 Purpose of Analytic Type Definitions
Purpose of Analytic Type Definitions
This chapter discusses:
Purpose of analytic type definitions.
Relationship of record attributes to data caching behavior.
Synchronization order.
Purpose of Analytic Type Definitions
You create analytic type definitions for use with PeopleSoft Optimization Framework and Analytic Calculation Engine. In PeopleSoft Optimization Framework, you create analytic type definitions to group optimization records, optimization transactions, and optimization plug-ins together as one entity.
See Creating Analytic Type Definitions.
In Analytic Calculation Engine, you create analytic type definitions to group records and an analytic model together as one entity. You follow the same procedure to create analytic type definitions for both PeopleSoft Optimization Framework and Analytic Calculation Engine.
When creating a new analytic model definition, you create the analytic type definition in this developmental sequence:
Create and save an analytic model definition.
See Understanding the Analytic Model Definition Creation Process.
Create an analytic type definition and define records.
See Example: Working with an Analytic Type and an Analytic Model, Creating Record Definitions.
Associate the analytic model with the analytic type.
In the cube collection properties, map a main record in the analytic type to the cube collection.
You can also map an aggregate record in the analytic type to the cube collection.
See Mapping a Cube Collection to Main and Aggregate Records.
In the cube collection properties, map the fields in the record to data cubes and dimensions.
When updating an analytic model definition, create an analytic type definition during this developmental sequence:
Update the records in the analytic type definition.
Create a new cube collection in the analytic model definition.
In the cube collection properties, map one of the updated records to the cube collection.
See Mapping a Cube Collection to Main and Aggregate Records.
In the cube collection properties, map fields of the updated record to data cubes and dimensions.
 Example: Working with an Analytic Type and an Analytic Model
Example: Working with an Analytic Type and an Analytic Model
This example illustrates the typical process for creating an analytic type definition to be used with a new analytic model.
Note. For simplicity, this example maps only one cube collection to a main record, although the analytic model definition in this example contains several records which would be used with several cube collections. The record used in this example is mapped to a read/write cube collection for loading data from the database, receiving end user input, and persisting data back to the database.
See Understanding Cube Collections.
You create an analytic type definition called QE_ACE_DGCPROB and define the records that are used in the analytic model. You insert all of these records (except derived/work records) into the analytic type definition and set the attributes of the records, as shown in this example:

Example of defining the records within the QE_ACE_DBCPROB analytic type definition
Next, you create an analytic model definition called QE_ACE_DGCMODEL, with data cubes and dimensions that are related in this manner:
|
Data Cube |
Attached Dimensions |
|
SALARY input data cube |
These dimensions are attached to the SALARY data cube:
|
|
EXPENSE input data cube |
These dimensions are attached to the EXPENSE data cube:
|
|
BONUS_PERCENT input data cube |
These dimensions are attached to the BONUS_PERCENT data cube:
|
Note. At this step in the process, you do not create the analytic model definition's cube collections.
On the Models tab, you associate the analytic type with the QE_ACE_DGCMODEL analytic model, as shown in this example:
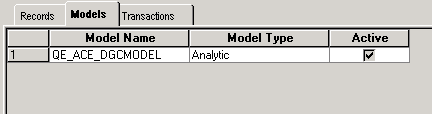
Example of associating the QE_ACE_DBCPROB analytic type to the QE_ACE_DGCMODEL analytic model
Next, you open the analytic model definition and create a read/write cube collection called QE_ACE_EMPLOYEE1_IN. On the General tab of the cube collection's properties, you map the cube collection to the QE_ACE_EMPL1 main record, as shown in this example:
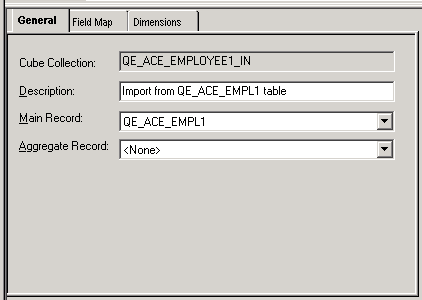
Example of mapping the QE_ACE_EMPLOYEE1_IN cube collection to the QE_ACE_EMPL1 main record
Note. This cube collection does not use an aggregate record.
On the Field Map tab, you map the fields in the QE_ACE_EMPL1 record to the data cubes and dimensions, as shown in this example:
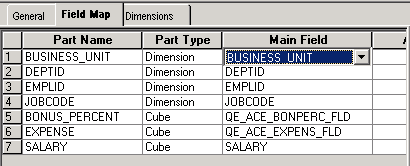
Example of mapping data cubes and dimensions to the fields of the QE_ACE_EMPL1 record
When mapping dimensions and data cubes, you may want to map dimensions to the key fields in the main record and data cubes to the non-key fields in the main record. The PeopleSoft system, however, does enable you to map dimensions to non-key and data cubes to key fields. To perform the most appropriate mapping, you must have a deeper understanding of the relationship between data cubes and dimensions.
See Data Cubes and Dimensions.
See Also
Designing Analytic Type Definitions
Relationship of Record Attributes to Data Caching Behavior
When you create an analytic type definition, how you set the record attributes determines the caching behavior of the data that is used in the analytic model. This section describes analytic type definition record attributes and their effects on data caching.
When you map a cube collection to a record that contains a Read Once attribute in the analytic type, the application data is read only once during analytic model load time. Map cube collections to Read Once records to load data that the user should not change during the analytic model's life cycle. You can specify the Read Once attribute for these record types:
SQL tables.
SQL views.
Dynamic views.
Query views.
Note. Data cubes that exist in a cube collection that is mapped to a main record with a Read Once attribute cannot exist in any other cube collection that is mapped to a main record with the Read Once attribute.
When you map a cube collection to a record that contains a Readable attribute in the analytic type, the application data is read during analytic instance load time and is updated with new data after:
Each analytic model recalculation.
You recalculate an analytic model by using the AnalyticModel class Recalculate method. The AnalyticModel class is one of the Analytic Calculation Engine classes.
See Recalculate.
Each Save action that is triggered by a PeopleSoft Pure Internet Architecture page with an analytic grid.
Each time data is updated using the CubeCollection class SetData method.
The CubeCollection class is one of the Analytic Calculation Engine classes.
See SetData.
Map cube collections to Readable records to load data that should be refreshed more than once during the analytic model's life cycle.
You can specify the Readable attribute for the SQL table record type.
Note. Data cubes that exist in a cube collection that is
mapped to a main record with the Readable attribute cannot exist in any other
cube collection that is mapped to a main record with the Readable or Read
Once attributes.
When a cube collection is mapped to either a Writable-only record or
a record with the Readable and Writable attributes, all data cubes in the
cube collection should share the same set of dimensions.
When you map a cube collection to a record that contains a Writable attribute in the analytic type, the data in the cube collection is written back to the application database after:
Each analytic model recalculation.
You recalculate an analytic model by using the AnalyticModel class Recalculate method. The AnalyticModel class is one of the Analytic Calculation Engine classes.
See Recalculate.
Each Save action that is triggered by a PeopleSoft Pure Internet Architecture page with an analytic grid.
Each time data is updated using the CubeCollection class SetData method.
The CubeCollection class is one of the Analytic Calculation Engine classes.
See SetData.
You can specify the Read Once attribute for the SQL table record type.
If the analytic type contains a writable-only record that uses a primary key field, you must set up the application to clear the data in the database for the writable record before recalculating the analytic instance.
Note. After the data is written back to the database, the
data cubes that are mapped to the writable-only record are cleared from the
analytic instance, resulting in 0 or empty values in the analytic grid.
When a cube collection is mapped to either a Writable-only record or
a record with the Readable and Writable attributes, all data cubes in the
cube collection should share the same set of dimensions.
Use the Scenario Managed attribute to indicate that the record pertains to multiple analytic instances. A scenario managed record is read from and written back to the database according to the other attributes that are specified for the record.
Typically, one user views and edits one analytic instance, although Analytic Calculation Engine supports multiple users per analytic instance.
Records that contain the scenario managed attribute must have a PROBINST key field. The PROBINST key field is used to segment the data of scenario managed records, resulting in a different data set loaded for each analytic instance. This is an example of a record with a PROBINST key field:
|
PROBINST key field |
ACCT field |
TRANS_DATE field |
REGION field |
|
BUDGET01 |
100 |
January |
EUROPE |
|
BUDGET01 |
100 |
Feb |
EUROPE |
|
BUDGET02 |
110 |
Feb |
ASIA |
|
BUDGET02 |
110 |
March |
ASIA |
|
BUDGET03 |
120 |
March |
USA |
In this example:
The users of the BUDGET01 analytic instance can access only the first and second rows of this record.
The users of the BUDGET02 analytic instance can access only the third and fourth rows of this record.
The users of the BUDGET03 analytic instance can access only the fifth row of this record.
Note. Data cubes that exist in a cube collection that is mapped to a main record with the Scenario Managed attribute cannot exist in any other cube collection that is mapped to a derived/work main record.
See Scenario Management.
Records based on dynamic views can be Scenario Managed. For these records, the associated SQL must contain a meta string for qualifying the analytic instance.
The following example shows a Dynamic View record:
SELECT PROBINST, QE_BAM_MONTH_FLD, QE_BAM_REGION_FLD, QE_BAM_PRODUCT_FLD, QE_BAM_UNIT_FLD, QE_BAM_SALES_FLD, QE_BAM_PRDSALES_FL FROM PS_QE_BAM_FACT_TBL WHERE PROBINST = %ProbInst
If a Union clause is present the WHERE PROBINST= %ProbInst must be added to the individual clauses making up the SQL Union. In addition all the fields that are part of the dynamic view must be selected in the analytic type definition. This is enforced by PeopleSoft Application Designer.
See Also
Configuring Analytic Type Records
Synchronization Order
In Analytic Calculation Engine, the synchronization order indicates the order in which the analytic calculation engine reads the records in the analytic type definition. Records that are used as aggregate records should have a higher synchronization order than records that are used as main records.