27 HCM抽出の管理
この章の内容は次のとおりです。
抽出コンポーネント: 連携方法
HCM抽出機能は、データ・ファイルおよびレポートを生成するための柔軟性のあるツールです。このトピックでは、抽出コンポーネントを使用して、アプリケーションで抽出したりレポートする情報を定義する方法について説明します。アプリケーションで情報を表示、書式設定および提供する方法についても説明します。
抽出定義
抽出定義とは、抽出データ・グループ、基準、レコード、属性、拡張条件および出力提供オプションで構成される抽出の完全な設定を指します。抽出定義は次のもので構成されます。
-
抽出する論理エンティティの数に応じて、1つ以上の抽出データ・グループ。
-
収集する情報のグループの数に応じて、1つ以上の抽出レコード。
-
収集するデータの個別フィールドの数に応じて、1つ以上の属性。
HCM抽出を使用して、Oracle Fusion HCMデータベースから大量のHCMデータを抽出、アーカイブ、変換、レポートおよび提供します。出力は、次の形式で生成できます。
-
CSV
-
XML
-
Excel
-
HTML
-
RTF
-
PDF
抽出した情報は、Eメール、FAXおよび他の提供モードで配布できます。抽出の一般的な例として、従業員の受信ボックスに配信されるPDF給与明細、第三者のサービス・プロバイダに転送される給与および福利厚生データ、共存シナリオなどでのOracle Fusionアプリケーションとレガシー・アプリケーションの間でのHRおよびタレント・データ交換があります。
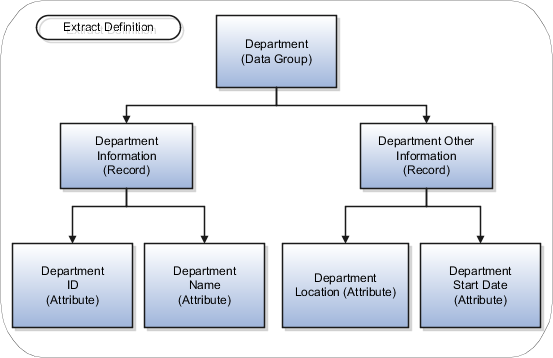
データ・グループ
拡張データ・グループは、個人、アサイメント、福利厚生などのビジネス・エリアまたは論理エンティティを表します。アプリケーションは、この情報を使用してデータベース・アイテム・グループを取得します。1つのデータ・グループをプライマリまたはルート・データ・グループとして定義し、このデータ・グループがデータ抽出の開始ポイントとなります。
抽出データ・グループ接続は、現在のデータ・グループと親データ・グループの間の関連詳細を収集します。データ・グループ接続によって、データ・グループ間の階層関係が形成されます。
抽出データ・グループ基準を使用して、抽出データ・グループに対してアプリケーションで実行する必要がある一連のフィルタリング条件を定義できます。基準条件は、式またはFastFormulaを使用して指定します。
抽出レコード
抽出レコードは、抽出に必要なすべてのフィールドの関連データまたは物理コレクションのグループ化を表します。たとえば、従業員データ・グループには、基本詳細、支払詳細、事業所詳細、プライマリ連絡先などのレコードを設定できます。抽出レコードは、必要な順序で編成できる属性のコレクションです。たとえば、データ・グループに3つのレコードがある場合、アプリケーションがレコードを処理する順序を指定できます。次のデータ・グループを選択して、アプリケーションが次にどのデータ・グループを処理するかを指定することもできます。
属性
属性は、抽出レコード内の個別フィールドです。HCM抽出の最下位の属性レベルであり、個人名、個人姓、個人生年月日などの情報を表します。
次の図は、データ・グループ定義内の情報の階層を示しています。
HCM抽出タイプ: 説明
選択した抽出のタイプによって、抽出の目的が決まります。自動的に生成されるパラメータも決まります。たとえば、給与インタフェース抽出タイプを選択した場合は、変更のみパラメータおよび他のパラメータが作成されます。抽出タイプは、「HCM抽出定義の管理」ページで選択できます。
次の表では、様々な抽出タイプとそのタイプを選択する理由をリストしています。
| 抽出タイプ | 目的 |
|---|---|
|
全プロファイル |
従業員および給与データの完全なアーカイブに使用します。 |
|
給与インタフェース |
データを第三者の給与サービス・プロバイダに提供する場合に使用します。 |
|
支払 |
給与支払方法アーカイブに使用します。たとえば、小切手や銀行振替による支払があります。 |
|
福利厚生会社 |
データを第三者の福利厚生サービス・プロバイダに提供する場合に使用します。 |
|
アーカイブ検索 |
給与明細などの完全にアーカイブされたデータに基づいてレポートを作成する場合に使用します。 |
|
年度末アーカイブ |
年度末アーカイブ(HR、福利厚生)に使用します。 |
|
HRアーカイブ |
すべてのHRアーカイブに使用します。 |
|
給与アーカイブ |
すべての給与または給与明細のアーカイブに使用します。 |
|
その他の給与アーカイブ |
すべての給与アーカイブに使用します。 |
給与インタフェース抽出定義: 概要
給与インタフェース抽出タイプの抽出定義により、第三者給与プロバイダに送信するデータが決まります。次の表では、ビジネス固有の抽出要件にあわせて使用または定義できる事前定義済給与インタフェース抽出定義をリストしています。
| 抽出定義 | 目的 | 出力 |
|---|---|---|
|
グローバル給与インタフェース |
給与データをエレメント・エントリ値または「総支給項目の計算」プロセスによって作成されたバランス結果から導出します。 |
eTextおよびXML |
|
NGAの給与インタフェース |
NGA Human Resourcesによる第三者の給与処理のためにPayroll Exchangeと統合する汎用のHRおよび給与関連データを抽出します。この抽出は、データをNGA Human Resources標準に準拠するHR-XML形式に変換します。 特別な変更が必要ない場合は、事前定義済の「NGAの給与インタフェース・レポートの実行」プロセスを使用します。 |
XML |
|
US ADP PayForceサードパーティ・アドホック抽出 |
給与データを、日付期間または給与期間の共通のHRデータや給与データなどのエレメント・エントリから導出します。出力形式は、Automatic Data Processing (ADP) PayForce標準に準拠します。 |
eTextおよびXML |
|
US ADP PayForceサードパーティ定期抽出 |
給与データを、給与期間に「総支給項目の計算」プロセスによって作成されたバランス結果から導出します。出力形式は、ADP PayForce標準に準拠します。 |
eTextおよびXML |
ユーザー・エンティティ詳細の表示: 説明
抽出定義を作成する場合は、データ・グループを作成するためにユーザー・エンティティ詳細が必要になります。「データ交換」タスク・ペインを使用するか、「抽出定義の管理」タスクの「設計」タブでデータ・グループを作成するときに、「ユーザー・エンティティ詳細の表示」UIにアクセスできます。
「ユーザー・エンティティ詳細の表示」ページを使用して、次の操作を実行できます。
-
ユーザー・エンティティ内の使用可能なデータベース・アイテムの表示。
-
ルート・データ・グループで使用するユーザー・エンティティの検証。
-
ユーザー・エンティティのタイプ(単一行、複数行、履歴、有効日など)のレビュー。
-
ユーザー・エンティティが使用するSQL問合せのレビュー。
-
データ・セット内の行数の計算。
-
ユーザー・エンティティによって使用および設定されたコンテキストのレビュー。
-
ユーザー・エンティティを使用している抽出の確認。
次の項では、「ユーザー・エンティティ詳細の表示」UIから導出できる情報について詳しく説明します。
ユーザー・エンティティ詳細のレビュー
「ユーザー・エンティティ詳細の表示」UIでユーザー・エンティティを検索し、「ユーザー・エンティティ詳細」タブをクリックします。
「ルート・データ・グループに有効」の値が「はい」の場合、ユーザー・エンティティをルート・データ・グループとして使用できます。ユーザー・エンティティがルート・データ・グループに有効である場合、「複数行」の値が「はい」で「コンテキスト必須」が「いいえ」であるかどうかも確認できます。PER_EXT_SEC_PERSON_UEユーザー・エンティティは、「複数行」の値が「はい」で「コンテキスト必須」が「いいえ」であるため、ルート・データ・グループとして使用できます。
ユーザー・エンティティが複数行ユーザー・エンティティでない場合は、このエンティティをルート・データ・グループとして使用できません。複数行ユーザー・エンティティが単一行ユーザー・エンティティに必要なコンテキストを設定している場合、通常は単一行ユーザー・エンティティのデータベース・アイテム・グループが導出されたデータベース・アイテム・グループとして複数行ユーザー・エンティティに含まれます。たとえば、PER_PER_PERSON_DETAILS_UEユーザー・エンティティは、複数行ユーザー・エンティティではありません。
ユーザー・エンティティが履歴の場合は、有効日に関係なくデータを取得します。たとえば、PER_EXT_ASSIGNMENT_BASIC_HISTORY_UEユーザー・エンティティは、アサイメントの履歴詳細全体を取得します。
ユーザー・エンティティが履歴でない場合は、有効日現在のデータを取得します。たとえば、PER_EXT_PAY_EMPLOYEES_UEユーザー・エンティティは、有効日現在の個人、アサイメントおよび給与の詳細を取得します。
SQL問合せのレビュー
「ユーザー・エンティティ詳細の表示」UIでユーザー・エンティティを検索し、「問合せ」タブをクリックします。このタブには、ユーザー・エンティティがデータを抽出するために使用するSQL問合せがリストされます。拡張フィルタ基準の作成に役立つ表体系と別名をレビューできます。ユーザー・エンティティがルート・データ・グループとして有効な場合は、SQL問合せによって戻される行を計算できます。ただし、戻される行の数は推定であり、抽出で実際に戻される行の数とは一致しない場合があります。実際の抽出出力は、抽出で使用されるフィルタ基準、式およびFastFormulaによって異なります。
ユーザー・エンティティ・コンテキストのレビュー
「ユーザー・エンティティ詳細の表示」UIでユーザー・エンティティを検索し、「コンテキスト」タブをクリックします。「必須コンテキスト」セクションに、抽出でユーザー・エンティティを使用するために設定する必要があるコンテキストがリストされます。たとえば、PER_PER_PHONES_UEユーザー・エンティティにはPERSON_IDコンテキストが必要であるため、このユーザー・エンティティを使用するにはPERSON_IDコンテキストを設定する必要があります。通常、履歴ではないユーザー・エンティティにはEFFECTIVE_DATEコンテキストが必要です。ただし、EFFECTIVE_DATEコンテキストはデフォルトで設定されるため、このコンテキストを明示的に設定する必要はありません。「設定済コンテキスト」セクションに、ユーザー・エンティティによって設定されたコンテキストがリストされます。たとえば、PER_EXT_SEC_PERSON_UEユーザー・エンティティは、他のユーザー・エンティティが使用できるPERSON_ID、ORGANIZATION_IDおよびENTERPRISE_IDコンテキストを設定します。
ユーザー・エンティティを使用している抽出の確認
「ユーザー・エンティティ詳細の表示」UIでユーザー・エンティティを検索し、「ユーザー・エンティティを使用した抽出」タブをクリックします。別の抽出でユーザー・エンティティが使用されている場合は、抽出設計をレビューしてユーザー・エンティティの使用状況を把握できます。抽出設計をコピーし、要件にあわせて変更することもできます。
頻繁に使用されるユーザー・エンティティ
ユーザー・エンティティは、HCM抽出を使用して定義されたデータ・グループに関連付けられている論理エンティティです。このトピックでは、頻繁に使用されるユーザー・エンティティおよびそれらのユーザー・エンティティを使用して抽出できるデータのタイプについて説明します。データ・グループを定義するときに、アプリケーションでユーザー・エンティティを選択します。
次の表では、最も頻繁に使用されるユーザー・エンティティをリストしています。
| ユーザー・エンティティ名とコード | 説明 |
|---|---|
|
個人(PER_EXT_SEC_PERSON_UE) |
企業全体のすべての個人およびすべての個人関連属性を取得します。 |
|
就業者給与(PER_EXT_PAY_EMPLOYEES_UE) |
企業全体のすべての就業者とその給与、すべての個人、就業者、給与関連属性およびエレメント・エントリ・データを取得します。 |
|
抽出アサイメント基本履歴(PER_EXT_ASSIGNMENT_BASIC_HISTORY_UE) |
アサイメント有効開始日のアサイメント履歴を取得します。 |
|
抽出アサイメント基本情報(PER_EXT_SEC_ASSIGNMENT_BASIC_UE) |
有効日のアサイメント・データを取得します。 |
|
アサイメント範囲(PER_EXT_SEC_ASSIGNMENT_RANGE_UE) |
有効日のアサイメント履歴を取得します。 |
|
抽出現在および将来の個人(PER_EXT_SEC_PERSON_NOW_FUTURE_UE) |
現在および将来の個人詳細を取得します。Personタイプを制限するには、拡張フィルタ基準を指定します。 |
|
抽出現在および将来のアサイメント(PER_EXT_SEC_ASSIGNMENT_NOW_FUTURE_UE) |
現在および将来のアサイメントを取得します。 |
「ユーザー・エンティティ詳細の表示」タスクを使用してユーザー・エンティティに関する詳細を表示できます。
HCM抽出テンプレート: 説明
ワーク・ストラクチャと就業者詳細を生成する抽出をすばやく設定するには、事前定義済のワーク・ストラクチャおよび就業者抽出テンプレートを使用します。ワーク・ストラクチャ抽出は、ビジネス・ユニット、法的エンティティ、部門、等級、ジョブ、事業所およびポジションの詳細を生成します。就業者抽出は、個人名、電話番号、Eメール、国別識別子、住所、国別仕様、有給休暇、休暇欠勤、雇用関係、勤務条件、アサイメント、勤務メジャー、上長および給与の詳細を生成します。
これらの抽出を使用するには、抽出をコピーし、要件にあわせて構成します。抽出テンプレートを直接実行することはできません。これらの抽出は複雑で詳細です。有効日に関係なくすべての詳細を戻すように履歴ユーザー・エンティティで設計されているため、大量のデータを抽出したり時間がかかる場合があります。
これらの抽出テンプレートを使用する場合は、不要なデータ取得や時間のかかるデータ取得を回避するために次の操作を実行してください。
-
フィルタ基準を定義します。たとえば、特定の事業所に関連するデータを抽出する場合は、データ・グループ・フィルタ条件に式またはFastFormulaを含めます。
-
不要なデータ・グループを削除します。たとえば、ポジションに関心がない場合は、ポジション・データ・グループを削除できます。
-
すべての詳細をレビューして、すべての情報が要件に関連することを確認します。
ワーク・ストラクチャおよび就業者抽出テンプレートの使用方法
就業者またはワーク・ストラクチャ抽出テンプレートを使用するには、次のようにします。
-
就業者またはワーク・ストラクチャ抽出定義をコピーして新規抽出を作成します。
-
コピーした抽出を更新します。
-
FastFormulaを生成し、コンパイルします。
-
抽出設計を検証します。
-
パラメータを調整します。
抽出の定義: 作業例
この例は、デスクトップ・インタフェースを使用して抽出定義を作成するために必要な手順を示しています。デスクトップ・インタフェースにアクセスするには、「HCM抽出定義の管理」ページで「レイアウトの切替え」ボタンをクリックします。抽出定義を作成する前に、次の詳細を把握する必要があります。
-
抽出する情報
-
データを抽出する必要があるストラクチャ
-
このデータの提供方法(ファイル形式、提供メカニズム、周期情報など)
FAST銀行は、世界中に子会社を持つグローバル組織です。外部のビジネス・レポート要件の一部として、FAST銀行は会社全体の部門と従業員の詳細(部門ごとにグループ化)を抽出する必要があります。この情報は、Eメールを使用して、XMLファイルで第三者に、PDFファイルでHRマネージャに送信する必要があります。次の表では、このシナリオにおける主な決定事項を要約しています。
| 考慮する決定事項 | この例の場合 |
|---|---|
|
このタイプのレポートを作成するには、いくつの抽出を作成するか。 |
1つの抽出定義を作成してヘッドカウント・レポートを定義します。 |
|
いくつのデータ・グループを作成するか。 |
情報の機能グループが2つあるため、2つのデータ・グループ(1つは部門用、もう1つは従業員用)を作成します。 |
|
いくつのレコードを作成するか。 |
データ・グループ内の属性のサブグループに基づいてレコードの数を決定します。この例では、部門データ・グループ用に次の2つのレコードを作成します。
従業員データ・グループ用に1つのレコード(Employee Details)を作成します。 |
|
いくつの属性を作成するか。 |
レポートに必要な特定の情報に基づいて属性の数を決定します。Department Detailsレコードには次の属性を作成します。
Department Summaryレコードには次の属性を作成します。
Employee Detailsレコードには次の属性を作成します。
|
|
FastFormulaを作成するか。 |
FastFormulaは、次のレベルで使用できます。
|
抽出定義の作成
-
「HCM抽出定義の管理」ページで、「作成」をクリックします。
-
「レイアウトの切替え」ボタンを使用して、デスクトップ・インタフェースで抽出を開きます。
-
「セッション有効日」に「01-Jan-2000」と入力します。
セッション有効日は、現在のセッションのすべての有効日対応に適用される有効開始日です。
-
名前として「FAST Bank Extract」と入力し、タイプとして「HRアーカイブ」を選択します。アプリケーションによって、抽出名に基づいてタグ名が自動的に作成され、この名前を使用してXML出力ファイルが生成されます。
-
「保存」をクリックします。抽出定義が保存され、抽出のタイプに基づいてパラメータが自動的に生成されます。パラメータによって抽出の出力が制御されます。この例では、次のパラメータが作成されます。
-
有効日
-
国別仕様データ・グループ
-
パラメータ・グループ
-
レポート・カテゴリ
-
要求ID
-
開始日
-
抽出データ・グループの作成
-
ナビゲーション・ツリーから抽出データ・グループ・リンクを選択し、抽出データ・グループ・リージョンを開きます。
-
「作成」をクリックして新しいデータ・グループを定義します。データ・グループは、1つ以上の論理データ・エンティティに属しているデータを表します。
-
データ・グループを作成するために、次の表に示すように、フィールドを設定します。
フィールド名 入力 名前
Departments
ユーザー・エンティティ
PER_EXT_SEC_ORGANIZATION_UE
ルート・データ・グループ
はい(このオプションの選択によって、このデータ・グループが抽出実行の開始点として選択されます。)
-
「保存して別の作成」を選択して、従業員のデータ・グループを作成します。
-
データ・グループを作成するために、次の表に示すように、フィールドを設定します。
フィールド名 入力 名前
Employees
ユーザー・エンティティ
PER_EXT_SEC_ASSIGNMENT_UE
ルート・データ・グループ
いいえ
抽出データ・グループ接続の作成
-
ナビゲーション・ツリーで抽出データ・グループを選択して、表にデータ・グループを表示します。
-
「Employees」データ・グループを選択し、データ・グループ接続の詳細を定義します。
-
データ・グループ接続を作成するために、次の表に示すように、フィールドを設定します。
フィールド名 入力 親データ・グループ
Departments
親データ・グループ・データベース・アイテム
PER_EXT_ORG_ORGANIZATION_ID
データ・グループ・データベース・アイテム
PER_EXT_ASG_ORG_ID
-
各データ・グループのデータ・グループ基準を定義します。
抽出レコードの作成
-
ナビゲーション・ツリーで「Departments」データ・グループを選択し、「抽出レコード」リージョンで「作成」アイコンを選択します。抽出レコードは、すべての必須フィールドの物理コレクションを表します。データ・グループに3つのレコードがある場合は、順序フィールドを使用して、アプリケーションがレコードを処理する順序を指定できます。「次のデータ・グループ」を選択して、アプリケーションが次にどのデータ・グループを処理するかを指定することもできます。
-
Departmentsデータ・グループ用に次の2つのレコードを作成します。
-
Departmentsデータ・グループの2つのレコードを作成するために、次の表に示すように、フィールドを設定します。
フィールド Department Summary Department Details 名前
Department Summary
Department Details
有効開始日
1/1/00
1/1/00
順序
20
10
タイプ
トレーラ・レコード
ヘッダー・レコード
プロセス・タイプ
FastFormula
FastFormula
次のデータ・グループ
該当なし
Employees
-
レコードを保存し、「Employees」データ・グループを選択して、「抽出レコード」リージョンで「作成」アイコンを選択します。
-
Employeesデータ・グループ用に1つのレコードを作成します。
-
Employeesデータ・グループのレコードを作成するために、次の表に示すように、フィールドを設定します。
フィールド名 入力 名前
Employee Details
有効開始日
1/1/00
順序
10
タイプ
詳細レコード
プロセス・タイプ
FastFormula
属性の作成
-
ナビゲーション・ツリーで「Departments」データ・グループを選択し、「Department Details」レコードを選択します。
抽出属性は、レコードの個別フィールドです。
-
Department Detailsレコードに次の抽出属性を作成し、「保存」を選択します。
-
Department Detailsレコードの抽出属性を作成するために、次の表に示すように、フィールドを設定します。
フィールド名 属性入力 属性入力 名前
Department Name
Department Location
タイプ
データベース・アイテム・グループ
データベース・アイテム・グループ
データベース・アイテム・グループ
組織名
組織事業所国
-
レコードを選択し、「Department Summary」レコードを選択します。
-
「抽出属性」リージョンで「作成」アイコンを選択します。
-
Department Summaryレコードに次の抽出属性を作成し、「保存」を選択します。
-
Department Summaryレコードの抽出属性を作成するために、次の表に示すように、フィールドを設定します。
フィールド名 属性入力 属性入力 属性入力 名前
Record Code
Report Date
Employee Count
データ型
テキスト
日付
数値
タイプ
文字列
パラメータ・エレメント
要約エレメント
文字列値
999
該当なし
該当なし
パラメータ
有効日
該当なし
該当なし
集計関数
該当なし
該当なし
カウント
集計レコード名
該当なし
該当なし
Employees Employee Details
-
ナビゲーション・ツリーで「Employees」データ・グループを選択し、「Employee Details」レコードを選択します。
-
Employee Detailsレコードに次の抽出属性を作成し、「保存」を選択します。
-
Employee Detailsレコードの抽出属性を作成するために、次の表に示すように、フィールドを設定します。
フィールド名 属性入力 属性入力 属性入力 名前
Full Name
Gender
Date of Birth
開始日
1/1/00
1/1/00
1/1/00
データ型
テキスト
テキスト
日付
タイプ
データベース・アイテム・グループ
デコード・データベース・アイテム・グループ
データベース・アイテム・グループ
データベース・アイテム・グループ
個人氏名
個人性別
個人生年月日
-
Employee Detailsレコードの抽出属性をさらに作成するために、次の表に示すように、フィールドを設定します。
フィールド名 属性入力 属性入力 属性入力 名前
Salary
Bonus
Tax rate
開始日
1/1/00
1/1/00
1/1/00
データ型
数値
数値
テキスト
タイプ
データベース・アイテム・グループ
レコード計算
ルール
データベース・アイテム・グループ
アサイメント給与額
該当なし
該当なし
計算式
該当なし
Salary * 0.5
該当なし
ルール
該当なし
該当なし
FAST Bank Tax Rule
提供オプションの定義
-
抽出実行ツリーにナビゲートして、抽出定義設定を検証します。
-
「XSDのエクスポート」を選択して、この抽出設定のXMLスキーマ定義(.XSD)ファイルをダウンロードします。このエクスポート済ファイルには、抽出定義の構造(データ・グループ、レコードおよび属性)が含まれています。
-
「抽出提供オプション」リージョンを選択して、抽出定義の書式設定とレイアウトのオプションを定義します。
-
次の表に示すように、提供オプションのフィールドを設定します。
フィールド 値 値 開始日
1/1/00
1/1/00
終了日
12/31/12
12/31/12
BIパブリッシャ・テンプレート
レポート・レイアウト
EFTレイアウト
出力タイプ
PDF
EFT
提供タイプ
Email
FTP
提供オプション名
Email to HR
FTP to 3rd Party
出力名
HeadcountReport
EFTReport
-
「追加詳細」リージョンで各提供オプションの詳細情報を定義します。たとえば、FTP提供タイプのサーバー、ユーザー名およびパスワードを追加します。
-
レポート・カテゴリとして「FAST Bank Extract」と入力し、「送信」をクリックします。
抽出の送信
抽出定義によって、抽出と同じ名前の抽出プロセス(給与フロー)が自動的に作成されます。抽出プロセスを使用すると、複数のタスクの実行順序(タスクの前、後など)を定義できます。
-
「抽出の送信」タスクを選択し、「FAST Bank Extract」プロセスを選択します。
-
「次」を選択します。
-
「給与フロー」(抽出プロセス)に「FAST Bank Extract - Jan 2012」と入力します。
-
「終了日」に「1/1/15」と入力します。
-
「次」を選択します。タスクが抽出プロセスの異なる他のタスクに依存している場合は、対応詳細を指定できます。たとえば、このタスクは、別のタスクが実行中のため待機する必要があります。
-
「次」を選択して抽出をレビューします。抽出をスケジュールするか、すぐに実行します。
-
「送信」を選択します。
-
「OKしてチェックリストを表示」を選択して、プロセスのステータスを表示します。
-
「抽出結果の表示」タスクを選択して、抽出の実行結果をレビューします。「FAST Bank Extract」プロセスを検索します。
-
「FAST Bank Extract - Jan 2012」の「タスクに進む」を選択し、眼鏡をクリックして、レポート名の選択によりレポート出力を表示します。
簡易インタフェースの使用方法: 作業例
この例は、データ・グループ、レコードおよび属性の作成など、簡易インタフェースを使用したHCM抽出の作成方法を示しています。FAST銀行は、世界中に子会社を持つグローバル組織です。外部のレポート要件の一部として、FAST銀行は会社全体の部門と従業員の詳細を取得する必要があります。この情報は、XMLファイルで第三者に、従業員詳細が部門別にグループ化されたヘッドカウント・レポートとしてHRマネージャに送信する必要があります。
次の表では、このシナリオにおける主な決定事項を要約しています。
| 考慮する決定事項 | この例の場合 |
|---|---|
|
このタイプのレポートを作成するには、いくつの抽出を作成するか。 |
1つの抽出定義を作成してヘッドカウント・レポートを定義します。 |
|
いくつのデータ・グループを作成するか。 |
情報の機能グループが2つあるため、2つのデータ・グループ(1つは部門用、もう1つは従業員用)を作成します。 |
|
いくつのレコードを作成するか。 |
データ・グループ内の属性のサブグループに基づいてレコードの数を決定します。この例では、部門データ・グループ用に次の2つのレコードを作成します。
従業員データ・グループ用に1つのレコード(Employee Details)を作成します。 |
|
いくつの属性を作成するか。 |
レポートに必要な特定の情報に基づいて属性の数を決定します。Department Detailsレコードには次の属性を作成します。
Department Summaryレコードには次の属性を作成します。
Employee Detailsレコードには次の属性を作成します。
|
|
FastFormulaを作成するか。 |
FastFormulaは、次のレベルで使用できます。
|
抽出定義の作成
-
「抽出定義の管理」ページで、「作成」をクリックします。
-
名前として「FAST Bank Extract」、開始日として「01-JAN-2010」と入力し、タイプとして「HRアーカイブ」を選択します。アプリケーションは、この名前を使用してXML出力ファイルを生成します。
-
「保存」をクリックします。抽出定義が保存され、抽出のタイプに基づいてパラメータが自動的に生成されます。パラメータによって抽出の出力が制御されます。
「レイアウトの切替え」ボタンを使用して、デスクトップ・インタフェースで抽出を開きます。デスクトップ・インタフェースを使用して、ドラッグ・アンド・ドロップ・システムを使用せずにHCM抽出を作成および定義します。抽出を定義するためのほとんどのタスクは、簡易インタフェースで実行できます。
抽出データ・グループとレコードの作成
-
「設計」アイコンを選択して、データ・グループとレコードを作成します。
-
「作成」アイコンを選択するか「HCMデータ・オブジェクト」ツリーを使用して、データ・グループをローカル・エリアにドラッグ・アンド・ドロップします。
-
ドラッグ・アンド・ドロップ・アクションを使用して、組織オブジェクトをローカル・エリアにドラッグします。このアクションによって、関連付けられているレコード・オブジェクトが自動的に作成されます。
-
データ・グループを次の情報で更新します。
フィールド名 入力 名前
Departments
ユーザー・エンティティ
PER_EXT_SEC_ORGANIZATION_UE
ルート・データ・グループ
はい(このオプションの選択によって、このデータ・グループが抽出実行の開始点として選択されます。)
-
次の情報を使用して、レコード・オブジェクトを更新し、別のレコード・オブジェクトを作成します。
-
Departmentsデータ・グループの2つのレコードを作成するために、次の表に示すように、フィールドを設定します。
フィールド Department Summary Department Details 名前
Department Summary
Department Details
有効開始日
1/1/00
1/1/00
順序
20
10
タイプ
トレーラ・レコード
ヘッダー・レコード
プロセス・タイプ
FastFormula
FastFormula
次のデータ・グループ
該当なし
Employees
-
「保存」を選択し、Employeesデータ・オブジェクトをローカル・エリアにドラッグして別のデータ・グループを作成します。このアクションによって、関連付けられているレコード・オブジェクトが自動的に作成されます。
-
データ・グループを次の情報で更新します。
フィールド名 入力 名前
Employees
ユーザー・エンティティ
PER_EXT_SEC_ASSIGNMENT_UE
ルート・データ・グループ
いいえ
-
レコード・オブジェクトを次の情報で更新します。
-
Employeesデータ・グループのレコードを作成するために、次の表に示すように、フィールドを設定します。
フィールド名 入力 名前
Employee Details
有効開始日
1/1/00
順序
10
タイプ
詳細レコード
プロセス・タイプ
FastFormula
抽出データ・グループ接続の作成
-
「Employees」データ・グループの「リンク」アイコンを選択し、「追加」アイコンを選択して接続を追加します。
-
データ・グループ接続を作成するために、次の表に示すように、フィールドを設定します。
フィールド名 入力 親データ・グループ
Departments
親データ・グループ・データベース・アイテム
PER_EXT_ORG_ORGANIZATION_ID
データ・グループ・データベース・アイテム
PER_EXT_ASG_ORG_ID
-
「フィルタ」アイコンを選択して、各データ・グループのデータ・グループ・フィルタ基準を定義します。
属性の作成
-
「Departments」データ・グループの「Departments Details」レコードを選択し、「構成」アイコン内の「属性の作成」オプションを選択します。
-
Department Detailsレコードの抽出属性を作成するために、次の表に示すように、フィールドを設定します。
フィールド名 属性入力 属性入力 名前
Department Name
Department Location
タイプ
データベース・アイテム・グループ
データベース・アイテム・グループ
データベース・アイテム・グループ
組織名
組織事業所国
-
「Department Summary」レコードを選択し、前述の方法で次の抽出属性詳細を入力します。
-
Department Summaryレコードの抽出属性を作成するために、次の表に示すように、フィールドを設定します。
フィールド名 属性入力 属性入力 属性入力 名前
Record Code
Report Date
Employee Count
データ型
テキスト
日付
数値
タイプ
文字列
パラメータ・エレメント
要約エレメント
文字列値
999
該当なし
該当なし
パラメータ
有効日
該当なし
該当なし
集計関数
該当なし
該当なし
カウント
集計レコード名
該当なし
該当なし
Employees Employee Details
-
「Employees」データ・グループ内の「Employee Details」レコードを選択し、同じ方法で次の抽出属性詳細を入力します。
-
Employee Detailsレコードの抽出属性を作成するために、次の表に示すように、フィールドを設定します。
フィールド名 属性入力 属性入力 属性入力 名前
Full Name
Gender
Date of Birth
開始日
1/1/00
1/1/00
1/1/00
データ型
テキスト
テキスト
日付
タイプ
データベース・アイテム・グループ
デコード・データベース・アイテム・グループ
データベース・アイテム・グループ
データベース・アイテム・グループ
個人氏名
個人性別
個人生年月日
提供オプションの定義
-
「提供」アイコンを選択してから「追加」アイコンを選択して、提供オプションを定義します。
-
次の表に示すように、提供オプションのフィールドを設定します。
フィールド 値 値 開始日
1/1/00
1/1/00
終了日
12/31/12
12/31/12
BIパブリッシャ・テンプレート
レポート・レイアウト
EFTレイアウト
出力タイプ
PDF
EFT
提供タイプ
Email
FTP
提供オプション名
Email to HR
FTP to 3rd Party
出力名
HeadcountReport
EFTReport
-
FTP提供タイプのサーバー、ユーザー名、パスワードなどの追加情報を入力します。
-
レポート・カテゴリとして「FAST Bank Extract」と入力し、「送信」をクリックします。
-
抽出定義詳細を表示し、「検証」アイコンを選択して「検証」ページで構造が有効であることを確認します。
-
「XSDのエクスポート」を選択して、この抽出設定のXMLスキーマ定義(.XSD)ファイルをダウンロードします。このエクスポート済ファイルには、抽出定義の構造(データ・グループ、レコードおよび属性)が含まれています。
抽出の送信
抽出定義によって、抽出と同じ名前の抽出プロセス(給与フロー)が自動的に作成されます。抽出プロセスを使用すると、複数のタスクの実行順序(タスクの前、後など)を定義できます。
-
「抽出の送信」タスクを選択し、「FAST Bank Extract」プロセスを選択します。
-
「次」を選択します。
-
「給与フロー」(抽出プロセス)に「FAST Bank Extract - Jan 2012」と入力します。
-
「終了日」に「1/1/15」と入力します。
-
「次」を選択します。タスクが抽出プロセスの異なる他のタスクに依存している場合は、対応詳細を指定できます。たとえば、このタスクは、別のタスクが実行中のため待機する必要があります。
-
「次」を選択して抽出をレビューします。抽出をスケジュールするか、すぐに実行します。
-
「送信」を選択します。
-
「OKしてチェックリストを表示」を選択して、プロセスのステータスを表示します。
-
「抽出結果の表示」タスクを選択して、抽出の実行結果をレビューします。「FAST Bank Extract」プロセスを検索します。
-
「FAST Bank Extract - Jan 2012」の「タスクに進む」を選択し、眼鏡をクリックして、レポート名の選択によりレポート出力を表示します。
抽出の検証: 仕組み
「抽出定義の管理」タスクの検証機能を使用して、「設計」タブで入力したデータが有効であることと送信時に問題がないことを確認します。抽出の作成後、「検証」タブに移動し、「検証」をクリックします。抽出設計に問題がある場合は、検証メッセージが表示されます。
抽出の検証方法
抽出を検証すると、アプリケーションによって抽出設計に対する検証が実行され、次のことが確認されます。
-
ルート・データ・グループが定義されていること。
-
非ルート・データ・グループがルート・データ・グループに直接的または間接的に(たとえば、ルート・データ・グループにリンクされている別の非ルート・データ・グループを介して)リンクされていること。
-
データ・グループの順序が定義されている場合に、次のデータ・グループも処理用に定義されていること。
-
抽出で使用されているすべてのFastFormulaが存在し、コンパイル済または有効であること。
-
BIパブリッシャの検証中に問題が検出されないこと。
検証に成功した場合、抽出が有効としてマークされること。ただし、検証に失敗した場合、抽出は無効としてマークされ、抽出を送信するとエラーが発生します。
抽出実行詳細の表示: 説明
「抽出実行詳細の表示」タスクを使用すると、抽出実行情報をレビューしたり、失敗した抽出実行や期待した結果が生成されなかった抽出実行に対してトラブルシューティングを実行できます。「検索」領域で、使用できる様々なフィルタを使用して、抽出または抽出実行を検索します。「検索結果」領域で、分析する抽出実行をクリックします。
「抽出実行詳細の表示」ページで、次の情報をレビューできます。
-
パラメータ
-
アーカイブ詳細
-
プロセス詳細
-
変更のみ詳細
-
提供オプション
パラメータ
「パラメータ」タブには、抽出実行用に設定されたパラメータが表示されます。たとえば、「ベースラインのみ」、「変更のみ」、「プロセス開始日」、「プロセス終了日」、「プロセス構成グループ」などがあります。これらのパラメータをExcelスプレッドシートにエクスポートすることもできます。
アーカイブ詳細
「アーカイブ詳細」タブには、抽出実行によって抽出されたレコードの数が表示されます。
プロセス詳細
「プロセス詳細」タブには、プロセスとその階層がリストされます。プロセス・ステータス、開始時間と終了時間および経過時間を表示できます。失敗した抽出実行や時間のかかる抽出実行のトラブルシューティングに役立つプロセス・ログ・ファイルをダウンロードすることもできます。
抽出提供オプション
「提供オプション」タブは、「抽出定義の管理」タスクで提供オプションを「WebCenterコンテンツ」または「インバウンド・インタフェース」として設定した場合にのみ表示されます。抽出実行が送信されて正常に完了すると、出力ファイルをダウンロードすることもできます。
変更のみ詳細
「変更のみ詳細」タブで、最終成功実行からの属性の変更をレビューできます。このタブは、抽出が「変更のみ」モードで実行された場合にのみ表示されます。「変更のみ」パラメータが設定されているかどうかは、「パラメータ」タブで確認できます。属性を選択し、属性値を入力して、最終成功実行からの属性の変更を確認できます。
抽出の管理に関するFAQ
簡易インタフェースとは何ですか。
簡易インタフェースは、HCM抽出を定義および設計するための使いやすいグラフィカル・インタフェースです。抽出を定義するためのほとんどのタスクを簡易インタフェースで実行できますが、有効日を入力するには、デスクトップ・インタフェースを使用する必要があります。
抽出データ・グループ接続とは何ですか。
データ・グループ接続を使用すると、エンティティ間の親子関係のマスター詳細を定義できます。たとえば、EmployeesおよびDepartmentsデータ・グループは、部門IDでリンクされています。
抽出を無効にするには、どうすればよいですか。
抽出は、「データ交換」領域の「抽出定義の管理」タスクを使用して無効にできます。無効にする抽出を検索して開きます。抽出のステータスを「非アクティブ」に変更します。抽出を無効にした後は、抽出実行を再送信できません。無効にした抽出について前に送信した実行が格納されており、レビューに使用できます。
抽出実行を送信できないのはなぜですか。
次の場合は、抽出実行を送信できません。
-
抽出のステータスが非アクティブの場合。非アクティブな抽出は、無効であることを示します。抽出実行を送信するには、ステータスがアクティブである必要があります。非アクティブな抽出は、「抽出の送信」タスクで送信できません。
-
抽出が無効である場合。抽出の作成後、その抽出を検証して検証エラーが発生した場合、抽出は無効としてマークされます。無効な抽出を送信しようとすると、プロセスは失敗し、エラーが表示されます。検証エラーを解決し、抽出を検証してください。次に、抽出実行を再送信してください。
非アクティブな抽出を検出できないのはなぜですか。
デフォルトでは検索結果に表示されるのはアクティブな抽出のみであるため、非アクティブな抽出は検出できません。非アクティブな抽出を表示するには、「データ交換」作業領域の「抽出定義の管理」タスクを使用します。「検索」ページの「ステータス」ドロップダウン・リストで「非アクティブ」を選択し、「検索」をクリックします。
検索結果にアクティブな抽出と非アクティブな抽出の両方を表示する場合は、「ステータス」ドロップダウン・リストでブランク・オプションを選択します。
既存の抽出を検証する必要がありますか。
いいえ。既存の抽出を検証する必要はありません。検証されていない抽出は、「未検証」としてマークされます。検証されていない抽出は送信できます。ただし、抽出設計に問題がある場合は、エラーが発生するか、結果データが正しくない可能性があります。エラーを回避するには、送信前に抽出を検証します。
抽出実行プロセスのログ・ファイルをダウンロードするには、どうすればよいですか。
「抽出結果の表示」タスクを使用します。抽出を検索し、抽出実行を選択します。「詳細」領域の「プロセス詳細」タブに、抽出実行プロセスがリストされます。「ログ」列を使用して、プロセスのログ・ファイルをダウンロードできます。ログ・ファイルをレビューして、期待したデータが取得されなかったレコードを特定したり、時間のかかるプロセスを特定できます。
ユーザー・エンティティをルート・データ・グループとして使用できるかどうかを検証するには、どうすればよいですか。
「ユーザー・エンティティ詳細の表示」UIでユーザー・エンティティを検索します。ユーザー・エンティティが複数行ユーザー・エンティティで、コンテキストを必要としない場合は、このユーザー・エンティティをルート・データ・グループとして使用できます。
「ユーザー・エンティティ詳細の表示」UIにアクセスする方法は、次のとおりです。
-
「データ交換」タスク・ペインからアクセスできます。
-
「抽出定義の管理」タスクの「設計」タブでデータ・グループを作成するときにアクセスできます。
正常実行のみを対象として、変更のみの抽出を実行できますか。
はい。「最終正常実行からの変更を含める」オプションを使用して、変更のみの抽出を実行するときに、正常に完了しなかった抽出実行を除外します。変更のみの抽出を実行するときに、正常に完了した抽出実行と正常に完了しなかった抽出実行からの両方のアーカイブが含められるようにする場合は、このオプションを未選択のままにします。
ベースライン抽出を作成して実行するには、どうすればよいですか。
抽出で「ベースラインのみ」パラメータを使用してベースラインを作成し、これに対してすべての後続変更のみの抽出を実行できます。このパラメータを使用すると、抽出を実行するときにXMLファイルが生成されず、何も出力されないため、時間を節約できます。「ベースラインのみ」パラメータの「表示」オプションを「はい」または「必須」に設定します。これにより、完全抽出を作成する時間が短縮され、アプリケーション内で使用されるストレージが削減されます。
抽出を作成してアーカイブを削除できますか。
はい。データの完全抽出を作成するとき、「アーカイブの削除」パラメータを使用すると、アーカイブとXMLファイルを後日削除できる柔軟性がもたらされます。「アーカイブの削除」パラメータの「表示」オプションを「はい」または「必須」に設定します。アプリケーションにより、アーカイブとXMLファイルが生成され、WebCenter Contentなどの宛先に提供されます。「アーカイブの削除」パラメータには、アプリケーションで抽出データがその宛先に提供された後にアーカイブとXMLファイルを削除するオプションがあります。アプリケーションによってWebCenter Contentなどに出力が提供された後、このオプションを使用してアーカイブ・データとXMLファイルを破棄すると、これらの抽出アーカイブが削除されることでストレージの消費が削減されます。
抽出によって生成されるすべてのデータを破棄するかどうかを柔軟に選択することもでき、たとえば、必要でないすべてのデータを削除するには、「アーカイブ情報および生成済XML出力の削除」オプションを使用します。または、「アーカイブ情報のみ削除」オプションを選択して、アーカイブ・データは削除し、生成されたXMLデータは保持することもできます。XMLデータは、レポート目的や将来の参照のために、保持することが適切な場合があります。