Alter Database (Aggregate Storage)
Click here for non-aggregate storage version
Change database-wide settings. Permission required: create_application.
Syntax
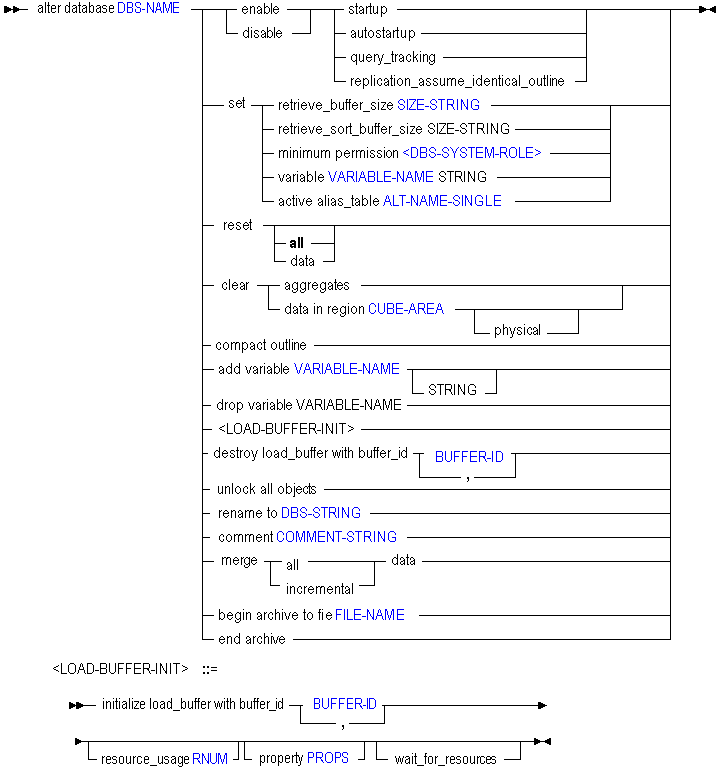
You can change the following database-wide settings using alter database.
| Keyword | Description | ||
|---|---|---|---|
enable startup | Enable users to start the database directly or as a result of requests requiring the database to be started. Startup is enabled by default. | ||
disable startup | Prevent all users from starting the database directly or as a result of requests that would start the database. Startup is enabled by default. | ||
enable autostartup | Automatically start the database when the application to which it belongs starts. Autostartup is enabled by default. This setting is applicable only when startup is enabled. | ||
disable autostartup | Prevent automatic starting of the database when the application to which it belongs starts. Autostartup is enabled by default. | ||
enable query_tracking | Begin collecting query data for this database, to be used for query-based view optimization. To utilize the results of query tracking, use the optional based on query_data clause found in either of the following statements:
Query tracking is disabled by default. | ||
disable query_tracking | Stop collecting query data for query-based view optimization. Query tracking is disabled by default. | ||
set retrieve_buffer_size | Change the database retrieval buffer size. This buffer holds extracted row data cells before they are evaluated by the RESTRICT or TOP/BOTTOM Report Writer commands. The default size is 10 KB. The minimum size is 2 KB. Increasing the size may improve retrieval performance. | ||
set retrieve_sort_buffer_size | Change the database retrieval sort buffer size. This buffer holds data until it is sorted. The Report Writer and Essbase Query Designer use the retrieval sort buffer. The default size is 10 KB. The minimum size is 2 KB. Increasing the size may improve retrieval performance. | ||
set minimum permission | Set a level of permission that all users or groups can have to the database. Users or groups with higher granted permissions than the minimum permission are not affected. | ||
set variable | Change the value of an existing subsitution variable on the database. The value must not exceed 256 bytes. It may contain any character except a leading ampersand (&). | ||
set active alias_table | Set an alias table as the primary table for reporting and any additional alias requests. Only one alias table can be used at a time. This setting is user-specific; it only sets the active alias table for the user issuing the statement. | ||
reset | Clear all data and linked-reporting objects from the database, but preserve the outline.
| ||
reset all | Clear all data, Linked Reporting Objects, and the outline. | ||
reset data | Same as using reset. | ||
clear aggregates | Delete all aggregate views. | ||
compact outline | Compact the outline file to remove the records of members that have been deleted. Compaction helps keeps the outline file at an optimal size. | ||
add variable | Create a database-level substitution variable by name, and optionally assign a string value for the variable to represent. You can assign or change the value later using set variable. A substitution variable acts as a global placeholder for information that changes regularly. Substitution variables may be referenced by calculations and report scripts. If substitution variables with the same name exist at server, application, and database levels, the order of precedence for the variables is as follows: a database level substitution variable supersedes an application level variable, which supersedes a server level variable. | ||
drop variable | Remove a substitution variable and its corresponding value from the database. | ||
initialize load_buffer | Create a temporary buffer in memory for loading data. Data load buffers are used in aggregate storage databases for allocations, custom calculations, and lock and send operations. Multiple data load buffers can exist on a single aggregate storage database. You can control the share of aggregate storage cache resources the load buffer is allowed to use and how long to wait for resources to become available before aborting load buffer operations. You can also set properties that determine how missing and zero values, duplicate values, and multiple values for the same cell in the data source are processed.
| ||
destroy load_buffer | Destroy the temporary data-load memory buffer. | ||
unlock all objects | Unlock all objects on the database that are in use by a user or process. | ||
rename to | Rename the database. When you rename a database, the database directory is also renamed. | ||
comment | Create a description of the database. The maximum number of characters is 80. This description is available to database administrators. To annotate the database for Spreadsheet Add-in users, use set note. | ||
merge all|incremental data [remove_zero_cells] | Merge incremental data slices. Use these keywords:
| ||
clear data in region … | Clear the data in the specified region. There are two methods for clearing data from a region:
The region must be symmetrical. Members in any dimension in the region must be stored members. When physically clearing data, members in the region can be upper-level members in alternate hierarchies. (If the region contains upper-level members from alternate hierarchies, you may experience a decrease in performance.) Members cannot be dynamic members (members with implicit or explicit MDX formulas), nor can they be from an attribute dimension. To remove cells with a value of zero, use the alter database MaxL statement with the merge grammar and the remove_zero_cells keyword. | ||
enable replication_assume_identical_outline | Optimize the replication of an aggregate storage database when the aggregate storage database is the target and a block storage database is the source and the two outlines are identical. Replication optimization affects only the target aggregate storage application; the source block storage application is not affected. This functionality does not apply to block storage replication. This statement can be enabled only at the database level. To enable this functionality at the server or application (or database) level, use the REPLICATIONASSUMEIDENTICALOUTLINE configuration setting in the essbase.cfg file. | ||
disable replication_assume_identical_outline | Do not optimize the replication of an aggregate storage database when the aggregate storage database is the target and a block storage database is the source and the two outlines are identical. | ||
begin archive to file | Prepare the database for backup by an archiving program, and prevent writing to the files during backup. Begin archive achieves the following outcomes:
Begin archive and end archive do not perform the backup; they simply protect the database during the backup process. | ||
end archive | Return the database to read-write mode after backing up the database files. |
Example
alter database AsoSamp.Sample clear aggregates;
Deletes all aggregate views in the AsoSamp.Sample database.
alter database AsoSamp.Sample initialize load_buffer with buffer_id 1;
alter database AsoSamp.Sample initialize load_buffer with buffer_id 1 resource_usage .5 property ignore_missing_values, ignore_zero_values;
Creates a data-load buffer in memory for the AsoSamp.Sample database. The buffer can use only 50% of available resources. Missing values and zeros in the data source are ignored.
alter database AsoSamp.Sample disable query_tracking;
Turns off the harvesting of query data for the AsoSamp.Sample database.
alter database AsoSamp.Sample merge all data;
Merges all incremental data slices into the main slice in the AsoSamp.Sample database.
alter database AsoSamp.Sample merge incremental data;
Merges all incremental data slices into a single data slice within the AsoSamp.Sample database.
alter database AsoSamp.Sample merge all data remove_zero_cells;
Merges all incremental data slices into the main slice in the AsoSamp.Sample database, and removes cells with a value of zero.
alter database AsoSamp.Sample clear data in region '{Jan, Budget}';Clears all Budget data for the month of Jan, using the logical method, from the AsoSamp.Sample database.
alter database AsoSamp.Sample clear data in region '{Jan, Budget}' physical;Clears all Budget data for the month of Jan, using the physical method, from the AsoSamp.Sample database.
alter database AsoSamp.Sample clear data in region 'CrossJoin({Jan},{Forecast1, Forecast2})';Clears all January data for the Forecast1 and Forecast2 scenarios from the AsoSamp.Sample database.