1 障害回復の概要
エンタープライズ障害回復 (DR) のベストプラクティスとは基本的に、障害に耐え (「ビジネスの継続性」)、最小限の介入で、理想的にはデータを損失することなく通常の業務を再開する (「ビジネスの再開」) 耐障害性のあるハードウェアおよびソフトウェアシステムを設計および実装することです。エンタープライズ DR 目標と現実的な予算制約の両方を充足する耐障害性環境の構築には、費用と時間がかかるうえ、企業の強力なコミットメントも必要になります。
通常 DR 計画は、次に示すいずれかまたは複数の障害に対処します。
-
天災 (地震、嵐、洪水など) またはその他の原因 (火災、破壊行為、盗難など) によってもたらされた広域または長期的な IT 設備の損傷。
-
IT 設備に不可欠なサービス (電力、冷却設備、ネットワークアクセスの喪失など) の長期的な喪失。
-
重要な人員の流出。
DR 計画プロセスは、企業がどのようなタイプの障害に対する耐性を確保し業務を再開できるようにするのかを明確にし、その障害のタイプの特徴を明らかにすることから始まります。計画プロセスでは、ビジネスの継続性 (BC) とビジネスの再開 (BR) に関する大枠の要件を、達成する耐障害性の程度も含めて明確化します。DR 計画の成果物として得られるのは、設定された制約のもとこれらの要件を充足する、耐障害性システム、アプリケーション、およびデータの回復と再開のためのアーキテクチャーです。一般的な DR 制約として、回復時間目標 (RTO)、回復ポイント目標 (RPO)、予算があります。DR アーキテクチャーにビジネス制約を加えたものが DR 手順です。これはすべてのシステム要件を真の「エンドツーエンド」方式で統合したもので、DR プロセス全体に予測可能な結果をもたらすことを保証します。
一般的に耐障害性システムは、冗長性をとおして堅牢性と回復性を実現します。多大な費用をかけて構築された完全冗長システムには、そのアーキテクチャーに単一障害点がなく、最悪ケースの障害時にも、その制限のなかで業務を継続、再開できます。スペースシャトルや航空機の飛行制御システムが完全冗長システムのよい例です。一般的に、重要度の低い IT アプリケーションには、冗長性に劣り堅牢性の低いシステムを使用します。このようなシステムは比較的少ない費用で構築でき、障害の発生後は、回復可能なシステムやアプリケーション、データを修復するためのサービス停止が必ず発生します。
最終的には、ビジネスの特性や顧客の要件、DR に投入できる予算が DR 要件を構成する際の重要要素となります。包括的な DR ソリューションには多大な費用がかかりますが、これは必ず設計する必要があります。起こりうる障害に対し、やみくもに資金やハードウェア、ソフトウェアを投入し、ビジネスの継続と再開を祈るというわけにはいきません。賢明な計画作成と設計をしておくことで、サービスの完全再開までに多少長めのサービス停止時間やサービス低下 (またはその両方) が発生するかもしれませんが、それでも信頼できる限定的な DR ソリューションを実現できます。
ただし、どんなに入念な計画を立てたとしても、起こりうるすべての DR シナリオを予期して、対応することはできないということを理解しておいてください。たとえば、あるシステムで発生した小さな問題が、時間の経過とともに別のシステムに広がって、最初のシステムとは別の形で影響を及ぼし、適用できる回復シナリオがない大きな障害に発展することもあります。同様に、サービス契約の根本的な仮定が崩れれば、場合によっては企業のサービス契約の履行能力が損なわれます。たとえば、重要な部品やサービスを利用できなくなった場合や、DR プロバイダのサービス提供能力が提示されていた堅牢性を下回る場合などです。しかし本当に重要なのは、対応策を計画していた最悪ケースのシナリオを上回る障害が発生した場合、回復できない場合があるということです。
回復時間目標 (RTO) の定義
RTO とは、障害の発生後、一定レベルの業務遂行能力を取り戻すのに要する時間を定めたサービスレベル目標です。たとえば、DR 能力がなければ 1 時間以上の継続が見込まれる計画外のサービス停止が発生したときに、すべての本番システムを障害発生前の 80% の能力で 30 分以内に再稼働させることをビジネス要件の RTO で規定されることがあります。RTO の決定に影響する制約には、RPO の処理時間、対応能力のある IT スタッフの確保、障害後に実施する必要のある手動の IT プロセスの煩雑性などがあります。完全な耐障害性を持つシステムに RTO は適用されません。これらのシステムは障害の発生中およびそれ以降に暗黙のうちに回復され、サービスが中断しないためです。
DR 計画では、定義された BC 要件の一部またはすべてに対し、それぞれ別の RTO を設定することがあります。業務のタイプによって異なる RTO が必要になる場合もあります。たとえば、オンラインシステムとバッチウィンドウには、それぞれ異なる RTO を設定することがあります。また、フェーズで区切られた DR 計画のステージごとに異なる RTO を設定する場合もあり、この場合は各フェーズに 1 つずつ RTO を設定します。回復可能なアプリケーションのサービスレベルのそれぞれに異なる RTO を設定することもあります。
RTO 計画のなかでも、きわめて重要なのが BC データの可用性要件です。DR 回復プロセスに入力する必要のあるデータが障害回復サイトに存在しない場合、オンサイトのデータを取得するための時間が発生し RTO を遅らせることになります。たとえば、オフサイトのストレージボールトにあるデータの取得には時間がかかります。障害回復操作の開始前に最新の入力データが回復サイトに複製されていれば、回復プロセスは迅速に進みます。
回復ポイント目標 (RPO) の定義
RPO とは、回復可能なすべてのシステムが障害回復プロセスによって回復されたあとのビジネスの状態または最新性を定めたビジネスの継続性の目標です。概念的には、RPO は障害発生前の既知の「ロールバック」または同期ターゲットという意味で理解されています。つまり RPO とは障害発生後の回復ポイントであり、中断した回復可能アプリケーションはこのポイントから処理を再開できます。ある RPO から障害発生時までの間に発生したトランザクションは一切回復できません。RPO は完全耐障害性システムには適用されません。これらのシステムのビジネスの継続性は、障害の影響を受けないためです。
図1-1 は、DR 計画者が検討する必要のあるさまざまな回復ポイントを示して、RPO の概念を図解したものです。計画では、選択した RTO を考慮した実現可能な RPO を設定する (その逆も同様) 必要があります。一般的に、RPO が障害発生時刻に近くなるように規定した障害回復計画では、求められる耐障害性のレベルが高くなり、RPO の間隔が長い計画よりも実装に費用がかかります。RTO の場合と同様に、DR 計画者が各 BC 要件、各 DR 計画フェーズ、または各アプリケーションサービスレベルに対し、それぞれ別の RPO を設定することもあります。
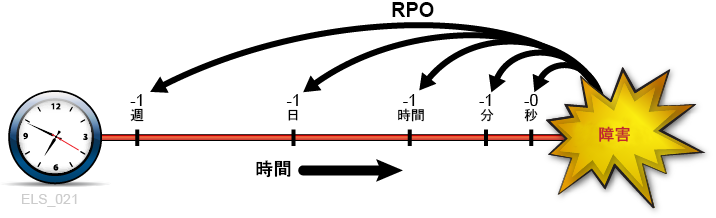
RPO 計画では、各回復可能システムを回復させるために必要な支援要素 (データ、メタデータ、アプリケーション、プラットフォーム、設備、人員など) もすべて洗い出す必要があります。計画は、これらの要素が回復で求められるレベルのビジネス最新性で使用できることも保証する必要があります。RPO 計画のなかでも、きわめて重要なのが BC データの最新性要件です。たとえば BC 要件で 1 時間の RPO が指定されている場合、回復プロセスに供給するデータまたはメタデータにその RPO までの最新性がなければ、RPO を達成できません。組織の DR プロセスでは、設定した RTO 内で、定義したすべての RPO を達成できる手順を指定することになります。
RPO 回復に必要なシステムメタデータには OS カタログ構造とテープ管理システム情報が含まれます。選択したすべての RPO を有効にするには、障害回復プロセス中にこれらのアイテムを更新する必要があります。たとえば、DR 回復プロセスに入力する各種のメタデータの整合性を確保するため、RPO 時点で再作成される既存のデータセットはカタログから除外し、RPO から障害発生時の間に更新されたデータセットは RPO 時点またはそれよりも前の時点のバージョンに戻し、テープ関連のカタログ変更があればそれらをテープ管理システムと同期する必要があります。
一時的なサービス停止への対応
障害回復は、本番サイトを長期間にわたって使用不能な状態にする非常に長い期間のサービス停止に対する改善措置です。これ以降この概要の章では障害回復について説明しますが、放置しておくと本番に悪影響を与えかねない比較的短時間のサービス停止についても、緩和手順を策定しておくことが重要です。たとえば、サービス停止の発生により、あるハードウェアまたはネットワーク設備が 1 - 2 時間使用できない状態でも、簡単な暫定措置を行なって「機能低下モード」で本番を続けられることがあります。一時的サービス停止の手順には、問題を分離する方法や必要な修正内容、報告先のほか、サービス回復後に通常の業務環境に復帰する方法などを記述します。
主要概念: 同期ポイント回復
規定された RPO で本番アプリケーションを再開させることが、実際の障害回復および DR テストで行われるもっとも重要なアクティビティーです。高い回復性を備えた DR 環境では、他社提供のアプリケーションであろうとも社内開発のアプリケーションであろうとも、回復可能アプリケーションのそれぞれが主要な DR 要件を強制します。つまり、それらのアプリケーションは、その実行中に発生した計画外の中断の影響を緩和するため、あらかじめ計画された同期ポイントと呼ばれる期間から再開するように設計されています。中断したアプリケーションを同期ポイントから再開したときの状態は、かりにアプリケーションが中断しなかった場合の状態と同じです。
回復可能アプリケーションの再開手順は、アプリケーションとその入力の特性によって異なります。実際の障害回復や DR テストで使用するアプリケーション再開手順は多くの場合、通常の本番で障害が発生したときに行うアプリケーション再開手順と同じです。実際の障害回復または DR テストの本番再開手順を再利用すると、DR 手順の作成とメンテナンスを簡素化できるうえ、実証された手順を活用できるため、可能な場合は再利用してください。もっとも簡単なケースでは、回復可能アプリケーションが 1 つのジョブステップで、そのステップから呼び出されるプログラムの先頭に 1 つの同期ポイントが設定されます。この場合、回復手順は中断されたジョブを再発行するのと同じくらい単純です。これより少し複雑な再開手順では、アプリケーションが最後の実行時に出力したデータセットをすべてカタログから除外し、そのあとにアプリケーションを再開させることになります。
同期ポイントを複数の内部同期ポイントから選択できるアプリケーションの場合、再開手順はそれほど容易ではありません。これらの同期ポイントをチェックポイント/再開手法を使用して実装しているアプリケーションは、自身の進捗を定期的に記録しており、記録したチェックポイント情報を使用して、中断発生前の、記録されている最後の内部同期ポイントの状態で再稼働します。再開手順は各同期ポイントの要件に準拠したものになります。チェックポイントを使用している場合、アプリケーション回復でチェックポイントが有効になっている間は、チェックポイントに関連付けられたデータセットが期限切れになったり、カタログから除外されたり、消去されたりしないようにします。既存の入力データセットを変更するジョブステップに同期ポイントを作成するもっとも簡単な方法は、ステップの実行前に各変更可能データセットのバックアップコピーを作成する方法です。これらの変更可能入力データセットは、DD 文または動的割り当てリクエストで JCL 属性 DISP=MOD を検索することで簡単に特定できます。ジョブステップが失敗または中断した場合、変更されたデータセットを破棄し、バックアップコピーから同入力データセットを回復して、回復したコピーからステップを再開するだけです。元データを期限切れにする、カタログから除外する、または消去するジョブステップが失敗または中断し、これらのジョブステップを再開させる場合にも、これらのバックアップコピーが役立ちます。
RPO の同期ポイント回復との関連付け
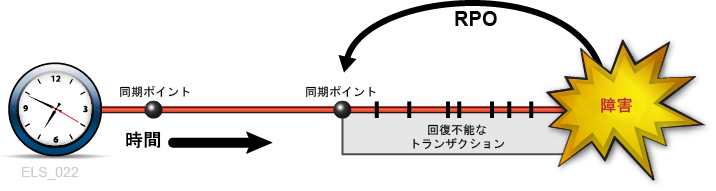
RPO と同期ポイントが整合している場合、この同期ポイント用に作成したアプリケーション再開手順を実行すると、アプリケーションはまるで中断が発生しなかったかのように、このポイントを起点として再開されます (図1-2)。この RPO から障害発生時までの間に処理されたトランザクションは一切回復できません。
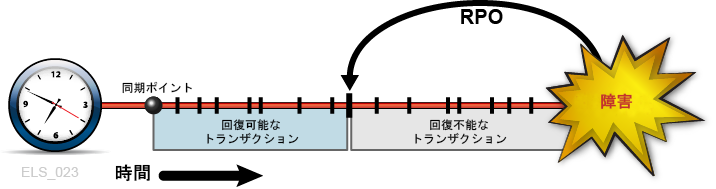
BC 要件によっては、同期ポイントと同期ポイントの間に RPO が設定されることもあります。このような場合の内部同期ポイント回復は補助データに依存します。補助データには、最後の同期ポイントの作成後に発生したアプリケーションの重要な状態変更やイベントが記述されています。たとえば、RPO を障害の 1 分前にした場合を考えます。回復可能アプリケーションがチェックポイントを使用して進捗を記録する設計になっていて、チェックポイントを 1 分間隔で取得するにはオーバーヘッドが重すぎるとします。このとき考えられる解決方法の 1 つは、チェックポイントの間隔を長めに設定し、各チェックポイントの間にコミットされたすべてのトランザクションをログに記録することです。このトランザクションログを補助入力データとしてチェックポイント回復プロセスで使用し、最後の同期ポイントを越えた RPO から再開させることができます。この例では、アプリケーション再開手順は最後のチェックポイントデータと補助トランザクションログにアクセスし、チェックポイント以降 RPO 前の期間に処理されたすべてのコミット済みトランザクションを回復します。(図1-3) このように同期ポイント回復では、複数のソースからの入力データを使用して目標の RPO を達成できます。RPO から障害発生時までの間に処理されたトランザクションは一切回復できません。
データの高可用性 (D-HA) 計画
企業が保有するもっとも貴重な資産の 1 つはデータです。ビジネスに影響する重要なデータの損失を防ぎ、データを必要なときに目的に応じて使用できるようにするため、多くの企業がデータの保護に細心の注意を払い、投じる資金を増やしています。深刻なデータ損失に対処できなかった企業は悲惨な結末を迎えかねません。データ損失を防止するもっとも一般的な方法は、重要データのコピーを別のストレージメディアまたはサブシステムに保管し、さらにこれらのコピーの一部を物理的に別の場所に保管する方法です。磁気カートリッジテープや CD-ROM、DVD など、リムーバブルストレージメディアに保存されたコピーは、通常オフサイトのストレージ拠点に保管されます。さらにコピーを作成して、アプリケーションがデータを処理できるオンサイトの IT 設備に保管する方法も一般的です。重要データのコピーを作成して保管することでデータの冗長性が増し、データの耐障害性も向上します。リムーバブルメディア、特に磁気カートリッジテープについては、データの冗長性を高めるだけでは、それを使用するアプリケーションに高可用性を提供することはできません。たとえば、メインフレーム仮想テープのための Oracle の VSM システムは、データを MVC と呼ばれる物理的なテープボリュームに保存します。VSM は MVC のコピーを自動的に作成するため、データの冗長性が高くなり、メディアの故障やテープカートリッジの配置ミスによるリスクを低減できます。本番 VSM システムは MVC に保存されているデータを取得する際、さまざまな専用ハードウェアコンポーネントを使用します。これには、VTSS バッファーデバイスのほか、自動テープライブラリやライブラリに接続された RTD と呼ばれるテープドライブなどが含まれ、これらも VTSS バッファーデバイスに接続されています。ホストアプリケーションはこれらの VSM コンポーネントすべてに依存しており、これらと連携して MVC からデータを取得します。多くの人は 1 つのコンポーネント障害を、地震でデータセンターを完全に失う場合の障害と同等なものとして考えませんが、ある 1 つの重要な VSM コンポーネントに障害が発生しバックアップもなかったとしたら、複製した MVC のコピーをいくつ持っていても MVC データは取り戻せません。このように、MVC のコピーを作成することは脆弱性とリスクを緩和する実証されたベストプラクティスではありますが、障害が発生したときのデータ高可用性 (D-HA) を必ずしも十分に保証できるわけではありません。D-HA 要件は DR 計画の主要なビジネス継続性要件です。通常 D-HA は、冗長性を高めて単一障害点 (ストレージシステムの障害発生時にアプリケーションからデータにアクセスできなくなる) を取り除くことで実現します。たとえば冗長コンポーネントが含まれている VSM システムは VSM システムの耐障害性を高めます。複数の VTSS デバイス、冗長 SL8500 ハンドボット、および複数の RTD を設置する理由は、アプリケーションから MVC 上の重要データまでのデータパスから VSM の単一障害点を取り除くためです。耐障害性の向上と D-HA の促進のため、VSM アーキテクチャーは全体的に冗長コンポーネントの追加をサポートする設計になっています。
高可用性物理テープ
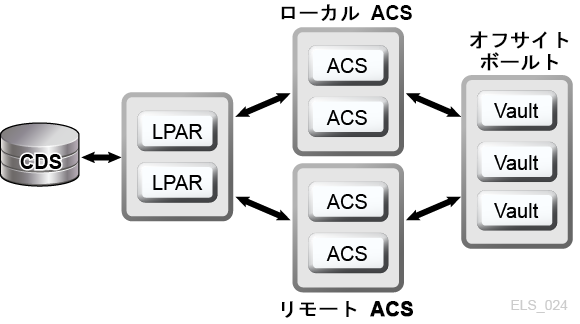
Oracle のメインフレームテープ自動化ソリューションは、データの冗長コピーを TapePlex (1 つの CDS によってマッピングされるテープコンプレックス) 内の別の ACS 内に保管することで、物理テープアプリケーションの D-HA を実現します。たとえば、1 つの TapePlex を備える IT 設備で動作するアプリケーションは、その TapePlex 内の 1 つ以上の ACS にテープデータセットの複製コピーを簡単に保存できます。この手法では、冗長メディア、冗長テープトランスポート、および冗長自動テープライブラリの追加によって、D-HA が向上します。単純なケースでは、アプリケーションが重要なデータセットの冗長コピーを 1 つの SL8500 ライブラリ (冗長電子デバイス、各レール上にデュアルハンドボット、各レール上に複数のライブラリが接続されデータセットメディアと互換するテープトランスポートが搭載されているもの) 内の異なる 2 つのカートリッジテープに保存します。SL8500 ライブラリが単一障害点にならないようにするには、2 台目の SL8500 を ACS に追加して、重要なデータセットの冗長コピーをさらにここに保存します。IT 設備自体が単一障害点にならないようにするには、冗長データセットのコピーをオフサイトで保管するか、またはチャネルが拡張されたテープトランスポートを持つリモートの ACS に冗長データセットのコピーを作成します (図1-4)。
異なる複数の物理的な場所にそれぞれ CDS がある場合 (つまり、各場所のハードウェアが別個の TapePlex を表している場合)、これらの各場所に物理テープのコピーを作成できます。SMC クライアント/サーバー機能を使用し、データセットのコピーがリモートの TapePlex に向かうようにポリシーを定義すると、JCL を変更せずに、ジョブを使用して別の TapePlex にある ACS にテープのコピーを作成できます。
高可用性仮想テープ
VSM は MVC の N-plexing (N 重化) とクラスタ技術によりメインフレーム仮想テープの D-HA を実現します。VSM の N 重化では、複数の MVC コピー (二重化、四重化など) を 1 つ以上の ACS に作成することで、さらに高い冗長性を実現します (図1-5)。N 重化のコピーを受信する ACS には、チャネルが拡張されたテープトランスポートを持つリモート ACS またはローカルライブラリを使用できます。VSM 移行ポリシーによって VTSS のバッファー常駐 VTV がローカルまたはリモートの MVC に移行され、これがオフサイトのボールトに循環されます。
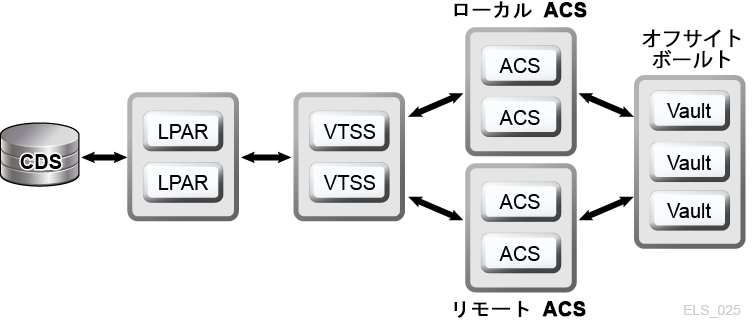
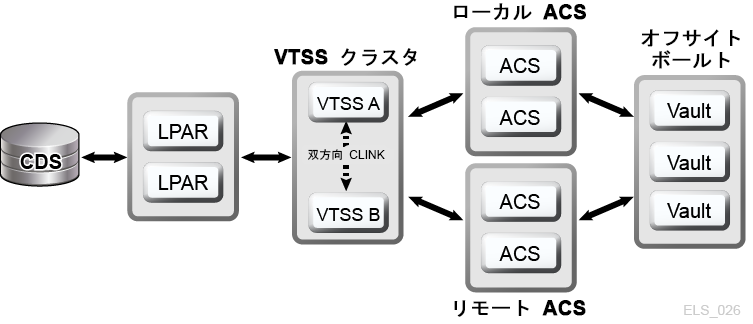
VSM クラスタはネットワークで接続された複数の VTSS デバイス (ノード) で構成され、通信リンク (CLINK) をとおしてデータ交換を実行します。CLINK は単方向チャネルまたは双方向チャネルのいずれかです。もっとも簡単な VSM クラスタ構成は同一 TapePlex 内にある 2 つの VTSS ノードが単方向 CLINK でリンクされる構成ですが、一般的には双方向 CLINK が使用されます (図1-6)。各クラスタノードが別々のサイトに配置されることもあります。VSM 単方向ストレージポリシーは VTSS A から VTSS B への単方向 CLINK を使用した仮想テープボリューム (VTV) の自動レプリケーションを制御します。双方向ストレージポリシーと双方向 CLINK は、VTSS A から VTSS B へのレプリケートとその逆のレプリケートを可能にします。
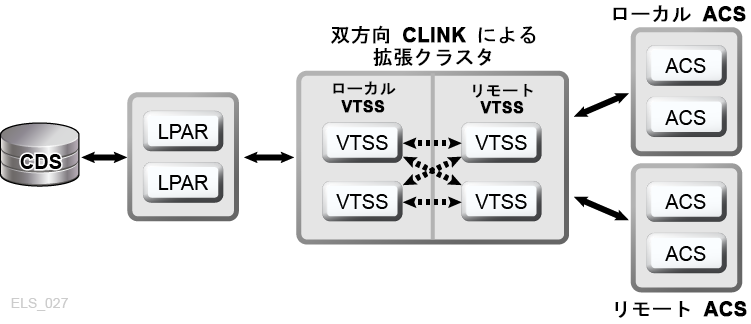
VSM 拡張クラスタリングは、TapePlex 内の 3 つ以上の VTSS デバイス間での多対多の接続を可能にし、さらに高いデータ可用性を実現します (図1-7)。このように複数のサイトで TapePlex 内に VTSS クラスタデバイスを設置すると、各サイトが単一障害点になることがなくなるため、冗長性が向上します。
Oracle の LCM 製品はボールトと本番ライブラリ間のリサイクルプロセスを管理することで、MVC ボリュームのオフサイトボールトプロセスを合理化します。LCM のボールト機能は、期限切れデータの量が指定のしきい値を超えたときに、保管していた MVC ボリュームを戻すスケジュールを管理します。
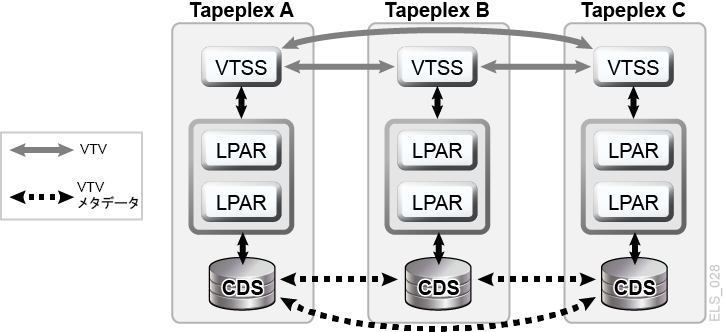
VSM Cross-Tapeplex Replication クラスタ (CTR クラスタ) では VTSS クラスタデバイスを別々の TapePlex に配置して、ある TapePlex から別の 1 つまたは複数の TapePlex に VTV をレプリケートできます。これにより、単方向または双方向の CLINK をとおした多対多のクラスタレプリケーションモデルを実現します (図1-8)。送信側と受信側の TapePlex が別々のサイトに置かれることもあります。レプリケートされた VTV は読み取り専用ボリュームとして受信側 TapePlex の CDS に入力されます。これにより、受信側 TapePlex で実行されているアプリケーションによる変更からデータを保護できます。受信側 TapePlex の CDS には、CTR でレプリケートされた VTV のコピーは送信側 TapePlex の所有物であることが記述され、さらに確実な保護のため、自己所有以外の VTV に TapePlex が変更を加えるのを CTR が阻止します。
D-HA と同期ポイント回復
物理ボリューム (MVC または MVC 以外) のコピーを複数作成するとデータの冗長性は向上しますが、これらのコピーによって同期ポイント回復に関する特別な考慮が必要になります。同期ポイント回復でもっとも重要な点は、障害回復の用途として有効である期間は、同期ポイントで作成されたデータを読み取り専用の状態にしておく必要があるという点です。つまり、障害回復に使用される物理テープボリュームのコピーは、読み取り専用にしておく必要があるということです。これを実現する方法の 1 つとして、テープ処理能力のないオフサイトのボールトの場所にこれらのコピーを送る方法があります。変更処理が行われる非保護のコピーは同期ポイント回復には使用できません。更新された時点でコンテンツは同期ポイントを反映したものではなくなるからです。仮想テープ環境は、同期ポイント回復のための複数のボリュームコピーの管理に新たな側面をもたらします。VTV コピーを複数の VSM バッファーと複数の MVC 上に同時に存在させることも可能です。VTV のすべての MVC がオフサイトに保管されている場合でも、VSM バッファー内に残っているオンサイトの VTV のコピーは変更可能です。バッファーに常駐している更新された VTV コピーは、その VTV が障害回復用に保管されているオフサイトのコピーを無効にするような新しい同期ポイントに属しているという場合を除き、同期ポイント回復には使用しないでください。
実際の障害回復の実施
実際の障害回復の成功は、適切な DR サイトや訓練を受けた人員、実証された DR 手順を準備できたかどうかのほか、同期ポイントを持つ回復可能本番作業負荷が規定の RPO を達成できるかどうか、これらの RPO の達成に必要なすべての入力データやシステムメタデータがあるかどうかなどに左右されます。入力データとシステムメタデータは必要なときに DR サイトで使用でき、それらのデータは求めるレベルの最新性である必要があります。入念な計画と周到な準備、十分なリハーサル実行により、実際の障害回復の手順は規定された RPO と RTO の達成に向けスムーズに流れます。DR サイトが本番サイトとして機能している間は、DR サイトで生成された本番データに適切な保護を施す必要があります。たとえば、本番の作業負荷が冗長データのコピーを 3 か所のリモートサイトにレプリケートするという D-HA アーキテクチャーがあり、DR サイトが障害発生前のリモートレプリケーションサイトの 1 つであるとします。本番サイトで障害が発生し作業負荷が DR サイトに移ると、この DR サイトで本番作業負荷がローカルで実行されるため、このサイトはリモートレプリケーションサイトとして機能できなくなります。3 つのリモートレプリケーションサイトを持つという D-HA 要件を満たすため、本番が DR サイトで行われている間は、3 つ目のリモートレプリケーションサイトとして別のサイトを新たにオンラインにする必要があります。この例は、D-HA 要件を徹底的に分析することで、本番が DR サイトに移ったときに満たすべき重要 D-HA 要件をすべて満たす DR 計画の作成が可能になるということを示しています。包括的な DR 計画には、本番を DR サイトで回復する手順だけでなく、本番サイトの修復が完了して稼働準備が整ったときに DR サイトを空けるための手順 (DR サイトが唯一の本番代替サイトである場合) も含まれます。たとえば、本番サイトが業務を再開できるようになったとき、本番データをそのサイトに戻す必要があります。DR サイトと本番サイト間の双方向クラスタリングを使用する方法では、DR サイトで実行されている本番作業を以前の本番サイトにデータレプリケーションによって再入力するための時間を十分に確保できます。必要であれば、または時間や効率性のうえで有効であれば、物理的な MVC を回復された本番サイトに移送する方法でも構いません。どの方法を選択するかは障害回復後要件によって異なります。
DR テストの計画
実際の障害回復の準備がどれだけ周到に整っているかを評価するには、予定している DR テストサイトで本番の作業負荷を回復した場合の DR システムの効率性と効果をテストします。DR テスト環境として専用の DR テストプラットフォームを用意することもできますが、通常は、本番と DR テストシステムでリソースを共有した方が経済的です。本番と共有のリソースを使用して、本番と並行的に行う DR テストのことを並行 DR テストと呼びます。本番システムと DR テストシステムでアプリケーションを並行的に実行する必要がある場合は、これら 2 つのアプリケーションインスタンスが同時実行時に互いに干渉しないように DR 計画を作成する必要があります。通常は、本番システムと DR テストシステムを別々の LPAR に分離し、DR テストシステムからの本番データへのアクセスを制限する方法で十分な分離を確保できます。DR テストは断片的に実行されることが多く、この方法では本番環境全体をまとめて回復するテストを行うのではなく、テスト対象のアプリケーションを指定してアプリケーションごとに別々の時間にテストします。DR テストシステムに使用する専用ハードウェアの数を減らすには、対象を指定したテストが非常に有効です。たとえば、回復可能アプリケーションの DR テストで非常に少量の VSM リソースしか使用しない場合、これらのリソースを本番システムと DR テストシステムとで共有し、DR テストサイクル用として DR テストシステムにリソースを再割り当てします。この方法では DR テストシステムのハードウェア費用を抑えることができますが、DR テストの実行中に本番システムのパフォーマンスに影響を及ぼす恐れがあります。しかし、通常 DR テストサイクルが共有リソースを DR テストシステムに専念させるパーセンテージは非常に低く、縮小された本番環境が並行 DR テストから受ける影響はそう大きくありません。それでも、DR テストの実行のために本番が変更を余儀なくされたり、影響を受けたりすることを認めない方針の企業もあります。DR 回復プロセスを実証するための監査で、DR テストの結果と本番の結果が完全に一致することが求められる場合があります。この要求にこたえるには、予定されている本番の直前に同期ポイントを設定し、本番の結果のコピーを保存して、DR テストサイトでこの同期ポイントで本番実行を回復し、この出力と保存してあった本番の結果とを比較する方法を使用できます。結果の相違点が調査する必要のある相違点ということになります。この相違を適時解決できなければ、企業の実際の障害回復能力が脅かされます。DR テストの目的が複雑な作業負荷の回復であろうと単一のアプリケーションの回復であろうと、DR テストプロセスは実際の障害回復で使用するのと同じ手順で実行する必要があります。これが DR テストの正当性を証明する唯一の確実な方法です。
DR テストのためのデータ移動
DR テスト用のアプリケーションデータを DR テストサイトにステージングするには、物理的なデータ移動を行う方法と電子的にデータを移動する方法の 2 つがあります。物理的なデータ移動では、次で説明する物理的なエクスポート/インポートのプロセスで、物理テープカートリッジを DR テストサイトに移送する作業が含まれます。電子的なデータ移動では、リモートテープドライブ、リモート RTD または VSM クラスタ技術を使用して、アプリケーションデータのコピーを DR テストサイトに作成します。どちらのデータ移動方法でも DR テストは可能ですが、電子的なデータ移動には物理的なデータ移動が伴わずテープを紛失する危険もないうえ、実際の障害回復で必要になる場所にデータを配置するか、DR テストサイクルの前に VSM バッファーにデータをステージングするため、データのアクセス時間も短縮できます。仮想ボリュームの電子的なデータ移動を行うには、1 つの TapePlex 内で VSM 拡張クラスタリングを使用するか、2 つの TapePlex 内で Cross-Tapeplex Replication を使用します。1 つの TapePlex 内のデータについては、Oracle の並行障害回復テスト (CDRT) ソフトウェアで DR テストを簡単に実行できます。
物理的なエクスポート/インポートを使用する DR テスト
仮想テープと物理テープを使用する本番アプリケーションの DR テストを実行する例を考えます。最近の本番実行を再現し、テストの結果が最近の本番の出力と一致するかどうかを確認する方法で、このアプリケーションを DR テストサイトでテストすることが目標です。この準備として、本番で使用されたすべての入力データセットのコピーおよび比較に使用する本番出力のコピーを保存する必要があります。DR テストサイトは分離されており、本番サイトと共有している機器はないと仮定します。次の物理的なエクスポート/インポートのプロセスを使用して、DR テストを実行できます。
本番サイト
-
必要な VTV および物理ボリュームのコピーを作成します。
-
これらの VTV コピーをエクスポートします。
-
関連する MVC コピーと物理ボリュームのコピーを本番 ACS から取り出します。
-
取り出した MVC および物理ボリュームを DR テストサイトに移送します。
DR テストサイト
-
移送したボリュームを DR の ACS に挿入します。
-
挿入したボリュームを使用して OS カタログとテープ管理システムを同期します。
-
VTV/MVC データをインポートします。
-
アプリケーションを実行します。
-
結果を比較します。
-
このテストで挿入したすべてのボリュームを取り出します。
-
取り出したボリュームを本番サイトに移送します。
本番サイト
-
移送したボリュームを本番 ACS に挿入します。
このプロセスでは DR テストシステムと本番システムが分離しているため、本番と並列的に DR テストを安全に実行できます。DR テストシステムには専用の CDS があり、前述の DR テストプロセスは DR テストの準備として、DR テスト CDS にボリューム情報を入力します。これにより、本番で使用されているのと同じボリュームおよびデータセット名を使用して、回復するアプリケーションをテストできます。仮想テープデータセットの場合、Oracle の LCM ソフトウェアのボールト機能で VTV の MVC への配置を簡単に実行可能であり、本番サイトでのボリュームのエクスポートと取り出し、DR テストサイトでのそれらのボリュームのインポート、本番サイトに戻すための取り出しといった、一連の往復的な手順も効率的に実行できます。物理的なエクスポート/インポートでは、物理的なテープの取り扱いにかかる費用や、本番サイトと DR テストサイト間のテープカートリッジの移送にかかる費用など、サイト費用が発生します。機密データの移送を輸送業者に依頼する場合は、暗号化したテープカートリッジを使用する必要があります。サイト間で移動するテープカートリッジの移送や取り扱いにかかる時間は DR テストの適時性に影響を及ぼします。
CDRT を使用した DR テスト
計画を作成し、本番サイトと DR サイトに十分なハードウェアを確保できる場合、CDRT と電子的なデータ移動を使用して DR サイトへの物理的なテープカートリッジ移送を省くことができ、専用の分離した DR テストサイトを維持する場合よりも経済的に並行 DR テストを実行できます。CDRT は想定できるほぼすべての本番作業負荷、構成、RPO、RTO の DR テストに対応します。DR テスト手順では、CDRT の開始と DR テスト後のクリーンアップ処理にいくつか追加の手順が必要になります。CDRT を使用した DR テストを実行する前に、テストに必要なすべてのアプリケーションデータとシステムメタデータ (OS カタログ情報とテープ管理システム情報) を DR テストサイトに電子的な方法で移動しておく必要があります。VSM クラスタリングまたは VTV コピーを DR サイトで MVC に移行する方法で、アプリケーションデータを電子的に移動できます。次に CDRT を使用して、本番 CDS を忠実に反映した特別な CDS を DR テストシステム用に作成します。本番システムと DR テストシステムは分離された環境であり、DR テスト環境では本番 CDS の代わりに特別な DR テスト CDS を使用します。CDRT は本番 CDS 内の情報から DR テスト CDS を作成します。ここには、DR テストの開始前に DR テストサイトに電子的に移動されたすべてのボリュームのメタデータが格納されています。これにより DR テストアプリケーションで、本番で使用されているのと同じボリュームシリアル番号とテープデータセット名を使用できるようになります。CDRT は DR テストシステムに動作上の制約を課すことで、DR 環境が本番環境に干渉することを防止します。ELS VOLPARM/POOLPARM 機能を使用して MVC 用に別の volser 範囲を定義し、CDRT の排他的利用のため VTV をスクラッチすると、さらに高い保護を適用できます。CDRT では DR テストシステムによる本番 MVC からの読み取りと、DR テストサイクルのたびに論理的に消去される専用の MVC プールへの書き込みが許可されます。仮想テープアプリケーションの CDRT では、DR テストサイクルの期間中、少なくとも 1 つの専用 VTSS デバイスが必要になります。DR テストを促進させるため、これらの専用 VTSS は本番から一時的に再割り当てることができ、DR テスト VSM システムは、本番作業負荷と並行的に本番 ACS にアクセスできます。図1-9 および図1-10 は、本番 VSM クラスタを分割して、クラスタデバイスを CDRT DR テストシステムに貸し出した状態を示しています (この例では、DR テストサイトの VTSS2)。このクラスタを分割した場合、レプリケーションの代わりに移行を使用するよう本番ポリシーを変更し、VTSS1 が冗長 VTV コピーを DR サイトの ACS01 に作成し、クラスタの分割中は VTSS1 が容量への書き込みをしないようにします。VTSS2 は本番に対してオフラインになり、DR テスト LPAR に対してオンラインになります。図1-9 では、CDRT により本番 CDS のリモートコピーから DR テスト CDS が作成されています。DR テストサイクル中、VTSS1 内のボリュームと ACS00 にアクセスできるのは本番システムのみで、DR テストシステムのみが VTSS2 にアクセスできます。本番システムと DR テストシステムは ACS01 内のボリュームに同時にアクセスできます。図1-9 と 図1-10 では本番 CDS のリモートコピーを DR サイトで保持しているため (リモートミラー化などによって)、実際の障害回復で使用する最新の本番 CDS を DR サイトで利用できます。ただし、CDRT によってリモート CDS コピーから作成される DR テスト CDS は本番 CDS の特殊な DR テストバージョンであるため、CDRT でしか使用されません。DR テストサイクルの終了後、本番クラスタを構成し直す前に、本番データの消失 (これは、VTSS1 にも存在する VTV の新しいバージョンが VTSS2 に含まれている場合に発生します) を回避するため DR VTSS をパージする必要があります。また、クラスタを構成し直すときに本番ポリシーを変更し、移行からレプリケーションに戻す必要があります。ここで示したような本番クラスタの分割を採用できない場合は、DR テスト専用の独立した VTSS を DR サイトに用意します。この場合、テストに必要な VTV は MVC コピーからリコールされます。
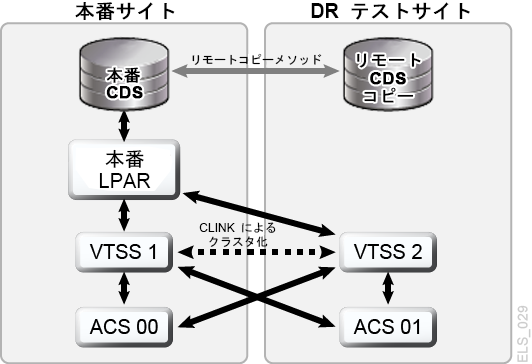
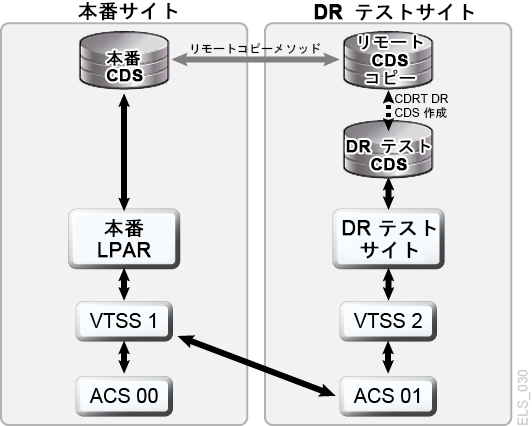
VSM Cross-Tape Replication を使用した DR テスト
VSM Cross-Tapeplex Replication では、クラスタ化された対称的な本番 TapePlex 設計により、CDRT を使用したり、DR テスト専用の VTSS ハードウェアを使用したりすることなく、また、本番環境を DR テスト用に変更することなく DR テストを実行できます。たとえば CTR では、各本番 TapePlex が、同じ CTR クラスタ内の別の本番 TapePlex にデータをレプリケートします。本番 CTR のピアツーピアクラスタによって専用の DR テストサイトを用意する必要がありません。CTR はさまざまなタイプのクラスタ化 TapePlex 設計を実現できるため、実現可能な RPO または RTO を使用して、あらゆるタイプの本番作業負荷および構成の DR テストを簡単に実行できます。簡単な例では、双方向 CTR クラスタが 2 つの本番 TapePlex を対称的に結合し、各 TapePlex が互いに相手の TapePlex にデータをレプリケートします (図1-11)。受信側の TapePlex はレプリケートされた VTV を自身の CDS に読み取り専用のステータスで入力し、送信側 TapePlex の所有であることを示すマークを VTV に付けます。この例の TapePlex A アプリケーションの DR テストでは、アプリケーションデータを TapePlex B でレプリケートして、アプリケーションを TapePlex B で回復します。
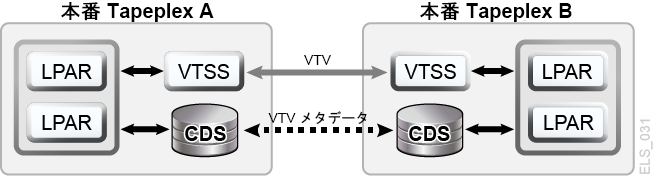
CTR クラスタのピア接続設計の対称性により、ピアサイトにあるテスト対象の回復するアプリケーションは、DR テスト中も本番時と同じように稼働します。ピア CDS には DR テストに必要なレプリケートされたボリューム情報のすべてが保存されており、DR テストは本番と並行で実行され、VTSS ハードウェアは本番の作業負荷と DR テストの作業負荷の同時使用をサポートします。本番 VTSS クラスタが各 TapePlex 内に存在する場合は、DR テスト中にハードウェアを TapePlex 間で共有するためにクラスタを分割する必要はありません。アプリケーションの DR テストが実行される本番 TapePlex は CTR でレプリケートされた VTV を変更できないため、DR テストサイクル中、レプリケートされたすべての本番データは完全に保護されます。もっとも重要な点は、CTR ベースの DR テストでは、検証済みの DR テスト手順によって実際の障害回復時で同じ結果が得られるということです。CTR でレプリケートされた VTV に対して更新操作が試行されると、SMC ホストソフトウェアがメッセージを発行するため、既存の入力データセットを変更するアプリケーションであるとしてアプリケーションを特定するのに役立ちます。前述の同期ポイントの管理に関するベストプラクティスに従うことで、同期ポイント回復でバックアップコピーが必要になったときに、アプリケーションが変更を加える前のデータセットのコピーが本番環境に必ず保存されているという状態を確保できます。