| Oracle® Database Express Edition 2日でデータベース管理者 11g リリース2 (11.2) B66471-01 |
|



 前 |
 次 |
この章では、Oracle Database XEからエクスポート(アンロード)する方法と、それにインポート(ロード)する方法について説明します。メタデータ(データベース・オブジェクト定義)、データ、またはメタデータとデータの両方をエクスポートおよびインポートできます。この章の内容は、次のとおりです。
データをエクスポートして、後で別のOracleデータベースやOracle以外のデータベースにインポート(ロード)できます。データがロードに適合する形式の場合は、Oracle以外のデータベースからアンロードしたデータをOracleデータベースにロードできます。
この章の内容は次のとおりです。
利便性の面および使用可能な機能の幅から、別のツール(コマンドライン・ユーティリティ)を使用する必要がない場合は、エクスポートおよびインポートの操作にSQL Developerを使用します。
SQL Developerでは、メタデータおよびデータのエクスポートとインポート用の便利なウィザードが提供されます。
メタデータまたはデータ(あるいはその両方)をエクスポートするには、エクスポート・ウィザードを使用します(「ツール」、「データベース・エクスポート」の順にクリックします)。
メタデータまたはデータ(あるいはその両方)をインポートするには、インポートする素材が作成された方法やインポートするデータの形式にあわせて、適切な方法を使用します。この方法には、スクリプト・ファイルを実行したり、データのインポート・ウィザードを使用してデータファイル(.csvファイル、Microsoft Excelの.xlsファイルなど)からのインポートを実行したりする方法があります。
SQL Developerを使用してエクスポートおよびインポート操作を実行する次の例を参照してください。
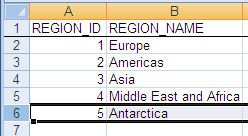
たとえば、表とそのデータを(同じOracleデータベースまたは別のOracleデータベースの)別のスキーマに作成できるように、HRのサンプル・スキーマの一部であるREGIONS表をエクスポートすると仮定します。
REGIONS表をアンロードする手順は、次のとおりです。
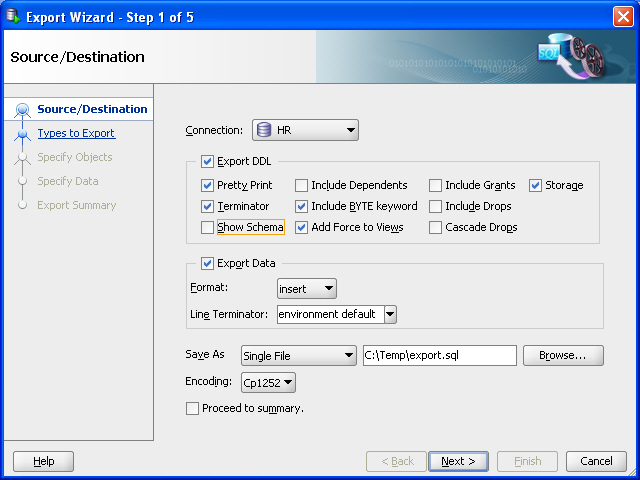
SQL Developerで、「ツール」、「データベース・エクスポート」の順にクリックします。図10-1に、エクスポート・ウィザードの最初のページを示しますが、選択内容が反映されるエントリはこの後で設定します。
次のオプション以外は、「ソース/宛先」ページのオプションのデフォルト値を受け入れます。
接続: HRを選択します。
スキーマの表示: このオプションの選択を解除して(チェックを外して)、作成される.sqlスクリプト・ファイル内のCREATE文およびINSERT文にスキーマ名のHRが含まれないようにします。(これにより、ユーザーは任意の名前(たとえば、HRという名前以外)で、スキーマに表を再作成できるようになります。)
「別名保存」の場所: ローカル・ハード・ドライブ上の任意のフォルダを入力または参照し、スクリプト・ファイルのファイル名を指定します。(図の場合、このファイルは、C:\temp\export.sqlです。)この場所に、CREATE文およびINSERT文が含まれるスクリプト・ファイルが作成されます。
|
注意: ウィザードのこのページや他のページのオプションの説明を参照するには、「ヘルプ」ボタンをクリックします。たとえば、「フォーマット」には、デフォルトの |
「次へ」をクリックします。
「エクスポートするタイプ」ページで、「すべて切替え」の選択を解除し、「表」のみを選択します(表のみをエクスポートするからです)。
「次へ」をクリックします。
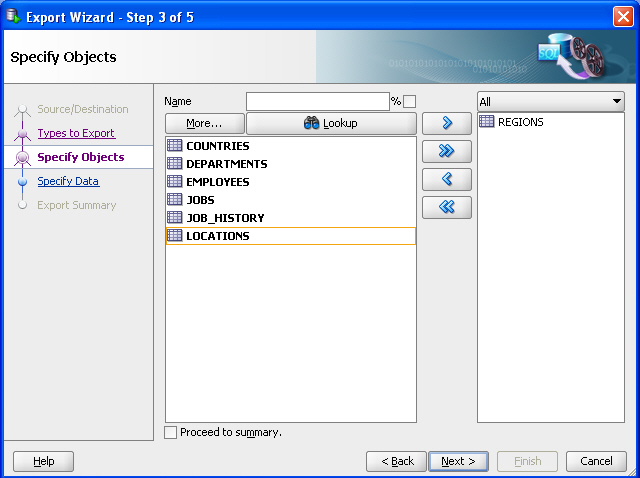
「オブジェクトの指定」ページで、「参照」をクリックし、左側のREGIONS表をダブルクリックして、右側の列に移動します。図10-2に、これらの操作の結果を示します。
「次へ」をクリックします。
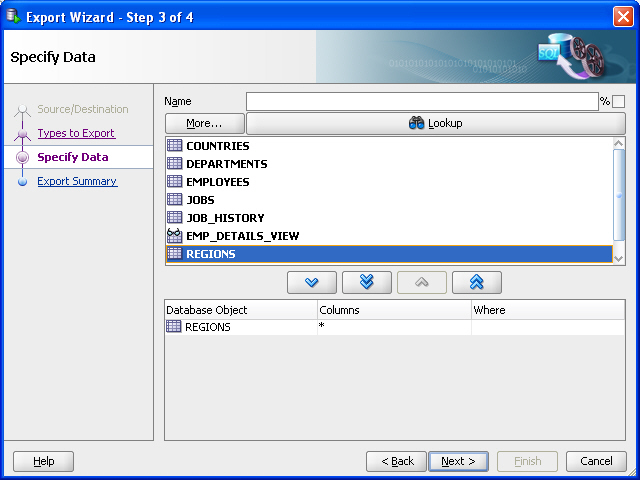
「データの指定」ページで、デフォルトを受け入れ、「次へ」をクリックします。
デフォルトでは、指定された1つまたは複数の表からすべてのデータがエクスポートされますが、エクスポートされるデータを制限する場合は、このページの下部で1つ以上のWHERE句を指定できます。
「サマリー」ページで、情報を確認し、求めているとおりの内容である場合は、「終了」をクリックします。(指定した情報の場合は、これによって、エクスポート・スクリプトがC:\temp\export.sqlとして作成されます。)
変更を行う必要がある場合は、適切なページに戻って変更を行い、再度「サマリー」ページまで進みます。
たとえば、「例: 表のメタデータおよびデータのエクスポート」でエクスポートしたREGIONS表を再作成しますが、別のスキーマに再作成すると仮定します。この別のスキーマは、既存のものであっても、作成するものであってもかまいません。
たとえば、「例: ユーザーの作成」の手順に従って、NICKという名前のユーザーを作成したとします。C:\temp\export.sql内のスクリプトを起動して、NICKというユーザーのスキーマにREGIONS表を再作成するには、SQL Developerを使用して次の手順を実行します。
NICKのデータベース接続をまだ作成していない場合は、接続を作成します。
NICKの接続をオープンします。
NICKの接続のSQLワークシートで、次のように入力します。
@c:\temp\export.sql
「スクリプトの実行」アイコンをクリックします。
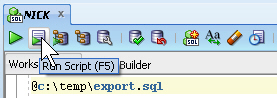
「スクリプト出力」ペインに、REGIONS表が作成されて、4つの行が挿入されたことが表示されます。
「接続」ナビゲータで、NICKの接続の下の「表」ノードを展開します。これで、REGIONS表が表示されます。
オプションで、「接続」ナビゲータのREGIONS表をクリックし、メイン表示領域の「列」および「データ」タブで情報を確認します。
たとえば、同じ列定義を使用して表にデータをインポートできるように、HRのサンプル・スキーマの一部であるREGIONS表からデータのみをエクスポートすると仮定します。これは、(同じOracleデータベースまたは別のOracleデータベースの)別のスキーマのREGIONS表である可能性があります。
同じデータベース・エクスポート・ウィザードを使用しますが、データのみをエクスポートし、DDL (データベース・オブジェクトを作成するためのデータ定義言語文)はエクスポートしません。
REGIONS表のデータをエクスポートする手順は、次のとおりです。
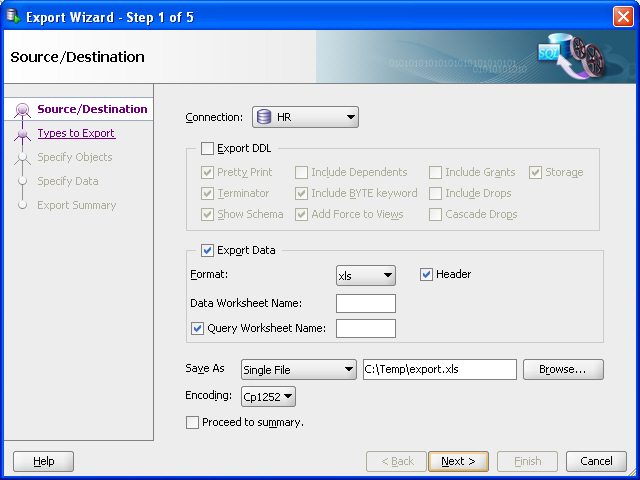
SQL Developerで、「ツール」、「データベース・エクスポート」の順にクリックします。図10-3に、エクスポート・ウィザードの最初のページを示しますが、選択内容が反映されるエントリはこの後で設定します。
次のオプション以外は、「ソース/宛先」ページのオプションのデフォルト値を受け入れます。
接続: HRを選択します。
DDLのエクスポート: このオプションの選択を解除します(チェックを外します)。.sqlスクリプト・ファイルが生成される場合(この例では生成されません)、そのファイルにはCREATE文は含まれずに、INSERT文のみが含まれるようになります。
フォーマット: データがMicrosoft Excelの.xlsファイルに保存されるように、「xls」を選択します。
「別名保存」の場所: ローカル・ハード・ドライブ上の任意のフォルダを入力または参照し、.xlsファイルのファイル名を指定します。(図の場合、このファイルは、C:\temp\export.xlsです。)
「次へ」をクリックします。
「エクスポートするタイプ」ページで、「すべて切替え」の選択を解除し、「表」のみを選択します(表のデータのみをエクスポートするからです)。
「次へ」をクリックします。
「オブジェクトの指定」ページで、「参照」をクリックし、左側のREGIONS表をダブルクリックして、ページ下部の行に表示します。図10-2に、これらの操作の結果を示します。
デフォルトでは、指定された1つまたは複数の表からすべてのデータがエクスポートされますが、エクスポートされるデータを制限する場合は、このページの下部で1つ以上のWHERE句を指定できます。
「次へ」をクリックします。
「サマリー」ページで、情報を確認し、求めているとおりの内容である場合は、「終了」をクリックします。(指定した情報の場合は、これによって、REGIONS表のデータがC:\temp\export.xlsファイルにエクスポートされます。)
変更を行う必要がある場合は、適切なページに戻って変更を行い、再度「サマリー」ページまで進みます。
たとえば、「例: Microsoft Excelファイルへのデータのエクスポート」でエクスポートしたデータを、元の(REGIONS)表と同じ列定義を持つ新しい表にインポートすると仮定します。
たとえば、「例: ユーザーの作成」の手順に従って、NICKという名前のユーザーを作成したとします。このユーザーは、エクスポートしたデータを取得し、そのExcelファイルに1行を追加して、そのファイルをREGIONS表と同じ列定義を持つ新しい表にインポートしようとしています。(この例はそれほど重要ではなく、Excelファイルへ行を追加することがよくあるということでもありませんが、単に一部の機能を説明するために紹介しています。)
これらの目的を達成するには、次の手順に従います。
SQL Developerで、NICKのデータベース接続をまだ作成していない場合は、接続を作成します。
NICKの接続をオープンします。
NICKの接続のSQLワークシートで、次のように入力します。
create table new_regions ( region_id number primary key, region_name varchar2(25));
「スクリプトの実行」アイコンをクリックします。
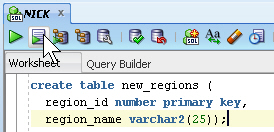
「スクリプト出力」ペインに、NEW_REGIONS表が作成されたことが表示されます。
「接続」ナビゲータで、NICKの接続の下の「表」ノードを展開します。これで、NEW_REGIONS表が表示されます。
NEW_REGIONS表が表示されない場合は、NICKの接続を切断し(「接続」ナビゲータで「NICK」を右クリックして「切断」を選択)、再接続して、「表」ノードを展開します。
Microsoft Excelを使用し、エクスポートしたデータが含まれるファイル(たとえば、c:\temp\export.xls)を開いて、任意で1行以上の行を追加します。
図10-5に、元のファイルにAntarcticaリージョンの1行を追加したものを示します。
Microsoft Excelの.xlsファイルを保存して閉じます。
SQL Developerで、「接続」ナビゲータのNICKの表示のNEW_REGIONS表を右クリックして、「データのインポート」を選択します。
表示されたダイアログ・ボックスで、c:\tempフォルダにナビゲートし、export.xlsを選択して、「開く」をクリックします。
データのインポート・ウィザードで、すべてのデフォルトを受け入れ、各ページの「次へ」をクリックして「サマリー」まで進み、そのページで「終了」をクリックします。(ウィザードの各ページのオプションの詳細を参照するには、「ヘルプ」ボタンをクリックします。)
.xlsファイルのデータがNEW_REGIONS表にロードされ、コミットされます。
SQL Developerのエクスポートおよびインポート・ウィザードでニーズが満たされない場合は、Oracle Database XEで使用可能ないずれかのコマンドライン・ユーティリティを使用できます。これらの他のツールについて、次の項で説明します。
Oracle Database XEでは、データのエクスポートおよびインポート用の数々の強力なユーティリティが提供されます。表10-1に、これらのオプションのサマリーを示します。
表10-1 他のエクスポート/インポート・データ・オプションのサマリー
| 機能またはユーティリティ | 説明 |
|---|---|
|
SQL*Loaderユーティリティ |
|
|
データ・ポンプ・エクスポートおよびデータ・ポンプ・インポート・ユーティリティ |
|
|
エクスポートおよびインポート・ユーティリティ |
|
表10-2では、ロード、アンロード、インポートおよびエクスポートの例を示し、それぞれで使用する適切なオプションを提案しています。
表10-2 インポート/エクスポートの例と推奨オプション
| インポート/エクスポートの例 | 推奨オプション |
|---|---|
|
区切られていないデータをロードする必要がある。レコードは固定長で、フィールド定義は列の位置に依存する。 |
SQL*Loader |
|
ロードするデータがタブ区切りのテキスト・データであり、存在する表が10より多い。 |
SQL*Loader |
|
ロードするデータがテキスト・データであり、ある選択基準(たとえば、部門番号3001の従業員のレコードのみ)を満たすレコードのみをロードする。 |
SQL*Loader |
|
別のOracleデータベースへ、スキーマ全体をインポートまたはエクスポートする。データにはXMLTypeデータが存在しない。 |
データ・ポンプ・エクスポートおよびデータ・ポンプ・インポート |
|
別のOracleデータベースへデータをインポートまたはエクスポートする。データにはXMLTypeデータが含まれるが、 |
インポート( |
|
関連項目: データ・ポンプ、インポートおよびエクスポート・ユーティリティ、およびSQL*Loaderの詳細は、Oracle Databaseユーティリティを参照してください |
SQL*Loaderは、外部データファイルからOracleデータベースの表にデータをロードします。データファイルには、固定レコード形式、可変レコード形式またはストリーム・レコード形式(デフォルト)があります。
通常のSQL*Loaderセッションの入力は制御ファイルで、制御ファイルはSQL*Loaderの動作といくつかのデータ(制御ファイルそのものの最後、または別のデータファイルに存在)を制御します。
SQL*Loaderセッションの出力先は、データがロードされるOracle Database、ログ・ファイル、不良ファイルで、廃棄ファイルに出力される場合もあります。このログ・ファイルにはロード中に発生したエラーに関する記述など、ロードに関する詳細情報が記録されます。不良ファイルには、SQL*LoaderまたはOracle Databaseによって拒否レコードが書き込まれます。廃棄ファイルには、制御ファイルに指定されているレコード選択基準に一致しなかったため、ロード対象から除外されたレコードが入ります。
SQL*Loaderは、状況に応じて、従来型パス、ダイレクト・パスおよび外部表の3つの異なるデータのロード方法を使用します。
従来型パス・ロードは、デフォルトのロード方法です。それは、SQLのINSERT文を実行して、表をOracleデータベースに移入します。この方法では、SQL文が生成されてOracleに渡されてから実行されるため、追加のオーバーヘッドが発生するので、他の方法に比べて時間がかかる可能性があります。また、SQL*Loaderで従来型パス・ロードを実行する場合は、その他のすべてのプロセスと均等にバッファ・リソースの競合が発生するため、時間がかかる可能性があります。
ダイレクト・パス・ロードでは、他のユーザーとデータベース・リソースの競合が発生しません。Oracleデータ・ブロックをフォーマット化して、それを直接データベース・ファイルに書き込むことで、通常発生するデータ処理の大半を回避できるため、Oracleデータベースのオーバーヘッドを大幅に削減します。そのため、通常、ダイレクト・パス・ロードは、従来型パスよりも速くデータをロードできます。ただし、ダイレクト・パス・ロードにはいくつかの制限があるため、従来型パス・ロードを使用する必要がある場合もあります。たとえば、ダイレクト・パス・ロードは、クラスタ化された表、または表に対して保留中のトランザクションが存在する表には使用できません。
ダイレクト・パス・ロードを使用する必要がある場合と必要がない場合の十分な説明については、『Oracle Databaseユーティリティ』を参照してください。
外部表ロードでは、データ・ファイルに含まれているデータの外部表が作成されます。ロード処理では、INSERT文が実行され、データ・ファイルのデータがターゲット表に挿入されます。外部表ロードでは、外部表の作成に使用されるINSERT文の一部としてSQL関数およびPL/SQLファンクションを使用することによってロードされるデータを変更できます。
外部表の詳細は、『Oracle Database管理者ガイド』を参照してください。
SQL*Loaderを使用して、次のことが可能です。
ネットワークを介したデータのロード。これは、SQL*Loaderクライアントを、SQL*Loaderサーバーが実行されているシステムと別のシステムで実行できることを意味します。
同一のロード・セッションでの複数のデータ・ファイルからのデータのロード。
同一のロード・セッションでの複数の表へのデータのロード。
データのキャラクタ・セットの指定。
ロード・データの選択(レコード値に基づいたロード)。
ロード前の、SQL関数を使用したデータ処理。
指定した列に対する、一意の順序キーの生成。
オペレーティング・システムのファイル・システムを使用したデータ・ファイルへのアクセス。
ディスク、テープまたはNamed Pipeからのデータのロード。
高度なエラー・レポートの生成による、トラブルシューティングの支援。
複合オブジェクト・リレーショナル・データの任意のロード。
セカンダリ・データ・ファイル(SDF)を使用した、LOBおよびコレクションのロード。
次の例では、HRのサンプル・スキーマにdependentsという名前の新しい表を作成します。それには、HRスキーマのemployees表にリストされている従業員の扶養家族に関する情報が含まれます。この表を作成した後に、SQL*Loaderを使用して、扶養家族に関するデータをフラット・データファイルからdependents表にロードします。
この例には、データファイルとSQL*Loader制御ファイルが必要です(これらは最初の2つの手順で作成します)。
現在の作業ディレクトリに、dependents.datというデータファイルを作成します。このファイルは、表計算アプリケーションなどの様々な方法を使用したり、単純にテキスト・エディタに入力して作成できます。それには、次の内容が含まれます。
100,"Susan, Susie",Kochhar,17-JUN-1997,daughter,101,NULL, 102,David,Kochhar,02-APR-1999,son,101,NULL, 104,Jill,Colmenares,10-FEB-1992,daughter,119,NULL, 106,"Victoria, Vicki",Chen,17-JUN-1997,daughter,110,NULL, 108,"Donald, Donnie",Weiss,24-OCT-1989,son,120,NULL,
このファイルはCSV (カンマ区切り値)ファイルで、ファイル内のカンマはフィールド間のデリミタとしての役割を果たします。正式な名前の別名も提供されている場合(つまり、名前フィールドにカンマが含まれる場合)、名前が含まれるフィールドは二重引用符で囲まれます。
現在の作業ディレクトリに、dependents.ctlというSQL*Loader制御ファイルを作成します。このファイルは、任意のテキスト・エディタを使用して作成できます。それには、次の内容が含まれます。
LOAD DATA INFILE dependents.dat INTO TABLE dependents REPLACE FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ( dep_id, first_name, last_name, birthdate, relation, relative_id, benefits )
次の操作を1つ実行します。
Linuxの場合: ターミナル・セッションを開始し、Oracle Database XEのホスト・コンピュータにoracleユーザー・アカウントでログインします。
Windowsの場合: Oracle Database XEのホスト・コンピュータに、Oracle Database XEをインストールしたユーザーでログインし、コマンド・ウィンドウを開きます。
Linuxの場合は、環境変数が「Linuxプラットフォームの環境変数の設定」の手順に従って設定されていることを確認します。
SQLコマンドライン(SQL*Plus)を起動し、コマンド・プロンプトで次のように入力して、hrというユーザーで接続します。
sqlplus hr/hr
SQLプロンプトで、次のようにdependents表を作成します。
CREATE TABLE dependents (
dep_id NUMBER(6),
first_name VARCHAR2(20),
last_name VARCHAR2(25) CONSTRAINT dep_last_name_nn NOT NULL,
birthdate DATE,
relation VARCHAR2(25),
relative_id NUMBER(6) CONSTRAINT emp_dep_rel_id_fk REFERENCES employees
(employee_id),
benefits CLOB
)
/
last_name列の制約は、値の指定が必須であることを示しています。relative_id列の制約は、その列がemployees表のemployee_id列の値に一致する必要があることを示しています。benefits列には、文字データの大きなブロックを保持できるように、CLOBのデータ型が設定されています。(この例では、使用可能な給付金情報がまだ存在しないため、dependents.datのデータファイルでは、この列はNULLで表示されます。)
「Table created」のメッセージが表示されたら、exitと入力して、SQLコマンドラインを終了します。
現在の作業ディレクトリ(制御ファイルおよびデータ・ファイルを作成した場所)内から、システム・プロンプトで、次のSQL*Loaderコマンドを発行します。
sqlldr hr/hr DATA=dependents.dat CONTROL=dependents.ctl LOG=dependents.log
dependents.datファイル内のデータがdependents表にロードされ、次のメッセージが表示されます。
Commit point reached - logical record count 5
ロードに関する情報は、dependents.logというログ・ファイルに書き込まれます。ログ・ファイルの内容は、たとえば次のようになります。
Control File: dependents.ctl
Data File: dependents.dat
Bad File: dependents.bad
Discard File: none specified
(Allow all discards)
Number to load: ALL
Number to skip: 0
Errors allowed: 50
Bind array: 64 rows, maximum of 256000 bytes
Continuation: none specified
Path used: Conventional
Table DEPENDENTS, loaded from every logical record.
Insert option in effect for this table: REPLACE
Column Name Position Len Term Encl Datatype
------------------------------ ---------- ----- ---- ---- ---------------------
DEP_ID FIRST * , O(") CHARACTER
FIRST_NAME NEXT * , O(") CHARACTER
LAST_NAME NEXT * , O(") CHARACTER
BIRTHDATE NEXT * , O(") CHARACTER
RELATION NEXT * , O(") CHARACTER
RELATIVE_ID NEXT * , O(") CHARACTER
BENEFITS NEXT * , O(") CHARACTER
Table DEPENDENTS:
5 Rows successfully loaded.
0 Rows not loaded due to data errors.
0 Rows not loaded because all WHEN clauses were failed.
0 Rows not loaded because all fields were null.
Space allocated for bind array: 115584 bytes(64 rows)
Read buffer bytes: 1048576
Total logical records skipped: 0
Total logical records read: 5
Total logical records rejected: 0
Total logical records discarded: 0
Run began on Mon Dec 05 16:16:29 2005
Run ended on Mon Dec 05 16:16:42 2005
Elapsed time was: 00:00:12.22
CPU time was: 00:00:00.09
これで、他の表と同じように、dependents表を操作できるようになりました。
Oracle Database XEでは、データのエクスポートおよびインポート用に次のコマンドライン・ユーティリティが提供されます。
データ・ポンプ・エクスポートおよびデータ・ポンプ・インポート
エクスポートおよびインポート
次の各項では、各ユーティリティの概要を説明します。各ユーティリティを使用する際の要約については、表10-2を参照してください。
|
関連項目: コマンドライン・パラメータの説明や追加の例など、これらのユーティリティの詳細は、『Oracle Databaseユーティリティ』を参照してください。 |
データ・ポンプ・エクスポート・ユーティリティは、データとメタデータをダンプ・ファイル・セットと呼ばれる一連のオペレーティング・システム・ファイルにエクスポートします。データ・ポンプ・インポート・ユーティリティは、エクスポート・ダンプ・ファイル・セットをターゲットのOracleデータベースにインポートします。
ダンプ・ファイル・セットは、表データ、データベース・オブジェクトのメタデータ、制御情報を含む1つ以上のディスク・ファイルで構成されています。ファイルは固有のバイナリ形式で書き込まれるため、ダンプ・ファイル・セットは、データ・ポンプ・インポート・ユーティリティによってのみインポートできます。ダンプ・ファイル・セットは、同じデータベースにインポートするか、または別のシステムへ移動してそのシステムのOracleデータベースにロードできます。
ダンプ・ファイルの書込みは、データ・ポンプ・クライアント・アプリケーションではなく、データベースによって行われるので、ファイルが書き込まれるディレクトリのディレクトリ・オブジェクトを作成する必要があります。ディレクトリ・オブジェクトとは、ホストのオペレーティング・システムのファイル・システム内のディレクトリの別名のデータベース・オブジェクトです。
データ・ポンプ・エクスポートおよびデータ・ポンプ・インポートを使用すると、データおよびメタデータのサブセットを移動できます。これを行うには、データ・ポンプ・パラメータを使用して、エクスポート・モードおよびインポート・モードと、各種のフィルタ基準を指定します。
エクスポートおよびインポートは、ネットワーク経由でも実行できます。ネットワーク・エクスポートでは、ソース・データベース・インスタンスのデータは、接続されたデータベース・インスタンスのダンプ・ファイル・セットに書き込まれます。ネットワーク・インポートでは、ダンプ・ファイルを介さずに、ソース・データベースから直接ターゲット・データベースをロードできます。これにより、エクスポートおよびインポート操作を同時に実行して、合計経過時間を最小限に抑えることができます。
また、データ・ポンプ・エクスポートおよびデータ・ポンプ・インポートでは、一連の対話型コマンドが提供されるので、実行中のエクスポート・ジョブおよびインポート・ジョブを監視して変更できます。
|
注意: データ・ポンプ・エクスポートおよびデータ・ポンプ・インポートでは、XMLTypeデータはサポートされません。XMLTypeデータをエクスポートしてインポートする必要がある場合は、「エクスポートおよびインポート・ユーティリティを使用したデータのエクスポートとインポート」で説明されているエクスポートおよびインポート・オプションを使用してください。 |
この例では、HRのサンプル・スキーマにいくつかの変更を行い、現在のHRのスキーマに影響を与えずにこれらの変更をテストするものと仮定します。HRスキーマをエクスポートして、それを新しいHRDEVスキーマにインポートし、そこで開発作業を行い、テストを実行することができます。この操作を行うには、次の手順に従います。
次の操作を1つ実行します。
Windowsの場合: Oracle Database XEのホスト・コンピュータに、Oracle Database XEをインストールしたユーザーでログインし、コマンド・ウィンドウを開きます。
Linuxの場合: ターミナル・セッションを開始し、Oracle Database XEのホスト・コンピュータにoracleユーザー・アカウントでログインします。
Linuxの場合は、環境変数が「Linuxプラットフォームの環境変数の設定」の手順に従って設定されていることを確認します。
コマンド・プロンプトで、使用しているオペレーティング・システムに対応するコマンドを発行して、エクスポート・ファイルが配置されるディレクトリを作成します。
Windowsの場合:
MKDIR c:\oraclexe\app\tmp
Linuxの場合:
mkdir /usr/lib/oracle/xe/tmp
SQLコマンドライン(SQL*Plus)を起動し、コマンド・プロンプトで次のように入力して、SYSTEMユーザーで接続します。
sqlplus SYSTEM/password
ここで、passwordは、Oracle Database XEのインストール時(Windows)または構成時(Linux)に指定したSYSおよびSYSTEMユーザー・アカウントのパスワードです。
SQLプロンプトで、次のコマンドを入力して、先ほど作成したtmpディレクトリ用のディレクトリ・オブジェクトをdmpdirという名前で作成し、それに対する読取りと書込みのアクセス権をHRユーザーに付与します。
Windowsの場合:
CREATE OR REPLACE DIRECTORY dmpdir AS 'c:\oraclexe\app\tmp'; GRANT READ,WRITE ON DIRECTORY dmpdir TO hr;
Linuxの場合:
CREATE OR REPLACE DIRECTORY dmpdir AS '/usr/lib/oracle/xe/tmp'; GRANT READ,WRITE ON DIRECTORY dmpdir TO hr;
システム・コマンド・プロンプトで次のコマンドを発行して、HRのスキーマをschema.dmpという名前のダンプ・ファイルにエクスポートします。
expdp SYSTEM/password SCHEMAS=hr DIRECTORY=dmpdir DUMPFILE=schema.dmp LOGFILE=expschema.log
ここで、passwordは、SYSTEMユーザーのパスワードです。
エクスポート操作が実行されると、次のようなメッセージが表示されます。
Connected to: Oracle Database 11g Express Edition Release 11.2.0.1.0 - Production Starting "SYSTEM"."SYS_EXPORT_SCHEMA_01": SYSTEM/******** SCHEMAS=hr DIRECTORY=dmpdir DUMPFILE=schema.dmp LOGFILE=expschema.log Estimate in progress using BLOCKS method... Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA Total estimation using BLOCKS method: 448 KB Processing object type SCHEMA_EXPORT/USER Processing object type SCHEMA_EXPORT/SYSTEM_GRANT Processing object type SCHEMA_EXPORT/ROLE_GRANT Processing object type SCHEMA_EXPORT/DEFAULT_ROLE Processing object type SCHEMA_EXPORT/TABLESPACE_QUOTA Processing object type SCHEMA_EXPORT/PRE_SCHEMA/PROCACT_SCHEMA Processing object type SCHEMA_EXPORT/SEQUENCE/SEQUENCE Processing object type SCHEMA_EXPORT/TABLE/TABLE Processing object type SCHEMA_EXPORT/TABLE/INDEX/INDEX Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/CONSTRAINT Processing object type SCHEMA_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS Processing object type SCHEMA_EXPORT/TABLE/COMMENT Processing object type SCHEMA_EXPORT/PROCEDURE/PROCEDURE Processing object type SCHEMA_EXPORT/PROCEDURE/ALTER_PROCEDURE Processing object type SCHEMA_EXPORT/VIEW/VIEW Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/REF_CONSTRAINT Processing object type SCHEMA_EXPORT/TABLE/TRIGGER Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS . . exported "HR"."COUNTRIES" 6.093 KB 25 rows . . exported "HR"."DEPARTMENTS" 6.640 KB 27 rows . . exported "HR"."EMPLOYEES" 15.77 KB 107 rows . . exported "HR"."JOBS" 6.609 KB 19 rows . . exported "HR"."JOB_HISTORY" 6.585 KB 10 rows . . exported "HR"."LOCATIONS" 7.710 KB 23 rows . . exported "HR"."REGIONS" 5.296 KB 4 rows Master table "SYSTEM"."SYS_EXPORT_SCHEMA_01" successfully loaded/unloaded ****************************************************************************** Dump file set for SYSTEM.SYS_EXPORT_SCHEMA_01 is: C:\ORACLEXE\APP\TMP\SCHEMA.DMP Job "SYSTEM"."SYS_EXPORT_SCHEMA_01" successfully completed at 11:48:46
schema.dmpファイルおよびexpschema.logファイルが、dmpdirディレクトリに書き込まれます。
schema.dmpダンプ・ファイルを別のスキーマ、今回の場合はHRDEVにインポートします。REMAP_SCHEMAコマンド・パラメータを使用して、元のスキーマ以外のスキーマにオブジェクトをインポートすることを示します。HRDEVというユーザー・アカウントは存在しないため、インポート・プロセスによって自動的に作成されます。この例では、constraint、ref_constraint、index以外のすべてをインポートします。表がすでに存在する場合、その表はエクスポート・ファイル内の表に置換されます。
オペレーティング・システムのコマンド・プロンプトで、次のコマンドを発行します。
impdp SYSTEM/password SCHEMAS=hr DIRECTORY=dmpdir DUMPFILE=schema.dmp
REMAP_SCHEMA=hr:hrdev EXCLUDE=constraint, ref_constraint, index
TABLE_EXISTS_ACTION=replace LOGFILE=impschema.log
ここで、passwordは、SYSTEMユーザーのパスワードです。
インポート操作が実行されると、次のようなメッセージが表示されます(この出力は、dmpdirディレクトリのimpschema.logファイルにも書き込まれます)。
Connected to: Oracle Database 11g Express Edition Release 11.2.0.1.0 - Production Master table "SYSTEM"."SYS_IMPORT_SCHEMA_01" successfully loaded/unloaded Starting "SYSTEM"."SYS_IMPORT_SCHEMA_01": SYSTEM/******** SCHEMAS=hr DIRECTORY=dmpdir DUMPFILE=schema.dmp REMAP_SCHEMA=hr:hrdev EXCLUDE=constraint, ref_constraint, index TABLE_EXISTS_ACTION=replace LOGFILE=impschema.log Processing object type SCHEMA_EXPORT/USER Processing object type SCHEMA_EXPORT/SYSTEM_GRANT Processing object type SCHEMA_EXPORT/ROLE_GRANT Processing object type SCHEMA_EXPORT/DEFAULT_ROLE Processing object type SCHEMA_EXPORT/TABLESPACE_QUOTA Processing object type SCHEMA_EXPORT/PRE_SCHEMA/PROCACT_SCHEMA Processing object type SCHEMA_EXPORT/SEQUENCE/SEQUENCE Processing object type SCHEMA_EXPORT/TABLE/TABLE Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA . . imported "HRDEV"."COUNTRIES" 6.093 KB 25 rows . . imported "HRDEV"."DEPARTMENTS" 6.640 KB 27 rows . . imported "HRDEV"."EMPLOYEES" 15.77 KB 107 rows . . imported "HRDEV"."JOBS" 6.609 KB 19 rows . . imported "HRDEV"."JOB_HISTORY" 6.585 KB 10 rows . . imported "HRDEV"."LOCATIONS" 7.710 KB 23 rows . . imported "HRDEV"."REGIONS" 5.296 KB 4 rows Processing object type SCHEMA_EXPORT/TABLE/COMMENT Processing object type SCHEMA_EXPORT/PROCEDURE/PROCEDURE Processing object type SCHEMA_EXPORT/PROCEDURE/ALTER_PROCEDURE Processing object type SCHEMA_EXPORT/VIEW/VIEW Processing object type SCHEMA_EXPORT/TABLE/TRIGGER Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS Job "SYSTEM"."SYS_IMPORT_SCHEMA_01" successfully completed at 11:49:49
これで、HRDEVスキーマに、HRスキーマのデータが移入されました。
新しく作成したHRDEVのユーザー・アカウントにパスワードを割り当てます。それを行うには、SQLコマンドラインを起動して、SYSTEMユーザーで接続し(手順4と同様)、SQLプロンプトで次のALTER USER文を入力します。
ALTER USER hrdev IDENTIFIED BY hrdev;
この文により、hrdevというパスワードが割り当てられます。
これで、HRスキーマの本番データに影響を与えることなく、HRDEVスキーマで作業を行うことができます。
エクスポートおよびインポート・ユーティリティは、Oracleデータベース間でデータベース・オブジェクトを移動する簡単な方法をユーザーに提供します。それらを起動するには、それぞれexpおよびimpコマンドを使用します。これらのユーティリティでは、XMLTypeデータのサポートが提供されますが、データ・ポンプ・エクスポート・ユーティリティおよびデータ・ポンプ・インポート・ユーティリティではサポートされません。
|
注意: エクスポートおよびインポート・ユーティリティでは、FLOATおよびDOUBLEのデータ型はサポートされません。データにこれらの型が含まれ、XMLTypeデータが含まれない場合は、「データ・ポンプ・エクスポートおよびデータ・ポンプ・インポートを使用したエクスポートおよびインポート」で説明されているデータ・ポンプ・エクスポートおよびデータ・ポンプ・インポートを使用する必要があります。 |
Oracle Databaseに対してエクスポート・ユーティリティを実行すると、オブジェクト(表など)が抽出された後で、存在しているその関連のオブジェクト(索引、コメント、権限など)が抽出されます。抽出されたデータは、エクスポート・ダンプ・ファイルに書き込まれます。ダンプ・ファイルは、Oracleのバイナリ形式のダンプ・ファイルで、インポート・ユーティリティを使用した場合のみ読取りが可能です。ダンプ・ファイルの作成に使用したエクスポート・ユーティリティより前のバージョンのインポート・ユーティリティは使用できません。
|
注意: エクスポート(exp)ユーティリティによって生成されたダンプ・ファイルをインポートできるのは、インポート(imp)ユーティリティのみで、データ・ポンプ・インポート(impdp)ユーティリティではインポートできません。 |
データ・ポンプ・インポートおよびデータ・ポンプ・エクスポートと同様に、エクスポート・ユーティリティでエクスポートしたデータは、インポート・ユーティリティを使用して、同じまたは別のOracleデータベースにインポートできます。
エクスポート・ユーティリティとインポート・ユーティリティの詳細および使用方法の例は、『Oracle Databaseユーティリティ』を参照してください。