11g リリース1(11.1.4)
B69964-01
目次
|
Oracle Fusion Applicationsセールス・ガイド 11g リリース1(11.1.4) B69964-01 |
目次 |
前へ | 次へ |
この章の内容は次のとおりです。
予測モデルは、販売データを分析して、購入パターンおよび販売の受注/失注率を評価します。このモデルを使用すると、特定のターゲット製品に対する購入可能性が高い顧客プロファイルを識別できます。モデル結果を評価した後は、収集された見識を参考にするユーザーに引合の推奨を伝えるために、引合の生成をスケジュールできます。各引合の推奨には、受注可能性に加え、類似する顧客に対する同一製品の過去の類似したディールからの予測収益や営業サイクル期間の平均が含まれます。
Oracle Fusion Sales Predictor Engineを使用すると、営業パターンを理解でき、将来の営業行動に対する方向性が提供されます。販売予測因子はOracleテクノロジを活用し、購入可能性、見積収益および見積営業サイクルに基づいてインテリジェントな製品推奨および営業引合を生成します。
販売予測因子では、営業パターンの予測により、次のビジネス・ソリューションが提供されます。
ホワイトスペース分析: 顧客に製品推奨のリストを提供します。ホワイトスペースという用語は、顧客が所有する製品セットにおけるギャップを示します。分析は、営業担当がギャップを識別し、そのギャップを埋めるのに役立ちます。
類似した商談分析: 各商談の収益明細に類似する商談およびホワイトスペース分析と類似する予測のリストを提供します。この分析は、成功した営業を複製するためにFusionの商談管理で使用されます。
販売予測因子は、次のOracleテクノロジを使用して営業パターンを予測します。
Oracle Real-Time Decisions(RTD)
Oracle Data Mining(ODM)
Oracle Business Rules(OBR)
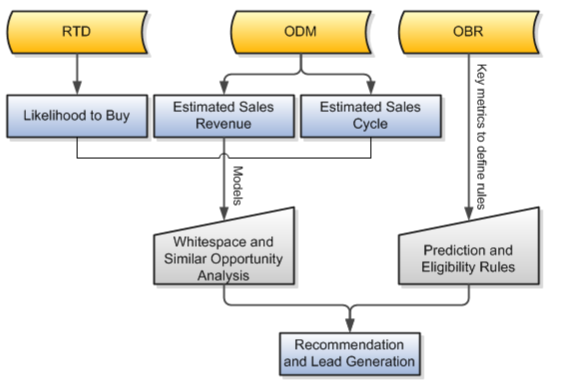
Oracle RTDプラットフォームはルールと予測分析の両方を組み合せたOracle BIテクノロジで、リアルタイム企業意思決定管理に対するソリューションを提供します。高性能なトランザクション・サーバーが、ビジネス・プロセス内で決定を自動的にレンダリングして見識を示し、プロセスのデータ・フローから処理可能なインテリジェンスを作成します。販売予測因子はRTDからの入力を使用し、RTDの相関分析を通じて、有望な商談に関する営業担当の洞察を補います。この分析は、特定の顧客が製品を購入する可能性を予測します。
Oracle Data Miningは、Oracle Databaseのカーネルに埋め込まれているOracle Databaseテクノロジで、分析モデルの作成に使用されるデータ・マイニング・アルゴリズムと統計関数の包括的なライブラリを備えています。販売予測因子はODMのクラスタリング・アルゴリズムを活用して、セグメントを作成します。これらのセグメントは、見積収益や見積営業期間など、予測を数値化するのに使用されます。これらの予測は、類似した商談見識を得るために商談管理で使用されたり、RTDホワイトスペース分析で使用されます。
OBRは、ルールの定義に使用されるキー・メトリックを活用するFusion Middlewareの一部です。ルールを実行するランタイム・エンジンと、パフォーマンスに影響を与えずにルールを大量に処理できるビジネス・ルール・オーサリング環境を提供します。OBRエディタには、コーディング知識がないかそれに近い場合も単純なルールから複雑なルールまで記述できるように、タブ形式のメニュー駆動型アプローチが用意されています。OBRエディタを使用すると、予測および適格性のルールを記述して営業推奨を生成できます。
予測モデルを生成して分析した後、または予測および適格性のルールを記述した後は、サンプル販売アカウントに対して製品推奨をシミュレートできます。予測が正しく、要件に適合していると考えられる場合は、推奨から営業引合を生成するプロセスをスケジュールします。
販売予測因子の出力は、営業商談に対する新規引合を作成するために顧客センターおよび商談管理でレビューされます。
特定のアカウントに最良の製品を販売する品質の高い引合を営業担当に提供する1つの方法は、ターゲット製品に対してターゲット顧客セグメントを識別するルールを使用することです。過去の営業履歴が皆無かそれに近い新製品、需要不足のため販促する必要がある製品、マーケティング・イニシアチブに沿うために奨励する必要がある製品などは、独自に予測ルールを記述する必要がある状況に該当します。
多くの会社には、製品のターゲットとして該当する最良の顧客について、市場および業界に関する深い見識を持つ製品のエキスパートがいます。これらのエキスパートは、データ・マイニング・モデルが提供する情報を使用して、知識を検証し、相関パターンを抽出します。その後、製品の推奨および予測を制御する独自の予測ルールを記述します。
予測ルールを作成すると、選択した各ターゲット製品に対して、一連のビジネス・インテリジェンスで生成された見積購入可能性、収益および営業サイクルのメトリックが自動的に作成されます(製品の過去の販売データがある場合)。ビジネス・インテリジェンス・メトリックは、モデル予測とは異なる事前定義の算式に基づいて計算されます。製品のエキスパートは、提供されたメトリックを予測ルールに使用する値の決定に役立つガイドとして使用します。ユーザー定義の製品推奨および関連する予測とともに、指定のルール条件を満たすターゲット顧客に対して引合が生成されます。
ルール管理には、ルールをより効率的に作成して管理する方法が用意されています。ルールは、キャンペーンや販売リージョンなどのビジネス要件に照らして作成できます。たとえば、「北米」という営業キャンペーンのフォルダを作成し、北米リージョンのキャンペーンに関連するすべてのルールを論理的にグループ化できます。
Fusionのルール管理は、予測ルールと適格性ルールのどちらも同じ方法で機能します。
予測ルール: 予測ルールを作成し、ターゲット製品に対するターゲット顧客セグメントを識別して引合推奨を生成できます。予測ルール・ベースの推奨は、マーケット・インテリジェンス、ビジネス・インテリジェンスおよび質的データを活用します。
適格性ルール: 適格性のルールまたは条件を作成し、顧客が製品に適格であるために満たす必要がある条件を定義できます。適格性ルールは、予測モデルとルール・ベースの推奨の両方に適用されます。
ルール・フォルダを使用すると、複数のルールおよびルール・セットを論理的にグループ化して管理できます。ルール・フォルダは、適格性または予測のいずれか1つのルール・タイプのみのルールおよびルール・セットで構成されます。ルール・フォルダを使用して、キャンペーン、四季の行事、販売リージョン、またはルールを作成しているコンテキストに関連する論理的なグループでルールを管理できます。
検索結果の表示は、ルール・フォルダまたはルールのいずれかのビューを選択することで表示対象を選択できます。ルール・フォルダ・ビューはデフォルトのビューで、存在するすべてのルール・フォルダが検索結果に表示されます。予測ルールと適格性ルールの全体で、製品に影響するすべてのルールまたはルール・フォルダを表示できます。
フォルダに格納されているすべてのルールを表示するには、ルール・ビューでフォルダ名を使用して検索します。また、ルール・ビューでは、予測ルールと適格性ルールの両方のタイプについて、検索基準を満たすルールを表示して比較できます。たとえば、特定の製品の条件を指定するルールをすべて表示できます。
予測モデルまたはビジネス予測ルールのいずれか(または両方)に基づいて予測を活用し、会社のマーケティング機能に対して営業引合を生成できます。製品推奨のシミュレートでも、モデルまたは予測ルールを使用できます。
予測モデルは、既存の製品ラインについて、顧客と購入パターン間の強い相関を示す十分な履歴商談の収益データが蓄積され、有用な統計分析が得られる場合に使用します。予測モデルは、製品のターゲット顧客を検出し、顧客ごとに見積収益および営業サイクルを予測します。
次の場合は、予測ルールを使用します。
新しい製品オファリングの場合
履歴データが皆無かそれに近い場合
使用可能な履歴データはあるが、営業およびマーケティングの見識による将来のトレンドが規範的でない場合
市場のトレンドに連続性がないため、過去が将来の目安にならない場合(たとえば、経済的、社会的または政治的な変化)
アナリストは、営業目的をサポートする予測ルールを作成します。Oracle Fusion Transactional Business Intelligenceは、使用可能な履歴データを分析し、ターゲットの製品または製品グループについて、次のメトリックを提供します。
購入可能性
営業サイクル
収益
予測ルールは、予測モデルの分析を活用して定式化できます。指定の製品についてデータが不十分な場合、アナリストは、対応する類似製品に対して実行された分析に基づいて、類似した製品についてターゲットとする顧客を識別できます。この分析から得られる見識により、アナリストと製品エキスパートの営業環境に対する知識が強化されます。予測モデルの評価は、予測ルール定式化および営業ユーザーに使用可能にする販売予測メトリック値の基礎として機能します。
販売カタログには多数の製品がありますが、一般に、そのうちの20%の製品が収益の80%をもたらします。
推奨対象に選択される製品のみについて、モデル情報学習を実行したり、予測ルールまたは推奨適格条件を記述できます。推奨対象として選択された製品のみについて引合を生成することもできます。
製品の選択は、ビジネス目的に基づく必要があります。たとえば、実績が低い製品の販売を増やしたり、在庫削減目標を達成する必要がある場合は、独自の製品選択を使用して、その目的を達成するための引合を生成できます。推奨に適した一連の製品を選択した後、特に新製品の場合や有用な相関統計を生成するための販売履歴データが不十分な場合は、営業目的に対応する予測ルールを作成できます。
選択した製品または製品グループは、ビジネス・ニーズや市場状況の変化に応じて変更できます。現在、需要が高い製品が12か月以内には購入者がいなくなる可能性もあるため、推奨製品セットの製品は柔軟に更新できます。
販売予測因子では、推奨可能な一連の製品を製品階層のあらゆるレベルで管理し、目的のレベルで推奨を予測できます。
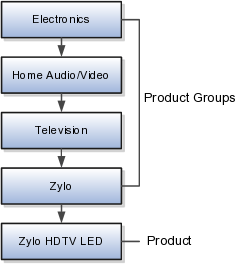
たとえば、前述の階層で、「Zylo HDTV LED television」という製品を選択する場合は、特定の製品を選択するか、製品階層の製品グループ(「Television」や「Home Audio/Video」など)を選択できます。販売予測因子では、推奨を生成し、その決定を適用するレベルを決定できます。
顧客セグメントで特定の製品を販売しないようにするルールも設定できます。適格条件の管理により、モデルで導出される推奨がこれらのルールを偶発的に違反しないようにできます。たとえば、UKでは220ボルトのテレビのみが作動するため、UKの顧客には110ボルトのテレビを販売しないようにする適格性ルールを設定できます。予測ルールを介した営業目的の達成と適格条件を介した営業ポリシーへの準拠は、推奨対象として選択する製品を判断する上で役立ちます。
レポートおよび図を使用して、予測モデルで検出された予測および相関を分析します。次のシナリオでは、これらのレポートを使用する場合の例を示します。
最近、750VR Serversと仕様が似ているGreen Serversという新型をリリースしました。Green Serversに対する予測ルールを定式化して引合を生成するために、750VRのレポートから見識を使用します。購入可能性モデル・レポートで750VR Serversを検索し、製品名をクリックして、このサーバーのモデル詳細を表示します。
「上位予測因子」タブには、検出された予測モデルが製品の販売に貢献する誘引となった属性が表示されます。「産業」は重要性が高いプロファイル属性であり、産業のレポートには、医療、ハイテクおよび金融サービス産業の顧客がこのサーバーを購入する可能性の高いことが示されています。750VR Serversは、反面、石油&ガス、小売および自動車産業にはあまり販売されていません。「国」属性では、ブラジル、フランスおよび米国の顧客がこのサーバーを購入する可能性が高いことがわかります。反面、750VR Serversはオーストラリアとエクアドルではあまり販売されていません。
「最良プロファイル」タブには、750VR Serversを購買する理想的な候補で構成されるすべてのパラメータの組合せが示されます。
この例では、予測モデルと予測ルールの両方を使用して営業引合を生成する方法を示します。
北米の販売実績のレビュー、分析および測定を担当する営業アナリストであるとします。新しい四半期の販売プランでは、複数のサーバーについて積極的に奨励することが強調されているため、可能なかぎり早く引合を提供する必要があります。過去の営業商談収益データを使用して予測モデル情報学習を実施し、モデルを使用して過去2四半期の営業引合を生成しました。現四半期に積極的に奨励する必要があるサーバーは、次のとおりです。
8000RT Servers
900VR Servers
550 VR Servers
DG 150 Green Servers(新製品)
予測モデルと予測ルールの両方を使用して引合を生成します。
モデル・レポートをレビューして、パターンが現在の市場状況に適切かどうかを確認します。
モデル結果がビジネス・ニーズをサポートしない製品に対して予測ルールを作成します。
モデルから、または予測ルールから製品推奨をシミュレートし、適切な引合が生成されるかどうかを判断します。
適切な場合は、引合を生成します。
DG 150 Green Serversという新製品には営業履歴がほとんどなく、このサーバーに関する予測モデルの品質は低い値です。製品エキスパートの支援に加え、営業目的を十分に理解した上で、この製品について独自の予測ルールを作成します。
|
フィールド |
値 |
|---|---|
|
フォルダ・タイプ |
予測 |
|
名前 |
DG 150 Green Servers |
|
摘要 |
DG 150 Green Serversの予測ルール |
|
開始日 |
01/06/2012 |
|
終了日 |
01/06/2013 |
|
フィールド |
値 |
|---|---|
|
名前 |
USのターゲット・ハイテク顧客 |
|
摘要 |
USのハイテク顧客はDG 150 Green Serversの大きな販売ターゲットです。購入可能性 > 70% |
|
ルール・フォルダ |
「DG 150 Green Servers」と自動的に入力されます。 |
|
開始日 |
01/06/2012 |
|
終了日 |
01/06/2013 |
モデル分析に基づいて、見込、収益および営業サイクルの見積が計算されます。これらの値は、推奨として、または独自の値の定義および見直しを行うためのガイドとして使用するか、営業目的を実現するために完全に上書きできます。
|
フィールド |
値 |
|---|---|
|
名前 |
DG 150 Green Servers |
|
見積購入可能性 |
75 |
|
見積収益 |
150000 |
|
見積営業サイクル |
40 |
サーバーに対するモデル結果の分析に基づいてシミュレーションを実行し、評価対象サーバーに対して適切な顧客がターゲットとして設定されることを確認できます。
|
フィールド |
値 |
|---|---|
|
基準 |
モデル予測 |
|
ランク付け基準 |
購入可能性 |
|
販売アカウント1 |
Pinnacle Technologies |
|
販売アカウント2 |
Maple Networks |
|
販売アカウント3 |
Serenity Systems |
評価対象サーバーに対するモデル結果の評価に基づいて、3件の販売アカウントに対するモデル情報は正しいと考えられます。シミュレーションによりモデル分析が検証されることで、モデル結果に基づく引合の生成および配布の信頼性が確保されます。モデルからの引合の生成で3種類のサーバーの営業目的が達成されることを確信できます。
新しいシミュレーションを実行して、DG 150 Green Server用に作成した予測ルールをテストします。ルール定義に基づいてシミュレーションを実行する前に、DG 150 Green Serverを米国のハイテク産業の顧客に販売することを想定していますが、シミュレーションを実行することでそれを確認できます。
|
フィールド |
値 |
|---|---|
|
基準 |
予測ルール |
|
ランク付け基準 |
購入可能性 |
|
販売アカウント1 |
Pinnacle Technologies |
|
販売アカウント2 |
Maple Networks |
|
販売アカウント3 |
Serenity Systems |
予測ルールの情報が正しく、適切な引合が生成されることを確信できます。
|
フィールド |
値 |
|---|---|
|
摘要 |
西部リージョンの営業引合の作成 |
|
生成元 |
予測ルール |
|
選択オプション |
営業テリトリ別 |
|
営業テリトリ |
西部全体の営業 |
|
フィールド |
値 |
|---|---|
|
生成元 |
モデル |
|
選択オプション |
プロファイル別 |
|
産業 |
ハイテク |
モデル情報学習では、過去の商談行動の実際の受注および失注について顧客の人口統計および行動の属性に関係する数学的モデルを評価するために、既存の顧客のデータをマイニングします。次に、モデル結果を活用して、予測または製品推奨を生成します。モデル情報学習では、次の予測が作成されます。
顧客が購入する可能性のある製品
製品からの見積収益
製品を販売する見積営業サイクル
Oracle Fusion Sales Predictor Engineでは、予測分析を使用して顧客および顧客資産のホワイトスペース分析を実行します。また、Oracle Real-Time Decisions(RTD)を使用して顧客による特定の製品に対する購入可能性を予測し、Oracle Data Mining(ODM)を使用して特定の引合に対する営業サイクルと収益を予測します。
購入可能性は、顧客属性(顧客プロファイル、販売オーダー・パターン、所有資産、過去の購買パターンなど)とクローズしたディールの成功との相関を調査する回帰スコアリング・モデルの(RTDへの)実装から導出されます。販売予測因子では有意性しきい値50を使用しますが、これは、RTDが少なくとも50製品の受注商談を使用して情報学習を実施した後、回帰モデルを使用して購入可能性を予測することを意味します。
見積収益および見積営業サイクルは、商談データのパターンを識別するODMセグメンテーション・データ・マイニング・モデルから導出されます。販売予測因子では、クラスタを使用して営業サイクルと収益に関する予測を作成します。ODMクラスタリング・アルゴリズムでは、人口統計プロファイルおよびインストール・ベース・プロファイル(つまり、顧客がすでに所有している製品)に基づいて、類似する顧客を25のセグメントにグループ化します。
販売予測因子では、2つのクラスタリング・モデルが作成されます。
人口統計クラスタ - 顧客の人口統計に基づいて顧客をクラスタリングします。
製品クラスタ - 顧客が所有する製品に基づいて顧客をクラスタリングします。
見積営業サイクルおよび見積収益を予測するために、クラスタリング・モデルは次のように機能します。
クラスタリング・モデルは、クラスタ・モデルと製品の組合せをそれぞれ1行で表す推奨表を作成します。たとえば、各モデルには5つのクラスタが含まれ、1000の製品がある場合、推奨表の行数は5*5*1000行です。
推奨表の各行には、営業サイクルと収益の最小、最大、中央、平均に加え、人口統計クラスタと製品クラスタに含まれる全商談の統計、および各行に定義された製品の組合せが格納されます。
引合が生成された場合、引合の製品は、人口統計クラスタおよび製品クラスタのIDも使用して推奨表の行を識別します。
この行の統計は、営業収益および営業サイクルの見積に使用されます。
予測ルールは、営業用に品質の高い引合を提供するために、ターゲット製品に対するターゲット顧客を識別します。次のシナリオでは、予測ルールを使用する必要がある場合の例を示します。
営業責任者は、新製品の販売先として、以前に初期モデルを購入した北米の大規模製造業の顧客が有望と判断します。営業管理者は、次の条件を使用して新製品の新しい予測ルールを作成します。
従業員規模 > 10,000
産業 = 製造業
リージョン = 北米
資産 = 以前のモデル名
製品エキスパートは、ターゲット製品がルール基準を満たす顧客に販売された場合の予測収益は500,000ドル、30日の営業サイクルが必要と予測しました。購入可能性は95パーセントに設定しました。
製品担当者は、予測に加え、製品が売れない理由を調査します。製品のモデル品質レポートをチェックし、モデルの品質が低いことを検出します。営業責任者は米国東部の製薬会社に対する製品の販売が有望と判断し、営業管理者はこれらの顧客の条件を考慮した、製品の新しい予測ルールを作成します。
6か月前に数人の営業担当を新規に雇用しました。それ以降、これらの新しい営業担当は、製品を販売する際に古い製品コードを使用していたことが判明しました。モデルには、これらの製品の正確な履歴データがありません。そのため、モデルでは見逃される引合を生成するために、エキスパートの知識に基づいて予測ルールを使用します。
独自の予測ルールおよび推奨適格条件を編集および作成できます。
次に、シミュレーションおよび引合生成で予測ルールを使用する場合に、推奨適格条件を使用して、製品推奨のシミュレーションおよび営業引合の生成から不適格な顧客を除外する例を示します。
ソフトウェアを販売していますが、特定の国に対する特定の種類のソフトウェアの販売は政府により規制されています。規制対象となる国の顧客について、これらの製品の推奨を回避するルールを記述します。
よく似た2つの化学製品を販売していますが、製造業では両方の製品が使用され、医療産業では1製品のみが使用基準を満たしています。医療産業の顧客に対し、一方の化学製品を不適格にするルールを記述します。
製品ラインの1つは、利益率が低いため、新規の顧客にのみ販売されます。そのラインがクロスセルとして誰かにオファーされないようにルールを記述します。
最新モデルの顕微鏡を中心とした営業キャンペーンを開始しています。前のモデルを昨年購入した顧客には、このモデルをオファーする必要がありません。1年以内に前のモデルを購入した顧客には、新規モデルを不適格とするルールを指定します。
モデル情報学習は、将来の状況を予測するために、パターンおよび関係を抽出する一連のアルゴリズムを使用して、データに含まれる本質的な構造を検出する処理です。予測モデルは、履歴商談の収益データを参考にして、顧客が次に購入しそうな製品、見積収益および予測営業サイクルを予測します。
モデルには、履歴データを収集および分析するための初期学習が必要です。その後、営業環境がどのくらい動的であるかに基づいて追加学習をスケジュールできます。最近の営業期間にクローズした収益項目のみを処理するように選択できます。処理を指定の製品ファミリおよび販売リージョンのみに制限することもできます。営業履歴が安定的で一貫性がある場合は、一定期間にわたって追加学習するように選択できます。急激な変化(市場状況、供給、需要、季節的要因など)がある場合は、完全に新しいモデル情報学習を実行できます。
引合を生成する前に、シミュレーションを使用して、モデルまたはルールのいずれかの予測から指定の顧客に推奨する製品をプレビューし、予測ルールが正しく評価されるかどうかを確認します。
推奨適格条件の基準は、特定の製品または製品グループについて顧客が適格または不適格な場合を定義します。分析計算では、予測ルールの前に推奨適格条件が最初に処理され、不適格な顧客がその後の計算から除外されます。たとえば、前年にModel 1000という顕微鏡を購入した顧客は、新型のModel 2000の購入対象として不適格です。
予測ルールは、産業または製品に関する専門知識に基づいて作成し、事前定義の条件を満たす顧客に販売する製品を識別します。予測ルールは、予測および引合を生成するための統計モデルの使用にかわるものです。たとえば、新製品が発表された場合、営業履歴が少ない製品の販促を実施する場合、またはマーケティング・イニシアチブに沿って製品を奨励する場合に予測ルールを使用します。たとえば、3年以上前にModel 1000という顕微鏡を購入した顧客に対して、新しいModel 2000を推奨します。
2つ以上の予測ルールが重複または矛盾する場合は、更新日が最新の予測ルールが優先されます。
次の例では、2つのルールが重複します。
ルール1
米国の顧客
ターゲット製品: Model 2000顕微鏡
ルール2
米国東部の顧客
ターゲット製品: Model 2000顕微鏡
ルール2が最後に編集された場合は、引合生成プロセスの実行時に、米国東部の顧客に対するModel 2000顕微鏡の予測メトリックにより、ルール1のメトリックが上書きされます。ルール1に定義された予測メトリックは、米国内(米国東部内でなく)の顧客に対して生成された引合に適用されます。
次の例では、2つのルールが矛盾します。
ルール1: 米国以外の顧客がMicroscope 2000のターゲット(この製品を基本的に米国以外のあらゆる場所の全顧客に位置付け)
ルール2: 米国の顧客がMicroscope 2000のターゲット
この場合、2つのルール間の矛盾により、すべての顧客(米国または米国以外)に対してModel 2000の引合が生成され、これは意図に反する結果です。各ルールがもう一方のルールの目的を損なうことになります。
推奨適格条件は、常に予測ルールの前に評価されます。たとえば、推奨適格条件によって、ある顧客が特定の製品に適格でないと判断された場合は、予測ルールでその顧客がその特定の製品のターゲットとなるかどうかに関係なく、その顧客は不適格となります。
はい。属性が親フォルダの条件を満たしているかぎり、フォルダ名、開始日と終了日、および「アクティブ」ステータスをルール作成ページから変更できます。
作成した予測ルールで推奨する各製品に対して、購入可能性(パーセント)、販売収益、営業サイクル(日数)の3つの各予測について見積が計算されます。これらは、製品に対する現在の販売実績のガイドラインとして機能します。これらの予測は、エキスパートの市場に関する知識を使用して上書きできます。
製品または製品グループが新しい場合や、過去の販売データが不十分な場合、見積は提供されません。市場に関する専門知識に基づいて見積を入力する必要があります。
0から100の数値でモデルの予測力を示します。モデル品質の値が高いほど、結果として生じる予測は、イベントの無作為抽出に対する予測より大きい影響を与えます。したがって、見込み客に対してモデル品質が高い製品をターゲットに絞って優先し、営業の成果を向上させます。
重要度は、属性と結果がともに変化する傾向を示す度合いです。全体の重要度とは、予測モデルを介して識別される属性の有用性または相関です。
いいえ。一度に実行できる引合生成プロセスまたはモデル情報学習プロセスは1つのみです。発行したプロセスは、現在実行中のプロセスの完了後に実行するようにキューに配置されます。