 Feed Publishing Framework
Feed Publishing Framework
This chapter discusses:
Feed Publishing framework.
Feed data types.
Feed types and options.
Feed security.
Feed publication.
My feeds.
Feed Publishing Framework
The Feed Publishing Framework provides:
A set of application programming interfaces (APIs) and code samples to assist application developers in creating new types of feeds and integrating them with existing features.
Unified interfaces for content owners and administrative users to create, configure, and maintain feed definitions of various types.
Interfaces for end users to discover related feeds and search feed definitions.
Multiple language support.
The following diagram shows the Feed Publishing Framework architecture. For this diagram, use this legend:
Orange boxes - Integration Broker components
Light blue boxes - Portal components or GUI
Yellow boxes - Data storage
White boxes - Feed framework core
Red lines - Incoming request
Black lines - Response
Gold arrows - Data to and from database

Feed Publishing Framework architecture
This section discusses:
Feed publishing runtime engine.
Feed document generation and delivery.
Feed document properties.
Feed data type application classes.
Creation of new feed data types.
 Feed Publishing Runtime Engine
Feed Publishing Runtime Engine
The centerpiece of the feed document generation is the runtime engine. The runtime engine:
Handles the feed identification and authorization.
Sets the data source settings and data source parameter value.
Executes the data source object to collect data.
Transforms feed data to an Atom 1.0 feed document.
When the runtime engine receives a request, it first locates the feed definition based on the feed ID, and then it determines whether the current user has access to the feed. If the user has permission, the process continues. If the user does not have permission, the process stops and the system displays an error.
Next, the runtime engine creates an instance of the feed data type application class associated with the specific feed definition, restores the Data Source Setting values and the Data Source Parameter values saved with the feed definition, and sets the runtime information, such as the requested language. At this time, the runtime engine also evaluates the runtime values of data source parameters with usage types of Admin Specified, System Variable, and User Specified.
Then, the runtime engine instructs the feed object to collect the data and return the feed data in an Atom 1.0 feed document. The runtime engine does not have direct knowledge about the feed data. All business logic relevant to data collection are encapsulated in the feed data type application class PeopleCode.
By default, the currently authenticated user of the request is used for gathering the feed data. Different users requesting the same feed may receive different feed data based on their permission. This behavior can be overridden by specifying the Feed Authorization options when you create a feed definition; that is, a user ID can be specified alone with a selection that specifies whether to use this user to generate feed documents for all requests of that feed or only for anonymous requests. This option is a per feed definition, and it will be stored with the feed definition.
Feed Document Generation and Delivery
By default, all feeds managed by the framework will be served as real-time feeds through Integration Broker framework by using the GetFeed service operation.
A GetFeed service operation (PTFP_GETFEED) uses the runtime engine to locate the feed definition and generate feed document in Atom 1.0 format. Transformation can be done in the service operation level to get feed documents in other formats. Integration Broker manages user authentication, caching, and feed data type service operation-level security.
The primary task of the GetFeed service operation handler is to collect the request information and then forward it to the runtime engine. The handler also catches the exceptions raised by the runtime engine and reports them in the specific way applicable to Integration Broker.
By default, the GetFeed service operation only has one required parameter, the feed ID, and three optional parameters, the language code, the portal name, and the node name. The feed URL given out by the framework contains only these parameters, when applicable.
When a feed request comes in, the Integration Broker copies the values of the query parameters to the corresponding fields defined in the default feed request message definition. Then, the service operation passes this information to the runtime engine for further processing. If other query parameters exist in the request URL, then the service operation collects and passes them to the runtime engine. These additional query parameter values override the values of Data Source Parameters for which the usage types are User Specified.
Any feed data type can override this default behavior by providing its own feed request message definition extended from the default one, as well as by using a different method for generating the feed URL to include more default query parameters. Regardless, the feed ID query parameter should always be a required parameter. We do not recommend the use of query parameters for data source settings or non-user-specified data source parameters.
Feed Document Properties
The runtime engine returns an Atom 1.0 feed document. The properties of the feed definition become the feed header properties of the feed document. Each item in the feed-format-neutral object collection becomes one entry of the feed document. A list of the data mapping relationships follows.
The feed data source uses a feed-format-neutral object collection to collect data. This table describes the mapping between the Atom 1.0 feed-level elements and the feed definition properties:
|
Atom 1.0 Feed-Level Element |
Feed Definition Property |
|
author |
Author. |
|
category |
Feed data type and feed category. |
|
contributor |
Contributor. |
|
generator |
Latest entry in PSRELEASE table. |
|
icon |
Icon. |
|
id |
System-generated URL to open the feed. |
|
link |
Alternate link: The content web page URL associated with the feed, which is provided by the data source. Self link: System-generated URL to open the feed. |
|
logo |
Logo. |
|
rights |
Copyright. |
|
subtitle |
Feed description. |
|
title |
Feed title. |
|
update |
Current date and time of request. |
This table describes the mapping between the Atom 1.0 entry-level elements and properties of items in the feed-format-neutral object collection. The real values of these properties are determined by the data source at runtime:
|
Atom 1.0 Entry-Level Element |
Item Property |
|
author |
Author. |
|
category |
Category. Note. This item allows multiple entries. |
|
content |
FullContent, if available. |
|
contributor |
Contributor. Note. This item allows multiple entries. |
|
id |
GUID, if available, or content URL. |
|
link |
Alternate link: contentURL. Other links: enclosure, if available. Note. This item allows multiple entries. |
|
published |
Date and time published. |
|
rights |
Copyright. |
|
source |
NA |
|
summary |
Description. |
|
title |
Title. |
|
updated |
Date and time updated. |
Note. If any property contains empty values, the corresponding element is not added.
Feed Data Type Application Classes
The feed data type application class bridges the data and the feed definition. It has two roles:
At design time, it provides information to the framework about how to define the feed definition for this type of data.
At runtime, the framework uses the application class to collect feed data.
Design Time Role of Application Classes
At design time, the feed data type application class provides information about a specific type of data to the framework, including a list of data source settings, list of data source parameters and their default values, data security, and name of the default feed service definition. The feed data type application class handles events such as processes that occur when you delete a feed definition. The framework uses all of this information in the feed definition creation and maintenance.
Every feed data type may have zero to three data source settings. The data source settings uniquely define the feed data source of the given type of data. You must define and store the values of the data source settings with the feed definition. The feed data type application class can also provide the prompt information for each data source setting.
Every feed data type may have zero or more data source parameters. The data source parameters are used to fine tune the feed or personalize the feed; for example, a news publication feed should include all child sections or a workspace feed should not include discussion data. Values of data source parameters are determined at runtime based on the usage type, fixed value, system variable value, user-specified value, and so on. The default values of data source parameters are stored with the feed definition. The Feed Data Type application class could provide the description, prompt information, default values, and default usage type for each data source parameter.
Runtime Role of Application Classes
At runtime, the runtime engine finds the feed definition and the associated feed data type application class based on the requested feed ID. It creates an instance of the feed data type application class associated with the specific feed definition, restores the data source setting values and the data source parameter values saved with the feed definition, evaluates the runtime values of those data source parameters based on their usage type, and sets other runtime information. It then executes the object to retrieve the content data of the feed.
The feed data type application class uses a feed-format-neutral object collection to temporarily store the data. It does not transform data to a feed document directly. This design enables application developers to expand the object model or use their own data objects. The advantages of using a feed-format-neutral object collection instead of the feed-format-specific XML document are:
It shields you from having to deal with the complex details of a specific feed format.
It minimizes the possibility of using a wrong XML element or structure.
It standardizes the use of specific elements within the feed.
It enables easier migration to newer feed format standards or a completely different feed format.
Creation of New Feed Data Types
To create new types of feeds, application developers implement a new Feed Data Type application class from the base class provided by the framework, and they associate it with one feed data type service definition. This application class encapsulates all business logic about how to define the feed definition and how to gather feed data. At runtime, it uses a feed-format-neutral object collection to temporary store the data. It does not transform data to feed document directly.
Additional development work is required to enable content owners to publish content as feeds directly from content maintenance pages and to add feed subscription links to view content pages.
See Also
Developing New Feed Data Types
Feed Data TypesThis section discusses the delivered feed data types:
List of feeds (FEED).
Integration Broker generic message feeds (GENERICFEED).
PeopleSoft Query feeds (PSQUERY).
Worklist feeds (WORKLIST).
SES feed data source feeds (PTSF_SES_FEED_DT).
List of Feeds (FEED)
A list of feeds feed enables feed administrators to generate a feed that displays a list of all feeds of a specific feed data type.
See Publishing a List of Feeds Feed.
Integration Broker Generic Message Feeds (GENERICFEED)
Integration Broker generic message feeds enable administrators to expose Integration Broker messages used in asynchronous, one-way service operations as feeds.
See Creating and Using Integration Broker Generic Message Feeds.
PeopleSoft Query Feeds (PSQUERY)
PeopleSoft Query feeds enable query administrators to expose query outputs as feeds.
Note. Any user with access to Query Manager can publish query feeds.
See Creating and Using Query Feeds.
Worklist Feeds (WORKLIST)
Worklist feeds enable workflow administrators to expose worklists as feeds.
See Creating and Using Worklist Feeds.
SES Data Source Feeds (PTSF_SES_FEED_DT)
SES feeds are used internally by PeopleTools as a search data source.
Feed Types and OptionsThis section discusses:
Real-time feeds.
Scheduled feeds.
Paged feeds.
Incremental feeds.
Real-Time Feeds
Real-time feeds are dynamic—that is, they are produced when the user requests them. Real-time feeds are created using Integration Broker synchronous service operations. These service operations are similar to other Integration Broker service operations except that the service operation handler returns an ATOM_1_0 message.
Whenever the HTTP listening connector gets a request for a real-time feed, it invokes the appropriate synchronous service operation. It uses either the PS_TOKEN or basic authentication credentials. User authentication and service operation authorization are handled by Integration Broker; feed authorization is handled by the Feed Publishing Framework. If a user has access to the feed, then the service operation handler adjudicates any HTTP request parameters passed to it, generates an Atom feed, and returns it in an ATOM_1_0 response message.
Scheduled Feeds
Scheduled feeds are published asynchronously and stored as messages in Integration Broker queues.
Scheduled feeds can be further classified into up-front feeds and generic feeds. When using up-front feeds, the messages published to the Integration Broker queues are feed messages. When using generic feeds, the messages published to Integration Broker queues are either PeopleSoft rowset or XML messages. They are not feed (Atom) XML messages.
When a user requests the feed, the GetFeed (PTFP_GETPREPUBFEED) synchronous service operation is invoked by the HTTP listening connector. The GetFeed service operation handler fetches the appropriate feed messages from Integration Broker queues and collates them into a single feed message. The GetFeed service operation handler collates the messages for up-front feeds into a single feed message; for generic feeds, it wraps the feed element tags to the Integration Broker messages and then collates them into a single feed message.
Note. Unlike real-time feeds, for which you can create your own service operation to deliver the feed, scheduled feeds always use the PTFP_GETPREPUBFEED service operation to deliver feeds.
Paged Feeds
A paged feed is a feed that has been split into pages (also known as segments) to improve system performance in delivering large feed documents and to improve performance for consuming a feed. A paged feed is presented with first, last, next, and previous links to allow access to additional pages in the feed document.
Paged feeds are supported for scheduled feeds only. The framework supports paged feeds via Integration Broker message segments. %MaxMessageSize is recommended when creating Integration Broker message segments for paged feeds.
When setting the paging property for a feed, select either Segmented or No Paging to determine how the framework displays the complete feed:
Segmented
This option is designed for feeds intended for crawlers or system synchronization.
This option is not supported by most feed readers or clients.
Feed links (first, next, previous, last) are added to the feed XML.
Feed entries are not restricted by the Max Rows Limit parameter.
No paging
This option is designed for feeds intended for end user viewing.
This option is supported by all feed readers or clients.
Feed entries are restricted by the Max Rows Limit parameter.
The following table describes how paged feed options and Integration Broker message segment options affect the output of the framework:
|
Integration Broker Message Option |
Feed Option - Segmented |
Feed Option - No Paging |
|
Segmented |
|
|
|
Non-segmented |
|
|
See Also
Publishing Integration Broker Generic Message Feeds
Incremental Feeds
An incremental feed is a feed that has been published and updated with time stamps that allow the feed content to be delivered incrementally. An incremental feed allows the Feed Publishing Framework to deliver only the feed content that has changed since the user last requested the feed.
Note. The incremental feed option is incompatible with the paged feed option. For the delivered feed data types that can be specified as paged, the Incremental option is disabled when Segmented is selected.
Incremental feeds save network bandwidth by using HTTP conditional GET headers. The HTTP conditional GET headers supported are:
ETag
If-None-Match
Last-Modified
If-Modified-Since
Note. Not all feed readers support incremental feeds, which requires that the reader retain the feed request time stamp and present that data as part of the next feed request.
The following diagram illustrates how HTTP conditional headers are used with incremental feeds. With the initial feed request, the feed reader does not include any HTTP conditional headers. In the response, the PeopleSoft system sends the complete feed data and includes two HTTP conditional headers: ETag equals the feed ID and Last-Modified equals the feed request time stamp. When the feed reader makes a subsequent feed request, it includes two HTTP conditional headers: If-None-Match equals the ETag sent by the PeopleSoft system and If-Modified-Since equals Last-Modified sent by the system. In the response, the PeopleSoft system sends just the incremental feed data and includes the same two HTTP conditional headers as the initial response; Last-Modified now represents the latest feed request time stamp.
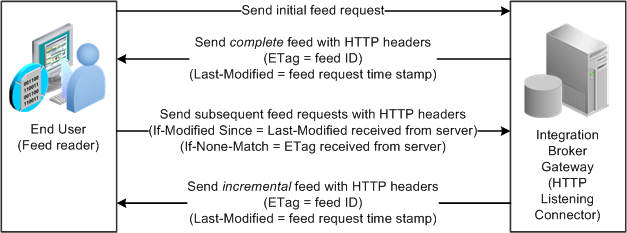
Incremental feeds
As delivered, the Feed Publishing Framework provides support for scheduled, incremental feeds. For the feed data source, you must define the DSPARAMETER_INCREMENTAL data source parameter and assign an appropriate value to it. For real-time, incremental feeds, you must also define the DSPARAMETER_INCREMENTAL data source parameter. In addition, you must implement the PeopleCode to deliver an incremental feed in the data source's execute method.
See Also
Publishing Integration Broker Generic Message Feeds
Feed SecurityThis section discusses security for:
Creating feed data types.
Publishing feeds.
Viewing feeds.
Security for Creating Feed Data Types
Security for creating new feed data types is based on permission lists. To create new feed data types, the user must be authorized to access pages in the PTFP_DATATYPE component on the PTFP_FEED_PUBLISHING menu.
Note. Users with access to the PTPT1300 (Portal Administrators) permission list automatically have access to these pages.
See Setting Up Permission Lists.
Security for Publishing Feeds
You publish feeds by accessing the hidden Publish as Feed pages when you click the Publish as Feed link on a page. This link is located on different pages in the applications based on the type of feed. The link is currently available through:
Workflow pages (WORKLIST and WORKLIST_DETAILS).
Query Manager pages (QUERY_MANAGER).
Define IB generic message feed pages (PTFP_GENERIC_FEED).
Define feed data type pages (PTFP_DATATYPE).
To access the link, you must be authorized to access the specific application pages where you find the link.
Security for Viewing Feeds
The two levels of feed security are:
Feed-level security.
Data-level security.
The Feed Publishing Framework manages feed-level security. Feed-level security determines which feeds are visible to the user when accessing the My Feeds page or any related hover menus. You can configure feed security to be:
Public.
Public feeds run under context of the default user that is associated with the ANONYMOUS node.
Realtime.
Every time a user accesses a feed during search or execution, the data source object determines whether the current user has access to the feed. This security option has an advantage in that the feed security is always in sync with the data source. This security option can greatly affect performance of feed searches and should only be used when the data security is constantly changing, or the data security could not be defined using role or permission list based security model.
Permission list and roles.
You assign access to the feed based on permission lists and roles.
Data-level security is checked by each data type supporting application class when the runtime engine executes it to collect feed data. It is always checked in real time. Users who have access to a feed but not the data will receive a feed document that contains no entries. Different users who subscribe to the same feed might receive different feed data, depending on their permissions. You can sync the feed data security to the feed definition using the Publish Feed Definition pages.
Important! Developers are responsible for building data-level security into the data source application class logic; data-level security is not automatic.
Feed Publication
You use the Publish as Feed link to publish data as a feed. The Publish as Feed link provides access to the four feed publishing pages:
Publish Feed Definition (PTFP_PUB_AS_FEED)
Advanced Feed Options (PTFP_PUB_AS_ADVOPT)
Publish as Feed (PTFP_PUB_AS_LIST)
Publish Feed Definition to Sites (PTFP_PUB_AS_SITES)
Note. The framework provides these pages; however, each data type might alter or replace them as necessary.
See Publishing Feeds.
My Feeds
End users can search and view feeds by using the My Feeds page (PTFP_VIEW) link, which you find in the menu navigation. Search for feeds specific to the user and then click the feed document link to view it in a new browser window. You can also add the feed URL to feed readers, or you can export the search results to an OPML (Outline Processor Markup Language) file and save the list for later use.