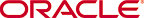| Oracle® Big Data Connectorsユーザーズ・ガイド リリース2 (2.3) E48215-03 |
|


 前 |
 次 |
この章では、ビッグ・データに対するRのサポートについて説明します。内容は次のとおりです。
Oracle R Advanced Analytics for HadoopはRパッケージのコレクションであり、次の機能を提供します。
Apache Hive表、Apache Hadoop計算インフラストラクチャ、ローカルR環境およびOracleデータベース表を操作するインタフェース
Hadoop MapReduceジョブとしてRまたはJavaで記述される予測分析技術、HDFSファイルのデータに適用可能
このパッケージは、他のRパッケージと同様にインストールしてロードします。簡単なR関数を使用して、次のようなタスクを実行できます。
Hive対応透過層を使用したHDFSデータへのアクセスとデータの変換
マッパーとリデューサを記述するためのR言語の使用
Rメモリー、ローカル・ファイルシステム、HDFS、HiveおよびOracle Database間でのデータのコピー
Hadoop MapReduceジョブとして実行し、それらの場所に結果を返すRプログラムのスケジュール設定
Oracle R Advanced Analytics for Hadoopでいくつかの分析アルゴリズムを使用できます。具体的には、線形回帰、予測用ニューラル・ネットワーク、低ランクの行列因数分解を使用した行列補完、クラスタリング、非負行列因子分解を使用できます。これらはJavaまたはRのいずれかで記述されます。
Oracle R Advanced Analytics for Hadoopを使用するには、MapReduceプログラミング、Rプログラミングおよび統計手法をよく理解しておく必要があります。
Oracle R Advanced Analytics for Hadoop のAPI
Oracle R Advanced Analytics for Hadoopでは、次の接頭辞の関数を使用して、ローカルRクライアントからApache Hadoopへのアクセスを提供します。
hadoop: Hadoop MapReduceへのインタフェースを提供する関数を特定します。
hdfs: HDFSへのインタフェースを提供する関数を特定します。
orch: 様々な関数を特定します。orchはORCH関数の一般的な接頭辞です。
ore: Hiveデータストアへのインタフェースを提供する関数を特定します。
Oracle R Advanced Analytics for Hadoopは、主なオブジェクト・タイプとしてデータ・フレームを使用しますが、HDFSとのデータ交換を行うためにベクトルや行列でも機能できます。APIは、Rの数字、整数および文字のデータ型をサポートします。
APIのすべてがORCHライブラリに含まれます。関数は、第9章にアルファベット順で示します。
HDFSに格納されるデータにOracle R Advanced Analytics for Hadoopがアクセスするには、入力ファイルが次の要件に従う必要があります。
MapReduceジョブの入力ファイルはすべて、1つの論理ファイルの一環として1つのディレクトリに格納される必要があります。有効なHDFSディレクトリ名とファイル名の拡張子が受け入れられます。
該当ディレクトリ内の、アンダースコア(_)で始まる名前のファイルは無視されます。
入力ファイルは、次のようにカンマ区切り(CSV)形式にします。
key := string | ""
value := string[,value]
line := [key\t]value
string := char[string]
char := regexp([^,\n])
入力ファイル形式の例
次に、受け入れられるCSV入力ファイルの例を示します。
キーを使用するCSVファイル:
"1\tHello,world" "2\tHi,there"
キーを使用しないCSVファイル:
"Hello,world" "Hi,there"
NULLキーを使用するCSVファイル:
"\tHello,world" "\tHi,there"
Apache Hiveは、HiveQLと呼ばれる問合せ言語(SQLとよく似ている)によって、代替のストレージおよび取得メカニズムをHDFSファイルに提供します。Hiveでは、分散処理にMapReduceが使用されます。ただし、データは構造化され、データ検出をサポートする追加のメタデータがあります。Oracle R Advanced Analytics for HadoopではHiveQLのデータ準備と分析機能が使用されますが、R言語構文も使用できます。
接頭辞がoreのR関数(ore.connectなど)を使用して、Hiveへの接続とオブジェクトの管理を行うことができます。Oracle R Enterpriseも使用する場合、これらの関数を認識します。Oracle R Enterpriseのore関数は、Oracle Databaseでオブジェクトを作成して管理し、Oracle R Advanced Analytics for Hadoopのore関数は、Hiveデータベースでオブジェクトを作成して管理します。一度に1つのデータベース(HiveまたはOracle Databaseのいずれか)に接続できますが、同時に両方のデータベースに接続することはできません。
Oracle R Advanced Analytics for Hadoopでは次のORE関数がサポートされます。
as.ore as.ore.character as.ore.frame as.ore.integer as.ore.logical as.ore.numeric as.ore.vector is.ore is.ore.character is.ore.frame is.ore.integer is.ore.logical is.ore.numeric is.ore.vector ore.create ore.drop ore.get ore.pull ore.push ore.recode
このリリースでは、ore.factor、ore.listまたはore.objectはサポートされません。
aggregate
fivenum
IQR
median
quantile
sd
var*
*ベクトルの場合のみ
Oracle R Advanced Analytics for Hadoopは、次のメソッドを含む標準汎用R関数もオーバーロードしてHiveオブジェクトを操作します。
casefold、chartr、gsub、nchar、substr、substring、tolower、toupper
このリリースでは、greplやsubはサポートされません。
attach、show
[, $, $<-, [[, [[<-
サブセット関数: head、tail
メタデータ関数: dim、length、NROW、nrow、NCOL、ncol、names、names<-、colnames、colnames<-
変換関数: as.data.frame、as.env、as.list
算術演算子: +、-、*、^、%%、%/%、/
Compare、Logic、xor、!
テスト関数: is.finite、is.infinite、is.na、is.nan
数学的変換: abs、acos、asin、atan、ceiling、cos、exp、expm1、floor、log、log10、log1p、log2、logb、round、sign、sin、sqrt、tan、trunc
基礎統計: colMeans、colSums、rowMeans、rowSums、Summary、summary、unique
by、merge
unlist、rbind、cbind、data.frame、eval
このリリースでは、dimnames、interaction、max.col、row.names、row.names<-、scale、split、subset、transform、withまたはwithinはサポートされません。
ifelse、Logic、xor、!
サポートされません。
算術演算子: +、-、*、^、%%、%/%、/
テスト関数: is.finite、is.infinite、is.nan
abs、acos、asin、atan、ceiling、cos、exp、expm1、floor、log、log1p、log2、log10、logb、mean、round、sign、sin、sqrt、Summary、summary、tan、trunc、zapsmall
このリリースでは、atan2、besselI、besselK、besselJ、besselY、diff、factorial、lfactorial、pmax、pminまたはtabulateはサポートされません。
show、length、c
テスト関数: is.vector、is.nan
変換関数: as.vector、as.character、as.numeric、as.integer、as.logical
[, [<-, |
by、Compare、head、%in%、paste、sort、table、tail、tapply、unique
このリリースでは、interaction、lengthb、rankまたはsplitはサポートされません。
例8-1に、簡単なデータ準備とデータ処理を示します。詳細は、「Hiveデータ型のサポート」を参照してください。
例8-1 Rを使用したHive表のデータの処理
# Connect to Hive ore.connect(type="HIVE") # Attach the current envt. into search path of R ore.attach() # create a Hive table by pushing the numeric columns of the iris data set IRIS_TABLE <- ore.push(iris[1:4]) # Create bins based on Petal Length IRIS_TABLE$PetalBins = ifelse(IRIS_TABLE$Petal.Length < 2.0, "SMALL PETALS", + ifelse(IRIS_TABLE$Petal.Length < 4.0, "MEDIUM PETALS", + ifelse(IRIS_TABLE$Petal.Length < 6.0, + "MEDIUM LARGE PETALS", "LARGE PETALS"))) #PetalBins is now a derived column of the HIVE object > names(IRIS_TABLE) [1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "PetalBins" # Based on the bins, generate summary statistics for each group aggregate(IRIS_TABLE$Petal.Length, by = list(PetalBins = IRIS_TABLE$PetalBins), + FUN = summary) 1 LARGE PETALS 6 6.025000 6.200000 6.354545 6.612500 6.9 0 2 MEDIUM LARGE PETALS 4 4.418750 4.820000 4.888462 5.275000 5.9 0 3 MEDIUM PETALS 3 3.262500 3.550000 3.581818 3.808333 3.9 0 4 SMALL PETALS 1 1.311538 1.407692 1.462000 1.507143 1.9 0 Warning message: ORE object has no unique key - using random order
Oracle R Advanced Analytics for Hadoopは、tinyint、smallint、bigint、int、floatおよびdoubleなどの文字列や数値のデータ型の列を含むHive表にアクセスできます。次の複雑なデータ型はサポートされません。
array binary map struct timestamp union
サポートされないデータ型を含むHive表にアクセスしようとすると、エラー・メッセージが表示されます。表にアクセスするには、サポートされるデータ型に列を変換する必要があります。
サポートされるデータ型への列の変換するには、次の手順を実行します。
Hiveコマンド・インタフェースを開きます。
$ hive hive>
サポートされないデータ型の列を特定します。
hive> describe table_name;
列のデータを表示します。
hive> select column_name from table_name;
サポートされるデータ型のみを使用して、変換されたデータの表を作成します。
適切な変換ツールを使用して、データを新しい表にコピーします。
例8-2に配列の変換を示します。例8-3と例8-4に、タイムスタンプ・データの変換を示します。
例8-2 文字列の列への配列の変換
R> ore.sync(table="t1")
Warning message:
table t1 contains unsupported data types
.
.
.
hive> describe t1;
OK
col1 int
col2 array<string>
hive> select * from t1;
OK
1 ["a","b","c"]
2 ["d","e","f"]
3 ["g","h","i"]
hive> create table t2 (c1 string, c2 string, c2 string);
hive> insert into table t2 select col2[0], col2[1], col2[2] from t1;
.
.
.
R> ore.sync(table="t2")
R> ore.ls()
[1] "t2"
R> t2$c1
[1] "a" "d" "g"
例8-3では、timestampデータ型の文字列への自動変換が使用されます。データは、tstmpという列があるt5という表に格納されます。
例8-3 タイムスタンプ列の変換
hive> select * from t5; hive> create table t6 (timestmp string); hive> insert into table t6 SELECT tstmp from t5;
例8-4では、Hiveのget_json_object関数を使用して、JSON表からOracle R Advanced Analytics for Hadoopで使用する個別の表に、関連する2つの列を抽出します。
例8-4 JSONファイルのタイムスタンプ列の変換
hive> select * from t3;
OK
{"custId":1305981,"movieId":null,"genreId":null,"time":"2010-12-30:23:59:32","recommended":null,"activity":9}
hive> create table t4 (custid int, time string);
hive> insert into table t4 SELECT cast(get_json_object(c1, '$.custId') as int), cast(get_json_object(c1, '$.time') as string) from t3;
Hiveコマンド言語インタフェース(CLI)は問合せの実行に使用され、Linuxクライアントのサポートを提供します。JDBCやODBCはサポートされません。
ore.create関数は、Hive表をテキスト・ファイルのみで作成します。ただし、Oracle R Advanced Analytics for Hadoopは、テキスト・ファイルまたは順序ファイルのいずれかで格納されるHive表にアクセスできます。
ore.exec関数を使用して、RコンソールからHiveコマンドを実行できます。デモの場合、hive_sequencefileデモを実行します。
Oracle R Advanced Analytics for Hadoopは、デフォルトのHiveデータベースのみの表とビューにアクセスできます。他のデータベースのオブジェクトに対する読取りアクセス権を許可するには、デフォルトのデータベースでそのオブジェクトを公開する必要があります。たとえば、ビューを作成できます。
Oracle R Advanced Analytics for Hadoopには、Hiveでの順序付けの概念がありません。Hiveで存続するRフレームがHiveから抜け出してメモリーに入ると、そのフレームの順序は同じになりません。Oracle R Advanced Analytics for Hadoopは、順序付けが重要ではない大規模なHDFSデータセットのデータのクリーン・アップとフィルタ処理のサポートを主な目的として設計されています。順序付けられていないHiveフレームを操作する場合、次の警告メッセージが表示されます。
Warning messages: 1: ORE object has no unique key - using random order 2: ORE object has no unique key - using random order
これらの警告を抑制するには、次のようにRセッションでore.warn.orderオプションを設定します。
R> options(ore.warn.order = FALSE)
表9-1に、分析目的でRデータ・フレームにHive表をロードする例を示します。次のOracle R Advanced Analytics for Hadoop関数が使用されます。
hdfs.attach ore.attach ore.connect ore.create ore.hiveOptions ore.sync
例8-5 Hive表のロード
# Connect to HIVE metastore and sync the HIVE input table into the R session.
ore.connect(type="HIVE")
ore.sync(table="datatab")
ore.attach()
# The "datatab" object is a Hive table with columns named custid, movieid, activity, and rating.
# Perform filtering to remove missing (NA) values from custid and movieid columns
# Project out three columns: custid, movieid and rating
t1 <- datatab[!is.na(datatab$custid) &
!is.na(datatab$movieid) &
datatab$activity==1, c("custid","movieid", "rating")]
# Set HIVE field delimiters to ','. By default, it is Ctrl+a for text files but
# ORCH 2.0 supports only ',' as a file separator.
ore.hiveOptions(delim=',')
# Create another Hive table called "datatab1" after the transformations above.
ore.create (t1, table="datatab1")
# Use the HDFS directory, where the table data for datatab1 is stored, to attach
# it to ORCH framework. By default, this location is "/user/hive/warehouse"
dfs.id <- hdfs.attach("/user/hive/warehouse/datatab1")
# dfs.id can now be used with all hdfs.*, orch.* and hadoop.* APIs of ORCH for further processing and analytics.
Oracle R Advanced Analytics for Hadoopは、基本レベルのデータベース・アクセスを提供します。データベース表の内容をHDFSに移動したり、HDFS分析の結果をデータベースに戻したりすることができます。
その後、Oracle R Enterpriseという個別の製品を使用して、この小規模データセットに対してさらに分析を実行できます。この製品を使用すると、R言語を使用して、データベースの表、ビューおよびその他のデータ・オブジェクトに統計分析を実行できます。Business IntelligenceおよびIn-Database分析のサポートを含む、データベース・オブジェクトへの透過的なアクセス権があります。
Oracle Databaseに格納されるデータへのアクセスは、常にDBAから付与されるアクセス権に制限されます。
Oracle R Enterpriseは、Oracle Database Enterprise EditionへのOracle Database Advanced Analyticsオプションに含まれています。Oracle Big Data Connectorのいずれかではありません。
|
関連項目: Oracle R Enterpriseユーザーズ・ガイド |
Oracle R Advanced Analytics for Hadoopは、Sqoopを使用して、HDFSとOracle Database間でデータを移動します。Sqoopは、Oracle R Advanced Analytics for Hadoopに対して次のような複数の制限を設けます。
BINARY_FLOAT列またはBINARY_DOUBLE列を含むOracle表はインポートできません。回避策として、これらの列の型をNUMBERに変換するビューを作成できます。
列名はすべて大文字にする必要があります。
次のシナリオで、Oracle R Advanced Analytics for HadoopとOracle R Enterpriseを使用するケースを確認してください。
Oracle R Advanced Analytics for Hadoopを使用すると、アクセス権を持つファイルをHDFS上で検索して、そのうち1つのファイルのデータに対してR計算を実行できます。また、ローカル・ファイルシステムのテキスト・ファイルに格納されているデータを計算用にHDFSにアップロードし、DBMS_SCHEDULERを使用してRスクリプトをHadoopクラスタで実行するようスケジュールして、結果をPC上のローカル・ファイルにダウンロードできます。
Oracle R Enterpriseを使用すると、Rインタフェースを開いてOracle Databaseに接続し、データベースの権限に基づいて使用可能になる表とビューを操作できます。行の除外、導出された列の追加、新しい列の投影および視覚的で統計的な分析を行うことができます。
Oracle R Advanced Analytics for Hadoopを使用すると、Rで記述されたCPU負荷の高い計算の場合、MapReduceジョブをHadoopにデプロイできます。計算には、HDFS (Oracle R Enterpriseを含む)またはOracle Databaseに格納されているデータを使用できます。計算の結果をOracle DatabaseやRコンソールに返し、視覚化したり、追加処理を行うことができます。
表8-1に分析関数を示します。詳細は、Rのヘルプを使用してください。
表8-1 分析関数の説明
| 関数 | 説明 |
|---|---|
|
|
|
|
|
|
|
tall-and-skinny QR (TSQR)因数分解と並列分散を使用して線形モデルを調整します。この関数は、 Oracle R Enterpriseの |
|
|
jellyfishアルゴリズム、またはMahout alternating least squares with weighted regularization (ALS-WR)アルゴリズムを使用して、低ランクの行列因数分解モデルを調整します。 |
|
|
入力と出力の間の複雑な非線形の関係をモデル化したり、データのパターンを見つけたりするニューラル・ネットワークを提供します。 |
|
|
jellyfishアルゴリズムを使用して非負行列因子分解モデルを作成する主なエントリ・ポイントを提供します。この関数は、入力をメモリーに収める必要がないため、Rの |
|
|
Rの |
|
|
入力した |
|
|
|
|
|
|
|
|
|
|
|
|
hadoop.exec関数とhadoop.run関数には、結果のMapReduceジョブを構成するためのオプションの引数configがあります。この引数は、mapred.configクラスのインスタンスになります。
mapred.configクラスには次のスロットがあります。
マッパー、リデューサおよびコンバイナでHDFS.*関数にアクセスできるようにするにはTRUEに設定し、アクセスを制限するにはFALSE (デフォルト)に設定します。
マッパーからデータの出力構造を定義するサンプルRデータ・フレーム・オブジェクト。マッパーによって入力データ形式が変わる場合のみ必要です。その後、リデューサでは、マッパーで生成されたデータの入力ストリームを正確に解析するサンプル・データ・フレームが必要になります。
マッパーが、受信したレコードと完全に同じレコードを出力する場合、このオプションを省略できます。
使用するマッパー関数がマッパーから受け取る行数。
0は、Hadoopで指定されるすべての行を特定のマッパーのマッパー関数に送信します。この設定は、各マッパーのデータのかなりの部分がRメモリーに収まることがわかっている場合のみ使用します。収まらない場合、Rプロセスが失敗してメモリー割当てエラーが生じます。
1は、一度に1行のみをマッパーに送信します(デフォルト)。マッパーのパフォーマンスを改善するにはこの値を増やします。これにより、マッパー関数の起動数が減少します。これは、関数が小規模の場合に特に重要です。
nは、一度に少なくともn行をマッパーに送信します。この構文では、nは1よりも大きな整数になります。一部のアルゴリズムでは、関数に対して最低限の行数が必要です。
実行するマッパーの数。マッパーを連続して実行するには1を指定し、並列で実行するには1よりも大きな整数を指定します。値を指定しない場合、マッパーの数は、クラスタ、作業負荷およびHadoop構成の容量で決まります。
マッパーのデータ値としてキーを複製するにはTRUE、キーをキーとしてのみ使用するにはFALSE (デフォルト)に設定します。
HDFSファイルをマッパーに送る前に分割するための下方境界を制御します。このオプションは、Hadoopのmapred.min.split.sizeオプションの値を反映し、バイト単位で設定されます。
リデューサからデータの出力構造を定義するサンプルRデータ・フレーム・オブジェクト。これはオプションのパラメータです。
サンプル・データ・フレームは、出力HDFSオブジェクトのメタデータの生成に使用されます。サンプリングと解析のステップをなくすことで、ジョブの実行時間を短縮します。また、列名とその他のメタデータを指定できるため、出力データ形式も改善されます。サンプル・データ・フレームを指定しない場合、出力HDFSファイルはサンプリングされ、メタデータが自動で生成されます。
リデューサに対して同時に指定されるデータ値の数。「map.split」の値を参照してください。リデューサは、同時にすべての値を受け取ることを予測するため、reduce.splitを0 (ゼロ)以外の値に設定した場合、リデューサで一部のデータセットを処理する必要があります。
実行するリデューサの数。リデューサを連続して実行するには1を指定し、並列で実行するには1よりも大きな整数を指定します。値を指定しない場合、リデューサの数は、クラスタ、作業負荷およびHadoop構成の容量で決まります。
リデューサのデータ値としてキーを複製するにはTRUE、キーをキーとしてのみ使用するにはFALSE (デフォルト)に設定します。
診断情報を生成するにはTRUE、それ以外はFALSEに設定します。
ORCHパッケージには、Oracle R Advanced Analytics for Hadoopを使用してHadoopクラスタで実行するRプログラムの調整に役立つサンプル・コードが含まれます。このトピックでは、これらの例と実演について説明します。
Oracle R Advanced Analytics for Hadoopには、様々なデモが用意されています。これらを実行する手順を次に説明します。
エラーが発生したら、作業領域イメージを保存せずにRを終了し、新しいセッションを開始してください。また、ローカル・ファイル・システムおよびHDFSファイル・システムに作成された一時ファイルを削除する必要もあります。
# rm -r /tmp/orch* # hadoop fs -rm -r /tmp/orch*
Rプログラムのデモ
HDFSのファイルとディレクトリのコピー、移動および削除を示します。
このプログラムでは、次のORCH関数が使用されます。
hdfs.cd hdfs.cp hdfs.exists hdfs.ls hdfs.mkdir hdfs.mv hdfs.put hdfs.pwd hdfs.rmdir hdfs.root hdfs.setroot
このデモを実行するには、次のコマンドを使用します。
R> demo("hdfs_cpmv", package="ORCH")
HDFSとローカル・ファイルシステム間、およびHDFSとOracle Database間でのデータ転送を示します。
|
注意: このデモでは、Oracle R EnterpriseクライアントがOracle Big Data Applianceに、Oracle R EnterpriseサーバーがOracle Databaseホストにそれぞれインストールされている必要があります。このデモを完了するには、Oracle R Advanced Analytics for HadoopおよびOracle R Enterpriseを使用してOracle Databaseに接続する必要があります。詳細は、 |
このプログラムでは、次のORCH関数が使用されます。
hdfs.cd hdfs.describe hdfs.download hdfs.get hdfs.pull hdfs.pwd hdfs.rm hdfs.root hdfs.setroot hdfs.size hdfs.upload orch.connected ore.dropFoot 1 ore.is.connectedFootref 1
このデモを実行するには、次のコマンドを使用して、ここで示したore.connectおよびorch.connectのパラメータを実際のOracle Databaseにあわせて置き換えます。
R> ore.connect("RQUSER", "orcl", "localhost", "welcome1") Loading required package: ROracle Loading required package: DBI R> orch.connect("localhost", "RQUSER", "orcl", "welcome1", secure=F) Connecting ORCH to RDBMS via [sqoop] Host: localhost Port: 1521 SID: orcl User: RQUSER Connected. [1] TRUE R> demo("hdfs_datatrans", package="ORCH")
HDFSディレクトリに関連する関数の使用を示します。
このプログラムでは、次のORCH関数が使用されます。
hdfs.cd hdfs.ls hdfs.mkdir hdfs.pwd hdfs.rmdir hdfs.root hdfs.setroot
このデモを実行するには、次のコマンドを使用します。
R> demo("hdfs_dir", package="ORCH")
Rデータ・フレームとHDFS間でのデータの転送方法を示します。
このプログラムでは、次のORCH関数が使用されます。
hdfs.attach hdfs.describe hdfs.exists hdfs.get hdfs.put hdfs.pwd hdfs.rm hdfs.root hdfs.sample hdfs.setroot
このデモを実行するには、次のコマンドを使用します。
R> demo("hdfs_putget", package="ORCH")
Irisデータセットの選択内容をHiveに移動し、種類(要約、平均、最小、最大、標準偏差、中央値および四分位範囲(IQR))ごとにこれらの集計を実行します。
このプログラムでは、次のORCH関数を使用してHive表を設定します。これらの関数は、すべてのHiveデモ・プログラムで使用され、Rヘルプで説明されています。
ore.attach ore.connect ore.push
このデモを実行するには、次のコマンドを使用します。
R> demo("hive_aggregate", package="ORCH")
基本分析とデータ処理操作を示します。
このデモを実行するには、次のコマンドを使用します。
R> demo("hive_analysis", package="ORCH")
このデモは、基本のR関数を使用して、行数(nrow)、列数(length)、最初の5行(head)、列のクラスとデータ型(classとis.*)、および各列の値の文字数(nchar)といった、Hive表に関する情報を取得します。
このプログラムを実行するには、次のコマンドを使用します。
R> demo("hive_basic", package="ORCH")
Irisデータセットの花弁のサイズに基づき、Hiveに瓶を作成します。
このプログラムを実行するには、次のコマンドを使用します。
R> demo("hive_binning", package="ORCH")
Irisデータセットを使用して、複数の列関数(min、max、sd、mean、fivenum、var、IQR、quantile、log、log2、log10、absおよびsqrtなど)の使用を示します。
このプログラムを実行するには、次のコマンドを使用します。
R> demo("hive_columnfns", package="ORCH")
AIRQUALITYデータセットを使用して、RとHiveでのnullの処理に関する違いを示します。
このプログラムでは、Rヘルプで説明されている次のORCH関数が使用されます。
ore.attach ore.connect ore.na.extract ore.push
このプログラムを実行するには、次のコマンドを使用します。
R> demo("hive_nulls", package="ORCH")
HiveとクライアントRデスクトップ間でのIrisデータセット分割の処理を示します。
このプログラムでは、Rヘルプで説明されている次のORCH関数が使用されます。
ore.attach ore.connect ore.pull ore.push
このプログラムを実行するには、次のコマンドを使用します。
R> demo("hive_pushpull", package="ORCH")
carsデータセットを使用して、順序ファイルとして格納されるHive表の作成方法と使用方法を示します。
このプログラムでは、Rヘルプで説明されている次のORCH関数が使用されます。
ore.attach ore.connect ore.create ore.exec ore.sync ore.drop
このプログラムを実行するには、次のコマンドを使用します。
R> demo("hive_sequencefile", package="ORCH")
Rで記述されたマッパーとリデューサの簡単な例を示します。この例ではcarsデータセットが使用されます。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.get hdfs.put hdfs.rm hdfs.setroot orch.keyval
このプログラムを実行するには、次のコマンドを使用します。
R> demo("mapred_basic", package="ORCH")
並列モデルの構築でマッパーとリデューサを実行し、HDFSに描画を並列で保存して、グラフを表示します。ここではirisデータセットが使用されます。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.download hdfs.exists hdfs.get hdfs.id hdfs.put hdfs.rm hdfs.rmdir hdfs.root hdfs.setroot hdfs.upload orch.export orch.pack orch.unpack
このプログラムを実行するには、次のコマンドを使用します。
R> demo("mapred_modelbuild", package="ORCH")
orch.lmアルゴリズムを使用して線形モデルを調整し、そのモデルとRのlmアルゴリズムを比較します。ここではirisデータセットが使用されます。
このプログラムでは、次のORCH関数が使用されます。
hdfs.cd hdfs.get hdfs.put hdfs.pwd hdfs.rm hdfs.root hdfs.setroot orch.lmFootref 1 predict.orch.lmFootref 1
このプログラムを実行するには、次のコマンドを使用します。
R> demo("orch_lm", package="ORCH")
jellyfishアルゴリズムを使用して、低ランクの行列因数分解モデルを調整します。
このプログラムでは、次のORCH関数が使用されます。
hdfs.cd hdfs.get hdfs.mkdir hdfs.pwd hdfs.rmdir hdfs.root hdfs.setroot orch.evaluateFootref 1 orch.export.fitFootref 1 orch.lmfFootref 1
このプログラムを実行するには、次のコマンドを使用します。
R> demo("orch_lmf_jellyfish", package="ORCH")
Mahout ALS-WRアルゴリズムを使用して、低ランクの行列因数分解モデルを調整します。
このプログラムでは、次のORCH関数が使用されます。
hdfs.cd hdfs.mkdir hdfs.pwd hdfs.rmdir hdfs.root orch.evaluateFootref 1 orch.lmfFootref 1 orch.recommendFootref 1
このプログラムを実行するには、次のコマンドを使用します。
R> demo("orch_lmf_mahout_als", package="ORCH")
Oracle R Advanced Analytics for Hadoopニューラル・ネットワーク・アルゴリズムを使用してモデルを構築します。ここではirisデータセットが使用されます。
このプログラムでは、次のORCH関数が使用されます。
hdfs.cd hdfs.put hdfs.pwd hdfs.rm hdfs.root hdfs.sample hdfs.setroot orch.neuralFootref 1
このプログラムを実行するには、次のコマンドを使用します。
R> demo("orch_neural", package="ORCH")
非負行列因子分解モデルを作成するRのNMFパッケージのフレームワークとorch.nmf関数の統合を示します。
このデモでは、NMFパッケージで提供されるGolubデータセットが使用されます。
このプログラムでは、次のORCH関数が使用されます。
hdfs.cd hdfs.mkdir hdfs.pwd hdfs.rmdir hdfs.root hdfs.setroot orch.nmf.NMFalgoFootref 1
このプログラムには、複数のRパッケージ(NMF、Biobase、BiocGenericsおよびRColorBrewer)が必要で、それらはまだインストールされていない可能性があります。ここでは、そのインストール手順を説明します。
|
注意: 依存パッケージを更新するかどうか尋ねられたら、常に「Update/None」と応答してください。インストールされるRパッケージはサポートされているバージョンです。これらを更新すると、Oracle Big Data Applianceソフトウェアのチェックが失敗し、ルーチン・メンテナンス時に問題が発生します。新しいパッケージをインストールしたら、必ずbdacheckswユーティリティを実行してください。詳細は、『Oracle Big Data Applianceオーナーズ・ガイド』のbdacheckswユーティリティに関する項を参照してください。
Hadoopクライアントを使用している場合は、Oracle Big Data Applianceではなく、そのクライアントにパッケージをインストールします。 |
NMFのインストール手順:
次の場所にあるCRANアーカイブからNMFをダウンロードします。
http://cran.r-project.org/src/contrib/Archive/NMF/NMF_0.5.06.tar.gz
標準のインストール方法でNMFをインストールします。
R> install.packages("/full_path/NMF_0.5.06.tar.gz", REPOS=null)
BioConductorプロジェクトからのBiobaseおよびBiocGenericsのインストール手順:
次のようにbiocLiteパッケージを実行します。
R> source("http://bioconductor.org/biocLite.R")
Biobaseパッケージをインストールします。
R> biocLite("Biobase")
BiocGenericsパッケージをインストールします。
R> biocLite("BiocGenerics")
RColorBrewerのインストール手順:
次のように標準の方法で、CRANからパッケージをインストールします。
R> install.packages("RColorBrewer")
orch_nmfデモの実行手順:
必須パッケージをロードします(このセッションでまだロードされていない場合)。
R> library("NMF")
R> library("Biobase")
R> library("BiocGenerics")
R> library("RColorBrewer")
デモを実行します。
R> demo("orch_nmf", package="ORCH")
ランダムに生成された値を使用したbaggedクラスタリングの例を示します。マッパーは、データの一部に対してK平均法クラスタリング分析を実行し、リデューサのセントロイドを生成します。リデューサは、セントロイドを階層クラスドに組み込み、HDFSにhclustオブジェクトを格納します。
このプログラムでは、次のORCH関数が使用されます。
hadoop.exec hdfs.put is.hdfs.id orch.export orch.keyval orch.pack orch.unpack
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/demos/demo-bagged.clust.R") Call: c("hclust", "d", "single") Cluster method : single Distance : euclidean Number of objects: 6
K平均法クラスタリングを実行します。
このプログラムでは、次のORCH関数が使用されます。
hadoop.exec hdfs.get orch.export orch.keyval orch.pack orch.unpack
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/demos/demo-kmeans.R") centers x y 1 0.3094056 1.32792762 2 1.7374920 -0.06730981 3 -0.6271576 -1.20558920 4 0.2668979 -0.98279426 5 0.4961453 1.11632868 6 -1.7328809 -1.26335598 removing NaNs if any final centroids x y 1 0.666782828 2.36620810 2 1.658441962 0.33922811 3 -0.627157587 -1.20558920 4 -0.007995672 -0.03166983 5 1.334578589 1.41213532 6 -1.732880933 -1.26335598
例では、Oracle R Advanced Analytics for HadoopのAPIの使用方法を示します。これらの例は、インストール・アーカイブ・ファイルから抽出後、テキスト・エディタで表示できます。これらはORCH2.1.0/ORCHcore/examples ディレクトリにあります。次に、例の実行手順を説明します。
キーと値のペアの使用方法を示します。マッパー関数は、距離の値が30よりも大きな車をcarsデータセットから選択し、リデューサ関数は、速度ごとの距離の平均を計算します。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.get hdfs.put orch.keyval
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-filter1.R") Running cars filtering and mean example #1: val1 val2 1 10 34.00000 2 13 38.00000 3 14 58.66667 4 15 54.00000 5 16 36.00000 6 17 40.66667 7 18 64.50000 8 19 50.00000 9 20 50.40000 10 22 66.00000 11 23 54.00000 12 24 93.75000 13 25 85.00000
値の使用方法のみを示します。マッパー関数は、距離が30よりも大きく速度が14よりも大きな車をcarsデータセットから選択し、リデューサ関数は、速度と距離の平均を1つの値ペアで計算します。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.get hdfs.put orch.keyval
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-filter2.R") Running cars filtering and mean example #2: val1 val2 1 59.52 19.72
HDFSへのローカル・ファイルのロード方法を示します。マッパー関数とリデューサ関数は、example-filter2.Rと同じです。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.download hdfs.upload orch.keyval
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-filter3.R") Running cars filtering and mean example #3: [1] "\t59.52,19.72"
並列モデルの構築方法とグラフの生成方法を示します。マッパーは、irisデータセットの花弁の長さに基づきデータをパーティション化し、リデューサは基本のR統計とグラフィック関数を使用して、データを線形モデルに調整してグラフを描画します。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.download hdfs.exists hdfs.get hdfs.id hdfs.mkdir hdfs.put hdfs.rmdir hdfs.upload orch.pack orch.export orch.unpack
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-group.apply.R") Running groupapply example. [[1]] [[1]]$predict . . . [3] [[3]]$predict 2 210 3 4 5 6 7 8 4.883662 5.130816 4.854156 5.163097 4.109921 4.915944 4.233498 4.886437 9 10 11 12 13 14 15 16 4.789593 4.545214 4.136653 4.574721 4.945451 4.359849 4.013077 4.730579 17 18 19 20 21 22 23 24 4.827423 4.480651 4.792367 4.386581 4.666016 5.007239 5.227660 4.607002 25 26 27 28 29 30 31 32 4.701072 4.236272 4.701072 5.039521 4.604228 4.171709 4.109921 4.015851 33 34 35 36 37 38 39 40 4.574721 4.201216 4.171709 4.139428 4.233498 4.542439 4.233498 5.733065 41 42 43 44 45 46 47 48 4.859705 5.851093 5.074577 5.574432 6.160034 4.115470 5.692460 5.321730 49 50 51 52 53 54 55 56 6.289160 5.386293 5.230435 5.665728 4.891986 5.330054 5.606714 5.198153 57 58 59 60 61 62 63 64 6.315892 6.409962 4.607002 5.915656 4.830198 6.127753 5.074577 5.603939 65 66 67 68 69 70 71 72 5.630671 5.012788 4.951000 5.418574 5.442532 5.848318 6.251329 5.512644 73 74 75 76 77 78 79 80 4.792367 4.574721 6.409962 5.638995 5.136365 4.889212 5.727516 5.886149 81 82 83 84 85 86 87 88 5.915656 4.859705 5.853867 5.980218 5.792079 5.168646 5.386293 5.483137 89 4.827423 [[3]]$pngfile [1] "/user/oracle/pngfiles/3" [1] "/tmp/orch6e295a5a5da9"
このプログラムでは、/tmpディレクトリに3つのグラフィック・ファイルが生成されます。図8-1に最後の内容を示します。
K平均法クラスタリング関数を定義し、クラスタリング・テストのランダム・ポイントを生成します。結果は出力されるかグラフで描画されます。
このプログラムでは、次のORCH関数が使用されます。
hadoop.exec hdfs.get hdfs.put orch.export
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-kmeans.R") Running k-means example. val1 val2 1 1.005255389 1.9247858 2 0.008390976 2.5178661 3 1.999845464 0.4918541 4 0.480725254 0.4872837 5 1.677254045 2.6600670
複数のマッパーと、すべての結果をマージする1つのリデューサの定義方法を示します。プログラムでは、irisデータセットを使用して線形回帰を計算します。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.get hdfs.put orch.export orch.pack orch.unpack
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-lm.R") Running linear model example. Model rank 3, yy 3.0233000000E+02, nRows 150 Model coefficients -0.2456051 0.2040508 0.5355216
carsデータセットで一次元のロジスティック回帰を実行します。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.put orch.export
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-logreg.R") Running logistic regression. [1] 1924.1
レコードの数が無制限のマッパーを、同時入力でデータ・フレームとして実行する方法を示します。マッパーは、距離が30よりも大きな車をcarsデータセットから選択し、距離の平均を計算します。リデューサは結果をマージします。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.get hdfs.put
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-map.df.R")) Running example of data.frame mapper input: val1 val2 1 17.66667 50.16667 2 13.25000 47.25000
レコードの数が無制限のマッパーを、同時入力でリストとして実行する方法を示します。マッパーは、距離が30よりも大きな車をcarsデータセットから選択し、距離の平均を計算します。リデューサは結果をマージします。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.get hdfs.put
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-map.list.R" Running example of list mapper input: val1 val2 1 15.9 49
HDFSを使用したモデルとグラフの作成方法を示します。マッパーは、irisデータセットのキーと値のペアをリデューサに提供します。リデューサは、データセットから抽出されたデータで線形モデルを作成し、結果を描画して3つのHDFSファイルに保存します。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.download hdfs.exists hdfs.get hdfs.id hdfs.mkdir hdfs.put hdfs.rmdir hdfs.upload orch.export orch.pack
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-model.plot.R" Running model building and graph example. [[1]] [[1]]$predict . . . [[3]]$predict 2 210 3 4 5 6 7 8 5.423893 4.955698 5.938086 5.302979 5.517894 6.302640 4.264954 6.032087 9 10 11 12 13 14 15 16 5.594622 6.080090 5.483347 5.393163 5.719353 4.900061 5.042065 5.462257 17 18 19 20 21 22 23 24 5.448801 6.392824 6.410097 5.032427 5.826811 4.827150 6.358277 5.302979 25 26 27 28 29 30 31 32 5.646442 5.959176 5.230068 5.157157 5.427710 5.924630 6.122271 6.504099 33 34 35 36 37 38 39 40 5.444983 5.251159 5.088064 6.410097 5.406619 5.375890 5.084247 5.792264 41 42 43 44 45 46 47 48 5.698262 5.826811 4.955698 5.753900 5.715536 5.680989 5.320252 5.483347 49 50 5.316435 5.011336 [[3]]$pngfile [1] "/user/oracle/pngfiles/virginica" [1] "/tmp/orch6e29190de160"
3つのグラフィック・ファイルが生成されます。図8-2に最後の内容を示します。
図8-2 example-model.plot.Rの出力例(fit-virginica.png)
複数のマップ・タスク間でのデータの分散方法を示します。マッパーは、irisデータセットの一部の入力データからデータ・フレームを生成します。リデューサは、データ・フレームを1つの出力データセットにマージします。
このプログラムでは、次のORCH関数が使用されます。
hadoop.exec hdfs.get hdfs.put orch.export orch.keyvals
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-model.prep.R") v1 v2 v3 v4 1 5.1 4.90 4.055200 0.33647224 2 4.9 4.20 4.055200 0.33647224 3 4.7 4.16 3.669297 0.26236426 . . . 299 6.2 18.36 221.406416 1.68639895 300 5.9 15.30 164.021907 1.62924054
簡単なRプログラムを、HadoopクラスタでMapReduceジョブとして実行可能なプログラムに変換する方法を示します。この例では、プログラムは、基本のR関数を使用してcarsデータセットに関する計算を実行し、線形モデルをグラフに描画します。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run orch.keyvals orch.unpack
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
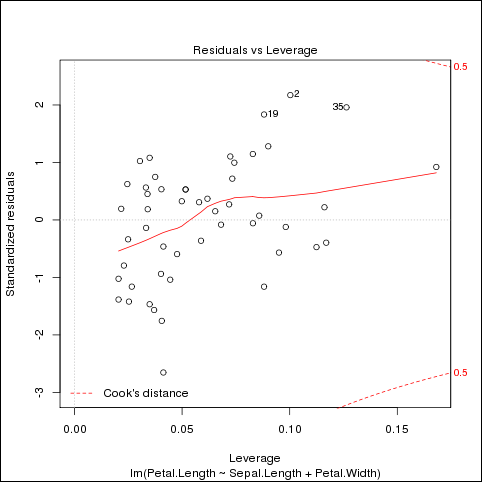
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-rlm.R" [1] "--- Client lm:" Call: lm(formula = speed ~ dist, data = cars) Residuals: Min 1Q Median 3Q Max -7.5293 -2.1550 0.3615 2.4377 6.4179 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 8.28391 0.87438 9.474 1.44e-12 *** dist 0.16557 0.01749 9.464 1.49e-12 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.156 on 48 degrees of freedom Multiple R-squared: 0.6511, Adjusted R-squared: 0.6438 F-statistic: 89.57 on 1 and 48 DF, p-value: 1.49e-12
[Ctrl]キーを押しながら[C]キーを押してRプロンプトを表示し、グラフィック・ウィンドウを閉じます。
R> dev.off()
図8-3に、プログラムによって生成される4つのグラフを示します。
マッパーでのデータの分割方法を示します。最初のジョブでは、リスト・モードでマッパーを実行し、マッパーでリストを分割します。次のジョブでは、マッパーでデータ・フレームを分割します。どちらのジョブでもcarsデータセットが使用されます。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.get hdfs.put orch.keyval
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-split.map.R") Running example of list splitting in mapper key count splits 1 NA 50 6 Running example of data.frame splitting in mapper key count splits 1 NA 50 8
リデューサでcarsデータセットのデータを分割する方法を示します。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.get hdfs.put orch.keyval
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-split.reduce.R") Running example of data.frame reducer input ^C key count 1 1 9 2 1 9 3 1 9 . . . 20 1 9 21 1 5
MapReduceジョブでの合計演算の実行方法を示します。最初のジョブでは数値のベクトルを合計し、2番目のジョブではデータ・フレームのすべての列を合計します。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run orch.keyval
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-sum.R" val2 1 6 val2 val3 1 770 2149
Hadoopでプログラムをテストするために大規模なデータセットを行列に生成する方法を示します。マッパーはランダム・データのサンプルを生成し、リデューサはそのサンプルをマージします。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.put orch.export orch.keyvals
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。出力はありません。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-teragem.matrix.R" Running TeraGen-PCA example: R>
Hadoopでプログラムをテストするために大規模なデータセットをデータ・フレームに生成する方法を示します。マッパーはランダム・データのサンプルを生成し、リデューサはそのサンプルをマージします。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.put orch.export orch.keyvals
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。出力はありません。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-teragen2.xy.R") Running TeraGen2 example.R>
Hadoopでプログラムをテストするために大規模なデータセットをデータ・フレームに生成する方法を示します。1つのマッパーはランダム・データの小規模サンプルを生成し、リデューサはそのサンプルをマージします。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run hdfs.put orch.export orch.keyvals
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。出力はありません。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-teragem2.xy.R" Running TeraGen2 example. R>
ランダムに生成された値のセットに関するTeraSortジョブの例を示します。
このプログラムでは、次のORCH関数が使用されます。
hadoop.run
このプログラムを実行するには、必ずrootを/tmpに設定してから、ファイルを実行します。
R> hdfs.setroot("/tmp") [1] "/tmp" R> source("/usr/lib64/R/library/ORCHcore/examples/example-terasort.R" Running TeraSort example: val1 1 -0.001467344 2 -0.004471376 3 -0.005928546 4 -0.007001193 5 -0.010587280 6 -0.011636190
Oracle R Advanced Analytics for Hadoopでは、Sqoopユーティリティを起動してOracle Databaseに接続し、データの抽出または結果の格納を実行します。
Sqoopは、HDFSまたはHiveと構造化データベースとの間でデータのインポートとエクスポートを行うHadoopのコマンドライン・ユーティリティです。Sqoopという名前は、"SQL to Hadoop"に由来します。Oracle R Advanced Analytics for Hadoopでのデータベース・ユーザー・パスワードの格納方法とSqoopへの送信方法について、次に説明します。
Oracle R Advanced Analytics for Hadoopでは、毎回パスワードを再入力する必要のないモードでユーザーがデータベース接続を確立した場合にのみユーザー・パスワードを格納します。パスワードは暗号化されてメモリーに格納されます。「orch.connect」を参照してください。
Oracle R Advanced Analytics for Hadoopでは、Sqoop用の構成ファイルを生成し、Sqoopのローカルでの起動に使用します。ファイルには、ユーザーへの要求または暗号化されたメモリー内表現から取得されたユーザーのデータベース・パスワードが含まれます。ファイルは、ローカル・ユーザー・アクセス権限のみ持ちます。ファイルが作成され、権限が明示的に設定された後、ファイルが書込み用に開かれ、データが挿入されます。
Sqoopでは、構成ファイルを使用して特定のデータベース・ジョブ用にカスタムJARファイルを動的に生成し、JARファイルをHadoopクライアント・ソフトウェアに渡します。パスワードは、コンパイルされたJARファイル内に格納されます。プレーン・テキストには格納されません。
JARファイルは、ネットワーク接続を介してHadoopクラスタに転送されます。ネットワーク接続と転送プロトコルは、Hadoopに固有です(ポート5900など)。
構成ファイルは、SqoopでJARファイルのコンパイルが終了し、Hadoopジョブが起動されたら、削除されます。
脚注の説明
脚注 1: 使用情報については、Rのhelp関数を使用します。