4 Using Property Graphs in a Big Data Environment
This chapter provides conceptual and usage information about creating, storing, and working with property graph data in a Big Data environment.
4.1 About Property Graphs
Property graphs allow an easy association of properties (key-value pairs) with graph vertices and edges, and they enable analytical operations based on relationships across a massive set of data.
4.1.1 What Are Property Graphs?
A property graph consists of a set of objects or vertices, and a set of arrows or edges connecting the objects. Vertices and edges can have multiple properties, which are represented as key-value pairs.
Each vertex has a unique identifier and can have:
-
A set of outgoing edges
-
A set of incoming edges
-
A collection of properties
Each edge has a unique identifier and can have:
-
An outgoing vertex
-
An incoming vertex
-
A text label that describes the relationship between the two vertices
-
A collection of properties
Figure 4-1 illustrates a very simple property graph with two vertices and one edge. The two vertices have identifiers 1 and 2. Both vertices have properties name and age. The edge is from the outgoing vertex 1 to the incoming vertex 2. The edge as a text label knows and a property type identifying the type of relationship between vertices 1 and 2.
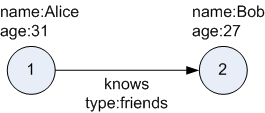
The property graph data model is not based on standards, but is similar to the W3C standards-based Resource Description Framework (RDF) graph data model. The property graph data model is simpler and much less precise than RDF. These differences make it a good candidate for use cases such as these:
-
Identifying influencers in a social network
-
Predicting trends and customer behavior
-
Discovering relationships based on pattern matching
-
Identifying clusters to customize campaigns
4.1.2 What Is Big Data Support for Property Graphs?
Property graphs are supported for Big Data in Hadoop. This support consists of a data access layer and an analytics layer. A choice of databases in Hadoop provides scalable and persistent storage management.
Figure 4-2 provides an overview of the Oracle property graph architecture.
Figure 4-2 Oracle Property Graph Architecture
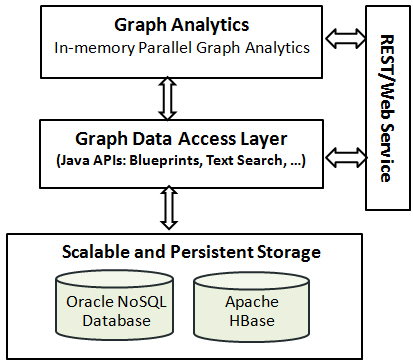
Description of "Figure 4-2 Oracle Property Graph Architecture"
4.1.2.1 Analytics Layer
The analytics layer enables you to analyze property graphs using MapReduce programs in a Hadoop cluster. It provides over 30 analytic functions, including path calculation, ranking, community detection, and a recommender system.
4.1.2.2 Data Access Layer
The data access layer provides a set of Java APIs that you can use to create and drop property graphs, add and remove vertices and edges, search for vertices and edges using key-value pairs, create text indexes, and perform other manipulations. The Java APIs include an implementation of TinkerPop Blueprints graph interfaces for the property graph data model. The APIs also integrate with the Apache Lucene and Apache SolrCloud, which are widely-adopted open-source text indexing and search engines.
4.2 Getting Started With Property Graphs
To get started with property graphs:
-
The first time you use property graphs, ensure that the software is installed and operational.
-
Create your Java programs, using the classes provided in the Java API.
4.3 About Property Graph Data Formats
The following graph formats are supported:
4.3.1 GraphML Data Format
The GraphML file format uses XML to describe graphs. Example 4-1 shows a GraphML description of the property graph shown in Figure 4-1.
Example 4-1 GraphML Description of a Simple Property Graph
<?xml version="1.0" encoding="UTF-8"?>
<graphml xmlns="http://graphml.graphdrawing.org/xmlns">
<key id="name" for="node" attr.name="name" attr.type="string"/>
<key id="age" for="node" attr.name="age" attr.type="int"/>
<key id="type" for="edge" attr.name="type" attr.type="string"/>
<graph id="PG" edgedefault="directed">
<node id="1">
<data key="name">Alice</data>
<data key="age">31</data>
</node>
<node id="2">
<data key="name">Bob</data>
<data key="age">27</data>
</node>
<edge id="3" source="1" target="2" label="knows">
<data key="type">friends</data>
</edge>
</graph>
</graphml>
See Also:
"The GraphML File Format" at4.3.2 GraphSON Data Format
The GraphSON file format is based on JavaScript Object Notation (JSON) for describing graphs. Example 4-2 shows a GraphSON description of the property graph shown in Figure 4-1.
Example 4-2 GraphSON Description of a Simple Property Graph
{
"graph": {
"mode":"NORMAL",
"vertices": [
{
"name": "Alice",
"age": 31,
"_id": "1",
"_type": "vertex"
},
{
"name": "Bob",
"age": 27,
"_id": "2",
"_type": "vertex"
}
],
"edges": [
{
"type": "friends",
"_id": "3",
"_type": "edge",
"_outV": "1",
"_inV": "2",
"_label": "knows"
}
]
}
}
See Also:
"GraphSON Reader and Writer Library" athttps://github.com/tinkerpop/blueprints/wiki/GraphSON-Reader-and-Writer-Library
4.3.3 GML Data Format
The Graph Modeling Language (GML) file format uses ASCII to describe graphs. Example 4-3 shows a GML description of the property graph shown in Figure 4-1.
Example 4-3 GML Description of a Simple Property Graph
graph [
comment "Simple property graph"
directed 1
IsPlanar 1
node [
id 1
label "1"
name "Alice"
age 31
]
node [
id 2
label "2"
name "Bob"
age 27
]
edge [
source 1
target 2
label "knows"
type "friends"
]
]
See Also:
"GML: A Portable Graph File Format" by Michael Himsolt athttp://www.fim.uni-passau.de/fileadmin/files/lehrstuhl/brandenburg/projekte/gml/gml-technical-report.pdf
4.3.4 Oracle Flat File Format
The Oracle flat file format exclusively describes property graphs. It is more concise and provides better data type support than the other file formats. The Oracle flat file format uses two files for a graph description, one for the vertices and one for edges. Commas separate the fields of the records.
Example 4-4 shows the Oracle flat files that describe the property graph shown in Figure 4-1.
Example 4-4 Oracle Flat File Description of a Simple Property Graph
Vertex file:
1,name,1,Alice,, 1,age,2,,31, 2,name,1,Bob,, 2,age,2,,27,
Edge file:
1,1,2,knows,type,1,friends,,
See Also:
"Oracle Flat File Format Definition"4.4 Using Java APIs for Property Graph Data
Creating a property graph involves using the Java APIs to create the property graph and objects in it.
4.4.1 Overview of the Java APIs
The Java APIs that you can use for property graphs include:
4.4.1.1 Oracle Big Data Spatial and Graph Java APIs
Oracle Big Data Spatial and Graph property graph support provides database-specific APIs for Apache HBase and Oracle NoSQL Database. The data access layer API (oracle.pg.*) implements TinkerPop Blueprints APIs, text search, and indexing for property graphs stored in Oracle NoSQL Database and Apache HBase.
To use the Oracle Big Data Spatial and Graph API, import the classes into your Java program:
import oracle.pg.nosql.*; // or oracle.pg.hbase.*
import oracle.pgx.config.*;
import oracle.pgx.common.types.*;
Also include TinkerPop Blueprints Java APIs.
See Also:
Oracle Big Data Spatial and Graph Java API Reference4.4.1.2 TinkerPop Blueprints Java APIs
TinkerPop Blueprints supports the property graph data model. The API provides utilities for manipulating graphs, which you use primarily through the Big Data Spatial and Graph data access layer Java APIs.
To use the Blueprints APIs, import the classes into your Java program:
import com.tinkerpop.blueprints.Vertex; import com.tinkerpop.blueprints.Edge;
See Also:
"Blueprints: A Property Graph Model Interface API" athttp://www.tinkerpop.com/docs/javadocs/blueprints/2.3.0/index.html
4.4.1.3 Apache Hadoop Java APIs
The Apache Hadoop Java APIs enable you to write your Java code as a MapReduce program that runs within the Hadoop distributed framework.
To use the Hadoop Java APIs, import the classes into your Java program. For example:
import org.apache.hadoop.conf.Configuration;
See Also:
"Apache Hadoop Main 2.5.0-cdh5.3.2 API" at4.4.1.4 Oracle NoSQL Database Java APIs
The Oracle NoSQL Database APIs enable you to create and populate a key-value (KV) store, and provide interfaces to Hadoop, Hive, and Oracle Database.
To use Oracle NoSQL Database as the graph data store, import the classes into your Java program. For example:
import oracle.kv.*; import oracle.kv.table.TableOperation;
See Also:
"Oracle NoSQL Database Java API Reference" at4.4.1.5 Apache HBase Java APIs
The Apache HBase APIs enable you to create and manipulate key-value pairs.
To use HBase as the graph data store, import the classes into your Java program. For example:
import org.apache.hadoop.hbase.*; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.filter.*; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.conf.Configuration;
See Also:
"HBase 0.98.6-cdh5.3.2 API" athttp://archive.cloudera.com/cdh5/cdh/5/hbase/apidocs/index.html?overview-summary.html
4.4.2 Opening and Closing a Property Graph Instance
When describing a property graph, use these Oracle Property Graph classes to open and close the property graph instance properly:
-
OraclePropertyGraph.getInstance: Opens an instance of an Oracle property graph. This method has two parameters, the connection information and the graph name. The format of the connection information depends on whether you use HBase or Oracle NoSQL Database as the backend database. -
OraclePropertyGraph.clearRepository: Removes all vertices and edges from the property graph instance. -
OraclePropertyGraph.shutdown: Closes the graph instance.
In addition, you must use the appropriate classes from the Oracle NoSQL Database or HBase APIs.
4.4.2.1 Using Oracle NoSQL Database
For Oracle NoSQL Database, the OraclePropertyGraph.getInstance method uses the KV store name, host computer name, and port number for the connection:
String kvHostPort = "cluster02:5000"; String kvStoreName = "kvstore"; String kvGraphName = "my_graph"; // Use NoSQL Java API KVStoreConfig kvconfig = new KVStoreConfig(kvStoreName, kvHostPort); OraclePropertyGraph opg = OraclePropertyGraph.getInstance(kvconfig, kvGraphName); opg.clearRepository(); // . // . Graph description // . // Close the graph instance opg.shutdown();
If in-memory analytical functions are required for your application, then it is recommended that you use GraphConfigBuilder to create a graph config for Oracle NoSQL Database, and instantiates OraclePropertyGraph with the config as an argument.
As an example, the following code snippet constructs a graph config, gets an OraclePropertyGraph instance, loads some data into that graph, and gets an in-memory analyst.
import oracle.pgx.api.Pgx;
import oracle.pgx.config.*;
import oracle.pgx.api.analyst.*;
import oracle.pgx.common.types.*;
...
String[] hhosts = new String[1];
hhosts[0] = "my_host_name:5000"; // need customization
String szStoreName = "kvstore"; // need customization
String szGraphName = "my_graph";
int dop = 8;
PgNosqlGraphConfig cfg = GraphConfigBuilder.forNosql()
.setName(szGraphName)
.setHosts(Arrays.asList(hhosts))
.setStoreName(szStoreName)
.addEdgeProperty("lbl", PropertyType.STRING, "lbl")
.addEdgeProperty("weight", PropertyType.DOUBLE, "1000000")
.build();
OraclePropertyGraph opg = OraclePropertyGraph.getInstance(cfg);
String szOPVFile = "../../data/connections.opv";
String szOPEFile = "../../data/connections.ope";
// perform a parallel data load
OraclePropertyGraphDataLoader opgdl = OraclePropertyGraphDataLoader.getInstance();
opgdl.loadData(opg, szOPVFile, szOPEFile, dop);
...
Analyst analyst = opg.getInMemAnalyst();
...
4.4.2.2 Using Apache HBase
For Apache HBase, the OraclePropertyGraph.getInstance method uses the Hadoop nodes and the Apache HBase port number for the connection:
String hbQuorum = "bda01node01.example.com, bda01node02.example.com, bda01node03.example.com";
String hbClientPort = "2181"
String hbGraphName = "my_graph";
// Use HBase Java APIs
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", hbQuorum);
conf.set("hbase.zookeper.property.clientPort", hbClientPort);
HConnection conn = HConnectionManager.createConnection(conf);
// Open the property graph
OraclePropertyGraph opg = OraclePropertyGraph.getInstance(conf, conn, hbGraphName);
opg.clearRepository();
// .
// . Graph description
// .
// Close the graph instance
opg.shutdown();
// Close the HBase connection
conn.close();
If in-memory analytical functions are required for your application, then it is recommended that you use GraphConfigBuilder to create a graph config, and instantiates OraclePropertyGraph with the config as an argument.
As an example, the following code snippet sets the configuration for in memory analytics, constructs a graph config for Apache HBase, instantiates an OraclePropertyGraph instance, gets an in-memory analyst, and counts the number of triangles in the graph.
int dop = 8;
Map<PgxConfig.Field, Object> confPgx = new HashMap<PgxConfig.Field, Object>();
confPgx.put(PgxConfig.Field.ENABLE_GM_COMPILER, false);
confPgx.put(PgxConfig.Field.NUM_WORKERS_IO, dop + 2);
confPgx.put(PgxConfig.Field.NUM_WORKERS_ANALYSIS, 8); // <= # of physical cores
confPgx.put(PgxConfig.Field.NUM_WORKERS_FAST_TRACK_ANALYSIS, 2);
confPgx.put(PgxConfig.Field.SESSION_TASK_TIMEOUT_SECS, 0); // no timeout set
confPgx.put(PgxConfig.Field.SESSION_IDLE_TIMEOUT_SECS, 0); // no timeout set
PgxConfig.init(confPgx);
int iClientPort = Integer.parseInt(szClientPort);
int iSplitsPerRegion = 2;
PgHbaseGraphConfig cfg = GraphConfigBuilder.forHbase()
.setName(hbGraphName)
.setZkQuorum(hbQuorum)
.setZkQuorum(szQuorum)
.setZkClientPort(iClientPort)
.setZkSessionTimeout(60000)
.setMaxNumConnections(dop)
.setLoadEdgeLabel(true)
.setSplitsPerRegion(splitsPerRegion)
.addEdgeProperty("lbl", PropertyType.STRING, "lbl")
.addEdgeProperty("weight", PropertyType.DOUBLE, "1000000")
.build();
OraclePropertyGraph opg = OraclePropertyGraph.getInstance(cfg);
Analyst analyst = opg.getInMemAnalyst();
long triangles = analyst.countTriangles(false).get();
4.4.3 Creating the Vertices
To create a vertex, use these Oracle Property Graph methods:
-
OraclePropertyGraph.addVertex: Adds a vertex instance to a graph. -
OracleVertex.setProperty: Assigns a key-value property to a vertex. -
OraclePropertyGraph.commit: Saves all changes to the property graph instance.
The following code fragment creates two vertices named V1 and V2, with properties for age, name, weight, height, and sex in the opg property graph instance. The v1 properties set the data types explicitly.
// Create vertex v1 and assign it properties as key-value pairs
Vertex v1 = opg.addVertex(1l);
v1.setProperty("age", Integer.valueOf(31));
v1.setProperty("name", "Alice");
v1.setProperty("weight", Float.valueOf(135.0f));
v1.setProperty("height", Double.valueOf(64.5d));
v1.setProperty("female", Boolean.TRUE);
Vertex v2 = opg.addVertex(2l);
v2.setProperty("age", 27);
v2.setProperty("name", "Bob");
v2.setProperty("weight", Float.valueOf(156.0f));
v2.setProperty("height", Double.valueOf(69.5d));
v2.setProperty("female", Boolean.FALSE);
4.4.4 Creating the Edges
To create an edge, use these Oracle Property Graph methods:
-
OraclePropertyGraph.addEdge: Adds an edge instance to a graph. -
OracleEdge.setProperty: Assigns a key-value property to an edge.
The following code fragment creates two vertices (v1 and v2) and one edge (e1).
// Add vertices v1 and v2
Vertex a = opg.addVertex(1l);
v1.setProperty("name", "Alice");
v1.setProperty("age", 31);
Vertex v2 = opg.addVertex(2l);
v2.setProperty("name", "Bob");
v2.setProperty("age", 27);
// Add edge e1
Edge e1 = opg.addEdge(1l, v1, v2, "knows");
e1.setProperty("type", "friends");
4.4.5 Deleting the Vertices and Edges
You can remove vertex and edge instances individually, or all of them simultaneously. Use these methods:
-
OraclePropertyGraph.removeEdge: Removes the specified edge from the graph. -
OraclePropertyGraph.removeVertex: Removes the specified vertex from the graph. -
OraclePropertyGraph.clearRepository: Removes all vertices and edges from the property graph instance.
The following code fragment removes edge e1 and vertex v1 from the graph instance. The adjacent edges will also be deleted from the graph when removing a vertex. This is because every edge must have an beginning and ending vertex. After removing the beginning or ending vertex, the edge is no longer a valid edge.
// Remove edge e1 opg.removeEdge(e1); // Remove vertex v1 opg.removeVertex(v1);
The OraclePropertyGraph.clearRepository method can be used to remove all contents from an OraclePropertyGraph instance. However, use it with care because this action cannot be reversed.
4.4.6 Dropping a Property Graph
To drop a property graph from the database, use the OraclePropertyGraphUtils.dropPropertyGraph method. This method has two parameters, the connection information and the graph name.
The format of the connection information depends on whether you use HBase or Oracle NoSQL Database as the backend database. It is the same as the connection information you provide to OraclePropertyGraph.getInstance.
4.4.6.1 Using Oracle NoSQL Database
For Oracle NoSQL Database, the OraclePropertyGraphUtils.dropPropertyGraph method uses the KV store name, host computer name, and port number for the connection. This code fragment deletes a graph named my_graph from Oracle NoSQL Database.
String kvHostPort = "cluster02:5000"; String kvStoreName = "kvstore"; String kvGraphName = "my_graph"; // Use NoSQL Java API KVStoreConfig kvconfig = new KVStoreConfig(kvStoreName, kvHostPort); // Drop the graph OraclePropertyGraphUtils.dropPropertyGraph(kvconfig, kvGraphName);
4.4.6.2 Using Apache HBase
For Apache HBase, the OraclePropertyGraphUtils.dropPropertyGraph method uses the Hadoop nodes and the Apache HBase port number for the connection. This code fragment deletes a graph named my_graph from Apache HBase.
String hbQuorum = "bda01node01.example.com, bda01node02.example.com, bda01node03.example.com";
String hbClientPort = "2181"
String hbGraphName = "my_graph";
// Use HBase Java APIs
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", hbQuorum);
conf.set("hbase.zookeper.property.clientPort", hbClientPort);
HConnection conn = HConnectionManager.createConnection(conf);
// Drop the graph
OraclePropertyGraphUtils.dropPropertyGraph(conf, hbGraphName);
4.5 Managing Text Indexing for Property Graph Data
Indexes in Oracle Big Data Spatial and Graph allow fast retrieval of elements by a particular key/value or key/text pair. These indexes are created based on an element type (vertices or edges), a set of keys (and values), and an index type.
Two types of indexing structures are supported by Oracle Big Data Spatial and Graph: manual and automatic.
-
Automatic text indexes provide automatic indexing of vertices or edges by a set of property keys. Their main purpose is to enhance query performance on vertices and edges based on particular key/value pairs.
-
Manual text indexes enable you to define multiple indexes over a designated set of vertices and edges of a property graph. You must specify what graph elements go into the index.
Oracle Big Data Spatial and Graph provides APIs to create manual and automatic text indexes over property graphs for Oracle NoSQL Database and Apache HBase. Indexes are managed using the available search engines, Apache Lucene and SolrCloud. The rest of this section focuses on how to create text indexes using the property graph capabilities of the Data Access Layer.
-
Using Automatic Indexes with the Apache Lucene Search Engine
-
Uploading a Collection's SolrCloud Configuration to Zookeeper
-
Updating Configuration Settings on Text Indexes for Property Graph Data
4.5.1 Using Automatic Indexes with the Apache Lucene Search Engine
The supplied examples ExampleNoSQL6 and ExampleHBase6 create a property graph from an input file, create an automatic text index on vertices, and execute some text search queries using Apache Lucene.
The following code fragment creates an automatic index over an existing property graph's vertices with these property keys: name, role, religion, and country. The automatic text index will be stored under four subdirectories under the /home/data/text-index directory. Apache Lucene data types handling is enabled. This example use a DOP (parallelism) of 4 for re-indexing tasks.
OraclePropertyGraph opg = OraclePropertyGraph.getInstance(
args, szGraphName);
String szOPVFile = "../../data/connections.opv";
String szOPEFile = "../../data/connections.ope";
// Do a parallel data loading
OraclePropertyGraphDataLoader opgdl =
OraclePropertyGraphDataLoader.getInstance();
opgdl.loadData(opg, szOPVFile, szOPEFile, dop);
// Create an automatic index using Apache Lucene engine.
// Specify Index Directory parameters (number of directories,
// number of connections to database, batch size, commit size,
// enable datatypes, location)
OracleIndexParameters indexParams =
OracleIndexParameters.buildFS(4, 4, 10000, 50000, true,
"/home/data/text-index ");
opg.setDefaultIndexParameters(indexParams);
// specify indexed keys
String[] indexedKeys = new String[4];
indexedKeys[0] = "name";
indexedKeys[1] = "role";
indexedKeys[2] = "religion";
indexedKeys[3] = "country";
// Create auto indexing on above properties for all vertices
opg.createKeyIndex(indexedKeys, Vertex.class);
By default, indexes are configured based on the OracleIndexParameters associated with the property graph using the method opg.setDefaultIndexParameters(indexParams).
Indexes can also be created by specifying a different set of parameters. This is shown in the following code snippet.
// Create an OracleIndexParameters object to get Index configuration (search engine, etc).
OracleIndexParameters indexParams = OracleIndexParameters.buildFS(args)
// Create auto indexing on above properties for all vertices
opg.createKeyIndex("name", Vertex.class, indexParams.getParameters());
The code fragment in the next example executes a query over all vertices to find all matching vertices with the key/value pair name:Barack Obama. This operation will execute a lookup into the text index.
Additionally, wildcard searches are supported by specifying the parameter useWildCards in the getVertices API call. Wildcard search is only supported when automatic indexes are enabled for the specified property key. For details on text search syntax using Apache Lucene, see https://lucene.apache.org/core/2_9_4/queryparsersyntax.html.
// Find all vertices with name Barack Obama.
Iterator<Vertices> vertices = opg.getVertices("name", "Barack Obama").iterator();
System.out.println("----- Vertices with name Barack Obama -----");
countV = 0;
while (vertices.hasNext()) {
System.out.println(vertices.next());
countV++;
}
System.out.println("Vertices found: " + countV);
// Find all vertices with name including keyword "Obama"
// Wildcard searching is supported.
boolean useWildcard = true;
Iterator<Vertices> vertices = opg.getVertices("name", "*Obama*").iterator();
System.out.println("----- Vertices with name *Obama* -----");
countV = 0;
while (vertices.hasNext()) {
System.out.println(vertices.next());
countV++;
}
System.out.println("Vertices found: " + countV);
The preceding code example produces output like the following:
----- Vertices with name Barack Obama-----
Vertex ID 1 {name:str:Barack Obama, role:str:political authority, occupation:str:44th president of United States of America, country:str:United States, political party:str:Democratic, religion:str:Christianity}
Vertices found: 1
----- Vertices with name *Obama* -----
Vertex ID 1 {name:str:Barack Obama, role:str:political authority, occupation:str:44th president of United States of America, country:str:United States, political party:str:Democratic, religion:str:Christianity}
Vertices found: 1
See Also:
Exploring the Sample Programs4.5.2 Using Manual Indexes with the SolrCloud Search Engine
The supplied examples ExampleNoSQL7 and ExampleHBase7 create a property graph from an input file, create a manual text index on edges, put some data into the index, and execute some text search queries using Apache SolrCloud.
When using SolrCloud, you must first load a collection's configuration for the text indexes into Apache Zookeeper, as described in Uploading a Collection's SolrCloud Configuration to Zookeeper.
The following code fragment creates a manual text index over an existing property graph using four shards, one shard per node, and a replication factor of 1. The number of shards corresponds to the number of nodes in the SolrCloud cluster.
OraclePropertyGraph opg = OraclePropertyGraph.getInstance(args,
szGraphName);
String szOPVFile = "../../data/connections.opv";
String szOPEFile = "../../data/connections.ope";
// Do a parallel data loading
OraclePropertyGraphDataLoader opgdl =
OraclePropertyGraphDataLoader.getInstance();
opgdl.loadData(opg, szOPVFile, szOPEFile, dop);
// Create a manual text index using SolrCloud// Specify Index Directory parameters: configuration name, Solr Server URL, Solr Node set,
// replication factor, zookeeper timeout (secs),
// maximum number of shards per node,
// number of connections to database, batch size, commit size,
// write timeout (in secs)
String configName = "opgconfig";
String solrServerUrl = "nodea:2181/solr"
String solrNodeSet = "nodea:8983_solr,nodeb:8983_solr," +
"nodec:8983_solr,noded:8983_solr";
int zkTimeout = 15;
int numShards = 4;
int replicationFactor = 1;
int maxShardsPerNode = 1;
OracleIndexParameters indexParams =
OracleIndexParameters.buildSolr(configName,
solrServerUrl,
solrNodeSet,
zkTimeout,
numShards,
replicationFactor,
maxShardsPerNode,
4,
10000,
500000,
15);
opg.setDefaultIndexParameters(indexParams);
// Create manual indexing on above properties for all vertices
OracleIndex<Edge> index = opg.createIndex("myIdx", Edge.class);
Vertex v1 = opg.getVertices("name", "Barack Obama").iterator().next();
Iterator<Edge> edges
= v1.getEdges(Direction.OUT, "collaborates").iterator();
while (edges.hasNext()) {
Edge edge = edges.next();
Vertex vIn = edge.getVertex(Direction.IN);
index.put("collaboratesWith", vIn.getProperty("name"), edge);
}
The next code fragment executes a query over the manual index to get all edges with the key/value pair collaboratesWith:Beyonce. Additionally, wildcards search can be supported by specifying the parameter useWildCards in the get API call.
// Find all edges with collaboratesWith Beyonce.
// Wildcard searching is supported using true parameter.
edges = index.get("collaboratesWith", "Beyonce").iterator();
System.out.println("----- Edges with name Beyonce -----");
countE = 0;
while (edges.hasNext()) {
System.out.println(edges.next());
countE++;
}
System.out.println("Edges found: "+ countE);
// Find all vertices with name including Bey*.
// Wildcard searching is supported using true parameter.
edges = index.get("collaboratesWith", "*Bey*", true).iterator();
System.out.println("----- Edges with collaboratesWith Bey* -----");
countE = 0;
while (edges.hasNext()) {
System.out.println(edges.next());
countE++;
}
System.out.println("Edges found: " + countE);
The preceding code example produces output like the following:
----- Edges with name Beyonce -----
Edge ID 1000 from Vertex ID 1 {country:str:United States, name:str:Barack Obama, occupation:str:44th president of United States of America, political party:str:Democratic, religion:str:Christianity, role:str:political authority} =[collaborates]=> Vertex ID 2 {country:str:United States, music genre:str:pop soul , name:str:Beyonce, role:str:singer actress} edgeKV[{weight:flo:1.0}]
Edges found: 1
----- Edges with collaboratesWith Bey* -----
Edge ID 1000 from Vertex ID 1 {country:str:United States, name:str:Barack Obama, occupation:str:44th president of United States of America, political party:str:Democratic, religion:str:Christianity, role:str:political authority} =[collaborates]=> Vertex ID 2 {country:str:United States, music genre:str:pop soul , name:str:Beyonce, role:str:singer actress} edgeKV[{weight:flo:1.0}]
Edges found: 1
See Also:
Exploring the Sample Programs4.5.3 Handling Data Types
Oracle's property graph support indexes and stores an element's Key/Value pairs based on the value data type. The main purpose of handling data types is to provide extensive query support like numeric and date range queries.
By default, searches over a specific key/value pair are matched up to a query expression based on the value's data type. For example, to find vertices with the key/value pair age:30, a query is executed over all age fields with a data type integer. If the value is a query expression, you can also specify the data type class of the value to find by calling the API get(String key, Object value, Class dtClass, Boolean useWildcards). If no data type is specified, the query expression will be matched to all possible data types.
When dealing with Boolean operators, each subsequent key/value pair must append the data type's prefix/suffix so the query can find proper matches. The following topics describe how to append this prefix/suffix for Apache Lucene and SolrCloud.
4.5.3.1 Appending Data Type Identifiers on Apache Lucene
When Lucene's data types handling is enabled, you must append the proper data type identifier as a suffix to the key in the query expression. This can be done by executing a String.concat() operation to the key. If Lucene's data types handling is disabled, you must insert the data type identifier as a prefix in the value String. Table 4-1 shows the data type identifiers available for text indexing using Apache Lucene (see also the Javadoc for LuceneIndex).
Table 4-1 Apache Lucene Data Type Identifiers
| Lucene Data Type Identifier | Description |
|---|---|
|
TYPE_DT_STRING |
String |
|
TYPE_DT_BOOL |
Boolean |
|
TYPE_DT_DATE |
Date |
|
TYPE_DT_FLOAT |
Float |
|
TYPE_DT_DOUBLE |
Double |
|
TYPE_DT_INTEGER |
Integer |
|
TYPE_DT_SERIALIZABLE |
Serializable |
The following code fragment creates a manual index on edges using Lucene's data type handling, adds data, and later executes a query over the manual index to get all edges with the key/value pair collaboratesWith:Beyonce AND country1:United* using wildcards.
OraclePropertyGraph opg = OraclePropertyGraph.getInstance(args,
szGraphName);
String szOPVFile = "../../data/connections.opv";
String szOPEFile = "../../data/connections.ope";
// Do a parallel data loading
OraclePropertyGraphDataLoader opgdl =
OraclePropertyGraphDataLoader.getInstance();
opgdl.loadData(opg, szOPVFile, szOPEFile, dop);
// Specify Index Directory parameters (number of directories,
// number of connections to database, batch size, commit size,
// enable datatypes, location)
OracleIndexParameters indexParams =
OracleIndexParameters.buildFS(4, 4, 10000, 50000, true,
"/ home/data/text-index ");
opg.setDefaultIndexParameters(indexParams);
// Create manual indexing on above properties for all edges
OracleIndex<Edge> index = opg.createIndex("myIdx", Edge.class);
Vertex v1 = opg.getVertices("name", "Barack Obama").iterator().next();
Iterator<Edge> edges
= v1.getEdges(Direction.OUT, "collaborates").iterator();
while (edges.hasNext()) {
Edge edge = edges.next();
Vertex vIn = edge.getVertex(Direction.IN);
index.put("collaboratesWith", vIn.getProperty("name"), edge);
index.put("country", vIn.getProperty("country"), edge);
}
// Wildcard searching is supported using true parameter.
String key = "country";
key = key.concat(String.valueOf(oracle.pg.text.lucene.LuceneIndex.TYPE_DT_STRING));
String queryExpr = "Beyonce AND " + key + ":United*";
edges = index.get("collaboratesWith", queryExpr, true /*UseWildcard*/).iterator();
System.out.println("----- Edges with query: " + queryExpr + " -----");
countE = 0;
while (edges.hasNext()) {
System.out.println(edges.next());
countE++;
}
System.out.println("Edges found: "+ countE);
The preceding code example might produce output like the following:
----- Edges with name Beyonce AND country1:United* -----
Edge ID 1000 from Vertex ID 1 {country:str:United States, name:str:Barack Obama, occupation:str:44th president of United States of America, political party:str:Democratic, religion:str:Christianity, role:str:political authority} =[collaborates]=> Vertex ID 2 {country:str:United States, music genre:str:pop soul , name:str:Beyonce, role:str:singer actress} edgeKV[{weight:flo:1.0}]
Edges found: 1
The following code fragment creates an automatic index on vertices, disables Lucene's data type handling, adds data, and later executes a query over the manual index from a previous example to get all vertices with the key/value pair country:United* AND role:1*political* using wildcards.
OraclePropertyGraph opg = OraclePropertyGraph.getInstance(args,
szGraphName);
String szOPVFile = "../data/connections.opv";
String szOPEFile = "../data/connections.ope";
// Do a parallel data loading
OraclePropertyGraphDataLoader opgdl =
OraclePropertyGraphDataLoader.getInstance();
opgdl.loadData(opg, szOPVFile, szOPEFile, dop);
// Create an automatic index using Apache Lucene engine.
// Specify Index Directory parameters (number of directories,
// number of connections to database, batch size, commit size,
// enable datatypes, location)
OracleIndexParameters indexParams =
OracleIndexParameters.buildFS(4, 4, 10000, 50000, false, "/ home/data/text-index ");
opg.setDefaultIndexParameters(indexParams);
// specify indexed keys
String[] indexedKeys = new String[4];
indexedKeys[0] = "name";
indexedKeys[1] = "role";
indexedKeys[2] = "religion";
indexedKeys[3] = "country";
// Create auto indexing on above properties for all vertices
opg.createKeyIndex(indexedKeys, Vertex.class);
// Wildcard searching is supported using true parameter.
String value = "*political*";
value = String.valueOf(LuceneIndex.TYPE_DT_STRING) + value;
String queryExpr = "United* AND role:" + value;
vertices = opg.getVertices("country", queryExpr, true /*useWildcard*/).iterator();
System.out.println("----- Vertices with query: " + queryExpr + " -----");
countV = 0;
while (vertices.hasNext()) {
System.out.println(vertices.next());
countV++;
}
System.out.println("Vertices found: " + countV);
The preceding code example might produce output like the following:
----- Vertices with query: United* and role:1*political* -----
Vertex ID 30 {name:str:Jerry Brown, role:str:political authority, occupation:str:34th and 39th governor of California, country:str:United States, political party:str:Democratic, religion:str:roman catholicism}
Vertex ID 24 {name:str:Edward Snowden, role:str:political authority, occupation:str:system administrator, country:str:United States, religion:str:buddhism}
Vertex ID 22 {name:str:John Kerry, role:str:political authority, country:str:United States, political party:str:Democratic, occupation:str:68th United States Secretary of State, religion:str:Catholicism}
Vertex ID 21 {name:str:Hillary Clinton, role:str:political authority, country:str:United States, political party:str:Democratic, occupation:str:67th United States Secretary of State, religion:str:Methodism}
Vertex ID 19 {name:str:Kirsten Gillibrand, role:str:political authority, country:str:United States, political party:str:Democratic, occupation:str:junior United States Senator from New York, religion:str:Methodism}
Vertex ID 13 {name:str:Ertharin Cousin, role:str:political authority, country:str:United States, political party:str:Democratic}
Vertex ID 11 {name:str:Eric Holder, role:str:political authority, country:str:United States, political party:str:Democratic, occupation:str:United States Deputy Attorney General}
Vertex ID 1 {name:str:Barack Obama, role:str:political authority, occupation:str:44th president of United States of America, country:str:United States, political party:str:Democratic, religion:str:Christianity}
Vertices found: 8
4.5.3.2 Appending Data Type Identifiers on SolrCloud
For Boolean operations on SolrCloud text indexes, you must append the proper data type identifier as suffix to the key in the query expression. This can be done by executing a String.concat() operation to the key. Table 4-2 shows the data type identifiers available for text indexing using SolrCloud (see the Javadoc for SolrIndex).
Table 4-2 SolrCloud Data Type Identifiers
| Solr Data Type Identifier | Description |
|---|---|
|
TYPE_DT_STRING |
String |
|
TYPE_DT_BOOL |
Boolean |
|
TYPE_DT_DATE |
Date |
|
TYPE_DT_FLOAT |
Float |
|
TYPE_DT_DOUBLE |
Double |
|
TYPE_DT_INTEGER |
Integer |
|
TYPE_DT_SERIALIZABLE |
Serializable |
The following code fragment creates a manual index on edges using SolrCloud, adds data, and later executes a query over the manual index to get all edges with the key/value pair collaboratesWith:Beyonce AND country1:United* using wildcards.
OraclePropertyGraph opg = OraclePropertyGraph.getInstance(args,
szGraphName);
String szOPVFile = "../../data/connections.opv";
String szOPEFile = "../../data/connections.ope";
// Do a parallel data loading
OraclePropertyGraphDataLoader opgdl =
OraclePropertyGraphDataLoader.getInstance();
opgdl.loadData(opg, szOPVFile, szOPEFile, dop);
// Create a manual text index using SolrCloud// Specify Index Directory parameters: configuration name, Solr Server URL, Solr Node set,
// replication factor, zookeeper timeout (secs),
// maximum number of shards per node,
// number of connections to database, batch size, commit size,
// write timeout (in secs)
String configName = "opgconfig";
String solrServerUrl = "nodea:2181/solr"
String solrNodeSet = "nodea:8983_solr,nodeb:8983_solr," +
"nodec:8983_solr,noded:8983_solr";
int zkTimeout = 15;
int numShards = 4;
int replicationFactor = 1;
int maxShardsPerNode = 1;
OracleIndexParameters indexParams =
OracleIndexParameters.buildSolr(configName,
solrServerUrl,
solrNodeSet,
zkTimeout,
numShards,
replicationFactor,
maxShardsPerNode,
4,
10000,
500000,
15);
opg.setDefaultIndexParameters(indexParams);
// Create manual indexing on above properties for all vertices
OracleIndex<Edge> index = opg.createIndex("myIdx", Edge.class);
Vertex v1 = opg.getVertices("name", "Barack Obama").iterator().next();
Iterator<Edge> edges
= v1.getEdges(Direction.OUT, "collaborates").iterator();
while (edges.hasNext()) {
Edge edge = edges.next();
Vertex vIn = edge.getVertex(Direction.IN);
index.put("collaboratesWith", vIn.getProperty("name"), edge);
index.put("country", vIn.getProperty("country"), edge);
}
// Wildcard searching is supported using true parameter.
String key = "country";
key = key.concat(oracle.pg.text.solr.SolrIndex.TYPE_DT_STRING);
String queryExpr = "Beyonce AND " + key + ":United*";
edges = index.get("collaboratesWith", queryExpr, true /** UseWildcard*/).iterator();
System.out.println("----- Edges with query: " + query + " -----");
countE = 0;
while (edges.hasNext()) {
System.out.println(edges.next());
countE++;
}
System.out.println("Edges found: "+ countE);
The preceding code example might produce output like the following:
----- Edges with name Beyonce AND country_str:United* -----
Edge ID 1000 from Vertex ID 1 {country:str:United States, name:str:Barack Obama, occupation:str:44th president of United States of America, political party:str:Democratic, religion:str:Christianity, role:str:political authority} =[collaborates]=> Vertex ID 2 {country:str:United States, music genre:str:pop soul , name:str:Beyonce, role:str:singer actress} edgeKV[{weight:flo:1.0}]
Edges found: 1
4.5.4 Uploading a Collection's SolrCloud Configuration to Zookeeper
Before using SolrCloud text indexes on Oracle Big Data Spatial and Graph property graphs, you must upload a collection's configuration to Zookeeper. This can be done using the ZkCli tool from one of the SolrCloud cluster nodes.
A predefined collection configuration directory can be found in dal/opg-solr-config under the installation home. The following shows an example on how to upload the PropertyGraph configuration directory.
-
Copy dal/opg-solr-config under the installation home into /tmp directory on one of the Solr cluster nodes. For example:
scp –r dal/opg-solr-config user@solr-node:/tmp
-
Execute the following command line like the following example using the ZkCli tool on the same node:
$SOLR_HOME/bin/zkcli.sh -zkhost 127.0.0.1:2181 -cmd upconfig –confname opgconfig -confdir -/tmp/opg-solr-config
4.5.5 Updating Configuration Settings on Text Indexes for Property Graph Data
Oracle's property graph support manages manual and automatic text indexes through integration with Apache Lucene and SolrCloud. At creation time, you must create an OracleIndexParameters object specifying the search engine and other configuration settings to be used by the text index. After a text index for property graph is created, these configuration settings cannot be changed. For automatic indexes, all vertex index keys are managed by a single text index, and all edge index keys are managed by a different text index using the configuration specified when the first vertex or edge key is indexed.
If you need to change the configuration settings, you must first disable the current index and create it again using a new OracleIndexParameters object. The following code fragment creates two automatic Apache Lucene-based indexes (on vertices and edges) over an existing property graph, disables them, and recreates them to use SolrCloud.
OraclePropertyGraph opg = OraclePropertyGraph.getInstance(
args, szGraphName);
String szOPVFile = "../../data/connections.opv";
String szOPEFile = "../../data/connections.ope";
// Do parallel data loading
OraclePropertyGraphDataLoader opgdl =
OraclePropertyGraphDataLoader.getInstance();
opgdl.loadData(opg, szOPVFile, szOPEFile, dop);
// Create an automatic index using Apache Lucene.
// Specify Index Directory parameters (number of directories,
// number of connections to database, batch size, commit size,
// enable datatypes, location)
OracleIndexParameters luceneIndexParams =
OracleIndexParameters.buildFS(4, 4, 10000, 50000, true,
"/home/data/text-index ");
// Specify indexed keys
String[] indexedKeys = new String[4];
indexedKeys[0] = "name";
indexedKeys[1] = "role";
indexedKeys[2] = "religion";
indexedKeys[3] = "country";
// Create auto indexing on above properties for all vertices
opg.createKeyIndex(indexedKeys, Vertex.class, luceneIndexParams.getParameters());
// Create auto indexing on weight for all edges
opg.createKeyIndex("weight", Edge.class, luceneIndexParams.getParameters());
// Disable auto indexes to change parameters
opg.getOracleIndexManager().disableVertexAutoIndexer();
opg.getOracleIndexManager().disableEdgeAutoIndexer();
// Recreate text indexes using SolrCloud
// Specify Index Directory parameters: configuration name, Solr Server URL, Solr Node set,
// replication factor, zookeeper timeout (secs),
// maximum number of shards per node,
// number of connections to database, batch size, commit size,
// write timeout (in secs)
String configName = "opgconfig";
String solrServerUrl = "nodea:2181/solr"
String solrNodeSet = "nodea:8983_solr,nodeb:8983_solr," +
"nodec:8983_solr,noded:8983_solr";
int zkTimeout = 15;
int numShards = 4;
int replicationFactor = 1;
int maxShardsPerNode = 1;
OracleIndexParameters solrIndexParams =
OracleIndexParameters.buildSolr(configName,
solrServerUrl,
solrNodeSet,
zkTimeout,
numShards,
replicationFactor,
maxShardsPerNode,
4,
10000,
500000,
15);
// Create auto indexing on above properties for all vertices
opg.createKeyIndex(indexedKeys, Vertex.class, solrIndexParams.getParameters());
// Create auto indexing on weight for all edges
opg.createKeyIndex("weight", Edge.class, solrIndexParams.getParameters());
4.6 Property Graph Support for Secure Oracle NoSQL Database
Oracle's property graph support works with both secure and non-secure Oracle NoSQL Database installations. This topic provides information about secure Oracle NoSQL Database installations. It assumes that a password store is configured for the database (see the Oracle NoSQL Database Security Guide at http://docs.oracle.com/cd/NOSQL/html/SecurityGuide/index.html for details).
On the client side, you must create a login properties file named login_properties.txt, which contains settings like the trust store and SSL transport. For detailed information, see "Using the Authentication APIs" at http://docs.oracle.com/cd/NOSQL/html/GettingStartedGuideTables/authentication.html.
To specify the login properties file, use a Java VM setting with the following format:
-Doracle.kv.security=/<your-path>/login_properties.txt
You can also set this Java VM property for applications (including in-memory analytics) deployed into a J2EE container. For example, before starting WebLogic Server, you can set an environment variable in the following format to refer to the login properties configuration file:
setenv JAVA_OPTIONS "-Doracle.kv.security=/<your-path>/login_properties.txt"
4.7 Using the Groovy Shell with Property Graph Data
The Oracle Big Data Spatial and Graph property graph support includes a built-in Groovy shell (based on the original Gremlin Groovy shell script). With this command-line shell interface, you can explore the Java APIs.
To start the Groovy shell, go to the dal/groovy directory under the installation home (/opt/oracle/oracle-spatial-graph/property_graph by default). For example:
cd /opt/oracle/oracle-spatial-graph/property_graph/dal/groovy/
Included are the scripts gremlin-opg-nosql.sh and gremlin-opg-hbase.sh, for connecting to an Oracle NoSQL Database and an Apache HBase, respectively.
The following example connects to an Oracle NoSQL Database, gets an instance of OraclePropertyGraph with graph name myGraph, loads some example graph data, and gets the list of vertices and edges.
$ ./gremlin-opg-nosql.sh
opg-nosql>
opg-nosql> hhosts = new String[1];
==>null
opg-nosql> hhosts[0] = "bigdatalite:5000";
==>bigdatalite:5000
opg-nosql> cfg = GraphConfigBuilder.forNosql().setName("myGraph").setHosts(Arrays.asList(hhosts)).setStoreName("mystore").addEdgeProperty("lbl", PropertyType.STRING, "lbl").addEdgeProperty("weight", PropertyType.DOUBLE, "1000000").build();
==>{"db_engine":"NOSQL","loading":{},"format":"pg","name":"myGraph","error_handling":{},"hosts":["bigdatalite:5000"],"node_props":[],"store_name":"mystore","edge_props":[{"type":"string","name":"lbl","default":"lbl"},{"type":"double","name":"weight","default":"1000000"}]}
opg-nosql> opg = OraclePropertyGraph.getInstance(cfg);
==>oraclepropertygraph with name myGraph
opg-nosql> opgdl = OraclePropertyGraphDataLoader.getInstance();
==>oracle.pg.nosql.OraclePropertyGraphDataLoader@576f1cad
opg-nosql> opgdl.loadData(opg, new FileInputStream("../../data/connections.opv"), new FileInputStream("../../data/connections.ope"), 1, 1, 0, null);
==>null
opg-nosql> opg.getVertices();
==>Vertex ID 5 {country:str:Italy, name:str:Pope Francis, occupation:str:pope, religion:str:Catholicism, role:str:Catholic religion authority}
[... other output lines omitted for brevity ...]
opg-nosql> opg.getEdges();
==>Edge ID 1139 from Vertex ID 64 {country:str:United States, name:str:Jeff Bezos, occupation:str:business man} =[leads]=> Vertex ID 37 {country:str:United States, name:str:Amazon, type:str:online retailing} edgeKV[{weight:flo:1.0}]
[... other output lines omitted for brevity ...]
The following example customizes several configuration parameters for in-memory analytics. It connects to an Apache HBase, gets an instance of OraclePropertyGraph with graph name myGraph, loads some example graph data, gets the list of vertices and edges, gets an in-memory analyst, and execute one of the built-in analytics, triangle counting.
$ ./gremlin-opg-hbase.sh
opg-hbase>
opg-hbase> dop=2; // degree of parallelism
==>2
opg-hbase> confPgx = new HashMap<PgxConfig.Field, Object>();
opg-hbase> confPgx.put(PgxConfig.Field.ENABLE_GM_COMPILER, false);
==>null
opg-hbase> confPgx.put(PgxConfig.Field.NUM_WORKERS_IO, dop + 2);
==>null
opg-hbase> confPgx.put(PgxConfig.Field.NUM_WORKERS_ANALYSIS, 3);
==>null
opg-hbase> confPgx.put(PgxConfig.Field.NUM_WORKERS_FAST_TRACK_ANALYSIS, 2);
==>null
opg-hbase> confPgx.put(PgxConfig.Field.SESSION_TASK_TIMEOUT_SECS, 0);
==>null
opg-hbase> confPgx.put(PgxConfig.Field.SESSION_IDLE_TIMEOUT_SECS, 0);
==>null
opg-hbase> PgxConfig.init(confPgx);
==>null
opg-hbase>
opg-hbase> iClientPort = 2181;
==>2181
opg-hbase> cfg = GraphConfigBuilder.forHbase() .setName("myGraph") .setZkQuorum("bigdatalite") .setZkClientPort(iClientPort) .setZkSessionTimeout(60000) .setMaxNumConnections(dop) .setLoadEdgeLabel(true) .setSplitsPerRegion(1) .addEdgeProperty("lbl", PropertyType.STRING, "lbl") .addEdgeProperty("weight", PropertyType.DOUBLE, "1000000") .build();
==>{"splits_per_region":1,"max_num_connections":2,"node_props":[],"format":"pg","load_edge_label":true,"name":"myGraph","zk_client_port":2181,"zk_quorum":"bigdatalite","edge_props":[{"type":"string","default":"lbl","name":"lbl"},{"type":"double","default":"1000000","name":"weight"}],"loading":{},"error_handling":{},"zk_session_timeout":60000,"db_engine":"HBASE"}
opg-hbase> opg = OraclePropertyGraph.getInstance(cfg);
==>oraclepropertygraph with name myGraph
opg-hbase> opgdl = OraclePropertyGraphDataLoader.getInstance();
==>oracle.pg.hbase.OraclePropertyGraphDataLoader@3451289b
opg-hbase> opgdl.loadData(opg, "../../data/connections.opv", "../../data/connections.ope", 1, 1, 0, null);
==>null
opg-hbase> opg.getVertices();
==>Vertex ID 78 {country:str:United States, name:str:Hosain Rahman, occupation:str:CEO of Jawbone}
...
opg-hbase> opg.getEdges();
==>Edge ID 1139 from Vertex ID 64 {country:str:United States, name:str:Jeff Bezos, occupation:str:business man} =[leads]=> Vertex ID 37 {country:str:United States, name:str:Amazon, type:str:online retailing} edgeKV[{weight:flo:1.0}]
[... other output lines omitted for brevity ...]
opg-hbase> analyst = opg.getInMemAnalyst();
==>oracle.pgx.api.analyst.Analyst@534df5ff
opg-hbase> triangles = analyst.countTriangles(false).get();
==>22
For detailed information about the Java APIs, see the Javadoc reference information in doc/dal/ and doc/pgx/ under the installation home (/opt/oracle/oracle-spatial-graph/property_graph/ by default).
4.8 Exploring the Sample Programs
The software installation includes a directory of example programs, which you can use to learn about creating and manipulating property graphs.
4.8.1 About the Sample Programs
The sample programs are distributed in an installation subdirectory named examples/dal. The examples are replicated for HBase and Oracle NoSQL Database, so that you can use the set of programs corresponding to your choice of backend database. Table 4-3 describes the some of the programs.
Table 4-3 Property Graph Program Examples (Selected)
| Program Name | Description |
|---|---|
|
ExampleNoSQL1 ExampleHBase1 |
Creates a minimal property graph consisting of one vertex, sets properties with various data types on the vertex, and queries the database for the saved graph description. |
|
ExampleNoSQL2 ExampleHBase2 |
Creates the same minimal property graph as Example1, and then deletes it. |
|
ExampleNoSQL3 ExampleHBase3 |
Creates a graph with multiple vertices and edges. Deletes some vertices and edges explicitly, and other implicitly by deleting other, required objects. This example queries the database repeatedly to show the current list of objects. |
4.8.2 Compiling and Running the Sample Programs
To compile and run the Java source files:
-
Change to the examples directory:
cd examples/dal
-
Use the Java compiler:
javac -classpath ../../lib/'*' filename.java
For example:
javac -classpath ../../lib/'*' ExampleNoSQL1.java -
Execute the compiled code:
java -classpath ../../lib/'*':./ filename args
The arguments depend on whether you are using Oracle NoSQL Database or Apache HBase to store the graph. The values are passed to
OraclePropertyGraph.getInstance.
Apache HBase Argument Descriptions
Provide these arguments when using the HBase examples:
-
quorum: A comma-delimited list of names identifying the nodes where HBase runs, such as
"node01.example.com, node02.example.com, node03.example.com". -
client_port: The HBase client port number, such as
"2181". -
graph_name: The name of the graph, such as
"customer_graph".
Oracle NoSQL Database Argument Descriptions
Provide these arguments when using the NoSQL examples:
-
host_name: The cluster name and port number for Oracle NoSQL Database registration, such as
"cluster02:5000". -
store_name: The name of the key-value store, such as
"kvstore" -
graph_name: The name of the graph, such as
"customer_graph".
4.8.3 About the Example Output
The example programs use System.out.println to retrieve the property graph descriptions from the database where it is stored, either Oracle NoSQL Database or Apache HBase. The key name, data type, and value are delimited by colons. For example, weight:flo:30.0 indicates that the key name is weight, the data type is float, and the value is 30.0.
Table 4-4 identifies the data type abbreviations used in the output.
4.8.4 Example: Creating a Property Graph
ExampleNoSQL1 and ExampleHBase1 create a minimal property graph consisting of one vertex. The code fragment in Example 4-5 creates a vertex named v1 and sets properties with various data types. It then queries the database for the saved graph description.
The OraclePropertyGraph.getInstance arguments (args) depend on whether you are using Oracle NoSQL Database or Apache HBase to store the graph. See "Compiling and Running the Sample Programs".
Example 4-5 Creating a Property Graph
// Create a property graph instance named opg
OraclePropertyGraph opg = OraclePropertyGraph.getInstance(args);
// Clear all vertices and edges from opg
opg.clearRepository();
// Create vertex v1 and assign it properties as key-value pairs
Vertex v1 = opg.addVertex(1l);
v1.setProperty("age", Integer.valueOf(18));
v1.setProperty("name", "Name");
v1.setProperty("weight", Float.valueOf(30.0f));
v1.setProperty("height", Double.valueOf(1.70d));
v1.setProperty("female", Boolean.TRUE);
// Save the graph in the database
opg.commit();
// Display the stored vertex description
System.out.println("Fetch 1 vertex: " + opg.getVertices().iterator().next());
// Close the graph instance
opg.shutdown();
System.out.println displays the following output:
Fetch 1 vertex: Vertex ID 1 {age:int:18, name:str:Name, weight:flo:30.0, height:dbl:1.7, female:bol:true}
See ** opg javadoc ulink** for the following:
OraclePropertyGraph.addVertex OraclePropertyGraph.clearRepository OraclePropertyGraph.getInstance OraclePropertyGraph.getVertices OraclePropertyGraph.shutdown Vertex.setProperty
4.8.5 Example: Dropping a Property Graph
ExampleNoSQL2 and ExampleHBase2 create a graph like the one in "Example: Creating a Property Graph", and then drop it from the database.
The code fragment in Example 4-6 drops the graph. See "Compiling and Running the Sample Programs" for descriptions of the OraclePropertyGraphUtils.dropPropertyGraph arguments.
Example 4-6 Dropping a Property Graph
// Drop the property graph from the database OraclePropertyGraphUtils.dropPropertyGraph(args); // Display confirmation that the graph was dropped System.out.println("Graph " + graph_name + " dropped. ");
System.out.println displays the following output:
Graph graph_name dropped.
See the Javadoc for OraclePropertyGraphUtils.dropPropertyGraph.
4.8.6 Examples: Adding and Dropping Vertices and Edges
ExampleNoSQL3 and ExampleHBase3 add and drop both vertices and edges.
The code fragment in Example 4-7 creates three vertices. It is a simple variation of Example 4-5.
Example 4-7 Creating the Vertices
// Create a property graph instance named opg
OraclePropertyGraph opg = OraclePropertyGraph.getInstance(args);
// Clear all vertices and edges from opg
opg.clearRepository();
// Add vertices a, b, and c
Vertex a = opg.addVertex(1l);
a.setProperty("name", "Alice");
a.setProperty("age", 31);
Vertex b = opg.addVertex(2l);
b.setProperty("name", "Bob");
b.setProperty("age", 27);
Vertex c = opg.addVertex(3l);
c.setProperty("name", "Chris");
c.setProperty("age", 33);
The code fragment in Example 4-8 uses vertices a, b, and c to create the edges.
Example 4-8 Creating the Edges
// Add edges e1, e2, and e3
Edge e1 = opg.addEdge(1l, a, b, "knows");
e1.setProperty("type", "partners");
Edge e2 = opg.addEdge(2l, a, c, "knows");
e2.setProperty("type", "friends");
Edge e3 = opg.addEdge(3l, b, c, "knows");
e3.setProperty("type", "colleagues");
The code fragment in Example 4-9 explicitly deletes edge e3 and vertex b. It implicitly deletes edge e1, which was connected to vertex b.
Example 4-9 Deleting Edges and Vertices
// Remove edge e3
opg.removeEdge(e3);
// Remove vertex b and all related edges
opg.removeVertex(b);
This example queries the database to show when objects are added and dropped. The code fragment in Example 4-10 shows the method used.
Example 4-10 Querying for Vertices and Edges
// Print all vertices
vertices = opg.getVertices().iterator();
System.out.println("----- Vertices ----");
vCount = 0;
while (vertices.hasNext()) {
System.out.println(vertices.next());
vCount++;
}
System.out.println("Vertices found: " + vCount);
// Print all edges
edges = opg.getEdges().iterator();
System.out.println("----- Edges ----");
eCount = 0;
while (edges.hasNext()) {
System.out.println(edges.next());
eCount++;
}
System.out.println("Edges found: " + eCount);
The examples in this topic may produce output like the following:
----- Vertices ----
Vertex ID 3 {name:str:Chris, age:int:33}
Vertex ID 1 {name:str:Alice, age:int:31}
Vertex ID 2 {name:str:Bob, age:int:27}
Vertices found: 3
----- Edges ----
Edge ID 2 from Vertex ID 1 {name:str:Alice, age:int:31} =[knows]=> Vertex ID 3 {name:str:Chris, age:int:33} edgeKV[{type:str:friends}]
Edge ID 3 from Vertex ID 2 {name:str:Bob, age:int:27} =[knows]=> Vertex ID 3 {name:str:Chris, age:int:33} edgeKV[{type:str:colleagues}]
Edge ID 1 from Vertex ID 1 {name:str:Alice, age:int:31} =[knows]=> Vertex ID 2 {name:str:Bob, age:int:27} edgeKV[{type:str:partners}]
Edges found: 3
Remove edge Edge ID 3 from Vertex ID 2 {name:str:Bob, age:int:27} =[knows]=> Vertex ID 3 {name:str:Chris, age:int:33} edgeKV[{type:str:colleagues}]
----- Vertices ----
Vertex ID 1 {name:str:Alice, age:int:31}
Vertex ID 2 {name:str:Bob, age:int:27}
Vertex ID 3 {name:str:Chris, age:int:33}
Vertices found: 3
----- Edges ----
Edge ID 2 from Vertex ID 1 {name:str:Alice, age:int:31} =[knows]=> Vertex ID 3 {name:str:Chris, age:int:33} edgeKV[{type:str:friends}]
Edge ID 1 from Vertex ID 1 {name:str:Alice, age:int:31} =[knows]=> Vertex ID 2 {name:str:Bob, age:int:27} edgeKV[{type:str:partners}]
Edges found: 2
Remove vertex Vertex ID 2 {name:str:Bob, age:int:27}
----- Vertices ----
Vertex ID 1 {name:str:Alice, age:int:31}
Vertex ID 3 {name:str:Chris, age:int:33}
Vertices found: 2
----- Edges ----
Edge ID 2 from Vertex ID 1 {name:str:Alice, age:int:31} =[knows]=> Vertex ID 3 {name:str:Chris, age:int:33} edgeKV[{type:str:friends}]
Edges found: 1
4.9 Oracle Flat File Format Definition
A property graph can be defined in two flat files, specifically description files for the vertices and edges.
4.9.1 About the Property Graph Description Files
A pair of files describe a property graph:
-
Vertex file: Describes the vertices of the property graph. This file has an
.opvfile name extension. -
Edge file: Describes the edges of the property graph. This file has an
.opefile name extension.
It is recommended that these two files share the same base name. For example, simple.opv and simple.ope define a property graph.
4.9.2 Vertex File
Each line in a vertex file is a record that describes a vertex of the property graph. A record can describe one key-value property of a vertex, thus multiple records/lines are used to describe a vertex with multiple properties.
A record contains six fields separated by commas. Each record must contain five commas to delimit all fields, whether or not they have values:
vertex_ID, key_name, value_type, value, value, value
Table 4-5 describes the fields composing a vertex file record.
Table 4-5 Vertex File Record Format
| Field Number | NameFoot 1 | Description |
|---|---|---|
|
1 |
vertex_ID |
An integer that uniquely identifies the vertex |
|
2 |
key_name |
The name of the key in the key-value pair If the vertex has no properties, then enter a space ( 1,%20,,,, |
|
3 |
value_type |
An integer that represents the data type of the value in the key-value pair: 1 String2 Integer3 Float4 Double5 Date6 Boolean10 Serializable Java object |
|
4 |
value |
The encoded, nonnull value of key_name when it is neither numeric nor date |
|
5 |
value |
The encoded, nonnull value of key_name when it is numeric |
|
6 |
value |
The encoded, nonnull value of key_name when it is a date Use the Java
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd'Th'HH:mm:ss.SSSXXX"); encode(sdf.format((java.util.Date) value));
|
Footnote 1 Names do not appear in the vertex files, but are provided here to simplify field references.
4.9.3 Edge File
Each line in an edge file is a record that describes an edge of the property graph. A record can describe one key-value property of an edge, thus multiple records are used to describe an edge with multiple properties.
A record contains nine fields separated by commas. Each record must contain eight commas to delimit all fields, whether or not they have values:
edge_ID, source_vertex_ID, destination_vertex_ID, edge_label, key_name, value_type, value, value, value
Table 4-6 describes the fields composing an edge file record.
Table 4-6 Edge File Record Format
| Field Number | NameFoot 1 | Description |
|---|---|---|
|
1 |
edge_ID |
An integer that uniquely identifies the edge |
|
2 |
source_vertex_ID |
The vertex_ID of the outgoing tail of the edge. |
|
3 |
destination_vertex_ID |
The vertex_ID of the incoming head of the edge. |
|
4 |
edge_label |
The encoded label of the edge, which describes the relationship between the two vertices |
|
5 |
key_name |
The encoded name of the key in a key-value pair If the edge has no properties, then enter a space ( 100,1,2,likes,%20,,,, |
|
6 |
value_type |
An integer that represents the data type of the value in the key-value pair: 1 String2 Integer3 Float4 Double5 Date6 Boolean10 Serializable Java object |
|
7 |
value |
The encoded, nonnull value of key_name when it is neither numeric nor date |
|
8 |
value |
The encoded, nonnull value of key_name when it is numeric |
|
9 |
value |
The encoded, nonnull value of key_name when it is a date Use the Java
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd'Th'HH:mm:ss.SSSXXX"); encode(sdf.format((java.util.Date) value));
|
Footnote 1 Names do not appear in the edge files, but are provided here to simplify field references.
4.9.4 Encoding Special Characters
The encoding is UTF-8 for the vertex and edge files. Table 4-7 lists the special characters that must be encoded as strings when they appear in a vertex or edge property (key-value pair) or an edge label. No other characters require encoding.
4.9.5 Example Property Graph in Oracle Flat File Format
An example property graph in Oracle flat file format is as follows. In this example, there are two vertices (John and Mary), and a single edge denoting that John is a friend of Mary.
%cat simple.opv 1,age,2,,10, 1,name,1,John,, 2,name,1,Mary,, 2,hobby,1,soccer,, %cat simple.ope 100,1,2,friendOf,%20,,,,
4.10 Example Python User Interface
The Oracle Big Data Spatial and Graph support for property graphs includes an example Python user interface. It can invoke a set of example Python scripts and modules that perform a variety of property graph operations.
Instructions for installing the example Python user interface are in the /property_graph/examples/pyopg/README file under the installation home (/opt/oracle/oracle-spatial-graph by default).
The example Python scripts in /property_graph/examples/pyopg/ can used with Oracle Spatial and Graph Property Graph, and you may want to change and enhance them (or copies of them) to suit your needs.
To invoke the user interface to run the examples, use the script pyopg.sh.
The examples include the following:
-
Example 1: Connect to an Oracle NoSQL Database and perform a simple check of number of vertices and edges. To run it:
cd /opt/oracle/oracle-spatial-graph/property_graph/examples/pyopg ./pyopg.sh connectONDB("mygraph", "kvstore", "localhost:5000") print "vertices", countV() print "edges", countE()In the preceding example,
mygraphis the name of the graph stored in the Oracle NoSQL Database,kvstoreandlocalhost:5000are the connection information to access the Oracle NoSQL Database. They must be customized for your environment. -
Example 2: Connect to an Apache HBase and perform a simple check of number of vertices and edges. To run it:
cd /opt/oracle/oracle-spatial-graph/property_graph/examples/pyopg ./pyopg.sh connectHBase("mygraph", "localhost", "2181") print "vertices", countV() print "edges", countE()In the preceding example,
mygraphis the name of the graph stored in the Apache HBase, andlocalhostand2181are the connection information to access the Apache HBase. They must be customized for your environment. -
Example 3: Connect to an Oracle NoSQL Database and run a few analytical functions. To run it:
cd /opt/oracle/oracle-spatial-graph/property_graph/examples/pyopg ./pyopg.sh connectONDB("mygraph", "kvstore", "localhost:5000") print "vertices", countV() print "edges", countE() import pprint analyzer = analyst() print "# triangles in the graph", analyzer.countTriangles() graph_communities = [{"commid":i.getId(),"size":i.size()} for i in analyzer.communities().iterator()] import pandas as pd import numpy as np community_frame = pd.DataFrame(graph_communities) community_frame[:5] import matplotlib as mpl import matplotlib.pyplot as plt fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(16,12)); community_frame["size"].plot(kind="bar", title="Communities and Sizes") ax.set_xticklabels(community_frame.index); plt.show()The preceding example connects to an Oracle NoSQL Database, prints basic information about the vertices and edges, get an in memory analyst, computes the number of triangles, performs community detection, and finally plots out in a bar chart communities and their sizes.
-
Example 4: Connect to an Apache HBase and run a few analytical functions. To run it:
cd /opt/oracle/oracle-spatial-graph/property_graph/examples/pyopg ./pyopg.sh connectHBase("mygraph", "localhost", "2181") print "vertices", countV() print "edges", countE() import pprint analyzer = analyst() print "# triangles in the graph", analyzer.countTriangles() graph_communities = [{"commid":i.getId(),"size":i.size()} for i in analyzer.communities().iterator()] import pandas as pd import numpy as np community_frame = pd.DataFrame(graph_communities) community_frame[:5] import matplotlib as mpl import matplotlib.pyplot as plt fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(16,12)); community_frame["size"].plot(kind="bar", title="Communities and Sizes") ax.set_xticklabels(community_frame.index); plt.show()The preceding example connects to an Apache HBase, prints basic information about the vertices and edges, gets an in-memory analyst, computes the number of triangles, performs community detection, and finally plots out in a bar chart communities and their sizes.
For detailed information about this example Python interface, see the following directory under the installation home:
property_graph/examples/pyopg/doc/