| Oracle® Data Minerユーザーズ・ガイド リリース4.1 E62045-01 |
|


 前 |
 次 |
データ・ノードでは、マイニング操作用のデータを指定し、データを変換するか、データを表に保存します。Oracle Data Mining操作の入力は、Oracle Databaseの表やビュー、またはデータ・フローの一部であるOracle Data Minerノードです。
データ・ノードは、「コンポーネント」ペインの「データ」セクションで使用できます。
次のデータ・ノードでは、ワークフロー内のデータを指定し、表を作成および変更できます。
表またはビュー作成ノードは、接続しているスキーマの表に結果を保存できるタイプのノードです。たとえば、表またはビュー作成ノードを使用して、適用ノードの結果を表に保存します。
表作成ノードでは、可能な場合は圧縮が自動的に使用されます。
表作成ノードはパラレルに実行できます。
表またはビュー作成ノードの利点は、次のとおりです。
データの永続性: 表またはビュー作成ノードでは、データベースのビューまたは表としてノードに入るデータを保存します。表を作成すると、実際のデータが永続化されます。ビューを作成すると、SQL定義(完全系統)が永続化されます。このノードからの出力は、ビューまたは表で提供されたデータです。
パフォーマンスの向上: 「結合」や「集計」などの複雑な変換を1つ以上実行し、変換の結果を表として保存すると、それ以降の操作が高速化されます。たとえば、「集計」と「結合」を実行し、この変換結果が含まれる表を作成して、その表をモデル作成用の入力として使用できます。したがって、表は結合ノードから作成します。分類モデルは、この表に対して作成されます。
表またはビュー作成ノードでは次のタスクを実行できます。
表またはビュー作成ノードを作成して、データ・フローを表またはビューに保存します。表またはビュー作成ノードを、データ・フローを作成する任意のノード(適用ノードなど)に接続できます。
表またはビュー作成ノードを作成するには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動し、「データ」を展開します。
「コンポーネント」ペインが表示されていない場合は、SQL Developerメニュー・バーで「表示」に移動して「コンポーネント」をクリックします。または、[Ctrl]を押しながら[Shift]と[P]を押して、「コンポーネント」ペインをドッキングします。
「データ」セクションで、「表またはビューの作成」アイコンをクリックします。
表またはビュー作成ノードを「コンポーネント」ペインから「ワークフロー」にドラッグ・アンド・ドロップします。これにより、表またはビュー作成ノードがワークフローに追加されます。
表の作成元であるノードを右クリックして、コンテキスト・メニューの「接続」をクリックします。
選択したノードから表またはビュー作成ノードに線を描画し、再度クリックします。
表またはビュー作成ノードのデフォルト設定をそのまま使用するか、デフォルト設定を編集できます。コンテキスト・メニューの「編集」をクリックします。
表を作成するには、表またはビュー作成ノードを右クリックして、コンテキスト・メニューから「実行」を選択します。
可能な場合、表は自動的に圧縮されます。
ノードの実行後、ノードを右クリックして、「データの表示」を選択し、結果を表示します。
表を圧縮すると次の利点があります。
ディスク領域の節約
バッファ・キャッシュでのメモリー使用の削減
読取り中の問合せの実行速度の増加
Oracle Data Minerは、表の作成時に、ネストされた列DM_NESTED_*がデータに含まれていないと判断すると、圧縮を使用して表を作成します。Oracle Data Minerは、表作成ノードに表を作成し、分類および回帰モデル構築でのテスト用の分割データ・セットを作成します。
Oracle Data Minerは、表作成ノードについて、主キーが定義されていないこと、および索引が定義されていないことも確認します。
表またはビュー作成ノードの操作を変更できます。表またはビュー作成ノードを編集するには、次の手順を実行します。
ノードをダブルクリックするか、右クリックして、「編集」を選択します。「表またはビュー作成ノードの編集」ダイアログ・ボックスが開きます。
「表またはビュー作成ノードの編集」ダイアログ・ボックスでは、次の変更が可能です。
名前: デフォルトの表名が表示されます。表またはビューのデフォルト名を一意で有効な名前に変更できます。
タイプ: デフォルトでは、オブジェクト・タイプは「表」です。適切なオプションを選択して、デフォルトを「ビュー」に変更できます。
自動入力列の選択: このチェック・ボックスの選択を解除して、入力列を手動で選択および編集します。次のタスクを実行できます。
列の削除: 列を選択し、 をクリックします。
をクリックします。
列の編集: 列を選択し、 をクリックします。「列の選択」ダイアログ・ボックスが開きます。
をクリックします。「列の選択」ダイアログ・ボックスが開きます。
|
注意: JSONデータが存在する場合は、その列を選択し、をクリックして、データ・ガイドの編集ダイアログ・ボックスでデータ・ガイドの設定を指定します。 |
JSONデータのみに関して、「ターゲット・タイプ」列のデータ型エントリを編集します。「ターゲット」列のデータ型をクリックして、インプレース・ドロップダウン・リストからオプションを選択します。
各列の「キー」、「索引」および「別名」を指定します。
|
注意: 別のオブジェクトを結合する表を作成すると、索引の追加により結合が高速化されます。 |
JSON設定: 「JSON設定」をクリックして、データ・ガイドの生成方法を決定するノード設定を指定します。このオプションは、JSONデータにのみ適用できます。
「OK」をクリックします。
デフォルトでは、すべての列が選択されています。「表またはビューの作成」の定義を完了するには、少なくとも1つの属性を選択する必要があります。次のタスクを実行できます。
列の削除: 「選択した属性」セクション内の属性を選択し、それを「使用可能な属性」セクションに移動します。「OK」をクリックします。
列の追加: 「使用可能な属性」セクション内の属性を選択し、それを「選択した属性」セクションに移動します。「OK」をクリックします。
コンテキスト・メニューを表示するには、表またはビューの作成ノードを右クリックします。次のタスクを実行できます。
編集。詳細は、「表またはビュー作成ノードの編集」を参照してください。
実行。ノードが実行される方法の詳細は、「データ・ソース・ノードの実行」を参照してください。
データの表示。詳細は、「データ・ソース・ノード・ビューア」を参照してください。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
「プロパティ」ペインで、表またはビューの作成ノードの特性やプロパティを調査および変更できます。「プロパティ」ペインで、表またはビューの作成ノードを管理する手順:
ノードを右クリックし、「プロパティに移動」をクリックします。
「プロパティ」ペインがSQL Developerウィンドウの右下のパネルに開きます。表またはビューの名前によって、表またはビュー作成のプロパティが識別されます。「プロパティ」ペインは、次のように構成されています。
表またはビューの名前が表示されます。次のタスクを実行できます。
表またはビューの名前を変更: 表のデフォルト名を変更した場合、ノードの名前はその表の名前に一致するように変更されます。たとえば、表のデフォルト名をPREDICTIONSに変更した場合、表またはビューの作成ノードの名前もPREDICTIONSに変更されます。
オブジェクト・タイプを表からビューに変更: デフォルトのタイプは「表」です。ビューを作成するには、「ビュー」をクリックします。
表の列を表示します。デフォルト設定では自動動作が可能です。「自動入力列の選択」の選択を解除すると、表内の列を手動で選択および編集できます。次のことを実行できます。
列の削除: 削除する列を選択し、をクリックします。
列の編集: 列を選択し、をクリックします。必要な変更の編集を次で実行します。
「列の選択」ダイアログ・ボックス
JSONデータの場合は「データ・ガイドの編集」ダイアログ・ボックス
「自動入力列の選択」が選択されている場合、次のシナリオが考えられます。
シナリオ1: 入力が接続されている場合
入力ノードのすべての列が選択されます。ノードは有効になります。少なくとも1つの列が指定に含まれていることを前提とします。
シナリオ2: 入力が切断されている場合
すべての列が自動的に削除されます。ノードは無効になります。
シナリオ3: 入力ノードが編集されている場合
次の編集シナリオが考えられます。
列の追加: 互換性がある場合は、表またはビュー作成ノードに列が追加されます。
列の削除: 表またはビュー作成ノードから列が削除されます。
列の編集: 列が編集されている場合、列のデータ型の変更により、ノードで無効な状態がトリガーされる可能性があります。
|
注意: 「自動入力列の選択」オプションの選択が解除されている場合は、表またはビュー作成ノードに対して列指定を手動で追加および削除する必要があります。 |
データ・ソース・ノードでは、ワークフローのソース・データを定義します。たとえば、データ・ソース・ノードで、モデルの構築データを指定します。ユーザーがアクセスできる表またはビューはすべて、ソースとして選択できます。このノードでは、入力ノードの接続が許可されません。データ・ソース・ノードは、データベース・リソースを使用して、自身を定義します。データベース・リソースが変更された場合は、ノード定義のリフレッシュが必要になることがあります。たとえば、リソースが削除または再作成された場合です。
データ・ソース・ノードはパラレルに実行できます。
データ・ソース・ノードでは、特定のデータ型のみが許可されています。他のデータ型を持つ列は除外されます。
基本的なOracleデータ型のほとんどが、データ・ソース・ノードでサポートされています。オブジェクト・ベースのデータ型を含めることはできますが、各オブジェクト・タイプをよく理解する必要があります。オブジェクト・データ型では、オブジェクト階層の適切なレベルで記憶域句を定義する必要があります。
VARCHAR2
CHAR
FLOAT
NUMBER
CLOB
NESTED_NUMERICALS
NESTED_CATEGORICALS
次のデータ型は、Oracle Data Mining 12cリリース1 (12.1)でサポートされています。
BINARY_DOUBLE
BINARY_FLOAT
DM_NESTED_BINARY_DOUBLES
DM_NESTED_BINARY_DOUBLES
BLOB (テキストの場合のみ)
Oracle Data Mining 12cリリース1 (1.2)以上に接続されている場合、BINARYデータ型とBLOBはOracle Data Minerでサポートされます。
次の日時データ型は、部分的にサポートされています。
DATE
TIMESTAMP
TIMESTAMP_WITH_LOCAL_TIMEZONE
TIMESTAMP_WITH_TIMEZONE
TIMESTAMP_WITH_LOCAL_TIMEZONE
Oracle Database 12.1.0.2では、次のデータ型のJSONデータがサポートされています。Oracle Data Minerは、次のデータ型から擬似JSON データ型を導出します。
VARCHAR2
CLOB
BLOB
RAW
NCLOB
NVARCHAR2
「変換」を使用した変換では、DATE、TIMESTAMP、TIMESTAMP_WITH_LOCAL_TIMEZONEおよびTIMESTAMP_WITH_TIMEZONEの日時データ型を部分的にサポートしています。
日時データ型を持つ属性は、「等幅」または「カスタム」ビニングを使用してビニングできます。
「統計」または「値」の欠損値処理を、日時データ型を持つ属性に適用できます。
日時型を持つ属性は、データの参照ノードによって分析されます。
日時データ型は、Oracle Data Minerの他の関数では使用できません。特に、日時データ型は、モデル構築のターゲットにすることはできません。
データ・ソース・ノードでは、次のタスクを実行できます。
ワークフローを作成した後に、データ・ソース・ノードを作成します。データ・ソース・ノードを作成し、データをアタッチするには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動し、「データ」を展開します。
「コンポーネント」ペインが表示されていない場合は、SQL Developerメニュー・バーで「表示」に移動して「コンポーネント」をクリックします。または、[Ctrl]を押しながら[Shift]と[P]を押して、「コンポーネント」ペインをドッキングします。
「データ」セクションで、データ・ソース・ノード・アイコンをクリックします。
データ・ソース・ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。これにより、データ・ソース・ノードがワークフローに追加されます。「データ・ソースの定義」ダイアログ・ボックスが開きます。
「データ・ソースの定義」ダイアログ・ボックスで、表またはビューを選択できます。デフォルトでは、スキーマ内の表がリストされます。「スキーマ・リストの編集」ダイアログ・ボックスで、アクセス権を持つ他のスキーマから表を追加できます。
「次へ」をクリックします。
「データ・ソースの定義」の「列の選択」ダイアログ・ボックスで、表に対して属性を追加または削除します。
「終了」をクリックします。
「表の選択」ウィンドウで、使用する表またはビューを選択します。「OK」をクリックします。「プロパティ」ペインには、選択した表またはビューに関する情報が表示されます。これで、ノードを実行できます。
ノードのデフォルト名は、選択した表またはビューの名前になります。表としてSH.CUSTOMERSを選択した場合、ノードの名前はCUSTOMERSになります。
デフォルトでは、接続しているスキーマの表およびビューがリストされます。
他のスキーマを追加するには、次の手順を実行します。
スキーマを初めて追加する場合は、「スキーマの追加」をクリックします。
スキーマをすでに追加している場合は、「スキーマの編集」をクリックします。
「スキーマ・リストの編集」ダイアログ・ボックスが開きます。「使用可能なスキーマ」は、ユーザーがアクセス権を持つスキーマのリストです。これらのスキーマのいずれかの表およびビューを表示するには、その名前を「選択したスキーマ」に移動します。
たとえば、SHスキーマの表を表示するには、「SH」を「選択したスキーマ」リストに移動します。「OK」をクリックします。
データ・ソースの定義ウィザードに戻ります。「他のスキーマからの表を含める」を選択します。追加されたスキーマの表およびビューがリストされます。たとえば、「SH」を選択すると、「使用可能な表/ビュー」リストにSH.CUSTOMERSなどの表が表示されるようになります。これらの表をデータ・ソースとして選択できます。
このインタフェースを使用して、次のことを実行できます。
新しいデータ・ソース・ノードの表および属性を定義します。
既存のデータ・ソース・ノードを編集します。
使用できない表またはビューを使用するワークフローをインポートした場合は、このウィザードを使用して、欠落しているデータ・ソースを置換するためのデータ・ソースを定義できます。ウィザードでは、JSONデータ型を持つ入力列を検出することもできます。
このウィザードには次の2つのステップがあります。
表の選択: ここでは、ユーザーがアクセス権を持つ表およびビューが表示されます。スキーマは、接続しているスキーマに加えて、「スキーマ・リストの編集」を使用して追加したスキーマとなります。表タイプまたはビュー・タイプを選択します。列およびデータが次のタブの下部ペインに表示されます。
列: 選択した表の列がグリッドにリストされます。各列について、「データ型」、「マイニング型」、「長さ」、「精度」、「スケール」および「列ID」が表示されます。
データ: 列IDに従って配置された表内のデータを表示します。
表内のすべての属性を含めるには、「終了」をクリックします。
表内の一部の属性を手動で除外するには、「次へ」をクリックします。
既存のノードの表選択を変更するには、「データ・ソース・ノードの編集」をクリックします。
列の選択: デフォルトでは、データ・ソースの定義ウィザードは「表」または「ビュー」内のすべての列を含めます。次のタスクを実行できます。
列を含めるには、属性を「使用可能な属性」から「選択された属性」セクションに移動します。
JSONデータの場合、ドロップダウン・リストを使用できます。JSONデータを使用する入力表がある場合、ウィザードは列をJSON列として検出し、その列を「データ型」列に表示します。ウィザードがJSONデータを検出できない場合は、ドロップダウン・リストをクリックして、列のデータ型を手動で変更できます。
データ・ガイド設定の指定: JSONデータ型の場合にのみ適用されます。属性を選択し、をクリックして、データ・ガイドの編集ダイアログ・ボックスでデータ・ガイド設定を指定します。
JSON設定: 「JSON設定」をクリックして、データ・ガイドの生成方法を決定するノード設定を指定します。このオプションは、JSONデータにのみ適用できます。
「データ・ガイドの編集」ダイアログ・ボックスでは、ユーザーは選択したJSON型の列にデータ・ガイドの生成方法を指定できます。このダイアログ・ボックスは、次の2つのタブで構成されます。
構造: 選択した列のJSONデータ構造を表示します
データ: インポートまたは生成されたデータ・ガイド表の内容を表示します
次のタスクを実行できます。
データ・ガイドの生成: ノードの実行中または再実行中はいつでも新しいデータ・ガイド表を生成できます。データ・ガイドを生成するには、「データ・ガイド生成」ドロップダウン・リストから次のオプションのいずれかを選択します。
デフォルト: 「JSON設定」ダイアログ・ボックスでオプション「必要に応じてデータ・ガイドを生成」が選択されている場合、データ・ガイド表はノードが実行中または再実行中であれば生成されます。そうでない場合、データ・ガイドは生成されません。
オン: ノードの実行中または再実行中いつでも新しいデータ・ガイド表が生成されるようにするには、このオプションを選択します。
オフ: ノードの実行中または再実行中に新しいデータ・ガイド表が生成されないようにするには、このオプションを選択します。
ワークフローからインポート: 「データ・ガイドの選択」ダイアログ・ボックスを使用して、同じワークフロー内または別のワークフローのデータ・ソース・ノードまたは表作成ノードで定義されている既存のJSON型の列からデータ・ガイドをインポートするには、このオプションを選択します。
ファイルからインポート: CSVファイルからデータ・ガイドをインポートするには、このオプションを選択します。このプロセスでは、データ・ガイドを検証、すなわち、インポート操作中の列ヘッダー、JSONパス形式、JSON型などの正確性を確認します。
データ・ガイドの削除: 現在のデータ・ガイド表を削除するには、をクリックします。
データ・ガイドのエクスポート: 現在のデータ・ガイド表をCSVファイルにエクスポートするには、このオプションを選択します。生成されたデータ・ガイドが、基礎となるJSONデータを完全には表していないことが判明した場合は、データ・ガイドをエクスポートして、欠落しているJSONパスを追加するオプションがあります。その後、データ・ソースをインポートして戻して、生成済のデータ・ソースを置換できます。
「データ・ガイドの選択」ダイアログ・ボックスでは、同じワークフロー内または別のワークフローのデータ・ソース・ノードまたは表作成ノードで定義されている既存のJSON型の列からデータ・ガイドをインポートできます。生成済のJSONスキーマを持つ、完了したノードのみが表示されます。データ・ガイド表をインポートするには、次の手順を実行します。
「表示」フィールドで、ドロップダウン・リストからワークフローを選択します。
インポートするノードを選択します。
「OK」をクリックします。
「JSON解析設定」ダイアログ・ボックスで、データ・ガイドの生成方法を決定するノード設定を指定できます。データ・ガイドは、JSON構造(JSON問合せノードなど)がUIに存在する場合は常に使用されます。データ・ガイド表の生成(特に大きなJSONデータの場合)は時間がかかるため、次の設定によって表の生成がある程度制御されます。
必要に応じてデータ・ガイドを生成: デフォルトで、このオプションが選択されています。JSON型の列の場合にデータ・ガイドが生成されます。JSONデータが製品で使用されていない場合は、このオプションの選択を解除します。したがって、データ・ガイドは生成されません。
サンプリング: 列に格納されている処理対象のJSONドキュメントの数を定義して、データ・ガイド表を生成します。JSONドキュメントには、特定の行のJSON列の内容全体が含まれます。
ドキュメントの最大数: 2000 (デフォルト)。この設定を変更するには、矢印を使用します。
処理するドキュメント値の制限: データ・ガイド表を生成するために解析するドキュメント内のJSON値(数字、文字列、ブール)の数を定義します。
ドキュメント当たりの最大数: 10,000 (デフォルト)。この設定を変更するには、矢印を使用します。
既存のデータ・ソース・ノードを編集するには、次の手順を実行します。
ノードをダブルクリックするか、右クリックして、「編集」を選択します。「データ・ソース・ノードの編集」が開きます。
「データ・ソース・ノードの編集」ダイアログ・ボックスで、現在のデータ・ソースで選択した属性を変更できます。次のタスクを実行できます。
属性選択の変更: 属性選択を変更するには、矢印を使用して、属性を「使用可能な属性」ペインから「選択された属性」ペインに移動します。たとえば、ATTRIBUTE1をデータ・ソースから移動するには、ATTRIBUTE1を「選択された属性」リストから「使用可能な属性」リストに移動します。完了後、「OK」をクリックします。
別の表の選択: 別の表またはビューを選択するには、「編集」をクリックします。「データ・ソースの定義」ダイアログ・ボックスが開きます。
有効なデータ・ソース・ノードを実行するには、ノードを右クリックして、「実行」を選択します。
Oracle Data Minerサーバーは、選択した表またはビューのサンプルを生成します。使用される表のサイズおよびサンプリングのタイプは、ノードの「サンプル」設定によって決まります。
ノードが完了したが、実行中の子ノードにデータを提供する必要がある場合は、そのノードが検証のために実行され、列および表がまだ存在していることが確認されます。エラーがある場合、そのノードの状態は「エラー」に設定され、影響を受ける属性は「無効」に設定されます。
コンテキスト・メニューを表示するには、データ・ソース・ノードを右クリックします。コンテキスト・メニューでは、次を選択できます。
編集: 「データ・ソース・ノードの編集」ダイアログ・ボックスを開きます。
属性: 「属性の選択」ダイアログ・ボックスを開きます。
実行: 「データ・ソース・ノードの実行」の説明に従って、ノードを実行します。
データの表示: データ・ソース・ノード・ビューアのダイアログ・ボックスを開きます。
パラレル問合せ: 詳細は、「パラレル処理について」。
ランタイム・エラーの表示。エラーがある場合にのみ表示されます。
検証エラーの表示。検証エラーがある場合にのみ表示されます。
「属性の選択」ダイアログ・ボックスでは、属性を「使用可能な属性」リストと「選択された属性」リスト間で移動できます。属性の選択を解除するには、属性を「使用可能な属性」リストに移動します。
「使用可能な属性」リストで属性を検索できます。
シャトル・コントロールを使用して、属性をリスト間で移動できます。
属性の選択が終了したら、「OK」をクリックします。
データを表示するには、ノードを右クリックして、コンテキスト・メニューから「データの表示」を選択します。データ・ビューアが開きます。
|
注意: データ・ソース・ノードが有効状態の場合にのみ、データを表示できます。 |
データ・ビューアには次のタブがあります。
「データ」タブには、データのサンプルが表示されます。データ・ビューアは、「キャッシュ」で定義されたサンプリングからのデータまたはソース表に遡るノード系統から取得されたデータの行のグリッド表示を提供します。
MINING_DATA_BUILD_Vの「データ」タブ: 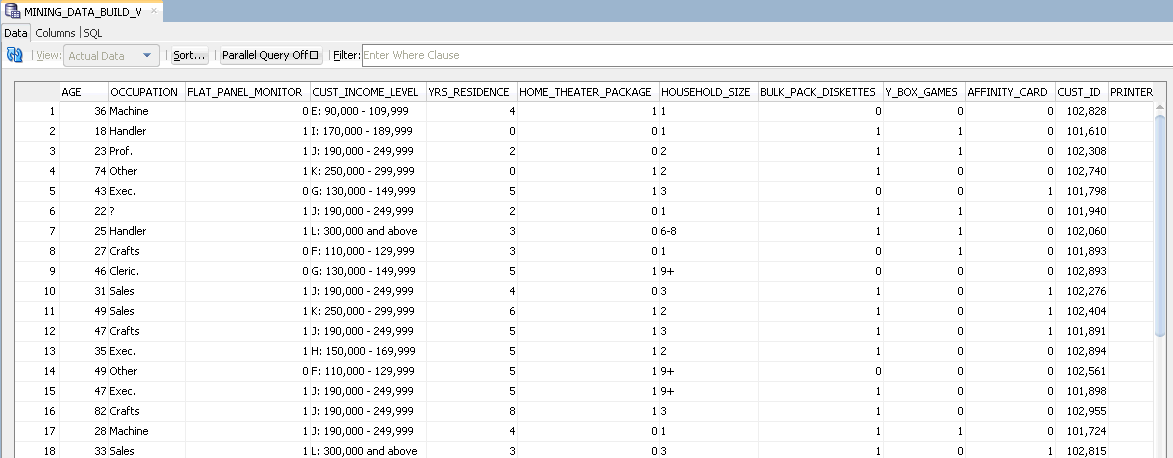
図viewdata.gifの説明
次のタスクを実行できます。
リフレッシュ:  をクリックして、データをリフレッシュします。
をクリックして、データをリフレッシュします。
表示: 「表示」をクリックし、「実際のデータ」またはキャッシュされたデータを選択します。
キャッシュされたデータは、「プロパティ」ペインの「キャッシュ」セクションでデータをキャッシュしている場合にのみ使用できます。
ソート: 「ソート」をクリックして、適用可能な基準に従ってデータをソートします。「ソートする列の選択」ダイアログ・ボックスが表示されます。
フィルタ: 「フィルタ」フィールドで、WHERE句を入力してデータを選択します。
このダイアログ・ボックスでは、次のことを実行できます。
ソートする複数の列の選択
列の順序付けの決定
列を基準とした昇順または降順の決定
「NULLS FIRST」を指定して、Null値が実際のデータ値に先行して表示されるようにします
ソート順序は、クリアするまで維持されます。
ソート設定を一時的にオーバーライドするために、列ヘッダーもソート対応となっています。
「列」タブは、ノードからの出力であるすべての列のリストです。各列について、「名前」、「データ型」、「マイニング型」、「長さ」、精度とスケール(浮動小数点の場合)および「列ID」が表示されます。
ノードが実行されていない場合、データベースによって提供された表またはビューの構造が表示されます。
ノードが正常に実行されると、ノードの指定時に定義されたサンプリングに基づいて、サンプル表の構造が表示されます。
表示される列を制限する複数のフィルタリング・オプションがあります。(または)/(および)の接尾辞を指定したフィルタ設定を使用すると、スペースで区切られた複数の文字列を入力できます。たとえば、「名前/データ型/マイニング型(いずれか)」が選択されている場合、フィルタ文字列A Bでは、「名前」、「データ型」または「マイニング型」が文字AまたはBで始まるすべての列が生成されます。
「SQL」タブには、「SQLの詳細」テキスト領域があります。このテキスト領域には、「データ」タブに表示される実際のビューで提供されるデータを生成するSQLコードが表示されます。
SQLは、実際のデータにアクセスするために必要な系統に応じて親ノードからのSQLが含まれる、積み重ね型の式にすることができます。
SQLをコピーして、そのSQLを適切なSQLインタフェースで実行できます。「すべて選択」([Ctrl]+[A])および「コピー」([Ctrl]+[C])が有効化されています。
検索コントロールは、一致したテキストをハイライトし、前方検索および後方検索を実行する標準の検索コントロールです。
データ・ソース・ノードのプロパティでは、データ・ソース・ノードの特性を調査および変更できます。「プロパティ」ペインを開くには、ノードを右クリックし、コンテキスト・メニューから「プロパティに移動」を選択します。データ・ソース・ノードの「プロパティ」ペインには、次のセクションがあります。
「データ」セクションは、次のように構成されています。
ソース表: データ・ソース・ノードのソース表またはビューの名前が表示されます。ノードに関連付けられているソース表がない場合は、「ソース表」の右にある「…」をクリックします。データ・マイニング・アカウントからアクセスできる表およびビューのリストが表示されます。表またはビューを選択できます。表またはビューを変更する場合もこのプロセスを使用できます。
データ: 属性をグリッドに表示します。各属性について、名前、別名およびデータ型が表示されます。次のタスクを実行できます。
属性の別名の作成(適切なセルに別名を入力)。
属性のフィルタ。
属性の削除。属性を選択し、をクリックします。
属性の編集。属性を選択し、をクリックします。
データ・ソースに含める属性の選択。
ノードのリフレッシュ。をクリックします。
「キャッシュ」セクションには、出力データのキャッシュを生成するオプションがあります。変換プリファレンスを使用して、このデフォルトを変更できます。
次のタスクを実行できます。
出力データのキャッシュ生成による結果表示の最適化: キャッシュを生成する場合は、このオプションを選択します。
デフォルト設定では、キャッシュを生成しません。
サンプリング・サイズ: キャッシュを選択したり、デフォルト設定をオーバーライドできます。
デフォルトのサンプリング・サイズは「行数」です
デフォルト値は2000です
「詳細」セクションには、ノードの名前、およびノードについてのコメントが表示されます。次のフィールドで名前とコメントを変更できます。
ノード名
ノード・コメント
データの参照ノードでは、入力データ・ソースのプロファイルを提供します。データの統計を参照は、すべてのデータ、またはデータのサンプルのいずれかに基づきます。データの参照ノードでは、次のことを実行できます。
各列に共通の統計およびヒストグラムを表示します。オプションで、「GROUP BY」属性を選択し、生成されたヒストグラムの多変量ビューを表示できます。
すべての統計分析の結果が含まれる出力フローを生成します。データ入力の任意のソースをデータの参照ノードに接続できます。たとえば、データの参照ノードを適用ノードにアタッチできます。
サポートされているすべてのデータ型、および日時データ型については次のデータ型を使用して属性を分析します。
DATE
TIMESTAMP
TIMESTAMP_WITH_TIMEZONE
TIMESTAMP_WITH_LOCAL_TIMEZONE
データの参照ノードをパラレルに実行します。
グラフを作成します。
SQL Developerを使用して、データの参照ノードによって生成された統計をエクスポートします。
データの参照ノードで次のタスクを実行できます。
データの参照ノードを作成し、それをデータ・ソースに接続して、データ・ソースのデータを分析します。データの参照ノードは任意のデータ・ソースに接続できます。
データの参照ノードを作成するには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動し、「データ」を展開します。
「コンポーネント」ペインが表示されていない場合は、SQL Developerメニュー・バーで「表示」に移動して「コンポーネント」をクリックします。または、[Ctrl]を押しながら[Shift]と[P]を押して、「コンポーネント」ペインをドッキングします。
「データ」セクションで、「データの参照」をクリックします。
データの参照ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。これにより、データの参照ノードがワークフローに追加されます。
分析するワークフローのノードを右クリックして、コンテキスト・メニューの「接続」をクリックします。
分析するノードからデータの参照ノードに線を描画して、再度クリックします。
統計を生成し、データを分析するには、「データの参照」ノードを右クリックして、「実行」をクリックします。
ノードを実行したら、ノードを右クリックして、「データの表示」をクリックします。データがデータの参照ノード・データ・ビューアに表示されます。
デフォルトでは、データ・ソースのすべての属性が表示されます。分析する特定の属性を指定できます。
データの参照ノードを編集するには、ノードをダブルクリックするか、ノードを右クリックして、「編集」を選択します。
「データの参照ノードの編集」エディタには、次のタブがあります。
「入力」タブをクリックして、分析する属性を指定します。デフォルトでは、データ・ソースのすべての属性が表示されます。
デフォルトでは、「GROUP BY」属性は選択されていません。「GROUP BY」には、「データの参照」でビニングできるデータ型に限定された属性のソート済リストが表示されます。「GROUP BY」属性を選択すると、選択した属性に基づいてデータを分析できます。たとえば、データにAGEおよびGENDERが属性として含まれているとします。「GROUP BY」属性として「AGE」を選択した場合、GENDERのヒストグラムには、各GENDER値の年齢構成が表示されます。
次のいずれかの方法で、分析する属性のリストを変更します。
データの参照ノードを右クリックして、「編集」を選択します。「属性の選択」ダイアログ・ボックスが開きます。
データの参照ノードを選択します。データの参照ノードの「プロパティ」ペインの「検索」タブでは、属性のリストを変更できます。
デフォルトでは、データ・ソースのすべての属性が選択されます。ある属性の統計を表示しない場合は、その属性を「選択された属性」リストから「使用可能な属性」リストに移動します。
リストを名前またはデータ型でソートできます。
完了したら「OK」をクリックします。
「統計」タブをクリックして、計算する統計を指定します。参照ノードの「プロパティ」ペインの「統計」セクションを使用して、統計を変更することもできます。
「統計」タブには、使用可能な統計のリストが含まれます。各統計について、簡単な定義、およびその統計を計算する場合のコストが示されます。
デフォルトの選択を1つでも変更した場合は、「デフォルトに戻す」をクリックして、すべての選択をデフォルトの選択に変更します。
個別の統計を名前で検索できます。
デフォルトでは、Oracle Data Minerによって次の統計が計算されます。
平均
個別パーセント
最大
中間
最小
モード(サンプル)
パーセントNULL
標準偏差
分散
デフォルトの統計には、低または中の計算コストがあります。
歪度と尖度の計算は高コストです。これらは、デフォルトでは選択されていません。必要な場合は、これらを選択できます。
サンプルを使用したモードの計算は、低コストの操作です。使用可能なすべてのデータを使用したモードの計算は、非常に高コストの操作です。サンプル・データまたは使用可能なすべてのデータを使用してモードを計算するには、「データの参照ノードの編集」ダイアログ・ボックスで「モード(サンプル)」をクリックします。
デフォルトでは、2000レコードのサンプルを使用してモード計算します。使用可能なすべてのデータを使用してモードを計算できます。この計算は非常に高コストとなります。
使用可能なすべてのデータを使用するには、「使用可能なデータ」オプションをクリックし、「OK」をクリックします。
データの参照ノードのコンテキスト・メニューでは、次のことを選択できます。
編集: 「属性の選択」ダイアログ・ボックスを開きます。
データの表示: データ・ソース・ノード・ビューアのダイアログ・ボックスを開きます。
パラレル問合せ: 詳細は、「パラレル処理について」。
ランタイム・エラーの表示。エラーがある場合にのみ表示されます。
検証エラーの表示。検証エラーがある場合にのみ表示されます。
参照ノードによって計算された統計をMicrosoft Excelスプレッドシートにエクスポートできます。エクスポートするには、次の手順を実行します。
参照ノードが実行されている場合、そのノードは、自身が計算した統計をデータベース表に書き込みます。表の名前は、データの参照ノードの「プロパティ」ペインの「出力」セクションにあります。表の名前がOUTPUT_8_3であるとします。
ノードの「プロパティ」ペインが表示されていない場合は、参照ノードを右クリックし、「プロパティに移動」を選択します。
SQL Developerで、「接続」タブに移動します。データ・マイニングに使用した接続を展開します。
「表」を展開します。「OUTPUT_8_3」を見つけて、「OUTPUT_8_3」を右クリックします。
コンテキスト・メニューで「エクスポート」を選択します。エクスポート・ウィザードが開きます。
エクスポート・ウィザードで、次のことを実行します。
「DDLのエクスポート」の選択を解除します。
「データのエクスポート」セクションで、エクスポート先のMicrosoft Excelのバージョンを「フォーマット」ドロップダウン・リストから選択します。
ファイル名を指定します。または、デフォルトをそのまま使用します。
「次へ」をクリックします。
「終了」をクリックします。SQL Developerは、表をスプレッドシートにエクスポートします。
スプレッドシートには、統計が含まれます。データの参照ノードによって生成されたヒストグラムの名前が含まれます。
個々のヒストグラムをエクスポートするには、そのヒストグラムを右クリックして、グラフィックを保存します。
ノードが正常に実行されると、データを表示できます。データを表示するには、ノードを右クリックして、「データの表示」を選択します。ビューアが新しいタブに開きます。
ビューアでは、データの参照ノードによって実行された統計およびその他の分析を表示できます。
ビューアでは、次のタブに情報が表示されます。
「統計」タブには、データの参照ノードで計算された統計が表示されます。
属性が「統計」グリッドにリストされます。各属性について、統計の名前、データ型、ヒストグラムおよびサマリーが表示されます。
属性の大きいバージョンのヒストグラムを表示するには、属性を選択します。ヒストグラムがグリッドの下に表示されます。属性にNull値が含まれる場合、ヒストグラムには「Nullのビン」のラベルが付いた個別のビンがあります。ヒストグラムには、NULLではないが、他のビンに含まれない値で構成される「その他」ビンも含まれる場合があります。
ヒストグラムの詳細は、大きいヒストグラムに移動し、属性名を右クリックします。次の選択が可能です。
クリップボードにコピー: ヒストグラムをMicrosoft Windowsクリップボードにコピーします。このヒストグラムを、ワード・プロセッサや画像エディタなどのリッチ・エディタに貼り付けることができます。
画像を別名で保存: 画像を、ファイル・システムに保存できるPNGファイルにエクスポートします。
データの表示: ヒストグラムの作成に使用されたデータがポップアップ・ウィンドウに表示されます。属性名、属性値または属性パーセントを検索できます。終了したら、「閉じる」をクリックします。
Oracle Data Minerで作成されたヒストグラムは、データのサンプルを使用し、表示されるたびに少し異なる可能性があります。
すべてのデータ型について、ヒストグラムが作成されます。個別値の数字、NULL値のパーセンテージ、および個別値の数が表示されます。
属性のデータ型に従って計算された追加の統計:
文字属性VARCHAR2の場合、モードが計算されます。
数値属性「NUMBER」または「FLOAT」の場合は、次の計算が実行されます。
平均
最小値
最大値
標準偏差
歪度(分布の非対称の測定)
尖度(そのモードに関するリージョン内での頻度分布を示す曲線のフラット度またはピーク度の測定)
「プロパティ」ペインを開くには、ノードを右クリックし、コンテキスト・メニューから「プロパティに移動」を選択します。
データの参照ノードの「プロパティ」ペインには、次のセクションがあります。
「入力」セクションでは、分析される属性がリストされます。
属性がグリッドにリストされます。各属性について、名前およびデータ型が表示されます。属性のリストを名前またはデータ型でソートするには、グリッド内のヘッダーをクリックします。
「GROUP BY」属性を指定できます。リストから属性を選択します。
デフォルト設定を選択したり、次のように列を選択できます。
列を選択するには、「自動入力列の選択」の選択を解除します。
属性を削除するには、属性を選択し、をクリックします。
属性を編集するには、をクリックします。
「属性の選択」ダイアログ・ボックスが開きます。
「出力」セクションには、データ・ソースの列がリストされます。各列の名前およびデータ型がグリッドにリストされます。グリッドを名前(デフォルト)またはデータ型で検索できます。
検索をクリアするには、をクリックします。
「ビン」を使用して、ヒストグラムを作成できます。このタブには、次のタイプのビンについてデフォルトのビン数がリストされます。
数値型ビン
カテゴリ型ビン
日付型ビン
Null値
その他の値
これらすべてのビン・タイプのデフォルトのビン数は10です。デフォルトでは、ビンの最大数を指定します。
データは、データ分析をサポートするためにサンプリングされます。デフォルトでは、サンプルを使用します。「サンプル」タブでは、次のことを選択できます。
すべてのデータを使用: デフォルトでは、「すべてのデータを使用」の選択は解除されています。
サンプリング・サイズ: デフォルトは「行数」で、デフォルト値は2000です。サンプリング・サイズを「パーセント」に変更できます。
デフォルトは60パーセントです。
グラフ・ノードは、数値データの2次元グラフを作成します。グラフ・ノードは、データ・プロバイダではありません(つまり、別のノードには接続できません)。
|
注意: グラフ・ノードではコードを生成できません。 |
次のタスクを実行できます。
折れ線グラフ、散布図、棒グラフ、ヒストグラム、ボックスなど、様々なタイプのグラフを1つ以上作成して編集します。
実際のデータおよびサンプル・データを使用してグラフを作成します。
グラフ・ノードをパラレルに実行します。
グラフ・ノードでは、数値データの2次元グラフを複数の方法で作成できます。次のタイプのグラフを作成できます。
線プロット: 線を使用して、データ・ポイントを接続します。線プロットは、2つの変数が相関関係にあるかどうかを識別する場合に役立ちます。Oracle Data Minerでは、2次元の線プロットをサポートしています。
棒プロット: 値を比較します。棒の高さは、測定された値または頻度を表します。
ヒストグラム: 間隔における観測の頻度に等しい領域を持つ、各間隔上に垂直に描画された隣接する長方形(ビン)として、頻度を表示します。
散布図: 2つの個別値セットで値を表示します。1つの変数が水平軸上の位置を決定し、もう一方の変数が垂直軸上の位置を決定します。
ボックス・プロットまたはボックス・グラフ: データの分位を使用して、数値データのグループをグラフィカルに示します。
グラフ・ノードでは、1つ以上の軸を指定する必要があります。軸は、数値データで構成される必要があります。
ボックス・プロットは、データの分位を使用して、数値データのグループをグラフィカルに示します。ボックスの下部および上部は、1番目および3番目の分位であり、ボックス内の帯は2番目の分位(中央値)です。Data Minerで作成されたタイプのボックス・プロットは、ウィスカーがすべてのデータの最小値および最大値を示します。
グラフ・ノードでは、次のデータ型がサポートされています。
NUMBER
FLOAT
日時データ型もサポートされています。
DATE
TIMESTAMP
TIMESTAMP_WITH_TIMEZONE
TIMESTAMP_WITH_LOCAL_TIMEZONE
グラフ・ノードを作成し、コンテキスト・メニューから追加のタスクを実行できます。
グラフ・ノードを作成して、数値データ、および数値変数間の関係を視覚化します。
グラフ・ノードを作成するには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動します。
「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
ワークフロー・エディタで、「データ」を展開し、「グラフ」をクリックします。
グラフ・ノードを「コンポーネント」ペインから「ワークフロー」ペインにドラッグ・アンド・ドロップします。グラフ・ノードがワークフローに追加されます。
グラフを作成するデータが含まれているノードを右クリックします。コンテキスト・メニューから「接続」を選択します。
グラフ・ノードまで線を描画し、再度クリックします。
サンプル・データを使用してグラフを作成するには、グラフ・ノードを右クリックして、「実行」をクリックします。
グラフ・ノードをダブルクリックするか、ノードを右クリックして、コンテキスト・メニューから「編集」を選択します。
グラフが定義されていない場合は、「新規グラフ」ダイアログ・ボックスが開きます。ここで、グラフを定義できます。
グラフが定義されている場合は、グラフ・ノード・エディタで、新規グラフを追加するか、既存のグラフを編集できます。
グラフ・ノードの実行が終了すると、グラフがグラフ・ノード・エディタに自動的に表示されます。グラフを編集できます。新しいグラフを定義したり、グラフの設定や属性を変更したり、グラフを削除することもできます。
コンテキスト・メニューを表示するには、グラフ・ノードを右クリックします。コンテキスト・メニューには次のオプションがあります。
編集。「データ・ソース・ノードの編集」ダイアログ・ボックスを開きます。
実行。詳細は、「グラフ・ノードの実行」を参照してください。
SQLを保存: このオプションは無効になっています。このノードに対するSQL問合せを生成できないことを示します。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
検証エラーの表示。エラーがある場合にのみ表示されます。
検証エラーの表示。検証エラーがある場合は、表示されます。
グラフ・ノードを実行するには、グラフ・ノードを右クリックして、「実行」をクリックします。グラフ・ノードを実行して、サンプル・データを生成します。サンプル・データを生成しない場合は、ノードに提供されているデータを使用してグラフが作成されます。
|
注意: グラフ・ノードが含まれるワークフローをインポートする場合は、グラフ・ノードを実行して、グラフを表示する必要があります。 |
「グラフの表示」オプションによって、グラフ・ノード・エディタが開きます。すべてのグラフがグラフ・ノード・エディタに表示されます。
「新規グラフ」ダイアログ・ボックスでは、デフォルト名を使用してグラフを定義します。ここで、グラフの名前を変更できます。
作成するグラフのタイプを次のうちから選択し、そのタイプのグラフを定義する手順に従います。
定義したグラフがコンテナに表示されます。グラフを作成したら、定義を編集できます。グラフの追加、グラフの削除、グラフの構成に使用されたデータの表示、グラフィックとしてのグラフの保存を実行することもできます。
「折れ線」または「散布図」を作成するには、次の手順を実行します。
「折れ線」をクリックして、折れ線グラフを作成します。折れ線グラフがデフォルト・タイプです。
散布図を作成するには、「散布図」をクリックします。
折れ線グラフまたは散布図の場合は、次の詳細情報を入力します。
タイトル: これは、グラフのタイトルです。デフォルト名を使用または異なる値を指定できます。
コメント: グラフの説明を入力します。これはオプションのフィールドです。
「折れ線グラフ設定」では、次の情報を指定します。
X軸: グラフのX軸の属性を選択します。
Y軸: グラフのY軸の属性を選択します。
GROUP BY: オプションのGROUP BY属性を選択するには、このオプションをクリックします。このオプションを使用して、「GROUP BY」属性値に基づいた系列を作成します。
「GROUP BY」の属性を選択します。グループ化の実行方法を指定するには、「設定」をクリックします。
「OK」をクリックします。
棒グラフは、選択した属性(X軸)の値を頻度カウント(Y軸)に対してプロットします。棒グラフを指定するには、次の手順を実行します。
「棒」をクリックします。
棒グラフ設定について、次の情報を指定します。
タイトル グラフの名前です。デフォルト名を使用または異なる値を入力できます。
コメント: 棒グラフの説明を指定します。これはオプションのフィールドです。
棒グラフ設定について、次の情報を指定します。
X軸: グラフのX軸に沿ってプロットされる1つの属性を選択します。この属性は、「トップN」またはビニング(デフォルト)のいずれかを使用して処理されます。
処理を指定するには、「設定」をクリックします。
Y軸: グラフのY軸に沿ってプロットされる1つの属性を選択します。頻度カウントの値を「統計」として指定します。たとえば、「平均」、「最小」、「最大」、「中間」、「カウント」です。「統計」を選択した場合、ビン内の値が集計されます。
GROUP BY: オプションのGROUP BY属性を選択するには、このオプションをクリックします。この属性によって、ビン内の値がグループ化されます(棒の積上げ)。
「GROUP BY」の属性を選択します。グループ化の実行方法を指定するには、「設定」をクリックします。
「OK」をクリックします。
ヒストグラムは、X軸に沿った選択済の属性値を、Y軸に沿った頻度カウントに対してプロットします。ヒストグラムを作成する手順:
「ヒストグラム」をクリックします。
ヒストグラムについて、次の情報を入力します。
タイトル ヒストグラムの名前です。デフォルト名を使用または異なる値を入力できます。
コメント: ヒストグラムの説明を入力します。これはオプションのフィールドです。
ヒストグラムについて、次の設定を指定します。
X軸: グラフのX軸に沿ってプロットする属性を選択します。この属性は、「トップN」またはビニング(デフォルト)のいずれかを使用して処理されます。処理を指定するには、「設定」をクリックします。
GROUP BY: オプションのGROUP BY属性を選択するには、「GROUP BY」をクリックします。この属性によって、ビン内の値がグループ化されます(棒の積上げ)。
GROUP BYの実行方法を指定するには、「設定」をクリックします。
デフォルトでは、GROUP BY属性を使用するヒストグラムは「積上げ棒グラフ」として表示されます。
 (積上げ棒グラフ・アイコン)をクリックし、
(積上げ棒グラフ・アイコン)をクリックし、 (二重Y棒グラフ・アイコン)を選択します。
(二重Y棒グラフ・アイコン)を選択します。
無効な値を指定した場合は、問題を説明するメッセージが表示されます。
「OK」をクリックします。
ボックス・プロットは、選択した属性(X軸)のビニングされたデータをまとめます。
ボックス・プロットまたはボックス・グラフを指定するには、「ボックス」をクリックします。
ボックス・グラフの次の詳細情報を入力します。
タイトル: ボックス・グラフの名前です。デフォルト名を使用または異なる値を入力できます。
コメント: ボックス・グラフの説明を入力します。これはオプションのフィールドです。
ボックス・グラフについて、次の設定を指定します。
X軸: グラフのX軸に沿ってプロットされる属性を選択します。この属性は、「トップN」またはビニング(デフォルト)のいずれかを使用してビニングされます。
処理を指定するには、「設定」をクリックします。
GROUP BY: オプションのGROUP BY属性を選択するには、「GROUP BY」をクリックします。この属性では、Y軸上の値を提供します。
グループ化の実行方法を指定するには、「設定」をクリックします。
無効な値を指定した場合は、問題を説明するメッセージが表示されます。
「OK」をクリックします。
選択した属性のデータ型に応じて、「設定」をクリックしたときに、次のダイアログ・ボックスのいずれかが表示されます。
軸またはGROUP BY属性のカテゴリ属性を指定する場合は、「設定」をクリックして、「表示する値を選択」ダイアログ・ボックスを表示します。
属性の値が「値」列にリストされます。次の値のいずれかを選択します。
すべて
なし
デフォルト
デフォルトでは、「トップN」を使用して、頻度が高い値が選択されます。
値のチェック・ボックスをクリックして、特定の値を選択します。
検索ボックスを使用して、値を検索できます。
終了したら、「OK」をクリックして、グラフの定義に戻ります。
軸またはGROUP BY属性の数値属性を指定する場合は、「設定」をクリックして、「軸処理の設定」ダイアログ・ボックスを表示します。
オプションは、次のとおりです。
RAW値 (そのまま)
自動的にビニング: 軸値に等幅ビニングを使用します。デフォルトのビン数は10です。この値は変更できます。
デフォルトでは、Null値を表示しません。Null値を表示するには、チェック・ボックスを選択します。
「OK」をクリックして、グラフの定義に戻ります。
少なくとも1つのグラフがグラフ・ノードに定義されている場合は、グラフ・ノードをダブルクリックして、グラフ・ノード・エディタを開きます。
グラフが定義されていない場合は、「新規グラフ」ダイアログ・ボックスが開きます。
エディタには、定義済のすべてのグラフが表示されます。各グラフはコンテナ内にあります。グラフ・コンテナは、グリッドにレイアウトされます。
既存のグラフを変更したり、ノードにグラフを追加できます。グラフの詳細を表示するためにズームインすることもできます。
次のアイコンは、ノードのすべてのグラフに適用できます。
新規グラフを追加するには、 をクリックして「新規グラフ」ダイアログ・ボックスを開きます。
をクリックして「新規グラフ」ダイアログ・ボックスを開きます。
表示をリフレッシュするには、をクリックします。
グラフの作成に使用するデータを選択するには、「表示」をクリックします。オプションは、次のとおりです。
実際のデータ: デフォルトを表示しますが、グラフ・ノードを実行した場合は除きます。その場合は、ノードが提供されているすべてのデータを使用してグラフを作成します。
サンプル・データ: サンプル・データを生成するためにグラフ・ノードを実行した場合にのみ使用可能です。
新規グラフまたは既存グラフの名前が、次のコントロールとともにグラフのコンテナの上部に表示されます。
グラフのサイズを調整する(ズームインおよびズームアウト)には、 をクリックします。
をクリックします。
現在のグラフを編集するには、をクリックします。グラフを編集または追加すると、結果が自動的にエディタに表示されます。
現在のグラフを削除するには、をクリックします。
グラフの特定の値を調べるには、グラフを拡大します。
グラフの詳細を調べるには、選択した値にズームインします。たとえば、選択したX軸値の詳細を確認するには、マウスを使用してそれらの値を囲む選択ボックスを描画します。ディスプレイには、選択ボックス内の値の詳細が表示され、軸が展開されます。複数回ズームできます。選択した値の表示が終了したら、ズームインした回数だけグラフをクリックして、元のグラフに戻ります。
グラフを編集する場合、次のことを実行できます。
既存のグラフ・タイプの属性を変更します。たとえば、折れ線グラフを編集する場合は、X軸とY軸を変更したり、GROUP BY属性を追加できます。軸処理や表示する値を変更できます(グラフでこれらの項目が使用されている場合)。
別のグラフ・タイプを指定します。グラフのタイプを変更できます。たとえば、折れ線グラフをヒストグラムに変更できます。グラフのタイプを変更するには、ウィンドウの上部にあるボタンをクリックし、次のように必要な情報を指定します。
グラフ・ノードのプロパティは、表示中のノード名で識別されます。「プロパティ」ペインでは、グラフ・ノードの特性を調査および変更できます。
「プロパティ」ペインを開くには、ノードを右クリックし、「プロパティに移動」を選択します。
グラフ・ノードの「プロパティ」ペインは、次のセクションで構成されています。
データ:使用するキャッシュ設定を示します。
サンプル・データを生成すると、オプション「出力データのキャッシュ生成による結果表示の最適化」が選択されます。
デフォルト値は2000レコードです。この値は変更できます。
SQL問合せノードの単純なユースケースは、特別なデータ準備を実行するSQL問合せを記述することです。SQL問合せノードを使用して、モデル構築の入力を提供します。SQL問合せノードでは、次のことを実行できます。
できるかぎり最小限の制約でSQL問合せを手動で入力します。
Oracle Data Minerワークフローの一部として、様々な方法を組み込みます。既存のデータを使用して、SQL問合せをデータのソースとして、または変換として挿入できます。
データベースに登録されているOracle R Enterpriseスクリプトを実行します。
パラレル・プロセスまたはパラレル問合せを実行します。
SQL問合せノードでは、次の入力が必要です。
データ・ソース・ノードや変換ノードなど、ゼロから複数のデータ・プロバイダ・ノード。
モデル構築ノードやモデル・ノードなど、ゼロから複数の入力モデル・プロバイダ・ノード。
データ・プロバイダ・ノードは次のように使用されます。
データ・プロバイダ・ノードが0個の場合は、Oracle Data Miner内で定義する必要がある入力ソースによる制約がないSQL SELECT文を使用して、元となるデータ・ソース・ノードを定義します。この文には、次のような独自の内部表参照を含めることができます。
Select * from a, b where a.id = b.id
データ・プロバイダ・ノードが0個の場合、ソース表またはビューはData Minerで非表示になります。コード生成では、生成されたSQL文でそのような表をパラメータ化できません。
データ・プロバイダ・ノードが1個以上ある場合、式ビルダー・インタフェース内で各データ・フローを参照できます。Oracle Data Minerワークフロー内のすべてのデータ・ソースを引き続き公開できます。
モデル・プロバイダ・ノードが入力として接続されていると、ユーザーはノードに含まれるモデル名のリストを表示できます。これは、モデル名が必要なSQLを作成する場合に役立ちます。
Oracle Data Minerには、SQL問合せの記述に役立つスニペットが含まれます。
Oracle Advanced Analyticsオプションの構成要素であるOracle R Enterpriseは、オープン・ソースの統計プログラミング言語であるRとその環境をエンタープライズ対応およびビッグ・データ対応にします。Oracle R Enterpriseは、RとOracle Databaseを統合します。大量のデータが関与する問題用に設計されています。
Rのユーザーは、データベースの並列性とスケーラビリティを利用するRスクリプトを開発、改良およびデプロイして、予測分析およびデータ分析を実行できます。
Oracle Data Miner 4.1のSQL問合せノードは、登録されているRスクリプトをデータベースに統合するための簡易インタフェースを提供します。これにより、Rの開発者はデータ分析用の有用なスクリプトを提供できます。
|
注意: Oracle R Enterpriseは、Oracle Data Minerの接続先と同じデータベースにサーバーとともにインストールされる必要があります。詳細は、『Oracle R Enterpriseインストレーションおよび管理ガイド』を参照してください。 |
次のインタフェースを使用する埋込みRスクリプトを実行できます。
rqEval
rqTableEval
rqRowEval
rqGroupEval
Oracle R Enterpriseデータベース・ロールがOMDRUSERロールに追加されました。OMDRUSERロールには、次の2つのロールが両方含まれています。
RQUSER
RQADMIN
RQUSERロールとRQAMINロールが、Oracle Data Minerリポジトリのインストール時にデータベース構成で使用できない場合、これらのロールは、Oracle R Enterpriseのインストール後、DBAが手動でODMRUSERロールに追加する必要があります。
Rスクリプトを使用するには、Rスクリプトを登録する必要があります。スクリプトは、SYS接続を介して、SQL*PlusまたはSQLワークシートを使用して登録できます。
登録されたRスクリプトは、SQL問合せノードの「Rスクリプト」タブ上にリストされます。Rコード・スニペット(スクリプトの記述に役立つ部分的なコード)もあります。スニペットは、構文のみの場合や、例が含まれる場合もあります。SQLワークシートの使用時や、SQL問合せノードを使用したRコードの作成または編集時に、スニペットを挿入および編集できます。
SQL問合せノードを作成したり、コンテキスト・メニューやSQL問合せノード・エディタを使用して関連タスクを実行することもできます。
SQL問合せを記述するためにSQL問合せノードを作成します。SQL問合せノードを作成する手順:
「コンポーネント」ペインで、ワークフロー・エディタに移動します。
「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
データ・ソース・ノードや変換ノードなど、0個以上のデータ・プロバイダ・ノードを作成します。
モデル構築ノードやモデル・ノードなど、0個以上のモデル・プロバイダ・ノードを作成します。
ワークフロー・エディタで、「データ」を展開し、SQL問合せの作成をクリックします。
SQL問合せノードをワークフロー・ペインにドラッグ・アンド・ドロップします。SQL問合せノードがワークフローに追加されます。
データ・プロバイダ・ノードまたはモデル・プロバイダ・ノードを右クリックします。各ノードについて、コンテキスト・メニューから「接続」を選択します。
SQL問合せノードまで線を描画して、再度クリックします。必要なすべてのノードを接続していることを確認してください。
SQL問合せノードをダブルクリックするか、コンテキスト・メニューから「編集」を選択して、「SQL問合せノード・エディタ」を開きます。
SQL問合せを記述し、それを検証またはプレビューします。
「OK」をクリックします。
SQL問合せノード・エディタを使用すると、SQL問合せを定義および検証できます。
エディタに用意されている指定を、問合せ構築テキスト領域にドラッグ・アンド・ドロップしたりダブルクリックできます。
ウィンドウの左側のタブには、問合せの記述に関するヘルプが表示されます。
「ソース」は、データ・プロバイダ・ノードとモデル・プロバイダ・ノードの両方を含む入力ノードのリストです。「ソース」リストで項目を選択すると、「メッセージ」ボックスに情報が表示されます。
「スニペット」は、計算のタイプ別に並べられた標準のSQL Developerスニペット(部分的なSQLコード)です。
スニペットのカテゴリである「予測問合せ」は、DBMS_PREDICTIVE_ANALYTICS PL/SQLパッケージを使用して問合せを記述する場合に役立ちます。
スニペットの詳細は、SQL Developerの概要および使用方法の、スニペットを使用した部分的なコードの挿入に関する項を参照してください。
スニペットの機能の簡単な説明については、その名前の上にカーソルを置きます。情報がツールヒントに表示されます。
「PL/SQLファンクション」は、ユーザー・スキーマでのPL/SQLファンクションのリストです。
「Rスクリプト」は、登録されているRスクリプトのリストで、このタブは、Oracle R Enterpriseがインストールされている場合にのみ表示されます。
テキスト領域にSQLを記述します。
テキスト領域の下には次のものがあります。
列 - 列およびデータ型をリストします。
プレビュー - 問合せによって返される少数の行を表示します。
「OK」または「検証」をクリックすると、次のことが確認されます。
問合せでは、少なくとも1つの出力列が生成されます。
すべてのデータ型はOracle Data Minerでサポートされるデータ型です。ほとんどのスカラー・データ型がサポートされています。サポートされていない最も一般的なデータ型は、ユーザー・カスタム・オブジェクト・タイプです。
サポートされていないデータ型が見つかった場合は、表が作成され、エラー・メッセージが列パネルの上に表示されます。列リスト内の許容できないすべてのデータ型は、列名の横にある無効アイコンでマーク付けされます。
問合せの解析中に検証エラーが発生しなかった場合、「列」タブには列のデータ型が表示され、「データ」タブには結果の簡単なサンプルが表示されます。
検証エラーが発生した場合は、検証パネルが「列」および「データ」タブに表示されます。
コンテキスト・メニューを表示するには、データ・ソース・ノードを右クリックします。コンテキスト・メニューでは、次のオプションを使用できます。
編集。「SQL問合せノード・エディタ」を開きます。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合にのみ表示されます。
検証エラーの表示。検証エラーがある場合は、表示されます。
表更新ノードは、ノードへのデータ入力で選択された列を使用して既存の表を更新します。入力列は、既存の表の列にマッピングされます。
表更新ノードはパラレルに実行できます。
表更新ノードは、データベース・リソースを使用して、自身を定義します。データベース・リソースが変更された場合は、ノード定義のリフレッシュが必要になることがあります。たとえば、リソースが削除または再作成された場合です。
表更新ノードの入力は、データ・フローを生成する任意のノードです。表更新ノードには1つのノードのみを接続できます。
表更新ノードの出力は、データ・フローです。データ・フローをデータ・ソースとして使用できます。出力を表またはビューとして保存するには、表またはビュー作成ノードを使用します。
表更新ノードは、特定のデータ型をサポートしています。Bなどのその他のタイプをサポートしたり、手動マッピングでこれらの追加タイプをサポートすることもできます。
厳密に一致するデータ型は列に存在しないが、その列のデータ型にある程度安全なデフォルトの暗黙的変換がある場合は、それらの列を手動でマッピングできます。たとえば、BINARY_DOUBLEをNUMBERに、またはNVARCHAR2をVARCHAR2にマッピングできます。このようなマッピングでは、次のように一部のデータが損失する可能性があります。
BINARY_DOUBLEまたはBINARY_FLOATをNUMBERにマッピングすると、精度が損われる場合があります
NVARCHAR2およびNCHARをVARCHAR2にマッピングすると、NVARCHAR2とNCHARはVARCHAR2とは潜在的に異なる文字セットに基づいているため、データが損われる可能性があります。マッピングが機能するには、NVARCHAR2とNCHARがVARCHAR2と同じ文字セットに基づくようにデータベースが設定されている必要があります。
次の項目で示しているように、表更新ノードを作成し、コンテキスト・メニューおよびエディタから関連タスクを実行できます。
表更新ノードを作成して、既存の表内の選択した列のデータを使用して、その表を更新します。表更新ノードは、データ・フローを作成する任意のノード(適用ノードなど)に接続できます。
表更新ノードを作成するには、次の手順を実行します。
「コンポーネント」ペインで、ワークフロー・エディタに移動します。「コンポーネント」ペインが表示されていない場合は、「表示」に移動して「コンポーネント」をクリックします。
ワークフロー・エディタで、「データ」を展開し、「表の更新」をクリックします。
表更新ノードをワークフロー・ペインにドラッグ・アンド・ドロップします。これにより、表更新ノードがワークフローに追加されます。
更新するデータ・フローを生成するワークフロー内のノードにマウスを置きます。ノードを右クリックして、コンテキスト・メニューから「接続」を選択します。
表更新ノードまで線を描画し、再度クリックします。
「表更新ノードの編集」ダイアログ・ボックスが開きます。表更新ノードの特性を定義できます。
次のいずれかを実行できます。
表更新ノードのデフォルト設定をそのまま使用します。
「表更新ノードの編集」のデフォルト設定を編集します。
表を更新するには、表更新ノードを右クリックして、「実行」を選択します。
表更新ノードの実行が完了したら、結果を表示できます。ノードを右クリックして、「データの表示」を選択します。
「自動入力列の選択」オプションが選択されている場合、シナリオごとの動作は次のとおりです。
入力が接続されている場合 - 更新する選択済の表が表更新ノードにある場合、その表内の、既存の列と一致する列はその列に自動的にマッピングされます。少なくとも1つの列が仕様に含まれていた場合、ノードは有効になります。
入力が切断されている場合 - すべての列が自動的に削除されます。ノードは無効になります。
入力ノードが編集されている場合:
列が入力ノードに追加された場合、その列は、既存の表に一致する列が存在すれば、更新ノードに追加されます。
列が削除された場合、その列はノードから削除されます。
列が編集された場合、次の2つの可能性があります。
編集された列が既存の列と一致しなくなった場合、その列は削除されます。
編集された列が既存の列と一致する場合、その列は追加されます。
「自動入力列の選択」が選択されていない場合、表更新ノードに対して手動で列指定を追加および削除する必要があります。
「表更新ノードの編集」ダイアログ・ボックスには、表更新ノードの指定があります。表更新ノードを編集するには、次の手順を実行します。
名前: 表の名前を表示します。既存の表を選択するには、「表の参照」をクリックし、既存の表を選択します。または、「新規」をクリックして、新しい表を作成できます。S
自動入力列の選択: このオプションはデフォルトで選択されています。他の列を選択するには、このオプションの選択を解除します。
このオプションの選択を解除した場合は、をクリックして入力列を選択します。矢印を使用して、属性を「使用可能な属性」から「選択された属性」に移動します。
既存の行の削除: このオプションが選択されている場合は、表内の既存の行が削除されてから、表が更新されます。デフォルトでは、このオプションは選択されていません。
列は「データ」グリッドにリストされます。
新しい表の名前を受け入れるか、別の名前を選択します。付属の表のすべての属性がリストされます。
属性を削除するには、をクリックします。
属性を編集するには、をクリックします。
「属性の選択(表更新)」ダイアログ・ボックスが開きます。
デフォルトでは、すべての列が選択されています。データに列を含めない場合は、属性を「選択された属性」から「使用可能な属性」に移動します。
「OK」をクリックします。
このタブには、更新する表の列が表示されます。各列について、入力名、ターゲット名およびターゲット(データ)タイプが表示されます。
デフォルトでは、オプション「自動入力列の選択」が選択されています。「自動入力列の選択」の選択を解除した場合は、をクリックして、入力列を手動で選択する必要があります。
矢印を使用して、属性を「使用可能な属性」から「選択された属性」に移動します。
コンテキスト・メニューを表示するには、データ・ソース・ノードを右クリックします。コンテキスト・メニューでは、次のオプションを使用できます。
編集。「表更新ノードの編集」ダイアログ・ボックスを開きます。
データの表示。表更新ノード・データ・ビューアのダイアログ・ボックスを開きます。
パラレル問合せ。詳細は、「パラレル処理について」を参照してください。
ランタイム・エラーの表示。エラーがある場合にのみ表示されます。
検証エラーの表示。検証エラーがある場合にのみ表示されます。
ノードが正常に実行されると、データを表示できます。データを表示するには、ノードを右クリックして、「データの表示」を選択します。データ・ビューアは、データ・ソース・ノード・ビューアと同じです。
「プロパティ」ペインを表示するには、ノードを右クリックし、コンテキスト・メニューから「プロパティに移動」を選択します。
表更新のプロパティは、次のセクションで構成されています。
このタブには、更新する表の名前が表示されます。デフォルトでは、既存の行は削除されません。既存の行を削除するには、「既存の行の削除」を選択します。
このタブには、更新する表の列が表示されます。各列について、入力名、ターゲット名およびターゲット(データ)タイプが表示されます。
デフォルトでは、「自動入力列の選択」が選択されています。
「自動入力列の選択」の選択を解除した場合は、をクリックして、入力列を手動で選択する必要があります。矢印を使用して、属性を「使用可能な属性」リストから「選択された属性」リストに移動します。
サーバー上のデータが変更された場合、ノードのリフレッシュが必要となる場合があります。リフレッシュするには、をクリックします。