 Understanding Jobstreams
Understanding Jobstreams
This chapter provides an overview of jobstreams and discusses how to:
Set up chunking.
Work with engine metadata.
Set up job metadata.
Set up jobstreams.
Work with record suites.
Create additional instances of temporary tables.
Remove extraneous temporary tables from record suites.
Run jobstreams.
Track jobs.
View engine messages.
Understanding Jobstreams
This section discusses:
Jobstreams.
Jobstream terminology
Jobstream processing.
Jobstream record suites.
Jobstream chunking.
Spawn process.
Resolver engine.
Resolver and chunking.
Process monitor.
 Jobstreams
Jobstreams
To help streamline your processing, PeopleSoft provide jobstreams which use temporary tables for intermediate processing. Jobstreams enable different users to run their own jobs using instances of the same processing engines at the same time. Jobstreams enhance performance by sharing temporary tables passed between jobs.
Instead of locking up the fact (primary input) tables, jobstreams use temporary tables for intermediate processing. A set of delivered temporary tables, referred to as a record suite, is assigned when the first job of a jobstream is run, and then the tables are released when the last job of a jobstream is completed. The use of record suites frees up the fact tables so that another user can access them and run a concurrent job. Each job then has its own record suite for a jobstream.
There are several steps involved in setting up a jobstream. PeopleSoft delivers predefined processing engines and engine metadata, jobs and job metadata, jobstreams, and record suites. If you use the predefined metadata, the only item that you have to specify before you run an engine is one or more record suites for each jobstream for a given setID.
The following diagram illustrates the components that make up a jobstream:
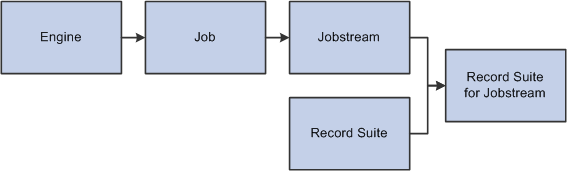
Jobstream overview
Jobstreams work by creating a copy of the processing engine. When you run a jobstream, you can:
Run multiple engines sequentially in one jobstream.
Run each individual engine in its own jobstream.
Run one sequential jobstream for multiple fiscal years or accounting periods.
Suppose you want to run the Activity-Based Management engine, Data Manager engine, and Merge engine at the end of the business day. You can select a jobstream that runs all three engines automatically. Each engine runs sequentially and populates specific temporary tables, with the Merge engine transferring the data from the temporary tables back to the fact tables. You only need to initiate the jobstream, no further action is required.
The Merge (PF_MERGE) engine merges the output temporary tables into the final tables for use as input for other processes. PF_MERGE is the last job in all jobstreams except when the POST job is run at the end of a jobstream.
The following diagram illustrates how jobstream setup works:
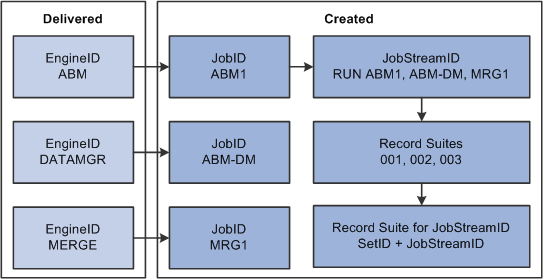
Jobstream setup
In the above diagram, note that the engine IDs on the left side of the illustration are delivered with PeopleSoft EPM. You create the job and jobstream IDs, and then assign record suites to the jobstream.
The following diagram illustrates how the Merge engine moves output from the Activity-Based Management (ABM) engine to the into final fact tables:
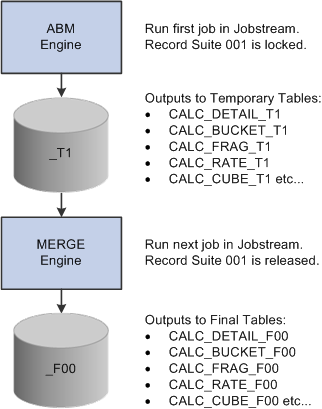
Merge engine process
Jobstream Terminology
The following terms apply to jobstreams in PeopleSoft EPM applications:
|
Engine Metadata |
Identifies the PeopleSoft application engine process that you want to run by engine ID. |
|
Job Metadata |
Enables you to create an instance or copy of a PeopleSoft application engine program to use in your jobstream. |
|
Jobstream |
Enables you to combine job IDs into a jobstream ID to pass data from one job to the next. Every job you run must be in a jobstream, whether it is a combination of sequential jobs or a single job. All jobs in the jobstream must be run for the same parameters (business unit, scenario, fiscal year, and so on). |
|
Consist of a group of temporary tables with the same temp table append for processing instances of an application engine. Temporary tables are used during engine processing to free up the original fact tables so other users can access them and provide faster run times. A jobstream has exclusive use of the record suite during its execution, so there is no table locking or sharing. For example, you might create a jobstream to first run the ABM engine, then the Data Manager engine, and finally run the Merge process. Each engine runs sequentially and populates specific temporary tables, with the Merge engine transferring the data from the temporary tables back to the fact tables. |
|
|
Jobstream Record Suites |
Assign record suites to the jobstream ID you create (using the appropriate setID). The setID used must be the same setID assigned to the run control parameter business unit under record group PF_03. |
Jobstream Processing
When you run a jobstream, the following occurs:
Record suite 001 is locked and the first engine runs placing its output into the appropriate temporary table in record suite 001.
The next engine runs getting its input from the temporary tables generated by the first job and putting its output into other temporary tables in record suite 001.
The last job in the jobstream (either PF_MERGE or PF_POST) reads the data in the temporary tables, merges it, and then writes the output to the final target tables. The system releases the record suite.
Note. Not all processes use jobstreams. For example, PF_SUMM does, but PF_MODIFICATION does not. Exceptions are noted in the PeopleBooks documentation as appropriate.
Jobstream Record Suites
When you initially process a jobstream, the system checks which record suites are assigned to the specified setID and jobstream ID.
This process enables you to reserve a set of record suites for a specific type of engine. For example, if record suites 001 and 002 are assigned to PeopleSoft Activity-Based Management (ABM) jobstreams, and 003 is authorized for PeopleSoft Asset Liability Management (ALM), then PeopleSoft ALM jobstreams never compete for record suite availability with ABM jobstreams.
Jobstream Chunking
Chunking is a mechanism that enables you to select a smaller chunk of data for further processing and to parallel process data in multiple chunks. It enables you to horizontally partition source data so that only a subset of data is processed by an engine. The enables users to run multiple engines with different criteria and to run them in parallel to reduce the processing time.
During a jobstream run, chunking occurs when technical scenario is associated with the run scenario based on the scenario selected on the Technical Scenarios page. After a jobstream identifies that chunking has been requested, the jobstream initiates the PF_CHUNK application engine program to process each chunking selection. The jobstream then invokes a parallel application engine PF_SPAWN to process each chunking selection. This program spawns a job for each chunking definition.
The number of jobs that can be spawned in parallel is restricted to the number of available record suites. You require one record suite for the jobstream process and one for each of the spawned processes.
Because all jobs that use the same technical scenario may not require chunking, the decision to chunk is based on the chunking selection in the engine metadata and chunking criteria specified on the Technical Scenarios page.
Spawn Process
The spawn application engine process (PF_SPAWN) provides greater control over jobstream processing by enabling jobs to be launched as needed.
Spawn Process Tables
PF_SPAWN creates the following tables to store data while the jobstream runs:
The PF_SPWN_JOB_TBL table stores all required information about spawned jobs.
Entries in this table are deleted once all spawned jobs are complete.
The PF_SPWN_CTL_T temporary table passes the run control parameters for each spawned job.
Use the sequence number field to control the order of the spawned jobs.
The PF_SPWN_CRIT_T table stores all of the required spawn criteria for each of the spawned jobs.
Resolver Engine
The Resolver engine further enhances and increases application performance by reducing the amount of data an engine needs to process. You do not invoke the Resolver (PF_ENG_PROC.RESOLVE) engine. The system invokes it automatically as part of startup processing to resolve all records and tablemaps specified in the engine metadata for an engine. An application needs to explicitly invoke the Resolver engine to resolve datamaps, filters, constraints, and data sets referenced in business rules.
Resolution occurs on the setID, business unit, scenario ID, effective date, as of date, fiscal year, and accounting period. The resolution process only moves the data that matches the run control values from the table to the associated temporary table as defined in the record metadata. The engine works only on the data in the temporary table.
Individual engines call the Resolver engine as part of their run processes.
Note. The Resolver engine is limited to resolving tables for only one value at a time. For example, it cannot resolve for multiple business units.
Resolver and ChunkingAs part of chunking, the Resolver engine applies chunk criteria to the record that is being chunked based on the criteria defined on the Technical Scenarios page. When the system invokes the Resolver engine, it checks all the records that it needs to resolve to see if the record requires chunking. If this is the case, the Resolver engine checks the record to see if the chunk field exists in the record. If the field exists, the system appends chunk criteria to the resolver query for this record.
Below is an example of chunk criteria:
(CUST_ID IN (SELECT CUST_ID FROM PS_CUSTiINTFC_F00 WHERE CUST_ID BETWEEN ⇒ ('1000','10000'))
In this case the CUST_ID is the chunk field that exists in the record being resolved.
Process MonitorDuring job processing, use Process Monitor to review the status of reports and processes. You can monitor process requests, server status, and the status of any job in the queue. If there are messages related to a process, you can view them from Process Monitor, as well. For example, if a process encounters an error, or if a server is down, you can find out almost immediately.
See PeopleSoft PeopleTools PeopleBook: PeopleSoft Process Scheduler
Failed Jobstreams and the Process Monitor
When a jobstream fails, one of the following status messages appear:
Error: Indicates that the program that is associated with the process request encountered an error while processing transactions within the program. In this case, delivered programs are coded to update the run status to Error before terminating.
No Success: Indicates that the program encountered an error within the transaction. No Success is different from Error because the process is marked as restartable.
Success With Application Error: Indicates that a jobstream has completed, but with an application error. For example, a jobstream may result in an application error due to unavailable record suites.
Setting Up Chunking
This section discusses how to:
Establish chunking in the engine metadata.
Set up chunking criteria.
Establishing Chunking in the Engine MetadataTo set up chunking you access the Engine Metadata - State Variables or Engine Metadata - Source TableMaps pages to set up application engine parameters. On the State Variables page, you specify the records to be chunked during the resolve process. Alternatively, on the Source TableMaps page you can specify the tablemaps to be chunked. The next section in this chapter details the pages in the Engine Metadata component on which you define this setup.
As the next step, go to the Technical Scenarios page to set up the chunking criteria. Technical scenarios enable you to set up the object type values that the Resolver uses to chunk the records and tablemaps you are resolving. You establish the records or tablemaps to resolve on the Engine Metadata - State Variables and Engine Metadata - Source TableMaps pages.
See Also
Pages Used to Set Up Chunking|
Page Name |
Definition Name |
Navigation |
Usage |
|
Engine Metadata - State Variables |
PF_META_ENG_TBL2 |
EPM Foundation, Job Processing, Setup Engines and Jobstreams, Engine Metadata, State Variables |
Specify records to be chunked during the resolve process. |
|
Engine Metadata - Source TableMaps |
PF_META_ENG_TBL4 |
EPM Foundation, Job Processing, Setup Engines and Jobstreams, Engine Metadata, Source TableMaps |
Specify source tablemaps to be chunked during the resolve process. |
|
Technical Scenario |
PF_CHUNK_DFN |
EPM Foundation, Business Metadata, Business Framework, Technical Scenarios |
Set up the object type values that the Resolver uses to chunk the record or tablemap you are resolving. |
Setting Up Chunking Criteria
Access the Technical Scenarios page (EPM Foundation, Business Metadata, Business Framework, Technical Scenarios).
|
Scenario ID |
Select the scenario ID to which to link this technical scenario. When a jobstream runs for this scenario, the chunking is invoked. |
|
Enter the technical scenario ID to identify the chunking selection. You may enter as many chunk codes as you like for each scenario. Each chunk code may have different chunk criteria. |
|
|
Chunk By |
Select the object type to use for chunking. You must select the object type you selected in the Engine Metadata component. Note. You can apply only one chunking criteria to a tablemap. The system does not support duplicate object types. |
|
Constraint Code |
Select the constraint that filters the values for your objects at run time. |
|
DataMap Column |
Select one column from the datamap of the constraint. This should be, but is not restricted to, the column that matches the object type you have selected. For example, if your chunk object type is PRODUCT ID, then your datamap column from the constraint may be PRODUCT_ID or PRODUCT_TYPE. You may copy chunking criteria to another effective date for the same scenario only. You need to be very careful about defining chunk criteria. You need to make sure to define your chunks to cover a complete set of data without any duplicates. |
Note. If you delete a scenario with chunking criteria, the
chunking criteria are automatically deleted.
You can enter multiple technical scenarios to process data in multiple
chunks. Remember, that all technical scenarios should select a mutually exclusive
data set. The data is also not necessarily processed in the order defined.
Warning! If you enter an invalid or duplicate constraint code, the jobstream abends at run time.
You have established the chunk objects and the chunking criteria. Chunking initiates when there is a technical scenario associated with the run scenario.
For chunking to be successful, you must ensure that:
The object type selected in the Engine Metadata component matches the one in the technical scenario used by the engine. This initiates the chunking process.
The column you select for the chunking criteria on the Technical Scenarios page must be in the record or any record of a tablemap you have selected for chunking. This completes the chunking process.
Note. You can only resolve (chunk) a record once in an engine. The system resolves tablemaps first. Any records resolved as part of the tablemap are not resolved again in the state record.
Working with Engine Metadata
PeopleSoft EPM delivers predefined engine metadata. Unless you create your own application engine processes as part of your implementation, you do not need to create any engine metadata. However, you do need to create different instances of the delivered engines to enable parallel processing, described in the next section.
In most cases, you only use the pages described in this section to review and modify the delivered engine metadata. You may also use them to define chunking selections.
If you do add an application engine process, use the pages described to add the engine metadata for the new application engine.
This section discusses how to:
Review, modify, or add engine metadata.
Review, modify, or add state variables.
Define rule state variables.
Specify source tablemaps.
Specify source trees.
Pages Used to Work with Engine Metadata|
Page Name |
Definition Name |
Navigation |
Usage |
|
Engine Metadata |
PF_META_ENG_TBL1 |
EPM Foundation, Job Processing, Setup Engines and Jobstreams, Engine Metadata |
Review delivered engine metadata and modify if required. Add new metadata for a new application engine process. Unless you create your own application engine process, you do not need to create any engine metadata. |
|
Engine Metadata - State Variables |
PF_META_ENG_TBL2 |
EPM Foundation, Job Processing, Setup Engines and Jobstreams, State Variables |
Review state variables modify if required. These state variables enable dynamic changes to application engine inputs. |
|
Engine Metadata - Rule State Variables |
PF_META_ENG_TBL3 |
EPM Foundation, Job Processing, Setup Engines and Jobstreams, Rule State Variables |
Define rule state variables. This enables dynamic changes in the application engine. |
|
Engine Metadata - Source TableMaps |
PF_META_ENG_TBL4 |
EPM Foundation, Job Processing, Setup Engines and Jobstreams, Source TableMaps |
Specify source tablemaps if the engine needs to resolve a set of tables before running. |
|
Engine Metadata - Source Trees |
PF_META_ENG_TBL5 |
EPM Foundation, Job Processing, Setup Engines and Jobstreams, Source Trees |
Specify source trees to be flattened during the application engine initialization phase. |
Reviewing, Modifying, or Adding Engine Metadata
Access the Engine Metadata page (EPM Foundation, Job Processing, Setup Engines and Jobstreams, Engine Metadata).
|
Engine ID |
Displays the unique identifier for the application engine. |
|
Program Name |
Select a delivered application engine program. |
|
Engine Group |
Select an engine group to tie the engine to a column on the Scenario definition page. When an engine is run, it picks up the model ID from the Scenario Definition page and uses it to process the rules and data. |
|
Displays the name of the state record. The state record defines which record is used to define state variables on the next page in this component. It is a prompt for the state variable column on that grid. |
|
|
Default Chunk Merge Method |
Select a value to determine the method for the reloads of a chunked job merge to the main jobstream. Values are: Last in: Merges any duplicate data last, replacing the old data. First in: Merges any duplicate data so that the original data remains. Aggregate: Merges any duplicate data and aggregates it. Append: Appends any duplicate data. |
|
Process Wait Time (Seconds) |
Displays the seconds of lag time before the next process runs. The default for this field is set on the Installation Options - Web Services page. You can override the default setting here if required. |
|
Balancing Rules |
Enter any balancing rules that you want to run with this engine. The program name appears. |
|
Run Sequence |
Displays the sequence number for the run. This number must be unique. |
|
Section |
This is not a required field. It is used to help you focus on the problem area when there is an out-of-balance situation. Before a section can be considered valid on the job totals page, it must be defined in the engine metadata. Valid section codes to be entered on the Engine Metadata page are the actual application engine section within the application engine program. |
Reviewing or Modifying State Variables
Access the Engine Metadata - State Variables page (EPM Foundation, Job Processing, Setup Engines and Jobstreams, State Variables).
PeopleSoft delivers predefined state variables that enable dynamic changes to application engine inputs. State variables can include the input and output tables that an engine requires, so that the table name does not have to be hard-coded in the application engine program. You rarely need to change state variables. However, you can select records for chunking.
In the Bind Variables Names group box specify the following:
|
State Variable |
Specify the record field name. The prompt list only shows those state record fields for the state record specified on the Engine Metadata page. When the engine runs, the record stub is stored in this field on the state record. The page must be saved before the prompt works. |
|
Record Metadata |
Select this option if this is record metadata. |
|
Table Name |
Specify the table that is used in the application engine to populate the state variables with the record stub. |
|
Final Table |
Select this option if this is the final output table. |
|
Chunk |
Select this option to enable chunking for this record. The Chunk By and Merge Method fields display. |
|
Chunk By |
Select the object type for the chunking for example by Group ID, Job Code, Model ID, and so on. This field defaults to Group ID.The object type you select here must match that selected on the Technical Scenarios page. |
|
Merge Method |
Select a value to determine the method for the reloads of a chunked job merge to the main jobstream. Values are: Last in: Merges any duplicate data last, replacing the old data. First in: Merges any duplicate data so that the original data remains. Aggregate: Merges any duplicate data and aggregates it. Append: Appends any duplicate data. You set the default on the Engine Metadata page. |
Warning! If at least one chunk check box is selected, the Merge Method list box appears for the tables that are marked as Final. You may override the default merge method.
Record Stub and Table Status
The following table defines the relationship between record metadata and table status:
|
Record Metadata Selected? |
Final Table Selected? |
Chunk Selected? |
Information |
|
Yes |
No |
Yes |
Typical input. Record stub is put into state record and table is resolved. |
|
Yes |
Yes |
Yes |
Typical output. Record stub is put into state record, temporary table is truncated, and the table is marked so that it is not resolved in the jobstream. |
|
No |
Yes |
No |
Record stub is put into state record and temporary table is truncated. |
|
No |
No |
No |
Record stub is put into state record. |
Defining Rule State Variables
Access the Engine Metadata - Rule State Variables page (EPM Foundation, Job Processing, Setup Engines and Jobstreams, Rule State Variables).
|
Table Name |
Select the parent table of the rule to be resolved. You identify only the parent table because both parent and child tables are resolved. This rule table is resolved automatically as part of running the application engine. The description for the table appears. |
Specifying Source TableMaps
Access the Engine Metadata - Source TableMaps page (EPM Foundation, Job Processing, Setup Engines and Jobstreams, Source TableMaps).
|
TableMap Code |
Displays only predefined tablemaps that are available for selection. The selected tablemap is automatically resolved as part of the application engine execution. |
|
Chunk |
If you select this check box, you enable the chunking of a tablemap within the Resolver. The Chunk By Field automatically displays a default value of GROUP_ID |
|
Chunk By Field |
Select an object type for chunking for example by Group ID, Job Code, Model ID,and so on. This field defaults to Group ID. This object type must match the type selected on the Technical Scenarios page. |
Specifying Source Trees
Access the Engine Metadata - Source Trees page (EPM Foundation, Job Processing, Setup Engines and Jobstreams, Source Trees).
|
Tree ID |
Select the trees to be resolved during the application engine initialization phase. If the run control parameters do not match the tree parameters, the application engine logs a message that the tree is not resolved. |
Setting Up Job Metadata
Job metadata (in other words, job ID) represents an instance, or copy, of a PeopleSoft application engine program and is used in the creation of a Jobstream. A job ID can be reused multiple times in the same jobstream or across multiple jobstreams. This enables you to use the same application engine more than once without having to define multiple job IDs. PeopleSoft deliver predefined job IDs for many of the jobs you need to run, but you can create additional job IDs if necessary.
After you complete the creation of a job ID, you can create a jobstream that runs just one engine or a combination of engines sequentially.
Page Used to Set Up Job Metadata|
Page Name |
Definition Name |
Navigation |
Usage |
|
Job Metadata |
PF_META_JOB_TBL1 |
EPM Foundation, Job Processing, Setup Engines and Jobstreams, Job Metadata |
Create a job ID to define an instance an engine. |
Creating a Job ID
Access the Job Metadata page (EPM Foundation, Job Processing, Setup Engines and Jobstreams, Job Metadata).
|
Job ID |
Displays the unique identifier for the instance of the engine. |
|
Engine ID |
Select the correct engine ID for the instance you are defining. |
|
Limit Use to One Instance |
Select this check box to make a job ID unique. If this check box is selected, the job ID specified cannot be reused. You should deselect this check box for Job IDs that you create. |
Setting Up Jobstreams
All jobs must be placed in a jobstream—you can add a single job or combine multiple jobs and pass data from one job to the next. All engines in a jobstream must run with the same run parameters (business unit, scenario ID, fiscal year, and so on). Additionally, jobstreams use the table appends defined on the Record Suites page to enable parallel processing of the same engines and tables by multiple users.
PeopleSoft EPM is delivered with a number of predefined jobstreams. Refer to your application-specific PeopleBooks for details on these jobstreams.
If a job in a jobstream cannot access a locked record suite during processing, the jobstream is sent to queue and waits for reprocessing once the record suite becomes available. You specify the queuing method on the Jobstream page.
Page Used to Define a Jobstream|
Page Name |
Definition Name |
Navigation |
Usage |
|
Jobstream |
PF_JOBSTRM_DFN1 |
EPM Foundation, Job Processing, Setup Engines and Jobstreams, Processes in Jobstream, Jobstream |
Define a jobstream by specifying which engines (job IDs) to run and the order in which to run them. |
Defining Jobstreams
Access the Jobstream page (EPM Foundation, Job Processing, Setup Engines and Jobstreams, Processes in Jobstream, Jobstream).
|
Jobstream ID |
Displays the unique identifier for the series of jobs to be run. |
|
Jobstream Type |
Select the type of jobstream you are defining. |
|
Retry Enabled? |
Select this check box if you want a jobstream to queue if its related record suite is locked. If this check box is selected the jobstream queues automatically when its record suite is locked and reruns when the record suite becomes available. |
Number of Attempts
|
Unlimited Attempts |
Select this option to have a queued jobstream attempt reprocessing indefinitely. |
|
Maximum Number of Attempts |
Select this option if you want a queued jobstream to attempt reprocessing a limited number of times. In addition, specify the number of times you wish to have a queued jobstream attempt reprocessing. Once this option is selected, the Retry Interval (seconds) field becomes available for input. Note. After the queued jobstream reaches the maximum number of reprocessing attempts specified in this field, the jobstream fails and a Warning status is set in the Process Monitor. |
|
Retry Interval (seconds) |
Specify the amount of time (in seconds) that should elapse between each reprocessing attempt. |
Jobstream Information
|
Jobstream Sequence |
Enter a unique number, such as 100, for the first job ID this jobstream should run. The next job ID to run is 200. Note. The actual sequence number is not important; it represents the sequence in which you want to run jobs. The sequence number must be unique. |
|
Job ID |
Select the job ID form the drop-down list box. The Job ID is created on the Job Metadata page and represents a unique instance of an engine for this jobstream. |
After you create a jobstream, you can go back to the Job Metadata page and verify the Jobstream ID and Job Use fields. They are now populated.
Linking Jobstreams Sequentially
You can link multiple jobstreams sequentially using PeopleTools JobSet functionality. JobSets enable you to schedule any application engine process using a schedule JobSet definition. Because a jobstream is an application engine process, you can use the jobset to sequentially link multiple jobstreams together. Using the JobSet functionality you can:
Use different run control IDs for each process within a jobset.
Run processes from different operating systems or servers.
Monitor processes from the process scheduler.
See PeopleSoft PeopleTools PeopleBook: PeopleSoft Process Scheduler
Working with Record Suites
PeopleSoft delivers three predefined record suites: 001, 002, and 003. Record suites are a group of temporary tables with the same temp table append for processing instances of an application engine. In order for your jobstream to run, you must associate record suites with the jobstream ID. You can also create new record suites and add them.
This section discusses how to:
Create new record suites.
Set up record suites.
Associate record suites with a jobstream.
Pages Used to Work with Record Suites|
Page Name |
Definition Name |
Navigation |
Usage |
|
Record Suite |
PF_RECSUITE_DFN1 |
EPM Foundation, Job Processing, Setup Record Suites, Define Record Suite, Record Suite |
Set up the record suites that are delivered with PeopleSoft EPM. You might need to create more temporary tables. |
|
Jobstream Record Suites |
PF_REC_JOB_TBL1 |
EPM Foundation, Job Processing, Setup Record Suites, Jobstream Record Suites, Jobstream Record Suites |
Associate record suites with a jobstream. You usually assign all three record suites to each jobstream ID. |
Creating Record Suites
You can create record suites in addition to those delivered with PeopleSoft EPM.
To create new record suites:
Select PeopleTools, Utilities, Administration, PeopleTools Options.
Increase the number of temp table instances to the desired number.
Add new record suites on the Record Suite page described below.
Build the EPM_TEMP_RECORDS project.
Note. Be aware that this also builds 001, 002, and 003 again.
Setting Up Record Suites
Access the Record Suite page (EPM Foundation, Job Processing, Setup Record Suites, Define Record Suite, Record Suite).
|
Record Suite ID |
Displays the unique identifier for the record suite. |
|
Table Append |
Enter the number to be used as the table append for the record suite. The number must be less than or equal to the number that is defined in the temp table instances field on the PeopleTools, Utilities, Administration PeopleTools Options page. You may define chunking record suites as well. |
Associate Record Suites with a Jobstream
Access the Jobstream Record Suites page (EPM Foundation, Job Processing, Setup Record Suites, Jobstream Record Suites, Jobstream Record Suites).
|
SetID |
Displays the setID that you pointed to for your record group. For example, if the run control is for business unit CORP1 and it points to setID MODEL, you must create a jobstream and record suite combination for MODEL. |
|
Jobstream ID |
Displays the jobstream ID to which you are assigning the record suites. |
|
Record Suite ID |
Select the record suite to be used by the jobstream. You can add more than one record suite. |
Creating Additional Instances of Temporary Tables for Record Suites
You can add instances of temporary tables to a record suite per your business requirements. To create additional instances of the temporary tables:
In Application Designer copy all tables in the relevant project and change the last two characters of the table name.
Rebuild the project.
Your new temporary table suite is ready. Repeat this process to create additional temporary table suites.
|
Project Name |
Description |
|
All delivered views that give secure access to EPM objects. |
|
|
One instance of the temporary tables needed to run all the EPM engines. |
|
|
Incremental project that contains one instance of newly added temporary tables only. |
|
|
All EPM-specific changes to the PPLTOOLS project. |
Note. If you are altering the number of temporary table instances, change the default setting of 3 to the desired number on the PeopleTools Option page (located at PeopleTools, Utilities, PeopleTools Option) and rebuild EPM_TEMP_RECORDS project in PeopleSoft Application Designer.
See PeopleSoft PeopleTools PeopleBook: PeopleSoft Application Designer Developer's Guide
Removing Extraneous Temporary Tables from Record Suites
Jobstreams use record suites and their corresponding temporary tables to process data. PeopleSoft delivers record suites with an entire set of EPM temporary tables, regardless of the products you license. For example, if you only purchase the Global Consolidations analytical application, the delivered record suites still contain temporary tables for all other EPM products—such as ABM and Budgeting. The following diagram depicts this scenario:
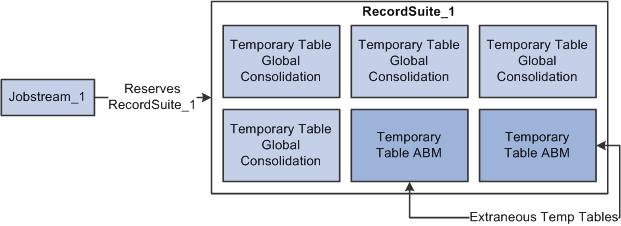
Record suite with extraneous temporary tables
Each delivered record suite can potentially contain hundreds or thousands of extraneous temporary tables—due to the fact that the total number of EPM temporary tables exceed 3,300. Each time a record suite is processed with these superfluous temporary tables, processing efficiency is severely degraded. However, PeopleSoft provide functionality that enables you to remove unnecessary temporary tables from the EPM database
Understanding the Temporary Table Removal ProcessExtra temporary tables are removed from the EPM database by running the Clean Temporary Tables application engine (PF_CLEAN_TMP). To identify the temporary tables that need to be removed from EPM, all temporary tables are assigned an ownerID. Each owner ID is assigned to a specific EPM product. While temporary tables can only be assigned to one owner ID, you can assign several owner IDs to a single product. The following diagram depicts the hierarchical relationship between temporary tables and the products.
Temporary table to product hierarchy
The Clean Temporary Tables process uses the product, ownerID, and customer licensing information (plus the relationships between these objects), to identify the tables that should be removed from the EPM database. The information is stored in the following EPM tables:
PS_PF_PROD_TO_OWNR: Contains product code, ownerID, and record type, and identifies the relationship between EPM product and ownerID.
PSRECDEFN: Identifies the relationship between EPM temporary tables and ownerID.
PSINSTALLATION: Identifies which EPM products you have licensed.
At runtime the Clean Temporary Tables application engine uses the information stored in the aforementioned tables to identify and delete all instances of temporary tables that are not required by your licensed product(s). It then regenerates the EPM_TEMP_RECORDS and EPM_TEMP_RECORDS_INC application designer projects with the new temporary tables.
All temporary tables being shared among applications belong to a special ownerID named AppCommon and are not deleted. There are also fundamental temporary tables associated with the ownerID EPM Foundation and are not deleted.
After running the Clean Temporary Tables process, all temporary tables that have been dropped from the database are logged in the PF_TMPTBL_LOG table. You can view the results of this process using the Cleanup Log page.
The Clean Temporary Tables application engine should be run after every install, upgrade or patch of PeopleSoft EPM products. After it runs, open the EPM_TEMP_RECORDS_INC project in Application Designer, and if not empty, rebuild the project to ensure that newly added temporary tables are built.
Delivered EPM_TEMP_RECORDS_INC Project
The EPM_TEMP_RECORDS_INC project is provided to help you integrate new temporary tables into EPM when you have added (licensed) a new EPM product but already run the Clean Temporary Tables process. Keep in mind that when you run the Clean Temporary Tables process, you delete temporary tables associated with any uninstalled EPM product. Therefore, when you introduce a new EPM product you also add new temporary tables back into the related projects. As described in this chapter, when you add new temporary tables to a project, you have to rebuild the project. The EPM_TEMP_RECORDS_INC project is an incremental project which contains only newly added temporary tables. You can use the EPM_TEMP_RECORDS_INC project to rebuild your temporary tables, instead of using the EPM_TEMP_RECORDS project with the entire set of your temporary tables. Because of its smaller size, rebuilding the EPM_TEMP_RECORDS_INC project saves you processing time.
See Creating Additional Instances of Temporary Tables for Record Suites.
Pages Used to Remove Temporary Tables from EPM|
Page Name |
Definition Name |
Navigation |
Usage |
|
Clean Up Temporary Tables |
PF_RUN_CLEAN_TMP |
EPM Foundation, Job Processing, Temporary Tables, Cleanup Temp Tables, Clean Up Temporary Tables |
Run the Clean Temporary Tables application engine. |
|
Cleanup Log |
PF_TMPTBL_VW |
EPM Foundation, Job Processing, Temporary Tables, Cleanup Log |
View temporary tables dropped from the EPM database. |
Dropping Extraneous Temporary Tables from EPMAccess the Clean Up Temporary Tables page (EPM Foundation, Job Processing, Temporary Tables, Cleanup Temp Tables, Clean Up Temporary Tables).
|
When |
Select the frequency in which you would like the PF_CLEAN_TMP process to run. |
|
Run |
Click to run the PF_CLEAN_TMP process. |
Viewing the Temporary Tables Dropped from EPM
Access the Cleanup Log page (EPM Foundation, Job Processing, Temporary Tables, Cleanup Log).
|
Product Name |
Displays the product associated with the deleted temporary tables. |
|
DateTime |
Displays the date and time the process was run. |
|
Number of temporary tables |
Displays the total number of temporary tables associated with the selected product. |
|
Installed Product |
Indicates whether this is an installed product. Only temporary tables from non-installed products should be dropped. |
|
Tables Dropped |
Displays the total number of temporary tables dropped from the EPM database. |
|
Table Name |
Displays the name of the temporary table deleted from the EPM database. |
|
Object Owner ID |
Displays the Owner ID associated with a particular temporary table. |
Running Jobstreams
This section discusses how to:
Run jobstreams.
Run multiple jobstreams.
Set up email notification.
Pages Used to Run a Jobstream and Multiple Jobstreams|
Page Name |
Definition Name |
Navigation |
Usage |
|
Run Jobstream |
RUN_PF_JOBSTREAM |
EPM Foundation, Job Processing, Update/Run Jobstreams, Run Jobstream |
Run a jobstream. |
|
Run Multiple Jobstream |
RUN_PF_MULTIPERIOD |
EPM Foundation, Job Processing, Update/Run Jobstreams, Run Multiple Jobstream |
Run a jobstream for multiple fiscal years and accounting periods. |
|
Jobstream Email Notification |
PF_EMAIL_MSG |
Click Specify Email Parameters on the Run Jobstream or Run Multiple Jobstreams page. |
Set up email parameters for automatically notifying users when a jobstream is complete or abended. |
Running Jobstreams
Access the Run Jobstream page (EPM Foundation, Job Processing, Update/Run Jobstreams, Run Jobstream).
|
Select this check box to disable the Fiscal Year and Period fields. Enter an as of date for the jobstream run. |
|
|
Send Email Notification |
Select this check box to send an email notification to all of the email addresses that you define by clicking the Specify Email Parameters link. The email notification informs the recipients that the jobstream is complete or has abended. |
|
Description |
Enter a description for the jobstream run. The Metadata Search engine uses this description to find the data later. |
|
Unit and Scenario ID |
Select the business unit and scenario ID combination. |
|
Fiscal Year and Period |
Enter the fiscal year and period for this jobstream run. This field does not appear if you select the As Of Dated Jobstream check box. |
|
Jobstream ID |
Select the jobstream you want to run. |
|
Select this check box if you are processing the same job an additional time using identical parameters and want the system to re-resolve the tables. Re-resolving means that data is re-selected from the permanent table and moved to temporary tables of the assigned record suite. Note. This option may slow down processing if you are assigned to the same record suite assigned the previous time that the engine was run. |
|
|
Last Run On |
Displays the date and time this jobstream was last run. |
|
As Of Date |
Displays the as of date for an as-of-dated jobstream. If you are using the Fiscal Year and Period, this field displays the last day of the fiscal year and period combination based on the calendars you defined. |
|
View Messages |
Once a jobstream has run, click to view the engine messages generated by the jobstream. This page is described later in this chapter. |
|
Select this option to release the last record suite used by this jobstream. |
|
|
Select this option to release all record suites. All record suites are now available to jobstreams. Warning! Before clearing all record suites, make sure that no jobs are running. |
Running Multiple Jobstreams
Access the Run Multiple Jobstream page (EPM Foundation, Job Processing, Update/Run Jobstreams, Run Multiple Jobstream).
|
Program Name |
Displays the name of the jobstream program. |
|
Send Email Notification |
Select this check box to send an email notification to all of the email addresses that you define by clicking the Specify Email Parameters link. The email notification informs the recipients that the jobstream is complete or has abended. |
|
Description |
Enter a description for the jobstream run. The Metadata Search engine uses this description to find the data later. |
|
Business Unit and Scenario ID |
Select the business unit and scenario ID combination. |
|
From Year and From Period , To Year and To Period |
Enter the fiscal years and periods to include in this jobstream. Unlike the Run Jobstream page, on which you can only specify one fiscal year and period combination, you can specify a range of years and periods. |
|
Jobstream ID |
Select the jobstream you want to run. |
|
Rerun |
Select this check box if you are processing the same job an additional time using identical parameters and want the system to re-resolve the tables. Re-resolving means that data is re-selected from the permanent table and moved to temporary tables of the assigned record suite. Note. This option may slow down processing if you are assigned to the same record suite assigned the previous time that the engine was run. |
|
Last Run On |
Displays the date and time this jobstream was last run. |
|
Run |
Click this button to access the Process Scheduler Request page on which you define the parameters for running the jobstream. |
|
Process Monitor |
Click this button to access Process Monitor pages to check process scheduler results. Process Monitor provides updated information on the progress of reports and processes. From a Web browser, you can monitor process requests and the status of different servers that run your reports. If there are messages related to a process, you can view them from Process Monitor, as well. |
Setting up Email Notification
Access the Jobstream Email Notification page (Click Specify Email Parameters on the Run Jobstream or Run Multiple Jobstreams page.).
Use this page to list the email addresses of those recipients who should receive a notification when the jobstream completes or abends. You can enter a subject for the email and any text you would like to send.
Tracking Jobs
There are a number of pages enabling you to track the progress of your jobs. This section discusses how to:
Review record suites.
Review record suite history.
Review records in a jobstream.
Review jobstream history.
Review temporary tables.
Review temporary table history.
Pages Used to Track Jobs|
Page Name |
Definition Name |
Navigation |
Usage |
|
Record Suites |
PF_RECSUITE_TBL1 |
EPM Foundation, Job Processing, Review Jobstream Content, Review Record Suites, Record Suites |
View all of the defined record suites. |
|
Jobstream Job Detail |
PF_JOBSTRM_TBL2S |
Click the
|
View runtime parameters to determine whether a record suite is in use. |
|
Record Suite History |
PF_RECSUITE_HIS1 |
EPM Foundation, Job Processing, Review Jobstream Content, Record Suite History |
View the process instances, job description, and run control IDs that were run in the specified record suite. |
|
Jobstream |
PF_JOBSTRM_TBL1 |
EPM Foundation, Job Processing, Review Jobstream Content, Review Jobstream |
View the current status of a jobstream for all defined record suites. |
|
Jobstream History |
PF_JOBSTRM_HIS1 |
EPM Foundation, Job Processing, Review Jobstream Content, Jobstream History |
View the job ID, record suites, and run control parameters that have been run for a selected jobstream. |
|
Temporary Table |
PF_TEMP_REC_TBL1 |
EPM Foundation, Job Processing, Temporary Tables, Temporary Table |
View, for each record suite, the temporary tables that have been populated. This page also displays the run controls that were used to populate them. |
|
Temporary Table History |
PF_TEMP_REC_HIS1 |
EPM Foundation, Job Processing, Temporary Tables, Temp Table History |
Review table usage for a record suite. |
Reviewing Record Suites
Access the Record Suites page (EPM Foundation, Job Processing, Review Jobstream Content, Review Record Suites, Record Suites).
Reviewing Record Suite History
Access the Record Suite History page (EPM Foundation, Job Processing, Review Jobstream Content, Record Suite History).
Use this page to review the process instances, job description, and run control IDs that were run in the selected record suite. A start and end time also display as well as an in use sw flag.
Reviewing Records in a Jobstream
Access the Jobstream page (EPM Foundation, Job Processing, Review Jobstream Content, Review Jobstream).
Use this page to view the current status of a jobstream for all the defined record suites.
Reviewing Jobstream History
Access the Jobstream History page (EPM Foundation, Job Processing, Review Jobstream Content, Jobstream History).
Use this page to view the job ID, record suites, and run control parameters that have been run for a jobstream.
Reviewing Temporary Tables
Access the Temporary Table page (EPM Foundation, Job Processing, Temporary Tables, Temporary Table).
Use this page to view for a given record suite the temporary tables that have been populated. This page also shows the run control parameters.
Reviewing Temporary Table History
Access the Temporary Table History page (EPM Foundation, Job Processing, Temporary Tables, Temp Table History).
Use this page to review table usage for a record suite.
Viewing Engine Messages
After you run a job or jobstream, view the process information and run control parameters for the engine that you just ran using the Messages component. You can access this component directly from the Run Jobstream page by clicking the View Engine Messages link.
This section discusses how to view engine messages
Pages Used to View Engine Messages|
Page Name |
Definition Name |
Navigation |
Usage |
|
Engine Messages - Message Header |
PF_ENGMSG_HEAD |
EPM Foundation, Job Processing, Review Jobstream Content, Engine Messages, Message Header |
View display-only process information such as record suite ID and engine ID, as well as the run control parameters for this process instance. |
|
Engine Messages - Message Detail |
PF_ENGMSG_LOG |
EPM Foundation, Job Processing, Review Jobstream Content, Engine Messages, Message Detail |
View display-only process information such as source name, field name, and field value. |
|
Message Detail |
PF_ENGMSG_MSG |
Click the
|
View the detailed error message. |
Viewing Engine Messages
Access the Message Header page (EPM Foundation, Job Processing, Review Jobstream Content, Engine Messages, Message Header).
|
Process Information |
View details such as the process instance, record suite, engine ID, jobstream ID, run control, table append, as well as the start and end date and time. |
|
Run Control Parameters |
Displays the defined run control parameters for the instance (business unit, scenario ID, fiscal year and accounting period, and as of date if applicable). |
Go to the next page in the component to view engine message details.
Access the Engine Messages - Message Detail page (EPM Foundation, Job Processing, Review Jobstream Content, Engine Messages, Message Detail).
For a given process instance, engine ID, jobstream ID and run control you can view the message details.