| Oracle® Database高可用性ベスト・プラクティス 12cリリース1 (12.1) E57730-02 |
|


 前 |
 次 |
この章では、Enterprise Managerを使用したシステムの監視、およびアプリケーション・スタックのすべての階層での高可用性環境の監視と維持に関するベスト・プラクティスを示します。
この章には、次の項目が含まれます。
ホスト、ネットワーク、データベース操作、アプリケーション、およびその他のシステム・コンポーネントを継続的に監視することで、問題を早期に検出できます。早期の検出により、問題を迅速に回避または解決できるため、ユーザーのシステム使用感が向上します。また、監視では、システムのパフォーマンス、拡大および再発する問題の傾向を示すシステム・メトリックを取得できます。この情報を使用して、予防対策の促進、セキュリティ・ポリシーの適用、およびジョブ処理の管理を行うことができます。データベース・サーバーでは、堅牢な監視システムで可用性を測定し、データベース・サーバーを使用不可能にする危険性のあるイベントを検出すると同時に、重大な障害については担当各所に即座に通知する必要があります。
監視システムは、それ自体が高可用性を保持し、監視対象のリソースと同じ運用ベスト・プラクティスと可用性プラクティスに準拠している必要があります。監視システムに障害が発生すると、すべての監視対象システムで診断データを取得することや管理者に問題を通知することができなくなります。
Enterprise Managerには、様々な通知オプションを備えた管理および監視機能が付属しています。環境の可用性およびパフォーマンスを監視する方法と、環境内の変化に対応してツールを使用する方法の推奨事項が含まれます。
Enterprise Managerの主なメリットは、ホスト・オペレーティング・システムからユーザー・アプリケーション(またはパッケージ・アプリケーション)までのアプリケーション・スタック全体で複数のコンポーネントを管理できることです。Enterprise Managerは、アプリケーションの各レイヤーをターゲットとして扱います。ターゲット(データベース、アプリケーション・サーバー、ハードウェアなど)は、同じタイプの他のターゲットとともに表示するか、アプリケーション・タイプごとにグループ化することができます。また、関連するターゲットを、高可用性コンソールから単一のビューで確認することも可能です(詳細は11.3.3項「高可用性コンソールを使用したデータベース可用性の管理」を参照)。各ターゲット・タイプには、特定のターゲットに関連する詳細情報のサマリーを含む、デフォルトで生成されるホームページがあります。異なるタイプのターゲットは、機能ごとに(つまり、同じアプリケーションをサポートするリソースとして)グループ化できます。
すべてのターゲットは、Oracle Management Agentによって監視されます。すべての管理エージェントは、任意のホスト上で稼働し、ターゲットのセットを監視対象とします。ターゲットは、管理エージェントが使用するホストとは別のホスト上にあってもかまいません。たとえば、管理エージェントでは、エージェントをネイティブにホストしないストレージ・アレイを監視できます。管理エージェントをホストにインストールすると、そのホストはマシン上の他のターゲットとともに自動的に検出されます。
さらにEnterprise Managerには、最大可用性アーキテクチャ(MAA)のベスト・プラクティス実装を支援するMAAアドバイザ(詳細は11.3.4項「MAAアドバイザを使用した高可用性ソリューションの構成」を参照)が用意されています。MAAアドバイザのページでは、大部分の停止タイプにOracleソリューションを推奨し、各ソリューションの利点を説明しています。
Oracle HA環境でのEnterprise Managerを使用したインフラストラクチャの監視に加えて、Oracle Auto Service Request (ASR)を使用して、特定のハードウェア障害の発生時にOracleのサーバー、ストレージ・システム、コンポーネントおよびEngineered Systemsの自動ケース生成を使用することにより、問題をより迅速に解決できます。詳細は、次の場所にあるMy Oracle Supportのノート1185493.1の『Oracle Auto Service Request』を参照してください。
https://support.oracle.com/rs?type=doc&id=1185493.1
|
関連項目: Enterprise Manager ArchitectureおよびOracle Management Agentの詳細は、Enterprise Manager Cloud Control概要を参照してください |
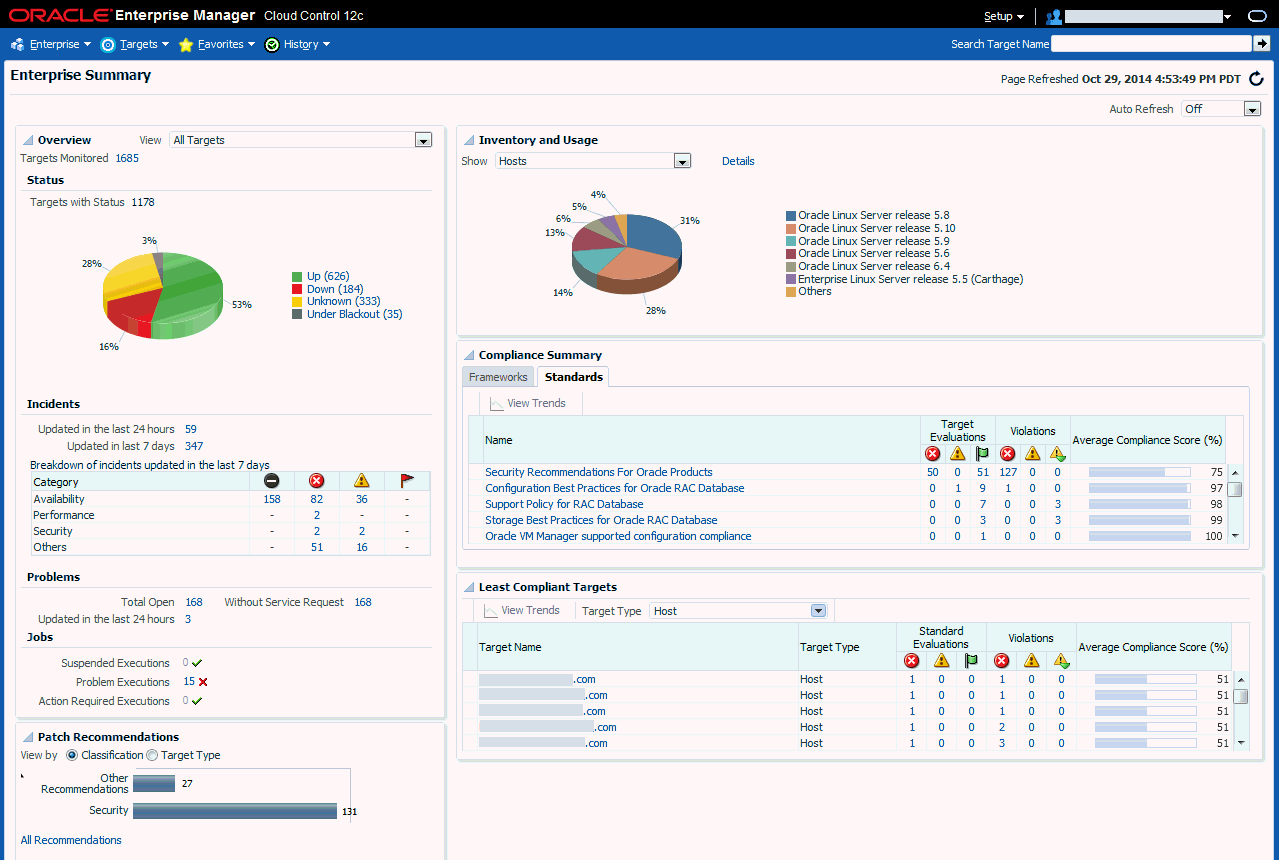
管理者は、Enterprise Managerの「ホーム」ページを選択してロールに基づいた最適な情報を表示できます。すべての検出されたターゲットの可用性を示す図11-1に示されている「エンタープライズ・サマリー」ページなどの一連の提示されたページから選択します。管理者はホーム・ページとしてEnterprise Managerの任意のページを選択することもできます。
「エンタープライズ・サマリー」ページでは、クリティカルのインシデントや失敗したジョブから推奨パッチやコンプライアンス違反に至るまで、可用性に影響を与える可能性がある様々な領域にわたるロールアップ情報が結合されたビューを管理者に提供し、詳しく分析するための関連する詳細へのドリルイン、クリティカルの問題に対するアクションの実行、可用性を確保するための環境の予防的なメンテナンスを可能にします。
すべてのターゲットを対象とする現在の可用性のスナップショット。「ステータス」円グラフにより、管理者は、使用可能なターゲット(「稼働中」)、使用不可能なターゲット(「停止中」)、コンソールとの通信が途絶えているターゲット(「不明」)、または特にメンテナンス操作などの理由で監視が一時停止状態になっているターゲット(ブラックアウト中)を即座に判別できます。いずれかのステータスをクリックするとその状態のターゲットのリストにドリルダウンし、さらに個別のターゲットにドリルインして分析および修正処理を行います。
監視対象システム全体で認識されているインシデント数と問題数の概要。リンクをクリックするとドリルダウンし、適合するインシデントがインシデント・マネージャに表示されます。管理者は、「エンタープライズ」、「モニタリング」、「インシデント・マネージャ」の順に選択するか、[Ctrl]+[Shift]+[I]を押すと、Enterprise Managerページから直接インシデント・マネージャにアクセスできます。
全Enterprise Managerジョブの一時停止中の実行、問題のある実行(停止中または失敗)および必要なアクション実行の数。ステータス・グループの隣にある数をクリックすると、それぞれのジョブのリストが表示されます。
分類またはターゲット・タイプ別に表示可能なパッチ推奨。ドリルダウンすると、選択したパッチ・セットの詳細が「パッチと更新版」ページに表示されるか、すべての推奨が表示されます。
すべての管理対象ターゲットのコンプライアンス基準評価の結果、重大度、関連する違反の合計数を含む、コンプライアンス・フレームワークおよびコンプライアンス基準別に表示されるコンプライアンス・サマリー。ドリルダウンすると「コンプライアンス・レポート」ページが表示され、違反のソースとタイプが判明します。
コンプライアンス基準評価の結果、重大度、関連する違反の合計数を含む、選択したターゲット・タイプ別の最も準拠していないターゲットのビュー。ドリルダウンすると、違反のソースとタイプが判明します。
次の項では、ベスト・プラクティス、構成の推奨およびこれらの機能に関する追加情報への関連リンクについて説明します。使用する環境のビジネス・ニーズおよび詳細にあわせて監視を調整することで、このページに表示されるデータにより、管理者は効率的に環境の可用性を管理できます。
これらの機能の使用可能性は、Enterprise Managerシステム自体の可用性の確保に依存します。Enterprise Managerシステムの可用性を確保するためのEnterprise Managerの構成、操作および診断のベスト・プラクティスについては、My Oracle Support Note (Doc ID 1940179.1)の『EM Operational Considerations and Troubleshooting Whitepaper Master Index』を参照してください。
|
関連項目: My Oracle Support Note (Doc ID 1940179.1)の『EM Operational Considerations and Troubleshooting Whitepaper Master Index』 |
Enterprise Managerは問題の監視、管理および解決に対して包括的なアプローチを行い、イベント管理、インシデント管理および問題管理の3つのレベルにプロセスを編成します。
イベントは何か管理対象ターゲットで発生したことを示し、多くの場合、何か異常なことが発生したことを示します。イベントの例としては、メトリック・アラート、可用性アラート、コンプライアンス違反、ジョブ・イベントなどがあります。
インシデントは、ビジネスへのイベントの潜在的な影響のため、ともに管理する必要がある1つ以上の重大なイベントで構成されています。インシデントの解決は、ビジネスへの影響の軽減に重点が置かれます。インシデントは自動または手動で作成され、インシデント・マネージャで管理されます。
問題はインシデントの根本原因です。問題の解決は、根本原因の解決に重点が置かれます。管理者は、サポート・ワークベンチを使用して自動診断リポジトリ(ADR)からの詳細を用いてOracleサポートで問題のサービス・リクエスト(SR)をオープンし、インシデント・マネージャで問題を管理します。
インシデント・ルール・セットおよびインシデント・ルールでは、Enterprise Managerがイベント、インシデントおよび問題に対して行う自動アクションの方法を指定します。ルール・セットには、エンタープライズ・ルール・セットとプライベート・ルール・セットの2つのタイプのルール・セットがあります。エンタープライズ・ルール・セットでは完全なアクション・セットを指定しますが、プライベート・ルール・セットでは所有者に対して電子メール通知を送信することしかできません。エンタープライズ・ルール・セットは順番に評価され、複数のパスで評価されることもあり、プライベート・ルール・セットより先に評価されます。イベントに対して作成されるインシデントは1つのみであるため、順番は重要です。イベントと一致する最初のルールがインシデントを作成するルールです。ワークフローまたは通知アクションを指定した一致ルールがそれぞれ実行されます。イベントに対して複数の一致ルールがある場合、実行される最後のルールにより優先度、割当てなどの最終値が決定され、管理者は同じイベントについて複数の通知を受信することがあります。ルール・セットおよびルールは有効化および無効化できます。
メトリック・アラートおよび可用性アラートは、複数の要因の組合せにより生成され、特定のメトリックに対して定義されるイベントのタイプです。メトリックは管理エージェントにより調査されてOracle Management Repositoryに送信されるデータ・ポイントで、ターゲットの状態を判別します。可用性アラートは、簡易ハートビート・テストによるコンポーネントの可用性の評価である場合があります。メトリック・アラートは、特定のパフォーマンス測定(ディスク・ビジーまたは特定の待機イベントを待機するプロセスの割合など)の評価である場合があります。
どのメトリックでも、エラー、警告、クリティカルおよびクリアという4つの状態をチェックできます。管理者は、次のようなポリシーを決定する必要があります。
どのオブジェクトを監視するか(データベース、ノード、リスナー、またはその他のサービス)。
何を計測対象として調査するか(可用性、CPUビジー割合など)。
どの程度の頻度でメトリックを調査するか。
事前定義されたしきい値をメトリックが超えたときに何を実行するか。
これらすべての項目は、システムのビジネス要件に基づいて決定します。たとえば、すべてのコンポーネントで可用性を監視する場合でも、一部のシステムは業務時間中にのみ監視することが可能です。特定のパフォーマンス問題のあるシステムでは、問題をデバッグするために、追加のパフォーマンス・トレース機能を有効化できます。
インシデント・ルールでは、メトリック・アラートなどのイベントに対するアクションを実行したり、すべてのターゲット、特定のタイプのターゲット、特定のグループのターゲットまたは個々のターゲットに対する操作を定義できます。たとえば、管理者は、データベース・ターゲットの可用性を監視して、データベースに障害が発生した場合は電子メール・メッセージを生成するインシデント・ルールを作成できます。インシデント・ルールを有効化すると、すべての既存のデータベースと今後作成されるデータベースに対して評価されます。これらのルールにアクセスするには、「設定」に移動し、インシデントを選択して「インシデント・ルール」を選択します。
ルールでは、サービス可用性に影響する可能性のある問題など、即座に対処する必要のある問題や、Oracleエラーまたはアプリケーション・エラーを監視します。サービス可用性は、アプリケーション・スタックの任意のレイヤー(ノード、データベース、リスナー、重大なアプリケーション・データなど)の停止によって影響を受けます。データベースに接続できない、またはアプリケーション機能に不可欠なデータにアクセスできないなどのサービス可用性の障害については、迅速に特定してレポートを確認し、問題に対処する必要があります。アーカイブ・ログ・ディレクトリが一杯であるなど、サービス停止につながる可能性のある問題も、システム停止を避けるために適切に対処する必要があります。
Enterprise Managerには、可用性を監視するための強力な開始フレームワークを提供するデフォルトのインシデント・ルールが用意されています。Oracleのデフォルトのインシデント・ルール・セットは変更できませんが、即時使用可能なインシデント・ルール・セットの独自のコピーを作成して、個々のサイトのポリシーと適合するようにルールを変更することができます。サイト固有のターゲットまたはアプリケーションに対するインシデント・ルールで構成されるインシデント・ルール・セットを作成することもできます。また、特定の時間間隔でユーザーに通知する通知スケジュールを構成して自動カバレージ・ポリシーを作成できます。
次の4つの論理カテゴリを使用して、インシデント・ルールを管理するための戦略を実装します。
高可用性
場合に応じて、ミッション・クリティカルのシステムの可用性に重点を置くエンタープライズ・ルール・セットを作成します。識別するメトリックが警告またはクリティカルのしきい値を超えた場合、管理者に通知します。ルール・セットに指定したインシデントの作成が優先するようにするには、Oracleの即時利用可能なルール・セットより上にルール・セットを配置します。
キー・パフォーマンス・インジケータ
場合に応じて、システム全体のパフォーマンスおよびスループットを表すキー・パフォーマンス・インジケータに重点を置くエンタープライズ・ルール・セットを作成します。識別するメトリックが警告またはクリティカルのしきい値を超えた場合、管理者に通知します。確実に必要なサービス・レベルが達成されるように監視します。高可用性ルール・セットによって作成されないが、即時利用可能なルール・セットに優先する場合、ルール・セットに指定したインシデントの作成が発生するようにするには、Oracleの即時利用可能なルール・セットより上に、高可用性ルール・セットより下にルール・セットを配置します。
ADRインシデント
Oracleの即時利用可能によって自動的に作成されるADRインシデントを使用します。場合に応じて、前述のカテゴリのルール・セットにこれらのインシデントの通知を組み込んで、関連するインシデントや操作エラーを管理者に通知します。必要な場合、追加のエラー監視に対応するために「DBアラート・ログ」メトリックを有効化します。
管理者の選択
各管理者が個々の管理者によって管理されるプライベートなルール・セットを作成して、最も関心があることを決定します。正常に管理および運用するための詳細やインサイトを提供したり、より深い調査、より長い期間、または夜間に管理者を起こす必要がない、より優先度が低い問題に対応することに重点を置きます。これらのルールはより頻繁に変更できます。
次に例を示します。ミッション・クリティカルのシステムの一部であるデータベースの高速リカバリ領域がいっぱいになろうとしています。FRAの十分な領域を確保することは、可用性には不可欠です。データベースは、高可用性ルール・セットに関連付けられているターゲットのグループに関連付けられています。ルール・セットには「リカバリ領域空き領域(%)」メトリックのタイプ「メトリック・アラート」イベントを評価するルールが含まれ、管理者に電子メール通知が送信されます。ルールは重大度が警告またはクリティカルであるかどうかを評価するよう構成され、適切な方法で適切な通知が送信されます。Enterprise ManagerによりFRAが警告のしきい値を超えたことが検出されると、タイプ「メトリック・アラート」のイベントが発生します。高可用性ルール・セットのルールが評価されます。Enterprise ManagerはFRAのルールを処理する際に、「メトリック・アラート」イベントの重大度が警告であることを判別し、FRAが警告のしきい値を超えた場合に、標準の電子メール・アドレスで管理者に電子メールを送信するようにアクションが指定されていたため、標準の電子メール・アカウントで管理者に電子メールを送信します。FRAがクリティカルのしきい値を超えた場合、ルール・アクションにより管理者のページャ・アドレスに電子メールが送信されます。ほとんどのメトリックとは異なり、「リカバリ領域空き領域(%)」の警告およびクリティカルのしきい値は編集できません。別のしきい値が必要な場合は、メトリック拡張を作成できます。
次のベスト・プラクティスを使用します。
エンタープライズ・ルール・セットを作成する場合、カスタム・ルール・セットが先に起動するように、Oracleの即時利用可能なインシデント・ルール・セットより上にそれらを配置します。
監視テンプレートを使用して、各ターゲット・タイプにメトリックを構成します。これにより、環境内の同様のターゲットに対してメトリックを標準化できます。異なる環境(開発、本番など)および異なるアプリケーションまたはハードウェア構成(記憶域領域または処理の違いでしきい値が異なる場合など)において、同じターゲット・タイプに別のテンプレートがあることがあります。
管理グループとテンプレート・コレクションを使用して、監視テンプレートが管理グループに追加されたターゲットに自動的に適用されるようにします。これにより、監視テンプレートをターゲットに手動で適用する必要がなくなります。
メトリックのしきい値が高可用性の要件にあうように、各環境の各ターゲット・タイプに適切に設定されていることを確認してください。表11-1、表11-2、表11-4および表11-5におけるメトリックのしきい値の設定について検討します。監視頻度は、各コンポーネントの品質保証契約(SLA)に基づいて決定します。
主なメトリック・アラートおよびターゲットの可用性イベントに基づいて、各環境で適切に管理者に通知するインシデント・ルールを作成します。
ビーコン機能を使用して、個々のアプリケーションのパフォーマンスを追跡します。ビーコンを設定すると、通常のアプリケーション作業のかわりとなるユーザー・トランザクションを実行できます。Enterprise Managerでは、このトランザクションのレスポンス時間を分析用のコンポーネントに分割します。また、このトランザクションの実行時間が事前定義済の制限値を超えた場合、アラートを起動できます。
電子メールでメッセージを受信できるページャ、携帯電話またはモバイル・デバイスを持つ管理者も対して複数の電子メール・アドレスを構成します。これらのデバイス用の電子メール・アドレスを使用するページャの電子メール・タイプおよび標準の電子メール・アドレス用の電子メールの電子メール・アドレスを使用します。クリティカル通知ができるだけ早く受信されるように、インシデント・ルール内の「ページ」フィールドに管理者を追加して、これらのデバイスに関連付けられている電子メール・アドレスにクリティカル・アラートの通知を送信するか、「電子メール宛先」フィールドに管理者を追加して、標準の電子メール・アドレスに警告イベントの通知を送信することで、クリティカル・メッセージと警告メッセージを区別します。
通知を送信する場合、通知メソッドを追加して各インシデントでそれらを使用します。デフォルトでは、潜在的な問題について管理者にアラートを送信する最も簡単な方法は、前述の電子メールを送信することです。この通知メソッドを拡張するため、電子メール以外の方法でアラートを送信するSNMPトラップまたはオペレーティング・システム・スクリプトへのコールアウトを追加できます。これにより、電子メール・システムのコンポーネントが停止した場合に問題が発生することを回避できます。「Enterprise Manager」ページの上部にある「設定」リンクを使用して、スクリプトとSNMPv1トラップの「通知メソッド」を選択するか、「SNMPv3トラップ」を選択して、追加の通信メソッドを設定します。
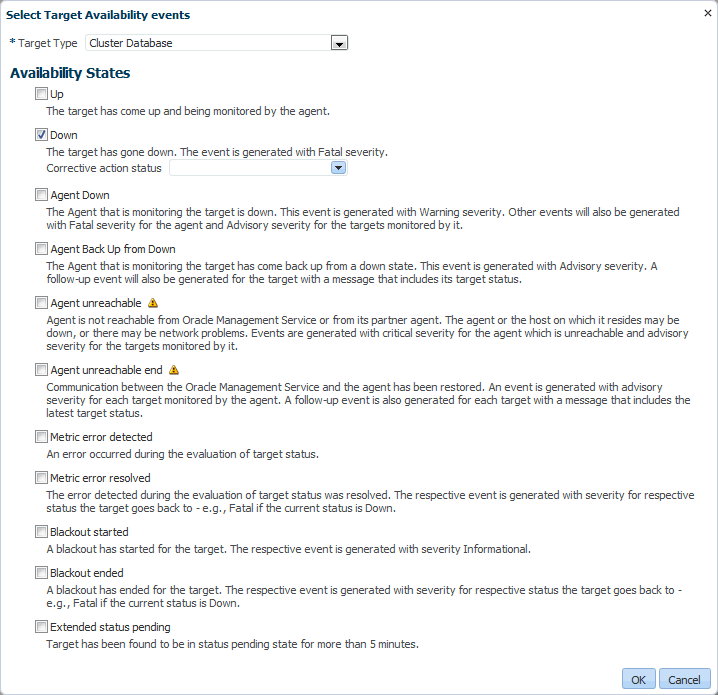
ターゲットの可用性の計算でエラーが発生した場合に、管理者に通知するようインシデント・ルールを作成または変更します。「ターゲット可用性」タイプのルールの編集または作成時に、「ターゲットの可用性イベントを選択」フォームのターゲット・タイプの「可用性状態」で「メトリック・エラー検出」を選択します。これにより、コンポーネントの可用性の誤った読取りが発生することもありますが、システム管理者にとって最高度の通知レベルが保証されます。このオプションを選択できる「ターゲットの可用性イベントを選択」フォームの例である図11-2「可用性のインシデント・ルールの設定」を参照してください。
|
関連項目:
|
図11-2は、「クラスタ・データベース」の可用性状態で「停止中」オプションが選択されている「ターゲットの可用性イベントを選択」ページを示しています。
サービス停止の原因となる可能性のある領域管理の条件は、表11-1のメトリックを使用して監視します。
表11-1 領域を監視するための推奨事項
| メトリック | 推奨事項 |
|---|---|
|
表領域使用率(%) |
このデータベース・レベルのメトリックを設定すると、各表領域の使用可能な領域の使用率(%)をチェックできます。クラスタ・データベースでは、このメトリックは、メンバー・インスタンス単位ではなく、クラスタ・データベース・ターゲット・レベルで監視されます。このメトリックを使用する場合、管理者は、Enterprise Managerがテスト対象とするしきい値の割合と、メッセージを管理者に生成および送信する前に検出を必要とするエラーの発生数を選択できます。使用済領域の割合がしきい値の引数で指定された値を超えると、警告アラートまたはクリティカル・アラートが生成されます。 デフォルト設定は、85%を警告、97%を領域使用率のクリティカルしきい値とすることをお薦めしますが、これらの値はシステムの使用状況に応じて適切に調整してください。また、このメトリックは、特定の表領域を監視するようカスタマイズできます。 注意: 「ジョブ・ライブラリ」には次の名前のEnterprise Managerジョブがあります。
このジョブは、すべての Database Plugin 12.1.0.6以降、TEMPおよびUNDO表領域の監視は、2つの新しいメトリック「表領域使用率(%) (一時)」と「表領域使用率(%) (UNDO)」に分かれました。詳細は、https://support.oracle.com/CSP/main/article?cmd=show&type=NOT&id=1927636.1にあるMy Oracle Support Note (Doc ID) 1927636.1の『Testing and Troubleshooting the 'Tablespace Space Full (%)' metric in Enterprise Manager 12.1.0.4』を参照してください。 |
|
ダンプ領域使用率(%) |
このメトリックを設定すると、ダンプ出力先ディレクトリを監視できます。最初にエラーが発生したときに最大量の診断情報を保存するためには、ダンプ領域が使用可能である必要があります。設定は、70%で警告、90%でエラーとすることをお薦めしますが、これらの値はシステムの使用状況に応じて調整してください。 このメトリックは、「ダンプ領域」メトリック・グループで設定します。 |
|
リカバリ領域空き領域(%) |
これは、15分ごと、またはファイル作成時のいずれか早い方の時点で、サーバーにより評価されるデータベース・レベルのメトリックです。このメトリックは、アラート・ログにも出力されます。クラスタ・データベースでは、このメトリックは、メンバー・インスタンス単位ではなく、クラスタ・データベース・ターゲット・レベルで監視されます。 クリティカルのしきい値は3%未満、警告のしきい値は15%未満に設定されます。これらのしきい値はカスタマイズできません。アラートの最初の発生時にアラートが返され、使用可能な領域が15%を超えるまでアラートは消去されません。 |
|
ファイル・システム空き領域(%) |
デフォルトでは、このメトリックはデフォルトの警告のしきい値20%およびクリティカルのしきい値5%を使用するホストのファイル・システムを監視します。ファイル・システムで個別にしきい値を設定できます。 |
|
アーカイブ領域使用率(%) |
アーカイブ領域保存先で使用されている領域の割合を返すには、このメトリックを設定します。各アーカイブ領域保存先で個別にしきい値を設定できます。使用済領域がしきい値引数で指定したしきい値を超えると、警告アラートまたはクリティカル・アラートが生成されます。 共有アーカイブ領域を使用しないクラスタ・データベースを監視する場合、クラスタ・データベース・レベルでこのメトリックを無効化し、データベース・インスタンス・レベルでこのメトリックを有効化します。 データベースが データベースが高速リカバリ領域にアーカイブするようを構成されている場合、このメトリックは適用できません。かわりに、高速リカバリ領域を監視する「リカバリ領域空き領域(%)」メトリックを使用します。 |
Enterprise Manager 12cでは、データベース・アラート・ログを監視するメカニズムは、サポート・ワークベンチと緊密に統合されており、レポートされる各問題またはインシデントに対してパッケージを生成し、それらをサポートに迅速にアップロードできるという利点があります。
サポート・ワークベンチとの統合の一環として、エラーは様々なクラスとグループに分類され、それぞれ異なるメトリックによって処理されます。最上位レベルの分類には、インシデントおよび操作エラーという2種類のエラー・クラスがあります。
インシデントは、データベース・アラート・ログ・ファイルに記録されるエラーであり、監視されているデータベースでクリティカル・エラー条件が検出されたことを示します。たとえば、クリティカル・エラー条件には、一般的な内部エラーやアクセス違反があります。
操作エラーは、データベース・アラート・ログ・ファイルに記録されるエラーであり、監視されているデータベースでデータベースの操作に影響する可能性のあるエラーが検出されたことを示します。たとえば、操作エラーには、アーカイバのハングやメディア障害があります。
Enterprise Managerは、これらのインシデントおよび操作エラーに対してクリティカル・イベントを自動的に作成します。これらのイベントが監視ニーズに対して十分ではない場合、メトリックの2つのカテゴリのいずれかを使用して、テキスト・アラート・ログを監視する11gより前の古い手法を使用した追加のメトリック・セットに対して警告およびクリティカルしきい値を構成することで拡張できます。これを行うには、無効化されたDatabase Plugin 12.1.0.4以上のDBアラート・ログ・メトリックのグループ・メトリック、または無効化された以前のリリースのアラート・ログ・メトリックのグループ・メトリックを有効化します。
DBアラート・ログまたはアラート・ログ・メトリックを使用する場合、管理者が無視する必要があると判断したエラーがEnterprise Managerでメトリック・アラート・イベントを発生させないように、管理者はアラート・ログ・フィルタ式をメンテナンスできます。これを行うには、アラート・ログ・フィルタ式を編集します。アクセスするには、使用する手法に応じて、「データベース・ターゲット」メニュー、「モニタリング」、「メトリックおよび収集の設定」の順にナビゲートし、DBアラート・ログまたはアラート・ログの下の一般的なアラート・ログ・エラーの右にある編集アイコンをクリックします。
|
注意: Enterprise Manager 12cのアラート・ログの監視の詳細は、次の場所にあるOracle Support Note 1538482.1の『Database Alert log monitoring in 12c explained』を参照してください
Database Plugin 12.1.0.4のアラート・ログの監視に対する変更の詳細は、次の場所にあるMy Oracle Support Note (Doc ID) 1587020.1の『Changes to Alert Log Monitoring in Database Plugin 12.1.0.4』を参照してください
|
処理容量を超えることがないようシステムを監視します。これらのメトリックの警告とクリティカルのしきい値は、表11-2の推奨事項に従って、システムの使用パターンに基づいて変更する必要があります。
表11-2 処理容量を監視するための推奨事項
| メトリック | 推奨事項 |
|---|---|
|
プロセス制限使用率(%) |
このメトリックのしきい値を設定すると、現在のプロセス数が |
|
セッション制限使用率(%) |
このメトリックのしきい値を設定すると、インスタンスがデータベースに許可されている同時接続の最大数に接近したときに警告を生成できます。 |
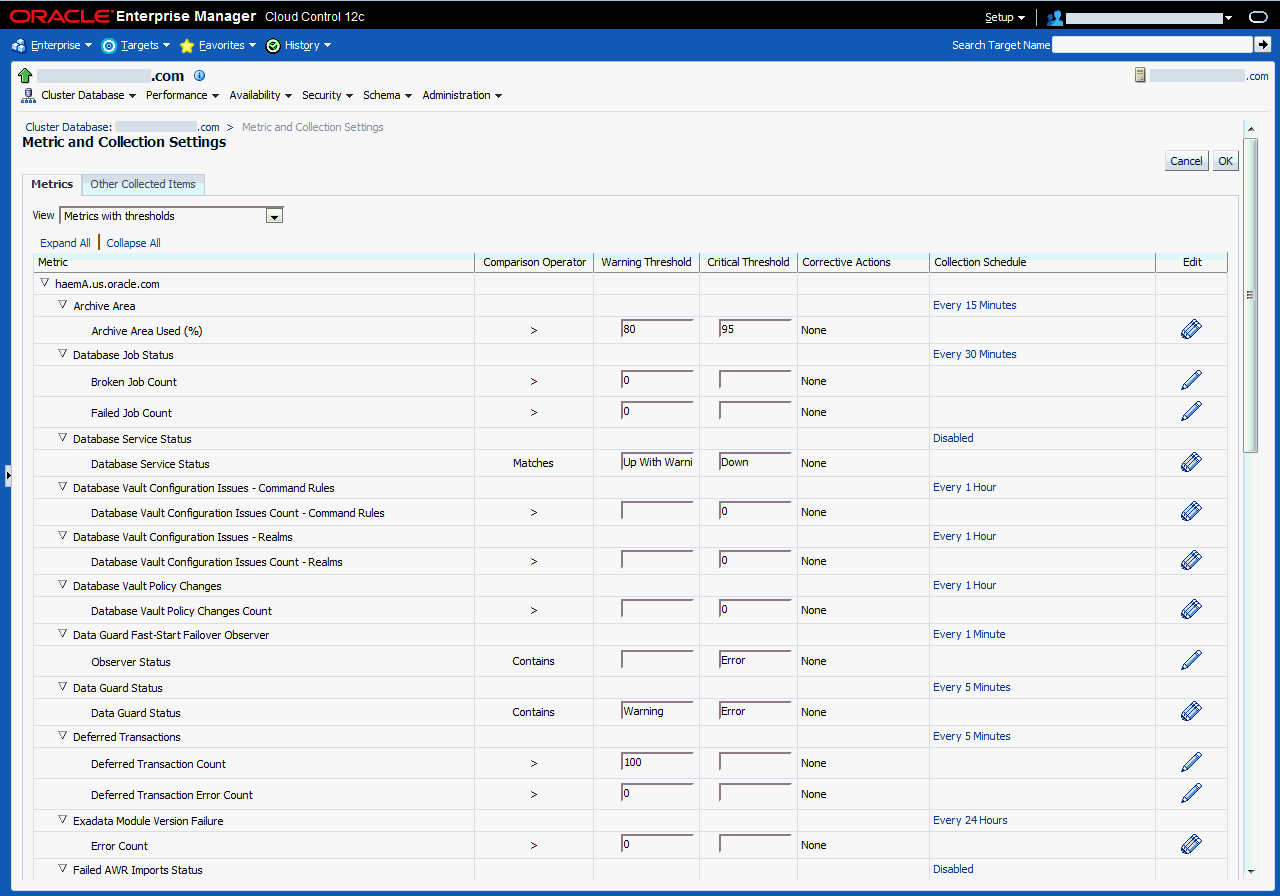
図11-3は、メトリックを設定および編集するための「メトリックと収集設定」ページを示しています。ドキュメント・ライブラリには、すべてのメトリックの完全なリファレンス情報が含まれています。特定のメトリックに関するリファレンス情報にアクセスするには、ドキュメント・ライブラリの検索機能を使用してください。
|
関連項目:
|
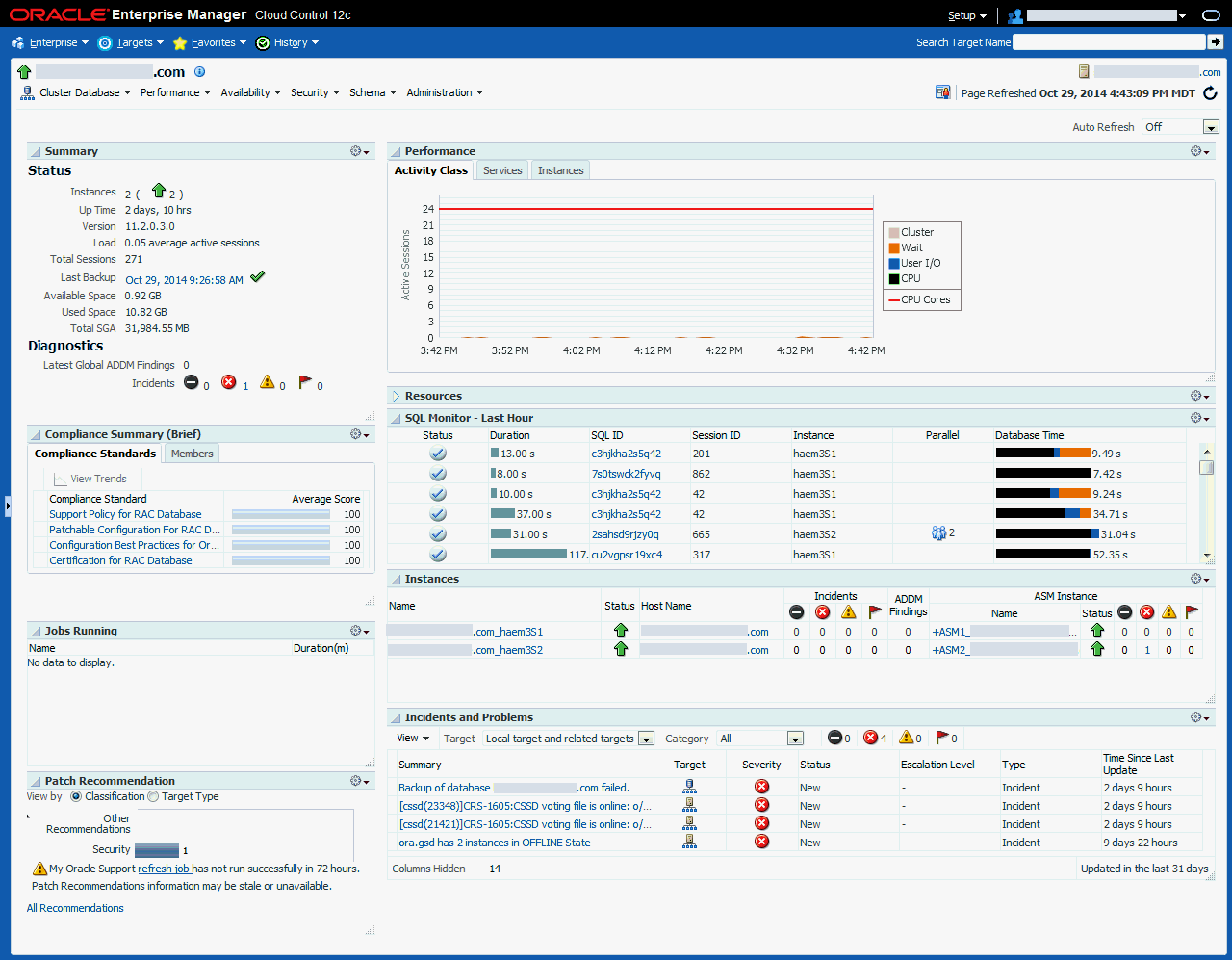
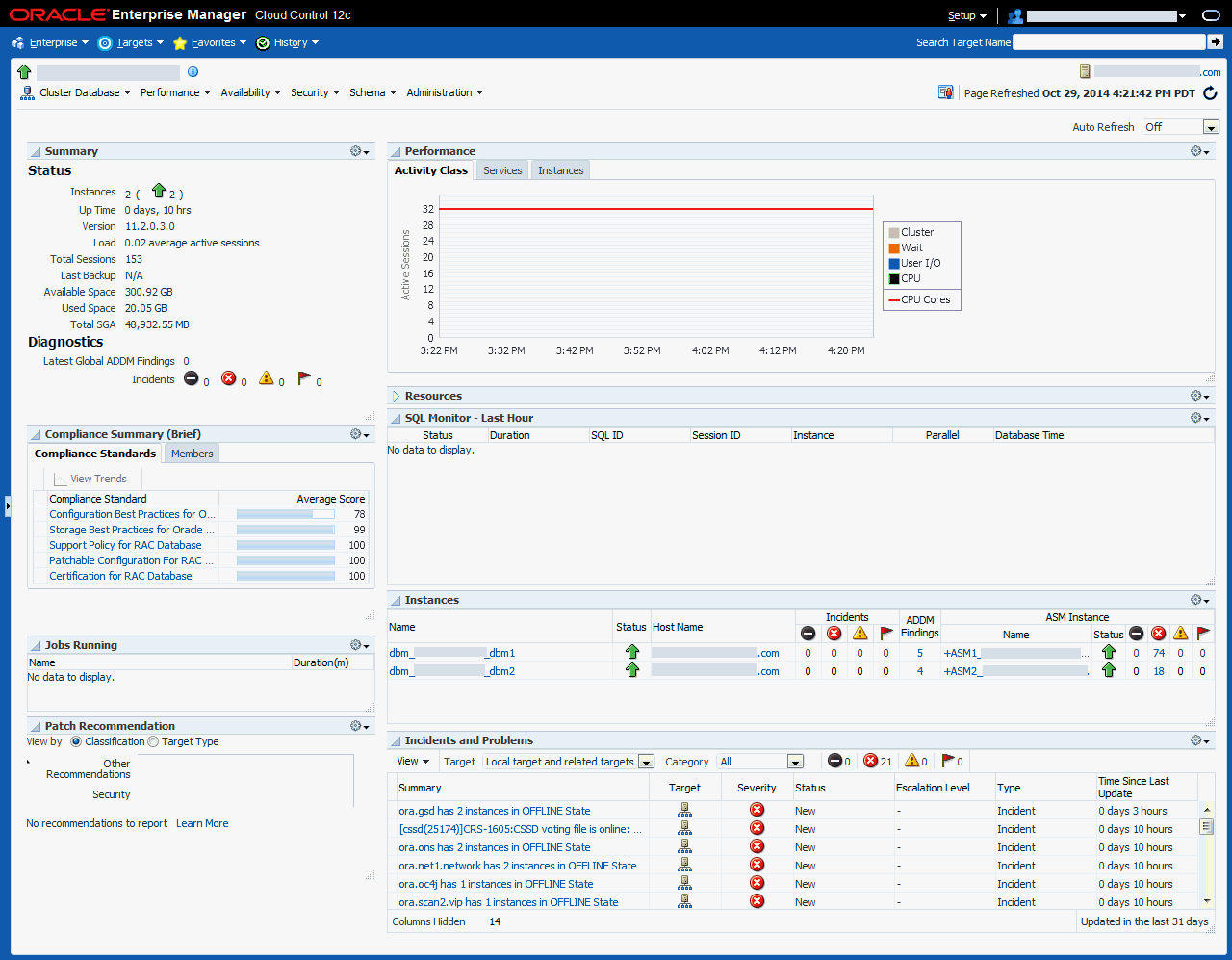
図11-4のデータベース・ターゲットの「ホーム」ページでは、システム・パフォーマンス、領域の使用量、およびバックアップ・レポートへのリンクが付いた最終バックアップの日付、時間およびステータスなどの可用性にとって重要な情報が示されています。
図11-4に示すように、「インシデントと問題」表にターゲットの最新のインシデントと問題が表示されます。「サマリー」列のリンクをクリックすると、インシデントと問題の詳細が表示されます。
パフォーマンス分析とパフォーマンス・ベースライン
Enterprise Managerのデータベース・ターゲットのメトリックの多くは、パフォーマンスに関連します。パフォーマンス品質保証契約に到達しないシステムは、高可用性システムの要件を満たしません。パフォーマンスの問題が大規模なシステム停止の原因となることはまれですが、それでも顧客の一部に対するサービスを停止させる可能性があります。このタイプの停止は、一般的にアプリケーション・サービス低下と呼ばれます。サービス低下の主な原因は、1つ以上のインフラストラクチャ・コンポーネントの断続的または部分的障害です。ITマネージャは、インフラストラクチャ・コンポーネントの稼働状況(レスポンス時間、待機時間および可用性)と、エンド・ユーザーに提供されるアプリケーション・サービスの品質に対するこれらのコンポーネントの影響を把握しておく必要があります。
品質保証契約を満たす通常の動作から導出されたパフォーマンス・ベースラインは、パフォーマンス・メトリック・アラートの構成要素を決定します。ベースライン・データは、アプリケーションを本番稼働する初日から収集し、次の項目を含む必要があります。
アプリケーション統計(トランザクション量、レスポンス時間、Webサービス時間)
データベース統計(トランザクション率、REDO速度、ヒット率、上位5位の待機イベント、上位5位のSQLトランザクション)
オペレーティング・システム統計(CPU、メモリー、I/O、ネットワーク)
Enterprise Managerを使用して、データベース・パフォーマンスのベースライン・スナップショットをキャプチャし、自動ワークロード・リポジトリ(AWR)ベースラインを作成できます。使用する環境で実行可能な場合は、AWR保存期間を増やすことをお薦めします。出発点として30日をお薦めします。Enterprise Managerは、これらの値をシステム・パフォーマンスと比較し、結果を「データベース・ターゲット」ページに表示します。基準のベースラインから値が大きく逸脱した場合に、アラートを送信することも可能です。自動ワークロード・リポジトリの詳細は、「自動パフォーマンス・チューニング機能の使用」を参照してください。
ある顧客システムに特定のしきい値を設定するために使用できる式はありません。しきい値は、値の変動を考慮して、メトリックの通常運用の値より数パーセント上の値を使用して決定される必要があります。変動によっては、1つの出発点としてベースライン値を取得して、1.15を掛けて警告のしきい値に設定し、1.25を掛けてクリティカルのしきい値に設定することができます。システムごとに値がそれぞれ異なるため、重要なのは、通常運用時にべ―スラインに関連付けられたシステムとパフォーマンス・データを理解し、候補値を設定して監視し、必要に応じて調整することです。システムの動作は時間の経過とともに、使用パターン、システム・ボリューム、ハードウェアおよびソフトウェアの更新など、様々な理由で変更される可能性があるため、システムのベースラインとしきい値は定期的に再評価する必要があります。
必要に応じて、すべてのデータベース・ターゲットに対して表11-3に示したメトリックにしきい値を設定し、インシデント・ルールに組み込んで通知を提供します。
表11-3 パフォーマンス関連メトリックに関する推奨事項
| メトリック | レベル | 推奨事項 |
|---|---|---|
|
I/Oリクエスト(1秒当たり) |
インスタンス |
このメトリックは、データベースのI/O読取りおよび書込みリクエストの合計率を示します。このメトリックは、操作の数がユーザー定義のしきい値を超えたときにアラートを送信します。このメトリックは、Enterprise Managerでも使用できるオペレーティング・システム・レベルのメトリックと組み合せて使用します。 このメトリックは、システムで使用可能な合計I/Oスループット、使用可能なI/Oチャネルの数、ネットワーク帯域幅(SAN環境の場合)、ディスク・キャッシュの効果(ストレージ・アレイ・デバイスを使用している場合)、最大I/Oレート、およびデータベースで使用可能なスピンドルの数に基づいて設定します。 |
|
データベースCPU時間(%) |
インスタンス |
このメトリックは、CPUで費やされるデータベース・コール時間の割合を示します。データベースCPU時間が50%から25%に急激に低下した場合など、システムの稼働状況に変化があったことを検出するために使用できます。
|
|
待機時間(%) |
インスタンス |
過剰なアイドル時間は、1つ以上のリソースにボトルネックが発生していることを示します。このインスタンス・レベルのメトリックは、アプリケーションが問題なく動作しているときのシステム待機時間に基づいて設定します。 |
|
ネットワーク・バイト/秒 |
インスタンス |
このメトリックは、Oracleによって生成されるネットワーク・トラフィックをレポートします。このメトリックは、潜在的なネットワーク・ボトルネックを示します。このメトリックは、ピーク期間中の実際の使用状況に基づいて設定します。 |
|
ページインされたページ/秒 |
ホスト |
UNIXベースのシステムでは、1秒当たりにページインされたページ数(フォルト・メモリー参照を解決するためのディスクからの読取り)を表します。このメトリックは、 Microsoft Windowsの場合、このメトリックはハード・ページ・フォルトを解決するためにページがディスクから読み込まれた1秒当たりの回数です。ハード・ページ・フォルトは、プロセスが作業セットまたは物理メモリー内の他の場所にない仮想メモリー内のページを参照し、ディスクから取得する必要がある場合に発生します。ページがない場合、読込み操作を最大限に活用するため、システムは隣接した複数のページをメモリーに読み込もうとします。 |
|
実行キューの長さ |
ホスト |
UNIXベースのシステムでは、「実行キューの長さ」メトリックは最後の間隔におけるメモリーおよび実行対象サブジェクト内の平均プロセス数を表します(1分平均、5分平均、15分平均)。 「実行キューの長さ」がCPU数のときにアラートを生成することをお薦めします。(これを行う別の方法として、「平均のロード」メトリックを監視し、「最大CPU」と比較することもできます。) このメトリックは、Microsoft Windowsでは使用できません。 |
|
関連項目:
|
Data Guard構成の可用性を監視し、インシデント・ルールに組み込んで通知を提供するには、Enterprise Managerのメトリックにしきい値を設定します。前の項でパフォーマンス関連メトリックについて説明したように、システムを監視し、使用する環境で正常とする状況を理解した上で、(該当する場合)通常運用の値より数パーセント上の値にしきい値を設定します。しきい値の一部として、ビジネスのリカバリ時間の目標(RTO)、リカバリ・ポイントの目標(RPO)およびサービス・レベル合意(SLA)を考慮します。時間の経過とともにしきい値を再評価して、しきい値がまだ適切であるか確認してください。表11-4に、Data Guardデータベースの監視に利用できるメトリックを示します。
表11-4 Data Guardメトリックを設定するための推奨事項
| メトリック | 推奨事項 |
|---|---|
|
Data Guard構成におけるシステムの問題について通知します。 |
|
|
プライマリ・データベースに対するスタンバイの遅れを表示します(単位は秒)。遅れが、ユーザーが指定したしきい値(指定した場合)を超過すると、このメトリックによりスタンバイ・データベース上でアラートが生成されます。RTOおよびSLA考慮事項に基づいて警告とクリティカルのしきい値を設定します。 |
|
|
このスタンバイ・データベースにフェイルオーバーするのに必要な時間のおよその秒数を表示します。RTOおよびSLA考慮事項に基づいて警告とクリティカルのしきい値を設定します。 |
|
|
このスタンバイ・データベース上でのREDO Apply速度を表示します(単位はKB/秒)。通常運用から偏差を識別するための警告とクリティカルのしきい値を設定します。 |
|
|
このスタンバイ・データベースでまだ利用できないREDOのおよその秒数を表示します。ラグがあるのは、REDOデータが未転送だったり、ギャップがある可能性があったりするためです。遅れが、ユーザーが指定したしきい値(指定した場合)を超過すると、このメトリックによりスタンバイ・データベース上でアラートが生成されます。RPO考慮事項に基づいて警告とクリティカルのしきい値を設定します。 |
次の推奨事項に従って、Enterprise Managerをシステム管理のプロアクティブな部分として、また問題の通知と分析に使用します。
Enterprise Managerには、管理対象ターゲットがどのくらい標準に適合しているかを自動的に追跡して報告するコンプライアンス管理フレームワークが含まれています。これらの標準には、業界、Oracle標準および内部標準が含まれます。Enterprise Managerには、データベース、Exadataデータベース・マシン、Fusion Middlewareなどを含む、Oracleハードウェアとソフトウェアのあらかじめインストールされたコンプライアンス標準セットが同梱されています。これらの標準には、すべてのデータベースに対するベスト・プラクティスの推奨事項が含まれます。既存のフレームワークまたは標準から類似作成するか、新しいフレームワークまたは標準を作成することで、ユーザー定義のコンプライアンス・フレームワークおよびコンプライアンス標準を作成することもできます。
標準を有効にするには、コンプライアンス・ライブラリにナビゲートし、必要な標準を適切なターゲットに関連付けます。セキュリティ標準などの一部の標準を利用する場合、必要な情報を収集するために、最初にテンプレ-トをターゲットに適用する必要があります。Oracleデータベース・コンプライアンス標準にOracle提供の監視テンプレートが必要となる場合の詳細は、『Oracle Enterprise Manager Cloud Control Oracle Databaseコンプライアンス標準』を参照してください。図11-5に示すように、コンプライアンス結果がターゲットのホーム・ページの「コンプライアンス・サマリー」領域に表示されます。
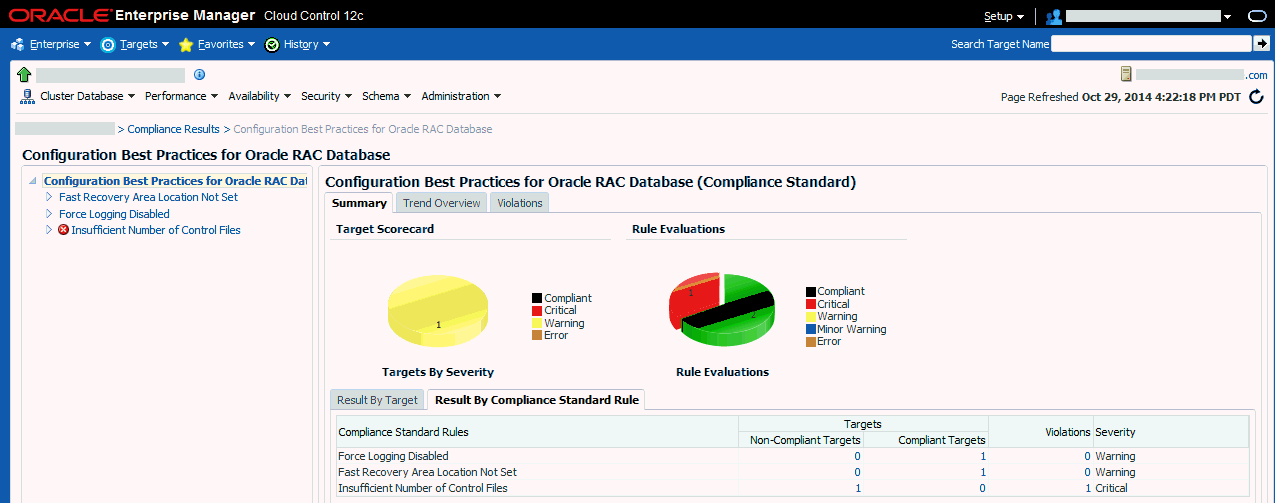
コンプライアンス標準結果の詳細を表示するには、「コンプライアンス・サマリー」領域内のリンクを選択します。図11-6では、ターゲットと選択したコンプライアンス標準に対する「コンプライアンス結果」ページが示されています。
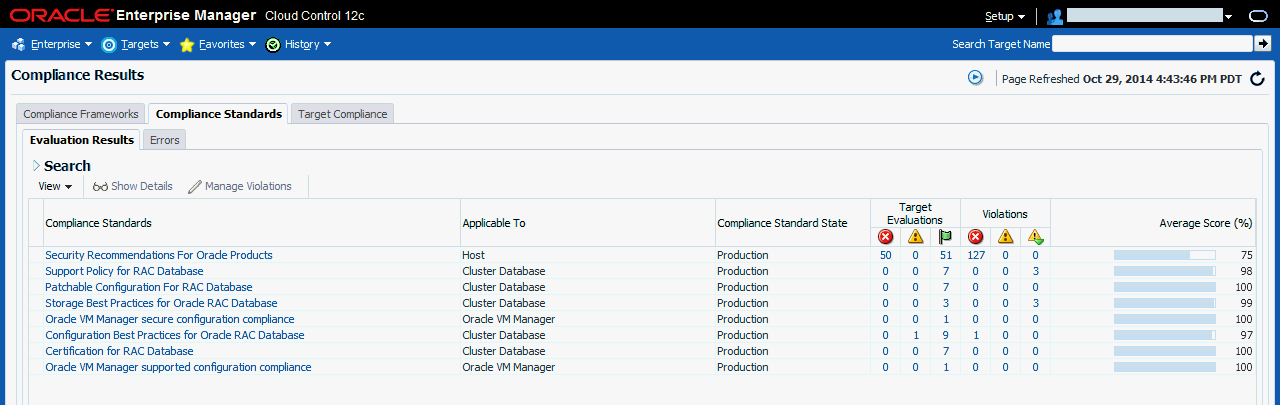
すべてのコンプライアンス標準の結果を表示するには、図11-7に示すように、「エンタープライズ」メニューから「コンプライアンス」、「結果」の順に選択します。
|
関連項目:
|
このリリースの6か月以内の推奨パッチを実装することで、本番環境を最新の状態に維持することをお薦めします。Enterprise Manager 12cでは、使いやすさを最大化してパッチ適用に関連する停止時間を最小化するパッチ管理ソリューションが提供されているため、管理者は推奨事項を満たすことができます。使用している環境のパッチ・リストの推奨事項に関する最新の詳細は、My Oracle Support (MOS)を参照してください。
オンライン・モードでは、パッチ・ワークフローとMOSが統合され、Oracleパッチ推奨、手動のパッチ検索、ナレッジ記事やサービス・リクエストなどのMOSリソースへのアクセスおよびマージ・パッチを使用したパッチ競合の自動解決を可能にする、一貫したインタフェースを提供します。オフライン・モードでは、Enterprise ManagerがMOSに接続できず、ソフトウェア・ライブラリに手動でアップロードされるパッチを使用する環境をサポートします。管理者は、インターネット・アクセスが使用可能なシステムでのMOSへのアクセス、ローカル・ホストへのパッチのダウンロード、Enterprise ManagerまたはEnterprise Managerコマンドライン・インタフェース(emcli)の使用によるソフトウェア・ライブラリへのパッチのアップロードを行うことができます。
パッチ計画ではパッチ適用ワークフローのエンドツーエンドのオーケストレーションが提供され、管理者は1つ以上のターゲットに対して1つのグループとしてパッチ・リストを準備、検証および適用できます。パッチ計画は、仮パッチ、診断パッチ、パッチ・セット更新(PSU)およびクリティカル・パッチ・アップデート(CPU)を含む個別パッチをサポートしています。また、パッチ計画は一部のターゲットに対するパッチ・セットもサポートしています。
パッチ計画はテスト可能でパッチ・テンプレートとして保存することができるので、パッチ計画を最初から作成するのではなく、パッチ計画をパッチ・テンプレートから作成することで、複数の管理者が簡単に複数の環境にわたって常にパッチをデプロイできるようになります。
Enterprise Managerのパッチ管理ソリューションは、インプレース・パッチ適用(Oracleホームに直接パッチが適用される)とホーム外パッチ適用(既存のOracleホームはクローニングされ、クローン・ホームにパッチが適用される)の両方をサポートしています。停止時間を最小化するには、ホーム外パッチ適用(サポートされている場合)を使用します。
このソリューションでは、Oracle RAC、Oracle Grid Infrastructure、Oracle Data Guardなど一部のターゲットの場合、ローリング・モード(ノードは停止され、パッチが適用されたら1つずつ再起動される)およびパラレル・モード(すべてのノードが停止され、すべてのノードに対して同時にパッチが適用される)でのパッチ適用もサポートされています。停止時間を最小化するには、ローリング・モードのパッチ適用(サポートされている場合)を使用します。
あるシステムのパッチ・レベルを調査して、それらを1対1または1対多の関係において複数のシステム間で比較できます。この場合、1台のシステムをベースラインとして区別し、他の複数のシステムにおけるメンテナンス要件の実証に使用できます。この機能は、データベース・パッチと同様に、オペレーティング・システム・パッチにも使用可能です。
|
関連項目:
|
高可用性(HA)コンソールは、各データベースの可用性を一箇所で監視できる、ダッシュボード・スタイルのページです。あらゆるデータベース上で使用でき、データベースがData Guard構成の一部の場合、HAコンソールで、プライマリ・データベースから任意のスタンバイ・データベースにビューを変更することができます。
HAコンソールを使用して、次の操作を行います。
関連ターゲット(スタンバイ・データベースなど)からのイベントなどの、高可用性イベントの表示
データベースのステータスなど、高可用性サマリーの表示
最後のバックアップ・ステータスの表示
高速リカバリ領域が構成されている場合、その使用量の表示
Oracle Data Guardが構成されている場合: Data Guardサマリーの表示、任意のデータベース・ターゲットに対するData Guardスタンバイ・データベースのセットアップ、管理リポジトリを含むデータベース以外のデータベース・ターゲットのスイッチオーバーとフェイルオーバーの管理、およびData Guard構成の状態の集中監視
Oracle RACが構成されている場合: 上位サービスなどのOracle RACサービスのサマリーの表示
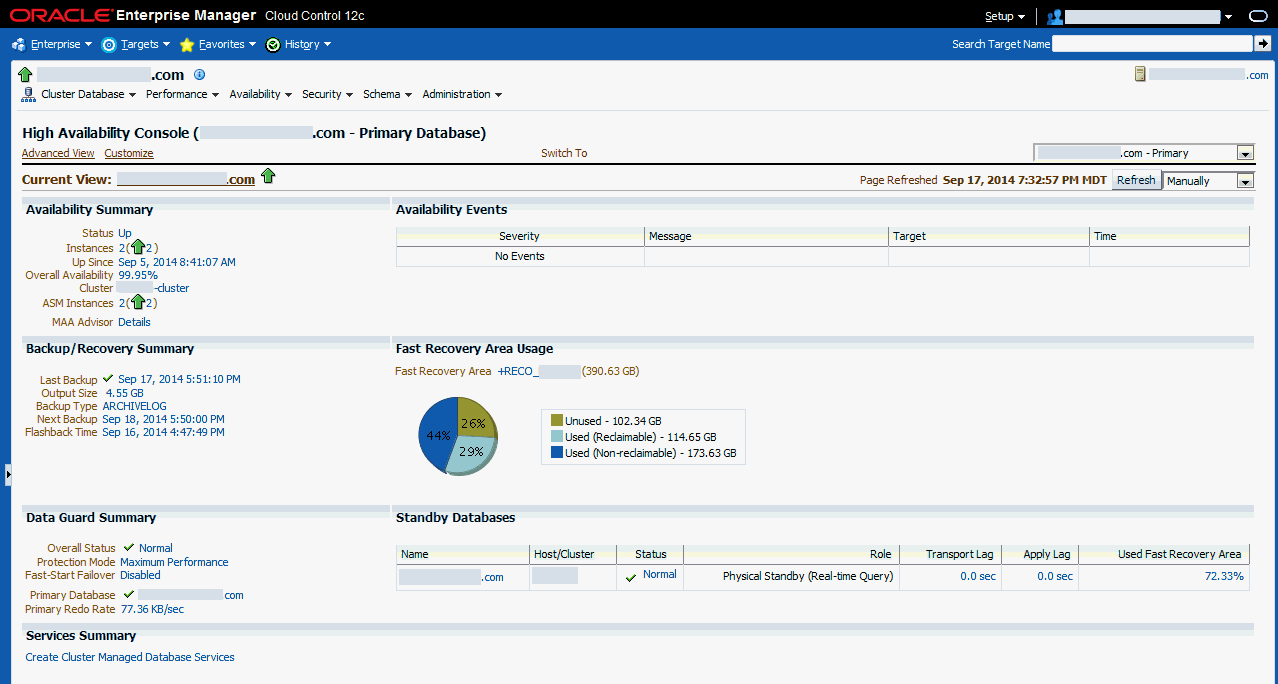
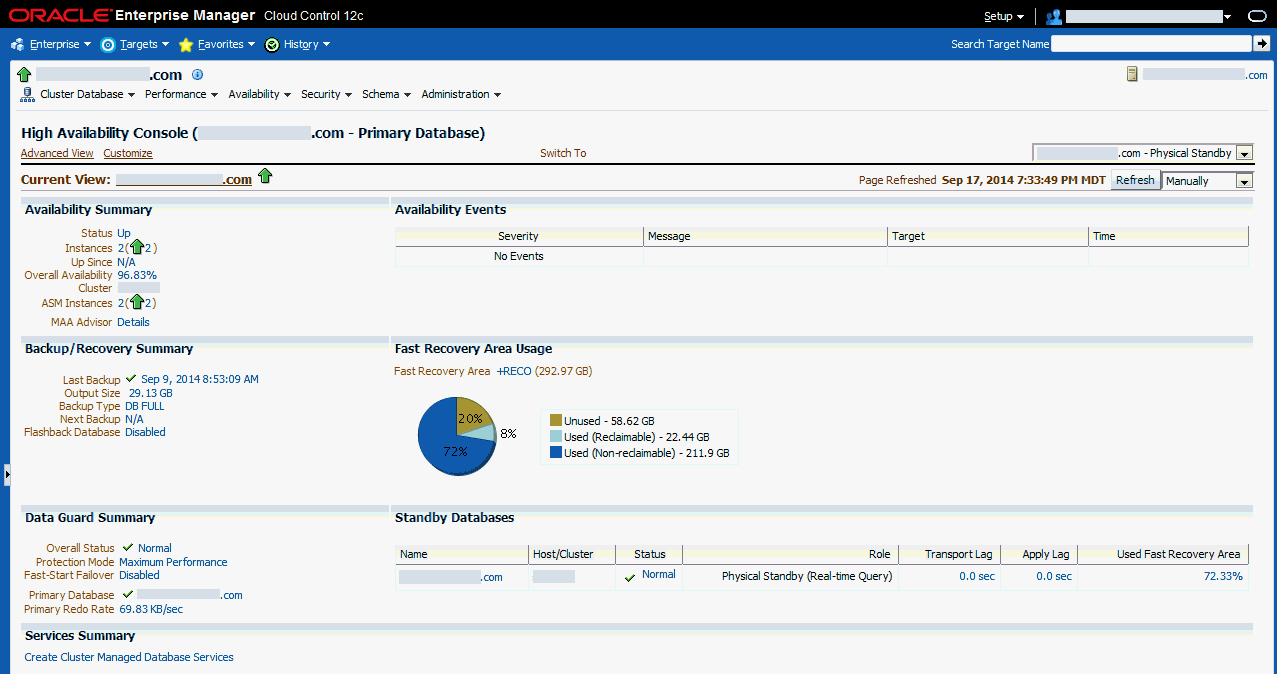
図11-8はHAコンソールを示します。この図は、プライマリ・データベースの要約情報、詳細および履歴統計を示し、プライマリ・ターゲットのスタンバイ・データベース、様々なData Guardスタンバイ・パフォーマンス・メトリックと設定、およびデータ保護モードを示しています。
図11-8では、「可用性のサマリー」に、プライマリ・データベースが稼働中で、その可用性が現在99.95%であることが示されています。「可用性のサマリー」には、Oracle ASMインスタンスのステータスも示されています。「可用性イベント」表には、特定の高可用性イベント(アラート)が示されます。メッセージをクリックすると、詳細情報を表示することができます(あるいは、そのイベントが簡略表示に戻ります)。このデータベースの特定のソリューション領域を設定、管理および構成するには、「可用性のサマリー」の「MAAアドバイザ」の横で「詳細」をクリックして、「最大可用性アーキテクチャ(MAA)アドバイザ」ページ(第11.3.4項「MAAアドバイザを使用した高可用性ソリューションの構成」で詳細に説明されています)に移動します。
「バックアップ/リカバリ・サマリー」領域には、「最終バックアップ」および「次のバックアップ」情報が表示されます。ここには、両方の時間と最終バックアップのステータス、サイズおよびタイプが含まれます。この領域には、フラッシュバック・データベースが有効化されている場合にデータベースをリセットできるフラッシュバック時間も含まれています。「高速リカバリ領域の使用量」領域には、高速リカバリ領域に関する情報が表示されます。グラフは、高速リカバリ領域のおよそ73%が現在使用されていることを示しています。グラフをクリックすると、メトリック詳細のページが表示されます。
「Data Guardサマリー」領域は、プライマリ・データベースが「最大パフォーマンス」モードで稼働していて、ファスト・スタート・フェイルオーバーが無効化されていることを示しています。「保護モード」の隣のリンクをクリックすると、データ保護モードを変更できます。「スタンバイ・データベース」表を見ると、フィジカル・スタンバイ・データベースはプライマリ・データベースのメトリック(「適用ラグ」/「トランスポート・ラグ」)に追随して0秒を示し、「高速リカバリ領域の使用」(FRA)は72.33%です。「プライマリ・データベースREDO率」の横にある値をクリックすると、REDO傾向を示すグラフが表示されます。Data Guardが構成されていない場合、コンソールの隅の「切替え」ボックスは表示されません。
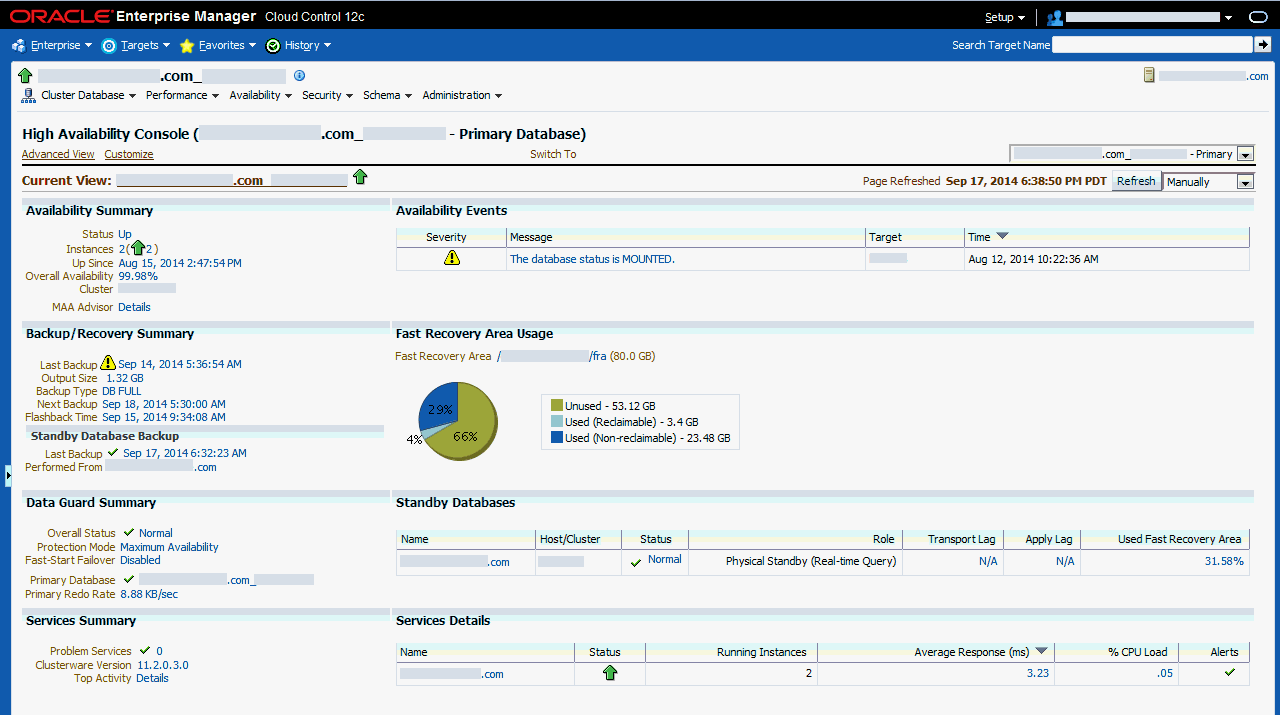
図11-9は、図11-8と同様の情報を示していますが、この情報はリアルタイム問合せを実行しているフィジカル・スタンバイ・データベースであるスタンバイ・データベースに関するものです。「スタンバイ・データベース」表を見ると、「適用ラグ」/「「トランスポート・ラグ」メトリックは、フィジカル・スタンバイ・データベースがプライマリ・データベースに追随していることを示し、「高速リカバリ領域の使用」(FRA)は72%です。Data Guardが構成されていない場合、コンソールの隅の「切替え」ボックスは表示されません。
図11-10は、「サービス・サマリー」および「サービスの詳細」領域のサンプル値を示しています。これらの領域は、上位アクティビティや問題のサービスの詳細へのリンクを含む、Oracle RAC Servicesに関するサマリー情報と詳細情報を示します。
|
関連項目: データベース管理の詳細は、『Oracle Enterprise Manager Cloud Control概要』を参照してください。 |
MAA Advisorは、最適な高可用性アーキテクチャを実現するためのOracleベスト・プラクティスの実装を支援するために設計されています。
高可用性コンソールの「可用性のサマリー」セクションでは、MAAアドバイザへのリンクで次のことが可能です。
各停止タイプ(サイト障害、コンピュータ障害、ストレージ障害、ヒューマン・エラーおよびデータ破損)の推奨Oracleソリューションの表示
構成ステータスの表示、「Oracleソリューション」列のリンクを使用した「Enterprise Manager」ページへの移動、およびそこでのソリューションの構成
各ソリューションの利点の把握
ホワイト・ペーパー、ドキュメントなどの情報があるMAA Webサイトへのリンク
「MAAアドバイザ」ページの表には、停止タイプ、それぞれの停止に対するOracleソリューション、構成ステータス、および利点が表示されます。MAAアドバイザを使用すると、次のようにして高可用性ソリューションを表示できます。
推奨のみ: プライマリ・データベースの推奨ソリューション(デフォルト・ビュー)のみを簡略表示します。
すべてのソリューション: この拡張ビューには、この構成のすべてのプライマリ・データベースとスタンバイ・データベースのすべての推奨構成およびステータスが表示されます。これには、データベース名を提供し、データベースのロール(「プライマリ」、「フィジカル・スタンバイ」または「ロジカル・スタンバイ」)を示す追加の「ターゲット名: ロール」列が含まれます。
図11-11は、「表示」で「すべてのソリューション」ビューが選択された「MAAアドバイザ」ページの例を示しています。
図11-11 Enterprise Managerの「最大可用性アーキテクチャ(MAA)アドバイザ」ページ
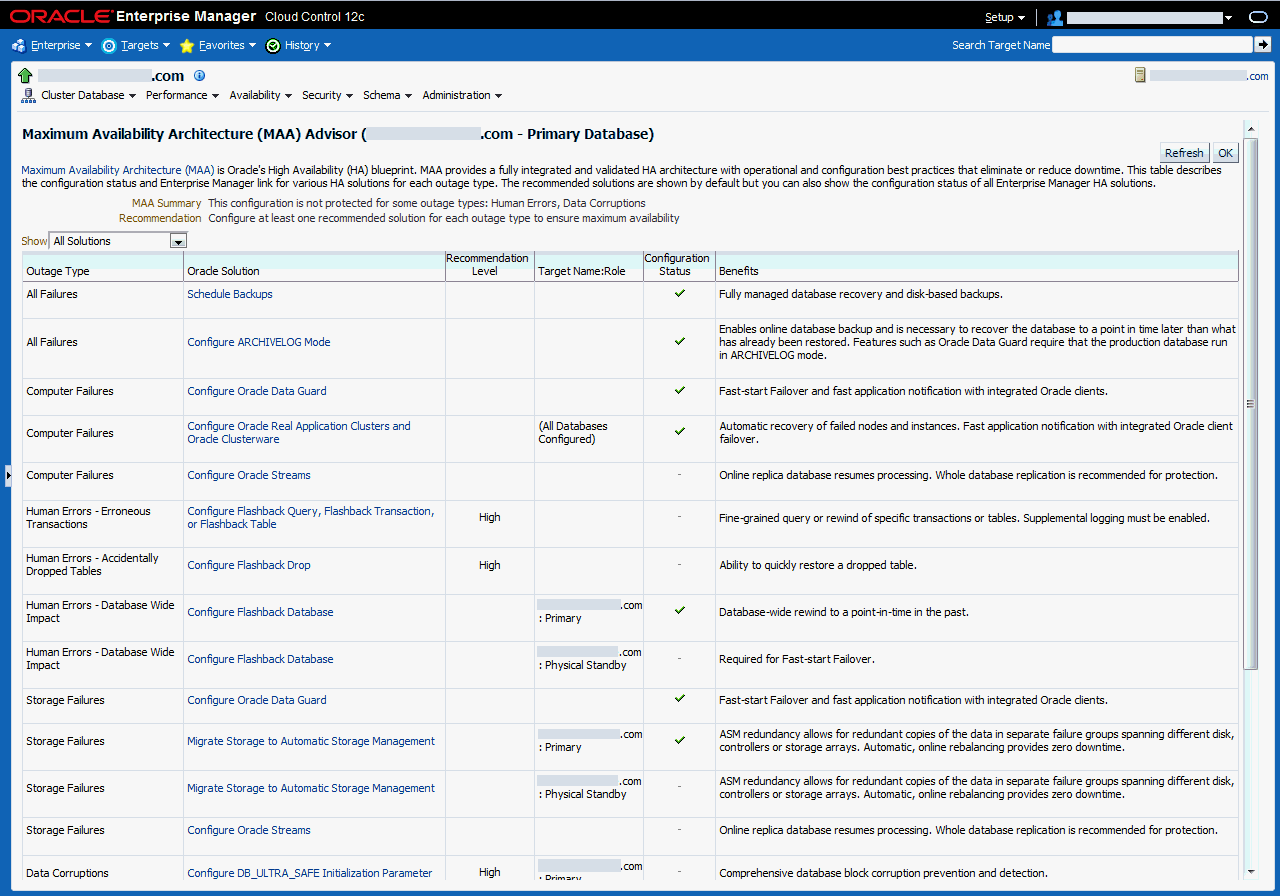
「Oracleソリューション」列でリンクをクリックすると、移動先のページで特定のソリューション領域をセットアップ、管理および構成することができます。ソリューションの構成が終わったら、「リフレッシュ」をクリックして構成ステータスを更新します。ページがリフレッシュされたら、「高可用性コンソール」ページで「MAAアドバイザ」の「詳細」をクリックして、更新された値を参照します。
クラスタ状態モニター(CHM)はリアルタイムにオペレーティング・システムのメトリックを収集し、後で分析するためにリポジトリに格納して、Oracleサポートの支援を受けながら、Oracle ClusterwareおよびOracle RACの多くの問題の原因を判断します。また、ノードでのメモリーのオーバーコミットメントを検出するためのメトリックを提供することによって、Oracle Databaseにおけるサービスのクオリティ管理(Oracle Database QoS Management)とあわせて使用することもできます。この情報により、Oracle Database QoS Managementは、負荷を軽減し、既存のワークロードを保持するためのアクションを実行できます。
|
関連項目: Oracle Clusterware環境の管理の概要およびクラスタ状態モニター(CHM)の詳細は、『Oracle Clusterware管理およびデプロイメント・ガイド』を参照してください。 |