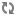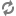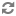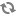The most basic type of statement provided by the Endeca Analytics API is the aggregation operation with GROUP BY, which buckets a set of Endeca records into a resulting set of aggregated Oracle Commerce Guide Search records.
In most Analytics applications, all Analytics statements are aggregation operations.
To define the set of resulting buckets for an aggregation operation, the operation must specify a set of GROUP BY dimensions and/or properties. The cross product of all values in these grouping dimensions and/or properties defines the set of candidate buckets. After associating input records with buckets, the results are automatically pruned to include only non-empty buckets. Aggregation operations correspond closely to the SQL GROUP BY concept, and the text-based Analytics syntax re-uses SQL keywords.
Example 3. Examples of GROUP BY
For example, suppose we have sales transaction data with records consisting of the following fields (properties or dimensions):
{ TransId, ProductType, Amount, Year, Quarter, Region,
SalesRep, Customer }such as:
{ TransId = 1, ProductType = "Widget", Amount = 100.00,
Year = 2009, Quarter = "09Q1", Region = "East",
SalesRep = "J. Smith", Customer = "Customer1" }If an Analytics statement uses "Region" and "Year" as GROUP BY dimensions, the statement results contain an aggregated Oracle Commerce Guide Search record for each valid, non-empty "Region" and "Year" combination. In the text-based syntax, this example would be expressed as:
DEFINE RegionsByYear AS GROUP BY Region, Year
resulting in the aggregates of the form { Region, Year }, for example:
{ "East", "2008" }
{ "West", "2009" }
{ "East", "2009" }The following Java code represents the equivalent operation using the programmatic API:
Statement stmnt = new Statement();
stmnt.setName("RegionsByYear");
GroupByList g = new GroupByList();
g.add(new GroupBy("Region"));
g.add(new GroupBy("Year"));
stmnt.setGroupByList(g);The above example performs simple leaf-level group-by operations. It is also possible to group by a specified depth of each dimension. For example, if the "Region" dimension in the above example contained hierarchy such as Country, State, City, and the grouping was desired at the State level (one level below the root of the dimension hierarchy), the following Java syntax would be used:
g.add(new GroupBy("Region",1)); // Depth 1 is Stateor in text form:
GROUP BY "Region":1
A GROUP BY key can be the result of a computation (the output of a SELECT expression), as long as that expression itself does not contain an aggregation function.
For example, the following syntax represents a correct usage of GROUP BY:
SELECT COALESCE(Person, 'Unknown Person') as Person2, ... GROUP BY Person2
The following syntax is incorrect and results in an error (because Sales2 contains an aggregation function):
SELECT SUM(Sales) as Sales2, ... GROUP BY Sales2
You can also use a GROUP statement to aggregate results into a single bucket.
For example, if you would like to use the SUM statement to return a single sum across a set of records, write the following query:
RETURN "ReviewCount" AS SELECT SUM(number_of_reviews) AS "NumReviews" GROUP
This query returns one record for the property
"NumReviews" where the value is the sum over the
property
"number_of_reviews".