| Oracle® Data Minerユーザーズ・ガイド リリース4.1 E62045-01 |
|


 前 |
 次 |
Oracle Data Minerのグラフィカル・ユーザー・インタフェース(GUI)は、SQL Developer 4.0のGUIをベースにしています。SQL Developerユーザー・インタフェースを参照してください。SQL Developerで、「ヘルプ」、SQL Developerの概要および使用方法の順にクリックすると、SQL Developer GUIの概要を確認できます。次の各項では、データ・マイニングおよびOracle Data Minerに固有の共通の手順とメニューについて説明します。
その他(検索、フィルタ、チャートやグラフの保存)
Oracle Data Minerのウィンドウでは、一般に、左側でナビゲーション操作(オブジェクトの検索および選択)を行うと、選択したオブジェクトに関する情報が右側に表示されます。
|
注意: ここでは、デフォルトのインタフェースについて説明します。ただし、Oracle Data Minerのプリファレンスを設定することによって、Oracle Data Minerの外観や動作の数多くの側面をカスタマイズできます。 |
次に単純なワークフローを示します。

「Data Miner」タブについて: 左側のペインに配置されています。ここでデータベース接続を管理します。
ワークフロー・ジョブ: 左側のペインに配置されています。実行中のタスクのステータスを確認できます。
コンポーネント: 右側のペインに配置されています。ここでワークフローのノードを選択します。
メニュー・バー: ウィンドウの上部に配置されています。
ワークフローはウィンドウの中央のペインに表示されます。
プロパティ: このペインは任意の場所に配置できます。確認しているワークフローのすぐ下に「プロパティ」ペインを配置すると便利です。
一部の設定は固定設定です。固定設定を変更した場合は、新しい値がデフォルト値になります。
Oracle SQL Developerウィンドウの上部のメニューには、標準エントリに加え、Oracle Data Minerに固有の機能のエントリも配置されています。
キーボード・ショートカットを使用してメニューおよびメニュー項目にアクセスできます。たとえば、「ファイル」メニューにアクセスするには[Alt]を押しながら[F]を押し、「編集」メニューにアクセスするには[Alt]を押しながら[E]を押し、ヘルプ・トピックの全文検索機能にアクセスするには[Alt]+[H]、[Alt]+[S]の順に押します。[F10]キーを押して「ファイル」メニューを表示することもできます。
メニューのすぐ下にあるアイコンを使用すると、次のような各種アクションを実行できます。
新: 新しいデータベース接続などの新しいデータベース・オブジェクトを定義するための新規ギャラリを開きます。
開く: ファイルを開きます。
保存: 現在選択しているオブジェクトに対する変更を保存します。
すべて保存: 開いているすべてのオブジェクトに対する変更を保存します。
元に戻す: 直前の操作を元に戻します。
「元に戻す」には複数の形式があります。たとえば、直前のノード作成を元に戻すには「作成を元に戻す」を使用し、直前のノード編集を元に戻すには「ノードの編集を元に戻す」を使用します。
やり直し: 直前に元に戻した操作を再び実行します。
「やり直し」には複数の形式があります。たとえば、直前のノード作成をやり直すには「作成のやり直し」を使用し、直前のノード編集をやり直すには「ノードの編集のやり直し」を使用します。
戻る: 直前に表示していたペインに移動します。下矢印を使用して、タブ表示を指定します。
進む: 表示済のペインのリストで、現在のペインの次のペインに移動します。または、下矢印を使用して、タブ表示を指定します。
次のメニューには、Oracle Data Minerに固有の機能が用意されています。
「ヘルプ」メニュー: Oracle Data Minerオンライン・ヘルプ
次のオプションは、Oracle Data Minerの「表示」メニューから選択できます。
Data Miner
次のData Minerインタフェースのいずれかを選択して開きます。
「Data Minerの接続」。「Data Miner」タブとも呼ばれます。
たとえば、Data Minerの「表示」メニューにあるオプション「Data Minerの接続」を使用すると、「Data Miner」タブおよび関連するウィンドウが開きます。
GUIの状態によっては、Data Minerの「表示」で次のことも実行できます。
表示
リポジトリの削除
「構造」ウィンドウには、現在アクティブなワークフローまたは特定のモデル・ビューアの構造が表示されます。
ツリーまたはワークフローのノードはフラット・リストに一覧表示され、親子関係は示されません。リンクは、ノードを結合するキーです。
「構造」ウィンドウでノードやリンクを表示すると、選択した項目がワークフロー・エディタに即座に表示されます。このプロパティは、複雑なワークフローまたはツリー内をナビゲートしているときに役立ちます。
データ・ソース・ノードと分類構築ノードで構成された2ノード・ワークフローsimpleがあるとします。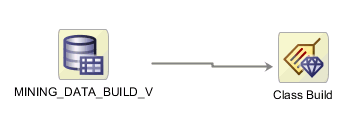
図simplework.gifの説明
「構造」ウィンドウのワークフローsimpleのビュー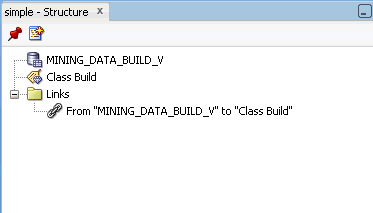
図simplestruct.gifの説明
「構造」ウィンドウで項目を選択すると、ワークフロー内で対応する項目が選択されます。たとえば、「リンク」フォルダに移動し、"DATA_MINING_BUILD_V"から"Class Build"までを選択すると、simple内で2つのノード間のリンクが強調表示されます。
次のモデル・ビューアには、「ツリー」タブが含まれています。
クラスタリング・モデル用のk-MeansおよびO-Clusterモデル・ビューア
DT分類モデル用のディシジョン・ツリー・モデル・ビューア
モデル・ビューアの「ツリー」タブには、モデルによって生成されたルールの関係が示されます。これらのツリーは大規模で複雑になる場合があります。ワークフローのノード間をナビゲートする場合と同様に、「構造」ウィンドウを使用してツリーのノード間をナビゲートできます。「構造」ウィンドウで、「リンク」フォルダ内のノードまたは項目を選択します。モデル・ビューアでそのノードまたはリンクが自動的に強調表示されます。
「構造」ウィンドウでは、次のコントロールがサポートされています。
現在のビューに「構造」ウィンドウを固定するには、 をクリックします。
をクリックします。
固定されたウィンドウでは、アクティブ・ウィンドウでアクティブになっている選択は追跡されません。
「構造」ウィンドウの新規インスタンスを開くには、 をクリックします。
をクリックします。
新規ビューは、「構造」ウィンドウに新規タブとして表示されます。
次のオプションは、Oracle Data Minerの「ツール」メニューから選択できます。
「ツール」メニューの「Data Miner」オプションには、次のオプションが用意されています。
表示: 「Data Miner」タブおよび「ワークフロー・ジョブ」を開きます。
リポジトリの削除: Data Minerリポジトリを削除します。
これらのアクションは、通常、Oracle Data Minerインストールの一環として実行されます。
|
関連項目: 『Oracle Data Minerインストレーションおよび管理ガイド』 |
Oracle Data Minerではプリファレンスを設定できます。プリファレンスを設定するには、「ツール」→「プリファレンス」をクリックします。「プリファレンス」で、「Data Miner」をクリックします。Data Minerのプリファレンスは、次のいくつかの部分に分かれています。
ノードの設定: モデル・ノード、パラレル処理および「変換」ノードの設定で構成されます。
ビューア: データ・ビューアおよびモデル・ビューアの設定で構成されます。
「ワークフローのインポート/エクスポート」ディレクトリ
ノードの設定では、次のワークフロー・ノードの動作を指定します。
モデルの設定では、次のプロパティを指定します。
これらのプリファレンスでは、適用ノードの動作を指定します。
「自動適用設定のデフォルト」は、「自動」または「手動」のいずれかです。デフォルトでは、「自動」に設定されています。
「自動データ設定のデフォルト」は、「自動」(デフォルト)または「手動」のいずれかです。
「デフォルト列順序」は、「データ列が先」または「適用列が先」のいずれかです。「データ列が先」がデフォルト値として設定されています。
モデル構築オプションのデフォルト値を指定します。デフォルト値は次のマイニング機能ごとに異なります。
項目値の最大個別件数のデフォルト値は10です。デフォルト値を別の整数に変更できます。
分類ノードでは、デフォルトで4つのモデル(それぞれ次の1つに基づく)が自動的に生成されます。
ディシジョン・ツリー
一般化線形モデル
Naive Bayes
サポート・ベクター・マシン
4つすべてのモデルにおいて、入力データ、ターゲットおよびケースID (ケースIDが指定されている場合)は同じです。
モデルの構築にデフォルト・アルゴリズムのいずれかを使用しない場合は、該当するアルゴリズムの選択を解除します。ただし、選択を解除したアルゴリズムに基づくモデルを分類ノードに後で追加することは可能です。
このノードでは、デフォルトで次のテスト結果がチューニング用に生成されます。
パフォーマンス・メトリック
パフォーマンス・マトリックス(混同マトリックス)
ROC曲線(バイナリのみ)
リフトおよびベネフィットデフォルト値は、頻度別の上位5つのターゲット値に設定されます。デフォルト設定を編集できます。モデル・チューニング用に選択したメトリックはデフォルトでは生成されません。モデル・チューニングのメトリックを選択できます。
任意のテスト結果の選択を解除できます。たとえば、「パフォーマンス・マトリックス」の選択を解除した場合は、パフォーマンス・マトリックスがデフォルトで生成されなくなります。
デフォルトでは、分割データがテスト・データに使用されます。データの40%はテストに使用され、分割データが表として作成されます。テストに使用されるパーセンテージを変更したり、分割データを表ではなくビューとして作成することもできます。表を作成する場合は、パラレルに作成できます。テストにはすべての構築データを使用することも、個別のテスト・ソースを使用することもできます。
クラスタリング・ノードでは、デフォルトで2つのモデル(それぞれO-Clusterおよびk-Meansに基づく)が構築されます。
Oracle Database 12c以上に接続している場合は、「期待値の最大化」モデルもクラスタリング・ノードで構築されるため、合計で3つのモデルが構築されることになります。
ノード内のすべてのクラスタリング・モデルにおいて、入力データおよびケースID (ケースIDが指定されている場合)は同じです。
デフォルトでアルゴリズムのいずれもモデルの構築に使用しないようにする場合は、該当するアルゴリズムの選択を解除します。ただし、選択を解除したアルゴリズムに基づくモデルをクラスタリング・ノードに後で追加することは可能です。
特徴抽出ノードでは、デフォルトで「Non-Negative Matrix Factorization」モデルが構築されます。
Oracle Database 12c以上に接続している場合は、「主要コンポーネント分析」モデルもこのノードで構築されます。このノードで「単一値分解」モデルが構築されるように指定することもできます。
モデルの構築にデフォルト・アルゴリズムのいずれかを使用しない場合は、該当するアルゴリズムの選択を解除します。ただし、選択を解除したアルゴリズムに基づくモデルを分類ノードに後で追加することは可能です。
回帰ノードでは、デフォルトで2つのモデル(それぞれ一般化線形モデルおよびサポート・ベクター・マシンに基づく)が構築されます。
ノード内のすべてのモデルにおいて、入力データ、ターゲットおよびケースID (ケースIDが指定されている場合)は同じです。
モデルの構築にデフォルト・アルゴリズムのいずれかを使用しない場合は、該当するアルゴリズムの選択を解除します。ただし、選択を解除したアルゴリズムに基づくモデルを回帰ノードに後で追加することは可能です。
デフォルトでは、「パフォーマンス・メトリック」と「残差」の2つのテスト結果が計算されます。
デフォルトでは、分割データがテスト・データに使用されます。分割データはビューとして作成され、そのうち40%が使用されます。
モデル詳細ノードでは、デフォルトでは「自動設定」が使用されます。特定のモデル詳細ノードの「自動設定」の選択を解除することも、すべてのモデル詳細ノードの「自動設定」の選択を解除することもできます。
テスト・ノードでは、デフォルトでは「自動設定」が使用されます。次のことを実行できます。
特定のテスト・ノードの「自動設定」の選択を解除します。
すべてのテスト・ノードの「自動設定」の選択を解除します。
ノードのパラレル処理のデフォルト設定を指定できます。
パラレル処理を有効にする手順:
「パラレル」列で、対象のノード・タイプに対応するチェック・ボックスを選択します。
すべてのノード・タイプに対してパラレル処理を設定する場合は、「すべて」をクリックします。
いずれのノード・タイプにもパラレル処理を設定しない場合は、「なし」をクリックします。
ノード・タイプに並列度を指定する方法:
ノード・タイプを選択し、 をクリックします。デフォルトの並列度はシステムによって決定されます。
をクリックします。デフォルトの並列度はシステムによって決定されます。
値を指定するには、「程度値」を選択します。デフォルト値は1です。指定した値は、そのノード・タイプの「並列度」列に表示されます。
ノード・タイプにパラレル処理を指定しても、そのノードによって生成される問合せがパラレルに実行されるとはかぎりません。
特定のノードのプリファレンスをオーバーライドできます。
これらの値は、モデル構築時のテキストの処理方法を表すものです。
デフォルトのカテゴリ型のカットオフ値は200です
デフォルトの変換はトークンです。
トークンの変換設定では、次のデフォルト値が使用されます。
言語: 英語、ステミングあり(選択解除)
ストップリスト: デフォルト・ストップリスト
トークンの最大数: 3000
テーマの変換では、次のデフォルト値が使用されます。
言語: 英語、ステミングあり(選択解除)
ストップリスト: デフォルト・ストップリスト
ドキュメント全体のテーマの最大数: 3000
次のプリファレンスはすべての変換に適用されます。
表示を最適化するためのキャッシュ・サンプル表の生成:
デフォルト設定では、キャッシュ・サンプル表は生成されません。大量のデータを処理する場合は、キャッシュ・サンプル表を生成すると便利です。
個々の変換のオプションは次のとおりです。
このプリファレンスでは、「列のフィルタ」変換の動作を指定します。次のデータ品質の基準を指定できます。
% Nullが次の値以下: データ・ソースの列内のNULL値の最大許容パーセンテージを示します。デフォルト値は95%です。
% 一意が次の値以下: データ・ソースの列内で一意な値の最大許容パーセンテージを示します。デフォルト値は95%です。
% 定数が次の値以下: データ・ソースの列内の定数値の最大許容パーセンテージを示します。
「属性重要度」はデフォルトでは選択されていません。次の設定を指定できます。
重要度カットオフ: 0から1.0までの数値です。デフォルトのカットオフは0です。
上位N: 属性の最大数です。デフォルトは100です。
列フィルタでは、データ品質と属性重要度を決定する際にデフォルトで「サンプリング」が使用されます。デフォルトでは、「サンプル・サイズ」として2000レコードが使用されます。サンプリングを無効にしてすべてのデータを使用したり、サンプル・サイズを増やすことができます。
これらのプリファレンスでは、「結合」変換の動作を制御します。
キー列の自動削除:
自動
手動
デフォルト
自動データ列のデフォルト:
自動
手動
デフォルト
「サンプリング」には、次の2つのプリファレンスがあります。
サンプリング・タイプ: デフォルトでは、「サンプリング・タイプ」として「ランダム」が使用され、「シード」は12,345になります。「シード」の値は変更可能です。
「サンプリング・タイプ」は「TopN」に変更可能です。
サンプリング・サイズ: サンプリング・サイズは行数またはパーセンテージのいずれかです。デフォルトのサイズは、2000行または60%のいずれかです。
「ビューア」設定では、次の動作を指定します。
次のプリファレンスがあります。
「精度」は最大有効桁数(10進)で、最上位有効数字は一番左のゼロ以外の桁で、最下位有効数字は一番右の既知の桁となります。「精度」は0以上の整数です。
これらのプリファレンスでは、データの参照ノードに表示されるデータのデータ精度を指定します。
パーセンテージ・ベースの値と数値のどちらについてもデフォルト精度は4です。これらの値のいずれかまたは両方を変更できます。
「深度/区域」および「グラフ形式」の各プリファレンスを指定します。
デフォルトの「深度/区域」は0です。
デフォルトの「グラフ形式」は「航海」です。
これらの一般プリファレンスはすべてのモデル・ビューアに適用されます。
「精度レベル設定」では、次の精度を指定します。
「パーセンテージ・ベースの値」については、デフォルト精度は4です。
「数値」については、精度は8です。
「フェッチ・サイズ設定」では、フェッチされる項目の数を指定します。デフォルトのフェッチ・サイズは次のとおりです。
相関ルール・モデル:1000
クラスタリング・ルール・モデル: 20
その他すべてのモデル: 10,000
ツリー表示には、追加で次のプリファレンスがあります。
デフォルト・ノード表示: 詳細ヘッダー
デフォルト・レイアウト: 垂直
クラスタのツリー・ノードの設定もあります。
クラスタ・ツリーの各ツリー・ノード:
「重心の属性名」の最大表示長は25
「重心値」の最大表示長は25
デフォルト・ノード表示: ヒストグラムおよび詳細ヘッダー。
ターゲット値のソート基準: ルート・ノード順序。信頼度順にソートすることもできます。
デフォルト・レイアウト: 垂直。「水平」を選択することもできます。
ディシジョン・ツリーのツリー・ノードの設定もあります。
ディシジョン・ツリーの各ツリー・ノードにおいて、ターゲット値の長さは25文字です。
ワークフロー・エディタのオプションとデフォルト設定は次のとおりです。
ノード・サポート: デフォルトで選択されています。ノードの作成時または接続時にウィザードが自動的に表示されます。たとえば、ワークフローにデータ・ソース・ノードを追加すると、データ・ソース・エディタが自動的に開きます。このオプションの選択を解除できます。
リンク・スタイル: 「ダイレクト」が選択されています。ダイレクト・リンク・スタイルでは、リンクは、始点となるノードと終点となるノードを結び、短い線が付いた直線となります。ダイレクト・リンク・スタイルを使用した場合、よりコンパクトでダイレクトなダイアグラム・レイアウトが作成されます。直交リンク・スタイルを選択できます。
代替リンク・ルーティング: デフォルトでは選択が解除されています。
「ワークフロー・ディレクトリ」は、ワークフローのインポート元として使用したり、作業のエクスポート先として使用するデフォルト・ディレクトリです。「ワークフロー・ディレクトリ」のデフォルト値は、Oracle Data Minerがインストールされているオペレーティング・システムのデフォルト値になります。たとえば、Microsoft Windowsオペレーティング・システムの場合、「ワークフロー・ディレクトリ」は「マイ ドキュメント」になります。
「ワークフロー・ディレクトリ」を変更するには、新しいディレクトリの名前を入力するか、「参照」をクリックしてディレクトリを参照します。ディレクトリ名の指定後、「OK」をクリックします。
「ワークフロー・ジョブ」のプリファレンスでは、表示する接続とワークフロー・ステータスの表示期間を指定します。
ナビゲータで選択した接続を自動的に表示: このオプションはデフォルトで選択されています。この選択は解除できます。このオプションの選択を解除した場合は、接続を明示的に選択する必要があります。
次より古いジョブを表示しない 24 時間: このオプションはデフォルトで選択されています。このオプションを変更できます。
「ダイアグラム」メニューは、ワークフローを開いたときに使用可能になります。このメニューのオプションを使用して、ワークフロー・ノードを配置します。
「ダイアグラム」メニューには、次のオプションが用意されています。
このオプションを使用して、ワークフローのノードを選択します。
ノードを接続する方法: 「ダイアグラム」を選択し、「接続」をクリックします。選択したノードから線を描画することによって、そのノードを別のノードに接続します。有効な選択のみを行うことができます。
接続を取り消す方法: どこにも接続されていない線を取り消すには、[Esc]を押します。この操作は、ノードのコンテキスト・メニューにある「接続」オプションと同じです。
このオプションを使用すると、一連の要素の位置合せを行ったり、要素のサイズを正規化できます。
水平方向の位置合せ
垂直方向の位置合せ
サイズ調整
このオプションを使用すると、選択した要素をダイアグラム内で(水平方向および垂直方向に)均等に配置できます。
水平方向の配置: 選択したダイアグラム要素の左右の配置を変更します。
垂直方向の配置: 選択したダイアグラム・オブジェクトの上下の配置を変更します。
このオプションを使用すると、選択したノードを他のすべてのノードの前面に移動できます。
このオプションを使用すると、選択したノードを他のすべてのノードの背面に移動できます。
ビューをズームするには、「ダイアグラム」に移動して「ズーム」をクリックします。このメニューが表示されます。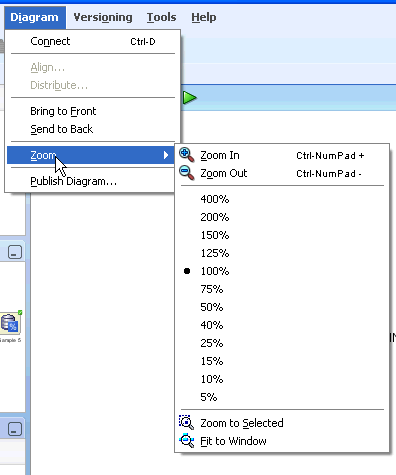
図diagram_zoom.gifの説明
デフォルトのズーム設定は100%です。デフォルト設定に戻すには、100%を選択します。
ワークフロー全体をズームインまたはズームアウトする方法: それぞれ および
および をクリックするか、特定のパーセンテージを設定します。
をクリックするか、特定のパーセンテージを設定します。
特定のノード(複数可)をズームする方法: ノードを選択し、「ダイアグラム」に移動して「ズーム」をクリックします。
ワークフロー全体をウィンドウに合せる方法: 「ウィンドウに合せる」を選択します。
このオプションを使用すると、現在のワークフローをシステムにグラフィック・ファイルとして保存できます。
ダイアグラムを公開するには、次の手順を実行します。
グラフィック・ファイルとして保存するワークフローを開きます。
「ダイアグラム」に移動して「公開」を選択します。
グラフィック・ファイルの保存先を参照します。
グラフィック・ファイルの形式を選択します。サポートされているファイル形式は次のとおりです。
PNG (デフォルト)
SVG
SVGZ
JPEG
「OK」をクリックします。ワークフローがグラフィック・ファイルとして保存されます。
「ワークフロー・ジョブ」には、実行中のすべてのタスクと最近実行したタスクが接続別に表示されます。タスクとは、選択したノードとその前提条件となる祖先ノードをすべて実行することです。
「ワークフロー・ジョブ」の表示には次の条件が適用されます。
「ワークフロー・ジョブ」には、直近に実行したワークフローが表示されます。
2つ以上のタスクがアクティブになっている場合は、「ワークフロー・ジョブ」ウィンドウが自動的に表示されます。
「ワークフロー・ジョブ」には、デフォルトでは、タブで選択した接続が自動的に表示されます。別の接続のタスクを表示するには、タブの上部にあるリストから接続を選択します。
「ワークフロー・ジョブ」では、タスクの表示期間を指定します。
「ワークフロー・ジョブ」のコンテキスト・メニューから複数のタスクを実行できます。グリッドの線を右クリックするか、グリッドの線の下の領域を右クリックします。
「ワークフロー・ジョブ」を表示するには、次の手順を実行します。
SQL Developerのメニュー・バーで、「表示」に移動して「Data Miner」をクリックします。
「Data Miner」タブが表示されない場合は、「ツール」に移動して「Data Miner」をクリックします。「Data Miner」で、「表示」をクリックします。
「Data Miner」で、「ワークフロー・ジョブ」をクリックします。
「ワークフロー・ジョブ」では、次のタスクを実行できます。
特定のタスクの表示: タスクが実行されている接続を選択します。接続は、「ワークフロー・ジョブ」のグリッドのすぐ上にあるドロップダウン・リストに一覧表示されます。
実行中のワークフローの終了:  をクリックします。
をクリックします。
ログの表示: 「ワークフロー・ジョブ」でプロセスを右クリックし、「ログの表示」をクリックします。
「ワークフロー・ジョブ」のグリッドには、次の情報が表示されます。
ワークフロー名
プロジェクト名
ステータス。値は次のとおりです。
アクティブ: ワークフローが実行されたことを示します。 で示されます。
で示されます。
非アクティブ: ワークフローがアイドル状態であることを示します。
停止済: ワークフローが停止されたことを示します。
スケジュール済: ワークフローの実行がスケジュールされていることを示します。
失敗: ワークフローの実行が失敗したことを示します。 で示されます。
で示されます。
選択した接続におけるデータ・マイニング・イベントのログを表示するには、「ワークフロー・ジョブ」でエントリを右クリックし、「イベント・ログの表示」を選択します。または、ワークフローの上部、タブのすぐ下にある をクリックします。
をクリックします。
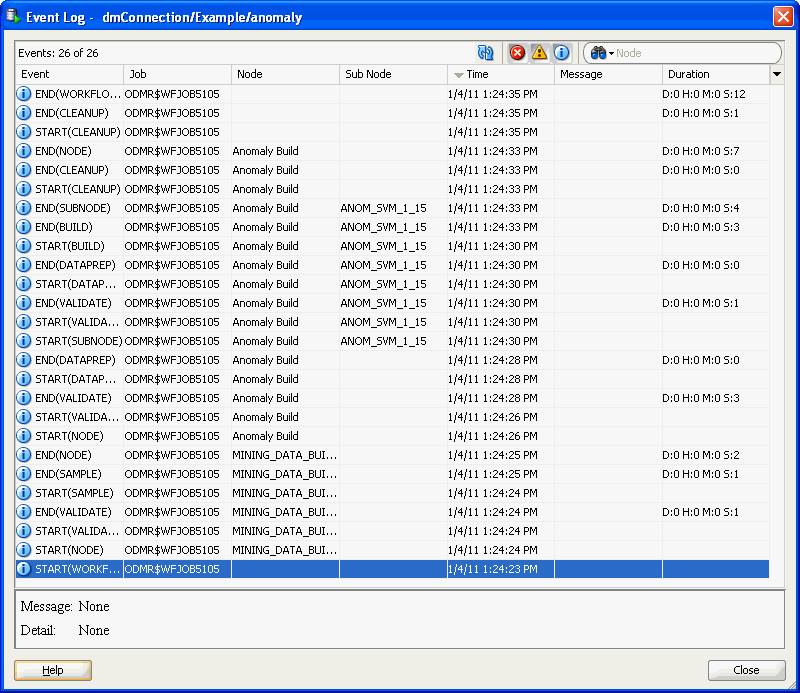
デフォルトでは、すべてのエラーが表示されます。エラーまたは情報イベントを表示できます。イベントの合計件数と表示件数がリストの上部に示されます。たとえば、「イベント: 90の2」は、90個のイベントのうち2個が表示されていることを意味しています。
各エラーまたは警告にはメッセージと詳細が関連付けられています。イベントを選択します。「イベント・ログ」ウィンドウの下部のペインにメッセージと詳細が表示されます。
選択した接続におけるデータ・マイニング・イベントごとに、次の情報が表示されます。
イベント: Oracle Data Minerでは、イベントはアクションの開始と終了を示します(START(WORKFLOW)やEND(WORKFLOW)など)。各ノードは順番に処理されます。
ジョブ: イベントを処理するジョブの名前。これらのジョブはOracle Data Miner内部で使用されます。
ノード: 処理中のノードの名前。すべてのイベントがノードに関連付けられるとはかぎりません。
SubNode: ノード処理の内部的なステップ。たとえば、異常構築ノードには、モデルを構築するサブノードが含まれています。
時間: イベントの開始時間。
メッセージ: イベントに関するメッセージ。イベントで問題が発生しなかった場合、メッセージは表示されません。
メッセージ詳細など、メッセージに関する追加情報を表示するには、イベントを選択します。イベント・リストの下にあるペインにメッセージと詳細が表示されます。すべてのイベントにメッセージやメッセージ詳細が関連付けられるとはかぎりません。
期間: イベントの処理に費やされた期間。期間はENDイベントに対して表示されます。期間は日数、時間数、分数および秒数で表示されます。
すべてのエラーが表示されます。イベント・リストの上にあるアイコンをクリックして、表示するイベントのタイプを選択できます。
エラーおよび失敗したイベントを表示するには、をクリックします。
デフォルトでは、エラーのみが表示されます。
警告を表示するには、 をクリックします。
をクリックします。
情報メッセージ(処理の開始と終了など)を表示するには、 をクリックします。
をクリックします。
リフレッシュするには、 をクリックします。
をクリックします。
イベントを検索するには、 の横にある下矢印をクリックします。
の横にある下矢印をクリックします。「ノード」(デフォルト)で検索することも、「すべて」を使用してノード以外のすべてを検索することもできます。
情報メッセージは、ワークフロー実行時の内部的な処理の開始と終了を示します。次の情報メッセージは、異常検出モデルの構築が成功したことを示しています。ワークフローの実行にかかった時間は5分12秒です。26個のイベントが発生しました。
コンテキスト・メニューを表示するには、「ワークフロー・ジョブ」のグリッドの線を右クリックするか、グリッドの空白領域を右クリックします。コンテキスト・メニューのオプションは次のとおりです。
ワークフローに移動:結果に対応するワークフローを表示します。
最新順にソート:エントリをソートします。
プリファレンス: 「ワークフロー・ジョブ」を表示します。
プロジェクトは接続に存在します。プロジェクトには、データ・マイニング・プロセスで作成されたすべてのワークフローが含まれています。
接続には少なくとも1つのプロジェクトを作成する必要があります。
この項では、いくつかの共通コントロールおよびタスクについて説明します。
「フィルタ」: フィルタに関する一般情報について説明します。
検索をフィルタで絞り込むには、次の手順を実行します。
該当する項目のみが表示するには、をクリックします。言い換えると、このオプションを使用して不要な項目を除外できます。
いくつかのフィルタ・オプションとデフォルト・オプションが用意されています。別のフィルタ・オプションを選択するには、双眼鏡アイコンの横にある三角形をクリックします。
検索をクリアするには、 をクリックします。
をクリックします。
SQL Developerのデータのインポート・ウィザードを使用して、データをデータベース表にインポートします。表を作成してその表にデータをインポートすることも、既存の表にデータをインポートすることもできます。言い換えると、オペレーティング・システム・ファイルのデリミタ付きデータをデータベースにインポートできます。
データをインポートするには、次の手順を実行します。
SQL Developerで、「接続」に移動します。
データ・マイニングに使用する接続を開きます。
「表」ノードまたは表名を右クリックし、「データのインポート」を選択します。
データのインポート元ファイルを指定します。XLS、TXT、CSVのいずれかの形式のファイルを指定できます。
「OK」をクリックします。
フィルタ・オプションを使用すると、Oracle Data Miner (DR)オブジェクトおよびOracle Data Mining (DM)オブジェクトを除外できます。データ・マイニングに関連付けられている表をフィルタするには、次の手順を実行します。
SQL Developerで、「接続」に移動します。
データ・マイニングに使用するユーザー・アカウントを開き、「表」を選択します。
「接続」のツールバーで、 をクリックします。
をクリックします。
次のフィルタ基準を選択します。
NAME NOT LIKE DR$% NAME NOT KLIKE DM$% NAME NOT LIKE ODMR$%
「OK」をクリックして表をフィルタ処理します。
チャート、グラフ、グリッド、クラスタ・ツリー・ルールおよびディシジョン・ツリー・ルールをエクスポートして外部ドキュメントで使用できます。エクスポートは、次のように、Microsoft Windowsのクリップボードにコピーしたり、ファイルに保存することによって行います。次のことを実行できます。
チャートをクリップボードにコピーするか、ファイルに保存: チャートをコピーするには、チャートを右クリックして、コンテキスト・メニューの次のいずれかのオプションを選択します。
クリップボードにコピー
画像を別名で保存
データの表示
データ・グリッドをクリップボードにコピー: 「グラフ・データ」ダイアログ・ボックスで1つまたは複数の行をコピーできます。データ・グリッドをコピーする手順:
「グラフ・データ」ダイアログ・ボックスでコピーする行を[Ctrl]キーを押しながら選択します。複数の行を選択するには、[Ctrl]キーと[Shift]キーを押しながら行をクリックします。
[Ctrl]キーを押しながら[C]キーを押し、選択した行をコピーします。
選択した行をクリップボードに貼り付けるには、[Ctrl]キーを押しながら[V]キーを押します。
チャートのデータ・コンテンツをコピーおよび表示: チャートのデータ・コンテンツをコピーするには、右クリックして、コンテキスト・メニューの次のいずれかのオプションを選択します。
画像をクリップボードにコピー
画像を別名で保存
クラスタ・ツリー・ルールおよびディシジョン・ツリー・ルールをクリップボードにコピーするか、ファイルに保存: クラスタ・ツリー・ルールおよびディシジョン・ツリー・ルールをクリップボードにコピーするか、ファイルに保存するには、モデル・ビューアの「ルールの保存」オプションを使用します。