48 Managing Downloaded Sites
Downloaded sites are managed either from the Site Capture file system or the interface, depending on whether they are statically captured or archived.
This chapter contains the following topics:
48.1 Managing Statically Captured Sites
For every crawler that a user creates in the Site Capture interface, Site Capture creates an identically named folder in its file system. This custom folder, <crawlerName>, is used to organize the crawler's configuration file, captures, and logs as shown in Figure 48-1, "Site Capture's Custom Folders: <crawlerName>", while describes the <crawlerName> folder and its contents.
Note:
To access static captures and logs, you will have to use the file system. Archive captures and logs are managed from the Site Capture interface (their location in the file system is included in this section).Figure 48-1 Site Capture's Custom Folders: <crawlerName>
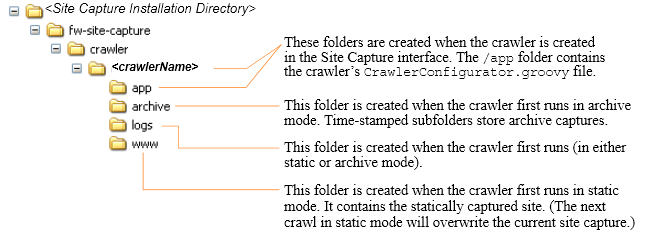
Description of ''Figure 48-1 Site Capture's Custom Folders: <crawlerName>''
Table 48-1 <crawlerName> Folder and Its Contents
| Folder | Description |
|---|---|
|
|
Represents a crawler. For every crawler that a user defines in the Site Capture interface, Site Capture creates a Note: In addition to the subfolders (described below), the |
|
|
Contains the crawler's |
|
|
The The Note: Archive captures are accessible from the Site Capture interface. Each zip file contains a URL log named |
|
|
Contains only the latest statically captured site (when the same crawler is rerun in static mode, it overwrites the previous capture). The site is stored as The Note: Static captures are accessible only from the Site Capture file system. |
|
|
Contains log files with information about crawled URLs. Log files are stored in the
Note: If the crawler captured in both static mode and archive mode, the The |

48.2 Managing Archived Sites
Archived sites can be managed from different forms of the Site Capture interface. Figure 48-3, "Paths to Archive Information" shows some of the pathways to various information: archives, jobs, site preview, crawler report, and URL log:
Figure 48-3 Paths to Archive Information
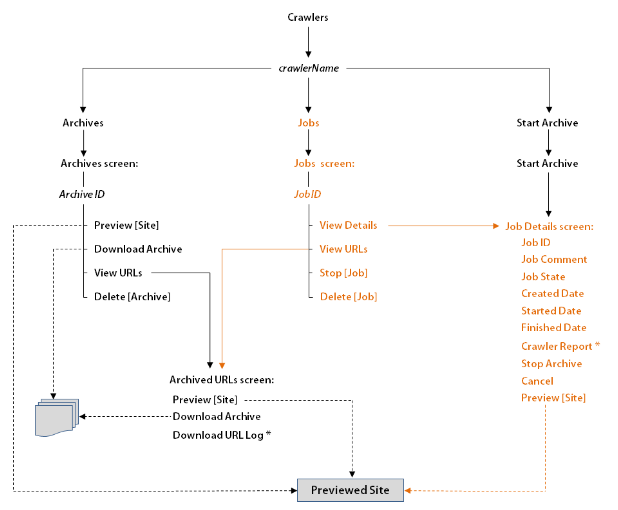
Description of ''Figure 48-3 Paths to Archive Information''
-
For example, to preview a site, start at the Crawlers form, point to a crawler (crawlerName), select Archives from the pop-up menu (which opens the Archives form), point to an Archive ID, and select Preview from the pop-up menu.
-
Dashed lines represent multiple paths to the same option. For example, to preview a site, you can follow the crawler's Archives path, Jobs path, or Start Archive path. To download an archive, you can follow the Archives path or the Jobs path.
-
The crawler report and URL log are marked by an asterisk (*).
48.3 Summary
This section summarizes notes and tips for managing crawlers and captured data.
This section contains the following topics:
48.3.1 Creating and Editing Crawlers
When creating crawlers and editing their configuration code, consider the following information:
-
Crawler names are case sensitive.
-
Every crawler's configuration file is named
CrawlerConfigurator.groovy. The file is used to inject dependency. Hence, its name must not be changed. -
A crawler can be configured to start at one or more seed URIs on a given site and to crawl one or more paths. Additional Java methods enable you to set parameters such as crawl depth, invoke post-crawl commands, specify session timeout, and more. Interfaces can be implemented to define logic for extracting links, rewriting URLs, and sending email at the end of a crawl session. For more information, see the Oracle Fusion Middleware WebCenter Sites Developer's Guide.
-
When a crawler is created and saved, its
CrawlerConfigurator.groovyfile is uploaded to the Site Capture file system and made editable in the Site Capture interface. -
While a crawler is running a static site capture process, it cannot be invoked to run a second static capture process.
-
While a crawler is running an archive capture process, it can be invoked to run a second archive capture process. The second process will be marked as Scheduled and will start after the first process ends.
48.3.2 Deleting a Crawler
If you need to delete a crawler (which includes all of its captured information), do so from the Site Capture interface, not the file system. Deleting from the interface prevents broken links. For example, if a crawler ran in archive mode, deleting it from the interface removes two sets of information - the crawler's archives and logs, and database references to those archives and logs. Deleting the crawler from the file system retains database references to archives and logs that no longer exist, thus creating broken links in the Site Capture interface.
48.3.3 Scheduling a Crawler
Only archive crawls can be scheduled.
-
When setting a crawler's schedule, consider the site's publishing schedule and avoid overlapping the two.
-
You can create multiple schedules for a single crawler – for example, one schedule to invoke the crawler periodically, and another schedule to invoke the crawler at one particular and unique time.
-
When creating multiple schedules, ensure they do not overlap.
48.3.4 Monitoring a Static Crawl
To determine whether a static crawl is in progress or completed, look for the crawler's lock file in the <SC_INSTALL_DIR>/fw-site-capture/<crawlerName>/logs folder. The lock file is transient. It is created at the start of the static capture process to prevent the crawler from being invoked for an additional static capture. The lock file is deleted when the crawl session ends.
48.3.5 Stopping a Crawl
Before running a crawler, consider the number of links to be crawled and the crawl depth, both of which determine the duration of the crawler's session.
-
If you need to terminate an archive crawl, use the Site Capture interface (Select Stop Archive on the Job Details form ).
-
If you need to terminate a static crawl, you will have to stop the application server.
48.3.6 Downloading Archives
Avoid downloading large archive files (exceeding 250MB) from the Site Capture interface. Instead, use the getPostExecutionCommand to copy the files from the Site Capture file system to your preferred location.
Archive size can be obtained from the crawler report, on the Job Details form. Paths to the Job Details form are shown in Figure 48-3, "Paths to Archive Information". For information about the getPostExecutionCommand method, see the Oracle Fusion Middleware WebCenter Sites Developer's Guide.
48.3.7 Previewing Sites
If your archived site contains links to external domains, its preview is likely to include those links, especially when the crawl depth and number of links to crawl are set to large values (in the crawler's groovy file). Although the external domains can be browsed, they are not archived.
48.3.8 Configuring Publishing Destination Definitions
-
If you are running publishing-triggered site capture, you can set crawler parameters in a single statement on the publishing destination definition:
CRAWLERCONFIG=crawler1;crawler2&CRAWLERMODE=dynamic -
While you can specify multiple crawlers on a publishing destination definition, you can set only one capture mode. All crawlers will run in that mode. To run some of the crawlers in a different mode, configure another publishing destination definition.
48.3.9 Accessing Log Files
-
For statically captured sites, log files are available only in the Site Capture file system:
-
The
inventory.dbfile, which lists statically crawled URLs, is located in the/fw-site-capture/crawler/<crawlerName>folder.
Note:
Theinventory.dbfile is used by the Site Capture system. It must not be deleted or modified.-
The
crawler.logfile is located in the<SC_INSTALL_DIR>/fw-site-capture/logs/folder. (Thecrawler.logfile uses the term "VirtualHost" to mean "crawler.")
-
-
For statically captured and archived sites, a common set of log files exists in the site Capture file system:
-
audit.log,which lists the crawled URLs, timestamps, crawl depth, HTTP status, and download time. -
links.txt, which lists the crawled URLs -
report.txt, which is the crawler report
The files named above are located in the following folder:
/fw-site-capture/crawler/<crawlerName>/logs/yyyy/mm/ddNote:
For archived sites,report.txtis also available in the Site Capture interface, on the Job Details form, where it is called the Crawler Report. (Paths to the Job Details form are shown in Figure 48-3, "Paths to Archive Information"). -
-
The archive process also generates a URL log for every crawl. The log is available in two places:
-
In the Site Capture file system, where it is called
__inventory.db. This file is located within the zip file in the following folder:/fw-site-capture/crawler/<crawlerName>/archive/yyyy/mm/ddNote:
The__inventory.dbfile is used by the Site Capture system. It must not be deleted or modified. -
In the Site Capture interface, in the Archived URLs form (whose path is shown in Figure 48-3, "Paths to Archive Information").
-