| Oracle® Identity Manager Oracle E-Business HRMSコネクタ・ガイド リリース11.1.1 E91916-02 |
|


 前 |
 次 |
この章では、特定のビジネス要件に対応するためにコネクタの機能を拡張する実行可能な手順について説明します。このセクションのトピックは次のとおりです:
デフォルトでは、コネクタで、Oracle Identity Managerとターゲット・システム間のリコンシリエーションおよびプロビジョニング操作に使用される属性マッピングのセットが提供されます。ビジネス要件に応じて、リコンシリエーションおよびプロビジョニング操作用の属性を追加し、追加属性をマップできます。これを行うには、新規属性をOIM_EMPLOYEE_WRAPPER.pckラッパー・パッケージのget_schema()ストアド・プロシージャに追加することにより、コネクタ・スキーマを拡張します。
コネクタ・スキーマを拡張する場合、次の概念を理解する必要があります。
属性の初期化
次の初期化文には、コネクタ・スキーマの属性定義が含まれる内部配列が保持されています。
attr.extend(NUM);
ここで、NUMは、初期化する配列のサイズを定義します。配列のサイズは、常に定義される属性の数以上にする必要があります。たとえば、初期化文attr.extend(20);では、初期化時に20個の属性の内部配列が保持されます。
属性の定義
初期化後、次の形式の文を追加することにより、属性ごとの情報を定義します。
attr (ORD_NO) := attributeinfo(ATTR_NAME,ATTR_TYPE,CREATE_FLAG,UPDATE_FLAG,REQUIRED_FLAG,READ_FLAG);
この形式の詳細は次のとおりです。
ORD_NOは配列内での属性の順序です。これは必須です。
ATTR_NAMEは子属性または単一値属性の名前です。
ATTR_TYPEは子属性または単一値属性のSQLデータ型です。
CREATE_FLAGは、作成プロビジョニング操作時に属性が必要かどうかを示すフラグです。
UPDATE_FLAGは属性が更新可能かどうかを示すフラグです。
REQUIRED_FLAGは属性が必須かどうかを示すフラグです。
READ_FLAGは属性が読取り可能かどうかを示すフラグです。
各フラグの値1または0は、それぞれTrueまたはFalseを示します。たとえば、フラグの値1, 0, 1, 0は、属性が必須属性で、作成プロビジョニング操作時に想定する必要があることを意味しています。
属性の配列の拡張
次の文を指定することにより、初期化後に配列のサイズを増やすことができます。
attr.extend;
この文を指定するたびに、配列のサイズが1ずつ増加します。
デフォルトでは、表4-4に示したフィールドが、Oracle Identity Managerとターゲット・システム間のリコンシリエーション用にマップされます。必要に応じて、信頼できるソースのリコンシリエーション用に追加フィールドを追加できます。次の項で、新規属性を追加するために実行する手順について説明します。
信頼できるソースのリコンシリエーション用の新しい属性を追加するために実行する手順のサマリーは次のとおりです。
DBラッパー・パッケージを更新して新規単一値属性をget_schema()ストアド・プロシージャのメイン属性リストに含めます。詳細は、第5.2.2項「信頼できるソースのリコンシリエーション用のコネクタ・スキーマの拡張」を参照してください。
OIMアーティファクトを更新します。詳細は、第5.2.3項「信頼できるソースのリコンシリエーション用のアーティファクトの更新」を参照してください。
コネクタ・バンドルを更新して新規属性をsearch.propertiesファイルに含めます。詳細は、第5.2.4項「コネクタ・バンドルの更新」を参照してください。
次のように、DBラッパー・パッケージを更新することによりコネクタ・スキーマを拡張して、信頼できるソースのリコンシリエーション用の新規属性を含める必要があります。
任意のSQLクライアントを開きます。たとえば、SQL Developerなどです。
OIM_EMPLOYEE_WRAPPER.pckラッパー・パッケージの本体を開きます。
get_schema()ストアド・プロシージャを選択します。ストアド・プロシージャで定義されている属性のリストが表示されます。
定義済属性の数が初期化済属性の数を超えた場合、次のようにします。
次の属性の初期化文を追加します。
attr.extend;
次の形式で追加する新規属性の定義を入力します。
attr (ORD_NO) := attributeinfo(ATTR_NAME,ATTR_TYPE,CREATE_FLAG,UPDATE_FLAG,REQUIRED_FLAG,READ_FLAG);
たとえば、ユーザー・アカウントの血液型を含む新規属性を追加する場合、次の文を指定します。
attr.extend;
attr (28) := attributeinfo('BLOOD_TYPE','varchar2',1,1,0,1);
この例では、フラグの値1,1,0,1は、作成プロビジョニング操作時にBLOOD_TYPE属性が必須で、更新および読取り可能であるという意味です。
定義済属性の数が初期化済属性の数を超えていない場合、新規属性の定義のみを追加します。たとえば、attr (28) := attributeinfo('BLOOD_TYPE','varchar2',1,1,0,1);です。
ラッパー・パッケージを再コンパイルします。
コネクタ・アーティファクトを更新して、第5.2.2項「信頼できるソースのリコンシリエーション用のコネクタ・スキーマの拡張」で追加した新規属性を含める必要があります。コネクタ・アーティファクトを更新するには、次の手順を実行します。
Oracle Identity Managerでのユーザー定義フィールド(UDF)の作成手順の詳細は、『Oracle Fusion Middleware Oracle Identity Managerの管理』のカスタム属性の作成に関する項を参照してください。
次のように、リソース・オブジェクトを更新して、第5.2.3.2項「Oracle EBS HRMS Trustedユーザー・リソース・オブジェクトの更新」で作成した新規属性に対応するリコンシリエーション・フィールドを追加します。
Oracle Identity Manager Design Consoleにログインします。
「リソース管理」フォルダを開き、「リソース・オブジェクト」をダブルクリックします。
Oracle EBS HRMS Trustedユーザー・リソース・オブジェクトを検索して開きます。
「Object Reconciliation」タブで、「ADD Field」をクリックして、「Add Reconciliation Field」ダイアログ・ボックスを開きます。
「フィールド名」フィールドに、属性の名前を入力します。たとえば、Blood Typeと入力します。
「フィールド・タイプ」リストから、フィールドのデータ型を選択します。たとえば、「文字列」を選択します。
属性を必須属性として指定する場合は、そのためのチェック・ボックスを選択します。
「保存」アイコンをクリックしてダイアログ・ボックスを閉じます。
次のようにして、(第5.2.3.1項「ユーザー定義フィールドの作成」で作成した) UDF用のリコンシリエーション・フィールド・マッピングをプロセス定義に作成します。
「Process Management」を開き、「Process Definition」をダブルクリックします。
Oracle EBS HRMS Trustedユーザープロセス定義を検索して開きます。
「リコンシリエーション・フィールド・マッピング」タブで、「フィールド・マップの追加」をクリックします。
「Add Reconciliation Field Mapping」ダイアログ・ボックスの「Field name」リストから、リソース・オブジェクトに作成された属性に割り当てた名前を選択します。たとえば、Blood Typeを選択します。
「ユーザー属性」リストで、前の手順で選択したフィールド名に対応する属性を選択します。たとえば、BloodTypeを選択します。
「保存」アイコンをクリックしてダイアログ・ボックスを閉じます。
リコンシリエーション属性マッピングの参照定義に、次のようにして属性のエントリを追加します。
「管理」を開き、「参照定義」をダブルクリックします。
Lookup.EBSHRMS.ReconAttrMap.Trusted参照定義を検索して開きます。
行を追加するには、「追加」をクリックします。
「Code Key」列に、リソース・オブジェクトの属性に対して設定した名前を入力します。たとえば、Blood Typeと入力します。
「デコード」列に、SQL問合せで返される列名を入力します。たとえば、BLOOD_TYPEと入力します。
「Save」アイコンをクリックします。
リコンシリエーション・プロファイルを作成して、リソース・オブジェクト(前述の項)に行われた変更をすべてMDSにコピーします。
「リソース管理」フォルダを開き、「リソース・オブジェクト」をダブルクリックします。
Oracle EBS HRMS Trustedユーザー・リソース・オブジェクトを検索して開きます。
「Object Reconciliation」タブで、「Create Reconciliation Profile」をクリックします。
「Save」アイコンをクリックします。
コネクタ・バンドル(org.identityconnectors.ebs-1.0.1115.jar)を更新して、前述の項で行った更新をすべて含める必要があります。これを行うには、次のようにします。
org.identityconnectors.ebs-1.0.11150.jarファイルの内容を選択したディレクトリに抽出します。
テキスト・エディタで、構成ディレクトリにあるsearch.propertiesを開きます。
新規作成した属性に対応する列名を含む必要があるSQL問合せを検索します。たとえば、HRMS_CURRENT_EMPLOYEE_RECON_QUERY問合せを検索します。
新規追加した属性に対応する列名がすでにSQL問合せに含まれている場合、この項で説明する残りの手順をスキップできます。
新規追加した列名に関する情報がSQL問合せに含まれていない場合、この情報を含むように変更します。たとえば、HRMS_CURRENT_EMPLOYEE_RECON_QUERY問合せ(検索オプション)を変更してPAPF.BLOOD_TYPE AS blood_typeを含めます。Blood Type属性はPER_ALL_PEOPLE_F表内にあり、PAPFは表の別名です。
HRMS_CURRENT_FUTURE_EMPLOYEE_RECON_QUERY (検索オプションと同期オプションの両方)やHRMS_CURRENT_EMPLOYEE_RECON_QUERY (同期オプション)などの他のSQL問合せが該当する場合は、手順3から5を繰り返してそれらを更新します。たとえば、HRMS_CURRENT_EMPLOYEE_RECON_QUERYおよびHRMS_CURRENT_FUTURE_EMPLOYEE_RECON_QUERYの問合せを、付録B「HRMS TrustedコネクタのサンプルのSQL問合せ」にリストされているSQL問合せで更新します。
変更を保存して、ファイルを閉じます。
更新した問合せを確認します。
次のコマンドを実行して、コネクタ・バンドル(org.identityconnectors.ebs-1.0.11150.jar)を更新します。
jar -cvfm org.identityconnectors.ebs-1.0.11150.jar META-INF/MANIFEST.MF *
Oracle Identity ManagerのJAR更新ユーティリティを実行して、Oracle Identity Managerデータベースに対して既存のコネクタ・バンドルを新規コネクタ・バンドル(手順9で更新済)に置き換えます。このユーティリティは、Oracle Identity Managerのインストール時に次の場所にコピーされます。
|
注意: このユーティリティを使用する前に、Oracle WebLogic ServerをインストールしたディレクトリにWL_HOME環境変数が設定されていることを確認してください。 |
Microsoft Windowsの場合:
OIM_HOME/server/bin/UpdateJars.bat
UNIXの場合:
OIM_HOME/server/bin/UpdateJars.sh
ユーティリティを実行すると、Oracle Identity Manager管理者のログイン資格証明、Oracle Identity Managerホスト・コンピュータのURL、コンテキスト・ファクトリ値、アップロードするJARファイルのタイプおよびJARファイルがアップロードされる場所の入力を求めるプロンプトが表示されます。JARタイプの値として4を指定します。
コネクタ・バンドルJARが正常に更新されたらOracle Identity Managerを再起動します。
デフォルトでは、表3-4に示した属性が、リコンシリエーション用にOracle Identity Managerとターゲット・システム間でマップされます。同様に、表3-3で示した属性が、Oracle Identity Managerとターゲット・システムとの間のプロビジョニング用にマップされます。必要に応じて、ターゲット・リソースのリコンシリエーションおよびプロビジョニング用に追加フィールドをマップできます。次の項で、新規属性を追加するために実行する手順について説明します。
信頼できるソースのリコンシリエーション用の新規属性を追加するために実行する手順のサマリーは次のとおりです。
DBラッパー・パッケージを更新して新規単一値属性をget_schema()ストアド・プロシージャに含めます。詳細は、第5.3.2項「ターゲット・リソースのリコンシリエーションおよびプロビジョニング用のコネクタ・スキーマの拡張」を参照してください。
コネクタのアーティファクトを更新して新規属性を含めます。詳細は、第5.3.3項「コネクタ・アーティファクトの更新」を参照してください。
コネクタ・バンドルを更新して新規属性をsearch.propertiesファイルに含めます。詳細は、第5.3.4項「search.propertiesファイルの更新」を参照してください。
コネクタ・バンドルを更新して新規属性をProcedures.propertiesファイルに含めます。詳細は、第5.3.5項「Procedures.propertiesファイルの更新」を参照してください。
次のように、DBラッパー・パッケージを更新することによりコネクタ・スキーマを拡張して、ターゲット・リソースのリコンシリエーションおよびプロビジョニング用の新規属性を含める必要があります。
任意のSQLクライアントを開きます。たとえば、SQL Developerなどです。
OIM_EMPLOYEE_WRAPPER.pckラッパー・パッケージの本体を開きます。
get_schema()ストアド・プロシージャを選択します。ストアド・プロシージャで定義されている属性のリストが表示されます。
定義済属性の数が初期化済属性の数を超えた場合、次のようにします。
次の属性の初期化文を追加します。
attr.extend;
次の形式で追加する新規属性の定義を入力します。
attr (ORD_NO) := attributeinfo(ATTR_NAME,ATTR_TYPE,CREATE_FLAG,UPDATE_FLAG,REQUIRED_FLAG,READ_FLAG);
たとえば、ユーザー・アカウントの血液型を含む新規属性を追加する場合、次の文を指定します。
attr.extend;
attr (28) := attributeinfo('BLOOD_TYPE','varchar2',1,1,0,1);
この例では、フラグの値1,1,0,1は、作成プロビジョニング操作時にBLOOD_TYPE属性が必須で、更新および読取り可能であるという意味です。
定義済属性の数が初期化済属性の数を超えていない場合、新規属性の定義のみを追加します。たとえば、attr (28) := attributeinfo('BLOOD_TYPE','varchar2',1,1,0,1);です。
ラッパー・パッケージを再コンパイルします。
コネクタ・アーティファクトを更新して、第5.3.2項「ターゲット・リソースのリコンシリエーションおよびプロビジョニング用のコネクタ・スキーマの拡張」で追加した新規値属性を含める必要があります。コネクタ・アーティファクトを更新するには、次の手順を実行します。
プロセス・フォームのフィールドとして属性を追加するには、次の手順を実行します。
「開発ツール」を開き、「フォーム・デザイナ」をダブルクリックします。
UD_EBS_HRMSプロセス・フォームを検索して開きます。
「Create New Version」をクリックして、フォームのバージョンを作成します。
「Label」フィールドで、バージョン名を入力します。たとえば、version#1と入力します。
「Save」アイコンをクリックします。
「現行バージョン」リストから、ステップ4で作成された現在のバージョンを選択します。
「Add」をクリックして新規属性を作成し、その属性の値を指定します。
たとえば、Blood Type属性を追加する場合は、「追加列」タブに次の値を入力します。
| フィールド | 値 |
|---|---|
| 名前 | UD_EBS_HRMS_BLOOD_TYPE |
| バリアント型 | String |
| 長さ | 50 |
| フィールド・ラベル | Blood Type |
| フィールド・タイプ | TextField |
| 順序 | 22 |
「Save」アイコンをクリックします。
「Make Version Active」をクリックします。
次のように、リソース・オブジェクトを更新して、第5.2.3.1項「ユーザー定義フィールドの作成」で作成した新規属性に対応するリコンシリエーション・フィールドを追加します。
「リソース管理」フォルダを開き、「リソース・オブジェクト」をダブルクリックします。
Oracle EBS HRMSユーザー・リソース・オブジェクトを検索して開きます。
「Object Reconciliation」タブで、「ADD Field」をクリックして、「Add Reconciliation Field」ダイアログ・ボックスを開きます。
「フィールド名」フィールドに、属性の名前を入力します。たとえば、Blood Typeと入力します。
「Field Type」リストから、フィールドのデータ・タイプを選択します。たとえば、Stringを選択します。
属性を必須属性として指定する場合は、そのためのチェック・ボックスを選択します。
「保存」アイコンをクリックしてダイアログ・ボックスを閉じます。
次のようにして、カスタム属性用のリコンシリエーション・フィールド・マッピングをプロセス定義に作成します。
「Process Management」を開き、「Process Definition」をダブルクリックします。
Oracle EBS HRMS Targetプロセス定義を検索して開きます。
「リコンシリエーション・フィールド・マッピング」タブで、「フィールド・マップの追加」をクリックします。
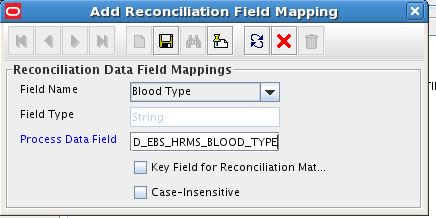
「Add Reconciliation Field Mapping」ダイアログ・ボックスの「Field name」リストから、リソース・オブジェクトに作成された属性に割り当てた名前を選択します。たとえば、Blood Typeを選択します。
「プロセス・データ」フィールドをダブルクリックして、表示されたポップアップから第5.3.3.1項「プロセス・フォーム・フィールドの作成」で作成した新規追加フィールドを選択します。
図5-1は、「フィールド名」リストおよび「プロセス・データ」フィールドが設定されているリコンシリエーション・フィールド・マッピングの追加ダイアログ・ボックスです。
「保存」アイコンをクリックしてダイアログ・ボックスを閉じます。
リコンシリエーション属性マッピングの参照定義に、次のようにして属性のエントリを追加します。
「管理」を開き、「参照定義」をダブルクリックします。
Lookup.EBSHRMS.UM.ReconAttrMap参照定義を検索して開きます。
行を追加するには、「追加」をクリックします。
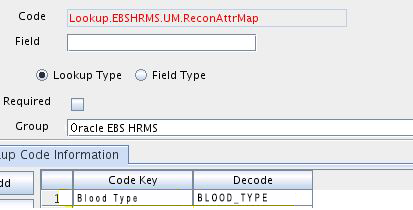
「Code Key」列に、リソース・オブジェクトの属性に対して設定した名前を入力します。たとえば、Blood Typeと入力します。
「デコード」列に、SQL問合せで返される列名を入力します。たとえば、BLOOD_TYPEと入力します。
図5-2に、新たにエントリが追加されたLookup.EBSHRMS.UM.ReconAttrMap参照定義を示します。
図5-2 新たに追加されたエントリを表示するLookup.EBSHRMS.UM.ReconAttrMap Lookup Definition参照定義
「Save」アイコンをクリックします。
プロビジョニング属性マッピングの参照定義に、次のようにして属性のエントリを追加します。
「管理」を開き、「参照定義」をダブルクリックします。
Lookup.EBSHRMS.UM.ProvAttrMap参照定義を検索して開きます。
行を追加するには、「追加」をクリックします。
「Code Key」列に、リソース・オブジェクトの属性に対して設定した名前を入力します。たとえば、Blood Typeと入力します。
「デコード」列に、SQL問合せで返される列名を入力します。たとえば、BLOOD_TYPEと入力します。
「Save」アイコンをクリックします。
リコンシリエーション・プロファイルを作成して、リソース・オブジェクト(前述の項)に行われた変更をすべてMDSにコピーします。
「リソース管理」フォルダを開き、「リソース・オブジェクト」をダブルクリックします。
Oracle EBS HRMS Targetリソース・オブジェクトを検索して開きます。
「Object Reconciliation」タブで、「Create Reconciliation Profile」をクリックします。
「Save」アイコンをクリックします。
次のように、新規追加した属性でのプロビジョニング操作の処理用にプロセス・タスクを作成することにより、プロセス定義を更新します。:
「プロセス管理」を開いて、「プロセス定義」をダブルクリックします。
Oracle EBS HRMSプロセス定義を検索して開きます。
「タスク」タブで、「追加」をクリックします。
新しいタスクの作成ダイアログ・ボックスが表示されます。
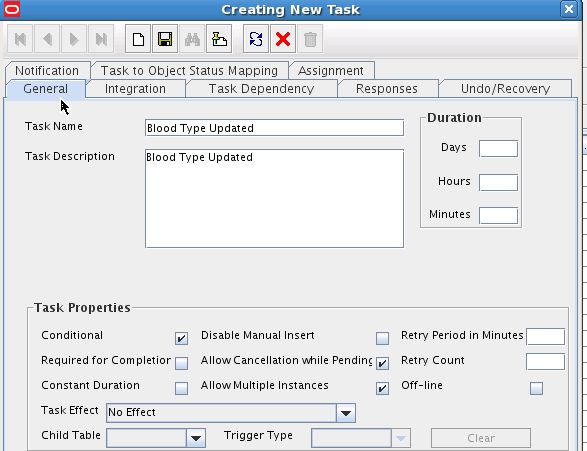
「タスク名」フィールドに、プロセス・タスクの名前を入力します。たとえば、Blood Type Updatedと入力します。
「タスクの説明」フィールドに、タスクの説明を入力します。たとえば、Task to update Blood Type attributeと入力します。
「タスク・プロパティ」リージョンで、要件に合ったプロパティを選択します。たとえば、「タスク・プロパティ」リージョンで次のアクションを実行します。
次のチェック・ボックスを選択します。
条件付き
Allow Cancellation While Pending
複数のインスタンスを許可
「タスクの結果」リストから、「無効」を選択します。
図5-3に、関連する詳細が設定された「新規タスクの作成」ダイアログ・ボックスを示します。
「Save」アイコンをクリックします。
「統合」タブで、「追加」をクリックして、前述の手順で作成したプロセス・タスクにアダプタを割り当てます。
ハンドラ・セクション・ダイアログ・ボックスで「アダプタ」オプションを選択します。
「ハンドラ名」リージョンに表示されるアダプタのリストから、プロセス・タスクに割り当てるアダプタを選択します。たとえば、adpORACLEEBSHRMSUPDATESINGLEATTRIBUTESアダプタを選択します。
「保存」アイコンをクリックしてダイアログ・ボックスを閉じます。
「統合」タブの「アダプタ変数」リージョンの表から、マップする変数を選択します。たとえば、fieldName変数をクリックします。
「マップ」をクリックします。
変数のデータ・マッピングの編集ダイアログ・ボックスで、必要に応じてアダプタ変数マッピングを作成します。たとえば、次のマッピングを作成します。
変数名: fieldName
マップ先: Literal
修飾子: String
リテラル値: UD_EBS_HRMS_BLOOD_TYPE
「保存」アイコンをクリックしてダイアログ・ボックスを閉じます。
「アダプタ変数」リージョンの残りの変数について、手順12から15を実行します。次の表に、各変数について「マップ先」、「修飾子」および「リテラル値」リストから選択可能なサンプル値を示します。
| 変数 | マップ先 | 修飾子 | リテラル値 |
|---|---|---|---|
| fieldOldValue | Process Data | Blood Type、Old Value:select | NA |
| AdapterReturnCode | Response Code | NA | NA |
| objectType | Literal | String | __PERSON__ |
| ItResourceName | Literal | String | UD_EBS_HRMS_IT_RESOURCE_NAME |
| fieldValue | Process Data | Blood Type | NA |
| processInstanceKey | Process Data | Process Instance | NA |
「プロセス定義」フォームの「保存」アイコンをクリックします。
「レスポンス」タブで「追加」をクリックして、SUCCESSレスポンス・コードをステータスCとともに追加します。これにより、カスタム・タスクが正常に実行されると、タスクのステータスが「完了」として表示されます。同様に、CONNECTION_FAILEDレスポンス・コードをステータスRとともに追加します。
「Save」アイコンをクリックしてダイアログ・ボックスを閉じ、プロセス定義を保存します。
次のように、search.propertiesファイルを更新して、新規属性を含めます。
org.identityconnectors.ebs-1.0.1115.jarファイルの内容を選択したディレクトリに抽出します。
テキスト・エディタで、構成ディレクトリにあるsearch.propertiesを開きます。
新規作成した属性に対応する列名を含む必要があるSQL問合せを検索します。たとえば、TARGET_HRMS_CURRENT_EMPLOYEE_RECON_QUERY問合せを検索します。
新規追加した属性に対応する列名がすでにSQL問合せに含まれている場合、この項で説明する残りの手順をスキップできます。
新規追加した列名に関する情報がSQL問合せに含まれていない場合、この情報を含むように変更します。たとえば、TARGET_HRMS_CURRENT_EMPLOYEE_RECON_QUERY問合せ(検索オプション)を変更してPAPF.BLOOD_TYPE AS blood_typeを含めます。Blood Type属性はPER_ALL_PEOPLE_F表内にあり、PAPFは表の別名です。
TARGET_HRMS_CURRENT_EMPLOYEE_RECON_QUERY問合せにBlood Type列を含むサンプルの問合せについては付録A「HRMS TargetコネクタのサンプルのSQL問合せ」を参照してください。
TARGET_HRMS_CURRENT_EMPLOYEE_RECON_QUERY (検索オプション)やHRMS_TERMINATED_EMPLOYEE_RECON_QUERYなどの他のSQL問合せが該当する場合は、手順3から5を繰り返してそれらの問合せを更新します。たとえば、TARGET_HRMS_CURRENT_EMPLOYEE_RECON_QUERY SQL問合せを変更してPAPF.BLOOD_TYPE AS blood_typeおよびperson.BLOOD_TYPEを選択問合せに含めます。
変更を保存して、ファイルを閉じます。
更新した問合せを確認します。
次のコマンドを実行して、コネクタ・バンドル(org.identityconnectors.ebs-1.0.1115.jar)を更新します。
jar -cvfm org.identityconnectors.ebs-1.0.11150.jar META-INF/MANIFEST.MF *
Oracle Identity ManagerのJAR更新ユーティリティを実行して、新規コネクタ・バンドル(手順9で更新済)をOracle Identity Managerデータベースに対して更新します。このユーティリティは、Oracle Identity Managerのインストール時に次の場所にコピーされます。
|
注意: このユーティリティを使用する前に、Oracle WebLogic ServerをインストールしたディレクトリにWL_HOME環境変数が設定されていることを確認してください。 |
Microsoft Windowsの場合:
OIM_HOME/server/bin/UpdateJars.bat
UNIXの場合:
OIM_HOME/server/bin/UpdateJars.sh
ユーティリティを実行すると、Oracle Identity Manager管理者のログイン資格証明、Oracle Identity Managerホスト・コンピュータのURL、コンテキスト・ファクトリ値、アップロードするJARファイルのタイプおよびJARファイルがアップロードされる場所の入力を求めるプロンプトが表示されます。JARタイプの値として4を指定します。
作成および更新プロビジョニング操作時に新規追加したBlood Type属性をサポートするには、Procedures.propertiesファイルで起動されるストアド・プロシージャを更新する必要があります。これを行うには、次のようにします。
テキスト・エディタで、編集のためにProcedures.propertiesファイルを開きます。
個人の作成および個人の更新のプロビジョニング操作を起動するために使用されるラッパー・パッケージおよびストアド・プロシージャの名前を検索して決定します。たとえば、OIM_EMPLOYEE_WRAPPER.CREATE_PERSON_APIおよびOIM_EMPLOYEE_WRAPPER.UPDATE_PERSON_APIは、ユーザー作成およびユーザー更新プロビジョニング操作に使用されるラッパー・パッケージおよびストアド・プロシージャです。
次のように、前述の手順で決定したストアド・プロシージャを更新します。
任意のSQLクライアントを開きます。たとえば、SQL Developerなどです。
ラッパー・パッケージを開いて、新規追加した属性(例: Blood Type)をユーザー作成およびユーザー更新ストアド・プロシージャに追加します。たとえば、OIM_EMPLOYEE_WRAPPERパッケージを開いて、新規追加した属性をCREATE_PERSON_APIおよびUPDATE_PERSON_APIストアド・プロシージャに追加します。
図5-4では、新規追加した属性を含めるためにOIM_EMPLOYEE_WRAPPERパッケージで更新する必要があるストアド・プロシージャを強調表示しています。
図5-4 OIM_EMPLOYEE_WRAPPERパッケージで更新されるストアド・プロシージャ
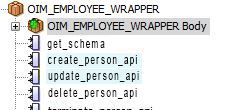
CREATE_PERSON_APIストアド・プロシージャを選択して、新規追加した属性を含めるように入力パラメータを更新します。
図5-5では、CREATE_PERSON_APIおよびUPDATE_PERSON_APIの両方のストアド・プロシージャで新規追加された属性を強調表示しています。
OIM_EMPLOYEE_WRAPPER Bodyを開いて、CREATE_PERSON_APIストアド・プロシージャを選択します。
新規追加した属性を含むプロシージャでHR_EMPLOYEE_API.create_employee APIのコールを更新します。
図5-6は、更新済のHR_EMPLOYEE_API.create_employee APIを示しています。
図5-6 新規追加した属性を含むHR_EMPLOYEE_API.create_employee API

新規追加した属性を含むプロシージャでHR_CONTINGENT_WORKER_API.create_cwk APIのコールを更新します。
図5-7は、更新済のHR_CONTINGENT_WORKER_API.create_cwk APIを示しています。
図5-7 新規追加した属性を含むHR_CONTINGENT_WORKER_API.create_cwk API

手順3.cから3.fを繰り返して、新規追加した属性を含めるようにUPDATE_PERSON_APIストアド・プロシージャを更新します。
ラッパー・パッケージを再コンパイルします。
デフォルトでは、表3-4に示した属性が、リコンシリエーション用にOracle Identity Managerとターゲット・システム間でマップされます。同様に、表3-3で示した属性が、Oracle Identity Managerとターゲット・システムとの間のプロビジョニング用にマップされます。必要に応じて、ターゲット・リソースのリコンシリエーションおよびプロビジョニング用に追加の複数値属性をマップできます。新しい複数値属性を追加する手順の詳細は、『Oracle Identity Manager Oracle E-Business Suite User Managementコネクタ・ガイド』のリコンシリエーションおよびプロビジョニング用の新しい複数値属性の追加に関する項を参照してください。
|
注意: この項ではオプションの手順を説明します。この手順は、リコンシリエーション時のデータの変換を構成する場合にのみ実行します。 |
要件に応じて、リコンサイルされた単一値データの変換を構成できます。たとえば、電子メールを使用して、Oracle Identity Managerの「電子メール」フィールドに異なる値を作成します。
データの変換を構成するには、次の手順を実行します。
必要な変換ロジックをJavaクラスに実装するコードを記述します。
次のサンプル変換クラスは、ターゲット・システムのEMAIL_ADDRESS列からフェッチした値を使用して、「電子メール」属性の値を作成します。
package oracle.iam.connectors.common.transform;
import java.util.HashMap;
public class TransformAttribute {
/*
Description:Abstract method for transforming the attributes
param hmUserDetails<String,Object>
HashMap containing parent data details
param hmEntitlementDetails <String,Object>
HashMap containing child data details
*/
public Object transform(HashMap hmUserDetails, HashMap hmEntitlementDetails,String sField) {
/*
* You must write code to transform the attributes.
Parent data attribute values can be fetched by
using hmUserDetails.get("Field Name").
*To fetch child data values, loop through the
* ArrayList/Vector fetched by hmEntitlementDetails.get("Child Table")
* Return the transformed attribute.
*/
String sEmail= "trans" + (String)hmUserDetails.get(sField);
return sEmail;
}
}
Javaクラスを保持するJARファイルを作成します。
Oracle Identity Manager JARアップロード・ユーティリティを実行して、JARファイルをOracle Identity Managerデータベースに投稿します。このユーティリティは、Oracle Identity Managerのインストール時に次の場所にコピーされます。
|
注意: このユーティリティを使用する前に、Oracle WebLogic ServerをインストールしたディレクトリにWL_HOME環境変数が設定されていることを確認してください。 |
Microsoft Windowsの場合:
OIM_HOME/server/bin/UploadJars.bat
UNIXの場合:
OIM_HOME/server/bin/UploadJars.sh
ユーティリティを実行すると、Oracle Identity Manager管理者のログイン資格証明、Oracle Identity Managerホスト・コンピュータのURL、コンテキスト・ファクトリ値、アップロードするJARファイルのタイプおよびJARファイルがアップロードされる場所の入力を求めるプロンプトが表示されます。JARタイプの値として1を指定します。
次のように変換用の参照定義を作成し、それにエントリを追加します。
Design Consoleにログインします。
「Administration」を開き、「Lookup Definition」をダブルクリックします。
「コード」フィールドで、使用しているコネクタに応じて、次のいずれかの値を入力します。
「Lookup Type」オプションを選択します。
「Lookup Code Information」タブで「Add」をクリックします。
新しい行が追加されます。
コード・キー列に、変換済の値を格納するリソース・オブジェクト・フィールド名を入力します。例: Email
デコード列に、変換ロジックを実装するクラスの名前を入力します。たとえば、oracle.iam.connectors.common.transform.TransformAttributeと入力します。
参照定義に変更を保存します。
次のように、構成参照定義にエントリを追加して、変換を有効にします。
「Administration」を開き、「Lookup Definition」をダブルクリックします。
コネクタに応じて、次の参照定義のいずれかを検索して開きます。
次のように、変換に使用する参照定義の名前を保持するエントリを作成します。
コード・キー: Recon Transformation Lookup
デコード: 使用しているコネクタに応じて、次のいずれかの値を入力します。
参照定義に変更を保存します。
要件に応じて、リコンサイルおよびプロビジョニングされた単一値データの検証を構成できます。たとえば、「電子メール」属性からフェッチしたデータを検証して、そのデータに番号記号(#)が含まれていないことを確認します。また、プロセス・フォームの「名」フィールドに入力したデータを検証して、プロビジョニング操作中にターゲット・システムに番号記号(#)が送信されないようにします。
検証チェックで合格しないデータについては、次のメッセージが表示されるか、ログ・ファイルに記録されます。
oracle.iam.connectors.icfcommon.recon.SearchReconTask : handle : Recon event skipped, validation failed [Validation failed for attribute: [FIELD_NAME]]
データの検証を構成するには:
必要な検証ロジックをJavaクラスに実装するコードを記述します。
次のサンプル検証クラスは、「電子メール」属性の値に番号記号(#)が含まれるかどうかを確認します。
package com.validate;
import java.util.*;
public class MyValidation {
public boolean validate(HashMap hmUserDetails,
HashMap hmEntitlementDetails, String field) {
/*
* You must write code to validate attributes. Parent
* data values can be fetched by using hmUserDetails.get(field)
* For child data values, loop through the
* ArrayList/Vector fetched by hmEntitlementDetails.get("Child Table")
* Depending on the outcome of the validation operation,
* the code must return true or false.
*/
/*
* In this sample code, the value "false" is returned if the field
* contains the number sign (#). Otherwise, the value "true" is
* returned.
*/
boolean valid=true;
String sEmail=(String) hmUserDetails.get(field);
for(int i=0;i<sEmail.length();i++){
if (sEmail.charAt(i) == '#'){
valid=false;
break;
}
}
return valid;
}
}
Javaクラスを保持するJARファイルを作成します。
Oracle Identity Manager JARアップロード・ユーティリティを実行して、JARファイルをOracle Identity Managerデータベースに投稿します。このユーティリティは、Oracle Identity Managerのインストール時に次の場所にコピーされます。
|
注意: このユーティリティを使用する前に、Oracle WebLogic ServerをインストールしたディレクトリにWL_HOME環境変数が設定されていることを確認してください。 |
Microsoft Windowsの場合:
OIM_HOME/server/bin/UploadJars.bat
UNIXの場合:
OIM_HOME/server/bin/UploadJars.sh
ユーティリティを実行すると、Oracle Identity Manager管理者のログイン資格証明、Oracle Identity Managerホスト・コンピュータのURL、コンテキスト・ファクトリ値、アップロードするJARファイルのタイプおよびJARファイルがアップロードされる場所の入力を求めるプロンプトが表示されます。JARタイプの値として1を指定します。
リコンシリエーションのプロセス・フォーム・フィールドを検証するJavaクラスを作成した場合は、次の手順を実行します。
Design Consoleにログインします。
「Administration」を開き、「Lookup Definition」をダブルクリックします。
「コード」フィールドに、参照定義の名前としてLookup.Oracle EBSHRMS.UM.ReconValidationを入力します。
「コード」フィールドで、使用しているコネクタに応じて、次のいずれかの値を入力します。
「Lookup Type」オプションを選択します。
「Lookup Code Information」タブで「Add」をクリックします。
新しい行が追加されます。
コード・キー列に、リソース・オブジェクト・フィールド名を入力します。たとえば、Emailと入力します。
デコード列に、クラス名を入力します。たとえば、com.validate.MyValidation.と入力します。
参照定義に変更を保存します。
コネクタに応じて、次の参照定義のいずれかを検索して開きます。
次の値を使用してエントリを作成します。
コード・キー: Recon Validation Lookup
デコード: 使用しているコネクタに応じて、次のいずれかの値を入力します。
参照定義に変更を保存します。
プロビジョニングのプロセス・フォーム・フィールドを検証するJavaクラスを作成した場合は、次の手順を実行します。
|
注意: ここで説明している手順は、HRMS Targetコネクタを使用している場合のみ実行します。 |
Design Consoleにログインします。
「Administration」を開き、「Lookup Definition」をダブルクリックします。
「コード」フィールドに、参照定義の名前としてLookup.EBSHRMS.UM.ProvValidationを入力します。
「Lookup Type」オプションを選択します。
「Lookup Code Information」タブで「Add」をクリックします。
新しい行が追加されます。
「Code Key」列に、プロセス・フォーム・フィールド名を入力します。デコード列で、クラス名を入力します。
参照定義に変更を保存します。
Lookup.EBSHRMS.UM.Configuration参照定義を検索して開きます。
次の値を使用してエントリを作成します。
コード・キー: Provisioning Validation Lookup
デコード: Lookup.EBSHRMS.UM.ProvValidation
参照定義に変更を保存します。