1 Introducción a la recuperación ante desastres
Las mejores prácticas de recuperación ante desastres (DR) empresarial consisten, principalmente, en el diseño y la implementación de sistemas de software y hardware con tolerancia a fallos que pueden sobrevivir a un desastre (“continuidad empresarial”) y reanudar las operaciones normales (“reanudación empresarial”) con una intervención mínima y, en condiciones ideales, sin pérdida de datos. Construir entornos con tolerancia a fallos para cumplir con los objetivos de DR empresarial y las limitaciones presupuestarias reales puede resultar costoso y demorar mucho tiempo; además, exige un fuerte compromiso de la empresa.
Los planes de DR suelen abordar uno o más de los siguientes tipos de desastres:
-
Daños significativos de las instalaciones de TI debido a un desastre natural (terremoto, huracán, inundación, etc.) u otras causas (incendio, vandalismo, hurto, etc.).
-
Pérdida significativa de servicios críticos de las instalaciones de TI, por ejemplo, pérdida de alimentación, refrigeración y acceso a la red.
-
Pérdida de personal clave.
El proceso de planificación de DR comienza con la identificación y la caracterización de los tipos de desastres a los que debe sobrevivir una empresa para, luego, reanudar sus operaciones. El proceso de planificación identifica requisitos de alto nivel de continuidad empresarial (BC) y reanudación empresarial (BR), entre ellos, el nivel necesario de tolerancia a fallos. A partir de la planificación de DR se genera una arquitectura de recuperación y reanudación para sistemas, aplicaciones y datos con tolerancia a fallos, a fin de satisfacer estas necesidades sujetas a limitaciones establecidas. Normalmente, las limitaciones de DR son el objetivo de tiempo de recuperación (RTO), el objetivo de punto de recuperación y el presupuesto disponible. La arquitectura de DR junto con las limitaciones empresariales favorecen la creación de procedimientos de DR que integran todos los elementos del sistema de una manera verdaderamente integral para garantizar resultados predecibles en relación con el proceso completo de DR.
Los sistemas con tolerancia a fallos, por lo general, alcanzan la solidez y la capacidad de recuperación mediante la redundancia. Un sistema completamente redundante, que suele lograrse a un alto costo, no tiene un solo punto de fallo dentro de su arquitectura y puede funcionar durante las operaciones y reanudarlas a partir del peor desastre posible dentro de sus límites. Los sistemas de control de vuelo de aviones y transbordadores espaciales son buenos ejemplos de sistemas completamente redundantes. Las aplicaciones de TI menos críticas, por lo general, utilizan sistemas menos resistentes y menos redundantes. La construcción de estos sistemas es menos costosa, pero necesariamente implicará una interrupción del servicio después del desastre. Durante esta interrupción, la empresa trabajará para restablecer sus datos, aplicaciones y sistemas recuperables.
En última instancia, la naturaleza de una empresa, las necesidades de los clientes y el presupuesto disponible para DR son los factores clave para la determinación de los requisitos de DR. Una solución integral de DR puede ser muy costosa, pero es necesario diseñarla. No puede tirar el dinero, el hardware ni el software ante un posible desastre y tener la esperanza de sobrevivir y reanudar sus operaciones empresariales. No obstante, aunque realice una planificación y un diseño inteligentes, es posible que se vea afectado por interrupciones más prolongadas del servicio, un servicio degradado, o ambos, hasta que se puedan reanudar todos los servicios, pero, de todas maneras, puede contar con una solución limitada y confiable de DR.
De todas maneras, debe entender que quizás no exista ningún nivel de planificación que permita anticipar todos los posibles escenarios de DR o responder a ellos. Por ejemplo, lo que comienza como un problema aparentemente trivial de un sistema se puede propagar, con el transcurso del tiempo, y afectar a otros sistemas de distintas maneras y, finalmente, causar un desastre para el cual no hay una posible recuperación. De manera similar, la capacidad de una empresa para cumplir con los acuerdos de servicio puede verse afectada si las suposiciones clave no resultan ciertas, por ejemplo, si el servicio o las piezas clave no se encuentran disponibles, o si la capacidad de prestación del servicio del proveedor de DR no es tan sólida como se promociona. No obstante, lo más importante que se debe tener en cuenta es que si ocurre un desastre que supera el peor escenario para el cual usted se preparó, quizás la recuperación no sea posible.
Definición del objetivo de tiempo de recuperación (RTO)
RTO es un objetivo de nivel de servicio del tiempo que lleva lograr la capacidad operativa deseada después de que ocurre un desastre. Por ejemplo, las necesidades de la empresa pueden determinar un RTO en el que todos los sistemas de producción funcionen al 80 % de la capacidad previa al desastre en el plazo de los 30 minutos posteriores a una interrupción no planificada del servicio de más de una hora (si no existiera capacidad de DC). El tiempo de procesamiento de RPO, la disponibilidad de personal calificado de TI y la complejidad de los procesos manuales de TI necesarios después de un desastre son ejemplos de limitaciones que pueden determinar el RTO. El RTO no se aplica a los sistemas con tolerancia completa a fallos, porque estos sistemas se recuperan implícitamente durante un desastre y después de él, sin interrupción del servicio.
Los planificadores de DR pueden establecer distintos RTO para algunos o todos los requisitos de BC definidos. Los diversos tipos de operaciones empresariales pueden exigir distintos RTO, por ejemplo, RTO diferentes para sistemas en línea que para ventanas de lotes. Además, se pueden aplicar distintos RTO en las diversas etapas de un plan de DR en fases, en el cual cada fase tiene un RTO definido. Incluso una aplicación recuperable puede tener distintos RTO para cada uno de sus diversos niveles de servicio.
Los requisitos de disponibilidad de los datos de BC son sumamente importantes para la planificación de RTO. Cuando los datos que se deben introducir en el proceso de DR no están presentes en el sitio de recuperación ante desastres, el tiempo que lleve recuperar los datos en el sitio demorará el RTO. Por ejemplo, llevará tiempo recuperar los datos que residen en almacenes fuera del sitio. La recuperación puede continuar rápidamente si los datos de entrada actualizados están duplicados en el sitio de recuperación antes del comienzo de las operaciones de recuperación ante desastres.
Definición del objetivo de punto de recuperación (RTO)
El RPO es un objetivo de continuidad empresarial que indica el estado o el nivel de actividad de la empresa, y que se logra después de que el proceso de recuperación ante desastres ha restablecido todos los sistemas recuperables. Conceptualmente, el RPO es un estado de sincronización objetivo o una "reversión" que se conoce antes de que ocurra un desastre. Es decir, que el RPO es el punto de recuperación posterior a un desastre a partir del cual las aplicaciones recuperables interrumpidas pueden reanudar el procesamiento. Todas las transacciones que ocurren durante el intervalo entre el RPO y el momento del desastre son irrecuperables. El RPO no se aplica a sistemas con tolerancia completa ante fallos porque el desastre no afecta la continuidad empresarial de estos sistemas.
En Figura 1-1, se ilustran los conceptos de RPO. En la imagen, se sugieren diversos puntos de recuperación para que tengan en cuenta los planificadores de DR. La planificación debe garantizar que el RPO deseado sea factible frente al RTO elegido y viceversa. Por lo general, los planes de recuperación ante desastres que exigen los RPO más próximos al momento de un desastre requieren una mayor tolerancia ante fallos y son más costosos de implementar, en comparación con los RPO más lejanos. Al igual que con los RTO, los planificadores de DR pueden establecer distintos RPO para diferentes requisitos de BC, fases de los planes de DR o niveles de servicio de las aplicaciones.
Figura 1-1 Objetivos de punto de recuperación
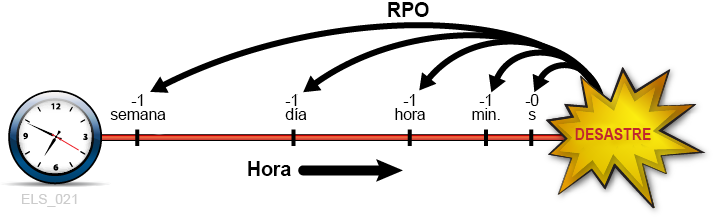
Descripción de Figura 1-1 Objetivos de punto de recuperación
De manera más amplia, la planificación de RPO debe identificar todos los elementos complementarios que deben estar presentes para restablecer cada sistema recuperable, incluidos los datos, los metadatos, las aplicaciones, las plataformas, las instalaciones y el personal. La planificación también debe garantizar que estos elementos estén disponibles en el nivel deseado de actividad de la empresa para recuperación. Los requisitos de actividad de los datos de BC son especialmente cruciales para la planificación de RPO. Por ejemplo, si según los requisitos de BO, se requiere un RPO de una hora, cualquier dato o metadato que alimente el proceso de recuperación debe estar actualizado hasta el RPO, de lo contrario, no se puede alcanzar el RPO. Los procesos de DR de la organización especificarán los procedimientos necesarios para alcanzar todos los RPO definidos en el plazo de los RTO establecidos.
Los metadatos del sistema necesarios para la recuperación del RPO incluyen estructuras de catálogo de OS e información del sistema de gestión de cintas. Estos elementos de deben actualizar durante el proceso de recuperación ante desastres para activar todos los RPO elegidos. Por ejemplo, para garantizar la coherencia entre las diversas entradas de metadatos en el proceso de DR, los juegos de datos existentes que se recrearán en el RPO se deben descatalogar; los juegos de datos actualizados entre el RPO y el momento del desastre se deben restaurar a la versión que existía en el RPO o antes de este; y cualquier cambio de catálogo relacionado con cintas debe estar sincronizado con el sistema de gestión de cintas.
Manejo de interrupciones temporales
La recuperación ante desastres ofrece reparación para interrupciones muy prolongadas que pueden dejar a un sitio de producción inutilizable durante un período prolongado. Si bien el resto de esta introducción trata las prácticas de recuperación ante desastres, sería igualmente importante desarrollar procedimientos para mitigar las interrupciones relativamente breves que podrían afectar negativamente la producción si no se controlan. Considere, por ejemplo, una interrupción del servicio en que ciertas funciones de hardware o de red permanecen no disponibles durante una o dos horas, pero la producción puede continuar durante esta interrupción en “modo degradado” con unos pocos y rápidos ajustes temporales. Un procedimiento de interrupción temporal debe documentar cómo aislar el problema, qué cambios realizar, a quién notificar y cómo regresar al entorno operativo normal después del restablecimiento del servicio.
Concepto clave: recuperación de punto de sincronización
El reinicio de las aplicaciones de producción en los RPO definidos es una actividad clave que se realiza durante una verdadera recuperación ante desastres y durante las pruebas de DR. Los entornos de DR con mayor capacidad de recuperación garantizan que cada aplicación recuperable, ya sea de terceros o desarrollada internamente, aplique un requisito clave de DR, a saber: que la aplicación esté diseñada para reiniciarse de un momento planificado denominado "punto de sincronización", a fin de mitigar los efectos de una interrupción no programada durante su ejecución. Cuando una aplicación interrumpida se reinicia en un punto de sincronización, los resultados son los mismos que si la aplicación no hubiera sido interrumpida.
El procedimiento de reinicio para una aplicación recuperable depende de la naturaleza de la aplicación y sus entradas. A menudo, el procedimiento de reinicio de una aplicación para una verdadera recuperación ante desastres o pruebas de DR es el mismo procedimiento de que utiliza para reiniciar la aplicación en caso de que falle durante una ejecución de producción normal. En los casos en que es posible, la reutilización de los procedimientos de reinicio de producción para una verdadera recuperación ante desastres o pruebas de DR simplifica la creación y el mantenimiento de los procedimientos de DR, y aprovecha estos procedimientos probados. En el caso más sencillo, una aplicación recuperable constituye un paso de trabajo único con un solo punto de sincronización, que es el comienzo del programa invocado por ese paso. En ese caso, el procedimiento de recuperación puede ser tan sencillo como volver a ejecutar el trabajo interrumpido. Un procedimiento de inicio levemente más complejo podría implicar que la aplicación deba descatalogar todos los juegos de datos de salida durante su última ejecución y que, luego, deba reiniciar la aplicación.
Los procedimientos de reinicio para aplicaciones que tienen varios puntos de sincronización interna entre los cuales se puede elegir pueden no ser tan sencillos. Las aplicaciones que usan técnicas de punto de control/reinicio para implementar estos puntos de sincronización registran periódicamente su progreso y pueden, por ejemplo, usar la información registrada del punto de control para reiniciarse en el último punto de sincronización interna registrado antes de una interrupción. Los procedimientos de reinicio cumplirán con los requisitos de cada punto de sincronización. Mientras los puntos de control están en uso, los juegos de datos asociados con un punto de control no deben caducar, no se deben descatalogar ni se deben reutilizar mientras el punto de control sigue siendo válido para la recuperación de aplicaciones. Una manera sencilla de establecer un punto de sincronización para un paso de trabajo que modifica sus juegos de datos existentes es hacer una copia de seguridad de cada juego de datos modificable antes de ejecutar el paso. Estos juegos de datos de entrada modificables se pueden identificar fácilmente al buscar el atributo de JCL DISP=MOD en sentencias DD o en solicitudes de asignación dinámica. Si un paso de trabajo falla o se interrumpe, simplemente, deseche los juegos de datos de entrada modificados, restaure esos juegos de datos de entrada de las copias de seguridad y reinicie el paso a partir de las copias restauradas. Estas copias de seguridad también son útiles para reiniciar un paso de trabajo que falló o se interrumpió, el cual había caducado, descatalogado o reutilizado los originales.
Relación de RPO con la recuperación de punto de sincronización
Cuando el RPO se alinea con un punto de sincronización, al realizar el procedimiento de reinicio de la aplicación que se desarrolló para este punto de sincronización, se reanudará la aplicación a partir de este origen como si no se hubiera producido una interrupción (Figura 1-2). Se supone que todas las transacciones procesadas después de este RPO hasta el desastre son irrecuperables.
Figura 1-2 El RPO en el punto de sincronización
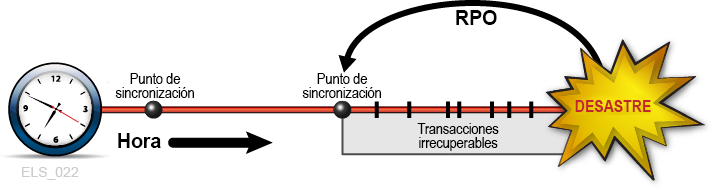
Descripción de Figura 1-2 El RPO en el punto de sincronización
En otros momentos, los requisitos de BC pueden justificar la ubicación del RPO entre los puntos de sincronización. En estos casos, la recuperación de punto de intersincronización se basa en datos complementarios que describen cualquier cambio o evento crítico relativo al estado de la aplicación que ocurre después del establecimiento del punto de sincronización más reciente. Considere, por ejemplo, el RPO de un minuto antes de un desastre. Suponga que se diseña una aplicación recuperable para usar puntos de control para registrar su progreso, pero suponga que la sobrecarga que implica el uso de estos puntos de control a intervalos de un minuto no se puede tolerar. Una solución sería tomar estos puntos de control con menor frecuencia y registrar todas las transacciones confirmadas entre los puntos de control. El log de esta transacción se convierte, luego, en datos de entrada complementarios utilizados por el proceso de recuperación del punto de control que se reiniciarán a partir de un RPO más allá del punto de sincronización más reciente. En este ejemplo, el procedimiento de reinicio de la aplicación accede a los datos más recientes del punto de control y aplica el log de la transacción complementaria para restablecer todas las transacciones confirmadas procesadas después del punto de control y antes del RPO (Figura 1-3). De esta manera, la recuperación de punto de sincronización puede alcanzar un RPO objetivo mediante los datos de entrada de varios orígenes. Se supone que todas las transacciones procesadas después del RPO hasta el desastre son irrecuperables.
Figura 1-3 RPO entre puntos de sincronización
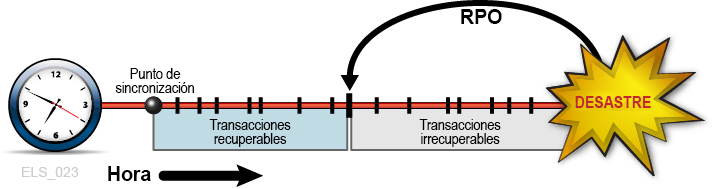
Descripción de Figura 1-3 RPO entre puntos de sincronización
Planificación para la alta disponibilidad de datos (D-HA)
Los datos suelen ser uno de los activos más valiosos de una empresa. La mayoría de las compañías cuidan rigurosamente los datos empresariales críticos y realizan inversiones adicionales para protegerlos contra la pérdida y para garantizar que los datos estén disponibles para su objetivo previsto cuando sea necesario. Una empresa que no puede hacer frente a la pérdida de datos críticos puede sufrir consecuencias desastrosas. Quizás la manera más habitual de proteger los datos contra la pérdida es almacenar copias de datos críticos en distintos subsistemas o medios de almacenamiento, y almacenar algunas de estas copias en distintas ubicaciones físicas. Las copias almacenadas en medios de almacenamiento extraíbles, entre ellas, las cintas de cartuchos magnéticos, los CD-ROM y los DVD suelen almacenarse en ubicaciones de almacenamiento externas. Las copias adicionales también suelen almacenarse en el sitio, en instalaciones de TI en que las aplicaciones pueden procesar los datos. La creación y el almacenamiento de copias de datos críticos aumentan la redundancia de los datos y mejora la tolerancia a fallos. Para los medios extraíbles y, en particular, para las cintas de cartuchos magnéticos, el solo hecho de aumentar la redundancia de los datos no suele ser suficiente para garantizar que los datos también tengan alta disponibilidad para las aplicaciones que los utilizarán. Por ejemplo, el sistema VSM de Oracle para cintas virtuales de mainframe almacena datos en volúmenes de cintas virtuales denominados MVC. El sistema VSM puede hacer copias automáticamente para mejorar la redundancia de los datos y reducir el riesgo debido a un fallo de medios físicos o a un cartucho de cintas mal colocado. Un sistema de producción VSM utiliza varios componentes de hardware especializados para recuperar datos almacenados en un MVC, incluido un dispositivo de buffer de VTSS, una biblioteca de cintas automatizada y unidades de cinta conectadas a bibliotecas (denominadas RTD), que también se conectan al dispositivo de buffer de VTSS. Las aplicaciones host dependen de todos estos componentes de VSM que funcionan juntos para recuperar datos de los MVC. Si bien la mayoría de las personas no consideraría el simple fallo de un componente como un desastre equiparable a la pérdida de un centro de datos entero en un terremoto, ciertamente, podría ser imposible recuperar datos de un MVC si un único componente crítico de VSM falla sin una copia de seguridad, independientemente de cuantas copias redundantes de MVC existan. Por lo tanto, si bien la creación de copias de MVC es una de las mejores prácticas comprobadas para mitigar la vulnerabilidad y los riesgos, no siempre garantiza de forma suficiente la alta disponibilidad de los datos (D-HA) en la presencia de fallos. Los requisitos de D-HA son requisitos clave de continuidad empresarial para la planificación de DR. Por lo general, la D-HA se logra aumentando las redundancias para eliminar los puntos únicos de fallo que no permiten a las aplicaciones acceder a los datos durante los fallos del sistema. Por ejemplo, un sistema VSM que incluye componentes redundantes mejora la tolerancia a fallos del sistema VSM. La instalación de varios dispositivos VTSS, handbots redundantes de SL8500 y varias RTD tiene el propósito de eliminar los puntos únicos de fallo de VSM de la ruta de datos de la aplicación a los datos críticos almacenados en un MVC. La arquitectura de VSM está diseñada para admitir la agregación de componentes redundantes para aumentar la tolerancia a fallos promover la D-HA.
Cinta física de alta disponibilidad
Las soluciones de automatización de cintas de mainframe de Oracle activan la D-HA para aplicaciones de cinta físicas mediante el almacenamiento de copias redundantes de datos en distintos ACS dentro de un sistema TapePlex, es decir, dentro de un complejo de cintas asignado por un solo CDS. Por ejemplo, las aplicaciones que se ejecutan en instalaciones de TI con un solo sistema TapePlex pueden almacenar fácilmente copias duplicadas de juegos de datos de cintas en uno o más ACS dentro de ese TapePlex. Esta técnica mejora la D-HA mediante la agregación de medios redundantes, transportes de cinta y bibliotecas de cintas automatizadas. En un caso simple, una aplicación almacena copias redundantes de juegos de datos críticos en dos cintas de cartuchos distintas en una sola biblioteca SL8500 con electrónica redundante, handbots duales en cada guía y dos o más transportes de cinta conectados a la biblioteca en cada guía, que son compatibles con los medios del juego de datos. Para eliminar la biblioteca SL8500 como un punto potencial único de fallo, se agrega una segunda SL8500 al ACS para almacenar copias aun más redundantes del juego de datos críticos. Para eliminar las instalaciones de TI como punto único de fallo, las copias de juegos de datos redundantes se pueden almacenar fuera del sitio o crear en un ACS remoto con transportes de cintas mediante una extensión de canal (Figura 1-4).
Figura 1-4 Configuración de cinta física FD-HA

Descripción de Figura 1-4 Configuración de cinta física FD-HA
También puede hacer dos o más copias de cintas físicas en distintas ubicaciones físicas cuando una ubicación tiene su propio CDS independiente, es decir, cuando el hardware de cada ubicación representa un TapePlex independiente. Al usar la función de cliente/servidor del SMC y definir políticas para dirigir copias de juegos de datos a un TapePlex remoto, los trabajos pueden crear copias de cintas en un ACS de otro TapePlex sin cambios en JCL.
Cinta virtual de alta disponibilidad
VSM ofrece tecnologías de agrupación en clusters y creación de varios complejos para replicación en MVC para activar la D-HA para cinta virtual de mainframe. La creación de varios complejos para replicación en VSM implica la creación de varias copias de MVC (por ejemplo, duplicados, cuadruplicados) en uno o más ACS para mayor redundancia (Figura 1-5). Los ACS que reciben copias de las que se crean varios complejos para replicación pueden ser bibliotecas locales o ACS remotos con transportes de cinta mediante una extensión de canal. Las políticas de migración de VSM controlan el movimiento de VTV que residen en el buffer de VTSS a MVC locales o remotos, que pueden ser trasladados a almacenes externos.
Figura 1-5 Configuración de creación de varios complejos para replicación en VSM para D-HA
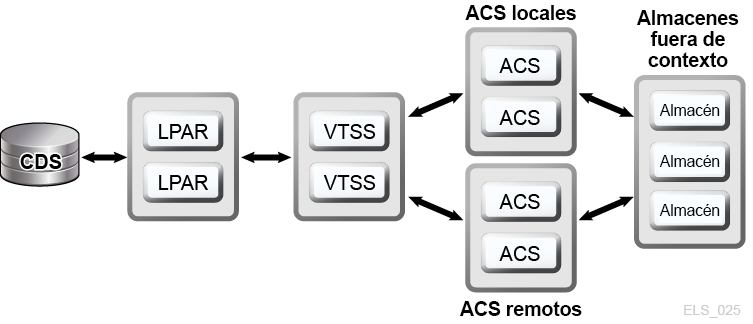
Descripción de Figura 1-5 Configuración de creación de varios complejos para replicación en VSM para D-HA
Un cluster de VSM comprende dos o más dispositivos VTSS (nodos) conectados en red para intercambio de datos en un enlace de comunicaciones (CLINK). Los CLINK son canales unidireccionales o bidireccionales. La configuración de cluster de VSM más sencilla consiste en dos nodos VTSS en el mismo TapePlex enlazado con un CLINK unidireccional, pero, habitualmente, se implementan CLINK bidireccionales (Figura 1-6). Cada nodo de cluster se puede ubicar en un sitio distinto. Las políticas de almacenamiento unidireccional de VSM controlan la replicación automática de volúmenes de cintas virtuales (VTV) de VTSS A a VTSS B en un CLINK unidireccional. Las políticas de almacenamiento bidireccional y los CLINK bidireccionales permiten que VTSS A se replique en VTSS B y viceversa.
Figura 1-6 Configuración de cluster de VSM de D-HA
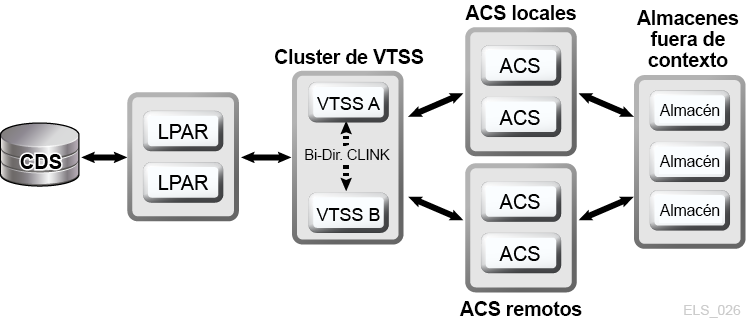
Descripción de Figura 1-6 Configuración de cluster de VSM de D-HA
La agrupación en clusters ampliada de VSM permite la conectividad de varios a varios entre tres o más dispositivos VTSS en un TapePlex para alcanzar niveles de disponibilidad de datos aun más altos (Figura 1-7). Como se muestra, la instalación de dispositivos de cluster de VTSS en uno o más sitios dentro de un TapePlex aumenta la redundancia, ya que elimina cada sitio como punto único de fallo.
Figura 1-7 Configuración de cluster ampliado de D-HA (no se muestran los almacenes externos)
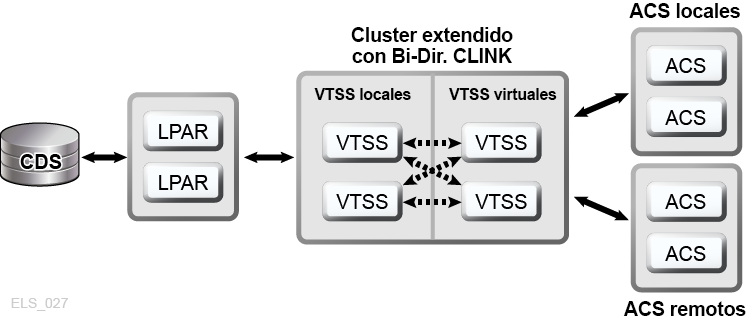
Descripción de Figura 1-7 Configuración de cluster ampliado de D-HA (no se muestran los almacenes externos)
La LCM de Oracle simplifica los procesos de almacenamiento en sitios externos para volúmenes de MVC mediante la gestión del proceso de reciclaje entre los almacenes y las bibliotecas de producción. La función de almacenamiento de LCM programa la devolución de volúmenes de MVC almacenados cuando la cantidad de datos caducados supera un umbral especificado.
Un cluster de replicación cruzada entre sistemas TapePlex (cluster CTR) de VSM permite que los dispositivos de cluster de VTSS residan en distintos TapePlex y ofrece la capacidad de replicar VTV de un TapePlex a uno o más TapePlex distintos, lo que permite modelos de replicación de clusters de varios a varios en CLINK unidireccionales o bidireccionales (Figura 1-8). El envío y la recepción de TapePlex puede estar ubicado en distintos sitios. Los VTV replicados se introducen en el CDS del TapePlex receptor como volúmenes de solo lectura. Esto ofrece una protección de datos segura contra la alteración que pueden causar las aplicaciones que se ejecutan en el TapePlex receptor. El CDS del TapePlex receptor también indica que las copias de VTV replicadas por CTR son propiedad del TapePlex emisor y, como protección adicional, la CTR garantiza que un TapePlex no pueda modificar ningún VTV que no le pertenezca.
Figura 1-8 Configuración de replicación cruzada entre sistemas TapePlex de VSM de D-HA
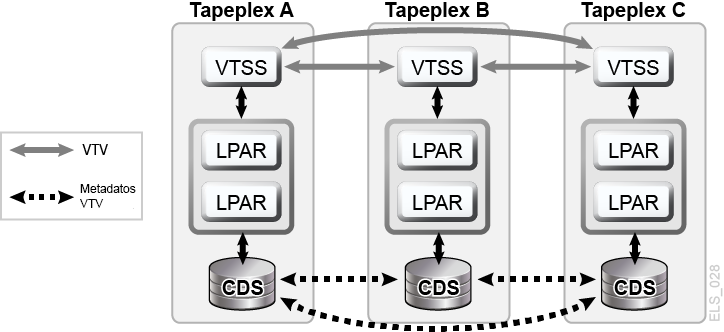
Descripción de Figura 1-8 Configuración de replicación cruzada entre sistemas TapePlex de VSM de D-HA
D-HA y recuperación de punto de sincronización
La creación de varias copias de volúmenes físicos (MVC o distintos de MVC) mejora la redundancia de los datos; no obstante, estas copias requieren consideraciones especiales para la recuperación de punto de sincronización. Lo más importante de la recuperación de punto de sincronización es garantizar que los datos creados en un punto de sincronización se mantengan en un estado de solo lectura mientras siguen siendo válidos para uso en recuperación ante desastres. Esto significa que las copias de volúmenes de cinta físicos que se pueden usar para recuperación ante desastres se deben mantener en el estado de solo lectura. Una manera de hacer esto es enviar estas copias a una ubicación de almacén externo donde no hay capacidad de procesamiento de cintas. Es importante tener en cuenta que las copias no protegidas que sufren alteraciones no se pueden utilizar para recuperación de punto de sincronización, porque el contenido actualizado deja de reflejar el punto de sincronización asociado. Los entornos de cintas virtuales agregan una dimensión adicional a la gestión de copias de varios volúmenes para recuperación de punto de sincronización. Pueden existir copias de VTV en varios buffers de VSM y en varios MVC al mismo tiempo. Incluso cuando todos los MVC de un determinado VTV se almacenan en un sitio externo, las copias de VTV que permanecen en el sitio en buffers de VSM pueden modificarse. No es posible usar una copia actualizada de un VTV que reside en un buffer para recuperación de punto de sincronización, a menos que este VTV pertenezca a un nuevo punto de sincronización que invalide las copias externas almacenadas para uso durante la recuperación ante desastres.
Realización de una verdadera recuperación ante desastres
El éxito de una operación de verdadera recuperación ante desastres yace en contar con un sitio de DR adecuado, personal capacitado, un procedimiento de DR comprobado, una carga de trabajo de producción recuperable con puntos de sincronización para cumplir con los RPO definidos y todos los datos de entrada y metadatos del sistema necesarios para cumplir con estos RPO. Los datos de entrada y los metadatos del sistema deben estar accesibles en el sitio de DR cuando se los necesita y deben estar disponibles en los niveles de actividad necesarios. Con una planificación minuciosa, una preparación rigurosa y una ejecución de comprobada eficacia, las operaciones de verdadera recuperación ante desastres pueden fluir sin inconvenientes según lo planificado para lograr los RPO y los RTO definidos. Los datos de producción generados en el sitio de DR deben estar protegidos de manera adecuada mientras el sitio de DR funciona como sitio de producción. Suponga, por ejemplo, que la arquitectura de D-HA requiere una carga de trabajo de producción para replicar copias de datos redundantes en tres sitios remotos, y suponga que el sitio de DR es uno de estos sitios de replicación remotos antes de un desastre. Cuando el sitio de producción experimenta un desastre y su carga de trabajo se traslada al sitio de DR, este sitio ya no puede funcionar como sitio de replicación remoto para la carga de trabajo de producción que ahora se ejecuta localmente en dicho sitio. Para cumplir con el requisito de D-HA de tres sitios de replicación remotos, se debe agregar un nuevo tercer sitio de replicación remoto durante el período en que la producción se mantenga en el sitio de DR. Este ejemplo ilustra de qué manera un análisis exhaustivo de los requisitos de D-HA permite a los planificadores de DR abordar todos los requisitos críticos de D-HA que se deben cumplir cuando la producción se traslada a un sitio de DR. Un plan integral de DR comprende no solamente las actividades para restablecer la producción en el sitio DR, sino que también incluye el proceso de desocupación del sitio de DR mientras el sitio de producción se encuentra en reparación y hasta que quede listo para volver a usarse, si consideramos al sitio de DR solamente como un sustituto temporal para producción. Por ejemplo, cuando el sitio de producción está listo para reanudar las operaciones, los datos de producción se deben restablecer en dicho sitio. Los métodos incluyen la agrupación en clusters bidireccional entre el sitio de DR y el sitio de producción, lo que permite tiempo suficiente para que el trabajo de producción que se ejecuta en el sitio de DR vuelva a rellenar el sitio de producción anterior mediante la replicación de datos. No obstante, puede ser necesario, u oportuno o eficaz, simplemente transportar los MVC físicos nuevamente al sitio de producción restablecido. Los métodos elegidos dependerán de las necesidades de recuperación posteriores al desastre.
Planificación de pruebas de DR
La preparación para una verdadera recuperación ante desastres se evalúa probando la eficacia y la eficiencia de los procedimientos y sistema de DR para recuperar una carga de trabajo de producción en un sitio de prueba de DR designado. El entorno de prueba de DR debe ser un entorno de prueba de DR dedicado, pero, normalmente, es más económico compartir recursos entre los sistemas de prueba de DR y de producción. Las pruebas de DR que se realizan simultáneamente con la producción y que comparten el uso de recursos con la producción se conocen como "pruebas concurrentes de DR". Si una aplicación debe ejecutarse en paralelo en sistemas prueba de DR y de producción, los planificadores de DR deben garantizar que estas dos instancias de la aplicación no interfieran entre sí mientras se ejecutan de manera simultánea. El aislamiento de los sistemas de prueba de DR y de producción en LPAR independientes y la limitación del acceso a los datos de producción desde el sistema de prueba de DR suele proporcionar una separación suficiente. Las pruebas de DR se suelen realizar en etapas para permitir la realización de pruebas específicas de distintas aplicaciones en distintos momentos, en lugar de realizarse una prueba de recuperación de todo el entorno de producción de una vez. Las pruebas específicas son clave para reducir la cantidad de recursos de hardware dedicado que se necesita para el sistema de prueba de DR. Por ejemplo, si las pruebas de DR de una aplicación recuperable requieren solo un pequeño subconjunto de recursos de VSM, esos recursos se pueden compartir entre los sistemas de prueba de DR y de producción, y se pueden reasignar al sistema de prueba de DR para el ciclo de prueba de DR. Este enfoque reduce el costo de hardware para el sistema de DR a riesgo de afectar el rendimiento del sistema de producción mientras se ejecuta la prueba de DR. No obstante, por lo general, un ciclo de prueba de DR dedica solo un pequeño porcentaje de recursos compartidos a la prueba de DR, y el entorno de producción disminuido no se ve afectado en gran medida por las pruebas simultáneas de DR. Sin embargo, algunas organizaciones tienen políticas que impiden afectar o alterar la producción para facilitar las pruebas de DR. Es posible que los auditores exijan una coincidencia exacta entre los resultados de pruebas de DR y de producción para certificar el proceso de DR. Una manera de cumplir con este requisito consta en establecer un punto de sincronización justo delante de una ejecución programada de producción, guardar una copia de los resultados de producción, recuperar la ejecución de producción en este punto de sincronización en el sitio de prueba de DR y comparar el resultado con los resultados de producción guardados. Cualquier diferencia entre los resultados destacará una brecha que se deberá investigar. La imposibilidad de detectar estas brechas oportunamente podría en riesgo poner la capacidad de recuperación ante desastres de una organización. Independientemente de si una prueba de DR está diseñada para recuperar una carga de trabajo compleja o una aplicación única, el proceso de prueba de DR se debe realizar con los mismos procedimientos que se utilizarían para una verdadera recuperación ante desastres. Esta es la única manera segura de comprobar la realización correcta de la prueba de DR.
Movimiento de datos para pruebas de DR
Hay dos métodos para organizar los datos de aplicación para pruebas de DR en un sitio de prueba de DR: movimiento físico de datos y movimiento electrónico de datos. El movimiento físico de datos implica el transporte de cartuchos de cinta físicos al sitio de prueba de DR en un proceso que se describe a continuación y que se conoce como "importación/exportación física". El movimiento electrónico de datos utiliza unidades de cinta remotas, RTD remotas y técnicas de cluster de VSM para crear copias de los datos de aplicación en un sitio de prueba de DR. Ambos métodos de movimiento de datos permiten la realización de pruebas de DR; no obstante, el movimiento electrónico de datos evita la transferencia física de los datos y los posibles problemas de la pérdida de cintas, entre otros. La transferencia electrónica también mejora el tiempo de acceso a los datos, ya que los coloca donde se los necesita para una verdadera recuperación ante desastres o los almacena provisionalmente en un buffer de VSM antes de un ciclo de prueba de DR. El movimiento electrónico de datos para volúmenes virtuales se puede realizar dentro de un solo TapePlex mediante el uso de una agrupación en clusters ampliada de VSM, o entre dos TapePlex mediante la replicación cruzada entre sistemas TapePlex. Para los datos que se encuentran dentro de un solo TapePlex, el software de prueba concurrente de recuperación ante desastres (CDRT) de Oracle simplifica las pruebas de DR.
Pruebas de DR con exportación/importación física
Suponga que desea realizar pruebas de DR para una aplicación de producción que utiliza cinta virtual y física. Su objetivo es probar esta aplicación en el sitio de prueba de DR repitiendo una ejecución de producción reciente y verificando que el resultado de la prueba coincida con el resultado de la producción reciente. Como parte de la preparación, deberá guardar copias de los juegos de datos de entrada utilizados por la ejecución de producción y una copia del resultado de la producción para comparación. Suponga que el sitio de prueba de DR está aislado y no comparte equipos con la producción. Usted podría realizar la prueba de DR mediante este proceso de exportación/importación física.
Sitio de producción:
-
Haga una copia de los VTV y los volúmenes físicos requeridos.
-
Exporte esas copias de VTV.
-
Expulse las copias asociadas de MVC y las copias de volúmenes físicos del ACS de producción.
-
Transporte los MVC y los volúmenes físicos expulsados al sitio de prueba de DR.
Sitio de prueba de DR:
-
Introduzca los volúmenes transportados en el ACS de DR.
-
Sincronice los catálogos de OS y el sistema de gestión de cintas con los volúmenes introducidos.
-
Importe los datos de VTV/MVC.
-
Ejecute la aplicación.
-
Compare los resultados.
-
Expulse todos los volúmenes introducidos para esta prueba.
-
Transporte los volúmenes expulsados nuevamente al sitio de producción.
Sitio de producción:
-
Introduzca los volúmenes transportados nuevamente en el ACS de producción.
Este proceso permite que las pruebas de DR continúen de forma segura y en paralelo con la producción, ya que el sistema de prueba de DR está aislado del sistema de producción. El sistema de prueba de DR tiene su propio CDS, y el proceso de prueba de DR, como se indica anteriormente, introduce información de los volúmenes en el CDS de prueba de DR a modo de preparación para la prueba de DR. Esto permite que la aplicación recuperada se pruebe con los mismos nombres de juegos de datos y volúmenes que utiliza en producción. Para los juegos de datos de cintas virtuales, la función de almacenamiento del software LCM de Oracle simplifica la colocación de los VTV en los MVC y agiliza los pasos circulares que requieren exportar y expulsar volúmenes en el sitio de producción, importar esos volúmenes en el sitio de prueba de DR y expulsar dichos volúmenes para moverlos nuevamente al sitio de producción. La exportación/importación física le genera gastos al sitio por la manipulación de cintas físicas y gastos de mensajería por el transporte de cartuchos de cinta entre los sitios de producción y de prueba de DR. Los datos confidenciales que se transportan mediante servicio de mensajería se deben transportar en cartuchos de cinta cifrados. Los plazos de las pruebas de DR se ven afectados por el tiempo que se dedica a transportar y manipular los cartuchos de cinta entre los sitios.
Pruebas de DR con CDRT
Si se planifica y se cuenta con recursos suficientes de hardware en los sitios de producción y de DR, la CDRT combinada con el movimiento electrónico de datos puede eliminar la necesidad de transportar cartuchos de cinta física al sitio de DR y permite la realización concurrente de pruebas de DR de una manera más económica que si se mantiene un sitio de prueba de DR dedicado y aislado. La CDRT permite la realización de pruebas de DR de prácticamente cualquier carga de trabajo, configuración, RPO o RTO imaginable. El proceso de prueba de DR incluirá unos pocos pasos adicionales para iniciar la CDRT y una limpieza después de la prueba de DR. Antes de ejecutar una prueba de DR con CDRT, debe mover electrónicamente todos los datos de aplicación y metadatos del sistema (información de catálogo de OS e información del sistema de gestión de cintas) necesarios para la prueba al sitio de prueba de DR. Puede mover datos de aplicación electrónicamente mediante la agrupación en clusters de VSM o la migración de copias de VTV a los MVC del sitio de prueba. A continuación, puede usar la CDRT para crear un CDS especial para el sistema de prueba de DR que refleje el CDS de producción. Los sistemas de producción y de prueba de DR son entornos separados, y el entorno de prueba de DR utilizará el CDS especial de prueba de DR en lugar del CDS de producción. Debido a que la CDRT crea el CDS de prueba de DR a partir de información del CDS de producción, contiene metadatos de todos los volúmenes que se movieron electrónicamente al sitio de prueba de DR antes de la prueba de DR. Esto permite a las aplicaciones de DR utilizar los mismos números de serie de volúmenes y nombres de juegos de datos utilizados en la producción. La CDRT aplica restricciones operativas sobre el sistema de prueba de DR para evitar que el entorno de DR interfiera en el entorno de producción. Puede reforzar estas protecciones mediante las capacidades VOLPARM/POOLPARM de ELS para definir rangos de volser separados para los MVC y reutilizar los VTV para uso exclusivo de CDRT. La CDRT permite al sistema de prueba de DR leer los MVC de producción y escribir en su propia agrupación dedicada de MVC, que se borra lógicamente después de cada prueba de DR. Para aplicaciones de cinta virtual, la CDRT requiere al menos un dispositivo VTSS dedicado durante el ciclo de prueba de DR. Estos VTSS dedicados se pueden reasignar temporalmente desde la producción para facilitar una prueba de DR, y la prueba de DR y el sistema VSM pueden acceder a los ACS de producción en paralelo con la carga de trabajo de producción. En Figura 1-9 y Figura 1-10, se muestra la división de un cluster de producción de VSM para prestar un dispositivo de cluster al sistema de prueba de DR de la CDRT, en este caso, VTSS2, en el sitio de prueba de DR. Cuando este cluster se divide, debe modificar las políticas de producción para sustituir la migración por la replicación, de modo que VTSS1 cree copias redundantes de VTV en el sitio de DR en ACS01, y de modo que VTSS1 no se llene hasta el límite de su capacidad mientras el cluster se divide. VTSS2 se deja fuera de línea para la producción y se coloca en línea para la LPAR de prueba de DR. En Figura 1-9, CDRT ha creado el CDS de prueba de DR a partir de una copia remota del CDS de producción. Solo el sistema de producción puede acceder a los volúmenes de VTSS1 y ACS00 durante el ciclo de prueba de DR, y solo el sistema de prueba de DR puede acceder a VTSS2. Los sistemas de producción y de prueba de DR comparten el acceso concurrente a volúmenes de ACS01. En Figura 1-9 y Figura 1-10, se mantiene una copia remota del CDS de producción en el sitio de prueba de DR, por ejemplo, mediante reflejo remoto, para garantizar que un CDS de producción actualizado esté disponible en el sitio de DR para el uso de una verdadera recuperación ante desastres. No obstante, se debe tener en cuenta que el CDS de prueba de DR creado por la CDRT a partir de la copia remota de CDS es una versión especial de la prueba de DR del CDS de producción que solo puede usar la CDRT. Antes de volver a conformar el cluster de producción, después de la finalización del ciclo de prueba de DR, el VTSS de DR se debe purgar para evitar la pérdida de datos de producción, como sucedería si VTSS2 tuviera una versión más reciente de un VTV que también existiera en VTSS1. También debe modificar las políticas de producción para realizar una reversión de una migración a una replicación cuando se vuelve a conformar el cluster. Si no es posible dividir un cluster de producción como se muestra aquí, otra posibilidad es mantener un VTSS independiente en el sitio de DR exclusivamente para la realización de pruebas de DR. En este caso, los VTV necesarios para la prueba para se recuperarán a partir de las copias de MVC.
Figura 1-9 Cluster de producción con un VTSS2 de nodo de cluster remoto en el sitio de prueba de DR
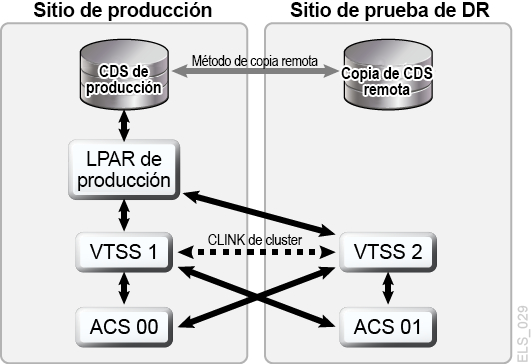
Descripción de Figura 1-9 Cluster de producción con un VTSS2 de nodo de cluster remoto en el sitio de prueba de DR
Figura 1-10 Configuración de producción con un VTSS2 prestado para pruebas de DR de CDRT
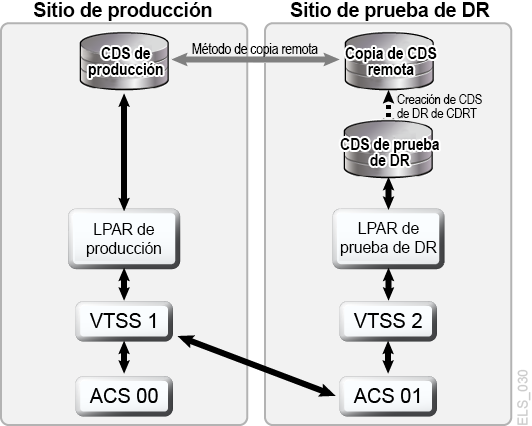
Descripción de Figura 1-10 Configuración de producción con un VTSS2 prestado para pruebas de DR de CDRT
Pruebas de DR con replicación cruzada de sistemas Tape de VSM
La replicación cruzada entre sistemas TapePlex de VSM permite diseños de TapePlex de producción simétricos y en cluster que facilitan la realización de pruebas de DR sin el uso de CDRT, sin la necesidad de hardware de VTSS dedicado exclusivamente a las pruebas de DR y sin alterar el entorno de producción para realiza las pruebas de DR. Por ejemplo, CTR permite a cada TapePlex de producción replicar datos en los otros TapePlex de producción en el mismo cluster de CTR. Los clusters de punto a punto de CTR de producción pueden eliminar la necesidad de un sitio de prueba de DR dedicado. CTR permite distintos tipo de diseños de TapePlex en cluster y facilita las pruebas de DR de cualquier configuración o carga de trabajo de producción, con cualquier RPO o RTO factible. En un ejemplo simple, un cluster bidireccional de CTR une dos sistemas TapePlex simétricamente y cada TapePlex replica datos en el otro TapePlex (Figura 1-11). Un TapePlex receptor introduce un VTV replicado en su CDS en el estado de solo lectura y marca el VTV para indicar que es de propiedad del TapePlex emisor. En este ejemplo, las pruebas de DR para una aplicación de TapePlex A implican la replicación de datos de aplicación en el TapePlex B y la recuperación de la aplicación en el TapePlex B.
Figura 1-11 Cluster de CTR de producción simétrica para pruebas de DR
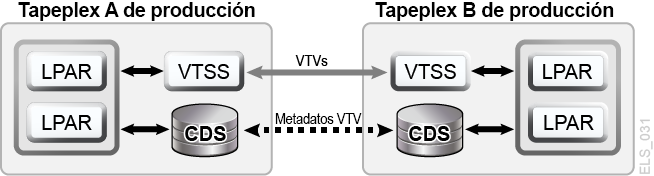
Descripción de Figura 1-11 Cluster de CTR de producción simétrica para pruebas de DR
La simetría del diseño de este cluster de punto a punto significa que la aplicación recuperada que se está probando en el sitio del mismo nivel se ejecuta de la misma manera durante una prueba de DR que durante la producción. El CDS del mismo nivel contiene toda la información replicada de volúmenes necesaria para las pruebas de DR, que continúan en paralelo con la producción, y el mismo hardware de VTSS admite el uso concurrente de las cargas de trabajo de prueba de DR y producción. Los clusters de producción de VTSS pueden existir dentro de cada TapePlex, y no es necesario dividirlos para compartir el uso del hardware en distintos sistemas TapePlex para pruebas de DR. El TapePlex de producción en el cual se realiza la prueba de DR de la aplicación no puede modificar ningún VTV replicado por CTR; por lo tanto, todos los datos de producción replicados se mantienen completamente protegidos durante el ciclo de prueba de DR. Más importante aún, las pruebas de DR basadas en CTR garantizan que un procedimiento de prueba de DR validado tendrá idénticos resultados durante una verdadera recuperación ante desastres. El software de host de SMC emitirá un mensaje si se realiza un intento de actualizar un VTV replicado por CTR, lo cual permite identificar la aplicación como aquella que modifica un juego de datos de entrada existente. Mediante el seguimiento de las mejores prácticas para la gestión de puntos de sincronización que se indican anteriormente, debe poder garantizar que el entorno de producción guarde una copia de este juego de datos antes de que la aplicación lo modifique, en caso de que se necesite una copia de seguridad para la recuperación de punto de sincronización.