21 OAAM Offline
OAAM supports OAAM online and OAAM offline. OAAM online can be used to perform real-time risk evaluations. OAAM offline can be used to perform risk evaluations on historical or non-real time login/transactional data.
This chapter provides information about setting up OAAM Offline for rule evaluation and fraud detection.
This chapter contains the following sections:
21.1 Concepts
This section provides a brief introduction to OAAM Offline and contains the following sections:
21.1.1 What is OAAM Offline?
OAAM Offline can be used for the following purposes:
-
Standalone security tool
OAAM Offline can be used to analyze transactions and logins. Users who do not have an OAAM production system could use an offline system as their primary risk analysis system.
-
Research and development tool
OAAM Offline can be used to create and verify new policies and rules using non real-time customer data without impacting customers in the real-time environment. Users are able to run complicated rules that would take too long to execute in a production system on a secondary system. They run simpler rules in OAAM and use OAAM Offline as the secondary system.
-
Supplemental offline analysis tool
OAAM Offline can be used in the tuning of rules and verification of rules behavior against customer and transaction data without impacting customers in real-time environment.
21.1.2 OAAM Offline Architecture
OAAM Offline is a standalone application.Unlike OAAM Online, OAAM Offline does not involve a client application. The relationship between the source data, the loaders, the Web server that hosts OAAM Offline, and the database that stores the customer login and transaction data is shown in Figure 21-1, "OAAM Offline Architecture".
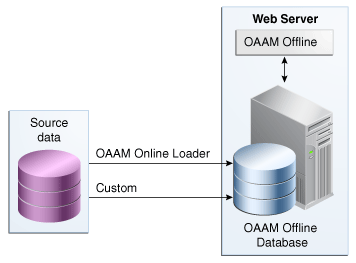
OAAM Offline has its own database. This database has an identical schema to that of the OAAM Online version. It is used to load customer data to perform risk analysis and tune rules. OAAM Offline can support both login and transaction data. For information on the types of loaders that are used to load data, refer to Section 21.1.7, "Data Loaders."
If you want to load the customer data (source data) into the Offline database, you will need to create a Load Job, and a data loader is required to load the data into the database.
21.1.3 Jobs
A job is a collection of tasks that can be run by OAAM. You can perform a variety of jobs such as load data, run risk evaluation, roll up monitor data, and so on. OAAM supports the following jobs:
| Jobs | Descriptions |
|---|---|
|
Load |
A Load Job reads records from a remote data source, converts the data into OAAM login sessions, and stores the login sessions in the OAAM offline datastore. |
|
Run |
A Run Job performs risk analysis on a set of OAAM sessions. When a Run starts execution, it performs a clean up for the records in the Job's data filter. This clean up involves deleting rule logs, alerts, and actions and resetting risk scores and authentication statuses. |
|
Load and Run |
A Load and Run Job is a combination of a Load Job and a Run Job. After each record is processed by the Load Job, the result is fed directly into the Run Job. |
|
Monitor Data Rollup |
A Monitor Data Rollup Job consolidates monitor data utilized in the dashboard and some risk evaluations on a regular basis. This job consolidates data to optimize the database when processed. |
Users can schedule jobs and run them offline. For information on jobs, refer to Chapter 22, "Scheduling and Processing Jobs in OAAM."
21.1.4 What is a Load Job and How Do You Set One Up
A Load Job reads records from a remote data source, converts the data into OAAM login sessions, and stores the login sessions in the OAAM offline datastore.
The process for creating a Load Job is as follows:
-
Specify the type of loader to use to load the data into the Offline database and the database connection details. If you are using the OAAM loader, the mapping details of the remote database to the OAAM schema is already provided, but you can edit these on the database-side if necessary.
-
Specify a data filter to define the set of records in the database to be loaded.
-
Set up the scheduling for when to run the Load Job.
A Load Job begins by connecting to the database defined in the Job's connection properties, and executes a SQL Query constructed from the Job's data mapping properties and filtered by the values in the Job's Data Filter. It then takes the results from that query and generates login records in the OAAM Offline database. As it generates the logins, it also runs the device identification checkpoint so that cookies are assigned. For information on creating a Load Job, refer to Section 22.4.1, "Creating Load Jobs," and for information on data loaders, refer to Section 21.1.7, "Data Loaders,"
21.1.5 What is a Run Job and How Do You Set One Up?
A Run Job performs risk analysis on a set of OAAM sessions.
The process for creating a Run Job is:
-
Define how and under what conditions the OAAM policies are applied to the sessions.
-
Set up the data filter to define the set of records in the database to be loaded or run.
-
Set up the scheduling for when to run the Run Job.
When a Run starts execution, it performs a clean up for the records in the Job's data filter. This clean up involves deleting rule logs, alerts, and actions and resetting risk scores and authentication statuses. The Run Job is executed based on the Run Type. For information on creating Run Jobs, refer to Section 22.4.2, "Creating Run Jobs,"
21.1.6 Load and Run Job
A Load and Run Job is a combination of a Load Job and a Run Job. After each record is processed by the Load Job, the result is fed directly into the Run Job.
21.1.7 Data Loaders
Loaders load the customer login or transaction data that will be processed for jobs.
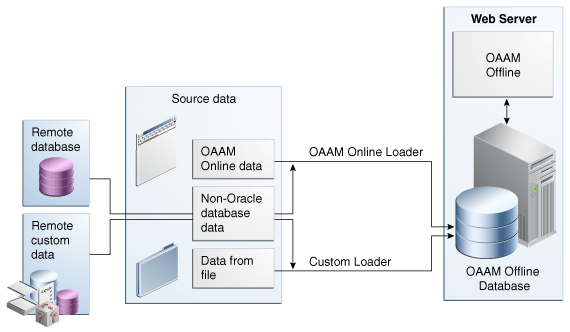
The standard OAAM Loader that is shipped with OAAM is used to load login data that can be easily mapped to the OAAM schema. The data can be from an OAAM schema database or a remote database.
A Custom data loader is required for complex mapping and for transactional use cases. Login and transaction data can be loaded from almost any source including files. For more information on developing a custom loader, refer to the "Developing a Custom Loader for OAAM Offline" chapter of the Oracle Fusion Middleware Developer's Guide for Oracle Adaptive Access Manager.
Table 21-2 summarizes the differences between the default and custom loaders.
Table 21-2 OAAM Loader vs. Custom Loader
| Loaders | Shipped With OAAM | Loads any data | Loads from any source | Complex data mapping | Use case |
|---|---|---|---|---|---|
|
OAAM Loader |
Yes. Default loader |
No Loads login data |
No Loads from an OAAM schema database or a remote database that is mapped to the OAAM schema |
No Data mapping must be simple and straight forward |
Use Case: Configure a Solution to Run Risk Evaluations Offline |
|
Custom Loader |
No. Custom development For information, refer to Developing a Custom Loader in the Oracle Fusion Middleware Developer's Guide for Oracle Adaptive Access Manager. |
Yes Loads login and transaction data |
Yes Loads from remote, custom source including files |
Yes Used if the data cannot be mapped easily and requires complex SQL queries or some manipulations |
Use Case: Load Transactional Data and Run Risk Evaluations from Multiple Sources |
21.1.8 Run Type
The Run type defines how and under what conditions the OAAM policies are applied to the sessions. A Run Job using the OAAM Run type reads the set of session records from the database. Pre-authentication checkpoints are run for all sessions in the set. Post-authentication checkpoints are run only for sessions where the user is successfully authenticated.
If you must change the checkpoints to run, refer to Section 21.9, "Changing the Checkpoints to Run." A Custom Run Job may perform other tasks or run checkpoints differently than our standard checkpoints.
21.1.9 OAAM Offline User Interface
The user interfaces of OAAM Online and Offline are identical except for the dashboard and job creation and job monitoring pages.
21.1.9.1 Dashboard Differences
The OAAM Offline Dashboard is similar to the OAAM Online Dashboard except for the details listed:
Uses Non Real-time Customer Data
The OAAM Offline Dashboard uses non real-time customer data from OAAM Online or from a remote, custom source instead of real-time data.
The OAAM Offline Dashboard provides access to the "Risk Analysis" dashboard, which shows the progress of the current load or run task.
21.1.9.2 Job Interface for Load, Run, and Load and Run
The Jobs search page enables you to search for jobs to display and view their details. The Job Creation wizard provides a step-by-step guide through the job definition and scheduling process for Load, Run, and Load and Run Jobs. These jobs are not available in OAAM Online.
21.1.9.3 Job Queue
The Job Queue page displays the job instance currently processing and progress in terms of estimated completion time and percentage complete progress. You can cancel or pause and resume a job instance processing from the queue interface. If a job is not set to process via scheduling it will not appear in the Job Queue.
21.2 Access Control
Access permissions for the offline environment is detailed in the following table.
Table 21-3 Offline Environment
| Role | Access |
|---|---|
|
CSR and CSR Managers |
No access |
|
Fraud investigators and Investigation Managers |
Same access as online including security dashboard |
|
System Administrators |
Same access as online (Environment node) and full access to scheduler node |
|
Security Administrator |
Same access as online except the Environment node and full access to scheduler node |
21.3 Installation and Configuration of OAAM Offline System
This section describes the steps to configure OAAM Offline.
21.3.1 Overview
Table 21-4 presents a summary of the tasks for configuring OAAM Offline. The table also provides information on where to find more details about each task.
Table 21-4 Tasks in OAAM Offline Setup
| Task | Description | Documentation |
|---|---|---|
|
Task 1 - Install OAAM offline |
OAAM offline installation is similar to the OAAM online installation. |
|
|
Task 2 - Create the offline database schema |
OAAM Offline has its own database. This offline database has an identical schema to that of the OAAM Online version. |
Refer to Section 21.3.3, "Create the Offline Database Schema." |
|
Task 3 - Configure database connectivity |
When you configure OAAM Offline with the Oracle Fusion Middleware Configuration Wizard, you will be able to set values for the Schema Owner, Schema Password, Database and Service, Host Name, and Port |
|
|
Task 4 - Log in to OAAM Offline |
Log in to OAAM Offline. |
|
|
Task 5 - Set up the environment |
After installing and configuring OAAM Offline, you must set up the base environment. |
21.3.2 Install OAAM Offline
Oracle Adaptive Access Manager (Offline) is included in the Oracle Identity and Access Management Suite. You can use the Oracle Identity and Access Management 11g Installer to install OAAM Offline.
21.3.3 Create the Offline Database Schema
You must create and load the OAAM offline schema before installing OAAM offline. For OAAM, Oracle recommends the Oracle Database Enterprise Edition for production deployments although the Standard Edition can be used as well. You create and load the schema using the Oracle Fusion Middleware Repository Creation Utility (RCU), which is available on the Oracle Technology Network (OTN) Website. You can access the OTN website at:
http://www.oracle.com/technetwork/index.html
Later, you will load customer login and/or transaction data into the OAAM Offline database, and OAAM Offline will use this database to perform risk analysis. The following sections provide best practices for the OAAM Offline database.
21.3.4 Configure Database Connectivity
When you configure OAAM Offline with the Oracle Fusion Middleware Configuration Wizard, you will be able to set values for Schema Owner, Schema Password, Database and Service, Host Name, and Port. You will also be able to test the connectivity.
21.3.5 Log In to OAAM Offline
To sign in to OAAM Offline, follow these steps:
-
In a browser window, enter the URL to the Oracle Adaptive Access Manager Offline 11g Sign In page.
http://host:port/oaam_offline/
where
-
hostrefers to the Oracle Adaptive Access Manager Offline managed server host -
portrefers to the OAAM Admin Offline managed server port -
/oaam_offline/refers to the OAAM Offline Admin Sign In page
-
-
In the Sign In page, enter your credentials.
-
Click the Sign In button.
21.3.6 Environment Set Up
After installing and configuring OAAM Offline, you must complete the following tasks to set up the base environment:
-
Set Up Encryption and Database Credentials for Oracle Adaptive Access Manager
-
Configure How Checkpoint Data Is Handled in Load and Run Jobs
21.3.6.1 Import the Snapshot
Import the snapshot that is used by both OAAM Online and Offline. The use of snapshots online and offline are identical. The Snapshot is a zip file that contains the default policies, rules, groups, and any other information that is needed to configure OAAM Offline. The OAAM snapshot file is located in the MW_HOME/IDM_ORACLE_HOME/oaam/init directory. Refer to Chapter 2, "Setting Up the OAAM Environment" for information on loading the snapshot.
21.3.6.2 Set Up Encryption and Database Credentials for Oracle Adaptive Access Manager
Encryption is used to protect data within Oracle Adaptive Access Manager from unauthorized access. The process uses methods and a key or keys to encode plain text into a non-readable form. A key is required to decrypt the encrypted information and make it readable again. Authorized persons who own the key can decrypt information that is encrypted with the same key. For instructions to set up encryption and database credentials for OAAM Offline, refer to Section 2.4, "Setting Up Encryption and Database Credentials,".
21.3.6.3 Enable Autolearning
To use Autolearning (pattern analysis):
-
Import default entities.
-
Import autolearning policies and rules if you are not using the default snapshot. These are required in order to perform the autolearning run on the data.
-
Enable Auto-learning properties
vcrypt.tracker.autolearning.enabled=true vcrypt.tracker.autolearning.use.auth.status.for.analysis=true vcrypt.tracker.autolearning.use.tran.status.for.analysis=true
For more information, refer to Section 15.6, "Before You Begin to Use Autolearning."
-
Define and enable patterns.
-
Perform load and the run at the same time.
Patterns are supported with Autolearning, but if you reload the same data, the evaluation does not occur and hence would not be useful in that case.
21.3.6.4 Enable Configurable Actions
If you want configurable actions enabled in your system, follow this process:
-
Enable the configurable action property.
Set
dynamicactions.enabledtotrue. -
Make sure the configurable action definitions are configured in the Oracle Adaptive Access Manager database.
A user can see the list of available configurable actions before adding a new one.
-
Determine what configurable actions must be added to which checkpoint and the preconditions for executing those configurable actions.
-
If the existing Configuration Actions are not sufficient, develop and deploy custom ones. See the Oracle Fusion Middleware Developer's Guide for Oracle Adaptive Access Manager for details on developing a configurable action.
Although some configurable actions are provided with the product, you may have to develop custom templates for your particular requirements.
-
Define the custom action template
-
Load the action template
-
-
Associate the configurable actions to the Checkpoint.
For information on enabling configurable actions, refer to Chapter 16, "Managing Configurable Actions."
21.3.6.5 Import IP Location Data
IP location data is used by the risk policies framework to determine the risk of fraud associated with a given IP address (location). To be able to determine location of the login or transaction, this data must be uploaded. For information, see Section 26.3, "Importing IP Location Data."
21.3.6.6 Configure How Checkpoint Data Is Handled in Load and Run Jobs
Performing a Load and Run job multiple times appends rule data to existing sessions, resulting in duplicate checkpoints for each time the job is performed. If you want old checkpoint data to be erased before checkpoint rules are run, ensure that bharosa.ra.loadrun.resetbeforerun has been set to true. If you do not want existing checkpoint data to be erased when performing Load and Run multiple times, set this property to false.
21.4 Scheduling Jobs
For information on scheduling jobs, refer to Chapter 22, "Scheduling and Processing Jobs in OAAM." The chapter describes how to define, schedule, and run Oracle Adaptive Access Manager batch jobs.
21.5 Testing Policies and Rules
OAAM policies/rules for a new deployment or an existing deployment can be tested using OAAM Offline.
21.5.1 New Deployment Using OAAM Offline
You can use a combination of OAAM Offline and BIP reports to test the effect of policies and rules on users. To do this:
-
Deploy an offline instance of OAAM to perform batch analysis
-
Configures the OAAM loader or develop your own to load a set of production data into the offline environment to use as the test set.
-
Run policies/rules against the test set of data multiple times to view the impact of policy changes.
For example, in a new deployment, you can load a month of your production data into OAAM and run the base policies to see how many alerts and actions would have been generated if OAAM had been used in production for one month. The BIP reports are useful to gather aggregate values for the rules and outcomes. In the results you will see that as OAAM learns the behaviors, users will generate fewer alerts and actions. If you add any new rules or edit any rule thresholds you can do another run and compare BIP report outcomes to those from the original run.
21.5.2 Existing Deployment Using OAAM Offline
If you have OAAM already in production, you can export a set of production data on which to test the effects of policy/rule changes.
-
Set up a scheduled data load to update the offline environment data every 24 hours
-
When the security team wants to add a new rule or edit a rule threshold they can first run 24 hours of data against the current policies in production and run BIP reports exported to XLS.
-
Then the team can make the edits and run a second time on the same data set and run the same BIP reports.
-
Comparing the reports from Run 1 and Run 2 will reflect how the user population was effected by the policy changes. In other words, if the first run generates 100 alerts and the second run generates 125 alerts, the effect of the edits is 25 additional alerts are generated.
You can also license third party tools for further testing options. For example, IntegratID (http://integratid.com/) has the ARM Automator tool which can be used to simulate very specific traffic scenarios on which to test.
For example, if you want to test if a velocity rule will trigger if a user logs in from Los Angeles at 10:24 am PST then logs in from New York City at 10:45 am PST using the same device.
21.6 What to Expect in OAAM Offline
Setting Up Patterns In Autolearning
In online systems, the administrator can set up patterns at any time and the pattern processing starts for the logins after that point. In offline systems, the administrator must set up the properties and the patterns prior to starting the Load Job, so that when the Load Job runs, the patterns processing occurs simultaneously. This is one of the key differences between online and offline systems.
You cannot perform the load and then the run if you want Auto-learning. Only "Load and Run" is supported for pattern processing. Choose Load and Run as the job type when you are creating jobs. A Load and Run Job is a combination of a Load Job and a Run Job. After each record is processed by the Load Job, the result is fed directly into the Run Job. After the Load and Run Job is submitted, you must navigate to the Job Queue and search for the job in order to view its status and other details.
Offline data come with timestamps. In autolearning, when buckets are created they are created with the timestamp of the login that resulted in its creation. On each subsequent update to the bucket count, OAAM updates the time stamp with the timestamp of the login (request) that caused that update. Autolearning based rules use the timestamp of the bucket to help calculate sum and percentage. For example, a user logged into the system on 12th Monday and 22nd Sunday this month. The buckets are populated properly, but the rules evaluation cannot identify the "update" timestamp and hence does not work.
21.7 Monitoring OAAM Offline
This section describes how to monitor OAAM Offline using the Dashboard and Server Logs.
21.7.1 Using Dashboard to Monitor the Loader Process
The OAAM Offline Dashboard uses non-real time customer data from OAAM Online or from a remote, custom source instead of real-time data to provide:
-
Views of the statistics on the rate of logins
-
An overview of activity
-
High-level personalized views of the status of user behavior and key transactions
The "Risk Analysis" dashboard shows the progress of the current load or run task. Risk Analysis statistics are provided for
-
load data: the data loaded from OAAM Online or from a remote, custom source
-
run data: the data that policies are run against. You can run the rules against the entire database or against a subset of the database
Information is shown for the percent complete, number of records processed, number of records remaining, and estimated complete time, and so on.
Use the following sections of the Dashboard to monitor the loader process:
-
The performance panel on the top gives the throughput in terms of logins per minute, transactions loaded per minute, and so on. A trending graph is shown of the different types of data based on performance so that loader trends can be monitored.
-
The dashboard on the bottom presents historical data. Select Performance from the Dashboard list. Performance can be monitored in terms of average response time of APIs, Rules, and so on. Trend graph are available for the selection.
Offline Job data is based on when records were processed, not timestamp.
21.7.2 Enable Rule Logging
For rules logs to be processed, the value of vcrypt.tracker.rules.trace.policySet.min.ms must be -1.
Rule logging for detailed information can be turned on by setting:
vcrypt.tracker.rules.trace.policySet=true vcrypt.tracker.rules.trace.policySet.min.ms=-1
21.7.3 Database Query Logs for Performance Monitoring
Make sure you have the following properties set:
bharosa.db.query.performance.warning.print.stack=false bharosa.db.query.performance.warning.threshold.ms=200
The server writes SQLs that took more than 200ms to execute to log file. Random SQLs in logs are fine, considering the load being handled.
21.7.4 Oracle Adaptive Access Manager Server Logs
For every 1000 requests processed, the loader process prints the time taken to process those 1000 requests. These logs provide a good indication of throughput.
21.7.5 Database Tuning
You can monitor and tune the performance of the database using tools like Oracle Enterprise Manager Fusion Middleware Control.
21.7.6 Manageability
Offline uses Oracle Dynamic Monitoring Service (DMS) for performance monitoring. Information about monitoring performance is in Chapter 23, "Monitoring OAAM Administrative Functions and Performance."
21.8 Loading from Non-Oracle or Non-Microsoft Server SQL Server Database
The OAAM Loader type is configured to be able to load from an Oracle or Microsoft SQL Server database. If you are not using an Oracle or Microsoft Server SQL Server Database, perform the steps in Section 21.8.1, "Specifying Offline Loader Database Platforms for Non-Oracle or Non-Microsoft Server SQL Server Databases" and Section 21.8.2, "Creating a View of a Non-OAAM Database". If you are using a Microsoft Server SQL Server database, perform the steps in Section 21.8.2, "Creating a View of a Non-OAAM Database."
21.8.1 Specifying Offline Loader Database Platforms for Non-Oracle or Non-Microsoft Server SQL Server Databases
If you want to load from a different type of database, there are two steps that must be followed. You must deploy the jar file containing the JDBC driver for the database, and create properties of the following form using the Properties Editor and changing the bold bracketed values:
oaam.offline.loader.databaseplatform.enum.[identifier]=[number > 10] oaam.offline.loader.databaseplatform.enum.[identifier].name=[Human Readable Name] oaam.offline.loader.databaseplatform.enum.[identifier].driver=[Driver Class Name]
Note:
If you add multiple database types, that [number > 10] must be unique for each one.For example, to set up for IBM DB2, you would set the following properties:
oaam.offline.loader.databaseplatform.enum.db2=11 oaam.offline.loader.databaseplatform.enum.db2.name=IBM DB2 oaam.offline.loader.databaseplatform.enum.db2.driver=COM.app.db2.jdbc.app.DB2Driver
21.8.2 Creating a View of a Non-OAAM Database
Users who want to load from a non-OAAM database will need to create a view in their remote data source. This section explains how to set up the required database view in the remote database.
21.8.2.1 The OAAM_LOAD_DATA_VIEW
The standard OAAM Loader for OAAM Offline requires a table or view with a specific name and structure to exist in the remote data source. By default the view already exists in the OAAM schema, but if you want to load from a non-OAAM schema, then you are required to create a view in the remote data source that conforms to the specification of an OAAM load data view. The structure is given in the following table.
Table 21-5 OAAM_LOAD_DATA_VIEW
| Field Name | Data Type | Description |
|---|---|---|
|
LOGIN_TIMESTAMP |
Date/Time |
The login time. |
|
SESSION_ID |
Character |
Uniquely identifies a login record. |
|
USER_ID |
Character |
The user's User ID. |
|
LOGIN_ID |
Character |
The user's Login ID. This may be the same as the USER_ID if the load data source does not distinguish between User ID and Login ID. |
|
DEVICE_ID |
Character |
Identifies the user's device. |
|
GROUP_ID |
Character |
The application ID. |
|
IP_ADDRESS |
Integer |
The IP address, in the form of a long integer. |
|
AUTH_STATUS |
Integer |
The auth status. If loading from a non-OAAM schema, this field should be a decode function that converts the remote data source's authentication status into an OAAM authentication status, defined by the user defined enum auth.status.enum. If the remote schema has no concept of auth status, then this value should be -1. |
|
CLIENT_TYPE |
Integer |
The client type. When loading from a non-OAAM schema, this should be -1. |
|
USER_AGENT |
Character |
The user agent string from the browser. |
|
FLASH_FINGERPRINT |
Character |
This field represents the digital fingerprint. It may be null if not supported by the load data source. |
|
DIGITAL_COOKIE |
Character |
This field represents the digital cookie set by OAAM. When loading from a non-OAAM schema, this should be null. |
|
EXP_DIGITAL_COOKIE |
Character |
This field represents the expected digital cookie set by OAAM. When loading from a non-OAAM schema, this should be null. |
|
SECURE_COOKIE |
Character |
This field represents the secure cookie set by OAAM. When loading from a non-OAAM schema, this should be null. |
|
EXP_SECURE_COOKIE |
Character |
This field represents the expected secure cookie set by OAAM. When loading from a non-OAAM schema, this should be null. |
21.8.2.2 Schema Examples
The OAAM Schema and custom schema are shown below.
21.8.2.2.1 OAAM Schema
The following example shows the SQL for the OAAM_LOAD_DATA_VIEW that ships with OAAM.
CREATE OR REPLACE FORCE VIEW OAAM_LOAD_DATA_VIEW (
LOGIN_TIMESTAMP, SESSION_ID, USER_ID, LOGIN_ID, DEVICE_ID, GROUP_ID,
IP_ADDRESS, AUTH_STATUS, CLIENT_TYPE, USER_AGENT, FLASH_FINGERPRINT,
DIGITAL_COOKIE, EXP_DIGITAL_COOKIE, SECURE_COOKIE, EXP_SECURE_COOKIE) AS
SELECT l.create_time LOGIN_TIMESTAMP, l.request_id SESSION_ID, l.user_id USER_ID,
l.user_login_id LOGIN_ID, l.node_id DEVICE_ID, l.user_group_id GROUP_ID,
l.remote_ip_addr IP_ADDRESS, l.auth_status AUTH_STATUS, l.auth_client_type_code
CLIENT_TYPE,
(SELECT t1.data_value FROM v_fprints t1 WHERE t1.fprint_id=l.fprint_id) USER_AGENT,
(SELECT t2.data_value FROM v_fprints t2 WHERE t2.fprint_id=l.digital_fp_id)
FLASH_FINGERPRINT,
l.sent_dig_sig_cookie DIGITAL_COOKIE, l.expected_dig_sig_cookie EXP_DIGITAL_COOKIE,
l.sent_secure_cookie SECURE_COOKIE, l.expected_secure_cookie EXP_SECURE_COOKIE
FROM vcrypt_tracker_usernode_logs l;
For discussion purposes, consider this statement in two parts.
The first part starts at the beginning and ends before the Select. This part is required and cannot be modified.
The second part starts with the Select and continues to the end of the statement. If loading from a non-OAAM schema, this part would be customized to select data from that schema.
21.8.2.2.2 Custom Schema Example
In this example, you would want to load from a table that looks like the following. You would want to have "Banking" as your Application ID, and you would not want to load test data.
LOGINS
| Field Name | Data Type | Description |
|---|---|---|
|
LOGIN_TIME |
Date/Time |
The login time. |
|
LOGIN_ID |
Integer |
Primary Key |
|
USER_NAME |
Character |
The user's Login ID. |
|
DEVICE_ID |
Character |
Identifies the user's device. |
|
IP_ADDRESS |
Character |
The IP address, in dot notation. |
|
AUTH_STATUS |
Character |
'S' = Success, 'I' = Invalid User, 'F' = Wrong Password. |
|
USER_AGENT |
Character |
The user agent string from the browser. |
|
IS_TEST |
Integer |
0 = Real Data, 1 = Test data |
In this case, a decode statement is needed to convert the custom authentication status to an OAAM authentication status, and the IP address needs to be parsed to convert it into a long integer. A view must be created that looks like the following.
CREATE OR REPLACE FORCE VIEW OAAM_LOAD_DATA_VIEW (
LOGIN_TIMESTAMP, SESSION_ID, USER_ID, LOGIN_ID, DEVICE_ID, GROUP_ID,
IP_ADDRESS, AUTH_STATUS, CLIENT_TYPE, USER_AGENT, FLASH_FINGERPRINT,
DIGITAL_COOKIE, EXP_DIGITAL_COOKIE, SECURE_COOKIE, EXP_SECURE_COOKIE) AS
SELECT l.login_time LOGIN_TIMESTAMP, cast(l.login_id AS varchar2(256)) SESSION_ID,
l.user_name USER_ID, l.user_name, LOGIN_ID, l.device_id DEVICE_ID,
'Banking' GROUP_ID,
to_number(substr(l.ip_address, 1, instr(l.ip_address, '.')-1))*16777216
to_number(substr(l.ip_address, instr(l.ip_address, '.', 1, 1)+1,
instr(l.ip_address, '.', 1, 2)-instr(l.ip_address, '.', 1, 1)-1))*65536
to_number(substr(l.ip_address, instr(l.ip_address, '.', 1, 2)+1,
instr(l.ip_address, '.', 1, 3)-instr(l.ip_address, '.', 1, 2)-1))*256
to_number(substr(l.ip_address, instr(l.ip_address, '.', 1, 3)+1)) IP_ADDRESS,
decode(l.auth_status, 'S', 0,
'I', 1,
'F', 2,
-1) AUTH_STATUS,
-1 CLIENT_TYPE, l.user_agent USER_AGENT, null FLASH_FINGERPRINT,
null DIGITAL_COOKIE, null EXP_DIGITAL_COOKIE, null SECURE_COOKIE,
null EXP_SECURE_COOKIE
FROM logins l
WHERE l.is_test = 0
Here, you map your user_name to USER_ID and LOGIN_ID, you map a literal string "Banking" to GROUP_ID, you parse your ip_address string and convert it to a long integer, you use a decode statement to convert your auth_status, you map -1 to CLIENT_TYPE, and you map literal null to FLASH_FINGERPRINT, DIGITAL_COOKIE, EXP_DIGITAL_COOKIE, SECURE_COOKIE, and EXP_SECURE_COOKIE.
21.9 Changing the Checkpoints to Run
A Run Job using the OAAM Load type reads the session records from the database, applies policies for the Pre-Authentication and Post-Authentication checkpoints. Pre-authentication checkpoints are run for all sessions if the PreAuth property is set to true. By default it is set to true. Post-authentication checkpoints are run only for sessions where the user is successfully authenticated and the PostAuth property is set to true.
If you have customized checkpoints and policies in addition to or instead of our standard checkpoints and policies and you would like to change whether checkpoints run or not, you will have to create or edit the following properties using the Properties Editor:
profile.type.enum.[checkpoint-key].isPreAuth or profile.type.enum.[checkpoint-key].isPostAuth
Setting the isPreAuth or isPostAuth property to true or false for a given checkpoint changes which checkpoint to run. The Pre-Authentication checkpoints are run first and then Post-Authentication checkpoints are run second. The sequence of the checkpoints cannot be changed since checkpoints have a numerical order and they are run in that order.
21.10 Migration
Migration of custom loaders from 10g is not supported.
21.11 Use Cases
This section present common use cases for OAAM Offline and running jobs.
21.11.1 Use Case: Upgrading a Deployment with Multiple Scheduled Jobs
Chuck is an administrator who is expected to upgrade a 10g deployment with multiple scheduled jobs to 11.1.2 offline without any interruption in the schedule.
Requires: upgrade assistant
Solution: Chuck runs the upgrade assistant to upgrade the 10g offline to 11.1.2 and the scheduled jobs are migrated to the new environment.
21.11.2 Use Case: Configure a Solution to Run Risk Evaluations Offline
George is a security and compliance officer. He has been asked to configure a solution to run risk evaluations offline that are deemed too expensive to run in real-time. Part of the purpose of this process is to use configurable actions to provision users, devices, IPs, and other data such as locale into/out of groups to profile their behaviors.
Requires: Login Loader, Load/Run, Configuration Actions, and BIP
Solution: George exports the configured groups and imports them into the production database for use in real-time risk analysis. He uses the OAAM Loader that is already configured to pull data into the offline database and map it correctly. He also uses the standard run task to perform the entire login chain of checkpoints on every session in the selection.
Procedure: In the OAAM Administration Console George defines the source of the data as the OAAM production database and how much data to load (1 month) and run by specifying a date range. He can choose to load a selection and run checkpoints on only a sub-selection of that data if he wants. Lastly he either configures a single date/time to load and run or a reoccurring load and run or simply clicks Start to start the load and run now. (He can configure a configurable action to add users who were blocked into the "blacklisted group")
After the load and run are complete, George generates a few BI Publisher aggregate reports showing metrics for the total numbers of each action, alert, risk scores by checkpoint and total members added/removed from each profiling group.
Outline of the general tasks and questions/issues a user faces in this flow
-
Configure data source.
-
Map data into useful structure - login (OOTB).
-
Selection of data to load - all or a specific selection.
-
Run checkpoints also.
-
Load now or start at a set time.
-
Scheduling when the load happens or recurring.
-
View the results in a useful format to understand the insights found by the risk evaluations and profiling performed.
21.11.3 Use Case: Run Login Analysis on the Same Data Multiple Times (Reset Data)
George is a security and compliance officer. He has been asked to configure a solution to test new/edited risk evaluations offline before they are deployed to run in production.
Requires: OAAM Loader, Universal Risk Snapshot, and Security Policies
Solution: He uses the OAAM Loader that is already configured to pull data into the offline database and map it correctly. He also uses the standard run task to perform the entire login chain of checkpoints on every session in the selection.
Procedure: In the OAAM Administration Console George defines the source of the data as the OAAM production database and how much data to load and run by specifying a date range. He can choose to load a selection and run checkpoints on only a sub-selection of that data if he wants. He selects data for the last month. George then exports a snapshot from the production OAAM Admin and restores it into OAAM offline testing environment. He configures a load and run for all the data. He gives a base name for the run "Production state 08/11/2010." When the first instance of the run occurs it is automatically given a name using the base name appended with the start data/time "Production state 08/11/2010_18:01.80112010". Once the run is complete his team makes edits and additions to the security policies they had designed. George starts another run that is automatically named "Production state 08/11/2010_23:12.80112010" on all the data. This second run will ignore any data created in the first run so the results will not be skewed. Actions alerts and scores generated by the first run will not affect the results of the second run or any other run. Once the second run is complete he generates a report showing aggregate outcome values for the two runs so they can be compared side by side. George is satisfied with the results so he backs up a snapshot and restores it into the production environment.
General tasks and questions/issues a user faces in this flow
-
Configure data source.
-
Map data into useful structure - login (OOTB).
-
Selection of data to load - all or a specific selection.
-
Run checkpoints also.
-
Load now or start at a set time.
-
Scheduling when the load happens or reoccurring.
-
View the results in a useful format to understand the insights found by the risk evaluations and profiling performed.
21.11.4 Use Case: Monitor Data Rollup
Gram is an IT Administrator who must make sure the monitor data used in the dashboard is kept optimized. He must configure a consolidation of the data to automatically run three times a week from now on.
Solution: Gram will use the Monitor Data Rollup task that is already available to consolidate the Monitor data three times a week. He will configure the database connection properties to map to the OAAM Production database correctly.
Procedure: In the OAAM Administration Console (online) Gram defines the source of the data as the OAAM production database and how much data to consolidate by specifying a date range. He configures the monitor data rollup with the proper rollup unit and cutoff date. He then schedules to run the job for 3 times a week.
21.11.5 Use Case: Consolidation of the Dashboard Monitor Data
Gram is an IT Administrator who must make sure the monitor data used in the dashboard is kept optimized on a daily basis. He must configure a consolidation of the data to automatically run daily from now on.
Solution: Gram will use the Monitor Data Rollup task that is already available to consolidate the monitor data daily. He will configure the database connection properties to map to the OAAM Production database correctly.
Procedure: In the OAAM Administration Console (online) Gram defines the source of the data as the OAAM production database and how much data to consolidate by specifying a date range. He configures the monitor data rollup with the rollup unit as daily and cutoff time to 1. He then schedules to run the job for 3 times a week. When he views the historical dashboard, he realizes that some of the hourly granularity in the hourly trending view in the bottom part dashboard is lost which is expected.
21.11.6 Use Case: Load Transactional Data and Run Risk Evaluations from Multiple Sources
George is a security and compliance officer. He has been asked to configure a solution to monitor employee usage of their gas cards to identify any employees that may be abusing the resource.
Solution: George wants to run risk evaluations against the motor pool vehicle type data, employee details on type of vehicles used and gas card transaction records. This data comes from three different sources and is available in CSV format. George worked with his team and a contractor to develop a custom data loader that meets his requirements.
This loader maps the incoming data to the OAAM schema utilizing entities and transactions he previously defined in the OAAM Administration Console. His team also developed a custom run task to evaluate using two transaction checkpoints. They developed the run task so administrators can select which of the two checkpoints they want to run.
Procedure: In the OAAM Administration Console George defines how much data to load and run by specifying a date range. He can choose to load a selection and run rules on only a sub-selection of that data if he wants. Once George determines what data to run risk evaluations on he selects what checkpoints to run. He can select one or more to run at a time. Lastly he either configures a single date/time to load and run or a reoccurring load and run or simply clicks start to kick off the load and run now.
After the run and load and run is complete George's team runs both an aggregate and listing reports they developed. One displays total numbers of each alert per month but also trending of each alert by day of the month so they can see any spikes. The other shows the employees that triggered alerts, each with a list of the alerts they triggered and when.
Outline of General Tasks: Below is an outline of the general tasks and questions/issues a user faces in this flow.
-
Configure data sources
-
Map data into OAAM schema - Transaction (Custom)
-
Selection of data to load - all or a specific selection?
-
Run rules also?
-
What checkpoints do I want to run?
-
Load now or start at a set time?
-
Scheduling when the load happens or reoccurring
-
Reporting to view results in a useful form for the business users.
21.11.7 Use Case: Using OAAM Offline (Standard Loading)
The user flow for OAAM Offline usage is shown below.
-
Install the offline system.
-
Load data.
-
Run rules against the data.
Checkpoint evaluation follows the same order as online.
In post -authentication, for rules with challenge actions, the authentication status will be set to pending.
Alerts will be generated for suspicious activities.
-
Examine dashboard and reports.
-
Discover hacking attempts.
-
Create new rules and policies to trap the attacks.
-
Run the old data through the new rules and policies.
-
Reexamine reports to see if the new rules helped.
-
Test the rules in pre-production.
-
Implement new rules and policies on Oracle Adaptive Access Manager production system.
21.12 Best Practices
This section outlines some best practices for administrators using OAAM Offline.
21.12.1 Configuring Worker/Writer Threads
While creating the loader configuration, start with 10 worker threads and watch the throughput (number of requests processed per minute) using the Dashboard.
If the throughput is not satisfactory, increase writer threads in increments of 5. Higher number of writer threads does not necessarily result in better throughput. Adjust the number of worker threads for max throughput for the given hardware.
21.12.2 Database Server with Good I/O Capability
Make sure the host that runs the database server has good I/O capability. Offline processing is I/O intensive.
21.12.3 Database Indexes
Make sure to obtain and apply the latest Oracle Adaptive Access Manager database patch to ensure that the proper indexes are present.
21.12.4 Setting Memory Buffer Size
Load/ Run pauses only after buffer is flushed. When there is need for pause/resume, keep the throttle size lower. The default is 100.
21.12.5 Quality of Input Data
If data is to be loaded into a database, make sure the data is valid as per mappings. Source data validation (basic sanity checks) is easier to perform before starting the load. It will save loading cycles and the incorrect processing of information.
Validations are:
-
Check for null or empty required fields (like user name)
-
Ensure that there are not too many log ins/transactions from the same user, and incorrect delimiter or escaping resulted in user id "0" being logged in more than 30% time. These kinds of errors will not necessarily result in an error, but they will slow loading process and process the data incorrectly.
-
Check that the combination of fields expected to be unique and the data are unique.
-
Make sure the source data does not have duplicate records/content. Duplicate records will skew the results and might raise false alerts.
-
Make sure the field that identifies the request (Request Identifier) is unique.
-
To avoid data truncation, make sure source data is not truncated while loading into database if the source data is loaded into database before it is fed to Oracle Adaptive Access Manager.
21.12.6 Configuring Device Data
If the source data does not have secure cookies and/or digital cookies, send constant secure cookies and/or digital cookies and turn off rotating cookies in Oracle Adaptive Access Manager.
21.12.7 Availability
Failover is not instantaneous. The system uses a leasing mechanism to tell whether the Job is still alive, and fails over when the lease expires, which may take as much as 10 minutes.
21.12.8 OAAM Loader vs. File-based and Custom Loaders
The OAAM Loader is preferred over the file-based and custom loaders since the OAAM Loader is optimized. It provides better control and is easier to use and faster:
-
For pausing and resuming
-
For working with partial data set
Instead of using a file-based/custom loader, you may want to consider loading file or storing data in a temporary database using standard tools and then using the temporary database to load data into the database.
21.12.9 Custom Loader Usage
Custom Loaders can be used for the following
-
If the data cannot be mapped easily and requires complex SQL queries or some manipulations
-
Requires custom Java code to map data
-
Requires loading Transaction data
-
Requires loading login and transaction data
For guidelines for developing a custom loader, refer to "Developing a Custom Loader" in the Oracle Fusion Middleware Developer's Guide for Oracle Adaptive Access Manager.