| Oracle® Big Data Connectorsユーザーズ・ガイド リリース2 (2.5) E53261-01 |
|


 前 |
 次 |
この章では、Oracle XQuery for Hadoopを使用して大量の半構造化データを抽出および変換する方法について説明します。内容は次のとおりです。
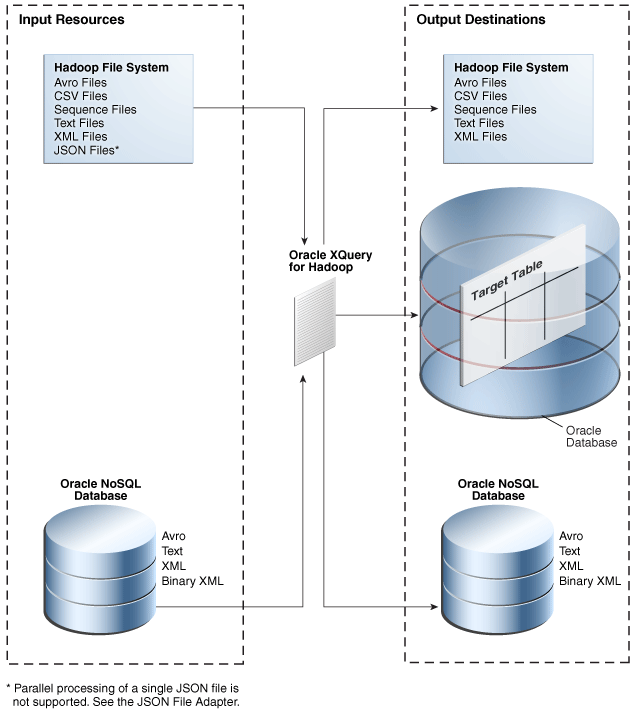
Oracle XQuery for Hadoopは、半構造化されたビッグ・データの変換エンジンです。Oracle XQuery for Hadoopでは、XQuery言語で表された変換を一連のMapReduceジョブに解釈して実行します(これらのジョブはApache Hadoopクラスタ上で並列で実行されます)。ユーザーは、スケーラビリティやパフォーマンスを犠牲にせずに、JavaおよびMapReduceの複雑性に取り組むのではなくデータ移動および変換ロジックに集中できます。
入力データは、Hadoop Distributed File System (HDFS)など、Hadoopのファイル・システムAPIを介してアクセス可能なファイル・システムに配置するか、Oracle NoSQL Databaseに格納できます。Oracle XQuery for Hadoopでは、変換結果をHadoopファイル、Oracle NoSQL DatabaseまたはOracle Databaseに書き込むことができます。
また、Oracle XQuery for Hadoopには、大規模なXMLファイルをサポートするためにApache Hiveに対する拡張が用意されています。これらの拡張はOracle Big Data Applianceでのみ使用できます。
Oracle XQuery for Hadoopは、XPath、XQueryおよびXQuery Update Facilityなどの円熟した業界標準に基づいています。他のOracle製品と完全に統合されているため、Oracle XQuery for Hadoopを使用すると、次のことが可能です。
Oracle Loader for Hadoopを使用してデータをOracle Databaseに効率的にロードすること。
Oracle NoSQL Databaseに読取り/書込みサポートを提供すること。
図5-1に、Oracle XQuery for Hadoopを使用したデータ・フローの概要を示します。
Oracle XQuery for HadoopはXQuery開発者が使用するように設計されています。XQueryをよく理解している場合はすぐに開始できます。XQuery初心者は、最初に言語の基本を習得する必要があります。この情報については、このガイドには記載されていません。
|
関連項目:
|
Oracle XQuery for Hadoopを使用する場合は、次の基本的な手順に従います。
初めてOracle XQuery for Hadoopを使用する場合は、ソフトウェアがインストールおよび構成されていることを確認します。
「Oracle XQuery for Hadoopの設定」を参照してください。
HadoopクラスタのノードまたはクラスタのHadoopクライアントとして設定されているシステムにログインします。
Oracle XQuery for Hadoop関数を使用するXQuery変換を作成します。入出力には様々なアダプタを使用できます。
「Oracle XQuery for Hadoopの関数について」および「XQuery変換の作成」を参照してください。
XQuery変換を実行します。
「問合せの実行」を参照してください。
次の手順に従って、Oracle XQuery for Hadoopを使用して単純な問合せを作成し、実行します。
Helloの行を含むhello.txtというテキスト・ファイルを現在のディレクトリに作成します。
$ echo "Hello" > hello.txt
ファイルをHDFSにコピーします。
$ hdfs dfs -copyFromLocal hello.txt
次の内容でhello.xqという問合せファイルを現在のディレクトリに作成します。
import module "oxh:text";
for $line in text:collection("hello.txt")
return text:put($line || " World!")
問合せを実行します。
$ hadoop jar $OXH_HOME/lib/oxh.jar hello.xq -output ./myout -print
13/11/21 02:41:57 INFO hadoop.xquery: OXH: Oracle XQuery for Hadoop 2.3.0 (build 2.3.0-cdh-4.4.0). Copyright (c) 2013, Oracle. All rights reserved.
13/11/21 02:42:01 INFO hadoop.xquery: Submitting map-reduce job "oxh:hello.xq#0" id="3593921f-c50c-4bb8-88c0-6b63b439572b.0", inputs=[hdfs://bigdatalite.localdomain:8020/user/oracle/hello.txt], output=myout
.
.
.
出力ファイルを確認します。
$ hdfs dfs -cat ./myout/part-m-00000
Hello World!
Oracle XQuery for Hadoopは、ビッグ・データセットに対してcollectionおよびput関数を使用して読取りおよび書込みを実行します。
collection関数は、HadoopファイルまたはOracle NoSQL Databaseからデータを項目のコレクションとして読み取ります。Hadoopファイルは、Hadoopのファイル・システムAPIを介してアクセスできるファイルです。Oracle Big Data Applianceおよび大半のHadoopクラスタでは、このファイル・システムはHadoop Distributed File System (HDFS)です。
put関数は、Oracle Database、Oracle NoSQL DatabaseまたはHadoopファイルに格納されたデータセットに対して単一の項目を追加します。
次の例は、項目をソースから読み取って別の場所に書き込むOracle XQuery for Hadoopの単純な問合せです。
for $x in collection(...) return put($x)
Oracle XQuery for Hadoopには、特定の形式およびソースについてputおよびcollection関数を定義する際に使用できる一連のアダプタが付属しています。各アダプタには2つのコンポーネントがあります。
利便性を考慮して事前定義された一連の組込みputおよびcollection関数。
カスタムputおよびcollection関数の定義に使用できる一連のXQuery関数の注釈。
他の共通して使用する関数もOracle XQuery for Hadoopに含まれています。
次に、Oracle XQuery for Hadoopアダプタについて簡単に説明します。
Avroファイル・アダプタは、HDFSに格納されたAvroコンテナ・ファイルへのアクセスを提供します。Avroコンテナ・ファイルに対して読取り/書込みを行うcollectionおよびput関数が含まれています。
「Avroファイル・アダプタ」を参照してください。
JSONファイル・アダプタは、HDFSに格納されたJSONファイルへのアクセスを提供します。JSONファイルを読み取るためのcollection関数とJSONデータを直接解析するための一連のhelper関数が含まれています。出力を書き込むには、別のアダプタを使用する必要があります。
「JSONファイル・アダプタ」を参照してください。
Oracle Databaseアダプタは、データをOracle Databaseにロードします。このアダプタは、JDBCまたはOCIを使用してOracleデータベースの表に出力先を指定するためのカスタムput関数をサポートしています。データベースへのライブ接続が使用可能でない場合、このアダプタはデータ・ポンプまたはHDFSのデリミタ付きテキスト・ファイルへの出力もサポートします。ファイルは、SQL*Loaderなどの異なるユーティリティで、または外部表を使用してOracleデータベースにロードできます。このアダプタはデータをデータベースから移動しないため、collection関数やget関数はありません。
サポートされるOracle Databaseのバージョンについては、「ソフトウェア要件」を参照してください。また「Oracle Databaseアダプタ」も参照してください。
Oracle NoSQL Databaseアダプタは、Oracle NoSQL Databaseに格納されたデータへのアクセスを提供します。データはAvro、XML、バイナリXMLまたはテキストとして読取りまたは書込みできます。このアダプタにはcollection、getおよびput関数が含まれています。
「Oracle NoSQL Databaseアダプタ」を参照してください。
順序ファイル・アダプタは、Hadoop順序ファイルへのアクセスを提供します。順序ファイルは、キーと値のペアで構成されるHadoop形式です。
このアダプタには、テキスト、XMLまたはバイナリXMLを格納するHDFS順序ファイルに対して読取り/書込みを行うcollectionおよびput関数が含まれています。
「順序ファイル・アダプタ」を参照してください。
テキスト・ファイル・アダプタは、CSVファイルなどのテキスト・ファイルへのアクセスを提供します。テキスト・ファイルに対して読取り/書込みを行うcollectionおよびput関数が含まれています。
JSONファイル・アダプタは、テキスト・ファイルに格納されたJSONオブジェクトに対するサポートを拡張します。
「テキスト・ファイル・アダプタ」および「JSONファイル・アダプタ」を参照してください。
XMLファイル・アダプタは、HDFSに格納されたXMLファイルへのアクセスを提供します。大規模なXMLファイルを読み取るためのcollection関数が含まれています。出力を書き込むには、別のアダプタを使用する必要があります。
「XMLファイル・アダプタ」を参照してください。
問合せでは次の追加モジュールの関数を使用できます。
標準XQuery算術関数を使用できます。
「XQuery言語のサポートについて」を参照してください。
Hadoopモジュールは、Hadoopに固有の関数の集合です。
「Hadoopモジュール」を参照してください。
この一連の関数は、期間、日付および時間の値を解析します。
「期間、日付および時間の関数」を参照してください。
これらの関数は、データ値を囲む空白を追加および削除します。
「文字列関数」を参照してください。
この章では、Oracle XQuery for Hadoopを使用してXQuery変換を作成する方法について説明します。この項の内容は次のとおりです。
Oracle XQuery for Hadoopの変換は、次の追加要件に従う必要があることを除き、他のXQuery変換と同様の方法で作成します。
主要なXQuery式(問合せ本文)は、次のいずれかの形式で指定する必要があります。
FLWOR1
または
(FLWOR1, FLWOR2,... , FLWORN)
この構文で、FLWORはトップレベルのFLWOR (For、Let、Where、Order by、Returnの頭文字)式です。
|
関連項目: 次のサイトにある『W3C XQuery 3.0: An XML Query Language』のFLWOR式に関する項 |
トップレベルの各FLWOR式には、Oracle XQuery for Hadoopのcollection関数全体を反復するfor句が必要です。このfor句には位置指定変数を使用できません。
collection関数については、第6章を参照してください。
トップレベルの各FLOWR式には、オプションのlet、whereおよびgroup by句を使用できます。order by、count、window句など、その他のタイプの句は無効です。
トップレベルの各FLWOR式では、Oracle XQuery for Hadoopのput関数の呼出しで1つ以上の結果を返す必要があります。put関数については、第6章を参照してください。
問合せ本文は更新式である必要があります。put関数はすべて更新関数として分類されるため、Oracle XQuery for Hadoopのすべての問合せは更新問合せとなります。
Oracle XQuery for Hadoopでは、%*:put注釈は、関数が更新であることを示します。この場合、%updating注釈またはupdatingキーワードは不要です。
|
関連項目: 更新式については、次のサイトにある『W3C XQuery Update Facility 1.0』のXQuery 1.0に対する拡張に関する項
|
Oracle XQuery for HadoopはXQuery 1.0仕様をサポートしています。
言語については、次のサイトにあるW3Cの『XQuery 1.0: An XML Query Language』を参照してください。
関数については、次のサイトにあるW3Cの『XQuery 1.0 and XPath 2.0 Functions and Operators』を参照してください。
さらに、Oracle XQuery for Hadoopは、次のXQuery 3.0機能をサポートしています。各リンクによって、W3Cの『XQuery 3.0: An XML Query Language』の関連する項に移動します。
group by句
for句とallowing emptyモディファイア
http://www.w3.org/TR/xquery-30/#id-xquery-for-clauseを参照してください。
注釈
文字列連結式
http://www.w3.org/TR/xquery-30/#id-string-concat-exprを参照してください。
標準関数
fn:analyze-string fn:unparsed-text fn:unparsed-text-lines fn:unparsed-text-available fn:serialize fn:parse-xml
http://www.w3.org/TR/xpath-functions-30/を参照してください。
三角関数と指数関数
http://www.w3.org/TR/xpath-functions-30/#trigonometryを参照してください。
Hadoop分散キャッシュ機能を使用して補助ジョブ・データにアクセスできます。このメカニズムは、一方が比較的小さいファイルである場合の結合問合せに役立ちます。分散キャッシュからアクセスされるファイルが小さいほど、問合せは高速になります。
ファイルを分散キャッシュに配置するには、Oracle XQuery for Hadoopを呼び出すときに-files Hadoopコマンドライン・オプションを使用します。分散キャッシュからファイルを読み取る問合せで、XMLの場合はfn:doc関数を、テキスト・ファイルの場合はfn:unparsed-textまたはfn:unparsed-text-linesのいずれかを呼び出す必要があります。例7を参照してください。
Oracle XQuery for Hadoopは、Java言語でカスタム外部関数を実装して拡張できます。Java実装は、パラメータを備えた静的メソッドで、XQuery API for Java (XQJ)仕様に定義されているタイプを返す必要があります。
カスタムJava関数バインディングは、%ora-java:binding注釈を使用して外部関数定義に注釈を指定することで、Oracle XQuery for Hadoopに定義されます。この注釈の構文は、次のとおりです。
%ora-java:binding("java.class.name[#method]")
実装メソッドが格納されているJavaクラスの完全修飾名。
Javaメソッド名。XQuery関数名にデフォルト設定されます。オプション。
%ora-java:bindingの例については、例8を参照してください。
カスタムJava関数が格納されているJARファイルはすべて-libjarsコマンドライン・オプションに指定する必要があります。次に例を示します。
hadoop jar $OXH_HOME/lib/oxh.jar -libjars myfunctions.jar query.xq
Oracle XQuery for Hadoopは、次の基準に従う場合、ユーザー定義のXQueryライブラリ・モジュールおよびXMLスキーマをサポートします。
Oracle XQuery for Hadoopを呼び出すメインの問合せが存在するクライアント上の同じディレクトリに、ライブラリ・モジュールまたはXMLスキーマ・ファイルを配置します。
import moduleまたはimport schema文のロケーションURIパラメータを使用してメインの問合せからライブラリ・モジュールまたはXMLスキーマをインポートします。
Oracle XQuery for Hadoopを呼び出す場合は、ライブラリ・モジュールまたはXMLスキーマ・ファイルを-filesコマンドライン・オプションに指定します。
ユーザー定義のXQueryライブラリ・モジュールおよびXMLスキーマの使用例は、例9を参照してください。
|
関連項目: 次のサイトにある『XQuery 3.0: An XML Query Language』のロケーションURIに関する項
|
これらの例では、HDFSに次のテキスト・ファイルがあります。ファイルには、異なるWebページへのアクセス・ログが格納されます。各行はWebページへのアクセスを表し、時間、ユーザー名、アクセスしたページ、およびステータス・コードが格納されます。
mydata/visits1.log 2013-10-28T06:00:00, john, index.html, 200 2013-10-28T08:30:02, kelly, index.html, 200 2013-10-28T08:32:50, kelly, about.html, 200 2013-10-30T10:00:10, mike, index.html, 401 mydata/visits2.log 2013-10-30T10:00:01, john, index.html, 200 2013-10-30T10:05:20, john, about.html, 200 2013-11-01T08:00:08, laura, index.html, 200 2013-11-04T06:12:51, kelly, index.html, 200 2013-11-04T06:12:40, kelly, contact.html, 200
この問合せは、ユーザーkellyがアクセスしたページをフィルタ処理し、そのファイルをテキスト・ファイルに書き込みます。
import module "oxh:text";
for $line in text:collection("mydata/visits*.log")
let $split := fn:tokenize($line, "\s*,\s*")
where $split[2] eq "kelly"
return text:put($line)
この問合せは、次の行を含むテキスト・ファイルを出力ディレクトリに作成します。
2013-11-04T06:12:51, kelly, index.html, 200 2013-11-04T06:12:40, kelly, contact.html, 200 2013-10-28T08:30:02, kelly, index.html, 200 2013-10-28T08:32:50, kelly, about.html, 200
次の問合せは、ページに対する1日当たりのアクセス数を計算します。
import module "oxh:text";
for $line in text:collection("mydata/visits*.log")
let $split := fn:tokenize($line, "\s*,\s*")
let $time := xs:dateTime($split[1])
let $day := xs:date($time)
group by $day
return text:put($day || " => " || fn:count($line))
この問合せは、次の行を含むテキスト・ファイルを作成します。
2013-10-28 => 3 2013-10-30 => 3 2013-11-01 => 1 2013-11-04 => 2
この例は、他のファイルに加え、HDFSの次のテキスト・ファイルを問い合せます。このファイルには、ユーザーID、姓名、年齢などのユーザー・プロファイル情報がコロン(:)区切りで格納されています。
mydata/users.txt john:John Doe:45 kelly:Kelly Johnson:32 laura:Laura Smith: phil:Phil Johnson:27
次の問合せは、users.txtとログ・ファイルの結合を実行します。30歳を超えるユーザーが各ページにアクセスした回数を計算します。
import module "oxh:text";
for $userLine in text:collection("mydata/users.txt")
let $userSplit := fn:tokenize($userLine, "\s*:\s*")
let $userId := $userSplit[1]
let $userAge := xs:integer($userSplit[3][. castable as xs:integer])
for $visitLine in text:collection("mydata/visits*.log")
let $visitSplit := fn:tokenize($visitLine, "\s*,\s*")
let $visitUserId := $visitSplit[2]
where $userId eq $visitUserId and $userAge gt 30
group by $page := $visitSplit[3]
return text:put($page || " " || fn:count($userLine))
この問合せは、次の行を含むテキスト・ファイルを作成します。
about.html 2 contact.html 1 index.html 4
次の問合せは、任意のページにアクセスした各ユーザーのアクセス数を計算します。ページにアクセスしたことがないユーザーは除外されます。
import module "oxh:text";
for $userLine in text:collection("mydata/users.txt")
let $userSplit := fn:tokenize($userLine, "\s*:\s*")
let $userId := $userSplit[1]
for $visitLine in text:collection("mydata/visits*.log")
[$userId eq fn:tokenize(., "\s*,\s*")[2]]
group by $userId
return text:put($userId || " " || fn:count($visitLine))
この問合せは、次の行を含むテキスト・ファイルを作成します。
john 3 kelly 4 laura 1
|
注意: 2つのcollection関数の結果を結合する場合は、等価結合のみがサポートされます。ソースの一方または両方がcollection関数からのソースでない場合は、任意の結合条件が許可されます。 |
この例は例3の2番目の問合せと類似していますが、ページにアクセスしなかったユーザーもカウントします。
import module "oxh:text";
for $userLine in text:collection("mydata/users.txt")
let $userSplit := fn:tokenize($userLine, "\s*:\s*")
let $userId := $userSplit[1]
for $visitLine allowing empty in text:collection("mydata/visits*.log")
[$userId eq fn:tokenize(., "\s*,\s*")[2]]
group by $userId
return text:put($userId || " " || fn:count($visitLine))
この問合せは、次の行を含むテキスト・ファイルを作成します。
john 3 kelly 4 laura 1 phil 0
次の問合せは、ページにアクセスしたユーザーを検出します。
import module "oxh:text";
for $userLine in text:collection("mydata/users.txt")
let $userId := fn:tokenize($userLine, "\s*:\s*")[1]
where some $visitLine in text:collection("mydata/visits*.log")
satisfies $userId eq fn:tokenize($visitLine, "\s*,\s*")[2]
return text:put($userId)
この問合せは、次の行を含むテキスト・ファイルを作成します。
john kelly laura
次の問合せは、コードが401のWebページ・アクセスを検索し、XQueryのtext:trace()関数を使用してtrace*ファイルに書き込みます。残りのアクセス・レコードはデフォルトの出力ファイルに書き込みます。
import module "oxh:text";
for $visitLine in text:collection("mydata/visits*.log")
let $visitCode := xs:integer(fn:tokenize($visitLine, "\s*,\s*")[4])
return if ($visitCode eq 401) then text:trace($visitLine) else text:put($visitLine)
この問合せは、次の行を含むtrace*テキスト・ファイルを生成します。
2013-10-30T10:00:10, mike, index.html, 401
この問合せは、次の行を含むデフォルトの出力ファイルも生成します。
2013-10-30T10:00:01, john, index.html, 200 2013-10-30T10:05:20, john, about.html, 200 2013-11-01T08:00:08, laura, index.html, 200 2013-11-04T06:12:51, kelly, index.html, 200 2013-11-04T06:12:40, kelly, contact.html, 200 2013-10-28T06:00:00, john, index.html, 200 2013-10-28T08:30:02, kelly, index.html, 200 2013-10-28T08:32:50, kelly, about.html, 200
次の問合せは例3の2番目の問合せの代替バージョンですが、fn:unparsed-text-lines関数を使用してHadoop分散キャッシュのファイルにアクセスします。
import module "oxh:text";
for $visitLine in text:collection("mydata/visits*.log")
let $visitUserId := fn:tokenize($visitLine, "\s*,\s*")[2]
for $userLine in fn:unparsed-text-lines("users.txt")
let $userSplit := fn:tokenize($userLine, "\s*:\s*")
let $userId := $userSplit[1]
where $userId eq $visitUserId
group by $userId
return text:put($userId || " " || fn:count($visitLine))
問合せを実行するhadoopコマンドには、Hadoopの-filesオプションを使用する必要があります。「Hadoop分散キャッシュのデータへのアクセス」を参照してください。
hadoop jar $OXH_HOME/lib/oxh.jar -files users.txt query.xq
この問合せは、次の行を含むテキスト・ファイルを作成します。
john 3 kelly 4 laura 1
次の問合せは、java.lang.String#formatメソッドを使用して入力データを書式設定します。
import module "oxh:text";
declare %ora-java:binding("java.lang.String#format")
function local:string-format($pattern as xs:string, $data as xs:anyAtomicType*) as xs:string external;
for $line in text:collection("mydata/users*.txt")
let $split := fn:tokenize($line, "\s*:\s*")
return text:put(local:string-format("%s,%s,%s", $split))
この問合せは、次の行を含むテキスト・ファイルを作成します。
john,John Doe,45 kelly,Kelly Johnson,32 laura,Laura Smith, phil,Phil Johnson,27
|
関連項目: 次のサイトにある『Java Platform Standard Edition 7 API Specification』のStringクラスに関する項 |
この例では、mytools.xqというライブラリ・モジュールを使用します。
module namespace mytools = "urn:mytools";
declare %ora-java:binding("java.lang.String#format")
function mytools:string-format($pattern as xs:string, $data as xs:anyAtomicType*) as xs:string external;
次の問合せは前の例と同等ですが、string-format関数をmytools.xqライブラリ・モジュールから呼び出します。
import module namespace mytools = "urn:mytools" at "mytools.xq";
import module "oxh:text";
for $line in text:collection("mydata/users*.txt")
let $split := fn:tokenize($line, "\s*:\s*")
return text:put(mytools:string-format("%s,%s,%s", $split))
この問合せは、次の行を含むテキスト・ファイルを作成します。
john,John Doe,45 kelly,Kelly Johnson,32 laura,Laura Smith, phil,Phil Johnson,27
問合せを実行するには、hadoop jarコマンドを使用してoxhユーティリティを呼び出します。基本的な構文は次のとおりです。
hadoop jar $OXH_HOME/lib/oxh.jar [generic options] query.xq -output directory [-clean] [-ls] [-print] [-skiperrors] [-version]
XQueryファイルを識別します。「XQuery変換の作成」を参照してください。
問合せの実行前に、出力ディレクトリからすべてのファイルを削除します。
問合せ実行後に、出力ディレクトリの内容をリスト表示します。
問合せの出力ディレクトリを指定します。ファイル・アダプタのput関数によって、このディレクトリにファイルが作成されます。書き込まれた値は、1つ以上のファイルに展開されます。作成されるファイル数は、問合せがどのように複数のタスクに分散されているかによって異なります。デフォルトでは、part-m-00000など、各出力ファイルの名前はpartで始まります。
put関数の説明は、「Oracle XQuery for Hadoopの関数について」を参照してください。
出力ディレクトリ内の全ファイルの内容を標準出力(画面)に印刷します。Avroファイルの印刷時は、各レコードがJSONテキストとして印刷されます。
エラーで処理が停止しないように、エラー・リカバリをオンに切り替えます。
問合せ処理中に発生したすべてのエラーがカウントされ、問合せ終了時に合計がログに記録されます。また、タスクごとに最初の20件のエラーのエラー・メッセージがログに記録されます。次の構成プロパティを参照してください。
oracle.hadoop.xquery.skiperrors.countersoracle.hadoop.xquery.skiperrors.maxoracle.hadoop.xquery.skiperrors.log.maxOracle XQuery for Hadoopのバージョンを表示し、問合せを実行せずに終了します。
任意の汎用的なhadoopコマンドライン・オプションを指定できます。Oracle XQuery for Hadoopは、org.apache.hadoop.util.Toolインタフェースを実装し、MapReduceアプリケーションを構築する標準的なHadoopの方法に従います。
Oracle XQuery for Hadoopでは、次の汎用オプションが一般的に使用されます。
ジョブ構成ファイルを識別します。「Oracle XQuery for Hadoopの構成プロパティ」を参照してください。
Oracle DatabaseまたはOracle NoSQL Databaseのアダプタを使用している場合は、このファイルに様々なジョブ・プロパティを設定できます。「Oracle Loader for Hadoop構成プロパティおよび対応する%oracle-property注釈」および「Oracle NoSQL Databaseアダプタの構成プロパティ」を参照してください。
構成プロパティを識別します。「Oracle XQuery for Hadoopの構成プロパティ」を参照してください。
分散キャッシュに追加するファイルのカンマ区切りリストを指定します。「Hadoop分散キャッシュのデータへのアクセス」を参照してください。
|
関連項目: 汎用オプションの詳細は、次のサイトを参照してください。
|
問合せの開発では、問合せをクラスタに送信する前に、ローカルで実行できます。ローカル実行を使用することで、小さいデータセットで問合せが動作する様子を確認し、潜在的な問題を迅速に診断できます。
ローカル・モードでは、HDFSではなくローカル・ファイル・システムに対して相対的なURIで解決し、問合せをシングル・プロセスで実行します。
問合せをローカル・モードで実行するには、次の手順を実行します。
Hadoopの-jtおよび-fs汎用引数をlocalに設定します。この例では、「例: Hello World!」に記載されている問合せをローカル・モードで実行します。
$ hadoop jar $OXH_HOME/lib/oxh.jar -jt local -fs local ./hello.xq -output ./myoutput -print
問合せのローカル出力ディレクトリ内の結果ファイルを、この例のようにして確認します。
$ cat ./myoutput/part-m-00000
Hello World!
Oracle XQuery for Hadoopでは、構成プロパティを指定する汎用メソッドをhadoopコマンドで使用します。構成ファイルを指定する場合は-confオプションを使用し、個別のプロパティを指定する場合は-Dオプションを使用します。「問合せの実行」を参照してください。
型: String
デフォルト値: 定義されていません。
説明: 問合せの出力ディレクトリを設定します。このプロパティは、-outputコマンドライン・オプションと同等です。「Oracle XQuery for Hadoopのオプション」を参照してください。
型: String
デフォルト値: /tmp/user_name/oxh。user_nameは、Oracle XQuery for Hadoopを実行しているユーザーの名前です。
説明: 一時ファイルを格納するために、Oracle XQuery for HadoopのHDFS一時ディレクトリを設定します。
型: String
デフォルト値: クライアント・システムのタイムゾーン
説明: XQueryの暗黙的なタイムゾーンで、date、timeまたはdatetime値にタイムゾーンがない場合に、比較または算術の操作に使用されます。値はJava TimeZoneクラスによって記述された形式である必要があります。次のサイトにある『Java 7 API Specification』のTimeZoneクラスの説明を参照してください。
http://docs.oracle.com/javase/7/docs/api/java/util/TimeZone.html
型: Boolean
デフォルト値: false
説明: エラー・リカバリをオンにする場合はtrueに設定し、エラー発生時に処理を停止する場合はfalseに設定します。このプロパティは、-skiperrorsコマンドライン・オプションと同等です。
型: Boolean
デフォルト値: true
説明: エラー・コード別にエラーを分類する場合はtrueに設定し、すべてのエラーを単一のカウンタでレポートする場合はfalseに設定します。
型: Integer
デフォルト値: Unlimited
説明: 単一のMapReduceタスクがリカバリできるエラーの最大数を設定します。
型: Integer
デフォルト値: 20
説明: 単一のMapReduceタスクでログに記録するエラーの最大数を設定します。
型: String
デフォルト値: 定義されていません。
説明: 指定のしきい値レベルでタスクごとにlog4jロガーを構成します。プロパティを値OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALLのいずれかに設定します。このプロパティが設定されていない場合、Oracle XQuery for Hadoopはlog4jを構成しません。
Oracle XQuery for Hadoopでは、次のサードパーティ製品がインストールされます。
特に断りがないかぎり、あるいは、サードパーティ・ライセンス(LGPLなど)の条項で求められている場合、Apache Licensed Codeに関連するすべてのステートメントを含めた、この項のライセンスとステートメントは、告知のみを目的とするものです。
The following is included as a notice in compliance with the terms of the Apache 2.0 License, and applies to all programs licensed under the Apache 2.0 license:
You may not use the identified files except in compliance with the Apache License, Version 2.0 (the "License.")
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
A copy of the license is also reproduced in "Apache Licensed Code."
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and limitations under the License.
[The BSD License]
Copyright © 2010 Terence Parr
All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
Neither the name of the author nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Copyright 1999-2008 The Apache Software Foundation
This product includes software developed by The Apache Software Foundation (http://www.apache.org).
This product includes also software developed by:
the W3C consortium (http://www.w3c.org)
the SAX project (http://www.saxproject.org)
The <sync> task is based on code Copyright (c) 2002, Landmark Graphics Corp that has been kindly donated to the Apache Software Foundation.
Portions of this software were originally based on the following:
software copyright (c) 1999, IBM Corporation, http://www.ibm.com.
software copyright (c) 1999, Sun Microsystems, http://www.sun.com.
voluntary contributions made by Paul Eng on behalf of the Apache Software Foundation that were originally developed at iClick, Inc., software copyright (c) 1999
W3C® SOFTWARE NOTICE AND LICENSE
http://www.w3.org/Consortium/Legal/2002/copyright-software-20021231
This work (and included software, documentation such as READMEs, or other related items) is being provided by the copyright holders under the following license.By obtaining, using and/or copying this work, you (the licensee) agree that you have read, understood, and will comply with the following terms and conditions.
Permission to copy, modify, and distribute this software and its documentation, with or without modification, for any purpose and without fee or royalty is hereby granted, provided that you include the following on ALL copies of the software and documentation or portions thereof, including modifications:
The full text of this NOTICE in a location viewable to users of the redistributed or derivative work.
Any pre-existing intellectual property disclaimers, notices, or terms and conditions.If none exist, the W3C Software Short Notice should be included (hypertext is preferred, text is permitted) within the body of any redistributed or derivative code.
Notice of any changes or modifications to the files, including the date changes were made.(We recommend you provide URIs to the location from which the code is derived.)
THIS SOFTWARE AND DOCUMENTATION IS PROVIDED "AS IS," AND COPYRIGHT HOLDERS MAKE NO REPRESENTATIONS OR WARRANTIES, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO, WARRANTIES OF MERCHANTABILITY OR FITNESS FOR ANY PARTICULAR PURPOSE OR THAT THE USE OF THE SOFTWARE OR DOCUMENTATION WILL NOT INFRINGE ANY THIRD PARTY PATENTS, COPYRIGHTS, TRADEMARKS OR OTHER RIGHTS.
COPYRIGHT HOLDERS WILL NOT BE LIABLE FOR ANY DIRECT, INDIRECT, SPECIAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF ANY USE OF THE SOFTWARE OR DOCUMENTATION.
The name and trademarks of copyright holders may NOT be used in advertising or publicity pertaining to the software without specific, written prior permission.Title to copyright in this software and any associated documentation will at all times remain with copyright holders.
This formulation of W3C's notice and license became active on December 31 2002.This version removes the copyright ownership notice such that this license can be used with materials other than those owned by the W3C, reflects that ERCIM is now a host of the W3C, includes references to this specific dated version of the license, and removes the ambiguous grant of "use".Otherwise, this version is the same as the previous version and is written so as to preserve the Free Software Foundation's assessment of GPL compatibility and OSI's certification under the Open Source Definition.Please see our Copyright FAQ for common questions about using materials from our site, including specific terms and conditions for packages like libwww, Amaya, and Jigsaw.Other questions about this notice can be directed to site-policy@w3.org.
Joseph Reagle <site-policy@w3.org>
This license came from: http://www.megginson.com/SAX/copying.html
However please note future versions of SAX may be covered under http://saxproject.org/?selected=pd
SAX2 is Free!
I hereby abandon any property rights to SAX 2.0 (the Simple API for XML), and release all of the SAX 2.0 source code, compiled code, and documentation contained in this distribution into the Public Domain.SAX comes with NO WARRANTY or guarantee of fitness for any purpose.
David Megginson, david@megginson.com
2000-05-05
Copyright 2010 The Apache Software Foundation
This product includes software developed at The Apache Software Foundation (http://www.apache.org/).
C JSON parsing provided by Jansson and written by Petri Lehtinen.The original software is available from http://www.digip.org/jansson/.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use Apache Avro except in compliance with the License.You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions and limitations under the License.
License for the Jansson C JSON parser used in the C implementation:
Copyright (c) 2009 Petri Lehtinen <petri@digip.org>
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
License for the Json.NET used in the C# implementation:
Copyright (c) 2007 James Newton-King
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
License for msinttypes used in the C implementation:
Source from:
http://code.google.com/p/msinttypes/downloads/detail?name=msinttypes-r26.zip
Copyright (c) 2006-2008 Alexander Chemeris
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
The name of the author may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE AUTHOR "AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
License for Dirent API for Microsoft Visual Studio used in the C implementation:
Source from:
http://www.softagalleria.net/download/dirent/dirent-1.11.zip
Copyright (C) 2006 Toni Ronkko
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the ``Software''), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS'', WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.IN NO EVENT SHALL TONI RONKKO BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Xerces Copyright © 1999-2002 The Apache Software Foundation.All rights reserved.Licensed under the Apache 1.1 License Agreement.
The names "Xerces" and "Apache Software Foundation must not be used to endorse or promote products derived from this software or be used in a product name without prior written permission.For written permission, please contact apache@apache.org.
This software consists of voluntary contributions made by many individuals on behalf of the Apache Software Foundation.For more information on the Apache Software Foundation, please see http://www.apache.org.
The Apache Software License, Version 1.1
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
The end-user documentation included with the redistribution, if any, must include the acknowledgements set forth above in connection with the software ("This product includes software developed by the ….)Alternately, this acknowledgement may appear in the software itself, if and wherever such third-party acknowledgements normally appear.
The names identified above with the specific software must not be used to endorse or promote products derived from this software without prior written permission.For written permission, please contact apache@apache.org.
Products derived from this software may not be called "Apache" nor may "Apache" appear in their names without prior written permission of the Apache Group.
THIS SOFTWARE IS PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.IN NO EVENT SHALL THE APACHE SOFTWARE FOUNDATION OR ITS CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
This product includes software developed by The Apache Software Foundation (http://www.apache.org/).
Portions of this software were originally based on the following:
software copyright (c) 2000-2003, BEA Systems, <http://www.bea.com/>.
Aside from contributions to the Apache XMLBeans project, this software also includes:
one or more source files from the Apache Xerces-J and Apache Axis products, Copyright (c) 1999-2003 Apache Software Foundation
W3C XML Schema documents Copyright 2001-2003 (c) World Wide Web Consortium (Massachusetts Institute of Technology, European Research Consortium for Informatics and Mathematics, Keio University)
resolver.jar from Apache Xml Commons project, Copyright (c) 2001-2003 Apache Software Foundation
Piccolo XML Parser for Java from http://piccolo.sourceforge.net/, Copyright 2002 Yuval Oren under the terms of the Apache Software License 2.0
JSR-173 Streaming API for XML from http://sourceforge.net/projects/xmlpullparser/, Copyright 2005 BEA under the terms of the Apache Software License 2.0
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License.You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions and limitations under the License.
This copy of Woodstox XML processor is licensed under the Apache (Software) License, version 2.0 ("the License").See the License for details about distribution rights, and the specific rights regarding derivate works.
You may obtain a copy of the License at:
http://www.apache.org/licenses/
A copy is also included with both the downloadable source code package and jar that contains class bytecodes, as file "ASL 2.0".In both cases, that file should be located next to this file: in source distribution the location should be "release-notes/asl"; and in jar "META-INF/"
This product currently only contains code developed by authors of specific components, as identified by the source code files.
Since product implements StAX API, it has dependencies to StAX API classes.
For additional credits (generally to people who reported problems) see CREDITS file.