| Oracle® Health Sciences Data Management Workbench User's Guide Release 2.3.1 Part Number E35217-02 |
|
|
View PDF |
| Oracle® Health Sciences Data Management Workbench User's Guide Release 2.3.1 Part Number E35217-02 |
|
|
View PDF |
This section contains the following topics:
To find a clinical data model:
For study models, select the study and lifecycle area context in the Home page and then go to the Study Configuration page.
For library models, go to the Library page and select a Study Type.
In the Clinical Data Model field, type part or all of the model's name and press Enter. The system lists all data models in the study or library whose name contains the string you typed.
Select the clinical data model you want by clicking its name or pressing the Down arrow and press Enter.
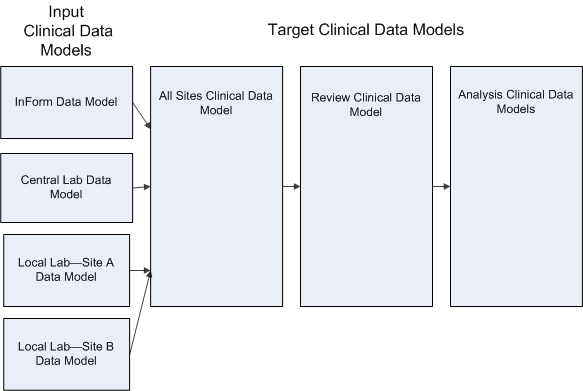
An Oracle Health Sciences Data Management Workbench (Oracle DMW) clinical data model is a logical group of tables.
You must create a clinical data model for each external data source—InForm or lab—in each study. When you upload SAS datasets or properly formatted text files, or connect to an InForm study reporting database, the system automatically creates tables in the corresponding model with the same structure.
You can create other clinical data models with tables that have structures better suited to reviewing, analyzing, or reporting data—for example, your company's internal standard or CDISC standards SDTM or ODM—and transform raw clinical data to these structures in an appropriate sequence; see Chapter 5, "Transforming Data to Standard Structures."
Library Models You can develop a library of clinical data models that are available for reuse in any study. If you update a library model, you can synchronize study models that were created based on the library model. However, if you have made changes in the study data model, you will lose them if you synchronize with the library model.
Study Models You can create a clinical data model for use in a particular study by:
Copying an existing library model into the study
Applying a study template that contains the model you want
Uploading SAS or text files from which the system can read the data structure and automatically create tables to match; see "Required Syntax for Table Metadata Text Files" for more information.
Manually defining each table and column
Before you can load data into a clinical data model you must install the model. This process creates a database schema for the model and creates actual database tables from the table metdata. You cannot run any transformation programs or validation checks until you install the model and the program.
When you install a clinical data model, the system automatically creates or updates a query that selects all columns and rows from all tables in the data model, including any masking of blinded data. The system uses this view to display data on the Listings page. This view also serves as the starting point for custom listings.
Note:
When you install a transformation, the system also installs its target clinical data model.The system supports blinding sensitive data at several levels: whole tables, whole columns, whole rows meeting specified criteria, and cells meeting specified criteria. You can specify masking values for use with blinded columns, rows, and cells.
See the Oracle Life Sciences Data Hub Implementation Guide for information about blinding-related security user privileges.
Note:
A cell is the intersection of a table column and row; a single data point for a record.Blinding requirements vary by source type:
Text files: Tables created by uploading text metadata files can be created with some blinding-related attributes set; see "Required Syntax for Table Metadata Text Files".
SAS: tables created by uploading SAS datasets are created as nonblinded by default. If data should be blinded, you must define blinding attributes manually for tables in the input data model.
Note:
You can create a table initially from a text metadata file and subsequently load data into it from a SAS file.InForm: Hidden data in InForm has different behavior and rules than blinded data in Oracle DMW, so you must manually define blinding within Oracle DMW for InForm data during initial study setup. By default, all tables are created as not blinded.
As you define downstream clinical data models for review and analysis, you must define the blinding attributes of tables and columns, rows, and cells that are targets of blinded source tables, including masking values.
The system does not allow you to map a blinded source table to a nonblinded target table unless you have special privileges and explicitly authorize the creation of the target table as nonblinded. This authorization is intended to be used only when the mapping is done in such a way that the target table contains no blinded data: only columns and rows containing nonblinded data are mapped to the target table. The authorization action is audited.
When you create a custom listing or a validation check, the system generates the target table. If any of the source tables are blinded, the system makes the whole target table blinded by default. To see any data on the Custom or VC Listings page, you must explicitly authorize the creation of the target table as nonblinded. You must then use the Expression Builder to mask specific columns, rows, or cells to ensure that no sensitive data that would break the blind is displayed. Special privileges are required for the authorization.
Note:
If the target table is blinded, users with the required privileges can view the real data (not the masking values) if they request to do so. Each such access is audited.A person with the required privileges can unblind the data in a table so that users with normal privileges can see the sensitive data, normally at the end of a study. Unblinding undoes all types of blinding: whole table, whole column, or row or cell values meeting specified criteria.
Special privileges are required to unblind data and to view unblinded data.
To unblind data a blinded table:
Navigate to the table in its clinical data model in the Study Configuration tab.
Select the table and click the Edit icon.
Deselect the Blinded check box.
Click OK.
You must define a primary key for every table you create. This is required to trace the data lineage of each record from one clinical data model to the next and to support sending discrepancies back to their source system and recognizing them when the source system sends them back to Oracle DMW. You can define a primary key in the Constraints user interface tab or by uploading a text file; see "Required Syntax for Table Metadata Text Files".
All the data you plan to compare in a validation check must be included in the same clinical data model.
You must check out a clinical data model to modify it. Each checkout creates a new version.
Each clinical data model begins with a validation status of Development and must be promoted to Quality Control and then Production before being used in a production environment; see "Using the Validation Lifecycle".
Clinical data models are required in every study.
To create a clinical data model:
Select the appropriate study in the Home page and click Study Configuration.
Click the Add icon (+) for Clinical Data Models. The Create Clinical Data Model window appears.
Enter a name and description for the model; see "Naming Objects" for restrictions.
Select the model type:
Input if its data will be loaded from an external system such as InForm or a lab.
Target if its data will be derived from another model in the system.
If you selected Input, select an Input Type:
File if you plan to load data from files, as from a lab.
InForm if you plan to load data from InForm. In this case, skip the next step. Click OK and go to "Configuring the InForm Connector".
File Type (Required if Input Type is File): Select the type of file to be loaded into this model: SAS or Text. If the lab that is sending you data for this model may send both types of files, you must define two models, one for each file type.
Under Select from source select the source, if any:
None to define tables and columns manually.
Load from file to create tables by uploading files. The system can create tables from SAS Transport (CPort or XPort) files, or a .zip file that contains one or more SAS datasets or text metadata (.mdd) files. Metadata files are the only way to automatically create tables with all blinding attributes set; see "Required Syntax for Table Metadata Text Files".
Note:
You can create a table initially from a metadata file and subsequently load data into it from a SAS file.Browse to the file.
Import from Library to copy a library model. Additional fields appear.
You can type all or part of the name of the model you want to copy and/or the library that contains it to filter the models displayed. The library, or namespace, is the therapeutic area or whatever other category your company uses.
Select the model and click OK.
Click OK.
Notes:
If you have not already created a primary key for every table in the model, you must do so and then install or reinstall the model.If the model is an input model, configure its method of importing data:
For InForm models, go to InForm Configuration; see "Configuring the InForm Connector".
For File models, go to Watcher Configuration; see "Configuring File Watcher".
Click Install Model. You must install the model before you can load data. The model must be installable.
A model is not installable if it does not have any tables or if any of its tables are not installable. A table is not installable if it has no columns.
In addition, the table must have a primary key constraint and if the table has a Blinding Flag set to Yes, blinding must be completely defined. However, these requirements do not prevent the installation of the model.
This section contains the following topics:
If you create a study model from a library model or a study template, all the tables and columns are included. If you are creating an InForm input model, the system creates tables and columns automatically; you can skip this section and go to "Configuring the InForm Connector".
You can upload certain types of files (see below) into a clinical data model to automatically create a table with columns in the same structure as in the file. You can do this either when you first create a model or afterward by modifying the model:
Navigate to the clinical data model to which you want to add a table.
Select the model and click Check Out. (If someone else has checked it out, you cannot work on it.)
Click the Edit icon (a pencil) in the upper left corner. The Edit Clinical Data Model Table window opens.
Under Select from source, select Load from file. A Browse field appears.
Browse to the file you want to load and click Browse. The file must be one of the following and must be compatible with the File Input Type setting for the model:
SAS dataset—creates one table
SAS CPort file—creates multiple tables
SAS XPort file—creates multiple tables
MDD file—creates one table
Zipped file containing one or more .mdd files (one .mdd file per table).
You can include data files in the zipped file; they must have an extension of .txt or .csv and contain data in the required format; see "Required Syntax for Table Metadata Text Files". Metadata and data files must use the table name as the file name, plus the appropriate extension.
Click OK. See "Setting Additional Attributes" below.
To add tables to the clinical data model manually or to specify blinding attributes:
Navigate to the model to which you want to add a table. Check out the model if it is not already checked out.
Note:
Do not make structural changes to tables in InForm models; see "Modifying an InForm Input Model" for information on the changes that are and are not allowed.In the Tables tab, click the Add icon (+). The Create Clinical Data Model Table window opens.
Enter values in the following fields:
Name: Enter a name for the table; see "Naming Objects" for restrictions.
Description: (Optional) Enter a description of the table.
Oracle Name: By default, the system populates this with the value you entered for the name. However, it should not be longer than 30 characters; see "Automatic Name Truncation".
SAS Name: By default, the system populates this with the value you entered for the name. However, it should not be longer than 32 characters; see "Automatic Name Truncation".
SAS Label: (Optional) By default, the system populates this with the value you entered for the name. It can be up to 256 characters.
Alias: Enter an alternate name for the table to be used consistently across studies for tables that store the same type of information but may have different names; for example, if the table's name is DEMO or DEMOG, enter DEMOGRAPHY. The system uses aliases to generate proposed mappings between tables in different models.
You can use aliases to provide an easily identifiable, user-friendly name for the table. However, shorter names work better in the user interface.
You can enter multiple aliases separated by commas, with no space after the comma.
UOW (Unit of Work) Processing Type: See "Setting Data Processing-Related Attributes"
SDTM Identifier: If this table corresponds to an SDTM standard Subject or Subject Visit table, select its identifier from the list; see "Adding Subject Visit and Subject Tables" for information about requirements.
Set blinding attributes; see "Setting Blinding-Related Attributes".
Click OK.
Oracle DMW tables have attributes that SAS datasets do not have. After uploading the file and creating the table(s) you must set these attributes in the clinical data model page.
A primary key is required. You can add a primary key to each dataset before uploading the dataset or upload the file to create the table(s), then click the Edit icon for each table in turn and follow instructions in "Adding Constraints to a Table".
By default, a table's Blinding Flag is set to No. If the table will ever contain blinded data, you must change this setting. If it will contain blinded data but you want to display the table's nonsensitive data, you must specify column-, row-, or cell-level blinding. You can set the Blinding Flag and Blinding Status in an .mdd file; see "Required Syntax for Table Metadata Text Files", but you must define the blinding type and criteria in the user interface; see "Data Blinding" for further information.
After you create a table, set its blinding attributes:
Blinded: Select if the table may ever contain any sensitive data that should be hidden. The default value is unchecked. This setting corresponds to the Blinding Flag table attribute.
Blinding Type: (Available only if Blinded is selected.) Select one:
Table: Select to hide all data in the table. The table appears in the Default Listings page, but none of its data is displayed unless a user with special privileges requests to view it. Such viewing is audited.
Column: Select to mask all values in one or more columns, or in certain rows. Then click OK and select the columns.
Note:
If you select Column, you must specify a masking value for the blinded column by editing the column definition in the Columns tab. If you want to mask the values only in some rows—cell-level blinding—you can enter masking criteria during column definition too; see "Adding Columns to a Table" and "Specifying Masking Attributes for a Column".Row: Select to hide certain rows in their entirety, or mask the values in certain cells.
Blinding Criteria: (Available only for Row-level blinding.) Click Expression Builder to specify which rows should be hidden from users with insufficient privileges. The Expression Builder window opens.
Build an expression. For example, to hide all rows whose Test column's value is LiverCount, select column Test, operator is, and value LiverCount.
Available operations include: less than, less than or equal to, greater than, greater than or equal to, is, is not, is blank, is not blank.
You can add as many criteria as you need, combining criteria with and, or, not, or (). See "Using the Expression Builder" for more information.
After you create a table and define its primary key, set its UOW (Unit of Work) Process Type attribute; see "Data Processing Types and Modes".
Note:
You must define a primary key before you set the UOW Process Type attribute. When you define a primary key, the Process Type attribute value changes to Reload. Click the Edit icon (a pencil) to specify the UOW Process Type value.Select one of the following:
Non UOW: Jobs writing to the table will use Reload processing by default.
Subject: Jobs writing to the table will use UOW processing with Subject as the unit of work. The table must have a column designated with the Subject SDTM Identifier, and must have a primary key that includes the Subject column.
Subject Visit: Jobs writing to the table will use UOW processing with Subject Visit as the unit of work. The table must have one column designated with the Subject SDTM Identifier and another with the Visit SDTM Identifier, and both columns must be included in the primary key.
Tip:
Always define tables as UOW if the Subject column is part of the primary key and as Subject Visit UOW if both columns are part of the primary key, because:Many tables serve as both sources and targets, and defining tables with UOW processing facilitates UOW processing when the table serves as a source, even if it is not possible to use UOW processing when the table is a target—for example, for tables whose data is loaded from an external system.
If a table is defined as UOW the system will use UOW processing if possible; if not it will use Reload processing.
See "Data Processing Types and Modes" and "Loading Data"for more information.
To add columns to a table manually:
In the Column tab, click the Add icon (+). The Create Clinical Data Model Column window opens. The system automatically checks out the table if it is not already checked out.
Enter values in the following fields:
Name: Enter a name for the column; see "Naming Objects" for restrictions.
Description: (Optional) Enter a description of the column.
Oracle Data Type: Select the appropriate data type: Varchar2, Number, or Date. All standard rules for Oracle data types apply.
DATE. For each Date value, Oracle stores the following information: century, year, month, date, hour, minute, and second. Although date and time information can be represented in both character and number datatypes, the Date datatype has special associated properties.
NUMBER. Stores zero, positive, and negative fixed and floating-point numbers. A Number column can contain a number with or without a decimal marker and/or a sign (-).
VARCHAR2. Specifies a variable-length character string. For each row, the system stores each value in the column as a variable-length field unless a value exceeds the column's maximum length, in which case the system returns an error.
Length: The requirements vary according to the data type:
DATE: No length required.
VARCHAR2: (Required) The default value is 50. The value must be between 1 and 4000.
NUMBER: (Required) The default value is 10. The maximum value is 38.
If the data type is Number you must also enter a value for Precision; the total number of digits to the right of the decimal point allowed. For example, if Precision is set to 2 and a data value of 34.333 is entered in this column, the system stores the data value as 34.33. Oracle guarantees the portability of numbers with precision ranging from 1 to 38.
SDTM Identifier: If the column corresponds to one of the standard identifiers supported by DMW and has a compatible data type, it is good practice to select it from the list because the system uses this information in several ways; see "Using SDTM Identifiers for Columns".
Oracle Name: By default, the system populates this with the value you entered for the name. However, it should not be longer than 30 characters; see "Automatic Name Truncation".
SAS Name: By default, the system populates this with the value you entered for the name. However, it should not be longer than 32 characters; see "Automatic Name Truncation".
SAS Label: (Optional) By default, the system populates this with the value you entered for the name. It can be up to 256 characters.
SAS Format: By default, the system enters a dollar sign ($) followed by the value you entered in the Length field.
Default Value: (Optional). You can enter a value to serve as the default for this column.
Aliases: Enter one or more aliases, or alternate names for the column. If you want more than one alias, enter a comma-separated list with no spaces; for example: dm,demo,demog,demography
The system uses these in automapping transformations.
Nullable: If selected, having a value in this column is not required. This is the default value. If not selected, all rows must have a value in this column.
Code List: (Optional) If the column should be populated with a limited set of values that are defined in a code list, select the appropriate therapeutic area (or other category) and then the code list. You can apply a code list only to columns with a data type of varchar2.
Note:
If the table may need to be pivoted from a horizontal (short fat) structure to a vertical (tall skinny) structure during a transformation, the pivot column must be associated with a code list; see "Pivot".Enter masking attribute values; available only if the table has a masking type of Column; see "Specifying Masking Attributes for a Column".
Click OK.
If a column corresponds to one of the standard identifiers supported by DMW and has a compatible data type, it is good practice select it from the list. The system uses these identifiers:
In the Automap feature for transformations.
USUBJID and VISITNUM SDTM identifiers are required in any table to support filtering records in the Listings pages.
USUBJID and VISITNUM SDTM identifiers are required in tables supporting Subject Visit Unit of Work processing.
USUBJID is required in tables supporting Subject Unit of Work processing.
Oracle DMW supports these identifiers:
Actual Visit Date (Not an SDTM variable; date)
Country of Investigator Site (COUNTRY; varchar2)
Visit Cycle (EPOCH; varchar2)
Investigator ID (INVID; varchar2)
Investigator Name (INVNAM; varchar2)
Site ID (SITEID; varchar2)
Site Name (Not an SDTM variable; varchar2)
Study ID (STUDYID; varchar2)
Subject ID within study (SUBJID; varchar2)
Unique Subject ID across studies (USUBJID; varchar2)
Visit Name (VISIT; varchar2)
Visit Day (VISITDY; varchar2)
Visit Number (VISITNUM; number)
Visit Start Date (SVSTDTC; varchar2)
If you selected a blinding type of Column for a table, at least one of the columns in the table must have a masking level specified as either column or cell. The default value is None, so you do not need to change nonblinded columns.
Select the column and click the Edit icon.
Select a Masking Level:
Cell: Masks the real data only in certain rows in this column. You must enter masking criteria to specify which row values are masked.
Column: Masks the real data in this column in every row.
None: No rows are masked in this column.
Masking Value: Do one of the following to specify what value(s) to display instead of the real values:
Enter a constant value to be displayed in every row.
Enter an expression that generates multiple values for the system to display.
Use the expression builder to create an expression to generate multiple values for the system to display.
Masking Criteria (Required only for cell-level masking): Click the Expression Builder icon to specify the criteria for blinding cells in the column; see "Using the Expression Builder".
All clinical data model tables must have a primary key. This is required to support data lineage tracing; see "How the System Tracks Data Lineage". If you create tables by uploading text files you can define constraints at the same time; see "Required Syntax for Table Metadata Text Files". InForm tables' constraints are imported as part of a metadata load and cannot be modified in the input model.
If you upload SAS files you must create the primary key and any other constraints manually:
Navigate to the model that contains the table and select the table in the Tables tab.
In the Constraints tab, click the Add icon (+).
Enter values:
Constraint Enter a name for the constraint. It must be unique among constraints for the table and must not contain special characters or Oracle or SQL reserved words.
Description (Optional)
Constraint Type Select one:
Bitmap Index: A bitmap index stores rowids (row IDs) associated with a key value as a bitmap. Each bit in the bitmap corresponds to a possible rowid. If a particular bit is set, the row with the corresponding rowid contains the key value.
Check: The check constraint allows you to specify allowable values for a particular column. Enter one allowed value in the Add Value field and click the arrow icon to move the value into the right-hand column; repeat for each value.
If any row contains a different value for the column, the system does not insert the record but generates an error to the program writing to the table instance. If the program does not handle the error, the job fails.
Note:
You can also use code lists to specify allowed values for a column, but the system behavior is different: it inserts the record with the nonconforming value and reports a violation.Non-Unique Index: A non-unique index keeps rows sorted on the specified column or columns to speed up queries.
Primary Key: (Required) A primary key is a column or set of columns whose value(s) identify a row in a table as unique. The system uses the primary key to trace data lineage; see "How the System Tracks Data Lineage".
Primary key columns cannot have a null value in any row.
The system automatically creates an index based on the primary key, which it uses to enforce a unique constraint and to speed up queries on the table.
Check Supports Duplicate if you want to support inserting records with the same primary key value within a single data load, which is normally not desirable but may be required in a few cases. Selecting this option ensures that all records are loaded and not deleted but requires careful checking of the data. See "Supporting Duplicate Primary Keys in a Load" for more information.
Unique Key A unique key is similar to a primary key in that it can include one or more columns whose value(s) identify a row as unique. The difference is that the system allows null values in the columns that are part of a unique key.
Any number of rows can include null (empty) values. A null in a column (or even all nullable columns in a composite unique key) satisfies the unique key constraint. However, you cannot have identical non-null values in the columns of a partially null composite unique key constraint.
Notes:
The Not Null constraint is handled as an attribute called Nullable for each column.For more information on Oracle constraints, see Oracle® Database SQL Language Reference 11g Release 2 (11.2) at http://docs.oracle.com/cd/E11882_01/server.112/e26088.pdf
Columns: To include a column in the constraint, select it from the list on the left and use the arrow icon (>>>) to move it to the right.
Oracle DMW supports filtering data and discrepancies by subject and visit. You may wish to track subject visit completeness using flags and custom programs. To support this functionality, you must include one Subject Visit table in at least one clinical data model in each study.
Oracle DMW ships with SDTM-compatible tables that you can copy. Alternatively, you can designate existing tables as your Subject and Subject Visit tables as long as they comply with the requirements in the following sections:
Although Oracle DMW ships with both Subject and Subject Visit tables, the system uses only the Subject Visit table to support filters.
To copy Subject or Subject Visit tables into a clinical data model:
In the Study Configuration page, select the clinical data model, check it out, and click Copy Subject/Visit from Library. The Copy Subject/Visit from Library window opens.
Select one:
Copy from Library: Allows you to copy the Subject, Subject Visit, or both tables created in a library clinical data model by your company; see "Subject Visit Table Requirements".
Default Structure: Allows you to copy the Subject, Subject Visit, or both tables that are shipped with Oracle DMW. The table and columns are already associated with the appropriate SDTM identifiers; see "Shipped Subject Table Metadata" and "Shipped Subject Visit Table Metadata".
If you selected Copy from Library, select the study type—therapeutic area or other category—that contains the library model whose table(s) you want to copy, and then select the library model.
If you selected Default Structure, proceed to the next step.
Select one:
Subject to copy only the Subject table
Subject Visit to copy only the Subject Visit table
Both to copy both
Click OK.
If you designate an existing table as the Subject Visit table, it must satisy these Subject Visit Table Requirements. Alternatively, you can copy the shipped Subject table; see Shipped Subject Visit Table Metadata.
If you designate another table as the SDTM Subject table:
Its primary key must include the Unique Subject ID and Visit Number columns in that order, and no other columns.
These columns must be linked to USUBJID and VISITNUM SDTM identifiers.
Filter Requirements See "Defining Tables to Support Filtering in the Listings Pages" for information on additional requirements.
The shipped Subject Visit table follows SDTM specifications.
Primary Key The shipped Subject Visit table's primary key is the USUBJID and VISITNUM columns.
Columns The shipped Subject Visit table columns are:
STUDYID (Study Identifier) is the unique ID of the study.
DOMAIN (Domain Abbreviation) is an abbreviation for the CDISC domain; for example AE, CM. In the Subject Visit table the value must be SV.
USUBJID (Unique Subject Identifier) is the unique ID for each subject across all studies for all applications or submissions involving the product.
VISITNUM (Visit Number) is the clinical encounter number; a numeric version of VISIT, used for sorting. Decimal numbering may be useful for inserting unplanned visits.
VISIT (Visit Name) is the protocol-defined description of the clinical encounter of description of unplanned visit. May be used in addition to VISITNUM and/or VISITDY as a text description of the clinical encounter.
VISITDY (Planned Study Day of Visit) is the planned study day of the start of the visit based on RFSTDTC in Demographics.
SVSTDTC (Start Date/Time of Visit) is the start date/time of a subject's visit, represented in ISO 8601 character format.
SVENDTC (Study Day of End of Visit) is the end date/time of a subject's visit, represented in ISO 8601 character format.
SVSTDY (Study Day of Start of Visit) is the study day of start of visit relative to the sponsor-defined RFSTDTC.
SVENDY (Study Day of End of Visit) is the study day of end of visit relative to the sponsor-defined RFSTDTC.
SVUPDES (Description of Unplanned Visit) is a description of what happened to the subject during an unplanned visit. Null for protocol-defined visits.
Note:
The system does not use the Subject table internally.The shipped Subject table is based on the CDISC SDTM Implementation Guide (Version 3.1.2). It includes all SDTM columns and also COUNTRY and SITE_ID columns.
Primary Key The shipped Subject table's primary key is the Subject ID, called USUBJID.
Columns The shipped Subject table columns are:
STUDYID is the unique ID of the study.
DOMAIN is an abbreviation for the SDTM Domain.
USUBJID is the unique ID for each subject across studies. This is the primary key of the table.
SESEQ is the sequence number.
ELEMENT is a basic building block for time within a study.
ETCD is the element code.
SESTDTC is the start timestamp of the element, including date and time.
SEENDTC is the end timestamp of the element, including date and time.
TAETORD in the planned order of elements within a study arm.
EPOCH is a set of elements.
SEUPDES is a description of an unplanned element.
Users can create and reuse filters in the Listings pages to display only the data they need to work on at a particular time; see "Creating and Using Filters". To support this functionality, you must define tables as follows:
The Filter logic looks first at the Subject Visit table and finds each distinct Subject/Visit combination that meets the criteria of the filter. It then displays those Subject/Visits in the table that the user is viewing in the Listings page.
The user must specify the clinical data model that contains the Subject Visit table to use. The table can be in any clinical data model, but the user must have view privileges on the table. Therefore, if you have one group of users with security privileges to only one clinical data model and another group of users with access only to a different model, you need to have a Subject Visit table in both models or grant all users access to the Subject Visit table in one model. You can grant access to a single table in a model; see "Applying Security".
You must create at least one Subject Visit table in one clinical data model that has the SDTM ID for Study Visit table and meets the Subject Visit Table Requirements.
In addition, the user can filter on values in certain Subject Visit table columns only if the Subject Visit table contains the columns and the columns are linked to the following SDTM identifiers: COUNTRY, SITENAME, SITEID, INVNAM, INVID, EPOCH, VISIT, VISITNUM, VISITDY, SVSTDTC, SUBJID, USUBJID. See "Using SDTM Identifiers for Columns".
Filter logic requires a join of the Subject Visit table with the table being viewed in the Listings page on the USUBJID and VISITNUM columns. Therefore, all tables whose records users may need to view and act on must have columns for unique subject ID and visit number, and those columns must be linked to the corresponding SDTM identifiers USUBJID and VISITNUM.
A special privilege is required for making filters public. There is a separate privilege for each lifecycle area. These privileges, MRKFILPUB_DEV, MRKFILPUB_QC, and MRKFILPUB_PROD, have been added to the predefined roles DME_STUDY_DEVELOPER, DME_STUDY_QC, and DME_STUDY_PROD, respectively. The predefined role DME_STUDY_ADMIN has all three.
The system uses a database connection to import data and metadata from InForm and a web service to send discrepancies and query comments back to InForm. You configure both for each study's InForm input clinical data model in the Development lifecycle area. The system applies these settings to the QC and Production lifecycle areas as well.
Note:
There can be only one InForm clinical data model in a study, and it must be configured from a metadata load from the InForm reporting database. Do not make any manual structural changes to tables or columns in the InForm model. It must reflect the structure in InForm. If you make changes to the structure in InForm, reload the metadata. See "Modifying an InForm Input Model" for details.InForm models are not included in study templates.
Navigate to the study and model and then the InForm Configuration tab.
Remote Location: Select or add the InForm reporting database; see "Adding or Editing a Remote Location". You can also correct existing remote locations as necessary by selecting them and clicking the Edit icon.
Remote Study Account Name: Enter the name of the database account that owns the study tables and views in the InForm reporting database to be loaded into Oracle DMW.
InForm LifeCycle: Select the InForm lifecycle stage—Development, Quality Control, or Production—from which you want to load data into the current DMW lifecycle area. You can load data from any of these lifecycle stages into an Oracle DMW Development or QC lifecycle area. You can load only Production data into a Production lifecycle area.
You select the Oracle DMW lifecycle area context when you select a study in the Home page.
Webservice Location: Select the appropriate web service location or add it; see "Adding or Editing a Web Service Location". This is required to send Oracle DMW-originated discrepancies to InForm as InForm queries.
You can correct an existing one if needed by selecting it and clicking the Edit icon.
Schedule Production Data Load: Select check box to schedule data loads at regular intervals in a production environment. This option is available only when the current lifecycle context is Production and you must have data load privileges to set the schedule; see "Scheduling Data Loads in the Production Lifecycle Area".
In all lifecycle areas you can load data manually as needed by clicking Load Data if you have the required privileges; see "Loading Data".
InForm URL: Enter the URL for the study's InForm website; for example:
http://your_InForm.your_company.com/your_trial/pfts.dll
After you enter a value, an arrow icon appears. Click the icon to test the URL you entered. If the InForm login screen opens, you have succeeded. (The new window may open behind the current one.)
Save.
Click Load Metadata. The system reads table structures for the study in InForm and recreates them in Oracle DMW. This button is displayed only if you have the privileges required to use it. To check the progress of the job, click Refresh.
In the Development lifecycle area, loading metadata automatically installs the area and no additional installation is required. In the QC and Production lifecycle areas you must click Install Model to create the actual database tables based on the InForm metadata, which is required before loading data; see "Loading and Synchronizing InForm Metadata". You can then load data; see "Loading Data".
You can add or edit a remote location only if data loading is not enabled.
Provide information about the InForm reporting database for the study to create the database link:
Enter a value for:
Name: Enter a name for the InForm database. Do not use spaces, slashes, or special characters other than underscore (_).
ConnectString: Enter the text for the Using clause of the Create Database Link SQL statement. This is normally the same as the Description clause of a TNSNAMES definition; for example:
(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=host_name.company_domain.com)(PORT=1521))(CONNECT_DATA=(SERVER=DEDICATED)(SERVICE_NAME=trial_name.world)))
Note:
No spaces are allowed.Username: Enter the name of the Oracle DMW read-only access account that has been set up in the InForm database for this remote location. See the section "Create Oracle Accounts for the DMW InForm Connector" in the Oracle Health Sciences Data Management Workbench Installation Guide for further details. The system will use this account to connect.
Password: Enter the password for the same user account. The system changes and encrypts the password after creating the database link.
In the unlikely event that you need to change the password, your InForm database administrator must change the password for the Oracle DMW read-only access account. You can then select Enable Password Entry? in the Edit Remote Location window and enter the new password. The system then recreates the database link and changes and encrypts the password.
Click Test Connection to make sure it is set up correctly. The system returns a success or failure message above the Test Connection button.
Click OK.
You can add or edit a web service location only if data loading is not enabled.
Enter a value for:
Name: Enter a name for the web service location.
WSDL URL: Enter the web service URL for the InForm Adapter's Enhanced Discrepancy Interface; for example:
http://your_InForm_Adapter_Server_Name/InFormAdapter/Discrepancy/ DiscrepancyService.svc?wsdl
Trial Name: Enter the study name as defined when the trial was registered in the InForm Adapter; see the Oracle Health Sciences InForm Adapter Installation Guide for details.
Username: Enter the name of the account set up for authenticating Oracle DMW web service transactions. The default name is DMW_AUTH. See the section "Create Users in InForm" in the Oracle Health Sciences Data Management Workbench Installation Guide.
Enter the name of a valid user account on the web service location. The system will use this user name to connect.
Note:
The Username and Password fields are not displayed if your company chose to install Oracle DMW supporting HTTP, not HTTPS.Password: Enter the password required for the same user account. The system encrypts the password.
Click Test Connection to make sure it is set up correctly. The system returns a success or failure message above the Test Connection button.
Click OK.
In an InForm model's InForm Configuration tab, click Load Data to immediately load the latest data from InForm.
The system loads data into the lifecycle area currently in context—the one you selected on the Home page, now displayed at the top of the page.
The InForm lifecycle stage of the data being loaded depends on the setting of the Remote Study Account field, whose lifecycle stage is indicated in the InForm Lifecycle field.
Data Loading Rules You can load data at any InForm lifecycle stage into a model's Development or QC lifecycle area. You can load only InForm Production data into a model's Production lifecycle area.
To load data into either the QC or Production lifecycle area:
The validation status of the model must be equal to or greater than the model's lifecycle stage; that is, a QC lifecycle model must have a validation status of at least QC, and a Production lifecycle model must have a validation status of Production.
The most current version of the model must be installed.
Data loading must be enabled, not suspended.
If you need to stop data loading temporarily, click Suspend.
The system replaces the Suspend button with the Resume button. When the issue is resolved, click Resume.
If the lifecycle context is Production and you have Production data loading privileges, you can schedule data loads:
Install the model if it has not already been installed.
If the status currently allows data loading—if the Suspend button is active— click Suspend.
Specify a Fetch Frequency: the number of minutes between automatic data loads.
Note:
A data load will not start until the previous one completes.Save.
Click Resume. The first scheduled data load starts immediately.
If you have the required privileges, you can click the Load Metadata button to create or update tables in the InForm clinical data model. In the Development lifecycle area, loading metadata automatically installs the area and no additional installation is required. In the QC and Production lifecycle areas you must click Install Model to create or update the actual database tables based on the InForm metadata, which is required before loading data.
If InForm data structures are changed during the course of the study—for example, columns added or increased in length—the system detects these changes during the next data load and, if the user associated with the data load has the appropriate privileges, automatically reloads the metadata and synchronizes the changes.
If the user doesn't have privileges to load metadata:
The data load fails.
The log file states that metadata must be reloaded.
The message "Metadata needs to be reloaded" is displayed in the InForm Configuration tab for the clinical data model.
A user with the required privileges must then click the Load Metadata button to reload and synchronize metadata.
The required privileges for InForm configuration, including metadata loading, are part of the roles DMW_STUDY_INFORM_CONFIG and DMW_STUDY_ADMIN .
Data loading, suspending, and resuming privileges are included in the roles DMW_STUDY_DEVELOPER, DMW_STUDY_QC, and DMW_STUDY_PROD for each lifecycle area, respectively, as well as DMW_STUDY_ADMIN.
This section contains the following topics:
For input clinical data models that load data from files, such as lab models, configure the File Watcher feature to look for data files that match your specifications in a location created for this purpose at intervals you specify. When the File Watcher service finds a file that matches your specifications in the relevant location it puts it in the queue for the Distributed Processing (DP) Server to load data from the file into the database tables of the input model.
You can load data in SAS CPORT or XPORT files or .zip files with multiple SAS datasets or text files; one dataset or text file per clinical data model table. Text data files can be .txt or .csv format, and .txt files can be delimited or use fixed column lengths.
The data in the file and the tables and columns in the clinical data model must have the same structure or the data load fails. You can create tables and columns initially by uploading the same data files you want to load, but if structural modifications are required afterward you must make them manually in the user interface and reinstall the model.
Each data load can automatically trigger downstream transformations and validation checks so that the data updates are automatically processed and propagated to your downstream models. To set this up, check the Can Trigger attribute for this model when you add it as a source to a transformation; see "Creating Model Mappings".
By default, each study has six File Watchers, one for each combination of the two file types—SAS and text— and three lifecycle stages—Development, Quality Control, and Production. Each of the six study File Watchers watches a single folder to detect files to load. You specify one or more file name patterns to watch for for each file-type input clinical data model.
You can configure File Watcher for a clinical data model either before or after installing the model.
You can see information about data files that have been detected and submitted for loading on the Detected Files tab; see "Viewing Detected Files and Forcing Actions".
See "Setting Up File Watcher for the Instance".
To configure the study File Watcher for the clinical data model:
In the Study Configuration page, navigate to the clinical data model's Watcher Configuration tab. The page displays the type of file being loaded (specified during clinical data model definition) and the three study File Watchers for that file type.
Enter data load parameter values. These differ for each file type:
In the Data Source field, select the name of the original source of the data being loaded, such as Lab XYZ.
Your administrator creates a list of data sources; see "Viewing and Setting Up Lab Data Sources".
Save. You must also create one or more file specifications; see "Creating File Specifications"
For SAS files there are two data load parameters:
SAS File Type: The allowed values are CPORT, XPORT, and SAS Dataset.
Max Errors: The number of errors allowed per dataset before the load fails.
For Text files you must specify either:
Fixed: If you specify Fixed format, the system uses the target table column length to determine the length of each data value. The file must contain the correct number of characters for each value in each record, in column order.
Delimited: The system uses a delimiter character you specify to determine when one column value ends and the next one begins. You must also specify:
Delimiter Character: For delimited files, enter the character to be inserted between column values in each row; for example, a comma (,) or a pipe (|).
Enclosing Character: If any data value may contain the delimiter character, you need to surround each data point with another character. Specify the character used to enclose each value. The default character is double quotation marks (").
Note:
With either Fixed or Delimited format the files can have an extension of either .txt or .csv, and you can upload multiple text files at the same time by including them in a .zip file. The system extracts and processes the files.For either type, specify:
Skip Records: If you want to prevent loading records at the beginning of the file, enter the number of records you want the system to skip. The default value is zero (0).
Max Errors: Tolerance factor; the maximum number of invalid rows you are willing to tolerate before the load process with an error. The default value is 0. See "Format Checks on Loaded Files" for more information.
Rows Before Commit: Enter the number of rows you want the system to process before committing processed rows to the database.
Date Format: Enter the exact date format used in the data file, if any. Do not enter a value here if the data file does not contain a date field. When you start to type a value, the system displays a list of values from which you can select.
File specifications determine which of the files that are detected by the Watcher will actually be loaded into the clinical data model lifecycle area. All of the study's files for a particular lifecycle stage are in the same watched folder, so you must use different file naming conventions for each clinical data model.
File specifications contain a file name pattern to watch for and a schedule for loading detected files that match that file name pattern.
When you create or update a File Specification, log in as a user with the security privileges required to load data into the corresponding lifecycle tables. The system uses the account that defined or most recently updated the File Specification to run the data load job.
Under Watcher Policies, click the Add icon (+) and enter values:
Enter a name and description for the File Specification.
File Name: Enter a file name or regular expression for files to be loaded into the selected lifecycle stage for the clinical data model. All of the study's files for a particular lifecycle stage are in the same watched folder, so you must be sure that file names are unique across all models in the study. For example, you can use a naming convention includes the model name, but using the model name is not required.
For example, Study A with file input models DMX, DMY, and DMZ, where labs are expected to include a date just before the extension:
StudyA_DMX_.*.zip
StudyA_specialLabs_.*.cport
StudyA_DMZ_.*.zip
Note:
File name pattern regular expressions use the POSIX standard Extended Regular Expression syntax found here:http://docs.oracle.com/cd/B28359_01/server.111/b28286/ap_posix001.htm.
An asterisk (*) in POSIX Extended Regular Expression syntax looks for any preceding character. The dot (.) before the asterisk (*) in the examples above means "any character or no characters."
Note:
Any File Watcher Policy created in Oracle DMW 2.3 will continue to work in 2.3.1, now called a File Specification. The 2.3.1 File Name field contains the value defined as the Child Path in 2.3, which could include folders. In 2.3.1 the system continues to watch for the folder and file pattern specified as the Child Path, even though the new File Name field cannot include a folder. If you try to change a File Name value that includes a folder, you get an error.Execution Priority: Enter the priority for loading data corresponding to this File Specification relative to others: Low, Normal, or High. The system uses this value to determine when to run these load jobs.
Incremental: The system loads all data in the file, inserting new records, updating records with changes, and refreshing the timestamps of records that are reloaded without change. It does not delete any records.
Full: The system inserts, updates, and refreshes reloaded records as in incremental processing and in addition, compares the unique keys of records in the file to existing records and deletes any records that are not included in the file.
UOW Load: For each UOW (Unit of Work—either subject or subject visit) that has any new or changed records, the system processes all records, inserting new records, updating records with changes, and refreshing the timestamps of records that are reloaded without change. The system does not process records for units of work—subjects or subject visits—that have no new or changed records. The system deletes any existing records that are not reloaded within processed units of work. It does not delete records that are not present in the source if no other records from the same unit of work are reloaded.
Tip:
You may want to create two File Specifications, one for a frequent Incremental or UOW Load and another for a less frequent Full load. Incremental loads are faster and can be run on a subset of data. Full loads are more time-consuming but they detect when to delete data. Be careful to always load the complete set of current data when you use Full processing; see Chapter 9, "Data Processing".Note:
All deletions are "soft" deletions: records have an end timestamp equal to the load's date and time and are no longer available in the system. However, they still exist in the database and have an audit trail.Dataload Type: Select Immediate or Scheduled.
Immediate: The Watcher searches continuously and queues the job as soon as it finds a file. This option loads data as soon as possible, continuously.
Scheduled: The Watcher searches at the interval you specify and queues the job as soon as it finds a file.
Frequency: If you selected Scheduled, select a frequency for the Watcher Policy to look for a new data file in the specified location in days, hours, or minutes.
Start Datetime: If you selected Scheduled, enter the date and time when you want scheduled file watching to begin.
End Datetime: Enter the date and time when you want file watching to end. You can enter a date far in the future and change it at any time.
Click OK to save.
You can stop the system from watching for a particular filename pattern by selecting the file specification and clicking the appropriate icon:
If the file specification is currenting running, select it and click the Suspend icon (||).
If the file specification is currenting suspended, select it and click the Resume icon (>).
If you configured File Watcher for a model in Oracle DMW 2.3, you can upgrade it to the 2.3.1 structure, which is simpler and more secure, by clicking the Migrate button.
Migrated Watchers look for files in the folders defined for the Study File Watchers; see "Setting Up Study File Watchers". Existing File Specifications will continue to work but you may wish to delete these File Specifications and create new ones to coordinate with the 2.3.1 Study File Watchers.
In the Detected Files tab you can see a list of all detected files and their status.
You can also load or reload and delete files from here, overriding any scheduled load or deletion, by selecting the file and clicking Data Load or Delete. This may be useful if a load failed and needs to be retried, or if a file was faulty.
You can see information about files that have been detected and submitted. Once a data load job has been started, you can see the job status in the Data Loads tab on the Home page; see "Viewing Data Load Information". To see the data, go to the Listings page.
For each detected file the system displays:
File Name
File Spec Name: The name of the File Specification
Status: The possible statuses are:
DETECTED: The file has been detected in the watched folder but has not yet been submitted. (The scheduled submission time is in the Data Load Date column.)
SUBMITTED: The file has been submitted. This status does not change when the load is completed. However, you can go to the Data Load tab on the Home page to see if the load was successful.
MISSING: The file was detected but deleted before or after it was submitted, but before the scheduled deletion date.
DELETED: The file was deleted by File Watcher as scheduled.
File Modified
Data Load Date
Deletion Date
Detection Date
Error
Date Missing
If you have the required privileges, you can:
Load Data You can select a file and click Load Data to immediately load the file; for example, if the original load failed. The system will not load the file on the scheduled date, if any, after a manual load.
Delete You can also delete any of the files listed at any time.
See "Viewing Data Load Information" for job statuses. To see the data, go to the Listings page.
Each study has three lifecycle areas: Development, Quality Control, and Production. Each clinical data model has a validation status of either Development, Quality Control, Production, or Retired. When you install a model, the system creates a database schema for it in the lifecycle area corresponding to its validation status. The schema also contains the installed packages for the transformation programs that write to tables in the model and the validation checks and saved custom listings that run on data in the model.
When you first create a clinical data model, the system gives the new model a validation status of Development.
When you have finished working on the model, upgrade its validation status to QA. The model then appears in the list of models in the QC lifecycle. A user with QC privileges can install the model in the QC area, creating a schema for the model and database tables in it for all the metadata tables. The QC user then upgrades the model's validation status to Production. A user with Production privileges can then install the model in the Production lifecycle area, creating a schema for it there.
When you check a model out to modify it, the system creates a new version of it with a validation status of Development. The installed version of the object in the QC and Production areas continue to function as before.
The system installs models in Upgrade mode, which can handle nondestructive changes to table structure like adding a column. However, if table metadata is changed in a destructive way, such as removing a column, the system displays a warning that installing the model would result in a loss of data. If you choose to continue anyway, the system drops and replaces the table and its data is deleted.
You must handle transformations and validation checks the same way—upgrade their validation status and then install them in the next higher lifecycle area.
You select the lifecycle area you want to work in at the bottom of the Home page in the Lifecycle Mode section. You may have privileges to work in only one.
To change the validation status of a clinical data model, table, transformation, validation check, or saved custom listing:
Select the object and click Update Validation Status. The object must be checked in. The validation status applies to the current checked in version.
The Validation Status Update window opens, displaying the current validation status.
From the Validation Status drop-down list, select the new status:
Development: This is the default status for all new objects and is intended for objects being worked on or tested.
Quality Control: This is intended as the status for objects that have passed initial testing and are undergoing formal testing. Objects must have a status of Installable to be promoted to QC from Development. Objects with this status are eligible to be in the Development or Quality Control Lifecycle area.
Production: This is intended as the status for objects that have passed formal testing and are suitable for use in an active or frozen study. Objects with this status are eligible to be in any lifecycle area, including Production.
Retired: Objects with this status are no longer available for use. If you set a library model to Retired, users can no longer create study models based on the library model. You cannot set an installed study model to Retired.
Click OK or, if your company's standards require supporting documentation such as test results or a requirements document to justify the change in validation status, click the + icon in the Supporting Documents pane. The Add Supporting Document window opens.
Enter a name and description for the document and browse for the document on your computer, then click OK. The system uploads the document.
To view data, a user must belong to a user group with access to the table containing the data. To create and modify studies, clinical data models, tables, validation checks, and transformations—all of which are metadata objects—a user must belong to a user group with access to the object. The user must also have a role in the user group with the privileges required to view data or create or modify the object.
Objects are contained within other objects: therapeutic areas (or another organizational category) contain studies, which contain clinical data models, each with a Development, Quality Control, and Production lifecycle area, which contain tables, transformations, and validation checks installed as database tables and packages. Studies also contain the metadata for models, transformations and validation checks; see "Object Ownership".
When you assign a user group to an object the user group assignment is automatically inherited by all the objects contained in it. For example, when a user group is assigned to a study, the user group has access to all objects in a study. Or, when a user group is assigned to a clinical data model, it has access to all objects in the model, including the Development, Quality Control, and Production lifecycle areas. If you want a user group to have access to only one lifecycle area, you must either assign it explicitly to the one it should have access to, or assign it at a higher level and revoke its access to the areas it should not have access to.
For information about setting up user groups, roles, and user accounts, see the Oracle Life Sciences Data Hub System Administrator's Guide.
To change user group assignments to an object:
Select the object and click Apply Security. The Apply Security window opens with the name of the object displayed and a list of all user groups currently associated with the object in any way. The Assignment Status column shows the current state of each user group's access to the object:
Inherited: The user group has access to the object because it was explicitly assigned to an object that directly or indirectly contains the current object.
Assigned: The user group has access to the object because it was explicitly assigned to the object.
Revoked: The user group does not have access to the object. Its inherited access has been revoked from the object.
User groups that do not have access to the object are not displayed.
In the Assign To field, select one of the following:
Metadata: This choice assigns the user group to the definitional metadata for the object. Access to object metadata is required to modify studies, clinical data models, tables, validation checks, and transformations.
Note:
To create models, transformations, and validation checks, the user needs to belong to a user group assigned to the study metadata, and have Create privileges on the object type to be created: model, transformation, or validation check. See the Oracle Life Sciences Data Hub Implementation Guide for more information.Development: This choice assigns the user group to the installed object in the Development lifecycle area database schema. This access is required for creating, modifying, or executing the object in the Development lifecycle area and loading or viewing data in the Development lifecycle area.
QC: This choice assigns the user group to the installed object in the Quality Control (QC) lifecycle area database schema. This access is required for testing or executing the object in the QC lifecycle area and loading or viewing data in the QC lifecycle area.
Production: This choice assigns the user group to the installed object in the Production lifecycle area database schema. This access is required for executing the object in the Production lifecycle area and loading or viewing data in the Production lifecycle area.
Make a user group assignment change:
To assign a user group that is not currently associated with the object, click Assign. The Assign User Group window appears. Query for the user group if necessary, then select it and click Apply.
To revoke the access of a user group that has an Inherited status, select the group and click Revoke.
To reinstate the access of a group whose status is Revoked, select the group and click Unrevoke.
To remove the access of a group whose status is Assigned, select the group and click Unassign.
This section contains the following topics:
See also "Adding and Modifying Tables Manually"
In target models and file-type input models you can create tables and columns initially by uploading SAS files, but if any modifications are required afterward you must make them manually in the user interface and reinstall the model.
Note:
DO NOT add or remove tables or columns or make any other structural changes to an InForm clinical data model. The InForm model must have exactly the same table and column structures as in InForm. If you change these structures in InForm, use the Load Metadata job in the InForm Configuration tab to synchronize the changes here. See "Modifying an InForm Input Model".However, nonstructural changes are allowed; see "Manual Changes Allowed in InForm Models".
To view or modify a clinical data model:
Navigate to the model in the Study Configuration or Library page.
To modify the model, click Check Out. The system creates a new version of the model for you to modify. This button is visible only if you have the privileges required to modify the model.
Make changes. If you have the required privileges, you can:
Add, modify, or delete tables by clicking on the appropriate icon and making the changes; see "Adding Tables to a Clinical Data Model".
Add, modify, or delete columns in a table by selecting the table in the upper pane and clicking the appropriate icon in the Columns tab and making the changes; see "Adding Columns to a Table".
Add, modify, or delete constraints in a table by selecting the table in the upper pane and clicking the appropriate icon in the Constraints tab and making the changes; see "Adding Constraints to a Table".
Update to Current Library Version If the study model was created from a library model and the library model has been updated, the Upgrade to Latest Version button appears. Click it to update your study model to the new library version.
Note:
Any changes that have been made to the study model will be lost.Update Validation Status Click this button to change the validation status (possible values are Development, Quality Control, or Production) or to upload a supporting document for the validation status change; see "Updating Validation Status". The system displays this button only if you have the privileges required.
Click Install Model. You must install the model after you make changes; otherwise the system continues to use the old version. The model must have a status of Installable.
A model is not installable if it does not have any tables or if any of its tables are not installable. A table is not installable if it has no columns.
The InForm model must have exactly the same table structures as in InForm. If you change these structures in InForm, use the Load Metadata job in the InForm Configuration tab to synchronize the changes automatically.
DO NOT make any manual structural changes in an InForm clinical data model, including:
Adding or dropping tables or columns
Modifying table or column names
Modifiying column data type, length, precision or nullable status
Adding or removing constraints or unique indexes
Automatic Synchronization If data structures are changed in InForm during the course of the study, the system detects these changes during the next data load and, if the user associated with the data load has the required privileges, automatically reloads the metadata and synchronizes the changes.
If the user doesn't have privileges, the dataload fails with a message in the log file that metadata needs to be reloaded. A user with the required privileges can then click the Load Metadata button to reload and synchronize metadata.
You can modify table and column attributes, including:
Blinding-related attributes
SAS-related attributes
Column and table aliases
To check out an InForm model:
Go to the InForm Configuration tab.
Click the Suspend button to suspend data loading. The Check Out button appears.
Check out the model.
Make your changes; see:
"Adding and Modifying Tables Manually" for information on adding tables aliases and SDTM identifiers—but do not add or remove tables or modify other things
"Adding Columns to a Table" for information on adding column aliases, code lists, and SDTM identifiers—but do not add or remove columns or do other things
Click Install Model. You must install the model after you make changes; otherwise the system continues to use the old version. The model must have a status of Installable.
A model is not installable if it does not have any tables or if any of its tables are not installable. A table is not installable if it has no columns.
To delete a clinical data model, select it in the Clinical Data Model pane and click the red X Remove icon. You must have the Remove Model privilege to do this.
If a clinical data model was created from a library model, and a new version of the library model exists, the Upgrade to Latest Version button appears. Click the button to synchronize the study model with the library model.
After you have installed a study clinical data model and loaded data into its tables, you can view the data in the Listings page; see "Viewing All Study Data Using Default Listings".
|
Copyright © 2013, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|