| Oracle® Database Migration Assistant for Unicodeガイド リリース2.0 E59465-03 |
|


 前 |
 次 |
この章では、キャラクタ・セット移行プロセスの一般的なシナリオにおけるDatabase Migration Assistant for Unicodeの使用手順を示します。ここに示されている例に従えば、このツールを使用してデータベースを移行できます。この章で示す手順のほとんどは、すべてのシナリオに共通です。
この章は次の項で構成されています。
DMUで使用できるようにデータベースを初期化する場合、次のタスクを実行します。
必要なパッチをインストールする手順は、次のとおりです。
ダウンロードした最新のDMUリリース・ノートで、ご使用のデータベースでDMUを使用するために必要なデータベース・パッチがあるかどうかを確認します。次に、opatchユーティリティを使用して、必要なパッチがすでにインストールされているかどうかを確認します。最後に、ORACLE_HOME環境変数をデータベースのOracleホーム・ディレクトリに設定し、現在のディレクトリをOracleホームのOPatchサブディレクトリに変更して、次の文を発行します。
opatch lsinventory –patch
opatchユーティリティで有効なoraInst.locファイルが存在しないことが特定された場合、データベースのOracleホーム内でそのファイルを見つけて、次の例に示すようにその位置を-invPtrLocパラメータに渡します。
opatch lsinventory –patch –invPtrLoc ../oraInst.loc
opatchユーティリティの出力は次のようになります。
Invoking OPatch 10.2.0.5.0
Oracle interim Patch Installer version 10.2.0.5.0
Copyright (c) 2005, Oracle Corporation. All rights reserved..
Oracle Home : C:\oracle\product\10.2.0\db_1
Central Inventory : C:\Program Files\Oracle\Inventory
from : n/a
OPatch version : 10.2.0.5.0
OUI version : 10.2.0.5.0
OUI location : C:\oracle\product\10.2.0\db_1\oui
Log file location : C:\oracle\product\10.2.0\db_1\cfgtoollogs\opatch\opatch2010-05-17_22-50-28PM.log
Lsinventory Output file location : C:\oracle\product\10.2.0\db_1\cfgtoollogs\opatch\lsinv\lsinventory2010-05-17_22-50-28PM.txt
--------------------------------------------------------------------------
Interim patches (2) :
Patch 5556081 : applied on Mon Feb 08 15:50:52 CET 2010
Created on 9 Nov 2006, 22:20:50 hrs PST8PDT
Bugs fixed:
5556081
Patch 5557962 : applied on Mon Feb 08 15:50:45 CET 2010
Created on 9 Nov 2006, 23:23:06 hrs PST8PDT
Bugs fixed:
4269423, 5557962, 5528974
--------------------------------------------------------------------------
OPatch succeeded.
個別パッチの中に必要なデータベース・パッチが一覧表示されているかどうかを確認します。欠落しているパッチがあれば、My Oracle Supportサイトからダウンロードしてインストールします。次に、パッチに含まれているドキュメントでインストール手順を確認します。これらのパッチは次の場所にあります。
DMUで使用できるようにデータベースが初期化されていない場合、専用のデータベース・カーネル関数にアクセスするために必要なPL/SQLサポート・パッケージをそのデータベースに含めることはできません。
サポート・パッケージをインストールする手順は、次のとおりです。
データベースのOracleホーム・ディレクトリから、SQL*Plusユーティリティを実行できるオペレーティング・システム・ユーザーとしてデータベース・サーバー・ホストに接続します。
SQL*Plusユーティリティを起動し、SYSDBA権限を持つユーザーとして接続します。たとえば、LinuxまたはMicrosoft Windowsでは、次のコマンドを入力します。
sqlplus / as sysdba
ログイン後、次のコマンドを実行します。
SQL> @?/rdbms/admin/prvtdumi.plb
スクリプトからの出力は次のようになります。
Library created. Package created. No errors. Package body created. No errors.
さらに、インストールしたデータベース・パッチのインストール・ドキュメントで指示されていれば、前述の手順を実行する必要があります。
メンテナンスを容易にするために、また他の本番表領域のフラグメンテーションを回避するために、DMUの移行リポジトリを構成するデータベース・オブジェクト(表および索引)には個別の表領域を使用することをお薦めします。この推奨事項に従うには、以降の手順で移行リポジトリに選択できる適切な表領域を作成しておきます。表領域の作成手順は、『Oracle Database 2日でデータベース管理者』または『Oracle Database管理者ガイド』を参照してください。
移行リポジトリに表領域を作成する手順は、次のとおりです。
デフォルトのエクステント割当てポリシーを使用し、自動拡張機能をオンにして、表領域をローカルで管理することをお薦めします。
(SYSDBAとして実行した)次のSQL問合せの結果を表領域の初期サイズとして使用します。
SELECT CEIL((t.cnt*300+c.cnt*1000)/1048576)||' MB'
"Initial Size"
FROM (SELECT COUNT(*) cnt FROM sys.tab$) t,
(SELECT COUNT(*) cnt
FROM sys.col$
WHERE obj# IN (SELECT obj# FROM sys.tab$)
AND BITAND(property,65536)=0
AND type# IN (1,8,58,96,112)
AND charsetform=1) c
クレンジング・エディタで使用する行識別子を多数収集した場合や、多数の変換可能セルを含む多数の表に対して変換方法「更新可能な行のみを変換」を適用した場合、表領域のサイズが非常に拡大する可能性があります。このため、表領域が必要なだけ大きくなるように自動拡張機能をオンにすることをお薦めします。
「データベース接続の作成」を参照してください。
リポジトリのインストールが完了すると、DMUワークフローの事前定義済のポイントで、データベースで追加、変更または削除された可能性のある文字データを含むオブジェクトが考慮されるようにリポジトリが自動的にリフレッシュされます。また、移行メニューから選択してリポジトリをリフレッシュまたは再インストールできます。
移行リポジトリをリフレッシュする手順は、次のとおりです。
リポジトリを明示的にリフレッシュしてデータベース・オブジェクトへの最新の変更を即時に適用するには、移行メニューまたはナビゲータ・ペインのデータベース・ノードのコンテキスト・メニューから「DMUリポジトリのリフレッシュ」を選択します。リフレッシュが完了すると、リポジトリが正常にリフレッシュされたことを示す確認メッセージが表示されます。
移行リポジトリを再インストールする手順は、次のとおりです。
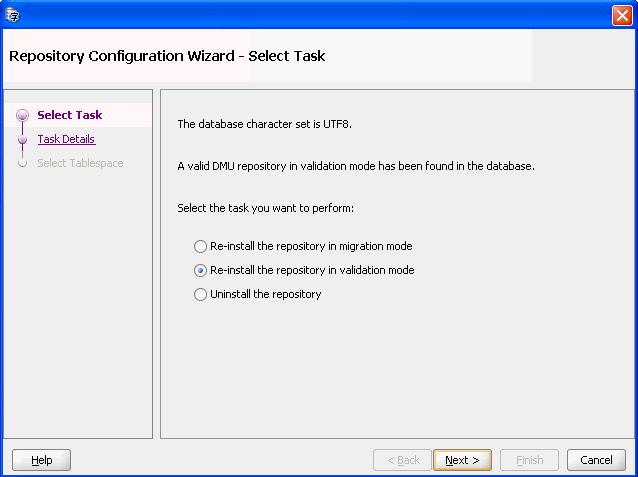
リポジトリを明示的に再インストールするには、移行メニューまたは「検証」メニューから「DMUリポジトリの構成」を選択します。図4-1「リポジトリ構成ウィザード - 再インストール」が表示されます。
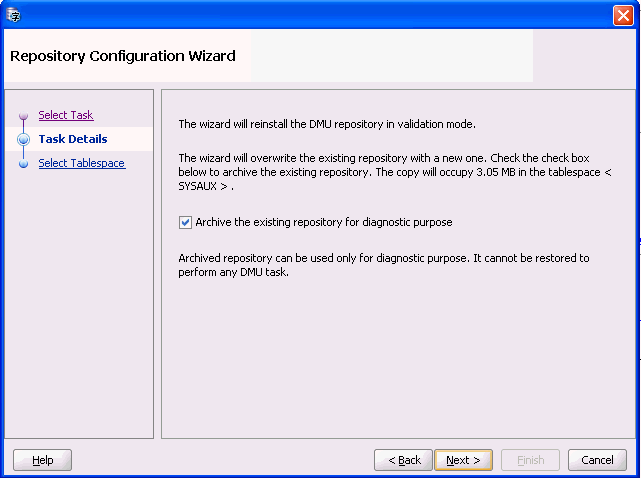
移行モードまたは検証モードのいずれかを選択します。「次へ」をクリックします。図4-2「リポジトリ構成ウィザード - 再インストール/アーカイブ」が表示されます。
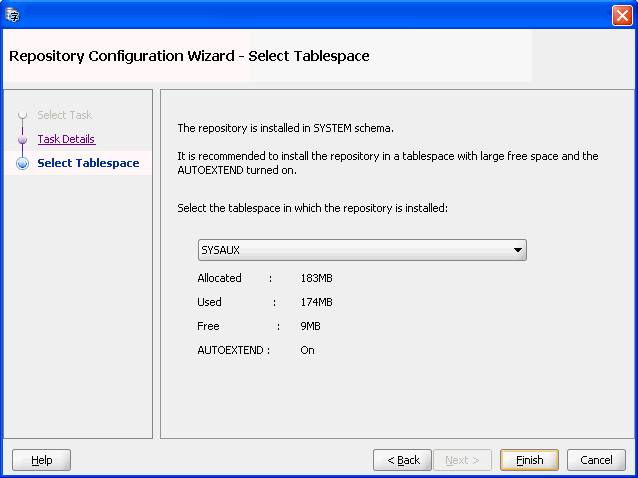
「診断目的で既存のリポジトリをアーカイブする」が選択されていることを確認し、「次へ」をクリックします。図4-3「リポジトリ構成ウィザード - 表の選択」が表示されます。
「完了」をクリックします。リポジトリが再インストールされます。
次の手順は、現行のデータのスキャンです。一般に、この手順の目的は、問題の原因を分析し、データの問題を解決するためのクレンジング方針を選択することです。
スキャンは、データベースから文字値を読み取ってターゲット・キャラクタ・セットに変換し、変換で変更される値、列に収まらない値、データ型に収まらない値、または無効な文字コードが含まれる値の数をカウントするプロセスです。列内の値の変換後の最大長など、追加の統計も計算されます。DMUでは、計算されたカウントおよび統計がスキャン結果として移行リポジトリに格納されます。テスト変換の結果の文字値自体は削除されます。これらは永続的にデータベースに格納されません。
データベースをUnicodeに変換する前に、表のVARCHAR2列、CHAR列、LONG列およびCLOB列の文字データを分析して、データの破損なく変換が正常に完了することを妨げる可能性のある問題がないかどうか査定する必要があります。DMUではデータの分析中に、データベース内の文字列値が宣言済キャラクタ・セットからターゲットのUnicodeキャラクタ・セットに変換され、各値がチェックされて次のことが判別されます。
変換結果が元の値と異なるかどうか
変換結果がその列の長さ制限に収まるかどうか
変換結果がそのデータ型に収まるかどうか
変換結果に置換文字は含まれないか、つまり、変換後の各ソース文字コードが列の宣言済キャラクタ・セットで有効かどうか
この項の内容は次のとおりです。
データベースのスキャンを開始する前に、移行プロセスの準備中に「移行の準備の確認」の説明に従って収集した言語およびキャラクタ・セットの情報をDMUに指定する必要があります。
データベース・プロパティを設定する手順は、次のとおりです。
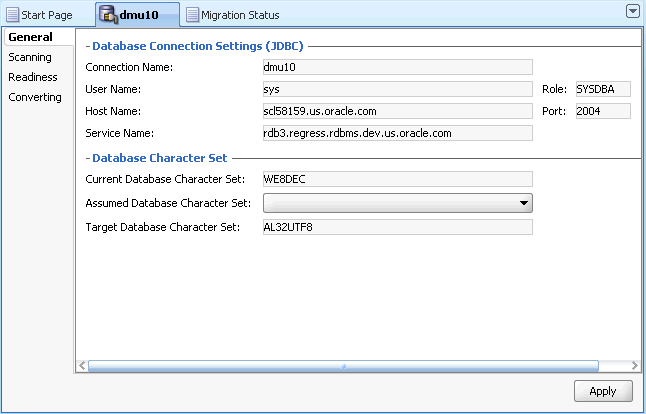
データベース・プロパティ・タブ(図4-4を参照)を開きます。このタブは、データベースに接続すると、DMUウィンドウのクライアント・ペイン内に自動的に開きます。このタブのタイトルは、接続の名前です。
また、このタブは、ナビゲータ・ペインでデータベース・ノードを右クリックし、コンテキスト・メニューから「プロパティ」を選択しても表示されます。このタブの左サイドバーから、「一般」サブタブを選択します。このサブタブで、想定データベース・キャラクタ・セット・プロパティを、データベース内のデータの特定された実際のキャラクタ・セットに設定します。パススルー構成の場合とは異なり、データベースが適切なキャラクタ・セット構成で使用されていれば、このプロパティは現行データベース・キャラクタ・セット・プロパティと同じです。
これで、データベースの内容の最初のスキャンを実行する準備ができました。このプロセスは、スキャン・ウィザードを使用して開始します。スキャン結果に、データの損失なくデータを完全に変換するためにクレンジングの必要なデータがあるかどうかが示されます。また、DMUでは、スキャン結果を使用して各表に最も効率的な変換方法が選択されます。
DMUユーザー・インタフェースの3つの要素を使用して、スキャン・プロセスを制御し、スキャン結果を参照できます。スキャン・プロセスの開始にはスキャン・ウィザードを使用し、このプロセスの監視にはスキャンの進行状況タブを使用し(「スキャンの進行状況の監視」を参照)、スキャン結果の表示にはデータベース・スキャン・レポート・タブを使用します(「データベース・スキャン・レポートの概要」を参照)。
DMUでは、スキャン中に、変換可能な値、または拡張の問題や無効なバイナリ表現の問題のある値を含む列セルの行識別子アドレスが収集されることがあります。
マルチバイト・データベースでは、CLOB列はスキャンされず、ナビゲータ・ペインにも表示されません。マルチバイト・データベース(AL32UTF8キャラクタ・セットおよびUTF8キャラクタ・セットのデータベースを含む)はいずれも、同じ内部記憶域キャラクタ・セット(Unicode UTF-16)でCLOB値を格納するため、あるマルチバイト・キャラクタ・セットから別のマルチバイト・キャラクタ・セットにデータベース・キャラクタ・セットを移行する場合にCLOB値を変換する必要はありません。
列値のテスト変換に使用されたソース・キャラクタ・セットが、列の想定キャラクタ・セットです。「データのクレンジング」を参照してください。
スキャン・ウィザードを使用してデータベースをスキャンする手順は、次のとおりです。
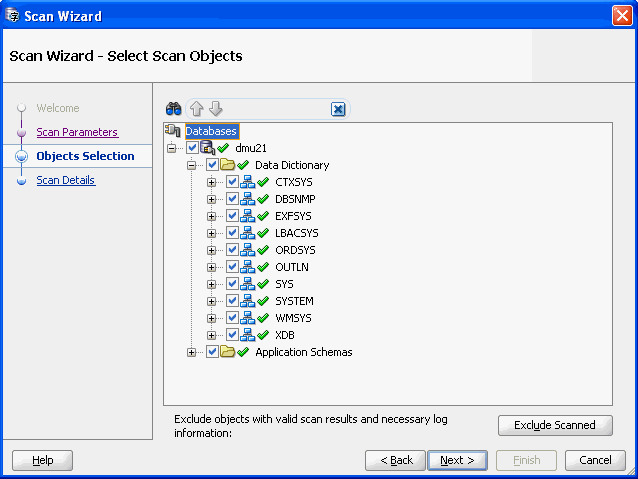
「スキャン」ウィザードを開くには、「移行」メニューから「データベースのスキャン」を選択するか、「ナビゲータ」ペインで対応するオブジェクト・ノードのコンテキスト・メニューから「データベースのスキャン」、「スキーマのスキャン」、「表のスキャン」または「列のスキャン」を選択します。図4-5「スキャン・ウィザード - ようこそ」に示すようなスキャン・ウィザードが表示されます。
また、変換の詳細タブから変換プロセスを開始した後、DMUでスキャン・ウィザードが開かれることもあります。変換方法「変換可能な行のみを更新」を使用してデータベース内の1つ以上の表を変換する場合、DMUではこのウィザードが開かれます。追加のスキャンによって、この変換方法で必要な行識別子アドレスが収集されます。変換フェーズ中に開かれるスキャン・ウィザードでは、図4-6「スキャン・ウィザード - ようこそ: 行識別子の収集」に示すように第一画面が異なります。また、オブジェクト選択ページがありません。変換フェーズの詳細は、「データベースの変換」を参照してください。
「次へ」をクリックして、「ようこそ」ページをスキップします。
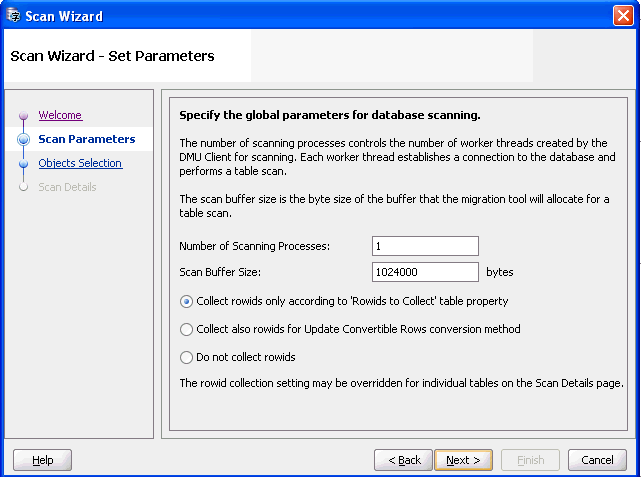
図4-7「スキャン・ウィザード - パラメータの設定」に示すようなウィザードの2番目のページでは、スキャン・プロセスの一般的なパラメータを設定できます。
「スキャン・プロセス数」は、スキャン・プロセスを実行するためにDMUで生成されるスレッドの数です。スレッドごとに個別のデータベース接続が開かれます。DMUによって各スレッドに表のセットが割り当てられて、個別にスキャンされます。サイズの大きい表はチャンクに分割されて、複数のスレッドによりスキャンされることがあります。サイズの小さい表は、すべて1つのスレッドによりスキャンされます。このパラメータのデフォルト値は、データベースのCPU_COUNT初期化パラメータの値です。このパラメータを大きくして、データベース・サーバーのCPUおよびディスクのパラレル処理を活用することによってスキャンの回数が減るかどうかを確認したり、パラメータを小さくして、スキャン・プロセスがビジー状態の本番データベースのパフォーマンスに与える影響を小さくすることができます。
スキャン・バッファ・サイズ・パラメータは、DMUで表をスキャンするために各データベース・サーバー・セッションに割り当てられるバッファのサイズ(バイト)を制御します。デフォルト値は1000KBです。1回のスキャンで使用される合計バッファ領域は、スキャン・プロセスの数にこのプロパティ値を乗算した値です。このプロパティの値を大きくすると、割り当てられたバッファ・メモリーがデータベース・サーバー上の使用可能なRAMに収まっているかぎり、スキャンの速度が上がる可能性があります。
3つのラジオ・ボタンを使用して、このスキャンに選択した表に対して初期の行識別子収集レベルを定義できます。この初期レベルは、後からウィザードのスキャンの詳細ページ(手順5を参照)で変更できます。表プロパティ「収集する行識別子」のみに基づいて行IDを収集するオプションは、各表の初期の行識別子収集レベルとして表プロパティ収集する行識別子の値を使用するようにDMUに指定します。このプロパティの詳細は、「表プロパティ: スキャン」を参照してください。
変換方法が「変換可能な行を更新」の場合に行識別子も収集するオプションを選択すると、DMUでは変換方法が変換可能な行のみを更新」の場合に行識別子アドレスが事前に収集されます。このオプションを指定すると、この変換方法が割り当てられているすべての選択済表に対して初期の行識別子収集レベルが「すべて変換」に設定され、それ以外の選択済表に対しては収集する行識別子プロパティの値に設定されます。通常、この変換方法の行識別子は、変換フェーズの開始時に自動的に開始される前述の追加スキャンによって収集されます。
行識別子を事前収集すると、この追加スキャンの必要がなくなるため、必要な停止期間を短縮し、業務に対してデータベースを閉じる時間も短縮できます。ただし、表の行識別子を事前収集した最後のスキャンが実行された後で、他の変換可能な行が追加された場合、これらの行は変換フェーズ中に変換されず、移行後は不適切にエンコードされたデータになります。このため、事前収集機能は、内容が静的であることが確認されている大きな表に対してのみ使用してください。表の最初のスキャン中にはまだ変換メソッドが表に割り当てられていないため、変換方法が「変換可能な行を更新」の場合に行識別子も収集するオプションは適用されません。
最後のオプション「行識別子を収集しない」を使用すると、現在のスキャン中の行識別子収集をオフに切り替えることができます。これは、変換可能なセルおよび変換可能性の問題を含むセルをカウントするが、スキャン済のいずれの表に対してもクレンジング・エディタのフィルタリング・オプションを使用する必要はない場合に便利です。収集する行識別子プロパティが「すべて変換」に固定されているSYSスキーマ内の特殊なデータ・ディクショナリ表に対して行識別子収集をオフにすることはできません。
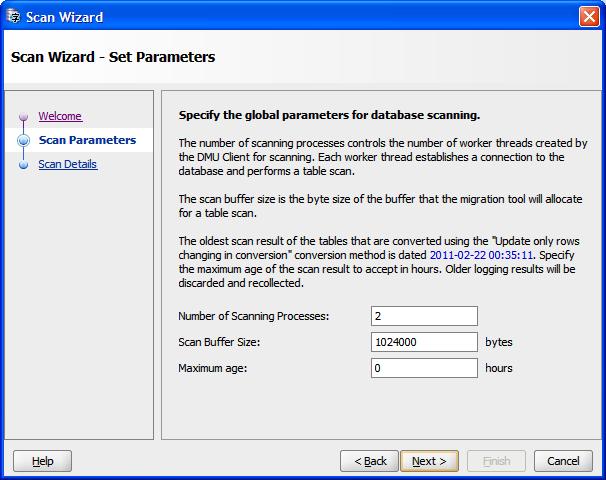
変換フェーズ中にDMUで行識別子の収集のために開かれるスキャン・ウィザードでは、図4-8「スキャン・ウィザード - パラメータの設定: 行識別子収集」に示すようにスキャン・パラメータ・ページが変わります。このページでは、変換方法が「変換可能な行を更新」の場合に行識別子も収集するチェック・ボックスが自動的に選択され、追加のパラメータ「最大保持時間」があります。このパラメータを使用すると、最近の最大保持時間中に行識別子が事前収集された表の再スキャンをスキップできます。また、古いと思われる事前収集済の行識別子を削除できます。
変換プロセスの詳細は、「データベースの変換」を参照してください。
「次へ」をクリックしてスキャン・パラメータを受け入れ、オブジェクト選択ページを開きます。
最初のスキャンでは通常、移行メニューからスキャン・ウィザードを開くことによりデータベース内のすべての表を選択します。それ以降のスキャンでは、たとえば、クレンジング・アクションによりスキャン結果が無効化された場合や、オブジェクトに対する最新のDMLアクティビティを、新たに発生した可能性のある変換問題のコンテキストで分析するなどの理由で、スキャン結果をリフレッシュするデータベース・オブジェクトのサブセットを選択できます。
無効化されたスキャン結果のみを再計算する場合、データベース・ノードを選択してデータベース内のすべての列を選択してから、「スキャン済を除外」をクリックします。このオプションを選択すると、DMUによって有効なスキャン結果がすでに存在するすべての列が自動的に選択解除されます。この後、既存のスキャン結果をリフレッシュする追加の表および列を手動で選択できます。
変換方法が「変換可能な行を更新」の場合に行識別子も収集するオプションを選択した場合、スキャン済を除外オプションを使用しても、以前のスキャンで必要な業識別子が収集されていない表は除外されません。
変換の開始前、できれば新しいデータがデータベースに追加されることのない停止期間中に、データベース内のすべてのスキャン結果をリフレッシュすることを強くお薦めします。これにより、変換の必要なすべてのデータが考慮されます。
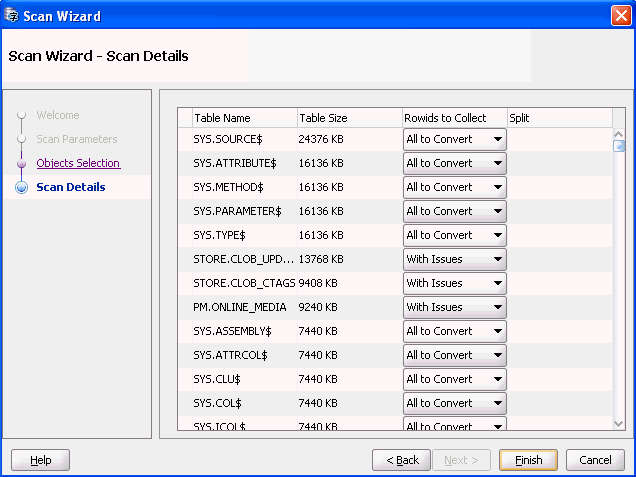
「次へ」をクリックしてオブジェクト選択を受け入れ、スキャンの詳細ページを開きます。ウィザードではすべての選択済オブジェクトに対してスキャン計画を準備する必要があるため、このページが表示されるまでに時間がかかることがあります。
図4-10「スキャン・ウィザード - スキャンの詳細」に示すスキャンの詳細ページで、スキャン対象として選択したすべてのオブジェクトが含まれていることを確認できます。また、収集する行識別子列でフィールドを選択すると開かれるドロップダウン・リストで行識別子収集レベルを設定することもできます。行識別子レベルとして選択できる項目は、「なし」(収集を実行しない)、「すべて変換」(変換の必要なしとして分類されていないすべてのデータに対して行識別子を収集する)および「問題あり」(変換問題のあるデータに対してのみ行識別子を収集する)です。問題のあるデータ・セルの行識別子がスキャン中に収集された場合は、クレンジング・エディタのフィルタリング機能と検索機能を使用してクレンジングが必要なデータを検索するほうが時間がかかりません。クレンジング・エディタの詳細は、第6章「DMUを使用したデータのクレンジング」を参照してください。
スキャン・ウィザードで設定した行識別子収集レベルは、現在のスキャンに対してのみ有効です。表プロパティ「収集する行識別子」は変更されず、スキャン・ウィザードの次の起動時まで保持されることはありません。
DMUでは、サイズの大きい表は自動的にチャンクに分割され、複数のスキャン・プロセスによりパラレル・スキャンが実行されます。ただし、必要な場合は、分割列の対応するチェック・ボックスを選択解除して表の分割を回避できます。
「完了」をクリックすると、スキャンが開始されます。
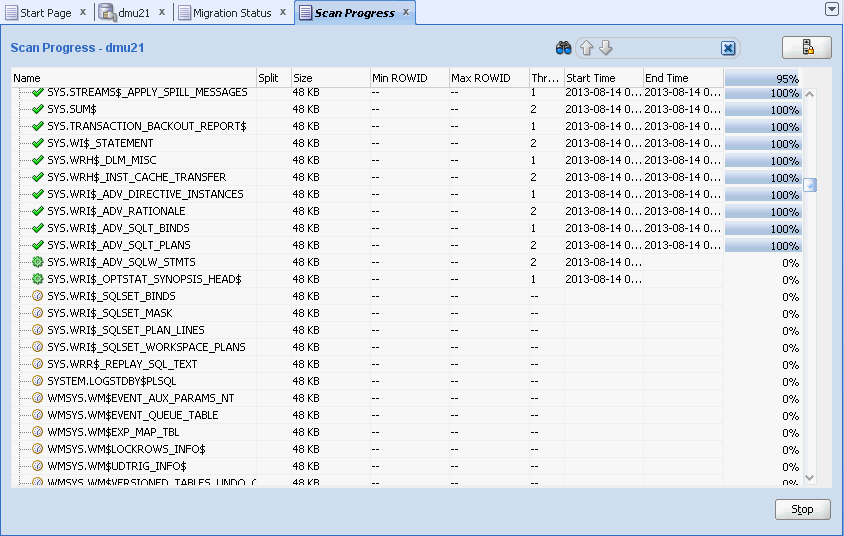
スキャンが開始されると、DMUによって図4-11に示すようなスキャンの進行状況タブが自動的に開きます。このタブを使用して、スキャン・タスクの進行状況を監視できます。
スキャンの進行状況タブには、スキャンされたセット内のすべての表のスキャン情報を表示するグリッドが含まれています。タブ・グリッドの列は次のとおりです。
名前
この列には、グリッドの対応する行で説明されている表の名前が表示されます。名前の左側にあるアイコンは、スキャン・ステータスを示します。緑色のチェック・マークは、表のスキャンが完了していることを示します。緑色のスプロケット形状のアイコンは、現在スキャン中の表を示します。時計は、スキャンを待機している表を示します。
表が複数のチャンクに分割されている場合、ステータス・アイコンの左側にあるプラス記号をクリックすると、表が分割されたすべてのチャンクの情報が表示されます。
|
注意: 緑色のチェック・マーク・アイコンの意味は、スキャンの進行状況タブとナビゲータ・ペイン/スキャン・レポート・タブとでは異なります(「データベース・スキャン・レポートの概要」を参照)。スキャンの進行状況タブのこのアイコンは、表のスキャンが正常に完了したことを示しますが、表に問題のあるデータが含まれているかどうかを示しません。ナビゲータ・ペインまたはスキャン・レポート・タブのこのアイコンは、表、スキーマまたはデータベースのスキャンが完了したこと、また表の内容にUnicodeへの正常な変換を妨げる可能性のある問題が含まれていないことを意味します。 |
分割
表示される数字は、対応する表が分割されたときのチャンクの数です。チャンク情報を示すグリッド行では、この列は空になります。
サイズ
この列には、対応する表または表チャンクのサイズが示されます。グリッドの一番上の行には、スキャンされたセット内のすべての表の追加されたサイズが示されます。
最小ROWID
チャンクの場合、この列にはチャンク内の最初の行の行識別子が示されます。表の場合は空になります。
最大ROWID
チャンクの場合、この列にはチャンク内の最後の行の行識別子が示されます。表の場合は空になります。
スレッドID
この列に示される数字は、対応する表または表チャンクをスキャンしている、またはそのスキャンを完了した特定のスレッドのIDです。
開始時間
この列には、対応する表または表チャンクのスキャンが開始された時間が示されます。表が分割されている場合、その行にすべてのチャンクの最早(最小)開始時間が示されます。グリッドの一番上の行には、スキャン・タスク全体の開始時間が示されます。
終了時間
この列には、対応する表または表チャンクのスキャンが完了した時間が示されます。表が分割されている場合、その行にすべてのチャンクの最後の(最大)開始時間が示されます。グリッドの一番上の行には、スキャン・タスク全体の終了時間が示されます。
進行状況
この列には、進行状況バーと、対応する表または表チャンクのスキャンが完了している割合が表示されます。グリッドの一番上の行には、スキャン・タスクの全体的な進行状況が示されます。
表のスキャン中にデータベース・エラーが発生した場合、表に対応するグリッド行のこの列に、報告されたエラー・メッセージの最初の部分が表示されます。最初の部分をクリックすると、メッセージ・テキスト全部を表示するダイアログ・ボックスが開きます。
対応する表がスキャン・スレッドに割り当てられている場合、DMUではタブ・グリッドが自動的に下にスクロールして新しいグリッド行が表示されます。自動スクロールを一時停止するには、スキャンの進行状況タブの右上隅にあるスクロール・ロック・アイコンをクリックします。これにより、グリッドの一番上の行にある進行状況インジケータを参照して、スキャンの全体的な進行状況を監視できます。自動スクロールを再開するには、スクロール・ロック・アイコンを再度クリックします。
スキャン・プロセスを一時停止するには、スキャンの進行状況タブの一番下にある「停止」をクリックします。ボタンが「続行」に変わります。「続行」をクリックすると、スキャンが再開されます。詳細は、「データベース・スキャン・レポート: スキャンの停止」を参照してください。
スキャンが完了すると、DMUで情報ダイアログ・ボックスが表示されます。これで、データベース・スキャン・レポート・タブでスキャン結果を分析できるようになります。
スキャンの完了後、最新のスキャン結果は、第3章「DMUでのオブジェクト・プロパティの表示および設定」で説明されている各種プロパティ・タブのスキャン・サブタブで参照するか、もっと便利にデータベース・スキャン・レポート・タブで参照できます。
スキャン結果の内容に応じて、「クレンジング・シナリオ1: 問題のないデータベース」、「クレンジング・シナリオ2: 拡張の問題のクレンジング」または「クレンジング・シナリオ3: 無効な表現の問題のクレンジング」で説明されている移行シナリオのいずれかに従う必要があります。
データベース・スキャン・レポートを表示する手順は、次のとおりです。
移行メニューから「データベース・スキャン・レポート」を選択して、データベース全体のスキャン結果が含まれるデータベース・スキャン・レポート・タブを開きます。1つのスキーマ内の表、1つの表、または1つの列に対してデータベース・スキャン・レポート・タブを開くには、ナビゲータ・ペインで対応するスキーマ・ノード、表ノードまたは列ノードのコンテキスト・メニューから「スキャン・レポート」を選択します。
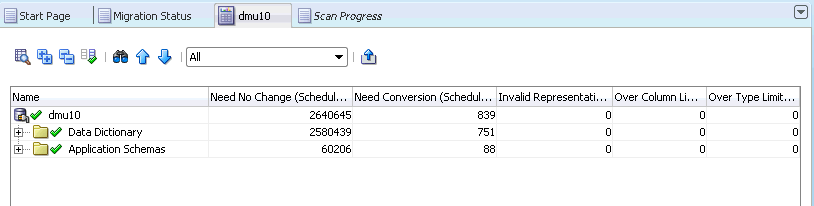
図4-12「データベース・スキャン・レポート」に、データベース全体のデータベース・スキャン・レポート・タブを示します。
データベース・スキャン・レポート・タブには一番上にツールバーがあり、そのツールバーの下に結果グリッドがあります。次の3つの方法を使用して、データベース・スキャン・レポートで目的のスキャン結果をすばやく見つけ、さらにレポートをエクスポートできます。
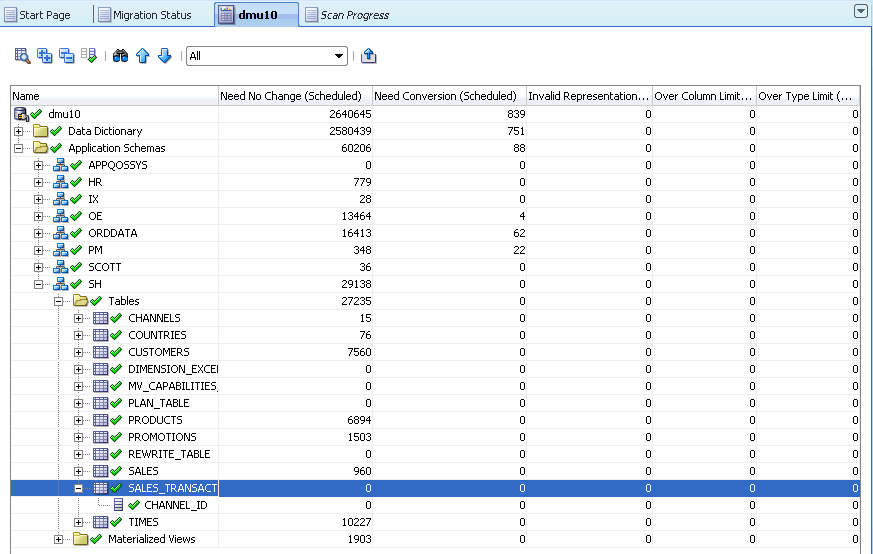
結果グリッドは、ツリー表形式のユーザー・インタフェース項目であり、スキャン結果およびオプションでその他のデータベース・オブジェクト・プロパティを表示します。グリッドの最初の列には、ナビゲータ・ペインのツリーと同じ外観のデータベース・オブジェクト・ツリーが含まれます(「DMUユーザー・インタフェースの概要」を参照)。ツリーのルートは、データベース・スキャン・レポートが開かれたデータベース、スキーマ、表または列です。ツリーの各ノードは、グリッドの行に関連付けられています。この行には、ノードに対応するデータベース・オブジェクトの様々なプロパティが表示されます。
ノード名の左側にあるステータス・アイコンは、ノードで説明されているデータベース・オブジェクトの変換可能性ステータスを示します。アイコンの意味は、表2-1「Database Migration Assistant for Unicodeのアイコン」で定義されています。
ノードの左側のプラス・アイコンをクリックすると、ノードを開いてその子ノードの結果を表示したり、ノードを閉じて子ノードの結果を非表示にすることができます。ノードのすべての下位ノードを一度に開くには、そのノードを含む行を選択して「すべて開く」(ツールバーの2番目のアイコン)をクリックします(表2-1「Database Migration Assistant for Unicodeのアイコン」を参照)。すべての下位ノードを一度に閉じるには、ノードを選択して「すべて閉じる」(ツールバーの3番目のアイコン)をクリックします。
データベース・スキャン・レポート・タブが開いたときにデフォルトでグリッド内に表示される列は、「変更の必要なし(スケジュール済)」、「変換が必要(スケジュール済)」、「無効なバイナリ表現(スケジュール済)」、「列制限超過(スケジュール済)」および「型制限超過(スケジュール済)」です。これらの列に表示される値は、対応するノードのプロパティ・タブのスキャン・サブタブで「スケジュール済クレンジングの結果を含める」という見出しの下に表示されるスキャン結果と同じです。これらのスキャン結果については、第3章「DMUでのオブジェクト・プロパティの表示および設定」を参照してください。
「レポートのカスタマイズ」(ツールバーの4番目のアイコン)をクリックすると、スキャン・レポートのカスタマイズ・ダイアログ・ボックスが開きます。このダイアログ・ボックスでは、デフォルトのプロパティ列とともに表示する追加のプロパティ列を選択できます。デフォルトの列を非表示にすることもできます。使用可能な列は、第3章「DMUでのオブジェクト・プロパティの表示および設定」で説明されているプロパティに対応しています。変更の必要なし列、変換が必要列、無効なバイナリ表現列、列制限超過列および型制限超過列(最後に「(スケジュール済)」が付かない)は、スキャン・サブタブの「現在のデータ」という見出しの下に表示されるスキャン結果に対応しています。
データベース・スキャン・レポートのグリッド列に表示されるプロパティが特定のノード・タイプにのみ有効である場合、そのグリッド列の他のノード・タイプに対応する行には何もテキストが表示されません。たとえば、変換方法プロパティは表にのみ有効です。これがデータベース・スキャン・レポート・タブに追加された場合、データベース、スキーマおよび列に対するグリッド行の変換方法列には何も表示されません。
データベース・スキャン・レポートのグリッド行を右クリックすると、コンテキスト・メニューから「スキャン」、「クレンジング・エディタ」または「プロパティ」を選択できます。スキャン・メニュー項目を選択すると、現在のグリッド行で説明されているオブジェクトのみがスキャン対象として選択されたスキャン・ウィザードが開きます。これにより、このオブジェクトのスキャン結果をリフレッシュするようにDMUにすばやく指定できます。クレンジング・エディタでは、選択した表または表列に対してクレンジング・エディタ・タブが開きます。クレンジング・エディタ・タブの詳細は、第6章「DMUを使用したデータのクレンジング」を参照してください。「プロパティ」をクリックすると、選択したグリッド行で説明されているオブジェクトのプロパティ・タブが開きます(第3章「DMUでのオブジェクト・プロパティの表示および設定」を参照)。
データ・ディクショナリ表のコンテキスト・メニューには、「クレンジング・エディタ」ではなく「データ・ビューア」が表示されます。「データ・ビューア」をクリックすると開くデータ・ビューア・タブは、クレンジング・エディタの読取り専用バージョンです。
変換可能性の問題があるデータを含むデータベース列を見つけるには、黄色い三角形のアイコンが付いたデータベース・スキャン・レポート・ノードを開きます。このアイコンは、そのノードの下位にある1つ以上の列に変換可能性の問題があることを示します。このようなアイコンが付いたノードを開き、そのノードの子を調べて同じアイコンの付いた子ノードを見つけ、それらのノードを開くという操作を、列ノードに達するまで行います。黄色い三角形のアイコンが付いた列ノードは、クレンジングが必要なデータベース列を表しています。グリッドの無効なバイナリ表現(スケジュール済)列、列制限超過(スケジュール済)列および型制限超過(スケジュール済)列のゼロでない値は、特定のデータベース列で見つかった各タイプの問題の数を示します。これらのカウンタはリンクとして表示され、クリックするとクレンジング・エディタ・タブまたはデータ・ビューア・タブが直接開いて、問題を詳しく調べることができます。
データベース・スキャン・レポート・タブの便利な機能の1つに、フィルタリング機能があります。図4-13「データベース・スキャン・レポート: フィルタリング」に示すように、タブのツールバーのドロップダウン・フィルタ・リストを開いて、レポートに表示する結果タイプを選択できます。
使用可能なフィルタは次のとおりです。
すべて
フィルタリングをオフに切り替えます。すべてのオブジェクトが表示されます。
スキャン済
有効なスキャン結果を持つオブジェクトのみを表示します。
スキャン失敗
データベース・エラーが報告されたためにスキャンできなかったオブジェクトを表示します。
未スキャン
有効なスキャン結果を持たないオブジェクトを表示します。オブジェクトに有効なスキャン結果が存在しない場合、オブジェクトがまだスキャンされていない、クレンジング・アクションやDDLによってスキャン結果が無効化された、またはオブジェクトの最後のスキャンが失敗したことが理由です。
変換の必要なし
有効なスキャン結果を持ち、変換の必要のない不変データを含むオブジェクトを表示します。
変換の必要あり、問題なし
有効なスキャン結果を持ち、変換の必要のない不変データと変換の必要がある変換可能データが混在しているオブジェクトを表示します。これらのオブジェクトの変換中に問題の発生は予期されません。
変換をブロック
データベースを変換するために事前に解決する必要のある未解決の変換可能性問題を持つオブジェクトを表示します。
無効な表現あり
有効なスキャン結果を持ち、無効なバイナリ表現(つまり、宣言済列キャラクタ・セットで有効でない文字コード)を持つデータを含むオブジェクトを表示します。
データ型制限超過
有効なスキャン結果を持ち、変換後にデータ型制限を超えるデータを含むオブジェクトを表示します。
列制限超過
有効なスキャン結果を持ち、変換後にその列制限を超えるデータを含むオブジェクトを表示します。
長さの問題あり
有効なスキャン結果を持ち、変換後にその列制限またはデータ型制限を超えるデータを含むオブジェクトを表示します。
不変でない
有効なスキャン結果を持ち、変換が必要なデータを含むオブジェクトを表示します。データには変換可能性の問題がある場合とない場合があります。つまり、「変換が必要」、「無効な表現」、「列制限超過」および「型制限超過」のいずれかのカテゴリに属します。
問題あり
有効なスキャン結果を持ち、DMUで検索する潜在的な問題のあるデータを含むオブジェクトを表示します。データ・ディクショナリ・スキーマの場合、これにはDMUで変換できない列内の変換可能データも含まれます。
フィルタを選択すると、データベース列のすべてのノードおよび関連するグリッド行のうち、スキャン結果がフィルタリング条件を満たしていないものは非表示になります。ノードのすべての子が非表示の場合、そのノードも非表示になります。ただし、レポートのルート・ノードは例外で、非表示になることはありません。
データベース・スキャン・レポート・タブが1つのデータベース列に対して開かれた場合、フィルタリングは無意味なので、無効になっています。
また、ツールバーの最初のアイコン(フィルタリング済オブジェクトの再スキャン・ボタン)を選択して、スキャン・レポートでフィルタリングされたオブジェクトを再スキャンすることもできます。たとえば、スキャン・レポートで列制限超過フィルタを設定した場合、フィルタリング済オブジェクトの再スキャン・ボタンを選択すると、列制限超過の問題が存在するすべての表が再スキャン対象として選択されます。
データベース・スキャン・レポート・タブには、サイズの大きいスキャン・レポートでのスキャン結果を簡単に分析するための検索機能もあります。検索を開始するには、次のいずれかのツールバー・ボタンをクリックします。
検索
ツールバーの5番目のボタンを選択すると、オブジェクトの検索基準を指定できるダイアログ・ボックスが開きます。
前を検索
ツールバーの6番目のボタンをクリックすると、最初に検索された項目の前のインスタンスが強調表示されます。
次を検索
ツールバーの6番目のボタンをクリックすると、最初に検索された項目の次のインスタンスが強調表示されます。
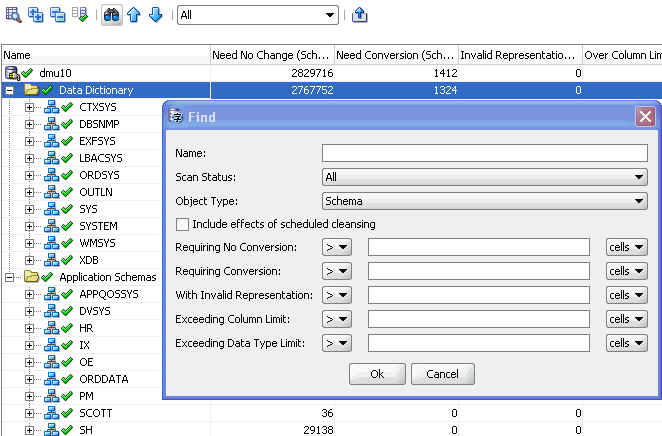
「検索」を選択すると、図4-14「データベース・スキャン・レポート: 検索」に示すようなダイアログ・ボックスが表示されます。
このダイアログ・ボックスでは、検出するオブジェクトを説明する次の検索基準を指定できます。
名前
オブジェクトの名前に含まれる文字列を(大/小文字を区別して)指定します。
スキャン・ステータス
オブジェクトのスキャン・ステータスを指定します。
オブジェクト・タイプ
スキーマ、表また列のいずれを検索するかを指定します。1つのタイプのみを選択できます。
スケジュール済クレンジングの結果を含める
検索の結果にスケジュール済クレンジング・アクションの結果を含める場合は、このオプションを選択します。このオプションを選択した場合、見出しに「(スケジュール済)」という語が付くグリッド列に比較対象の結果が表示されます。
変換の必要なし
比較演算子を選択し、「変更の必要なし」の結果と比較する値を選択します。
変換の必要あり
比較演算子を選択し、「変換の必要あり」の結果と比較する値を選択します。
無効な表現あり
比較演算子を選択し、「無効なバイナリ表現」の結果と比較する値を選択します。
列制限超過
比較演算子を選択し、「列制限超過」の結果と比較する値を選択します。
データ型制限超過
比較演算子を選択し、「型制限超過」の結果と比較する値を選択します。
「OK」を選択すると、「オブジェクト・タイプ」で選択した最初のスキーマ、表または列のグリッド行のうち、指定した基準のすべてを満たすものが、スキャン・レポートで強調表示されます。「前を検索」または「次を検索」ツールバー・ボタンを選択すると、基準を満たす同じタイプの前の行または次の行が強調表示されます。
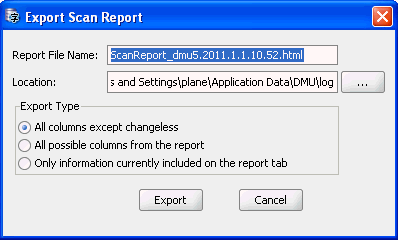
将来の参照用にスキャン結果を保存する場合は、スキャン結果をHTMLファイルにエクスポートできます。「HTMLとしてエクスポート」(ツールバーの最後のボタン)を選択します。これにより、図4-15「スキャン・レポートのエクスポート」に示すようなスキャン・レポートのエクスポート・ダイアログ・ボックスが開きます。
HTMLファイルの名前およびディレクトリ(フォルダ)を指定します。エクスポート・タイプ・グループ内のいずれかのオプションを選択すると、それに応じて次のいずれかの内容がエクスポートされます。
変換が必要であるか、または変換可能性の問題のあるデータを含む列およびその親オブジェクトのグリッド行のみ
スキャン・レポートの内容全部
レポート・タブに表示されている(非表示になっても閉じてもいない)結果グリッドの行および列のみ
「エクスポート」をクリックして、HTMLレポートを作成します。
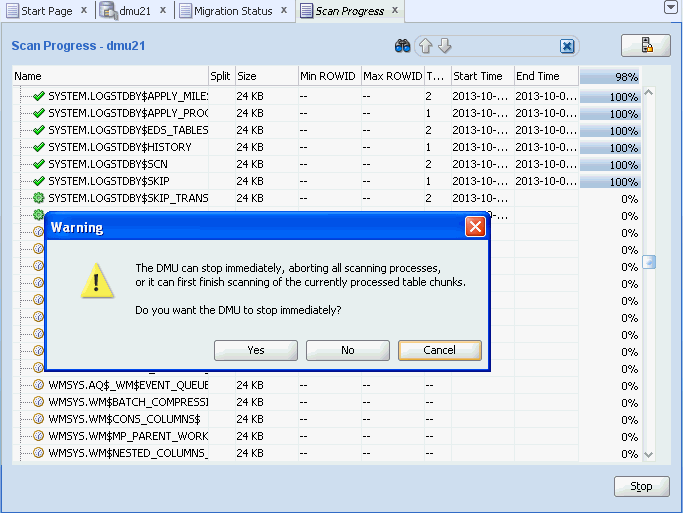
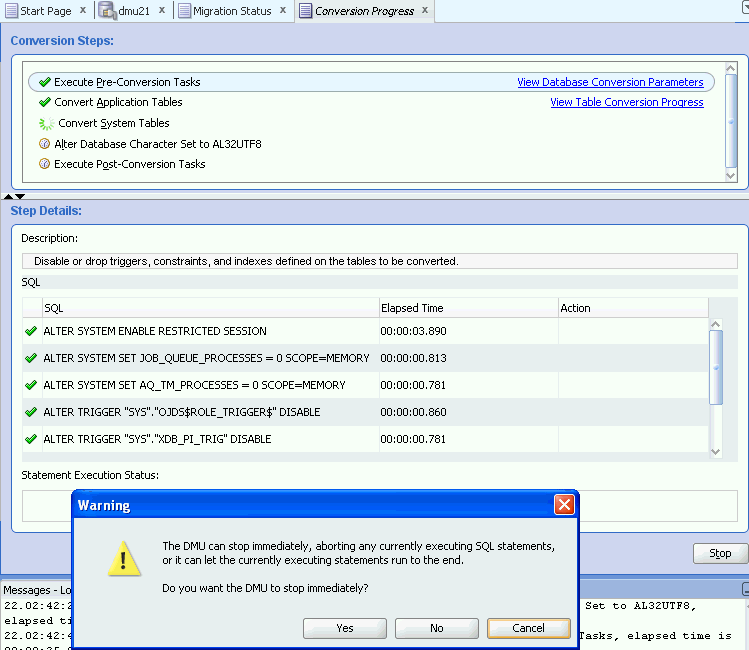
「停止」をクリックすると処理中のスキャンを停止することができ、その場合には警告ダイアログが表示されます。「はい」を選択してスキャンをただちに強制終了するか、「いいえ」を選択して現行プロセスが終了してからスキャン・プロセスを停止するか、または「取消」を選択してスキャンに戻るかを選択できます。
スキャン・プロセスで特定されたデータ問題は、データベースを変換する前に解決する必要があります。DMUでは、すべての問題が解決されるか、無視できるとして明示的にマークされるまで、変換プロセスを開始できません。変換可能性の問題を解決するために実行できるアクションを、クレンジング・アクションと呼びます。
|
関連項目:
|
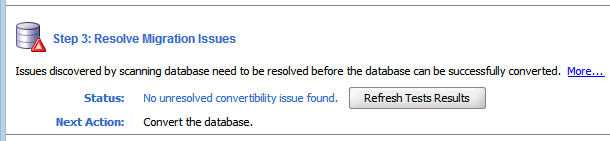
最後の手順はデータベース・キャラクタ・セットを実際に変換することであり、これはデータベース内のすべての問題を解決した後で実行できます(移行ステータスタブの画面を「図4-17 移行ステータス - 未解決の問題なし」に示します)。
データベースを変換する手順は、次のとおりです。
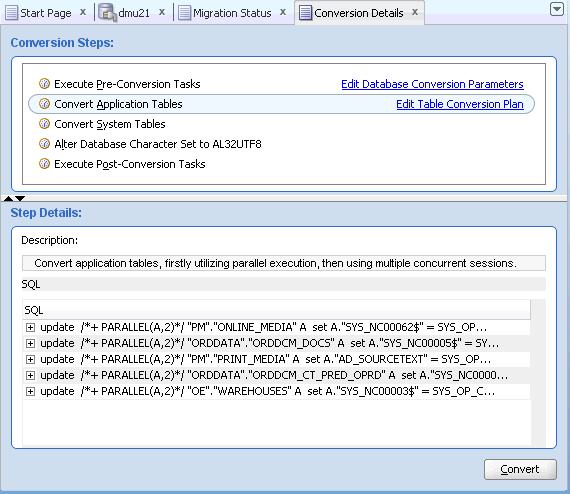
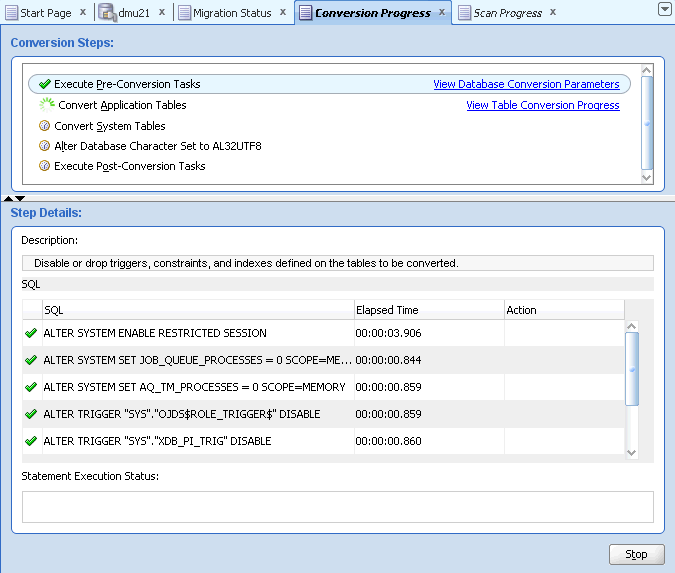
変換プロセスを開始するために、移行メニューまたはナビゲータ・ペインのデータベース・ノードのコンテキスト・メニューから「データベースの変換」を選択します。DMUでは、変換フェーズで実行するSQL文のリストが変換計画として生成され、DMUウィンドウのクライアント・ペインに、図4-18「変換の詳細タブ」に示すような変換の詳細タブが表示されます。このタブの変換ステップ領域に、変換プロセスの一連のステップが表示されます。リスト内のステップをクリックすると、ステップの詳細領域に、ステップの一部として実行されるSQL文のリストが表示されます。このタブの機能の詳細は、「変換の詳細タブ」を参照してください。
「データベース変換パラメータの編集」をクリックして、データベース・プロパティ・タブの変換サブタブを表示します。このサブタブで設定できるパラメータの詳細は、「データベース・プロパティの表示および設定」を参照してください。
「表変換計画の編集」をクリックして、アプリケーション表の変換計画の詳細を表示します。表示されたダイアログ・ボックスの上半分には、変換中に処理されるすべての表のリストが含まれます。リストから表を選択すると、下半分に、表およびその依存オブジェクトの処理に使用されるSQL文が表示されます。このリストは、プロパティ「変換方法」、「ターゲット表領域」、「LONG位置の保持」および「パラレル実行」を設定することでカスタマイズできます。これらのパラメータの詳細は、「データベース・プロパティの表示および設定」を参照してください。
変換の詳細タブの変換ボタンをクリックして、変換プロセスを開始します。DMUによって、データベースに存在する予期しないセッションや、最も古いスキャン結果の経過時間に関して警告が表示されることがあります。以下の説明に従って警告を確認します。警告メッセージを受け入れて続行します。
DMUの変換フェーズで使用されるSQL文ALTER DATABASE CHARACTER SETは、文を実行しているセッションが、データベースにログインしている唯一のユーザー・セッションである場合にのみ成功します。このため、変換の開始前に、DMU自体によって開かれていないデータベースにログインしているユーザー・セッションがあれば、DMUによって警告が表示されます。障害になっているセッションの詳細を調べるには、SQL*PlusまたはSQL Developerで次のSQL文を使用します。
SELECT sid, serial#, username, status,
osuser, machine, process, program
FROM v$session
WHERE username IS NOT NULL
AND program <> 'Database Migration Assistant for Unicode';
前述の問合せにより戻された行内の列V$SESSION.PROGRAMに、オペレーティング・システムに依存する形式(Jnnn: nnnは小数点桁数3桁、例: "ORACLE.EXE (J000)")のOracle Database実行可能ファイル名が含まれている場合、その行で説明されているユーザー・セッションは、PL/SQLパッケージDBMS_JOBまたはDBMS_SCHEDULERを介して送信されたジョブを実行するためにデータベース・サーバー自体によって作成されたものです。データベース内で現在実行されているジョブを特定するには、データ・ディクショナリ・ビューDBA_JOBS_RUNNINGおよびDBA_SCHEDULER_RUNNING_JOBSを問い合せることができます。変換を開始する前に、すべてのジョブで作業が完了していること、およびそのセッションがV$SESSIONにもう表示されていないことを確認してください。
新たに別のジョブが開始されることがないように、次のSQL文を発行します。
ALTER SYSTEM SET job_queue_processes=0 SCOPE=MEMORY
すでに実行中のDBMS_SCHEDULERジョブを停止するには、プロシージャDBMS_SCHEDULER.STOP_JOBを使用します。DBMS_JOBジョブは、データベースを即時モードで停止しないかぎり停止できません。
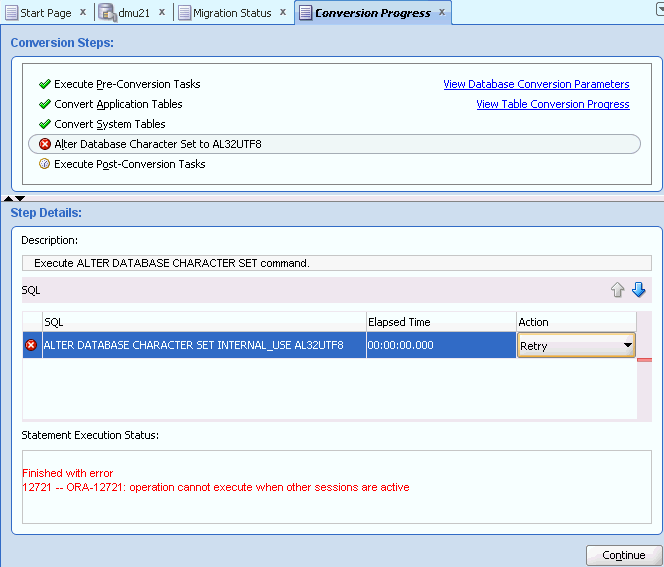
セッションを切断せずに予期しないセッションに関する警告メッセージを受け入れると、変換は開始されますが、ステップALTER DATABASE CHARACTER SET TO target_character_setは失敗し、「ORA-12721: この操作は他のセッションがアクティブなときには実行できません」と報告されます。この時点でも、障害となっているセッションを切断し、次の項の説明に従って変換を再開できます。
データベースに最も古いスキャン結果が存在するという警告メッセージによって、スキャン結果の失効を評価できます。DMUでは、表データに対するDML変更は監視されず、データの変換可能性の問題があるかどうかや、既存のスキャン結果で特定されたもの以外に新たに変換の必要な列がデータベースに存在しているかは判断されません。スキャン結果が古すぎる場合、最近追加されたデータが変換されないまま残ったり、不適切に変換される可能性があります。全体データベース・スキャンは、移行の停止期間に入ってから、すべてのアプリケーションが停止され、新しいデータがデータベースに取り込まれることがない状態で、変換開始直前に実行することをお薦めします。データベースが非常に大きいために全体データベース・スキャンに時間がかかる場合は、常に不変データのみ含まれることがわかっているすべての大きな表を特定し、スキャン・ウィザードでそれらの表を選択解除できます。
すべての警告を受け入れた後、変換方法「変換可能な行のみを更新」を使用して変換する表がデータベースに存在していれば、DMUでスキャン・ウィザードが開かれ、これらの表が再スキャンされます。これは、表の必要な行識別子情報が使用可能であり、最新の状態になっていることを確認するために行われます。停止期間中に全体データベース・スキャンを実行したばかりの場合、または影響を受けるすべての表を、表識別子の収集レベルを「すべて変換」として最適な時間スケジュールで個別にスキャンした場合は、表の既存の行識別子情報を受け入れることもできます。スキャン・ウィザードのスキャン・パラメータ・ページの最長期間パラメータを使用して、使用可能な行識別子情報のうち指定した時間値を経過していないもののみを受け入れるようにDMUに指定します。スキャンが完了すると、変換プロセスが開始されます。
変換が開始されると、変換の詳細タブの形式が変わり、変換プロセスの進行状況情報が表示されます。表変換計画の編集リンクは表変換進行状況の表示リンクになります。「表変換進行状況の表示」をクリックすると、表変換進行状況ダイアログ・ボックスが開いて、アプリケーション表の詳細な変換進行状況を参照できます。
変換が完了すると、DMUで確認メッセージが表示されます。いずれかの変換SQL文で発生したエラーがある場合、変換ステップ・リストのステップ名の隣と、ステップの詳細リスト内の影響を受けるSQL文の隣にそのことを示す赤いアイコンが付きます。エラーが発生した文をクリックすると、変換の詳細タブの一番下にエラーの詳細が表示されます。
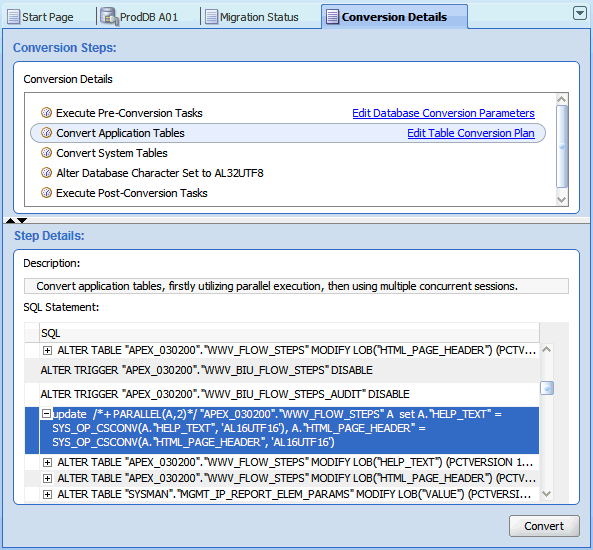
変換の詳細タブは、2つのモードで動作します。「データベースの変換」を選択してこのタブを開くと、最初はタブは計画モードで動作します。このタブには、DMUでデータベースをターゲット・キャラクタ・セットに変換するために実行するように計画されているSQL文のリストが含まれます。これらの文は、変換ステップ領域に一覧表示されたステップに分類されています。変換ステップをクリックすると、DMUによって、ステップの詳細領域に、そのステップに関連付けられているSQL文が表示されます。SQL文の左側にプラス・アイコンが表示されている場合、このアイコンをクリックすると、領域を開いて文のテキスト全部を表示できます。
データベース変換パラメータの編集リンクをクリックすると、データベース・プロパティ・タブの変換サブタブがダイアログ・ボックス内に開きます。使用可能なパラメータの詳細は、「列プロパティ: 変換」を参照してください。
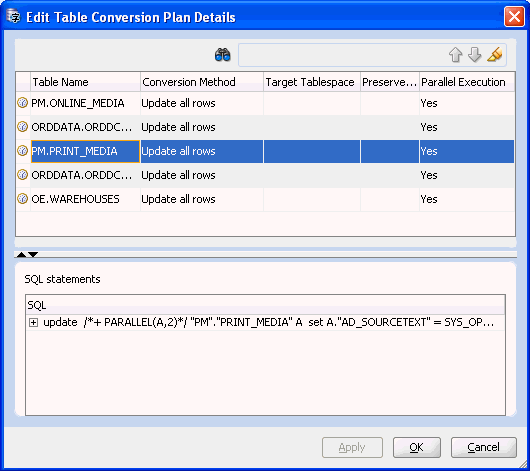
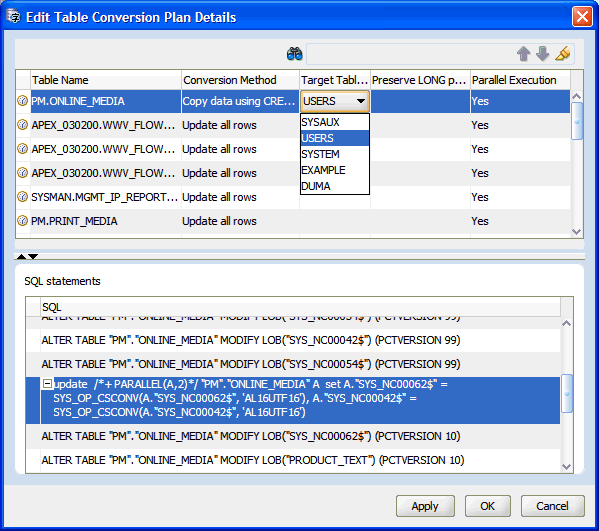
表変換計画の編集リンクをクリックすると、DMUによって、「表変換計画の詳細の編集ダイアログ」で説明されている表変換計画の詳細の編集ダイアログ・ボックスが開きます。
変換を開始する準備ができたら、タブの一番下にある「変換」をクリックします。変換の詳細タブが、図4-21「変換の詳細タブ: 監視モード」に示すような監視モードに切り替わります。
監視モードでは、「変換」ボタンのかわりに「停止」ボタンが表示されます。「停止」をクリックすると、警告ダイアログが表示されます。このダイアログでは、ただちに変換プロセスを強制終了するか(「はい」)、現行稼働プロセスが終了した後に停止するか(「いいえ」)、または変換操作に戻るかの選択肢があります(「取消」)。
監視モードでは、表変換計画の編集リンクは表変換進行状況の表示リンクに変わります。このリンクをクリックすると、表変換進捗の表示ダイアログ・ボックスが監視モードで開きます。
緑色のチェック・マークは、すでに実行が正常に完了しているステップおよびSQL文を示します。アニメーションの円アイコンは現在実行されているステップを示し、スプロケット形状のアイコンは現在実行されているSQL文を示します。
データベースの変換プロセス中にエラーが報告された場合、図4-22「変換エラー・タブ」に示すように、現在実行されているステップおよびエラーの原因となった文に赤色のXエラー・アイコンが付きます。変換プロセスは一時停止されます。
エラーの発生した文をクリックすると、報告されたデータベース・エラー・メッセージが文実行ステータス・フィールドに表示されます。文を再試行またはスキップするようにDMUに指定するには、「SQL文」領域の「アクション」列にあるドロップダウン・リストから対応するオプションを選択します。文を変換プロセスから除外するとデータベースが整合しない状態になる可能性があるため、スキップ・オプションは非常に慎重に使用してください。エラーの発生した文の処理方法を選択した後、「続行」をクリックして変換プロセスを再開します。
変換プロセスが完了すると、DMUによって確認ダイアログ・ボックスが表示されます。ナビゲータ・ペインからステータス・アイコンが削除されます。「移行」メニューから「DMUリポジトリの構成」を選択すると、Unicode検証モードでリポジトリを再インストールできるようになりました。
図4-23に示す表変換計画の詳細の編集ダイアログ・ボックスでは、個々の表の変換パラメータを変更できます。表のパラメータを変更するには、ダイアログ・ボックスの上部グリッド内の対応するセルをクリックします。その表の変換方法で編集が許可されていれば、セルを編集できるようになります。ダイアログ・ボックスの上部グリッド内の表の行をクリックすると、表の変換に関連付けられているSQL文が下部グリッドに表示されます。
個々の表に設定できる変換パラメータは、次のとおりです。
変換方法
ターゲット表領域
LONG位置の保持
パラレル実行
最初の3つのパラメータについては、「表プロパティ: 変換」を参照してください。パラレル実行パラメータでは、特定の表に対するSQL文に、データベースのパラレルDDL機能およびパラレルDML機能を使用するためのパラレル・ヒントを追加するかどうかを指定します。
ダイアログ・ボックスの一番上にある検索ツールバーを使用すると、名前に特定の部分文字列を含む表をすばやく見つけることができます。検索ボックスに部分文字列を入力して、[Enter]を押します。複数の名前で部分文字列が見つかった場合、これらの名前をナビゲートできる矢印アイコンが有効になります。マーカー・ペンのアイコンをクリックすると、一致する表が強調表示されます。
準備が完了したら、「OK」をクリックしてパラメータ変更を受け入れ、ダイアログ・ボックスを閉じます。ダイアログ・ボックスを閉じずに変更を受け入れる場合は、「適用」をクリックします。「適用」または「OK」をクリックすると、変更した表のSQL文が再生成されます。
表変換計画の詳細の編集ダイアログ・ボックスを監視モードで開くには、変換プロセス中に表変換の進行状況の表示リンクをクリックする方法もあります。監視モードでは、ダイアログ・ボックスの上部グリッドに、個々の表の変換に使用された時間を示す「経過時間」と、すでに処理された表データの割合を報告する「進行状況」という2つの追加の列が表示されます。また下部グリッドにも、個々のSQL文の実行に使用された時間を示す「経過時間」と、文が失敗した場合に選択するアクション(「再試行」または「スキップ」)を示す「アクション」という2つの追加の列が表示されます。
DMUでは、データベースをUnicodeに移行するのみでなく、既存のAL32UTF8またはUTF8データベースの内容を検証することもできます。このようなデータベースは過去に変換されていたり、最初はUnicodeキャラクタ・セットで作成されたものである可能性があります。どちらの場合も、DMUを使用して現在のデータを確認できます。
すでにAL32UTF8またはUTF8に変換されたデータベースや、これらのキャラクタ・セットでの新規データベースに対してDatabase Migration Assistant for Unicodeを使用して、すべてのデータが実際に宣言済データベース・キャラクタ・セットになることを確認できます。データの検証プロセスと移行プロセスは異なるため、DMUユーザー・インタフェースも2つの使用タイプでは異なります。DMUで表示されるユーザー・インタフェースのタイプは、リポジトリのインストール時に決定されます。現行データベース・キャラクタ・セットがAL32UTF8でもUTF8でもない場合、DMUでは自動的に移行モードがアクティブになります。現行データベース・キャラクタ・セットがAL32UTF8の場合、検証モードがアクティブになります。現行データベース・キャラクタ・セットがUTF8の場合、リポジトリ構成ウィザード(「移行リポジトリのインストール」を参照)の最初のページで、(推奨されるUnicodeキャラクタ・セットである)AL32UTF8に移行するか、または検証モードをアクティブにするかを選択できます。データベースをUnicodeに移行した後で検証モードをアクティブにするには、移行リポジトリを再インストールします。
スキャンを実行して現在の文字データの検証を実行し、データベース・スキャン・レポートで問題が発生していないか確認できます。このレポートには、有効なUTF-8文字コードにならないバイト・シーケンスがどの表列に含まれているかが示されます。無効なデータが報告された場合、GUIでこのデータを表示し、問題の場所を分析できます。また、DMUではクレンジング・エディタでデータを修正することもできます。無効なデータが報告されなくなるまで、問題のスキャンと解決のプロセスを繰り返すことができます。
通常、データを修正するには、無効なデータをデータベースに格納しているアプリケーションの構成問題を解決する必要があります。エンコードされた文字データが間違ってAL32UTF8またはUTF8データベースに格納される場合、その原因として最も一般的なのは、クライアント構成の問題(通常はパススルー構成の問題)です。AL32UTF8およびUTF8データベースを検証モードで定期的にスキャンして、できるだけ早期にエンコーディングの問題を検出する必要があります。
検証モードと移行モードのDMUユーザー・インタフェースは似ています。主な相違点は次のとおりです。
図4-25に示すように、移行ステータス・タブが検証ステータス・タブになります。
移行メニューが「検証」メニューになります。
移行メニューのデータベースの変換項目は、「検証」メニューでは無効な列の変換項目になります。この項目をクリックすると、列を想定キャラクタ・セットからデータベース・キャラクタ・セットに変換する手順が開始されます。
データベース・スキャン・レポートには、データベース・オブジェクト名、現在のデータベース内容のスキャン結果、および想定キャラクタ・セット・プロパティのみが表示されます。これ以外のレポート列は使用できません。
クレンジング・エディタ・タブのコンテキスト・メニューには、列変更のスケジュール・ダイアログ・ボックスおよび属性変更のスケジュール・ダイアログ・ボックスを開くためのオプションはありません。即時の操作である「列の変更」および「属性の変更」のみが実行可能です。
クレンジング・エディタのツールバーには、スケジュール済クレンジングの影響を表示ボタンはありません。
無効な列の変換プロセスの変換の詳細タブは、変換ステップの数が少ないことを除いて、移行モードの変換ステップのユーザー・インタフェースとほぼ同じです。
表変換計画ダイアログ・ボックスは、移行モードよりも簡略的です。これには変換される表と列および関連付けられたSQL文が表示されますが、表レベルの変換パラメータを設定することはできません。また、このバージョンのダイアログ・ボックスに変換の進行状況は表示されません。変換の進行状況は、変換の詳細タブでのみ監視できます。
無効な列の変換を妨げている問題が残っている場合は、検証ステータス・パネルにある手順3の「ステータス」フィールドの下に表示されます。ステータスで解決されていない変換問題が存在しないことが示されるまで、報告された問題を確認して解決する必要があり、解決後に想定キャラクタ・セットにタグ付けされている列のUnicodeへの変換を続行できます。
Unicodeとしてのデータを検証する手順は、次のとおりです。
リポジトリをインストールします。
前述のように、DMUリポジトリは検証モードでインストールされます。インストール後のリポジトリは繰り返し使用して、検証プロセスを何度でも適用できます。リポジトリを再インストールする必要があるのは、データベースまたはDMUをアップグレードする場合のみです。
データベースをスキャンします。
データベース全部または選択したスキーマ、表または列がスキャンされ、不正なコードが検出されます。データベース全部をスキャンすることを強くお薦めしますが、データベースが大きすぎて定期的にスキャンすると本番の作業への影響を避けられない場合や、以前の移行プロセスで実際には小さな表セットにのみASCIIデータが含まれていることが判明した場合は、オブジェクトのサブセットのみをスキャンするように選択することもできます。
スキャン結果に変換の必要がないデータを含む列のみが示された場合、データベースの内容は適正であり、検証プロセスのこの部分は完了です。
データベース・プロパティ・タブのスキャン・サブタブにあるU+FFFDを無効な文字として報告するプロパティの値は、DMUでのUnicodeデフォルト置換文字U+FFFD (AL32UTF8およびUTF8ではバイト・シーケンス0xEF 0xBF 0xBD)の解釈方法を指定します。このプロパティ値が「はい」の場合、この文字は無効なデータとして処理されます。これはデフォルトの動作であり、その理由は、データにこの文字が存在していると、通常は、実際のキャラクタ・セットで正しくタグ付けされていない入力のキャラクタ・セット変換の結果としてこのデータが生成されたことを意味するためです。なんらかの内部処理の目的で文字U+FFFDを使用する必要があり、DMUでそれを無効と報告されないようにする場合は、このプロパティ値を「いいえ」に変更します。
移行モードの場合と同じように、スキャンを開始し、結果を参照します。詳細は、「データベースのスキャン」を参照してください。
データをクレンジングします。
スキャン結果でいずれかの列に無効なバイナリ表現のあるデータが含まれることが示された場合、このデータのソースを診断し、関連付けられたアプリケーションまたは構成の問題を解決する必要があります。無効なバイナリ表現を含むデータの考えられる理由は、「クレンジング・シナリオ3: 無効な表現の問題のクレンジング」を参照してください。
無効な表現の問題をクレンジングするには、2つのオプションがあります。列の内容がバイナリの場合は列をバイナリ・データ型に移行し、列が他のキャラクタ・セットでエンコードされている場合は列をデータベース・キャラクタ・セットで変換します。列データを変換する最初の手順は、列の想定キャラクタ・セット・プロパティを設定して、適切なキャラクタ・セットでデータにタグ付けすることです。詳細は、「クレンジング・シナリオ3: 無効な表現の問題のクレンジング」および「想定キャラクタ・セットの設定」を参照してください。
いずれの列の想定キャラクタ・セット・プロパティも変更されていない場合、スキャン結果にデータ長の問題は表示されません。ただし、列のこのプロパティを変更して列を再スキャンした場合、列制限またはデータ型制限を超えるセルが報告されることがあります。次の手順に進む前に、長さの問題を解決する必要があります。即時モードでの列の長さ調整または別のデータ型への移行は、移行モードと同じ方法で実行できます。詳細は、第6章「DMUを使用したデータのクレンジング」(特に「列の変更」)を参照してください。
検証モードでのクレンジング・アクションは、すべて即時アクションです。新しい値がスキャン結果およびデータ表示に即時に適用されるという点で、想定キャラクタ・セット・プロパティの設定は即時性のある操作ですが、設定時にキャラクタ・セット変換は実行されません。キャラクタ・セット変換は、個別の変換ステップで実行する必要があります。列の「想定キャラクタ・セット」が適切に設定されていれば、スキャンで列は無効なバイナリ表現の問題がないとして報告されます。検証ステータス・タブを選択して、列を想定キャラクタ・セットからデータベース・キャラクタ・セットに変換するための変換ステップが必要かどうかを確認します。変換ステップを実行するまでは、データベースはまだクリーンになっていません。
クレンジング・アクションを実行すると、影響を受ける表のスキャン結果が無効化されます。表を再スキャンして、クレンジング・アクションが正常に完了したことを確認します。列の想定キャラクタ・セット・プロパティを設定した場合、再スキャンを行うと、データの切捨ての問題なく列データを想定キャラクタ・セットからデータベース・キャラクタ・セットに変換できるかどうかがわかります。
間違ってエンコードされたデータを変換します。
クレンジング中、いずれかの列に想定キャラクタ・セット・プロパティが設定されている場合、この手順を実行して、列の内容を想定キャラクタ・セットからデータベース・キャラクタ・セットに変換する必要があります。この手順では、データベース・キャラクタ・セットとは異なる想定キャラクタ・セットでマークされているすべての列が、データベース・キャラクタ・セットに物理的に変換されます。変換はSQL UPDATE文を使用して実行されます。このプロセスを開始するには、「検証」メニューまたはナビゲータ・ペインのデータベース・ノードのコンテキスト・メニューから「無効な列の変換」を選択し、表示される変換の詳細タブで「変換」をクリックします。
列の内容が変換されると、想定キャラクタ・セット・プロパティがデータベース・キャラクタ・セットに再設定されます。変換された列を再スキャンして、変換が正常に完了したことを確認できます。
検証プロセスは定期的に行い、システムの構成に変更(たとえば、アプリケーションやデータベースのアップグレード、新規アプリケーションの追加、新規の国からの新規アプリケーション・ユーザーの追加など)を行った後には必ず再適用してください。新しい構成になったデータベースにはスキャン済データが格納されている可能性が高いため、構成変更後、ある程度の時間が経過してからスキャンを実行してください。
データベース・キャラクタ・セットがUTF8の場合、DMUリポジトリは検証モードでインストールされるため、データベースをAL32UTF8に移行する場合は、このリポジトリをアンインストールしてから、移行モードを選択して再びインストールする必要があります。
DMUの使用中に問題が発生した場合、その後の分析に使用する診断パッケージを作成すると、オラクル社がその問題を解決する際に役立ちます。このパッケージは、プロジェクト・ログ・ファイル、スキャン・レポート、およびDMUの現行リポジトリ表とアーカイブ済リポジトリ表が入ったデータ・ポンプ・ダンプ・ファイルを含むjarファイルです。
診断パッケージを作成する手順は、次のとおりです。
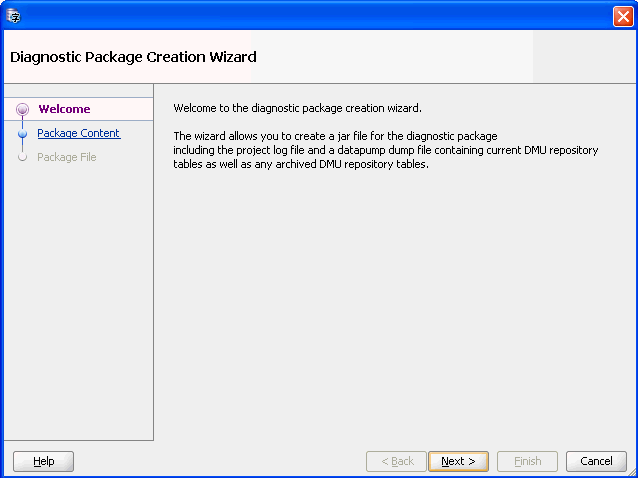
移行メニューから「診断パッケージの作成」をクリックします。図4-26「診断パッケージ・ウィザード」が表示されます。
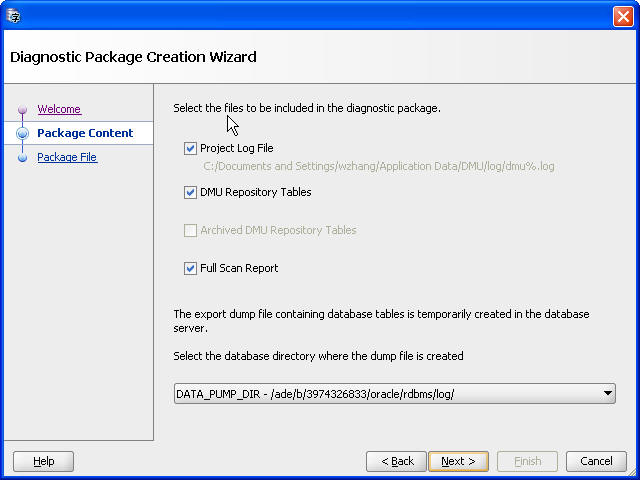
「次へ」をクリックします。図4-27「診断パッケージ・ウィザード - パッケージの内容」が表示されます。
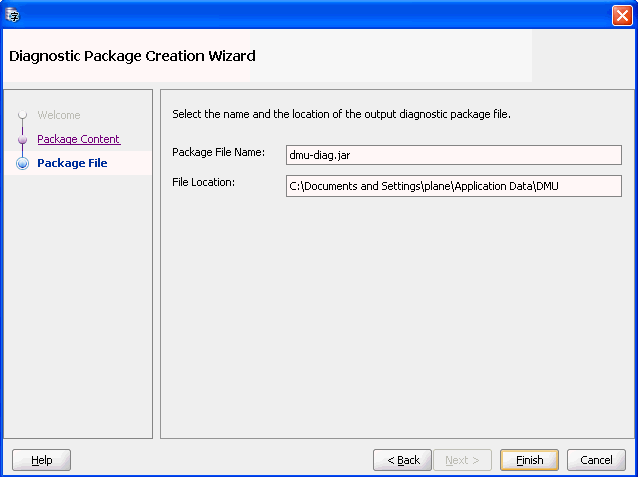
「次へ」をクリックします。図4-28「診断パッケージ・ウィザード - パッケージ・ファイル」が表示されます。
「完了」をクリックすると、選択したパスで診断jarファイルが作成されます。