| Oracle® Database Migration Assistant for Unicodeガイド リリース2.0 E59465-03 |
|


 前 |
 次 |
この章では、Database Migration Assistant for Unicodeを使用する際に考慮する必要のある様々な高度なトピックを扱います。内容は次のとおりです。
状況によっては、選択した列または表を移行プロセスのスキャン・ステップまたは変換ステップから除外します。これに該当する状況は次のとおりです。
1つの列に複数のキャラクタ・セットが存在する問題を解決する必要があります(「多言語列の使用」を参照)。
データベースにバイナリ・データを含む文字列が存在しています。アプリケーションが社内で開発されていないなどの理由で、データベースにアクセスするアプリケーションを変更することができないため、列をバイナリ・データ型(RAW、LONG RAWまたはBLOB)に移行することができません。アプリケーションがこれまでどおりパススルー構成でデータにアクセスできるように、列の変換は回避する必要があります。
データベースに数TBものデータを含む非常に大きな表が存在しますが、それには変換可能なデータが含まれていないことがわかっています。このような表には次のような制約があります。
現行データベース・キャラクタ・セットがマルチバイトの場合を除いて、CLOB列を含むことはできません。
内部アプリケーション・コード、「はい」/「いいえ」のフラグ、クレジット・カード番号、または基本のASCII文字のみ使用することがわかっているその他のデータを含む文字列のみを含むことができます。
エンド・ユーザーが英語のテキストのみを入力することが予測されていても、非ASCII文字をサポートするキーボードからユーザーが入力したデータを含むことはできません。Microsoft Windowsが実行されているコンピュータの標準的なキーボードでは、常にこのような文字の入力が許可されます。
このような大きな表をスキャンから除外すると、データベース全部のスキャン時間を短縮できます。非常に大きな表であっても、少なくとも1回はスキャンすることを強くお薦めします。
DVD-ROMジュークボックスなどの低速ストレージ・デバイスの読取り専用表領域に格納されたアーカイブ・データは、非常に大きな表の場合と同様に、スキャンから除外できます。この場合も、表に変換の必要なデータが含まれていないことを確認する必要があります。
なんらかの重要な理由で読取り/書込みに変更できない読取り専用表領域または読取り専用表があります。DMUで変換できない変換可能データが表領域または表に含まれていても、データベースのそれ以外の部分はUnicodeに変換できます。表領域でそのデータを受け入れます(そうしない場合、適切な回避策を実行するか、DMUで後から検証モードでデータを変換するかしないかぎり、表は変換後に読取り不可になります)。
オンラインに戻すことができないオフラインの表領域またはオフラインのデータ・ファイルがある場合、読取り専用表領域の場合と同様に、DMUではこの表領域またはデータ・ファイル内のデータのスキャンまたは変換を実行できません。データベースのこれ以外の部分は変換する必要があるため、後で表領域またはデータ・ファイルをオンラインに戻したときに表領域またはデータ・ファイルの内容が読取り不可になる可能性があることを承諾します。DMUを検証モードで使用して、後からこのデータを変換できます。
読取り専用モードおよびオフライン・モードのデータベース・オブジェクトの詳細は、「アクセス不能データの処理」を参照してください。
表をスキャンから除外するには、スキャン・ウィザードのオブジェクト選択ページで、単にその表を選択解除します。
列を変換から除外するには、その列プロパティ・タブを開いて(「列プロパティの表示および設定」を参照)、変換サブタブの変換から除外するプロパティを「はい」に設定します。DMUでは、変換ステップの開始を妨げている変換可能性の問題をチェックする際に、変換から除外される列を考慮しません。表を変換から除外するには、その変換可能列をすべて除外します。
データベース内の特定のタイプのデータは、アプリケーションからアクセスできないことがあります。データは更新不能であったり、読取りすらできない場合もあります。DMUでは更新不能データは変換できず、読取り不能データは変換もスキャンもできません。アクセス制限のあるデータは、次のいずれかのデータベース・オブジェクトに含まれるデータです。
リリース11.1以降のすべてのOracle Databaseでは、データベース表の読取り専用モードをサポートしています。このため、表の内容が更新されないように保護する場合、ユーザーは表を読取り専用モードに変更できます。読取り専用表に対して問合せ、制約の変更、セグメントの移動、縮小または拡大を行うことはできますが、その列値はどのような方法でも変更できず、新しい行を追加することもできません。ユーザーは、必要に応じて何度でも、表を読取り/書込みモードに変更してから読取り専用モードに戻すことができます。
読取り専用表は更新できないため、DMUで変換が必要となることがあっても、その内容は変換できません。このため、DMUでは、変換の試行前に読取り専用表が読取り/書込みモードに自動的に変更されます。変換後、モードは読取り専用に戻ります。
変換方法として「CREATE TABLE AS SELECTを使用してデータをコピー」を使用して読取り専用表を変換する場合、読取り専用表を再作成することもできます。
表領域は読取り専用モードに設定できます。これにより、それに格納されているデータの更新が禁止されます。読取り専用表領域のデータ・ファイルは、DVD-ROMなどの読取り専用媒体に格納し、ほとんどアクセスされないアーカイブ・データ用の安価なストレージとして使用されるジュークボックスに移動できます。また、データ・ファイルを標準的な読取り/書込みディスク・ストレージ・デバイスに残すこともできます。たとえば、非常に大きなデータベース内の履歴データを頻繁に読取り専用表領域に移動するとします。このような表領域は、読取り専用モードに設定した直後に1回のみバックアップします。読取り専用表領域は変更できないため、それ以降のバックアップは必要ありません。これにより、非常に大きなデータベースのバックアップ時間を大幅に短縮できます。
表のいずれかのセグメント(パーティション、CLOB、VARRAYおよびIOTオーバーフロー・セグメントを含む)に変換の必要なデータが含まれ、そのセグメントが読取り専用表領域に属している場合、DMUでは正常に表を変換できません。DMUによって移行ステータス・タブにこれが変換可能性の問題として報告され、問題を解決するまで変換手順を開始できません。
この変換可能性の問題を解決する方法は、問題のある表領域が読取り専用モードにされた理由によって異なります。バックアップ時間を短縮することが理由であった場合、データがまだ標準的なディスク・デバイスにあれば、表領域を読取り/書込みモードにして、データベースの残りの部分とともに変換し、再び読取り専用モードに設定してからバックアップをリフレッシュします。
表領域が読取り専用モードに設定されて、読取り専用媒体に移動された場合、実行できる解決方法は次のとおりです。
変換可能データを含むすべての読取り専用表領域を格納するのに十分なディスク・ストレージを(永続的または一時的に)配置できる場合、表領域をこのストレージにコピーして読取り/書込みに設定し、データベースの残りの部分とともに変換してから、再び読取り専用にし、その後はディスク・ストレージに残すか、読取り専用媒体に戻します。変換可能データを含む読取り専用表領域の数が多い場合、この解決方法は実行できないことがあります。
メイン・データベース(移行するデータベース)と同じキャラクタ・セットで補助データベースを作成します。トランスポータブル表領域機能を使用して読取り専用表領域を新しいデータベースに移動し、データ・ファイルは物理的に現在の場所に残します。メイン・データベース内に新しいデータベースへのデータベース・リンクを作成します。補助ビューを作成するか、アプリケーションを変更することによって、メイン・データベースに接続するアプリケーションに補助データベース内の読取り専用データが表示されるようにします。データは、データベース・リンクを介してトランスポートされる間に変換されます。
表領域または表領域内の選択済データ・ファイルがオフライン・モードに設定されていることがあります。オフラインの表領域またはデータ・ファイルに含まれるデータには、読取りアクセスも書込みアクセスもできません。オフライン・モードは、名前変更やストレージ・デバイス間での移動など、データ・ファイルの様々な管理操作で必要となります。
表のいずれかのセグメント(パーティション、CLOB、VARRAYおよびIOTオーバーフロー・セグメントを含む)に変換の必要なデータが含まれ、そのセグメントがオフラインの表領域またはデータ・ファイルに属している場合、DMUでは表のスキャンも変換もできません。このような表領域またはデータ・ファイルは、影響を受ける表をスキャンまたは変換する前に、オンライン・モードに戻す必要があります。そうしない場合、スキャン・ステップおよび変換ステップでORA-00376のようなエラーが報告されます。
オフラインのデータ・ファイル内に変換可能データが見つかると、DMUの移行ステータス・タブにエラーが報告され、変換ステップを開始できません。
外部表とは、データがデータベース外部のファイルにある表のことです。データベースには表の列の定義(メタデータ)が含まれますが、表を参照する問合せが発行されると、表の行が外部ファイルからフェッチされます。Oracle Databaseでは、外部ファイルを読み取る2つのアクセス・ドライバ(ORACLE_LOADERおよびORACLE_DATAPUMP)をサポートしています。ORACLE_LOADERは、SQL*Loaderでサポートされる形式のテキスト・ファイルを読み取ります。ORACLE_DATAPUMPは、データ・ポンプ・エクスポート・ユーティリティ(expdp)およびデータ・ポンプ・インポート・ユーティリティ(impdp)と互換性のあるバイナリ・ファイルをサポートしています。
外部表を変更するDML文はサポートされていません。CREATE TABLE … ORGANIZATION EXTERNAL … AS SELECT文を使用して外部表を作成すると、外部ファイルORACLE_DATAPUMPが作成されてデータが挿入されますが、データベース内部から後でこれを変更することはできません。ORACLE_LOADERファイルは、データベース外部で作成および変更する必要があります。DMUでは、データベースの内容とともに外部ファイルが変換されることはありません。
外部表が作成されると、そのデータ・ファイルのキャラクタ・セットが次のように設定されます。
ORACLE_DATAPUMPドライバまたはデータ・ポンプ・エクスポート・ユーティリティによってファイルが作成されると、ORACLE_DATAPUMPファイルのキャラクタ・セットがデータ・ファイル自体に格納されます。
ORACLE_LOADERファイルのキャラクタ・セットは、外部表定義のアクセス・パラメータ句のCHARACTERSETパラメータで指定できます。このパラメータを指定しない場合、データベース・キャラクタ・セットを使用してファイルの内容が解釈されます。
外部ファイルの宣言済キャラクタ・セットがデータベース・キャラクタ・セットと異なる場合、データベースはデータの読取り中に自動的にデータを変換します。データベース・キャラクタ・セットは変更されるが、外部ファイルのキャラクタ・セットは変更されない場合、データベースは自動的に新しい構成に適応し、外部ファイルが新しいデータベース・キャラクタ・セットに変換されます。
|
注意: ORACLE_LOADERファイルのキャラクタ・セットが外部表定義のアクセス・パラメータ句で明示的に宣言されていない場合、データベース・キャラクタ・セットが変更されると、外部ファイルのキャラクタ・セットの暗黙的な宣言も変更されます。ファイル自体が新しいデータベース・キャラクタ・セットに変換されない場合、外部ファイル宣言はファイルの実際のキャラクタ・セットに一致しなくなり、外部表を正しく読み取ることができなくなります。
データベースをUnicodeに移行する前に、欠落している明示的なキャラクタ・セット宣言をすべての外部表定義に追加するか、ファイルの内容を新しいデータベース・キャラクタ・セットに変換する必要があります。 |
DMUでは、外部表は変換されませんが、移行プロセスのスキャン・ステップには含められます。スキャン結果には、新しいUnicodeデータベース・キャラクタ・セットへの変換後にデータが拡張しても、移行後にもファイルの内容が宣言済の列の長さに収まるかどうかが示されます。また、外部ファイルに不正な文字コードが存在する場合は結果に警告が表示されます。ファイルの内容をオンザフライで変換する必要がある場合、これらのコードは読取り不可になります。
スキャン・レポートに無効なバイナリ表現の問題が示されている場合、「データの無効なバイナリ記憶域表現」および「クレンジング・シナリオ3: 無効な表現の問題のクレンジング」の説明に従って、無効なコードのソースを特定する必要があります。
次の各項で、報告された様々な問題から外部表をクレンジングするために実行できるアクションについて説明します。
スキャン・レポートに外部表の内容の長さの問題が示されている場合、表を変更して影響を受ける列の長さを調整するか、それらをキャラクタ・セマンティクスに移行できます。DMUでは外部表に対するクレンジング・アクションをサポートしていないため、これはSQL*PlusやSQL Developerなどの別のツールで行う必要があります。データが拡張して4000バイトを超える場合、VARCHAR2列をCLOBに変更する必要があることがあります。列データ型をCLOBに変更するには、外部表を再作成する必要があります。これはメタデータのみの変更が行われる操作なので短時間ですみますが、許可などの依存オブジェクトは再作成する必要があることに注意してください。
パススルー構成でORACLE_LOADERドライバによって外部表の文字値が読み取られる場合、つまりデータ・ファイルの宣言済キャラクタ・セットとデータベース・キャラクタ・セットが同じであるのに、データの内容の実際のキャラクタ・セットは異なる場合、外部表定義のアクセス・パラメータ句で実際のキャラクタ・セットを宣言することにより、この構成を修復できます。データベースを変換する前に本番データベース内の宣言を変更すると、パススルー構成が壊れて表が読取り不可になるため、これは行わないでください。
データベースの変換前に、「想定キャラクタ・セットの設定」の説明に従って、影響を受ける外部表の列の想定キャラクタ・セット・プロパティをデータ・ファイルの特定された実際のキャラクタ・セットに変更してから、表を再スキャンして、データ・ファイル・キャラクタ・セット宣言の修正後に新たに発生した可能性のある長さの問題や無効なバイナリ表現の問題を特定する必要があります。
データベース内の影響を受けるすべてのアクセス・パラメータ句を変更するスクリプトを作成し、DMUの変換フェーズが正常に完了した後で直接それを実行することをお薦めします。
パススルー構成でORACLE_DATAPUMPドライバによって外部表の文字値が読み取られる場合、つまり前の項で説明したキャラクタ・セット構成においては、データベースがUnicodeに変換された後で、データ・ポンプ入力ファイルが実際のキャラクタ・セットで適切に再びタグ付けされていることを確認する必要があります。
キャラクタ・セット宣言はデータ・ポンプ・ファイルに内部的に格納されているため、簡単には変更できません。宣言を修正するには、より複雑な手順を実行する必要があります。あるいは、ORACLE_LOADER形式で提供されるように外部表ファイルを調整して、外部表のアクセス・パラメータ句のキャラクタ・セット宣言を完全に制御できます。
データ・ポンプ・ファイルがパススルー構成で使用されている場合、そのソース(エクスポートされた)データベースもこの構成で使用されます(そうでなければ、間違ってタグ付けされたファイルが生成されることはありません)。このため、データ・ポンプ・ファイルのキャラクタ・セット宣言を修正する場合は、そのソース・データベースのデータベース・キャラクタ・セットを修正する方法が推奨されます。
ソース・データのキャラクタ・セットを制御できない場合は、次の操作を実行する必要があります。
データ・ポンプ・ファイルのキャラクタ・セットで空の補助データベースを作成します。
ファイルをインポートします。これはパススルー構成で行われます。
データベース・キャラクタ・セットをファイルの実際のキャラクタ・セットに変更します。
ファイルをエクスポートして、(Unicodeへの移行後に)メイン・データベース内の外部表にそれらのファイルを使用します。
Character Set Scannerユーティリティ(csscan)およびcsalter.plbスクリプトを使用してデータベース・キャラクタ・セットを変更することによりパススルー構成を修正する方法の詳細は、Oracleサポートに問い合せてください。
次のPL/SQLコードを使用すると、データ・ポンプ・ファイルのキャラクタ・セットを特定できます。
DECLARE
et_directory_name VARCHAR2(30) := '<directory object name>';
-- for example, 'DATA_PUMP_DIR'
et_file_name VARCHAR2(4000) := '<file name>';
-- for example, 'EXPDAT.DMP'
et_file_info ku$_dumpfile_info;
et_file_type NUMBER;
BEGIN
dbms_datapump.get_dumpfile_info
( filename => et_file_name
, directory => et_directory_name
, info_table => et_file_info
, filetype => et_file_type );
FOR i IN et_file_info.FIRST..et_file_info.LAST LOOP
IF et_file_info.EXISTS(i) THEN
IF et_file_info(i).item_code = 11 THEN
dbms_output.put_line( 'Character set of the file is ' ||
et_file_info(i).value );
END IF;
END IF;
END LOOP;
END;
外部表内の無効なバイナリ表現の問題の分析で、いくつかの文字値に破損した文字コードが含まれることが示された場合(通常は、ユーザー・エラー、アプリケーションの欠陥、または一時的な構成の問題が原因です)、再度エクスポートまたはアンロードされたソース・データベースおよび影響を受けるファイル内で値を修正する必要があります。
ORACLE_LOADERファイルを使用すると、テキスト・エディタで直接ファイル内の無効なコードを修正できます。ただし、この解決方法を適用できるのは、同じソース・データベース内容から生成された新しいバージョンでファイルが定期的に置換されない場合のみです。
外部表内の無効なバイナリ表現の問題は、バイナリ・データが外部表ドライバによって文字データとして宣言およびフェッチされている場合にも起こります。このタイプの問題をクレンジングするには、影響を受ける列に対してRAWやBLOBなどのバイナリ・データ型を使用するように外部表を再定義する必要があります。
パススルー構成を引き続き使用して、UTF8やAL32UTF8などのマルチバイト・キャラクタ・セットを使用するデータベースにバイナリ・データをフェッチすることはお薦めしません。このような構成は、現在または将来に予期しない問題を引き起こす可能性があります。
Oracle Databaseユーティリティ・ガイドに、ORACLE_LOADERドライバのパフォーマンス・ヒントがいくつか示されています。Unicodeへのキャラクタ・セット移行のコンテキストでは、特に次のヒントが関連します。
シングルバイト・キャラクタ・セットは、最も速く処理される。
固定幅キャラクタ・セットは、可変幅キャラクタ・セットより速く処理される。
可変幅キャラクタ・セットのバイト長セマンティクスは、文字長セマンティクスより早く処理される。
キャラクタ・セットを変換するより、データ・ファイルのキャラクタ・セットをデータベースのキャラクタ・セットに一致させる方が速く処理される。
ORACLE_LOADERファイルを現行キャラクタ・セットのままにするか、新しいUnicodeデータベース・キャラクタ・セットでファイルが提供されるように調整するかを選択できる場合は、前述のヒントから導かれる次の結果を考慮する必要があります。
ファイルの現行キャラクタ・セットがマルチバイトの場合、ファイルにUTF8またはAL32UTF8データベース・キャラクタ・セットを使用しても、解析時間(ファイルをレコードおよびフィールドに分割するために必要な時間)に大きな影響はありませんが、変換時間は短縮されます。パフォーマンスは、外部表を参照する問合せのほうがよくなります。
ファイルの現行キャラクタ・セットがシングルバイトの場合、ファイルにUTF8またはAL32UTF8データベース・キャラクタ・セットを使用すると解析の速度は遅くなりますが、変換時間は短縮されます。どちらがより効率的かを判断するために、両方の構成を比較テストする必要があります。
ファイルをシングルバイト・キャラクタ・セットからUTF8またはAL32UTF8に変換する場合、問合せパフォーマンスを最大にすることが重要であれば、フィールドの長さおよび位置を文字でなくバイトで表現するよう試みてください。
DMUでは、データ・ディクショナリに属する表は、それを所有するスキーマに基づいて分類されます。DMUでデータ・ディクショナリ内にあるとみなされるスキーマは、ナビゲータ・パネルのデータ・ディクショナリ・ノードの下に表示されたスキーマです(「DMUのインタフェースおよびナビゲーションの概要」を参照)。データ・ディクショナリ・スキーマ内にSYSやSYSTEMなどの独自の表を作成すると、DMUではこれが他のデータ・ディクショナリ表として処理されます。ユーザー表をデータ・ディクショナリ・スキーマ内に作成することはお薦めしません。このリリースのDMUでは、データ・ディクショナリ表に保持されているメタデータ・サブセットのみのキャラクタ・セット変換がサポートされています。したがって、次の各項で説明するように、DMUではデータ・ディクショナリ表はデータベース内の他の表とは異なる方法で処理されます。
ほとんどのデータ・ディクショナリ表は、ユーザー定義表と同じ方法でスキャンされます。データが列制限を超える、データがデータ型制限を超える、データに無効なバイナリ表現があるといった通常の変換可能性の問題も、同様の方法で報告されます。ただし、ターゲットのUnicodeキャラクタ・セットに変換する必要のあるデータが報告される方法が異なります。このリリースのDMUでは、いくつかの例外を除いてデータ・ディクショナリの内容の変換はサポートされていないため、変換の必要なデータを含む変換不可能な列には黄色い三角形の警告アイコンが付き、データベース変換ステップの開始を妨げる変換可能性の問題があるとみなされます。データベース・スキャン・レポートのフィルタリング条件「問題あり」にも、これらの列が含まれています(「データベース・スキャン・レポート: フィルタリング」を参照)。
「データの表示」タブ(「データの表示」を参照)は、データ・ディクショナリやその他の変更不可能な表に対するクレンジング・エディタの読取り専用バージョンであり、変換不可能なデータ・ディクショナリ列に、「プリファレンス」ダイアログ・ボックスのクレンジング・エディタ・タブで構成されている専用の色で(デフォルトではオレンジ色の背景に黒色で)変換可能な値が表示されます。
DMUにより変換されるいくつかの列の変換可能データ(「データ・ディクショナリ表の変換」に一覧表示されています)は、問題として報告されません。
実装上の理由で、表SYS.SOURCE$、SYS.ARGUMENT$、SYS.IDL_CHAR$、SYS.VIEW$、SYS.PROCEDUREINFO$およびSYS.PLSCOPE_IDENTIFIER$は常に、収集する行識別子パラメータを「すべて変換」に設定してスキャンされます。詳細は、「データ・ディクショナリ表の変換」を参照してください。
Oracleではデータ・ディクショナリ表の構造を変更することも、その内容を更新することもサポートされていないため、DMUではこのような表に対するクレンジング・アクションは実行できません。データ・ディクショナリ表の列に想定キャラクタ・セットを設定できますが、選択したキャラクタ・セットは、「データの表示」タブに列が表示されるときにのみ考慮されます。変換に使用されるソース・キャラクタ・セットは常に、想定データベース・キャラクタ・セットです。
データ・ディクショナリの内容(メタデータ)についてデータ長の問題が報告された場合、この問題をクレンジングするには、メタデータを短いバージョンで置換する必要があります。同じ長さ問題は、DMUを使用する移行のみでなくすべてのキャラクタ・セット移行方法に影響を与えるため、別の変換方法を使用する場合(データ・ポンプ・ユーティリティを使用してデータを移動する場合など)でも、これらの問題はクレンジングする必要があります。
最もよくある長さ問題は、変換後にオブジェクト名が許容される長さを超えることです。識別子の通常の長さ制限は30バイトしかないため、非ASCII文字を含むそれより長い識別子(特に非Latinスクリプトで記述された識別子)は簡単に制限を超えてしまいます。たとえば、15文字を超えるギリシャ語またはロシア語の識別子は、EL8MSWIN1253またはCL8MSWIN1251からUTF8またはAL32UTF8に変換されると、30バイトの制限を超えます。中国語、日本語および韓国語の文字は通常、2バイトから3バイトに拡張されるため、10文字を超える識別子は問題となります。
識別子を短くするには、適切なSQL文またはPL/SQLパッケージ・コールを使用して、対応するデータベース・オブジェクトの名前を変更する必要があります。名前変更のみで済むオブジェクトもありますが、ほとんどのオブジェクトは削除してから新しい名前で再作成する必要があります。オブジェクトを削除すると、一部の依存オブジェクトも一緒に削除されます。これらも同様に再作成する必要があります。
たとえば、表、ビュー、順序またはプライベート・シノニムの名前を変更するには、SQL文RENAMEを使用します。表の列の名前を変更するには、SQL文ALTER TABLE RENAME COLUMNを使用します。ただし、クラスタについては名前変更のみ行うことはできません。一度削除してから別の名前で再作成する必要があります。ただし、クラスタを削除する前に、クラスタに格納されているすべての表を削除する必要があります。権限、索引、トリガー、行レベルのセキュリティ・ポリシー、アウトラインなど、表に作成された補助オブジェクトが多数存在する可能性があるため、最終的に多数のオブジェクトを再作成することになる可能性があります。このような場合は、データ・ポンプ・ユーティリティおよびメタデータAPIを使用すると便利です。
|
関連項目: データ・ポンプ・ユーティリティおよびメタデータAPIの詳細は、『Oracle Databaseユーティリティ』を参照してください。 |
データベース・オブジェクトの名前を変更した後、このオブジェクトを参照するすべてのアプリケーション・コードを、新しい名前を使用するように変更する必要があります。これには、データベース内のPL/SQLとJavaコード、および影響を受けるすべてのクライアント・アプリケーションも含まれます。
拡張されて最大許容長を超えることが多いメタデータ・タイプには他に、様々なデータベース・オブジェクトのフリー・テキスト・コメントがあります。同様に、長さの問題が報告されていれば、コメントを短いバージョンで更新して問題をクレンジングする必要があります。ほとんどのコメントは、適切なSQL文またはPL/SQLパッケージ・コールを使用して更新できます。
データ・ディクショナリの問題をクレンジングする適切な文を特定するための推奨方法は、「メタデータの特定」を参照してください。
データの無効なバイナリ表現の一般的な原因は、「データの無効なバイナリ記憶域表現」で説明されているパススルー・シナリオです。このような構成においてSQL文またはPL/SQLコールが発行されると、データベース・キャラクタ・セットで無効な文字または不適切な意味の文字を使用した名前のデータベース・オブジェクトが作成され、使用される可能性があります。たとえば、WE8MSWIN1252データベースでは意味のない表名が日本語のJA16SJISクライアントでは正しく表示されるとして解釈される場合や、データベース・キャラクタ・セットでは判読できないのに、別のキャラクタ・セットで表示すると適切に表示されるコメントがPL/SQLモジュールに含まれる場合があります。
引用符なしの識別子で許可される文字制約によってデータベース・オブジェクト名は最初から表示可能になっているため、データベース・オブジェクト名の無効なバイナリ表現の問題が発生することはほとんどありません。オブジェクト・コメントの無効なバイナリ表現のほうが発生する可能性は高くなりますが、修正するのも簡単です。
パススルー構成が原因で起こる無効なバイナリ表現の問題がアプリケーション・データにも共通の問題である場合、このような問題をクレンジングするには、データベースの想定データベース・キャラクタ・セット・プロパティをデータベースの内容の実際のキャラクタ・セットに設定します(「データベース・プロパティ: 一般」を参照)。あるいは、「データ・ディクショナリ表のクレンジング」で説明されている方法を使用して、影響を受けるメタデータを変換可能性の問題のないバージョンで更新します。
PL/SQLおよびJavaソース・コードまたはビュー定義における無効な表現の問題を解決するには、メタデータAPIを使用して、オブジェクトを作成するDDL文を取得し、文のテキスト内の問題のある文字を修正して、オブジェクトを再作成する文を実行します。オブジェクト名が影響を受けない場合は、権限などの関連オブジェクトを再作成ずに、CREATE OR REPLACE構文を使用してコードを変更します。
データ・ディクショナリの変換可能性の問題を解決するプロセスで難しいのは、データベース・スキャン・レポートで示された問題を、影響を受ける表および列に格納されているメタデータのタイプにマップする手順です。DMUインタフェースに表示されるデータ・ディクショナリ表は通常、ドキュメント化されていません。その内容を表示するためのドキュメント化された方法は、DBA_TABLES、DBA_TAB_COLUMNS、DBA_RULES、DBA_SCHEDULER_JOBSなどのデータ・ディクショナリを介する方法です。
変換可能性の問題のあるメタデータのタイプを特定するには、次の方法をこの順序どおりに試行してください。
「データの表示」タブで、問題のある文字値を確認します(「データの表示」を参照)。値そのものが、それが属するメタデータをすでに示している場合もあります。たとえば、値が「This column keeps customer e-mail」であればそれが列コメントであることがわかり、値が「HR_EMPLOYEE_V」であれば名前のビューの一般的な規則に一致するため、この値がビュー名であることがわかります。
cat*.sqlおよびcd*.sqlというSQLスクリプト・ファイル内に問題が報告されていて、データベースのOracleホーム・ディレクトリのrdbms/admin/サブディレクトリ内にある表の名前を検索します。これらのスクリプトは、『Oracle Databaseリファレンス』でドキュメント化されているデータ・ディクショナリ・ビューを定義するものです。表およびその列をドキュメント化された適切なビューにマップすると、報告された問題がどのメタデータに含まれるかがわかります。
Oracleサポートに問い合せるか、Oracle Technology Network Webサイトのグローバリゼーション・フォーラムで質問を投稿してください。
変換可能性の問題が報告されているメタデータを特定した後は、Oracleドキュメントを参照してこのメタデータを変更する適切な手順を特定してください。
DMUでは、データ・ディクショナリ内の次のデータのみが変換されます。
CLOB列 - これはシングルバイト・データベースでのみ必要です
XDB.X$QN%やXDB.X$NM%のような名前のバイナリXMLトークン・マネージャ表
PL/SQLソース・コード(CREATE PROCEDURE、CREATE FUNCTION、CREATE PACKAGE、CREATE PACKAGE BODY、CREATE TYPE BODY、CREATE TRIGGERおよびCREATE LIBRARYのテキスト)。タイプ指定(CREATE TYPE)は変換されません
ビュー定義(CREATE VIEWのテキスト)
次の列:
SYS.SCHEDULER$_JOB.NLS_ENV - データベース・スケジューラ・ジョブ(DBMS_SCHEDULER)のNLS環境
SYS.SCHEDULER$_PROGRAM.NLS_ENV - データベース・スケジューラ・ジョブ・プログラム(DBMS_SCHEDULER)のNLS環境
SYS.JOB$.NLS_ENV - レガシー・ジョブ(DBMS_JOB)のNLS環境
CTXSYS.DR$INDEX_VALUE.IXV_VALUE - Oracle Textポリシーの属性値
CTXSYS.DR$STOPWORD.SPW_WORD - Oracleのすべてのストップリスト内のすべてのストップワード
SYS、SYSTEMおよびCTXSYSスキーマ内の、様々なデータベース・オブジェクトに対するユーザー・コメントを含む50種類を超える列
PL/SQLソース・コードおよびビュー・ソース・テキストは、複数の表で保持されます。DMUでは、ソース・コードおよびビュー定義の処理中に次の列がチェックされます。
SYS.VIEW$.TEXT - ビュー定義テキスト
SYS.SOURCE$.SOURCE – PL/SQLおよびJavaソース・コード
SYS.ARGUMENT$.PROCEDURE$ – PL/SQL引数定義: プロシージャ名
SYS.ARGUMENT$.ARGUMENT – PL/SQL引数定義: 引数名
SYS.ARGUMENT.DEFAULT$ – PL/SQL引数定義: デフォルト値
SYS.PROCEDUREINFO$.PROCEDURENAME - パッケージ内で宣言されているプロシージャおよびファンクションの名前
SYS.IDL_CHAR$.PIECE - PL/SQLの内部表現
SYS.PLSCOPE_IDENTIFIER$.SYMREP - PL/SQLの内部表現(この表はOracle Databaseバージョン11.1以前は存在していませんでした)
DMUでは、前述の表および列内の変換可能な文字データは変換可能性の問題として報告されません。データ・ディクショナリのその他の表および列内の変換可能データにはいずれも、スキャン・レポートおよび移行ステータス・タブで変換可能性の問題があることを示すフラグが付きます。フラグの付いたデータが削除されるまでは、データベース変換ステップを開始できません。
DMUでは、次の表はスキャンされません。
列ヒストグラム統計が含まれるSYS.HISTGRM$
SYS.WRI$_OPTSTAT_OPRやSYS.WRI$_OPTSTAT_%_HISTORYのような名前の表で保持されている自動ワークロード・リポジトリ・オブジェクト統計履歴
SYSTEMスキーマ内のDMUリポジトリ表
CSMIGスキーマ内のCSSCANリポジトリ表
これらの表の内容も、DMUでデータベース変換を開始できるかどうかを決定する際には考慮されません。
SYS.HISTGRM$表は、(エンドポイント値を格納する)EPVALUE列にバイナリ・データが含まれる可能性があるため、スキャンされません。ヒストグラムおよびその他の表統計は文字列内のデータのバイナリ表現に依存するため、移行後にデータベース内のすべての変換済表の統計を再収集する必要があります。統計を収集すると、SYS.HISTGRM$表の内容がリフレッシュされ、新しいデータベース・キャラクタ・セットで再検証されます。統計をリフレッシュしない場合、オプティマイザが不適切な動作をする可能性があります。
同様に、自動ワークロード・リポジトリで保持されている履歴オブジェクト統計も、文字データのバイナリ表現に依存しているため、移行後に失効します。DMUでは、これらの統計は移行されません。これらは、移行後にDBMS_STATS.PURGE_STATS(SYSTIMESTAMP)をコールして手動でパージする必要があります。
|
関連項目:
|
DMUおよびCSSCANリポジトリのデータは、データベースが新しいデータベース・キャラクタ・セットに移行されると無効になります。したがって、これをデータベースとともに移行しても無意味です。移行後にリポジトリを削除し、まだ必要であれば再作成する必要があります。移行後にDMUリポジトリを再作成する場合は、検証モードを選択してください(「Unicodeとしてのデータの検証」を参照)。
SYSスキーマには、自動ワークロード・リポジトリ(AWR)を構成するWRI$、WRH$%およびWRR$_で始まる名前の表が多数含まれています。このリポジトリには、「無視されるデータ・ディクショナリ表」で説明されている履歴オブジェクト統計に加えて、重要なシステム統計(V$SYSSTATやV$SQLAREAなどの様々な固定ビューで表示される統計など)のスナップショットが格納されます。
オブジェクト名やSQL文に非ASCII文字(文字リテラルやコメントなど)が使用されている場合、それらがAWR表に取り込まれることがあります。DMUのスキャンでは、このような文字が変換可能なデータ・ディクショナリ内容として報告され、その場合はデータベースは変換できません。このデータを完全に削除するには、SYSDBA権限でSQL*Plusにログインして次のコマンドを実行することにより、自動ワークロード・リポジトリを再作成します。
SQL> @?/rdbms/admin/catnoawr.sql SQL> @?/rdbms/admin/catawr.sql
Oracle Databaseバージョン10.2.0.4以上ではcatawr.sqlスクリプトは存在しないため、AWRの内容をパージする前にOracle Databaseパッチ・セット10.2.0.5をインストールすることをお薦めします。
「不適切なキャラクタ・セット宣言のクレンジング」で説明されているように、クレンジング・エディタで列の内容を分析中に、列内のすべての値を同時に正しく表示する列の想定キャラクタ・セットはないが、それぞれの値はいずれかの選択済キャラクタ・セットで正しく表示されることがわかる場合があります。これは、その列に異なるキャラクタ・セットのデータが混在しているということです。この情報は、データベースのデータ・ソースの分析により収集されることもあります。
パススルー・シナリオにおいては、各種のキャラクタ・セットを使用するクライアントがデータをすべてこの列に格納すると、1つの列に複数のキャラクタ・セットが含まれる可能性があります。
このリリースのDMUには、このタイプの変換可能性の問題をクレンジングするための機能は含まれていません。1つのCHAR列またはVARCHAR2列で複数のキャラクタ・セットを処理する必要がある場合は、次の手順が推奨されます。
1つのCHAR列またはVARCHAR2列で複数のキャラクタ・セットを使用する手順は、次のとおりです。
影響を受ける列の1つの値の実際のキャラクタ・セットを特定するのに役立つ補助データを探します。たとえば、次のようなデータがあります。
値に関連付けられた国コード
値を入力したオペレータの識別子
値を入力する責任のある子会社の識別子
補助データを値の有効なキャラクタ・セットにマップするマッピング表を作成します。会社のワークステーションが特定のタイプに統一されている場合、通常は、分析された値のソース国によって、値の入力に使用されるクライアント・キャラクタ・セットが定義されます。
複数のキャラクタ・セットのデータを含む列を、変換から除外されるようにマークします(「列プロパティ: 変換」を参照)。
列に長さの問題がないことを確認します。必要な場合、問題のある値を拡張または短縮してクレンジングします。CLOBには移行しないでください。長さの問題を確認する方法の詳細は、次の例5-1を参照してください。
データベースを変換します。
マッピング表を使用して、SQL関数CONVERTで2番目の引数にターゲットのUnicodeキャラクタ・セット、3番目の引数に特定済の値キャラクタ・セットを指定して、影響を受ける列を変換します。
例5-1 多言語列の考慮事項
データベースに、CUSTOMER_NAME_ORIGINAL列とCREATED_BY列を持つ表CUSTOMERSが含まれているとします。VARCHAR2(80 BYTE)として定義された列CUSTOMER_NAME_ORIGINALには、母国語の顧客名が複数のキャラクタ・セットで含まれています。列CREATED_BYには、顧客データを入力した従業員のシステムIDが含まれています。このデータベースをキャラクタ・セットAL32UTF8に移行するとします。
CUSTOMER_NAME_ORIGINAL列に複数のキャラクタ・セットが存在するという問題を解決するために、まず、従業員のシステムIDを従業員のワークステーションのクライアント・キャラクタ・セットにマップするマッピング表を作成します。アプリケーション内のシステムIDを定義する表を使用すると、従業員が勤務している国を特定し、その従業員が使用しているクライアント・ワークステーションのキャラクタ・セットを判別できる場合があります。さらに、作成したマッピング表はCREATED_BY_TO_CHARSET_MAPPINGという名前であり、それにCREATED_BY列およびCHARACTER_SET列が含まれるとします。このような表の内容の例を次に示します。
CREATED_BY CHARACTER_SET ---------- ------------- ... JSMITH WE8MSWIN1252 JKOWALSKI EE8MSWIN1250 SKUZNETSOV CL8MSWIN1251 WLI ZHS16GBK ...
ここで、データベースの他の部分の変換中にデータが破損するのを回避するために、CUSTOMER_NAME_ORIGINAL列の変換から除外するプロパティを「はい」に設定します。
次のSQLを実行して、CUSTOMER_NAME_ORIGINALに長さの問題がないか確認します。
SELECT c.ROWID
FROM customers c, created_by_to_charset_mapping csm
WHERE VSIZE(CONVERT(c.customer_name_original,
'AL32UTF8',
csm.character_set)) > 80
AND c.created_by = csm.created_by
何も行が戻されない場合、長さの問題はありません。それ以外の場合、戻された行識別子を参照して、問題のある値を見つけます。
データベースの準備ができたら、AL32UTF8に変換します。新しいデータベース・キャラクタ・セットでの必要に応じて、アプリケーション構成を変更します。
データベース変換後、次の更新文を実行します。
UPDATE customers c
SET c.customer_name_original =
(SELECT CONVERT(c.customer_name_original,
'AL32UTF8',
csm.character_set)
FROM created_by_to_charset_mapping csm
WHERE csm.created_by = c.created_by)
これにより、想定キャラクタ・セットに従って列の各値が変換されます。顧客データを入力した従業員、または関連する言語を話す従業員に、変換後の値が正しいかどうかの検証を依頼します。
この項で説明する変換可能性の問題は、それほど頻繁には発生しませんが、現在DMUでは自動的には処理されないため、ツール外部から追加のスキャン・ステップおよびクレンジング・ステップを実行する必要がある場合があります。
この項の内容は、次のとおりです。
次の2つの状況では、データベースの内容がUnicodeに変換された後に、表のいくつかの行が一意キーまたは主キーの制約を満たさなくなる可能性があります。
一意キーまたは主キーの列に長さの問題がある(変換で一部の値が列またはデータ型の長さ制限を超える)のに、この列の問題のあるデータの変換を許可するプロパティを「はい」に設定しました。この場合、DMUで変換ステップ中に、既存の長さ制約に収まるように自動的に列が切り捨てられます。ただし、切り捨てられた末尾の部分のみ異なっていたため、切捨て後の値が列にすでに存在する別の値と同じになることがあります。
各種のOracleキャラクタ・セットにおいて、1つのUnicodeコード・ポイントにマップされる文字コードは複数存在します。これは通常、次のことが原因です。
キャラクタ・セット定義または様々なベンダーによるその解釈への変更履歴に対して、互換性マッピングを提供しようとしたこと。
実際のマッピングが一連のUnicodeコードで構成されるなどの理由でUnicodeに正確にマップできないコードに対して、簡易マッピングを提供しようとしたこと(これはOracleの変換アーキテクチャではサポートされていません)。
Unicode規格の統合ルールにより、特定の漢字(中国語)文字グループ内の文字がレガシーの東アジア・キャラクタ・セットで別々にエンコードされていても、このようなグループには1つのコード・ポイントが割り当てられます。
1つの列内の2つの文字値が、その列の想定キャラクタ・セットでUnicodeの同一ポイントにマップされる文字部分だけ異なっている場合、それらはUnicodeへの変換後に同じになります。
DMUでサポートされる次のキャラクタ・セットには、Unicodeの同一コード・ポイントにマップされるコードが複数あります。
BG8PC437S
IW8MACHEBREW
IW8MACHEBREWS
JA16EUCTILDE
JA16MACSJIS
JA16SJIS
JA16SJISTILDE
JA16SJISYEN
JA16VMS
KO16KSCCS
LA8ISO6937
ZHS16MACCGB231280
ZHT16BIG5
ZHT16CCDC
ZHT16HKSCS
ZHT16HKSCS31
ZHT16MSWIN950
影響を受ける文字コードを確認するには、Oracle Locale Builderユーティリティを使用できます。このユーティリティの詳細は、『Oracle Databaseグローバリゼーション・サポート・ガイド』を参照してください。
前述の2つの問題のいずれかによって一意キーまたは主キーの制約が影響を受ける可能性がある場合、適切な一意ファンクション索引を作成することにより、実際に問題があるかどうかを確認できます。たとえば、文字列tab1.col1およびtab1.col2と数字列tab1.col3に一意キーまたは主キーの制約がある場合は、次のような索引の作成を試行します。
CREATE UNIQUE INDEX i_test
ON tab1(SYS_OP_CSCONV(col1,'AL32UTF8','<assumed character set of col1>'),
SYS_OP_CSCONV(col2,'AL32UTF8','<assumed character set of col2>'),
col3)
TABLESPACE ...
UTF8が実際のターゲット・キャラクタ・セットの場合、'AL32UTF8'を'UTF8'で置き換えてください。列の想定キャラクタ・セットがデータベース・キャラクタ・セットと同じであれば(デフォルト)、SYS_OP_CSCONVの3番目のパラメータは省略できます。「ORA-01452: CREATE UNIQUE INDEXは実行できません。重複するキーがあります」と報告されて文が失敗した場合、列には一意性の問題があります。
上のCREATE INDEX文では、列の長さ調整スケジュールが計画されていないこと、および文字長セマンティクスを使用して列が定義されていないことが前提となっています。col1をn1バイトに、col2をn2バイトに拡張する場合は、次の文を使用します。
CREATE UNIQUE INDEX i_test
ON tab1(SYS_OP_CSCONV(SUBSTRB(RPAD(col1,n1,' '),1,n1),
'AL32UTF8','<assumed character set of col1>'),
SYS_OP_CSCONV(SUBSTRB(RPAD(col2,n2,' '),1,n2),
'AL32UTF8','<assumed character set of col2>'),
col3)
TABLESPACE ...;
ターゲット・キャラクタ・セットがUTF8の場合、'AL32UTF8'を'UTF8'で置き換えてください。
col1およびcol2が文字長セマンティクスを使用して定義されており、その文字長がそれぞれn1とn2である場合は、次の文を使用します。
CREATE UNIQUE INDEX i_test
ON tab1(SYS_OP_CSCONV(SUBSTRB(RPAD(col1,4*n1,' '),1,4*n1),
'AL32UTF8','<assumed character set of col1>'),
SYS_OP_CSCONV(SUBSTRB(RPAD(col2,4*n2,' '),1,4*n2),
'AL32UTF8','<assumed character set of col2>'),
col3)
TABLESPACE ...;
ターゲット・キャラクタ・セットがUTF8の場合、'AL32UTF8'を'UTF8'で置き換えてください。
Oracleデータベース索引内の索引キーの最大サイズ(つまり、すべてのキー列の最大バイト長に行識別子の長さと長さバイト数を足した値)は、索引の表領域内のデータ・ブロック・サイズから約25%のオーバーヘッドを引いた値以下にする必要があります。
データベース変換中に索引キーに属する文字列の最大バイト長が拡大する場合、次のいずれかが原因です。
新しいデータベース・キャラクタ・セットの列の文字長に基づいてこれが再計算されています。
または
列に対して長さ調整のクレンジング・アクションが定義されています。
最大バイト長に達すると、索引キーがその最大許容長を超えることがあります。
このリリースのDMUでは、変換ステップで変更される索引キーの長さは事前に確認されません。したがって、ALTER TABLE, CREATE INDEX文またはALTER DATABASE CHARACTER SET文からの変換中に、「ORA-01450: キーが最大長(最大値)を超えました」または「ORA-01404: ALTER COLUMNによる索引が大きすぎます」が報告される可能性があります。
変換の試行前に、長さ調整のクレンジング・アクションがスケジュールされている、または文字長セマンティクスを使用するVARCHAR2列とCHAR列に定義されているすべての索引を確認して、それらがこの問題による影響を受けないことを確認する必要があります。最も簡単な方法は、元のデータベースのコピーで移行をテストすることです。コピーには、計画されているすべてのクレンジング・アクションとともにDMUリポジトリを含める必要があります。実際のアプリケーション・データがテストに影響を与えることはないので、テスト時間を短縮するためにサイズの大きい変換可能表はすべて切り捨てることができます。
DMUではパーティション・バウンドの変換が必要なデータベースの変換はサポートされていませんが、このようなデータベースはデータ・ポンプ・ユーティリティを使用して移行できます。移行プロセスの準備中に、パーティションの整合性に関連する次の潜在的な問題を考慮する必要があります。
Oracle Databaseでは、パーティション化キー列の値をパーティション・バウンドと比較することにより、表の行をレンジ・パーティション間に分散します。この比較では、バイナリ・ソート順序が使用されるため、ディスクに格納されているとおりの値のバイト表現がバイトごとに比較されます。文字列の場合、表現はデータベース・キャラクタ・セットに依存し、Unicodeへの変換中に変更される可能性があります。パーティション・バウンドのバイナリ表現が変更されると、パーティションの順序が変更され、パーティション間の行の分散が大きく変更される可能性があります。
パーティション化列に変換可能なデータが含まれるすべてのレンジ・パーティション表を分析し、さらに必要に応じて、データベースをUnicodeに移行した後も適切に行が分散されるようにパーティション定義を調整する必要があります。
まれですが、パーティション・レンジ・バウンドとパーティション・リスト値に、「変換可能性の問題: 一意性の検証」で説明されている一意性の問題が発生することもあります。パーティション表にこのような問題が発生した場合、パーティション定義を適宜調整しないと、表を正常にインポートできません。
DMUでは、削除されてごみ箱の中にある表の文字列も、通常の表と同様にスキャンされます。そのスキャン結果はデータベース・スキャン・レポートに含められます。通常のアプリケーション表とは異なり、ごみ箱内の削除済の表に変換の必要なデータを含めることはできません。変換可能データを含む表をごみ箱から削除するまでは、変換ステップを開始できません。
削除済の表に対するクレンジング・アクションはサポートされていません。
DMUでは、PL/SQLストアド・モジュール(ストアド・プロシージャ、ストアド・ファンクションおよびパッケージ)の名前の変換はサポートされていませんが、次の要素内に非ASCII文字を含むPL/SQLソース・コードおよびビュー定義は自動的に変換されます。
パッケージ内で宣言されているプロシージャ、ファンクションおよびタイプの名前
変数名や型名などのローカル識別子
文字リテラル
コメント
DMUでは、変換ステップでデータ・ディクショナリから関連するCREATE OR REPLACE PACKAGE|PACKAGE BODY|PROCEDURE|FUNCTION|TYPE|TYPE BODY|VIEW文がフェッチされてターゲット・キャラクタ・セットに変換され、データベース・キャラクタ・セットがUTF8またはAL32UTF8に変更された後で実行されます。
DMUでは、変換された識別子がその長さ制約(通常は30バイト)を超えるかどうかはチェックされません。Unicodeへの変換後に識別子が許容値よりも長くなった場合、結果のPL/SQLモジュールが作成されますが、そのコンパイルは失敗し、通常は「PLS-00114: 識別子'<identifier>'が長すぎます。」と報告されます。このモジュールのステータスは「無効」になります。
データベース変換後に、すべてのPL/SQLストアド・モジュールのステータスを確認する必要があります。識別子が長すぎるためにいずれかのモジュールが無効な状態になっている場合は、その識別子の定義および識別子が参照されるすべての場所において、その識別子を手動で短縮する必要があります。
データベースをUnicodeに移行すると必ず、このデータベースに接続するアプリケーションは影響を受けます。影響の程度は、次のようないくつかの要因によって決まります。
アプリケーションで、データベースに格納できるようになった新しい言語の処理を行うか。
新しい言語をサポートするには、通常、Unicodeデータを処理できるようにアプリケーションを適応させる必要があります。シングルバイト・キャラクタ・セットのみを処理するようにプログラミングされているアプリケーションを、Unicode文字の全レパートリーを処理できるようにするには、大規模な変更が必要となります。これに対し、アプリケーションにこれまでと同じ文字数制限を使用する場合は、Oracleクライアント/サーバーのキャラクタ・セット変換を利用して最小限の変更を行うのみで済むことがあります。
複雑なスクリプトを使用する言語には、アプリケーションからのGUIサポートが必要か。
アラビア系文字やインド系文字などの複雑なスクリプトで記述されたテキストを表示および受け入れるためには、複雑なスクリプト・レンダリング機能が必要です。複雑なレンダリングとは、たとえば、隣接する文字を結合したり(右から左に読むフラグメントと左から右に読むフラグメントが混在している場合)、ワード内の文字の位置に応じて文字の形状を変更することなどです。
アプリケーションの構築に使用されているテクノロジは何か。
アプリケーションの開発に使用された開発フレームワークによって、新しい言語を受け入れるようにアプリケーションを変更することは比較的簡単な場合もあれば、非常に難しい場合もあります。幸い、JavaやMicrosoft Windowsなど、現在使用されているほとんどの環境では、複雑なスクリプト・レンダリングおよびUnicode処理に対する組込みサポートまたはインストール可能なサポートが提供されています。このサポートを利用すると、アプリケーションを適応させるプロセスは簡略になりますが、プロセスを省略できるわけではありません。
アプリケーションは社内で開発されたものか、それともサードパーティ・ベンダーによって開発されたものか。
ソース・コードが利用できるアプリケーションしか適応させることはできません。ベンダーが開発したアプリケーションは、そのベンダーが適応させる必要があります。これが不可能であれば、アプリケーションを別のソフトウェア・ソリューションで置換する必要がある場合もあります。
次の場合は、これらの考慮事項に加えて、移行に関連する変更をアプリケーションに加える必要があります。
クレンジング・アクションによって表構造が変更された、列の長さが調整された、または別のデータ型に移行された場合。
文字の最大バイト幅が拡大されたなど、データベース・キャラクタ・セットの特性が変更された場合。
新しく処理対象となった言語に追加の要件がある場合。これには、新しいソート・ルール、新しい日付または数字フォーマット・ルール、非グレゴリオ暦のサポートなどが含まれます。
古いレガシー・キャラクタ・セットからUnicodeに変更され、文字列のバイナリ・ソート順序が変更された場合。
アプリケーションを新しい言語に適応させる方法の詳細はこのガイドでは取り扱いませんが、次の各項で、移行済データベースで引き続き既存のアプリケーションを実行するために必要となる可能性のある最小限の変更について説明します。
バックエンド・データベースをUnicodeに移行した後も、既存のアプリケーションの一部は変更せずに実行する場合があります。たとえば、アプリケーションをUnicodeに適応させるためにソース・コードにアクセスできない場合や、経済的な理由でアプリケーションを変更できない場合などです。
バックエンド・データベースをUnicodeに移行した後もアプリケーションを変更せずに実行するためには、そのアプリケーションでこれから使用される可能性のあるすべてのUnicode文字が、そのアプリケーションが最初に記述されたレガシー・キャラクタ・セットにも存在していることが必要になります。つまり、アプリケーションがたとえばISO 8859-1規格のキャラクタ・セット(WE8ISO8859P1)のみを処理するように記述されていた場合、このアプリケーションがアクセスするデータベース内容のサブセット内で使用できるのは、それに対応するUnicode文字であるU+0000 - U+007FおよびU+00A0 - U+00FFのみです。
この要件が満たされていれば、NLS_LANG環境設定で指定されているアプリケーションのクライアント・キャラクタ・セットは前述のレガシー・キャラクタ・セットに設定される(移行の前後で実際にNLS_LANGは変わらない)はずであり、アプリケーションで使用されるレガシー・エンコーディングとデータベースで使用されるUnicodeエンコーディングの間の文字データ変換はクライアント/サーバー通信プロトコルによって処理されます。
アプリケーションにより処理される文字が標準のUS7ASCII文字のみの場合、すべてのASCII文字のUTF8およびAL32UTF8バイナリ・コードはUS7ASCIIと同じになるため、アプリケーションの変更は必要ありません。したがって、処理されるバイトはデータベース・キャラクタ・セットの移行前と移行後で変わりません。
ASCII範囲外の文字(アクセント付きラテン文字など)のバイナリ・コードは、データベース・キャラクタ・セットの変更後、クライアント側では変わりませんが、データベース側では変更されます。最も重要な違いは通常は、文字コード内のバイト数です。アクセント付きラテン文字およびキリル文字やギリシャ文字は、WE8MSWIN1252やCL8MSWIN1251などのシングルバイト・レガシー・キャラクタ・セットではそれぞれ1バイトを使用しますが、UTF8およびAL32UTF8では2バイトを使用します。ユーロ通貨記号などの特定の特殊文字は、3バイトを使用します。したがって、長さがバイトで表現される影響を受ける列、PL/SQL変数およびユーザー定義データ型属性がデータベース側にあれば、アプリケーションからデータがデータベースに入力されるときにクライアント/サーバー・キャラクタ・セット変換で追加されるバイトに対応できるように、これらを調整する必要があります。
データ長の制御をデータベースに依存せずにアプリケーション自らが長さ制限を制御している場合、およびアプリケーションで処理されるすべてのデータがそのアプリケーションを介してのみデータベースに入力される場合、影響を受ける列、PL/SQL変数およびユーザー定義データ型の属性のバイト長は、通常は3を掛けて適宜拡大することにより調整できます。戻されたエラー(ORA-12899など)の処理によるデータ長の制御をアプリケーションがデータベースに依存している場合、またはアプリケーションのデータが外部ソースから入力される場合、SQLおよびPL/SQLで長さを調整する方法として、元の絶対的な長さの数値は保持し、長さセマンティクスをバイトから文字に変更することをお薦めします。つまり、VARCHAR2(10 [BYTE])列またはPL/SQL変数をVARCHAR2(10 CHAR)列または変数に変更する必要があります。
前述の長さ問題は既存のデータベース内容にも影響を与えることは明らかなので、通常は、データベース・キャラクタ・セット移行プロセスのクレンジング・ステップで列および属性の長さを事前に拡大しておく必要があります。データ型が%TYPE属性で表現されている場合を除いて、PL/SQL変数は個別に調整する必要があります。
基本の文字データ型には絶対的な長さ制限があるため、大きな問題が存在します。データベースに格納されるVARCHAR2値は4000バイトを超えることができず、CHAR値は200タイプを超えることができません。したがって、データ型の制限に違反せずに該当する数のランダム文字コードを実際に格納できるようにするには、VARCHAR2列および属性は1333文字(UTF8の場合)または1000文字(AL32UTF8の場合)までしか拡張できません。アプリケーションでこれより長い値がすでに通常処理されている場合、アプリケーションを引き続き実行するには、たとえば、VARCHAR2データ型でなくCLOBデータ型を使用するように変更する必要がある可能性があります。
前述の長さ問題とは別に、一部のアプリケーションはデータベースからの問合せされた文字値の特定のバイナリ・ソート順序に依存していることがあります。US7ASCIIおよびWE8ISO8859P1キャラクタ・セットの文字はUTF8とAL32UTF8で順序は同じですが、これ以外のキャラクタ・セットの文字の順序は同じではありません。UTF8またはAL32UTF8データベース内のレガシー・キャラクタ・セットのバイナリ順序をシミュレートするために、Oracle Local Builderユーティリティを使用してカスタムの言語定義を作成する必要がある場合があります。一般に、カスタムの言語定義を作成すると、データベース管理が複雑になるうえそのコストも高くなり、問合せのパフォーマンスに影響を与える可能性があるため、アプリケーションを特定のバイナリ・ソート順序に依存しないように変更する方法をお薦めします。
次の項で説明するように、これらの変更に加えて、アプリケーション・コードのデータベース側で新しいUnicode文字エンコーディングに必要な変更を行う必要があります。
|
関連項目: カスタムの言語定義の作成の詳細は、『Oracle Databaseグローバリゼーション・サポート・ガイド』を参照してください。 |
SQLコードとPL/SQLコードはデータベース内部で実行されるため、それを処理するキャラクタ・セット、つまり処理されたデータのエンコードに使用されるキャラクタ・セット(この場合はデータベース・キャラクタ・セット)は、データベースをUnicodeに移行すると必ず変更されます。これに対し、クライアント側のアプリケーション・コードでは、NLS_LANGの設定が変わっていなければ、移行後もそれを処理するキャラクタ・セットを保持できます。
ほとんどのPL/SQL文、式、関数およびプロシージャは、データベース・キャラクタ・セットとは無関係に動作するため、適応させる必要はありません。ただし、処理するキャラクタ・セットが異なると結果が異なる関数も多数あります。次の関数を含むSQLコードおよびPL/SQLコードは、Unicodeへの移行に対応するために適宜確認して変更する必要があります。
特定のバイナリ文字コードに依存する関数: CHR、ASCIIおよびDUMP
文字コード幅(バイト)に依存する関数: LENGTHB、VSIZE
バイト・オフセットを使用する関数: INSTRB、SUBSTRB
キャラクタ・セット変換関数: CONVERT
文字列からバイナリへのキャスト: UTL_RAW.CAST_TO_VARCHAR2、UTL_RAW.CAST_TO_RAW、UTL_I18N.STRING_TO_RAW、UTL_I18N.RAW_TO_CHAR
また、標準パッケージUTL_FILEを使用すると、文字データをデータベース・キャラクタ・セットで外部ファイルに格納できます。これらのファイルのコンシューマは、新しいファイル・エンコーディングを処理できるように適応させる必要があります。
SQL式およびPL/SQL式の確認は、ビュー定義、PL/SQLストアド・モジュール、ユーザー定義データ型メソッド、トリガー、チェック制約のみでなく、イベント・ルール条件(DBMS_RULE_ADMを参照)、行レベルのセキュリティ(RLS/VPD)ポリシー(DBMS_RLSを参照)、ファイン・グレイン監査ポリシー(DBMS_FGAを参照)、またSQL式やPL/SQL式から参照されるその他の補助データベース・オブジェクト定義でも行う必要があります。
|
注意: あまり一般的ではありませんが、行レベルのセキュリティまたはファイン・グレイン監査ポリシーは、文字エンコーディングに依存するSQL式を使用して定義できます。このようなポリシーをすべて確認して、データベース・キャラクタ・セットの変更により機密性の高いデータの保護が損われることがないよう確認してください。 |
データベースが、一般的にパススルー構成と呼ばれる構成になっていて、クライアントのキャラクタ・セットがデータベース・キャラクタ・セットと同じになるように定義されている(通常はNLS_LANGクライアント設定になっている)場合は、データベースの文字データが、宣言されているデータベース・キャラクタ・セットとは異なるキャラクタ・セットで格納されている可能性があります。このシナリオにおいて推奨される解決策は、DMUの想定データベース・キャラクタ・セット機能でデータの実際のキャラクタ・セットを指定して、データベースをUnicodeに移行することです。業務上または技術上の制約によってUnicodeへの移行をすぐには実行できない場合も、少なくとも、データベースの内容と一致するようにデータベース・キャラクタ・セット宣言を修正することをお薦めします。
Database Migration Assistant for Unicodeリリース1.2では、このような場合にCSREPAIRスクリプトを使用してデータベース・キャラクタ・セット・メタデータを修復できます。CSREPAIRスクリプトはDMUクライアントと連携して動作し、DMUリポジトリにアクセスします。DMUで想定データベース・キャラクタ・セット・プロパティをターゲット・キャラクタ・セットに設定して全体データベース・スキャンを実行し、無効な表現の問題が報告されなくなると、データベース内のすべての既存データが想定データベース・キャラクタ・セットに従って定義されていることが確認されるため、その後でこれを使用してデータベース・キャラクタ・セット宣言をデータの実際のキャラクタ・セットに変更してください。CSREPAIRにより変更されるのはデータ・ディクショナリ・メタデータ内のデータベース・キャラクタ・セット宣言のみであり、データベース・データは変換されないことに注意してください。
CSREPAIRスクリプトは、インストールされたDMUのadminサブディレクトリにあります。CSREPAIRスクリプトを使用する際の要件は次のとおりです。
まず、DMUで想定データベース・キャラクタ・セット・プロパティをデータの実際のキャラクタ・セットに設定して、全体データベース・スキャンを正常に完了する必要があります。この場合、想定データベース・キャラクタ・セットは現在のデータベース・キャラクタ・セットと異なる必要があり、そうでない場合は何も行われません。DMUが無効なバイナリ表現を含むデータの存在を報告する場合は、CSREPAIRスクリプトの処理が中断されます。ただし、不変で、変換可能または長さ制限を超えるデータがスキャン結果でレポートされる場合には続行されます。
想定データベース・キャラクタ・セットのターゲット・キャラクタ・セットは、US7ASCIIのバイナリ・スーパーセットである必要があります。
シングルバイト・キャラクタ・セットからシングルバイト・キャラクタ・セットへの修復、またはマルチバイト・キャラクタ・セットからマルチバイト・キャラクタ・セットへの修復のみが、CLOBデータの変換が試行されないために許可されます。
想定キャラクタ・セットを列レベルで設定する場合、値は想定データベース・キャラクタ・セットと同じである必要があります。そうでない場合、CSREPAIRは実行されません。
CSREPAIRを実行するには、SYSDBA権限が必要です。Oracle Database 12cのプラガブル・データベース(PDB)でCSREPAIRを実行するには、SYSユーザーまたはローカルPDBおよびCDBの両方でSYSDBA権限を持つ共通ユーザーである必要があります。
一般的な例は、パススルー構成を介してWE8ISO8859P1データベースにWE8MSWIN1252データを格納する場合です。データベース・キャラクタ・セットをWE8ISO8859P1からWE8MSWIN1252に修正する手順は、次のとおりです。
DMUを設定し、ターゲットのWE8ISO8859P1データベースに接続します。
DMUでデータベース・プロパティ・タブを開きます。
想定データベース・キャラクタ・セット・プロパティを「WE8MSWIN1252」に設定します。
DMUを使用して全体データベース・スキャンを実行します。
データベース・スキャン・レポートを開き、無効な表現カテゴリの下に報告されているデータがないことを確認します。
DMUクライアントを終了します。
SQL*Plusユーティリティを起動し、SYSDBA権限を持つユーザーとして接続します。
CSREPAIRスクリプトを実行します。
SQL> @@CSREPAIR.PLB
完了すると、次のようなメッセージが表示されます。
データベース・キャラクタ・セットが正常にWE8MSWIN1252に変更されました。今すぐデータベースを再起動する必要があります。
データベースを停止して再起動します。
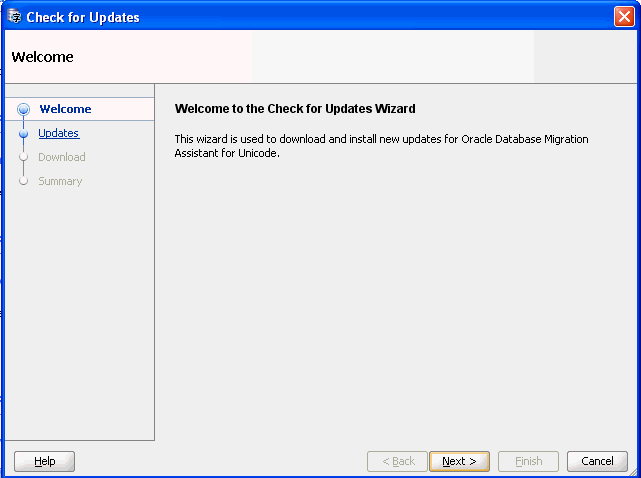
DMUライブ・アップデート機能を使用すると、DMUの最新バージョンの有無を確認して、これをインストールできます。これにより、DMU更新センターから新しいバージョンのDMUが使用可能かどうかを確認できます。新しいバージョンにアップグレードすることを選択すると、ライブ・アップデート機能によってソフトウェア・パッケージがダウンロードされ、既存のインストールが自動的にアップグレードされます。
DMUでは、起動時に新しいバージョンが使用可能かどうかを検出できます。新しいバージョンが見つかると、メイン・ウィンドウの右下隅にメッセージが表示されます。
DMUバージョンの更新の有無を確認する手順は、次のとおりです。
ライブ・アップデート機能を起動するために、メイン・ウィンドウの一番下にあるメッセージをクリックするか、「ヘルプ」メニューの「更新の確認」を選択します。
更新の確認ウィザードが表示されます。このウィザードではDMU更新センターからDMU更新が使用可能かどうかがチェックされ、自動的に更新をダウンロードしてインストールできます。
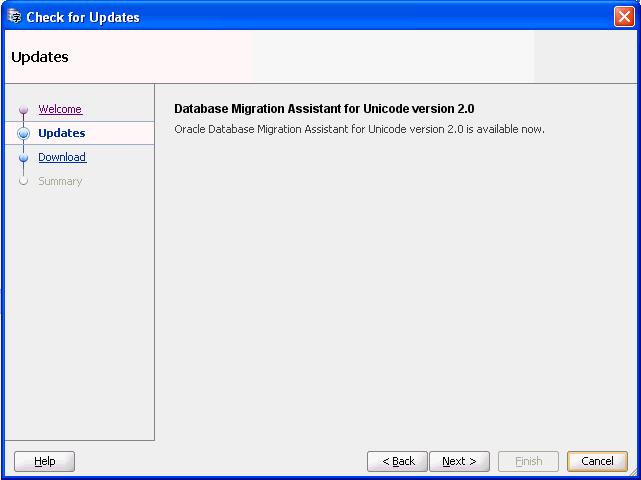
「次へ」をクリックします。ウィザードで、使用可能なDMU更新が表示されます。現在インストールされているバージョンより新しい使用可能なバージョンがない場合は、メッセージに現在のDMUバージョンが最新であることが示されます。
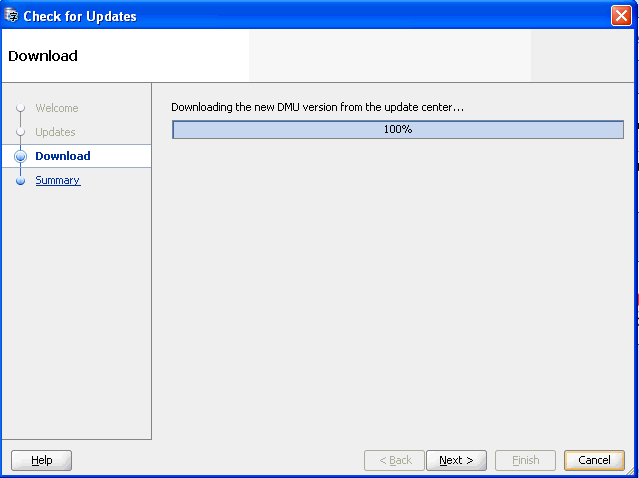
「次へ」をクリックします。ウィザードで、更新センターからの新しいDMUパッケージのダウンロードが開始されます。ダウンロードが完了するまで待ちます。
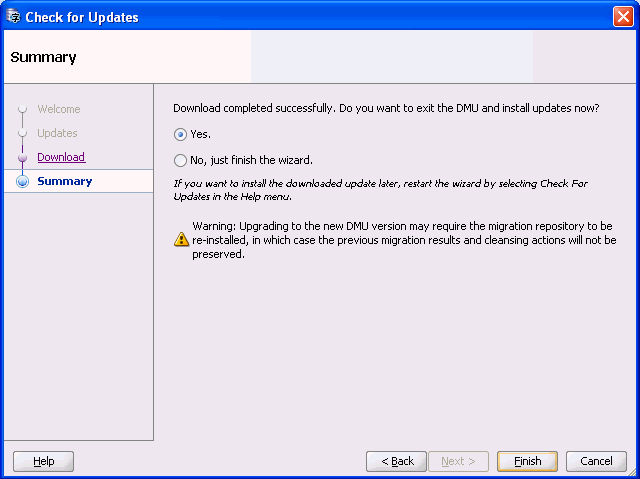
「次へ」をクリックします。「サマリー」ページが表示されます。このページでは、DMUを終了するか、新しいバージョンを今すぐインストールするか、またはインストールを後で完了するかを選択できます。「はい」を選択すると、DMUが終了し、バックグラウンドでインストール・プロセスが開始されます。インストールの完了後、新しいバージョンのDMUが再起動されます。
新しいDMUバージョンにアップグレードするために移行リポジトリを再インストールする必要がある場合がありますので注意してください。この場合、アップグレード後に以前のスキャン結果およびスケジュール済クレンジング・アクションは保持されません。
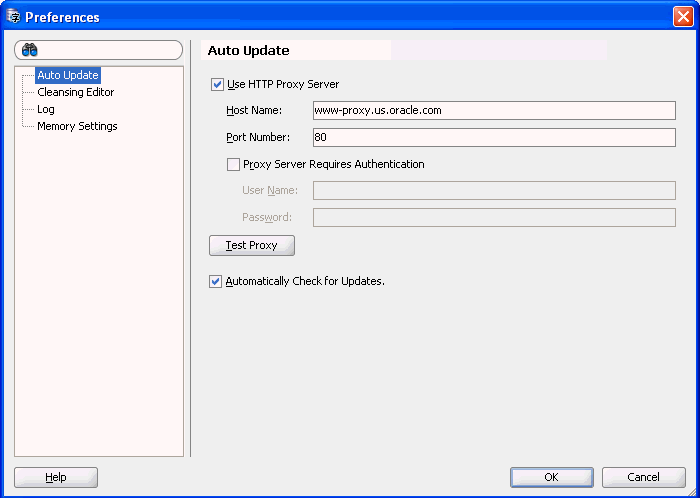
ファイアウォールを経由している場合や、プロキシを使用してWebページにアクセスする場合、DMU更新センターに接続する前に、「プリファレンス」ダイアログ・ボックスの自動更新ページでプロキシ設定を構成する必要があることがあります。
プロキシ設定を構成するには、ツール・メニューの「プリファレンス」を選択します。「Preferences」ダイアログが表示されます。
「HTTPプロキシ・サーバーの使用」を選択した場合、「ホスト名」フィールドとポート番号フィールドに値を入力します。
「プロキシ・サーバーでは認証が必要」を選択した場合、「ユーザー名」フィールドと「パスワード」フィールドに値を入力します。
「更新を自動的にチェックする」を選択した場合、DMUの起動時に新しいDMUバージョンがあるかどうかが確認されます。
「OK」をクリックして「プリファレンス」ダイアログを閉じ、プロキシ・サーバーの設定を完了します。
オラクル社は、障害のあるお客様にもオラクル社の製品、サービスおよびサポート・ドキュメントを簡単にご利用いただけることを目標としています。Oracle Database Migration Assistant for Unicodeでは、アクセシビリティ機能がサポートされます。
Oracle製品のアクセシビリティに関する追加情報は、http://www.oracle.com/accessibility/にある「Oracle Accessibility Program」を参照してください。
スクリーン・リーダーなどの障害支援技術がJavaベースのアプリケーションやアプレットで動作するためには、Windowsベースのコンピュータに、Sun社のJava Access Bridgeをインストールしておく必要があります。
アクセシビリティ機能を最大限に活用できるように、少なくとも次の構成をお薦めします。
Windows XP、Windows Vista
Java J2SE 1.6.0_24
Java Access Bridge 2.0.1
JAWS 12.0.522
Microsoft Internet Explorer 7.0版以上
Mozilla Firefox 3.5以上
スクリーン・リーダーとJava Access Bridgeの設定については、次の手順を参照してください。
スクリーン・リーダーがインストールされていない場合は、インストールします。
インストールの詳細は、スクリーン・リーダーのマニュアルを参照してください。
DMUをインストールします。
Java Access Bridge for Windowsバージョン2.0.1をダウンロードします。ダウンロードするファイルは、accessbridge-2_0_1.zipです。次にあります。
http://www.oracle.com/technetwork/java/javase/tech/index-jsp-136191.html
インストールとJava Access Bridgeの詳細は、このWebサイトから入手可能なJava Access Bridgeマニュアルを参照してください。
フォルダ(accessbridge_homeなど)に内容を抽出(解凍)します。
<accessbridge_home>¥installerフォルダからInstall.exeを実行してJava Access Bridgeをインストールします。
インストーラによりJDKバージョンの互換性がチェックされてから、「Available Java virtual machines」ダイアログが表示されます。
「Search Disks」をクリックします。次に、Program Filesディレクトリ(存在する場合)にJDKのバージョンが格納されているドライブのみを検索するように選択します。
JDKのインスタンスが多数含まれている大きいディスクの場合や、複数のディスクを検索する場合は、検索プロセスに時間がかかることがあります。ただし、ディスクの総当り検索が完了しないかぎり、Access Bridgeは最適に構成されず、システムのすべてのJava VMに正しくインストールされません。検索するディスクを選択したら、「Search」をクリックします。
「Install in All」をクリックして、Java Access Bridgeをダイアログに表示されている各Java仮想マシンにインストールすることを確認します。
「Installation Completed」メッセージが表示された時点で「OK」をクリックします。
DMUで作業するには次のファイルがシステム・パスに指定されている必要があるため、Winnt\System32ディレクトリ(あるいはWindows XPまたはVistaの同等のディレクトリ)にインストールされていることを確認し、ない場合は<accessbridge_home>\installerfilesからコピーします。
JavaAccessBridge.dll
JAWTAccessBridge.dll
WindowsAccessBridge.dll
PATHシステム変数には、システム・ディレクトリが必要です。
次のファイルがjdk\jre\lib\extディレクトリにインストールされていることを確認し、ない場合は<accessbridge_home>\installerfilesからコピーします。
access-bridget.jar
jaccess-1_4.jar
ファイルaccessibility.propertiesがjdk\jre\libディレクトリにインストールされていることを確認し、ない場合は\installerfilesからコピーします。
スクリーン・リーダーを起動します。
DMUを起動します。
前述の手順は、Windowsを実行中でWindowsベースのスクリーン・リーダーを使用していることを想定しています。DMUの起動後、最初にエラー情報(存在する場合)を含むコンソール・ウィンドウが開いてから、DMUのメイン・ウィンドウが表示されます。表示されるメッセージは、DMUの機能には影響しません。