおりです。概要
C コンパイラは、並列化しても安全であると判断したループに対して並列コードを生成します。通常、これらのループは、独立して実行可能な繰り返しを持っています。繰り返しが実行される順番や、並列に実行するかどうかといったことなどは、ループの実行結果に影響はありません。すべてではありませんが、ほとんどのベクトル処理用ループはこのような種類のループです。
C では別名が存在する (複数の変数が同一の実体である / を指す) 可能性があるため、並列化の安全性を判断することは困難です。コンパイラの作業を容易にするために、Sun ANSI/ISO C には別名の情報をコンパイラに渡すためのプラグマおよびポインタ修飾子が用意されています。
使用例
%cc -fast -xO4 -xautopar example.c -o exampleこの例では、通常の方法で実行できる
exampleという実行可能ファイルが生成されます。マルチプロセッサ上で実行する場合は、45 ページの「-xautopar」を参照してください。環境変数
並列化された C には、関連する環境変数として次の 3 つが存在します。
PARALLEL
マルチプロセッサ上で実行する場合は、
PARALLEL環境変数を設定してください。PARALLEL環境変数には、プログラムの実行に使用できるプロセッサの数を指定します。次は、PARALLELを 2 に設定する例を示しています。
%setenv PARALLEL 2対象マシンに複数のプロセッサが搭載されている場合は、スレッドは個々のプロセッサにマップできます。この例では、プログラムを実行すると、2 個のスレッドが生成され、各スレッド上でプログラムの並列化された部分が実行されるようになります。
SUNW_MP_THR_IDLE
現在のところ、プログラムの初期実行を行うスレッドが結合スレッドを作成します。作成されたこれらの結合スレッドは、プログラムの並列部分 (並列ループ、並列領域など) の実行に加わり、プログラムの順次実行部分が実行される間スピン待ち状態を維持します。これらの結合スレッドは、プログラムが終了するまで休眠または停止することはありません。並列化されたプログラムを 1 つのシステム上で実行する場合は、結合スレッドをスピン待ちにすると最高のパフォーマンスが得られます。ただし、スピン待ちのスレッドはシステム資源を使用します。
SUN_MP_THR_IDLE環境変数は、各スレッドが並列ジョブの分担部分を終えた後の各スレッドの状態を制御するために使用してください。
%setenv SUNW_MP_THR_IDLE<値><値> には、
spinまたはsleep[ns|nms]のどちらかを指定できます。デフォルトはspinであり、これはスレッドがスピン待ちに入ることを意味します。もう一方の選択肢、sleep[ns|nms]は、n に指定された時間だけスレッドをスピン待ち状態にし、その後休眠させることを意味します。待ち時間の単位は秒 (s:デフォルトの単位) かミリ秒 (ms) で、1s は 1 秒、10 ms は 10 ミリ秒を意味します。n に指定された時間が経過する前に新しいジョブが発生すると、スレッドはスピン待ちを中止し、新しいジョブを開始します。SUNW_MP_THR_IDLEに無効な値が含まれているか、値を持たない場合、デフォルトとしてspinが使用されます。STACKSIZE
プログラムを実行すると、マスタースレッドにはメインメモリースタックが、各スレーブスレッドには個別のスタックが保持されます。スタックとは、サブプログラムが呼び出されている間、引数と自動変数を保持するために使用される一時的なメモリーアドレス空間です。
メインスタックのデフォルトサイズは、およそ 8M バイトです。現在のスタックサイズの確認と設定には、
limitコマンドを使用します。次に例を示します。
マルチスレッド化されたプログラムの各スレーブスレッドは、それ自体のスレッドスタックを持ちます。このスタックはマスタースレッドのメインスタックに似ていますが、各スレッド固有のものです。スレッドのスタックには、スレッド固有の配列とその (スレッドに対して局所的な) 変数が割り当てられます。
スレーブスレッドはすべて、同じスタックサイズを持ちます。デフォルトのスタックサイズは、32 ビットアプリケーションの場合は 1M バイト、64 ビットアプリケーションの場合は 2M バイトです。このサイズは、
STACKSIZE環境変数で設定します。
% setenv STACKSIZE 8192<- スレッドのスタックサイズを 8M バイトに設定並列化されたほとんどのコードでは、通常、スレッドのスタックサイズをデフォルト値より大きな値に設定する必要があります。
時折、スタックサイズを増やす必要があるという警告メッセージがコンパイラによって表示されることがあります。しかし、通常 (とりわけスレッド固有 / 局所の配列が関わる場合)、設定すべきサイズは試行錯誤でしか把握できません。スタックサイズがスレッドを実行するには小さすぎる場合、プログラムはセグメント例外を生成して終了します。
キーワード
並列化された C では、キーワード
_Restrictを使用できます。詳細は、「_Restrict」を参照してください。データの依存性と干渉
C コンパイラは、プログラム中のループを解析して、ループの各繰り返しを安全に並列実行できるかどうかを判断します。この解析の目的は、ループ中の任意の 2 個の繰り返しが、互いに干渉しないかどうかを調べることです。通常、干渉は、ある繰り返しが書き込みを行なっている変数に対して、別の繰り返しが読み込みを行うと発生します。次に示すプログラムの一部を考えてみましょう。
コード例 4-1 依存性を持つループ for (i=1; i < 1000; i++) {sum = sum + a[i]; /* S1 */}この例では、2 個の連続した繰り返しである
iおよびi+1が、同じ変数sumに書き込みと読み込みを実行しています。したがって、このような 2 個の繰り返しを並列に実行するには、なんらかの方法で変数をロックすることが必要になります。ロックをしないと、2 個の連続した繰り返しを安全に並列実行することができなくなります。ところが、このロック機構を使用すると、オーバーヘッドが発生してプログラムの実行を遅くすることになります。コード例 4-1 のように、2 個の連続したループの繰り返しにデータの依存関係がある場合、C コンパイラはそのループの並列化を行いません。
コード例 4-2 依存性を持たないループ for (i=1; i < 1000; i++) {a[i] = 2 * a[i]; /* S1 */}この場合、ループ中における各繰り返しでは、異なる配列の要素が参照されています。したがって、ループ中の繰り返しを実行する順番を守る必要がありません。また、異なる繰り返しでアクセスするデータが互いに干渉しないため、ロックを使用せずに並列実行することが可能になります。
ループ内の 2 個の異なる繰り返しで、同じ変数を参照していないかどうかを判断するためにコンパイラが実行する解析を、「データ依存性解析」といいます。1 回でも変数に書き込みを実行している場合には、データ依存性によって並列化することができなくなります。コンパイラが実行する依存性解析の結果、次のいずれかの解答が得られます。
- 依存性があります。
この場合には、ループを安全に並列実行できません。上述のコード例 4-1 がこれに該当します。- ループ内に依存性がありません。
ループを任意の数のプロセッサを使用して並列に実行することができます。上述のコード例 4-2 がこれに該当します。- 依存性を確認できません。
コンパイラは、安全に実行することを重視して、ループに並列実行できないような依存関係が存在するものと仮定して、ループを並列化しません。コード例 4-3 では、2 個の異なる繰り返しで、配列
aの同じ要素に書き込みが実行されるかどうかは、配列bの要素に重複した要素が存在するかどうかによって決まります。コンパイラがこの事実を確認できない限り依存性があるものと判断され、ループは並列化されません。
コード例 4-3 依存性の有無を確認できないループ for (i=1; i < 1000; i++) {a[b[i]] = 2 * a[i];}並列実行モデル
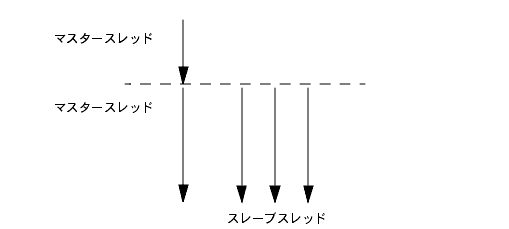
ループの並列実行は、Solaris スレッドによって実行されます。プログラムの初期実行を行うスレッドをマスタースレッドといいます。プログラムの起動時に、マスタースレッドによって複数のスレーブスレッドが生成されます (図 4-1 を参照)。プログラムの終了時には、すべてのスレーブスレッドが終了されます。オーバーヘッドを最小限に抑えるために、スレーブスレッドの生成は 1 回だけ実行されます。
図 4-1 マスタースレッドとスレーブスレッド起動後、マスタースレッドによってプログラムの実行が開始されますが、スレーブスレッドはアイドル状態で待機します。マスタースレッドが並列ループを検出すると、ループの異なる繰り返しがスレーブおよびマスタースレッドに割り当てられ、ループの実行が開始されます。それぞれのスレッドが実行を終了すると、残りのスレッドの終了と同期がとられます。この同期を取る点をバリアといいます。すべてのスレッドが分担した実行を終了してバリアに達するまで、マスタースレッドは残りのプログラムを実行することができません。スレーブスレッドは、バリアに達すると、他の並列化された部分が検出されるまで待ち状態になり、マスタースレッドがプログラムの実行を続行します。
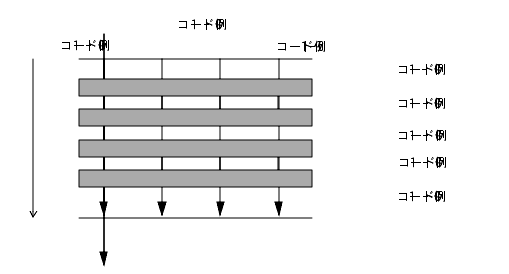
一般的な並列ループの中には、並列化で得られるメリットよりオーバーヘッドの方が多くなってしまうものがあります。このようなループでは、実行速度が大きく低下することがあります。
次の図ではループが並列化されていますが、水平の棒で示されたバリアは相当なオーバーヘッドを示しています。バリア間の作業は、図中に示すとおりに 1 つずつ実行される (順次実行) か、あるいは同時に実行 (並列実行) されます。ループの並列実行に必要な時間は、バリアの位置でマスタースレッドとスレーブスレッドの同期をとるために必要な時間よりはるかに短くてすみます。
図 4-2 ループの並列実行固有スカラーと固有配列
データの依存性が存在してもコンパイラがループを並列化できる場合があります。次の例を考えてみましょう。
コード例 4-4 依存性があるが並列化可能なループ for (i=1; i < 1000; i++) {t = 2 * a[i]; /* S1 */b[i] = t; /* S2 */}この例では、配列 a と b が重なりあっていないと仮定すると、2 回の繰り返しの間に、変数
tによる明らかなデータ依存性が存在します。繰り返しの 1回目と 2 回目に注目すると、以下のような文が実行されることになります。
コード例 4-5 繰り返し 1 と 2 文 1 および 3 によって変数
tが変更されるので、これらを並列実行することはできません。しかし、変数tは常に同じ繰り返しの中で計算されて使用されるので、コンパイラは繰り返しごとに変数tのコピーを使用することができます。したがって、このような変数による異なる繰り返し間での干渉を回避することができます。実際に変数tは、繰り返しを実行する各スレッドに固有の変数として使用されます。これを説明した例を、以下に示します。
コード例 4-6 各スレッドに固有の変数としての変数 tfor (i=1; i < 1000; i++) {pt[i] = 2 * a[i]; /* S1 */b[i] = pt[i]; /* S2 */}コード例 4-6 は、コード例 4-3 と基本的に同一なもので、それぞれのスカラー変数参照
tがここでは配列参照ptに置き換えられています。各繰り返しでは、ptの異なる要素が使用されるので、任意の 2 個の繰り返し間でのデータ依存性がなくなります。ただし、この方法では、大きな配列を余分に生成することになります。実際には、コンパイラによってスレッドごとに 1 個の変数だけが割り当てられ、その変数をループの実行で使用します。つまりこのような変数は、各スレッドごとに固有であるといえます。コンパイラは、配列変数を固有化してループを並列実行することもできます。次に例を示します。
コード例 4-7 配列変数を使用した並列化可能なループ for (i=1; i < 1000; i++) {for (j=1; j < 1000; j++) {x[j] = 2 * a[i]; /* S1 */b[i][j] = x[j]; /* S2 */}}コード例 4-7 では、この例では、外側のループの異なる繰り返しによって、配列
xの同じ要素が変更されるので、外側のループを並列化することはできません。しかし、外側のループを実行するそれぞれのスレッドに配列x全体のスレッド固有のコピーが存在すれば、外側の任意の 2 個のループ間で干渉が発生しません。これを説明した例を以下に示します。
コード例 4-8 スレッド固有配列を使用した並列化可能なループ for (i=1; i < 1000; i++) {for (j=1; j < 1000; j++) {px[i][j] = 2 * a[i]; /* S1 */b[i][j] = px[i][j]; /* S2 */}}スレッド固有スカラー変数の場合と同様に、配列をすべての繰り返しに対して展開する必要はありません。システムで実行されるスレッドの数に対してのみ展開すればいいことになります。これはコンパイラによって自動的に行われ、各スレッドのスレッド固有領域にオリジナルの配列がコピーされます。
ストアバック変数の使用
変数のスレッド固有化は、プログラムの並列化を向上させる上で便利な方法です。しかし、スレッド固有変数がループの外側で参照される場合には、その値が正しいことを保証することが必要になります。次の例を考えてみましょう。
コード例 4-9 ストアバック変数を使用した並列ループ コード例 4-9 では、文
S3で参照されている変数tの値が、ループを終了したときの最終結果になります。変数tがスレッド固有化され、ループの実行が終了した後、tの正しい値をオリジナルの変数に戻すことが必要になります。この操作をストアバック (書き戻し) といいます。これは、繰り返しの最後における t の値をオリジナルの変数 t に書き込むことで実現できます。多くの場合、この操作はコンパイラによって自動的に行われます。しかし、最終値を簡単に計算できないこともあります。
コード例 4-10 ストアバック変数を使用できないループ for (i=1; i < 1000; i++) {if (c[i] > x[i] ) { /* C1 */t = 2 * a[i]; /* S1 */b[i] = t; /* S2 */}}x = t*t; /* S3 */正しく実行した場合、文
S3のtの値は、必ずループの最後におけるtの値にはなりません。最後の繰り返しで、C1が真の場合に限って、最後のtの値に等しくなります。すべての場合におけるtの最終値を計算することは、非常に困難です。このような場合には、コンパイラはループを並列化しません。縮約変数の使用
ループの繰り返し間に本当の依存性が存在すると、依存性の原因となっている変数を簡単にスレッド固有化できない場合があります。このような状況は、たとえば、変数がある繰り返しから別の繰り返しで累積計算されているような場合に発生します。
コード例 4-11 並列化されるかどうか不明なループ for (i=1; i < 1000; i++) {sum += a[i]*b[i]; /* S1 */}コード例 4-11 では、ループで 2 個の配列の内積を計算して、変数
sumに格納しています。このループを単純な方法で並列化することはできません。ここでは、文S1の計算式に結合の法則を適用し、各スレッドに対してpsum[i]というスレッド固有変数を割り当てることができます。変数psum[i]のコピーはそれぞれ 0 に初期化します。各スレッドはスレッド固有の変数psum[i]に自分で計算した部分和を代入します。バリアに達したら、すべての部分和を合計してオリジナルの変数sumに代入します。この例では、和の縮約をしているので、変数sumを縮約変数といいます。しかし、スカラー変数を縮約変数にした場合には、丸め誤差が累積されて、sumの最終値に影響する可能性があることに注意してください。コンパイラは、ユーザーによる明確な指示がされた場合に、この操作を実行します。処理速度の向上
実行時間の大部分を占めるプログラム部分が並列化できない場合、速度の向上は期待できません。これは、基本的にアムダールの法則の結果から言えることです。たとえば、プログラム実行の 5% 部分に相当するループしか並列化できない場合、全体的に速度を向上できる限界は 5% です。しかし、実際には、負荷の量と並列実行に伴うオーバーヘッドによって、まったく速度が向上しないこともあります。
したがって、一般的な規則として、プログラムの並列化される部分が大きくなればなるほど、大幅な速度の向上を期待できます。
それぞれの並列ループには、起動時と終了時にわずかなオーバーヘッドがあります。起動時のオーバーヘッドには作業を分散するためのものがあり、終了時には、バリアでの同期によるものがあります。ループによって実行される作業量が比較的小さい場合には、速度の向上を期待できません。実際にループの実行が遅くなることもあります。したがって、プログラム実行の大部分が小さな並列ループから構成されている場合には、全体の実行速度が早くならずに、かえって遅くなることがあります。
コンパイラは、いくつかのループ変換を実行することで、ループの規模を大きくしようとします。この変換には、ループの交換およびループの融合が含まれます。したがって、一般的には、プログラム中の並列化部分が少ない場合や小さな並列化部分に分割される場合には、速度の向上を期待できません。
プログラムサイズが大きくなると、プログラムの並列度が向上することがあります。たとえば、あるプログラムが順次実行する部分がプログラムサイズの 2 乗に増加し、並列化可能な部分が 3 乗に増加するものとします。このプログラムでは、並列化された部分の作業量が順次実行する部分よりも早い勢いで増加します。したがって、資源の限界に達しない限り、ある時点で速度向上の効果が明確に表れます。
一般に並列 C の能力を有効利用するには、コンパイル指令を実験したり、プログラムの大きさやプログラムを再構成するといった調整を行う必要があります。
アムダールの法則
固定されたプログラムの速度の向上度は、一般にアムダールの法則によって予測されます。アムダールの法則は、あるプログラムの並列化による速度の向上は、プログラムの順次実行部分によって制限されることを単に述べています。次は、プログラムの速度向上に関する式です。F は (全実行時間を 1 とした場合の) 順次実行部分の実行時間の割合で、残りの時間が P 個のプロセッサに均等に分散されます。この式から分かるように、式の 2 番目の項の値がゼロになると、値が固定されている 1 番目の項によって全体的な速度の向上度が制限されます。
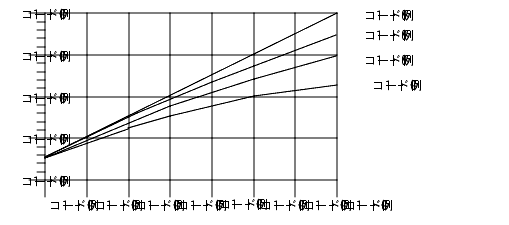
次の図に、この概念を表しました。黒く塗ってある部分がプログラム中の順次実行部分を表現していて、この部分は 1、2、4、8 プロセッサに対して一定であるのに対し、斜線部分がプログラムの並列部分で、複数のプロセッサ間で一様に分割されています。
図 4-3 固定された問題の処理速度の向上ただし実際には、複数のプロセッサに作業を分散し通信するためのオーバーヘッドが存在します。このようなオーバーヘッドは、プロセッサの数に対して固定であったり、そうでなかったりします。
図 4-4 には、プログラムに順次実行部分がそれぞれ 0%、2%、5%、10% 含まれる場合の理想的な速度向上が示されています。この図では、オーバーヘッドは想定されていません。
図 4-4 アムダールの法則による処理速度向上の曲線オーバーヘッド
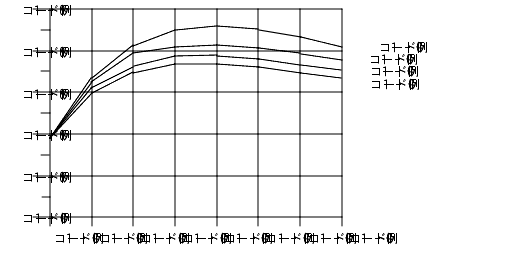
モデルにオーバーヘッドの影響を取り入れると、速度向上の曲線は大幅に変わります。ここでは、説明上 2 つの部分、つまり、プロセッサの数には無関係な固定部分と、使用されるプロセッサの 2 乗で増加する可変部分から成るオーバーヘッドを想定します。

この式で K1 と K2 は固定された係数です。この仮定では、速度向上の曲線は図 4-5 のようになります。
図 4-5 オーバーヘッドがある場合の速度向上の曲線この場合、速度の向上にピーク点があることに注目してください。ある点を越えると、プロセッサを増加させてもパフォーマンスが下がり始めます。
ガスタフソンの法則
アムダールの法則では、実際のプログラムを並列化するときの速度向上の効果を正しく予測できません。プログラムの順次実行部分に費やされる時間の割合は、プログラムサイズに依存することがあります。つまり、プログラムサイズが増加すると、速度向上が可能になる場合があります。例を使って説明します。
理想的にオーバーヘッドがゼロで、2 番目に入れ子にされたループが並列に実行されると仮定すると、プログラムサイズが小さい場合 (すなわち
nの値が小さい) と、プログラムの順次実行部分と並列実行部分の大きさがそれほど違わないことがわかります。ところが、nが大きくなると、並列実行部分に費やされる時間が順次実行の部分に対するものよりも早い勢いで大きくなります。このプログラムの場合は、プログラムサイズが大きくなるにつれてプロセッサの数を増やす方法が有効です。負荷バランスとループのスケジューリング
並列ループの繰り返しを複数のスレッドに分散する作業を「ループのスケジューリング」といいます。速度を最大限に向上させるには、作業をスレッドに均等に分散することによって、オーバーヘッドがあまり発生しないようにすることが重要です。コンパイラは、異なる状況に合わせて、いくつかの種類のスケジューリングをすることができます。
静的 (チャンク) スケジューリング
ループの個々の繰り返しが実行する作業が同じである場合には、システムの複数のスレッドに均一に作業を分散すると効果があります。この方法を静的スケジューリングといいます。
コード例 4-13 静的スケジューリングに向いたループ for (i=1; i < 1000; i++) {sum += a[i]*b[i]; /* S1 */}静的スケジューリング (チャンクスケジューリングともいう) では、各スレッドは同じ回数の繰り返しを実行します。たとえばスレッドの数が 4 であれば、上記の例では、各スレッドで 250 回の繰り返しが実行されます。割り込みが発生しないものと仮定し、各スレッドが同じ早さで作業を進行していくと、すべてのスレッドが同時に終了します。
セルフスケジューリング
各繰り返しで実行する作業が異なる場合、静的スケジューリングでは、一般に、よい負荷バランスを得ることができなくなります。静的スケジューリングでは、すべてのスレッドが、同じ回数の繰り返しを処理します。マスタースレッドを除くすべてのスレッドは、実行を終了すると、次の並列部分が検出されるまで待つことになります。残りのプログラムの実行はマスタースレッドが行います。
セルフスケジューリングでは、各スレッドが異なる小さな繰り返しを処理し、割り当てられた処理が終了すると、同じループのさらに別の繰り返しを実行することになります。
ガイド付きセルフスケジューリング
ガイド付きセルフスケジューリング (GSS) では、各スレッドは、連続した小数の繰り返しをいくつか受け持ちます。各繰り返しで作業量が異なるような場合には、GSS によって、負荷のバランスが保たれるようになります。
ループの変換
コンパイラは、プログラム中のループを並列に実行できるようにするために、ループ再構成のための変換を数回実行します。この変換のいくつかは、シングルプロセッサ上でのループの実行速度も向上させます。コンパイラが実行する変換を以下で説明します。
ループの分散
ループには、並列に実行できる文とできない文とが存在することがあります。通常、並列実行できない文はごく少数です。ループの分散によって、これらの文を別のループに移動し、並列実行可能な文だけから成るループを作ります。これを以下の例で説明します。
コード例 4-14 ループの分散に適したコード for (i=0; i < n; i++) {x[i] = y[i] + z[i]*w[i]; /* S1 */a[i+1] = (a[i-1] + a[i] + a[i+1]/3.0; /* S2 */y[i] = z[i] - x[i]; /* S3 */}配列
x、y、w、a、zが重なりあっていないと仮定すると、文S1およびS3を並列実行することはできますが、文S2はできません。このループを異なる 2 個のループに分割すると以下のようになります。
この変換の後、上記ループ
L1には並列実行を妨害する文が含まれていないので、これを並列実行できるようになります。ところが、2 番目のループL2は元のループの並列実行できない部分を引き継いだままです。ループの分散は、常に効果があって安全に実行できるとは限りません。コンパイラは、この効果と安全性を確認するための解析を実行します。
ループの融合
ループが小さい、すなわちループでの作業量が少ないと、大幅にパフォーマンスを向上させることはできません。これは、ループでの作業量に比べて、並列ループを起動するときのオーバーヘッドが大きくなるためです。このような状況では、コンパイラはループの融合を使用して、いくつかのループを 1 つの並列ループに融合し、ループを大きくします。同じ回数の繰り返しを行うループが隣接していると、ループの融合は簡単にしかも安全に行われます。次の例を考えてみましょう。
コード例 4-16 作業量の少ないループ for (i=0; i < 100; i++) {a[i] = a[i] + b[i]; /* S1 */}/* L2: 別の小さな並列ループ */for (i=0; i < 100; i++) {b[i] = a[i] * d[i]; /* S2 */}この例では、2 個の小さなループが隣どうしに記述されていて、以下のように安全に融合することができます。
コード例 4-17 融合された 2 つのループ for (i=0; i < 100; i++) {a[i] = a[i] + b[i]; /* S1 */b[i] = a[i] * d[i]; /* S2 */}これによって、並列ループの実行によるオーバーヘッドを半分にすることができます。ループの融合は、別の場合にも役に立ちます。たとえば、同じデータが 2 個のループで参照されている場合には、この 2 個のループを融合すると、参照を局所的なものにすることができます。
ただし、ループの融合は常に安全に実行できるとは限りません。ループの融合によって、元々存在していなかったデータの依存関係が生成されると、実行結果が正しくなくなることがあります。次の例を考えてみましょう。
コード例 4-18 安全でない融合の例 for (i=0; i < 100; i++) {a[i] = a[i] + b[i]; /* S1 */}/* L2: データの依存性がある小さなループ */for (i=0; i < 100; i++) {a[i+1] = a[i] * d[i]; /* S2 */}コード例 4-18 でループの融合が実行されると、文 S2 から
S1に対するデータの依存性が生成されます。実際に、文S1の右辺にあるa[i]の値が、文S2で計算されるものになります。これはループが融合されないと起こりません。コンパイラは、ループの融合を実行すべきかどうかを判断するために解析を行い、安全性と有効性を確認します。場合によっては、任意の数のループを融合できることがあります。このような方法でループの作業量を多くすると、並列実行が十分に有効であるようなループを生成することができます。ループの交換
入れ子になっているループの最も外側のループを並列化すると、発生するオーバーヘッドが小さいために、一般に大きな効果が期待できます。しかし、そのループに依存性がある場合は、並列化することは安全ではありません。以下の例で説明します。
コード例 4-19 並列化できない入れ子のループ for (i=0; i <n; i++) {for (j=0; j <n; j++) {a[j][i+1] = 2.0*a[j][i-1];}}この例では、添字変数
iを持つループは、連続する 2 つの繰り返しで依存関係があるために、並列化することができません。ただし、2 つのループを交換することができるため、交換すると並列ループ (jのループ) が今度は外側のループになります。
コード例 4-20 交換されたループ for (j=0; j<n; j++) {for (i=0; i<n; i++) {a[j][i+1] = 2.0*a[j][i-1];}}この結果生成されたループでは並列作業の分散に対するオーバーヘッドが 1 回で済むのに対して、元のループでは、
n回必要でした。コンパイラは、これまで説明したように、ループの交換をするかどうか決定するための解析を行い、安全性と有効性を確認します。別名と並列化
ANSI C の別名を使用すると、ループを並列化できなくなることがあります。別名とは、2 個の参照が記憶領域の同じ位置を参照する可能性のある場合に発生します。以下の例を考えてみましょう。
コード例 4-21 同じ記憶領域への参照を持つループ void copy(float a[], float b[], int n) {int i;for (i=0; i < n; i++) {a[i] = b[i]; /* S1 */}}変数
aおよびbは引数であるため、以下のように呼ばれる場合には、aおよびbが重なりあった記憶領域を参照している可能性があります。次のようなルーチンcopyが呼び出される例を考えてみましょう。
呼び出された側では、
copyループの連続した 2 回の繰り返しが、配列xの同じ要素を読み書きしている可能性があります。しかし、ルーチンcopyが次のように呼び出された場合には、実行される 20 回の繰り返しループで、重なりあう可能性がなくなります。
一般的に、ルーチンがどのように呼び出されるかをコンパイラが知っていない限り、この状況を正しく解析することは不可能になります。ANSI/ISO C では、ANSI C に対する拡張キーワードを装備することで、このような別名の問題に対して指示することが可能になっています。詳細については、「制限付きポインタ」を参照してください。
配列およびポインタの参照
別名の問題の一因は、配列参照とポインタ計算演算を定義できる C 言語の性質にあります。効率的にループを並列化するためには、プラグマを自動的または明示的に使用して、配列として配置されているすべてのデータを、ポインタではなく C の配列参照の構文を使用して参照する必要があります。ポインタ構文が使用されると、コンパイラはループの異なる繰り返し間でのデータの関係を解析できなくなります。そのため、安全性を考慮してループを並列化しなくなります。
制限付きポインタ
コンパイラが効率よくループを並列化できるようにするには、左辺値が記憶領域の特定の領域を示していなければなりません。別名とは、記憶領域の決まった位置を示していない左辺値のことです。オブジェクトへの 2 個のポインタが別名であるかどうかを判断することは困難です。これを判断するにはプログラム全体を解析することが必要であるため、非常に時間がかかります。
コード例 4-22 2 つのポインタを持つループ void vsq(int n, double * a, double * b) {int i;for (i=0; i<n; i++) {b[i] = a[i] * a[i];}}ポインタ
aおよびbが異なるオブジェクトをアクセスすることをコンパイラが知っている場合には、ループ内の異なるくり返しを並列に実行することができます。しかし、ポインタaおよびbでアクセスされるオブジェクトが重なりあっていれば、ループを安全に並列実行できなくなります。コンパイル時に関数vsq()を単純に解析するだけでは、aおよびbによるオブジェクトのアクセスが重なりあっているかどうかを知ることはできません。この情報を得るには、プログラム全体を解析することが必要になります。制限付きポインタを使ってオブジェクトを明確に区別すると、コンパイラによるポインタ別名の解析が実行可能になります。この制限付きポインタをサポートするために、Sun ANSI C コンパイラは、キーワード
"_Restrict"を認識できるように拡張されています。以下に、vsq()の関数パラメータを制限付きポインタとして宣言した例を示します。
ポインタ
aおよびbが制限付きポインタとして宣言されているので、aおよびbで示された記憶領域が区別されていることがわかります。この別名情報によって、コンパイラはループの並列化を実行することができます。
_Restrictはvolatileに似た型修飾子で、ポインタ型に対して有効です。なお、_Restrictは-Xa(デフォルト) もしくは-Xtモードでコンパイルされた場合に限って有効なキーワードです。この 2 通りのコンパイルモードに対してコンパイラは__RESTRICTマクロを定義するので、制限付きポインタを持った移植性のあるコードを書くことが容易になります。たとえば以下のコードは Sun コンパイラのすべてのコンパイラモードでコンパイルできるだけでなく、制限付きポインタをサポートしていないコンパイラでも、コンパイルできます。
制限付きポインタが ANSI/ISO C の標準になるとすれば、
restrictがキーワードになると思われます。関数vsq()で使用されているように、以下のプロセッサ指令を含むコードを書くと、restrictが ANSI C の標準になった場合の変更を最小限に抑えることができます。
これは、
restrictが ISO C 標準のキーワードであるためです。現在のキーワードとして、_Restrictが使われている理由は、_Restrictが実装された名前空間にあり、ユーザーの名前空間との衝突を発生させないためです。ソースコードを変更したくない場合は、次のコマンド行オプションで、関数の引数を値とするポインタを制限付きポインタとして指定することができます。
関数リストが指定されている場合には、指定された関数内のポインタパラメータは制限付きとして扱われます。指定されていない場合には、C のソースファイル全体のすべてのポインタ引数が制限付きとして扱われます。たとえば
-xrestrict=vsqを使用すると、上述の関数vsq()についての最初の例では、ポインタaおよびbがキーワード_Restrictによって修飾されます。
_Restrictを正しく使用することはとても重要です。区別できないオブジェクトを指しているポインタを制限付きポインタにしてしまうと、ループを正しく並列化することができなくなり、不定な動作をすることになります。たとえば、関数vsq()のポインタaおよびbが重なりあっているオブジェクトを指している場合には、b[i]とa[i+1]などが同じオブジェクトである可能性があります。このときaおよびbが制限付きポインタとして宣言されていなければ、ループは順次実行されます。aおよびbが間違って制限付きであると宣言されていれば、コンパイラはループを並列実行するようになりますが、この場合b[i+1]の結果はb[i]を計算した後でなければ得られないので、安全に実行することはできません。明示的な並列化およびプラグマ
すでに述べたように、並列化の適用や有効性をコンパイラだけで決めるには、情報が不十分なことがあります。Sun ANSI/ISO C では、プラグマをサポートしており、コンパイラだけでは不可能なループの並列化を効率よく実行することができます。
直列プラグマ
直列プラグマには 2 通りあり、どちらも
forループに適用されます。
#pragmaMPserial_loopは、次に存在するforループを自動的に並列化しないことを指示します。
#pragmaMPserial_loop_nestedは、次に存在するforループ、およびそのforループの中で入れ子になっているforループを自動的に並列化しないことを指示します。なお、serial_loop_nestedのスコープは、このプラグマが適用されるループの範囲を越えることはありません。並列プラグマ
MP taskloopプラグマは、オプションとして、以下の引数を取ることができます。
maxcpus(<プロセッサ数>)private(<スレッド固有変数リスト>)shared(<共有変数リスト>)readonly(<読み取り専用変数リスト>)storeback(<ストアバック変数リスト>)savelastreduction(<縮約変数リスト>)schedtype(<スケジューリング型>)
MP taskloopプラグマ 1 つに対して指定できるオプションは 1 つだけです。ただし、複数のプラグマの効果を重ねて、ソースコード内の現在のブロック内にある次のforループに適用することができます。
これらのオプションは、
forループの前に複数回指定できます。オプションが衝突を起こす場合には、コンパイラによって警告メッセージが出力されます。
forループの入れ子
MPtaskloopプラグマは、現在のブロック内にある次のforループに適用されます。Sun ANSI/ISO C によって並列化されたforループに入れ子は存在しません。並列化の適切性
MPtaskloopプラグマは、forループを並列化するように指示します。不規則なフロー制御や、一定しない増分による繰り返しを持った
forループに対しては、正当な並列化を実行できません。たとえば、setjmp、longjmp、exit、abort、return、goto、label、breakを含んだforループは並列化に適しません。特に重要なこととして、繰り返し間の依存性を持った
forループでも、明示的に並列化できる点に注意してください。すなわち、このようなループに対してMP taskloopプラグマが指定されていると、forループが並列化に適していないと判断されない限り、単にこの指示に従って並列化を実行してしまいます。このような明示的な並列化を行なった場合は、不正確な結果が発生しないかを確認してください。1 つのループに対して
serial_loopまたはserial_loop_nestedとtaskloopの両方のプラグマが指定されている場合には、最後の指定が優先的に使用されます。
for (i=0; i<100; i++) {# pragma MP taskloopfor (j=0; j<1000; j++) {...}}この例では、
iループは並列化されませんが、jループは並列化されます。プロセッサの数
#pragma MP taskloop maxcpus(<プロセッサ数>) は、指定が可能であれば、現在のループに対して使用されるプロセッサの数を指定します。
maxcpusに指定する値は正の整数でなければなりません。maxcpusが 1 であれば、指定されたループは直列に実行されます。なお、maxcpusを 1 に指定した場合には、serial_loopプラグマを指定したことと同等になる点に注意してください。また、maxcpusの値かPARALLEL環境変数のどちらか小さい方の値が使用されます。環境変数PARALLELが指定されていない場合には、この値に 1 が指定されているものとして扱われます。1 つの
forループに複数のmaxcpusプラグマが指定されている場合には、最後に指定された値が優先的に使用されます。変数の分類
ループに使用される変数は、「スレッド固有」、「共有」、「縮約」または「読み取り専用」のどれかに分類されます。1 つの変数は、これらの種類のうち 1 つにのみ属します。 変数の種類を縮約または読み取り専用にするには、明示的にプラグマで指示しなければなりません。詳しくは、「縮約変数」および 「読み取り専用変数」を参照してください。変数を「スレッド固有」または「共有」にするには明示的にプラグマを使用するか、または以下のスコープの規則にもとづいて決まります。
スレッド固有変数と共有変数のデフォルトのスコープの規則
スレッド固有変数は、
forループのある繰り返しを処理するためにそれぞれのプロセッサが専用に使用する値を保持します。別の言い方をすれば、forループのある繰り返しでスレッド固有変数に割り当てられた値は、そのループの別の繰り返しを処理しているプロセッサからは見えません。これに対して共有変数は、forループの繰り返しを処理しているすべてのプロセッサから現在の値にアクセスできる変数のことです。ループのある繰り返しを処理している 1 つのプロセッサが共有変数に代入した値は、そのループの別の繰り返しを処理しているプロセッサからでも見ることができます。共有変数を参照しているループを#pragma MP taskloop指令によって明示的に並列化する場合には、値の共有によって正確性に問題が起きないことを確認しなければなりません (競合条件の確認など)。明示的に並列化されたループの共有変数へのアクセスおよび更新では、コンパイラによる同期はとられません。明示的に並列化されたループの解析において、変数がスレッド固有と共有のどちらであるかを決定するために、以下の「デフォルトのスコープの規則」が使用されます。
- 変数がプラグマによって明示的に分類されていない場合には、その変数がポインタまたは配列として宣言されていて、かつループ内では配列構文を使用して参照している限り、その変数はデフォルトで共有変数として分類されます。
- ループのインデックス変数は常にスレッド固有変数として扱われ、また常にストアバック変数です。
明示的に並列化された
forループ内のすべての変数を、共有、スレッド固有、縮約、または読み取り専用として明示的に指定し、デフォルトのスコープの規則が適用されないようにすることを、強くお勧めします。コンパイラは、共有変数に対するアクセスの同期を一切実行しないので、たとえば、配列参照を含んだループに対して
MPtaskloopプラグマを使用する前には、十分な考察が必要になります。このように明示的に並列化されたループで、繰り返し間でのデータ依存性がある場合には、並列実行を行うと正しい結果を得られないことがあります。コンパイラによって、このような潜在的な問題を検出し、警告メッセージを出力することもできますが、一般的にこれを検出することは非常に困難です。なお、共有変数に対する潜在的な問題を持ったループでも、明示的に並列化を指示されると、コンパイラはこの指示に従います。スレッド固有変数
#pragma MP taskloop private(<スレッド固有変数リスト>)このプラグマは、現在のループでスレッド固有変数として扱われる必要のあるすべての変数を指定するために使用します。ループで使用されている別の変数は、それ自体が明確に共有、読み取り専用、または縮約であることが指定されていない限り、デフォルトのスコープの規則に従って、共有またはスレッド固有のどちらかに分類されます。
スレッド固有変数とは、それ自体の値がループのある繰り返しを処理するプロセッサ専用になっている変数のことです。別の言い方をすれば、ループのある繰り返しを処理しているプロセッサによってスレッド固有変数に代入された値は、そのループの別の繰り返しを処理しているプロセッサから見ることはできません。スレッド固有変数には、ループの繰り返しの開始時に初期値は代入されず、繰り返し内で最初に使用される前に、その繰り返し内で値が代入されなければなりません。値が設定される前にその値を参照するように明確に宣言されたスレッド固有変数を持つループを実行すると、その動作は保証されません。
共有変数
#pragma MP taskloop(<共有変数リスト>)このプラグマは、現在のループで共有変数として扱われる必要のあるすべての変数を指定するために使用します。ループで使用されている別の変数は、それ自体が明確にスレッド固有、読み取り専用、または縮約であることが指定されていない限り、デフォルトのスコープの規則に従って、共有またはスレッド固有のどちらかに分類されます。
共有変数とは、ある
forループの繰り返しを処理しているすべてのプロセッサから現在の値を見ることのできる変数のことです。ループのある繰り返しを処理しているプロセッサが共有変数に代入した値は、そのループの別の繰り返しを処理しているプロセッサからでも見ることができます。読み取り専用変数
#pragma MP taskloop readonly(<読み取り専用変数リスト>)このプラグマは、現在のループで読み取り変数として扱われる必要のあるすべての変数を指定するために使用します。
読み取り専用変数とは、共有変数の特殊なクラスのことで、ループのどの繰り返しでも、その値を変更できません。変数を読み取り専用として指定すると、ループの繰り返しを処理しているそれぞれのプロセッサに対して、個々にコピーされた変数値が使用されます。
ストアバック変数
#pragma MP taskloop storeback(<ストアバック変数リスト>)このプラグマは、現在のループでストアバック変数として扱われる必要のあるすべての変数を指定するために使用します。
ストアバック変数とは、ループの中で変数値が計算され、その値がループの終了後に使用される変数のことです。ループの最後の繰り返しにおけるストアバック変数の値が、ループの終了後に利用可能になります。このような変数は、その変数が明示的な宣言やデフォルトのスコープ規則によってスレッド固有変数となっている場合には、この指令を使用して明示的にストアバック変数として宣言するとよいでしょう。
なお、ストアバック変数に対する最終的な戻し操作 (ストアバック操作) は、明示的に並列化されたループの最後の繰り返しにおいて、その中で実際に値が変更されたかどうかには関係なく実行される点に注意してください。すなわち、ループの最後の繰り返しを処理するプロセッサと、ストアバック変数の最終的な値を保持しているプロセッサとは、異なる可能性があります。
for (i=1; i <= n; i++) {if (...) {x=...}}printf ("%d", x);上記の例では、
printf()呼び出しによって出力されるストアバック変数xの値は、iループを直列に実行した場合の出力値とは異なる可能性があります。なぜならば、明示的に並列化されたループでは、ループの最後の繰り返し (すなわちi==n のとき) を処理し、xに対してストアバック操作を行うプロセッサは、現在最後に更新されたxの値を保持するプロセッサとは同じでないことがあるからです。このような潜在的な問題に対し、コンパイラは警告メッセージを出力します。明示的に並列化されたループでは、配列として参照される変数をストアバック変数としては扱いません。したがって、このような変数にストアバック処理が必要な場合 (たとえば、配列として参照される変数がスレッド固有変数として宣言されている場合) には、その変数を <ストアバック変数リスト> に含める必要があります。
savelastこのプラグマは、ループ内のすべてのスレッド固有変数をストアバック変数として扱うために使用します。このプラグマの構文を以下に示します。
各変数をストアバック変数として宣言するときには、それぞれのスレッド固有変数をリストするよりも、この形式が便利であることがよくあります。
縮約変数
#pragma MP taskloop reduction(<縮約変数リスト>)このプラグマは、縮約変数リストにあるすべての変数が、そのループに対して縮約変数として扱われるために使用します。縮約変数とは、ループのある繰り返しを処理している個々のプロセッサによって、その値が部分的に計算され、最終値がすべての部分値から計算される変数のことをいいます。縮約変数リストにより、そのループが縮約ループであることをコンパイラに指示し、適切な並列縮約用のコードを生成できるようにします。以下の例を考えてみましょう。
for (i=0; i<n; i++) {x = x + a[i];}ここでは、変数
xが (和の) 縮約変数であり、iループが (和の) 縮約ループになっています。スケジューリングの制御
Sun ANSI/ISO C コンパイラには、指定されたループのスケジューリングを戦略的に制御するために、
taskloopプラグマと同時に使用するいくつかのプラグマが用意されています。このプラグマの構文を以下に示します。
このプラグマによって、並列化されたループをスケジュールするための <スケジューリング型> を指定することができます。<スケジューリング型> には、以下のいずれかを指定できます。
static
- 静的スケジューリングでは、ループ内のすべての繰り返しが、そのループを処理するすべてのプロセッサに均等に配分されます。次の例を考えてみましょう。
for (i=0; i<1000; i++) {...}- 上述の例では、4 個のプロセッサが、ループの繰り返しを 250 ずつ処理します。
self[<チャンクサイズ>]
- 自己スケジューリングでは、ループのすべての繰り返しが処理されるまで、固定された回数の繰り返し <チャンクサイズ> を、そのループを処理するそれぞれのプロセッサで処理します。オプション <チャンクサイズ> には、使用するチャンクサイズを指定します。<チャンクサイズ> は、正の整定数か、もしくは整数型の変数でなければなりません。変数の <チャンクサイズ> が指定された場合は、そのループを開始する前に、その変数が正の整数値であるかどうかが評価されます。チャンクサイズが指定されていない場合、もしくは、この値が正でない場合、チャンクサイズはコンパイラによって決められます。次の例を考えてみましょう。
for (i=0; i<1000; i++) {...}- この例では、ループを処理するそれぞれのプロセッサに割り当てられる繰り返し数は、割り当て順に以下のようになります。
- 120, 120, 120, 120, 120, 120, 120, 120, 40.
gss [<最小チャンクサイズ>]
- ガイド付き自己スケジューリング (GSS) では、ループのすべての繰り返しが処理されるまで、可変数の繰り返し (最小チャンクサイズ) を、そのループを処理するそれぞれのプロセッサで処理します。オプション <最小チャンクサイズ> を指定すると、可変なチャンクサイズが最低でも <最小チャンクサイズ> になるように設定されます。
<最小チャンクサイズ> は、正の整定数か、もしくは整数型の変数でなければなりません。変数の <最小チャンクサイズ> が指定された場合は、そのループを開始する前に、その変数が正の整数値であるかどうかが評価されます。最小チャンクサイズが指定されていない場合、もしくは、この値が正でない場合、チャンクサイズはコンパイラによって決められます。次の例を考えてみましょう。
for (i=0; i<1000; i++) {...}- この例では、ループを処理するそれぞれのプロセッサに割り当てられる繰り返し数は、割り当て順に以下のようになります。
- 250, 188, 141, 106, 79, 59, 45, 33, 25, 19, 14, 11, 10, 10, 10.
factoring [<最小チャンクサイズ>]
- ファクタリングスケジューリングでは、ループのすべての繰り返しが処理されるまで、可変数の繰り返し (最小チャンクサイズ) を、そのループを処理するそれぞれのプロセッサで処理します。オプション <最小チャンクサイズ> を指定すると、可変なチャンクサイズが最低でも <最小チャンクサイズ> になるように設定されます。
<最小チャンクサイズ> は、正の整定数か、もしくは整数型の変数でなければなりません。変数の <最小チャンクサイズ> が指定された場合は、そのループを開始する前に、その変数が正の整数値であるかどうかが評価されます。最小チャンクサイズが指定されていない場合、もしくは、この値が正でない場合、チャンクサイズはコンパイラによって決められます。次の例を考えてみましょう。
for (i=0; i<1000; i++) {...}- 上述の例では、ループを処理するそれぞれのプロセッサに割り当てられる繰り返し数は、割り当て順に解釈すると以下のようになります。
125, 125, 125, 125, 62, 62, 62, 62, 32, 32, 32, 32, 16, 16, 16, 16, 10, 10, 10, 10, 10, 10.
コンパイラオプション
|
サン・マイクロシステムズ株式会社 Copyright information. All rights reserved. |
ホーム | 目次 | 前ページへ | 次ページへ | 索引 |