| Oracle® Database Migration Assistant for Unicodeガイド リリース2.0 E59465-03 |
|


 前 |
 次 |
この章では、クレンジング中に使用するDatabase Migration Assistant for Unicode (DMU)のユーザー・インタフェースの要素を示し、これらを使用して様々なタスクを実行する方法について説明します。
この章は次の項で構成されています。
「変換可能性の問題の無視」で説明されているように、2つの列プロパティを使用して、データの問題を無視できる場合もあります。
クレンジング・アクションは、即時の場合とスケジュールの場合があります。即時アクションはデータベースの内容に対して直接実行され、その結果は即時に表示されます。スケジュール済クレンジング・アクションは移行リポジトリに登録され、移行プロセスの変換ステップで実行されます。したがって、スケジュール済アクションの結果は、変換までは仮想のものとなります。DMUでは、データベースの問題をスキャンするとき、「スケジュール済クレンジングの結果を含める」または「スケジュール済」という見出しの下に調整済のスキャン結果を表示することにより、スケジュール済のアクションを考慮に入れます。
スケジュール済クレンジング・アクションは、列変更のスケジュール・ダイアログ・ボックスおよび属性変更のスケジュール・ダイアログ・ボックスで定義します。その他のクレンジング・アクションはすべて即時アクションです。
アプリケーションでデータベースに特定のデータ依存性が適用されており、複数の表列に格納されているデータ値の整合性を保持する必要がある場合、DMUではこのようなユーザー・アプリケーション・スキーマの依存性は認識されないため、データ・クレンジング・プロセス中にデータ依存性を手動で維持する必要があります。
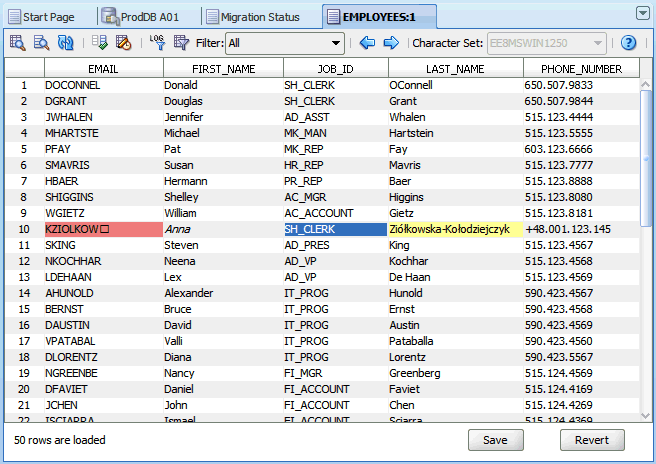
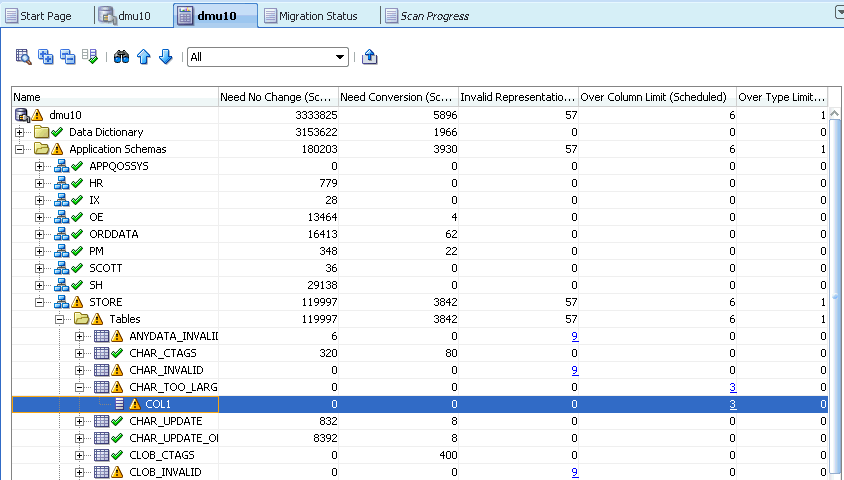
表に対するほとんどのクレンジング・アクションは、クレンジング・エディタ・タブから開始します。このタブを開くには、ナビゲータ・ペインの表ノードのコンテキスト・メニューから、またはデータベース・スキャン・レポートで「クレンジング・エディタ」を選択します。クレンジング・エディタは、データ・ディクショナリ表には使用できません。図6-1は、クレンジング・エディタ・タブを示しています。
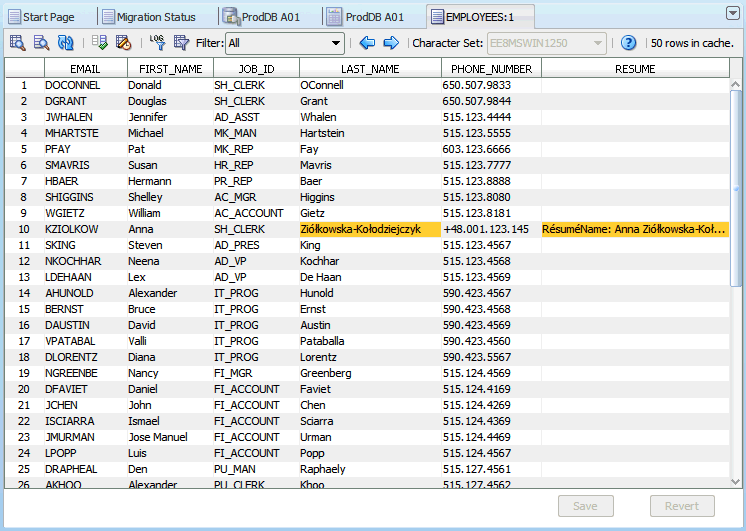
クレンジング・エディタ・タブには、ツールバー、エディタ・グリッドおよび2つのボタン(「保存」と「元に戻す」)が含まれています。エディタ・グリッドには、クレンジング・エディタが開かれた対象の表の内容が表示されます。このガイドの以降の部分では、この表を編集対象表と呼びます。グリッドの列は編集対象表の文字データ型列に対応しており、グリッドの行は表の行に対応しています。
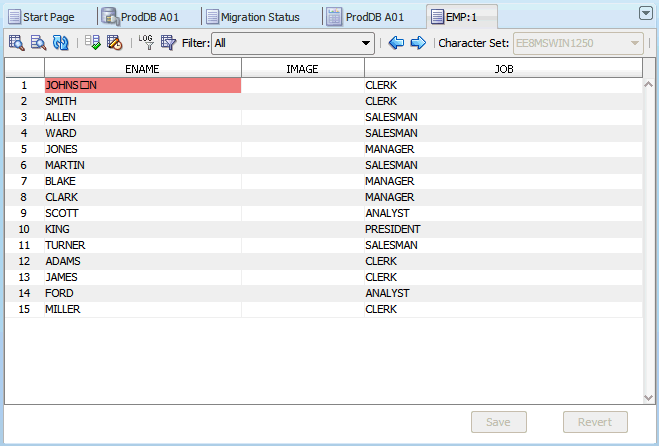
エディタ・グリッドは2つの選択モードのいずれかで動作します。1つのセルをクリックすると、そのセルが選択され、グリッドはセル選択モードに切り替わります。このモードでは、1つのセルのみを選択できます。選択したセルは、現在のセルと呼ばれます。(列の名前を含む)列見出しをクリックすると、グリッドは列選択モードに切り替わり、クリックした列が選択された列になります。[Ctrl]キーを押したままさらに列見出しをクリックすると、複数の列を追加で選択できます。図6-1「クレンジング・エディタ」では、10番目に表示された表行のJOB_ID列のセルが現在のセルとして選択されています。
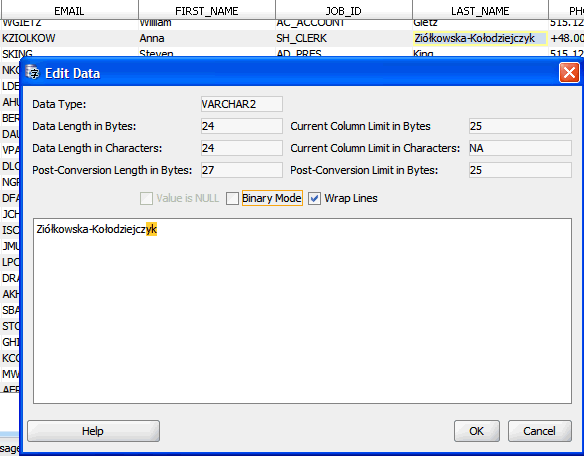
グリッド内のセルは、特定されたデータ問題を示すために特定の色で強調表示されています。詳細は、「データのクレンジング: 色の強調表示」を参照してください。図6-1では、10番目に表示された表行のEMAIL列内のセルが、無効な表現の問題を表すためにライト・コーラルの背景で表示され、同じ行のLAST_NAME列内のセルが、列の長さの問題を示すために黄色の背景で表示されています。
クレンジング・エディタの編集対象表は、現在のクレンジング・アクティビティに関連する行のみがエディタ・グリッドに表示されるようにフィルタリングできます。詳細は、「データベース・スキャン・レポート: フィルタリング」を参照してください。
クレンジング・エディタを使用すると、編集対象表の内容に対して様々なクレンジング・アクションを開始できます。セルをダブルクリックするか、現在のセルのコンテキスト・メニューから「データの編集」を選択すると、データの編集ダイアログ・ボックスが開いて、そのセルに格納されている値が表示されます。「データの編集」で説明されているように、値を短縮したり、不正な文字コードを削除するなどして、値を編集できます。編集した値は、クレンジング・エディタ・タブの一番下にある「保存」をクリックするまではデータベースに格納されません。編集が完了した値は、データベースに永続的に保存されるまで、イタリック・フォント・フェイスで表示されます。図6-1で10番目に表示された表行のFIRST_NAME列のセルは、変更はされたがまだ保存されていないものです。「元に戻す」をクリックすると、すべての編集変更を取り消して、セル値をデータベースからの現在の値に戻すことができます。
セル選択モードでセルを右クリックする(これによってセルが現在のセルになる)か、列選択モードで選択された列を右クリックすると、列の変更メニュー項目および列変更のスケジュール・メニュー項目を含むコンテキスト・メニューが表示されます。現在のセルまたは選択された列がユーザー定義データ型(ADT)の属性に対応している場合、コンテキスト・メニューにはこれらのかわりに「属性の変更」および「属性変更のスケジュール」が含まれます。複数の列を選択した場合に、そのいずれかのデータ型が異なっていると、コンテキスト・メニューには前述のメニュー項目はいずれも表示されません。4つのメニュー項目のうちいずれかをクリックすると、それに対応するダイアログ・ボックスが開きます(「列の変更」、「列変更のスケジュール」、「属性の変更」または「属性変更のスケジュール」を参照)。これらのダイアログ・ボックスでは、1つ以上の列にある変換可能性の問題をクレンジングするために表構造を変更できます。CLOBデータ型の列および属性には、これらのダイアログ・ボックスは使用できません。
列の変更メニュー項目または列変更のスケジュール・メニュー項目をクリックすると、変更対象の列がOracle e-Business Suiteインストールを構成するスキーマの1つに属していることが検出された場合、DMUで警告が表示されます。一般的には、Oracle e-Business Suite表の構造の変更はサポートされていません。影響を受ける表が自分で作成したカスタム表である場合か、Oracle Supportによって表の変更を推奨された場合にのみ、この警告を受け入れて変更を続行できます。
Oracle製品またはサード・パーティ製品とともにインストールされた表の構造を変更する場合は、事前にベンダーに相談してください。このような表を変更すると、それが属するアプリケーションが機能しなくなることがあるため、変更は通常はサポートされていません。
クレンジング・エディタを使用して、列に含まれる文字コードを解釈するためにDMUで使用されるキャラクタ・セットを変更できます。「想定キャラクタ・セットの設定」を参照してください。
以降に、クレンジング・エディタ・ツールバーの項目を、図6-1「クレンジング・エディタ」に表示されている順序で説明します。
表の再スキャン
編集対象表のみがスキャン対象としてマークされた状態でスキャン・ウィザード(「スキャン・ウィザードを使用したデータベースのスキャン」を参照)を開きます。これにより、その編集対象表を簡単に再スキャンできます。
選択した列の再スキャン
現在選択されている列のみがスキャン対象としてマークされた状態でスキャン・ウィザードを開きます。これにより、その編集対象表の一連の列を簡単に再スキャンできます。列が何も選択されていない場合、つまりエディタ・グリッドがセル選択モードになっている場合、現在のセルを含む列が再スキャン対象としてマークされます。
データのリフレッシュ
編集対象表の最新のデータを使用してグリッドを再ロードします。
表示する列の選択
エディタ・グリッドに含める列を選択できるダイアログ・ボックスを表示します。画面領域を節約するため、列自身に問題がなく、他の列の問題の分析に役立つデータも含まれていない場合、その列の選択を解除できます。特殊な読取り専用列を、編集対象表の行の行識別子が表示されたグリッドに追加することもできます。行識別子を使用すると、Oracle SQL Developerなどの他のデータベース・ツールで関連する行をすばやく見つけることができます。
スケジュール済クレンジングの影響を表示
スケジュール・クレンジング・アクションの結果を別の色で強調表示します。
「データのクレンジング: 色の強調表示」を参照してください。
収集された行識別子を使用してデータをフィルタリングする
スキャン中に収集された行識別子を使用してデータをフィルタリングします。
「データのフィルタリング」を参照してください。
フィルタリング条件のカスタマイズ
フィルタリング条件をカスタマイズできるダイアログ・ボックスを表示します。「データのフィルタリング」を参照してください。
次の選択項目が含まれる「フィルタ」ドロップダウン・リスト:
すべて
変換の必要あり
列制限超過
データ型制限超過
無効なバイナリ表現
「すべて」以外のオプションを選択すると、クレンジング・エディタによってフィルタが適用され、対応する変換可能性の問題がある行のみが表示されます。「データのフィルタリング」を参照してください。
問題のある前のセル
変換可能性の問題のある前のセルが現在のセルとして選択されます。セルはまず、同じ行の先行する各列で検索され、続いて先行する各行で最後の列から順に検索されます。
問題のある次のセル
変換可能性の問題のある次のセルが現在のセルとして選択されます。セルはまず、同じ行の後続の各列で検索され、続いて後続の各行で最初の列から順に検索されます。
キャラクタ・セット・ドロップダウン・リスト
想定列キャラクタ・セットとして選択できるキャラクタ・セットが含まれています。「想定キャラクタ・セットの設定」を参照してください。
変換可能性の問題のあるデータを含むセルは、他のセルの標準色とは別の色を使用して強調表示されます。デフォルトでは、長さの問題のあるセル、つまり変換後に列制限を超えるか、データ型制限を超えるセルは、黄色の背景で表示されます。無効なバイナリ表現の問題のあるセル、つまり宣言済(想定)キャラクタ・セットで無効な文字コードが含まれるセルは、ライト・コーラルの背景で表示されます。
値を含んでいる列の長さを調整したり、スケジュール済クレンジングの影響を表示ツールバー・ボタンをクリックするなどのスケジュール済クレンジング・アクションによってセル内の問題がクレンジングされた場合、デフォルトでセルの背景色が緑色に変わります。値の編集、想定列キャラクタ・セットの変更、列の変更ダイアログ・ボックスや属性の変更ダイアログ・ボックスを使用した列または属性の変更といった即時クレンジング・アクションを行うと、問題が完全に除去され、以前に影響を受けていたセルが変換可能になって強調表示がなくなります。
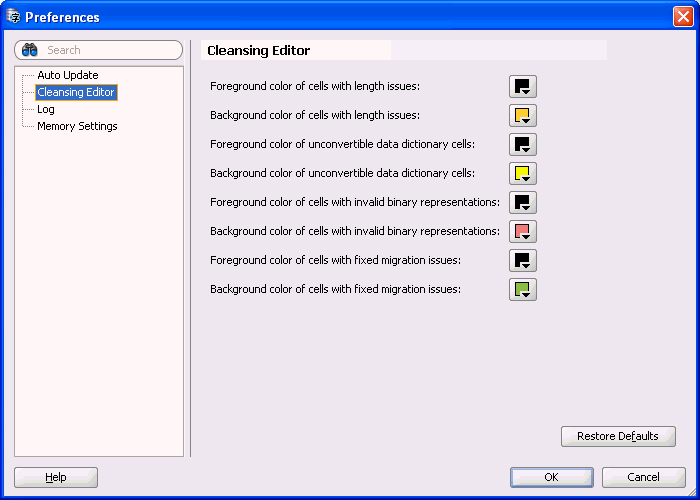
前述のデフォルト色は、図6-2「プリファレンス: クレンジング・エディタ」に示されている「プリファレンス」ダイアログ・ボックスのクレンジング・エディタ・ページでカスタマイズできます。「プリファレンス」ダイアログ・ボックスを開くには、ツール・メニューから「プリファレンス」を選択します。最初の2つの選択項目は長さ問題のあるセルに対応し、次の2つは変換不可能なデータ・ディクショナリ・セルのあるセルに対応し、その次の2つは無効なバイナリ表現のあるセルに対応し、最後の2つは解決された移行問題のあるセルに対応するものです。また、「デフォルトに戻す」をクリックすると、デフォルトの設定に戻すことができます。
クレンジング・エディタ・タブには、大きな表の操作を簡単にするための強力なフィルタリング機能が用意されています。エディタ・グリッドに含まれる行は、それに含まれる変換可能性の問題のタイプに基づいて、または任意のSQL条件に基づいてフィルタリングできます。
クレンジング・エディタ・ツールバーの「フィルタ」ドロップダウン・リストから、含める変換可能性の問題のタイプを選択できます。次の選択項目があります。
すべて
このオプションを選択すると、変換可能性の問題に基づくフィルタリングがオフになり、内容にかかわらずすべての行が含められます。
変換の必要あり
このオプションを選択すると、不変でないすべての行が表示され、変換の必要な、またオプションで長さの拡張または無効な表現の問題のあるデータが1つ以上の列に含まれます。
列制限超過
このオプションを選択すると、変換後に1つ以上の列値が列制限を超えるすべての行が表示されます。
データ型制限超過
このオプションを選択すると、変換後に1つ以上の列値がデータ型制限を超えるすべての行が表示されます。
無効なバイナリ表現
このオプションを選択すると、1つ以上の列に無効な文字コードが含まれるすべての行が表示されます。
DMUでは、次のいずれかの処理を実行することにより、特定のタイプの変換可能性の問題のある行を特定できます。
以前のスキャン・タスクによって移行リポジトリ内に収集された行識別子を参照します。
データベースからフェッチされるときに列値を分析します。
編集対象表でフィルタを通過する変換可能性の問題のタイプが存在する行の割合がごくわずかである場合、DMUでは、エディタ・グリッドに含める十分な行を見つけるまでに多数の行をフェッチして分析する必要があることがあります。このため、フィルタリングがオンになっていると、大きな表を検索する際のスピードが大幅に低下する可能性があります。通常は、収集された行識別子によって行を見つけるほうがはるかに高速です。ただし、収集された行識別子は表の最後のスキャンの時点における表の状態と一致しています。この状態は、行がすでに追加、更新または削除されているためにすでに失効している可能性があります。それでも通常は、クレンジング・セッションが比較的長期にわたる場合、問題が疎らに分散されている大きな表を定期的に再スキャンするほうが、収集された行識別子を使用せずに行をフィルタリングするよりも便利です。
収集された行識別子を使用するようにDMUを設定するには、クレンジング・エディタのスキャン・ログを使用してデータをフィルタリングするボタンをクリックします。このボタンは、表の最後のスキャン中に行識別子収集がオンになっていた場合にのみ有効になります。行識別子収集レベルは、表プロパティ・タブのスキャン・サブタブ(「表プロパティ: スキャン」を参照)またはスキャン・ウィザードのスキャンの詳細ページで設定できます(「スキャン・ウィザードを使用したデータベースのスキャン」を参照)。表プロパティ・タブの設定は永続的です。スキャン・ウィザードの設定は現在のスキャンにのみ適用され、表プロパティ・タブの値を上書きします。このレベルは「すべて変換」または「問題あり」に設定できます。最初のオプションを選択すると、不変でないすべての行の行識別子が収集されます。2つ目のオプションを選択すると、列制限を超える、データ型制限を超える、または無効なバイナリ表現があるなど、問題のある行の行識別子のみが収集されます。最初のオプションは、フィルタを「変換の必要あり」に設定する場合に使用します。2つ目のオプションは、フィルタを「列制限超過」、「データ型制限超過」または「無効なバイナリ表現」に設定する場合にのみ使用します。
表内に変換が必要な行が多数存在する場合、たとえば表にCLOB列が含まれていて、データベース・キャラクタ・セットがシングルバイトであるために、すべての変換可能な行の行識別子を収集するのに非常にコストがかかることがあります。一般に、このオプションは、変換を妨げる可能性のある変換可能データを見つける目的でデータ・ディクショナリ表に対してのみ使用してください。行識別子はセルごとに収集されるため、収集基準を満たすデータを含む複数のセルが1つの行に含まれている場合、その行の行識別子は複数のコピーに格納され、そのたびに別の列のIDが使用されます。
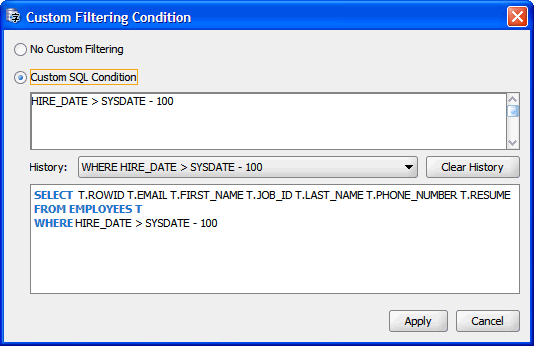
行の変換可能性ステータスに基づくフィルタリングの他に、DMUが編集対象表からデータを取得するためにデータベースに送信する問合せに追加する任意のSQL条件を指定できます。この条件は、図6-3 カスタム・フィルタリング条件に示すカスタム・フィルタリング条件ダイアログ・ボックスで指定します。このダイアログ・ボックスを開くには、クレンジング・エディタ・タブのツールバーで「フィルタリング条件のカスタマイズ」をクリックします。このダイアログ・ボックスでカスタムSQL条件オプションを選択して、必要な条件を入力します。「適用」をクリックします。条件が表に適用されて、フェッチする行のサブセットが作成され、次に変換可能性の問題に基づくフィルタリングがこのサブセットに適用されます。フィルタリング条件を削除するには、カスタム・フィルタリング条件ダイアログ・ボックスを再び開き、カスタム・フィルタリングなしオプションを選択して「適用」をクリックします。
データに無効な表現の問題がある場合(「データの無効なバイナリ記憶域表現」を参照)、その一般的な原因は、アプリケーションがパススルー構成を使用して、変換を行うこともデータベース・キャラクタ・セットを判別することもなくクライアント・キャラクタ・セットに直接データを格納することです。DMUを使用すると、このようなクライアント・キャラクタ・セット(データの実際のキャラクタ・セット)を特定して、それがデータベース・キャラクタ・セットと異なっていれば変換のソース・キャラクタ・セットとして使用できます。これにより、間違って格納されたデータをターゲットのUnicodeエンコーディングに正しく変換できます。データベース・キャラクタ・セットから標準的な変換を行うと、データが破損し、判読不能になります。DMUで選択できる列内のデータの宣言済キャラクタ・セットは、想定列キャラクタ・セットと呼ばれます。
想定列キャラクタ・セットは、Unicodeへの変換のみでなく、クレンジング・エディタ、データの編集ダイアログ・ボックスまたはデータの表示ダイアログ・ボックスに表示される列データが解釈されるときにも使用されます。表示されたデータが人間に判読できる形式になるのは、実際のキャラクタ・セットまたは実際のキャラクタ・セットのバイナリ・スーパーセットに従ってその解釈が行われた場合のみです。そうでない場合、表示された値には予期しない文字や置換文字が含まれます。(置換文字は通常、大文字サイズの四角い形状で表されます。この表示はプラットフォームによって異なります。)この事実に基づいて、列内のすべてのデータが正しく表示されていれば、想定列キャラクタ・セットが正しく選択されていることを確認できます。
列スキャン結果に問題のない変換可能な内容のみが報告されている場合でも、列の想定キャラクタ・セットを設定できます。これは、データベース・キャラクタ・セットと異なる実際のキャラクタ・セットのデータに、(判読可能なテキストが生成されなくても)データベース・キャラクタ・セットで有効として解釈される可能性のあるバイト・シーケンスが含まれていることがあるためです。これは特に、キャラクタ・セット定義でほとんどのバイト値(0..255)に有効な文字が割り当てられているシングルバイト・データベース・キャラクタ・セットについて当てはまります。CL8MSWIN1251がわかりやすい例で、1バイト値のみがどの文字にも割り当てられていません。
列の実際のキャラクタ・セットを特定するには、次のいずれかを実行します。
関連するアプリケーション構成、データベース・クライアントおよびクライアント・キャラクタ・セット(優先される方法)に関する必要な情報を収集します。
列の想定キャラクタ・セットとして一連のキャラクタ・セットを選択し、表示されるテキストの正確性(読みやすさ)を確認します。
2つ目の方法は、データの言語はわかっているが、そのエンコードに使用される特定のキャラクタ・セットがわからない場合に非常に便利です。たとえば、ある列のテキストが日本語であることはわかっているが、それがEUC-JP (JA16EUC)かShift-JIS (JA16SJIS)のどちらでエンコードされるかがわからない場合などです。
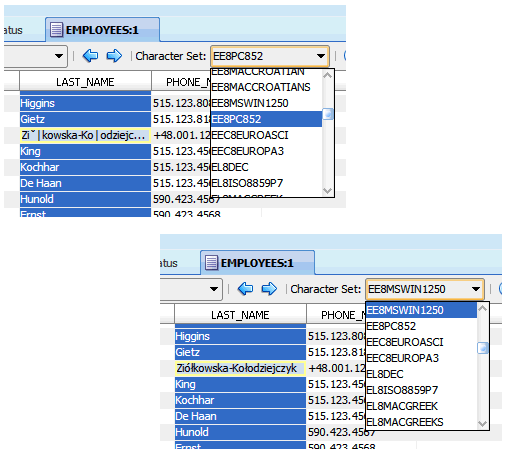
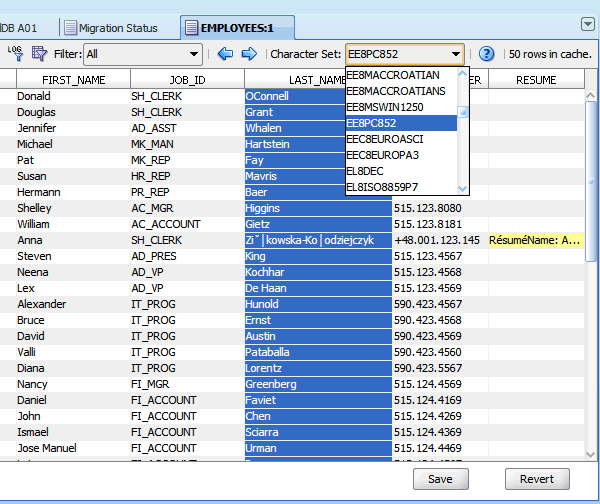
列の想定キャラクタ・セットをクレンジング・エディタで設定するには、図6-4「想定列キャラクタ・セットの設定」に示すように、列の見出しをクリックして列を選択し、ツールバーのキャラクタ・セット・ドロップダウン・リストで目的のキャラクタ・セットを選択します。選択した列の内容が、新しい解釈に従って再表示されます。データが判読できない場合、別のキャラクタ・セットを選択してみます。また、色の強調表示(「データのクレンジング: 色の強調表示」を参照)によって、選択したキャラクタ・セットに従って列内の一部のバイトを解釈できないことがわかります。
クレンジング・エディタで複数の列を選択した場合、その想定キャラクタ・セットすべてを一度に同じ値に設定できます。
選択した想定列キャラクタ・セットを追加の列処理で使用できるように移行リポジトリに永続的に保存するには、「保存」をクリックします。
データ・ビューアは、「データのクレンジング: ツールバーの使用」で説明されているクレンジング・エディタ・タブの読取り専用バージョンです。
データを表示する手順は、次のとおりです。
ナビゲータ・ペインのデータ・ディクショナリ表ノードのコンテキスト・メニューから、またはデータベース・スキャン・レポートで「データ・ビューア」を選択します。
データ・ビューアは、標準のアプリケーション表には使用できません。これは図6-1「クレンジング・エディタ」のクレンジング・エディタ・タブと似ていますが、クレンジングのスケジュールの影響を表示」ボタンが無効になっている点が異なります。「保存」ボタンと「元に戻す」ボタンはありません。また、コンテキスト・メニュー項目の「データの編集」、「列の変更」、「列変更のスケジュール」、「属性の変更」および「属性変更のスケジュール」は使用できません。データの編集メニュー項目のかわりに、「データの表示」で説明されているデータの表示ダイアログ・ボックスを開くためのデータの表示メニュー項目が使用可能になります。クレンジング・エディタの表示およびフィルタリングの機能はいずれも、データ・ビューアで使用可能です。列の内容の実際のキャラクタ・セットを分析するために、データ・ビューアで列の想定キャラクタ・セットを設定できますが、この選択を保存することはできません。
クレンジング・エディタで表セルをダブルクリックするか、現在のセルのコンテキスト・メニューから「データの編集」を選択するかして、図6-5「データの編集ダイアログ・ボックス」に示されているデータの編集ダイアログ・ボックスを開きます。セルの値は、ダイアログ・ボックスのメイン・テキスト領域に表示され、文字を追加、変更または削除することにより編集できます。値に行端文字(LF=0x0A)が含まれている場合、その値は複数の行で表示されます。行の折返しチェック・ボックスでは、テキスト領域の幅より長い行の表示方法を指定します。このチェック・ボックスを選択すると、ダイアログ・ボックスでは長い行がテキスト領域の複数の行で折り返されます。このチェック・ボックスを選択しない場合、行は折り返されず、ダイアログ・ボックスにはテキスト領域をスクロールするための水平スクロール・バーが表示されます。
データの編集ダイアログ・ボックスには、編集対象のテキスト値に関する次のデータが表示されます。
データ型
これは、値が属する列のデータ型(VARCHAR2、CHAR、LONG、CLOBなど)です。
データ長(バイト)
これは、編集対象の値がデータベースに格納された場合の長さ(バイト)です。
データ長(文字数)
これは、編集対象の値がデータベースに格納された場合の長さ(文字数)です。
変換後の長さ(バイト)
これは、編集対象の値がターゲットUnicodeキャラクタ・セットへの変換後にデータベースに格納された場合の長さ(バイト)です。
現在の列制限(バイト)
これは、値をデータベース内のその列に収めるための現在の最大長(バイト)です。
現在の列制限(文字数)
これは、値をデータベース内のその列に収めるための現在の最大長(文字数)です。列でバイト長セマンティクスが使用されている場合は、何も表示されません。
変換後の制限(バイト)
これは、値をUnicodeへの変換後にデータベース内のその列に収めるために許容される最大長(バイト)です。
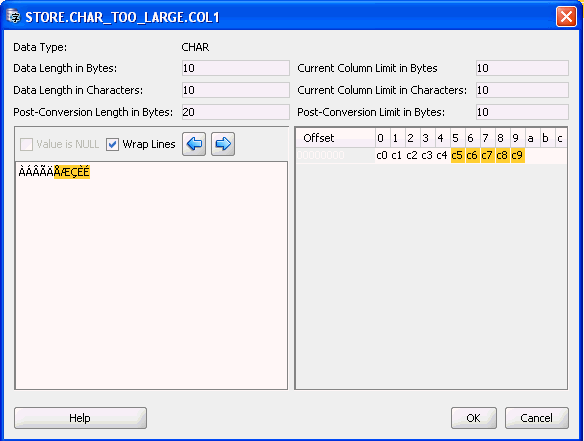
値を編集するときは、「データ長(バイト)」が「現在の列制限(バイト)」を超えていないこと、および「データ長(文字数)」が「現在の列制限(文字数)」(指定されている場合)を超えていないことを必ず確認してください。値の「列制限超過」の問題を解決するには、「変換後の長さ(バイト)」が「変換後の制限(バイト)」を超えていないことを確認する必要もあります。
現在の値が「変換後の制限(バイト)」を超える原因となっている文字は、黄色の背景で表示されます。これにより、「列制限超過」の問題を解決するために切り捨てる必要のある値の量をすばやく見積もることができます。
右下に、編集対象テキストが、データベースに格納されるときのテキストを構成(エンコード)するバイトに対応する一連の16進数として表示されます。
編集対象テキストを構成するバイトの数値を確認すると、次のことが可能になります。
文字列に無効に格納されているバイナリ値(イメージや暗号化結果など)の特定
このような値には通常、0x00から0x08まで、および0x10から0x1fまでのバイトが含まれます。これらの範囲のバイトは現在ほとんど使用されない制御コードなので、このようなバイトを含む値が純粋なテキスト値になることはほとんどありません。
破損した文字の特定
テキスト内の編集対象テキストに置換文字がある場合、バイナリ表示を参照して、これらの文字に対応する特定のバイトを分析できます。データの言語を特定して、この言語に有効なキャラクタ・セットの定義を参照することにより、問題を、データの不適切なキャラクタ・セットとして、あるいは破損した文字コード(ソフトウェアの不具合やハードウェア障害によりマルチバイト・コードからバイトが欠落したり、バイトがランダムになる)として診断できます。
編集対象の値にバイトを挿入、変更または削除して、破損の問題を解決できます。バイトをクリックすると、それが現在のバイトになります。編集領域内の任意の場所を右クリックすると、コンテキスト・メニューが開きます。現在のバイトの前にバイトを追加するには、「挿入」を選択します。値から現在のバイトを削除するには、「削除」を選択します。現在のバイトの値を変更するには、「変更」を選択します。バイトをダブルクリックすることは、バイトを選択して現在のバイトにしてから「変更」を選択することと同じです。
データの編集ダイアログ・ボックスで目的の変更をすべて行ったら、「OK」をクリックして変更を受け入れ、ダイアログ・ボックスを閉じます。ダイアログ・ボックスを閉じて変更を廃棄する場合は、「取消」をクリックします。変更を受け入れた後も、変更をデータベースに保存するために、クレンジング・エディタ・タブで「保存」をクリックする必要があります。
データの表示ダイアログ・ボックスは、データの編集ダイアログ・ボックスの読取り専用バージョンです。これはデータ・ディクショナリ表の値を表示するために使用するもので、値を直接変更することはできません。
データの編集ダイアログ・ボックスと同様に、データはテキスト形式またはバイナリ形式で表示されます。また、長い行を折り返したり、広げたりすることもできます。
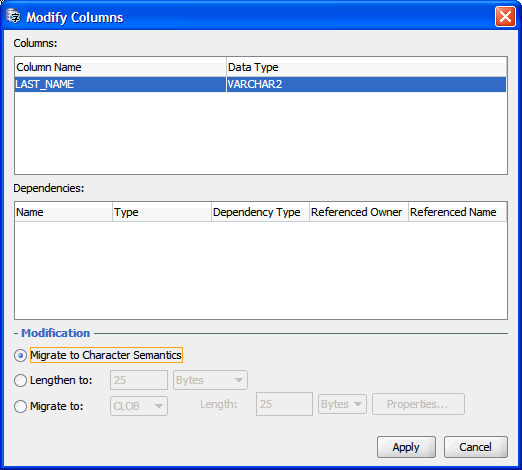
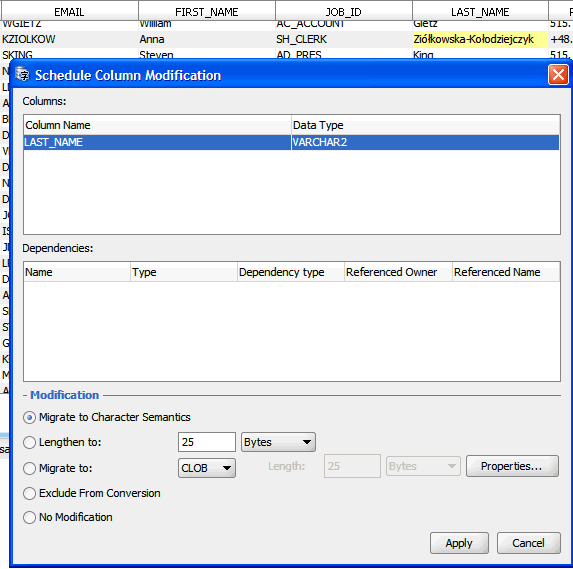
列の変更ダイアログ・ボックスを使用して実行できるクレンジング・アクションは、表の列定義(メタデータ)を即時に変更します。図6-6に、列の変更ダイアログ・ボックスを示します。これを開くには、クレンジング・エディタのコンテキスト・メニューから「列の変更」を選択します(「データのクレンジング: ツールバーの使用」を参照)。
「列」リスト・ボックスに、列の変更ダイアログ・ボックスで変更される列が表示されます。依存性リスト・ボックスには、ビューやPL/SQLプロシージャなど、これらの列に依存するために、列の変更後に更新または再コンパイルが必要となる可能性のあるデータベース・オブジェクトが表示されます。
列の変更ダイアログ・ボックスでは、列に対して次のクレンジング・アクションを指定できます。
キャラクタ・セマンティクスへの移行
列の長さセマンティクスをバイトから文字に変更できます。変更する列がVARCHAR2(n BYTE)として定義されている場合、列はVARCHAR2(n CHAR)になります。このような変更を行うと、n BYTE列に含まれる文字がnを超えることはなく、n CHAR列の基礎となるバイト長制限は、データベース・キャラクタ・セットの変更中に、長さn文字のすべての文字列を格納できるように自動的に拡大されます(ただし、これはデータ型制限を超えない場合にかぎります。つまり、データ型制限超過として報告された値は収まりません)。
調整後の長さ
列の長さを調整して新しい制限値(「オプション」ラベルの後の「編集」フィールドで指定)にすることを選択できます。同時に長さセマンティクスをバイトまたは文字に変更するには、次のドロップダウン・リストから目的のセマンティクスを選択します。「列制限超過」の問題を解決するには、すべての列に対して報告された変換後の最大長より大きい制限値を指定します。
移行後の型
一部のデータ型を新しいデータ型に移行できます。CHAR列は、VARCHAR2、CLOBまたはRAWに移行できます。VARCHAR2はCLOBまたはRAWに移行できます。LONG列はLONG RAWまたはCLOBに移行できます。CLOBへの移行を選択した場合、新しいCLOBセグメントの表領域および記憶域のプロパティを変更するためのプロパティ・ダイアログ・ボックスを使用できます。RAWまたはVARCHAR2への移行を選択した場合、新しい長さ制限(移行対象の列のいずれのバイト長制限も下回っていない値)を指定できます。VARCHAR2への移行を選択した場合、新しい長さに加えて長さセマンティクスを指定できます。VARCHAR2またはCLOBに移行すると、新しいデータ型は古いデータ型よりも大きくなるため、「データ型制限超過」の問題は解決されます。RAWまたはLONG RAWに移行すると、データベースでデータは実際にバイナリとして処理されるため、文字列にバイナリ・データが格納されることによる「無効なバイナリ表現」の問題は解決されます。
VARCHAR2、RAWおよびLONG RAWへの移行はメタデータのみの操作であるため、非常に高速です。CLOBに移行する場合、表のすべての行でデータを更新する必要があります。このため、表が大きい場合は非常に多くのリソースが消費されたり、データベース内に十分なUNDO領域がない場合には失敗することがあります。
クレンジング・アクションを定義した後、「適用」をクリックします。今すぐ列を変更してよいか確認を求められます。「はい」をクリックすると、適切なSQL DDL文がデータベースに送信されて即時に実行されます。
列変更のスケジュール・ダイアログ・ボックスは、前述の列の変更ダイアログ・ボックスとほとんど同じです。異なる点は次の2つです。
このダイアログ・ボックスで指定したクレンジング・アクションは、スケジュール済アクションです。これらは、「適用」を選択したときに即時に実行されません。かわりに移行リポジトリに保存され、キャラクタ・セット移行プロセスの変換ステップで実行されます。これにより、表構造の変更に関連する必要なアプリケーション・アップグレードをデータベース変換と同期できます。
変更なしオプションが使用可能です。これを使用すると、データベース変換の開始前に、以前のスケジュール済クレンジング・アクションを再び呼び出すことができます。
列の変更をスケジュールする手順は、次のとおりです。
クレンジング・エディタのコンテキスト・メニューから「列変更のスケジュール」を選択して、列変更のスケジュール・ダイアログ・ボックスを開きます(「データのクレンジング: ツールバーの使用」を参照)。図6-31「列変更のスケジュール: 列サイズの長さ調整」に示すような列変更のスケジュール・ダイアログ・ボックスが表示されます。
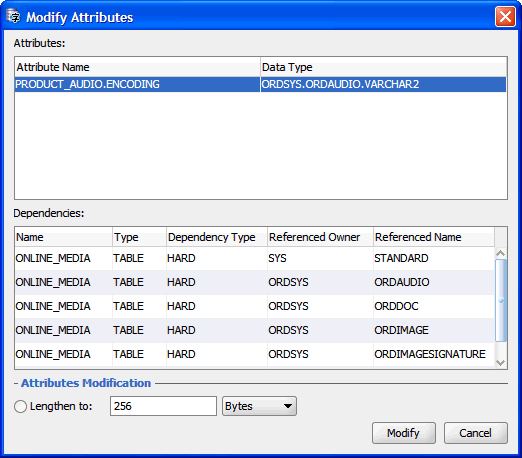
「属性の変更」ダイアログ・ボックスを使用して実行できるクレンジング・アクションは、ユーザー定義オブジェクト・タイプの属性(ADT)を即時に変更します。オブジェクトの属性を変更すると、その属性を参照するすべての表に影響を与えます。属性の変更ダイアログ・ボックスを使用して、オブジェクト属性値を格納する表列を変更する必要があります。このような列に列の変更ダイアログ・ボックスを使用することはできません。
属性リスト・ボックスに、属性の変更ダイアログ・ボックスで変更される属性が表示されます。依存性リスト・ボックスには、ビューやPL/SQLプロシージャなど、これらの属性に依存するために、属性の変更後に更新または再コンパイルが必要となる可能性のあるデータベース・オブジェクトが表示されます。
現在、属性の変更ダイアログ・ボックスで定義できるのは、属性の長さを調整して新しい制限値にするためのクレンジング・アクション1つのみです。編集フィールドで制限値を指定します。同時に長さセマンティクスをバイトまたは文字に変更するには、次のドロップダウン・リストから目的のセマンティクスを選択します。「列制限超過」の問題を解決するには、データベース内のすべての表に属性の値を格納するすべての列に対して報告された変換後の最大長より大きい制限値を指定します。
属性を変更する手順は、次のとおりです。
クレンジング・エディタのコンテキスト・メニューから「属性の変更」を選択します(「データのクレンジング: ツールバーの使用」を参照)。図6-7に示すような属性の変更ダイアログ・ボックスが表示されます。
クレンジング・アクションを定義した後、「変更」をクリックします。
今すぐ属性を変更してよいか確認を求められます。「はい」をクリックすると、適切なSQL DDL文がデータベースに送信されて即時に実行されます。
属性変更のスケジュール・ダイアログ・ボックスは、前述の属性の変更ダイアログ・ボックスとほとんど同じです。異なる点は次の2つです。
このダイアログ・ボックスで指定したクレンジング・アクションは、スケジュール済アクションです。これは、「適用」を選択したときに即時に実行されません。かわりに移行リポジトリに保存され、キャラクタ・セット移行プロセスの変換ステップで実行されます。これにより、表構造の変更に関連する必要なアプリケーション・アップグレードをデータベース変換と同期できます。
変更なしオプションが使用可能です。これを使用すると、データベース変換の開始前に、以前のスケジュール済クレンジング・アクションを再び呼び出すことができます。
属性変更のスケジュール・ダイアログ・ボックスを開くには、クレンジング・エディタのコンテキスト・メニューから「属性変更のスケジュール」を選択します(「データのクレンジング: ツールバーの使用」を参照)。
これは厳密にはクレンジング・アクションではありませんが、2つの列プロパティを使用して、報告された列内の変換可能性の問題を処理できます。これらのプロパティは、「列プロパティの表示および設定」で説明されている列プロパティ・タブの変換サブタブで設定できます。
1つ目のプロパティは、「問題のあるデータの変換を許可する」です。この列プロパティを「はい」に設定すると、その列に対して報告された変換可能性の問題は無視されます。つまり、これらがあっても変換ステップは開始されます。列はUnicodeに変換され、結果の値は列に収まるように自動的に切り捨てられます。無効な文字コードは置換文字に変換されます。このオプションは、変換後に完全に正しくなっている必要はないが、データベースからはまだ削除しない補助データまたは履歴データに変換可能性の問題がある場合に便利です。
2つ目のプロパティは、「変換から除外する」です。この列プロパティを「はい」に設定すると、その列は変換ステップでスキップされます。列の値は、キャラクタ・セット移行前の状態と同じになります。このオプションは、次のような列の変換を回避する場合に便利です。
パススルー構成で様々なクライアントが異なるキャラクタ・セットを使用しているために、複数のキャラクタ・セットの値が混在している列。DMUによりデータベースの他の部分が変換され、データベース・キャラクタ・セットがUnicodeに更新された後で、このような値を手動で変換する必要があります。
データ型がVARCHAR2であり、長さ制約が2000バイトより大きく、バイナリ・データを格納する列。このような列は、2000バイトの制約があるRAWに移行できないため、BLOBデータ型を介してこのデータをサポートするようにアプリケーションを更新する前に、Unicodeへの移行後にパススルー構成で列へのアクセスを維持するように決定できます。
変換から除外するようにマークされた列に対して変換可能性の問題が報告されていても、変換ステップは開始されます。このプロパティの設定の詳細は、「移行からの列および表の除外」を参照してください。
CHARおよびVARCHAR2表列の長さセマンティクスをバイト・セマンティクスからキャラクタ・セマンティクスに変更
キャラクタ・セマンティクスは、可変幅のマルチバイト文字列の記憶要件を定義する場合に役立ちます。たとえば、Unicodeデータベース(AL32UTF8)で、VARCHAR2列を英語の5文字とともに最大5文字の中国語文字を格納できるように定義する必要があるとします。バイト・セマンティクスを使用すると、この列には、長さ3バイトである中国語文字用に15バイトと、長さ1バイトである英語文字用に5バイト、合計20バイトが必要です。キャラクタ・セマンティクスを使用すると、この列に必要な文字数は10となります。キャラクタ・セマンティクスを使用すると、データベース・キャラクタ・セットとは関係なく文字数で列サイズを指定できます。Unicode移行で文字長セマンティクスを使用する利点の詳細は、「長さセマンティクスの変更」を参照してください。
即時クレンジング・モードまたはスケジュール・クレンジング・モードのいずれかで文字長セマンティクスに移行する一括クレンジング・アクションを定義できます。スケジュール・モードでは、文字長セマンティクスへの移行は、変換フェーズ中に本番環境を中断することなく適用されます。DMUを検証モードで使用している場合は、文字長セマンティクスへの即時の一括クレンジングのみが使用可能になります。
一括クレンジングでは、次のデータ型の列を文字長セマンティクスに移行することがサポートされています。
CHAR組込みデータ型の列
VARCHAR2組込みデータ型の列
ADTのVARCHAR2属性の列
次の列は除外されます。
ADTのCHAR属性の列
クラスタ内の列
パーティション・キーが定義されている列
一括クレンジングでは、通常のクレンジングの場合と同様に、Oracle提供のスキーマ(Oracle e-Business Suiteスキーマなど)の文字長セマンティクスの移行はサポートされていません。
「問題のあるデータの変換を許可する」列変換プロパティの設定
このプロパティを「はい」に設定すると、列のスキャン結果でいくつかの値に変換の問題がある、つまり変換後の値に置換文字が含まれるか、変換後の値が切り捨てられる問題があることが示された場合でも、DMUでデータの変換を実行できます。列またはデータ型の制限を超えたデータを自動的に切り捨てる場合や、破損した値があってもこのデータを使用するアプリケーションにとって大きな影響はないような場合には、これを使用すると便利です。
列値のすべてのバイト・パターンまたは文字パターンを置換または削除
場合によっては、個々のデータ例外の性質を分析した後、障害になっているバイトまたは文字を有効な同等のバイトまたは文字セットに置き換えるか、すべて削除することによってデータを変更できます。同じ問題の兆候が複数のデータベース・オブジェクトにある場合、そのような置換操作は一括での実行が望ましい可能性があります。パターンに基づいた置換クレンジング・オプションによって、選択したデータベース・オブジェクトのすべてのソース・パターンをターゲット・パターンへ置き換えることが可能になります。単一のバイトまたは文字を置き換えることもでき、バイトまたは文字を文字列で指定することもできます。
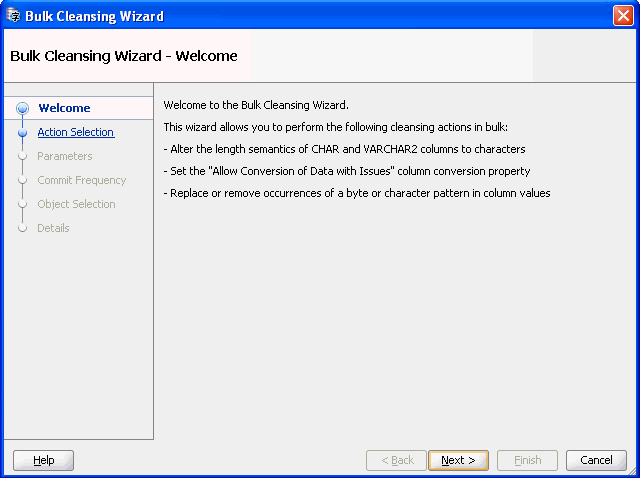
バイト・セマンティクスからキャラクタ・セマンティクスへデータを一括クレンジングする方法:
移行メニューで「一括クレンジング」を選択します。図6-8「一括クレンジング・ウィザード - ようこそ」のようなダイアログが表示されます。
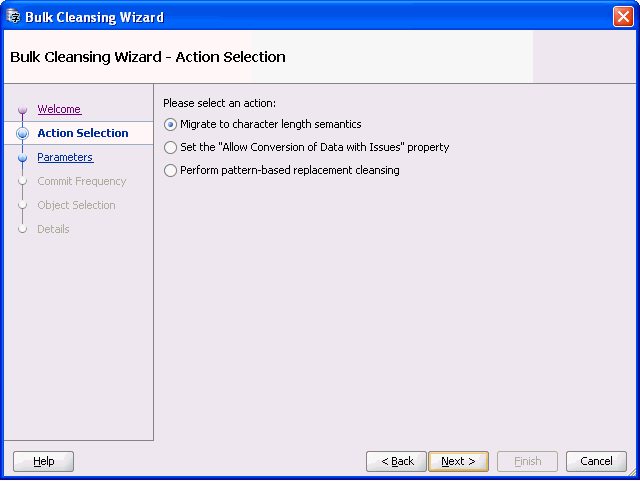
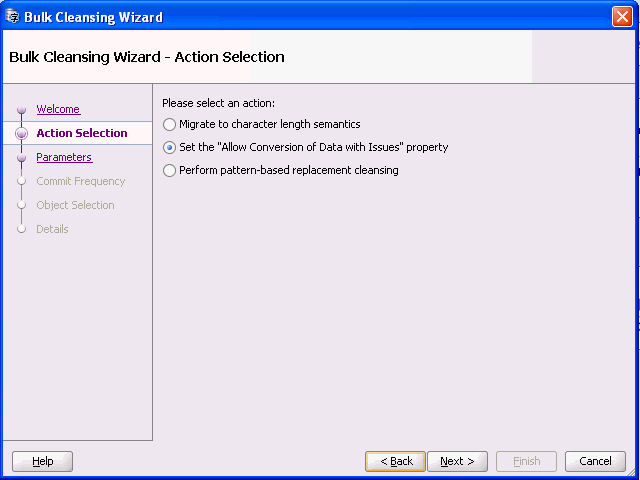
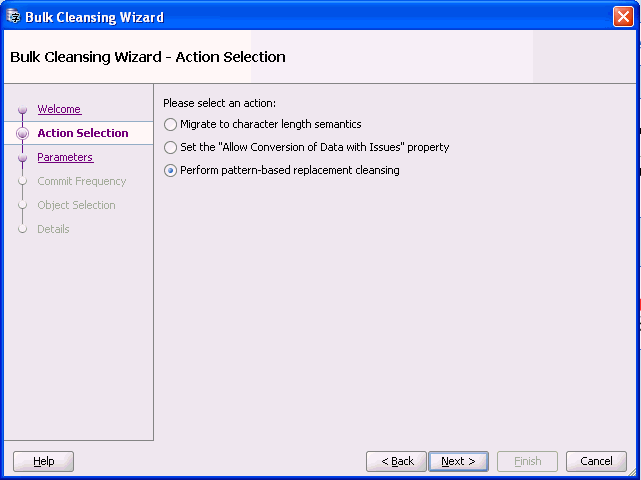
「次へ」をクリックすると、図6-9「一括クレンジング・ウィザード - アクション選択」が表示されます。
文字長 セマンティクスへ「移行」を選択し、「次へ」をクリックします。
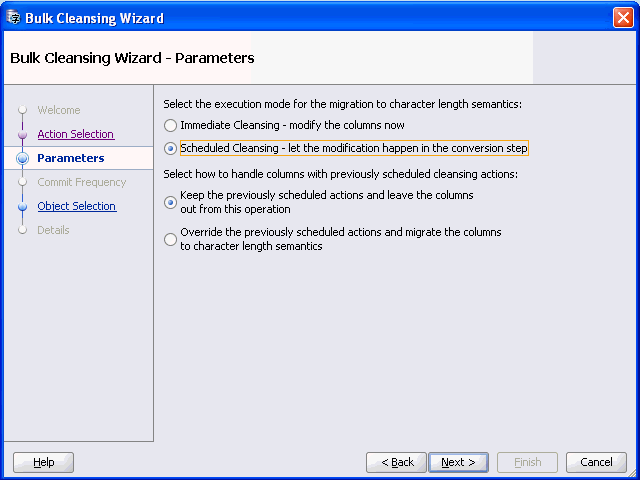
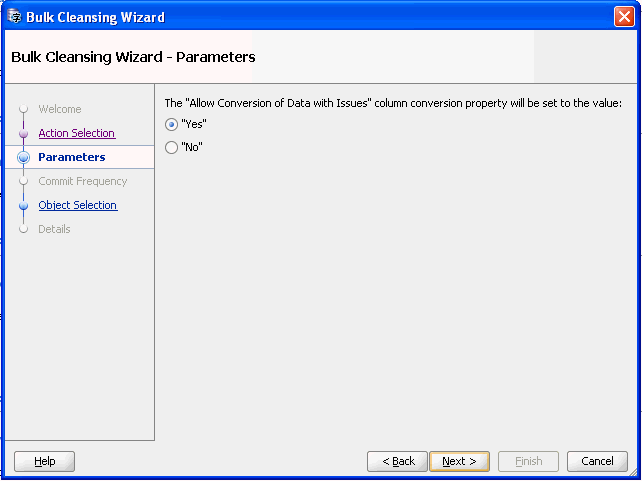
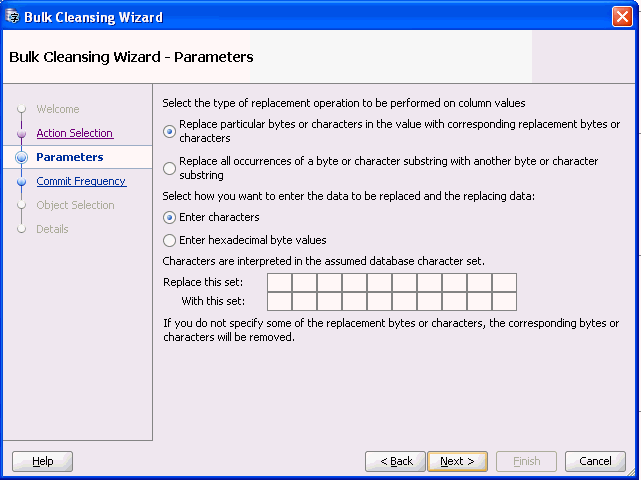
図6-10 一括クレンジング・ウィザード - パラメータが表示されます。
一括クレンジングの実行モードを選択します。スケジュール・クレンジング・モードの場合、以前にスケジュールされたクレンジング・アクションのある列の処理方法として、以前にスケジュールされたアクションを保持するか、そのアクションを上書きして列をキャラクタ長セマンティクスに移行するかを選択できます。
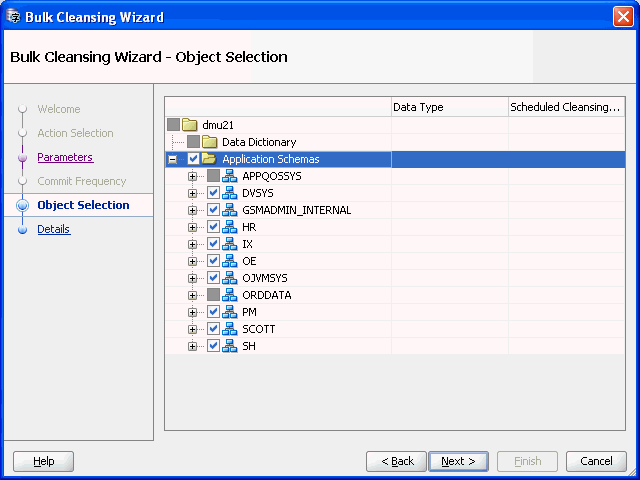
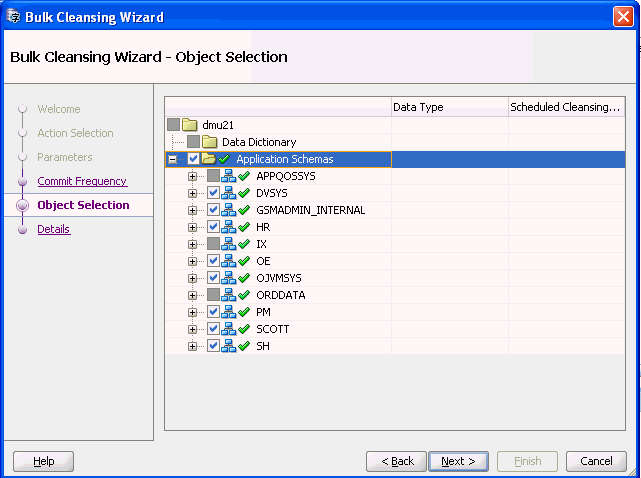
「次へ」をクリックすると、図6-11「一括クレンジング・ウィザード - オブジェクト選択」が表示されます。
文字長セマンティクスに移行するオブジェクトを選択します。データ型列に列の現在のデータ型が表示され、スケジュール済クレンジング・アクション列に既存のスケジュール済クレンジング・アクションが表示されます。すでに文字長セマンティクスを使用しているオブジェクトや、文字長セマンティクスへの移行がサポートされていないオブジェクトは、ナビゲータ・ツリーで選択不可能になっています。
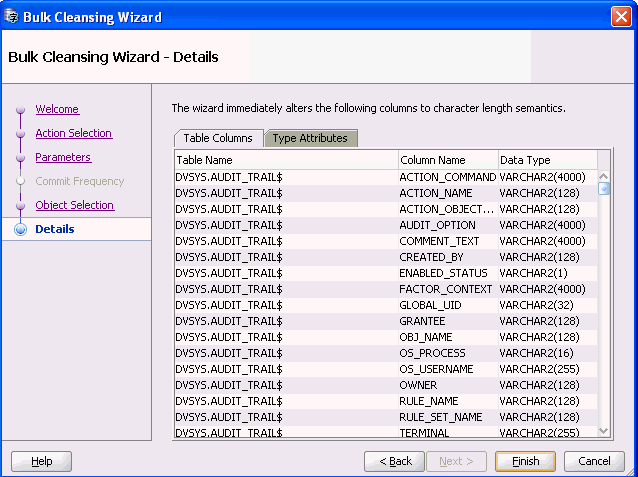
「次へ」をクリックすると、図6-12「一括クレンジング・ウィザード - 詳細」が表示されます。
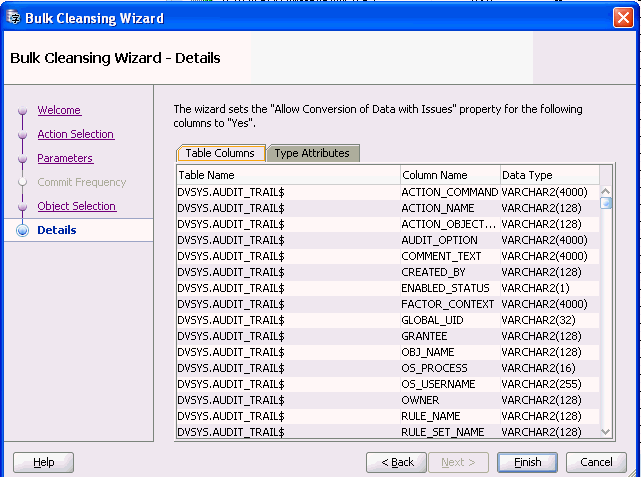
一括クレンジングの詳細ページに、文字長セマンティクスに移行される表列および型属性のリストが表示されます。
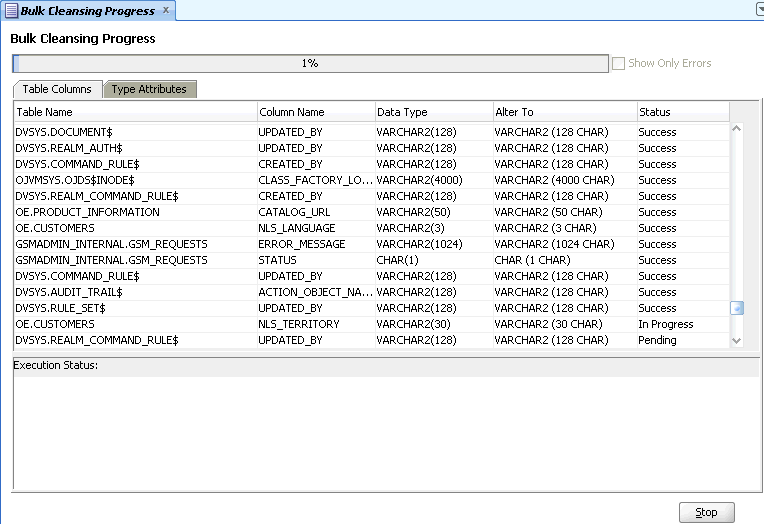
一括クレンジング操作を確認して開始するには、「完了」をクリックします。図6-13「一括クレンジングの進行状況」が表示されます。
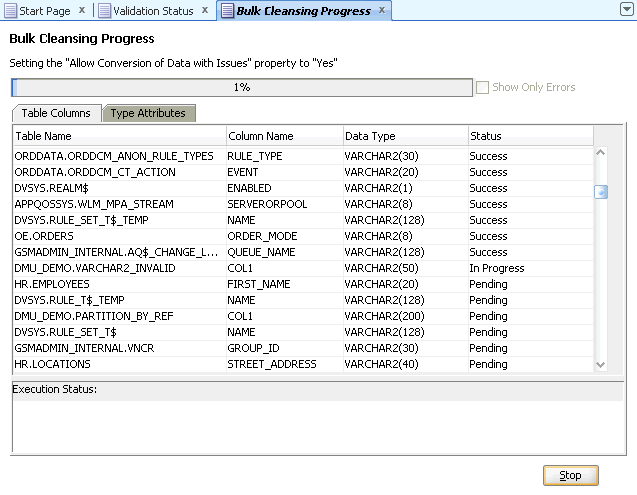
一括クレンジングのステータスは、一括クレンジングの進行状況パネルで監視できます。ある表列または型属性に対する操作がプロセス中に失敗した場合、そのエントリを強調表示すると、「ステータス」列およびパネルの一番下にエラー・メッセージが表示されます。エラーのあるエントリのみを表示するには、一番上のエラーのみを表示チェック・ボックスを選択します。
「停止」をクリックすることで、クレンジングを一時停止できます。
問題のあるデータの変換を許可することによるデータを一括クレンジングする方法:
移行メニューで「一括クレンジング」を選択します。図6-14「一括クレンジング・ウィザード - ようこそ」のようなダイアログが表示されます。
「次へ」をクリックすると、図6-15「一括クレンジング・ウィザード - アクション選択」が表示されます。
「問題のあるデータの変換を許可」の設定を選択します。「次へ」をクリックすると、図6-16「一括クレンジング・ウィザード - パラメータ」が表示されます。
必要な値を選択し、「次へ」をクリックすると、図6-17「一括クレンジング・ウィザード - オブジェクト選択」が表示されます。
「問題のあるデータの変換を許可」プロパティを設定するオブジェクトを選択します。データ型列に列の現在のデータ型が表示され、スケジュール済クレンジング・アクション列に既存のスケジュール済クレンジング・アクションが表示されます。
「次へ」をクリックすると、図6-18「一括クレンジング・ウィザード - 詳細」が表示されます。
一括クレンジング詳細ページは、「問題のあるデータの変換を許可」プロパティを設定する表の列および型属性のリストを表示します。一括クレンジング操作を確認して開始するには、「完了」をクリックします。図6-13「一括クレンジングの進行状況」が表示されます。
一括クレンジングのステータスは、一括クレンジングの進行状況パネルで監視できます。ある表列または型属性に対する操作がプロセス中に失敗した場合、そのエントリを強調表示すると、「ステータス」列およびパネルの一番下にエラー・メッセージが表示されます。エラーのあるエントリのみを表示するには、一番上のエラーのみを表示チェック・ボックスを選択します。
「停止」をクリックすることで、クレンジングを一時停止できます。
パターンに基づく置換によってデータを一括クレンジングする方法:
移行メニューで「一括クレンジング」を選択します。図6-20「一括クレンジング・ウィザード - ようこそ」のようなダイアログが表示されます。
「次へ」をクリックすると、図6-21「一括クレンジング・ウィザード - アクション選択」が表示されます。
パターンに基づく置換クレンジングの実行を選択すると、図6-22「一括クレンジング・ウィザード - パラメータ」が表示されます。
実行する置換操作のタイプおよびデータを入力する方法を選択します。単一のバイトまたは文字を置き換えることもでき、バイトまたは文字を文字列で使用することもできます。ソース値および置換値は、文字または16進バイト表現のいずれかで入力できます。置換バイトまたは文字の一部を空白のままにしておくと、対応するソース・バイトまたはソース文字が選択したターゲット列から削除されます。
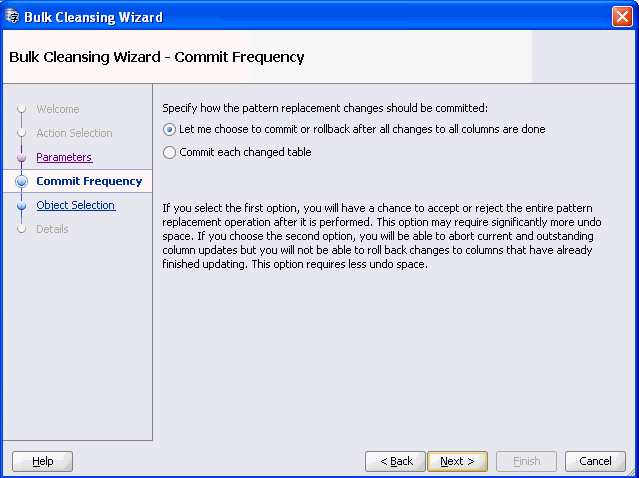
「次へ」をクリックすると、図6-23「一括クレンジング・ウィザード - コミット頻度」が表示されます。コミット頻度ページでは、パターン置換の変更をコミットする方法を指定できます。終了時に操作全体を受け入れるか拒否するかを選択する場合には、最初のオプションを選択します。すべての変更をすぐにコミットする場合には、2番目のオプションを選択します。
コミットする方法を指定します。「次へ」をクリックすると、図6-24「一括クレンジング・ウィザード - オブジェクト選択」が表示されます。
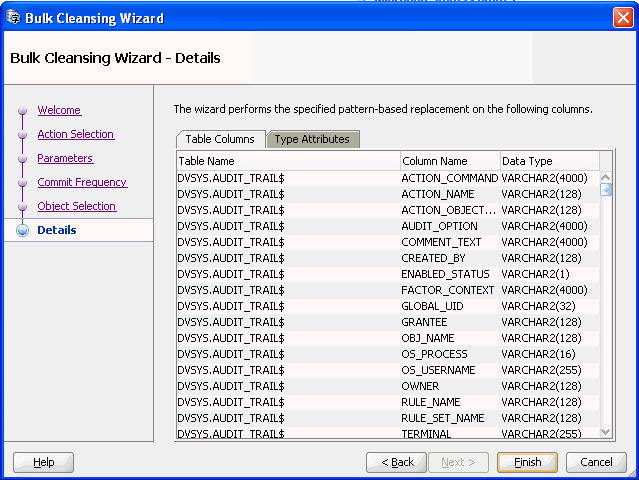
パターンに基づく置換が実行されるオブジェクトを選択します。「次へ」をクリックすると、図6-25「一括クレンジング・ウィザード - 詳細」が表示されます。
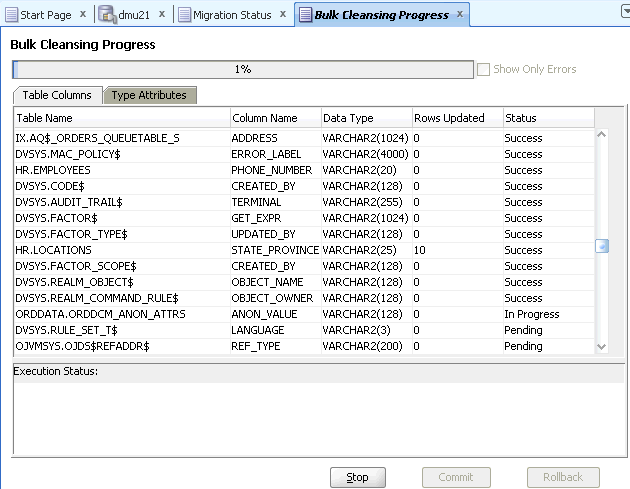
一括クレンジング詳細ページに、クレンジングされる表列および型属性のリストが表示されます。一括クレンジング操作を確認して開始するには、「完了」をクリックします。図6-26「一括クレンジングの進行状況」が表示されます。
一括クレンジングのステータスは、一括クレンジングの進行状況パネルで監視できます。ある表列または型属性に対する操作がプロセス中に失敗した場合、そのエントリを強調表示すると、「ステータス」列およびパネルの一番下にエラー・メッセージが表示されます。エラーのあるエントリのみを表示するには、一番上のエラーのみを表示チェック・ボックスを選択します。
「停止」をクリックすることで、クレンジングを一時停止できます。
例6-1 一括で無効なバイトを置換
この例では、データベースに次の図で示すように無効なバイト(WE8MSWIN1252データベース内に0x8Dおよび0x9D)が含まれています。
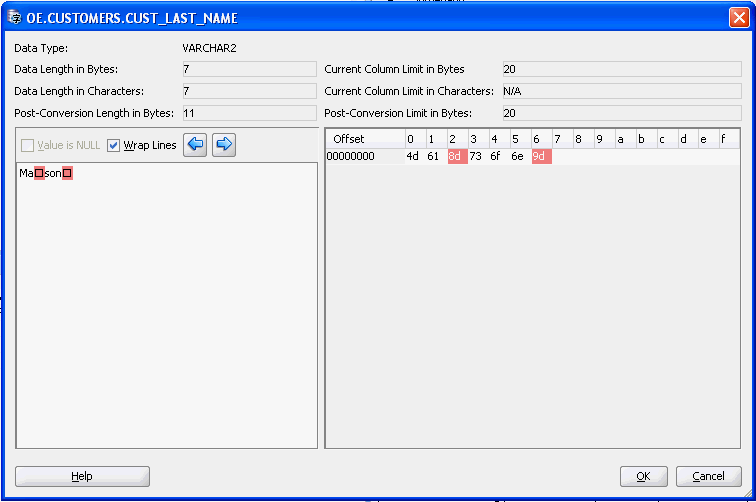
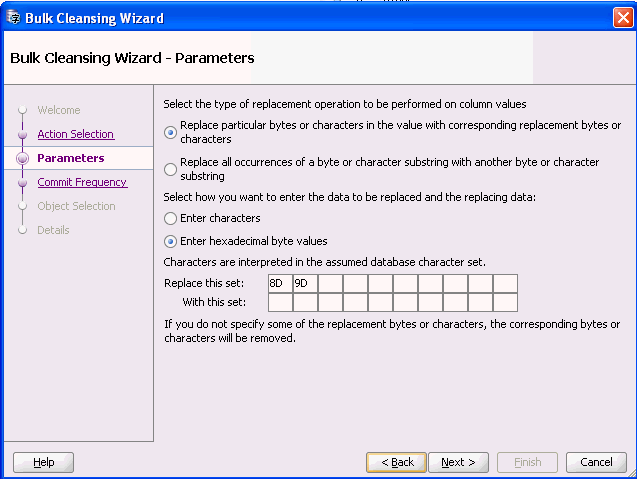
同じ無効データの兆候が複数ある場合、パターンに基づくクレンジングを実行することで一括で問題を解決できます。このケースでは、バイト値0x8dおよび0x9dは無視することができ、データの内容としては重要でないと考えると、次のようにパターンに基づく置換を定義してそれらをデータから削除できます。
これが完了すると、次のスクリーンショットで示すようなデータが表示されます。
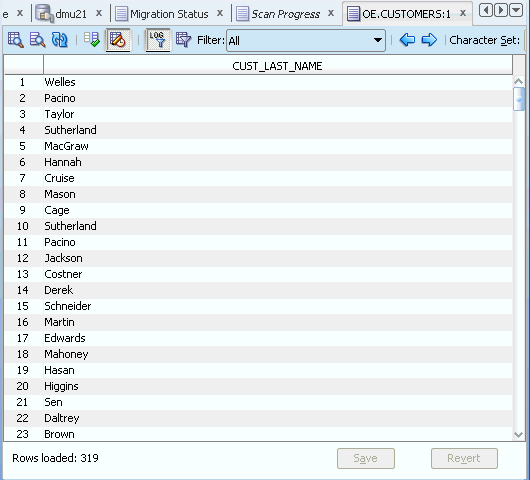
行8の無効なデータが削除されたことに注意してください。
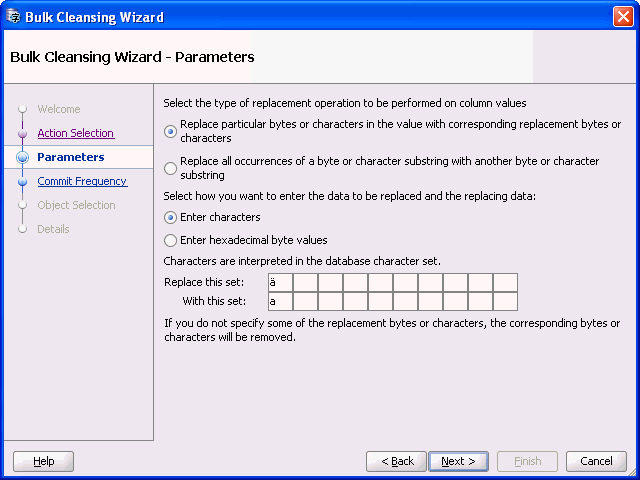
例6-2 一括で文字を置換
場合によっては、Unicodeに変換する際に列定義を変更することなく8ビット文字を7ビットの同等の文字に置き換えて、データ・サイズ拡張問題に対処できます。たとえば、次のスクリーンショットに示すように一括クレンジング・メソッドを使用してすべての文字äをaに置換できます。
データベース内のデータに問題がない場合、スキャン・レポートは図6-27「データベース・スキャン・レポート: データの問題なし」のような画面になります。
レポート列「変更の必要なし(スケジュール済)」には、ターゲットのUnicodeキャラクタ・セットですでに有効になっているデータベース内の文字列値(セル)の数が表示されます。つまり、これらのセルはNULLか、またはASCII文字のみを含みます(ただし、UTF8からAL32UTF8に移行する場合は、文字がUnicodeの基本多言語面からの他の有効なUTF-8コードになることがあります)。レポート列「変換が必要(スケジュール済)」には、Unicodeにするために変換が必要であるが、変換してもエラーやデータ損失は起こらない文字セルの数が表示されます。
レポート列「無効なバイナリ表現(スケジュール済)」、「列制限超過(スケジュール済)」および「型制限超過(スケジュール済)」には、データベースの内容に変換可能性の問題がないことを表すゼロが表示されます。データベース・ノードの左側にある緑色の「OK」アイコンも、これと同じ意味です。移行ステータス・タブでデータベース内にそれ以外の問題がないことが示されている場合(「移行ステータスの追跡」を参照)、「データベースの変換」で説明されている移行プロセスの実際の変換フェーズに進むことができます。
データベース内のデータに拡張の問題がない場合、スキャン・レポートは図6-28「データベース・スキャン・レポート: 拡張の問題」のような画面になります。「クレンジング・シナリオ1: 問題のないデータベース」で説明されている変更の必要なし(スケジュール済)列および変換が必要(スケジュール済)列に加えて、列制限超過(スケジュール済)列および型制限超過(スケジュール済)列にゼロでない値が含まれています。データベース・ノードの隣にある黄色い三角形のアイコンは、データに変換可能性の問題があることを示しています。
「列制限超過(スケジュール済)」として分類されたセルは、列の長さを調整しないかぎり、ターゲット・キャラクタ・セットへの変換後に列に収まらなくなります。「型制限超過(スケジュール済)」として分類されたセルは、長さがそのデータ型の制限を超えます。それらの列の長さを調整しても解決にはなりません。
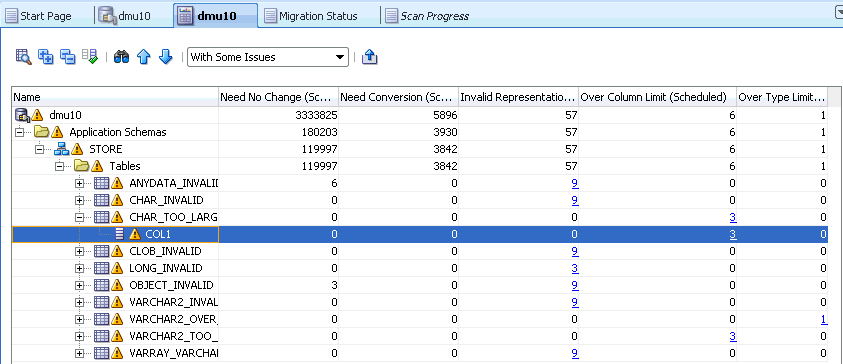
「名前」列のオブジェクト・ツリーを開くと、問題のあるセルが含まれているスキーマ、スキーマ内の表、および表内の列を特定できます。黄色い三角形のアイコンは、開くことができるノードを示しています。列制限超過(スケジュール済)列と型制限超過(スケジュール済)列は、スキーマ、表および列に対応するデータベース・オブジェクト内の問題のあるセルの数を示しています。
また、スキャン・レポート・タブの情報量を減らして、問題のある列のスキャン結果のみをDMUで表示することもできます。このためには、図6-29「スキャン結果のフィルタリング」に示すフィルタ・ドロップダウン・リストをクリックしてこれを開きます。問題ありオプションを選択すると、データ問題があるすべてのデータベース列が表示され、長さの問題ありオプションを選択すると、この項で説明されているデータ拡張の問題がある列のみが表示されます。
表レベルおよび列レベルでの列制限超過(スケジュール済)セルと型制限超過(スケジュール済)セルのゼロでないカウンタ値は、アクティブなリンクになっています。カウンタをクリックすると、DMUウィンドウのクライアント・ペイン内に図6-30「クレンジング・エディタ・タブ: 拡張問題」に示すようなクレンジング・エディタ・タブが開きます。このタブは、ナビゲータ・ペインまたはスキャン・レポート・ツリーで表ノードを右クリックして「クレンジング・エディタ」を選択しても開くことができます。
クレンジング・エディタ・タブに、対象となる表の内容が表示されます。デフォルトでは、長さ拡張の問題のあるデータ・セルは黄色の背景で表示されます。この色は、ツール・メニューから「プリファレンス」を選択すると開く「プリファレンス」ダイアログ・ボックスで変更できます。
問題のあるデータ・セルを特定するには、クレンジング・エディタの様々なフィルタリング機能および検索機能が役立ちます。これらの機能の詳細は、「データのフィルタリング」を参照してください。
クレンジング・エディタ・タブを開いた状態で、次の各項で説明されている報告された拡張問題のクレンジングを試行できます。
DMUで報告された問題のあるすべての表に対して、クレンジング・プロセスを繰り返します。スキャン・レポートまたは移行ステータス・タブに報告される問題がなくなったら、「データベースの変換」の説明に従って変換フェーズを開始できます。
列内の「列制限超過」の問題をクレンジングするには、次のオプションがあります。
列の長さを調整します。
列の長さセマンティクスをバイトから文字に変更します。
格納されている値を手動で短縮します。
変換中のDMUで値が切り捨てられるように設定します。
値を編集して、変換で拡張される文字を置換します。
より大きなデータ型に移行します。
どのクレンジング・アクションを選択するかは、クレンジング対象の表にアクセスするアプリケーションをユーザーが変更できるかどうかによって大きく左右されます。アプリケーションが自社で開発されていないなどの理由により自分でアプリケーションを変更できない場合、列の長さ調整、列の長さセマンティクスの変更、または別のデータ型への移行を行うと、バッファ・サイズやデータ・アクセス方法を変更後の列データ型に適応させるためにアプリケーション・コードを変更する必要があるため、このようなアクションは通常は実行できません。
列にアクセスするアプリケーションが拡張後の長さにあわせて自動的に適応される場合や、コード内の整然と定義された数箇所にわずかな手動変更を行うのみでよい場合は、列制限超過の問題に対処する方法として、列の長さの調整が最も効率的です。
列の長さを調整する手順は、次のとおりです。
列の長さを調整するには、クレンジング・エディタで列の任意のセルを右クリックしてコンテキスト・メニューを開きます。メニューで、「列変更のスケジュール」または「列の変更」を選択します。前者を選択すると、図6-31「列変更のスケジュール: 列サイズの長さ調整」に示すような列変更のスケジュール・ダイアログ・ボックスが開きます。後者を選択すると、列の変更ダイアログ・ボックスが開きますが、画面は変換から除外するオプションと変更なしオプションがないことを除けば同じです。
列変更のスケジュール・ダイアログ・ボックスでは、列に対して、移行プロセスの実際の変換フェーズになってから実行されるスケジュール済クレンジング・アクションを定義できます。このアクションは移行リポジトリに保存され、表の変換直前または変換中に表に適用されます。表はその時点まで変更されず、このアクションを定義してもデータベース内の現在の処理に影響はありません。変換時になってから、変更に適応させる新しいアプリケーション・バージョンをインストールする必要があります。
クレンジング・アクションを即時に実行する場合は、列の変更ダイアログ・ボックスを使用します。このダイアログ・ボックスで「適用」をクリックすると、DMUによって適切なSQL DLL文がデータベースに即時に送信されます。適用した変更をロールバックすることはできません。
列変更のスケジュール・ダイアログ・ボックスまたは列の変更ダイアログ・ボックスで列の長さを調整するには、「調整後の長さ」を選択し、変換後の列内のすべての値の最大長以上の値を新しい長さとして入力します。変換後の最大長は、列プロパティ・タブのスキャン・サブタブで報告されています。「列プロパティ」の項の「データベースのスキャン」を参照してください。
列の長さを調整するときは、ドロップダウン・リストの設定を「バイト」のままにしてください。「適用」をクリックします。
VARCHAR2列またはCHAR列の長さセマンティクスをバイトから文字に変更することは、列の長さ調整の特殊な形態です。列の長さセマンティクスを変更すると、データベースに対して、列に格納する値の制限を、文字のエンコーディングを構成する特定のバイト数ではなく特定の文字数にするように指定します。長さ制約はキャラクタ・セットとは無関係になります。データベースによって、文字長セマンティクスの各列の暗黙的なバイト制限値が、宣言された最大文字数を持つ文字値の最大可能バイト長に設定されます。この暗黙的なバイト制限値は、最大文字数をデータベース・キャラクタ・セットの文字コードの最大バイト数で掛けた値と等しくなります。
キャラクタ・セットの変換によって文字数は変わりません(ただし、ZHT16HKSCS31からの補完的なUnicode文字をUTF8の代替ペアに変換する場合は例外です)。したがって、nバイトに収まる文字数はn文字以下であるため、列の長さ制約がnバイトからn文字に変更されると、データベース・キャラクタ・セット変換後にすべての列値がこの制約に準拠します。暗黙的なバイト制限値は、データベース・キャラクタ・セット変更によって自動的に調整されます。ただし、この場合も文字値の最大長はそのデータ型(VARCHAR2の場合は4000バイト、CHARの場合は2000バイト)によって制限されることに注意してください。変換後にこの制限を超える値は、「型制限超過」として分類されます。このような値の処理については、「「型制限超過」の問題の処理」を参照してください。
Unicodeを処理できるようにアプリケーションを適応させるときにバイトでなく文字数で文字値制限を管理させる場合は、列の長さ調整ではなく文字長セマンティクスへの移行を選択してください。
長さセマンティクスを変更する手順は、次のとおりです。
列の長さセマンティクスを変更するには、前述の「列の長さの調整」の手順に従って、列変更のスケジュール・ダイアログ・ボックスまたは列の変更ダイアログ・ボックスを開きます。
まず、「調整後の長さ」ではなく「キャラクタ・セマンティクスへの移行」を選択します。
通常は必要ではありませんが、列を文字長セマンティクスに移行し、同時に宣言済の最大文字数を現在の宣言済の最大バイト数よりも大きくします。このためには、「調整後の長さ」を選択し、隣接するテキスト・フィールドに列の新しい文字制限値を入力して、ドロップダウン・リストから「文字」を選択します。
「適用」をクリックします。
列データ型を変更できない場合、格納されている文字値を、ターゲット・キャラクタ・セットへの変換後に拡張して列の長さ制限を超えることがないように変更する必要があります。これには次の3つの方法があります。
値を手動で短縮します。
変換中にDMUで値が自動的に短縮されるように設定します。
拡張する文字を拡張しない文字に置換します。
値を手動で短縮するには、「列制限超過」の問題があるセルの数が、操作を合理的な時間で完了できる程度の数であることが条件となります。値を手動で短縮する場合、クレンジングの結果を最もきめ細かく制御できますが、非常に時間がかかります。値の短縮は、家族の名前など、内容が正確に定義されているデータに対しては実行できないクレンジング・アクションです。
文字値を手動で短縮する手順は、次のとおりです。
クレンジング・エディタで黄色の背景でマークされている特定のセル内の文字値を短縮するには、そのセルをダブルクリックするか、右クリックしてコンテキスト・メニューから「データの編集」を選択します。図6-32「データの編集ダイアログ・ボックス」に示すように、編集対象の値を含むデータの編集ダイアログ・ボックスが表示されます。
データの編集ダイアログ・ボックスでは、編集対象の文字値の末尾部分(変換後に値が列の最大長を超える分)が黄色の背景でマークされています。したがって、黄色の背景が表示されなくなるまで値から文字を削除してください。また、「変換後の長さ(バイト)」に表示されている数字と「変換後の制限(バイト)」に表示されている数字を比較し、1つ目の数字が2つ目の数字以下になるまで文字を削除することもできます。
変更の準備ができたら、「OK」をクリックして新しい値を受け入れ、ダイアログ・ボックスを閉じます。新しい値はクレンジング・エディタに表示されますが、まだデータベースには格納されません。今度は、別のセルを編集できます。新しい値をデータベースに永続的に格納する場合は、クレンジング・エディタ・タブで「保存」をクリックします。「元に戻す」をクリックすると、最後の保存以降に行った変更を元に戻すことができます。
値の編集は常に、即時クレンジング・アクションです。手動での編集変更を、変換時になってから適用されるようにスケジュールすることはできません。
列のデータが履歴データであり、業務の目的に必要でなくなった場合や、重要な情報は常にセル値の先頭にのみ含まれている場合は、データが列の既存の長さ制約に準拠するように、変換中にDMUで値を自動的に切り捨てることを選択できます。この方法は、その結果がスキャン結果に反映されないため、クレンジング・アクションとはみなされません。ただし、DMUでは、データの変換可能性の問題によって変換を禁止するかどうかを決定する際に、ユーザーが自動切捨てを許可した列を無視します。
変換中に列値を切り捨てる手順は、次のとおりです。
列の既存の長さ制約に準拠するようにDMUで自動的に列値を切り捨てることを設定できます。手順は次のとおりです。
列プロパティ・タブを開きます。
準備状況サブタブを開きます。
例外データの変換を許可プロパティの値に「はい」を選択します。
列プロパティの設定の詳細は、第3章「DMUでのオブジェクト・プロパティの表示および設定」を参照してください。
列のデータ型の変更も列値の短縮もできない場合、拡張を回避する最後の手段として、拡張する非ASCII文字をASCII文字で置換します。次に例を示します。
改行なしスペース(ほとんどのシングルバイトISOおよびMicrosoft Windowsコード・ページでは0xA0)を標準のスペース(すべてのASCIIベース・キャラクタ・セットで0x20)で置換します。
スマート・クオーテーション・マーク文字('、'、"、"および„)をASCIIシングルクオーテーション・マーク(')およびダブルクオーテーション・マーク(")文字に置換します。
通貨記号を近似表現に置換します。つまり、¥ (円)はY、£ (ポンド)はLに、¢ (セント)はcになります。
Latin文字からアクセントを削除します(この操作後も許容可能な値になる場合)。
セル内の文字を置換するには、「手動での文字値の短縮」の説明に従って、データの編集ダイアログ・ボックスで文字を編集します。これは、編集するセルの数が少ない場合には有効です。多数のセル内の文字を置換する場合は、Oracle SQL Developerなどのデータベース・ツールを使用し、UPDATE SQL文をTRANSLATE関数とともに発行して、表内の関連するすべての文字を一度に置換します。
列にデータ型制限を超える値が含まれていない場合、列データ型の移行は必要ありません。ただし、このような値が将来発生すると予測される場合は、列データ型をより大きなデータ型に移行することを選択できます。次の選択項目があります。
CHAR列をVARCHAR2に移行します。
CHAR列をCLOBに移行します。
VARCHAR2列をCLOBに移行します。
LONG列をCLOBに移行します。
DMUでは、非推奨のLONGデータ型への移行をサポートしていません。
列データ型を移行する場合は通常、CHARとVARCHAR2の比較およびパディング・セマンティクスの違い、またはCLOB値の様々なフェッチ方法に対してアプリケーションを適応させるためにコードを変更する必要があります。
列のデータ型を移行する手順は、次のとおりです。
列のデータ型を移行するには、「列の長さ調整」の説明に従って、この列に対する列変更のスケジュール・ダイアログ・ボックスまたは列の変更ダイアログ・ボックスを開きます。次に、「調整後の長さ」を選択し、隣接するドロップダウン・リストからターゲット・データ型を選択します。ターゲット・データ型がVARCHAR2の場合、目的のターゲット長および長さセマンティクスを入力します。ターゲット・データ型がCLOBの場合、「プロパティ」をクリックしてCLOBのプロパティ・ダイアログ・ボックスを開きます。このダイアログ・ボックスで、CLOBセグメントの記憶域パラメータを入力できます。使用可能なオプションの詳細は、『Oracle Database SQL言語リファレンス』を参照してください。「適用」をクリックして、ダイアログ・ボックスを閉じてパラメータを保存します。
列変更のスケジュール・ダイアログ・ボックスまたは列の変更ダイアログ・ボックスで「適用」をクリックして、定義済のクレンジング・アクションを受け入れます。列の変更ダイアログ・ボックスを使用して即時にデータ型を移行することを選択した場合、移行後のデータ型がCLOBであると、移行する列データの量によっては、次の処理に長い時間がかかることがあります。
CHARからVARCHAR2に移行しても、CHAR値の末尾の空白は削除されません。空白を削除する必要がある場合は、Oracle SQL Developerなどのデータベース・ツールを使用し、UPDATE SQL文をRTRIM関数とともに発行します。
次の手順は、「型制限超過」のセルに関する問題を解決することです。列内の「型制限超過」の問題をクレンジングするには、次のオプションがあります(これらは、「列制限超過」の問題のクレンジングに使用できるオプションのサブセットです)。
より大きなデータ型に移行します。
格納されている値を手動で短縮します。
変換中のDMUで値が切り捨てられるように設定します。
値を編集して、変換で拡張される文字を置換します。
「「列制限超過」の問題」で説明されているように、どのクレンジング・アクションを選択するかは、クレンジング対象の表にアクセスするアプリケーションをユーザーが変更できるかどうかによって大きく左右されます。アプリケーションを自分で変更できない場合、より大きなデータ型に移行することはできません。
前述の使用可能なクレンジング・アクションを実行するために必要な手順は、「「列制限超過」の問題」を参照してください。
列変更のスケジュール・ダイアログ・ボックスまたは列の変更ダイアログ・ボックスで列クレンジング・アクションを定義した場合、またはデータの編集ダイアログ・ボックスで値を編集した場合、DMUでは、実行したクレンジング・アクションに基づいて結果が調整されるか、あるいはそれが不可能な場合はその列のスキャン結果が無効化されます。結果が無効化された場合は、列を再スキャンする必要があります。
スキャン結果をリフレッシュする手順は、次のとおりです。
列を再スキャンするには、スキャン・レポート・ツリーまたはナビゲータ・ツリーで列ノードを右クリックして、「スキャン」を選択します。この列のみがスキャン対象として選択された状態でスキャン・ウィザードが表示されます。
スキャン・パラメータを受け入れ、「完了」をクリックしてスキャンを開始します。
新しいスキャンでは、問題の分析中に、実行したばかりのクレンジング・アクションが考慮されます。列が適切にクレンジングされていれば、レポートの列制限超過(スケジュール済)列にその列の問題は報告されません。
スケジュール済クレンジング・アクションを定義した場合も、スキャン・レポート・タブのオプション・レポート列「列制限超過(スケジュール済)」(「データベースのスキャン」を参照)か、列プロパティ・タブのスキャン・サブタブに表示されたスキャン結果の現在のデータ列で、現在の表構造および内容の結果を確認できます。
データベース内のデータに無効な表現の問題がある場合、スキャン・レポートは「データベース・スキャン・レポートの概要」に示したような内容になりますが、レポート列「列制限超過(スケジュール済)」と「型制限超過(スケジュール済)」に加えて、あるいはそのかわりに、レポート列「無効な表現(スケジュール済)」にゼロでない値が表示されます。データベース・ノードの隣にある黄色い三角形のアイコンは、データに変換可能性の問題があることを示しています。
スキャン・レポートで長さ拡張の問題のある列を見つける場合と同様にして、無効なバイナリ表現の問題のあるセルを含む列を特定できます。詳細は、「データベースのスキャン」を参照してください。
セルの値に無効なバイナリ表現の問題があるということは、値が想定(宣言済)キャラクタ・セット(デフォルトではデータベース・キャラクタ・セット)で無効になることを意味します。値の一部のバイトが、宣言済キャラクタ・セットで有効な文字コードを構成しません。
値に無効なバイナリ表現がある場合、次の3つの理由が考えられます。
パススルー構成のアプリケーションで、バイナリ(純粋なテキストとして解釈されない値)が格納されています。最もよくある例は、イメージや固有のバイナリ形式のドキュメントがLONG列に格納される場合や、暗号化テキスト値(VARCHAR2結果を戻すDBMS_OBFUSCATION_TOOLKITプロシージャからの結果など)がVARCHAR2列に格納される場合です。
パススルー構成のアプリケーションで文字値が格納され、値がデータベース・キャラクタ・セットと異なる1つ以上のキャラクタ・セットでエンコードされています。最もよくある例は、US7ASCIIを使用するデータベースに各種のMicrosoft Windowsクライアント・キャラクタ・セットのデータが格納される場合や、各種のISO 8859データベース・キャラクタ・セットのデータが格納される場合です。
アプリケーションに、ソフトウェアの欠陥やハードウェアの障害で破損した文字コードを含む値が含まれています。
パススルー構成の詳細は、「データの無効なバイナリ記憶域表現」を参照してください。
特定の列に無効なバイナリ表現データがあり、その原因が3つのうちどれかを分析するには、この列の「無効な表現(スケジュール済)」のゼロでないカウンタ値をクリックして、この列のクレンジング・エディタ・タブを開きます。カウンタ値をクリックすると、DMUによって、DMUウィンドウのクライアント・ペインに、図6-33「クレンジング・エディタ・タブ: 無効なバイナリ表現の問題」に示すようなクレンジング・エディタ・タブが開きます。このタブは、ナビゲータ・ペインまたはスキャン・レポート・ツリーで表ノードを右クリックして「クレンジング・エディタ」を選択しても開くことができます。
問題のあるデータ・セルを特定するには、クレンジング・エディタの様々なフィルタリング機能および検索機能が役立ちます。これらの機能の詳細は、「データのクレンジング」を参照してください。
デフォルトでは、無効なバイナリ表現の問題があるデータ・セルはライト・コーラルの背景で表示されます。この色は、ツール・メニューから「プリファレンス」を選択すると開く「プリファレンス」ダイアログ・ボックスで変更できます。
拡張の問題の場合と同様に、無効なバイナリ表現の問題のあるセルをダブルクリックすると、図6-32「データの編集ダイアログ・ボックス」に示すようなデータの編集ダイアログ・ボックスが開きます。
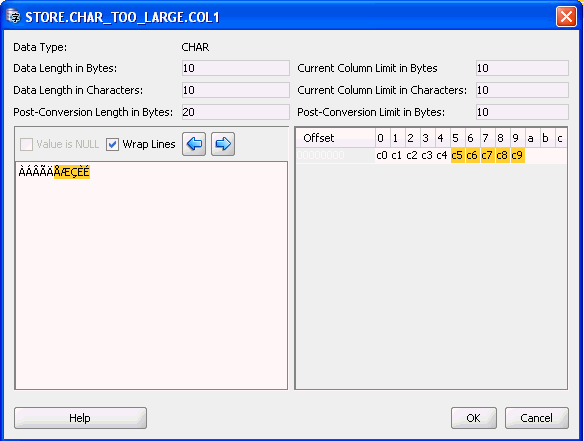
データの編集ダイアログ・ボックスの右下のペインに、バイナリ・データが表示されます。図6-34「データの編集ダイアログ・ボックス: バイナリ・データの表示」に示すように、編集対象の値を構成するバイトは2桁の16進文字で表示されます。
クレンジング・エディタ・タブとデータの編集ダイアログ・ボックスが開いた状態で、無効なバイナリ表現の問題の原因を特定し、次の各項で説明されている問題のクレンジングを試行できます。「スキャン結果のリフレッシュ」および「スケジュール済クレンジング・アクションの取消し」で説明されている考慮事項は、無効なバイナリ表現の問題のクレンジングにも同様に適用されます。
DMUで報告された問題のあるすべての表に対して、クレンジング・プロセスを繰り返します。スキャン・レポートまたは移行ステータス・タブに報告される問題がなくなったら、「データベースの変換」の説明に従って変換フェーズに進むことができます。
データの編集ダイアログ・ボックスの右下隅で、文字列に間違って格納されているバイナリ値を判別できます(このような値はダイアログ・ボックスの左下隅にガベージとして表示されているため)。ダイアログ・ボックスのバイナリ表示に0x00から0x08まで、および0x10から0x1fまでの範囲のバイトが多く表示されている場合、その値はバイナリです。これらのバイトは履歴目的のみでASCIIコントロール・コードに対応しているため、文字列に現れることはほとんどありません。
非常に長い一連のシングル・バイト(スペースを表すASCIIコードや、マイナス記号、プラス記号、アンダースコア、等記号、ピリオドなど、区切り線を引くために一般的に使用される文字を表すASCIIコードを除く)によって、バイナリ値であると判別できることもあります。
バイナリ値を格納する列に無効なバイナリ表現の問題がある場合、その問題をクレンジングするには、列のデータ型をRAWまたはLONG RAWに移行します。DMUでは、BLOBへの移行をサポートしていません。長さ2000バイトまでのCHAR列およびVARCHAR2列では、RAWへの移行がサポートされています。LONG列では、LONG RAWへの移行がサポートされています。
列をバイナリ型に移行する手順は、次のとおりです。
列をバイナリ・データ型に移行するには、クレンジング・エディタでその列の任意のセルを右クリックします。コンテキスト・メニューが表示されます。
メニューで、「列変更のスケジュール」または「列の変更」を選択します。前者を選択すると列変更のスケジュール・ダイアログ・ボックスが開き、後者を選択すると列の変更ダイアログ・ボックスが開きます。これらのダイアログ・ボックスの違い、および関連するクレンジング・モード(スケジュール・モードと即時モード)の違いについては、「列の長さの調整」を参照してください。
開かれるダイアログ・ボックス(図6-31「列変更のスケジュール: 列サイズの長さ調整」を参照)で「移行後の型」を選択し、隣接するドロップダウン・リストからターゲットのデータ型を選択します。ターゲットのデータ型がRAWの場合、目的の列の長さをバイト単位で入力します。この長さは、移行する列のすべての値の最大バイト長以上にする必要があります。
「適用」をクリックします。
データの編集ダイアログ・ボックスのバイナリ表示でそのバイナリ・データのバイト・パターン特性が明確になっていない場合、編集対象の値は、不適切に使用されているキャラクタ・セットの文字データである可能性があります。問題が疑われる場合は、アプリケーション開発者またはアプリケーション管理者に問い合せて、分析された列に格納されている情報のソースおよびタイプを特定してください。
不適切なキャラクタ・セット宣言を修正する手順は、次のとおりです。
列内のデータの実際のキャラクタ・セットを特定するために、クレンジング・エディタでその列を選択し、キャラクタ・セット・ドロップダウン・リストで、その列内のすべての値が判読可能になるまで、選択する値を繰り返し変更します。図6-35「想定列キャラクタ・セット」を参照してください。時間を節約するために、「移行の準備の確認」で推奨されているように、移行の開始前に収集した情報に基づいて、キャラクタ・セットをデータベースのデータ・ソース(クライアント、入力ファイル)で使用できるキャラクタ・セットに制限します。
試行したキャラクタ・セットのいずれでも列内のすべての値が正しく表示されないが、それぞれの値はいずれかのキャラクタ・セットで正しく表示される場合、その列には異なるキャラクタ・セットのデータが混在しています。このような問題は、DMU外部で解決する必要があります。
適切なキャラクタ・セットを特定した後は、クレンジング・エディタ・タブで「保存」をクリックして、それを永続的に列に割り当てます。その後、列を再スキャンします。その列には無効な表現の問題が報告されなくなるはずです。
列の想定キャラクタ・セットで判読できない列値はごくわずかであり、ある値では文字が判読できないのに別の値では判読できる場合、無効なバイナリ表現の問題は、ソフトウェアやハードウェアの障害によって文字値がランダムに破損したことが原因です。ソフトウェアの場合、アプリケーションがシングルバイト・アルゴリズムを使用してマルチバイト・データを処理していることが、マルチバイト・データベースにこのような破損が起こる一般的な理由です。このようなアプリケーションでは、マルチバイト文字の途中で文字列が分割されたり切り捨てられて、部分的に無効なコードが生成されることがあります。
ランダムに破損した値をクレンジングするには、「手動での文字値の短縮」の説明に従って、データの編集ダイアログ・ボックスで値を編集して修正します。